Connecting MPI in Visual Studio. Point-to-point operations. Custom Global Operations
Parallelization in C language
Example 3b. Parallelization in Fortran
Example 4a. Determining the characteristics of the system timer in C language
Example 4b. Defining system timer characteristics in Fortran
1.4. Sending and receiving messages between separate processes
1.4.1. Point-to-point operations
1.4.2. Sending and receiving messages with blocking
Example 5a. Exchange of messages between two processes in C language
Example 5b. Exchange of messages between two processes in Fortran
Example 6a. Message exchange between even and odd processes in C
Example 6b. Message exchange between even and odd processes in Fortran
Example 7a. Forwarding to a non-existent process in C
Example 7b. Forwarding to a non-existent process in Fortran
Example 8a. Buffered data sending in C language
Example 8b. Buffered data sending in Fortran language
Example 9a. Obtaining information about message attributes in C language
Example 9b. Obtaining information about message attributes in Fortran
Example 10a. Definition of latency and bandwidth in C language
Example 10b. Defining latency and throughput in Fortran
1.4.3. Sending and receiving messages without blocking
Example 11a. Exchange by ring topology using non-blocking operations in C language
Example 11b. Exchange over a ring topology using non-blocking operations in Fortran
Example 12a. Communication scheme "master - workers" in C language
Example 12b. Communication diagram "master - workers" in Fortran language
Example 13a. Matrix transposition in C language
Example 13b. Transposing a matrix in Fortran
1.4.4. Pending interaction requests
Example 14a. Scheme of an iterative method with exchange along a ring topology using deferred queries in the C language
Example 14b. Scheme of an iterative method with exchange over a ring topology using deferred queries in Fortran
1.4.5. Deadlock situations
Example 15a. Exchange over a ring topology using the MPI_Sendrecv procedure in C language
Example 15b. Exchange over a ring topology using the MPI_SENDRECV procedure in Fortran
1.5. Collective process interactions
1.5.1. General provisions
1.5.2. Barrier
Example 16a. Modeling barrier synchronization in C language
Example 16b. Modeling barrier synchronization in Fortran
1.5.3. Collective data transfer operations
1.5.4. Global Operations
Example 17a. Modeling global summation using a doubling scheme and the collective operation MPI_Reduce in C language
Example 17b. Modeling global summation using a doubling scheme and the collective operation MPI_Reduce in Fortran
1.5.5. Custom Global Operations
Example 18a. Custom global function in C language
Example 18b. Custom global function in Fortran
1.6. Groups and communicators
1.6.1. General provisions
1.6.2. Operations with process groups
Example 19a. Working with groups in C language
Example 19b. Working with groups in Fortran
1.6.3. Operations with communicators
Example 20a. Breaking down a communicator in C
Example 20b. Partitioning a communicator in Fortran
Example 21a. Renumbering processes in C language
Example 21b. Renumbering processes in Fortran
1.6.4. Intercommunicators
Example 22a. Master-worker scheme using an intercommunicator in C language
Example 22b. Master-worker circuit using an intercommunicator in Fortran
1.6.5. Attributes
1.7. Virtual topologies
1.7.1. General provisions
1.7.2. Cartesian topology
1.7.3. Graph topology
Example 23a. Master-worker diagram using graph topology in C language
Example 23b. Master-worker scheme using graph topology in Fortran
1.8. Sending different types of data
1.8.1. General provisions
1.8.2. Derived data types
Example 24a. Rearranging matrix columns into reverse order in C language
Example 24b. Rearranging matrix columns in reverse order in Fortran
1.8.3. Data Packing
Example 25a. Sending packed data in C language
Example 25b. Sending Packed Data in Fortran
1.9. info object
1.9.1. General provisions
1.9.2. Working with the info object
1.10. Dynamic process control
1.10.1. General provisions
1.10.2.Creation of processes
master.c
slave.c
Example 26a. Master-worker scheme using process spawning in C language
master.f
slave.f
Example 26b. Master-worker scheme using process spawning in Fortran
1.10.3. Client-server communication
server.c
client.c
Example 27a. Data exchange between server and client via public name in C language
server.f
client.f
