Cấu trúc điều khiển SQL
Công ty của tôi vừa trải qua quá trình đánh giá hàng năm và cuối cùng tôi đã thuyết phục họ rằng đã đến lúc tìm ra giải pháp tốt hơn để quản lý lược đồ/cảnh SQL của chúng tôi. Hiện tại chúng tôi chỉ có một số tập lệnh để cập nhật thủ công.
Tôi đã làm việc với Phiên bản cơ sở dữ liệu VS2008 tại một công ty khác và đó là một sản phẩm tuyệt vời. Sếp của tôi yêu cầu tôi xem SQL Compare của Redgate và tìm kiếm bất kỳ sản phẩm nào khác có thể tốt hơn. So sánh SQL cũng là một sản phẩm tuyệt vời. Tuy nhiên, họ dường như không hỗ trợ Perforce.
Bạn đã sử dụng nhiều loại sản phẩm cho việc này?
Bạn sử dụng công cụ nào để quản lý SQL?
Những gì phải được bao gồm trong các yêu cầu trước khi công ty của tôi mua hàng?
10 câu trả lời
Tôi không nghĩ có một công cụ nào có thể xử lý được tất cả các phần. Phiên bản cơ sở dữ liệu VS không cho phép bạn tạo cơ chế phát hành phù hợp. Việc chạy các tập lệnh riêng lẻ từ Trình duyệt Giải pháp không có khả năng mở rộng đủ tốt trong các dự án lớn.
Tối thiểu bạn cần
- IDE/trình soạn thảo
- kho mã nguồn có thể được khởi chạy từ IDE của bạn
- quy ước đặt tên và tổ chức các tập lệnh khác nhau trong các thư mục
- quá trình xử lý các thay đổi, quản lý các bản phát hành và thực hiện triển khai.
Viên đạn cuối cùng là nơi mọi thứ thường vỡ. Đó là lý do tại sao. Để có khả năng quản lý và theo dõi phiên bản tốt hơn, bạn muốn lưu trữ từng đối tượng db theo cách riêng của nó. tập tin riêng kịch bản. Nghĩa là, mọi bảng, thủ tục lưu sẵn, dạng xem, chỉ mục, v.v. đều được lưu trữ. có tập tin riêng của nó.
Khi có điều gì đó thay đổi, bạn cập nhật tệp và bạn có phiên bản mới trong kho lưu trữ của mình với thông tin cần thiết. Khi cần hợp nhất nhiều thay đổi vào một bản phát hành, việc xử lý các tệp riêng lẻ có thể rất phức tạp.
2 lựa chọn tôi đã sử dụng:
Ngoài việc cứu mọi người đồ vật riêng lẻ cơ sở dữ liệu trong các tệp của họ, bạn có các tập lệnh phát hành, là sự kết hợp của các tập lệnh riêng lẻ. Nhược điểm của việc này: bạn có mã ở 2 nơi với tất cả rủi ro và bất lợi. Tiềm năng: Chạy một bản phát hành dễ dàng như thực thi một tập lệnh đơn lẻ.
viết một công cụ nhỏ có thể đọc siêu dữ liệu tập lệnh từ tệp kê khai phát hành và thực thi từng tập lệnh được chỉ định trong tệp kê khai trên máy chủ đích. Không có nhược điểm nào ngoại trừ việc bạn phải viết mã. Cách tiếp cận này không hiệu quả đối với các bảng không thể xóa và tạo lại (khi bạn đang hoạt động và có dữ liệu), vì vậy bạn sẽ phải thay đổi tập lệnh cho các bảng. Vì vậy, nó thực sự sẽ là sự kết hợp của cả hai cách tiếp cận.
Tôi đang ở trong phe "tự viết kịch bản", vì các sản phẩm của bên thứ ba sẽ chỉ giúp bạn quản lý mã cơ sở dữ liệu. Tôi không có một tập lệnh cho từng đối tượng vì các đối tượng thay đổi theo thời gian và chín trong số mười lần chỉ cập nhật tập lệnh "bảng tạo" của tôi để có ba cột mới sẽ là không đủ.
Tạo cơ sở dữ liệu bằng nhìn chung một cách tầm thường. Thiết lập một loạt các tập lệnh TẠO, sắp xếp chúng một cách chính xác (tạo cơ sở dữ liệu trước lược đồ, lược đồ trước bảng, bảng trước thủ tục, gọi thủ tục trước cuộc gọi, v.v.) và thực hiện. Quản lý các thay đổi cơ sở dữ liệu không phải là dễ dàng:
- Nếu bạn thêm một cột vào một bảng, bạn không thể đơn giản bỏ bảng và tạo nó bằng một cột mới vì điều đó sẽ phá hủy tất cả dữ liệu sản xuất có giá trị của bạn.
- Nếu Fred thêm một cột vào bảng XYZ và Mary thêm một cột khác vào bảng XYZ, cột nào sẽ được thêm trước? Có, thứ tự của các cột trong bảng không quan trọng [vì bạn không bao giờ sử dụng SELECT *, phải không?], trừ khi bạn đang cố gắng quản lý cơ sở dữ liệu và theo dõi việc lập phiên bản, tại thời điểm đó bạn có hai cơ sở dữ liệu "thực" không giống nhau, trở thành người thực sự đau đầu. Chúng tôi sử dụng so sánh SQL không phải để quản lý mà để xem xét và theo dõi mọi thứ, đặc biệt là trong quá trình phát triển và một số tình huống "chúng khác nhau (nhưng không khác biệt)" mà chúng tôi có thể ngăn cản chúng tôi nhận thấy những khác biệt quan trọng.
- Tương tự như vậy, khi nhiều dự án (nhà phát triển) làm việc đồng thời và riêng biệt trên một cơ sở dữ liệu chung, nó có thể trở nên rất phức tạp. Có thể mọi người đang làm việc cho dự án Next Big Thing thì đột nhiên ai đó phải bắt tay vào sửa lỗi cho dự án Last Big Thing. Làm thế nào để bạn quản lý các sửa đổi mã cần thiết khi thứ tự phát hành có thể thay đổi và linh hoạt? (Thực sự là những khoảng thời gian buồn cười.)
- Thay đổi cấu trúc bảng có nghĩa là thay đổi dữ liệu và điều này có thể trở nên cực kỳ phức tạp khi bạn phải xử lý khả năng tương thích ngược. Bạn thêm cột "DeltaFactor", được rồi, vậy bạn sẽ làm gì để điền giá trị bí truyền này cho tất cả dữ liệu (đọc: di sản) hiện có của mình? Bạn đang thêm một bảng tra cứu mới và cột tương ứng, nhưng bạn điền nó như thế nào? hàng hiện có? Những tình huống này có thể không xảy ra thường xuyên nhưng khi xảy ra thì bạn phải tự mình xử lý. Các công cụ của bên thứ ba đơn giản là không thể đoán trước được nhu cầu logic kinh doanh của bạn.
Về cơ bản, tôi có tập lệnh TẠO cho mỗi cơ sở dữ liệu, theo sau là một loạt tập lệnh ALTER khi cơ sở mã của chúng tôi thay đổi theo thời gian. Mỗi tập lệnh sẽ kiểm tra xem nó có thể chạy được hay không: đây là "loại" cơ sở dữ liệu chính xác, các tập lệnh trước cần thiết đã được thực thi, tập lệnh này đã chạy. Chỉ khi quá trình kiểm tra được thông qua thì tập lệnh mới thực hiện các thay đổi của nó.
Là một công cụ, chúng tôi sử dụng SourceGear Fortress để quản lý mã nguồn cơ bản, Redgate SQL Compare để hỗ trợ và khắc phục sự cố chung cũng như một số tập lệnh gia đình dựa trên SQLCMD để triển khai "hàng loạt" tập lệnh với các thay đổi đối với nhiều máy chủ và cơ sở dữ liệu cũng như theo dõi xem ai đã áp dụng tập lệnh cơ sở dữ liệu nào vào thời điểm nào. Kết quả cuối cùng: Tất cả cơ sở dữ liệu của chúng tôi đều ổn định và ổn định và chúng tôi có thể dễ dàng chứng minh đó là phiên bản nào hoặc tại bất kỳ thời điểm nào.
Chúng tôi yêu cầu tất cả các thay đổi hoặc chèn cơ sở dữ liệu vào những thứ như bảng tra cứu phải được thực hiện trong tập lệnh và được lưu trong kiểm soát nguồn. Sau đó, chúng được triển khai theo cách tương tự như bất kỳ mã triển khai phiên bản nào khác phần mềm. Vì các nhà phát triển của chúng tôi không có quyền triển khai nên họ không có lựa chọn nào khác ngoài việc tạo tập lệnh.
Thông thường tôi sử dụng MS Server Management Studio để quản lý sql, làm việc với dữ liệu, phát triển cơ sở dữ liệu và gỡ lỗi nó, nếu tôi cần xuất một số dữ liệu sang tập lệnh sql hoặc tôi cần tạo một số đối tượng phức tạp trong cơ sở dữ liệu, tôi sử dụng EMS Quản lý SQL Studio cho SQL Server vì ở đó tôi có thể thấy rõ hơn những phần hẹp nào trong mã và thiết kế trực quan trong môi trường này giúp tôi dễ dàng hơn
Tôi có một dự án nguồn mở (được cấp phép theo LGPL) đang cố gắng giải quyết các vấn đề liên quan đến phiên bản lược đồ DB chính xác cho (và hơn thế nữa) SQL Server (2005/2008/Azure), bsn ModuleStore. Toàn bộ quá trình rất gần với khái niệm được giải thích trong bài đăng của Phillip Kelly tại đây.
Về cơ bản, một phần riêng biệt của bộ công cụ sẽ chuyển các đối tượng cơ sở dữ liệu SQL Server của lược đồ DB thành các tệp có định dạng chuẩn, do đó nội dung của tệp chỉ được thay đổi nếu đối tượng thực sự thay đổi (không giống như tập lệnh do VS thực hiện, cũng tạo tập lệnh, v.v., đánh dấu tất cả các đối tượng đã thay đổi, ngay cả khi chúng gần như giống hệt nhau).
Tuy nhiên, bộ công cụ này còn vượt xa điều này nếu bạn đang sử dụng .NET: nó cho phép bạn nhúng các tập lệnh SQL vào thư viện hoặc ứng dụng (dưới dạng tài nguyên nội tuyến), sau đó so sánh các tập lệnh nội tuyến được so sánh với trạng thái hiện tại trong cơ sở dữ liệu. Những thay đổi không phải bảng (những thay đổi không phải là "thay đổi mang tính phá hủy" như được định nghĩa bởi Martin Fowler) có thể được áp dụng tự động hoặc theo yêu cầu (ví dụ: tạo và xóa các đối tượng như dạng xem, hàm, thủ tục lưu trữ, loại, chỉ mục) và thay đổi tập lệnh (cần phải viết bằng tay) có thể được áp dụng trong cùng một quy trình; các bảng mới cũng như dữ liệu thiết lập của chúng cũng được tạo. Sau khi cập nhật, lược đồ cơ sở dữ liệu lại được so sánh với các tập lệnh để đảm bảo rằng việc cập nhật cơ sở dữ liệu thành công trước khi thực hiện các thay đổi.
Lưu ý rằng tất cả mã tập lệnh và mã so sánh đều chạy mà không có SMO, do đó bạn không gặp phải sự phụ thuộc đáng kể vào SMO khi sử dụng mô-đun bsn ModuleStore trong các ứng dụng.
Tùy thuộc vào cách bạn muốn truy cập cơ sở dữ liệu, bộ công cụ thậm chí còn cung cấp nhiều tính năng hơn - nó triển khai một số khả năng ORM và cung cấp một cách tiếp cận giao diện người dùng rất hay và hữu ích để gọi các thủ tục được lưu trữ, bao gồm hỗ trợ XML minh bạch với các lớp .NET XML nguyên gốc và cả đối với TVP (Tham số có giá trị theo bảng) là IEnumerable
Đây là tập lệnh của tôi để theo dõi proc và udf được lưu trữ cũng như các trình kích hoạt trong một bảng.
