Bài học về mật mã. Mật mã khối hiện đại. Thuật toán mã hóa hiện đại
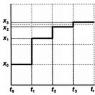
Như bạn còn nhớ, phép dịch chuyển, thay thế, hoán vị và mật mã Vernam áp dụng một thao tác cho từng ký tự cụ thể của văn bản. Chúng ta cần dịch chuyển - chúng ta dịch chuyển ký hiệu, áp dụng khóa - áp dụng nó cho ký hiệu, sau đó đến ký hiệu tiếp theo, v.v. cho đến khi chúng ta mã hóa tất cả các ký hiệu văn bản thô. Phương thức mã hóa này được gọi là mã hóa luồng - chúng tôi mã hóa từng ký tự riêng biệt. Một cách tiếp cận khác là chia bản rõ gốc thành các nhóm gồm nhiều ký tự (khối) và thực hiện các thao tác mã hóa trên mỗi khối. Đây là một phương pháp mã hóa khối.
Để làm rõ sự khác biệt giữa mật mã khối và mật mã dòng, hãy đưa ra một ví dụ: mật mã đơn giản thay thế.
Mã hóa luồng
Hãy mã hóa từ CIPHER bằng mật mã luồng thay thế:
Chúng tôi đã mã hóa từng ký tự và thu được một bản mã. Dễ như ăn bánh.
MÃ HÓA KHỐI
Hãy mã hóa từ AVADAKDAVRA. Vì mật mã là khối một nên chúng ta sẽ chia bản rõ thành các khối gồm bốn ký tự: AVAD | KIẾM | AVRA (trong thực tế, khối văn bản bao gồm 64-256 bit). Đối với mỗi khối, chúng tôi sẽ đưa ra bảng thay thế của riêng mình: 
Bây giờ chúng tôi mã hóa từng khối bằng bảng chữ cái tương ứng:  Nó hóa ra tốt hơn một chút so với cách tiếp cận nội tuyến, nếu chúng ta nói về độ bền. Rốt cuộc, chúng tôi đã học cách giải mã mật mã thay thế thông thường bằng một tay trái. Và với cách tiếp cận khối như vậy, kẻ tấn công sẽ phải vắt óc trước khi có thể chọn độ dài khối và sau đó áp dụng phương pháp phân tích mật mã để tìm mật mã thay thế cho mỗi khối.
Nó hóa ra tốt hơn một chút so với cách tiếp cận nội tuyến, nếu chúng ta nói về độ bền. Rốt cuộc, chúng tôi đã học cách giải mã mật mã thay thế thông thường bằng một tay trái. Và với cách tiếp cận khối như vậy, kẻ tấn công sẽ phải vắt óc trước khi có thể chọn độ dài khối và sau đó áp dụng phương pháp phân tích mật mã để tìm mật mã thay thế cho mỗi khối.
MẠNG FEISTEL
Bây giờ chúng ta đã sẵn sàng chuyển sang một chủ đề rất quan trọng mở ra cánh cửa đến một thế giới rộng lớn hệ thống hiện đại mã hóa. Mạng Feistel là một phương pháp mã hóa khối được phát triển bởi Horst Feistel tại phòng thí nghiệm IBM vào năm 1971. Ngày nay mạng lưới Feistel làm nền tảng số lượng lớn các giao thức mật mã. Chúng ta hãy thử tìm hiểu "trên ngón tay" nó là gì.
Mạng Feistel hoạt động trên các khối văn bản gốc, vì vậy chúng ta sẽ xem xét cơ chế hoạt động của nó trên một trong các khối. Các thao tác đối với các khối còn lại sẽ tương tự.
- Khối được chia thành hai phần bằng nhau - trái (L) và phải (R).
- Sau khi phân vùng, khối con bên trái được sửa đổi bởi hàm f sử dụng khóa K: x = f(L, K). Với tư cách là một hàm, bạn có thể tưởng tượng bất kỳ phép biến đổi nào mà bạn thích - ví dụ: mật mã dịch chuyển cũ tốt với khóa K.
- Khối con kết quả được thêm modulo 2 với khối con bên phải R, khối con này chưa được sử dụng trước đây: x=x+R
- Tiếp theo, các bộ phận kết quả được hoán đổi và dán lại với nhau.
Như bạn có thể thấy, mọi thứ khá đơn giản. Để hiểu cách thức hoạt động của nó, hãy nhìn vào sơ đồ:

Mạch này được gọi là tế bào Feistel. Bản thân mạng Feistel bao gồm một số ô. Các khối con thu được ở đầu ra của ô thứ nhất sẽ chuyển đến đầu vào của ô thứ hai, các khối con kết quả từ ô thứ hai sẽ chuyển đến đầu vào của ô thứ ba, v.v., tùy thuộc vào số vòng của mạng Feistel. Trong mỗi vòng như vậy, một phím tròn xác định trước sẽ được sử dụng. Thông thường, các phím tròn có nguồn gốc từ khóa chính chìa khoá bí mật K. Khi tất cả các vòng đã hoàn thành, các khối văn bản con sẽ được dán lại với nhau và thu được một bản mã bình thường.
Bây giờ chúng ta hãy xem hoạt động của mạng Feistel bằng một ví dụ. Hãy lấy từ AVADAKDAVRA và chia nó thành hai khối sáu ký tự - AVADAK | EDAVRA. Đối với hàm, chúng ta lấy mật mã dịch chuyển theo số vị trí được xác định bằng phím tròn. Đặt khóa bí mật K = . Là các phím tròn, chúng ta lấy K = 1, K = 2. Để cộng modulo 2, chúng ta chuyển văn bản thành mã nhị phân theo bảng chữ cái điện báo mà hiếm ai sử dụng.
Đây là những gì đã xảy ra:
Bây giờ hãy chạy khối đầu tiên qua mạng Feistel theo hai vòng: 
Hãy thử tự mã hóa khối thứ hai, tôi đã nhận được MOOSSTR.
Việc giải mã được thực hiện theo cách tương tự: văn bản mã hóa được chia thành các khối và sau đó là các khối con, khối con bên trái nhập vào hàm, được thêm modulo 2 với khối con bên phải, sau đó các khối con được hoán đổi. Sự khác biệt là các phím tròn được cung cấp theo thứ tự ngược lại, nghĩa là, trong trường hợp của chúng tôi, ở vòng đầu tiên, chúng tôi sẽ sử dụng khóa K = 2, và sau đó ở vòng thứ hai K = 1.
Nghiên cứu trên mạng Feistel đã chỉ ra rằng với các khóa tròn độc lập và hàm giả ngẫu nhiên kháng mật mã f, ba vòng của mạng Feistel sẽ đủ để văn bản mã hóa là giả ngẫu nhiên. Điều này cho thấy mật mã dựa trên mạng Feistel hiện khá an toàn.
GOST 28147-89 (MAGMA)
Hầu hết mọi thứ đều đã có trong kho vũ khí những khái niệm cần thiết, vì vậy chúng ta đã sẵn sàng chuyển sang chủ đề quan trọng đầu tiên về mật mã trong nước - GOST 28147-89. Điều đáng nói là chỉ có những kẻ lười biếng mới không viết về tiêu chuẩn này, vì vậy tôi sẽ cố gắng lần thứ một triệu và lần đầu tiên để trình bày ngắn gọn và không có một đám mây công thức nào phác thảo bản chất của các chế độ mã hóa của Magma vĩ đại và khủng khiếp. Nếu bạn quyết định tự đọc tiêu chuẩn, thì bạn nên dự trữ thời gian, sức lực, sự kiên nhẫn và thức ăn, bởi vì, như bạn biết, việc viết tiêu chuẩn bằng ngôn ngữ của con người bị nghiêm cấm.
Đặc điểm chính: khóa 256 bit, khối 64 bit.
Trước khi phân tích Magma, bạn cần tìm hiểu một khái niệm mới - bảng thay thế hoặc hộp S. Đây là loại bảng giống như bảng trong mật mã thay thế. Được thiết kế để thay thế các ký hiệu khối con bằng các ký hiệu được ghi trong bảng. Đừng nghĩ rằng hộp S là các số ngẫu nhiên được tạo bởi hàm rand(). Hộp S là kết quả của các chuỗi được tạo ra một cách chu đáo, bởi vì sức mạnh mật mã của toàn bộ mật mã dựa trên chúng.