Example 27b. Exchange of data between server and client using public name in Fortran language
1.10.4. Removing a process association
1.10.5. Socket Communication
1.11. One-way communications
1.11.1. General provisions
1.11.2. Working with a window
1.11.3. Data transfer
1.11.4. Synchronization
Example 28a
Example 28b
Example 29a. Exchange over a ring topology using one-way communications in C
Example 29b. Exchange over a ring topology using one-way communications in Fortran
Example 30a. Exchange over a ring topology using one-way communications in C
Example 30b. Exchange over a ring topology using one-way communications in Fortran
1.12. External interfaces
1.12.1. General queries
1.12.2. Information from status
1.12.3. Threads
1.13. Parallel I/O
1.13.1. Definitions
1.13.2. Working with files
1.13.3. Data access
Example 31a. Buffered reading from a file in C language
Example 31b. Buffered reading from a file in Fortran
Example 32a. Collective reading from a file in C language
Example 32b. Collective reading from a file in Fortran
1.14. Error processing
1.14.1. General provisions
1.14.2. Error handlers associated with communicators
1.14.3. Window-related error handlers
1.14.4. File-related error handlers
1.14.5. Additional procedures
1.14.6. Error codes and classes
1.14.7. Calling Error Handlers
Example 33a. Error handling in C language
Example 33b. Error Handling in Fortran
Chapter 2 OpenMP Parallel Programming Technology
2.1. Introduction
2.2. Basic Concepts
2.2.1. Compiling a program
Example 34a. Conditional compilation in C
Example 34b
Example 34c. Conditional compilation in Fortran
2.2.2. Parallel program model
2.2.3. Directives and procedures
2.2.4. Program Execution
2.2.5. Timing
Example 35a. Working with system timers in C
Example 35b. Working with system timers in Fortran
2.3. Parallel and serial areas
2.3.1. parallel directive
Example 36a. Parallel region in C language
Example 36b. Parallel region in Fortran
Example 37a. The reduction option in C language
Example 37b. The reduction option in Fortran
2.3.2. Shorthand notation
2.3.3. Environment Variables and Helper Procedures
Example 38a. Procedure omp_set_num_threads and option num_threads in C language
Example 38b. Procedure omp_set_num_threads and option num_threads in Fortran language
Example 39a. Procedures omp_set_dynamic and omp_get_dynamic in C language
Example 39b. Procedures omp_set_dynamic and omp_get_dynamic in Fortran
Example 40a. Nested Parallel Regions in C
Example 40b. Nested Parallel Regions in Fortran
Example 41a. Omp_in_parallel function in C language
Example 41b. Function omp_in_parallel in Fortran language
2.3.4. single directive
Example 42a. Single directive and nowait option in C language
Example 42b. Single directive and nowait option in Fortran
Example 43a. Copyprivate option in C language
Example 43b. copyprivate option in Fortran
2.3.5. master directive
Example 44a. Master directive in C language
Example 44b. master directive in Fortran
2.4. Data model
Example 45a. Private option in C language
Example 45b. The private option in Fortran
Example 46a. Shared option in C language
Example 46b. The shared option in Fortran
Example 47a. firstprivate option in C language
Example 47b. firstprivate option in Fortran
Example 48a. threadprivate directive in C language
Example 48b. threadprivate directive in Fortran
Example 49a. Copyin option in C language
Example 49b. copyin option in Fortran
2.5. Work distribution
2.5.1. Low-level parallelization
Example 50a. Procedures omp_get_num_threads and omp_get_thread_num in C language
Example 50b. Procedures omp_get_num_threads and omp_get_thread_num in Fortran
2.5.2. Parallel loops
Example 51a. for directive in C language
Example 51b. The do directive in Fortran
Example 52a. Schedule option in C language
Example 52b. schedule option in Fortran
Example 53a. Schedule option in C language
It so happened that I had to come into close contact with the study parallel computing and in particular MPI. Perhaps this direction is very promising today, so I would like to show the hubbrowsers the basics of this process.
Basic principles and example
The calculation of exponential (e) will be used as an example. One of the options for finding it is the Taylor series:e^x=∑((x^n)/n!), where the summation occurs from n=0 to infinity.
This formula can be easily parallelized, since the required number is the sum of individual terms and thanks to this, each individual processor can begin to calculate the individual terms.