Tạo bảng để lưu trữ mã nguồn Proc hiện có
Nhập một bảng có tất cả dữ liệu tập lệnh và kích hoạt hiện có
Tạo trình kích hoạt DDL để theo dõi các thay đổi đối với chúng
/****** Đối tượng: Bảng . Ngày tập lệnh: 17/9/2014 11:36:54 AM ******/ SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO CREATE TABLE . ( IDENTITY(1, 1) NOT NULL , (1000) NULL , (1000) NULL , (1000) NULL , (1000) NULL , NULL , NTEXT NULL ,CONSTRAINT PRIMARY KEY CLUSTERED ( ASC) VỚI (PAD_INDEX = OFF ,STATISTICS_NORECOMPUTE = TẮT,IGNORE_DUP_KEY = TẮT,ALLOW_ROW_LOCKS = BẬT,ALLOW_PAGE_LOCKS = BẬT) BẬT) TRÊN BẢNG THAY ĐỔI. THÊM MẶC ĐỊNH Ràng buộc ("") ĐỂ CHÈN VÀO . ( , , , , ,) CHỌN "sa" ,"loginitialdata" ,r.ROUTINE_NAME ,r.ROUTINE_TYPE ,GETDATE() ,r.ROUTINE_DEFINITION TỪ INFORMATION_SCHEMA.ROUTINES r UNION CHỌN "sa" ,"loginitialdata" ,v.TABLE_NAME , "view" ,GETDATE() ,v.VIEW_DEFINITION FROM INFORMATION_SCHema.VIEWS v UNION SELECT "sa" ,,"loginitialdata" ,o.NAME , "trigger" ,GETDATE() ,m.DEFINITION FROM sys.objects o JOIN sys. sql_modules m ON o.object_id = m.object_id WHERE o.type = "TR" ĐI TẠO TRIGGER TRÊN CƠ SỞ DỮ LIỆU ĐỂ TẠO_PROCEDURE,ALTER_PROCEDURE,DROP_PROCEDURE,CREATE_INDEX,ALTER_INDEX,DROP_INDEX,CREATE_TRIGGER,ALTER_TRIGGER,DROP_TRIGGER,ALTER_TABLE TER_VIEW ,CREATE_VIEW ,DROP_VIEW NHƯ BẮT ĐẦU THIẾT LẬP NOCOUNT TRÊN KHAI THÁC @data XML SET @data = Eventdata() CHÈN VÀO sysupdatelog GIÁ TRỊ (@data.value("(/EVENT_INSTANCE/LoginName)", "nvarchar(255)") ,@data.value("( /EVENT_INSTANCE /EventType)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE/ObjectName)", "nvarchar(255)") ,@data.value("(/EVENT_INSTANCE/ObjectType)" , " nvarchar(255)") ,getdate() ,@data.value("(/EVENT_INSTANCE/TSQLCommand/CommandText)", "nvarchar(max)")) THIẾT LẬP NOCOUNT TẮT KẾT THÚC ĐI THIẾT LẬP ANSI_NULLS TẮT ĐI THIẾT LẬP QUOTED_IDENTIFIER TẮT ĐI BẬT KÍCH HOẠT TRÊN CƠ SỞ DỮ LIỆU GO
Đôi khi bạn thực sự muốn sắp xếp những suy nghĩ của mình theo thứ tự, sắp xếp chúng. Và thậm chí còn tốt hơn nữa, theo thứ tự bảng chữ cái và chủ đề, để cuối cùng suy nghĩ rõ ràng cũng xuất hiện. Bây giờ hãy tưởng tượng sự hỗn loạn sẽ xảy ra trong " bộ não điện tử» bất kỳ máy tính nào không có cấu trúc rõ ràng về tất cả dữ liệu và Microsoft SQL Server:
Máy chủ MS SQL
Sản phẩm phần mềm này là một hệ thống quản lý cơ sở dữ liệu quan hệ (DBMS) được phát triển bởi Tập đoàn Microsoft. Ngôn ngữ Transact-SQL được phát triển đặc biệt được sử dụng để thao tác dữ liệu. Các lệnh ngôn ngữ để chọn và sửa đổi cơ sở dữ liệu được xây dựng trên cơ sở các truy vấn có cấu trúc:

Cơ sở dữ liệu quan hệ được xây dựng trên sự kết nối của tất cả các thành phần cấu trúc, bao gồm cả sự lồng nhau của chúng. Cơ sở dữ liệu quan hệ có hỗ trợ tích hợp cho các loại dữ liệu phổ biến nhất. Nhờ đó, SQL Server tích hợp hỗ trợ cấu trúc dữ liệu theo chương trình bằng cách sử dụng trình kích hoạt và thủ tục được lưu trữ.
Tổng quan về các tính năng của MS SQL Server

DBMS là một phần của dòng phần mềm chuyên dụng dài mà Microsoft đã tạo ra cho các nhà phát triển. Điều này có nghĩa là tất cả các liên kết của chuỗi (ứng dụng) này đều được tích hợp sâu sắc với nhau.
Nghĩa là, các công cụ của chúng dễ dàng tương tác với nhau, giúp đơn giản hóa đáng kể quá trình phát triển và viết mã chương trình. Một ví dụ về mối quan hệ như vậy là môi trường lập trình MS Visual Studio. Gói cài đặt của nó đã bao gồm SQL Server Express Edition.
Tất nhiên, đây không phải là DBMS phổ biến duy nhất trên thị trường thế giới. Nhưng chính xác là nó được chấp nhận nhiều hơn đối với các máy tính chạy Windows, do nó tập trung vào hệ điều hành này. Và không chỉ vì điều này.
Ưu điểm của MS SQL Server:
- Có mức độ hiệu suất cao và khả năng chịu lỗi;
- Nó là một DBMS nhiều người dùng và hoạt động theo nguyên tắc máy khách-máy chủ;
Phần client của hệ thống hỗ trợ tạo yêu cầu của người dùng và gửi đến server để xử lý.
- Tích hợp chặt chẽ với hệ điều hành Các cửa sổ;
- Hỗ trợ kết nối từ xa;
- Hỗ trợ các loại dữ liệu phổ biến, cũng như khả năng tạo trình kích hoạt và thủ tục lưu trữ;
- Hỗ trợ tích hợp cho vai trò của người dùng;
- Chức năng sao lưu cơ sở dữ liệu nâng cao;
- Mức độ bảo mật cao;
- Mỗi số bao gồm một số ấn bản chuyên biệt.
Sự phát triển của máy chủ SQL
Các tính năng của DBMS phổ biến này có thể dễ dàng nhận thấy nhất khi xem xét lịch sử phát triển của tất cả các phiên bản của nó. Chúng tôi sẽ chỉ trình bày chi tiết hơn về những bản phát hành mà các nhà phát triển đã thực hiện những thay đổi cơ bản và quan trọng:
- Microsoft SQL Server 1.0 – được phát hành vào năm 1990. Thậm chí sau đó, các chuyên gia lưu ý tốc độ cao xử lý dữ liệu, được chứng minh ngay cả với tải tối đaở chế độ nhiều người dùng;
- SQL Server 6.0 - phát hành năm 1995. Phiên bản này là phiên bản đầu tiên trên thế giới triển khai hỗ trợ con trỏ và sao chép dữ liệu;
- SQL Server 2000 - trong phiên bản này, máy chủ đã nhận được một công cụ hoàn toàn mới. Hầu hết các thay đổi chỉ ảnh hưởng đến phía người dùng của ứng dụng;
- SQL Server 2005 – khả năng mở rộng của DBMS đã tăng lên và quy trình quản lý và điều hành đã được đơn giản hóa rất nhiều. Một API mới đã được giới thiệu để hỗ trợ nền tảng phần mềm.MẠNG LƯỚI ;
- Các bản phát hành tiếp theo nhằm mục đích phát triển sự tương tác của DBMS ở cấp độ công nghệ đám mây và các công cụ phân tích kinh doanh.
Bộ hệ thống cơ bản bao gồm một số tiện ích dành cho cài đặt SQL Máy chủ. Bao gồm các:
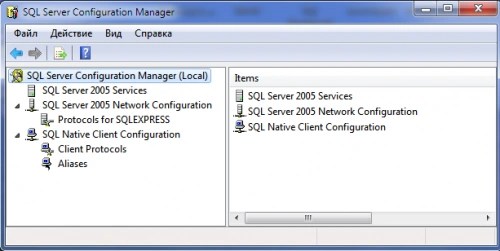
Quản lý cấu hình. Cho phép bạn quản lý tất cả cài đặt mạng và dịch vụ máy chủ cơ sở dữ liệu. Được sử dụng để định cấu hình SQL Server trong mạng.
- SQL Lỗi máy chủ và Báo cáo sử dụng:

Tiện ích này được sử dụng để định cấu hình gửi báo cáo lỗi tới bộ phận hỗ trợ của Microsoft.

Được sử dụng để tối ưu hóa hoạt động của máy chủ cơ sở dữ liệu. Nghĩa là, bạn có thể tùy chỉnh chức năng của SQL Server cho phù hợp với nhu cầu của mình bằng cách bật hoặc tắt một số tính năng và thành phần nhất định của DBMS.
Bộ tiện ích có trong Microsoft SQL Server có thể khác nhau tùy thuộc vào phiên bản và phiên bản của gói phần mềm. Ví dụ: trong phiên bản 2008 bạn sẽ không tìm thấy Cấu hình diện tích bề mặt máy chủ SQL.
Khởi động máy chủ Microsoft SQL
Ví dụ: phiên bản 2005 của máy chủ cơ sở dữ liệu sẽ được sử dụng. Máy chủ có thể được khởi động theo nhiều cách:
- Thông qua tiện ích Trình quản lý cấu hình máy chủ SQL. Trong cửa sổ ứng dụng ở bên trái, chọn “Dịch vụ SQL Server 2005” và ở bên phải - phiên bản máy chủ cơ sở dữ liệu mà chúng tôi cần. Chúng tôi đánh dấu nó và chọn “Bắt đầu” trong menu con của nút chuột phải.
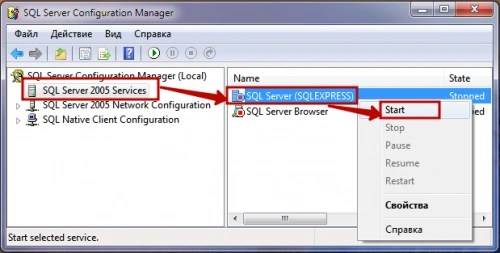
- Sử dụng môi trường Studio quản lý máy chủ SQL Express. Nó không được bao gồm trong gói cài đặt phiên bản Express. Do đó, nó phải được tải xuống riêng biệt từ trang web chính thức của Microsoft.
Để khởi động máy chủ cơ sở dữ liệu, hãy khởi chạy ứng dụng. Trong hộp thoại " Kết nối với máy chủ"Trong trường "Tên máy chủ", hãy chọn phiên bản chúng tôi cần. Trong lĩnh vực " Xác thực"để lại giá trị" Bài kiểm tra Tính xác thực của Windows " Và bấm vào nút “Kết nối”:

Cơ bản về quản trị máy chủ SQL
Trước khi khởi động MS SQL Server, bạn cần làm quen nhanh với các khả năng cơ bản về cấu hình và quản trị của nó. Hãy bắt đầu với cái nhìn tổng quan chi tiết hơn về một số tiện ích có trong DBMS:
- Cấu hình diện tích bề mặt máy chủ SQL– đây là nơi bạn nên đến nếu cần bật hoặc tắt bất kỳ tính năng nào của máy chủ cơ sở dữ liệu. Ở cuối cửa sổ có hai mục: mục đầu tiên chịu trách nhiệm về các thông số mạng và mục thứ hai, bạn có thể kích hoạt một dịch vụ hoặc chức năng bị tắt theo mặc định. Ví dụ: kích hoạt tích hợp với nền tảng .NET thông qua truy vấn T-SQL:
Được đăng bởi Mike Weiner
Đồng tác giả: Burzin Patel
Biên tập: Lubor Kollar, Kevin Cox, Bill Emmert, Greg Husemeier, Paul Burpo, Joseph Sack, Denny Lee, Sanjay Mishra, Lindsey Allen, Mark Souza
Microsoft SQL Server 2008 chứa một số cải tiến và chức năng mới giúp mở rộng chức năng của các phiên bản trước. Quản trị và duy trì cơ sở dữ liệu, duy trì khả năng quản lý, tính khả dụng, bảo mật và hiệu suất đều là trách nhiệm của quản trị viên cơ sở dữ liệu. Bài viết này mô tả mười tính năng mới hữu ích nhất trong SQL Server 2008 (theo thứ tự bảng chữ cái) giúp công việc DBA của bạn trở nên dễ dàng hơn. Bên cạnh đó mô tả ngắn gọn, đối với mỗi chức năng, các tình huống có thể ứng dụng của nó được đưa ra và khuyến nghị quan trọng bằng cách sử dụng.
