Thao tác với tệp sau khi phát hiện việc tiêm SQL. Đôi lời về các tùy chọn cURL hữu ích khác
Bài viết này đáng lẽ phải được viết lại từ lâu rồi (quá nhiều “tiết kiệm cho trận đấu”), nhưng tôi chưa bao giờ thực hiện được. Hãy để nó đè nặng và nhắc nhở chúng ta về tuổi trẻ chúng ta ngu ngốc như thế nào.
Một trong những tiêu chí chính cho sự thành công của bất kỳ tài nguyên Internet nào là tốc độ hoạt động của nó và mỗi năm người dùng ngày càng khắt khe hơn về tiêu chí này. Tối ưu hóa hoạt động của các tập lệnh PHP là một trong những phương pháp đảm bảo tốc độ hệ thống.
Trong bài viết này, tôi muốn giới thiệu với công chúng bộ sưu tập các mẹo và thông tin thực tế về tối ưu hóa tập lệnh. Tôi đã sưu tập bộ sưu tập này được một thời gian, nó dựa trên nhiều nguồn và thí nghiệm cá nhân.
Tại sao lại là một bộ sưu tập các mẹo và thông tin thực tế thay vì các quy tắc nghiêm ngặt? Bởi vì, như tôi đã thấy, không có khái niệm “tuyệt đối tối ưu hóa thích hợp" Nhiều kỹ thuật và quy tắc trái ngược nhau và không thể tuân theo tất cả. Bạn phải chọn một tập hợp các phương pháp có thể chấp nhận được để sử dụng mà không ảnh hưởng đến sự an toàn và thuận tiện. Tôi đã đưa ra quan điểm khuyến nghị và do đó tôi có lời khuyên cũng như sự thật mà bạn có thể làm theo hoặc không thể làm theo.
Để tránh nhầm lẫn, tôi chia tất cả các mẹo và thông tin thực tế thành 3 nhóm:
- Tối ưu hóa mã
- Tối ưu hóa vô dụng
Tối ưu hóa ở cấp độ logic ứng dụng và tổ chức
Nhiều mẹo và sự kiện liên quan đến nhóm tối ưu hóa này rất quan trọng và mang lại lợi ích rất lớn về thời gian.- Liên tục lập hồ sơ mã của bạn trên máy chủ (xdebug) và máy khách (firebug) để xác định các điểm tắc nghẽn mã
Cần lưu ý rằng cần phải lập hồ sơ cả phần máy chủ và phần máy khách, vì không phải tất cả lỗi máy chủ có thể được tìm thấy trên chính máy chủ. - Số lượng sử dụng trong chương trình chức năng tùy chỉnh, không ảnh hưởng đến tốc độ dưới bất kỳ hình thức nào
Điều này cho phép bạn sử dụng vô số chức năng tùy chỉnh trong chương trình. - Tích cực sử dụng các tính năng tùy chỉnh
Hiệu ứng tích cực đạt được do thực tế là các hoạt động bên trong hàm chỉ được thực hiện với các biến cục bộ. Hiệu quả của việc này lớn hơn chi phí của các lệnh gọi hàm tùy chỉnh. - Nên triển khai các hàm “cực kỳ nặng” bằng ngôn ngữ lập trình của bên thứ ba dưới dạng tiện ích mở rộng PHP
Điều này đòi hỏi kỹ năng lập trình ngôn ngữ của bên thứ ba, điều này làm tăng đáng kể thời gian phát triển, nhưng đồng thời cho phép bạn sử dụng các kỹ thuật vượt quá khả năng của PHP. - Xử lý tĩnh tập tin html nhanh hơn một tập tin php được giải thích
Sự khác biệt về thời gian trên máy khách có thể là khoảng 1 giây, do đó, nên tách biệt rõ ràng giữa tĩnh và được tạo. sử dụng PHP trang. - Kích thước của tệp được xử lý (được kết nối) ảnh hưởng đến tốc độ
Khoảng 0,001 giây được dành để xử lý mỗi 2 KB. Thực tế này thúc đẩy chúng tôi giảm thiểu mã tập lệnh khi chuyển nó đến máy chủ sản xuất. - Cố gắng không sử dụng require_once hoặc include_once mọi lúc
Các hàm này nên được sử dụng khi có thể đọc lại tệp; trong các trường hợp khác, nên sử dụng require và include . - Khi phân nhánh một thuật toán, nếu có các cấu trúc có thể không được xử lý và dung lượng của chúng khoảng 4 KB trở lên thì sẽ tối ưu hơn nếu đưa chúng vào bằng cách sử dụng include.
- Nên sử dụng xác minh dữ liệu đã gửi trên máy khách
Điều này là do khi kiểm tra dữ liệu ở phía máy khách, số lượng yêu cầu có dữ liệu không chính xác sẽ giảm mạnh. Hệ thống xác thực dữ liệu phía máy khách được xây dựng chủ yếu bằng cách sử dụng JS và các thành phần biểu mẫu cứng nhắc (chọn). - Nên xây dựng cấu trúc DOM lớn cho mảng dữ liệu trên client
Cái này rất phương pháp hiệu quả tối ưu hóa khi làm việc với việc hiển thị lượng lớn dữ liệu. Bản chất của nó tóm tắt như sau: một mảng dữ liệu được chuẩn bị trên máy chủ và được chuyển đến máy khách, đồng thời việc xây dựng cấu trúc DOM được cung cấp cho các hàm JS. Kết quả là tải được phân phối lại một phần từ máy chủ đến máy khách. - Hệ thống được xây dựng trên Công nghệ AJAX, nhanh hơn đáng kể so với các hệ thống không sử dụng công nghệ này
Điều này là do khối lượng đầu ra giảm và sự phân phối lại tải trên máy khách. Trong thực tế, tốc độ của hệ thống có AJAX cao hơn 2-3 lần. Bình luận: Ngược lại, AJAX tạo ra một số hạn chế trong việc sử dụng các phương pháp tối ưu hóa khác, chẳng hạn như làm việc với bộ đệm. - Khi nhận được yêu cầu đăng bài, hãy luôn trả lại nội dung nào đó, thậm chí có thể là khoảng trắng
Nếu không, máy khách sẽ được gửi một trang lỗi nặng vài kilobyte. Lỗi này rất phổ biến trong các hệ thống sử dụng công nghệ AJAX. - Truy xuất dữ liệu từ một tệp nhanh hơn từ cơ sở dữ liệu
Điều này phần lớn là do chi phí kết nối với cơ sở dữ liệu. Thật ngạc nhiên, một tỷ lệ lớn các lập trình viên lưu trữ tất cả dữ liệu trong cơ sở dữ liệu một cách điên cuồng, ngay cả khi việc sử dụng tệp nhanh hơn và thuận tiện hơn. Bình luận: Bạn có thể lưu trữ dữ liệu trong các tệp không được tìm kiếm; nếu không, bạn nên sử dụng cơ sở dữ liệu. - Không kết nối với cơ sở dữ liệu trừ khi cần thiết
Vì một lý do nào đó mà tôi không biết, nhiều lập trình viên kết nối với cơ sở dữ liệu ở giai đoạn đọc cài đặt, mặc dù sau đó họ có thể không thực hiện truy vấn cơ sở dữ liệu. Cái này thói quen xấu, tốn trung bình 0,002 giây. - Sử dụng kết nối liên tục tới cơ sở dữ liệu khi có một số lượng nhỏ máy khách hoạt động đồng thời
Lợi ích về thời gian là do không tốn chi phí kết nối với cơ sở dữ liệu. Sự khác biệt về thời gian là khoảng 0,002 giây. Bình luận: Tại số lượng lớn Người dùng không nên sử dụng các kết nối liên tục. Khi làm việc với các kết nối liên tục phải có cơ chế chấm dứt kết nối. - Cách sử dụng truy vấn phức tạp vào cơ sở dữ liệu nhanh hơn so với việc sử dụng một số
Sự khác biệt về thời gian phụ thuộc vào nhiều yếu tố (khối lượng dữ liệu, cài đặt cơ sở dữ liệu, v.v.) và được đo bằng phần nghìn và đôi khi thậm chí là phần trăm của giây. - Sử dụng các phép tính ở phía DBMS nhanh hơn các phép tính ở phía PHP đối với dữ liệu được lưu trữ trong cơ sở dữ liệu
Điều này là do thực tế là các tính toán như vậy ở phía PHP yêu cầu hai truy vấn tới cơ sở dữ liệu (nhận và thay đổi dữ liệu). Sự khác biệt về thời gian phụ thuộc vào nhiều yếu tố (khối lượng dữ liệu, cài đặt cơ sở dữ liệu, v.v.) và được đo bằng phần nghìn và phần trăm giây. - Nếu dữ liệu mẫu từ cơ sở dữ liệu hiếm khi thay đổi và nhiều người dùng truy cập vào dữ liệu này thì việc lưu dữ liệu mẫu vào một tệp là hợp lý.