The number of terms that will be calculated in each individual processor depends both on the length of the interval n and on the available number of processors k that can participate in the calculation process. So, for example, if the length of the interval is n=4, and five processors (k=5) are involved in the calculations, then the first to fourth processors will receive one term each, and the fifth will not be used. If n=10 and k=5, each processor will get two terms for calculation.
Initially, the first processor, using the MPI_Bcast broadcast function, sends to the others the value of the user-specified variable n. IN general case The MPI_Bcast function has the following format:
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root, MPI_Comm comm), where buffer is the address of the buffer with the element, count is the number of elements, datatype is the corresponding data type in MPI, root is the rank of the main processor that is handling forwarding, and comm is the name of the communicator.
In my case, the main processor, as already mentioned, will be the first processor with rank 0.
After the number n is successfully sent, each processor will begin calculating its terms. To do this, at each step of the cycle, a number equal to the number of processors participating in the calculations will be added to the number i, which is initially equal to the rank of the processor. If the number is in progress next steps the number i exceeds the user-specified number n, executing a loop for of this processor will stop.
During the execution of the cycle, the terms will be added to a separate variable and, after its completion, the resulting amount will be sent to the main processor. To do this, the MPI_Reduce reduction operation function will be used. IN general view it looks like this:
int MPI_Reduce(void *buf, void *result, int count, MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm)
It concatenates the input buffer elements of each process in the group using the op operation and returns the combined value to the output buffer of process number root. The result of such an operation will be a single value, which is why the casting function got its name.
After executing the program on all processors, the first processor will receive total amount terms, which will be the exponent value we need.
It should be noted that both in parallel and sequential methods exponent calculations, to find the factorial is used recursive function. When making a decision on how to parallelize the task being performed, I considered the option of finding the factorial also on different processors, but in the end this option was irrational for me.
The primary task is still finding the value of the exponent, and if processors start calculating each factorial of each term separately, this can lead to the exact opposite effect, namely a significant loss in performance and calculation speed.
This is explained by the fact that in this case it will begin to huge pressure on the communication environment, which is already often a weak link in parallel computing systems. If the factorial is calculated privately on each processor, the load on the communication lines will be minimal. This case can be called good example that the task of parallelization must also sometimes have its limits.
Code Execution Algorithm
1. The value of the number n is transferred from the visual shell to the program, which is then sent to all processors using the broadcast function.2. When the first main processor is initialized, a timer starts.
3. Each processor executes a loop, where the increment value is the number of processors in the system. At each iteration of the loop, a term is calculated and the sum of such terms is stored in the drobSum variable.
4. After the loop completes, each processor adds its drobSum value to the Result variable using the MPI_Reduce reduction function.
5. After completing calculations on all processors, the first main processor stops the timer and sends the resulting value of the Result variable to the output stream.
6. The time value measured by our timer in milliseconds is also sent to the output stream.
Code listing
The program is written in C++, we will assume that the arguments for execution are passed from outer shell. The code looks like this:#include "mpi.h"
#include
#include
using namespace std;double Fact(int n)
{
if (n==0)
return 1;
else
return n*Fact(n-1);
}int main(int argc, char *argv)
{
SetConsoleOutputCP(1251);
int n;
int myid;
int numprocs;
int i;
int rc;
long double drob,drobSum=0,Result, sum;
double startwtime = 0.0;
double endwtime;N = atoi(argv);
if (rc= MPI_Init(&argc, &argv))
{
cout<< "Startup error, execution stopped" << endl;
MPI_Abort(MPI_COMM_WORLD, rc);
}MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);if (myid == 0)
{Startwtime = MPI_Wtime();
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);for (i = myid; i<= n; i += numprocs)
{
drob = 1/Fact(i);
drobSum += drob;
}MPI_Reduce(&drobSum, &Result, 1, MPI_LONG_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
cout.precision(20);
if (myid == 0)
{
cout<< Result << endl;
endwtime = MPI_Wtime();
cout<< (endwtime-startwtime)*1000 << endl;
}MPI_Finalize();
return 0;
}
* This source code was highlighted with Source Code Highlighter.
