SQL Control Constructs
My company just went through their annual review process and I finally convinced them that it was time to find a better solution for managing our SQL schema/scenes. Currently we only have a few scripts for manual updating.
I worked with VS2008 Database Edition at another company and it is an amazing product. My boss asked me to take a look at SQL Compare by Redgate and look for any other products that might be better. SQL Comparison is also a great product. However, they don't seem to support Perforce.
Did you use a variety of products for this?
What tools do you use for SQL management?
What must be included in the requirements before my company makes a purchase?
10 answers
I don't think there is a tool that can handle all the parts. VS Database Edition doesn't allow you to create a decent release mechanism. Running individual scripts from the Solution Browser does not scale well enough in large projects.
At a minimum you need
- IDE/editor
- repository source code which can be launched from your IDE
- naming convention and organization of various scripts in folders
- the process of handling changes, managing releases, and performing deployments.
The last bullet is where things usually break. That's why. For better manageability and version tracking, you want to store each db object in its own own file script. That is, every table, stored procedure, view, index, etc. has its own file.
When something changes you update the file and you have a new version in your repository with necessary information. When it comes to merging multiple changes into a release, processing individual files can be cumbersome.
2 options I used:
In addition to saving everyone individual objects databases in their files, you have release scripts, which are a concatenation of individual scripts. The disadvantage of this: you have code in 2 places with all the risks and disadvantages. Potential: Running a release is as easy as executing a single script.
write a small tool that can read script metadata from the release manifest and execute the eadch script specified in the manifest on the target server. There is no downside to this except that you have to write code. This approach doesn't work for tables that can't be dropped and recreated (once you're live and you have the data), so you'll have change scripts for the tables. So it will actually be a combination of both approaches.
I'm in the "script it yourself" camp, as third party products will only get you as far as managing database code. I don't have one script for each object because objects change over time, and nine times out of ten just updating my "creation table" script to have three new columns would be inadequate.
Creation of databases by by and large trivially. Set up a bunch of CREATE scripts, order them correctly (create database before schemas, schemas before tables, tables before procedures, call procedures before calls, etc.) and do it. Managing database changes is not that easy:
- If you add a column to a table, you can't simply drop the table and create it with a new column because that will destroy all your valuable production data.
- If Fred adds a column to table XYZ and Mary adds another column to table XYZ, which column is added first? Yes, the order of the columns in the tables doesn't matter [because you never use SELECT *, right?], unless you're trying to manage the database and track versioning, at which point you have two "real" databases that don't look like like each other, become a real headache. We use SQL comparison not to manage, but to review and track things, especially during development, and the few "they're different (but it's not magger)" situations we can can prevent us from noticing differences that matter.
- Likewise, when multiple projects (developers) work simultaneously and separately on a common database, it can become very complex. Maybe everyone is working on the Next Big Thing project, when suddenly someone has to start working on bug fixes for the Last Big Thing project. How do you manage required code modifications when the release order is variable and flexible? (Funny times indeed.)
- Changing table structures means changing data, and this can become hellishly complicated when you have to deal with backwards compatibility. You add a "DeltaFactor" column, ok, so what do you do to populate this esoteric value for all your existing (read: legacy) data? You are adding a new lookup table and corresponding column, but how do you populate it for existing rows? These situations may not happen often, but when they do, you have to do it yourself. Third party tools simply cannot anticipate the needs of your business logic.
Essentially I have a CREATE script for each database followed by a series of ALTER scripts as our code base changes over time. Each script checks to see if it can be run: this is the correct "kind" of database, the necessary pre-scripts have been executed, this script is already running. Only when the checks are passed will the script execute its changes.
As a tool, we use SourceGear Fortress for underlying source code management, Redgate SQL Compare for general support and troubleshooting, and a number of SQLCMD-based home scripts to "bulk" deploy scripts with changes to multiple servers and databases and track who has applied which database scripts at what time. Final result: All our databases are stable and stable and we can readily prove which version is or was at any given time.
We require that all database changes or inserts to things like lookup tables be done in a script and saved in source control. They are then deployed in the same way as any other version deployment code software. Since our developers don't have deployment rights, they have no choice but to create scripts.
Usually I use MS Server Management Studio to manage sql, work with data, develop databases and debug it, if I need to export some data to sql script or I need to create some complex object in database, I use EMS SQL Management Studio for SQL Server because there I can see more clearly what narrow sections of my code and visual design in this environment give me easier
I have an open source project (licensed under LGPL) that is trying to solve problems related to the correct DB schema version for (and beyond) SQL Server (2005/2008/Azure), bsn ModuleStore. The whole process is very close to the concept explained by Phillip Kelly's post here.
Basically, a separate part of the toolkit scripts the SQL Server database objects of the DB schema into files with standard formatting, so the contents of the file are only changed if the object actually changed (unlike scripting done by VS, which also creates scripts etc., marking all objects that have changed, even if they are virtually identical).
But the toolkit goes beyond this if you're using .NET: it allows you to embed SQL scripts into a library or application (as inline resources), and then compare the compared inline scripts to the current state in the database. Non-table changes (those that are not "destructive changes" as defined by Martin Fowler) can be applied automatically or on demand (for example, creating and deleting objects such as views, functions, stored procedures, types, indexes) and change scripts (which need to be written down manually) can be applied in the same process; new tables are also created, as well as their setup data. After the update, the database schema is again compared with the scripts to ensure that the database update is successful before changes are made.
Note that all scripting and comparison code runs without SMO, so you don't have a painful SMO dependency when using the bsn ModuleStore module in applications.
Depending on how you want to access the database, the toolkit offers even more - it implements some ORM capabilities and offers a very nice and useful front-end approach for calling stored procedures, including transparent XML support with native .NET XML classes, and also for TVP (Table-Valued Parameters) as IEnumerable
Here is my script to track stored proc and udf and triggers in a table.
