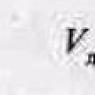Multiple regression equation in excel. Analysis of the analysis results. Linear Regression in MS Excel
28 Oct
Good afternoon, dear blog readers! Today we will talk about nonlinear regressions. The solution to linear regressions can be viewed at LINK.
This method used mainly in economic modeling and forecasting. Its goal is to observe and identify dependencies between two indicators.
The main types of nonlinear regressions are:
- polynomial (quadratic, cubic);
- hyperbolic;
- sedate;
- demonstrative;
- logarithmic
Can also be used various combinations. For example, for time series analytics in banking sector, insurance, and demographic studies use the Gompzer curve, which is a type of logarithmic regression.
In forecasting using nonlinear regressions, the main thing is to find out the correlation coefficient, which will show us whether there is a close relationship between two parameters or not. As a rule, if the correlation coefficient is close to 1, then there is a connection, and the forecast will be quite accurate. Another important element of nonlinear regressions is the average relative error ( A ), if it is in the interval<8…10%, значит модель достаточно точна.
This is where we will probably finish the theoretical block and move on to practical calculations.
We have a table of car sales over a period of 15 years (let's denote it X), the number of measurement steps will be the argument n, we also have revenue for these periods (let's denote it Y), we need to predict what the revenue will be in the future. Let's build the following table:
To study, we will need to solve the equation (dependence of Y on X): y=ax 2 +bx+c+e. This is a pairwise quadratic regression. In this case, we apply the least squares method to find out the unknown arguments - a, b, c. It will lead to a system of algebraic equations of the form:

To solve this system, we will use, for example, Cramer’s method. We see that the sums included in the system are coefficients of the unknowns. To calculate them, we will add several columns to the table (D,E,F,G,H) and sign according to the meaning of the calculations - in column D we will square x, in E we will cube it, in F we will multiply the exponents x and y, in H we square x and multiply with y.

You will get a table of the form filled with the things needed to solve the equation.


Let's form a matrix A system consisting of coefficients for unknowns on the left sides of the equations. Let's place it in cell A22 and call it " A=". We follow the system of equations that we chose to solve the regression.

That is, in cell B21 we must place the sum of the column where we raised the X indicator to the fourth power - F17. Let's just refer to the cell - “=F17”. Next, we need the sum of the column where X was cubed - E17, then we go strictly according to the system. Thus, we will need to fill out the entire matrix.
In accordance with Cramer's algorithm, we will type a matrix A1, similar to A, in which, instead of the elements of the first column, the elements of the right sides of the system equations should be placed. That is, the sum of the X column squared multiplied by Y, the sum of the XY column and the sum of the Y column.

We will also need two more matrices - let's call them A2 and A3 in which the second and third columns will consist of the coefficients of the right-hand sides of the equations. The picture will be like this.

Following the chosen algorithm, we will need to calculate the values of the determinants (determinants, D) of the resulting matrices. Let's use the MOPRED formula. We will place the results in cells J21:K24.

We will calculate the coefficients of the equation according to Cramer in the cells opposite the corresponding determinants using the formula: a(in cell M22) - “=K22/K21”; b(in cell M23) - “=K23/K21”; With(in cell M24) - “=K24/K21”.
We get our desired equation of paired quadratic regression:
y=-0.074x 2 +2.151x+6.523
Let us evaluate the closeness of the linear relationship using the correlation index.

To calculate, add an additional column J to the table (let's call it y*). The calculation will be as follows (according to the regression equation we obtained) - “=$m$22*B2*B2+$M$23*B2+$M$24.” Let's place it in cell J2. All that remains is to drag the autofill marker down to cell J16.

To calculate the sums (Y-Y average) 2, add columns K and L to the table with the corresponding formulas. We calculate the average for the Y column using the AVERAGE function.

In cell K25 we will place the formula for calculating the correlation index - “=ROOT(1-(K17/L17))”.

We see that the value of 0.959 is very close to 1, which means there is a close nonlinear relationship between sales and years.
It remains to evaluate the quality of fit of the resulting quadratic regression equation (determination index). It is calculated using the formula for the squared correlation index. That is, the formula in cell K26 will be very simple - “=K25*K25”.

