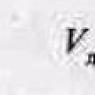Dynamic routing in Linux. Dynamic Routing Protocol RIP
The Lift mi Up network, together with its staff, is growing far and wide. Maintenance of the IT infrastructure was transferred to a separate specially created organization “Link Me Up”.
Just the other day, four more branches were purchased in different cities and investors discovered new dimensions of elevator movement. And the network grew from four routers to ten at once. At the same time, the number of subnets has now increased from 9 to 20, not counting point-to-point links between routers. And here the question of managing this entire economy arises. Agree, manually adding routes to all networks at each node is not much fun.
The situation is complicated by the fact that the network in Kaliningrad already has its own addressing, and the EIGRP dynamic routing protocol is running on it.
So today:
- Let's understand the theory of dynamic routing protocols.
- We are introducing “Lift mi Up” into the network OSPF protocol
- Configuring the transfer (redistribution) of routes between OSPF and EIGRP
- In this release we are adding a “Tasks” section. The following icons will help identify them throughout the article:
Dynamic routing protocol theory
First, let's understand the concept of “dynamic routing”. Until now, we used so-called static routing, that is, we manually wrote a routing table on each router. Using routing protocols allows us to avoid this tedious, monotonous process and errors associated with human factor. As the name implies, these protocols are designed to build routing tables themselves, automatically, based on the current network configuration. In general, this is a necessary thing, especially when your network is not 3 routers, but 30, for example.There are other aspects besides convenience. For example, fault tolerance. Having a network with static routing, it will be extremely difficult for you to organize backup channels - there is no one to monitor the availability of a particular segment.

For example, if in such a network the link between R2 and R3 is broken, then packets from R1 will continue to go to R2, where they will be destroyed, because there is nowhere to send them.

Dynamic routing protocols within a few seconds (or even milliseconds) learn about problems on the network and rebuild their routing tables, and in the case described above, packets will be sent along the current route

Another important point - traffic balancing. Dynamic routing protocols support this feature almost out of the box and you do not need to add redundant routes manually by calculating them.
Well, the implementation of dynamic routing makes it much easier network scaling. When you add a new element to a network or subnet on an existing router, you only need to perform a few steps to get everything working, with minimal chance of error, and information about the changes is instantly shared across all devices. Exactly the same can be said about global topology changes.
All routing protocols can be divided into two large groups: external ( E.G.P.- Exterior Gateway Protocol) and internal ( IGP- Interior Gateway Protocol). To explain the differences between them, we need the term “autonomous system”. In a general sense, an autonomous system (routing domain) is a group of routers under common management.
In the case of our updated AS network it will be like this:

So, internal routing protocols are used within an autonomous system, and external ones are used to connect autonomous systems with each other. In its turn, internal protocols routing is divided into Distance-Vector(RIP, EIGRP) and Link State(OSPF, IS-IS). In this article, we will not kick corpses, touch on the RIP and IGRP protocols due to their venerable age, as well as IS-IS due to its absence in PT.
The fundamental differences between these two types are as follows:
1) the type of information that routers exchange: routing tables for Distance-Vector and topology tables for Link State,
2) the process of choosing the best route,
3) the amount of information about the network that each router “keeps in its head”: Distance-Vector knows only its neighbors, Link State has an idea of the entire network.
As we can see, the number of routing protocols is small, but still not one or two. What happens if you run several protocols on the router at the same time? It may be that each protocol will have its own opinion on how best to reach a particular network. And if we also static routes are you set up? Who will the router give preference to and whose route will it add to the routing table? The answer to this question is associated with a new term: administrative distance (for our taste, a rather mediocre copy of the English Administrative distance, but they couldn’t come up with a better one). Administrative distance is an integer from 0 to 255, expressing the “measure of confidence” of the router in this route. The smaller the AD, the more trust. Here is a sign of such trust from Cisco’s point of view:
| Protocol | Administrative distance |
|---|---|
| Connected interface | 0 |
| Static route | 1 |
| Enhanced Interior Gateway Routing Protocol (EIGRP) summary route | 5 |
| External Border Gateway Protocol (BGP) | 20 |
| Internal EIGRP | 90 |
| IGRP | 100 |
| OSPF | 110 |
| Intermediate System-to-Intermediate System (IS-IS) | 115 |
| Routing Information Protocol (RIP) | 120 |
| Exterior Gateway Protocol (EGP) | 140 |
| On Demand Routing (ODR) | 160 |
| External EIGRP | 170 |
| Internal BGP | 200 |
| Unknown | 255 |
In today's article we will look at OSPF and EIGRP. You will see the first one everywhere and all the time, and the second one is very good in networks where only Cisco equipment is present.
Each of them has its own advantages and disadvantages. We can say that EIGRP is superior to OSPF, but all the advantages are offset by its proprietary nature. EIGRP is a Cisco proprietary protocol and no one else supports it.
In fact, EIGRP has many disadvantages, but this is not particularly discussed in popular articles. Here's just one of the problems: SIA
So let's get started.
OSPF
Articles and videos on how to configure OSPF mountains. There are much fewer descriptions of operating principles. In general, the thing here is that OSPF can be simply configured according to the manuals, without even knowing about SPF algorithms and incomprehensible LSAs. And everything will work and even, most likely, work perfectly - that’s what it’s designed for. That is, it’s not like with vlans, where you had to know the theory down to the header format.But what distinguishes an engineer from an IT guy is that he understands why his network functions the way it does, and he knows, no worse than OSPF itself, which route will be chosen by the protocol.
Within the framework of the article, which at this moment is already 8,000 characters, we will not be able to dive into the depths of the theory, but we will consider the fundamental points.
It’s very simple and clear, by the way, it’s written about OSPF on xgu.ru or in the English Wikipedia.
So, OSPFv2 works on top of IP, and specifically, it is designed only for IPv4 (OSPFv3 does not depend on layer 3 protocols and therefore can work with IPv6).
Let's look at how it works using the example of this simplified network:

To begin with, it must be said that in order for a friendship (adjacency relationship) to develop between routers, the following conditions must be met:
1) the same settings must be configured in OSPF Hello Interval on those routers that are connected to each other. By default it is 10 seconds on Broadcast networks such as Ethernet. This is a kind of KeepAlive message. That is, every 10 seconds, each router sends a Hello packet to its neighbor to say, “Hey, I'm alive,”
2) Must be the same Dead Interval on them. Typically these are 4 Hello intervals - 40 seconds. If no Hello is received from the neighbor during this time, then it is considered unreachable and PANIC begins the process of rebuilding the local database and sending updates to all neighbors.
3) Interfaces connected to each other must be in one subnet,
4) OSPF allows you to reduce the load on the CPU of routers by dividing the Autonomous System into zones. So here it is zone numbers must also match
5) Each router participating in the OSPF process has its own unique identifier - Router ID. If you do not take care of it, the router will select it automatically based on information about the connected interfaces (the highest address is selected from the interfaces active at the time the OSPF process starts). But again, a good engineer has everything under control, so usually a Loopback interface is created, which is assigned an address with a /32 mask and this is what is assigned to the Router ID. This can be convenient for maintenance and troubleshooting.
6) Must match MTU size
1) Calm. OSPF Status - DOWN
In this short moment, nothing happens on the network - everyone is silent.

2) The wind is rising: the router sends Hello packets to the multicast address 224.0.0.5 from all interfaces where OSPF is running. The TTL of such messages is one, so only routers located in the same network segment will receive them. R1 goes into state INIT.

The packages contain the following information:
- Router ID
- Hello Interval
- Dead Interval
- Neighbors
- Subnet mask
- Area ID
- Router Priority
- Addresses of DR and BDR routers
- Authentication password
The Hello message from router R1 carries its Router ID and does not contain Neighbors, because it does not have them yet.
After receiving this multicast message, router R2 adds R1 to its neighbor table (if all the necessary parameters match).

And it sends a new Hello message to R1 using Unicast, which contains the Router ID of this router, and the Neigbors list lists all its neighbors. Among other neighbors in this list there is Router ID R1, that is, R2 already considers it a neighbor.

3) Friendship. When R1 receives this Hello message from R2, it scrolls through the list of neighbors and finds its own Router ID in it, it adds R2 to its list of neighbors.

Now R1 and R2 are mutual neighbors of each other - this means that an adjacency relationship has been established between them and router R1 goes into state TWO WAY.

General advice for all tasks:
Even if you don’t immediately know the answer and solution, try to think about what the condition of the problem refers to:On a real network, when choosing the range of advertised subnets, you need to be guided by regulations and immediate needs.
- What features and protocol settings?
- Are these settings global or tied to a specific interface?
If you don't know or have forgotten the command, such reflections will most likely lead you to the correct context, where you can simply, with the help of a hint in command line, you can guess or remember how to set up what is required in the task.
Try to think in this way before you go to Google or some site looking for commands.
Before we move on to testing backup links and speed, let's do one more useful thing.
If we had the opportunity to catch traffic on the FE0/0.2 msk-arbat-gw1 interface, which faces the servers, then we would see that Hello messages fly off into the unknown every 10 seconds. There is no one to respond to Hello, there is no one to establish adjacency relationships with, so there is no point in trying to send messages from here.
It's very easy to turn off:
msk-arbat-gw1(config)#router OSPF 1
msk-arbat-gw1(config-router)#passive-interface fastEthernet 0/0.2
This command must be given for all interfaces that definitely do not have OSPF neighbors (including those towards the Internet).
As a result, you will have a picture like this:

*I can’t imagine how you haven’t gotten confused yet*
In addition, this command increases security - no one from this network will pretend to be a router and will not try to completely break us.
Now let's move on to the most interesting part - testing.
There is nothing complicated about setting up OSPF on all routers in the Siberian Ring - you can do it yourself.
And after that the picture should be as follows:
msk-arbat-gw1#sh ip OSPF neighbor
172.16.255.32 1 FULL/DR 00:00:31 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:31 172.16.2.18 FastEthernet0/1.5
172.16.255.80 1 FULL/BDR 00:00:36 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/BDR 00:00:37 172.16.2.197 FastEthernet1/0.911
St. Petersburg, Kemerovo, Krasnoyarsk and Vladivostok are directly connected.
msk-arbat-gw1#show ip routeEveryone knows everything about everyone.172.16.0.0/16 is variably subnetted, 25 subnets, 6 masks
S 172.16.2.4/30 via 172.16.2.2
O 172.16.2.160/30 via 172.16.2.130, 00:05:53, FastEthernet0/1.8
O 172.16.2.192/30 via 172.16.2.197, 00:04:18, FastEthernet1/0.911
S 172.16.16.0/21 via 172.16.2.2
S 172.16.24.0/22 via 172.16.2.18
O 172.16.24.0/24 via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.128.0/24 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.129.0/26 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.32/32 via 172.16.2.2, 00:24:03, FastEthernet0/1.4
O 172.16.255.48/32 via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.255.80/32 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.96/32 via 172.16.2.130, 00:04:18, FastEthernet0/1.8
via 172.16.2.197, 00:04:18, FastEthernet1/0.911
O 172.16.255.112/32 via 172.16.2.197, 00:04:28, FastEthernet1/0.911
What route is traffic delivered from Moscow to Krasnoyarsk? The table shows that krs-stolbi-gw1 is connected directly and the same can be seen from the trace:

msk-arbat-gw1#traceroute 172.16.128.1
1 172.16.2.130 35 msec 8 msec 5 msec
Now we tear up the interface between Moscow and Krasnoyarsk and see how long it takes for the link to be restored.
Not even 5 seconds pass before all the routers learned about the incident and recalculated their routing tables:
msk-arbat-gw1(config-subif)#do sh ip ro 172.16.128.0
Known via "OSPF 1", distance 110, metric 4, type intra area
Last update from 172.16.2.197 on FastEthernet1/0.911, 00:00:53 ago
Routing Descriptor Blocks:
* 172.16.2.197, from 172.16.255.80, 00:00:53 ago, via FastEthernet1/0.911
Route metric is 4, traffic share count is 1
Vld-gw1#sh ip route 172.16.128.0
Routing entry for 172.16.128.0/24
Known via "OSPF 1", distance 110, metric 3, type intra area
Last update from 172.16.2.193 on FastEthernet1/0, 00:01:57 ago
Routing Descriptor Blocks:
* 172.16.2.193, from 172.16.255.80, 00:01:57 ago, via FastEthernet1/0
Route metric is 3, traffic share count is 1
Msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abortion.
Tracing the route to 172.16.128.1
1 172.16.2.197 4 msec 10 msec 10 msec
2 172.16.2.193 8 msec 11 msec 15 msec
3 172.16.2.161 15 msec 13 msec 6 msec
That is, now traffic reaches Krasnoyarsk in this way:

As soon as you raise the link, the routers communicate again, exchange their databases, recalculate the shortest paths and enter them into the routing table.
The video makes all this more clear. I recommend familiarize.
After setting up OSPF on routers in the Siberian ring, all networks that are located behind the router in the central office in Moscow (msk-arbat-gw1) are accessible to Khabarovsk via two routes (via Krasnoyarsk and via Vladivostok). But, since the channel through Krasnoyarsk is better, you need to change the default settings so that Khabarovsk uses the channel through Krasnoyarsk when it is available. And he switched to Vladivostok only if something happened with the channel to Krasnoyarsk.
Like any good protocol, OSPF supports authentication - two neighbors can verify the authenticity of received OSPF messages before establishing adjacency relationships. We leave it to you to study on your own - it’s quite simple.
EIGRP
Now let's move on to another very important protocol.So, what's good about EIGRP?
- easy to configure
- fast switching on calculated in advance alternate route
- requires less router resources (compared to OSPF)
- summarization of routes on any router (in OSPF only on ABR\ASBR)
- traffic balancing on unequal routes (OSPF only on equal routes)
We decided to translate one of Ivan Pepelnyak’s blog entries, which addresses a number of popular myths about EIGRP:
- “EIGRP is a hybrid routing protocol.” If I remember correctly, this started with the first presentation of EIGRP many years ago and is usually understood as "EIGRP took the best of the link-state and distance-vector protocols." This is absolutely not true. EIGRP does not have any distinctive link-state features. It would be correct to say “EIGRP is an advanced distance-vector routing protocol.”
- “EIGRP is a distance-vector protocol.” Not bad, but not entirely true either. EIGRP differs from other DVs in the way it handles orphaned routes (or routes with increasing metric). All other protocols passively wait for updates from a neighbor (some, such as RIP, even block the route to prevent routing loops), while EIGRP is more active and requests information itself.
- “EIGRP is difficult to implement and maintain.” Not true. At one time, EIGRP in large networks with low-speed links was difficult to implement correctly, but only until stub routers were introduced. With them (as well as several corrections to the DUAL algorithm), it is almost worse than OSPF.
- “Like LS protocols, EIGRP maintains a table of the topology of the routes that are exchanged.” It's amazing how wrong this is. EIGRP has no idea at all what is beyond its immediate neighbors, while LS protocols know exactly the topology of the entire area to which they are connected.
- “EIGRP is a DV protocol that acts like LS.” Nice try, but still completely wrong. LS protocols build a routing table by passing through next steps:
- each router describes the network based on the information available to it locally (its links, the subnets it is in, the neighbors it sees) through a packet (or several) called an LSA (in OSPF) or LSP (IS-IS)
- LSAs are propagated throughout the network. Each router must receive every LSA created on its network. The information received from the LSA is entered into the topology table.
- Each router independently analyzes its topology table and runs the SPF algorithm to calculate the best routes to each of the other routers
EIGRP's behavior doesn't even come close to these steps, so why on earth it "acts like LS" is unclear.The only thing EIGRP does is store information received from a neighbor (RIP immediately forgets what cannot be used at the moment). In this sense, it is similar to BGP, which also stores everything in a BGP table and chooses the best route from there. The topology table (containing all information received from neighbors) gives EIGRP an advantage over RIP - it can contain information about a backup (not currently used) route.
Now a little closer to the theory of work:
Each EIGRP process maintains 3 tables:
- A neighbor table, which contains information about “neighbors”, i.e. other routers directly connected to the current one and participating in the exchange of routes. You can view it using the command show ip eigrp neighbors
- Network topology table, which contains route information received from neighbors. Let's watch as a team show ip eigrp topology
- The routing table, on the basis of which the router makes decisions about redirecting packets. View via show ip route
Metrics.
To assess the quality of a particular route, routing protocols use a certain number that reflects its various characteristics or a set of characteristics - a metric. The characteristics taken into account can be different - from the number of routers on a given route to the arithmetic average of the load on all interfaces along the route. Regarding the EIGRP metric, to quote Jeremy Cioara: “I got the impression that the creators of EIGRP, taking a critical look at their creation, decided that everything was too simple and worked well. And then they came up with a metric formula so that everyone would say “WOW, this is really complicated and looks professional.” See the complete formula for calculating the EIGRP metric: (K1 * bw + (K2 * bw) / (256 - load) + K3 * delay) * (K5 / (reliability + K4)), in which:
- bw is not just bandwidth, but (10000000/smallest bandwidth along the route in kilobits) * 256
- delay is not just a delay, but the sum of all delays on the way to tens of microseconds* 256 (delay in commands show interface, show ip eigrp topology and others is shown in microseconds!)
- K1-K5 are coefficients that serve to “include” one or another parameter in the formula.
Scary? it would be if it all worked as written. In fact, of all 4 possible terms of the formula, only two are used by default: bw and delay (coefficients K1 and K3 = 1, the rest are zero), which greatly simplifies it - we simply add these two numbers (while not forgetting that they are still calculated according to their own formulas). It is important to remember the following: the metric is calculated according to the worst indicator bandwidth along the entire length of the route.
If K5=0, then the following formula is used: Metric = (K1 * bw + (K2 * bw) / (256 - load) + (K3 * delay)
An interesting thing happened with MTU: quite often you can find information that MTU is related to the EIGRP metric. Indeed, MTU values are transmitted when exchanging routes. But, as we can see from the full formula, there is no mention of MTU there. The fact is that this indicator is taken into account in quite specific cases: for example, if a router must discard one of the routes that are equivalent in other characteristics, it will choose the one with a lower MTU. Although, not everything is so simple (see comments).
Let's define the terms used within EIGRP. Each route in EIGRP is characterized by two numbers: Feasible Distance and Advertised Distance (instead of Advertised Distance you can sometimes see Reported Distance, this is the same thing). Each of these numbers represents a metric, or cost (the more, the worse) of a given route from different measurement points: FD is “from me to the destination”, and AD is “from the neighbor who told me about this route to the place appointments." The answer to the logical question “Why do we need to know the cost from a neighbor if it is already included in the FD?” is a little lower (for now you can stop and rack your brains yourself, if you want).
For each subnet that EIGRP knows about, on each router there is a Successor router from among its neighbors, through which the best (with a lower metric), according to the protocol, route to this subnet goes. In addition, a subnet may also have one or more backup routes (the neighboring router through which such a route goes is called a Feasible Successor). EIGRP is the only routing protocol that remembers backup routes (OSPF has them, but they are contained, so to speak, in “raw form” in the topology table; they still need to be processed by the SPF algorithm), which gives it a performance advantage: as soon as the protocol determines that the main route (via successor) is unavailable, it immediately switches to the backup route. In order for a router to become a feasible successor for a route, its AD must be less than the FD successor of this route (that’s why we need to know AD). This rule is used to avoid routing loops.
Did the previous paragraph blow your mind? The material is difficult, so I’ll use an example again. We have this network:

From R1's point of view, R2 is the Successor for the 192.168.2.0/24 subnet. To become an FS for this subnet, R4 requires its AD to be less than the FD for this route. We have FD ((10000000/1544)*256)+(2100*256) =2195456, R4 has AD (from his point of view this is FD, i.e. how much does it cost him to get to this network) = ((10000000/100000 )*256)+(100*256)=51200. Everything converges, R4’s AD is less than the route’s FD, it becomes FS. *then the brain says: “BDASH”*. Now we look at R3 - he announces his network 192.168.1.0/24 to his neighbor R1, who, in turn, tells his neighbors R2 and R4 about it. R4 is unaware that R2 knows about this subnet and decides to tell him. R2 transmits the information that it has access through R4 to the subnet 192.168.1.0/24 further to R1. R1 strictly looks at the FD of the route and AD, which R2 boasts of (which, as is easy to understand from the diagram, will clearly be larger than the FD, since it includes him too) and shoos him away so as not to interfere with all sorts of nonsense. This situation is quite unlikely, but can occur under certain circumstances, for example, when the split-horizon mechanism is turned off. And now to a more likely situation: imagine that R4 is connected to the 192.168.2.0/24 network not via FastEthernet, but via a 56k modem (the delay for dialup is 20,000 usec), accordingly, it costs him ((10000000/56)*256 )+(2000*256)= 46226176. This is more than the FD for this route, so R4 will not become a Feasible Successor. But this does not mean that EIGRP will not use this route at all. It will just take longer to switch to it (more on that later).
Neighborhood
Routers don't talk about routes to just anyone - they must establish adjacency relationships before they can exchange information. After turning on the process with the router eigrp command, indicating the autonomous system number, we, with the network command, say which interfaces will participate and at the same time, information about which networks we want to distribute. Immediately, hello packets begin to be sent through these interfaces to the multicast address 224.0.0.10 (by default every 5 seconds for ethernet). All routers with EIGRP enabled receive these packets, then each receiving router does the following:- checks the sender address of the hello packet with the address of the interface from which the packet was received, and makes sure that they are from the same subnet
- compares the values of K-coefficients obtained from the package (in other words, which variables are used in calculating the metric) with its own. It is clear that if they differ, then the metrics for the routes will be calculated according to different rules which is unacceptable
- checks the autonomous system number
- optional: if authentication is configured, checks the consistency of its type and keys.
If the recipient is satisfied with everything, he adds the sender to the list of his neighbors and sends him (already in Unicast) an update packet, which contains a list of all routes known to him (aka full-update). The sender, having received such a packet, in turn, does the same. To exchange routes, EIGRP uses Reliable Transport Protocol (RTP, not to be confused with Real-time Transport Protocol, which is used in IP telephony), which implies delivery confirmation, so each of the routers, having received an update packet, responds with an ack packet (abbreviation from acknowledgement - confirmation). So, the neighborhood relationship has been established, the routers have learned from each other comprehensive information about the routes, what next? Then they will continue to send multicast hello packets to confirm that they are connected, and if the topology changes, update packets containing information only about the changes (partial update).
Now let's return to the previous scheme with the modem.

R2 for some reason lost contact with 192.168.2.0/24. It has no backup routes to this subnet (i.e., no FS). Like any responsible EIGRP router, it wants to reestablish connectivity. To do this, he begins to send special messages (query packets) to all his neighbors, who, in turn, not finding the desired route in themselves, ask all their neighbors, and so on. When the wave of requests reaches R4, he says “wait a minute, I have a route to this subnet! Bad, but at least something. Everyone forgot about him, but I remember.” He packs all this into a reply packet and sends it to the neighbor from whom he received the request (query), and further along the chain. Of course, this all takes more time than just switching to Feasible Successor, but in the end we get communication with the subnet.
And now is a dangerous moment: maybe you have already noticed and become wary after reading about this fan mailing. The failure of one interface causes something similar to a broadcast storm on the network (not on such a scale, of course, but still), and the more routers there are, the more resources will be spent on all these requests and responses. But that's not all that bad. A worse situation is possible: imagine that the routers shown in the picture are only part of a large and distributed network, i.e. some may be located many thousands of kilometers from our R2, on bad channels And so on. So, the trouble is that, having sent a query to a neighbor, the router must wait for a reply from him. It doesn’t matter what the answer is, but it must come. Even if the router already received a positive response, as in our case, he cannot put this route into operation until he waits for a response to all his requests. And maybe there are still requests somewhere in Alaska. This route state is called stuck-in-active. Here we need to get acquainted with the terms that reflect the state of the route in EIGRP: active\passive route. They are usually misleading. Common sense dictates that active means the route is “active”, enabled, running. However, here everything is the other way around: passive means “everything is fine,” and the active state means that this subnet is unavailable and the router is in active search another route, sending out a query and waiting for a reply. So, the stuck-in-active state can last up to 3 minutes! After this period has expired, the router breaks the neighbor relationship with the neighbor from whom it cannot wait for a response, and can use a new route through R4.
A story that chills the blood of a network engineer. 3 minutes of downtime is no joke. How can we avoid the heart attack of this situation? There are two ways out: summing up routes and the so-called stub configuration.
Generally speaking, there is another way out, and it is called route filtering. But this is such a voluminous topic that it would be better to write a separate article on it, but we already have half a book this time. So it's up to you.
As we already mentioned, in EIGRP route summarization can be carried out on any router. To illustrate, let’s imagine that subnets from 192.168.0.0/24 to 192.168.7.0/24 are connected to our long-suffering R2, which very conveniently sums up to 192.168.0.0/21 (remember binary math). The router advertises this summary route, and everyone else knows: if the destination address begins with 192.168.0-7, then it is to him. What happens if one of the subnets disappears? The router will send query packets with the address of this network (specific, for example, 192.168.5.0/24), but the neighbors, instead of continuing the vicious mailing on their own behalf, will immediately respond with sobering replays, saying that this is your subnet , you figure it out.
The second option is stub configuration. Figuratively speaking, stub means “end of the road”, “dead end” in EIGRP, i.e., to get into some subnet that is not connected directly to such a router, you will have to go back. A router configured as a stub will not forward traffic between subnets that it knows from EIGRP (in other words, which are marked with the letter D in show ip route). In addition, his neighbors will not send him query packets. The most common use case is hub-and-spoke topologies, especially with redundant links. Let’s take this network: on the left are branches, on the right is the main site, main office and so on. For fault tolerance, redundant links. EIGRP is running with default settings.

And now “attention, question”: what will happen if R1 loses connection with R4, and R5 loses LAN? Traffic from the R1 subnet to the main office subnet will follow the route R1->R5->R2 (or R3)->R4. Will it be effective? No. Not only will the subnet behind R1 suffer, but also the subnet behind R2 (or R3), due to the increased traffic volumes and its consequences. It is for such situations that stub was invented. Behind the routers in the branches there are no other routers that would lead to other subnets, this is the “end of the road”, then only back. Therefore, with a light heart, we can configure them as stubs, which, firstly, will save us from the problem with the “crooked route” outlined just above, and secondly, from the flood of query packets in case of loss of the route.
There are different modes of operation of a stub router; they are set with the eigrp stub command:
R1(config)#router eigrp 1By default, if you simply issue the eigrp stub command, the connected and summary modes are enabled. Of interest is the receive-only mode, in which the router does not advertise any networks, only listens to what its neighbors tell it (in RIP there is a passive interface command that does the same thing, but in EIGRP it completely disables the protocol on the selected interface, which does not allow establish a neighborhood).
R1(config-router)#eigrp stub?
connected Do advertise connected routes
leak-map Allow dynamic prefixes based on the leak-map
receive-only Set IP-EIGRP as receive only neighbor
redistributed Do advertise redistributed routes
static Do advertise static routes
summary Do advertise summary routes
Important points in the EIGRP theory that were not included in the article:
- Neighbor authentication can be configured in EIGRP
- Graceful shutdown concept
EIGRP Practice
Lift mi Up bought a factory in Kaliningrad. The brains of elevators are produced there: microcircuits, software. The factory is very large - three points around the city - three routers connected in a ring.
But bad luck - they already have EIGRP running as a dynamic routing protocol. Moreover, the addressing of end nodes is from a completely different subnet - 10.0.0.0/8. We changed all other parameters (link addresses, loopback interface addresses), but several thousand local network addresses with servers, printers, access points - not a job for a couple of hours - were postponed until later, and in the IP plan we reserved the 172.16 subnet for the future for Kaliningrad .32.0/20.
We currently use the following networks:


How is this miracle configured? Uncomplicated at first glance:
router eigrp 1
network 172.16.0.0 0.0.255.255
network 10.0.0.0
In EIGRP, the reverse mask can be specified, thereby indicating a narrower scope, or not specified, then the standard mask for this class will be selected (16 for class B - 172.16.0.0 and 8 for class A - 10.0.0.0)
Such commands are given on all routers Autonomous System. The AC is determined by the number in the router eigrp command, that is, in our case we have AC No. 1. This figure should be the same on all routers (unlike OSPF).
But there is a serious catch in EIGRP: by default, automatic summarization of routes in class form is enabled (in IOS versions up to 15).
Let's compare the routing tables on three Kaliningrad routers:
Network 10.0.0.1/24 is connected to klgr-center-gw1 and he knows about it:
klgr-center-gw1:
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:35:23, Null0
C 10.0.0.0/24 is directly connected, FastEthernet1/0
But doesn't know about 10.0.1.0/24 and 10.0.2.0/24/
Klgr-balt-gw1 knows about his two networks 10.0.1.0/24 and 10.0.2.0/24, but he hid the 10.0.0.0/24 network somewhere.
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:42:05, Null0
C 10.0.1.0/24 is directly connected, FastEthernet1/1.2
C 10.0.2.0/24 is directly connected, FastEthernet1/1.3
They both created route 10.0.0.0/8 with next hop address Null0.
But klgr-center-gw2 knows that subnets 10.0.0.0/8 are located behind both of its WAN interfaces.
D 10.0.0.0/8 via 172.16.2.41, 00:42:49, FastEthernet0/1
via 172.16.2.45, 00:38:05, FastEthernet0/0
Something very strange is happening.
But, if you check the configuration of this router, you will probably notice:
router eigrp 1
network 172.16.0.0
network 10.0.0.0
auto-summary
Automatic summation is to blame for everything. This is the biggest evil of EIGRP. Let's take a closer look at what's happening. klgr-center-gw1 and klgr-balt-gw1 have subnets from 10.0.0.0/8, they sum them up by default when they pass them on to their neighbors.
That is, for example, klgr-balt-gw1 transmits not two networks 10.0.1.0/24 and 10.0.2.0/24, but one generalized one: 10.0.0.0/8. That is, his neighbor will think that behind klgr-balt-gw1 this entire network is located.
But what happens if suddenly balt-gw1 receives a packet with destination 10.0.50.243, about which it knows nothing? For this case, the so-called Blackhole route is created:
10.0.0.0/8 is a summary, 00:42:05, Null0
The resulting packet will be thrown into this black hole. This is done to avoid routing loops.
So, both of these routers have created their own blackhole routes and ignore other people’s announcements. In reality, on such a network, these three devices will not be able to ping each other until... until you disable auto-summary.
The first thing you should do when configuring EIGRP is:
router eigrp 1
no auto-summary
On all devices. And everyone will be fine:
Klgr-center-gw1:
C 10.0.0.0 is directly connected, FastEthernet1/0
D 10.0.1.0 via 172.16.2.37, 00:03:11, FastEthernet0/0
D 10.0.2.0 via 172.16.2.37, 00:03:11, FastEthernet0/0
klgr-balt-gw1
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 via 172.16.2.38, 00:08:16, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet1/1.2
C 10.0.2.0 is directly connected, FastEthernet1/1.3
klgr-center-gw2:
10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 via 172.16.2.45, 00:11:50, FastEthernet0/0
D 10.0.1.0 via 172.16.2.41, 00:11:48, FastEthernet0/1
D 10.0.2.0 via 172.16.2.41, 00:11:48, FastEthernet0/1
Configuring route transfer between different protocols
Our task is to organize the transfer of routes between these protocols: from OSPF to EIGRP and vice versa, so that everyone knows the route to any subnet.This is called route redistribution.
To implement it, we need at least one junction point where two protocols will be launched simultaneously. This could be msk-arbat-gw1 or klgr-balt-gw1. Let's choose the second one.
From to EIGRP d OSPF:
klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1 subnets
We look at the routes on msk-arbat-gw1:
msk-arbat-gw1#sh ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static routeGateway of last resort is 198.51.100.1 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
O E2 10.0.0.0/8 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.1.0/24 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.2.0/24 via 172.16.2.34, 00:24:50, FastEthernet0/1.7
172.16.0.0/16 is variably subnetted, 30 subnets, 5 masks
O E2 172.16.0.0/16 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
O E2 172.16.2.36/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.40/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.44/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.2.192/30 via 172.16.2.197, 00:13:21, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.24.0/24 via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O 172.16.128.0/24 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.129.0/26 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.144.0/24 via 172.16.2.130, 00:13:21, FastEthernet0/1.8
O 172.16.160.0/24 via 172.16.2.197, 00:13:31, FastEthernet1/0.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O E2 172.16.255.64/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.65/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.66/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O 172.16.255.80/32 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.255.96/32 via 172.16.2.130, 00:13:21, FastEthernet0/1.8
via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.255.112/32 via 172.16.2.197, 00:13:31, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 via 198.51.100.1
Here are the ones with the E2 label - new imported routes. E2 - means that these are external routes of the 2nd type (External), that is, they were introduced into the OSPF process from outside
Now from OSPF to EIGRP. This is a little more complicated:
klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500
Without specifying the metric (this long set of numbers), the command will be executed, but redistribution will not occur.
Imported routes receive an EX label in the routing table and an administrative distance of 170, instead of 90 for internal ones:
klgr-gw2#sh ip routeGateway of last resort is not set
172.16.0.0/16 is variably subnetted, 30 subnets, 4 masks
D EX 172.16.0.0/24 [170 /33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.1.0/24 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.0/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.4/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.16/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D 172.16.2.32/30 [ 90 /30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
C 172.16.2.36/30 is directly connected, FastEthernet0/0
D 172.16.2.40/30 via 172.16.2.37, 00:38:59, FastEthernet0/0
via 172.16.2.46, 00:38:59, FastEthernet0/1
….
This is how it seems to be done in a simple way, but the simplicity is superficial - redistribution is fraught with many subtle and unpleasant moments when at least one redundant link is added between two different domains.
General advice - try to avoid redistribution if possible. The main rule of life works here - the simpler, the better.
Default route
Now is the time to check your Internet access. It works fine from Moscow, but if you check, for example, from St. Petersburg (remember that we deleted all static routes):PC>ping
Pinging 192.0.2.2 with 32 bytes of data:
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Ping statistics for 192.0.2.2:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
This is because neither spb-ozerki-gw1, nor spb-vsl-gw1, nor anyone else on our network knows about the default route except msk-arbat-gw1, on which it is statically configured.
To correct this situation, we just need to give one command in Moscow:
msk-arbat-gw1(config)#router ospf 1
msk-arbat-gw1(config-router)#default-information originate
After this, information about where the gateway of last resort is located avalanches across the network.
Internet is now available:
PC>tracert
Tracing route to 192.0.2.2 over a maximum of 30 hops:
1 3 ms 3 ms 3 ms 172.16.17.1
2 4 ms 5 ms 12 ms 172.16.2.5
3 14 ms 20 ms 9 ms 172.16.2.1
4 17 ms 17 ms 19 ms 198.51.100.1
5 22 ms 23 ms 19 ms 192.0.2.2
Useful commands for troubleshooting
1) The list of neighbors and the state of communication with them is called by the command show ip ospf neighbormsk-arbat-gw1:
Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:33 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:34 172.16.2.18 FastEthernet0/1.5
172.16.255.64 1 FULL/DR 00:00:33 172.16.2.34 FastEthernet0/1.7
172.16.255.80 1 FULL/DR 00:00:33 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/DR 00:00:33 172.16.2.197 FastEthernet1/0.911
2) Or for EIGRP: show ip eigrp neighbors
IP-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 172.16.2.38 Fa0/1 12 00:04:51 40 1000 0 54
1 172.16.2.42 Fa0/0 13 00:04:51 40 1000 0 58
3) Using the command show ip protocols You can view information about running dynamic routing protocols and their relationships.
Klgr-balt-gw1:
Routing Protocol is "EIGRP 1"
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: EIGRP 1, OSPF 1
Automatic network summarization is in effect
Automatic address summarization:
Maximum path: 4
Routing for Networks:
172.16.0.0
172.16.2.42 90 4
172.16.2.38 90 4
Distance: internal 90 external 170
Routing Protocol is "OSPF 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.255.64
It is an autonomous system boundary router
Redistributing External Routes from,
EIGRP 1
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.2.32 0.0.0.3 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.255.64 110 00:00:23
Distance: (default is 110)
4) To debug and understand the operation of protocols, it will be useful to use the following commands:
debug ip OSPF events
debug ip OSPF adj
debug EIGRP packets
Try trying different interfaces and see what happens in the debug, what messages are flying.
Authors
Marat eucariotMaxim aka gluck
I would like to express my gratitude to Dmitry JDima for the edits and invaluable comments, and to the irresistible Natasha Samoilenko for the tasks provided. Anton Avtushko for programming the blog site. And to the girl with the glorious name Nina for the site logo.
P.S.
Our upcoming podcast LinkMiAp needs a jingle and background music. We will be glad to help, and the name of the composer will be glorified for centuries.
P.P.S.
We no longer have enough of Packet Tracer's capabilities. The next step is moving on to something more serious. Any suggestions? I propose to organize a holivar in the comments on the topic IOU vs GNS.
Routing can be static or dynamic. For s static routing routing tables are required, which are created by the network administrator; they specify fixed (static) routes between any two routers. The administrator enters this information into the tables manually. The network administrator is also responsible for manually updating the tables if any network devices fail. A router running static tables can detect if a network link is down, but it cannot automatically change packet paths without administrator intervention.
Dynamic routing is executed regardless network administrator.
Dynamic routing protocols allow routers to automatically perform following operations:
· find other available routers in other network segments;
· use metrics to determine the shortest routes to other networks;
· determine when the network path to a certain router is unavailable or cannot be used;
· apply metrics for restructuring best routes when a certain network path becomes unavailable;
· re-find the router and network path after troubleshooting network problem on this way.
Bridge routers
Bridge router (brouter) is a network device that in some cases acts as a bridge, and in other cases as a router.
Rice. 3 Bridge router
For example, such a device can act as a bridge for certain protocols, such as NetBEUI (since it is non-routable), and as a router for other protocols, such as TCP/IP.
A bridge router can perform the following functions:
· effectively manage packets over a network with many protocols, including protocols that are routed and protocols that cannot be routed;
· reduce the load on channels by isolating and redirecting network traffic;
· connect networks;
· ensure the security of certain parts of the network by controlling access to them.
Bridge routers are used in multi-protocol networks such as NetBEUI, IPX/SPX and TCP/IP and are therefore also called multi-protocol routers.
The functions (routing or forwarding) they perform in relation to a protocol depend on two reasons:
· from network administrator directives specified for this protocol;
· whether the incoming frame contains routing information (if it does not, then packets of this protocol are usually sent to all networks).
If a bridge router is configured to forward protocol rather than routing, it forwards each frame using the Link Layer MAC sublayer address information just as a bridge does.
This is a significant capability for a network whose protocols include NetBEUI (since this protocol cannot be routed). For routed protocols such as TCP/IP, the bridge router forwards packets according to the addressing and routing information contained at the network layer.
Switches
Switches provide bridge functions and also allow you to increase the throughput of existing networks.

Rice. 4 Switch
Switches used in local area networks are similar to bridges in that they operate at the MAC sublayer of the Link Layer and analyze the device addresses in all incoming frames.
Like bridges, switches maintain a table of addresses and use this information to decide how to filter and forward LAN traffic. Unlike bridges, to increase data transfer speed and bandwidth network environment Switches use switching techniques.
LAN switches typically use one of two methods:
· When switching without packet buffering (cut-through switching), frames are sent in parts until the entire frame is received. Frame transmission begins as soon as the destination MAC address is read and the destination port is determined from the switch table. This approach provides relatively high speed transmission (partly due to the refusal to check for errors).
· In store-and-forward switching (also called buffered switching), transmission of a frame does not begin until it has been completely received. Once the switch receives a frame, it checks its checksum (CRC) before forwarding it to the target node. The frame is then stored (buffered) until the corresponding port and communication channel are free (they may be occupied by other data).
Latest models Switches (sometimes called routing switches) using store-and-forward switching can combine the functions of routers and switches and therefore operate at the Network layer to determine the shortest path to a destination node. One of the advantages of such switches is that they provide greater capabilities for segmenting network traffic, allowing you to avoid broadcast traffic that occurs on Ethernet networks.
Store-and-forward switching is more common than unbuffered switching, and some store-and-forward switches use built-in switching to improve performance. CPU. In principle, switches with their own processor are much faster than “simple” switches. However, in some cases, such switches can be overloaded with incoming traffic, with CPU utilization reaching 100% and the switch actually running slower than a switch without an internal processor.
Therefore, if you are using a switch with its own processor, it is important to determine the power of that processor and whether it matches the expected network load.
LAN switches support the following standards:
· Fast Ethernet;
· Gigabit Ethernet;
· 10 Gigabit Ethernet;
· Fast Token Ring;
One of the most common problems solved using switching mechanisms is reducing the likelihood of conflicts and increasing the throughput of Ethernet local networks. Ethernet switches use their MAC address tables to determine which ports should receive specific data.
Since each port is connected to a segment containing only one node, that node and segment have all the bandwidth (10 or 100 Mbps, 1 or 10 Gbps) at their disposal, since there are no other nodes; At the same time, the likelihood of conflicts decreases.
Another common application for switches is token ring networks. A Token Ring switch can perform bridge-only functions at the Data Link layer or operate as a source-routing bridge at the Network layer.
By switching directly to the segment that needs to receive data, switches can significantly increase network throughput without upgrading the existing transmission medium. As an example, consider a switchless Ethernet hub that has eight 10 Mbps segments connected to it. The speed of this hub will never exceed 10 Mbps, since it can only transfer data to one segment at a time. If the hub is replaced by an Ethernet switch, the overall network throughput will increase eightfold, or up to 80 Mbps, since the switch can send packets to each segment almost simultaneously. Currently, switches are not much more expensive than hubs, so they are the easiest way to increase the speed of a high-traffic network.
Managed switches are available, which, like managed hubs, have “intelligent” capabilities. For many networks, it makes sense to spend additional money on purchasing managed switches, supporting the SNMP protocol, which will increase the degree of network management and monitoring. Some switches can also support virtual local network technology (Virtual LAN, VLAN).
This technology, described by IEEE 802.1q standards, is a software method of dividing a network into subnets that are independent of its physical topology and contain logical groups. Members of a VLAN workgroup can be located on physically remote network segments, but they can be combined into one logical segment using software and VLAN switches, routers, and other network devices. It is best to use routing switches to implement VLANs because they reduce network management costs due to their ability to route packets between subnets. Layer 2 switches VLANs require switch ports to be associated with MAC addresses, which complicates VLAN management.
Gateways
Gateway term used in many contexts, but most commonly it refers to a software or hardware interface that allows interaction between two different types of network systems or programs.

Rice. 5 Gateway
For example, you can use the gateway to perform the following operations:
· convert widely used protocols (for example, TCP/IP) into specialized ones (for example, SNA);
Convert messages from one format to another;
· convert different addressing schemes;
· connect host computers to a local network;
· provide terminal emulation for connections to the host computer;
· redirect email to the desired network;
· connect networks with different architectures.
Gateways have many purposes, so they can operate at any OSI Layer.
Network gateways work on all known operating systems Oh. The main task of a network gateway is to convert the protocol between networks.
The router itself receives, routes and sends packets only among networks that use the same protocols.
A network gateway can, on the one hand, accept a packet formatted for one protocol (for example, Apple Talk) and convert it into a packet for another protocol (for example, TCP/IP) before sending it to another network segment. Network gateways can be hardware, software, or both, but are typically software installed on a router or computer. The network gateway must understand all the protocols used by the router. Typically network gateways are slower than network bridges, switches and regular routers.
A network gateway is a point on a network that serves as an exit to another network. On the Internet, a node or endpoint can be either a network gateway or a host. Internet users and computers that deliver web pages to users are hosts, and the nodes between various networks- These are network gateways. For example, a server that controls traffic between a company's local network and the Internet is a network gateway.
IN large networks a server acting as a network gateway, usually integrated with a proxy server and firewall. A network gateway is often combined with a router, which manages the distribution and conversion of packets across the network.
A network gateway can be a special hardware router or software installed on a regular server or personal computer. Most computer operating systems use the terms described above.
Windows computers usually use a built-in Network Connection Wizard, which specified parameters it establishes a connection to a local or global network. Such systems may also use the DHCP protocol.
WAN transmission equipment is designed to operate on regular telephone networks, as well as on leased lines such as T-lines and ISDN lines. They may have analog components (such as modems) or be completely digital (as for ISDN communications). Most often, this equipment either converts the signal for transmission to long distances, or creates multiple channels within one communication medium, thereby providing higher throughput.
Main types of transmission equipment of global networks:
· multiplexers;
· groups of channels;
· private telephone networks;
· telephone modems;
· ISDN adapters;
· cable modems;
· DSL modems and routers;
· access servers;
· routers.
Multiplexers
Multiplexers (multiplexer, MUX) are network devices that can receive signals from multiple inputs and transmit them to a common network environment.

Fig.1 Multiplexer
Multiplexers are essentially switches and are used in old and new technologies, including:
· in telephony for switching physical lines;
· when switching telecommunication virtual circuits to create multiple channels in one line (for example, in T-lines);
· in serial channels for connecting several terminals to one line (in local or global networks), for which this line is divided into several channels;
· in Fast Ethernet, X.25, ISDN, frame relay, ATM technologies and others (to create a variety of communication channels in one cable transmission medium).
Multiplexers operate on Physical OSI level, switching between channels. This uses one of three methods of electrical switching or a single method for transmission over an optical medium.
Electrical switching methods: multiple access channel multiplexing (TDMA), frequency division multiple access (FDMA) and statistical multiple access.
When transmitting over an optical medium, wavelength division multiplexing (WDM) is used. A light wave can be thought of as a spectrum consisting of waves of different wavelengths, measured in angstroms. An angstrom is equal to 10-10 m, and a light wave consists of individual waves with a length of 4000 to 7000 angstroms. Using spectral division, multiple incoming connections are converted into a set of different wavelengths within the spectrum of light transmitted along the fiber optic cable.
Channel groups
When first introduced, channel banks, or channel banks, were devices that allowed multiple incoming speech signals to pass over a single line, and multiplexers converted multiple data signals for transmission over a single line.

