Xây dựng trình phân loại học máy bằng Scikit-learn trong Python. Hướng dẫn về học máy bằng Python cho người đi nhờ xe
Học máy đang trên đà phát triển và thuật ngữ này đang dần dần len lỏi vào cái gọi là lãnh thổ từ thông dụng. Đây là trong đến một mức độ lớn do thực tế là nhiều người không hiểu đầy đủ ý nghĩa thực sự của thuật ngữ này. Nhờ vào phân tích của Google Xu hướng (thống kê về truy vấn tìm kiếm), chúng ta có thể nghiên cứu biểu đồ và hiểu mức độ quan tâm đến thuật ngữ “học máy” đã tăng lên như thế nào trong 5 năm qua:
Mục tiêu
Nhưng bài viết này không phải về sự nổi tiếng.học máy. Tám thuật toán học máy chính và cách sử dụng thực tế của chúng được mô tả ngắn gọn ở đây. Xin lưu ý rằng tất cả các mô hình đều được triển khai bằng Python và bạn phải có kiến thức tối thiểu về ngôn ngữ lập trình này. Lời giải thích chi tiết của từng phần có trong các video tiếng Anh đính kèm. Hãy để chúng tôi đặt trước ngay rằng những người mới bắt đầu hoàn chỉnh sẽ thấy văn bản này khó; nó phù hợp hơn cho các nhà phát triển tiếp tục và nâng cao, nhưng các chương của tài liệu có thể được sử dụng như một kế hoạch đào tạo xây dựng: điều gì đáng biết, điều gì đáng hiểu Đầu tiên.
Phân loại
Hãy bỏ qua thuật toán nếu bạn không hiểu điều gì đó. Sử dụng hướng dẫn này theo cách bạn muốn. Đây là danh sách:
- Hồi quy tuyến tính.
- Hồi quy logistic.
- Cây quyết định.
- Máy vectơ hỗ trợ.
- Phương pháp k-láng giềng gần nhất.
- Thuật toán rừng ngẫu nhiên.
- Phương pháp K-means.
- Phương pháp thành phần chính.
Sắp xếp mọi thứ theo thứ tự
Rõ ràng là bạn sẽ khó chịu nếu khi cố chạy mã của người khác, đột nhiên bạn không có ba gói cần thiết, và mã cũng đã được đưa ra trong phiên bản cũ ngôn ngữ. Vì vậy, để tiết kiệm thời gian quý báu của bạn, hãy truy cập thẳng vào Python 3.6.2 và nhập các thư viện cần thiết từ đoạn mã dán bên dưới. Dữ liệu được lấy từ bộ dữ liệu Bệnh tiểu đường và Iris từ Kho lưu trữ máy học UCI . Cuối cùng, nếu bạn muốn bỏ qua tất cả những điều này và chỉ xem mã, đây là liên kết đến Kho lưu trữ GitHub.
Nhập gấu trúc dưới dạng pd nhập matplotlib.pyplot dưới dạng plt nhập numpy dưới dạng np nhập seaborn dưới dạng sns %matplotlib nội tuyến
Hồi quy tuyến tính
Nó có lẽ là thuật toán học máy phổ biến nhất trên thế giới. khoảnh khắc này và đồng thời bị đánh giá thấp nhất. Nhiều nhà khoa học dữ liệu quên rằng giữa hai thuật toán có cùng hiệu suất, tốt hơn nên chọn thuật toán đơn giản hơn.Hồi quy tuyến tính là một thuật toán học máy có giám sát nhằm dự đoán kết quả dựa trên các tính năng liên tục. Hồi quy tuyến tính rất linh hoạt theo nghĩa là nó có khả năng chạy trên một biến đầu vào duy nhất (hồi quy tuyến tính đơn giản) hoặc trên nhiều biến ( hồi quy bội). Bản chất của thuật toán nàylà gán trọng số tối ưu cho các biến để tạo một đường (ax + b) sẽ được sử dụng để dự đoán đầu ra. Xem video để được giải thích rõ ràng hơn.
Bây giờ bạn đã hiểu bản chất của hồi quy tuyến tính, hãy tiếp tục và triển khai nó bằng Python.
Bắt đầu công việc
từ sklearn nhập tuyến tính_model df = pd.read_csv ("tuyến tính_regression_df.csv") df.columns = ["X", "Y"] df.head()Hình dung
sns.set_context("notebook", font_scale=1.1) sns.set_style("ticks") sns.lmplot("X","Y", data=df) plt.ylabel("Response") plt.xlabel("Giải thích ")Thực hiện
tuyến tính = Linear_model.LinearRegression() trainX = np.asarray(df.X).reshape(-1, 1) trainY = np.asarray(df.Y).reshape(-1, 1) testX = np.asarray(df .X[:20]).reshape(-1, 1) testY = np.asarray(df.Y[:20]).reshape(-1, 1) tuyến tính.fit(trainX, trainY) tuyến tính.score(trainX , trainY) print("Hệ số: \n", tuyến tính.coef_) print("Đoạn chặn: \n", tuyến tính.intercept_) print("Giá trị R²: \n", tuyến tính.score(trainX, trainY)) dự đoán = tuyến tính.predict(testX)Bảng cheat sẽ giúp bạn giải phóng tâm trí để thực hiện những nhiệm vụ quan trọng hơn. Chúng tôi đã thu thập được 27 bảng cheat tốt nhất mà bạn có thể và nên sử dụng.
Đúng, học máy đang phát triển nhảy vọt và tôi tin rằng bộ sưu tập của tôi sẽ trở nên lỗi thời, nhưng đối với tháng 6 năm 2017, nó còn hơn cả phù hợp.
Nếu bạn không muốn tải xuống tất cả các bảng cheat một cách riêng biệt, hãy tải xuống kho lưu trữ zip làm sẵn.
Học máy
Có khá nhiều sơ đồ và bảng hữu ích bao gồm việc học máy. Dưới đây là những cái đầy đủ và cần thiết nhất.
Kiến trúc mạng thần kinh
Với sự ra đời của kiến trúc mạng thần kinh mới, chúng trở nên khó theo dõi. Số lượng lớn các từ viết tắt (BiLSTM, DCGAN, DCIGN, có ai biết hết chúng không?) có thể khiến bạn nản lòng.
Vì vậy, tôi quyết định tập hợp một bảng ghi chú chứa nhiều kiến trúc như vậy. Hầu hết chúng liên quan đến mạng lưới thần kinh. Chỉ có một vấn đề với cách hình dung này: nguyên tắc sử dụng không được hiển thị. Ví dụ: bộ mã hóa tự động biến thiên (VAE) có thể trông giống bộ mã hóa tự động (AE), nhưng quá trình học thì khác.
Sơ đồ thuật toán Microsoft Azure
Bảng ghi chú học máy của Microsoft Azure để giúp bạn lựa chọn thuật toán đúng cho một mô hình phân tích dự đoán. Xưởng máy đào tạo của Microsoft Azure bao gồm một thư viện lớn về các thuật toán hồi quy, phân loại, phân cụm và phát hiện bất thường.