Ví dụ: bạn có thể sử dụng phương pháp đơn giản sau: chúng tôi lấy dữ liệu mẫu từ cơ sở dữ liệu và lưu nó dưới dạng một mảng được tuần tự hóa vào một tệp, sau đó bất kỳ người dùng nào cũng sử dụng dữ liệu từ tệp. Trong thực tế, phương pháp tối ưu hóa này có thể giúp tăng tốc độ thực thi tập lệnh lên nhiều lần. Bình luận: sử dụng phương pháp này cần phải viết các công cụ để tạo và thay đổi dữ liệu trong các tệp được lưu trữ. - Dữ liệu bộ đệm hiếm khi thay đổi với memcached
Việc đạt được thời gian có thể khá đáng kể. Bình luận: Bộ nhớ đệm có hiệu quả đối với dữ liệu tĩnh; đối với dữ liệu động, hiệu quả sẽ giảm đi và có thể âm. - Làm việc không có đối tượng (không có OOP) nhanh hơn khoảng ba lần so với làm việc với đối tượng
Nhiều bộ nhớ hơn cũng được tiêu thụ. Không may thay, Trình thông dịch PHP không thể làm việc với OOP nhanh như với các hàm thông thường. - Kích thước mảng càng lớn thì chúng hoạt động càng chậm
Lãng phí thời gian xảy ra do xử lý các cấu trúc lồng nhau.
Tối ưu hóa mã
Những lời khuyên và sự thật này giúp tốc độ tăng lên không đáng kể so với nhóm trước, nhưng khi kết hợp những kỹ thuật này lại với nhau thì có thể giúp bạn tiết kiệm thời gian hơn.- echo và print nhanh hơn đáng kể so với printf
Sự chênh lệch thời gian có thể lên tới vài phần nghìn giây. Điều này là do printf được sử dụng để xuất dữ liệu được định dạng và trình thông dịch sẽ kiểm tra toàn bộ dòng để tìm dữ liệu đó. printf chỉ được sử dụng để xuất dữ liệu cần định dạng. - echo $var."text" nhanh hơn echo "$var text"
Điều này là do công cụ PHP trong trường hợp thứ hai buộc phải tìm kiếm các biến bên trong chuỗi. Đối với lượng lớn dữ liệu và các phiên bản PHP cũ hơn, sự khác biệt về thời gian là đáng chú ý. - echo "a" nhanh hơn echo "a" đối với chuỗi không có biến
Điều này là do trong trường hợp thứ hai, công cụ PHP đang cố gắng tìm các biến. Đối với khối lượng dữ liệu lớn, sự khác biệt về thời gian là khá đáng chú ý. - echo "a","b" nhanh hơn echo "a"."b"
Việc xuất dữ liệu được phân tách bằng dấu phẩy nhanh hơn bằng dấu chấm. Điều này là do trong trường hợp thứ hai xảy ra nối chuỗi. Đối với khối lượng dữ liệu lớn, sự khác biệt về thời gian là khá đáng chú ý. Ghi chú:điều này chỉ hoạt động với hàm echo, có thể lấy nhiều dòng làm đối số. - $return="a"; $return.="b"; tiếng vang $ trở lại; nhanh hơn tiếng vang "a"; tiếng vang "b";
Nguyên nhân là do việc xuất dữ liệu cần thêm một số thao tác. Đối với khối lượng dữ liệu lớn, sự khác biệt về thời gian là khá đáng chú ý. - ob_start(); tiếng vang "a"; tiếng vang "b"; ob_end_flush(); nhanh hơn $return="a"; $return.="b"; tiếng vang $ trở lại;
Điều này là do tất cả công việc được thực hiện mà không cần truy cập vào các biến. Đối với khối lượng dữ liệu lớn, sự khác biệt về thời gian là khá đáng chú ý. Bình luận: Kỹ thuật này không hiệu quả nếu bạn đang làm việc với AJAX, vì trong trường hợp này bạn nên trả về dữ liệu dưới dạng một chuỗi. - Sử dụng "chèn chuyên nghiệp" hay?> a b
Dữ liệu tĩnh (bên ngoài Mã chương trình) được xử lý nhanh hơn đầu ra Dữ liệu PHP. Kỹ thuật này được gọi là chèn chuyên nghiệp. Đối với khối lượng dữ liệu lớn, sự khác biệt về thời gian là khá đáng chú ý. - readfile nhanh hơn file_get_contents , file_get_contents nhanh hơn require và require nhanh hơn include cho đầu ra nội dung tĩnh từ một tập tin riêng biệt
Theo thời gian đọc tệp tin rỗng dao động từ 0,001 đối với tệp đọc đến 0,002 đối với tệp bao gồm . - yêu cầu nhanh hơn bao gồm đối với các tệp được giải thích
Bình luận: khi phân nhánh một thuật toán, khi không thể sử dụng tệp được giải thích, bạn phải sử dụng include , bởi vì yêu cầu luôn bao gồm tệp. - if (...) (...) else if (...) () nhanh hơn switch
Thời gian phụ thuộc vào số lượng chi nhánh. - if (...) (...) else if (...) () nhanh hơn if (...) (...); nếu như (...) ();
Thời gian tùy thuộc vào số lượng chi nhánh và điều kiện. Bạn nên sử dụng else nếu có thể, vì đây là cấu trúc "có điều kiện" nhanh nhất. - Các điều kiện phổ biến nhất của cấu trúc if (...) (...) else if (...) () nên được đặt ở đầu nhánh
Trình thông dịch quét cấu trúc từ trên xuống dưới cho đến khi tìm thấy điều kiện thỏa mãn. Nếu trình thông dịch thấy rằng điều kiện được thỏa mãn thì nó sẽ không xem xét phần còn lại của cấu trúc. - < x; ++$i) {...} быстрее, чем for($i = 0; $i < sizeOf($array); ++$i) {...}
Điều này là do trong trường hợp thứ hai, thao tác sizeOf sẽ được thực thi ở mỗi lần lặp. Sự khác biệt về thời gian thực hiện phụ thuộc vào số lượng phần tử mảng. - x = sizeOf($array); cho($i = 0; $i< x; ++$i) {...} быстрее, чем foreach($arr as $value) {...} для не ассоциативных массивов
Sự khác biệt về thời gian là đáng kể và tăng lên khi mảng tăng lên. - preg_replace nhanh hơn ereg_replace, str_replace nhanh hơn preg_replace, nhưng strtr nhanh hơn str_replace
Sự khác biệt về thời gian phụ thuộc vào lượng dữ liệu và có thể đạt tới vài phần nghìn giây. - Hàm chuỗi nhanh hơn biểu thức thông thường
Quy tắc này là hệ quả của quy tắc trước. - Loại bỏ các biến mảng không còn cần thiết để giải phóng bộ nhớ.
- Tránh sử dụng tính năng ngăn chặn lỗi @
Việc ngăn chặn lỗi tạo ra một số thao tác rất chậm và vì tốc độ thử lại có thể rất cao nên tốc độ mất mát có thể đáng kể. - if (isset($str(5))) (...) nhanh hơn if (strlen($str)>4)(...)
Điều này là do strlen được sử dụng thay vì hàm chuỗi hoạt động tiêu chuẩn kiểm tra isset. - 0,5 nhanh hơn 1/2
Lý do là trong trường hợp thứ hai phép chia được thực hiện. - trả về nhanh hơn toàn cục khi trả về giá trị của một biến từ hàm
Điều này là do trong trường hợp thứ hai, một biến toàn cục được tạo. - $row["id"] nhanh hơn $row
Tùy chọn đầu tiên nhanh hơn 7 lần. - $_SERVER['REQUEST_TIME'] nhanh hơn time() để xác định khi nào tập lệnh sẽ chạy
- if ($var===null) (...) nhanh hơn if (is_null($var)) (...)
Lý do là trong trường hợp đầu tiên không có chức năng nào được sử dụng. - ++tôi nhanh hơn i++ , --tôi nhanh hơn, hơn là tôi--
Điều này là do các tính năng của lõi PHP gây ra. Chênh lệch thời gian nhỏ hơn 0,000001, nhưng nếu bạn lặp lại các quy trình này hàng nghìn lần thì hãy xem xét kỹ hơn việc tối ưu hóa này. - Tăng của biến khởi tạo i=0; ++tôi; nhanh hơn ++i chưa được khởi tạo
Sự khác biệt về thời gian là khoảng 0,000001 giây, nhưng do tốc độ lặp lại có thể xảy ra nên thực tế này cần được ghi nhớ. - Sử dụng các biến đã loại bỏ nhanh hơn việc khai báo các biến mới
Hoặc để tôi diễn đạt lại theo cách khác: Đừng tạo các biến không cần thiết. - Làm việc với các biến cục bộ nhanh hơn khoảng 2 lần so với biến toàn cục
Mặc dù chênh lệch thời gian chưa đến 0,000001 giây nhưng do Tân sô cao lặp lại, bạn nên cố gắng làm việc với các biến cục bộ. - Truy cập trực tiếp vào một biến sẽ nhanh hơn so với việc gọi một hàm trong đó biến này được xác định nhiều lần
Việc gọi một hàm mất nhiều thời gian gấp ba lần so với việc gọi một biến.
Tối ưu hóa vô dụng
Một số phương pháp tối ưu hóa không có tác dụng trong thực tế ảnh hưởng to lớn về tốc độ thực thi tập lệnh (tăng thời gian dưới 0,000001 giây). Mặc dù vậy, việc tối ưu hóa như vậy thường là chủ đề gây tranh cãi. Tôi đã trình bày những sự thật “vô dụng” này để bạn không đặc biệt chú ý đến chúng khi viết mã sau này.- echo nhanh hơn in
- bao gồm(" đường dẫn tuyệt đối") nhanh hơn include("đường dẫn tương đối")
- sizeOf nhanh hơn số lượng
- foreach ($arr as $key => $value) (...) nhanh hơn reset ($arr); while (list($key, $value) = each ($arr)) (...) cho mảng kết hợp
- Mã không được chú thích nhanh hơn mã được nhận xét vì nó để lại Thêm thời gianđể đọc tập tin
Thật là ngu ngốc khi giảm số lượng nhận xét vì mục đích tối ưu hóa; bạn chỉ cần thực hiện giảm thiểu các tập lệnh đang hoạt động (“chiến đấu”). - Biến có tên ngắn nhanh hơn biến có tên dài
Điều này là do việc giảm số lượng mã được xử lý. Tương tự như vậy điểm trước, bạn chỉ cần thực hiện giảm thiểu các tập lệnh đang hoạt động (“chiến đấu”). - Đánh dấu mã bằng tab nhanh hơn sử dụng dấu cách
Tương tự như điểm trước.