Giám sát hoạt động
Khi khắc phục sự cố về hiệu suất hoặc giám sát máy chủ trong thời gian thực, quản trị viên thường sẽ chạy một loạt tập lệnh hoặc kiểm tra các nguồn thông tin liên quan để thu thập dữ liệu tổng thể về các quy trình đang chạy và xác định nguyên nhân của sự cố. Trình giám sát hoạt động SQL Server 2008 tập hợp thông tin này để cung cấp thông tin nhanh về các quy trình đang chạy và đang chạy gần đây. Quản trị viên cơ sở dữ liệu có thể vừa xem thông tin cấp cao, vừa phân tích bất kỳ quy trình nào chi tiết hơn, đồng thời xem số liệu thống kê chờ đợi, giúp xác định và giải quyết vấn đề dễ dàng hơn.
Để mở Trình giám sát hoạt động, bấm chuột phải vào tên máy chủ đã đăng ký trong Object Explorer, sau đó chọn Giám sát hoạt động hoặc sử dụng biểu tượng chuẩn trên thanh công cụ trong Môi trường SQL Xưởng quản lý máy chủ. Giám sát hoạt động cung cấp cho quản trị viên một phần tổng quan có giao diện tương tự như Trình quản lý Nhiệm vụ của Windows, cũng như các thành phần để xem chi tiết các quy trình riêng lẻ, chờ tài nguyên, I/O tệp dữ liệu và các yêu cầu sử dụng nhiều tài nguyên gần đây, như trong Hình 2. 1.
Cơm. 1:Chế độ xem giám sát hoạt độngSQL Máy chủ2008 vào thứ TưSự quản lý Phòng thu

Ghi chú. Trình giám sát hoạt động sử dụng cài đặt tần suất làm mới dữ liệu có thể thay đổi bằng cách nhấp chuột phải. Nếu bạn chọn làm mới dữ liệu thường xuyên (dưới 10 giây một lần), hiệu suất của hệ thống làm việc được tải nặng có thể giảm.
Khi sử dụng Trình giám sát hoạt động, quản trị viên cũng có thể thực hiện các tác vụ sau:
· Tạm dừng và tiếp tục theo dõi hoạt động chỉ bằng một cú nhấp chuột phải. Điều này cho phép quản trị viên "lưu" thông tin trạng thái vào một thời điểm cụ thể và sẽ không bị cập nhật hoặc ghi đè. Nhưng đừng quên rằng khi cập nhật dữ liệu thủ công, mở rộng hoặc thu gọn một phần nào đó thì dữ liệu cũ sẽ được cập nhật và mất đi.
· Nhấp chuột phải vào một chi tiết đơn hàng để hiển thị toàn bộ văn bản truy vấn hoặc kế hoạch đồ họa thực thi bằng cách sử dụng mục menu “Các truy vấn sử dụng nhiều tài nguyên gần đây”.
· Theo dõi bằng Profiler hoặc chấm dứt các tiến trình trong khung nhìn Processes. Các sự kiện của ứng dụng Profiler bao gồm các sự kiện RPC:Hoàn thành, SQL:Bắt đầu hàng loạt Và SQL:Đợt Đã hoàn thành, Và Kiểm toánĐăng nhập Và Kiểm toánĐăng xuất.
Trình giám sát hoạt động cũng cho phép bạn giám sát hoạt động của bất kỳ phiên bản SQL Server 2005 cục bộ hoặc từ xa nào được đăng ký với SQL Server Management Studio.
Kiểm toán
Khả năng giám sát và ghi lại các sự kiện xảy ra, bao gồm ai đang truy cập vào đối tượng cũng như thời gian và nội dung của các thay đổi, giúp quản trị viên đảm bảo tuân thủ các tiêu chuẩn tuân thủ quy định hoặc bảo mật của tổ chức. Ngoài ra, hiểu rõ các sự kiện xảy ra trong môi trường cũng có thể giúp xây dựng kế hoạch giảm thiểu rủi ro và duy trì môi trường an toàn.
Trong SQL Server 2008 (chỉ dành cho phiên bản dành cho doanh nghiệp và nhà phát triển), SQL Server Audit cung cấp tính năng tự động hóa cho phép quản trị viên và những người dùng khác chuẩn bị, lưu và xem các bản kiểm tra của các thành phần cơ sở dữ liệu và máy chủ khác nhau. Chức năng này cung cấp khả năng kiểm tra chi tiết ở cấp độ máy chủ hoặc cơ sở dữ liệu.
Có các nhóm hành động kiểm tra cấp máy chủ, chẳng hạn như sau:
· FAILED_LOGIN_GROUP theo dõi các lần đăng nhập thất bại.
· BACKUP_RESTORE_GROUP báo cáo khi cơ sở dữ liệu được sao lưu hoặc khôi phục.
· DATABASE_CHANGE_GROUP kiểm tra thời gian cơ sở dữ liệu được tạo, sửa đổi hoặc xóa.
Các nhóm hành động kiểm tra cấp cơ sở dữ liệu bao gồm:
· DATABASE_OBJECT_ACCESS_GROUP được gọi bất cứ khi nào một câu lệnh CREATE, ALTER hoặc DROP được thực thi trên một đối tượng cơ sở dữ liệu.
· DATABASE_OBJECT_PERMISSION_CHANGE_GROUP được gọi khi các câu lệnh GRANT, REVOKE hoặc DENY được sử dụng trên các đối tượng cơ sở dữ liệu.
Có các hành động kiểm tra khác như CHỌN, XÓA và THỰC HIỆN. Để biết thêm thông tin, bao gồm danh sách đầy đủ tất cả các nhóm và hành động kiểm tra, hãy xem Nhóm hành động và hành động kiểm tra SQL Server.
Kết quả kiểm tra có thể được gửi đến một tệp hoặc nhật ký sự kiện (nhật ký hệ thống hoặc nhật ký sự kiện) để xem xét sau. Bảo mật Windows). Dữ liệu kiểm toán được tạo bằng cách sử dụng Sự kiện mở rộng- một tính năng mới khác trong SQL Server 2008.
Kiểm tra SQL Server 2008 cho phép quản trị viên trả lời các câu hỏi mà trước đây rất khó trả lời sau thực tế, chẳng hạn như “Ai đã bỏ chỉ mục này?”, “Quy trình lưu trữ được sửa đổi khi nào?”, “Thay đổi nào được thực hiện có thể ngăn cản người dùng truy cập vào bảng này? và thậm chí "Ai đã thực thi câu lệnh CHỌN hoặc CẬP NHẬT trên bảng [ dbo.Lương bổng] ?».
Để biết thêm thông tin về cách sử dụng tính năng kiểm tra SQL Server và các ví dụ về cách triển khai tính năng này, hãy xem Hướng dẫn tuân thủ SQL Server 2008.
Nén sao lưu
Các DBA đã đề xuất đưa tính năng này vào SQL Server từ lâu. Giờ thì mọi chuyện đã xong và vừa kịp lúc! TRONG Gần đây Ví dụ, vì một số lý do, do thời gian lưu trữ dữ liệu tăng lên và nhu cầu lưu trữ nhiều dữ liệu hơn về mặt vật lý, kích thước cơ sở dữ liệu bắt đầu tăng theo cấp số nhân. Khi sao lưu cơ sở dữ liệu lớn, bạn cần phân bổ dung lượng ổ đĩa đáng kể cho các tệp hỗ trợ cũng như phân bổ một khoảng thời gian đáng kể cho hoạt động.
Khi bạn sử dụng nén bản sao lưu SQL Server 2008, tệp sao lưu sẽ được nén khi nó được ghi, điều này không chỉ yêu cầu ít dung lượng ổ đĩa hơn mà còn giảm các thao tác I/O và mất ít thời gian hơn để hoàn thành sao lưu. Trong các thử nghiệm trong phòng thí nghiệm với dữ liệu người dùng thực, kích thước tệp sao lưu đã giảm 70-85% trong nhiều trường hợp. Ngoài ra, các thử nghiệm cho thấy thời gian thực hiện các thao tác sao chép và khôi phục đã giảm khoảng 45%. Cần lưu ý rằng việc xử lý bổ sung trong quá trình nén sẽ làm tăng tải bộ xử lý. Để tách quy trình sao chép tốn nhiều thời gian khỏi các quy trình khác và giảm thiểu tác động của nó đến hoạt động của chúng, bạn có thể sử dụng một chức năng khác được mô tả trong tài liệu này - Nguồn Thống đốc.
Tính năng nén được bật bằng cách thêm mệnh đề WITH COMPRESSION vào lệnh BACKUP (xem Sách trực tuyến về SQL Server để biết thêm thông tin) hoặc bằng cách đặt tùy chọn này trên trang Tùy chọn hộp thoại Sao lưu cơ sở dữ liệu. Để tránh phải thực hiện thay đổi đối với tất cả tập lệnh sao lưu hiện có, cài đặt chung đã được triển khai cho phép nén tất cả các bản sao lưu được tạo trên phiên bản máy chủ theo mặc định. (Tùy chọn này có sẵn trên trang Cài đặt cơ sở dữ liệu hộp thoại Thuộc tính máy chủ; nó cũng có thể được cài đặt bằng cách thực hiện thủ tục được lưu trữ sp_ cấu hình với giá trị tham số hỗ trợnénmặc định, bằng 1). Lệnh sao lưu yêu cầu tùy chọn nén rõ ràng và lệnh khôi phục sẽ tự động nhận dạng bản sao lưu đã nén và giải nén nó khi khôi phục.
Nén sao lưu là một tính năng cực kỳ hữu ích giúp tiết kiệm dung lượng và thời gian trên ổ đĩa. Để biết thêm thông tin về cách định cấu hình nén bản sao lưu, hãy xem ghi chú kỹ thuật Điều chỉnh hiệu suất nén sao lưu trongSQL Máy chủ 2008 . Ghi chú. Sao lưu nén chỉ được hỗ trợ trong các phiên bản SQL Server 2008 Enterprise và Developer, nhưng tất cả các phiên bản SQL Server 2008 đều cho phép bạn khôi phục các bản sao lưu nén.
Máy chủ quản lý tập trung
Thông thường một DBA quản lý nhiều phiên bản SQL Server cùng một lúc. Khả năng tập trung quản lý và điều hành nhiều phiên bản SQL vào một vị trí duy nhất giúp tiết kiệm đáng kể công sức và thời gian. Việc triển khai máy chủ quản lý tập trung, có sẵn trong SQL Server Management Studio thông qua thành phần Máy chủ đã đăng ký, cho phép quản trị viên thực hiện các hoạt động quản trị khác nhau trên nhiều Máy chủ SQL từ một bảng điều khiển quản lý duy nhất.
Máy chủ quản lý tập trung cho phép quản trị viên đăng ký một nhóm máy chủ và thực hiện các hoạt động sau trên chúng dưới dạng một nhóm duy nhất, ví dụ:
· Thực thi truy vấn nhiều máy chủ: Giờ đây, bạn có thể chạy tập lệnh trên nhiều Máy chủ SQL từ một nguồn duy nhất và dữ liệu sẽ được trả về nguồn đó mà không cần phải đăng nhập riêng vào từng máy chủ. Điều này có thể đặc biệt hữu ích khi bạn cần xem hoặc so sánh dữ liệu từ nhiều Máy chủ SQL mà không cần chạy truy vấn phân tán. Ngoài ra, với điều kiện cú pháp truy vấn được hỗ trợ bởi các phiên bản SQL Server trước đó khi khởi chạy từ trình chỉnh sửa truy vấn SQL Truy vấn Server 2008 cũng có thể chạy trên các phiên bản của SQL Server 2005 và SQL Server 2000. Để biết thêm thông tin, hãy xem blog nhóm làm việc Về Khả năng quản lý máy chủ SQL, hãy xem Chạy truy vấn nhiều máy chủ trong môi trường SQL Server 2008.