Sơ đồ thuật toán SAS
Bảng tính gian lận với thuật toán SAS sẽ cho phép bạn nhanh chóng tìm ra thuật toán phù hợp để giải quyết một vấn đề cụ thể. Các thuật toán được trình bày ở đây là kết quả tổng hợp phản hồi và lời khuyên từ một số nhà khoa học dữ liệu, nhà phát triển và chuyên gia máy học.

Bộ sưu tập các thuật toán
Hồi quy, chính quy hóa, phân cụm, cây quyết định, Bayesian và các thuật toán khác được trình bày ở đây. Tất cả đều được nhóm lại theo nguyên tắc hoạt động.

Ngoài ra danh sách ở định dạng đồ họa thông tin:

Thuật toán dự báo: “ủng hộ/chống lại”
Những bảng ghi chú này đã thu thập các thuật toán tốt nhất được sử dụng trong phân tích dự đoán. Dự báo là một quá trình trong đó giá trị của biến đầu ra được xác định từ một tập hợp các biến đầu vào.

Python
Không có gì đáng ngạc nhiên khi ngôn ngữ Python đã quy tụ được một cộng đồng lớn và nhiều tài nguyên trực tuyến. Đối với phần này tôi đã chọn những tấm cheat tốt nhất người mà tôi đã làm việc cùng.
Đây là tập hợp 10 thuật toán học máy được sử dụng phổ biến nhất với mã bằng Python và R. Bảng cheat thích hợp làm tài liệu tham khảo giúp bạn sử dụng các thuật toán học máy hữu ích.

Không thể phủ nhận rằng Python đang phát triển ngày nay. Các bảng ghi chú bao gồm mọi thứ bạn cần, bao gồm các hàm và định nghĩa về lập trình hướng đối tượng sử dụng ngôn ngữ Python làm ví dụ.

Và bảng ghi chú này sẽ là sự bổ sung tuyệt vời cho phần giới thiệu của bất kỳ hướng dẫn Python nào:

NumPy
NumPy là thư viện cho phép Python xử lý dữ liệu nhanh chóng. Khi mới học, bạn có thể gặp khó khăn trong việc ghi nhớ tất cả các chức năng và phương pháp, vì vậy ở đây chúng tôi đã thu thập các bảng cheat hữu ích nhất có thể giúp việc học thư viện dễ dàng hơn nhiều. Nhập/xuất, tạo mảng, sao chép, sắp xếp, di chuyển các phần tử và nhiều nội dung khác được đề cập.

Và ở đây phần lý thuyết được trình bày thêm:

Bạn có thể tìm thấy sơ đồ biểu diễn của một số dữ liệu trong bảng cheat này:

Tất cả thông tin cần thiết với sơ đồ:

Pandas là một thư viện cấp cao được thiết kế để phân tích dữ liệu. Các khung, bảng, đối tượng, chức năng gói tương ứng và các thứ khác thông tin cần thiếtđược thu thập trong một bảng cheat được sắp xếp thuận tiện:

Sơ đồ trình bày thông tin về thư viện Pandas:

Và bảng ghi chú này bao gồm phần trình bày chi tiết với các ví dụ và bảng biểu:

Nếu bạn bổ sung thư viện Pandas trước đó bằng gói matplotlib, bạn sẽ có thể vẽ biểu đồ cho dữ liệu nhận được. Matplotlib chịu trách nhiệm vẽ đồ thị bằng Python. Đây thường là gói liên quan đến trực quan hóa đầu tiên mà các lập trình viên Python mới làm quen sử dụng và các bảng ghi chú được trình bày sẽ giúp bạn nhanh chóng điều hướng chức năng của thư viện này.

Trong bảng cheat thứ hai, bạn sẽ tìm thấy nhiều ví dụ hơn đại diện trực quanđồ thị:

Thư viện Scikit-Learn Python với các thuật toán học máy không phải là thư viện dễ học nhất, nhưng với bảng cheat, nguyên tắc hoạt động của nó trở nên rõ ràng nhất có thể.

Sơ đồ biểu diễn:

Với lý thuyết, ví dụ và tài liệu bổ sung:

Dòng chảy căng
Một thư viện khác dành cho máy học, nhưng có chức năng riêng và khó hiểu. Dưới đây là bảng cheat hữu ích để học TensorFlow.
Mọi chuyên gia phân tích dữ liệu đều tự hỏi nên chọn ngôn ngữ lập trình nào. — Họ viết R hay Python? Để tìm ra câu trả lời tốt nhất cho câu hỏi này, trong hầu hết các trường hợp, công cụ tìm kiếm phổ biến Google. Nếu không có câu trả lời đúng, các ứng viên tiềm năng sẽ không bao giờ trở thành chuyên gia về máy học hoặc phân tích dữ liệu. Bài viết này cố gắng giải thích các chi tiết cụ thể của ngôn ngữ R và Python để sử dụng trong việc phát triển công nghệ học máy.
Học máy và khoa học dữ liệu đang là những phân khúc phát triển mạnh mẽ và ngày càng phát triển của các công nghệ tiên tiến ngày nay, giúp giải quyết nhiều vấn đề và thách thức phức tạp khác nhau trong việc phát triển các giải pháp và ứng dụng. Về vấn đề này, trên phạm vi toàn cầu, các nhà phân tích và chuyên gia phân tích dữ liệu đang phải đối mặt với nhiều thách thức nhất. nhiều cơ hội việc áp dụng sức mạnh và khả năng của họ vào các công nghệ như trí tuệ nhân tạo, IoT và dữ liệu lớn. Để giải quyết mới nhiệm vụ phức tạp các chuyên gia và chuyên gia yêu cầu công cụ đắc lực xử lý một lượng lớn dữ liệu và để tự động hóa các nhiệm vụ phân tích, nhận dạng và tổng hợp dữ liệu đã được phát triển nhiều loại nhạc cụ và thư viện máy học.
Trong quá trình phát triển thư viện máy học, các ngôn ngữ lập trình như R và Python chiếm vị trí dẫn đầu. Nhiều chuyên gia và nhà phân tích dành thời gian lựa chọn ngôn ngữ yêu cầu. Ngôn ngữ lập trình nào thích hợp hơn cho mục đích học máy?
Điểm giống nhau giữa R và Python
- Cả hai ngôn ngữ — R và Python — là những ngôn ngữ lập trình nguồn mở mã nguồn. Một số lượng lớn thành viên của cộng đồng lập trình đã đóng góp vào việc phát triển tài liệu và phát triển các ngôn ngữ này.
- Các ngôn ngữ có thể được sử dụng cho các dự án phân tích, phân tích dữ liệu và học máy.
- Cả hai đều có các công cụ nâng cao để hoàn thành các dự án khoa học dữ liệu.
- Trả tiền cho các chuyên gia phân tích dữ liệu thích làm việc trong R và Python gần như giống nhau.
- Phiên bản hiện tại của Python và R — xx
R và Python – sự cạnh tranh giữa các đối thủ
Chuyến tham quan lịch sử:
- Năm 1991, Guido Van Rossum, lấy cảm hứng từ sự phát triển của ngôn ngữ C, Modula-3 và ABC, đã đề xuất Ngôn ngữ mới lập trình - Python.
- Năm 1995, Ross Ihaka và Robert Gentleman đã tạo ra ngôn ngữ R, được phát triển tương tự như ngôn ngữ lập trình S.
Bàn thắng:
- Mục tiêu của việc phát triển Python là tạo ra sản phẩm phần mềm, đơn giản hóa quá trình phát triển và đảm bảo khả năng đọc mã.
- Trong khi đó ngôn ngữ R được phát triển chủ yếu để phân tích dữ liệu thân thiện với người dùng và giải quyết các vấn đề thống kê phức tạp. Nó là một ngôn ngữ định hướng thống kê chủ yếu.
Dễ học:
- Nhờ khả năng đọc mã của nó, Python rất dễ học. Đây là ngôn ngữ thân thiện với người mới bắt đầu, có thể học mà không cần bất kỳ kinh nghiệm lập trình nào trước đó.
- Ngôn ngữ R tuy khó nhưng sử dụng ngôn ngữ này trong lập trình càng lâu thì càng dễ học và hiệu quả giải các công thức thống kê phức tạp càng cao. Đối với những lập trình viên có kinh nghiệm, R là một lựa chọn đi đến.
Cộng đồng:
- Python nhận được sự hỗ trợ của nhiều cộng đồng khác nhau, trong đó các thành viên tận tâm phát triển ngôn ngữ cho các ứng dụng đầy hứa hẹn. Các lập trình viên và nhà phát triển, giống như thành viên của StackOverflow, người tham gia tích cực Cộng đồng Python.
- Ngôn ngữ R cũng được hỗ trợ bởi các thành viên của một cộng đồng đa dạng thông qua danh sách gửi thư, tài liệu đóng góp của người dùng, v.v.. Hầu hết các nhà thống kê, nhà nghiên cứu và chuyên gia phân tích dữ liệu đều tích cực tham gia vào việc phát triển ngôn ngữ.
Uyển chuyển:
- Python là ngôn ngữ đề cao năng suất nên khá linh hoạt trong việc phát triển. Các ứng dụng khác nhau. Để phát triển các ứng dụng quy mô lớn, Python chứa nhiều mô-đun và thư viện khác nhau.
- Ngôn ngữ R cũng linh hoạt trong việc phát triển các công thức phức tạp, thực hiện các bài kiểm tra thống kê, trực quan hóa dữ liệu, v.v. Nó bao gồm nhiều gói sẵn sàng sử dụng.
Ứng dụng:
- Python là người đi đầu trong phát triển ứng dụng. Nó được sử dụng để hỗ trợ phát triển trang web, phát triển trò chơi và khoa học dữ liệu.
- Ngôn ngữ R chủ yếu được sử dụng để phát triển các dự án phân tích dữ liệu tập trung vào thống kê và trực quan hóa.
Cả hai ngôn ngữ R và Python đều có ưu điểm và nhược điểm. Trong hầu hết các trường hợp, đây là những ngôn ngữ tập trung vào cụ thể, vì R tập trung vào thống kê và trực quan hóa, còn Python tập trung vào sự đơn giản trong việc phát triển bất kỳ ứng dụng nào.
Dựa vào đó, R có thể được sử dụng chủ yếu cho nghiên cứu ở các viện khoa học, khi tiến hành phân tích thống kê và trực quan hóa dữ liệu. Mặt khác, Python được sử dụng để đơn giản hóa quá trình cải tiến chương trình, xử lý dữ liệu, v.v. Ngôn ngữ R có thể rất hiệu quả đối với các nhà thống kê làm việc trong lĩnh vực phân tích dữ liệu và Python tốt hơn Thích hợp cho các lập trình viên và nhà phát triển tạo ra sản phẩm cho các chuyên gia khoa học dữ liệu.
Xin chào Habr!
Nhập numpy dưới dạng np import urllib # url với tập dữ liệu url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data" # tải xuống file raw_data = urllib.urlopen(url) # tải tệp CSV dưới dạng tập dữ liệu ma trận gọn gàng = np.loadtxt(raw_data, delimiter=",") # tách dữ liệu khỏi thuộc tính đích X =datadata[:,0:7] y = tập dữ liệu[:,8]
Hơn nữa, trong tất cả các ví dụ, chúng tôi sẽ làm việc với tập dữ liệu này, cụ thể là với ma trận thuộc tính-đối tượng X và giá trị của biến mục tiêu y.
Chuẩn hóa dữ liệu
Mọi người đều nhận thức rõ rằng hầu hết các phương pháp gradient (về cơ bản hầu hết tất cả các thuật toán học máy đều dựa trên) đều rất nhạy cảm với việc chia tỷ lệ dữ liệu. Vì vậy, trước khi chạy thuật toán, nó thường được thực hiện bình thường hóa, hay cái gọi là tiêu chuẩn hóa. Chuẩn hóa bao gồm việc thay thế các tính năng danh nghĩa sao cho mỗi tính năng nằm trong phạm vi từ 0 đến 1. Tiêu chuẩn hóa ngụ ý tiền xử lý dữ liệu như vậy, sau đó mỗi tính năng có giá trị trung bình là 0 và phương sai là 1. Scikit-Learn đã có sẵn các chức năng cho việc này:Từ tiền xử lý nhập sklearn # chuẩn hóa các thuộc tính dữ liệu normalized_X = preprocessing.normalize(X) # chuẩn hóa các thuộc tính dữ liệu được chuẩn hóa_X = preprocessing.scale(X)
Lựa chọn tính năng