GOST 28147 mô tả rất ít các bảng thay thế của nó. Nó chỉ nói rằng chúng là một phần tử bí mật bổ sung (cùng với khóa bí mật) và “được cung cấp dưới dạng theo cách quy định" Không có gì khác. Kể từ khi áp dụng GOST 28147, sự không chắc chắn về mặt khoa học và kỹ thuật liên quan đến việc lựa chọn hộp S đã làm nảy sinh những tin đồn và suy đoán. Đã có cuộc nói chuyện về các tiêu chí bí mật chỉ được biết đến bởi các nhà phát triển GOST. Đương nhiên, sự không chắc chắn này làm giảm niềm tin vào hệ thống mật mã.
Sự thiếu sót này đã tạo cơ sở tuyệt vời để chỉ trích tiêu chuẩn. Nhà mật mã học người Pháp Nicolas Courtois đã xuất bản một số bài báo chứa một số điều khoản gây tranh cãi liên quan đến sức mạnh của GOST. Courtois cho rằng tiêu chuẩn Nga rất dễ bị tấn công và không thể coi là quốc tế. Tuy nhiên, Courtois thực hiện phân tích của mình đối với các hộp S không phải là hộp thực tế, vì vậy bạn không nên dựa vào ý kiến của anh ấy.
Bây giờ hãy xem họ nghĩ ra điều gì bên trong những bức tường của Lubyanka u ám.
Chế độ thay thế dễ dàng
Ở chế độ thay thế đơn giản 32 vòng, theo tiêu chuẩn chúng ta cần 32 phím tròn. Để tạo khóa tròn, khóa 256 bit ban đầu được chia thành 8 khối 32 bit: K1…K8. Các phím K9...K24 là sự lặp lại theo chu kỳ của các phím K1...K8. Các phím K25…K32 là các phím K8…K1.
- Mỗi khối 64 bit được chia thành hai khối con - Ai và Bi.
- Khối con bên trái Ai được thêm modulo 232 bằng phím tròn K1: Ai+1 = Ai + Ki mod 232.
- Khối con bên trái đi qua hộp S.
- Các bit của khối con bên trái được dịch chuyển 11 vị trí (dịch chuyển theo chu kỳ).
- Khối con bên trái cộng với khối bên phải theo modulo 2: A = A ⊕ B . iii
- Khối con bên phải chấp nhận nghĩa gốc khối con bên trái: Bi+1 = Ai.
- Các khối con được hoán đổi.
Chỉ là một ví dụ về một vòng. Khóa 256 bit:
arvadek adava arvadek adava arvadek adava arvadek adava arva 00011 01010 11110 00011 01001 00001 01111 00011 01001 00011 11110 00011... . . . 00011 01010 11110 0 |
Sau đó, các phím tròn
K1 = 00011 01010 11110 00011 01001 00001 01 K2 = 111 00011 01001 00011 11110 00011 0001 K3 = . . . S - hộp= [ 1 , 15 , 13 , 0 , 5 , 7 , 10 , 4 , 9 , 2 , 3 , 14 , 6 , 11 , 8 , 12 ] |
Làm thế nào để sử dụng hộp S này? Rất đơn giản! Nếu đầu vào của S-box là 0 thì đầu ra sẽ là 1 (lấy ký hiệu thứ 0 của S-box), nếu là 4 thì đầu ra sẽ là 5 (lấy ký hiệu thứ 4), nếu đầu vào là 7 , thì đầu ra sẽ là 4, v.v.
Văn bản thô:
Được chia thành hai khối 32 bit gồm bit cao và bit thấp: 
Tất nhiên, ví dụ này hóa ra rất hoang đường, bởi vì GOST vẫn chưa phải là một tiêu chuẩn mà mọi người đều có thể tự mình trải qua.
Chế độ thay thế đơn giản quá đơn giản và có những nhược điểm đáng kể:
- một lỗi trong khối được mã hóa sẽ làm hỏng tất cả các bit của khối đó;
- khi mã hóa các khối văn bản gốc giống hệt nhau, người ta sẽ nhận được khối giống hệt nhau bản mã, có thể cung cấp thông tin nhất định cho người giải mã.
Vì vậy, chỉ nên sử dụng GOST 28147-89 ở chế độ thay thế đơn giản để mã hóa dữ liệu chính.
CHẾ ĐỘ CHƠI GAME
Chế độ này không có nhược điểm của chế độ thay thế đơn giản. Chế độ gamma được gọi như vậy vì nó sử dụng gamma, một chuỗi giả ngẫu nhiên được thêm modulo 2 vào bản rõ trong mỗi vòng. Gamma được hình thành từ thông điệp đồng bộ hóa S - một chuỗi giả ngẫu nhiên thay đổi theo mỗi lần lặp và được mã hóa ở chế độ thay thế đơn giản, sau đó nó chuyển thành gamma và được đặt chồng lên bản rõ.
Và bây giờ mọi thứ đã theo thứ tự.

Các bước 3–5 được lặp lại cho mỗi khối. Tất cả những thao tác này có thể được nhìn thấy trong sơ đồ. 
Việc giải mã được thực hiện theo cách tương tự; thay vì khối văn bản gốc, khối văn bản mã hóa được cung cấp.
Chế độ Gamma có phản hồi
Hãy phức tạp hơn. Thuật toán cũng tương tự như chế độ gamma nhưng gamma được hình thành dựa trên khối dữ liệu được mã hóa trước đó nên kết quả mã hóa của khối hiện tại cũng phụ thuộc vào các khối trước đó. 1. Thông báo đồng bộ S - Chuỗi giả ngẫu nhiên 64 bit.
2. S được mã hóa ở chế độ thay thế đơn giản.
3. Bản rõ được thêm modulo 2 vào gamma thu được.
4. Bản mã thu được sẽ được gửi dưới dạng thông báo đồng bộ hóa cho khối tiếp theo và cũng được gửi đến đầu ra. Bạn có thể thấy nó trông như thế nào trong sơ đồ. 
Chế độ chèn mô phỏng
Trong chế độ này, một phần chèn mô phỏng được tạo ra - một khối bổ sung có độ dài cố định, tùy thuộc vào văn bản và khóa nguồn. Khối nhỏ như vậy là cần thiết để xác nhận rằng không có biến dạng nào được đưa vào bản mã một cách vô tình hay cố ý - tức là để kiểm tra tính toàn vẹn. Chế độ này hoạt động như sau:
1. Một khối bản rõ trải qua 16 vòng ở chế độ thay thế đơn giản.
2. Một khối văn bản gốc khác được thêm vào khối kết quả modulo 2.
3. Tổng số này trải qua 16 vòng khác ở chế độ thay thế đơn giản.
4. Khối bản rõ tiếp theo được thêm vào và lặp lại thay thế dễ dàng và cứ như vậy cho đến khi không còn khối văn bản gốc nào nữa. 
Để xác minh, người nhận sau khi giải mã văn bản sẽ thực hiện một quy trình tương tự như mô tả. Nếu kết quả không khớp với phần chèn bắt chước được truyền đi, tất cả M khối tương ứng được coi là sai.
GOST 34.12-2015 (GRASSHOPPER)
Nhiều người cho rằng GOST 28147-89 đã lỗi thời và chưa đủ mạnh so với các thuật toán nước ngoài. Để thay thế nó, các nhà mật mã trong nước đã đưa ra một tiêu chuẩn mã hóa mới. Họ nói rằng điều này xảy ra do số lượng lớn các cuộc tấn công vào GOST cũ hoặc do độ dài khối này đã lỗi thời và quá nhỏ đối với các tập dữ liệu hiện đại. Những lý do thực sự không ai quảng cáo. Tất nhiên, có một số thay đổi về các đặc điểm chính.
Đặc điểm chính: khóa 256 bit, khối 128 bit.
Cũng cần phải nói rằng trong tiêu chuẩn mới, các hộp S đã được cố định và cân nhắc kỹ lưỡng nên bạn không cần phải phát minh ra các phương án thay thế ngẫu nhiên kỳ diệu của riêng mình. GOST mới có nhiều chế độ mã hóa hơn:
chế độ thay thế đơn giản (Sổ mã điện tử, ECB);
chế độ gamma (Bộ đếm, TLB);
chế độ gamma với phản hồi đầu ra (Phản hồi đầu ra, OFB);
chế độ thay thế đơn giản có tương tác (Cipher Block Chaining, SBC);
chế độ gamma với phản hồi văn bản mã hóa (Phản hồi mật mã, CFB);
chế độ tạo mô phỏng chèn (thuật toán Mã xác thực tin nhắn).