Tài liệu đã được sử dụng một phần để viết bài viết này.
Chạy tập tin đã tải xuống nhấn đúp chuột(Phải có máy ảo ).
3. Ẩn danh khi kiểm tra trang web có bị chèn SQL không
Thiết lập Tor và Privoxy trong Kali Linux
[Phần đang được phát triển]
Thiết lập Tor và Privoxy trên Windows
[Phần đang được phát triển]
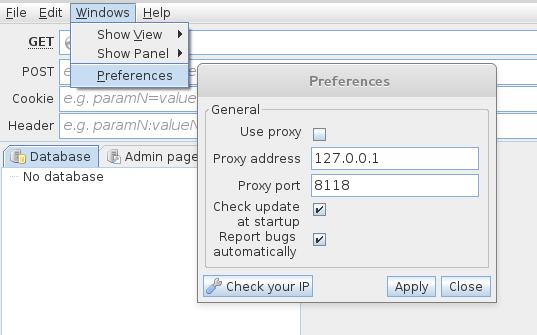
Cài đặt proxy trong jQuery SQL
[Phần đang được phát triển]
4. Kiểm tra trang web có bị chèn SQL bằng jQuery không
Làm việc với chương trình cực kỳ đơn giản. Chỉ cần nhập địa chỉ trang web và nhấn ENTER.
Ảnh chụp màn hình sau đây cho thấy trang web dễ bị tấn công bởi ba kiểu chèn SQL (thông tin về chúng được nêu ở góc dưới bên phải). Bằng cách nhấp vào tên của các mũi tiêm, bạn có thể chuyển đổi phương pháp được sử dụng:
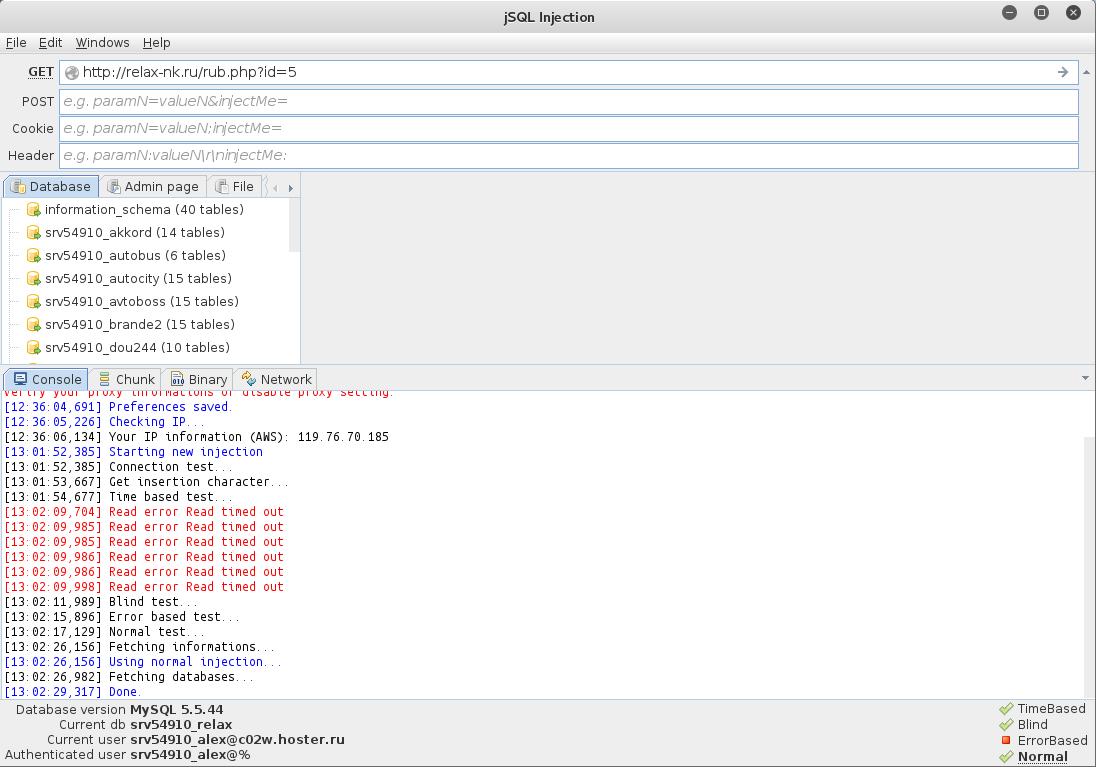
Ngoài ra, cơ sở dữ liệu hiện có đã được hiển thị cho chúng tôi.
Bạn có thể xem nội dung của mỗi bảng:
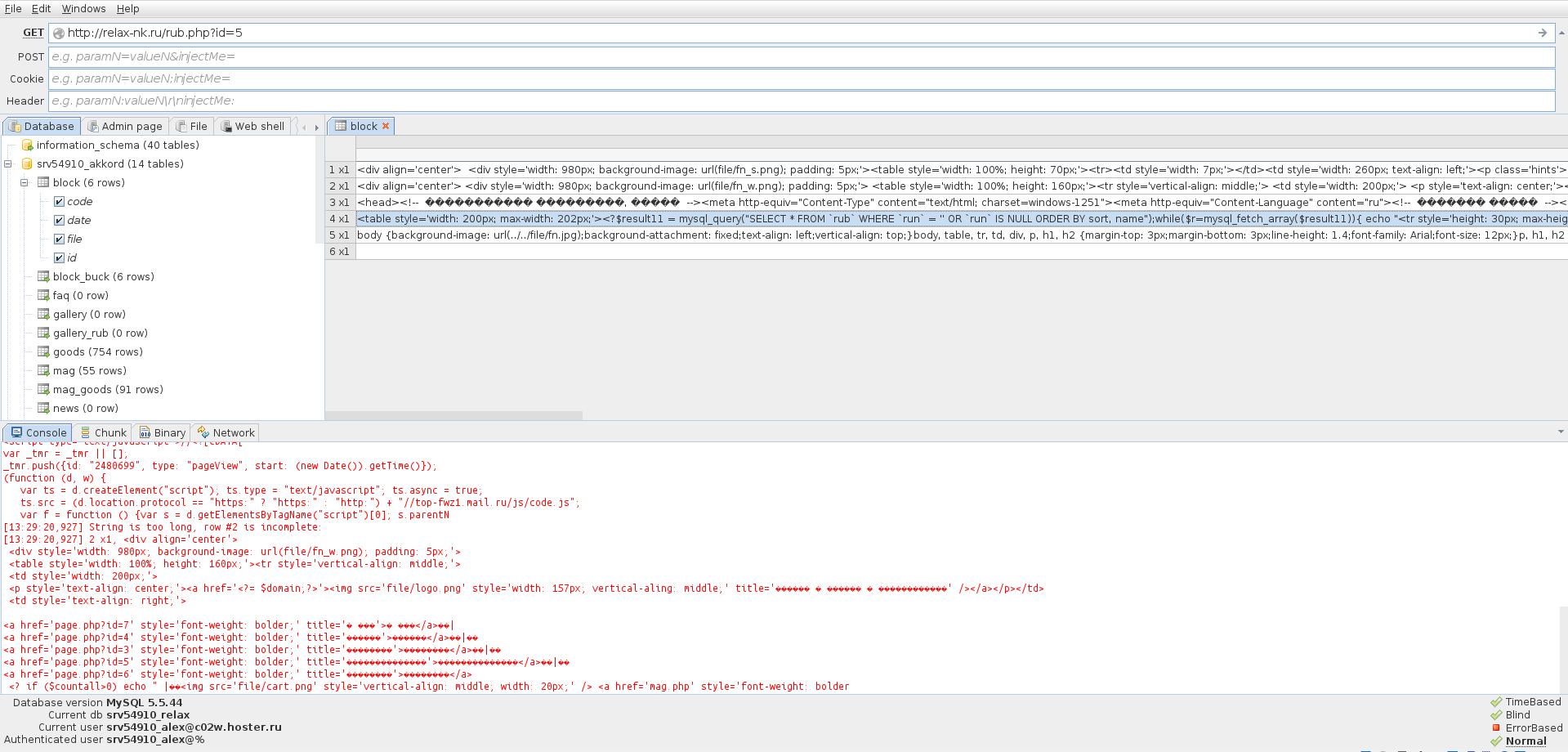
Thông thường, điều thú vị nhất về bảng là thông tin xác thực của quản trị viên.
Nếu bạn may mắn tìm thấy dữ liệu của quản trị viên thì còn quá sớm để vui mừng. Bạn vẫn cần tìm bảng quản trị để nhập dữ liệu này.
5. Tìm kiếm bảng quản trị bằng jQuery SQL
Để thực hiện việc này, hãy truy cập tab tiếp theo. Ở đây chúng tôi được chào đón bởi một danh sách địa chỉ có thể. Bạn có thể chọn một hoặc nhiều trang để kiểm tra:

Sự tiện lợi nằm ở chỗ bạn không cần phải sử dụng các chương trình khác.
