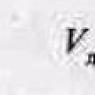Effective use of STL vectors. Scott Meyers - Using STL Effectively
Many books describe the capabilities of STL, but only this one talks about how to work with this library. Each of the book's 50 tips is supported by analysis and convincing examples, so the reader will not only learn how to solve a particular problem, but also when to choose a particular solution - and why.
“...There was no ribbon on it! There was no shortcut! There was no box and there was no bag!” Dr. Suess, How the Grinch Stole ChristmasPreface
“...There was no ribbon on it! There was no shortcut! There was no box and there was no bag!”
Dr. Suess, How the Grinch Stole ChristmasI first wrote about STL (Standard Template Library) in 1995. My book “More Effective C++” was finishing a brief overview libraries. But this was not enough, and soon I began to receive messages asking when the book “Effective STL” would be written.
I resisted this idea for several years. At first I did not have enough experience in STL programming and did not consider it possible to give advice. But time passed, and this problem was replaced by others. Undoubtedly, the appearance of the library meant a breakthrough in the field of efficient scalable architecture, but in the field of using STL, purely practical problems arose that it was impossible to turn a blind eye to. Adaptation of any STL programs, with the exception of the simplest ones, was associated with many problems, which was explained not only by differences in implementations, but also different levels Compiler template support. Textbooks on STL were rare, so understanding the “Tao of STL Programming” was not an easy task. And as soon as the programmer coped with this difficulty, another one arose - the search for sufficiently complete and accurate reference documentation. Even the smallest error when using the STL was accompanied by an avalanche of compiler diagnostic messages, the length of which reached several thousand characters, and in most cases they were about classes, functions and templates that were not mentioned in the program. With all due respect to STL and the developers of this library, I was hesitant to recommend it to mid-level programmers. I wasn't sure that STL could be used effectively.
Then I noticed something amazing. Despite all the porting problems and the poor quality of the documentation, despite the compiler messages that resembled a meaningless jumble of symbols, many of my clients still worked with the STL. Moreover, they not only experimented with the library, but used it in commercial versions of their programs! It was a revelation for me. I knew that programs using the STL had elegant architecture, but any library for which the programmer willingly subjected himself to porting difficulties, poor documentation, and confusing error messages had to have something more than good architecture. More and more professional programmers believed that even a bad implementation of the STL was better than no implementation at all.
Moreover, I knew that the situation with STL would improve. Libraries and compilers will gradually come closer to the requirements of the Standard (this is how it happened), high-quality documentation will appear (see the list of references on page 203), and compiler diagnostics will become more intelligible (in this area the situation leaves much to be desired, but the recommendations of Council 49 will help to you with decryption of messages). So, I decided to contribute to the STL movement. This is how this book appeared - 50 practical advice on using STL in C++.
At first I intended to write a book for the second half of 1999 and even sketched out its rough structure. But then plans changed, I paused work on the book and developed an introductory course on STL, which was taught to several groups of programmers. About a year later, I returned to the book and greatly expanded the material based on the experiences I had gained while teaching. In the book, I tried to cover the practical aspects of programming in STL, especially important for professional programmers.
Scott Douglas Meyers Stafford, Oregon April 2001Preface
“...There was no ribbon on it! There was no shortcut! There was no box and there was no bag!”
Dr. Suess, How the Grinch Stole Christmas
I first wrote about STL (Standard Template Library) in 1995. My book “More Effective C++” ended with a brief overview of the library. But this was not enough, and soon I began to receive messages asking when the book “Effective STL” would be written.
I resisted this idea for several years. At first I did not have enough experience in STL programming and did not consider it possible to give advice. But time passed, and this problem was replaced by others. Undoubtedly, the appearance of the library meant a breakthrough in the field of efficient scalable architecture, but in the field use STL encountered purely practical problems to which it was impossible to turn a blind eye. Adapting all but the simplest STL programs was fraught with many problems, due not only to differences in implementations, but also to different levels of compiler template support. Textbooks on STL were rare, so understanding the “Tao of STL Programming” was not an easy task. And as soon as the programmer coped with this difficulty, another one arose - the search for sufficiently complete and accurate reference documentation. Even the smallest error when using the STL was accompanied by an avalanche of compiler diagnostic messages, the length of which reached several thousand characters, and in most cases they were about classes, functions and templates that were not mentioned in the program. With all due respect to STL and the developers of this library, I was hesitant to recommend it to mid-level programmers. I wasn't sure about STL Can use effectively.