The coefficient of 0.920 is close to 1, which indicates a high quality of fit.
The last step is to calculate the relative error. Let's add a column and enter the formula there: “=ABS((C2-J2)/C2), ABS - module, absolute value. Draw the marker down and in cell M18 display the average value (AVERAGE), assign the percentage format to the cells. The result obtained - 7.79% is within the acceptable error values<8…10%. Значит вычисления достаточно точны.
If the need arises, we can build a graph using the obtained values.
An example file is attached - LINK!
Categories:// from 10/28/2017Regression analysis is one of the most popular methods of statistical research. It can be used to establish the degree of influence of independent variables on the dependent variable. Microsoft Excel has tools designed to perform this type of analysis. Let's look at what they are and how to use them.
Connecting the analysis package
But, in order to use the function that allows you to perform regression analysis, you first need to activate the Analysis Package. Only then the tools necessary for this procedure will appear on the Excel ribbon.
- Move to the “File” tab.
- Go to the “Settings” section.
- The Excel Options window opens. Go to the “Add-ons” subsection.
- At the very bottom of the window that opens, move the switch in the “Management” block to the “Excel Add-ins” position, if it is in a different position. Click on the “Go” button.
- A window of available Excel add-ins opens. Check the box next to “Analysis Package”. Click on the “OK” button.

Now, when we go to the “Data” tab, on the ribbon in the “Analysis” tool block we will see a new button - “Data Analysis”.

Types of Regression Analysis
There are several types of regressions:
- parabolic;
- sedate;
- logarithmic;
- exponential;
- demonstrative;
- hyperbolic;
- linear regression.
About performing the last type regression analysis in Excel we will talk in more detail later.
Linear Regression in Excel
Below, as an example, is a table showing the average daily air temperature outside and the number of store customers for the corresponding working day. Let's find out using regression analysis exactly how weather conditions in the form of air temperature can affect the attendance of a retail establishment.
The general linear regression equation is as follows: Y = a0 + a1x1 +…+ akhk. In this formula, Y means the variable on which we are trying to study the influence of factors. In our case, this is the number of buyers. The value of x is the various factors that influence the variable. The parameters a are the regression coefficients. That is, they are the ones who determine the significance of a particular factor. The index k denotes the total number of these same factors.


Analysis results analysis
The results of the regression analysis are displayed in the form of a table in the place specified in the settings.

