Cách tối ưu hóa truy vấn mysql. Tối ưu hóa truy vấn MySQL. Công cụ trợ giúp: Bộ công cụ Percona cho các chỉ mục không sử dụng
Làm cách nào để tối ưu hóa truy vấn MySQL?
Đối với một trang web thông thường, không được truy cập đặc biệt, không có nhiều khác biệt cho dù các truy vấn MySQL tới cơ sở dữ liệu có được tối ưu hóa hay không. Nhưng đối với các máy chủ sản xuất chịu tải nặng, sự khác biệt giữa SQL đúng và SQL không chính xác là rất lớn và trong thời gian chạy, chúng có thể ảnh hưởng đáng kể đến hoạt động và độ tin cậy của dịch vụ. Trong bài viết này tôi sẽ xem xét cách viết truy vấn nhanh và các yếu tố khiến chúng chậm lại.
Tại sao MySQL?
Ngày nay có rất nhiều cuộc thảo luận về Dig Data và các công nghệ mới khác. NoSQL và giải pháp đám mâyđiều này thật tuyệt, nhưng rất nhiều phần mềm phổ biến (như WordPress, phpBB, Drupal) vẫn chạy trên MySQL. Di chuyển đến giải pháp mới nhất có thể dẫn đến không chỉ việc thay đổi cấu hình trên máy chủ. Ngoài ra, hiệu quả của MySQL vẫn ở mức ổn, đặc biệt là phiên bản Percona.
Đừng mắc phải sai lầm phổ biến là ném ngày càng nhiều phần cứng vào việc giải quyết vấn đề truy vấn chậm và tải cao máy chủ - tốt hơn là đi đến tận gốc rễ của vấn đề. Tăng sức mạnh bộ xử lý và ổ cứng và thêm bộ nhớ truy cập tạm thời Nó giống nhau loại nhất định tuy nhiên, tối ưu hóa không phải là điều chúng ta sẽ nói đến trong bài viết này. Ngoài ra, bằng cách tối ưu hóa trang web và giải quyết vấn đề bằng phần cứng, tải sẽ chỉ tăng theo cấp số nhân. Vì vậy, đây chỉ là giải pháp ngắn hạn.
Hiểu biết tốt về SQL là công cụ quan trọng nhất đối với nhà phát triển web, nó sẽ cho phép bạn tối ưu hóa và sử dụng một cách hiệu quả. Cơ sở dữ liệu quan hệ dữ liệu. Trong bài viết này, chúng tôi sẽ tập trung vào cơ sở dữ liệu nguồn mở phổ biến thường được sử dụng cùng với PHP, MySQL.
Bài viết này dành cho ai?
Dành cho các nhà phát triển web, kiến trúc sư và nhà phát triển cơ sở dữ liệu và quản trị viên hệ thống, quen thuộc với MySQL. Nếu bạn chưa từng sử dụng MySQL trước đây thì bài viết này có thể không hữu ích lắm với bạn, nhưng tôi vẫn sẽ cố gắng cung cấp nhiều thông tin và hữu ích nhất có thể, ngay cả đối với những người mới sử dụng MySQL.
Sao lưu trước
Tôi khuyên bạn nên làm bước tiếp theo dựa trên MySQL mà bạn đang làm việc, nhưng đừng quên thực hiện bản sao lưu. Nếu bạn không có cơ sở dữ liệu để làm việc, tôi sẽ cung cấp các ví dụ để tạo cơ sở dữ liệu của riêng bạn khi thích hợp.
Tạo bản sao lưu MySQL thật dễ dàng bằng tiện ích mysqldump:
$ mysqldump myTab > myTab-backup.sql Bạn có thể tìm hiểu thêm về mysqldump.
Điều gì khiến truy vấn chậm?
Dưới đây là danh sách chung các yếu tố ảnh hưởng đến tốc độ yêu cầu và tải máy chủ:
- chỉ mục bảng;
- Điều kiện WHERE (và sử dụng chức năng nội bộ MySQL, ví dụ như IF hoặc DATE);
- sắp xếp theo ĐẶT HÀNG THEO;
- thường xuyên lặp lại các yêu cầu giống nhau;
- loại cơ chế lưu trữ dữ liệu (InnoDB, MyISAM, Memory, Blackhole);
- không sử dụng phiên bản Percona;
- cấu hình máy chủ (my.cnf / my.ini);
- đầu ra dữ liệu lớn (hơn 1000 hàng);
- kết nối không ổn định;
- cấu hình phân tán hoặc cụm;
- Thiết kế bàn kém.
Chỉ mục là gì?
Các chỉ mục được sử dụng trong MySQL để tìm kiếm các hàng có giá trị cột được chỉ định, chẳng hạn như với mệnh đề WHERE. Không có chỉ mục, MySQL phải bắt đầu từ hàng đầu tiên đọc toàn bộ bảng để tìm kiếm giá trị liên quan. Làm sao thêm bàn, chi phí càng nhiều.
Nếu bảng có chỉ mục trên các cột sẽ được sử dụng trong truy vấn, MySQL sẽ nhanh chóng tìm thấy các vị trí thông tin cần thiết mà không xem toàn bộ bảng. Điều này nhanh hơn nhiều so với việc tìm kiếm từng dòng một cách tuần tự.
Kết nối không ổn định?
Khi ứng dụng của bạn kết nối với cơ sở dữ liệu và một kết nối ổn định được định cấu hình, nó sẽ được sử dụng mọi lúc mà không cần phải mở kết nối mới mỗi lần. Cái này giải pháp tối ưuđối với môi trường làm việc.
Giảm sự lặp lại thường xuyên của các yêu cầu giống hệt nhau
Nhanh nhất và phương pháp hiệu quả Giải pháp mà tôi đã tìm thấy cho vấn đề này là tạo một kho truy vấn và kết quả thực thi của chúng bằng Memcached hoặc Redis. Với Memcache, bạn có thể dễ dàng lưu vào bộ đệm kết quả truy vấn của mình, ví dụ như sau:
kết nối ("localhost", 11211); $cacheResult = $cache->get("key-name"); if($cacheResult)( //không cần truy vấn $result = $cacheResult; ) else ( //chạy truy vấn của bạn $mysqli = mysqli("p:localhost","username","password","table" ); //thêm p: để lưu trữ lâu dài $sql = "CHỌN * TỪ bài viết TRÁI THAM GIA userInfo bằng cách sử dụng (UID) WHERE post.post_type = "post" || post.post_type = "bài viết" ĐẶT HÀNG THEO cột GIỚI HẠN 50" ; $mysqli->query($sql); $memc->set("key-name", $result->fetch_array(), MEMCACHE_COMPRESSED,86400); //Mật khẩu $cacheResult cho mẫu $template->gán(" bài viết", $cacheResult); ?> Bây giờ yêu cầu nặng nề, sử dụng LEFT JOIN, sẽ chỉ được thực thi cứ sau 86.400 giây một lần (nghĩa là một lần một ngày), điều này sẽ giảm đáng kể tải trên máy chủ MySQL, để lại tài nguyên cho các kết nối khác.
Lưu ý: Thêm p: vào đầu đối số máy chủ MySQLi để tạo kết nối liên tục.