Conclusion
Thus, we received a simple program for calculating the exponent using several processors at once. Probably, the bottleneck is storing the result itself, because with an increase in the number of digits, storing a value using standard types will not be trivial and this place requires elaboration. Perhaps, a fairly rational solution is to write the result to a file, although, in view of the purely educational function of this example, there is no need to focus much attention on this.This note shows how to install MPI, connect it to Visual Studio, and then use it with the specified parameters (number of compute nodes). This article uses Visual Studio 2015, because... This is the one my students had problems with (this note was written by students for students), but the instructions will probably work for other versions as well.
Step 1:
You must install the HPC Pack 2008 SDK SP2 (in your case there may already be a different version), available on the official Microsoft website. The bit capacity of the package and the system must match.
Step 2:
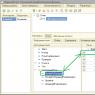
You need to configure the paths; to do this, go to the Debug - Properties tab:
“C:\Program Files\Microsoft HPC Pack 2008 SDK\Include”
In the Library Directories field:
“C:\Program Files\Microsoft HPC Pack 2008 SDK\Lib\amd64”
In the library field, if there is a 32-bit version, you need to enter i386 instead of amd64.


Msmpi.lib
:
Step 3:
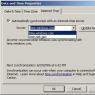
To configure the launch, you need to go to the Debugging tab and in the Command field specify:
“C:\Program Files\Microsoft HPC Pack 2008 SDK\Bin\mpiexec.exe”
In the Command Arguments field, specify, for example,
N 4 $(TargetPath)
The number 4 indicates the number of processes. 
To run the program you need to connect the library
The path to the project must not contain Cyrillic. If errors occur, you can use Microsoft MPI, available on the Microsoft website.
To do this, after installation, just enter the path in the Command field of the Debugging tab:
“C:\Program Files\Microsoft MPI\Bin\mpiexec.exe”
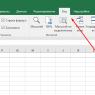
Also, before running the program, do not forget to indicate its bit depth:
Example of running a program with MPI:
#include
Running the program on 2 nodes: 
Annotation: The lecture is devoted to the consideration of MPI technology as a standard parallel programming for systems with distributed memory. The main modes of data transmission are considered. Concepts such as process groups and communicators are introduced. Covers basic data types, point-to-point operations, collective operations, synchronization operations, and time measurements.
Purpose of the lecture: The lecture is aimed at studying the general methodology for developing parallel algorithms.
Video recording of the lecture - (volume - 134 MB).
5.1. MPI: basic concepts and definitions
Let's consider a number of concepts and definitions that are fundamental to the MPI standard.
5.1.1. The concept of a parallel program
Under parallel program within the framework of MPI, we understand a set of simultaneously executed processes. Processes can be executed on different processors, but several processes can also be located on the same processor (in this case, they are executed in time-sharing mode). In the extreme case, a single processor can be used to execute a parallel program - as a rule, this method is used to initially check the correctness of the parallel program.
Each process of a parallel program is spawned from a copy of the same program code ( SPMP model). This program code, presented in the form of an executable program, must be available at the time the parallel program is launched on all processors used. The source code for the executable program is developed in the algorithmic languages C or Fortran using one or another implementation of the MPI library.
The number of processes and the number of processors used are determined at the time the parallel program is launched using the MPI program execution environment and cannot change during calculations (the MPI-2 standard provides for the possibility of dynamically changing the number of processes). All program processes are sequentially numbered from 0 to p-1, Where p is the total number of processes. The process number is called rank process.
5.1.2. Data transfer operations
MPI is based on message passing operations. Among the functions provided as part of MPI, there are different doubles (point-to-point) operations between two processes and collective (collective) communication actions for the simultaneous interaction of several processes.
To perform paired operations, different transmission modes can be used, including synchronous, blocking, etc. - a full consideration of possible transmission modes will be performed in subsection 5.3.
As noted earlier, the MPI standard provides for the need to implement most of the basic collective data transfer operations - see subsections 5.2 and 5.4.
5.1.3. Concept of communicators
Processes of a parallel program are combined into groups. Under communicator MPI refers to a specially created service object that combines a group of processes and a number of additional parameters ( context) used when performing data transfer operations.
Typically, paired data transfer operations are performed for processes belonging to the same communicator. Collective operations are applied simultaneously to all communicator processes. As a result, specifying the communicator to use is mandatory for data transfer operations in MPI.