One of the main indicators is R-squared. It indicates the quality of the model. In our case, this coefficient is 0.705 or about 70.5%. This is an acceptable level of quality. Dependency less than 0.5 is bad.
Another important indicator is located in the cell at the intersection of the “Y-intersection” row and the “Coefficients” column. This indicates what value Y will have, and in our case, this is the number of buyers, with all other factors equal to zero. In this table, this value is 58.04.
The value at the intersection of the columns “Variable X1” and “Coefficients” shows the level of dependence of Y on X. In our case, this is the level of dependence of the number of store customers on temperature. A coefficient of 1.31 is considered a fairly high influence indicator.
As you can see, using Microsoft Excel it is quite easy to create a regression analysis table. But only a trained person can work with the output data and understand its essence.
We are glad that we were able to help you solve the problem.
Ask your question in the comments, describing the essence of the problem in detail. Our specialists will try to answer as quickly as possible.
Did this article help you?
Method linear regression allows us to describe a straight line that best fits a series of ordered pairs (x, y). The equation for a straight line, known as the linear equation, is given below:
ŷ - expected value of y at set value X,
x - independent variable,
a - segment on the y-axis for a straight line,
b is the slope of the straight line.
The figure below illustrates this concept graphically:
The figure above shows the line described by the equation ŷ =2+0.5x. The y-intercept is the point at which the line intersects the y-axis; in our case, a = 2. The slope of the line, b, the ratio of the rise of the line to the length of the line, has a value of 0.5. A positive slope means the line rises from left to right. If b = 0, the line is horizontal, which means there is no relationship between the dependent and independent variables. In other words, changing the value of x does not affect the value of y.
ŷ and y are often confused. The graph shows 6 ordered pairs of points and a line, according to the given equation
This figure shows the point corresponding to the ordered pair x = 2 and y = 4. Note that the expected value of y according to the line at X= 2 is ŷ. We can confirm this with the following equation:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
The y value represents the actual point and the ŷ value is the expected value of y using a linear equation for a given value of x.
The next step is to determine the linear equation that best matches the set of ordered pairs, we talked about this in the previous article, where we determined the form of the equation using the least squares method.
Using Excel to Define Linear Regression
In order to use the regression analysis tool built into Excel, you must activate the add-in Analysis package. You can find it by clicking on the tab File -> Options(2007+), in the dialog box that appears OptionsExcel go to the tab Add-ons. In field Control choose Add-onsExcel and click Go. In the window that appears, check the box next to Analysis package, click OK.
In the tab Data in Group Analysis a new button will appear Data analysis.
To demonstrate how the add-in works, let's use data from a previous article, where a guy and a girl share a table in the bathroom. Enter the data from our bathtub example in Columns A and B of the blank sheet.
Go to the tab Data, in Group Analysis click Data analysis. In the window that appears Data analysis select Regression as shown in the figure and click OK.
Set the necessary regression parameters in the window Regression, as it shown on the picture:
Click OK. The figure below shows the results obtained:
These results are consistent with those we obtained by doing our own calculations in the previous article.
Regression analysis is a statistical research method that allows you to show the dependence of a particular parameter on one or more independent variables. In the pre-computer era, its use was quite difficult, especially when it came to large volumes of data. Today, having learned how to build regression in Excel, you can solve complex statistical problems in just a couple of minutes. Below are specific examples from the field of economics.
Types of Regression
This concept itself was introduced into mathematics by Francis Galton in 1886. Regression happens:
- linear;
- parabolic;
- sedate;
- exponential;
- hyperbolic;
- demonstrative;
- logarithmic.
Example 1
Let's consider the problem of determining the dependence of the number of team members who quit on the average salary at 6 industrial enterprises.
Task. At six enterprises, the average monthly salary and the number of employees who quit voluntarily were analyzed. In tabular form we have:
For the task of determining the dependence of the number of quitting workers on the average salary at 6 enterprises, the regression model has the form of the equation Y = a0 + a1×1 +…+аkxk, where хi are the influencing variables, ai are the regression coefficients, and k is the number of factors.
For this task, Y is the indicator of employees who quit, and the influencing factor is salary, which we denote by X.
Using the capabilities of the Excel spreadsheet processor
Regression analysis in Excel must be preceded by applying built-in functions to existing tabular data. However, for these purposes it is better to use the very useful “Analysis Pack” add-on. To activate it you need:
- from the “File” tab go to the “Options” section;
- in the window that opens, select the line “Add-ons”;
- click on the “Go” button located below, to the right of the “Management” line;
- check the box next to the name “Analysis package” and confirm your actions by clicking “Ok”.
If everything is done correctly, the required button will appear on the right side of the “Data” tab, located above the Excel worksheet.
Linear Regression in Excel
Now that we have all the necessary virtual tools at hand to carry out econometric calculations, we can begin to solve our problem. For this:
- click on the “Data Analysis” button;
- in the window that opens, click on the “Regression” button;
- in the tab that appears, enter the range of values for Y (the number of quitting employees) and for X (their salaries);
- We confirm our actions by pressing the “Ok” button.
As a result, the program will automatically fill a new spreadsheet with regression analysis data. Note! Excel allows you to manually set the location you prefer for this purpose. For example, this could be the same sheet where the Y and X values are located, or even a new workbook specifically designed to store such data.
Analysis of regression results for R-squared
In Excel, the data obtained during processing of the data in the example under consideration has the form:
First of all, you should pay attention to the R-squared value. It represents the coefficient of determination. In this example, R-square = 0.755 (75.5%), i.e., the calculated parameters of the model explain the relationship between the parameters under consideration by 75.5%. The higher the value of the coefficient of determination, the more suitable the selected model is for a specific task. It is considered to correctly describe the real situation when the R-square value is above 0.8. If R-squared is tcr, then the hypothesis about the insignificance of the free term of the linear equation is rejected.
In the problem under consideration for the free term, using Excel tools, it was obtained that t = 169.20903, and p = 2.89E-12, i.e., we have zero probability that the correct hypothesis about the insignificance of the free term will be rejected. For the coefficient for the unknown t=5.79405, and p=0.001158. In other words, the probability that the correct hypothesis about the insignificance of the coefficient for an unknown will be rejected is 0.12%.
Thus, it can be argued that the resulting linear regression equation is adequate.
The problem of the feasibility of purchasing a block of shares
Multiple regression in Excel is performed using the same Data Analysis tool. Let's consider a specific application problem.
The management of the NNN company must decide on the advisability of purchasing a 20% stake in MMM JSC. The cost of the package (SP) is 70 million US dollars. NNN specialists have collected data on similar transactions. It was decided to evaluate the value of the shareholding according to such parameters, expressed in millions of US dollars, as:
- accounts payable (VK);
- annual turnover volume (VO);
- accounts receivable (VD);
- cost of fixed assets (COF).
In addition, the parameter of the enterprise's salary debt (V3 P) in thousands of US dollars is used.
Solution using Excel spreadsheet processor
First of all, you need to create a table of source data. It looks like this:
- call the “Data Analysis” window;
- select the “Regression” section;
- In the “Input interval Y” box, enter the range of values of the dependent variables from column G;
- Click on the icon with a red arrow to the right of the “Input interval X” window and highlight the range of all values from columns B, C, D, F on the sheet.
Mark the “New worksheet” item and click “Ok”.
Obtain a regression analysis for a given problem.
Study of results and conclusions
We “collect” the regression equation from the rounded data presented above on the Excel spreadsheet:
SP = 0.103*SOF + 0.541*VO – 0.031*VK +0.405*VD +0.691*VZP – 265.844.
In a more familiar mathematical form, it can be written as:
y = 0.103*x1 + 0.541*x2 – 0.031*x3 +0.405*x4 +0.691*x5 – 265.844
Data for MMM JSC are presented in the table:
Substituting them into the regression equation, we get a figure of 64.72 million US dollars. This means that the shares of MMM JSC are not worth purchasing, since their value of 70 million US dollars is quite inflated.
As you can see, the use of the Excel spreadsheet and the regression equation made it possible to make an informed decision regarding the feasibility of a very specific transaction.
Now you know what regression is. The Excel examples discussed above will help you solve practical problems in the field of econometrics.
Shows the influence of some values (independent, independent) on the dependent variable. For example, how does the number of economically active population depend on the number of enterprises, wages and other parameters. Or: how do foreign investments, energy prices, etc. affect the level of GDP.
The result of the analysis allows you to highlight priorities. And based on the main factors, predict, plan the development of priority areas, and make management decisions.
Regression happens:
linear (y = a + bx);
· parabolic (y = a + bx + cx 2);
· exponential (y = a * exp(bx));
· power (y = a*x^b);
· hyperbolic (y = b/x + a);
logarithmic (y = b * 1n(x) + a);
· exponential (y = a * b^x).
Let's look at an example of building a regression model in Excel and interpreting the results. Let's take the linear type of regression.
Task. At 6 enterprises, the average monthly salary and the number of quitting employees were analyzed. It is necessary to determine the dependence of the number of quitting employees on the average salary.
The linear regression model has the following form:
Y = a 0 + a 1 x 1 +…+a k x k.
Where a are regression coefficients, x are influencing variables, k is the number of factors.
In our example, Y is the indicator of quitting employees. The influencing factor is wages (x).
Excel has built-in functions that can help you calculate the parameters of a linear regression model. But the “Analysis Package” add-on will do this faster.
We activate a powerful analytical tool:
1. Click the “Office” button and go to the “Excel Options” tab. "Add-ons".