Then I noticed something amazing. Despite all the porting problems and the poor quality of the documentation, despite the compiler messages that resembled a meaningless jumble of symbols, many of my clients still worked with the STL. Moreover, they not only experimented with the library, but used it in commercial versions of their programs! For me it
was a revelation. I knew that programs using the STL had elegant architecture, but any library for which the programmer willingly subjected himself to porting difficulties, poor documentation, and confusing error messages had to have something more than good architecture. More and more professional programmers believed that even a bad implementation of the STL was better than no implementation at all.
Moreover, I knew that the situation with STL would improve. Libraries and compilers will gradually come closer to the requirements of the Standard (this is how it happened), high-quality documentation will appear (see the list of references on page 203), and compiler diagnostics will become more intelligible (in this area the situation leaves much to be desired, but the recommendations of Council 49 will help to you with decryption of messages). So, I decided to contribute to the STL movement. This is how this book appeared - 50 practical tips on using STL in C++.
At first I intended to write a book for the second half of 1999 and even sketched out its rough structure. But then plans changed, I paused work on the book and developed an introductory course on STL, which was taught to several groups of programmers. About a year later, I returned to the book and greatly expanded the material based on the experiences I had gained while teaching. In the book, I tried to cover the practical aspects of programming in STL, especially important for professional programmers.
Scott Douglas Meyers Stafford, Oregon April 2001
From the C++ book by Hill MurrayPreface Language shapes the way we think and determines what we can think about. B.L. Worf C++ is universal language programming, designed to make programming more enjoyable for the serious programmer. Except for minor ones
From book Music Center on the computer author Leontyev Vitaly PetrovichPreface Hardly anyone can imagine a modern computer without sound. But at first it was like that. Computers were created for serious computing in special organizations, the only sounds of which were the noise of fans and the whirring of printers. WITH
From book Microsoft Office author Leontyev Vitaly PetrovichPreface There is no doubt that the so-called office programs– Most Popular and Most Useful programs of all that can live in the iron belly of your computer. And if you already know how to start a computer, install programs, work with
From the book Processes life cycle software author author unknown From the book INFORMATION TECHNOLOGY. SOFTWARE DOCUMENTATION MANAGEMENT GUIDE author author unknownPreface 1. DEVELOPED AND INTRODUCED by the Technical Committee for Standardization TC 22 “Information Technology”2. APPROVED AND ENTERED INTO EFFECT by Resolution of the State Standard of Russia dated December 20, 1993 No. 260 The standard was prepared on the basis of the use of the authentic text of technical
From book Human factor in programming author Konstantin Larry LPreface The Other Side software This book is about the other side of software - the one that looks into external world. This side of computers is about people - techies like you and me, and ordinary people like you and me. The notes collected here explore
From book 300 best programs for all occasions author Leontyev Vitaly PetrovichPreface All the Most Necessary Things in this world have one most unpleasant property: they are never at hand at the right time. Whether this is a consequence of the notorious “sandwich law” or elementary human absent-mindedness is unknown to science. The result is everything
From the book BPwin and Erwin. CASE development tools information systems authorPreface The creation of modern information systems is a daunting task, the solution of which requires the use of special techniques and tools. It is not surprising that in Lately has grown significantly among system analysts and developers
From the book Business Process Modeling with BPwin 4.0 author Maklakov Sergey VladimirovichPreface In 1998, the author's book was published on the tools for system analysis and design of information systems - BPwin and ERwin. (Maklakov S. BPwin and ERwin. CASE-tools for developing information systems. M: Dialog-MEPhI). The book went through two editions and
From the book XSLT Technology author Valikov Alexey NikolaevichPreface What is this book about? It is difficult to overestimate the impact that over the past couple of years has had on information Technology the emergence and spread of an extensible language XML markup(from English extensible Markup Language). XML technologies have found application in many areas and
From the book Techniques for creating interiors of various styles author Timofeev S. M.Preface 3ds Max - very popular program for creating interior projects. The program provides a lot of opportunities for creating a photorealistic picture of the future interior, allows you to convey several design concepts for the same room,
From the book 19 deadly sins that threaten software security by Howard MichaelPreface Computer theory is based on the assumption that machines behave deterministically. We typically expect a computer to behave the way we programmed it to. In fact, this is only an approximate assumption. Modern computers general
From the book How to Feed an Elephant, or the first steps to self-organization with Evernote by Sultanov GaniPreface The book is dedicated to the system of managing affairs and collecting information using the Evernote service. Here is what is written about this mini-book on the official Evernote blog: “The book will be especially interesting to those who have long been eyeing the GTD method of increasing personal effectiveness
From the book Introduction to Cryptography author Zimmermann PhilipPreface Cryptography is a common theme in children's comics and spy stories. Children once collected Ovaltine® labels to obtain Captain Midnight's Secret Decoder Ring. Almost everyone has watched a television film about an inconspicuous gentleman dressed in a suit with
From the iOS book. Programming Techniques author Nahavandipur VandadPreface This edition of the book is not just an expanded, but a completely revised version of the previous one. Everything has changed in iOS 7: appearance and functional side operating system, ways to use our iOS devices and, most importantly, principles
From the book The Fanatic Programmer by Chad FowlerPreface I'm sure there is something extraordinary in each of us, but a lot of time is spent understanding what is really important, trying to draw it out of ourselves. You can't become extraordinary if you don't love your environment, your tools, your field.