Create a table to store the existing proc source code
Input a table with all existing trigger and script data
Create a DDL trigger to track changes to them
/****** Object: Table . Script Date: 9/17/2014 11:36:54 AM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE . ( IDENTITY(1, 1) NOT NULL , (1000) NULL , (1000) NULL , (1000) NULL , (1000) NULL , NULL , NTEXT NULL ,CONSTRAINT PRIMARY KEY CLUSTERED ( ASC) WITH (PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = OFF ,IGNORE_DUP_KEY = OFF ,ALLOW_ROW_LOCKS = ON ,ALLOW_PAGE_LOCKS = ON) ON ) ON GO ALTER TABLE . ADD CONSTRAINT DEFAULT("") FOR GO INSERT INTO . ( , , , , ,) SELECT "sa" ,"loginitialdata" ,r.ROUTINE_NAME ,r.ROUTINE_TYPE ,GETDATE() ,r.ROUTINE_DEFINITION FROM INFORMATION_SCHEMA.ROUTINES r UNION SELECT "sa" ,"loginitialdata" ,v.TABLE_NAME , "view" ,GETDATE() ,v.VIEW_DEFINITION FROM INFORMATION_SCHEMA.VIEWS v UNION SELECT "sa" ,,"loginitialdata" ,o.NAME , "trigger" ,GETDATE() ,m.DEFINITION FROM sys.objects o JOIN sys.sql_modules m ON o.object_id = m.object_id WHERE o.type = "TR" GO CREATE TRIGGER ON DATABASE FOR CREATE_PROCEDURE ,ALTER_PROCEDURE ,DROP_PROCEDURE ,CREATE_INDEX ,ALTER_INDEX ,DROP_INDEX ,CREATE_TRIGGER ,ALTER_TRIGGER ,DROP_TRIGGER ,ALTER _TABLE ,ALTER_VIEW ,CREATE_VIEW ,DROP_VIEW AS BEGIN SET NOCOUNT ON DECLARE @data XML SET @data = Eventdata() INSERT INTO sysupdatelog VALUES (@data.value("(/EVENT_INSTANCE/LoginName)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE /EventType)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE/ObjectName)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE/ObjectType)", " nvarchar(255)") ,getdate() ,@data.value("(/EVENT_INSTANCE/TSQLCommand/CommandText)", "nvarchar(max)")) SET NOCOUNT OFF END GO SET ANSI_NULLS OFF GO SET QUOTED_IDENTIFIER OFF GO ENABLE TRIGGER ON DATABASE GO
Sometimes you really want to put your thoughts in order, sort them out. And even better, in alphabetical and thematic sequence, so that clarity of thinking finally comes. Now imagine what chaos would happen in " electronic brains» any computer without a clear structuring of all data and Microsoft SQL Server:
MS SQL Server
This software product is a relational database management system (DBMS) developed by Microsoft Corporation. A specially developed Transact-SQL language is used to manipulate data. Language commands for selecting and modifying a database are built on the basis of structured queries:

Relational databases are built on the interconnection of all structural elements, including due to their nesting. Relational databases have built-in support for the most common data types. Thanks to this, SQL Server integrates support for programmatically structuring data using triggers and stored procedures.
Overview of MS SQL Server Features

The DBMS is part of a long line of specialized software that Microsoft has created for developers. This means that all links of this chain (applications) are deeply integrated with each other.
That is, their tools easily interact with each other, which greatly simplifies the process of developing and writing program code. An example of such a relationship is the MS Visual Studio programming environment. Its installation package already includes SQL Server Express Edition.
Of course, this is not the only popular DBMS on the world market. But it is precisely it that is more acceptable for computers running Windows, due to its focus on this operating system. And not only because of this.
Advantages of MS SQL Server:
- Has a high degree of performance and fault tolerance;
- It is a multi-user DBMS and operates on the client-server principle;
The client part of the system supports creating user requests and sending them to the server for processing.
- Tight integration with operating system Windows;
- Support for remote connections;
- Support for popular data types, as well as the ability to create triggers and stored procedures;
- Built-in support for user roles;
- Advanced database backup function;
- High degree of security;
- Each issue includes several specialized editions.
Evolution of SQL Server
The features of this popular DBMS are most easily seen when considering the history of the evolution of all its versions. We will dwell in more detail only on those releases in which the developers made significant and fundamental changes:
- Microsoft SQL Server 1.0 – released back in 1990. Even then, experts noted high speed data processing, demonstrated even with maximum load in multi-user mode;
- SQL Server 6.0 - released in 1995. This version was the first in the world to implement support for cursors and data replication;
- SQL Server 2000 - in this version the server received a completely new engine. Most of the changes affected only the user side of the application;
- SQL Server 2005 – the scalability of the DBMS has increased, and the management and administration process has been greatly simplified. A new API has been introduced to support software platform.NET ;
- Subsequent releases were aimed at developing the interaction of the DBMS at the level of cloud technologies and business analytics tools.
The basic system kit includes several utilities for SQL settings Server. These include:
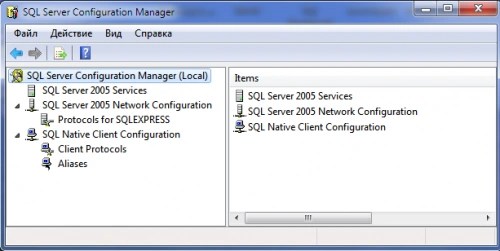
Configuration Manager. Allows you to manage all network settings and database server services. Used to configure SQL Server within a network.
- SQL Server Error and Usage Reporting:

The utility is used to configure sending error reports to Microsoft support.

Used to optimize the operation of the database server. That is, you can customize the functioning of SQL Server to suit your needs by enabling or disabling certain features and components of the DBMS.
The set of utilities included in Microsoft SQL Server may differ depending on the version and edition of the software package. For example, in the 2008 version you will not find SQL Server Surface Area Configuration.
Starting Microsoft SQL Server
For the example, the 2005 version of the database server will be used. The server can be started in several ways:
- Through the utility SQL Server Configuration Manager. In the application window on the left, select “SQL Server 2005 Services”, and on the right - the database server instance we need. We mark it and select “Start” in the submenu of the right mouse button.
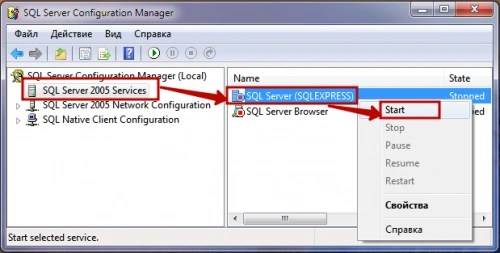
- Using the environment SQL Server Management Studio Express. It is not included in the Express edition installation package. Therefore, it must be downloaded separately from the official Microsoft website.