Rice. 2 Channel groups
The need to transmit voice, data and video has led to the rapid development of telecommunications channel groups, and today they can be used to both transmit voice signals and perform multiplexing of data, voice and video.
Thus, a channel group is a large multiplexer that combines telecommunication channels in one place, called a point of presence (POP). These circuits may be private T-1 lines, full T-1 and T-3 lines, ISDN circuits, or frame relay circuits. The first groups of D-1 type channels consisted of T-1 multiplexers.
Improvements in channel groups led to the introduction of D-4 and the less expensive Digital Access and Switching Systems (DACS). Where leased lines are heavily used, there are also groups of T-3, ISDN and frame relay circuits.
Within a point of presence (POP), several circuit groups communicate with each other so that incoming traffic from one circuit group can be switched to another circuit group and sent to the destination point. All channels on an incoming line (for example, a T-1 line) are combined and can be redirected to another channel group. You can also redirect only one of the incoming channels to another group. There are two routing methods for connecting groups of links, which are essentially similar to dynamic and static routing in networks. Thus, modern channel groups have routing tables that are either automatically maintained or configured by administrators.
Depending on the network architecture points of presence, routing information can be stored either centrally in one of the channel groups, or distributed among established groups.
Private telephone networks
To reduce the number of lines connected to the regional telephone company, some organizations deploy their own telephone services. For example, a company may have 100 offices with own phones, but no more than 50 employees can simultaneously call outside these offices. This company can save money by installing its own telephone system, which has 100 lines of communication with offices connected to a central exchange (automatic telephone exchange) or switching center, which is connected with 50 lines to the regional telephone company.
Initially, the most common private systems were office exchanges with outgoing and incoming communications (private branch exchange, PBX). They were manual switches that required an operator to make connections within the organization or when accessing an external telephone network.
Improvements have resulted in automatic business telephone systems, called private PBXs. shared network(private automatic exchange, PAX) and private automatic telephone exchanges with outgoing and incoming communications (private automatic branch exchange, PABX).

Rice. 3 Private automatic branch exchange, PABX
PAX stations still use a switch, and switching is performed both manually and automatically. PAX stations do not have a switch. Both types of exchanges include telephone trunk lines (similar to a network backbone), regular telephone lines, regional telephone company lines, telephones, and a processor-based switching system or computer that has memory, HDD and software. These stations can transmit video and data in addition to speech.
Centralized computer system often offers voicemail capabilities, call forwarding and call waiting, time tracking functions, and other services. Most often, such systems have a console for an operator who performs special functions (for example, processing extension numbers, accounts and other information). Sometimes there are modem lines for employees who connect to a computer network from home via a dial-up line.
Telephone modems
Modems have long played an important role in the development of global networks. The term modem is an abbreviation for the term modulator/demodulator.
The modem converts the output computer (digital) signal into an analog signal that can be transmitted over a telephone line. In addition, the modem converts the incoming analog signal into a digital signal that the computer can understand.

Rice. 4 Telephone modem
Modems for computers can be internal or external. The internal modem is inserted into the computer expansion slot on the motherboard.
An external modem is a stand-alone device that is connected to a computer's serial port using a special modem cable that matches the serial port connector.
There are three main types of connectors: the legacy 25-pin DB-25 connector, similar to a parallel printer port connector (but not suitable for parallel port operation); a 9-pin DB-9 connector and a round PS/2 connector for serial communications (such as on the IBM PC).
Also for serial connections, the Universal Serial Bus USB is used. The USB standard allows the connection of any type of peripheral devices (for example, printers, modems and tape drives) and in many cases replaces conventional parallel and serial ports. Both internal and external modems connect to telephone socket using a regular telephone cord with RJ-11 connectors at both ends.
Modem data transfer speed is measured by two similar, but not identical units: baud rate and the number of bits transmitted per second (bps). The baud rate represents the number of changes per second for a waveform carrying data. This speed reliably determined the speed of modems when they appeared (when they could transmit only one bit of data for each signal change).
The main influence on modem technology was Microcom, which was the first to develop the Microcom protocol Network Protocol(MNP). This standard describes classes of communications services (MNP classes 2 through 6, as well as class 10 for transmission using cell phones) and ensures efficient operation using error correction and data compression techniques.
The ITU has also developed standards for modem communications, including many MNP classes in its V.42 standard.
Modems operate in either synchronous or asynchronous mode. In synchronous communications, repeated data packets are controlled by a clock signal that begins each packet. In asynchronous mode, data is transferred in separate blocks separated by start and stop bits.
ISDN adapters
To connect a computer to an ISDN line, you need a device resembling a digital modem called a terminal adapter (TA).

Rice. 5 ISDN adapter
Existing terminal adapters cost almost the same as high-quality asynchronous or synchronous modems, but their performance is higher (for example, from 128 to 512 Kbps).
Terminal adapters convert digital signal into some protocol that is suitable for transmission over a digital telephone line. They usually have an analog phone jack that allows you to connect a regular phone or modem and use it on a digital line.
Most often, ISDN equipment allows you to connect to a single telephone line or copper pair (the same wire that connects your home or office telephone to telephone exchange), however it provides separate channels for computer data and regular analog voice communications. You can use either one analog and one digital line, or two digital or two analog lines at the same time.
DSL modems and routers
Another high-speed digital data service that competes with ISDN and cable modems is Digital Subscriber Line, DSL (Digital Subscriber Line) technology.
It is a method of transmitting digital data over the copper wire already installed in most telephone service offices (the newest DSL technology can be used with fiber optic telephone lines). To use DSL, you can install a smart adapter on your computer that is connected to the DSL network

Fig.1 Smart adapter connected to a DSL network
A smart adapter may look like a modem, but the adapter is completely digital, meaning it does not convert the DTE (computer or network device) digital signal to analog, but sends it directly to the telephone line. Two pairs of conductors connect the adapter and the telephone socket.
Communications over copper wire are simplex (one-way), that is, one pair is used to transmit outgoing data and the other is used to receive incoming signals, resulting in an uplink going to the telecommunications company and a downlink going to the user.
The maximum uplink speed is 1 Mbit/s, and the downlink speed can reach 60 Mbit/s. The maximum distance without a repeater (amplifying the signal) from the user to the telecommunications company is 5.5 km (which coincides with ISDN requirements).
A DSL line is connected to networks using a combined DSL adapter and router. As a result, this device can be used to distribute network traffic and as a firewall to provide access to network devices only to authorized subscribers.
With this connection, many users can access one DSL line through existing network, and the network will be protected from intrusion through this line. Usually for such a connection there is control software that allows you to monitor the line and diagnose it.
Access servers
An access server combines the functions of several devices used for global communication.
For example, one access server can perform data transmission using modem communications, X.25, T-1, T-3 and ISDN lines, as well as frame relay. Some access servers are designed for small and medium-sized networks.
Such servers have an Ethernet or Token Ring adapter to connect to the network. They also have several synchronous and asynchronous ports for connecting terminals, modems, pay phones, ISDN and X.25 lines. U small servers access usually ranges from 8 to 16 asynchronous ports and one or two synchronous ports.
Powerful access servers have a modular design with slots (from 10 to 20) for connecting communication cards, as shown in Fig. 4.14. One board, for example, can have 8 asynchronous ports and one synchronous. Another board may be designed to connect to a T-1 line, and another one may be designed to work with an ISDN line.

Rice. 2 Access servers
There may also be modular boards with built-in modems, for example, with 4 modems on one board. Some modular access servers are capable of supporting almost 70 modems. To ensure fault tolerance, the servers are also equipped with additional power supplies.
Routers
Using a remote router, networks located at great distances from each other (for example, in different cities) can be combined into global network. One router located in one city can connect a certain company to a remote router located in another company located in any other city.

Rice. 3 Router
Remote routers connect networks using ATM, ISDN, frame relay and high-speed serial line technologies, as well as X.25. A remote router, like a local one, can support multiple protocols, allowing you to connect remote networks various types. Similarly, a remote router can act as a firewall, restricting access to certain network resources.
Some remote routers have a modular design that allows different interfaces (for example, an ISDN line interface and a frame relay interface) to be inserted into expansion slots.
The advantage of such a router is that it can be gradually expanded as communication tasks become more complex, a problem that many organizations face.
So let's get started.
Articles and videos on how to configure OSPF mountains. There are much fewer descriptions of operating principles. In general, the thing here is that OSPF can be simply configured according to the manuals, without even knowing about SPF algorithms and incomprehensible LSAs. And everything will work and even, most likely, work perfectly - that’s what it’s designed for. That is, it’s not like with vlans, where you had to know the theory down to the header format.
But what distinguishes an engineer from an IT guy is that he understands why his network functions the way it does, and he knows, no worse than OSPF itself, which route will be chosen by the protocol.
Within the framework of the article, which at this moment is already 8,000 characters, we will not be able to dive into the depths of the theory, but we will consider the fundamental points.
It’s very simple and clear, by the way, it’s written about OSPF on xgu.ru or in the English Wikipedia.
So, OSPFv2 works on top of IP, and specifically, it is designed only for IPv4 (OSPFv3 does not depend on layer 3 protocols and therefore can work with IPv6).
Let's look at how it works using the example of this simplified network:

To begin with, it must be said that in order for a friendship (adjacency relationship) to develop between routers, the following conditions must be met:
1) the same settings must be configured in OSPF Hello Interval on those routers that are connected to each other. By default it is 10 seconds on Broadcast networks such as Ethernet. This is a kind of KeepAlive message. That is, every 10 seconds, each router sends a Hello packet to its neighbor to say, “Hey, I'm alive,”
2) Must be the same Dead Interval on them. Typically these are 4 Hello intervals - 40 seconds. If no Hello is received from the neighbor during this time, then it is considered unreachable and PANIC begins the process of rebuilding the local database and sending updates to all neighbors.
3) Interfaces connected to each other must be in one subnet,
4) OSPF allows you to reduce the load on the CPU of routers by dividing the Autonomous System into zones. So here it is zone numbers must also match
5) Each router participating in the OSPF process has its own unique identifier - Router ID. If you do not take care of it, the router will select it automatically based on information about the connected interfaces (the highest address is selected from the interfaces active at the time the OSPF process starts). But again, a good engineer has everything under control, so usually a Loopback interface is created, which is assigned an address with a /32 mask and this is what is assigned to the Router ID. This can be convenient for maintenance and troubleshooting.
6) MTU size must match
1) Calm. OSPF Status - DOWN
In this short moment, nothing happens on the network - everyone is silent.

2) The wind is rising: the router sends Hello packets to the multicast address 224.0.0.5 from all interfaces where OSPF is running. The TTL of such messages is one, so only routers located in the same network segment will receive them. R1 goes into state INIT.

The packages contain the following information:
- Router ID
- Hello Interval
- Dead Interval
- Neighbors
- Subnet mask
- Area ID
- Router Priority
- Addresses of DR and BDR routers
- Authentication password
The Hello message from router R1 carries its Router ID and does not contain Neighbors, because it does not have them yet.
After receiving this multicast message, router R2 adds R1 to its neighbor table (if all the necessary parameters match).

And it sends a new Hello message to R1 using Unicast, which contains the Router ID of this router, and the Neigbors list lists all its neighbors. Among other neighbors in this list there is Router ID R1, that is, R2 already considers it a neighbor.

3) Friendship. When R1 receives this Hello message from R2, it scrolls through the list of neighbors and finds its own Router ID in it, it adds R2 to its list of neighbors.

Now R1 and R2 are mutual neighbors of each other - this means that an adjacency relationship has been established between them and router R1 goes into state TWO WAY.

General advice for all tasks:
Even if you don’t immediately know the answer and solution, try to think about what the condition of the problem refers to:
- What features and protocol settings?
- Are these settings global or tied to a specific interface?
If you don't know or have forgotten the command, such reflections will most likely lead you to the correct context, where you can simply guess or remember how to configure what is required in the task using a hint on the command line.
Try to think in this way before you go to Google or some site looking for commands.
On a real network, when choosing the range of advertised subnets, you need to be guided by regulations and immediate needs.
Before we move on to testing backup links and speed, let's do one more useful thing.
If we had the opportunity to catch traffic on the FE0/0.2 msk-arbat-gw1 interface, which faces the servers, then we would see that Hello messages fly off into the unknown every 10 seconds. There is no one to respond to Hello, there is no one to establish adjacency relationships with, so there is no point in trying to send messages from here.
It's very easy to turn off:
msk-arbat-gw1(config)#router OSPF 1
msk-arbat-gw1(config-router)#passive-interface fastEthernet 0/0.2
This command must be given for all interfaces that definitely do not have OSPF neighbors (including those towards the Internet).
As a result, you will have a picture like this:

*I can’t imagine how you haven’t gotten confused yet*
In addition, this command increases security - no one from this network will pretend to be a router and will not try to completely break us.
Now let's move on to the most interesting part - testing.
There is nothing complicated about setting up OSPF on all routers in the Siberian Ring - you can do it yourself.
And after that the picture should be as follows:
msk-arbat-gw1#sh ip OSPF neighbor
172.16.255.32 1 FULL/DR 00:00:31 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:31 172.16.2.18 FastEthernet0/1.5
172.16.255.80 1 FULL/BDR 00:00:36 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/BDR 00:00:37 172.16.2.197 FastEthernet1/0.911
St. Petersburg, Kemerovo, Krasnoyarsk and Vladivostok are directly connected.
msk-arbat-gw1#sh ip route172.16.0.0/16 is variably subnetted, 25 subnets, 6 masks
S 172.16.2.4/30 via 172.16.2.2
O 172.16.2.160/30 via 172.16.2.130, 00:05:53, FastEthernet0/1.8
O 172.16.2.192/30 via 172.16.2.197, 00:04:18, FastEthernet1/0.911
S 172.16.16.0/21 via 172.16.2.2
S 172.16.24.0/22 via 172.16.2.18
O 172.16.24.0/24 via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.128.0/24 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.129.0/26 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.32/32 via 172.16.2.2, 00:24:03, FastEthernet0/1.4
O 172.16.255.48/32 via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.255.80/32 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.96/32 via 172.16.2.130, 00:04:18, FastEthernet0/1.8
via 172.16.2.197, 00:04:18, FastEthernet1/0.911
O 172.16.255.112/32 via 172.16.2.197, 00:04:28, FastEthernet1/0.911
Everyone knows everything about everyone.
What route is traffic delivered from Moscow to Krasnoyarsk? The table shows that krs-stolbi-gw1 is connected directly and the same can be seen from the trace:
1 172.16.2.130 35 msec 8 msec 5 msec

Now we tear up the interface between Moscow and Krasnoyarsk and see how long it takes for the link to be restored.
Not even 5 seconds pass before all the routers learned about the incident and recalculated their routing tables:
msk-arbat-gw1(config-subif)#do sh ip ro 172.16.128.0
Known via "OSPF 1", distance 110, metric 4, type intra area
Last update from 172.16.2.197 on FastEthernet1/0.911, 00:00:53 ago
Routing Descriptor Blocks:
* 172.16.2.197, from 172.16.255.80, 00:00:53 ago, via FastEthernet1/0.911
Route metric is 4, traffic share count is 1Vld-gw1#sh ip route 172.16.128.0
Routing entry for 172.16.128.0/24
Known via "OSPF 1", distance 110, metric 3, type intra area
Last update from 172.16.2.193 on FastEthernet1/0, 00:01:57 ago
Routing Descriptor Blocks:
* 172.16.2.193, from 172.16.255.80, 00:01:57 ago, via FastEthernet1/0
Route metric is 3, traffic share count is 1Msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abortion.
Tracing the route to 172.16.128.11 172.16.2.197 4 msec 10 msec 10 msec
2 172.16.2.193 8 msec 11 msec 15 msec
3 172.16.2.161 15 msec 13 msec 6 msec
That is, now traffic reaches Krasnoyarsk in this way:

As soon as you raise the link, the routers communicate again, exchange their databases, recalculate the shortest paths and enter them into the routing table.
The video makes all this more clear. I recommend familiarize.
Like any good protocol, OSPF supports authentication - two neighbors can verify the authenticity of received OSPF messages before establishing adjacency relationships. We leave it to you to study on your own - it’s quite simple.
EIGRP
Now let's move on to another very important protocol.So, what's good about EIGRP?
- easy to configure
- quick switching to calculated in advance alternate route
- requires less router resources (compared to OSPF)
- summarization of routes on any router (in OSPF only on ABR\ASBR)
- traffic balancing on unequal routes (OSPF only on equal routes)
We decided to translate one of Ivan Pepelnyak’s blog entries, which addresses a number of popular myths about EIGRP:
- “EIGRP is a hybrid routing protocol.” If I remember correctly, this started with the first presentation of EIGRP many years ago and is usually understood as "EIGRP took the best of the link-state and distance-vector protocols." This is absolutely not true. EIGRP does not have any distinctive link-state features. It would be correct to say “EIGRP is an advanced distance-vector routing protocol.”- “EIGRP is a distance-vector protocol.” Not bad, but not entirely true either. EIGRP differs from other DVs in the way it handles orphaned routes (or routes with increasing metric). All other protocols passively wait for updates from a neighbor (some, such as RIP, even block the route to prevent routing loops), while EIGRP is more active and requests information itself.
- “EIGRP is difficult to implement and maintain.” Not true. At one time, EIGRP in large networks with low-speed links was difficult to implement correctly, but only until stub routers were introduced. With them (as well as several corrections to the DUAL algorithm), it is almost worse than OSPF.
- “Like LS protocols, EIGRP maintains a table of the topology of the routes that are exchanged.” It's amazing how wrong this is. EIGRP has no idea at all what is beyond its immediate neighbors, while LS protocols know exactly the topology of the entire area to which they are connected.
- “EIGRP is a DV protocol that acts like LS.” Nice try, but still completely wrong. LS protocols build a routing table by going through the following steps:
- each router describes the network based on the information available to it locally (its links, the subnets it is in, the neighbors it sees) through a packet (or several) called an LSA (in OSPF) or LSP (IS-IS)
- LSAs are propagated throughout the network. Each router must receive every LSA created on its network. The information received from the LSA is entered into the topology table.
- Each router independently analyzes its topology table and runs the SPF algorithm to calculate the best routes to each of the other routers
EIGRP's behavior doesn't even come close to these steps, so why on earth it "acts like LS" is unclear.The only thing EIGRP does is store information received from a neighbor (RIP immediately forgets what cannot be used at the moment). In this sense, it is similar to BGP, which also stores everything in a BGP table and chooses the best route from there. The topology table (containing all information received from neighbors) gives EIGRP an advantage over RIP - it can contain information about a backup (not currently used) route.
Now a little closer to the theory of work:
Each EIGRP process maintains 3 tables:
- A neighbor table, which contains information about “neighbors”, i.e. other routers directly connected to the current one and participating in the exchange of routes. You can view it using the command show ip eigrp neighbors
- Network topology table, which contains route information received from neighbors. Let's watch as a team show ip eigrp topology
- The routing table, on the basis of which the router makes decisions about redirecting packets. View via show ip routeMetrics.
To assess the quality of a particular route, routing protocols use a certain number that reflects its various characteristics or a set of characteristics - a metric. The characteristics taken into account can be different - from the number of routers on a given route to the arithmetic average of the load on all interfaces along the route. Regarding the EIGRP metric, to quote Jeremy Cioara: “I got the impression that the creators of EIGRP, taking a critical look at their creation, decided that everything was too simple and worked well. And then they came up with a metric formula so that everyone would say “WOW, this is really complicated and looks professional.” See the complete formula for calculating the EIGRP metric: (K1 * bw + (K2 * bw) / (256 - load) + K3 * delay) * (K5 / (reliability + K4)), in which:
- bw is not just bandwidth, but (10000000/smallest bandwidth along the route in kilobits) * 256
- delay is not just a delay, but the sum of all delays on the way to tens of microseconds* 256 (delay in commands show interface, show ip eigrp topology and others is shown in microseconds!)
- K1-K5 are coefficients that serve to “include” one or another parameter in the formula.Scary? it would be if it all worked as written. In fact, of all 4 possible terms of the formula, only two are used by default: bw and delay (coefficients K1 and K3 = 1, the rest are zero), which greatly simplifies it - we simply add these two numbers (while not forgetting that they are still calculated according to their own formulas). It is important to remember the following: the metric is calculated according to the worst throughput indicator along the entire length of the route.
An interesting thing happened with MTU: quite often you can find information that MTU is related to the EIGRP metric. Indeed, MTU values are transmitted when exchanging routes. But, as we can see from the full formula, there is no mention of MTU there. The fact is that this indicator is taken into account in quite specific cases: for example, if a router must discard one of the routes that are equivalent in other characteristics, it will choose the one with a lower MTU. Although, not everything is so simple (see comments).Let's define the terms used within EIGRP. Each route in EIGRP is characterized by two numbers: Feasible Distance and Advertised Distance (instead of Advertised Distance you can sometimes see Reported Distance, this is the same thing). Each of these numbers represents a metric, or cost (the more, the worse) of a given route from different measurement points: FD is “from me to the destination”, and AD is “from the neighbor who told me about this route to the place appointments." The answer to the logical question “Why do we need to know the cost from a neighbor if it is already included in the FD?” is a little lower (for now you can stop and rack your brains yourself, if you want).
For each subnet that EIGRP knows about, on each router there is a Successor router from among its neighbors, through which the best (with a lower metric), according to the protocol, route to this subnet goes. In addition, a subnet may also have one or more backup routes (the neighboring router through which such a route goes is called a Feasible Successor). EIGRP is the only routing protocol that remembers backup routes (OSPF has them, but they are contained, so to speak, in “raw form” in the topology table; they still need to be processed by the SPF algorithm), which gives it a performance advantage: as soon as the protocol determines that the main route (via successor) is unavailable, it immediately switches to the backup route. In order for a router to become a feasible successor for a route, its AD must be less than the FD successor of this route (that’s why we need to know AD). This rule is used to avoid routing loops.
Did the previous paragraph blow your mind? The material is difficult, so I’ll use an example again. We have this network:
From R1's point of view, R2 is the Successor for the 192.168.2.0/24 subnet. To become an FS for this subnet, R4 requires its AD to be less than the FD for this route. We have FD ((10000000/1544)*256)+(2100*256) =2195456, R4 has AD (from his point of view this is FD, i.e. how much does it cost him to get to this network) = ((10000000/100000 )*256)+(100*256)=51200. Everything converges, R4’s AD is less than the route’s FD, it becomes FS. *then the brain says: “BDASH”*. Now we look at R3 - he announces his network 192.168.1.0/24 to his neighbor R1, who, in turn, tells his neighbors R2 and R4 about it. R4 is unaware that R2 knows about this subnet and decides to tell him. R2 transmits the information that it has access through R4 to the subnet 192.168.1.0/24 further to R1. R1 strictly looks at the FD of the route and AD, which R2 boasts of (which, as is easy to understand from the diagram, will clearly be larger than the FD, since it includes him too) and shoos him away so as not to interfere with all sorts of nonsense. This situation is quite unlikely, but can occur under certain circumstances, for example, when the split-horizon mechanism is turned off. And now to a more likely situation: imagine that R4 is connected to the 192.168.2.0/24 network not via FastEthernet, but via a 56k modem (the delay for dialup is 20,000 usec), accordingly, it costs him ((10000000/56)*256 )+(2000*256)= 46226176. This is more than the FD for this route, so R4 will not become a Feasible Successor. But this does not mean that EIGRP will not use this route at all. It will just take longer to switch to it (more on that later).
neighborhood
Routers don't talk about routes to just anyone - they must establish adjacency relationships before they can exchange information. After turning on the process with the router eigrp command, indicating the autonomous system number, we, with the network command, say which interfaces will participate and at the same time, information about which networks we want to distribute. Immediately, hello packets begin to be sent through these interfaces to the multicast address 224.0.0.10 (by default every 5 seconds for ethernet). All routers with EIGRP enabled receive these packets, then each receiving router does the following:
- checks the sender address of the hello packet with the address of the interface from which the packet was received, and makes sure that they are from the same subnet
- compares the values of K-coefficients obtained from the package (in other words, which variables are used in calculating the metric) with its own. It is clear that if they differ, then the metrics for the routes will be calculated according to different rules, which is unacceptable
- checks the autonomous system number
- optional: if authentication is configured, checks the consistency of its type and keys.If the recipient is satisfied with everything, he adds the sender to the list of his neighbors and sends him (already in Unicast) an update packet, which contains a list of all routes known to him (aka full-update). The sender, having received such a packet, in turn, does the same. To exchange routes, EIGRP uses Reliable Transport Protocol (RTP, not to be confused with Real-time Transport Protocol, which is used in IP telephony), which implies delivery confirmation, so each of the routers, having received an update packet, responds with an ack packet (abbreviation from acknowledgement - confirmation). So, the neighborhood relationship has been established, the routers have learned from each other comprehensive information about the routes, what next? Then they will continue to send multicast hello packets to confirm that they are connected, and if the topology changes, update packets containing information only about the changes (partial update).
Now let's return to the previous scheme with the modem.
R2 for some reason lost contact with 192.168.2.0/24. It has no backup routes to this subnet (i.e., no FS). Like any responsible EIGRP router, it wants to reestablish connectivity. To do this, he begins to send special messages (query packets) to all his neighbors, who, in turn, not finding the desired route in themselves, ask all their neighbors, and so on. When the wave of requests reaches R4, he says “wait a minute, I have a route to this subnet! Bad, but at least something. Everyone forgot about him, but I remember.” He packs all this into a reply packet and sends it to the neighbor from whom he received the request (query), and further along the chain. Of course, this all takes more time than just switching to Feasible Successor, but in the end we get communication with the subnet.
And now is a dangerous moment: maybe you have already noticed and become wary after reading about this fan mailing. The failure of one interface causes something similar to a broadcast storm on the network (not on such a scale, of course, but still), and the more routers there are, the more resources will be spent on all these requests and responses. But that's not all that bad. A worse situation is possible: imagine that the routers shown in the picture are only part of a large and distributed network, i.e. some may be located many thousands of kilometers from our R2, on bad channels, etc. So, the trouble is that, having sent a query to a neighbor, the router must wait for a reply from him. It doesn’t matter what the answer is, but it must come. Even if the router already received a positive response, as in our case, he cannot put this route into operation until he waits for a response to all his requests. And maybe there are still requests somewhere in Alaska. This route state is called stuck-in-active. Here we need to get acquainted with the terms that reflect the state of the route in EIGRP: active\passive route. They are usually misleading. Common sense dictates that active means the route is “active”, enabled, running. However, here everything is the other way around: passive means “everything is fine,” and the active state means that this subnet is unavailable, and the router is actively searching for another route, sending out a query and waiting for a reply. So, the stuck-in-active state can last up to 3 minutes! After this period has expired, the router breaks the neighbor relationship with the neighbor from whom it cannot wait for a response, and can use a new route through R4.
A story that chills the blood of a network engineer. 3 minutes of downtime is no joke. How can we avoid the heart attack of this situation? There are two ways out: summing up routes and the so-called stub configuration.