Cấu hình phân tán hoặc phân cụm
Khi dữ liệu ngày càng nhiều và tốc độ dịch vụ của bạn giảm xuống, sự hoảng loạn có thể xâm chiếm bạn. Giải pháp nhanh chóng có thể trở thành phân phối tài nguyên (sharding). Tuy nhiên, tôi không khuyên bạn nên làm điều này trừ khi bạn có kinh nghiệm tốt, vì việc phân phối vốn đã làm cho cấu trúc dữ liệu trở nên phức tạp.
Thiết kế bảng yếu
Việc tạo các lược đồ cơ sở dữ liệu không công việc khó khăn, nếu bạn tuân theo các nguyên tắc vàng khi làm việc có giới hạn và biết điều gì sẽ hiệu quả. Ví dụ: lưu trữ hình ảnh trong ô BLOB rất khó hiểu - lưu trữ đường dẫn tệp trong ô VARCHAR là giải pháp tốt hơn nhiều.
Đảm bảo thiết kế phù hợp cho mục đích sử dụng mong muốn là điều tối quan trọng trong việc tạo ứng dụng của bạn. Lưu trữ dữ liệu khác nhau trong các bảng khác nhau (ví dụ: danh mục và bài viết) và đảm bảo rằng các mối quan hệ nhiều với một và một với nhiều có thể dễ dàng được liên kết với ID. Sử dụng FOREIGN KEY trong MySQL là lý tưởng để lưu trữ dữ liệu xếp tầng trong bảng.
Khi tạo bảng, hãy nhớ những điều sau:
- Tạo các bảng hiệu quả để giải quyết vấn đề của bạn thay vì lấp đầy các bảng bằng những dữ liệu và mối quan hệ không cần thiết.
- Đừng mong đợi MySQL thực thi logic nghiệp vụ hoặc lập trình của bạn - dữ liệu phải sẵn sàng để chèn hàng của bạn ngôn ngữ kịch bản. Ví dụ: nếu bạn cần sắp xếp danh sách theo thứ tự ngẫu nhiên, hãy thực hiện theo Mảng PHP mà không sử dụng ORDER BY từ kho vũ khí MySQL.
- Sử dụng các loại chỉ mục ĐỘC ĐÁO cho các tập dữ liệu duy nhất và sử dụng TRÊN CẬP NHẬT KHÓA DUPLICATE để cập nhật ngày, chẳng hạn như để biết thời điểm một hàng được sửa đổi lần cuối.
- Sử dụng kiểu dữ liệu INT để lưu trữ số nguyên. Nếu bạn không chỉ định kích thước loại dữ liệu, MySQL sẽ làm điều đó cho bạn.
Để tối ưu hóa hiệu quả, chúng tôi phải áp dụng ba cách tiếp cận cho ứng dụng của bạn:
- Phân tích (ghi lại các truy vấn chậm, nghiên cứu hệ thống, phân tích truy vấn và thiết kế cơ sở dữ liệu)
- Yêu cầu thực hiện (có bao nhiêu người dùng)
- Hạn chế về công nghệ (tốc độ phần cứng, sử dụng MySQL không đúng cách)
Cột, bạn thấy đấy, lưu Thông tin quan trọng về yêu cầu. Các cột bạn nên chú ý nhất là could_keys và Extra.
Cột could_keys sẽ hiển thị các chỉ mục mà MySQL có quyền truy cập để thực hiện truy vấn. Đôi khi bạn cần chỉ định các chỉ mục để truy vấn của mình chạy nhanh hơn. Cột Bổ sung sẽ cho biết liệu WHERE hoặc ORDER BY bổ sung đã được sử dụng hay chưa. Điều quan trọng nhất cần chú ý là liệu Sử dụng Filesort có ở đầu ra hay không.
Những gì sử dụng Filesort được nêu trong phần trợ giúp của MySQL:
MySQL phải thực hiện thêm một bước nữa để tìm ra cách trả về các hàng ở dạng đã sắp xếp. Việc sắp xếp này diễn ra trên tất cả các hàng theo kiểu nối và lưu trữ khóa sắp xếp và con trỏ hàng cho tất cả các hàng khớp với mệnh đề WHERE. Các khóa được sắp xếp và các hàng được trả về theo đúng thứ tự.Một lượt vượt qua sẽ làm chậm ứng dụng của bạn và nên tránh bằng mọi giá. Một kết quả quan trọng khác của Extra mà chúng ta nên tránh là Sử dụng tạm thời. Nó nói rằng MySQL phải tạo một bảng tạm thời để thực hiện truy vấn. Rõ ràng là nó khủng khiếp sử dụng MySQL. Trong trường hợp này, kết quả truy vấn phải được lưu trữ trong Redis hoặc Memcache và không được người dùng thực thi lại.
Để tránh sự cố khi sử dụng Filesort, chúng ta phải đảm bảo rằng MySQL sử dụng INDEX. Hiện tại có một số khóa được chỉ định trong could_keys để chọn, nhưng MySQL chỉ có thể chọn một chỉ mục cho truy vấn cuối cùng. Ngoài ra, các chỉ mục có thể bao gồm một số cột và bạn cũng có thể nhập các gợi ý cho trình tối ưu hóa MySQL, trỏ đến các chỉ mục mà bạn đã tạo.
Gợi ý chỉ mục
Trình tối ưu hóa MySQL sẽ sử dụng số liệu thống kê dựa trên các truy vấn bảng để chọn chỉ mục tốt nhất để chạy truy vấn. Nó hoạt động khá đơn giản, dựa trên logic thống kê có sẵn nên có nhiều lựa chọn nhưng không phải lúc nào nó cũng hoạt động sự lựa chọn đúng đắn mà không cần sự giúp đỡ của gợi ý. Để đảm bảo rằng khóa chính xác (hoặc không chính xác) đã được sử dụng, hãy sử dụng các từ khóa FORCE INDEX, USE INDEX và IGNORE INDEX trong truy vấn của bạn. Bạn có thể đọc thêm về gợi ý chỉ mục trong Trợ giúp MySQL.
Để hiển thị các phím của bảng, hãy sử dụng lệnh SHOW INDEX. Bạn có thể chỉ định một số gợi ý để trình tối ưu hóa sử dụng.
Ngoài GIẢI THÍCH còn có từ khóa MÔ TẢ. Với DESCRIBE, bạn có thể xem thông tin bảng như sau:

Thêm chỉ mục
Để thêm chỉ mục trong MySQL, bạn phải sử dụng cú pháp CREATE INDEX. Có một số loại chỉ mục. FULLTEXT được sử dụng để tìm kiếm toàn văn bản và UNIQUE được sử dụng để lưu trữ dữ liệu duy nhất.
Để thêm chỉ mục vào bảng của bạn, hãy sử dụng cú pháp sau:
Mysql> TẠO CHỈ SỐ idx_bookname TRÊN `books` (bookname(10)); Điều này sẽ tạo một chỉ mục trên bảng sách sẽ sử dụng 10 chữ cái đầu tiên của cột lưu trữ tên sách và thuộc loại varchar. Trong trường hợp này, bất kỳ tìm kiếm nào có truy vấn WHERE trên tên sách có tối đa 10 ký tự trùng khớp sẽ tạo ra kết quả tương tự như quét toàn bộ bảng từ đầu đến cuối.
Chỉ số tổng hợp
Chỉ mục có ảnh hưởng lớn về tốc độ thực hiện truy vấn. Chỉ gán một khóa duy nhất chính là không đủ - khóa tổng hợp là một lĩnh vực ứng dụng thực sự trong thiết lập MySQL, đôi khi yêu cầu một số thử nghiệm A/B bằng cách sử dụng EXPLAIN.