Không có gì bí mật khi điều quan trọng nhất khi giải quyết vấn đề là khả năng lựa chọn chính xác và thậm chí tạo ra các tính năng. Trong văn học Anh điều này được gọi là Lựa chọn tính năng Và Kỹ thuật tính năng. Trong khi Kỹ thuật Tương lai khá quá trình sáng tạo và dựa nhiều hơn vào trực giác và kiến thức chuyên môn, Lựa chọn tính năng đã có một số lượng lớn thuật toán làm sẵn. Thuật toán “cây” cho phép tính toán nội dung thông tin của các đối tượng:Từ số liệu nhập sklearn từ sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # hiển thị tầm quan trọng tương đối của từng thuộc tính print(model.feature_importances_)
Tất cả các phương pháp khác theo cách này hay cách khác đều dựa trên việc liệt kê hiệu quả các tập hợp con của các đặc điểm để tìm ra tập hợp con tốt nhất mà mô hình được xây dựng mang lại chất lượng tốt nhất. Một thuật toán mạnh mẽ như vậy là thuật toán Loại bỏ tính năng đệ quy, cũng có sẵn trong thư viện Scikit-Learn:
From sklearn.feature_selection import RFE from sklearn.Tuyến_model import LogisticRegression model = LogisticRegression() # tạo mô hình RFE và chọn 3 thuộc tính rfe = RFE(model, 3) rfe = rfe.fit(X, y) # tóm tắt việc lựa chọn thuộc tính print(rfe.support_) print(rfe.ranking_)
Xây dựng thuật toán
Như đã lưu ý, Scikit-Learn triển khai tất cả các thuật toán học máy chính. Chúng ta hãy nhìn vào một số trong số họ.Hồi quy logistic
Nó thường được sử dụng để giải quyết các vấn đề phân loại (nhị phân), nhưng cũng cho phép phân loại nhiều lớp (phương pháp được gọi là phương pháp một đấu tất cả). Ưu điểm của thuật toán này là ở đầu ra của mỗi đối tượng ta có xác suất thuộc lớpTừ số liệu nhập sklearn từ sklearn.Tuyến_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print(model) # đưa ra dự đoán mong đợi = y dự đoán = model.predict(X) # tóm tắt sự phù hợp của mô hình print( số liệu.classification_report(dự kiến, dự đoán)) print(metrics.confusion_matrix(dự kiến, dự đoán))
Vịnh ngây thơ
Đây cũng là một trong những thuật toán học máy nổi tiếng nhất, nhiệm vụ chính của nó là khôi phục mật độ phân bố của dữ liệu mẫu huấn luyện. Thông thường phương pháp này cho chất lượng tốt trong các bài toán phân loại nhiều lớp.Từ số liệu nhập sklearn từ sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X, y) print(model) # đưa ra dự đoán mong đợi = y dự đoán = model.predict(X) # tóm tắt sự phù hợp của mô hình print( số liệu.classification_report(dự kiến, dự đoán)) print(metrics.confusion_matrix(dự kiến, dự đoán))
K-hàng xóm gần nhất
Phương pháp kNN (k-Hàng xóm gần nhất) thường được sử dụng như một phần của thuật toán phân loại phức tạp hơn. Ví dụ, đánh giá của nó có thể được sử dụng như một dấu hiệu cho một đối tượng. Và đôi khi, một kNN đơn giản về các tính năng được lựa chọn kỹ lưỡng sẽ mang lại chất lượng tuyệt vời. Với việc cài đặt tham số phù hợp (chủ yếu là số liệu), thuật toán thường cho chất lượng tốt trong các bài toán hồi quyTừ số liệu nhập sklearn từ sklearn.neighbors import KNeighborsClassifier # khớp mô hình lân cận k gần nhất với mô hình dữ liệu = KNeighborsClassifier() model.fit(X, y) print(model) # đưa ra dự đoán mong đợi = y dự đoán = model.predict( X) # tóm tắt sự phù hợp của mô hình print(metrics.classification_report(expected, dự đoán)) print(metrics.confusion_matrix(expected, dự đoán))
Cây quyết định
Cây phân loại và hồi quy (CART) thường được sử dụng trong các bài toán trong đó các đối tượng có đặc điểm phân loại và được sử dụng cho các bài toán hồi quy và phân loại. Cây rất thích hợp cho việc phân loại nhiều lớpTừ số liệu nhập sklearn từ sklearn.tree import DecisionTreeClassifier # khớp mô hình CART với mô hình dữ liệu = DecisionTreeClassifier() model.fit(X, y) print(model) # đưa ra dự đoán mong đợi = y dự đoán = model.predict(X) # tóm tắt mức độ phù hợp của mô hình print(metrics.classification_report(expected, dự đoán)) print(metrics.confusion_matrix(expected, dự đoán))
Máy Vector hỗ trợ
SVM (Máy vectơ hỗ trợ) là một trong những thuật toán học máy nổi tiếng nhất, chủ yếu được sử dụng cho nhiệm vụ phân loại. Cũng giống như hồi quy logistic, SVM cho phép phân loại nhiều lớp bằng phương pháp một đấu tất cả.Từ sklearn nhập số liệu từ sklearn.svm nhập SVC # khớp mô hình SVM với mô hình dữ liệu = SVC() model.fit(X, y) print(model) # đưa ra dự đoán mong đợi = y dự đoán = model.predict(X) # tóm tắt mức độ phù hợp của mô hình print(metrics.classification_report(expected, dự đoán)) print(metrics.confusion_matrix(expected, dự đoán))
Ngoài các thuật toán phân loại và hồi quy, Scikit-Learn còn có số lượng lớn các thuật toán phức tạp hơn, bao gồm phân cụm, cũng như các kỹ thuật được triển khai để xây dựng các thành phần của thuật toán, bao gồm Đóng bao Và Tăng cường.
Tối ưu hóa các tham số thuật toán
Một trong những giai đoạn khó khăn nhất trong việc xây dựng một thuật toán hiệu quả là một sự lựa chọn đúng thông số. Thông thường, điều này trở nên dễ dàng hơn khi có kinh nghiệm, nhưng bằng cách này hay cách khác, bạn phải đi quá xa. May mắn thay, Scikit-Learn đã triển khai khá nhiều chức năng cho mục đích này.Ví dụ: chúng ta hãy xem việc lựa chọn một tham số chính quy, trong đó chúng ta lần lượt thử một số giá trị:
Nhập numpy dưới dạng np từ sklearn.Tuyến_model nhập Ridge từ sklearn.grid_search import GridSearchCV # chuẩn bị một loạt giá trị alpha để kiểm tra alphas = np.array() # tạo và điều chỉnh mô hình hồi quy sườn, kiểm tra từng mô hình alpha = Ridge( ) Grid = GridSearchCV(estimator=model, param_grid=dict(alpha=alphas)) Grid.fit(X, y) print(grid) # tóm tắt kết quả của tìm kiếm lưới print(grid.best_score_) print(grid.best_estimator_. alpha)
Đôi khi, việc chọn ngẫu nhiên một tham số từ một phân đoạn nhất định nhiều lần sẽ hiệu quả hơn và đo lường chất lượng của thuật toán tại thông số này và do đó chọn cái tốt nhất:
Nhập numpy dưới dạng np từ scipy.stats nhập thống nhất dưới dạng sp_rand từ sklearn.Tuyến_model nhập Ridge từ sklearn.grid_search nhập RandomizedSearchCV # chuẩn bị phân phối đồng đều cho mẫu cho tham số alpha param_grid = ("alpha": sp_Rand()) # tạo và điều chỉnh mô hình hồi quy sườn, kiểm tra các giá trị alpha ngẫu nhiên model = Ridge() rsearch = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=100) rsearch.fit(X, y) print(rsearch) # tóm tắt kết quả của in tìm kiếm tham số ngẫu nhiên(rsearch.best_score_) print(rsearch.best_estimator_.alpha)
Chúng tôi đã xem xét toàn bộ quá trình làm việc với thư viện Scikit-Learn, ngoại trừ việc xuất kết quả trở lại thành một tệp, được cung cấp cho người đọc dưới dạng bài tập, vì một trong những ưu điểm của Python (và Scikit- Tìm hiểu chính thư viện) so với R là tài liệu tuyệt vời của nó. Trong các phần sau, chúng tôi sẽ xem xét chi tiết từng phần, đặc biệt, chúng tôi sẽ đề cập đến một điều quan trọng như Kỹ thuật làm đẹp.