Hãy nhìn vào các chế độ mới.
Chế độ thay thế dễ dàng với sự tham gia
Như đã thấy trong tiêu chuẩn trước, chế độ thay thế đơn giản là chế độ yếu nhất trong số các chế độ, vì vậy trong tiêu chuẩn mới, giờ đây nó nhô ra và trở nên không đơn giản chút nào.
- Vector khởi tạo nghe có vẻ đáng sợ nhưng thực tế nó chỉ là một chuỗi bit đi vào đầu vào.
- Vectơ được chia thành hai phần - L và R, một trong số đó được thêm modulo 2 với bản rõ và phần còn lại trở thành một nửa vectơ khởi tạo cho khối tiếp theo.
- Tổng của bản rõ và một phần của vectơ khởi tạo được truyền qua một mật mã thay thế đơn giản.
- Các khối bản mã thu được sẽ được dán lại với nhau.
Khi bạn nhìn vào sơ đồ, mọi thứ sẽ ngay lập tức trở nên rõ ràng.

Tất nhiên, vectơ khởi tạo không đơn giản như vậy: nó trải qua một loạt các phép biến đổi tuyến tính (sử dụng thanh ghi dịch chuyển tuyến tính) trước khi bắt đầu mã hóa một khối mới. Nhưng để làm quen với mật mã, chỉ cần hình dung ra sơ đồ như vậy là đủ. Việc giải mã ở chế độ này cũng không hoàn toàn rõ ràng, vì vậy tốt hơn hết bạn nên xem sơ đồ.
Về điểm cộng - Mã hóa. Trong số những phát triển trong nước có nhà cung cấp tiền điện tử CryptoPro CSP.
Một vài lời về sức mạnh của chế độ mã hóa. Nhiều nhà mật mã nước ngoài đã cố gắng chống lại tiêu chuẩn của chúng tôi, nhưng hiện tại chưa có một cuộc tấn công nào có thể được thực hiện ở trình độ phát triển công nghệ hiện tại. Trong số các lập trình viên tiêu chuẩn này trong một khoảng thời gian dài không phổ biến lắm vì rất khó hiểu thuật toán vận hành từ văn bản của nó và không có đủ mô tả rõ ràng hơn. Nhưng hiện nay đã có rất nhiều cách triển khai bằng nhiều ngôn ngữ lập trình. Vì vậy, hiện nay việc sử dụng GOST là hoàn toàn có thể thực hiện được và ở nhiều khía cạnh, nó vượt qua các tiêu chuẩn nước ngoài. Rốt cuộc lòng yêu nước ở đâu?!
Mã hóa dữ liệu là cực kỳ quan trọng để bảo vệ sự riêng tư. Trong bài viết này tôi sẽ nói về nhiều loại khác nhau và các phương pháp mã hóa được sử dụng để bảo vệ dữ liệu ngày nay.
Bạn có biết không?
Trở lại thời La Mã, mã hóa đã được Julius Caesar sử dụng để làm cho kẻ thù không thể đọc được các bức thư và tin nhắn. Nó đóng một vai trò quan trọng như một chiến thuật quân sự, đặc biệt là trong chiến tranh.
Khi khả năng của Internet tiếp tục phát triển, ngày càng có nhiều hoạt động kinh doanh của chúng ta được tiến hành trực tuyến. Trong số này, quan trọng nhất là ngân hàng Internet, thanh toán trực tuyến, email, trao đổi riêng tư và tin nhắn chính thức v.v., liên quan đến việc trao đổi dữ liệu và thông tin bí mật. Nếu dữ liệu này rơi vào tay kẻ xấu, nó có thể gây hại không chỉ người dùng cá nhân, nhưng cũng có tất cả hệ thống trực tuyến việc kinh doanh.
Để ngăn chặn điều này xảy ra, một số biện pháp mạng bảo mật để bảo vệ việc truyền dữ liệu cá nhân. Đứng đầu trong số này là các quá trình mã hóa và giải mã dữ liệu, được gọi là mật mã. Có ba phương pháp mã hóa chính được sử dụng trong hầu hết các hệ thống hiện nay: mã hóa băm, mã hóa đối xứng và bất đối xứng. TRONG dòng sau, Tôi sẽ nói chi tiết hơn về từng loại mã hóa này.
Các loại mã hóa
Mã hóa đối xứng
Trong mã hóa đối xứng, dữ liệu thông thường có thể đọc được, được gọi là văn bản thuần túy, được mã hóa để trở nên không thể đọc được. Việc xáo trộn dữ liệu này được thực hiện bằng cách sử dụng một phím. Sau khi dữ liệu được mã hóa, nó có thể được gửi an toàn đến người nhận. Tại người nhận, dữ liệu được mã hóa sẽ được giải mã bằng chính khóa đã được sử dụng để mã hóa.
Vì vậy, rõ ràng rằng chìa khóa là quan trọng nhất phần quan trọng mã hóa đối xứng. Nó phải được ẩn khỏi người ngoài vì bất kỳ ai có quyền truy cập vào nó đều có thể giải mã dữ liệu riêng tư. Đây là lý do tại sao loại mã hóa này còn được gọi là "khóa bí mật".
Trong các hệ thống hiện đại, khóa thường là một chuỗi dữ liệu được lấy từ mật khẩu mạnh hoặc từ một nguồn hoàn toàn ngẫu nhiên. Nó được đưa vào mã hóa đối xứng phần mềm, sử dụng nó để mã hóa dữ liệu đầu vào. Việc xáo trộn dữ liệu đạt được bằng cách sử dụng thuật toán đối xứng mã hóa, chẳng hạn như Tiêu chuẩn mã hóa dữ liệu (DES), Tiêu chuẩn mã hóa nâng cao (AES) hoặc Thuật toán mã hóa dữ liệu quốc tế (IDEA).
Những hạn chế
Liên kết yếu nhất trong loại mã hóa này là tính bảo mật của khóa, cả về mặt lưu trữ và truyền tải đến người dùng được xác thực. Nếu hacker lấy được khóa này, hắn có thể dễ dàng giải mã dữ liệu được mã hóa, làm mất đi toàn bộ mục đích mã hóa.
Một nhược điểm khác là phần mềm xử lý dữ liệu không thể hoạt động với dữ liệu được mã hóa. Vì vậy, để có thể sử dụng được phần mềm này thì trước tiên dữ liệu phải được giải mã. Nếu bản thân phần mềm bị xâm phạm thì kẻ tấn công có thể dễ dàng lấy được dữ liệu.
Mã hóa bất đối xứng
Mã hóa khóa bất đối xứng hoạt động tương tự khóa đối xứng, là nó sử dụng một khóa để mã hóa tin nhắn được truyền đi. Tuy nhiên, thay vì sử dụng cùng một khóa, anh ta sử dụng một khóa hoàn toàn khác để giải mã tin nhắn này.
Khóa được sử dụng để mã hóa có sẵn cho bất kỳ và tất cả người dùng mạng. Vì vậy nó được gọi là khóa "công khai". Mặt khác, khóa dùng để giải mã được giữ bí mật và chỉ dành cho mục đích sử dụng riêng tư của người dùng. Do đó, nó được gọi là khóa "riêng tư". Mã hóa bất đối xứng còn được gọi là mã hóa khóa công khai.
Vì với phương pháp này, khóa bí mật cần thiết để giải mã tin nhắn không cần phải được truyền đi mọi lúc và nó thường chỉ có người dùng (người nhận) biết nên khả năng tin tặc có thể giải mã được tin nhắn là rất lớn. thấp hơn.
Diffie-Hellman và RSA là những ví dụ về thuật toán sử dụng mã hóa khóa chung.
Những hạn chế
Nhiều hacker sử dụng man-in-the-middle như một hình thức tấn công để vượt qua kiểu mã hóa này. Trong mã hóa bất đối xứng, bạn được cấp một khóa chung được sử dụng để trao đổi dữ liệu một cách an toàn với người hoặc dịch vụ khác. Tuy nhiên, tin tặc sử dụng thủ thuật lừa đảo trên mạng để lừa bạn liên lạc với chúng trong khi khiến bạn tin rằng mình đang sử dụng đường dây an toàn.