· Nhập và xác định chính sách trên nhiều máy chủ: trong phạm vi chức năng Quản lý dựa trên chính sách(một tính năng mới khác trong SQL Server 2008, cũng được mô tả trong bài viết này), SQL Server 2008 cung cấp khả năng nhập các tệp chính sách vào các nhóm máy chủ quản lý trung tâm riêng lẻ và cho phép bạn xác định chính sách trên tất cả các máy chủ được đăng ký trong một nhóm cụ thể.
· Quản lý dịch vụ và truy cập Trình quản lý cấu hình máy chủ SQL: Công cụ Máy chủ từ Quản lý trung tâm giúp bạn tạo một trung tâm điều khiển nơi DBA có thể xem và thậm chí thay đổi (với các quyền thích hợp) trạng thái của dịch vụ.
· Nhập và xuất máy chủ đã đăng ký: Máy chủ đã đăng ký với Máy chủ quản lý trung tâm có thể được xuất và nhập khi chuyển giữa các quản trị viên hoặc các bản cài đặt khác nhau của SQL Server Management Studio. Tính năng này cung cấp giải pháp thay thế cho quản trị viên nhập hoặc xuất các nhóm cục bộ của riêng mình trong SQL Server Management Studio.
Hãy nhớ rằng các quyền được thực thi bằng Xác thực Windows, do đó, quyền và quyền của người dùng có thể khác nhau giữa các máy chủ khác nhau được đăng ký trong nhóm Máy chủ quản lý trung tâm. Để biết thêm thông tin, hãy xem Quản trị nhiều máy chủ bằng máy chủ quản lý trung tâm và blog của Kimberly Tripp: Máy chủ quản lý SQL trung tâmMáy chủ2008 - bạn có quen thuộc với họ không?
Người thu thập và quản lý dữ liệu Kho dữ liệu
Việc điều chỉnh và chẩn đoán hiệu suất tốn nhiều thời gian và có thể yêu cầu các kỹ năng SQL Server nâng cao cũng như hiểu biết về cấu trúc bên trong của cơ sở dữ liệu. Giám sát hệ thống Windows (Perfmon), SQL Server Profiler và các dạng xem quản lý động đã giải quyết được một số vấn đề này, nhưng chúng thường có tác động đến máy chủ, tốn nhiều công sức để sử dụng hoặc liên quan đến các phương pháp thu thập dữ liệu khác nhau khiến chúng khó kết hợp và diễn giải. .
Để cung cấp thông tin rõ ràng, hữu ích về hiệu suất hệ thống, SQL Server 2008 cung cấp một công cụ lưu trữ và thu thập dữ liệu hiệu suất có khả năng mở rộng hoàn toàn, Data Collector. Nó chứa một số tác nhân thu thập dữ liệu có thể dùng ngay, một kho lưu trữ dữ liệu hiệu suất tập trung được gọi là kho dữ liệu quản lý và một số báo cáo dựng sẵn để trình bày dữ liệu đã thu thập. Trình thu thập dữ liệu là một công cụ có thể mở rộng để thu thập và tổng hợp dữ liệu từ có nhiều nguồn, chẳng hạn như chế độ xem quản lý động, giám sát hiệu suất Perfmon và truy vấn Transact-SQL, theo tần suất thu thập dữ liệu có thể tùy chỉnh hoàn toàn. Trình thu thập dữ liệu có thể được mở rộng để thu thập dữ liệu về bất kỳ thuộc tính ứng dụng nào có thể đo lường được.
Một tính năng hữu ích khác của kho dữ liệu quản lý là khả năng cài đặt nó trên bất kỳ Máy chủ SQL nào và sau đó thu thập dữ liệu từ một hoặc nhiều phiên bản SQL Server. Điều này giảm thiểu tác động đến hiệu suất của hệ thống sản xuất, đồng thời cải thiện khả năng mở rộng trong bối cảnh giám sát và thu thập dữ liệu từ nhiều máy chủ. Trong thử nghiệm trong phòng thí nghiệm, mức giảm thông lượng quan sát được khi chạy tác nhân và chạy kho dữ liệu quản lý trên máy chủ bận (sử dụng khối lượng công việc OLTP) là khoảng 4%. Mức giảm hiệu suất có thể khác nhau tùy thuộc vào tần suất thu thập dữ liệu (thử nghiệm được đề cập được thực hiện trong khối lượng công việc kéo dài, với dữ liệu được truyền vào bộ lưu trữ cứ sau 15 phút) và nó cũng có thể tăng mạnh trong thời gian thu thập dữ liệu. Trong mọi trường hợp, bạn nên dự kiến sẽ giảm một số tài nguyên sẵn có vì quy trình DCExec.exe sử dụng một lượng bộ nhớ và tài nguyên CPU nhất định, đồng thời việc ghi vào kho lưu trữ dữ liệu quản lý sẽ làm tăng tải trên hệ thống con I/O và yêu cầu phân bổ không gian trong vị trí của dữ liệu và tệp nhật ký Trong sơ đồ (Hình 2) hiển thị một báo cáo thu thập dữ liệu điển hình.
Cơm. 2:Chế độ xem báo cáo của người thu thập dữ liệuSQL Máy chủ 2008

Báo cáo hiển thị hoạt động của SQL Server trong khoảng thời gian thu thập dữ liệu. Nó thu thập và hiển thị các sự kiện như thời gian chờ, mức sử dụng CPU, I/O và bộ nhớ cũng như số liệu thống kê về các truy vấn sử dụng nhiều tài nguyên. Quản trị viên cũng có thể đi sâu vào các yếu tố báo cáo, tập trung vào yêu cầu riêng hoặc các hoạt động để điều tra, xác định và giải quyết các vấn đề về hiệu suất. Các khả năng thu thập, lưu trữ và báo cáo dữ liệu này cho phép chủ động theo dõi tình trạng của SQLServers trong môi trường của bạn. Khi cần, chúng cho phép bạn xem lại dữ liệu lịch sử để hiểu và đánh giá những thay đổi ảnh hưởng đến hiệu suất trong khoảng thời gian được theo dõi. Trình thu thập dữ liệu và Kho dữ liệu quản lý được hỗ trợ trong tất cả các phiên bản SQLServer 2008 ngoại trừ SQLServerExpress.
nén dữ liệu
Quản lý cơ sở dữ liệu dễ dàng giúp việc thực thi dễ dàng hơn nhiều công việc thường ngày sự quản lý. Khi các bảng, chỉ mục và tệp tăng kích thước và trở nên rất cơ sở dữ liệu lớn quản lý dữ liệu (VLDB) quản lý dữ liệu và làm việc với các tệp cồng kềnh ngày càng trở nên phức tạp. Ngoài ra, nhu cầu ngày càng tăng về bộ nhớ và băng thông I/O vật lý tăng theo khối lượng dữ liệu được yêu cầu cũng làm tăng độ phức tạp quản trị và chi phí cho tổ chức. Kết quả là, trong nhiều trường hợp, quản trị viên và tổ chức phải mở rộng bộ nhớ hoặc băng thông I/O của máy chủ của họ hoặc chấp nhận giảm hiệu suất.
Tính năng nén dữ liệu được giới thiệu trong SQL Server 2008, giúp giải quyết những vấn đề này. Tính năng này cho phép quản trị viên nén có chọn lọc bất kỳ bảng, phân vùng bảng hoặc chỉ mục nào, do đó giảm dung lượng ổ đĩa, dung lượng bộ nhớ và các hoạt động I/O. Nén và giải nén dữ liệu sẽ tải bộ xử lý; tuy nhiên, trong nhiều trường hợp, chi phí bổ sung của CPU được bù đắp nhiều hơn mức tăng I/O. Trong các cấu hình mà I/O là nút cổ chai, việc nén dữ liệu cũng có thể mang lại hiệu suất tăng.
Trong một số thử nghiệm trong phòng thí nghiệm, việc bật nén dữ liệu giúp tiết kiệm 50-80% dung lượng ổ đĩa. Mức tiết kiệm dung lượng rất khác nhau: nếu dữ liệu chứa ít giá trị trùng lặp hoặc các giá trị được sử dụng tất cả byte được phân bổ cho loại dữ liệu đã chỉ định thì mức tiết kiệm là tối thiểu. Tuy nhiên, hiệu suất của nhiều khối lượng công việc không tăng. Tuy nhiên, khi làm việc với dữ liệu chứa nhiều dữ liệu số và nhiều giá trị lặp lại, người ta thấy mức tiết kiệm dung lượng ổ đĩa đáng kể và mức tăng hiệu suất dao động từ vài phần trăm đến 40-60% đối với một số khối lượng công việc truy vấn mẫu.
SQLServer 2008 hỗ trợ hai kiểu nén: nén hàng, nén các cột trong bảng riêng lẻ và nén trang, nén các trang dữ liệu bằng cách sử dụng nén hàng, tiền tố và từ điển. Mức độ nén đạt được rất khác nhau tùy thuộc vào kiểu dữ liệu và nội dung của cơ sở dữ liệu. Nói chung, việc sử dụng tính năng nén hàng giúp giảm chi phí hoạt động của ứng dụng nhưng cũng làm giảm tỷ lệ nén, nghĩa là tiết kiệm được ít dung lượng hơn. Đồng thời, việc nén trang dẫn đến sử dụng CPU và chi phí ứng dụng nhiều hơn nhưng cũng tiết kiệm được nhiều dung lượng hơn đáng kể. Nén trang là siêu tập hợp của nén hàng, nghĩa là, nếu một đối tượng hoặc một phần của đối tượng được nén bằng cách nén trang thì nén hàng cũng được áp dụng cho nó. Ngoài ra, SQLServer 2008 hỗ trợ định dạng lưu trữ số thập phân từ SQL Server 2005 SP2. Xin lưu ý rằng vì định dạng này là một tập hợp con của nén chuỗi nên định dạng này không được dùng nữa và sẽ bị xóa khỏi các phiên bản tương lai của sản phẩm.
Cả nén hàng và nén trang đều có thể được kích hoạt cho một bảng hoặc chỉ mục trong chế độ hoạt động, mà không ảnh hưởng đến tính khả dụng của dữ liệu cho các ứng dụng. Đồng thời, không thể nén hoặc giải nén một phần riêng biệt của bảng được phân vùng ở chế độ trực tuyến mà không tắt nó. Các thử nghiệm đã chỉ ra rằng cách tiếp cận tốt nhất là cách tiếp cận kết hợp, trong đó chỉ một số ít được nén. bàn lớn nhất: Điều này đạt được tỷ lệ tuyệt vời giữa tiết kiệm dung lượng ổ đĩa (đáng kể) và giảm hiệu suất (tối thiểu). Bởi vì một hoạt động thu gọn, như các hoạt động tạo hoặc xây dựng lại chỉ mục, cũng có các yêu cầu về dung lượng ổ đĩa sẵn có nên việc nén phải được thực hiện với các yêu cầu này. Sẽ cần một không gian trống tối thiểu trong quá trình nén nếu quá trình nén bắt đầu với các đối tượng nhỏ nhất.
Bạn có thể nén dữ liệu bằng câu lệnh Transact-SQL hoặc Trình hướng dẫn nén dữ liệu. Để xác định kích thước của một đối tượng có thể thay đổi như thế nào khi nó co lại, bạn có thể sử dụng quy trình lưu sẵn của hệ thống sp_ước lượng_dữ liệu_nén_tiết kiệm hoặc thuật sĩ nén dữ liệu. Nén cơ sở dữ liệu chỉ được hỗ trợ trong phiên bản SQLServer 2008 Enterprise và Developer. Nó được triển khai độc quyền trong cơ sở dữ liệu và không yêu cầu bất kỳ thay đổi nào đối với ứng dụng.
Để biết thêm thông tin về cách sử dụng tính năng nén, hãy xem Tạo bảng và chỉ mục nén.