2. At the bottom, under the drop-down list, in the “Manage” field there will be an inscription “Excel Add-ins” (if it is not there, click on the checkbox on the right and select). And the “Go” button. Click.
3. A list of available add-ons opens. Select “Analysis package” and click OK.

Once activated, the add-on will be available in the Data tab.

Now let's do the regression analysis itself.
1. Open the menu of the “Data Analysis” tool. Select "Regression".

2. A menu will open to select input values and output options (where to display the result). In the fields for the initial data, we indicate the range of the parameter being described (Y) and the factor influencing it (X). The rest may not be filled in.

3. After clicking OK, the program will display the calculations on a new sheet (you can select an interval to display on the current sheet or assign output to a new workbook).

First of all, we pay attention to R-squared and coefficients.
R-squared is the coefficient of determination. In our example – 0.755, or 75.5%. This means that the calculated parameters of the model explain 75.5% of the relationship between the studied parameters. The higher the coefficient of determination, the better the model. Good - above 0.8. Bad – less than 0.5 (such an analysis can hardly be considered reasonable). In our example – “not bad”.
The coefficient 64.1428 shows what Y will be if all variables in the model under consideration are equal to 0. That is, the value of the analyzed parameter is also influenced by other factors not described in the model.
The coefficient -0.16285 shows the weight of variable X on Y. That is, the average monthly salary within this model affects the number of quitters with a weight of -0.16285 (this is a small degree of influence). The “-” sign indicates a negative impact: the higher the salary, the fewer people quit. Which is fair.
It is known for being useful in various fields of activity, including such a discipline as econometrics, where this software utility is used in work. Basically, all actions of practical and laboratory classes are performed in Excel, which greatly facilitates the work by providing detailed explanations of certain actions. Thus, one of the analysis tools “Regression” is used to select a graph for a set of observations using the least squares method. Let's look at what this program tool is and what its benefits are for users. Below we also provide brief but clear instructions for building a regression model.
Main tasks and types of regression
Regression represents the relationship between given variables, thereby making it possible to predict the future behavior of these variables. Variables are various periodic phenomena, including human behavior. This type of Excel analysis is used to analyze the impact on a specific dependent variable of the values of one or a number of variables. For example, sales in a store are influenced by several factors, including assortment, prices and location of the store. Thanks to regression in Excel, you can determine the degree of influence of each of these factors based on the results of existing sales, and then apply the data obtained to forecast sales for another month or for another store located nearby.
Typically, regression is presented as a simple equation that reveals the relationships and strengths of relationships between two groups of variables, where one group is dependent or endogenous and the other is independent or exogenous. If there is a group of interrelated indicators, the dependent variable Y is determined based on the logic of reasoning, and the rest act as independent X variables.
The main tasks of building a regression model are as follows:
- Selection of significant independent variables (X1, X2, ..., Xk).
- Selecting the type of function.
- Constructing estimates for coefficients.
- Construction of confidence intervals and regression functions.
- Checking the significance of the calculated estimates and the constructed regression equation.
There are several types of regression analysis:
- paired (1 dependent and 1 independent variables);
- multiple (several independent variables).
There are two types of regression equations:
- Linear, illustrating a strict linear relationship between variables.
- Nonlinear - Equations that can include powers, fractions, and trigonometric functions.
Instructions for building a model
To perform a given construction in Excel, you must follow the instructions:

For further calculation, use the “Linear()” function, specifying Y Values, X Values, Const and Statistics. After this, determine the set of points on the regression line using the "Trend" function - Y Values, X Values, New Values, Const. Using the given parameters, calculate the unknown value of the coefficients, based on the given conditions of the problem.
In previous posts, the analysis often focused on a single numerical variable, such as mutual fund returns, Web page loading times, or soft drink consumption. In this and subsequent notes, we will look at methods for predicting the values of a numeric variable depending on the values of one or more other numeric variables.
The material will be illustrated with a cross-cutting example. Forecasting sales volume in a clothing store. The Sunflowers chain of discount clothing stores has been constantly expanding for 25 years. However, the company currently does not have a systematic approach to selecting new outlets. The location in which a company intends to open a new store is determined based on subjective considerations. The selection criteria are favorable rental conditions or the manager’s idea of the ideal store location. Imagine that you are the head of the special projects and planning department. You have been tasked with developing a strategic plan for opening new stores. This plan should include a forecast of annual sales for newly opened stores. You believe that retail space is directly related to revenue and want to factor this into your decision making process. How do you develop a statistical model to predict annual sales based on the size of a new store?
Typically, regression analysis is used to predict the values of a variable. Its goal is to develop a statistical model that can predict the values of a dependent variable, or response, from the values of at least one independent, or explanatory, variable. In this note, we will look at simple linear regression - a statistical method that allows you to predict the values of a dependent variable Y by the values of the independent variable X. Subsequent notes will describe the model multiple regression, designed to predict the values of the independent variable Y based on the values of several dependent variables ( X 1, X 2, …, X k).
Download the note in or format, examples in format
Types of regression models
Where ρ 1 – autocorrelation coefficient; If ρ 1 = 0 (no autocorrelation), D≈ 2; If ρ 1 ≈ 1 (positive autocorrelation), D≈ 0; If ρ 1 = -1 (negative autocorrelation), D ≈ 4.
In practice, the application of the Durbin-Watson criterion is based on comparing the value D with critical theoretical values d L And d U for a given number of observations n, number of independent variables of the model k(for simple linear regression k= 1) and significance level α. If D< d L , the hypothesis about the independence of random deviations is rejected (hence, there is a positive autocorrelation); If D>dU, the hypothesis is not rejected (that is, there is no autocorrelation); If d L< D < d U , there are no sufficient grounds for making a decision. When calculated value D exceeds 2, then with d L And d U It is not the coefficient itself that is compared D, and the expression (4 – D).
To calculate the Durbin-Watson statistics in Excel, let's turn to the bottom table in Fig. 14 Withdrawal of balance. The numerator in expression (10) is calculated using the function =SUMMAR(array1;array2), and the denominator =SUMMAR(array) (Fig. 16).

Rice. 16. Formulas for calculating Durbin-Watson statistics
In our example D= 0.883. The main question is: what value of the Durbin-Watson statistic should be considered small enough to conclude that a positive autocorrelation exists? It is necessary to correlate the value of D with the critical values ( d L And d U), depending on the number of observations n and significance level α (Fig. 17).