Effective use of STL and templates
Sergey Satsky
Introduction
With the help of finite state machines (hereinafter simply automata), you can successfully solve a wide class of problems. This circumstance has been noticed for a long time, therefore, in the literature on software design, discussions are often given on the topic of using automata (, ,). However, during the simulation process, the machine is viewed from a more high level than this is done at the time of its implementation using specific language programming.
The last time the C/C++ User's Journal addressed the issue of Finite State Machine design was in the May 2000 issue (). This issue featured an article by David Lafreniere, where the author described the approach he used. Much time has passed since then, and this article will attempt to take a different approach to design finite state machine taking into account modern trends in software design.
For convenience, consider a simple example that will be used below. Suppose you need to determine whether an input character sequence is an integer, a valid identifier, or an invalid string. By valid identifiers we mean those identifiers that begin with a letter and then contain letters and “/” or numbers. The machine that will help solve the problem is shown in Figure 1. The figure uses UML (Unified Modeling Language) notation.
Figure 1. An automaton that allows you to find out what the input string is.
It should be noted that various sources endow such a machine with various attributes. The champion in terms of their number is probably UML (). Here you can find deferred events, internal transitions, event triggers with parameters, additional conditions transitions (guard conditions), entry functions (entry actions), exit functions (exit actions), timer events, etc. However, here, for simplicity of presentation, we will omit additional attributes (we will return to some of them later) and focus on a simple model where there are states, events, and transitions between states.
On this moment all we have is a visual and easy-to-make model. How can we now move from it to C++ code? The simplest implementation method is a set of if statements in one form or another. For example:
switch(CurrentState) case State1: if (CurrentEvent == Event1) if (CurrentEvent == Event2) case State2:.. . |
Not too graphic, right? Now let’s imagine that we have dozens of events and dozens of states. This type of code is difficult to view. Particularly serious problems arise when maintaining code, when you need to return to it after a few months and make corrections.
Another possible implementation is a set of functions, each of which represents a state. Such a function will be able to return a pointer to the function that corresponds to the new state of the machine. This implementation also does not make the code easier to maintain.
Let's approach the problem from a slightly different angle. The picture is good, but in its original form it cannot in any way be transferred to original text. This means that even if a solution is found, it will be something intermediate between a picture and ordinary text.
Approach to implementing the machine
Such an intermediate representation of the machine can be a table. This method has been known for a long time, for example. Let's create a transition table for our machine (Table 1).
Table 1.
Here the first row lists the possible states, and the first column lists the possible events. At the intersections the states to which the transition must take place are indicated.
The representation of an automaton in the form of a table is much clearer than the “smeared” representation of the same automaton in the form conditional statements or transition functions. You can now try to translate the table into code.
Let's assume that we managed to translate the table into code. What would you like this code to look like? Let us formulate the requirements for it ():
The description of the machine (read table) should be concentrated in one place. This will make the machine easy to read, understand and modify.
The automaton representation must be type safe.
There should be no restrictions on the number of states and events.
We would like to represent events and states as abstract user-defined types.
If possible, I would like to make the machine flexible and easily expandable.
If possible, I would like to check the description of the machine.
If possible, we would like to exclude the incorrect use of the machine.
Requirements 1 and 7 mean that it would be good to place the entire description of the machine in the constructor. In the constructor, it is necessary to check the correctness of the description - requirement 6.
Requirement 2 means that no unsafe operations like reinterpret_cast should be used.