Generally speaking, there is another way out, and it is called route filtering. But this is such a voluminous topic that it would be better to write a separate article on it, but we already have half a book this time. So it's up to you.As we already mentioned, in EIGRP route summarization can be carried out on any router. To illustrate, let’s imagine that subnets from 192.168.0.0/24 to 192.168.7.0/24 are connected to our long-suffering R2, which very conveniently sums up to 192.168.0.0/21 (remember binary math). The router advertises this summary route, and everyone else knows: if the destination address begins with 192.168.0-7, then it is to him. What happens if one of the subnets disappears? The router will send query packets with the address of this network (specific, for example, 192.168.5.0/24), but the neighbors, instead of continuing the vicious mailing on their own behalf, will immediately respond with sobering replays, saying that this is your subnet , you figure it out.
The second option is stub configuration. Figuratively speaking, stub means “end of the road”, “dead end” in EIGRP, i.e., to get into some subnet that is not connected directly to such a router, you will have to go back. A router configured as a stub will not forward traffic between subnets that it knows from EIGRP (in other words, which are marked with the letter D in show ip route). In addition, his neighbors will not send him query packets. The most common use case is hub-and-spoke topologies, especially with redundant links. Let’s take this network: on the left are branches, on the right is the main site, main office, etc. For fault tolerance, redundant links. EIGRP is running with default settings.
And now “attention, question”: what will happen if R1 loses connection with R4, and R5 loses LAN? Traffic from the R1 subnet to the main office subnet will follow the route R1->R5->R2 (or R3)->R4. Will it be effective? No. Not only will the subnet behind R1 suffer, but also the subnet behind R2 (or R3), due to the increased traffic volumes and its consequences. It is for such situations that stub was invented. Behind the routers in the branches there are no other routers that would lead to other subnets, this is the “end of the road”, then only back. Therefore, with a light heart, we can configure them as stubs, which, firstly, will save us from the problem with the “crooked route” outlined just above, and secondly, from the flood of query packets in case of loss of the route.
There are different modes of operation of a stub router; they are set with the eigrp stub command:
R1(config)#router eigrp 1
R1(config-router)#eigrp stub?
connected Do advertise connected routes
leak-map Allow dynamic prefixes based on the leak-map
receive-only Set IP-EIGRP as receive only neighbor
redistributed Do advertise redistributed routes
static Do advertise static routes
summary Do advertise summary routes
By default, if you simply issue the eigrp stub command, the connected and summary modes are enabled. Of interest is the receive-only mode, in which the router does not advertise any networks, only listens to what its neighbors tell it (in RIP there is a passive interface command that does the same thing, but in EIGRP it completely disables the protocol on the selected interface, which does not allow establish a neighborhood).Important points in the EIGRP theory that were not included in the article:
- Neighbor authentication can be configured in EIGRP
- Graceful shutdown concept
EIGRP Practice
Lift mi Up bought a factory in Kaliningrad. The brains of elevators are produced there: microcircuits, software. The factory is very large - three points around the city - three routers connected in a ring.
But bad luck - they already have EIGRP running as a dynamic routing protocol. Moreover, the addressing of end nodes is from a completely different subnet - 10.0.0.0/8. We changed all other parameters (link addresses, loopback interface addresses), but several thousand local network addresses with servers, printers, access points - not a job for a couple of hours - were postponed until later, and in the IP plan we reserved the 172.16 subnet for the future for Kaliningrad .32.0/20.
We currently use the following networks:
How is this miracle configured? Uncomplicated at first glance:
router eigrp 1
network 172.16.0.0 0.0.255.255
network 10.0.0.0
In EIGRP, the reverse mask can be specified, thereby indicating a narrower scope, or not specified, then the standard mask for this class will be selected (16 for class B - 172.16.0.0 and 8 for class 8 - 10.0.0.0)Such commands are issued on all Autonomous System routers. The AC is determined by the number in the router eigrp command, that is, in our case we have AC No. 1. This figure should be the same on all routers (unlike OSPF).
But there is a serious catch in EIGRP: by default, automatic summarization of routes in class form is enabled (in IOS versions up to 15).
Let's compare the routing tables on three Kaliningrad routers:Network 10.0.0.1/24 is connected to klgr-center-gw1 and he knows about it:
klgr-center-gw1:
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:35:23, Null0
C 10.0.0.0/24 is directly connected, FastEthernet1/0
But doesn't know about 10.0.1.0/24 and 10.0.2.0/24/Klgr-balt-gw1 knows about his two networks 10.0.1.0/24 and 10.0.2.0/24, but he hid the 10.0.0.0/24 network somewhere.
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:42:05, Null0
C 10.0.1.0/24 is directly connected, FastEthernet1/1.2
C 10.0.2.0/24 is directly connected, FastEthernet1/1.3
They both created route 10.0.0.0/8 with next hop address Null0.But klgr-center-gw2 knows that subnets 10.0.0.0/8 are located behind both of its WAN interfaces.
D 10.0.0.0/8 via 172.16.2.41, 00:42:49, FastEthernet0/1
via 172.16.2.45, 00:38:05, FastEthernet0/0
Something very strange is happening.
But, if you check the configuration of this router, you will probably notice:router eigrp 1
network 172.16.0.0
network 10.0.0.0
auto-summary
Automatic summation is to blame for everything. This is the biggest evil of EIGRP. Let's take a closer look at what's happening. klgr-center-gw1 and klgr-balt-gw1 have subnets from 10.0.0.0/8, they sum them up by default when they pass them on to their neighbors.
That is, for example, msk-balt-gw1 transmits not two networks 10.0.1.0/24 and 10.0.2.0/24, but one generalized one: 10.0.0.0/8. That is, his neighbor will think that this entire network is located behind msk-balt-gw1.
But what happens if suddenly balt-gw1 receives a packet with destination 10.0.50.243, about which it knows nothing? For this case, the so-called Blackhole route is created:
10.0.0.0/8 is a summary, 00:42:05, Null0
The resulting packet will be thrown into this black hole. This is done to avoid routing loops.
So, both of these routers have created their own blackhole routes and ignore other people’s announcements. In reality, on such a network, these three devices will not be able to ping each other until... until you disable auto-summary.The first thing you should do when configuring EIGRP is:
router eigrp 1
no auto-summary
On all devices. And everyone will be fine:Klgr-center-gw1:
C 10.0.0.0 is directly connected, FastEthernet1/0
D 10.0.1.0 via 172.16.2.37, 00:03:11, FastEthernet0/0
D 10.0.2.0 via 172.16.2.37, 00:03:11, FastEthernet0/0
klgr-balt-gw110.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 via 172.16.2.38, 00:08:16, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet1/1.2
C 10.0.2.0 is directly connected, FastEthernet1/1.3
klgr-center-gw2:10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 via 172.16.2.45, 00:11:50, FastEthernet0/0
D 10.0.1.0 via 172.16.2.41, 00:11:48, FastEthernet0/1
D 10.0.2.0 via 172.16.2.41, 00:11:48, FastEthernet0/1Configuring route transfer between different protocols
Our task is to organize the transfer of routes between these protocols: from OSPF to EIGRP and vice versa, so that everyone knows the route to any subnet.
This is called route redistribution.To implement it, we need at least one junction point where two protocols will be launched simultaneously. This could be msk-arbat-gw1 or klgr-balt-gw1. Let's choose the second one.
From EIGRP to OSPF:
klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1 subnets
We look at the routes on msk-arbat-gw1:msk-arbat-gw1#sh ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static routeGateway of last resort is 198.51.100.1 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
O E2 10.0.0.0/8 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.1.0/24 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.2.0/24 via 172.16.2.34, 00:24:50, FastEthernet0/1.7
172.16.0.0/16 is variably subnetted, 30 subnets, 5 masks
O E2 172.16.0.0/16 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
O E2 172.16.2.36/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.40/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.44/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.2.192/30 via 172.16.2.197, 00:13:21, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.24.0/24 via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O 172.16.128.0/24 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.129.0/26 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.144.0/24 via 172.16.2.130, 00:13:21, FastEthernet0/1.8
O 172.16.160.0/24 via 172.16.2.197, 00:13:31, FastEthernet1/0.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O E2 172.16.255.64/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.65/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.66/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O 172.16.255.80/32 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.255.96/32 via 172.16.2.130, 00:13:21, FastEthernet0/1.8
via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.255.112/32 via 172.16.2.197, 00:13:31, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 via 198.51.100.1Here are the ones with the E2 label - new imported routes. E2 - means that these are external routes of the 2nd type (External), that is, they were introduced into the OSPF process from outside
Now from OSPF to EIGRP. This is a little more complicated:
klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500
Without specifying the metric (this long set of numbers), the command will be executed, but redistribution will not occur.Imported routes receive an EX label in the routing table and an administrative distance of 170, instead of 90 for internal ones:
klgr-gw2#sh ip routeGateway of last resort is not set
172.16.0.0/16 is variably subnetted, 30 subnets, 4 masks
D EX 172.16.0.0/24 [170 /33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.1.0/24 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.0/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.4/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.16/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D 172.16.2.32/30 [ 90 /30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
C 172.16.2.36/30 is directly connected, FastEthernet0/0
D 172.16.2.40/30 via 172.16.2.37, 00:38:59, FastEthernet0/0
via 172.16.2.46, 00:38:59, FastEthernet0/1
….This is how it seems to be done in a simple way, but the simplicity is superficial - redistribution is fraught with many subtle and unpleasant moments when at least one redundant link is added between two different domains.
General advice - try to avoid redistribution if possible. The main rule of life works here - the simpler, the better.Default route
Now is the time to check your Internet access. It works fine from Moscow, but if you check, for example, from St. Petersburg (remember that we deleted all static routes):PC>ping linkmeup.ruPinging 192.0.2.2 with 32 bytes of data:
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.Ping statistics for 192.0.2.2:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
This is because neither spb-ozerki-gw1, nor spb-vsl-gw1, nor anyone else on our network knows about the default route except msk-arbat-gw1, on which it is statically configured.
To correct this situation, we just need to give one command in Moscow:msk-arbat-gw1(config)#router ospf 1
msk-arbat-gw1(config-router)#default-information originate
After this, information about where the gateway of last resort is located avalanches across the network.Internet is now available:
PC>tracert linkmeup.ruTracing route to 192.0.2.2 over a maximum of 30 hops:
1 3 ms 3 ms 3 ms 172.16.17.1
2 4 ms 5 ms 12 ms 172.16.2.5
3 14 ms 20 ms 9 ms 172.16.2.1
4 17 ms 17 ms 19 ms 198.51.100.1
5 22 ms 23 ms 19 ms 192.0.2.2Useful commands for troubleshooting
1) The list of neighbors and the state of communication with them is called by the command show ip ospf neighbor
msk-arbat-gw1:Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:33 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:34 172.16.2.18 FastEthernet0/1.5
172.16.255.64 1 FULL/DR 00:00:33 172.16.2.34 FastEthernet0/1.7
172.16.255.80 1 FULL/DR 00:00:33 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/DR 00:00:33 172.16.2.197 FastEthernet1/0.911
2) Or for EIGRP: show ip eigrp neighborsIP-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 172.16.2.38 Fa0/1 12 00:04:51 40 1000 0 54
1 172.16.2.42 Fa0/0 13 00:04:51 40 1000 0 58
3) Using the command show ip protocols You can view information about running dynamic routing protocols and their relationships.Klgr-balt-gw1:
Routing Protocol is "EIGRP 1"
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: EIGRP 1, OSPF 1
Automatic network summarization is in effect
Automatic address summarization:
Maximum path: 4
Routing for Networks:
172.16.0.0
172.16.2.42 90 4
172.16.2.38 90 4
Distance: internal 90 external 170Routing Protocol is "OSPF 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.255.64
It is an autonomous system boundary router
Redistributing External Routes from,
EIGRP 1
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.2.32 0.0.0.3 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.255.64 110 00:00:23
Distance: (default is 110)
4) To debug and understand the operation of protocols, it will be useful to use the following commands:
debug ip OSPF events
debug ip OSPF adj
debug EIGRP packetsTry trying different interfaces and see what happens in the debug, what messages are flying.
Problem No. 7
Finally, a complex problem.
At the last meeting of Lift mi Up, it was decided that the Kaliningrad network should also be transferred to OSPF.
The transition must be completed without breaking the connection. It was decided that the best option would be to raise OSPF on three Kaliningrad routers in parallel with EIGRP and, after checking that all information about Kaliningrad routes had spread throughout the rest of the network and vice versa, disable EIGRP. for the site logo. Add tags