Quản lý dựa trên chính sách
Trong nhiều tình huống kinh doanh, cần phải duy trì các cấu hình cụ thể hoặc thực thi các chính sách, trên một SQLServer cụ thể hoặc nhiều lần trên một nhóm SQLServer. Quản trị viên hoặc tổ chức có thể yêu cầu một sơ đồ đặt tên cụ thể được áp dụng cho tất cả các bảng người dùng hoặc các thủ tục được lưu trữ đã được tạo hoặc có thể yêu cầu một số thay đổi cấu hình nhất định được áp dụng cho nhiều máy chủ.
Quản lý dựa trên chính sách (PBM) cung cấp cho quản trị viên phạm vi kiểm soát rộng rãi đối với môi trường. Chính sách có thể được tạo và kiểm tra sự tuân thủ. Nếu mục tiêu quét (chẳng hạn như công cụ cơ sở dữ liệu, cơ sở dữ liệu, bảng hoặc chỉ mục SQLServer) không đáp ứng các yêu cầu thì quản trị viên có thể tự động đặt cấu hình lại để đáp ứng các yêu cầu đó. Ngoài ra còn có một số chế độ chính sách (nhiều chế độ được tự động hóa) giúp dễ dàng xác minh việc tuân thủ chính sách, ghi lại các vi phạm chính sách và gửi thông báo, thậm chí khôi phục các thay đổi để đảm bảo tuân thủ chính sách. Để biết thêm thông tin về các chế độ định nghĩa và cách chúng liên quan đến các khía cạnh (khái niệm về quản lý dựa trên chính sách (PBM), cũng được thảo luận trong blog này), hãy xem Blog quản lý dựa trên chính sách của SQL Server.
Các chính sách có thể được xuất và nhập dưới dạng tệp XML để xác định và áp dụng trên nhiều phiên bản máy chủ. Ngoài ra, trong SQLServerQuản lý Studio và dạng xem Máy chủ đã đăng ký, bạn có thể xác định chính sách trên nhiều máy chủ được đăng ký trong nhóm máy chủ cục bộ hoặc nhóm máy chủ quản lý trung tâm.
Ở trước Phiên bản SQL Máy chủ có thể không triển khai tất cả chức năng quản lý dựa trên chính sách. Tuy nhiên, chức năng làm báo cáo các chính sách có thể được sử dụng trên máy chủ SQL Server 2005 và SQL Server 2000. Để biết thêm thông tin về cách sử dụng quản lý dựa trên chính sách, hãy xem Quản trị máy chủ bằng cách sử dụng Quản lý dựa trên chính sách trong Sách SQLServer trực tuyến. Để biết thêm thông tin về chính công nghệ chính sách cùng với các ví dụ, hãy xem Hướng dẫn tuân thủ SQL Server 2008.
Hiệu suất và tính đồng thời được dự đoán
Nhiều quản trị viên phải đối mặt với những thách thức đáng kể khi hỗ trợ SQLServers với khối lượng công việc thay đổi liên tục và đảm bảo mức hiệu suất có thể dự đoán được (hoặc giảm thiểu các biến thể trong kế hoạch truy vấn và hiệu suất). Những thay đổi không mong muốn về hiệu suất truy vấn, những thay đổi trong kế hoạch truy vấn và/hoặc các vấn đề về hiệu suất chung có thể do một số lý do gây ra, bao gồm tải tăng từ các ứng dụng chạy trên SQLServer hoặc bản nâng cấp lên phiên bản của cơ sở dữ liệu. Khả năng dự đoán các truy vấn và hoạt động chạy trên SQLServer giúp đạt được và duy trì các mục tiêu về tính khả dụng, hiệu suất và/hoặc tính liên tục trong kinh doanh dễ dàng hơn nhiều (đáp ứng các thỏa thuận cấp độ dịch vụ và thỏa thuận cấp độ hỗ trợ vận hành).
Trong SQLServer 2008, một số tính năng đã được thay đổi để cải thiện hiệu suất có thể dự đoán được. Do đó, một số thay đổi nhất định đã được thực hiện đối với cấu trúc kế hoạch của SQLServer 2005 ( thống nhất kế hoạch) và thêm khả năng quản lý khóa leo thang ở cấp độ bảng. Cả hai cải tiến đều thúc đẩy các tương tác hợp lý và dễ dự đoán hơn giữa ứng dụng và cơ sở dữ liệu.
Đầu tiên, cấu trúc quy hoạch (Plan Guide):
SQL Server 2005 đã giới thiệu những cải tiến về độ ổn định của truy vấn và khả năng dự đoán thông qua một tính năng mới vào thời điểm đó được gọi là “hướng dẫn kế hoạch”, cung cấp hướng dẫn chạy các truy vấn không thể thay đổi trực tiếp trong ứng dụng. Để biết thêm thông tin, hãy xem sách trắng Thực thi kế hoạch truy vấn. Mặc dù gợi ý truy vấn USE PLAN là một tính năng rất mạnh mẽ nhưng nó chỉ hỗ trợ các thao tác DML SELECT và thường khó sử dụng do tính nhạy cảm của cấu trúc kế hoạch đối với việc định dạng.
SQL Server 2008 mở rộng công cụ hướng dẫn kế hoạch theo hai cách: thứ nhất, nó mở rộng hỗ trợ cho gợi ý truy vấn USE PLAN, hiện tương thích với tất cả các câu lệnh DML (INSERT, UPDATE, DELETE, MERGE); thứ hai, một chức năng mới đã được giới thiệu thống nhất kế hoạch, cho phép bạn trực tiếp tạo bản phác thảo kế hoạch (ghim) của bất kỳ gói truy vấn nào tồn tại trong bộ nhớ đệm gói SQL Server, như minh họa trong ví dụ sau.
sp_create_plan_guide_from_handle
@name = N'MyQueryPlan',
@plan_handle = @plan_handle,
@statement_start_offset = @offset;
Hướng dẫn kế hoạch được tạo theo bất kỳ cách nào đều có vùng cơ sở dữ liệu; nó được lưu trữ trong một bảng sys.plan_guides. Cấu trúc kế hoạch chỉ ảnh hưởng đến quá trình lựa chọn kế hoạch truy vấn của trình tối ưu hóa, nhưng không loại bỏ nhu cầu biên dịch truy vấn. Ngoài ra còn thêm chức năng sys.fn_validate_plan_guide, để xem lại các cấu trúc gói SQL Server 2005 hiện có và đảm bảo chúng tương thích với SQL Server 2008. Ghim gói có sẵn trong các phiên bản SQL Server 2008 Standard, Enterprise và Developer.
Thứ hai, leo thang chặn:
Việc chặn leo thang thường gây ra sự cố chặn và đôi khi thậm chí là bế tắc. Quản trị viên đã phải khắc phục những vấn đề này. Trong các phiên bản trước của SQLServer, có thể kiểm soát việc leo thang khóa (cờ theo dõi 1211 và 1224), nhưng điều này chỉ có thể thực hiện được ở mức độ chi tiết ở cấp phiên bản. Đối với một số ứng dụng, điều này đã khắc phục được sự cố nhưng đối với những ứng dụng khác, nó lại gây ra nhiều sự cố hơn. vấn đề lớn. Một lỗ hổng khác trong thuật toán leo thang khóa của SQL Server 2005 là các khóa trên các bảng được phân vùng được leo thang trực tiếp lên cấp độ bảng chứ không phải đến cấp độ phân vùng.
SQLServer 2008 cung cấp giải pháp cho cả hai vấn đề. Nó thực hiện tham số mới, cho phép bạn kiểm soát việc leo thang khóa ở cấp độ bảng. Sử dụng lệnh ALTERTABLE, bạn có thể chọn tắt leo thang hoặc leo thang lên cấp phân vùng cho các bảng được phân vùng. Cả hai tính năng này đều cải thiện khả năng mở rộng và hiệu suất mà không có tác dụng phụ không mong muốn ảnh hưởng đến các đối tượng khác trong phiên bản. Khóa leo thang được đặt ở cấp đối tượng cơ sở dữ liệu và không yêu cầu bất kỳ thay đổi ứng dụng nào. Nó được hỗ trợ trong tất cả các phiên bản SQLServer 2008.
Thống đốc tài nguyên
Việc duy trì mức độ dịch vụ bền vững bằng cách ngăn chặn các yêu cầu không thực hiện được và đảm bảo nguồn lực được phân bổ cho khối lượng công việc quan trọng trước đây là một thách thức. Không có cách nào để đảm bảo việc phân bổ một lượng tài nguyên nhất định cho một nhóm yêu cầu và không có quyền kiểm soát các ưu tiên truy cập. Tất cả các yêu cầu đều có quyền bình đẳng trong việc truy cập tất cả các tài nguyên có sẵn.
Mới hàm SQL Resource Governor của Server 2008 giúp giải quyết vấn đề này bằng cách cung cấp khả năng phân biệt khối lượng công việc và phân bổ tài nguyên dựa trên nhu cầu của người dùng. Các giới hạn của Resource Governor có thể dễ dàng được cấu hình lại theo thời gian thực với tác động tối thiểu đến khối lượng công việc đang chạy. Việc phân phối khối lượng công việc trên nhóm tài nguyên được định cấu hình ở cấp độ kết nối và quy trình này hoàn toàn minh bạch đối với các ứng dụng.
Sơ đồ dưới đây cho thấy quá trình phân bổ nguồn lực. Trong trường hợp này, bạn đặt cấu hình ba nhóm khối lượng công việc (khối lượng công việc Quản trị, OLTP và Báo cáo) rồi chỉ định nhóm khối lượng công việc OLTP mức ưu tiên cao nhất. Đồng thời, hai nhóm tài nguyên được định cấu hình (Nhóm nhóm và Nhóm ứng dụng) với các giới hạn được chỉ định về kích thước bộ nhớ và thời gian của bộ xử lý (CPU). Bước cuối cùng là chỉ định khối lượng công việc Quản trị viên cho Nhóm quản trị và chỉ định khối lượng công việc OLTP và Báo cáo cho Nhóm ứng dụng.

Sau đây là các tính năng cần cân nhắc khi sử dụng bộ điều chỉnh tài nguyên.
- Resource Governor sử dụng thông tin xác thực đăng nhập, tên máy chủ hoặc tên ứng dụng làm "mã định danh nhóm tài nguyên", do đó, việc sử dụng một thông tin đăng nhập duy nhất cho mỗi ứng dụng cho một số lượng khách hàng nhất định trên mỗi máy chủ có thể khiến việc tổng hợp trở nên khó khăn hơn.
- Nhóm đối tượng ở cấp cơ sở dữ liệu, nơi quyền truy cập vào tài nguyên được kiểm soát dựa trên các đối tượng cơ sở dữ liệu đang được truy cập, không được hỗ trợ.
— Bạn chỉ có thể định cấu hình việc sử dụng tài nguyên bộ xử lý và bộ nhớ. Quản lý tài nguyên I/O không được triển khai.
- Không thể chuyển đổi động khối lượng công việc giữa các nhóm tài nguyên sau khi kết nối.
- Resource Governor chỉ được hỗ trợ trong các phiên bản SQL Server 2008 Enterprise và Developer và chỉ có thể được sử dụng cho SQL Server Database Engine; Quản lý dịch vụ SQL Phân tích máy chủ Dịch vụ (SSAS), Dịch vụ tích hợp máy chủ SQL (SSIS) và Dịch vụ báo cáo máy chủ SQL (SSRS) không được hỗ trợ.
Mã hóa minh bạch dữ liệu (TDE)
Nhiều tổ chức rất quan tâm đến vấn đề bảo mật. Có nhiều lớp khác nhau bảo vệ một trong những tài sản quý giá nhất của tổ chức—dữ liệu của nó. Thông thường, các tổ chức bảo vệ thành công dữ liệu đang được sử dụng thông qua các biện pháp bảo mật vật lý, tường lửa và các chính sách hạn chế truy cập nghiêm ngặt. Tuy nhiên, trong trường hợp mất Phương tiện vật lý với dữ liệu, chẳng hạn như đĩa hoặc băng có bản sao lưu, tất cả các biện pháp bảo mật được liệt kê đều vô ích, vì kẻ tấn công có thể chỉ cần khôi phục cơ sở dữ liệu và lấy toàn quyền truy cập vào dữ liệu. SQL
Server 2008 đưa ra giải pháp cho vấn đề này thông qua Mã hóa dữ liệu trong suốt (TDE). Với mã hóa TDE, dữ liệu trong hoạt động I/O được mã hóa và giải mã theo thời gian thực; Các tệp dữ liệu và nhật ký được mã hóa bằng Khóa mã hóa cơ sở dữ liệu (DEK). DEK là khóa đối xứng được bảo vệ bởi chứng chỉ được lưu trữ trong cơ sở dữ liệu chính của máy chủ hoặc khóa bất đối xứng được bảo vệ bởi Mô-đun quản lý khóa mở rộng (EKM).