To start the database server, launch the application. In the dialog box " Connection to the server"In the "Server name" field, select the instance we need. In field " Authentication" leave the value " Examination Windows authenticity " And click on the “Connect” button:

SQL Server Administration Basics
Before you start MS SQL Server, you need to briefly familiarize yourself with the basic capabilities of its configuration and administration. Let's start with a more detailed overview of several utilities included in the DBMS:
- SQL Server Surface Area Configuration– this is where you should go if you need to enable or disable any feature of the database server. At the bottom of the window there are two items: the first is responsible for network parameters, and in the second you can activate a service or function that is disabled by default. For example, enable integration with the .NET platform via T-SQL queries:
Posted by Mike Weiner
Co-author: Burzin Patel
Editors: Lubor Kollar, Kevin Cox, Bill Emmert, Greg Husemeier, Paul Burpo, Joseph Sack, Denny Lee , Sanjay Mishra, Lindsey Allen, Mark Souza
Microsoft SQL Server 2008 contains a number of improvements and new functionality that extend the functionality of previous versions. Administering and maintaining databases, maintaining manageability, availability, security, and performance are all the responsibilities of a database administrator. This article describes the ten most useful new features in SQL Server 2008 (in alphabetical order) that make your job as a DBA easier. Besides brief description, for each of the functions possible situations of its application are given and important recommendations by use.
Activity Monitor
When troubleshooting performance issues or monitoring a server in real time, an administrator will typically run a series of scripts or check relevant information sources to gather overall data about the processes running and identify the cause of the problem. SQL Server 2008 Activity Monitor brings this information together to provide at-a-glance information about running and recently running processes. The database administrator can both view high-level information and analyze any of the processes in more detail and view wait statistics, which makes it easier to identify and resolve problems.
To open Activity Monitor, right-click the registered server name in Object Explorer, then select Activity Monitor or use the standard icon on the toolbar in SQL environment Server Management Studio. Activity Monitor offers the administrator an overview section similar in appearance to Manager Windows tasks, as well as components for detailed viewing of individual processes, resource waiting, data file I/O, and recent resource-intensive requests, as shown in Fig. 1.
Rice. 1:Activity Monitor ViewSQL Server2008 in WednesdayManagement Studio

Note. Activity Monitor uses a data refresh frequency setting that can be changed by right-clicking. If you select frequent data refresh (every less than 10 seconds), the performance of a heavily loaded working system may decrease.
Using Activity Monitor, an administrator can also perform the following tasks:
· Pause and resume activity monitor with one right-click. This allows the administrator to "save" state information to a specific point in time and will not be updated or overwritten. But do not forget that when updating data manually, expanding or collapsing a section, the old data will be updated and lost.
· Right-click a line item to display the full query text or graphic plan execution using the menu item “Recent resource-intensive queries”.
· Trace with Profiler or terminate processes in the Processes view. Profiler application events include events RPC:Completed, SQL:BatchStarting And SQL:BatchCompleted, and AuditLogin And AuditLogout.
Activity Monitor also allows you to monitor the activity of any local or remote instance of SQL Server 2005 that is registered with SQL Server Management Studio.
Audit
The ability to monitor and record events that occur, including who is accessing objects and the timing and content of changes, helps an administrator ensure compliance with regulatory or organizational security compliance standards. In addition, understanding the events occurring in the environment can also help in developing a plan to reduce risks and maintain a safe environment.
In SQL Server 2008 (Enterprise and Developer editions only), SQL Server Audit provides automation that allows administrators and other users to prepare, save, and view audits of various server and database components. The function provides the ability to audit with detail at the server or database level.
There are server-level audit action groups, such as the following:
· FAILED_LOGIN_GROUP tracks failed login attempts.
· BACKUP_RESTORE_GROUP reports when the database was backed up or restored.
· DATABASE_CHANGE_GROUP audits the time a database was created, modified, or deleted.
Database-level audit action groups include the following:
· DATABASE_OBJECT_ACCESS_GROUP is called whenever a CREATE, ALTER, or DROP statement is executed on a database object.
· DATABASE_OBJECT_PERMISSION_CHANGE_GROUP is called when GRANT, REVOKE, or DENY statements are used on database objects.
There are other audit actions such as SELECT, DELETE and EXECUTE. For more information, including a complete list of all audit groups and actions, see SQL Server Audit Action Groups and Actions.
Audit results can be sent to a file or event log (system log or event log) for later review. Windows security). Audit data is created using Extended Events- another new feature in SQL Server 2008.
SQL Server 2008 audits allow an administrator to answer questions that were previously very difficult to answer after the fact, such as, “Who dropped this index?”, “When was the stored procedure modified?”, “What change was made that might prevent a user from accessing this table?” ? and even "Who executed the SELECT or UPDATE statement on the table [ dbo.Payroll] ?».
For more information about using SQL Server auditing and examples of how to implement it, see the SQL Server 2008 Compliance Guide.
Backup compression
DBAs have been proposing to include this feature in SQL Server for a long time. Now it's done, and just in time! IN Lately For a number of reasons, for example, due to the increased duration of data storage and the need to physically store more data, database sizes began to grow exponentially. When backing up a large database, you need to allocate significant disk space for files backup copy, as well as allocating a significant time period for the operation.
When you use SQL Server 2008 backup compression, the backup file is compressed as it is written, which not only requires less disk space, but also reduces I/O operations and takes less time to complete the backup. In lab tests with real user data, a 70-85% reduction in backup file size was observed in many cases. In addition, tests showed that the duration of copy and restore operations was reduced by approximately 45%. It should be noted that additional processing during compression increases the processor load. To separate the time-intensive copying process from other processes and minimize its impact on their operation, you can use another function described in this document - Resource Governor.
Compression is enabled by adding the WITH COMPRESSION clause to the BACKUP command (see SQL Server Books Online for more information) or by setting this option on page Options dialog box Database backup. To avoid the need to make changes to all existing backup scripts, a global setting has been implemented that enables compression of all backups created on a server instance by default. (This option is available on the page Database Settings dialog box Server properties; it can also be installed by executing the stored procedure sp_ configure with parameter value backupcompressiondefault, equal to 1). The backup command requires an explicit compression option, and the restore command automatically recognizes the compressed backup and decompresses it when restoring.
Backup compression is an extremely useful feature that saves disk space and time. For more information about configuring backup compression, see the technical note Tuning backup compression performance inSQL Server 2008 . Note. Compressed backups are supported only in SQL Server 2008 Enterprise and Developer editions, but all editions of SQL Server 2008 allow you to restore compressed backups.
Centralized management servers
Often a DBA manages many instances of SQL Server at once. The ability to centralize management and administration of many SQL instances into a single location saves significant effort and time. The centralized management server implementation, available in SQL Server Management Studio through the Registered Servers component, allows an administrator to perform various administrative operations on many SQL Servers from a single management console.
Centralized management servers allow the administrator to register a group of servers and perform the following operations on them as a single group, for example:
· Multi-server query execution: You can now run a script on multiple SQL Servers from a single source, and the data will be returned to that source, without having to log into each server separately. This can be especially useful when you need to view or compare data from multiple SQL Servers without running a distributed query. Additionally, provided that the query syntax is supported by previous versions of SQL Server, when launched from the editor SQL queries Server 2008 queries can also be run on instances of SQL Server 2005 and SQL Server 2000. For more information, see the blog working group On SQL Server Manageability, see Running Multiserver Queries in a SQL Server 2008 Environment.