Dynamic routing protocols are designed to automate the process of building routing tables for routers. The principle of their use is quite simple: routers, using the order established by the protocol, send certain information from their routing table to others and adjust their table based on data received from others.
This method of constructing and maintaining routing tables greatly simplifies the task of administering networks that may undergo changes (for example, expansion) or in situations where any routers and/or subnets fail.
It should be noted that the use of dynamic routing protocols does not eliminate the possibility of “manually” entering data into router tables. Entries made in this way are called static, and entries obtained as a result of information exchange between routers are called dynamic. In any routing table there is always at least one static entry - the default route.
Modern routing protocols are divided into two groups: vector-distance protocols and link-state protocols.
In vector-distance protocols, each router sends out a list of addresses of networks available to it (“vectors”), each of which is associated with a “distance” parameter (for example, the number of routers to this network, a value based on link performance, etc. .). The main representative of the protocols in this group is the RIP protocol (Routing Information Protocol).
Link-state protocols are based on a different principle. Routers exchange topological information with each other about connections in the network: which routers are connected to which networks. As a result, each router has a complete picture of the network structure (and this view will be the same for everyone), based on which it calculates its own optimal routing table. The protocol for this group is OSPF (Open Shortest Path First).
RIP protocol.
The RIP (Routing Information Protocol) protocol is the most simple protocol dynamic routing. It belongs to the vector-distance protocols.
Under a vector, RIP defines the IP addresses of networks, and the distance is measured in hops (“hops”)—the number of routers a packet must go through to reach a specified network. It should be noted that the maximum distance value for the RIP protocol is 15, the value 16 is interpreted in a special way “network unreachable”. This determined the main drawback of the protocol - it turns out to be inapplicable in large networks where routes exceeding 15 hops are possible.
RIP version 1 has a number of significant disadvantages for practical use. Important issues include the following:
- Estimatedka distances only taking into account the number of transitions. The RIP protocol does not take into account the actual performance of communication channels, which may be ineffective in heterogeneous networks, i.e. networks combining communication channels different devices,performance that use different network technologies.
- The Problem of Slow Convergence. Routers using the RIP protocol. They send out routing information every 30 seconds, and their work is not synchronized. In a situation where a certain router detects that some network has become unavailable, then in the worst case (if the problem was identified immediately after the next broadcast) it will notify its neighbors about this after 30 seconds. For neighboring routers everything will happen the same way. This means that information about the unavailability of a network can take a long time to spread to routers; obviously, the network will be in an unstable state.
- Broadcasting routing tables. The RIP protocol originally assumed that routers send information in broadcast mode. This means that the sent packet is forced to be received and analyzed at the link, network and transport levels by all computers on the network to which it is sent.
Partially these problems are solved in version 2 (RIP2).
OSPF protocol
OSPF (Routing (Open Shortest Path First)) is a newer dynamic routing protocol and is a link-state protocol.
The operation of the OSPF protocol is based on the use of a single database by all routers, which describes how and with which networks each router is connected. Describing each connection, communication routers
They add a metric to it - a value characterizing the “quality” of the channel. For example, 100 Mbps Ethernet networks use a value of 1, and 56 Kbps dial-up connections use a value of 1785. This allows OSPF routers (as opposed to RIP, where all channels are equal) to take into account real bandwidth and identify efficient routes. An important feature of the OSPF protocol is that it uses multicast rather than broadcast.
These features, such as multicast instead of broadcast, no restrictions on route length, periodic exchange of only short status messages, and consideration of the “quality” of communication channels allow the use of OSPF in large networks. However, such use can create a serious problem - a large amount of routing information circulating in the network and an increase in routing tables. And since the algorithm for finding efficient routes is quite complex in terms of computational volume, large networks may require high-performance and, therefore, expensive routers. Therefore, the ability to build efficient routing tables can be considered both an advantage and a disadvantage of the OSPF protocol.
So let's get started.
Articles and videos on how to configure OSPF mountains. There are much fewer descriptions of operating principles. In general, the thing here is that OSPF can be simply configured according to the manuals, without even knowing about SPF algorithms and incomprehensible LSAs. And everything will work and even, most likely, work perfectly - that’s what it’s designed for. That is, it’s not like with vlans, where you had to know the theory down to the header format.
But what distinguishes an engineer from an IT guy is that he understands why his network functions the way it does, and he knows, no worse than OSPF itself, which route will be chosen by the protocol.
Within the framework of the article, which at this moment is already 8,000 characters, we will not be able to dive into the depths of the theory, but we will consider the fundamental points.
It’s very simple and clear, by the way, it’s written about OSPF on xgu.ru or in the English Wikipedia.
So, OSPFv2 works on top of IP, and specifically, it is designed only for IPv4 (OSPFv3 does not depend on layer 3 protocols and therefore can work with IPv6).
Let's look at how it works using the example of this simplified network:
To begin with, it must be said that in order for a friendship (adjacency relationship) to develop between routers, the following conditions must be met:
1) the same settings must be configured in OSPF Hello Interval on those routers that are connected to each other. By default it is 10 seconds on Broadcast networks such as Ethernet. This is a kind of KeepAlive message. That is, every 10 seconds, each router sends a Hello packet to its neighbor to say, “Hey, I'm alive,”
2) Must be the same Dead Interval on them. Typically these are 4 Hello intervals - 40 seconds. If no Hello is received from the neighbor during this time, then it is considered unreachable and PANIC begins the process of rebuilding the local database and sending updates to all neighbors.
3) Interfaces connected to each other must be in one subnet,
4) OSPF allows you to reduce the load on the CPU of routers by dividing the Autonomous System into zones. So here it is zone numbers must also match
5) Each router participating in the OSPF process has its own unique identifier - Router ID. If you do not take care of it, the router will select it automatically based on information about the connected interfaces (the highest address is selected from the interfaces active at the time the OSPF process starts). But again, a good engineer has everything under control, so usually a Loopback interface is created, which is assigned an address with a /32 mask and this is what is assigned to the Router ID. This can be convenient for maintenance and troubleshooting.
6) MTU size must match
1) Calm. OSPF Status - DOWN
In this short moment, nothing happens on the network - everyone is silent.
2) The wind is rising: the router sends Hello packets to the multicast address 224.0.0.5 from all interfaces where OSPF is running. The TTL of such messages is one, so only routers located in the same network segment will receive them. R1 goes into state INIT.
The packages contain the following information:
- Router ID
- Hello Interval
- Dead Interval
- Neighbors
- Subnet mask
- Area ID
- Router Priority
- Addresses of DR and BDR routers
- Authentication password
The Hello message from router R1 carries its Router ID and does not contain Neighbors, because it does not have them yet.
After receiving this multicast message, router R2 adds R1 to its neighbor table (if all the necessary parameters match).
And it sends a new Hello message to R1 using Unicast, which contains the Router ID of this router, and the Neigbors list lists all its neighbors. Among other neighbors in this list there is Router ID R1, that is, R2 already considers it a neighbor.
3) Friendship. When R1 receives this Hello message from R2, it scrolls through the list of neighbors and finds its own Router ID in it, it adds R2 to its list of neighbors.
Now R1 and R2 are mutual neighbors of each other - this means that an adjacency relationship has been established between them and router R1 goes into state TWO WAY.
General advice for all tasks:
Even if you don’t immediately know the answer and solution, try to think about what the condition of the problem refers to:
- What features and protocol settings?
- Are these settings global or tied to a specific interface?
If you don't know or have forgotten the command, such reflections will most likely lead you to the correct context, where you can simply guess or remember how to configure what is required in the task using a hint on the command line.
Try to think in this way before you go to Google or some site looking for commands.
On a real network, when choosing the range of advertised subnets, you need to be guided by regulations and immediate needs.
Before we move on to testing backup links and speed, let's do one more useful thing.
If we had the opportunity to catch traffic on the FE0/0.2 msk-arbat-gw1 interface, which faces the servers, then we would see that Hello messages fly off into the unknown every 10 seconds. There is no one to respond to Hello, there is no one to establish adjacency relationships with, so there is no point in trying to send messages from here.
It's very easy to turn off:
msk-arbat-gw1(config)#router OSPF 1
msk-arbat-gw1(config-router)#passive-interface fastEthernet 0/0.2
This command must be given for all interfaces that definitely do not have OSPF neighbors (including those towards the Internet).
As a result, you will have a picture like this:
*I can’t imagine how you haven’t gotten confused yet*
In addition, this command increases security - no one from this network will pretend to be a router and will not try to completely break us.
Now let's move on to the most interesting part - testing.
There is nothing complicated about setting up OSPF on all routers in the Siberian Ring - you can do it yourself.
And after that the picture should be as follows:
msk-arbat-gw1#sh ip OSPF neighbor
172.16.255.32 1 FULL/DR 00:00:31 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:31 172.16.2.18 FastEthernet0/1.5
172.16.255.80 1 FULL/BDR 00:00:36 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/BDR 00:00:37 172.16.2.197 FastEthernet1/0.911
St. Petersburg, Kemerovo, Krasnoyarsk and Vladivostok are directly connected.
msk-arbat-gw1#sh ip route172.16.0.0/16 is variably subnetted, 25 subnets, 6 masks
S 172.16.2.4/30 via 172.16.2.2
O 172.16.2.160/30 via 172.16.2.130, 00:05:53, FastEthernet0/1.8
O 172.16.2.192/30 via 172.16.2.197, 00:04:18, FastEthernet1/0.911
S 172.16.16.0/21 via 172.16.2.2
S 172.16.24.0/22 via 172.16.2.18
O 172.16.24.0/24 via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.128.0/24 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.129.0/26 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.32/32 via 172.16.2.2, 00:24:03, FastEthernet0/1.4
O 172.16.255.48/32 via 172.16.2.18, 00:24:03, FastEthernet0/1.5
O 172.16.255.80/32 via 172.16.2.130, 00:07:18, FastEthernet0/1.8
O 172.16.255.96/32 via 172.16.2.130, 00:04:18, FastEthernet0/1.8
via 172.16.2.197, 00:04:18, FastEthernet1/0.911
O 172.16.255.112/32 via 172.16.2.197, 00:04:28, FastEthernet1/0.911
Everyone knows everything about everyone.
What route is traffic delivered from Moscow to Krasnoyarsk? The table shows that krs-stolbi-gw1 is connected directly and the same can be seen from the trace:
1 172.16.2.130 35 msec 8 msec 5 msec
Now we tear up the interface between Moscow and Krasnoyarsk and see how long it takes for the link to be restored.
Not even 5 seconds pass before all the routers learned about the incident and recalculated their routing tables:
msk-arbat-gw1(config-subif)#do sh ip ro 172.16.128.0
Known via "OSPF 1", distance 110, metric 4, type intra area
Last update from 172.16.2.197 on FastEthernet1/0.911, 00:00:53 ago
Routing Descriptor Blocks:
* 172.16.2.197, from 172.16.255.80, 00:00:53 ago, via FastEthernet1/0.911
Route metric is 4, traffic share count is 1Vld-gw1#sh ip route 172.16.128.0
Routing entry for 172.16.128.0/24
Known via "OSPF 1", distance 110, metric 3, type intra area
Last update from 172.16.2.193 on FastEthernet1/0, 00:01:57 ago
Routing Descriptor Blocks:
* 172.16.2.193, from 172.16.255.80, 00:01:57 ago, via FastEthernet1/0
Route metric is 3, traffic share count is 1Msk-arbat-gw1#traceroute 172.16.128.1
Type escape sequence to abortion.
Tracing the route to 172.16.128.11 172.16.2.197 4 msec 10 msec 10 msec
2 172.16.2.193 8 msec 11 msec 15 msec
3 172.16.2.161 15 msec 13 msec 6 msec
That is, now traffic reaches Krasnoyarsk in this way:
As soon as you raise the link, the routers communicate again, exchange their databases, recalculate the shortest paths and enter them into the routing table.
The video makes all this more clear. I recommend familiarize.
Like any good protocol, OSPF supports authentication - two neighbors can verify the authenticity of received OSPF messages before establishing adjacency relationships. We leave it to you to study on your own - it’s quite simple.
EIGRP
Now let's move on to another very important protocol.So, what's good about EIGRP?
- easy to configure
- quick switching to calculated in advance alternate route
- requires less router resources (compared to OSPF)
- summarization of routes on any router (in OSPF only on ABR\ASBR)
- traffic balancing on unequal routes (OSPF only on equal routes)
We decided to translate one of Ivan Pepelnyak’s blog entries, which addresses a number of popular myths about EIGRP:
- “EIGRP is a hybrid routing protocol.” If I remember correctly, this started with the first presentation of EIGRP many years ago and is usually understood as "EIGRP took the best of the link-state and distance-vector protocols." This is absolutely not true. EIGRP does not have any distinctive link-state features. It would be correct to say “EIGRP is an advanced distance-vector routing protocol.”- “EIGRP is a distance-vector protocol.” Not bad, but not entirely true either. EIGRP differs from other DVs in the way it handles orphaned routes (or routes with increasing metric). All other protocols passively wait for updates from a neighbor (some, such as RIP, even block the route to prevent routing loops), while EIGRP is more active and requests information itself.
- “EIGRP is difficult to implement and maintain.” Not true. At one time, EIGRP in large networks with low-speed links was difficult to implement correctly, but only until stub routers were introduced. With them (as well as several corrections to the DUAL algorithm), it is almost worse than OSPF.
- “Like LS protocols, EIGRP maintains a table of the topology of the routes that are exchanged.” It's amazing how wrong this is. EIGRP has no idea at all what is beyond its immediate neighbors, while LS protocols know exactly the topology of the entire area to which they are connected.
- “EIGRP is a DV protocol that acts like LS.” Nice try, but still completely wrong. LS protocols build a routing table by going through the following steps:
- each router describes the network based on the information available to it locally (its links, the subnets it is in, the neighbors it sees) through a packet (or several) called an LSA (in OSPF) or LSP (IS-IS)
- LSAs are propagated throughout the network. Each router must receive every LSA created on its network. The information received from the LSA is entered into the topology table.
- Each router independently analyzes its topology table and runs the SPF algorithm to calculate the best routes to each of the other routers
EIGRP's behavior doesn't even come close to these steps, so why on earth it "acts like LS" is unclear.The only thing EIGRP does is store information received from a neighbor (RIP immediately forgets what cannot be used at the moment). In this sense, it is similar to BGP, which also stores everything in a BGP table and chooses the best route from there. The topology table (containing all information received from neighbors) gives EIGRP an advantage over RIP - it can contain information about a backup (not currently used) route.
Now a little closer to the theory of work:
Each EIGRP process maintains 3 tables:
- A neighbor table, which contains information about “neighbors”, i.e. other routers directly connected to the current one and participating in the exchange of routes. You can view it using the command show ip eigrp neighbors
- Network topology table, which contains route information received from neighbors. Let's watch as a team show ip eigrp topology
- The routing table, on the basis of which the router makes decisions about redirecting packets. View via show ip routeMetrics.
To assess the quality of a particular route, routing protocols use a certain number that reflects its various characteristics or a set of characteristics - a metric. The characteristics taken into account can be different - from the number of routers on a given route to the arithmetic average of the load on all interfaces along the route. Regarding the EIGRP metric, to quote Jeremy Cioara: “I got the impression that the creators of EIGRP, taking a critical look at their creation, decided that everything was too simple and worked well. And then they came up with a metric formula so that everyone would say “WOW, this is really complicated and looks professional.” See the complete formula for calculating the EIGRP metric: (K1 * bw + (K2 * bw) / (256 - load) + K3 * delay) * (K5 / (reliability + K4)), in which:
- bw is not just bandwidth, but (10000000/smallest bandwidth along the route in kilobits) * 256
- delay is not just a delay, but the sum of all delays on the way to tens of microseconds* 256 (delay in commands show interface, show ip eigrp topology and others is shown in microseconds!)
- K1-K5 are coefficients that serve to “include” one or another parameter in the formula.Scary? it would be if it all worked as written. In fact, of all 4 possible terms of the formula, only two are used by default: bw and delay (coefficients K1 and K3 = 1, the rest are zero), which greatly simplifies it - we simply add these two numbers (while not forgetting that they are still calculated according to their own formulas). It is important to remember the following: the metric is calculated according to the worst throughput indicator along the entire length of the route.
An interesting thing happened with MTU: quite often you can find information that MTU is related to the EIGRP metric. Indeed, MTU values are transmitted when exchanging routes. But, as we can see from the full formula, there is no mention of MTU there. The fact is that this indicator is taken into account in quite specific cases: for example, if a router must discard one of the routes that are equivalent in other characteristics, it will choose the one with a lower MTU. Although, not everything is so simple (see comments).Let's define the terms used within EIGRP. Each route in EIGRP is characterized by two numbers: Feasible Distance and Advertised Distance (instead of Advertised Distance you can sometimes see Reported Distance, this is the same thing). Each of these numbers represents a metric, or cost (the more, the worse) of a given route from different measurement points: FD is “from me to the destination”, and AD is “from the neighbor who told me about this route to the place appointments." The answer to the logical question “Why do we need to know the cost from a neighbor if it is already included in the FD?” is a little lower (for now you can stop and rack your brains yourself, if you want).
For each subnet that EIGRP knows about, on each router there is a Successor router from among its neighbors, through which the best (with a lower metric), according to the protocol, route to this subnet goes. In addition, a subnet may also have one or more backup routes (the neighboring router through which such a route goes is called a Feasible Successor). EIGRP is the only routing protocol that remembers backup routes (OSPF has them, but they are contained, so to speak, in “raw form” in the topology table; they still need to be processed by the SPF algorithm), which gives it a performance advantage: as soon as the protocol determines that the main route (via successor) is unavailable, it immediately switches to the backup route. In order for a router to become a feasible successor for a route, its AD must be less than the FD successor of this route (that’s why we need to know AD). This rule is used to avoid routing loops.
Did the previous paragraph blow your mind? The material is difficult, so I’ll use an example again. We have this network:
From R1's point of view, R2 is the Successor for the 192.168.2.0/24 subnet. To become an FS for this subnet, R4 requires its AD to be less than the FD for this route. We have FD ((10000000/1544)*256)+(2100*256) =2195456, R4 has AD (from his point of view this is FD, i.e. how much does it cost him to get to this network) = ((10000000/100000 )*256)+(100*256)=51200. Everything converges, R4’s AD is less than the route’s FD, it becomes FS. *then the brain says: “BDASH”*. Now we look at R3 - he announces his network 192.168.1.0/24 to his neighbor R1, who, in turn, tells his neighbors R2 and R4 about it. R4 is unaware that R2 knows about this subnet and decides to tell him. R2 transmits the information that it has access through R4 to the subnet 192.168.1.0/24 further to R1. R1 strictly looks at the FD of the route and AD, which R2 boasts of (which, as is easy to understand from the diagram, will clearly be larger than the FD, since it includes him too) and shoos him away so as not to interfere with all sorts of nonsense. This situation is quite unlikely, but can occur under certain circumstances, for example, when the split-horizon mechanism is turned off. And now to a more likely situation: imagine that R4 is connected to the 192.168.2.0/24 network not via FastEthernet, but via a 56k modem (the delay for dialup is 20,000 usec), accordingly, it costs him ((10000000/56)*256 )+(2000*256)= 46226176. This is more than the FD for this route, so R4 will not become a Feasible Successor. But this does not mean that EIGRP will not use this route at all. It will just take longer to switch to it (more on that later).
neighborhood
Routers don't talk about routes to just anyone - they must establish adjacency relationships before they can exchange information. After turning on the process with the router eigrp command, indicating the autonomous system number, we, with the network command, say which interfaces will participate and at the same time, information about which networks we want to distribute. Immediately, hello packets begin to be sent through these interfaces to the multicast address 224.0.0.10 (by default every 5 seconds for ethernet). All routers with EIGRP enabled receive these packets, then each receiving router does the following:
- checks the sender address of the hello packet with the address of the interface from which the packet was received, and makes sure that they are from the same subnet
- compares the values of K-coefficients obtained from the package (in other words, which variables are used in calculating the metric) with its own. It is clear that if they differ, then the metrics for the routes will be calculated according to different rules, which is unacceptable
- checks the autonomous system number
- optional: if authentication is configured, checks the consistency of its type and keys.If the recipient is satisfied with everything, he adds the sender to the list of his neighbors and sends him (already in Unicast) an update packet, which contains a list of all routes known to him (aka full-update). The sender, having received such a packet, in turn, does the same. To exchange routes, EIGRP uses Reliable Transport Protocol (RTP, not to be confused with Real-time Transport Protocol, which is used in IP telephony), which implies delivery confirmation, so each of the routers, having received an update packet, responds with an ack packet (abbreviation from acknowledgement - confirmation). So, the neighborhood relationship has been established, the routers have learned from each other comprehensive information about the routes, what next? Then they will continue to send multicast hello packets to confirm that they are connected, and if the topology changes, update packets containing information only about the changes (partial update).
Now let's return to the previous scheme with the modem.
R2 for some reason lost contact with 192.168.2.0/24. It has no backup routes to this subnet (i.e., no FS). Like any responsible EIGRP router, it wants to reestablish connectivity. To do this, he begins to send special messages (query packets) to all his neighbors, who, in turn, not finding the desired route in themselves, ask all their neighbors, and so on. When the wave of requests reaches R4, he says “wait a minute, I have a route to this subnet! Bad, but at least something. Everyone forgot about him, but I remember.” He packs all this into a reply packet and sends it to the neighbor from whom he received the request (query), and further along the chain. Of course, this all takes more time than just switching to Feasible Successor, but in the end we get communication with the subnet.
And now is a dangerous moment: maybe you have already noticed and become wary after reading about this fan mailing. The failure of one interface causes something similar to a broadcast storm on the network (not on such a scale, of course, but still), and the more routers there are, the more resources will be spent on all these requests and responses. But that's not all that bad. A worse situation is possible: imagine that the routers shown in the picture are only part of a large and distributed network, i.e. some may be located many thousands of kilometers from our R2, on bad channels, etc. So, the trouble is that, having sent a query to a neighbor, the router must wait for a reply from him. It doesn’t matter what the answer is, but it must come. Even if the router already received a positive response, as in our case, he cannot put this route into operation until he waits for a response to all his requests. And maybe there are still requests somewhere in Alaska. This route state is called stuck-in-active. Here we need to get acquainted with the terms that reflect the state of the route in EIGRP: active\passive route. They are usually misleading. Common sense dictates that active means the route is “active”, enabled, running. However, here everything is the other way around: passive means “everything is fine,” and the active state means that this subnet is unavailable, and the router is actively searching for another route, sending out a query and waiting for a reply. So, the stuck-in-active state can last up to 3 minutes! After this period has expired, the router breaks the neighbor relationship with the neighbor from whom it cannot wait for a response, and can use a new route through R4.
A story that chills the blood of a network engineer. 3 minutes of downtime is no joke. How can we avoid the heart attack of this situation? There are two ways out: summing up routes and the so-called stub configuration.
Generally speaking, there is another way out, and it is called route filtering. But this is such a voluminous topic that it would be better to write a separate article on it, but we already have half a book this time. So it's up to you.As we already mentioned, in EIGRP route summarization can be carried out on any router. To illustrate, let’s imagine that subnets from 192.168.0.0/24 to 192.168.7.0/24 are connected to our long-suffering R2, which very conveniently sums up to 192.168.0.0/21 (remember binary math). The router advertises this summary route, and everyone else knows: if the destination address begins with 192.168.0-7, then it is to him. What happens if one of the subnets disappears? The router will send query packets with the address of this network (specific, for example, 192.168.5.0/24), but the neighbors, instead of continuing the vicious mailing on their own behalf, will immediately respond with sobering replays, saying that this is your subnet , you figure it out.
The second option is stub configuration. Figuratively speaking, stub means “end of the road”, “dead end” in EIGRP, i.e., to get into some subnet that is not connected directly to such a router, you will have to go back. A router configured as a stub will not forward traffic between subnets that it knows from EIGRP (in other words, which are marked with the letter D in show ip route). In addition, his neighbors will not send him query packets. The most common use case is hub-and-spoke topologies, especially with redundant links. Let’s take this network: on the left are branches, on the right is the main site, main office, etc. For fault tolerance, redundant links. EIGRP is running with default settings.
And now “attention, question”: what will happen if R1 loses connection with R4, and R5 loses LAN? Traffic from the R1 subnet to the main office subnet will follow the route R1->R5->R2 (or R3)->R4. Will it be effective? No. Not only will the subnet behind R1 suffer, but also the subnet behind R2 (or R3), due to the increased traffic volumes and its consequences. It is for such situations that stub was invented. Behind the routers in the branches there are no other routers that would lead to other subnets, this is the “end of the road”, then only back. Therefore, with a light heart, we can configure them as stubs, which, firstly, will save us from the problem with the “crooked route” outlined just above, and secondly, from the flood of query packets in case of loss of the route.
There are different modes of operation of a stub router; they are set with the eigrp stub command:
R1(config)#router eigrp 1
R1(config-router)#eigrp stub?
connected Do advertise connected routes
leak-map Allow dynamic prefixes based on the leak-map
receive-only Set IP-EIGRP as receive only neighbor
redistributed Do advertise redistributed routes
static Do advertise static routes
summary Do advertise summary routes
By default, if you simply issue the eigrp stub command, the connected and summary modes are enabled. Of interest is the receive-only mode, in which the router does not advertise any networks, only listens to what its neighbors tell it (in RIP there is a passive interface command that does the same thing, but in EIGRP it completely disables the protocol on the selected interface, which does not allow establish a neighborhood).Important points in the EIGRP theory that were not included in the article:
- Neighbor authentication can be configured in EIGRP
- Graceful shutdown concept
EIGRP Practice
Lift mi Up bought a factory in Kaliningrad. The brains of elevators are produced there: microcircuits, software. The factory is very large - three points around the city - three routers connected in a ring.
But bad luck - they already have EIGRP running as a dynamic routing protocol. Moreover, the addressing of end nodes is from a completely different subnet - 10.0.0.0/8. We changed all other parameters (link addresses, loopback interface addresses), but several thousand local network addresses with servers, printers, access points - not a job for a couple of hours - were postponed until later, and in the IP plan we reserved the 172.16 subnet for the future for Kaliningrad .32.0/20.
We currently use the following networks:
How is this miracle configured? Uncomplicated at first glance:
router eigrp 1
network 172.16.0.0 0.0.255.255
network 10.0.0.0
In EIGRP, the reverse mask can be specified, thereby indicating a narrower scope, or not specified, then the standard mask for this class will be selected (16 for class B - 172.16.0.0 and 8 for class 8 - 10.0.0.0)Such commands are issued on all Autonomous System routers. The AC is determined by the number in the router eigrp command, that is, in our case we have AC No. 1. This figure should be the same on all routers (unlike OSPF).
But there is a serious catch in EIGRP: by default, automatic summarization of routes in class form is enabled (in IOS versions up to 15).
Let's compare the routing tables on three Kaliningrad routers:Network 10.0.0.1/24 is connected to klgr-center-gw1 and he knows about it:
klgr-center-gw1:
10.0.0.0/8 is variably subnetted, 2 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:35:23, Null0
C 10.0.0.0/24 is directly connected, FastEthernet1/0
But doesn't know about 10.0.1.0/24 and 10.0.2.0/24/Klgr-balt-gw1 knows about his two networks 10.0.1.0/24 and 10.0.2.0/24, but he hid the 10.0.0.0/24 network somewhere.
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
D 10.0.0.0/8 is a summary, 00:42:05, Null0
C 10.0.1.0/24 is directly connected, FastEthernet1/1.2
C 10.0.2.0/24 is directly connected, FastEthernet1/1.3
They both created route 10.0.0.0/8 with next hop address Null0.But klgr-center-gw2 knows that subnets 10.0.0.0/8 are located behind both of its WAN interfaces.
D 10.0.0.0/8 via 172.16.2.41, 00:42:49, FastEthernet0/1
via 172.16.2.45, 00:38:05, FastEthernet0/0
Something very strange is happening.
But, if you check the configuration of this router, you will probably notice:router eigrp 1
network 172.16.0.0
network 10.0.0.0
auto-summary
Automatic summation is to blame for everything. This is the biggest evil of EIGRP. Let's take a closer look at what's happening. klgr-center-gw1 and klgr-balt-gw1 have subnets from 10.0.0.0/8, they sum them up by default when they pass them on to their neighbors.
That is, for example, msk-balt-gw1 transmits not two networks 10.0.1.0/24 and 10.0.2.0/24, but one generalized one: 10.0.0.0/8. That is, his neighbor will think that this entire network is located behind msk-balt-gw1.
But what happens if suddenly balt-gw1 receives a packet with destination 10.0.50.243, about which it knows nothing? For this case, the so-called Blackhole route is created:
10.0.0.0/8 is a summary, 00:42:05, Null0
The resulting packet will be thrown into this black hole. This is done to avoid routing loops.
So, both of these routers have created their own blackhole routes and ignore other people’s announcements. In reality, on such a network, these three devices will not be able to ping each other until... until you disable auto-summary.The first thing you should do when configuring EIGRP is:
router eigrp 1
no auto-summary
On all devices. And everyone will be fine:Klgr-center-gw1:
C 10.0.0.0 is directly connected, FastEthernet1/0
D 10.0.1.0 via 172.16.2.37, 00:03:11, FastEthernet0/0
D 10.0.2.0 via 172.16.2.37, 00:03:11, FastEthernet0/0
klgr-balt-gw110.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 via 172.16.2.38, 00:08:16, FastEthernet0/1
C 10.0.1.0 is directly connected, FastEthernet1/1.2
C 10.0.2.0 is directly connected, FastEthernet1/1.3
klgr-center-gw2:10.0.0.0/24 is subnetted, 3 subnets
D 10.0.0.0 via 172.16.2.45, 00:11:50, FastEthernet0/0
D 10.0.1.0 via 172.16.2.41, 00:11:48, FastEthernet0/1
D 10.0.2.0 via 172.16.2.41, 00:11:48, FastEthernet0/1Configuring route transfer between different protocols
Our task is to organize the transfer of routes between these protocols: from OSPF to EIGRP and vice versa, so that everyone knows the route to any subnet.
This is called route redistribution.To implement it, we need at least one junction point where two protocols will be launched simultaneously. This could be msk-arbat-gw1 or klgr-balt-gw1. Let's choose the second one.
From EIGRP to OSPF:
klgr-gw1(config)#router ospf 1
klgr-gw1(config-router)#redistribute eigrp 1 subnets
We look at the routes on msk-arbat-gw1:msk-arbat-gw1#sh ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, ia - IS-IS inter area
* - candidate default, U - per-user static route, o - ODR
P - periodic downloaded static routeGateway of last resort is 198.51.100.1 to network 0.0.0.0
10.0.0.0/8 is variably subnetted, 3 subnets, 2 masks
O E2 10.0.0.0/8 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.1.0/24 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
O E2 10.0.2.0/24 via 172.16.2.34, 00:24:50, FastEthernet0/1.7
172.16.0.0/16 is variably subnetted, 30 subnets, 5 masks
O E2 172.16.0.0/16 via 172.16.2.34, 00:25:11, FastEthernet0/1.7
C 172.16.0.0/24 is directly connected, FastEthernet0/0.3
C 172.16.1.0/24 is directly connected, FastEthernet0/0.2
C 172.16.2.0/30 is directly connected, FastEthernet0/1.4
C 172.16.2.16/30 is directly connected, FastEthernet0/1.5
C 172.16.2.32/30 is directly connected, FastEthernet0/1.7
O E2 172.16.2.36/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.40/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.2.44/30 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
C 172.16.2.128/30 is directly connected, FastEthernet0/1.8
O 172.16.2.160/30 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.2.192/30 via 172.16.2.197, 00:13:21, FastEthernet1/0.911
C 172.16.2.196/30 is directly connected, FastEthernet1/0.911
C 172.16.3.0/24 is directly connected, FastEthernet0/0.101
C 172.16.4.0/24 is directly connected, FastEthernet0/0.102
C 172.16.5.0/24 is directly connected, FastEthernet0/0.103
C 172.16.6.0/24 is directly connected, FastEthernet0/0.104
O 172.16.24.0/24 via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O 172.16.128.0/24 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.129.0/26 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.144.0/24 via 172.16.2.130, 00:13:21, FastEthernet0/1.8
O 172.16.160.0/24 via 172.16.2.197, 00:13:31, FastEthernet1/0.911
C 172.16.255.1/32 is directly connected, Loopback0
O 172.16.255.48/32 via 172.16.2.18, 01:00:55, FastEthernet0/1.5
O E2 172.16.255.64/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.65/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O E2 172.16.255.66/32 via 172.16.2.34, 01:00:55, FastEthernet0/1.7
O 172.16.255.80/32 via 172.16.2.130, 01:00:55, FastEthernet0/1.8
O 172.16.255.96/32 via 172.16.2.130, 00:13:21, FastEthernet0/1.8
via 172.16.2.197, 00:13:21, FastEthernet1/0.911
O 172.16.255.112/32 via 172.16.2.197, 00:13:31, FastEthernet1/0.911
198.51.100.0/28 is subnetted, 1 subnets
C 198.51.100.0 is directly connected, FastEthernet0/1.6
S* 0.0.0.0/0 via 198.51.100.1Here are the ones with the E2 label - new imported routes. E2 - means that these are external routes of the 2nd type (), that is, they were introduced into the OSPF process from outside
Now from OSPF to EIGRP. This is a little more complicated:
klgr-gw1(config)#router eigrp 1
klgr-gw1(config-router)#redistribute ospf 1 metric 100000 20 255 1 1500
Without specifying the metric (this long set of numbers), the command will be executed, but redistribution will not occur.Imported routes receive an EX label in the routing table and an administrative distance of 170, instead of 90 for internal ones:
klgr-gw2#sh ip routeGateway of last resort is not set
172.16.0.0/16 is variably subnetted, 30 subnets, 4 masks
D EX 172.16.0.0/24 [170 /33280] via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.1.0/24 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.0/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.4/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D EX 172.16.2.16/30 via 172.16.2.37, 00:00:07, FastEthernet0/0
D 172.16.2.32/30 [ 90 /30720] via 172.16.2.37, 00:38:59, FastEthernet0/0
C 172.16.2.36/30 is directly connected, FastEthernet0/0
D 172.16.2.40/30 via 172.16.2.37, 00:38:59, FastEthernet0/0
via 172.16.2.46, 00:38:59, FastEthernet0/1
….This is how it seems to be done in a simple way, but the simplicity is superficial - redistribution is fraught with many subtle and unpleasant problems when at least one redundant link is added between two different domains.
General advice - try to avoid redistribution if possible. The main rule of life works here - the simpler, the better.Default route
Now is the time to check your Internet access. It works fine from Moscow, but if you check, for example, from St. Petersburg (remember that we deleted all static routes):PC>ping linkmeup.ruPinging 192.0.2.2 with 32 bytes of data:
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.
Reply from 172.16.2.5: Destination host unreachable.Ping statistics for 192.0.2.2:
Packets: Sent = 4, Received = 0, Lost = 4 (100% loss),
This is because neither spb-ozerki-gw1, nor spb-vsl-gw1, nor anyone else on our network knows about the default route except msk-arbat-gw1, on which it is statically configured.
To correct this situation, we just need to give one command in Moscow:msk-arbat-gw1(config)#router ospf 1
msk-arbat-gw1(config-router)#default-information originate
After this, information about where the gateway of last resort is located avalanches across the network.Internet is now available:
PC>tracert linkmeup.ruTracing route to 192.0.2.2 over a maximum of 30 hops:
1 3 ms 3 ms 3 ms 172.16.17.1
2 4 ms 5 ms 12 ms 172.16.2.5
3 14 ms 20 ms 9 ms 172.16.2.1
4 17 ms 17 ms 19 ms 198.51.100.1
5 22 ms 23 ms 19 ms 192.0.2.2Useful commands for troubleshooting
1) The list of neighbors and the state of communication with them is called by the command show ip ospf neighbor
msk-arbat-gw1:Neighbor ID Pri State Dead Time Address Interface
172.16.255.32 1 FULL/DROTHER 00:00:33 172.16.2.2 FastEthernet0/1.4
172.16.255.48 1 FULL/DR 00:00:34 172.16.2.18 FastEthernet0/1.5
172.16.255.64 1 FULL/DR 00:00:33 172.16.2.34 FastEthernet0/1.7
172.16.255.80 1 FULL/DR 00:00:33 172.16.2.130 FastEthernet0/1.8
172.16.255.112 1 FULL/DR 00:00:33 172.16.2.197 FastEthernet1/0.911
2) Or for EIGRP: show ip eigrp neighborsIP-EIGRP neighbors for process 1
H Address Interface Hold Uptime SRTT RTO Q Seq
(sec) (ms) Cnt Num
0 172.16.2.38 Fa0/1 12 00:04:51 40 1000 0 54
1 172.16.2.42 Fa0/0 13 00:04:51 40 1000 0 58
3) Using the command show ip protocols You can view information about running dynamic routing protocols and their relationships.Klgr-balt-gw1:
Routing Protocol is "EIGRP 1"
Default networks flagged in outgoing updates
Default networks accepted from incoming updates
EIGRP metric weight K1=1, K2=0, K3=1, K4=0, K5=0
EIGRP maximum hopcount 100
EIGRP maximum metric variance 1
Redistributing: EIGRP 1, OSPF 1
Automatic network summarization is in effect
Automatic address summarization:
Maximum path: 4
Routing for Networks:
172.16.0.0
172.16.2.42 90 4
172.16.2.38 90 4
Distance: internal 90 external 170Routing Protocol is "OSPF 1"
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Router ID 172.16.255.64
It is an autonomous system boundary router
Redistributing External Routes from,
EIGRP 1
Number of areas in this router is 1. 1 normal 0 stub 0 nssa
Maximum path: 4
Routing for Networks:
172.16.2.32 0.0.0.3 area 0
Routing Information Sources:
Gateway Distance Last Update
172.16.255.64 110 00:00:23
Distance: (default is 110)
4) To debug and understand the operation of protocols, it will be useful to use the following commands:
debug ip OSPF events
debug ip OSPF adj
debug EIGRP packetsTry trying different interfaces and see what happens in the debug, what messages are flying.
Problem No. 7
Finally, a complex problem.
At the last meeting of Lift mi Up, it was decided that the Kaliningrad network should also be transferred to OSPF.
The transition must be completed without breaking the connection. It was decided that the best option would be to raise OSPF on three Kaliningrad routers in parallel with EIGRP and, after checking that all information about Kaliningrad routes had spread throughout the rest of the network and vice versa, disable EIGRP. for the site logo.OSPF EIGRP route redistribution packet tracer networks for the little ones Add tags