Tính năng TDE bảo vệ dữ liệu ở trạng thái nghỉ để dữ liệu được tập tin MDF, NDF và LDF không thể được xem bằng trình soạn thảo hex hoặc bất kỳ phương pháp nào khác. Tuy nhiên, dữ liệu hiện hoạt, chẳng hạn như kết quả của câu lệnh CHỌN trong SQL Server Management Studio, sẽ vẫn hiển thị đối với những người dùng có quyền xem bảng. Ngoài ra, do TDE được triển khai ở cấp cơ sở dữ liệu nên cơ sở dữ liệu có thể sử dụng các chỉ mục và khóa để tối ưu hóa các truy vấn. Không nên nhầm lẫn TDE với mã hóa cấp độ cột - nó là chức năng riêng biệt, cho phép bạn mã hóa ngay cả dữ liệu đang hoạt động.
Mã hóa cơ sở dữ liệu là quy trình một lần có thể được bắt đầu bằng lệnh Transact - SQL hoặc từ SQL Server Management Studio, sau đó chạy trên một luồng nền. Trạng thái mã hóa hoặc giải mã có thể được theo dõi bằng chế độ xem quản lý động sys.dm_database_encryption_keys. Trong các thử nghiệm trong phòng thí nghiệm, cơ sở dữ liệu 100 GB đã được mã hóa bằng thuật toán Mã hóa AES _128 mất khoảng một giờ. Mặc dù chi phí sử dụng TDE được xác định chủ yếu bởi khối lượng công việc của ứng dụng, nhưng trong một số thử nghiệm được tiến hành, chi phí này thấp hơn 5%. Một điều cần lưu ý là điều đó có thể ảnh hưởng đến hiệu suất là nếu TDE được sử dụng trên bất kỳ cơ sở dữ liệu nào trong phiên bản thì cơ sở dữ liệu hệ thống cũng được mã hóa tempDB. Cuối cùng, khi sử dụng đồng thời các chức năng khác nhau Những điều sau đây phải được tính đến:
- Khi bạn sử dụng tính năng nén sao lưu để nén cơ sở dữ liệu được mã hóa, kích thước của bản sao lưu đã nén sẽ lớn hơn so với khi không sử dụng mã hóa vì dữ liệu được mã hóa được nén kém.
- Mã hóa cơ sở dữ liệu không ảnh hưởng đến việc nén dữ liệu (hàng hoặc trang).
TDE cho phép tổ chức đảm bảo tuân thủ các tiêu chuẩn quy định và mức độ bảo vệ dữ liệu tổng thể. TDE chỉ được hỗ trợ trong các phiên bản SQL Server 2008 Enterprise và Developer; việc kích hoạt nó không yêu cầu thay đổi các ứng dụng hiện có. Để biết thêm thông tin, hãy xem Mã hóa dữ liệu trong SQL Server 2008 Enterprise Edition hoặc thảo luận trong Mã hóa dữ liệu minh bạch.
Tóm lại, SQL Server 2008 cung cấp các tính năng, cải tiến và khả năng giúp công việc quản trị viên cơ sở dữ liệu của bạn trở nên dễ dàng hơn. 10 tính năng phổ biến nhất được mô tả ở đây, nhưng SQL Server 2008 có nhiều tính năng khác giúp quản trị viên và những người dùng khác dễ dàng hơn. Danh sách "10 tính năng tốt nhất" về các lĩnh vực làm việc với SQL Server khác có thể được tìm thấy trong các bài viết khác "Top 10... trong SQL Server 2008" trên trang này. Để biết danh sách đầy đủ các tính năng và mô tả chi tiết của chúng, hãy xem Sách trực tuyến về SQL Server và trang web tổng quan về SQL Server 2008.
Môi trường SQL Server cung cấp một số cấu trúc điều khiển khác nhau, nếu không có cấu trúc đó thì không thể viết được các thuật toán hiệu quả.
Nhóm hai hoặc nhiều đội thành khối đơnđược thực hiện bằng cách sử dụng từ khóa BEGIN và END:
<блок_операторов>::=
Các lệnh được nhóm được trình thông dịch SQL coi là một lệnh duy nhất. Một nhóm tương tự là cần thiết cho các cấu trúc phân nhánh, có điều kiện và tuần hoàn đa biến. Các khối BEGIN...END có thể được lồng vào nhau.
Một số lệnh SQL không nên chạy cùng với các lệnh khác ( Chúng ta đang nói về về các lệnh sao lưu, thay đổi cấu trúc của bảng, các thủ tục được lưu trữ và những thứ tương tự), do đó việc đưa chúng vào cấu trúc BEGIN...END là không được phép.
Thông thường một phần nhất định của chương trình chỉ phải được thực thi nếu một số điều kiện logic. Cú pháp của câu lệnh điều kiện được hiển thị dưới đây:
<условный_оператор>::=
NẾU log_biểu thức
( sql_statement | câu lệnh_block )
(sql_statement | tuyên bố_block)]
Các vòng lặp được tổ chức bằng cách sử dụng cấu trúc sau:
<оператор_цикла>::=
KHI log_biểu thức
( sql_statement | câu lệnh_block )
( sql_statement | câu lệnh_block )
Vòng lặp có thể bị dừng cưỡng bức bằng cách thực thi lệnh BREAK trong phần thân của vòng lặp. Nếu bạn cần bắt đầu lại vòng lặp mà không đợi tất cả các lệnh trong phần thân được thực thi, bạn phải thực thi lệnh CONTINUE.
Để thay thế nhiều câu lệnh điều kiện đơn lẻ hoặc lồng nhau, hãy sử dụng cấu trúc sau:
<оператор_поливариантных_ветвлений>::=
TRƯỜNG HỢP đầu vào_giá trị
KHI NÀO (so sánh_value |
log_biểu thức) SAU ĐÓ
biểu thức đầu ra [,...n]
[ ELSE nếu không_out_biểu thức]
Nếu giá trị đầu vào và giá trị so sánh giống nhau thì cấu trúc trả về giá trị đầu ra. Nếu không tìm thấy giá trị của tham số đầu vào trong bất kỳ dòng WHEN...THEN nào, thì giá trị được chỉ định sau từ khóa ELSE sẽ được trả về.
Các đối tượng cơ bản của cấu trúc cơ sở dữ liệu máy chủ SQL
Chúng ta hãy nhìn vào cấu trúc logic của cơ sở dữ liệu.
Cấu trúc logic xác định cấu trúc của các bảng, mối quan hệ giữa chúng, danh sách người dùng, thủ tục được lưu trữ, quy tắc, mặc định và các đối tượng cơ sở dữ liệu khác.
Về mặt logic, dữ liệu trong SQL Server được tổ chức thành các đối tượng. Các đối tượng cơ sở dữ liệu SQL Server chính bao gồm các đối tượng sau.
Đánh giá ngắnđối tượng cơ sở dữ liệu chính.
Những cái bàn
Tất cả dữ liệu trong SQL được chứa trong các đối tượng được gọi là những cái bàn. Các bảng biểu thị một tập hợp bất kỳ thông tin nào về các đối tượng, hiện tượng, quá trình của thế giới thực. Không có đối tượng nào khác lưu trữ dữ liệu nhưng chúng có thể truy cập dữ liệu trong bảng. Các bảng trong SQL có cấu trúc giống như các bảng trong tất cả các DBMS khác và chứa:
· dòng; mỗi dòng (hoặc bản ghi) biểu thị một tập hợp các thuộc tính (thuộc tính) của một thể hiện cụ thể của một đối tượng;
· cột; mỗi cột (trường) đại diện cho một thuộc tính hoặc tập hợp các thuộc tính. Trường hàng là phần tử tối thiểu của bảng. Mỗi cột trong bảng có tên, kiểu dữ liệu và kích thước cụ thể.
đại diện
Chế độ xem là các bảng ảo có nội dung được xác định bằng một truy vấn. Giống như các bảng thực, các khung nhìn chứa các cột và hàng dữ liệu được đặt tên. Đối với người dùng cuối, dạng xem trông giống như một bảng nhưng thực tế nó không chứa dữ liệu mà biểu thị dữ liệu nằm trong một hoặc nhiều bảng. Thông tin mà người dùng nhìn thấy qua chế độ xem không được lưu trữ trong cơ sở dữ liệu dưới dạng một đối tượng riêng biệt.
Thủ tục lưu trữ
Các thủ tục lưu trữ là một nhóm các lệnh SQL được kết hợp thành một mô-đun. Nhóm lệnh này được biên dịch và thực thi dưới dạng một đơn vị duy nhất.
Gây nên
Trình kích hoạt là một lớp thủ tục lưu trữ đặc biệt được tự động khởi chạy khi dữ liệu được thêm, thay đổi hoặc xóa khỏi bảng.
Chức năng
Hàm trong ngôn ngữ lập trình là cấu trúc chứa mã được thực thi thường xuyên. Hàm thực hiện một số hành động với dữ liệu và trả về một số giá trị.
Chỉ mục
Chỉ mục là một cấu trúc được liên kết với một bảng hoặc dạng xem và được thiết kế để tăng tốc độ tìm kiếm thông tin trong đó. Một chỉ mục được xác định trên một hoặc nhiều cột, được gọi là cột được lập chỉ mục. Nó chứa các giá trị được sắp xếp của một cột hoặc các cột được lập chỉ mục có tham chiếu đến hàng tương ứng trong bảng hoặc dạng xem nguồn. Cải thiện năng suất đạt được bằng cách sắp xếp dữ liệu. Việc sử dụng chỉ mục có thể cải thiện đáng kể hiệu suất tìm kiếm, nhưng việc lưu trữ chỉ mục đòi hỏi không gian thêm trong cơ sở dữ liệu.
©2015-2019 trang web
Tất cả các quyền thuộc về tác giả của họ. Trang web này không yêu cầu quyền tác giả nhưng cung cấp quyền sử dụng miễn phí.
Ngày tạo trang: 2016-08-08
Nếu bạn đã từng viết các lược đồ khóa bằng các ngôn ngữ cơ sở dữ liệu khác để khắc phục tình trạng thiếu khóa (như tôi đã làm), bạn có thể có cảm giác rằng bạn phải tự mình giải quyết việc khóa. Hãy để tôi đảm bảo với bạn rằng trình quản lý khóa có thể được tin cậy hoàn toàn. Tuy nhiên, SQL Server cung cấp một số phương pháp quản lý khóa mà chúng ta sẽ thảo luận chi tiết trong phần này.
Không áp dụng cài đặt chặn hoặc thay đổi mức độ cách ly ngẫu nhiên- Tin tưởng vào trình quản lý khóa SQL Server để cân bằng sự tranh chấp và tính toàn vẹn của giao dịch. Chỉ khi bạn hoàn toàn chắc chắn rằng lược đồ cơ sở dữ liệu được cấu hình tốt và mã chương trình được đánh bóng theo đúng nghĩa đen, bạn mới có thể điều chỉnh một chút hành vi của trình quản lý khóa để giải quyết một vấn đề cụ thể. Trong một số trường hợp, việc đặt truy vấn chọn thành không khóa sẽ giải quyết được hầu hết các vấn đề.
Đặt mức cách ly kết nối
Mức cô lập xác định thời lượng chặn kết nối chung hoặc độc quyền. Việc đặt mức cách ly sẽ ảnh hưởng đến tất cả các truy vấn và tất cả các bảng được sử dụng trong suốt thời gian kết nối hoặc cho đến khi một mức cách ly được thay thế rõ ràng bằng một mức cách ly khác. Ví dụ sau đặt mức cách ly chặt chẽ hơn so với mặc định và ngăn các lần đọc không lặp lại:
THIẾT LẬP MỨC ĐỘ CÔ LẬP GIAO DỊCH ĐỌC LẶP LẠI Các mức cách ly hợp lệ là:
Đọc không cam kết? có thể tuần tự hóa
Đọc cam kết? ảnh chụp nhanh
Đọc lặp lại
Bạn có thể kiểm tra mức cách ly hiện tại của mình bằng lệnh Kiểm tra tính toàn vẹn cơ sở dữ liệu (DBCC):
CÁC LỰA CHỌN SỬ DỤNG DBCC
Kết quả sẽ như sau (viết tắt):
Đặt giá trị tùy chọn
đọc lặp lại mức cô lập
Mức cô lập cũng có thể được đặt ở cấp độ truy vấn hoặc bảng bằng cách sử dụng các tùy chọn khóa.