· Import and define policies on many servers: within functionality Policy-based management(another new feature in SQL Server 2008, also described in this article), SQL Server 2008 provides the ability to import policy files into individual groups of central management servers and allows you to define policies on all servers registered in a particular group.
· Manage services and access SQL Server Configuration Manager: The Servers from Central Management tool helps you create a control center where the DBA can view and even change (with the appropriate permissions) the state of services.
· Import and export of registered servers: Servers registered with Central Management Servers can be exported and imported when transferred between administrators or different installations of SQL Server Management Studio. This feature provides an alternative to an administrator importing or exporting his or her own local groups in SQL Server Management Studio.
Keep in mind that permissions are enforced using Windows Authentication, so user rights and permissions may vary across different servers that are registered in the Central Management Server group. For more information, see Administering Multiple Servers with Central Management Servers and Kimberly Tripp's blog: Central SQL Management ServersServer2008 - are you familiar with them?
Data Collector and Management Data Store
Performance tuning and diagnostics are time-consuming and may require advanced SQL Server skills as well as an understanding of the internal structure of databases. System Monitor Windows (Perfmon), SQL Server Profiler, and dynamic management views solved some of these problems, but they often had an impact on the server, were labor intensive to use, or involved methods for collecting disparate data that made them difficult to combine and interpret.
To provide clear, actionable information about system performance, SQL Server 2008 provides a fully extensible performance data collection and storage tool, the Data Collector. It contains several out-of-the-box data collection agents, a centralized repository of performance data called a management data warehouse, and several pre-built reports to present the collected data. Data Collector is a scalable tool that collects and aggregates data from various sources, such as dynamic management views, Perfmon performance monitor and Transact-SQL queries, according to fully customizable data collection frequency. The data collector can be extended to collect data on any measurable application attribute.
Another useful feature of the management data warehouse is the ability to install it on any SQL Server and then collect data from one or more SQL Server instances. This minimizes the impact on the performance of production systems, and also improves scalability in the context of monitoring and collecting data from many servers. In lab testing, the observed throughput loss when running agents and running the management data warehouse on a busy server (using an OLTP workload) was approximately 4%. The performance loss can vary depending on the frequency of data collection (the test mentioned was conducted under an extended workload, with data transferred to storage every 15 minutes), and it can also increase sharply during data collection periods. In any case, you should expect some reduction in available resources because the DCExec.exe process uses a certain amount of memory and CPU resources, and writing to the management data store will increase the load on the I/O subsystem and require space allocation in the location of the data and log files. In the diagram (Figure 2) shows a typical data collector report.
Rice. 2:Data Collector Report ViewSQL Server 2008

The report shows SQL Server activity during the data collection period. It collects and displays events such as waits, CPU, I/O and memory usage, as well as statistics on resource-intensive queries. The administrator can also drill down into report elements, focusing on separate request or operations to investigate, identify and resolve performance issues. These data collection, storage, and reporting capabilities enable proactive monitoring of the health of the SQLServers in your environment. When needed, they allow you to look back at historical data to understand and evaluate changes that impacted performance over the period being tracked. The Data Collector and Management Data Store are supported in all editions of SQLServer 2008 except SQLServerExpress.
Data compression
Ease of database management makes execution much easier routine tasks administration. As tables, indexes, and files grow in size and become very large databases data management (VLDB) data management and working with bulky files are becoming increasingly complex. In addition, the increasing demand for memory and physical I/O bandwidth that increases with the volume of data requested also increases administrative complexity and costs the organization. As a result, in many cases, administrators and organizations must either expand the memory or I/O bandwidth of their servers, or accept reduced performance.
Data compression, introduced in SQL Server 2008, helps resolve these issues. This feature allows the administrator to selectively compress any table, table partition, or index, thereby reducing disk space, memory footprint, and I/O operations. Compressing and decompressing data loads the processor; however, in many cases the additional CPU load is more than offset by the I/O gains. In configurations where I/O is a bottleneck, data compression can also provide performance gains.
In some lab tests, enabling data compression resulted in 50-80% disk space savings. Space savings varied widely: if the data contained few duplicate values, or the values used all the bytes allocated for the specified data type, the savings were minimal. However, the performance of many workloads did not increase. However, when working with data containing a lot of numeric data and a lot of repeating values, significant disk space savings and performance gains ranging from a few percent to 40-60% were observed for some sample query workloads.
SQLServer 2008 supports two types of compression: row compression, which compresses individual table columns, and page compression, which compresses pages of data using row, prefix, and dictionary compression. The level of compression achieved varies greatly depending on the data types and the contents of the database. In general, using row compression reduces the overhead on application operations, but also reduces the compression ratio, meaning less space is saved. At the same time, page compression results in more application overhead and CPU usage, but it also saves significantly more space. Page compression is a superset of row compression, that is, if an object or section of an object is compressed using page compression, row compression is also applied to it. Additionally, SQLServer 2008 supports the storage format vardecimal from SQL Server 2005 SP2. Please note that since this format is a subset of string compression, it is deprecated and will be removed from future versions of the product.
Both row compression and page compression can be enabled for a table or index in operational mode, without in any way affecting the availability of data for applications. At the same time, it is impossible to compress or decompress a separate section of a partitioned table in online mode without disabling it. Tests have shown that the best approach is a combined approach, in which only a few are compressed. largest tables: This achieves an excellent ratio of disk space savings (significant) to performance loss (minimal). Because a compact operation, like index creation or rebuild operations, also has requirements for available disk space, compaction must be performed with these requirements in mind. A minimum of free space will be required during the compression process if the compression starts with the smallest objects.
You can compress data using Transact-SQL statements or the Data Compression Wizard. To determine how an object might change in size when it shrinks, you can use the system stored procedure sp_estimate_data_compression_savings or data compression wizard. Database compression is only supported in SQLServer 2008 Enterprise and Developer editions. It is implemented exclusively in the databases themselves and does not require any changes to the applications.
For more information about using compression, see Creating Compressed Tables and Indexes.
Policy-based management
In many business scenarios, it is necessary to maintain specific configurations or enforce policies, either on a specific SQLServer or multiple times across a group of SQLServers. An administrator or organization may require a specific naming scheme to be applied to all user tables or stored procedures that are created, or may require certain configuration changes to be applied to multiple servers.