We'll talk about requirement 5 later, but now let's discuss requirement 3. B general case the number of possible states (that is, the number of columns in the table) is unknown. The number of events (that is, the number of rows in the table) is also unknown. It turns out that the constructor of the class, which will be an automaton, has a variable number of arguments. At first glance, this problem seems easy to solve using the C language functions va_arg(), va_copy(), va_end() and va_start()(). However, not all so simple. For these functions, it is necessary to provide signs for the end of lists, and in our case the number of elements in rows and columns is unknown. It is not advisable to specify the dimension. In addition, these functions are guaranteed to work only for POD (Plain Old Data), and for arbitrary types troubles are possible.
Let's approach from the other side. Let’s write how we would like to see the machine’s constructor:
By calling the constructor this way, by formatting the text in a monospace font, the description of the machine will be given the appearance of a table. Let's imagine:
SFiniteStateMachine A( “empty”, “number”, “identifier”, “unknown”, letter, “identifier”, “unknown”, “identifier”, “unknown”, digit, “number”, “number”, “identifier”, “unknown” |
The start state is simple: it's just an object of a class that represents the state. With a list of states, and even more so with a list of transitions, things are more complicated. It is not possible to list states separated by commas. Moreover, it would be convenient for SFiniteStateMachine to have a fixed number of arguments. It turns out that this is possible. After all, we can create temporary objects, each of which will deal with its own list.
Let's look at the list of states. The same problem remains here - an indefinite number of states. Operator overloading and the default constructor can help solve this problem. It would still not be possible to list the arguments separated by commas, but another separator would be suitable instead of a comma. Such a separator could be<<, то есть обработку списка состояний можно записать так:
Let's do the same with the list of transitions for one event. The only difference will be that each transition list has one more attribute - an event for which transitions are described. The STransitionsProxy constructor will take one argument: event, and the overloaded operator<< будет принимать состояния.
Overloaded operator<< проверит, что сначала идет список состояний, что список состояний только один, что в списках переходов нет повторяющихся событий и в переходах указаны только состояния, указанные в списке состояний. operator<< также проверит, что количество состояний в списках переходов равно количеству состояний в списке состояний. В результате конструктор SFiniteStateMachine будет выглядеть так:
The SFiniteStateMachine constructor will be tasked with checking the initial state. It should be in the list of states.
By formatting the text, we have already managed to give the constructor arguments the appearance of a table. However, that's not all. When describing the machine, all details related to the templates were omitted. In practice, this means that during construction you will also have to specify the types, which will further “litter” the text. Despite the problems associated with the preprocessor, it will help here. The constructor arguments will look something like this:
FSMBEGIN(“empty”) FSMSTATES “empty”<< “number” << “identifier” << “unknown” FSMEVENT(letter) “identifier”<< “unknown” << “identifier” << “unknown” FSMEVENT(digit) “number”<< “number” << “identifier” << “unknown” |
This recording is already acceptable for everyday use.
Implementation details
The implementation must include a number of supporting elements, in particular exceptions. The machine will issue them in case of an error in the description of states and transitions. When developing your own exception class, you can use inheritance from the standard exception class. This will make it possible to specify only a reference to the underlying standard exception class in the catch block. You can define your exception class like this:
Let's return to the designers. Since they deal with lists of variable length, it makes sense to use the containers provided by the STL() library to store elements. To store a one-dimensional list, we will use a vector container, and for a transition table, a vector of vectors:
Since the vector container supports operator , you can use a similar construction in the transition table to find the state to which you want to transition:
Of course, the automaton class will have to have a function that receives and processes the event. There are two options. The first is a function, the second is an overload of an operator. To give additional flexibility, we implement both options:
The question remains: what to do if an event comes for which the machine does not have a transition description? The options are to simply ignore such an event, throw an exception, or do something user defined. Let's use the idea of strategies () and include among the template arguments a functor that will determine the desired behavior strategy. This approach is fully consistent with requirement 5. In this case, you can set a default strategy - for example, throw an exception. Now the template header looks like this:
If you need other actions, you can always write your own functor in the image and likeness of SIgnoreStrategy and pass it to the template.