Tôi thực sự hy vọng rằng tài liệu này sẽ giúp các nhà khoa học dữ liệu mới bắt đầu giải quyết các vấn đề về học máy trong thực tế càng sớm càng tốt. Cuối cùng, tôi xin chúc những ai mới bắt đầu tham gia các cuộc thi học máy thành công và kiên nhẫn!
Python là một ngôn ngữ lập trình tuyệt vời để triển khai vì nhiều lý do. Trước hết, Python có cú pháp rõ ràng. Thứ hai, ở Python Nó rất dễ dàng để thao tác văn bản. PythonĐược sử dụng bởi nhiều người và tổ chức trên khắp thế giới, nó đang phát triển và được ghi chép đầy đủ. Ngôn ngữ này đa nền tảng và có thể được sử dụng hoàn toàn miễn phí.
Mã giả có thể thực thi được
Cú pháp trực quan Python thường được gọi là mã giả thực thi được. Cài đặt Python theo mặc định đã bao gồm các loại dữ liệu cấp cao như danh sách, bộ dữ liệu, từ điển, bộ, chuỗi, v.v. mà người dùng không cần phải triển khai nữa. Những kiểu dữ liệu cấp cao này giúp dễ dàng triển khai các khái niệm trừu tượng. Python cho phép bạn lập trình theo bất kỳ phong cách nào quen thuộc với bạn: hướng đối tượng, thủ tục, chức năng, v.v.
TRONG Python Văn bản dễ xử lý và thao tác, khiến nó trở nên lý tưởng để xử lý dữ liệu không phải số. Có một số thư viện để sử dụng Pythonđể truy cập các trang web và thao tác văn bản trực quan giúp dễ dàng truy xuất dữ liệu từ HTML-mã số.
Python phổ biến
Ngôn ngữ lập trình Python phổ biến và có nhiều ví dụ về mã giúp việc học trở nên dễ dàng và khá nhanh chóng. Thứ hai, tính phổ biến có nghĩa là có nhiều mô-đun có sẵn cho các ứng dụng khác nhau.
Python là một ngôn ngữ lập trình phổ biến trong giới khoa học cũng như tài chính. Một số thư viện dành cho tính toán khoa học như khoa học viễn tưởng Và NumPy cho phép bạn thực hiện các phép toán trên vectơ và ma trận. Nó cũng làm cho mã dễ đọc hơn và cho phép bạn viết mã trông giống như các biểu thức đại số tuyến tính. Bên cạnh đó, thư viện khoa học khoa học viễn tưởng Và NumPyđược biên soạn bằng ngôn ngữ cấp thấp (VỚI Và Fortran), giúp việc tính toán khi sử dụng các công cụ này nhanh hơn nhiều.
Dụng cụ khoa học Python làm việc tuyệt vời kết hợp với công cụ đồ họađược phép Matplotlib. Matplotlib có thể tạo ra các ô 2D và 3D và có thể xử lý hầu hết các loại ô thường được sử dụng trong cộng đồng khoa học.
Python Nó cũng có lớp vỏ tương tác cho phép bạn xem và kiểm tra các thành phần của chương trình đang được phát triển.
Mô-đun mới Python, dưới cái tên Pylab, cố gắng kết hợp các cơ hội NumPy, khoa học viễn tưởng, Và Matplotlib trong một môi trường và cài đặt. Gói hàng hôm nay Pylab Nó vẫn đang được phát triển, nhưng nó có một tương lai tuyệt vời.
Ưu điểm và nhược điểm Python
Mọi người sử dụng các ngôn ngữ lập trình khác nhau. Nhưng đối với nhiều người, ngôn ngữ lập trình chỉ đơn giản là một công cụ để giải quyết vấn đề. Python là một ngôn ngữ cấp cao nhất, điều này cho phép bạn dành nhiều thời gian hơn để tìm hiểu dữ liệu và tốn ít thời gian hơn để suy nghĩ về cách chúng sẽ được trình bày trên máy tính.
Hạn chế thực sự duy nhất Python là nó không thực thi mã chương trình nhanh như, chẳng hạn, Java hoặc C. Lý do cho điều này là Python- ngôn ngữ được giải thích. Tuy nhiên, có thể gọi biên dịch C-chương trình từ Python. Điều này cho phép bạn sử dụng tốt nhất nhiều ngôn ngữ khác nhau từng bước lập trình và phát triển chương trình. Nếu bạn đã thử nghiệm một ý tưởng bằng cách sử dụng Python và quyết định rằng đây chính xác là những gì bạn muốn triển khai trong hệ thống đã hoàn thiện, thì quá trình chuyển đổi từ nguyên mẫu sang chương trình làm việc này sẽ dễ dàng thực hiện được. Nếu chương trình được xây dựng theo nguyên tắc mô-đun, thì trước tiên bạn có thể đảm bảo rằng những gì bạn cần hoạt động theo mã được viết bằng Python, sau đó, để cải thiện tốc độ thực thi mã, hãy viết lại các phần quan trọng bằng ngôn ngữ C. Thư viện Tăng cường C++ làm cho việc này dễ dàng thực hiện. Các công cụ khác như Cython Và PyPy cho phép bạn tăng hiệu suất chương trình so với bình thường Python.
Nếu bản thân ý tưởng đang được chương trình triển khai là “xấu”, thì tốt hơn nên hiểu điều này bằng cách dành tối thiểu thời gian quý báu để viết mã. Nếu ý tưởng thành công thì bạn luôn có thể cải thiện hiệu suất bằng cách viết lại một phần các phần quan trọng của mã chương trình.
TRONG những năm trước một số lượng lớn các nhà phát triển, bao gồm cả những người có bằng cấp học thuật, đã làm việc để cải thiện hiệu suất của ngôn ngữ và các gói riêng lẻ của nó. Vì vậy, thực tế không phải là bạn sẽ viết mã bằng C, sẽ hoạt động nhanh hơn những gì đã có sẵn trong Python.
Tôi nên sử dụng phiên bản Python nào?
Hiện nay chúng được sử dụng rộng rãi phiên bản khác nhau cái này, cụ thể là 2.x và 3.x. Phiên bản thứ ba vẫn đang được phát triển tích cực, hầu hết các thư viện khác nhau đều được đảm bảo hoạt động trên phiên bản thứ hai, vì vậy tôi sử dụng phiên bản thứ hai, cụ thể là 2.7.8, tôi khuyên bạn nên làm như vậy. Không có thay đổi cơ bản nào trong phiên bản thứ 3 của ngôn ngữ lập trình này, vì vậy mã của bạn, với những thay đổi tối thiểu trong tương lai, nếu cần, có thể được chuyển sang sử dụng với phiên bản thứ ba.
Để cài đặt, hãy truy cập trang web chính thức: www.python.org/downloads/
chọn của bạn hệ điều hành và tải xuống trình cài đặt. Tôi sẽ không nói chi tiết về vấn đề cài đặt; các công cụ tìm kiếm sẽ dễ dàng giúp bạn việc này.
Tôi đang trên Hệ điều hành Macđã cài đặt phiên bản cho chính tôi Python khác với cái đã được cài đặt trên hệ thống và các gói thông qua trình quản lý gói Anaconda(Nhân tiện, cũng có các tùy chọn cài đặt cho các cửa sổ Và Linux).
Dưới các cửa sổ, Họ nói, Pythonđược chơi bằng tambourine, nhưng tôi chưa thử, tôi sẽ không nói dối.
NumPy
![]()
NumPy là gói chính dành cho tính toán khoa học trong Python. NumPy là một phần mở rộng của ngôn ngữ lập trình Python, bổ sung hỗ trợ cho các mảng và ma trận đa chiều lớn, cùng với một thư viện lớn các cấp độ cao hàm toán họcđể làm việc với các mảng này. Người tiền nhiệm NumPy, túi nhựa số, ban đầu được tạo bởi Jim Haganin với sự đóng góp của một số nhà phát triển khác. Năm 2005, Travis Oliphant đã tạo ra NumPy bằng cách kết hợp các tính năng của gói cạnh tranh mảng số V. số, thực hiện những thay đổi sâu rộng.
Để cài đặt trong Terminal Linux LÀM:
cập nhật sudo apt-get sudo apt-get cài đặt python-numpy
sudo apt - nhận bản cập nhật sudo apt - cài đặt python - gọn gàng |
Một mã đơn giản sử dụng NumPy tạo thành vectơ một chiều gồm 12 số từ 1 đến 12 và chuyển đổi nó thành ma trận ba chiều:
from numpy import * a = arange(12) a = a.reshape(3,2,2) print a
từ nhập numpy * a = phạm vi (12 ) một = một. định hình lại (3 , 2 , 2 ) in một |
Kết quả trên máy tính của tôi trông như thế này:

Nói chung, trong Terminal mã là Python Tôi không làm điều đó thường xuyên, ngoại trừ việc tính toán một cái gì đó nhanh chóng, chẳng hạn như trên máy tính. Tôi thích làm việc ở IDE PyCharm. Đây là giao diện của nó khi chạy đoạn mã trên

khoa học viễn tưởng
![]() khoa học viễn tưởng là một thư viện mã nguồn mở dành cho máy tính khoa học. Cho công việc khoa học viễn tưởng yêu cầu phải được cài đặt sẵn NumPy, cung cấp các giao dịch thuận tiện và nhanh chóng với mảng đa chiều. Thư viện khoa học viễn tưởng hoạt động với mảng NumPy và cung cấp nhiều quy trình tính toán thuận tiện và hiệu quả, chẳng hạn như để tích hợp và tối ưu hóa số. NumPy Và khoa học viễn tưởng dễ sử dụng nhưng vẫn đủ mạnh để thực hiện nhiều phép tính khoa học và kỹ thuật.
khoa học viễn tưởng là một thư viện mã nguồn mở dành cho máy tính khoa học. Cho công việc khoa học viễn tưởng yêu cầu phải được cài đặt sẵn NumPy, cung cấp các giao dịch thuận tiện và nhanh chóng với mảng đa chiều. Thư viện khoa học viễn tưởng hoạt động với mảng NumPy và cung cấp nhiều quy trình tính toán thuận tiện và hiệu quả, chẳng hạn như để tích hợp và tối ưu hóa số. NumPy Và khoa học viễn tưởng dễ sử dụng nhưng vẫn đủ mạnh để thực hiện nhiều phép tính khoa học và kỹ thuật.
Để cài đặt thư viện khoa học viễn tưởng V. Linux, thực thi trong terminal:
cập nhật sudo apt-get sudo apt-get cài đặt python-scipy
sudo apt - nhận bản cập nhật sudo apt - cài đặt python - scipy |
Tôi sẽ đưa ra một ví dụ về mã để tìm cực trị của hàm. Kết quả được hiển thị đã sử dụng gói matplotlib, thảo luận dưới đây.
nhập numpy dưới dạng np từ scipy nhập đặc biệt, tối ưu hóa nhập matplotlib.pyplot dưới dạng plt f = lambda x: -special.jv(3, x) sol = tối ưu hóa.minimize(f, 1.0) x = np.linspace(0, 10, 5000) plt.plot(x, Special.jv(3, x), "-", sol.x, -sol.fun, "o") plt.show()
nhập numpy dưới dạng np từ nhập scipy đặc biệt, tối ưu hóa f = lambda x : - đặc biệt . jv(3, x) sol = tối ưu hóa. giảm thiểu(f, 1.0) x = np. linspace(0, 10, 5000) làm ơn. cốt truyện (x , đặc biệt . jv (3 , x ) , "-" , sol . x , - sol . fun , "o" ) làm ơn. trình diễn() |
Kết quả là một biểu đồ có điểm cực trị được đánh dấu:

Để giải trí, hãy thử triển khai điều tương tự trong ngôn ngữ C và so sánh số dòng mã cần thiết để có được kết quả. Bạn đã nhận được bao nhiêu dòng? Một trăm? Năm trăm? Hai ngàn?
gấu trúc
![]() gấu trúc là một gói Python, được thiết kế để cung cấp cấu trúc dữ liệu nhanh, linh hoạt và biểu cảm giúp dễ dàng làm việc với dữ liệu "tương đối" hoặc "được gắn nhãn" một cách đơn giản và trực quan. gấu trúc phấn đấu trở thành khối xây dựng cấp cao chính để tiến hành Python phân tích thực tế các dữ liệu thu được từ thế giới thực. Ngoài ra, gói này được cho là mạnh mẽ và linh hoạt nhất mã nguồn mở một công cụ phân tích/xử lý dữ liệu, có sẵn bằng bất kỳ ngôn ngữ lập trình nào.
gấu trúc là một gói Python, được thiết kế để cung cấp cấu trúc dữ liệu nhanh, linh hoạt và biểu cảm giúp dễ dàng làm việc với dữ liệu "tương đối" hoặc "được gắn nhãn" một cách đơn giản và trực quan. gấu trúc phấn đấu trở thành khối xây dựng cấp cao chính để tiến hành Python phân tích thực tế các dữ liệu thu được từ thế giới thực. Ngoài ra, gói này được cho là mạnh mẽ và linh hoạt nhất mã nguồn mở một công cụ phân tích/xử lý dữ liệu, có sẵn bằng bất kỳ ngôn ngữ lập trình nào.
gấu trúc rất phù hợp để làm việc với nhiều loại dữ liệu khác nhau:
- Dữ liệu dạng bảng với các cột thuộc các loại khác nhau, như trong bảng SQL hoặc Excel.
- Dữ liệu chuỗi thời gian có thứ tự và không có thứ tự (không nhất thiết phải có tần số không đổi).
- Dữ liệu ma trận tùy ý (đồng nhất hoặc không đồng nhất) với các hàng và cột được gắn nhãn.
- Bất kỳ dạng tập dữ liệu quan sát hoặc thống kê nào khác. Dữ liệu thực sự không yêu cầu nhãn để được đặt trong cấu trúc dữ liệu gấu trúc.
Để cài đặt gói gấu trúc thực thi trong Terminal Linux:
cập nhật sudo apt-get sudo apt-get cài đặt python-pandas
sudo apt - nhận bản cập nhật sudo apt - cài đặt python - gấu trúc |
Một mã đơn giản có thể chuyển đổi mảng một chiều vào cấu trúc dữ liệu gấu trúc:
nhập gấu trúc dưới dạng pd nhập numpy dưới dạng np value = np.array() ser = pd.Series(values) print ser
nhập gấu trúc dưới dạng pd nhập numpy dưới dạng np giá trị = np. mảng ([ 2.0 , 1.0 , 5.0 , 0.97 , 3.0 , 10.0 , 0.0599 , 8.0 ] ) ser = pd. Chuỗi (giá trị) máy in |
Kết quả sẽ là:

matplotlib
![]()
matplotlib là một thư viện công trình đồ họa cho ngôn ngữ lập trình Python và phần mở rộng của nó cho toán học tính toán NumPy. Thư viện cung cấp API hướng đối tượng để nhúng biểu đồ vào các ứng dụng bằng công cụ GUI mục đích chung, chẳng hạn như WxPython, Qt, hoặc GTK+. Ngoài ra còn có thủ tục pylab-giao diện gợi nhớ MATLAB. khoa học viễn tưởng công dụng matplotlib.
Để cài đặt thư viện matpoltlib V. Linux chạy các lệnh sau:
cập nhật sudo apt-get sudo apt-get cài đặt python-matplotlib
sudo apt - nhận bản cập nhật sudo apt - cài đặt python - matplotlib |
Mã ví dụ sử dụng thư viện matplotlibđể tạo biểu đồ:
import numpy as np import matplotlib.mlab as mlab import matplotlib.pyplot as plt # dữ liệu ví dụ mu = 100 # giá trị trung bình của phân phối sigma = 15 # độ lệch chuẩn của phân phối x = mu + sigma * np.random.randn(10000) num_bins = 50 # biểu đồ của dữ liệu n, bins, Patch = plt.hist(x, num_bins, Normed=1, facecolor="green", alpha=0.5) # thêm một dòng "phù hợp nhất" y = mlab.normpdf(bins , mu, sigma) plt.plot(bins, y, "r--") plt.xlabel("Thông minh") plt.ylabel("Xác suất") plt.title(r"Biểu đồ IQ: $\mu=100 $, $\sigma=15$") # Tinh chỉnh khoảng cách để tránh bị cắt ylabel plt.subplots_ adjustment(left=0.15) plt.show()
nhập numpy dưới dạng np nhập matplotlib. mlab như mlab nhập matplotlib. pyplot như plt #dữ liệu mẫu mu = 100 # trung bình phân phối sigma = 15 # độ lệch chuẩn của phân phối x = mu + sigma * np . ngẫu nhiên. ngẫu nhiên (10000) số_thùng = 50 # biểu đồ dữ liệu n, thùng, bản vá = plt. hist(x, num_bins, định mức = 1, facecolor = "xanh", alpha = 0,5) # thêm một dòng "phù hợp nhất" y = mlab. Normpdf (bins, mu, sigma) làm ơn. cốt truyện(bins, y, "r--") làm ơn. xlabel("Thông minh") làm ơn. ylabel("Xác suất") làm ơn. tiêu đề (r "Biểu đồ IQ: $\mu=100$, $\sigma=15$") # Tinh chỉnh khoảng cách để tránh cắt nhãn y làm ơn. subplots_just (trái = 0,15 ) làm ơn. trình diễn() |
Kết quả của việc đó là:
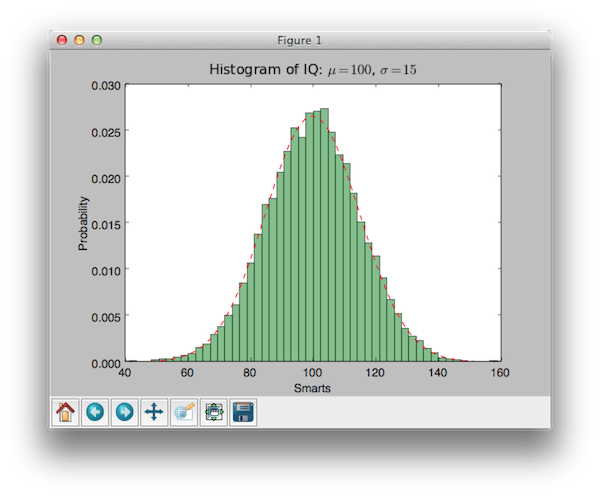
Tôi nghĩ nó rất dễ thương!
là một shell lệnh cho tính toán tương tác bằng một số ngôn ngữ lập trình, ban đầu được phát triển cho ngôn ngữ lập trình Trăn. cho phép bạn mở rộng khả năng trình bày, thêm cú pháp shell, tự động hoàn thành và lịch sử lệnh mở rộng. hiện cung cấp các tính năng sau:
- Các shell tương tác mạnh mẽ (loại thiết bị đầu cuối và dựa trên Qt).
- Trình chỉnh sửa dựa trên trình duyệt có hỗ trợ mã, văn bản, biểu thức toán học, biểu đồ nhúng và các khả năng trình bày khác.
- Hỗ trợ trực quan tương tác dữ liệu và sử dụng các công cụ GUI.
- Trình thông dịch tích hợp, linh hoạt để làm việc trong các dự án của riêng bạn.
- Các công cụ tính toán song song hiệu suất cao, dễ sử dụng.
Trang web IPython:
Để cài đặt IPython trên Linux, hãy chạy các lệnh sau trong terminal:
cập nhật sudo apt-get sudo pip cài đặt ipython
Tôi sẽ đưa ra một ví dụ về mã xây dựng hồi quy tuyến tínhđối với một số bộ dữ liệu có sẵn trong gói scikit-tìm hiểu:
import matplotlib.pyplot as plt import numpy as np from sklearn import bộ dữ liệu, Linear_model # Tải tập dữ liệu về bệnh tiểu đường disease =datadatas.load_diabetes() # Chỉ sử dụng một tính năng disease_X = disease.data[:, np.newaxis] disease_X_temp = disease_X[: , :, 2] # Chia dữ liệu thành các tập huấn luyện/kiểm tra bệnh tiểu đường_X_train = bệnh tiểu đường_X_temp[:-20] bệnh tiểu đường_X_test = bệnh tiểu đường_X_temp[-20:] # Chia mục tiêu thành các tập huấn luyện/kiểm tra bệnh tiểu đường_y_train = bệnh tiểu đường.target[:-20] bệnh tiểu đường_y_test = disease.target[-20:] # Tạo đối tượng hồi quy tuyến tính regr = Linear_model.LinearRegression() # Huấn luyện mô hình bằng các tập huấn luyện regr.fit(diabetes_X_train, disease_y_train) # Các hệ số print("Hệ số: \n", regr .coef_) # In lỗi bình phương trung bình("Tổng bình phương dư: %.2f" % np.mean((regr.predict(diabetes_X_test) - disease_y_test) ** 2)) # Điểm phương sai được giải thích: 1 là bản in dự đoán hoàn hảo ("Điểm phương sai: %.2f" % regr.score(diabetes_X_test, disease_y_test)) # Kết quả đầu ra của biểu đồ plt.scatter(diabetes_X_test, disease_y_test, color="black") plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), màu ="blue", linewidth=3) plt.xticks()) plt.yticks()) plt.show()
nhập matplotlib. pyplot như plt nhập numpy dưới dạng np từ bộ dữ liệu nhập sklearn, tuyến tính_model # Tải dữ liệu bệnh tiểu đường bệnh tiểu đường=bộ dữ liệu. Load_diabetes() # Chỉ sử dụng một tính năng bệnh tiểu đường_X = bệnh tiểu đường . dữ liệu [: , np . trục mới] |