Để hiểu rõ hơn về kiểu hack này, hãy xem xét hai bên tương tác, Sasha và Natasha, và một hacker, Sergei, với mục đích chặn cuộc trò chuyện của họ. Đầu tiên, Sasha gửi một tin nhắn qua mạng dành cho Natasha, yêu cầu cô cung cấp khóa công khai. Sergei chặn tin nhắn này và lấy được khóa chung liên quan đến cô ấy rồi sử dụng nó để mã hóa và gửi một tin nhắn sai cho Natasha chứa khóa chung của anh ấy thay vì của Sasha.
Natasha nghĩ rằng tin nhắn này đến từ Sasha nên mã hóa nó bằng khóa chung của Sergei và gửi lại. Tin nhắn này một lần nữa bị Sergei chặn lại, giải mã, sửa đổi (nếu muốn), mã hóa lại bằng khóa chung mà Sasha đã gửi ban đầu và gửi lại cho Sasha.
Vì vậy, khi Sasha nhận được tin nhắn này, anh ta đã tin rằng nó đến từ Natasha và không hề hay biết về hành vi chơi xấu.
Băm
Kỹ thuật băm sử dụng thuật toán được gọi là hàm băm để tạo ra một chuỗi đặc biệt từ dữ liệu đã cho, được gọi là hàm băm. Hàm băm này có các thuộc tính sau:
- cùng một dữ liệu luôn tạo ra cùng một hàm băm.
- Không thể tạo dữ liệu thô chỉ từ hàm băm.
- Nó không đáng để thử sự kết hợp khác nhau dữ liệu đầu vào để cố gắng tạo ra cùng một hàm băm.
Do đó, điểm khác biệt chính giữa băm và hai hình thức mã hóa dữ liệu còn lại là khi dữ liệu được mã hóa (băm), nó không thể được truy xuất trở lại dạng ban đầu (được giải mã). Thực tế này đảm bảo rằng ngay cả khi tin tặc có được mã băm thì nó cũng sẽ vô ích đối với anh ta vì anh ta sẽ không thể giải mã nội dung của tin nhắn.
Thông báo tóm tắt 5 (MD5) và Thuật toán băm an toàn (SHA) là hai thuật toán băm được sử dụng rộng rãi.
Những hạn chế
Như đã đề cập trước đó, gần như không thể giải mã dữ liệu từ một hàm băm nhất định. Tuy nhiên, điều này chỉ đúng nếu việc băm mạnh được thực hiện. Trong trường hợp triển khai kỹ thuật băm yếu, sử dụng đủ tài nguyên và tấn công lực lượng vũ phu, một hacker kiên trì có thể tìm thấy dữ liệu khớp với hàm băm.
Kết hợp các phương pháp mã hóa
Như đã thảo luận ở trên, mỗi phương pháp mã hóa trong số ba phương pháp mã hóa này đều có một số nhược điểm. Tuy nhiên, khi sử dụng kết hợp các phương pháp này, chúng sẽ tạo thành một phương pháp đáng tin cậy và có tính hệ thống hiệu quả mã hóa.
Thông thường, các kỹ thuật khóa riêng và khóa chung được kết hợp và sử dụng cùng nhau. Phương thức khóa riêng cho phép giải mã nhanh hơn, trong khi phương thức khóa chung cung cấp giải pháp an toàn hơn và hiệu quả hơn. Một cách thuận tiệnđể chuyển khóa bí mật. Sự kết hợp các phương pháp này được gọi là "phong bì kỹ thuật số". Chương trình mã hóa E-mail PGP dựa trên kỹ thuật "phong bì kỹ thuật số".
Băm được sử dụng như một phương tiện để kiểm tra độ mạnh của mật khẩu. Nếu hệ thống lưu trữ hàm băm của mật khẩu thay vì chính mật khẩu thì nó sẽ an toàn hơn, vì ngay cả khi tin tặc có được hàm băm này, anh ta cũng sẽ không thể hiểu (đọc) nó. Trong quá trình xác minh, hệ thống sẽ kiểm tra hàm băm của mật khẩu đến và xem kết quả có khớp với những gì được lưu trữ hay không. Bằng cách này, mật khẩu thực tế sẽ chỉ hiển thị trong những khoảnh khắc ngắn ngủi khi nó cần được thay đổi hoặc xác minh, giúp giảm đáng kể khả năng nó rơi vào tay kẻ xấu.
Băm cũng được sử dụng để xác thực dữ liệu bằng khóa bí mật. Một hàm băm được tạo bằng cách sử dụng dữ liệu và khóa này. Do đó, chỉ có dữ liệu và hàm băm được hiển thị và bản thân khóa không được truyền đi. Bằng cách này, nếu những thay đổi được thực hiện đối với dữ liệu hoặc hàm băm, chúng sẽ dễ dàng được phát hiện.
Tóm lại, những kỹ thuật này có thể được sử dụng để mã hóa dữ liệu một cách hiệu quả thành định dạng không thể đọc được để đảm bảo dữ liệu được an toàn. Hầu hết các hệ thống hiện đại thường sử dụng kết hợp các phương pháp mã hóa này cùng với triển khai mạnh mẽ các thuật toán để cải thiện tính bảo mật. Ngoài tính năng bảo mật, các hệ thống này còn cung cấp nhiều lợi ích kèm theo, chẳng hạn như xác minh danh tính người dùng và đảm bảo rằng dữ liệu nhận được không thể bị giả mạo.
Serge Panasenko,
Trưởng phòng phát triển phần mềm tại Ankad,
[email được bảo vệ]
Các khái niệm cơ bản
Quá trình chuyển đổi dữ liệu mở thành dữ liệu được mã hóa và ngược lại thường được gọi là mã hóa và hai thành phần của quá trình này lần lượt được gọi là mã hóa và giải mã. Về mặt toán học, phép biến đổi này được thể hiện bằng các phụ thuộc sau đây mô tả các hành động với thông tin ban đầu:
C = Ek1(M)
M" = Dk2(C),
trong đó M (tin nhắn) - mở thông tin(trong các tài liệu về bảo mật thông tin nó thường được gọi là " văn bản gốc");
C (văn bản mật mã) - văn bản mã hóa (hoặc mật mã) thu được do mã hóa;
E (mã hóa) - chức năng mã hóa thực hiện các phép biến đổi mật mã trên văn bản nguồn;
k1 (key) - tham số của hàm E, gọi là khóa mã hóa;
M" - thông tin thu được do giải mã;
D (giải mã) - chức năng giải mã thực hiện các phép biến đổi mật mã nghịch đảo trên bản mã;
k2 là khóa dùng để giải mã thông tin.
Khái niệm “khóa” trong tiêu chuẩn GOST 28147-89 (thuật toán mã hóa đối xứng) được định nghĩa như sau: “trạng thái bí mật cụ thể của một số tham số của thuật toán chuyển đổi mật mã, đảm bảo lựa chọn một chuyển đổi từ một tập hợp các chuyển đổi có thể cho của thuật toán này biến đổi". Nói cách khác, khóa là một phần tử duy nhất mà bạn có thể thay đổi kết quả của thuật toán mã hóa: cùng một văn bản nguồn khi được sử dụng các phím khác nhau sẽ được mã hóa khác nhau.
Để kết quả giải mã trùng khớp với tin nhắn gốc(tức là với M" = M), hai điều kiện phải được thỏa mãn đồng thời. Thứ nhất, hàm giải mã D phải tương ứng với hàm mã hóa E. Thứ hai, khóa giải mã k2 phải tương ứng với khóa mã hóa k1.
Nếu thuật toán mã hóa mạnh về mặt mật mã được sử dụng để mã hóa thì nếu không có khóa k2 chính xác thì không thể lấy được M" = M. Độ mạnh của mật mã là đặc điểm chính của thuật toán mã hóa và chủ yếu biểu thị mức độ phức tạp của việc lấy bản gốc văn bản từ văn bản được mã hóa không có khóa k2.