Ví dụ: nếu chúng ta cần tham chiếu hai cột trong điều kiện mệnh đề WHERE, khóa tổng hợp sẽ là một giải pháp lý tưởng.
Mysql> TẠO CHỈ SỐ idx_composite TRÊN người dùng (tên người dùng, đang hoạt động); Khi chúng tôi đã tạo khóa dựa trên cột tên người dùng, cột này lưu trữ tên người dùng và các cột hoạt động thuộc loại ENUM, xác định xem tài khoản của người đó có hoạt động hay không. Bây giờ mọi thứ đã được tối ưu hóa cho truy vấn sẽ sử dụng WHERE để tìm tên người dùng hợp lệ với tài khoản đang hoạt động (active = 1).
MySQL của bạn nhanh như thế nào?
Hãy bật tính năng lập hồ sơ để xem xét kỹ hơn các truy vấn MySQL. Điều này có thể được thực hiện bằng cách chạy lệnh set profiling=1, sau đó bạn cần chạy show profile để xem kết quả.
Nếu bạn đang sử dụng PDO, hãy chạy đoạn mã sau:
$db->query("đặt hồ sơ=1"); $db->query("chọn tiêu đề, nội dung, thẻ từ bài viết"); $rs = $db->query("hiển thị hồ sơ"); $db->query("đặt hồ sơ=0"); // vô hiệu hóa hồ sơ sau khi thực hiện truy vấn $records = $rs->fetchAll(PDO::FETCH_ASSOC); // lấy kết quả định hình $errmsg = $rs->errorInfo(); // Bắt một số lỗi ở đây Điều tương tự cũng có thể được thực hiện bằng mysqli:
$db = mysqli mới($host,$username,$password,$dbname); $db->query("đặt hồ sơ=1"); $db->query("chọn tiêu đề, nội dung, thẻ từ bài viết"); if ($result = $db->query("SHOWprofile", MYSQLI_USE_RESULT)) ( while ($row = $result->fetch_row()) ( var_dump($row); ) $result->close(); ) if ($result = $db->query("hiển thị hồ sơ cho truy vấn 1", MYSQLI_USE_RESULT)) ( while ($row = $result->fetch_row()) ( var_dump($row); ) $result->close( ); ) $db->query("đặt hồ sơ=0"); Điều này sẽ trả về cho bạn dữ liệu được định hình chứa thời gian thực hiện truy vấn trong phần tử thứ hai của mảng kết hợp.
Array(3) ( => string(1) "1" => string(10) "0.00024300" => string(17) "select title, body, tags from messages" ) Truy vấn này mất 0,00024300 giây để hoàn thành. Nó diễn ra khá nhanh nên chúng ta đừng lo lắng. Nhưng khi con số ngày càng lớn, chúng ta phải nhìn sâu hơn. Đi tới ứng dụng của bạn để thực hành với một ví dụ hoạt động. Kiểm tra hằng số DEBUG trong cấu hình cơ sở dữ liệu của bạn, sau đó bắt đầu khám phá hệ thống bằng cách bật đầu ra lược tả bằng cách sử dụng các hàm var_dump hoặc print_r. Bằng cách này, bạn có thể di chuyển từ trang này sang trang khác trong ứng dụng của mình, nhận được hồ sơ hệ thống thuận tiện.

Kiểm toán đầy đủ cơ sở dữ liệu trang web của bạn
Để thực hiện kiểm tra đầy đủ các yêu cầu của bạn, hãy bật ghi nhật ký. Một số nhà phát triển trang web lo lắng rằng việc ghi nhật ký sẽ ảnh hưởng lớn đến việc thực thi và làm chậm thêm các yêu cầu. Tuy nhiên, thực tế cho thấy sự khác biệt là không đáng kể.
Để kích hoạt tính năng ghi nhật ký trong MySQL 5.1.6, hãy sử dụng biến toàn cục log_slow_queries, bạn cũng có thể đánh dấu một tệp để ghi nhật ký bằng biến Slow_query_log_file. Điều này có thể được thực hiện bằng cách chạy truy vấn sau:
Đặt log_slow_queries toàn cầu = 1; đặt toàn cầu Slow_query_log_file = /dev/slow_query.log; Bạn cũng có thể chỉ định điều này trong tệp cấu hình /etc/my.cnf hoặc my.ini trên máy chủ của mình.
Sau khi thực hiện các thay đổi, đừng quên khởi động lại máy chủ MySQL bằng lệnh cần thiết, ví dụ như khởi động lại dịch vụ mysql nếu bạn đang sử dụng Linux.
Trong các phiên bản MySQL sau 5.6.1, biến log_slow_queries không được dùng nữa và thay vào đó, biến Slow_query_log được sử dụng. Ngoài ra, để gỡ lỗi thuận tiện hơn, bạn có thể kích hoạt đầu ra bảng bằng cách đặt biến log_output thành TABLE, tuy nhiên, chức năng này chỉ khả dụng kể từ MySQL 5.6.1.
Log_output = BẢNG; log_queries_not_USE_indexes = 1; long_query_time = 1; Biến long_query_time chỉ định số giây mà sau đó truy vấn được coi là chậm. Giá trị là 10 và tối thiểu là 0. Bạn cũng có thể chỉ định mili giây bằng phân số; bây giờ tôi chỉ ra một giây. Và bây giờ mọi yêu cầu được thực hiện lâu hơn 1 giây đều được ghi lại vào nhật ký trong bảng.
Việc ghi nhật ký sẽ được thực hiện trong các bảng mysql.slow_log và mysql.general_log của bạn Cơ sở dữ liệu MySQL dữ liệu. Để tắt ghi nhật ký, hãy thay đổi log_output thành NONE.
Đăng nhập vào máy chủ sản xuất
Trên máy chủ sản xuất phục vụ khách hàng, tốt hơn là chỉ sử dụng tính năng ghi nhật ký trong thời gian ngắn và giám sát tải để không tạo ra tải thêm. Nếu dịch vụ của bạn bị quá tải và cần chú ý ngay lập tức, hãy thử cách ly sự cố bằng cách chạy SHOW PROCESSLIST hoặc truy cập vào bảng information_schema.PROCESSLIST bằng cách chạy SELECT * FROM information_schema.PROCESSLIST;.
Ghi lại tất cả các yêu cầu trên máy chủ sản xuất có thể cung cấp cho bạn nhiều thông tin và trở thành phương thuốc tốt cho mục đích nghiên cứu khi kiểm tra một dự án, nhưng nhật ký trong thời gian dài sẽ không mang lại nhiều lợi ích cho bạn thông tin hữu ích so với nhật ký lên tới 48 giờ (cố gắng theo dõi tải cao điểmđể có cơ hội điều tra việc thực hiện truy vấn tốt hơn).
Lưu ý: Nếu bạn có một trang web gặp phải các đợt lưu lượng truy cập và đôi khi hầu như không có lưu lượng truy cập, chẳng hạn như trang web thể thao trong mùa giảm giá, thì hãy sử dụng thông tin này để xây dựng và nghiên cứu ghi nhật ký.
Ghi nhật ký nhiều yêu cầu
Điều quan trọng không chỉ là phải nhận thức được các truy vấn mất nhiều thời gian hơn một giây để thực thi mà bạn còn cần phải nhận thức được các truy vấn được thực hiện hàng trăm lần. Ngay cả khi các truy vấn được thực thi nhanh chóng, trong một hệ thống bận rộn, chúng có thể tiêu tốn hết tài nguyên.