Many sources describing finite state machines mention the ability to call functions when entering and exiting a state. This capability can easily be provided using the same strategy approach. It is convenient to define state entry and exit functions for a class representing a specific state. Remembering requirement 5, let's provide flexible management of this feature. Assuming that the state class functions will be called OnEnter and OnExit, we can write several ready-made functors: one that calls neither function, one that calls only OnEnter, one that calls only OnExit, and one that calls both functions.
template class SEmptyFunctor (return;) template class SOnEnterFunctor inline void operator() (SState & From, const SEvent & Event, SState & To) ( To.OnEnter(From, Event); ) template class SOnExitFunctor inline void operator() (SState & From, const SEvent & Event, SState & To) ( From.OnExit(Event, To); ) template class SOnMoveFunctor inline void operator() (SState & From, const SEvent & Event, SState & To) ( From.OnExit(Event, To); To.OnEnter(From, Event); ) |
The default strategy (not calling any function) can be passed as a template argument. The strategy for calling functions is likely to change more often than the strategy for dealing with an unknown event. Therefore, it makes sense to place it in the list of arguments before the strategy for reacting to an unknown event:
template class SFunctor = SEmptyFunctor class SUnknownEventStrategy = SThrowStrategy class SFiniteStateMachine (... ); |
Another issue with events is that an event can be generated inside a function called when a state is exited or entered. To handle such events, you need to design the function that receives the event accordingly. Taking into account such “internal” events, it is necessary to provide a queue in which the events will be placed. The code that handles transitions will have to do this until the queue is empty. We will use deque from STL as a container suitable for storing events. Since we only need to insert elements at the beginning and exclude from the end of the container, without random access, the deque container is best suited.
There is very little left. Sometimes you need to restore the machine to its original state. As in the case of events, we provide two options: a regular function and an overloaded operator<<. Для перегруженного operator << нужно определить специальный манипулятор:
The result of the operation of the machine is the state into which it has passed. To get the current state, we will write a function and overload the output operator into the stream of the automaton class:
As already mentioned, several macros are defined to reduce typing time and readability. They require pre-defined substitutions for event and state types. The requirement is due to the fact that the use of nested preprocessor directives is impossible. The template uses Proxy classes, which also need type information. Therefore, to use macros you will have to do this:
#define FSMStateType string // State type #define FSMEventType int // Event type #undef FSMStateType #undef FSMEventType |
There is an alternative: specify all types completely.
All that remains is to place the template in the namespace. After that you can use it.
Example of using the template
Let's write code to solve the problem posed at the beginning of the article.
#include #include using namespace std; #include "FiniteStateMachine.h" using namespace FSM; // Define the type for events enum Events ( letter = 0, digit = 1 ); int main(int argc, char ** argv) #define FSMStateType string #define FSMEventType Events SFiniteStateMachine< StateType, SEmptyFunctor SThrowStrategy FSMBEGIN("empty") FSMSTATES "empty"<< «number» << «identifier» << «unknown» FSMEVENT(letter) "identifier"<< «unknown» << «identifier» << «unknown» FSMEVENT(digit) "number"<< «number» << «identifier» << «unknown» #undef FSMStateType #undef FSMEventType cout<< «StartState is: » << MyMachine << endl; MyMachine<< digit << digit << letter; cout<< «The "unknown" state is expected. Current state is: » << MyMachine << endl; // Note: parentheses on the next line are required. They will provide // correct order of execution of operators cout<< «Reset the machine. Current state is: » << (MyMachine << ResetMachine) << endl; MyMachine<< letter << digit << letter; cout<< «The "identifier" state is expected. Current state is: » << MyMachine << endl; |
The example deliberately omits details such as exception handling and the introduction of functions that are called when entering and exiting a state. To demonstrate the ability to define user strategies, the MyMachine constructor specifies all parameters, including default parameters.
Requirements for client applications
Requirements are few. Event and state classes must have operator==, operator=, and a copy constructor defined. operator== is used to search for events and states in lists using the STL find algorithm. operator= is used when copying list elements. The copy constructor is used when initializing lists and other elements.
If the client uses the provided functor to call the entry and exit functions, then the state class must implement the corresponding functions: OnExit and OnEnter.
Advantages and disadvantages of the proposed solution
Advantages:
The template is strongly typed. This means that incorrectly written code will not be accepted by the compiler, and the error will not reach the runtime of the program.
The concepts of state and event have been expanded. Now these are arbitrary classes written by the user.
The reinterpret_cast operator is not used<…>, which can lead to incorrect results.
The entire description of the machine is concentrated in one place. There is no connection to the sequence of descriptions of reactions to events.
The flexibility of behavior is determined by user-defined functors. A set of ready-made functors is provided.