Rice. 17. Critical values of Durbin-Watson statistics (table fragment)
Thus, in the problem of sales volume in a store delivering goods to home, there is one independent variable ( k= 1), 15 observations ( n= 15) and significance level α = 0.05. Hence, d L= 1.08 and dU= 1.36. Because the D = 0,883 < d L= 1.08, there is a positive autocorrelation between the residuals, the least squares method cannot be used.
Testing hypotheses about slope and correlation coefficient
Above, regression was used solely for forecasting. To determine regression coefficients and predict the value of a variable Y for a given variable value X The least squares method was used. In addition, we examined the root mean square error of the estimate and the mixed correlation coefficient. If the analysis of residuals confirms that the conditions of applicability of the least squares method are not violated, and the simple linear regression model is adequate, based on the sample data, it can be argued that there is a difference between the variables in the population linear dependence.
Applicationt -criteria for slope. By testing whether the population slope β 1 is equal to zero, one can determine whether there is statistically significant dependence between variables X And Y. If this hypothesis is rejected, it can be argued that between the variables X And Y there is a linear relationship. The null and alternative hypotheses are formulated as follows: H 0: β 1 = 0 (there is no linear dependence), H1: β 1 ≠ 0 (there is a linear dependence). A-priory t-statistic is equal to the difference between the sample slope and the hypothetical value of the population slope, divided by the root mean square error of the slope estimate:
(11) t = (b 1 – β 1 ) / Sb 1
Where b 1
– slope of direct regression on sample data, β1 – hypothetical slope of direct population, ![]() , and test statistics t It has t-distribution with n – 2 degrees of freedom.
, and test statistics t It has t-distribution with n – 2 degrees of freedom.
Let's check whether there is a statistically significant relationship between store size and annual sales at α = 0.05. t-the criterion is displayed along with other parameters when used Analysis package(option Regression). The complete results of the Analysis Package are shown in Fig. 4, fragment related to t-statistics - in Fig. 18.
Rice. 18. Application results t
Since the number of stores n= 14 (see Fig. 3), critical value t-statistics at a significance level of α = 0.05 can be found using the formula: tL=STUDENT.ARV(0.025,12) = –2.1788, where 0.025 is half the significance level, and 12 = n – 2; t U=STUDENT.OBR(0.975,12) = +2.1788.
Because the t-statistics = 10.64 > t U= 2.1788 (Fig. 19), null hypothesis H 0 rejected. On the other side, R-value for X= 10.6411, calculated by the formula =1-STUDENT.DIST(D3,12,TRUE), is approximately equal to zero, so the hypothesis H 0 again rejected. The fact that R-value of almost zero means that if there were no true linear relationship between store size and annual sales, it would be virtually impossible to detect it using linear regression. Therefore, there is a statistically significant linear relationship between average annual store sales and store size.

Rice. 19. Testing the hypothesis about the population slope at a significance level of 0.05 and 12 degrees of freedom
ApplicationF -criteria for slope. An alternative approach to testing hypotheses about the slope of simple linear regression is to use F-criteria. Let us recall that F-test is used to test the relationship between two variances (for more details, see). When testing the slope hypothesis with a measure random errors is the error variance (the sum of squared errors divided by the number of degrees of freedom), so F-criterion uses the ratio of the variance explained by the regression (i.e. the value SSR, divided by the number of independent variables k), to the error variance ( MSE = S YX 2 ).
A-priory F-statistic is equal to the mean square of regression (MSR) divided by the error variance (MSE): F = MSR/ MSE, Where MSR=SSR / k, MSE =SSE/(n– k – 1), k– number of independent variables in the regression model. Test statistics F It has F-distribution with k And n– k – 1 degrees of freedom.
For a given significance level α, the decision rule is formulated as follows: if F>FU, the null hypothesis is rejected; otherwise it is not rejected. The results are presented in the form pivot table analysis of variance are shown in Fig. 20.

Rice. 20. An analysis of variance table to test the hypothesis about statistical significance regression coefficient
Likewise t-criterion F- the criterion is displayed in the table when used Analysis package(option Regression). Full results of the work Analysis package are shown in Fig. 4, fragment related to F-statistics – in Fig. 21.

Rice. 21. Application results F-criteria obtained using the Excel Analysis Package
The F-statistic is 113.23, and R-value close to zero (cell SignificanceF). If the significance level α is 0.05, determine the critical value F-distributions with one and 12 degrees of freedom can be obtained using the formula F U=F.OBR(1-0.05;1;12) = 4.7472 (Fig. 22). Because the F = 113,23 > F U= 4.7472, and R-value close to 0< 0,05, нулевая гипотеза H 0 is rejected, i.e. The size of a store is closely related to its annual sales.