Đây là lý do tại sao bạn luôn cần cảnh giác sau khi thực hiện các thay đổi trong một dự án đang hoạt động - đây là thời điểm quan trọng nhất đối với hoạt động của bất kỳ cơ sở dữ liệu nào.
Bộ đệm nóng và lạnh
Số lượng yêu cầu và tải máy chủ có tác động mạnh đến việc thực thi và cũng có thể ảnh hưởng đến thời gian thực hiện yêu cầu. Khi phát triển, bạn nên đặt ra quy tắc là mỗi yêu cầu không được mất quá một phần mili giây (0,0xx hoặc nhanh hơn) để hoàn thành trên máy chủ miễn phí.
Sử dụng Memcache có tác dụng mạnh mẽ trong việc giảm tải cho máy chủ và sẽ giải phóng tài nguyên thực hiện các yêu cầu. Đảm bảo rằng bạn đang sử dụng Memcached một cách hiệu quả và đã kiểm tra ứng dụng của mình bằng bộ đệm nóng (dữ liệu đã tải) và bộ đệm nguội.
Để tránh chạy trên máy chủ sản xuất có bộ đệm trống, bạn nên có một tập lệnh thu thập tất cả bộ đệm cần thiết trước khi khởi động máy chủ để lượng lớn máy khách không làm giảm thời gian khởi động hệ thống.
Sửa các truy vấn chậm
Bây giờ việc ghi nhật ký đã được thiết lập, bạn có thể đã tìm thấy một số truy vấn chậm trên trang web của mình. Hãy sửa chúng! Để làm ví dụ, tôi sẽ chỉ ra một số vấn đề thường gặp và bạn có thể thấy logic để khắc phục chúng.
Nếu bạn chưa tìm thấy truy vấn chậm, hãy kiểm tra cài đặt long_query_time nếu bạn sử dụng phương pháp ghi nhật ký này. Mặt khác, sau khi kiểm tra tất cả các truy vấn lược tả của bạn (đặt lược tả=1), hãy tạo danh sách các truy vấn mất nhiều thời gian hơn một phần mili giây (0,000x giây) và bắt đầu từ đó.
Những vấn đề chung
Dưới đây là sáu vấn đề phổ biến nhất mà tôi nhận thấy khi tối ưu hóa các truy vấn MySQL:
ĐẶT HÀNG THEO và sắp xếp tập tin
Việc ngăn chặn việc sắp xếp tệp đôi khi không thể thực hiện được do mệnh đề ORDER BY. Để tối ưu hóa, hãy lưu trữ kết quả trong Memcache hoặc thực hiện sắp xếp trong logic ứng dụng của bạn.
Sử dụng ORDER BY với WHERE và LEFT JOIN
ORDER BY làm cho truy vấn rất chậm. Nếu có thể, cố gắng không sử dụng ORDER BY. Nếu bạn cần sắp xếp thì hãy sử dụng sắp xếp theo chỉ mục.
Sử dụng ORDER BY trên các cột tạm thời
Đừng làm điều đó. Nếu bạn cần kết hợp các kết quả, hãy thực hiện điều đó trong logic ứng dụng của bạn; không sử dụng tính năng lọc hoặc sắp xếp trên bảng tạm thời truy vấn MySQL. Điều này đòi hỏi rất nhiều nguồn lực.
Bỏ qua chỉ mục FULLTEXT
Sử dụng THÍCH là cách tốt nhất để làm chậm quá trình tìm kiếm toàn văn.
Sự lựa chọn không hợp lý số lượng lớn dòng
Việc quên LIMIT trong truy vấn của bạn có thể làm tăng đáng kể thời gian tìm nạp từ cơ sở dữ liệu, tùy thuộc vào kích thước của bảng.
Sử dụng quá nhiều JOIN thay vì tạo các bảng hoặc dạng xem tổng hợp
Khi bạn sử dụng nhiều hơn ba hoặc bốn toán tử LEFT JOIN trong một truy vấn, hãy tự hỏi: mọi thứ ở đây có đúng không? Hãy tiếp tục trừ khi bạn có lý do chính đáng, chẳng hạn - truy vấn không được sử dụng thường xuyên cho đầu ra trong bảng quản trị hoặc kết quả đầu ra có thể được lưu vào bộ đệm. Nếu bạn cần chạy một truy vấn với một lượng lớn các thao tác nối bảng, thì tốt hơn nên nghĩ đến việc tạo các bảng tổng hợp từ các cột cần thiết hoặc sử dụng các khung nhìn.
Vì thế
Chúng tôi đã thảo luận những kiến thức cơ bản về tối ưu hóa và các công cụ cần thiết để hoàn thành công việc. Chúng tôi đã kiểm tra hệ thống bằng cách sử dụng tính năng lập hồ sơ và câu lệnh EXPLAIN để xem điều gì đang xảy ra với cơ sở dữ liệu và cách chúng tôi có thể cải thiện thiết kế.
Chúng tôi cũng đã xem xét một số ví dụ và những cạm bẫy kinh điển mà bạn có thể gặp phải khi sử dụng MySQL. Bằng cách sử dụng gợi ý chỉ mục, chúng ta có thể đảm bảo rằng MySQL sẽ chọn các chỉ mục cần thiết, đặc biệt khi có nhiều lựa chọn được thực hiện trên cùng một bảng. Để tiếp tục nghiên cứu chủ đề này, tôi khuyên bạn nên hướng tới dự án Percona.

Làm việc với cơ sở dữ liệu thường là điểm yếu nhất trong hiệu suất của nhiều Ứng dụng web. Và không chỉ các DBA mới phải lo lắng về điều này. Lập trình viên phải chọn cấu trúc đúng bảng, viết các truy vấn được tối ưu hóa và mã tốt. Sau đây là các phương pháp tối ưu hóa MySQL dành cho lập trình viên.
1. Tối ưu hóa truy vấn cho bộ đệm truy vấn
Hầu hết Máy chủ MySQL Bộ nhớ đệm truy vấn được kích hoạt. Một trong những cách tốt nhất cải thiện hiệu suất chỉ đơn giản là để lại bộ nhớ đệm cho cơ sở dữ liệu. Khi một truy vấn được lặp lại nhiều lần, kết quả của nó sẽ được lấy từ bộ đệm, nhanh hơn nhiều so với việc truy cập trực tiếp vào cơ sở dữ liệu. Vấn đề chính là nhiều người chỉ đơn giản sử dụng các truy vấn không thể lưu vào bộ nhớ đệm:
// yêu cầu sẽ không được lưu vào bộ nhớ đệm$r = mysql_query( "CHỌN tên người dùng TỪ người dùng WHERE signup_date >= CURDATE()"); //và nó sẽ như vậy! $hôm nay = ngày("Y-m-d" ); $r = mysql_query( "CHỌN tên người dùng TỪ người dùng WHERE signup_date >= "$today"");Lý do là truy vấn đầu tiên sử dụng hàm CURDATE(). Điều này áp dụng cho tất cả các hàm như NOW(), RAND() và các hàm khác có kết quả không xác định. Nếu kết quả của một hàm có thể thay đổi thì MySQL sẽ không lưu trữ truy vấn đó. TRONG trong ví dụ nàyđiều này có thể được ngăn chặn bằng cách tính toán ngày trước khi thực hiện truy vấn.