It is possible to dynamically create a description of a finite state machine. For example, you can create instances of Proxy classes, read the machine description from a file, and then create an SFiniteStateMachine instance.
There are no operations for creating and deleting objects using the new and delete operators.
There are no requirements for the classes of states and events (other than the ability to compare them).
Flaws:
There are a lot of copying operations when creating a machine. However, this disadvantage is partly compensated by the fact that usually the machine is created once and used many times.
You need to write two preprocessor directives or use a long prefix. However, this is just a typing problem.
Personally, I'm willing to put up with this short list of disadvantages for the sake of the benefits gained.
Possible ways to improve the template
The astute reader will notice that you can increase the flexibility and performance of the template. The following list highlights the improvements that are on the surface:
You can dispense with the SFiniteStateMachineProxy intermediate class. This will save on copying costs, but will introduce the potential for incorrect use of the template.
You can introduce manipulators that will allow you to explicitly indicate when describing transitions those that should be ignored, or generate an exception when they occur.
Thread safety
The template uses STL containers, which can cause problems in a multi-threaded environment. Since the goal when designing the template was to develop a platform-independent solution, there are no synchronization tools in the template. The presence of synchronization tools, as is known, depending on the situation, can be both an advantage and a disadvantage. If they are not needed, their presence will only create additional overhead. Adding synchronization tools to a template will not be difficult for an experienced developer.
Bibliography
C/C++ User's Journal, May 2000
Booch G., Rumbaugh J., Jacobson I. The Unified Modeling Language User Guide. Addison-Wesley, 2001
Meyers S. Effective STL. Addison-Wesley, 2001
Alexandrescu A. Modern C++ Design. Addison-Wesley, 2002
Lewis P., Rosenkrantz D., Stearns R. Compiler Design Theory. Addison-Wesley, 1976
Schildt H. C/C++ Programmer’s Reference. Second Edition. Williams, 2000
Meyers S. Effective C++. Second Edition. Addison-Wesley, 1998 and More Effective C++. Addison-Wesley, 1996
Sutter G. Exceptional C++. Addison-Wesley, 2002
Effective use of STL
Preface
“...There was no ribbon on it! There was no shortcut! There was no box and there was no bag!”
Dr. Suess, How the Grinch Stole Christmas
I first wrote about STL (Standard Template Library) in 1995. My book "More Effective C++" ended with a brief overview of the library. But this was not enough, and soon I began to receive messages asking when the book “Effective STL” would be written.
I resisted this idea for several years. At first I did not have enough experience in STL programming and did not consider it possible to give advice. But time passed, and this problem was replaced by others. Undoubtedly, the appearance of the library meant a breakthrough in the field of efficient scalable architecture, but in the field use STL encountered purely practical problems to which it was impossible to turn a blind eye. Adapting all but the simplest STL programs was fraught with many problems, due not only to differences in implementations, but also to different levels of compiler template support. Textbooks on STL were rare, so understanding the “Tao of STL Programming” was not an easy task. And as soon as the programmer coped with this difficulty, another one arose - the search for sufficiently complete and accurate reference documentation. Even the smallest error when using the STL was accompanied by an avalanche of compiler diagnostic messages, the length of which reached several thousand characters, and in most cases they were about classes, functions and templates that were not mentioned in the program. With all due respect to STL and the developers of this library, I was hesitant to recommend it to mid-level programmers. I wasn't sure about STL Can use effectively.
Then I noticed something amazing. Despite all the porting problems and the poor quality of the documentation, despite the compiler messages that resembled a meaningless jumble of symbols, many of my clients still worked with the STL. Moreover, they not only experimented with the library, but used it in commercial versions of their programs! It was a revelation for me. I knew that programs using the STL had elegant architecture, but any library for which the programmer willingly subjected himself to porting difficulties, poor documentation, and confusing error messages had to have something more than good architecture. More and more professional programmers believed that even a bad implementation of the STL was better than no implementation at all.
Moreover, I knew that the situation with STL would improve. Libraries and compilers will gradually come closer to the requirements of the Standard (this is how it happened), high-quality documentation will appear (see the list of references on page 203), and compiler diagnostics will become more intelligible (in this area the situation leaves much to be desired, but the recommendations of Council 49 will help to you with decryption of messages). So, I decided to contribute to the STL movement. This is how this book appeared - 50 practical tips on using STL in C++.