Rice. 22. Testing the population slope hypothesis at a significance level of 0.05 with one and 12 degrees of freedom
Confidence interval containing slope β 1 . To test the hypothesis that there is a linear relationship between variables, you can construct a confidence interval containing the slope β 1 and verify that the hypothetical value β 1 = 0 belongs to this interval. The center of the confidence interval containing the slope β 1 is the sample slope b 1 , and its boundaries are the quantities b 1 ±tn –2 Sb 1
As shown in Fig. 18, b 1 = +1,670, n = 14, Sb 1 = 0,157. t 12 =STUDENT.ARV(0.975,12) = 2.1788. Hence, b 1 ±tn –2 Sb 1 = +1.670 ± 2.1788 * 0.157 = +1.670 ± 0.342, or + 1.328 ≤ β 1 ≤ +2.012. Thus, there is a probability of 0.95 that the population slope lies between +1.328 and +2.012 (i.e., $1,328,000 to $2,012,000). Since these values are greater than zero, there is a statistically significant linear relationship between annual sales and store area. If the confidence interval contained zero, there would be no relationship between the variables. In addition, the confidence interval means that each increase in store area by 1,000 sq. ft. results in an increase in average sales volume of between $1,328,000 and $2,012,000.
Usaget -criteria for the correlation coefficient. correlation coefficient was introduced r, which is a measure of the relationship between two numeric variables. It can be used to determine whether there is a statistical difference between two variables. meaningful connection. Let us denote the correlation coefficient between the populations of both variables by the symbol ρ. The null and alternative hypotheses are formulated as follows: H 0: ρ = 0 (no correlation), H 1: ρ ≠ 0 (there is a correlation). Checking the existence of a correlation:

Where r = + , If b 1 > 0, r = – , If b 1 < 0. Тестовая статистика t It has t-distribution with n – 2 degrees of freedom.
In the problem about the Sunflowers chain of stores r 2= 0.904, a b 1- +1.670 (see Fig. 4). Because the b 1> 0, the correlation coefficient between annual sales and store size is r= +√0.904 = +0.951. Let's test the null hypothesis that there is no correlation between these variables using t-statistics:

At a significance level of α = 0.05, the null hypothesis should be rejected because t= 10.64 > 2.1788. Thus, it can be argued that there is a statistically significant relationship between annual sales and store size.
When discussing inferences regarding population slope, confidence intervals and hypothesis tests are used interchangeably. However, calculating the confidence interval containing the correlation coefficient turns out to be more difficult, since the type of sampling distribution of the statistic r depends on the true correlation coefficient.
Estimation of mathematical expectation and prediction of individual values
This section discusses methods for estimating the mathematical expectation of a response Y and predictions of individual values Y for given values of the variable X.
Constructing a confidence interval. In example 2 (see section above Least square method) regression equation allowed us to predict the value of the variable Y X. In the problem of choosing a place for point of sale average annual sales volume in a store with an area of 4000 sq. feet was equal to 7.644 million dollars. However, this estimate of the mathematical expectation of the general population is point-wise. To estimate the mathematical expectation of the population, the concept of a confidence interval was proposed. Similarly, we can introduce the concept confidence interval for the mathematical expectation of the response for a given variable value X:
Where  , =
b 0
+
b 1
X i– predicted value is variable Y at X = X i, S YX– root mean square error, n– sample size, Xi- specified value of the variable X, µ
Y|X =
Xi– mathematical expectation of the variable Y at X = X i, SSX =
, =
b 0
+
b 1
X i– predicted value is variable Y at X = X i, S YX– root mean square error, n– sample size, Xi- specified value of the variable X, µ
Y|X =
Xi– mathematical expectation of the variable Y at X = X i, SSX = 
Analysis of formula (13) shows that the width of the confidence interval depends on several factors. At a given significance level, an increase in the amplitude of fluctuations around the regression line, measured using the root mean square error, leads to an increase in the width of the interval. On the other hand, as one would expect, an increase in sample size is accompanied by a narrowing of the interval. In addition, the width of the interval changes depending on the values Xi. If the variable value Y predicted for quantities X, close to the average value , the confidence interval turns out to be narrower than when predicting the response for values far from the average.
Let's say that when choosing a store location, we want to construct a 95% confidence interval for the average annual sales of all stores whose area is 4000 square meters. feet:

Therefore, the average annual sales volume in all stores with an area of 4,000 sq. feet, with 95% probability lies in the range from 6.971 to 8.317 million dollars.
Calculate the confidence interval for the predicted value. In addition to the confidence interval for the mathematical expectation of the response for a given value of the variable X, it is often necessary to know the confidence interval for the predicted value. Although the formula for calculating such a confidence interval is very similar to formula (13), this interval contains the predicted value rather than the parameter estimate. Interval for predicted response YX = Xi for a specific variable value Xi determined by the formula:

Suppose that when choosing a location for a retail outlet, we want to construct a 95% confidence interval for the predicted annual sales volume for a store whose area is 4000 square meters. feet:

Therefore, the predicted annual sales volume for a store with an area of 4000 sq. feet, with a 95% probability lies in the range from 5.433 to 9.854 million dollars. As we can see, the confidence interval for the predicted response value is much wider than the confidence interval for its mathematical expectation. This is because the variability in predicting individual values is much greater than in estimating the mathematical expectation.
Pitfalls and ethical issues associated with using regression
Difficulties associated with regression analysis:
- Ignoring the conditions of applicability of the least squares method.
- Erroneous assessment of the conditions for the applicability of the least squares method.
- Incorrect choice of alternative methods when the conditions of applicability of the least squares method are violated.
- Application of regression analysis without deep knowledge of the subject of research.
- Extrapolating a regression beyond the range of the explanatory variable.
- Confusion between statistical and causal relationships.
Wide use spreadsheets And software for statistical calculations eliminated the computational problems that prevented the use of regression analysis. However, this led to the fact that regression analysis was used by users who did not have sufficient qualifications and knowledge. How can users know about alternative methods if many of them have no idea at all about the conditions of applicability of the least squares method and do not know how to check their implementation?
The researcher should not get carried away with crunching numbers - calculating the shift, slope and mixed correlation coefficient. He needs deeper knowledge. Let's illustrate this with a classic example taken from textbooks. Anscombe showed that all four data sets shown in Fig. 23, have the same regression parameters (Fig. 24).

Rice. 23. Four artificial data sets

Rice. 24. Regression analysis of four artificial data sets; done with Analysis package(click on the picture to enlarge the image)
So, from the point of view of regression analysis, all these data sets are completely identical. If the analysis had ended there, we would have lost a lot useful information. This is evidenced by the scatter plots (Figure 25) and residual plots (Figure 26) constructed for these data sets.

Rice. 25. Scatter plots for four data sets
Scatter plots and residual plots indicate that these data differ from each other. The only set distributed along a straight line is set A. The plot of the residuals calculated from set A does not have any pattern. This cannot be said about sets B, C and D. The scatter plot plotted for set B shows a pronounced quadratic pattern. This conclusion is confirmed by the residual plot, which has a parabolic shape. The scatter plot and residual plot show that data set B contains an outlier. In this situation, it is necessary to exclude the outlier from the data set and repeat the analysis. A method for detecting and eliminating outliers in observations is called influence analysis. After eliminating the outlier, the result of re-estimating the model may be completely different. The scatterplot plotted from data from set G illustrates an unusual situation in which the empirical model is significantly dependent on an individual response ( X 8 = 19, Y 8 = 12.5). Such regression models must be calculated especially carefully. So, scatter and residual plots are extremely necessary tool regression analysis and should be an integral part of it. Without them, regression analysis is not credible.

Rice. 26. Residual plots for four data sets
How to avoid pitfalls in regression analysis:
- Analysis of possible relationships between variables X And Y always start by drawing a scatter plot.
- Before interpreting the results of regression analysis, check the conditions for its applicability.
- Plot the residuals versus the independent variable. This will make it possible to determine how well the empirical model matches the observational results and to detect a violation of the variance constancy.
- To check the assumption about normal distribution errors, use histograms, stem-and-leaf plots, box plots, and normal distribution plots.
- If the conditions for the applicability of the least squares method are not met, use alternative methods(for example, quadratic or multiple regression models).
- If the conditions for the applicability of the least squares method are met, it is necessary to test the hypothesis about the statistical significance of the regression coefficients and construct confidence intervals containing the mathematical expectation and the predicted response value.
- Avoid predicting values of the dependent variable outside the range of the independent variable.
- Keep in mind that statistical relationships are not always cause-and-effect. Remember that correlation between variables does not mean there is a cause-and-effect relationship between them.
Summary. As shown in the block diagram (Figure 27), the note describes the simple linear regression model, the conditions for its applicability, and how to test these conditions. Considered t-criterion for testing the statistical significance of the regression slope. To predict the values of the dependent variable, we used regression model. An example is considered related to the choice of location for a retail outlet, in which the dependence of annual sales volume on the store area is examined. The information obtained allows you to more accurately select a location for a store and predict its annual sales volume. The following notes will continue the discussion of regression analysis and also look at multiple regression models.

Rice. 27. Structural scheme notes
Materials from the book Levin et al. Statistics for Managers are used. – M.: Williams, 2004. – p. 792–872
If the dependent variable is categorical, logistic regression must be used.