During calculations, new process groups and communicators can be created and existing groups of processes and communicators can be deleted. The same process can belong to different groups and communicators. All processes present in the parallel program are included in the communicator created by default with the identifier MPI_COMM_WORLD.
If it is necessary to transfer data between processes from different groups, it is necessary to create a global communicator ( intercommunicator).
A detailed discussion of MPI's capabilities for working with groups and communicators will be performed in subsection 5.6.
5.1.4. Data types
When performing message passing operations, you must specify the data to be sent or received in MPI functions. type sent data. MPI contains a large set basic types data that largely coincides with data types in the algorithmic languages C and Fortran. In addition, MPI has the ability to create new derived types data for a more accurate and concise description of the contents of forwarded messages.
A detailed discussion of MPI's capabilities for working with derived data types will be performed in subsection 5.5.
5.1.5. Virtual topologies
As noted earlier, paired data transfer operations can be performed between any processes of the same communicator, and all processes of the communicator take part in a collective operation. In this regard, the logical topology of communication lines between processes has the structure of a complete graph (regardless of the presence of real physical communication channels between processors).
At the same time (and this was already noted in Section 3), for the presentation and subsequent analysis of a number of parallel algorithms, it is advisable to have a logical representation of the existing communication network in the form of certain topologies.
MPI has the ability to represent multiple processes in the form gratings arbitrary dimension (see subsection 5.7). In this case, the boundary processes of the lattices can be declared neighboring and, thereby, based on the lattices, structures of the type torus.
In addition, MPI has tools for generating logical (virtual) topologies of any required type. A detailed discussion of MPI's capabilities for working with topologies will be performed in subsection 5.7.
And finally, one last set of notes before starting to look at MPI:
- Descriptions of functions and all examples of programs provided will be presented in the algorithmic language C; features of using MPI for the algorithmic language Fortran will be given in section 5.8.1,
- A brief description of the available implementations of MPI libraries and a general description of the execution environment of MPI programs will be discussed in section 5.8.2.
- The main presentation of MPI capabilities will be focused on the version 1.2 standard ( MPI-1); additional properties of the version 2.0 standard will be presented in clause 5.8.3.
When starting to study MPI, it can be noted that, on the one hand, MPI is quite complex - the MPI standard provides for the presence of more than 125 functions. On the other hand, the structure of MPI is carefully thought out - the development of parallel programs can begin after considering only 6 MPI functions. All additional features of MPI can be mastered as the complexity of the developed algorithms and programs increases. It is in this style – from simple to complex – that all educational material on MPI will be presented further.
5.2. Introduction to parallel program development using MPI
5.2.1. MPI Basics
Let us present the minimum required set of MPI functions, sufficient for the development of fairly simple parallel programs.
5.2.1.1 Initialization and termination of MPI programs
First function called MPI should be a function:
int MPI_Init (int *agrc, char ***argv);
to initialize the MPI program execution environment. The function parameters are the number of arguments on the command line and the text of the command line itself.
Last function called MPI must be a function:
int MPI_Finalize(void);
As a result, it can be noted that the structure of a parallel program developed using MPI should have the following form:
#include "mpi.h" int main (int argc, char *argv) (<программный код без использования MPI функций>MPI_Init(&agrc, &argv);<программный код с использованием MPI функций>MPI_Finalize();<программный код без использования MPI функций>return 0; )
It should be noted:
- File mpi.h contains definitions of named constants, function prototypes and data types of the MPI library,
- Functions MPI_Init And MPI_Finalize are mandatory and must be executed (and only once) by each process of the parallel program,
- Before the call MPI_Init function can be used MPI_Initialized to determine if a call has previously been made MPI_Init.
The examples of functions discussed above give an idea of the syntax for naming functions in MPI. The function name is preceded by the MPI prefix, followed by one or more words of the name, the first word of the function name begins with a capital character, and the words are separated by an underscore. The names of MPI functions, as a rule, explain the purpose of the actions performed by the function.
It should be noted:
- Communicator MPI_COMM_WORLD, as noted earlier, is created by default and represents all processes of the parallel program being executed,
- Rank obtained using the function MPI_Comm_rank, is the rank of the process that made the call to this function, i.e. variable ProcRank will take different values in different processes.