Các thuật toán mã hóa có thể được chia thành hai loại: đối xứng và mã hóa bất đối xứng. Đối với trường hợp trước, tỷ lệ khóa mã hóa và khóa giải mã được xác định là k1 = k2 = k (tức là hàm E và D sử dụng cùng một khóa mã hóa). Với mã hóa bất đối xứng, khóa mã hóa k1 được tính từ khóa k2 sao cho không thể chuyển đổi ngược lại, ví dụ: sử dụng công thức k1 = ak2 mod p (a và p là các tham số của thuật toán được sử dụng).
Mã hóa đối xứng
Các thuật toán mã hóa đối xứng có từ thời cổ đại: phương pháp che giấu thông tin này đã được hoàng đế La Mã Gaius Julius Caesar sử dụng vào thế kỷ 1 trước Công nguyên. e., và thuật toán do ông phát minh ra được gọi là “hệ thống mật mã Caesar”.
Hiện nay, thuật toán mã hóa đối xứng được biết đến nhiều nhất là DES (Data Tiêu chuẩn mã hóa), được phát triển vào năm 1977. Cho đến gần đây, nó là "tiêu chuẩn của Hoa Kỳ" vì chính phủ nước đó khuyến nghị sử dụng nó để thực hiện hệ thống khác nhau mã hóa dữ liệu. Mặc dù thực tế là DES ban đầu được lên kế hoạch sử dụng không quá 10-15 năm, những nỗ lực thay thế nó chỉ bắt đầu vào năm 1997.
Chúng tôi sẽ không trình bày chi tiết về DES (hầu hết tất cả các sách trong danh sách tài liệu bổ sung đều có miêu tả cụ thể) và hãy chuyển sang các thuật toán mã hóa hiện đại hơn. Điều đáng lưu ý là lý do chính cho việc thay đổi tiêu chuẩn mã hóa là do độ mạnh mật mã tương đối yếu của nó, lý do là độ dài khóa DES chỉ có 56 bit đáng kể. Được biết, bất kỳ thuật toán mã hóa mạnh nào cũng có thể bị bẻ khóa bằng cách thử tất cả các khóa mã hóa có thể (cái gọi là phương pháp vũ phu - lực lượng vũ phu tấn công). Có thể dễ dàng tính toán rằng một cụm gồm 1 triệu bộ xử lý, mỗi bộ xử lý tính toán 1 triệu khóa mỗi giây, sẽ kiểm tra 256 biến thể của khóa DES trong gần 20 giờ. khả năng tính toán là khá thực tế, rõ ràng là khóa 56-bit quá ngắn và thuật toán DES cần phải thay thế bằng cái mạnh hơn.
Ngày nay, hai thuật toán mã hóa mạnh hiện đại đang được sử dụng ngày càng nhiều: tiêu chuẩn nội địa GOST 28147-89 và tiêu chuẩn mật mã mới của Hoa Kỳ - AES (Tiêu chuẩn mã hóa nâng cao).
Tiêu chuẩn GOST 28147-89
Thuật toán được xác định bởi GOST 28147-89 (Hình 1) có độ dài khóa mã hóa là 256 bit. Nó mã hóa thông tin theo khối 64 bit (thuật toán như vậy được gọi là thuật toán khối), sau đó được chia thành hai khối con 32 bit (N1 và N2). Khối con N1 đang được xử lý theo một cách nào đó, sau đó giá trị của nó được cộng vào giá trị của khối con N2 (phép cộng được thực hiện theo modulo 2, tức là phép toán logic XOR được áp dụng - “độc quyền hoặc”), và sau đó các khối con được hoán đổi. Sự chuyển đổi nàyđược thực hiện một số lần nhất định (“vòng”): 16 hoặc 32, tùy thuộc vào chế độ hoạt động của thuật toán. Trong mỗi vòng, hai thao tác được thực hiện.
Đầu tiên là gõ phím. Nội dung của khối con N1 được thêm modulo 2 với phần 32 bit của khóa Kx. Chìa khóa đầy đủ mã hóa được biểu diễn dưới dạng ghép các khóa con 32 bit: K0, K1, K2, K3, K4, K5, K6, K7. Trong quá trình mã hóa, một trong các khóa con này sẽ được sử dụng, tùy thuộc vào số vòng và chế độ hoạt động của thuật toán.
Hoạt động thứ hai là thay thế bảng. Sau khi khóa, khối con N1 được chia thành 8 phần, mỗi phần 4 bit, giá trị của mỗi phần được thay thế theo bảng thay thế cho phần này của khối con. Khối con sau đó được quay bit sang trái 11 bit.
Thay thế bảng(Hộp thay thế - S-box) thường được sử dụng trong các thuật toán mã hóa hiện đại, vì vậy cần giải thích cách tổ chức hoạt động đó. Giá trị đầu ra của các khối được ghi vào bảng. Khối dữ liệu có kích thước nhất định (trong trường hợp của chúng tôi - 4 bit) có kích thước riêng biểu diễn số, trong đó chỉ định số lượng giá trị đầu ra. Ví dụ: nếu hộp S trông giống như 4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1 và khối 4 bit “0100” đến đầu vào (giá trị 4), thì theo bảng, giá trị đầu ra sẽ là 15, tức là “1111” (0 a 4, 1 a 11, 2 a 2 ...).
Thuật toán, được xác định bởi GOST 28147-89, cung cấp bốn chế độ hoạt động: thay thế đơn giản, chơi trò chơi, chơi trò chơi với nhận xét và tạo ra các tiền tố bắt chước. Chúng sử dụng cùng một chuyển đổi mã hóa được mô tả ở trên, nhưng vì mục đích của các chế độ là khác nhau nên việc chuyển đổi này được thực hiện khác nhau ở mỗi chế độ.
Đang ở chế độ thay thế dễ dàngĐể mã hóa từng khối thông tin 64 bit, 32 vòng mô tả ở trên được thực hiện. Trong trường hợp này, khóa con 32 bit được sử dụng theo trình tự sau:
K0, K1, K2, K3, K4, K5, K6, K7, K0, K1, v.v. - ở các vòng 1 đến 24;
K7, K6, K5, K4, K3, K2, K1, K0 - ở các vòng 25 đến 32.
Giải mã trong chế độ nàyđược thực hiện theo cách tương tự, nhưng với trình tự sử dụng khóa con hơi khác một chút:
K0, K1, K2, K3, K4, K5, K6, K7 - ở các vòng 1 đến 8;
K7, K6, K5, K4, K3, K2, K1, K0, K7, K6, v.v. - ở các vòng 9 đến 32.
Tất cả các khối được mã hóa độc lập với nhau, tức là kết quả mã hóa của mỗi khối chỉ phụ thuộc vào nội dung của nó (khối tương ứng của văn bản gốc). Nếu có một số khối văn bản gốc (thuần túy) giống hệt nhau thì các khối văn bản mã hóa tương ứng cũng sẽ giống hệt nhau, điều này mang lại thêm thông tin hữu ích cho một nhà giải mã đang cố gắng phá mật mã. Do đó, chế độ này được sử dụng chủ yếu để mã hóa các khóa mã hóa (sơ đồ nhiều khóa thường được triển khai, trong đó, vì một số lý do, các khóa được mã hóa lẫn nhau). Hai chế độ hoạt động khác nhằm mục đích mã hóa thông tin - gamma và gamma có phản hồi.
TRONG chế độ gamma Mỗi khối văn bản gốc được thêm từng bit theo modulo 2 vào khối gamma mật mã 64 bit. Mật mã gamma là một chuỗi đặc biệt thu được nhờ một số thao tác nhất định với các thanh ghi N1 và N2 (xem Hình 1).
1. Việc điền ban đầu của chúng được ghi vào các thanh ghi N1 và N2 - giá trị 64 bit được gọi là thông báo đồng bộ hóa.
2. Nội dung của thanh ghi N1 và N2 được mã hóa (trong trong trường hợp này- đồng bộ tin nhắn) ở chế độ thay thế đơn giản.
3. Nội dung của thanh ghi N1 được cộng modulo (232 - 1) với hằng số C1 = 224 + 216 + 28 + 24 và kết quả của phép cộng được ghi vào thanh ghi N1.
4. Nội dung của thanh ghi N2 được cộng modulo 232 với hằng số C2 = 224 + 216 + 28 + 1 và kết quả của phép cộng được ghi vào thanh ghi N2.
5. Nội dung của các thanh ghi N1 và N2 được xuất ra dưới dạng khối gamma 64 bit của mật mã (trong trường hợp này, N1 và N2 tạo thành khối gamma đầu tiên).