Thật không may, những lập trình viên bất cẩn lưu trữ mật khẩu trong biểu mẫu mở, không nhiều. Khá thường xuyên trong dòng mật khẩu chúng ta thấy một cái gì đó như
8743b52063cd84097a65d1633f5c74f5
Đây là một hàm băm. Bạn có thể giải mã nó bằng cách sử dụng vũ lực. Và... jQuery Tiêm có một tính năng mạnh mẽ được tích hợp sẵn.
6. Băm mạnh mẽ bằng cách sử dụng jQuery SQL
Sự tiện lợi chắc chắn là bạn không cần phải tìm kiếm các chương trình khác. Có hỗ trợ cho nhiều hàm băm phổ biến nhất.
Đây không phải là nhất lựa chọn tốt nhất. Để trở thành bậc thầy trong việc giải mã hàm băm, bạn nên sử dụng Sách “” bằng tiếng Nga.
Tuy nhiên, tất nhiên, khi không có chương trình nào khác hoặc không có thời gian để nghiên cứu, jQuery Tiêm với chức năng brute Force được tích hợp sẵn sẽ rất hữu ích.
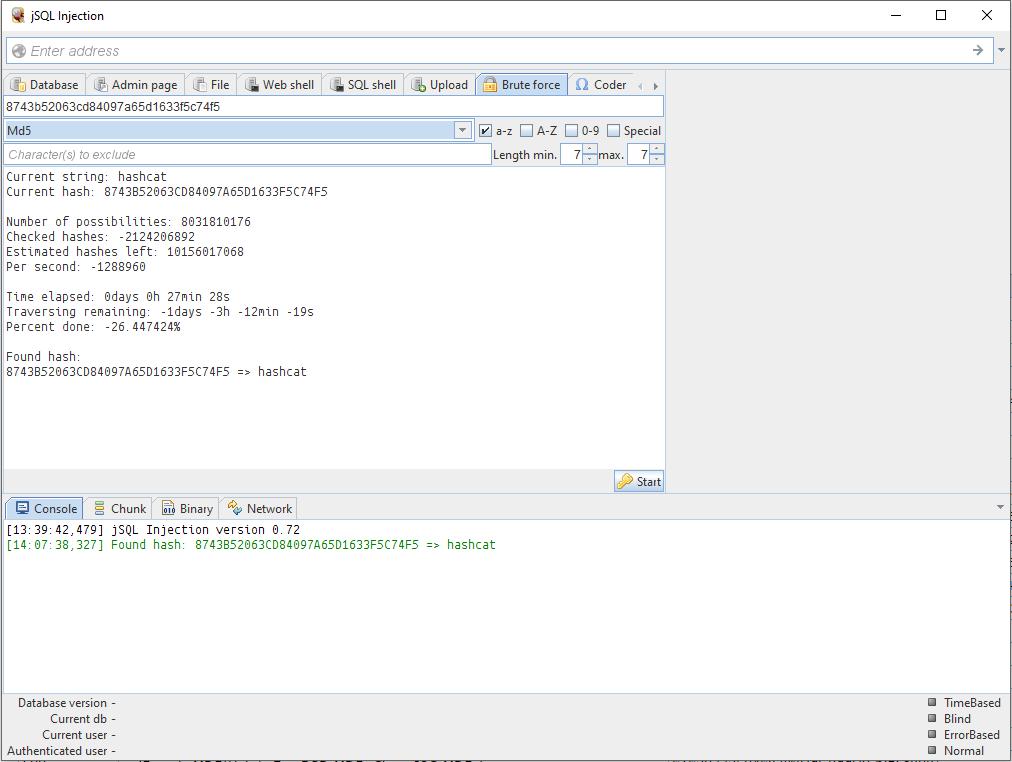
Có các cài đặt: bạn có thể đặt ký tự nào được bao gồm trong mật khẩu, phạm vi độ dài mật khẩu.
7. Thao tác với file sau khi phát hiện SQL SQL
Ngoài các thao tác với cơ sở dữ liệu - đọc và sửa đổi chúng, nếu phát hiện thấy việc tiêm SQL, các thao tác tệp sau có thể được thực hiện:
- đọc tập tin trên máy chủ
- tải tập tin mới lên máy chủ
- tải shell lên máy chủ
Và tất cả điều này được triển khai trong jQuery Tiêm!
Có những hạn chế - máy chủ SQL phải có đặc quyền về tệp. Những người nhạy cảm quản trị viên hệ thống họ bị vô hiệu hóa và truy cập vào hệ thống tập tin sẽ không thể có được nó.
Việc kiểm tra sự hiện diện của các đặc quyền tập tin khá đơn giản. Chuyển đến một trong các tab (đọc tệp, tạo shell, tải tệp mới lên) và thử thực hiện một trong các thao tác đã chỉ định.
Vẫn rất lưu ý quan trọng- chúng ta cần biết đường dẫn tuyệt đối chính xác đến tệp mà chúng ta sẽ làm việc - nếu không sẽ không có gì hoạt động.
Nhìn vào ảnh chụp màn hình sau:
 Đối với bất kỳ nỗ lực nào để thao tác trên một tệp, chúng tôi nhận được phản hồi sau: Không có đặc quyền FILE(không có đặc quyền tập tin). Và không thể làm được gì ở đây.
Đối với bất kỳ nỗ lực nào để thao tác trên một tệp, chúng tôi nhận được phản hồi sau: Không có đặc quyền FILE(không có đặc quyền tập tin). Và không thể làm được gì ở đây.
Thay vào đó, nếu bạn gặp một lỗi khác:
Sự cố khi ghi vào [directory_name]
Điều này có nghĩa là bạn đã chỉ định sai đường dẫn tuyệt đối nơi bạn muốn ghi tệp.
Để đoán được đường dẫn tuyệt đối, ít nhất bạn cần phải biết hệ điều hành trên đó máy chủ đang chạy. Để thực hiện việc này, hãy chuyển sang tab Mạng.
Một bản ghi như vậy (dòng win64) cho chúng ta lý do để cho rằng chúng ta đang làm việc với hệ điều hành Windows:
Keep-Alive: timeout=5, max=99 Máy chủ: Apache/2.4.17 (Win64) PHP/7.0.0RC6 Kết nối: Phương thức Keep-Alive: HTTP/1.1 200 OK Độ dài nội dung: 353 Ngày: Thứ Sáu, ngày 11 tháng 12 năm 2015 11:48:31 GMT X-Powered-By: PHP/7.0.0RC6 Loại nội dung: text/html; bộ ký tự=UTF-8
Ở đây chúng tôi có một số Unix (*BSD, Linux):
Mã hóa chuyển: chunked Ngày: Thứ Sáu, ngày 11 tháng 12 năm 2015 11:57:02 GMT Phương thức: HTTP/1.1 200 OK Keep-Alive: timeout=3, max=100 Kết nối: keep-alive Loại nội dung: text/html X- Được cung cấp bởi: PHP/5.3.29 Máy chủ: Apache/2.2.31 (Unix)
Và ở đây chúng ta có CentOS:
Phương thức: HTTP/1.1 200 OK Hết hạn: Thứ năm, ngày 19 tháng 11 năm 1981 08:52:00 GMT Set-Cookie: PHPSESSID=9p60gtunrv7g41iurr814h9rd0; path=/ Kết nối: keep-alive X-Cache-Lookup: MISS từ t1.hoster.ru:6666 Máy chủ: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.4.37 X-Cache: MISS từ t1.hoster.ru Kiểm soát bộ đệm: không lưu trữ, không có bộ đệm, phải xác nhận lại, post-check=0, pre-check=0 Pragma: không có bộ đệm Ngày: Thứ Sáu, ngày 11 tháng 12 năm 2015 12:08:54 GMT Mã hóa chuyển: chunked Content-Type: text/html; bộ ký tự=WINDOWS-1251
TRONG Windows điển hình thư mục cho các trang web là C:\Server\data\htdocs\. Nhưng trên thực tế, nếu ai đó “nghĩ đến” việc tạo một máy chủ trên Windows thì rất có thể người này chưa nghe nói gì về đặc quyền. Vì vậy, bạn nên bắt đầu thử trực tiếp từ thư mục C:/Windows/:
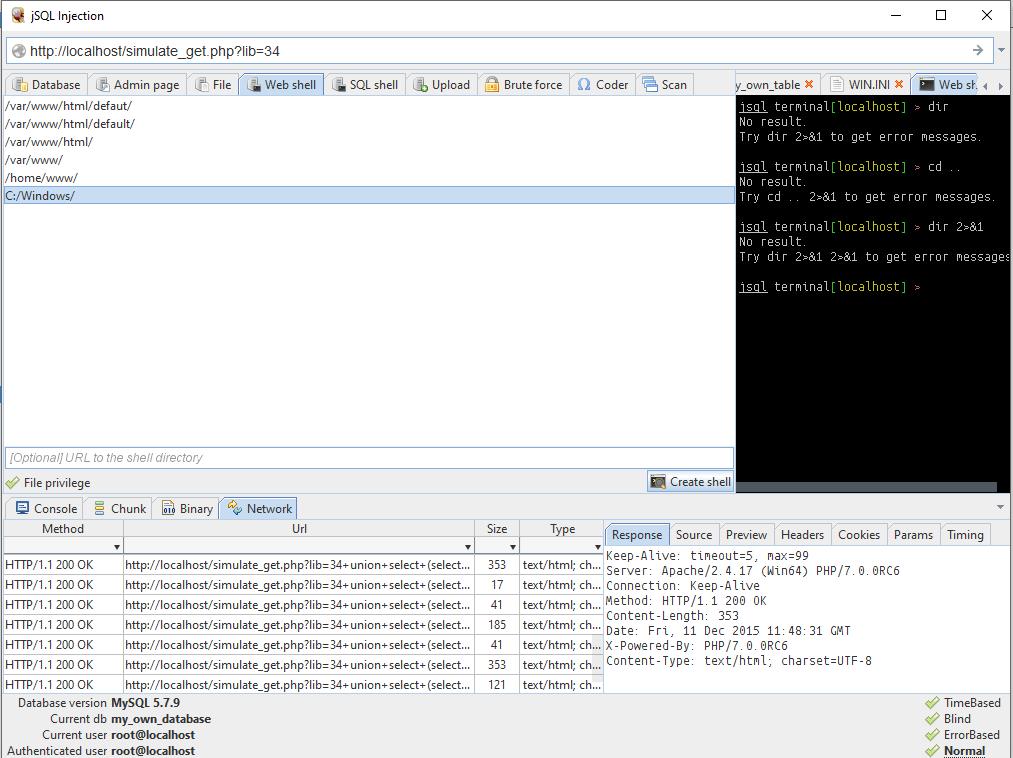
Như bạn có thể thấy, mọi thứ đều ổn trong lần đầu tiên.