Policy-based management (PBM) provides the administrator with a broad range of control over the environment. Policies can be created and checked for compliance. If a scan target (such as a database engine, database, table, or SQLServer index) does not meet the requirements, the administrator can automatically reconfigure it to meet those requirements. There are also a number of policy modes (many of which are automated) that make it easy to verify policy compliance, log policy violations and send notifications, and even roll back changes to ensure policy compliance. For more information about definition modes and how they relate to aspects (the concept of policy-based management (PBM), also discussed in this blog), see the SQL Server Policy-Based Management Blog.
Policies can be exported and imported as XML files to be defined and applied across multiple server instances. Additionally, in SQLServerManagement Studio and the Registered Servers view, you can define policies across multiple servers that are registered in a local server group or a central management server group.
In previous SQL versions Server may not implement all policy-based management functionality. However, the function making report policies can be used on SQL Server 2005 and SQL Server 2000 servers. For more information about using policy-based management, see Administering Servers Using Policy-Based Management in SQLServer Books Online. For more information about the policy technology itself, with examples, see the SQL Server 2008 Compliance Guide.
Predicted performance and concurrency
Many administrators face significant challenges supporting SQLServers with constantly changing workloads and ensuring predictable levels of performance (or minimizing variations in query plans and performance). Unexpected query performance changes, changes in query plans, and/or general performance issues can be caused by a number of reasons, including increased load from applications running on SQLServer or an upgrade to the version of the database itself. Predictability of queries and operations running on SQLServer makes it much easier to achieve and maintain availability, performance, and/or business continuity goals (meeting service level agreements and operational support level agreements).
In SQLServer 2008, several features have been changed to improve predictable performance. Thus, certain changes have been made to the plan structures of SQLServer 2005 ( consolidation of plans) and added the ability to manage lock escalation at the table level. Both improvements promote more predictable and streamlined interactions between the application and the database.
First, plan structures (Plan Guide):
SQL Server 2005 introduced improvements to query stability and predictability through a new feature at the time called “plan guides,” which provided instructions for running queries that could not be changed directly in the application. For more information, see the whitepaper Enforcing Query Plans. Although the USE PLAN query hint is a very powerful feature, it only supported DML SELECT operations and was often awkward to use due to the sensitivity of plan structures to formatting.
SQL Server 2008 expands the plan guide engine in two ways: first, it expands support for the USE PLAN query hint, which is now compatible with all DML statements (INSERT, UPDATE, DELETE, MERGE); secondly, a new function has been introduced consolidation of plans, which allows you to directly create a plan outline (pinning) of any query plan that exists in the SQL Server plan cache, as shown in the following example.
sp_create_plan_guide_from_handle
@name = N'MyQueryPlan',
@plan_handle = @plan_handle,
@statement_start_offset = @offset;
A plan guide created in any way has a database area; it is stored in a table sys.plan_guides. Plan structures only affect the query plan selection process of the optimizer, but do not eliminate the need to compile the query. Also added function sys.fn_validate_plan_guide, to review existing SQL Server 2005 plan structures and ensure they are compatible with SQL Server 2008. Plan pinning is available in SQL Server 2008 Standard, Enterprise, and Developer editions.
Secondly, escalation of blocking:
Blocking escalation often caused blocking problems and sometimes even deadlocks. The administrator had to fix these problems. In previous versions of SQLServer, it was possible to control lock escalation (trace flags 1211 and 1224), but this was only possible at instance-level granularity. For some applications this fixed the problem, but for others it caused more problems. big problems. Another flaw in SQL Server 2005's lock escalation algorithm was that locks on partitioned tables were escalated directly to the table level rather than to the partition level.
SQLServer 2008 offers a solution to both problems. It implements new parameter, which allows you to control lock escalation at the table level. Using the ALTERTABLE command, you can choose to disable escalation or escalate to the partition level for partitioned tables. Both of these features improve scalability and performance without unwanted side effects affecting other objects in the instance. Lock escalation is set at the database object level and does not require any application changes. It is supported in all editions of SQLServer 2008.
Resource Governor
Maintaining sustainable service levels by preventing runaway requests and ensuring resources are allocated to critical workloads has previously been challenging. There was no way to guarantee the allocation of a certain amount of resources to a set of requests, and there was no control over access priorities. All requests had equal rights to access all available resources.
New SQL function Server 2008's Resource Governor helps address this issue by providing the ability to differentiate workloads and allocate resources based on user needs. Resource Governor limits are easily reconfigured in real time with minimal impact to running workloads. The distribution of workloads across the resource pool is configured at the connection level, and the process is completely transparent to applications.
The diagram below shows the resource allocation process. In this scenario, you configure three workload pools (Admin, OLTP, and Report workloads) and then assign the OLTP workload pool highest priority. At the same time, two resource pools are configured (Pool pool and Application pool) with specified limits on memory size and processor (CPU) time. The final step is to assign the Admin workload to the Admin pool, and assign the OLTP and Report workloads to the Application pool.

The following are features to consider when using the resource governor.
- Resource Governor uses the login credential, hostname, or application name as the "resource pool identifier", so using a single login per application for certain numbers of clients per server can make pooling more difficult.
- Object grouping at the database level, where access to resources is controlled based on the database objects being accessed, is not supported.
— You can only configure the use of processor and memory resources. I/O resource management is not implemented.
- Dynamic switching of workloads between resource pools after connection is not possible.
- Resource Governor is only supported in SQL Server 2008 Enterprise and Developer editions and can only be used for the SQL Server Database Engine; SQL service management Server Analysis Services (SSAS), SQL Server Integration Services (SSIS), and SQL Server Reporting Services (SSRS) are not supported.
Transparent encryption data (TDE)
Many organizations pay great attention to security issues. There are many different layers that protect one of an organization's most valuable assets—its data. More often than not, organizations successfully protect the data in use through physical security measures, firewalls, and strict access restriction policies. However, in case of loss physical media with data, for example, a disk or tape with a backup copy, all the listed security measures are useless, since an attacker can simply restore the database and get full access to the data. SQL
Server 2008 offers a solution to this problem through Transparent Data Encryption (TDE). With TDE encryption, data in I/O operations is encrypted and decrypted in real time; Data and log files are encrypted using a Database Encryption Key (DEK). A DEK is a symmetric key protected by a certificate stored in the server's >master database, or an asymmetric key protected by an Extensible Key Management Module (EKM).
The TDE feature protects data at rest so that data is MDF files, NDF, and LDF cannot be viewed using a hex editor or any other method. However, active data, such as the results of a SELECT statement in SQL Server Management Studio, will remain visible to users who have permission to view the table. Additionally, because TDE is implemented at the database level, the database can use indexes and keys to optimize queries. TDE should not be confused with column level encryption - it is separate function, allowing you to encrypt even active data.