2. Sử dụng EXPLAIN cho các truy vấn SELECT của bạn
// tạo một câu lệnh đã chuẩn bị sẵn if ($stmt = $mysqli ->chuẩn bị( "CHỌN tên người dùng TỪ người dùng WHERE state=?")) { // liên kết các giá trị$stmt ->bind_param("s", $state ); // thực thi $stmt ->execute(); // liên kết kết quả$stmt ->bind_result($username ); // lấy dữ liệu$stmt ->tìm nạp(); printf("%s đến từ %s\n" , $username , $state ); $stmt ->đóng(); )13. Yêu cầu không được lưu vào bộ đệm
Thông thường, khi thực hiện một yêu cầu, tập lệnh sẽ dừng và chờ kết quả thực thi. Bạn có thể thay đổi điều này bằng cách sử dụng truy vấn không có bộ đệm.
Có một mô tả hay trong tài liệu về hàm mysql_unbuffered_query():
"mysql_unbuffered_query() gửi truy vấn SQL tới MySQL mà không truy xuất hoặc tự động đệm các hàng kết quả như mysql_query(). Một mặt, điều này tiết kiệm một lượng bộ nhớ đáng kể cho các truy vấn SQL tạo ra tập kết quả lớn. Mặt khác, bạn có thể bắt đầu làm việc với tập hợp kết quả cắt sau khi hàng đầu tiên được truy xuất: bạn không phải đợi truy vấn SQL đầy đủ chạy."
Tuy nhiên có hạn chế nhất định. Bạn sẽ phải đọc tất cả các bản ghi hoặc gọi mysql_free_result() trước khi có thể chạy một truy vấn khác. Ngoài ra, bạn không thể sử dụng mysql_num_rows() hoặc mysql_data_seek() trên kết quả hàm.
14. Lưu trữ IP trong UNSIGNED INT
Nhiều lập trình viên lưu trữ địa chỉ IP trong trường loại VARCHAR(15) mà không biết rằng nó có thể được lưu trữ ở dạng số nguyên. INT chiếm 4 byte và có kích thước trường cố định.
Đảm bảo sử dụng UNSIGNED INT vì IP có thể được viết dưới dạng số không dấu 32 bit.
Sử dụng INET_ATON() trong yêu cầu của bạn để chuyển đổi địa chỉ IP thành số và INET_NTOA() để chuyển đổi lại. Các hàm tương tự tồn tại trong PHP - ip2long() và long2ip() (trong PHP, các hàm này cũng có thể trả về giá trị âm. Lưu ý từ The_Lion).
15. Bảng kích thước cố định (tĩnh) nhanh hơn
Nếu mỗi cột trong bảng có kích thước cố định thì bảng đó được gọi là "tĩnh" hoặc "kích thước cố định". Ví dụ về các cột có độ dài không cố định: VARCHAR, TEXT, BLOB. Nếu bạn đưa trường như vậy vào bảng, trường đó sẽ không còn được sửa nữa và sẽ được MySQL xử lý theo cách khác.
Sử dụng các bảng như vậy sẽ tăng hiệu quả, bởi vì... MySQL có thể tra cứu các bản ghi trong đó nhanh hơn. Khi nào nên chọn dòng mong muốn table, MySQL có thể tính toán vị trí của nó rất nhanh. Nếu kích thước bản ghi không cố định, nó sẽ được tìm kiếm theo chỉ mục.
Các bảng này cũng dễ dàng lưu vào bộ đệm và khôi phục hơn sau khi cơ sở dữ liệu gặp sự cố. Ví dụ: nếu bạn chuyển đổi VARCHAR(20) thành CHAR(20), mục nhập sẽ chiếm 20 byte, bất kể nội dung thực tế của nó là gì.
Sử dụng phương pháp "tách dọc", bạn có thể di chuyển các cột có độ dài hàng thay đổi vào một bảng riêng biệt.
16. Tách dọc
Phân vùng dọc đề cập đến việc chia bảng thành các cột để cải thiện hiệu suất.
Ví dụ 1. Nếu địa chỉ được lưu trữ trong bảng người dùng, thì thực tế là bạn sẽ không cần đến chúng thường xuyên. Bạn có thể chia bảng và lưu trữ địa chỉ trong bàn riêng. Như vậy, bảng người dùng sẽ được giảm kích thước. Năng suất sẽ tăng lên.
Ví dụ 2: Bạn có trường "last_login" trong bảng. Nó được cập nhật mỗi khi người dùng đăng nhập vào trang web. Nhưng tất cả các thay đổi đối với bảng đều xóa bộ đệm của nó. Bằng cách lưu trữ trường này trong một bảng khác, bạn sẽ giữ những thay đổi đối với bảng người dùng ở mức tối thiểu.
Nhưng nếu bạn liên tục sử dụng các phép nối trên các bảng này sẽ dẫn đến hiệu suất kém.
17. Tách biệt các truy vấn DELETE và INSERT lớn
Nếu cần thực hiện một yêu cầu lớn để xóa hoặc chèn dữ liệu, bạn cần cẩn thận để không làm hỏng ứng dụng. Hiệu suất yêu cầu lớn có thể khóa bảng và khiến toàn bộ ứng dụng gặp trục trặc.
Apache có thể chạy nhiều tiến trình song song cùng một lúc. Do đó, nó hoạt động hiệu quả hơn nếu các tập lệnh được thực thi càng nhanh càng tốt.
Nếu bạn khóa bàn lâu dài(ví dụ: trong 30 giây hoặc lâu hơn), khi đó với lưu lượng truy cập trang web cao, một hàng đợi lớn các quy trình và yêu cầu có thể phát sinh, điều này có thể dẫn đến làm việc chậm trang web hoặc thậm chí là sự cố máy chủ.
Nếu bạn có các truy vấn như thế này, hãy sử dụng LIMIT để chạy chúng theo từng đợt nhỏ.
18. Cột nhỏ nhanh hơn
Đối với cơ sở dữ liệu, làm việc với ổ cứng có lẽ là điểm yếu nhất. Các bản ghi nhỏ và gọn thường tốt hơn về mặt hiệu suất vì... giảm công việc của đĩa.
Tài liệu MySQL có danh sách các yêu cầu lưu trữ dữ liệu cho tất cả các loại dữ liệu.
Nếu bảng của bạn chỉ lưu trữ một vài hàng thì sẽ không có ý nghĩa gì nếu đặt khóa chính thành loại INT; tốt hơn nên đặt khóa chính là MEDIUMINT, SMALLINT hoặc thậm chí TINYINT. Nếu bạn không cần lưu trữ thời gian, hãy sử dụng DATE thay vì DATETIME.
Tuy nhiên, hãy cẩn thận kẻo mọi chuyện không diễn ra như Slashdot.
19. Chọn loại bàn phù hợp
20. Sử dụng ORM
21. Hãy cẩn thận với các kết nối liên tục
Kết nối liên tục được thiết kế để giảm chi phí thiết lập giao tiếp với MySQL. Khi kết nối được tạo, nó vẫn mở sau khi tập lệnh hoàn tất. Lần tới, tập lệnh này sẽ sử dụng kết nối tương tự.
mysql_pconnect() trong PHP
Nhưng điều này chỉ nghe có vẻ tốt về mặt lý thuyết. Theo kinh nghiệm cá nhân của tôi (và kinh nghiệm của người khác), việc sử dụng tính năng này là không hợp lý. Bạn sẽ gặp vấn đề nghiêm trọng với giới hạn kết nối, giới hạn bộ nhớ, v.v.