Nhưng bản thân các shell của jQuery SQL đã làm tôi nghi ngờ. Nếu bạn có đặc quyền về tệp thì bạn có thể dễ dàng tải lên nội dung nào đó bằng giao diện web.
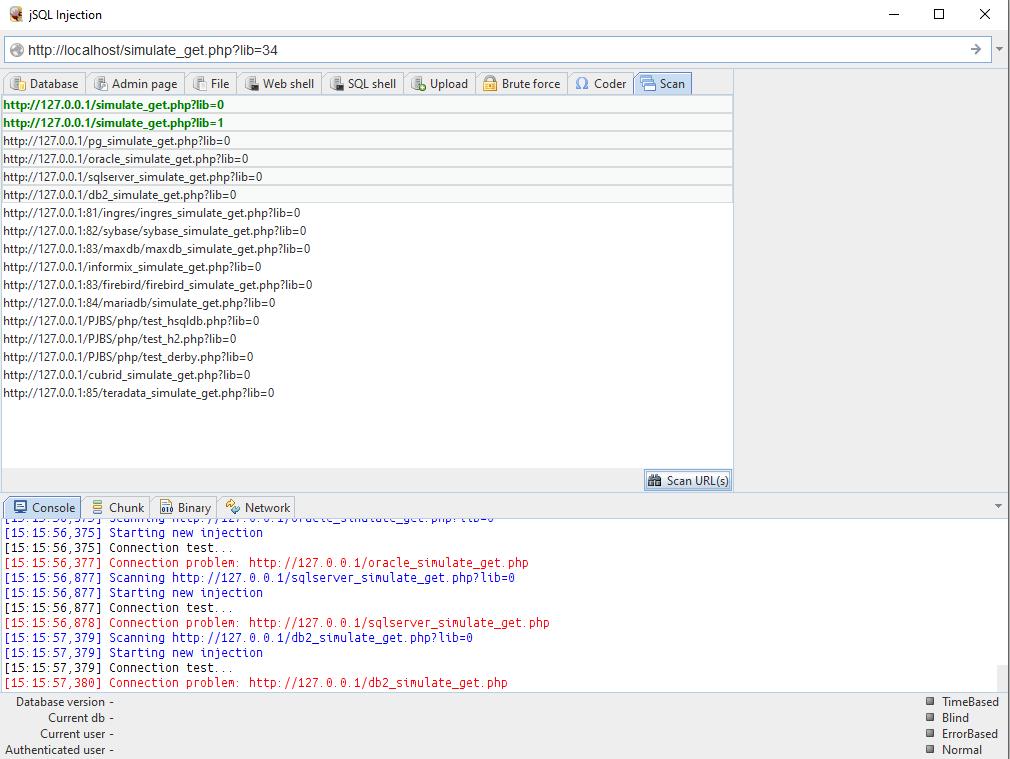
8. Kiểm tra hàng loạt các trang web để tìm kiếm SQL
Và thậm chí chức năng này còn có sẵn trong jQuery Tiêm. Mọi thứ cực kỳ đơn giản - tải xuống danh sách các trang web (bạn có thể nhập từ một tệp), chọn những trang bạn muốn kiểm tra và nhấp vào nút thích hợp để bắt đầu thao tác.
Kết luận từ việc tiêm SQL
Tiêm jQuery là tốt, công cụ đắc lựcđể tìm kiếm và sau đó sử dụng các nội dung SQL được tìm thấy trên các trang web. Của anh ấy lợi thế chắc chắn: dễ sử dụng, tích hợp sẵn các chức năng liên quan. jQuery Tiêm có thể là người bạn tốt nhất của người mới bắt đầu khi phân tích trang web.
Trong số những thiếu sót, tôi xin lưu ý rằng không thể chỉnh sửa cơ sở dữ liệu (ít nhất là tôi không tìm thấy chức năng này). Giống như tất cả các nhạc cụ có Giao diện đồ họa, một trong những nhược điểm của chương trình này có thể là do không thể sử dụng nó trong các tập lệnh. Tuy nhiên, chương trình này có thể tự động hóa một số - nhờ chức năng tích hợp sẵn kiểm tra hàng loạt các trang web.
Chương trình jQuery Tiêm thuận tiện hơn nhiều so với sqlmap. Nhưng sqlmap hỗ trợ nhiều kiểu chèn SQL hơn, có các tùy chọn để làm việc với tường lửa tệp và một số chức năng khác.
Điểm mấu chốt: Tiêm SQL - bạn tốt nhất hacker mới vào nghề.
Trợ giúp cho chương trình này trong Bách khoa toàn thư Kali Linux bạn sẽ tìm thấy trên trang này: http://kali.tools/?p=706
Vì vậy, hãy bắt đầu. Đầu tiên, hãy quyết định chính xác những gì chúng ta cần làm. Khi bạn nhấp vào một liên kết, để đếm số lần nhấp, chúng tôi cần sử dụng một tập lệnh đặc biệt để đếm số lần nhấp, sau đó cung cấp cho khách truy cập thông tin mà họ quan tâm (chuyển hướng đến tập tin cần thiết). Về nguyên tắc, trình tự (bằng cách nhấp vào và hiển thị thông tin) có thể bị đảo ngược, nhưng hãy nhớ rằng nếu bộ đếm được sử dụng để đếm số lượt tải tệp xuống, thì để tập lệnh được thực thi sau khi tải tệp xuống, bạn sẽ cần phải viết một tập lệnh tải tập tin đặc biệt. Tại sao bạn cần những vấn đề không cần thiết? Nguyên tắc hoạt động tương tự sẽ được áp dụng cho quầy truy cập. Trong trường hợp này, để tăng tốc độ tải trang, bạn có thể thực hiện mà không cần chuyển hướng và chỉ cần chèn mã truy cập vào trang tải.
Có vẻ như chúng ta đã tìm ra rồi phải không? Chà, bây giờ chúng ta hãy bắt đầu tháo rời đoạn mã đơn giản để thực hiện tất cả các ý tưởng của chúng ta. Để đơn giản cho ví dụ và để tập lệnh có thể hoạt động trên mọi máy chủ lưu trữ, chúng tôi sẽ lưu trữ dữ liệu trong một tệp.
$f =fopen(" stat.dat","một+"); đàn($f,LOCK_EX); $count =fread($f,100); @$count++; ftruncate($f ,0); fwrite($f ,$count); fflush($f); đàn($f ,LOCK_UN); fclose($f); |
Vâng, bạn đọc đúng rồi, đây là toàn bộ kịch bản. Bây giờ hãy tìm hiểu xem nó hoạt động như thế nào và như thế nào.
Dòng mã đầu tiên là $f =fopen(" stat.dat","một+"); chúng tôi mở tập tin stat.datđể đọc và viết, chúng tôi liên kết nó với biến tệp $f. Chính file này sẽ lưu trữ dữ liệu về trạng thái của bộ đếm. Để hoạt động chính xác, tôi khuyên bạn nên đặt quyền truy cập cho tệp này thành 777 hoặc tương tự với quyền truy cập đọc và ghi đầy đủ.
Dòng tiếp theo là đàn($f ,LOCK_EX); rất quan trọng để kịch bản hoạt động. Cô ấy đang làm gì? Nó chặn quyền truy cập vào tệp đối với các tập lệnh khác hoặc bản sao của tập lệnh này trong khi tập lệnh này đang chạy (hoặc cho đến khi nó bị xóa). Tại sao cái này lại quan trọng đến vậy? Hãy tưởng tượng một tình huống: tại thời điểm khi user1 nhấp vào liên kết khởi chạy tập lệnh đếm số lần nhấp, user2 nhấp vào cùng một liên kết, khởi chạy một bản sao của cùng một tập lệnh. Như bạn sẽ thấy bên dưới, tùy thuộc vào giai đoạn thực thi của tập lệnh do user1 khởi chạy, tập lệnh do user2 khởi chạy và chạy song song với bản sao của nó có thể chỉ cần đặt lại bộ đếm về 0. Hầu như tất cả những người mới lập trình PHP đều mắc lỗi này khi tạo các bộ đếm tương tự. Bây giờ, tôi nghĩ đã rõ tại sao chúng ta cần chặn quyền truy cập vào một tệp - trong trong trường hợp này tập lệnh do user2 khởi chạy sẽ đợi cho đến khi tập lệnh do user1 khởi chạy kết thúc (đừng sợ rằng điều này sẽ làm chậm quá trình tải trang - ngay cả những máy chủ chậm nhất cũng thực thi tập lệnh này trong một phần trăm giây).