Nếu cần khối gamma tiếp theo (tức là cần tiếp tục mã hóa hoặc giải mã), nó sẽ quay lại bước 2.
Để giải mã, gamma được tạo ra theo cách tương tự, sau đó văn bản mã hóa và bit gamma lại được XOR. Vì thao tác này có thể đảo ngược nên trong trường hợp thang đo được phát triển chính xác, sẽ thu được văn bản gốc (bảng).
Mã hóa và giải mã ở chế độ gamma
Để phát triển mật mã cần thiết để giải mã gamma, người dùng giải mã mật mã phải có cùng khóa và cùng giá trị của thông báo đồng bộ hóa đã được sử dụng khi mã hóa thông tin. Nếu không, sẽ không thể lấy được văn bản gốc từ văn bản được mã hóa.
Trong hầu hết các triển khai thuật toán GOST 28147-89, thông báo đồng bộ hóa không phải là bí mật, tuy nhiên, có những hệ thống trong đó thông báo đồng bộ hóa là thành phần bí mật giống như khóa mã hóa. Đối với các hệ thống như vậy, độ dài khóa hiệu dụng của thuật toán (256 bit) được tăng thêm 64 bit khác của thông báo đồng bộ hóa bí mật, cũng có thể được coi là thành phần khóa.
Trong chế độ gamma vòng kín, để điền vào các thanh ghi N1 và N2, bắt đầu từ khối thứ 2, không phải khối gamma trước đó được sử dụng mà là kết quả của việc mã hóa khối văn bản gốc trước đó (Hình 2). Khối đầu tiên trong chế độ này được tạo hoàn toàn giống với khối trước.
 |
Cơm. 2. Phát triển gamma mật mã ở chế độ gamma có phản hồi. |
Xét về chế độ tạo tiền tố bắt chước, cần xác định khái niệm chủ thể sinh sản. Tiền tố giả là mật mã kiểm tra tổng, được tính toán bằng khóa mã hóa và được thiết kế để xác minh tính toàn vẹn của tin nhắn. Khi tạo tiền tố bắt chước, việc sau được thực hiện: hoạt động sau đây: khối thông tin 64 bit đầu tiên tính tiền tố giả được ghi vào thanh ghi N1 và N2 và được mã hóa ở chế độ thay thế đơn giản giảm bớt (16 vòng đầu tiên trong số 32 vòng được thực hiện). Kết quả thu được được tính tổng modulo 2 với khối thông tin tiếp theo và kết quả được lưu trong N1 và N2.
Chu kỳ lặp lại cho đến khi khối cuối cùng thông tin. Nội dung 64-bit thu được của các thanh ghi N1 và N2 hoặc một phần của chúng là kết quả của các phép biến đổi này được gọi là tiền tố mô phỏng. Kích thước của tiền tố giả được chọn dựa trên độ tin cậy cần thiết của tin nhắn: với độ dài của tiền tố giả r bit, xác suất để một thay đổi trong tin nhắn sẽ không được chú ý là bằng 2-r. Thông thường, a. Tiền tố giả 32 bit được sử dụng, tức là một nửa nội dung của các thanh ghi. Điều này là đủ, vì giống như bất kỳ tổng kiểm tra nào, tệp đính kèm giả chủ yếu nhằm mục đích bảo vệ khỏi sự biến dạng thông tin do vô tình. Để bảo vệ chống lại việc cố ý sửa đổi dữ liệu, các biện pháp khác phương pháp mật mã- chủ yếu là chữ ký số điện tử.
Khi trao đổi thông tin, tiền tố bắt chước đóng vai trò như một loại phương tiện bổ sungđiều khiển. Nó được tính cho bản rõ khi bất kỳ thông tin nào được mã hóa và được gửi cùng với bản mã. Sau khi giải mã, giá trị mới của tiền tố giả sẽ được tính toán và so sánh với giá trị đã gửi. Nếu các giá trị không khớp, điều đó có nghĩa là văn bản mã hóa bị hỏng trong quá trình truyền hoặc sử dụng khóa không chính xác trong quá trình giải mã. Tiền tố giả đặc biệt hữu ích để kiểm tra tính chính xác của việc giải mã Thông tin mấu chốt khi sử dụng sơ đồ đa phím.
Thuật toán GOST 28147-89 được coi là một thuật toán rất mạnh - hiện tại chưa có đề xuất nào được tiết lộ nữa phương pháp hiệu quả hơn phương pháp "vũ phu" đã đề cập ở trên. Tính bảo mật cao của nó đạt được chủ yếu nhờ độ dài khóa lớn - 256 bit. Khi sử dụng thông báo đồng bộ bí mật, độ dài khóa hiệu dụng sẽ tăng lên 320 bit và việc mã hóa bảng thay thế sẽ bổ sung thêm các bit. Ngoài ra, cường độ mật mã phụ thuộc vào số vòng chuyển đổi, theo GOST 28147-89 phải là 32 (toàn bộ hiệu ứng phân tán dữ liệu đầu vào đạt được sau 8 vòng).
Tiêu chuẩn AES
Không giống như thuật toán GOST 28147-89, vốn vẫn được giữ bí mật trong một thời gian dài, tiêu chuẩn Mỹ Mã hóa AES, dự định thay thế DES, đã được lựa chọn thông qua một cuộc thi mở, nơi tất cả các tổ chức và cá nhân quan tâm có thể nghiên cứu và nhận xét về các thuật toán ứng viên.
Một cuộc cạnh tranh để thay thế DES được công bố vào năm 1997. Viện quốc gia Tiêu chuẩn và công nghệ Hoa Kỳ (NIST - Viện Tiêu chuẩn và Công nghệ Quốc gia). 15 thuật toán ứng cử viên đã được gửi tham gia cuộc thi, được phát triển bởi cả các tổ chức nổi tiếng trong lĩnh vực mật mã (RSA Security, Counterpane, v.v.) và các cá nhân. Kết quả của cuộc thi được công bố vào tháng 10 năm 2000: người chiến thắng là thuật toán Rijndael, được phát triển bởi hai nhà mật mã người Bỉ, Vincent Rijmen và Joan Daemen.
Thuật toán Rijndael không giống với hầu hết các thuật toán mã hóa đối xứng đã biết, cấu trúc của nó được gọi là “mạng Feistel” và tương tự như GOST 28147-89 của Nga. Điểm đặc biệt của mạng Feistel là giá trị đầu vào được chia thành hai hoặc nhiều khối con, một phần trong đó trong mỗi vòng được xử lý theo một luật nhất định, sau đó nó được xếp chồng lên các khối con chưa được xử lý (xem Hình 1).
Không giống như tiêu chuẩn mã hóa trong nước, thuật toán Rijndael biểu thị một khối dữ liệu dưới dạng mảng byte hai chiều có kích thước 4X4, 4X6 hoặc 4X8 (cho phép sử dụng một số kích thước cố định của khối thông tin được mã hóa). Tất cả các thao tác được thực hiện trên các byte riêng lẻ của mảng cũng như trên các cột và hàng độc lập.
Thuật toán Rijndael thực hiện bốn phép biến đổi: BS (ByteSub) - thay thế bảng từng byte của mảng (Hình 3); SR (ShiftRow) - dịch chuyển các hàng mảng (Hình 4). Với thao tác này, dòng đầu tiên không thay đổi và phần còn lại được dịch chuyển theo chu kỳ từng byte sang trái một số byte cố định, tùy thuộc vào kích thước của mảng. Ví dụ: đối với mảng 4X4, các dòng 2, 3 và 4 được dịch chuyển tương ứng 1, 2 và 3 byte. Tiếp đến là MC (MixColumn) - thao tác trên các cột mảng độc lập (Hình 5), khi mỗi cột được nhân với một ma trận cố định c(x) theo một quy luật nhất định. Và cuối cùng là AK (AddRoundKey) - thêm khóa. Mỗi bit của mảng được thêm modulo 2 với bit tương ứng của khóa tròn, lần lượt được tính theo một cách nhất định từ khóa mã hóa (Hình 6).
 |
| Cơm. 3. Hoạt động BS. |
 |
| Cơm. 4. Chiến dịch SR. |
 |
| Cơm. 5. Chiến dịch MC. |
Số vòng mã hóa (R) trong thuật toán Rijndael có thể thay đổi (10, 12 hoặc 14 vòng) và phụ thuộc vào kích thước khối và khóa mã hóa (cũng có một số kích thước cố định cho khóa).