Apache tạo ra nhiều luồng song song. Đây là lý do chính khiến các kết nối liên tục không hoạt động tốt như chúng ta mong muốn. Trước khi sử dụng mysql_pconnect(), hãy tham khảo ý kiến quản trị viên hệ thống của bạn.
Từ tác giả: một người bạn của tôi đã quyết định tối ưu hóa chiếc xe của anh ấy. Đầu tiên anh ấy tháo một bánh nên cắt nóc, sau đó là động cơ... Nói chung là bây giờ anh ấy đi được. Đây đều là hậu quả của việc tiếp cận sai lầm! Do đó, để DBMS của bạn tiếp tục chạy, việc tối ưu hóa MySQL phải được thực hiện chính xác.
Khi nào cần tối ưu hóa và tại sao?
Nó không đáng để đi vào cài đặt máy chủ và thay đổi các giá trị tham số một lần nữa (đặc biệt nếu bạn không biết điều này có thể kết thúc như thế nào). Nếu chúng ta coi chủ đề này là từ “tháp chuông” về việc cải thiện hiệu suất của các tài nguyên web, thì nó rộng đến mức cần phải dành toàn bộ ấn phẩm khoa học gồm 7 tập cho nó.
Nhưng rõ ràng là tôi không có được sự kiên nhẫn như vậy với tư cách là một nhà văn, và bạn với tư cách là một độc giả cũng vậy. Chúng tôi sẽ làm điều đó đơn giản hơn và cố gắng chỉ đi sâu hơn một chút vào nội dung tối ưu hóa của máy chủ MySQL và các thành phần của nó. Bằng cách thiết lập tối ưu tất cả các tham số DBMS, bạn có thể đạt được một số mục tiêu:
Tăng tốc độ thực hiện truy vấn.
Cải thiện hiệu suất máy chủ tổng thể.
Giảm thời gian chờ tải các trang tài nguyên.
Giảm mức tiêu thụ dung lượng máy chủ lưu trữ.
Giảm dung lượng đĩa tiêu thụ.
Chúng tôi sẽ cố gắng chia toàn bộ chủ đề tối ưu hóa thành nhiều điểm để ít nhiều rõ ràng điều gì khiến “nồi sôi”.
Tại sao phải thiết lập máy chủ
Trong MySQL, tối ưu hóa hiệu suất nên bắt đầu từ máy chủ. Trước hết, bạn nên tăng tốc độ hoạt động của nó và giảm thời gian xử lý các yêu cầu. Một phương tiện phổ biến để đạt được tất cả các mục tiêu trên là kích hoạt bộ nhớ đệm. Không biết “nó là gì”? Bây giờ tôi sẽ giải thích mọi thứ.
Nếu bộ nhớ đệm được bật trên phiên bản máy chủ của bạn, hệ thống MySQL sẽ tự động “ghi nhớ” truy vấn do người dùng nhập. Và những lần lặp lại tiếp theo, kết quả truy vấn này (để lấy mẫu) sẽ không được xử lý mà lấy từ bộ nhớ hệ thống. Hóa ra bằng cách này, máy chủ “tiết kiệm” thời gian đưa ra phản hồi và kết quả là tốc độ phản hồi của trang web tăng lên. Điều này cũng áp dụng cho tốc độ tải xuống tổng thể.
Trong MySQL, tối ưu hóa truy vấn có thể áp dụng cho các công cụ và CMS hoạt động trên cơ sở DBMS và PHP này. Trong trường hợp này, mã được viết bằng ngôn ngữ lập trình, để tạo ra một trang web động, yêu cầu một số bộ phận và nội dung cấu trúc của nó (hồ sơ, kho lưu trữ và các phân loại khác) từ cơ sở dữ liệu.
Nhờ kích hoạt bộ nhớ đệm trong MySQL, việc thực thi các truy vấn tới máy chủ DBMS nhanh hơn nhiều. Do đó, tốc độ tải của toàn bộ tài nguyên nói chung sẽ tăng lên. Và điều này có tác động tích cực đến cả trải nghiệm người dùng và vị trí của trang web trong kết quả tìm kiếm.
Kích hoạt và định cấu hình bộ nhớ đệm
Nhưng hãy chuyển từ lý thuyết “nhàm chán” sang thực hành thú vị. Chúng tôi sẽ tiếp tục tối ưu hóa hơn nữa cơ sở dữ liệu MySQL bằng cách kiểm tra trạng thái bộ nhớ đệm trên máy chủ cơ sở dữ liệu của bạn. Để thực hiện việc này, bằng cách sử dụng một truy vấn đặc biệt, chúng tôi sẽ hiển thị giá trị của tất cả các biến hệ thống:
Đó là một vấn đề hoàn toàn khác.
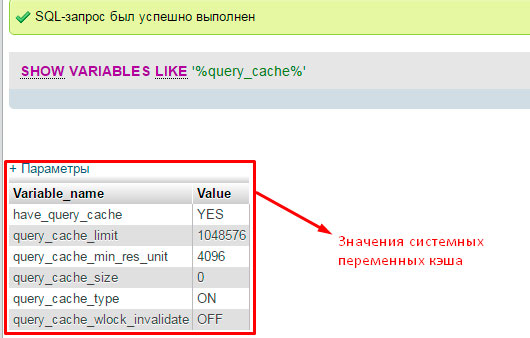
Chúng ta hãy đánh giá nhỏ về các giá trị thu được, điều này sẽ hữu ích cho chúng ta trong việc tối ưu hóa cơ sở dữ liệu Dữ liệu MySQL:
has_query_cache – giá trị cho biết bộ nhớ đệm truy vấn có “BẬT” hay không.
query_cache_type – hiển thị loại bộ đệm đang hoạt động. Chúng ta cần giá trị "BẬT". Điều này cho biết rằng bộ nhớ đệm được bật cho tất cả các loại lựa chọn (lệnh SELECT). Ngoại trừ những trường hợp sử dụng tham số SQL_NO_CACHE (cấm lưu thông tin về truy vấn này).
Chúng tôi có tất cả các cài đặt được đặt chính xác.
Chúng tôi đo bộ đệm cho các chỉ mục và khóa
Bây giờ bạn cần kiểm tra xem dung lượng RAM được phân bổ cho các chỉ mục và khóa. Bạn nên đặt tham số này, quan trọng để tối ưu hóa cơ sở dữ liệu MySQL, ở mức 20-30% dung lượng RAM có sẵn cho máy chủ. Ví dụ: nếu 4 “ha” được phân bổ cho một phiên bản DBMS, thì bạn có thể thoải mái đặt 32 “mét”. Nhưng tất cả phụ thuộc vào đặc điểm của một cơ sở dữ liệu cụ thể và cấu trúc (loại) bảng của nó.
Để đặt giá trị tham số, bạn cần chỉnh sửa nội dung của tệp cấu hình my.ini, tệp này ở Denver nằm ở đường dẫn sau: F:\Webserver\usr\local\mysql-5.5

Mở tệp bằng Notepad. Sau đó, chúng tôi tìm tham số key_buffer_size trong đó và đặt kích thước tối ưu cho hệ thống PC của bạn (tùy thuộc vào “ha” RAM). Sau này, bạn cần khởi động lại máy chủ cơ sở dữ liệu.