Với dòng mã thứ 3 $count =fread($f ,100); tất cả rõ ràng. Chúng ta đọc giá trị bộ đếm vào biến $count.
Bây giờ chúng ta chỉ cần ghi dữ liệu cập nhật vào tập tin. Để thực hiện việc này, trước tiên bạn cần xóa tệp ftruncate($f ,0); Đây là nơi có thể xảy ra tình huống nguy hiểm với việc đặt lại bộ đếm mà tôi đã nói đến. Tuy nhiên, chúng tôi sử dụng tính năng khóa tập tin nên không có gì phải lo sợ.
Viết dữ liệu cập nhật về giá trị bộ đếm fwrite($f ,$count );
Để an toàn, chúng tôi buộc phải xóa bộ đệm I/O cho tệp này fflush($f );
Xóa khóa khỏi tệp flock($f ,LOCK_UN); trên thực tế, bạn không cần phải xóa nó - nó sẽ tự động bị xóa sau khi đóng tệp. Tuy nhiên, để ví dụ được đầy đủ, tôi vẫn viết nó.
Đóng một tập tin fclose($f ); cũng không phải là một chức năng bắt buộc vì Tất cả các tệp được mở bởi tập lệnh, sau khi hoàn thành, sẽ tự động bị đóng. Nhưng một lần nữa, để ví dụ đầy đủ... =) Ngoài ra, nếu tập lệnh không kết thúc ở đây và bạn không cần phải làm việc với tệp nữa thì bạn nên đóng tệp ngay lập tức.
Được rồi, mọi chuyện đã kết thúc rồi. Như bạn có thể thấy, nó không hề khó chút nào. Bây giờ để đếm số lượt truy cập, bạn chỉ cần dán mã này vào trang. Và nếu bạn muốn đếm số lượt tải xuống của một tệp thì hãy chèn mã này vào một tệp PHP riêng, thay thế liên kết từ tên tệp bằng liên kết đến tập lệnh này và thêm chuyển hướng đến tệp tải xuống ở cuối kịch bản. Nó được thực hiện tốt nhất trong PHP: Header(" vị trí:/download_dir/file_to_download.rar");
Ồ vâng. Bạn cũng cần hiển thị giá trị bộ đếm, nếu không thì đếm cũng vô ích =). Tất nhiên, chúng tôi lấy các giá trị từ tệp. Bạn có thể làm điều đó như trong ví dụ về bộ đếm:
| $f =fopen(" stat.dat","một+"); đàn($f,LOCK_EX); $count =fread($f ,100); đàn($f ,LOCK_UN); fclose($f); Echo "Số lượt tải xuống/số lần nhấp chuột: $count "; |
cURL là một công cụ đặc biệt được thiết kế để truyền tệp và dữ liệu bằng cú pháp URL. Công nghệ này hỗ trợ nhiều giao thức như HTTP, FTP, TELNET và nhiều giao thức khác. cURL ban đầu được thiết kế để trở thành một công cụ dòng lệnh. Thật may mắn cho chúng ta, thư viện cURL được hỗ trợ bởi ngôn ngữ lập trình PHP. Trong bài viết này, chúng ta sẽ xem xét một số chức năng nâng cao của cURL, đồng thời đề cập đến ứng dụng thực tế của kiến thức thu được bằng PHP.
Tại sao lại là cURL?
Trên thực tế, có khá nhiều cách khác để lấy mẫu nội dung trang web. Trong nhiều trường hợp, chủ yếu là do lười biếng nên tôi đã sử dụng các hàm PHP đơn giản thay vì cURL:
$content = file_get_contents("http://www.nettuts.com"); // hoặc $lines = file("http://www.nettuts.com"); // hoặc readfile("http://www.nettuts.com");
Tuy nhiên, các chức năng này hầu như không có tính linh hoạt và chứa rất nhiều thiếu sót về mặt xử lý lỗi, v.v. Ngoài ra, có một số tác vụ nhất định mà bạn không thể thực hiện được bằng các tính năng tiêu chuẩn này: tương tác cookie, xác thực, gửi biểu mẫu, tải tệp lên, v.v.
cURL là một thư viện mạnh mẽ hỗ trợ nhiều giao thức, tùy chọn khác nhau và cung cấp thông tin chi tiết về các yêu cầu URL.
Cấu trúc cơ bản
- Khởi tạo
- Gán tham số
- Thực thi và lấy kết quả
- Giải phóng bộ nhớ
// 1. khởi tạo $ch = Curl_init(); // 2. chỉ định các tham số, bao gồm urlcurl_setopt($ch, CURLOPT_URL, "http://www.nettuts.com"); Curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); Curl_setopt($ch, CURLOPT_HEADER, 0); // 3. lấy kết quả là HTML $output = Curl_exec($ch); // 4. đóng kết nốicur_close($ch);
Bước # 2 (nghĩa là gọi Curl_setopt()) sẽ được thảo luận nhiều hơn trong bài viết này so với tất cả các bước khác, bởi vì Ở giai đoạn này, tất cả những điều thú vị và hữu ích nhất mà bạn cần biết đều diễn ra. Trong cURL có rất nhiều tùy chọn khác nhau phải được chỉ định để có thể định cấu hình yêu cầu URL một cách cẩn thận nhất. Chúng ta sẽ không xem xét toàn bộ danh sách mà chỉ tập trung vào những gì tôi cho là cần thiết và hữu ích cho bài học này. Bạn có thể tự nghiên cứu mọi thứ khác nếu chủ đề này khiến bạn quan tâm.
Kiểm tra lỗi
Ngoài ra, bạn cũng có thể sử dụng câu lệnh điều kiện để kiểm tra xem một thao tác đã hoàn tất thành công hay chưa:
// ... $output = Curl_exec($ch); if ($output === FALSE) ( echo "cURL Error: " .cur_error($ch); ) // ...
Ở đây tôi yêu cầu bạn lưu ý một điểm rất quan trọng: chúng ta phải sử dụng “=== false” để so sánh, thay vì “== false”. Đối với những người chưa biết, điều này sẽ giúp chúng tôi phân biệt giữa kết quả trống và giá trị boolean sai, điều này sẽ chỉ ra lỗi.
Tiếp nhận thông tin
Một bước bổ sung khác là lấy dữ liệu về yêu cầu cURL sau khi nó được thực thi.
// ...curl_exec($ch); $info =curl_getinfo($ch); echo "Đã lấy " . $info["total_time"] . "giây cho url". $thông tin["url"]; //…
Mảng trả về chứa thông tin sau:
- "url"
- "loại_nội dung"
- "http_code"
- “kích thước tiêu đề”
- “yêu cầu_kích thước”
- "thời gian tập tin"
- “ssl_verify_result”
- “chuyển hướng_count”
- "Tổng thời gian"
- “tênlookup_time”
- “kết nối_thời gian”
- “pretransfer_time”
- “kích thước_tải lên”
- “kích thước_tải xuống”
- “tốc độ_tải xuống”
- “tốc độ_tải lên”
- “tải xuống_content_length”
- “tải lên_content_length”
- “bắt đầu chuyển_thời gian”
- “redirect_time”
Phát hiện chuyển hướng tùy thuộc vào trình duyệt
Trong ví dụ đầu tiên này, chúng tôi sẽ viết mã có thể phát hiện các chuyển hướng URL dựa trên các cài đặt trình duyệt khác nhau. Ví dụ: một số trang web chuyển hướng trình duyệt của điện thoại di động hoặc bất kỳ thiết bị nào khác.
Chúng tôi sẽ sử dụng tùy chọn CURLOPT_HTTPHEADER để xác định các tiêu đề HTTP gửi đi của mình, bao gồm tên trình duyệt của người dùng và các ngôn ngữ có sẵn. Cuối cùng, chúng tôi sẽ có thể xác định trang web nào đang chuyển hướng chúng tôi đến các URL khác nhau.
// kiểm tra URL $urls = array("http://www.cnn.com", "http://www.mozilla.com", "http://www.facebook.com"); // kiểm tra trình duyệt $browsers = array("standard" => array ("user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5 .6 (.NET CLR 3.5.30729)", "ngôn ngữ" => "en-us,en;q=0.5"), "iphone" => mảng ("user_agent" => "Mozilla/5.0 (iPhone; U ; CPU như Mac OS X; en) AppleWebKit/420+ (KHTML, like Gecko) Phiên bản/3.0 Mobile/1A537a Safari/419.3", "ngôn ngữ" => "en"), "tiếng Pháp" => mảng ("user_agent" => "Mozilla/4.0 (tương thích; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)", "ngôn ngữ" => "fr,fr-FR;q=0.5")); foreach ($urls as $url) ( echo "URL: $url\n"; foreach ($browsers as $test_name => $browser) ( $ch =curl_init(); // chỉ định urlcur_setopt($ch, CURLOPT_URL , $url); // chỉ định tiêu đề cho trình duyệtcur_setopt($ch, CURLOPT_HTTPHEADER, array("User-Agent: ($browser["user_agent"])", "Accept-Language: ($browser["ngôn ngữ"] )" )); // chúng ta không cần nội dung trangcurl_setopt($ch, CURLOPT_NOBODY, 1); // chúng ta cần lấy các tiêu đề HTTPcur_setopt($ch, CURLOPT_HEADER, 1); // trả về kết quả thay vì đầu ra Curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $output = Curl_exec($ch); // có chuyển hướng HTTP không nếu (preg_match("!Location: (.*)!", $output , $matches) ( echo " $test_name: chuyển hướng đến $matches\n"; ) else ( echo "$test_name: no redirection\n"; ) ) echo "\n\n"; )
Đầu tiên, chúng tôi chỉ định danh sách URL của các trang web mà chúng tôi sẽ kiểm tra. Chính xác hơn, chúng tôi cần địa chỉ của các trang web này. Tiếp theo, chúng ta cần xác định cài đặt trình duyệt để kiểm tra từng URL này. Sau đó, chúng ta sẽ sử dụng một vòng lặp trong đó chúng ta sẽ xem qua tất cả các kết quả thu được.