Database encryption is a one-time process that can be started with the Transact - SQL command or from SQL Server Management Studio and then runs on a background thread. Encryption or decryption status can be monitored using the dynamic management view sys.dm_database_encryption_keys. During laboratory tests, a 100 GB database was encrypted using the algorithm AES encryption _128 took about an hour. Although the overhead of using TDE is determined primarily by the application workload, in some of the tests conducted this overhead was less than 5%. One thing to be aware of that may impact performance is that if TDE is used on any of the databases on the instance, then the system database is also encrypted tempDB. Finally, when used simultaneously various functions The following must be taken into account:
- When you use backup compression to compress an encrypted database, the size of the compressed backup will be larger than without using encryption because encrypted data is poorly compressed.
- Database encryption does not affect data compression (row or page).
TDE enables an organization to ensure compliance with regulatory standards and overall data protection levels. TDE is supported only in SQL Server 2008 Enterprise and Developer editions; its activation does not require changes to existing applications. For more information, see Data Encryption in SQL Server 2008 Enterprise Edition or the discussion in Transparent data encryption.
To summarize, SQL Server 2008 offers features, enhancements, and capabilities that make your job as a database administrator easier. The 10 most popular ones are described here, but SQL Server 2008 has many other features that make life easier for administrators and other users. Lists "10 best features" for other areas of working with SQL Server can be found in other articles "Top 10... in SQL Server 2008" on this site. For a complete list of features and their detailed descriptions, see SQL Server Books Online and the SQL Server 2008 overview website.
The SQL Server environment provides a number of different control constructs, without which it is impossible to write effective algorithms.
Grouping two or more teams into single block carried out using the BEGIN and END keywords:
<блок_операторов>::=
Grouped commands are treated as a single command by the SQL interpreter. A similar grouping is required for constructions of polyvariant branching, conditional and cyclic constructions. BEGIN...END blocks can be nested.
Some SQL commands should not be run together with other commands ( we're talking about about backup commands, changing the structure of tables, stored procedures and the like), therefore their joint inclusion in the BEGIN...END construct is not allowed.
Often a certain part of a program must be executed only if some logical condition. The syntax of the conditional statement is shown below:
<условный_оператор>::=
IF log_expression
( sql_statement | statement_block )
(sql_statement | statement_block) ]
Loops are organized using the following construction:
<оператор_цикла>::=
WHILE log_expression
( sql_statement | statement_block )
( sql_statement | statement_block )
The loop can be forcibly stopped by executing the BREAK command in its body. If you need to start the loop again without waiting for all commands in the body to be executed, you must execute the CONTINUE command.
To replace multiple single or nested conditional statements, use the following construct:
<оператор_поливариантных_ветвлений>::=
CASE input_value
WHEN (compare_value |
log_expression ) THEN
output_expression [,...n]
[ ELSE otherwise_out_expression ]
If the input value and the comparison value are the same, then the construct returns the output value. If the value of the input parameter is not found in any of the WHEN...THEN lines, then the value specified after the ELSE keyword will be returned.
Basic objects of the SQL server database structure
Let's look at the logical structure of the database.
Logical structure defines the structure of tables, relationships between them, list of users, stored procedures, rules, defaults and other database objects.
Logically, data in SQL Server is organized into objects. The main SQL Server database objects include the following objects.
Short review main database objects.
Tables
All data in SQL is contained in objects called tables. Tables represent a collection of any information about objects, phenomena, processes of the real world. No other objects store data, but they can access the data in the table. Tables in SQL have the same structure as tables in all other DBMSs and contain:
· lines; each line (or record) represents a set of attributes (properties) of a specific instance of an object;
· columns; each column (field) represents an attribute or collection of attributes. A row field is the minimum element of a table. Each column in a table has a specific name, data type, and size.
Representation
Views are virtual tables whose contents are determined by a query. Like real tables, views contain named columns and rows of data. To end users, a view looks like a table, but it doesn't actually contain data, but rather represents data located in one or more tables. The information that the user sees through the view is not stored in the database as a separate object.
Stored procedures
Stored procedures are a group of SQL commands combined into one module. This group of commands is compiled and executed as a single unit.
Triggers
Triggers are a special class of stored procedures that are automatically launched when data is added, changed, or deleted from a table.
Functions
Functions in programming languages are constructs that contain frequently executed code. The function performs some actions with the data and returns some value.
Indexes
An index is a structure associated with a table or view and designed to speed up the search for information in them. An index is defined on one or more columns, called indexed columns. It contains the sorted values of an indexed column or columns with references to the corresponding row in the source table or view. Improved productivity is achieved by sorting data. Using indexes can significantly improve search performance, but storing indexes requires extra space in the database.
©2015-2019 site
All rights belong to their authors. This site does not claim authorship, but provides free use.
Page creation date: 2016-08-08
If you've ever written locking schemes in other database languages to overcome the lack of locking (as I have), you may have been left with the feeling that you have to deal with locking yourself. Let me assure you that the lock manager can be completely trusted. However, SQL Server offers several methods for managing locks, which we will discuss in detail in this section.
Do not apply blocking settings or change isolation levels randomly- Trust the SQL Server lock manager to balance contention and transaction integrity. Only if you are absolutely sure that the database schema is well configured and the program code is literally polished, you can slightly adjust the behavior of the lock manager to solve a specific problem. In some cases, setting select queries to not lock will solve most problems.
Setting the connection isolation level
The isolation level determines the duration of the general or exclusive connection blocking. Setting the isolation level affects all queries and all tables used for the duration of the connection or until one isolation level is explicitly replaced by another. The following example sets tighter isolation than the default and prevents non-repeated reads:
SET TRANSACTION ISOLATION LEVEL REPEATABLE READ Valid isolation levels are:
Read uncommitted? serializable
Read committed? snapshot
Repeatable read
You can check your current isolation level using the Database Integrity Check (DBCC) command:
DBCC USEROPTIONS
The results will be as follows (abbreviated):
Set Option Value
isolation level repeatable read
Isolation levels can also be set at the query or table level using locking options.
Using Database Snapshot Level Isolation
There are two options for the isolation level of database snapshots: snapshot and read committed snapshot. Snapshot isolation works like a repeatable read without dealing with locking issues. Read commited snapshot isolation mimics SQL Server's default read commited level, also eliminating locking issues.
While transaction isolation is typically configured at the connection level, snapshot isolation must be configured at the database level because it
effectively tracks the versioning of rows in the database. Row versioning is a technology that creates copies of rows in the TempDB database for updating. In addition to the main loading of the TempDB database, row versioning also adds a 14-byte row identifier.
Using Snapshot Isolation
The following snippet enables the snapshot isolation level. To update the database and enable the snapshot isolation level, no other connections must be established to this database.