DBMS sử dụng một số hệ thống con bổ sung (cấp thấp hơn) và tất cả các cài đặt chính của chúng cũng được chỉ định trong tệp cấu hình này. Do đó, nếu bạn cần tối ưu hóa MySQL InnoDB, thì chào mừng bạn đến đây. Chúng tôi sẽ nghiên cứu chủ đề này chi tiết hơn trong một trong những tài liệu tiếp theo của chúng tôi.
Đo lường mức độ của chỉ số
Việc sử dụng các chỉ mục trong bảng làm tăng đáng kể tốc độ xử lý và tạo ra phản hồi DBMS cho một truy vấn đã nhập. MySQL liên tục “đo lường” mức độ sử dụng chỉ mục và khóa trong mỗi cơ sở dữ liệu. Để có được giá trị này, hãy sử dụng truy vấn:
HIỂN THỊ TRẠNG THÁI THÍCH "handler_read%"
HIỂN THỊ TRẠNG THÁI THÍCH "handler_read%" |

Trong kết quả thu được, chúng ta quan tâm đến giá trị ở dòng Handler_read_key. Nếu con số được chỉ ra là nhỏ thì điều này cho thấy rằng các chỉ mục hầu như không bao giờ được sử dụng trong cơ sở dữ liệu này. Và điều này thật tệ (như của chúng tôi).
Việc quản lý các chỉ mục—tức là cách chúng được tạo và duy trì—có thể tác động đáng kể đến hiệu suất của các truy vấn SQL.
Rất thường xuyên, các tối ưu hóa sau có thể được áp dụng:
- xóa các chỉ mục không sử dụng
- xác định các chỉ mục không được sử dụng và không hiệu quả
- cải thiện chỉ số
- tránh hoàn toàn các truy vấn sql!
- đơn giản hóa các truy vấn sql
- và các tùy chọn bộ nhớ đệm ma thuật
Kết hợp các truy vấn DDL
Các truy vấn thay đổi cấu trúc dữ liệu thường chặn bảng. Về mặt lịch sử, việc chạy truy vấn ALTER yêu cầu tạo một bản sao mới của bảng, việc này có thể tốn rất nhiều thời gian và ổ đĩa. Do đó, thay vì ba truy vấn với những thay đổi nhỏ, việc thực hiện một truy vấn kết hợp sẽ có lợi hơn nhiều. Điều này có thể tiết kiệm một lượng thời gian đáng kể cho các tác vụ quản trị cơ sở dữ liệu.
Loại bỏ các chỉ mục trùng lặp
Các chỉ mục trùng lặp có hại vì hai lý do: tất cả các yêu cầu thay đổi dữ liệu sẽ chậm hơn vì công việc kép được thực hiện để duy trì tính đầy đủ của chỉ mục. Ngoài ra, điều này còn tạo thêm tải cho hệ thống tệp vì kích thước của cơ sở dữ liệu trở nên lớn về mặt vật lý và dẫn đến tăng thời gian tạo bản sao lưu và thời gian khôi phục.
Một vài điều kiện đơn giản có thể dẫn đến các chỉ mục trùng lặp. Ví dụ: mysql không cần chỉ mục trên các trường CHÍNH.
Một chỉ mục trùng lặp cũng có thể tồn tại nếu phía bên trái của một trong các chỉ mục giống hệt với chỉ mục khác.
Tiện ích pt-duplicate-key-checker từ perkona-toolkit là một cách đơn giản và nhanh chóng để kiểm tra cấu trúc cơ sở dữ liệu của bạn xem có các chỉ mục không cần thiết hay không.
Xóa các chỉ mục không sử dụng
Ngoài các chỉ mục không bao giờ được sử dụng vì chúng trùng lặp, có thể có các chỉ mục không trùng lặp đơn giản là không bao giờ được sử dụng. Các chỉ mục như vậy có tác động tương tự như các chỉ mục trùng lặp. Trong mysql tiêu chuẩn không có cách nào để xác định chỉ mục nào không được sử dụng, nhưng một số phiên bản có tính năng tương tự, chẳng hạn như khi sử dụng bản vá Google MySQL.
Bản vá này giới thiệu một tính năng: SHOW INDEX_STATISTICS.
Và trong mysql thông thường, trước tiên bạn cần thu thập tất cả các truy vấn sql được sử dụng, chạy chúng và xem kế hoạch thực hiện, đồng thời thu thập thông tin về các chỉ mục được sử dụng trong từng trường hợp và đưa thông tin này vào một bảng duy nhất. Trong mọi trường hợp, đó là một kinh nghiệm hữu ích.
Tối ưu hóa các trường chỉ mục.
Ngoài việc tạo các chỉ mục mới để cải thiện hiệu suất, bạn có thể cải thiện hiệu suất thông qua các tối ưu hóa thiết kế bổ sung. Những tối ưu hóa này bao gồm việc sử dụng dữ liệu tùy chỉnh và các loại trường. Lợi ích trong trường hợp này là tải đĩa thấp hơn và khối lượng chỉ mục lớn hơn có thể vừa với RAM.
Loại dữ liệu
Một số loại có thể được thay thế dễ dàng trên nền tảng hiện có.
BIGINT vs INT
Khi khóa CHÍNH được xác định là TĂNG TỰ ĐỘNG LỚN, thường không có lý do gì để sử dụng nó. Kiểu dữ liệu INT UNSIGNED AUTO_INCREMENT có thể lưu trữ số lượng tối đa lên tới 4294967295. Nếu bạn thực sự có nhiều bản ghi hơn con số này, bạn có thể sẽ cần một kiến trúc khác.
Từ sự thay đổi như vậy từ BIGINT thành INT UNSIGNED, mỗi hàng của bảng bắt đầu chiếm ít dung lượng trên đĩa hơn 2 lần, ngoài ra, kích thước mà khóa CHÍNH chiếm giữ giảm từ 8 byte xuống còn 4.
Đây có lẽ là một trong những cải tiến đơn giản hữu hình nhất có thể được thực hiện khá dễ dàng.
DATETIME so với DẤU THỜI GIAN
Mọi thứ ở đây đều đơn giản: dấu thời gian - 4 byte, datetime - 8 byte.
Nên sử dụng bất cứ khi nào có thể vì:
- kiểm tra tính toàn vẹn dữ liệu bổ sung
- trường như vậy sẽ chỉ sử dụng 1 byte để lưu trữ 255 giá trị duy nhất
- Các trường như vậy thuận tiện hơn để đọc :)
Trong lịch sử, việc sử dụng các trường enum dẫn đến cơ sở phụ thuộc vào những thay đổi trong các giá trị có thể có trong enum. Đây là một yêu cầu chặn DDL. Kể từ MySQL 5.1, việc thêm các biến thể mới vào enum rất nhanh và không liên quan đến kích thước bảng.
NULL so với KHÔNG NULL
Nếu bạn không chắc chắn rằng một cột có thể chứa giá trị null (NULL) hay không thì tốt hơn nên xác định cột đó là NOT NULL. Chỉ mục trên cột như vậy sẽ có kích thước nhỏ hơn và dễ xử lý hơn.
Chuyển đổi loại tự động
Khi bạn chọn kiểu dữ liệu để nối các trường, có thể xảy ra trường hợp kiểu dữ liệu của trường không được xác định. Chuyển đổi tích hợp có thể là một chi phí hoàn toàn không cần thiết.
Đối với các trường số nguyên, hãy đảm bảo rằng SIGNED và UNSIGNED khớp nhau, đối với các loại trường biến, có thể không cần thiết phải chuyển đổi mã hóa khi nối, vì vậy hãy nhớ kiểm tra chúng. Một vấn đề phổ biến là tự động chuyển đổi giữa bảng mã latin1 và utf8.