Việc giải mã được thực hiện bằng các thao tác ngược sau. Việc đảo ngược bảng và thay thế bảng được thực hiện trên bảng nghịch đảo (so với bảng được sử dụng trong quá trình mã hóa). Hoạt động ngược lại với SR là xoay các hàng sang phải thay vì sang trái. Phép toán nghịch đảo của MC là phép nhân sử dụng các quy tắc tương tự với một ma trận khác d(x) thỏa mãn điều kiện: c(x) * d(x) = 1. Việc cộng khóa AK là nghịch đảo của chính nó, vì nó chỉ sử dụng XOR hoạt động. Những cái này hoạt động ngược lạiđược sử dụng trong quá trình giải mã theo trình tự ngược lại với chuỗi được sử dụng trong quá trình mã hóa.
Rijndael đã trở thành tiêu chuẩn mới cho việc mã hóa dữ liệu do có một số ưu điểm so với các thuật toán khác. Trước hết, nó cung cấp tốc độ cao mã hóa trên tất cả các nền tảng: cả trong triển khai phần mềm và phần cứng. Nó được phân biệt một cách không thể so sánh được cơ hội tốt nhất song song hóa các phép tính so với các thuật toán khác được gửi đến cuộc thi. Ngoài ra, yêu cầu tài nguyên cho hoạt động của nó là tối thiểu, điều này rất quan trọng khi được sử dụng trong các thiết bị có khả năng tính toán hạn chế.
Nhược điểm duy nhất của thuật toán có thể được coi là sơ đồ độc đáo vốn có của nó. Thực tế là các thuộc tính của thuật toán dựa trên mạng Feistel đã được nghiên cứu kỹ lưỡng và ngược lại, Rijndael có thể chứa các lỗ hổng ẩn chỉ có thể được phát hiện sau một thời gian kể từ khi nó bắt đầu được sử dụng rộng rãi.
Mã hóa bất đối xứng
Các thuật toán mã hóa bất đối xứng, như đã lưu ý, sử dụng hai khóa: k1 - khóa mã hóa hoặc công khai và k2 - khóa giải mã hoặc bí mật. Khóa công khai tính từ bí mật: k1 = f(k2).
Các thuật toán mã hóa bất đối xứng dựa trên việc sử dụng các hàm một chiều. Theo định nghĩa, hàm số y = f(x) là một chiều nếu: dễ dàng tính được với mọi những lựa chọn khả thi x và đối với hầu hết các giá trị có thể có của y, việc tính một giá trị của x sao cho y = f(x) là khá khó khăn.
Một ví dụ về hàm một chiều là phép nhân hai số lớn: N = P*Q. Bản thân phép nhân như vậy là một phép toán đơn giản. Tuy nhiên, hàm nghịch đảo (phân tích N thành hai thừa số lớn), gọi là nhân tử hóa, theo ước tính thời hiện đại, khá phức tạp. bài toán. Ví dụ: phân tích nhân tử N với kích thước 664 bit tại P ? Q sẽ yêu cầu khoảng 1023 thao tác và để tính nghịch đảo x cho số mũ mô đun y = ax mod p với a, p và y đã biết (có cùng kích thước a và p), bạn cần thực hiện khoảng 1026 thao tác. Ví dụ cuối cùng được đưa ra được gọi là Bài toán logarit rời rạc (DLP) và loại hàm này thường được sử dụng trong các thuật toán mã hóa bất đối xứng, cũng như trong các thuật toán được sử dụng để tạo chữ ký số điện tử.
Một lớp hàm quan trọng khác được sử dụng trong mã hóa bất đối xứng là hàm cửa sau một chiều. Định nghĩa của họ nêu rõ rằng một hàm là một chiều với cửa sau nếu nó là một chiều và nó có thể được tính toán một cách hiệu quả. chức năng trái ngược x = f-1(y), tức là nếu biết “đoạn bí mật” (một số bí mật nhất định, khi áp dụng thuật toán mã hóa bất đối xứng - giá trị của khóa bí mật).
Các chức năng cửa sau một chiều được sử dụng trong thuật toán mã hóa bất đối xứng RSA được sử dụng rộng rãi.
Thuật toán RSA
Được phát triển vào năm 1978 bởi ba tác giả (Rivest, Shamir, Adleman), nó có tên từ những chữ cái đầu tiên trong họ của các nhà phát triển. Độ tin cậy của thuật toán dựa trên độ khó của việc phân tích các số lớn và tính logarit rời rạc. Tham số chính Thuật toán RSA- mô đun của hệ thống N, theo đó mọi phép tính trong hệ thống được thực hiện và N = P*Q (P và Q là ngẫu nhiên bí mật đơn giản số lượng lớn, thường có cùng kích thước).
Khóa bí mật k2 được chọn ngẫu nhiên và phải đáp ứng các điều kiện sau:
1 trong đó GCD là ước số chung lớn nhất, tức là k1 phải nguyên tố cùng với giá trị của hàm Euler F(N), giá trị sau bằng số số nguyên dương trong khoảng từ 1 đến N cùng nguyên tố đến N và được tính như sau F(N) = (P - 1)*(Q - 1). Khóa công khai k1 được tính từ mối quan hệ (k2*k1) = 1 mod F(N) và vì mục đích này, thuật toán Euclide tổng quát (thuật toán tính ước số chung lớn nhất) được sử dụng. Việc mã hóa khối dữ liệu M bằng thuật toán RSA được thực hiện như sau: C=M [đến lũy thừa k1] mod N. Lưu ý rằng vì trong hệ thống mật mã thực sử dụng RSA, số k1 rất lớn (hiện tại kích thước của nó có thể đạt tới 2048 bit), tính toán trực tiếp M [đến lũy thừa k1] không có thật. Để có được nó, người ta sử dụng sự kết hợp của bình phương lặp lại của M và nhân các kết quả. Đảo ngược chức năng này đối với kích thước lớn là không khả thi; nói cách khác, không thể tìm được M với C, N và k1 đã biết. Tuy nhiên, với khóa bí mật k2, sử dụng các phép biến đổi đơn giản, người ta có thể tính được M = Ck2 mod N. Rõ ràng, ngoài chính khóa bí mật, cần phải đảm bảo tính bí mật của các tham số P và Q. Nếu kẻ tấn công lấy được các giá trị của chúng , anh ta sẽ có thể tính được khóa bí mật k2. Nhược điểm chính của mã hóa đối xứng là phải chuyển khóa “từ tay này sang tay khác”. Hạn chế này rất nghiêm trọng vì nó khiến không thể sử dụng mã hóa đối xứng trong các hệ thống có số lượng người tham gia không giới hạn. Tuy nhiên, mặt khác, mã hóa đối xứng có một số ưu điểm có thể thấy rõ so với những nhược điểm nghiêm trọng của mã hóa bất đối xứng. Đầu tiên trong số đó là tốc độ hoạt động mã hóa và giải mã thấp do thực hiện các hoạt động sử dụng nhiều tài nguyên. Một nhược điểm “lý thuyết” khác là sức mạnh mật mã của thuật toán mã hóa bất đối xứng chưa được chứng minh về mặt toán học. Điều này chủ yếu là do vấn đề logarit rời rạc - người ta vẫn chưa chứng minh được rằng giải pháp của nó trong thời gian chấp nhận được là không thể. Những khó khăn không cần thiết cũng được tạo ra do nhu cầu bảo vệ khóa chung khỏi bị thay thế - bằng cách thay thế khóa chung của người dùng hợp pháp, kẻ tấn công sẽ có thể mã hóa một tin nhắn quan trọng bằng khóa chung của mình và sau đó dễ dàng giải mã nó bằng khóa riêng của mình. Tuy nhiên, những thiếu sót này không ngăn cản việc sử dụng rộng rãi các thuật toán mã hóa bất đối xứng. Ngày nay có các hệ thống mật mã hỗ trợ chứng nhận khóa công khai, cũng như kết hợp các thuật toán mã hóa đối xứng và bất đối xứng. Nhưng đây là một chủ đề cho một bài