At first I intended to write a book for the second half of 1999 and even sketched out its rough structure. But then plans changed, I paused work on the book and developed an introductory course on STL, which was taught to several groups of programmers. About a year later, I returned to the book and greatly expanded the material based on the experiences I had gained while teaching. In the book, I tried to cover the practical aspects of programming in STL, especially important for professional programmers.
Scott Douglas Meyers Stafford, Oregon April 2001
Acknowledgments
Over the years it took me to understand STL, develop the course, and write this book, I received invaluable help and support from many people. I would like to especially acknowledge Mark Rodgers, who generously offered to review the course materials as they were written. I learned more about STL from him than from anyone else. Mark also served as the technical editor for this book, and his comments and additions helped improve much of the material.
Another prominent source of information was Usenet forums; dedicated to the C++ language, especially comp.lang.c++.moderated (“clcm”), comp.std.c++ and microsoft.public.vc.stl. For over ten years, participants at these and other conferences answered my questions and posed problems that I had to think about. I am deeply grateful to the Usenet community for its assistance in developing this book and my previous C++ publications.
My understanding of STL has been shaped by a number of publications, the most important of which are listed at the end of the book. I especially learned a lot of useful information from Josattis’s work “The C++ Standard Library”.
The ideas and observations that make up this book are mainly those of other authors, although it contains a number of my own discoveries. I have tried as best I can to trace the sources from which the material was drawn, but this task is doomed to failure since the information was collected from many sources over a long period of time. The list below is far from complete, but I can’t offer anything better. Please note that this list refers to the sources from which I learned about certain ideas and techniques, not the originators of them.
In Item 1, the note that node containers provide better support for transactional semantics comes from Section 5.11.2 of The C++ Standard Library. The example of using typedef when changing the memory allocator type from tip 2 was suggested by Mark Rogers. Tip 5 is inspired by Reeves' article "STL Gotchas". Tip 8 is based on tip 37 of Sutter's book Exceptional C++, and Kevlin Henney has provided important information about the problems encountered when using auto_ptr containers . On Usenet, Matt Austem provided examples of using memory allocators, which I included in Tip 11. Tip 12 is based on material on the SGI STL site on thread safety. The information on reference counting in a multi-threaded environment from tip 13 comes from Sutter's article. The idea for tip 15 was inspired by Reeves' article "Using Standard string in the Real World, Part 2". Methodology for directly recording data in vecto r, demonstrated in tip 16 was suggested by Mark Rogers. Tip 17 included information from Usenet and was written by Siemel Naran and Carl Barron. Tip 18 was taken from Sutter's article "When Is a Container Not a Container?" . For tip 20, Mark Rogers proposed the idea of converting a pointer to an object via dereference, and Scott Lewandowski developed the DereferenceLess version presented. Tip 21 is based on Doug Harrison's post on microsoft.public.vc.stl, but the decision to limit the scope of this tip to the issue of equality was my own. Tip 22 is based on Sutter's article "Standard Library News: sets and maps". Tip 23 was suggested by Austern's article "Why You Shouldn't Use set - and What to Use Instead"; David Smallberg improved my DataCompare implementation. The description of Dinkumware hashed containers is based on Plauger's article "Hash Tables". Mark Rogers disagrees with the conclusions of tip 26, but the tip was originally prompted by his observation that some container functions only accept arguments of type iterator . Tip 29 was inspired by discussions on Usenet involving Matt Ostern and James Kanze; I was also influenced by the article “A Sophisticated Implementation of User-Defined Inserters and Extractors” by Klaus Kreft and Angelika Langer. Tip 30 is based on section 5.4.2 of Josattis's book The C++ Standard Library. In Tip 31, Marco Dalla Gasperina offered an example of using nth_element to calculate the median, and using this algorithm to find percentiles is taken directly from section 18.7.1 of Stroustrup's The C++ Programming Language. Tip 32 was inspired by section 5.6.1 of Josattis's book The C++ Standard Library. Tip 35 was inspired by Austern's article "How to Do Case-Insensitive String Comparison", and posts by James Kanze and John Potter helped me better understand what was going on. The copy_if implementation in Item 36 is taken from Section 18.6.1 of Stroustrup's The C++ Programming Language. Tip 39 is based on the publications of Josattis, who first mentioned “stateful predicates” in his book “The C++ Standard Library” and in the article “Predicates vs. Function Objects". In my book, I use his example and recommend his solution, although the term “pure function” is mine. In tip 41, Matt Ostern confirmed my suspicions about the origin of the names mem_fun and mem_fun_ref. Tip 42 comes from a lecture given to me by Mark Rogers when I violated the recommendation of that tip. Mark Rogers also made the point in Item 44 that external searches in the map and multimap containers analyze both components of the pair, while searches by container functions only take into account the first component (the key). Tip 45 uses information from various clem contributors, including John Potter, Marcin Kasperski, Pete Becker, Dennis Yelle, and David Abrahams. David Smallberg gave me the idea of using equal_range to perform equivalence searches and count results in sorted sequential containers. Andrei Alexandrescu helped understand the conditions for the link-to-link problem mentioned in tip 50; The example given in the book is based on a similar example by Mark Rogers taken from the Boost website.