Sử dụng cách ly cấp độ ảnh chụp cơ sở dữ liệu
Có hai tùy chọn cho mức độ cô lập của ảnh chụp nhanh cơ sở dữ liệu: ảnh chụp nhanh và ảnh chụp nhanh đã cam kết đọc. Cách ly ảnh chụp nhanh hoạt động giống như đọc lặp lại mà không xử lý các vấn đề về khóa. Cách ly ảnh chụp nhanh đã cam kết đọc bắt chước mức độ cam kết đọc mặc định của SQL Server, đồng thời loại bỏ các vấn đề về khóa.
Trong khi cách ly giao dịch thường được cấu hình ở cấp độ kết nối thì cách ly ảnh chụp nhanh phải được cấu hình ở cấp cơ sở dữ liệu vì nó
theo dõi hiệu quả phiên bản của các hàng trong cơ sở dữ liệu. Lập phiên bản hàng là công nghệ tạo bản sao của các hàng trong cơ sở dữ liệu TempDB để cập nhật. Ngoài việc tải cơ sở dữ liệu TempDB chính, việc lập phiên bản hàng còn thêm mã định danh hàng 14 byte.
Sử dụng tính năng cách ly ảnh chụp nhanh
Đoạn mã sau đây cho phép mức cô lập ảnh chụp nhanh. Để cập nhật cơ sở dữ liệu và kích hoạt mức cách ly ảnh chụp nhanh, không cần thiết lập kết nối nào khác với cơ sở dữ liệu này.
THAY ĐỔI CƠ SỞ DỮ LIỆU Aesop
BẬT ALLOW_SNAPSHOT_ISOLATION
| Để kiểm tra xem tính năng cách ly ảnh chụp nhanh có được bật trên cơ sở dữ liệu hay không, hãy chạy truy vấn SVS sau: SELECT name, snapshot_isolation_state_desc FROM [ * sysdatabases.
Bây giờ giao dịch đầu tiên bắt đầu đọc và vẫn mở (tức là chưa được cam kết): SỬ DỤNG Aesop
BEGIN TRAN CHỌN Tiêu đề TỪ FABLE Ở ĐÂU FablD = 2
Kết quả sau đây sẽ thu được:
Tại thời điểm này, giao dịch thứ hai bắt đầu cập nhật cùng hàng đã được mở bởi giao dịch đầu tiên:
THIẾT LẬP Ảnh chụp mức độ cô lập giao dịch;
BEGIN TRAN UPDATE Truyện ngụ ngôn
SET Tiêu đề = ‘Rung chuyển bằng ảnh chụp nhanh’
Ở ĐÂU FablD = 2;
CHỌN * TỪ FABLE Ở ĐÂU FablD = 2
Kết quả là như sau:
Lắc lư với ảnh chụp nhanh
Điều đó không đáng ngạc nhiên sao? Giao dịch thứ hai có thể cập nhật hàng mặc dù giao dịch đầu tiên vẫn mở. Hãy quay lại giao dịch đầu tiên và xem dữ liệu gốc:
CHỌN Tiêu đề TỪ FABLE Ở ĐÂU FablD = 2
Kết quả là như sau:
Nếu bạn mở giao dịch thứ ba và thứ tư, họ sẽ thấy giá trị ban đầu của The Bald Knight như nhau:
Ngay cả sau khi giao dịch thứ hai thực hiện các thay đổi, giao dịch đầu tiên vẫn sẽ thấy giá trị ban đầu và tất cả các giao dịch tiếp theo sẽ thấy giá trị mới, Rocking with Snapshots.
Sử dụng ISOLATION Đọc ảnh chụp nhanh đã cam kết
Đọc cách ly ảnh chụp nhanh đã cam kết được bật bằng cú pháp tương tự:
THAY ĐỔI CƠ SỞ DỮ LIỆU Aesop
BẬT READ_COMMITTED_SNAPSHOT
Tương tự với Cách ly ảnh chụp nhanh, cấp độ nàyĐể loại bỏ các vấn đề chặn, nó cũng sử dụng phiên bản chuỗi. Sử dụng ví dụ được mô tả ở phần trước làm cơ sở, trong trường hợp này, giao dịch đầu tiên sẽ thấy những thay đổi được thực hiện bởi giao dịch thứ hai ngay khi chúng được cam kết.
Vì Read Commited là mức cô lập mặc định trong SQL Server nên chỉ cần thiết lập các tham số cơ sở dữ liệu.
Giải quyết xung đột viết
Các giao dịch ghi dữ liệu trong khi mức cách ly Ảnh chụp nhanh được đặt có thể bị chặn bởi các giao dịch ghi không được cam kết trước đó. Việc khóa như vậy sẽ không khiến giao dịch mới phải chờ - nó sẽ chỉ tạo ra lỗi. Để xử lý tình huống tương tự sử dụng biểu thức thử. . . bắt, đợi vài giây và thử lại giao dịch.
Sử dụng tùy chọn chặn
Các tham số chặn cho phép bạn thực hiện các điều chỉnh tạm thời đối với chiến lược chặn. Trong khi mức cô lập ảnh hưởng đến toàn bộ kết nối, các tùy chọn khóa lại dành riêng cho từng bảng trong một truy vấn cụ thể (Bảng 51.5). Tùy chọn VỚI (lock_option) được đặt sau tên bảng trong mệnh đề FROM của truy vấn. Đối với mỗi bảng, bạn có thể chỉ định nhiều tham số, được phân tách bằng dấu phẩy.
|
Bảng 51.5. Tùy chọn chặn |
Tham số chặn |
Sự miêu tả |
Mức độ cô lập. Không đặt hoặc giữ khóa. Tương đương với không chặn |
Mức cô lập giao dịch mặc định |
Mức độ cô lập. Giữ các khóa chia sẻ và độc quyền cho đến khi giao dịch được xác nhận |
Mức độ cô lập. Giữ khóa chung cho đến khi giao dịch hoàn tất |
Bỏ qua các hàng bị chặn thay vì chờ đợi |
Cho phép khóa ở cấp hàng thay vì cấp trang, phạm vi hoặc bảng |
Bật khóa cấp trang thay vì khóa cấp bảng |
Tự động chuyển khóa cấp độ hàng, trang và phạm vi sang mức độ chi tiết của bảng |
Tham số chặn |
Sự miêu tả |
Không áp dụng hoặc duy trì ổ khóa. Tương tự như ReadUnCommitd |
Kích hoạt khóa bảng độc quyền. Ngăn chặn các giao dịch khác hoạt động với bảng |
Giữ khóa chia sẻ cho đến khi giao dịch được thực hiện (giống như Serializable) |
Sử dụng khóa cập nhật thay vì khóa chung và giữ nó. Khóa ghi khác vào dữ liệu giữa lần đọc và ghi ban đầu |
Giữ khóa dữ liệu độc quyền cho đến khi giao dịch được xác nhận |
Ví dụ sau đây sử dụng tùy chọn khóa trong mệnh đề FROM của câu lệnh UPDATE để ngăn người quản lý tăng mức độ chi tiết của khóa:
SỬ DỤNG CẬP NHẬT OBXKites Sản phẩm
TỪ Sản phẩm VỚI (RowLock)
SET ProductName = ProductName + ' Đã cập nhật 1
Nếu một truy vấn chứa các truy vấn phụ, hãy lưu ý rằng quyền truy cập vào bảng của mỗi truy vấn sẽ tạo ra một khóa có thể được kiểm soát bằng các tham số.
Hạn chế khóa cấp chỉ mục
Mức độ cô lập và cài đặt chặn được áp dụng ở cấp độ kết nối và yêu cầu. Cách duy nhất để quản lý khóa cấp bảng là hạn chế mức độ chi tiết của khóa dựa trên các chỉ mục cụ thể. Bằng cách sử dụng thủ tục lưu trữ của hệ thống sp_indexoption, khóa hàng và/hoặc trang có thể bị vô hiệu hóa đối với một chỉ mục cụ thể bằng cú pháp sau: sp_indexoption 'index_name 1 .
AllowRowlocks hoặc AllowPagelocks,
Điều này có thể hữu ích trong một số trường hợp đặc biệt. Nếu bảng thường xuyên gặp phải tình trạng chờ do khóa trang thì việc tắt allowpagelocks sẽ thiết lập khóa cấp hàng. Độ chi tiết của khóa giảm sẽ có tác động tích cực đến cạnh tranh. Ngoài ra, nếu bảng hiếm khi được cập nhật nhưng được đọc thường xuyên thì việc khóa cấp hàng và cấp trang là không cần thiết; Trong trường hợp này, mức khóa tối ưu là ở cấp độ bảng. Nếu việc cập nhật được thực hiện không thường xuyên thì việc khóa độc quyền trên các bảng sẽ không gây ra nhiều vấn đề.
Thủ tục lưu trữ Sp_indexoption dành cho tinh chỉnh lược đồ dữ liệu; đó là lý do tại sao nó sử dụng khóa cấp chỉ mục. Để hạn chế khóa trên khóa chính của bảng, hãy sử dụng sp_help table_name để tìm tên của chỉ mục khóa chính.
Lệnh sau đây định cấu hình bảng ProductCategory làm bộ phân loại được cập nhật không thường xuyên. Lệnh sp_help trước tiên hiển thị tên chỉ mục khóa chính của bảng: sp_help ProductCategory
Kết quả (cắt ngắn) là:
chỉ số chỉ số chỉ số
phím mô tả tên
PK_____________ Danh mục sản phẩm 79A814 03 không bao gồm, Danh mục sản phẩmD
khóa chính, duy nhất nằm trên PRIMARY
Trong kho tên thật khóa chính, thủ tục lưu trữ của hệ thống có thể đặt các tham số khóa chỉ mục:
EXEC sp_indexoption
'Danh mục sản phẩm.РК__ Danh mục sản phẩm_______ 7 9A814 03',
'Cho phépRowlocks', sp_indexoption FALSE EXEC
'Danh mục sản phẩm.PK__ Danh mục sản phẩm _______ 79A81403',
'Cho phépPagelocks', SAI
Quản lý thời gian chờ khóa
Nếu một giao dịch đang chờ khóa thì việc chờ đợi này sẽ tiếp tục cho đến khi có thể khóa. Theo mặc định không có giới hạn thời gian chờ - về mặt lý thuyết nó có thể tồn tại mãi mãi.
May mắn thay, bạn có thể đặt thời gian chờ khóa bằng tùy chọn kết nối set lock_timeout. Đặt tham số này theo số mili giây hoặc nếu bạn không muốn giới hạn thời gian, hãy đặt thành -1 (là mặc định). Nếu tham số này được đặt thành 0, giao dịch sẽ bị từ chối ngay lập tức nếu có bất kỳ sự chặn nào. Trong trường hợp này, ứng dụng sẽ cực kỳ nhanh nhưng không hiệu quả.
Yêu cầu sau đây đặt thời gian chờ khóa thành hai giây (2000 mili giây):
SET Lock_Timeout 2 00 0
Nếu giao dịch vượt quá giới hạn thời gian chờ được định cấu hình, số lỗi 1222 sẽ được tạo.
Tôi thực sự khuyên bạn nên đặt giới hạn thời gian chờ khóa ở cấp độ kết nối. Giá trị này được chọn dựa trên hiệu suất điển hình của cơ sở dữ liệu. Tôi thích đặt thời gian chờ là năm giây.
Đánh giá hiệu suất tranh chấp cơ sở dữ liệu
Rất dễ dàng để tạo một cơ sở dữ liệu không giải quyết các vấn đề tranh chấp và khóa khi thử nghiệm trên một nhóm người dùng. Thử nghiệm thực tế- đây là lúc hàng trăm người dùng đồng loạt cập nhật đơn hàng.