viết riêng biệt. Đối với những độc giả thực sự quan tâm đến mã hóa, tác giả khuyên nên mở rộng tầm nhìn của họ với sự trợ giúp của những cuốn sách sau. Bạn có thể tìm thấy mô tả đầy đủ về các thuật toán mã hóa trong các tài liệu sau: Trong thế kỷ 21, mật mã đóng một vai trò quan trọng trong cuộc sống số của con người hiện đại. Chúng ta hãy xem xét ngắn gọn các cách để mã hóa thông tin. Rất có thể bạn đã gặp phải mật mã cơ bản và có thể biết một số phương pháp mã hóa. Ví dụ, Mật mã Caesar thường được sử dụng trong các trò chơi giáo dục dành cho trẻ em. ROT13 là một loại mã hóa tin nhắn phổ biến khác. Trong đó, mỗi chữ cái trong bảng chữ cái được dịch chuyển 13 vị trí, như thể hiện trong hình: Như bạn có thể thấy, mật mã này không cung cấp sự bảo mật thông tin thực sự đáng tin cậy: nó là một ví dụ đơn giản và rõ ràng về toàn bộ ý tưởng về mật mã. Ngày nay chúng ta nói về mật mã thường xuyên nhất trong bối cảnh của một số công nghệ. Thông tin cá nhân và tài chính được truyền đi một cách an toàn như thế nào khi chúng tôi mua hàng trực tuyến hoặc xem tài khoản ngân hàng? Làm cách nào bạn có thể lưu trữ dữ liệu một cách an toàn để không ai có thể mở máy tính của bạn, rút ổ cứng ra và có toàn quyền truy cập vào tất cả thông tin trên đó? Chúng tôi sẽ trả lời những câu hỏi này và những câu hỏi khác trong bài viết này. Trong an ninh mạng, có một số điều khiến người dùng lo lắng khi liên quan đến bất kỳ dữ liệu nào. Chúng bao gồm tính bảo mật, tính toàn vẹn và tính sẵn có của thông tin. Bảo mật– dữ liệu không thể được nhận hoặc đọc bởi người dùng trái phép. Tính toàn vẹn thông tin– tin tưởng rằng thông tin sẽ còn nguyên vẹn 100% và sẽ không bị kẻ tấn công thay đổi. Sự sẵn có của thông tin– có quyền truy cập vào dữ liệu khi cần thiết. Bài viết này cũng sẽ xem xét các dạng mật mã kỹ thuật số khác nhau và cách chúng có thể giúp đạt được các mục tiêu được liệt kê ở trên. Trước khi đi sâu vào chủ đề, chúng ta hãy trả lời một câu hỏi đơn giản: “mã hóa” chính xác nghĩa là gì? Mã hóa là việc chuyển đổi thông tin để che giấu nó khỏi những người không được ủy quyền, đồng thời cho phép người dùng được ủy quyền truy cập vào nó. Để mã hóa và giải mã dữ liệu đúng cách, bạn cần hai thứ: dữ liệu và khóa giải mã. Khi sử dụng mã hóa đối xứng, khóa để mã hóa và giải mã dữ liệu là như nhau. Hãy lấy một chuỗi và mã hóa nó bằng Ruby và OpenSSL: hồng ngọc require "openssl" require "pry" data_to_encrypt = "bây giờ bạn có thể đọc được thông tin của tôi!" cipher = OpenSSL::Cipher.new("aes256") khóa mật mã.encrypt = cipher.random_key iv = cipher.random_iv data_to_encrypt = cipher.update(data_to_encrypt) + cipher.final bind.pry true yêu cầu "openssl" yêu cầu "cọc" mật mã = OpenSSL::Cipher. mới("aes256") mật mã mã hóa khóa = mật mã. ngẫu nhiên_key iv = mật mã. ngẫu nhiên_iv data_to_encrypt = mật mã. cập nhật (data_to_encrypt) + mật mã. cuối cùng ràng buộc. nâng lên ĐÚNG VẬY Đây là những gì chương trình sẽ xuất ra: Xin lưu ý rằng biến dữ liệu_to_encrypt, ban đầu là dòng "bây giờ bạn có thể đọc được tôi!" giờ là một loạt các ký tự lạ. Hãy đảo ngược quá trình bằng cách sử dụng khóa ban đầu được lưu trữ trong một biến chìa khóa. Sau khi sử dụng cùng khóa mà chúng tôi đã đặt để mã hóa, chúng tôi giải mã tin nhắn và nhận được chuỗi gốc. Hãy xem xét các phương pháp mã hóa khác. Vấn đề với mã hóa đối xứng là: giả sử bạn cần gửi một số dữ liệu qua Internet. Nếu cần có cùng một khóa để mã hóa và giải mã dữ liệu thì hóa ra khóa đó phải được gửi trước. Điều này có nghĩa là khóa sẽ cần được gửi qua kết nối không an toàn. Nhưng bằng cách này, khóa có thể bị bên thứ ba chặn và sử dụng. Để tránh kết quả này, mã hóa bất đối xứng đã được phát minh. Để sử dụng mã hóa bất đối xứng, bạn cần tạo hai khóa có liên quan về mặt toán học. Một là khóa riêng mà chỉ bạn mới có quyền truy cập. Thứ hai là mở, có sẵn công khai. Hãy xem một ví dụ về giao tiếp sử dụng mã hóa bất đối xứng. Trong đó, máy chủ và người dùng sẽ gửi tin nhắn cho nhau. Mỗi người trong số họ có hai khóa: riêng tư và công khai. Người ta đã nói trước đó rằng các phím được kết nối. Những thứ kia. Một tin nhắn được mã hóa bằng khóa riêng chỉ có thể được giải mã bằng khóa chung liền kề. Do đó, để bắt đầu liên lạc, bạn cần trao đổi khóa chung. Nhưng làm thế nào bạn có thể hiểu rằng khóa chung của máy chủ thuộc về máy chủ cụ thể này? Có một số cách để giải quyết vấn đề này. Phương pháp phổ biến nhất (và phương pháp được sử dụng trên Internet) là sử dụng cơ sở hạ tầng khóa công khai (PKI). Trong trường hợp các trang web, có Cơ quan cấp chứng chỉ, có một thư mục gồm tất cả các trang web đã cấp chứng chỉ và khóa công khai. Khi bạn kết nối với một trang web, khóa công khai của trang web đó trước tiên sẽ được cơ quan cấp chứng chỉ xác minh. Hãy tạo một cặp khóa chung và khóa riêng: hồng ngọc require "openssl" require "pry" data_to_encrypt = "bây giờ bạn có thể đọc được thông tin của tôi!" key = OpenSSL::PKey::RSA.new(2048) bind.pry true yêu cầu "openssl" yêu cầu "cọc" data_to_encrypt = "bây giờ bạn có thể đọc được tôi!" khóa = OpenSSL::PKey::RSA. mới (2048) ràng buộc. nâng lên ĐÚNG VẬY Nó sẽ bật ra: Lưu ý rằng khóa riêng và khóa chung là các thực thể riêng biệt có mã định danh khác nhau. sử dụng #private_encrypt, bạn có thể mã hóa một chuỗi bằng khóa riêng và sử dụng #public_decrypt– Giải mã tin nhắn: Băm, không giống như mã hóa đối xứng và bất đối xứng, là hàm một chiều. Có thể tạo hàm băm từ một số dữ liệu, nhưng không có cách nào đảo ngược quá trình. Điều này làm cho việc băm không phải là một cách thuận tiện để lưu trữ dữ liệu, nhưng nó phù hợp để kiểm tra tính toàn vẹn của một số dữ liệu. Hàm lấy một số thông tin làm đầu vào và xuất ra một chuỗi dường như ngẫu nhiên và luôn có cùng độ dài. Hàm băm lý tưởng tạo ra các giá trị duy nhất cho các đầu vào khác nhau. Đầu vào giống nhau sẽ luôn tạo ra cùng một hàm băm. Do đó, băm có thể được sử dụng để xác minh tính toàn vẹn của dữ liệu.Mã hóa nào tốt hơn?
Nguồn thông tin bổ sung
Mật mã không chỉ là một thứ gì đó trên máy tính
Định nghĩa về an ninh mạng và hướng dẫn bắt đầu nhanh
Các phương pháp mã hóa cơ bản:
Mã hóa đối xứng


Mã hóa bất đối xứng


Băm thông tin