Using the STL vector container. Vector performance
The use of C++ standard library containers is always driven by simplicity, convenience, and performance. But like any “tool,” it must be used correctly, because a good and effective tool in the wrong hands can be useless or ineffective. In this short article, I will tell you how to use it as effectively as possible and what problems and pitfalls may arise when you first meet it.
Let's start from the very beginning
STL - Standard Template Library. That is, everything that is expressed by template(s) in the standard library is STL. But for the most part, STL is considered to be containers, algorithms and iterators.
STL has long been included in the standard C++ library, but still not everyone uses it fully, mainly due to ignorance of the existence of certain template classes.
And so let's return specifically to the vector.
A vector container is the same as an array that can contain any built-in or user-defined type. But compared to the built-in array, it has a number of advantages.
He knows his own size (method size())
- You can easily change the size (add, remove elements) during execution
- When deleting or cleaning, it calls class destructors (well, this advantage is debatable =))
Let's go over the main methods.
- push_back(element) - add an element to the end of the vector
pop_back(element) - remove the last element of a vector
insert(***) - three options (method reloading) for inserting into any area in a vector, the first parameter is the insertion position given to iterators, the rest indicate a container, or a quantity and a container, or a pair of iterators indicating from which to which position from another container take data.
erase(iterator or iterator from, and to) - deletes an element or sequence of elements from a vector
begin() - returns an iterator pointing to the beginning of the collection.
end() - returns an iterator pointing to the end of the collection. At the same time, he does not point to the very last element, but to the imaginary element behind the last one.
at(index) is an access method to the elements of a collection, unlike the operator, it checks for going beyond the boundaries of the collection, and if so, generates an exception.
clear() - deletes all elements of the collection, and if it contains class objects, calls their destructors. But if there are pointers to objects, then you will have a memory leak (memory leaks =)), so no one will call delete for you.
When iterating over a vector through iterators, you need to train yourself to write a pre-increment( ++it ), so he more effective.
Creating a static vector:
The most common case of problems with creating a static vector is creating it in a class.
To create a static vector in a class, you need to describe it in .h and define it in .cpp. In this case, I put everything in one file, just for the sake of simplicity. This way you can create not only a static vector, but also any other static container.
Now about efficiency
A vector is effective in cases where you need a container in which you will accumulate elements. That is, add. A vector is effective when added to the end using push_back(), and when removed from the end using pop_back().
When inserting or deleting in an arbitrary place (insert() and erase() methods), vector efficiency is worse compared to the list( list) or a two-way queue( deque). This is due to the fact that the vector stores data in memory sequentially, which gives fast random access and the ability to use the vector like a regular array. For example, in the same functions OpenGL Instead of a pointer to a C array, you can specify &vector_name.
A vector has not only a size (size()), but also a capacity (capacity()), the capacity is the maximum number of elements that, when added, will not cause the internal buffer to be redistributed. If this value is exceeded, the vector allocates a new internal buffer (allocator), and copies all elements from the old buffer to the new one, while removing from the old one. That is, if we store large class objects in it, then this operation will be quite expensive. This will be “felt” especially acutely on large objects with a complex destructor.
The capacity is specified by the implementation of the standard library itself.
If you store pointers to objects in a vector, then this greatly increases the efficiency of storing in a vector, especially large objects.
Storing small objects or built-in types in a vector is quite efficient.
Conclusion
If you don't intend to remove container elements often, and you don't need to insert elements at the beginning and middle. And you are going to store small objects, built-in types, or pointers to any objects (large or not so large =)). It’s better to prefer a vector, and remember what operations are done with it, what they do, inside it, among other things. And which of them will not be too expensive.
Did you like the post? Save it to come back to study the material!