Kiểm tra cạnh tranh cần phải được tổ chức hợp lý. Ở một cấp độ, nó phải chứa đựng việc sử dụng đồng thời cùng một hình thức cuối cùng của nhiều người dùng. Một chương trình .NET liên tục mô phỏng
người dùng xem và cập nhật dữ liệu. Một thử nghiệm tốt sẽ chạy 20 phiên bản của tập lệnh tải cơ sở dữ liệu liên tục, sau đó cho phép nhóm thử nghiệm sử dụng ứng dụng. Số lượng khóa sẽ giúp bạn xem màn hình hiệu suất được thảo luận trong Chương 49.
Tốt hơn là bạn nên thử nghiệm tính cạnh tranh nhiều người chơi nhiều lần trong quá trình phát triển. Như sách hướng dẫn thi MCSE nói, “đừng đặt bài kiểm tra thực tế lên hàng đầu”.
Khóa ứng dụng
SQL Server sử dụng rất mạch phức tạp chặn. Đôi khi một quy trình hoặc tài nguyên không phải là dữ liệu cần có khóa. Ví dụ: có thể cần phải chạy một quy trình gây hại nếu người dùng khác chạy một phiên bản khác của cùng quy trình.
Cách đây vài năm, tôi đã viết một chương trình đi cáp trong các dự án nhà máy điện hạt nhân. Sau khi thiết kế và thử nghiệm hình dạng của nhà máy, các kỹ sư sẽ nhập thành phần cáp, vị trí và loại cáp được sử dụng. Sau khi lắp một số dây cáp vào, chương trình đã hình thành lộ trình đặt chúng sao cho càng ngắn càng tốt. Quy trình này cũng đã tính đến các vấn đề an toàn hệ thống cáp và tách các cáp không tương thích. Đồng thời, nếu nhiều quy trình định tuyến được chạy đồng thời, mỗi phiên bản sẽ cố gắng định tuyến cùng một loại cáp, dẫn đến kết quả không chính xác. Chặn ứng dụng đã trở thành một giải pháp tuyệt vời cho vấn đề này.
Khóa ứng dụng mở ra cả một thế giới khóa SQL để sử dụng trong các ứng dụng. Thay vì sử dụng dữ liệu làm tài nguyên có thể khóa, khóa ứng dụng sẽ khóa việc sử dụng tất cả tài nguyên người dùng được khai báo trong thủ tục lưu trữ sp__GetAppLock.
Khóa ứng dụng có thể được áp dụng trong các giao dịch; trong trường hợp này, chế độ chặn có thể là Chia sẻ, Cập nhật, Độc quyền, IntentExclusice hoặc IntentShared. Giá trị trả về từ thủ tục cho biết liệu khóa có được áp dụng thành công hay không.
0. Khóa đã được cài đặt thành công.
1. Khóa được lấy khi một thủ tục khác giải phóng khóa của nó.
999. Khóa không được cài vì lý do khác.
Thủ tục lưu trữ sp_ReleaseApLock giải phóng khóa. Ví dụ sau đây minh họa cách sử dụng khóa ứng dụng theo lô hoặc quy trình: KHAI THÁC @ShareOK INT EXEC @ShareOK = sp_GetAppLock
@Resource = 'CableWorm',
@LockMode = 'Độc quyền'
NẾU @ShareOK< 0
...Lỗi xử lý mã
... Mã chương trình ...
EXEC sp_ReleaseAppLock @Resource = 'CableWorm'
Khi khóa ứng dụng được xem bằng Management Studio hoặc sp_Lock, chúng sẽ xuất hiện cùng loại APP. Danh sách sau đây là kết quả rút gọn của sp_Lock chạy cùng lúc với đoạn mã trên: spid dbid Objld Indld Type Resource Mode Status
57 8 0 0 APP Cabllf 94cl36 X CẤP
Có hai điểm khác biệt nhỏ cần lưu ý về cách xử lý khóa ứng dụng trong SQL Server:
Bế tắc không được phát hiện tự động;
Nếu một giao dịch nhận được khóa nhiều lần thì giao dịch đó phải giải phóng khóa đó với số lần chính xác như nhau.
Bế tắc
Bế tắc là một tình huống đặc biệt chỉ xảy ra khi các giao dịch có nhiều tác vụ cạnh tranh tài nguyên của nhau. Ví dụ: giao dịch đầu tiên đã có được khóa tài nguyên A và cần khóa tài nguyên B, đồng thời giao dịch thứ hai đã khóa tài nguyên B cần khóa tài nguyên A.
Mỗi giao dịch này chờ giao dịch kia mở khóa và không thể hoàn thành cho đến khi điều này xảy ra. Nếu không có tác động từ bên ngoài hoặc một trong các giao dịch kết thúc vì một lý do nhất định (ví dụ: do hết thời gian chờ), thì tình trạng này có thể tiếp tục cho đến ngày tận thế.
Bế tắc từng là một vấn đề nghiêm trọng, nhưng SQL Server giờ đây có thể giải quyết chúng thành công.
Tạo bế tắc
Cách dễ nhất để tạo tình huống bế tắc trong SQL Server là sử dụng hai kết nối trong trình soạn thảo truy vấn của Management Studio (Hình 51.12). Giao dịch thứ nhất và thứ hai cố gắng cập nhật cùng một hàng nhưng theo thứ tự ngược lại. Sử dụng cửa sổ thứ ba để chạy quy trình pGetLocks, bạn có thể giám sát các khóa.
1. Tạo cửa sổ thứ hai trong trình soạn thảo truy vấn.
2. Đặt mã khối Bước 2 vào cửa sổ thứ hai.
3. Đặt mã khối Bước 1 vào cửa sổ đầu tiên và nhấn phím
4. Trong cửa sổ thứ hai, thực hiện tương tự đoạn mã Bước 2.
5. Quay lại cửa sổ đầu tiên và thực thi mã khối Bước 3.
6. Sau một khoảng thời gian ngắn, SQL Server sẽ phát hiện bế tắc và tự động giải quyết.
Dưới đây là mã ví dụ.
– Giao dịch 1 — Bước 1 SỬ DỤNG OBXKites BẮT ĐẦU CẬP NHẬT GIAO DỊCH Liên hệ
ĐẶT Họ = 'Jorgenson'
Ở ĐÂU Mã liên hệ = 401′
Phúc. 51.12. Tạo tình huống bế tắc trong Management Studio bằng hai kết nối (cửa sổ của chúng nằm ở trên cùng)
Bây giờ giao dịch đầu tiên đã có được khóa độc quyền trên bản ghi có giá trị 101 trong trường Mã liên hệ. Giao dịch thứ hai sẽ có được khóa độc quyền trên hàng có giá trị 1001 trong trường Mã sản phẩm, sau đó cố gắng khóa độc quyền bản ghi đã bị khóa bởi giao dịch đầu tiên (Mã liên hệ=101).
– Giao dịch 2 — Bước 2 SỬ DỤNG OBXKites BẮT ĐẦU CẬP NHẬT GIAO DỊCH BỘ SẢN PHẨM Tên sản phẩm
= 'Bộ sửa chữa DeadLock'
Ở ĐÂU Mã sản phẩm = '1001'
SET FirstName = 'Neals'
Ở ĐÂU Mã liên hệ = '101'
CAM KẾT GIAO DỊCH
Vẫn chưa có bế tắc vì giao dịch 2 đang chờ giao dịch 1 hoàn thành, nhưng giao dịch 1 vẫn chưa đợi giao dịch 2 hoàn thành, trong tình huống này, nếu giao dịch 1 hoàn thành công việc của nó và thực thi câu lệnh COMMIT TRANSACTION thì tài nguyên dữ liệu sẽ. được phát hành và giao dịch 2 sẽ được an toàn sẽ có thể chặn khối cô ấy cần và tiếp tục hành động của mình.
Sự cố xảy ra khi giao dịch 1 cố cập nhật một hàng có ProductCode=l. Tuy nhiên, nó sẽ không nhận được khóa độc quyền cần thiết cho việc này vì bản ghi này bị khóa bởi giao dịch 2:
– Giao dịch 1 – Bước 3 CẬP NHẬT BỘ SẢN PHẨM Tên sản phẩm
= 'Trình kiểm tra nhận dạng DeadLock'
Ở ĐÂU Mã sản phẩm = '1001'
CAM KẾT GIAO DỊCH
Giao dịch 1 sẽ trả về thông báo lỗi sau vài giây. Sự bế tắc dẫn đến cũng có thể được nhìn thấy trong SQL Server Profiler (Hình 51.13):
Máy chủ: Msg 1205, Cấp 13,
Bang 50, Giao dịch dòng 1 (ID tiến trình 51) là
bị bế tắc về tài nguyên khóa bằng một quy trình khác và được chọn làm nạn nhân của bế tắc. Chạy lại giao dịch.
Giao dịch 2 sẽ hoàn thành công việc của mình như thể sự cố chưa từng tồn tại:
(1 hàng bị ảnh hưởng)
(1 hàng bị ảnh hưởng)

Cơm. 51.13. SQL Server Profiler cho phép bạn giám sát các bế tắc bằng cách sử dụng sự kiện Locks:Deadlock Graph và xác định tài nguyên gây ra bế tắc
Tự động phát hiện bế tắc
Như đã trình bày trong đoạn mã trên, SQL Server tự động phát hiện tình huống bế tắc bằng cách kiểm tra các quy trình chặn và khôi phục các giao dịch.
người hoàn thành khối lượng công việc ít nhất. SQL Server liên tục kiểm tra sự tồn tại của khóa chéo. Độ trễ phát hiện bế tắc có thể thay đổi từ 0 đến hai giây (trong thực tế, thời gian lâu nhất tôi phải chờ cho việc này là năm giây).
Xử lý bế tắc
Khi xảy ra bế tắc, kết nối được chọn là nạn nhân của bế tắc phải thử lại giao dịch của nó. Vì công việc phải được làm lại, nên điều tốt là giao dịch được quản lý để hoàn thành ít công việc nhất sẽ được khôi phục - đó là giao dịch sẽ được lặp lại từ đầu.
Mã lỗi 12 05 nên bắt được ứng dụng khách, sẽ khởi động lại giao dịch. Nếu mọi thứ diễn ra như mong đợi, người dùng thậm chí sẽ không nghi ngờ rằng bế tắc đã xảy ra.
Thay vì cho phép chính máy chủ quyết định chọn giao dịch nào làm “nạn nhân”, bản thân giao dịch đó có thể được “chơi như một quà tặng”. Đoạn mã sau, khi được đặt trong một giao dịch, sẽ thông báo cho SQL Server rằng nếu xảy ra bế tắc, giao dịch sẽ được khôi phục:
THIẾT LẬP DEADLOCKJPRIORITY THẤP
Giảm thiểu bế tắc
Mặc dù bế tắc rất dễ xác định và xử lý nhưng tốt nhất vẫn nên tránh chúng. Những khuyến nghị sau đây sẽ giúp bạn tránh được bế tắc.
Cố gắng giữ cho các giao dịch ngắn gọn và không có mã không cần thiết. Nếu một số mã không cần phải có trong một giao dịch thì nó phải được suy ra từ nó.
Không bao giờ tạo mã giao dịch phụ thuộc vào thông tin đầu vào của người dùng.
Cố gắng tạo các gói và thủ tục thu được các khóa theo cùng thứ tự. Ví dụ: bảng A được xử lý trước, sau đó mới đến bảng B, C, v.v. Vì vậy, một thủ tục sẽ đợi thủ tục thứ hai và theo định nghĩa, bế tắc không thể xảy ra.
Thiết kế bố cục vật lý để lưu trữ dữ liệu được lấy mẫu đồng thời càng chặt chẽ càng tốt trên các trang dữ liệu. Để đạt được điều này, hãy sử dụng chuẩn hóa và chọn các chỉ mục được nhóm một cách khôn ngoan. Giảm sự lây lan của tắc nghẽn sẽ giúp tránh sự leo thang của chúng. Các khối nhỏ sẽ giúp tránh sự cạnh tranh của chúng.
Không tăng mức cách nhiệt trừ khi cần thiết. Mức độ cách ly chặt chẽ hơn sẽ làm tăng thời gian khóa.