Thủ thuật mà chúng tôi sử dụng trong ví dụ này để đặt cài đặt cURL sẽ cho phép chúng tôi không lấy nội dung của trang mà chỉ lấy các tiêu đề HTTP (được lưu trữ trong $output). Tiếp theo, bằng cách sử dụng một biểu thức chính quy đơn giản, chúng ta có thể xác định xem chuỗi “Vị trí:” có xuất hiện trong tiêu đề nhận được hay không.
Khi bạn chạy mã này, bạn sẽ nhận được kết quả như thế này:
Tạo yêu cầu POST tới một URL cụ thể
Khi hình thành yêu cầu GET, dữ liệu được truyền có thể được chuyển đến URL thông qua “chuỗi truy vấn”. Ví dụ: khi bạn thực hiện tìm kiếm trên Google, cụm từ tìm kiếm sẽ được đặt trong thanh địa chỉ của URL mới:
Http://www.google.com/search?q=ruseller
Bạn không cần sử dụng cURL để mô phỏng yêu cầu này. Nếu sự lười biếng hoàn toàn vượt qua bạn, hãy sử dụng hàm “file_get_contents()” để nhận kết quả.
Nhưng vấn đề là một số biểu mẫu HTML gửi yêu cầu POST. Dữ liệu của các biểu mẫu này được vận chuyển qua phần thân của yêu cầu HTTP chứ không phải như trong trường hợp trước. Ví dụ: nếu bạn điền vào biểu mẫu trên diễn đàn và nhấp vào nút tìm kiếm, yêu cầu POST rất có thể sẽ được thực hiện:
Http://codeigniter.com/forums/do_search/
Chúng ta có thể viết một tập lệnh PHP có thể mô phỏng loại yêu cầu URL này. Trước tiên hãy tạo một tệp đơn giản để chấp nhận và hiển thị dữ liệu POST. Hãy gọi nó là post_output.php:
Print_r($_POST);
Sau đó, chúng tôi tạo một tập lệnh PHP để thực hiện yêu cầu cURL:
$url = "http://localhost/post_output.php"; $post_data = mảng ("foo" => "bar", "query" => "Nettuts", "action" => "Gửi"); $ch = Curl_init(); Curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // cho biết rằng chúng tôi có yêu cầu POST Curl_setopt($ch, CURLOPT_POST, 1); // thêm biếncurl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = Curl_exec($ch); Curl_close($ch); tiếng vang $ đầu ra;
Khi bạn chạy tập lệnh này, bạn sẽ nhận được kết quả như thế này:

Do đó, yêu cầu POST đã được gửi đến tập lệnh post_output.php, tập lệnh này xuất ra mảng $_POST siêu toàn cầu, nội dung mà chúng tôi thu được bằng cách sử dụng cURL.
Đang tải lên một tập tin
Trước tiên, hãy tạo một tệp để tạo tệp đó và gửi tệp đó đến tệp upload_output.php:
Print_r($_FILES);
Và đây là đoạn mã thực hiện chức năng trên:
$url = "http://localhost/upload_output.php"; $post_data = array ("foo" => "bar", // file cần tải lên "upload" => "@C:/wamp/www/test.zip"); $ch = Curl_init(); Curl_setopt($ch, CURLOPT_URL, $url); Curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); Curl_setopt($ch, CURLOPT_POST, 1); Curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $output = Curl_exec($ch); Curl_close($ch); tiếng vang $ đầu ra;
Khi bạn muốn tải một tập tin lên, tất cả những gì bạn phải làm là chuyển nó dưới dạng một biến bài đăng bình thường, đứng trước ký hiệu @. Khi bạn chạy tập lệnh đã viết, bạn sẽ nhận được kết quả sau:

Nhiều cURL
Một trong những điểm mạnh nhất của cURL là khả năng tạo "nhiều" trình xử lý cURL. Điều này cho phép bạn mở kết nối tới nhiều URL đồng thời và không đồng bộ.
Trong phiên bản cổ điển của yêu cầu cURL, quá trình thực thi tập lệnh bị tạm dừng và chờ hoàn thành thao tác URL yêu cầu, sau đó tập lệnh có thể tiếp tục. Nếu bạn có ý định tương tác với nhiều URL, điều này sẽ dẫn đến việc đầu tư khá nhiều thời gian, vì trong phiên bản cổ điển, bạn chỉ có thể làm việc với một URL mỗi lần. Tuy nhiên, chúng ta có thể khắc phục tình trạng này bằng cách sử dụng các trình xử lý đặc biệt.
Hãy xem mã ví dụ tôi lấy từ php.net:
// tạo một số tài nguyên cURL $ch1 = Curl_init(); $ch2 = Curl_init(); // chỉ định URL và các tham số kháccur_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/"); Curl_setopt($ch1, CURLOPT_HEADER, 0); Curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/"); Curl_setopt($ch2, CURLOPT_HEADER, 0); //tạo một trình xử lý nhiều cURL $mh =curl_multi_init(); //thêm một số trình xử lýcurl_multi_add_handle($mh,$ch1); Curl_multi_add_handle($mh,$ch2); $ hoạt động = null; //thực thi do ( $mrc = Curl_multi_exec($mh, $active); ) while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($active && $mrc == CURLM_OK) ( if (curl_multi_select($mh) != -1) ( do ( $mrc = Curl_multi_exec($mh, $active); ) while ($mrc == CURLM_CALL_MULTI_PERFORM); ) ) //đóngcur_multi_remove_handle($mh, $ch1); Curl_multi_remove_handle($mh, $ch2); Curl_multi_close($mh);
Ý tưởng là bạn có thể sử dụng nhiều trình xử lý cURL. Bằng cách sử dụng một vòng lặp đơn giản, bạn có thể theo dõi những yêu cầu nào chưa được hoàn thành.
Có hai vòng lặp chính trong ví dụ này. Vòng lặp do-while đầu tiên gọi Curl_multi_exec(). Chức năng này không thể chặn được. Nó chạy nhanh nhất có thể và trả về trạng thái của yêu cầu. Miễn là giá trị trả về là hằng số 'CURLM_CALL_MULTI_PERFORM', điều này có nghĩa là công việc vẫn chưa hoàn thành (ví dụ: tiêu đề http hiện đang được gửi tới URL); Đó là lý do tại sao chúng ta tiếp tục kiểm tra giá trị trả về này cho đến khi nhận được kết quả khác.
Trong vòng lặp tiếp theo, chúng ta kiểm tra điều kiện trong khi biến $active = "true". Đây là tham số thứ hai của hàm Curl_multi_exec(). Giá trị của biến này sẽ là "true" miễn là mọi thay đổi hiện tại đang hoạt động. Tiếp theo chúng ta gọi hàmcurl_multi_select(). Việc thực thi nó bị "chặn" khi có ít nhất một kết nối đang hoạt động cho đến khi nhận được phản hồi. Khi điều này xảy ra, chúng ta quay lại vòng lặp chính để tiếp tục thực hiện các truy vấn.
Bây giờ hãy áp dụng kiến thức này vào một ví dụ sẽ thực sự hữu ích cho nhiều người.
Kiểm tra liên kết trong WordPress
Hãy tưởng tượng một blog có số lượng bài đăng và tin nhắn khổng lồ, mỗi bài đều chứa các liên kết đến các tài nguyên Internet bên ngoài. Một số liên kết này có thể đã chết vì nhiều lý do. Trang này có thể đã bị xóa hoặc trang web có thể không hoạt động.
Chúng tôi sẽ tạo một tập lệnh sẽ phân tích tất cả các liên kết và tìm các trang web không tải và các trang 404, sau đó cung cấp cho chúng tôi báo cáo chi tiết.
Hãy để tôi nói ngay rằng đây không phải là một ví dụ về việc tạo plugin cho WordPress. Đây hoàn toàn là một nơi thử nghiệm tốt cho các thử nghiệm của chúng tôi.