ALTER DATABASE Aesop
SET ALLOW_SNAPSHOT_ISOLATION ON
| To check whether snapshot isolation is enabled on a database, run the following SVS query: SELECT name, snapshot_isolation_state_desc FROM [ * sysdatabases.
Now the first transaction starts reading and remains open (i.e. not committed): USE Aesop
BEGIN TRAN SELECT Title FROM FABLE WHERE FablD = 2
The following result will be obtained:
At this time, the second transaction begins updating the same row that was opened by the first transaction:
SET TRANSACTION ISOLATION LEVEL Snapshot;
BEGIN TRAN UPDATE Fable
SET Title = ‘Rocking with Snapshots’
WHERE FablD = 2;
SELECT * FROM FABLE WHERE FablD = 2
The result is as follows:
Rocking with Snapshots
Isn't that surprising? The second transaction was able to update the row even though the first transaction remained open. Let's return to the first transaction and see the original data:
SELECT Title FROM FABLE WHERE FablD = 2
The result is as follows:
If you open the third and fourth transactions, they will see the same original value of The Bald Knight:
Even after the second transaction commits the changes, the first one will still see the original value, and all subsequent transactions will see the new value, Rocking with Snapshots.
Using ISOLATION Read Commited Snapshot
Read Commited Snapshot isolation is enabled using similar syntax:
ALTER DATABASE Aesop
SET READ_COMMITTED_SNAPSHOT ON
Similar to Snapshot isolation, this level To remove blocking issues, it also uses string versioning. Using the example described in the previous section as a basis, in this case the first transaction will see the changes made by the second as soon as they are committed.
Because Read Commited is the default isolation level in SQL Server, only setting the database parameters is required.
Resolving Write Conflicts
Transactions that write data when the Snapshot isolation level is set may be blocked by previous uncommitted write transactions. Such a lock will not cause a new transaction to wait - it will simply generate an error. For processing similar situations use a try expression. . . catch, wait a couple of seconds and try the transaction again.
Using blocking options
Blocking parameters allow you to make temporary adjustments to the blocking strategy. While the isolation level affects the connection as a whole, the locking options are specific to each table in a particular query (Table 51.5). The WITH option (lock_option) is placed after the table name in the FROM clause of the query. For each table, you can specify multiple parameters, separated by commas.
|
Table 51.5. Blocking options |
Parameter blocking |
Description |
Isolation level. Does not set or hold a lock. Equivalent to no blocking |
Default transaction isolation level |
Isolation level. Holds shared and exclusive locks until the transaction is confirmed |
Isolation level. Holds a shared lock until the transaction completes |
Skip blocked rows instead of waiting |
Enable locking at the row level instead of the page, extent, or table level |
Enable page-level locking instead of table-level locking |
Automatic escalation of row, page and extent level locks to table level granularity |
Parameter blocking |
Description |
Failure to apply or maintain locks. Same as ReadUnCommitted |
Enable an exclusive table lock. Preventing other transactions from working with the table |
Hold a shared lock until the transaction commits (same as Serializable) |
Using an update lock instead of a general one and holding it. Locking other writes to data between initial reads and writes |
Holding an exclusive data lock until the transaction is confirmed |
The following example uses a locking option in the FROM clause of the UPDATE statement to prevent the manager from escalating the lock granularity:
USE OBXKites UPDATE Product
FROM Product WITH (RowLock)
SET ProductName = ProductName + ' Updated 1
If a query contains subqueries, be aware that each query's table access generates a lock, which can be controlled using parameters.
Index-level locking restrictions
Isolation levels and blocking settings are applied at the connection and request level. The only way to manage table-level locks is to limit the lock granularity based on specific indexes. Using the sp_indexoption system stored procedure, row and/or page locks can be disabled for a specific index using the following syntax: sp_indexoption 'index_name 1 .
AllowRowlocks or AllowPagelocks,
This may be useful in a number of special cases. If the table frequently experiences waits due to page locks, then setting allowpagelocks to off will establish row-level locking. Reduced lock granularity will have a positive effect on competition. Additionally, if the table is rarely updated but read frequently, row- and page-level locks are not desirable; In this case, the optimal locking level is at the table level. If updates are performed infrequently, then exclusive locking on tables will not cause much of a problem.
The Sp_indexoption stored procedure is for fine tuning data schemas; that's why it uses index-level locking. To restrict locks on a table's primary key, use sp_help table_name to find the name of the primary key index.
The following command configures the ProductCategory table as an infrequently updated categorizer. The sp_help command first displays the name of the table's primary key index: sp_help ProductCategory
The result (truncated) is:
index index index
name description keys
PK_____________ ProductCategory 79A814 03 nonclustered, ProductCategorylD
unique, primary key located on PRIMARY
In stock real name primary key, the system stored procedure can set the index locking parameters:
EXEC sp_indexoption
‘ProductCategory.РК__ ProductCategory_______ 7 9A814 03′,
'AllowRowlocks', FALSE EXEC sp_indexoption
‘ProductCategory.PK__ ProductCategory_______ 79A81403′,
'AllowPagelocks', FALSE
Managing lock wait times
If a transaction is waiting for a lock, then this wait will continue until the lock becomes possible. By default there is no timeout limit - theoretically it can last forever.
Luckily, you can set the lock timeout using the set lock_timeout connection option. Set this parameter to the number of milliseconds, or if you don't want to limit the time, set it to -1 (which is the default). If this parameter is set to 0, the transaction will be rejected immediately if there is any blocking. In this case, the application will be extremely fast, but ineffective.
The following request sets the lock timeout to two seconds (2000 milliseconds):
SET Lock_Timeout 2 00 0
If a transaction exceeds the configured timeout limit, error number 1222 is generated.
I strongly recommend setting a lock timeout limit at the connection level. This value is chosen based on the typical performance of the database. I prefer to set the timeout to five seconds.
Evaluating Database Contention Performance
It's very easy to create a database that doesn't address lock contention and contention issues when testing on a group of users. Real test- this is when several hundred users simultaneously update orders.
Competition testing needs to be properly organized. At one level, it must contain the simultaneous use of the same final form by multiple users. A .NET program that constantly simulates
user viewing and updating data. A good test should run 20 instances of a script that continuously loads the database, and then let the test team use the application. The number of locks will help you see the performance monitor discussed in Chapter 49.
It is better to test multiplayer competition several times during the development process. As the MCSE exam manual says, “don't let the real world test come first.”
Application locks
SQL Server uses very complex circuit blocking. Sometimes a process or resource other than data requires a lock. For example, it may be necessary to run a procedure that causes harm if another user runs another instance of the same procedure.