Cuối cùng hãy bắt đầu. Đầu tiên chúng ta cần lấy tất cả các liên kết từ cơ sở dữ liệu:
// cấu hình $db_host = "localhost"; $db_user = "gốc"; $db_pass = ""; $db_name = "wordpress"; $excluded_domains = mảng("localhost", "www.mydomain.com"); $max_connections = 10; // khởi tạo các biến $url_list = array(); $working_urls = mảng(); $dead_urls = mảng(); $not_found_urls = mảng(); $ hoạt động = null; // kết nối với MySQL if (!mysql_connect($db_host, $db_user, $db_pass)) ( die("Không thể kết nối: " . mysql_error()); ) if (!mysql_select_db($db_name)) ( die("Could không chọn db: " . mysql_error()); ) // chọn tất cả các bài đăng đã xuất bản có liên kết $q = "SELECT post_content FROM wp_posts WHERE post_content THÍCH "%href=%" AND post_status = "publish" AND post_type = "post " "; $r = mysql_query($q) hoặc die(mysql_error()); while ($d = mysql_fetch_assoc($r)) ( // tìm nạp liên kết bằng biểu thức thông thường if (preg_match_all("!href=\"(.*?)\"!", $d["post_content"], $match) ) ( foreach ($matches as $url) ( $tmp = parse_url($url); if (in_array($tmp["host"], $excluded_domains)) ( continue; ) $url_list = $url; ) ) ) / / xóa các bản sao $url_list = array_values(array_unique($url_list)); if (!$url_list) ( die("Không có URL để kiểm tra"); )
Đầu tiên, chúng tôi tạo dữ liệu cấu hình để tương tác với cơ sở dữ liệu, sau đó chúng tôi viết danh sách các miền sẽ không tham gia kiểm tra ($excluded_domains). Chúng tôi cũng xác định một số đặc trưng cho số lượng kết nối đồng thời tối đa mà chúng tôi sẽ sử dụng trong tập lệnh của mình ($max_connections). Sau đó, chúng tôi tham gia cơ sở dữ liệu, chọn các bài đăng có chứa liên kết và tích lũy chúng thành một mảng ($url_list).
Đoạn mã sau hơi phức tạp, vì vậy hãy xem qua nó từ đầu đến cuối:
// 1. nhiều trình xử lý $mh =curl_multi_init(); // 2. thêm một bộ URL cho ($i = 0; $i< $max_connections; $i++) { add_url_to_multi_handle($mh, $url_list); } // 3. инициализация выполнения do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 4. основной цикл while ($active && $mrc == CURLM_OK) { // 5. если всё прошло успешно if (curl_multi_select($mh) != -1) { // 6. делаем дело do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 7. если есть инфа? if ($mhinfo = curl_multi_info_read($mh)) { // это значит, что запрос завершился // 8. извлекаем инфу $chinfo = curl_getinfo($mhinfo["handle"]); // 9. мёртвая ссылка? if (!$chinfo["http_code"]) { $dead_urls = $chinfo["url"]; // 10. 404? } else if ($chinfo["http_code"] == 404) { $not_found_urls = $chinfo["url"]; // 11. рабочая } else { $working_urls = $chinfo["url"]; } // 12. чистим за собой curl_multi_remove_handle($mh, $mhinfo["handle"]); // в случае зацикливания, закомментируйте данный вызов curl_close($mhinfo["handle"]); // 13. добавляем новый url и продолжаем работу if (add_url_to_multi_handle($mh, $url_list)) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } } } // 14. завершение curl_multi_close($mh); echo "==Dead URLs==\n"; echo implode("\n",$dead_urls) . "\n\n"; echo "==404 URLs==\n"; echo implode("\n",$not_found_urls) . "\n\n"; echo "==Working URLs==\n"; echo implode("\n",$working_urls); function add_url_to_multi_handle($mh, $url_list) { static $index = 0; // если у нас есть ещё url, которые нужно достать if ($url_list[$index]) { // новый curl обработчик $ch = curl_init(); // указываем url curl_setopt($ch, CURLOPT_URL, $url_list[$index]); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_NOBODY, 1); curl_multi_add_handle($mh, $ch); // переходим на следующий url $index++; return true; } else { // добавление новых URL завершено return false; } }
Ở đây tôi sẽ cố gắng giải thích mọi thứ một cách chi tiết. Các số trong danh sách tương ứng với các số trong bình luận.
- 1. Tạo nhiều trình xử lý;
- 2. Chúng ta sẽ viết hàm add_url_to_multi_handle() sau. Mỗi lần nó được gọi, việc xử lý một url mới sẽ bắt đầu. Ban đầu, chúng tôi thêm 10 URL ($max_connections);
- 3. Để bắt đầu, chúng ta phải chạy hàmcurl_multi_exec(). Miễn là nó trả về CURLM_CALL_MULTI_PERFORM thì chúng ta vẫn còn việc phải làm. Chúng tôi cần điều này chủ yếu để tạo kết nối;
- 4. Tiếp theo là vòng lặp chính, vòng lặp này sẽ chạy miễn là chúng ta có ít nhất một kết nối đang hoạt động;
- 5. Curl_multi_select() bị treo khi chờ quá trình tìm kiếm URL hoàn tất;
- 6. Một lần nữa, chúng ta cần có cURL để thực hiện một số công việc, cụ thể là tìm nạp dữ liệu phản hồi trả về;
- 7. Thông tin được xác minh tại đây. Kết quả của việc thực hiện yêu cầu là một mảng sẽ được trả về;
- 8. Mảng trả về chứa trình xử lý cURL. Chúng tôi sẽ sử dụng nó để chọn thông tin về một yêu cầu cURL riêng biệt;
- 9. Nếu liên kết đã chết hoặc tập lệnh đã hết thời gian chờ, thì chúng ta không nên tìm bất kỳ mã http nào;
- 10. Nếu liên kết trả về cho chúng ta một trang 404 thì mã http sẽ chứa giá trị 404;
- 11. Nếu không, chúng ta có một liên kết đang hoạt động trước mặt. (Bạn có thể thêm các bước kiểm tra bổ sung cho mã lỗi 500, v.v...);
- 12. Tiếp theo, chúng tôi xóa trình xử lý cURL vì chúng tôi không cần nó nữa;
- 13. Bây giờ chúng ta có thể thêm một url khác và chạy mọi thứ chúng ta đã nói trước đó;
- 14. Ở bước này, script đã hoàn thành công việc của mình. Chúng tôi có thể xóa mọi thứ chúng tôi không cần và tạo báo cáo;
- 15. Cuối cùng, chúng ta sẽ viết một hàm thêm url vào trình xử lý. Biến tĩnh $index sẽ được tăng lên mỗi lần hàm này được gọi.
Tôi đã sử dụng tập lệnh này trên blog của mình (với một số liên kết bị hỏng mà tôi đã cố tình thêm vào để kiểm tra nó) và nhận được kết quả như sau:

Trong trường hợp của tôi, tập lệnh chỉ mất chưa đầy 2 giây để thu thập thông tin qua 40 URL. Hiệu suất tăng lên đáng kể khi làm việc với nhiều URL hơn. Nếu bạn mở mười kết nối cùng lúc, tập lệnh có thể thực thi nhanh hơn gấp mười lần.
Đôi lời về các tùy chọn cURL hữu ích khác
Xác thực HTTP
Nếu URL có xác thực HTTP thì bạn có thể dễ dàng sử dụng tập lệnh sau:
$url = "http://www.somesite.com/members/"; $ch = Curl_init(); Curl_setopt($ch, CURLOPT_URL, $url); Curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // chỉ định tên người dùng và mật khẩucur_setopt($ch, CURLOPT_USERPWD, "myusername:mypassword"); // nếu chuyển hướng được cho phép Curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // sau đó lưu dữ liệu của chúng tôi trong cURL Curl_setopt($ch, CURLOPT_UNRESTRICTED_AUTH, 1); $output = Curl_exec($ch); Curl_close($ch);
Tải lên FTP
PHP cũng có một thư viện để làm việc với FTP, nhưng không có gì ngăn cản bạn sử dụng các công cụ cURL tại đây:
// mở file $file = fopen("/path/to/file", "r"); // url phải chứa nội dung sau $url = "ftp://username: [email được bảo vệ]:21/path/to/new/file"; $ch = Curl_init(); Curl_setopt($ch, CURLOPT_URL, $url); Curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); Curl_setopt($ch, CURLOPT_UPLOAD, 1); Curl_setopt($ch, CURLOPT_INFILE, $fp); Curl_setopt($ch, CURLOPT_INFILESIZE, filesize("/path/to/file")); // chỉ định chế độ ASCII Cur_setopt($ch, CURLOPT_FTPASCII, 1); );curl_close($ch);
Sử dụng proxy
Bạn có thể thực hiện yêu cầu URL của mình thông qua proxy:
$ch = Curl_init(); Curl_setopt($ch, CURLOPT_URL,"http://www.example.com"); Curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // chỉ định địa chỉ Curl_setopt($ch, CURLOPT_PROXY, "11.11.11.11:8080"); // nếu bạn cần cung cấp tên người dùng và mật khẩucur_setopt($ch, CURLOPT_PROXYUSERPWD,"user:pass"); $output = Curl_exec($ch); Curl_close($ch);
Chức năng gọi lại
Cũng có thể chỉ định một chức năng sẽ được kích hoạt ngay cả trước khi yêu cầu cURL hoàn tất. Ví dụ: trong khi nội dung phản hồi đang tải, bạn có thể bắt đầu sử dụng dữ liệu mà không cần đợi tải đầy đủ.
$ch = Curl_init(); Curl_setopt($ch, CURLOPT_URL,"http://net.tutsplus.com"); Curl_setopt($ch, CURLOPT_WRITEFUNCTION,"progress_function"); Curl_exec($ch); Curl_close($ch); hàm Progress_function($ch,$str) ( echo $str; return strlen($str); )
Hàm như thế này PHẢI trả về độ dài của chuỗi, đây là một yêu cầu bắt buộc.
Phần kết luận
Hôm nay chúng ta đã học cách bạn có thể sử dụng thư viện cURL cho mục đích ích kỷ của riêng mình. Tôi hy vọng bạn thích bài viết này.
Cảm ơn! Chúc bạn ngày mới tốt lành!