Several years ago I wrote a program for cabling in nuclear power plant projects. Once the plant geometry was designed and tested, engineers entered the cable composition, location, and types of cables used. After several cables were inserted, the program formed the route for laying them so that it was as short as possible. The procedure also took into account safety issues cabling and separated incompatible cables. At the same time, if multiple routing procedures were run simultaneously, each instance would attempt to route the same cables, resulting in incorrect results. App blocking has become a great solution to this problem.
Application locking opens up a whole world of SQL locks for use in applications. Instead of using data as a lockable resource, application locks lock the use of all user resources declared in the sp__GetAppLock stored procedure.
Application locking can be applied in transactions; in this case, the blocking mode can be Shared, Update, Exclusive, IntentExclusice or IntentShared. The return value from the procedure indicates whether the lock was applied successfully.
0. The lock was installed successfully.
1. The lock was acquired when another procedure released its lock.
999. The lock was not installed for another reason.
The sp_ReleaseApLock stored procedure releases the lock. The following example demonstrates how an application lock can be used in a batch or procedure: DECLARE @ShareOK INT EXEC @ShareOK = sp_GetAppLock
@Resource = 'CableWorm',
@LockMode = 'Exclusive'
IF @ShareOK< 0
...Error handling code
... Program code ...
EXEC sp_ReleaseAppLock @Resource = 'CableWorm'
When application locks are viewed using Management Studio or sp_Lock, they appear with type APP. The following listing is a shortened output of sp_Lock running at the same time as the above code: spid dbid Objld Indld Type Resource Mode Status
57 8 0 0 APP Cabllf 94cl36 X GRANT
There are two small differences to note in how application locks are handled in SQL Server:
Deadlocks are not detected automatically;
If a transaction acquires a lock several times, it must release it exactly the same number of times.
Deadlocks
Deadlock is a special situation that occurs only when transactions with multiple tasks compete for each other's resources. For example, the first transaction has acquired a lock on resource A and needs to lock resource B, and at the same time the second transaction, which has locked resource B, needs to lock resource A.
Each of these transactions waits for the other to release its lock, and neither can complete until this happens. If there is no external influence or one of the transactions ends for a certain reason (for example, due to timeout), then this situation can continue until the end of the world.
Deadlocks used to be a serious problem, but SQL Server can now resolve them successfully.
Creating a Deadlock
The easiest way to create a deadlock situation in SQL Server is to use two connections in the query editor of Management Studio (Figure 51.12). The first and second transactions attempt to update the same rows, but in the opposite order. Using the third window to run the pGetLocks procedure, you can monitor locks.
1. Create a second window in the query editor.
2. Place the Step 2 block code in the second window.
3. Place the Step 1 block code in the first window and press the key
4. In the second window, similarly execute the code Step 2.
5. Return to the first window and execute the Step 3 block code.
6. After a short period of time, SQL Server will detect the deadlock and automatically resolve it.
Below is the example code.
– Transaction 1 — Step 1 USE OBXKites BEGIN TRANSACTION UPDATE Contact
SET LastName = 'Jorgenson'
WHERE ContactCode = 401′
Puc. 51.12. Creating a deadlock situation in Management Studio using two connections (their windows are located at the top)
Now the first transaction has acquired an exclusive lock on the record with the value 101 in the ContactCode field. The second transaction will acquire an exclusive lock on the row with a value of 1001 in the ProductCode field, and then attempt to exclusively lock the record already locked by the first transaction (ContactCode=101).
– Transaction 2 — Step 2 USE OBXKites BEGIN TRANSACTION UPDATE Product SET ProductName
= 'DeadLock Repair Kit'
WHERE ProductCode = '1001'
SET FirstName = 'Neals'
WHERE ContactCode = '101'
COMMIT TRANSACTION
There is no deadlock yet because transaction 2 is waiting for transaction 1 to complete, but transaction 1 is not yet waiting for transaction 2 to complete. In this situation, if transaction 1 completes its work and executes the COMMIT TRANSACTION statement, the data resource will be released and transaction 2 will be safely will be able to block the block she needs and continue her actions.
The problem occurs when transaction 1 tries to update a row with ProductCode=l. However, it will not receive the exclusive lock necessary for this, since this record is locked by transaction 2:
– Transaction 1 – Step 3 UPDATE Product SET ProductName
= 'DeadLock Identification Tester'
WHERE ProductCode = '1001'
COMMIT TRANSACTION
Transaction 1 will return the following error text message after a couple of seconds. The resulting deadlock can also be seen in SQL Server Profiler (Figure 51.13):
Server: Msg 1205, Level 13,
State 50, Line 1 Transaction (Process ID 51) was
deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
Transaction 2 will complete its work as if the problem never existed:
(1 row(s) affected)
(1 row(s) affected)

Rice. 51.13. SQL Server Profiler allows you to monitor deadlocks using the Locks:Deadlock Graph event and identify the resource causing the deadlock
Automatic deadlock detection
As demonstrated in the code above, SQL Server automatically detects a deadlock situation by checking for blocking processes and rolling back transactions.
who completed the least amount of work. SQL Server constantly checks for the existence of cross-locks. Deadlock detection latency can vary from zero to two seconds (in practice, the longest I've had to wait for this is five seconds).
Handling deadlocks
When a deadlock occurs, the connection selected as the deadlock victim must retry its transaction. Since the work must be redone, it is good that the transaction that managed to complete the least amount of work is rolled back - it is the one that will be repeated from the beginning.
Error code 12 05 should be caught client application, which should restart the transaction. If everything happens as expected, the user will not even suspect that a deadlock has occurred.
Instead of allowing the server itself to decide which transaction to choose as a “victim,” the transaction itself can be “played as a giveaway.” The following code, when placed in a transaction, informs SQL Server that if a deadlock occurs, the transaction should be rolled back:
SET DEADLOCKJPRIORITY LOW
Minimizing deadlocks
Even though deadlocks are easy to identify and handle, it is still best to avoid them. The following recommendations will help you avoid deadlocks.
Try to keep transactions short and free of unnecessary code. If some code does not need to be present in a transaction, it must be inferred from it.
Never make a transaction code dependent on user input.
Try to create packages and procedures that acquire locks in the same order. For example, table A is processed first, then tables B, C, etc. Thus, one procedure will wait for the second and deadlocks cannot occur by definition.
Design the physical layout to store concurrently sampled data as closely as possible on data pages. To achieve this, use normalization and choose clustered indexes wisely. Reducing the spread of blockages will help avoid their escalation. Small blocks will help avoid their competition.
Do not increase the insulation level unless necessary. A stricter level of isolation increases the duration of lockdowns.