Các loại cột
Một số loại dữ liệu thường được lưu trữ sai cột. Việc thay đổi loại khi làm như vậy có thể giúp lưu trữ hiệu quả hơn, đặc biệt khi các cột đó được đưa vào chỉ mục. Hãy xem xét một vài ví dụ điển hình.
địa chỉ IP
Địa chỉ IPv4 có thể được lưu trữ trong trường INT UNSIGNED, chỉ mất 4 byte. Một tình huống phổ biến xảy ra khi địa chỉ IP được lưu trữ trong trường VARCHAR(15), chiếm 12 byte. Sự thay đổi này có thể giảm kích thước xuống 2/3. Hàm INET_ATON() và INET_NTOA được sử dụng để chuyển đổi giữa một chuỗi có địa chỉ IP và giá trị số.
Đối với các địa chỉ IPv6 ngày càng trở nên phổ biến, điều quan trọng là phải lưu trữ giá trị số 128 bit của chúng trong các trường BINARY(16) và không sử dụng VARCHAR cho định dạng mà con người có thể đọc được.
Lưu trữ các trường md5 dưới dạng CHAR(32) là thông lệ. Nếu bạn sử dụng trường VARCHAR(32), bạn cũng thêm chi phí độ dài chuỗi bổ sung cho mỗi giá trị. Tuy nhiên, chuỗi md5 là giá trị thập lục phân - và nó có thể được lưu trữ hiệu quả hơn bằng cách sử dụng các hàm UNHEX() và HEX(). Trong trường hợp này, dữ liệu có thể được lưu trữ trong các trường BINARY(16). Hành động đơn giản này sẽ giảm kích thước trường từ 32 byte xuống 16 byte. Nguyên tắc tương tự có thể được áp dụng cho bất kỳ giá trị thập lục phân nào.
Dựa trên cuốn sách của Ronald Bradford.
→ Tối ưu hóa truy vấn MySQL
MySQL có nhiều chức năng để sắp xếp khác nhau ( ĐẶT BỞI), các nhóm ( NHÓM THEO), hiệp hội ( CHỖ NỐI BÊN TRÁI hoặc QUYỀN THAM GIA) và như thế. Tất cả chúng chắc chắn đều thuận tiện, nhưng trong điều kiện yêu cầu một lần. Ví dụ: nếu cá nhân bạn cần khai thác thứ gì đó trong cơ sở dữ liệu bằng cách sử dụng nhiều bảng và liên kết, thì ngoài các hàm trên, bạn có thể và thậm chí cần sử dụng các toán tử có điều kiện NẾU NHƯ. Sai lầm chính của những người mới lập trình là mong muốn áp dụng những truy vấn như vậy vào mã làm việc của trang web. Trong trường hợp này, một truy vấn phức tạp chắc chắn là hay nhưng có hại. Vấn đề là mọi toán tử truy vấn sắp xếp, nhóm, nối hoặc lồng nhau đều không thể được thực thi trong RAM và sử dụng ổ cứng để tạo các bảng tạm thời. Và ổ cứng, như bạn đã biết, là điểm nghẽn của máy chủ.
Quy tắc tối ưu hóa truy vấn mysql
1. Tránh các truy vấn lồng nhau
Đây là sai lầm nghiêm trọng nhất. Tiến trình cha sẽ luôn đợi tiến trình con hoàn tất và lúc này sẽ giữ kết nối với cơ sở dữ liệu, sử dụng đĩa và tải iowait. Hai yêu cầu song song tới cơ sở dữ liệu và thực hiện việc lọc cần thiết trong trình thông dịch máy chủ ( Perl, PHP, v.v.) sẽ được thực thi nhanh hơn mức độ lồng nhau.
Ví dụ trong Perl những gì không làm:
$sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) ( my $groupNAME = $dbh->selectrow_array("SELECT groupNAME FROM Group WHERE groupID = $row"); ### Giả sử bạn cần thu thập tên của nhóm ### và thêm chúng vào cuối mảng dữ liệu push @row => $groupNAME; ### Làm việc khác... )
hoặc không có trường hợp nào như thế này:
$sth = $dbh->prepare("SELECT elementID,elementNAME,groupID FROM tbl WHERE groupID IN(CHỌN groupID FROM các nhóm WHERE groupNAME = "Đầu tiên" HOẶC groupNAME = "Thứ hai" HOẶC groupNAME = "Thứ bảy")");
Nếu cần thực hiện những hành động như vậy, trong mọi trường hợp, tốt hơn là sử dụng hàm băm, mảng hoặc bất kỳ đường dẫn lọc nào khác.
Một ví dụ trong Perl, như tôi thường làm:
Nhóm % của tôi; $sth = $dbh->prepare("CHỌN groupID,groupNAME TỪ các nhóm WHERE groupID IN(2,3,7)"); $sth->execute(); while (my @row = $sth->fetchrow_array()) ( $groups($row) = $row; ) ### Bây giờ, hãy thực hiện tìm nạp chính mà không cần truy vấn con my $sth2 = $dbh->prepare("SELECT elementID ,elementNAME,groupID FROM tbl WHERE groupID IN(2,3,7)"); $sth2->execute(); while (@row của tôi = $sth2->fetchrow_array()) ( push @row => $groups($row); ### Hãy làm việc khác... )
2. Không sắp xếp, nhóm hoặc lọc trong cơ sở dữ liệu
Nếu có thể, đừng sử dụng các toán tử ORDER BY, GROUP BY hoặc JOIN trong truy vấn của bạn. Tất cả đều sử dụng bảng tạm thời. Nếu việc sắp xếp hoặc nhóm chỉ cần thiết để hiển thị các phần tử, ví dụ như theo thứ tự bảng chữ cái, thì tốt hơn là thực hiện các hành động này trong các biến trình thông dịch.
Ví dụ Perl về cách không sắp xếp:
$sth = $dbh->prepare("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7) ORDER BY elementNAME"); $sth->execute(); while (@row của tôi = $sth->fetchrow_array()) ( print qq($row => $row); )
Một ví dụ trong Perl về cách tôi thường sắp xếp:
$list = $dbh->selectall_arrayref("SELECT elementID,elementNAME FROM tbl WHERE groupID IN(2,3,7)"); foreach (sắp xếp ( $a-> cmp $b-> ) @$list)( print qq($_-> => $_->); )
Cách này nhanh hơn nhiều. Sự khác biệt đặc biệt đáng chú ý nếu có nhiều dữ liệu. Trong trường hợp bạn cần sắp xếp theo perlđối với một số trường, bạn có thể áp dụng sắp xếp Schwartz. Nếu cần sắp xếp ngẫu nhiên ORDER BY RAND() - hãy sử dụng sắp xếp ngẫu nhiên trong Perl.
3. Sử dụng chỉ mục
Mặc dù việc sắp xếp trong cơ sở dữ liệu có thể bị bỏ qua trong một số trường hợp, WHERE khó có thể thực hiện được. Vì vậy, đối với các trường sẽ được so sánh thì cần thiết lập chỉ mục. Chúng rất dễ làm.
Với yêu cầu này:
BẢNG THAY ĐỔI `any_db`.`any_tbl` THÊM CHỈ SỐ `text_index`(`text_fld`(255));
Trong đó 255 là độ dài khóa. Đối với một số loại dữ liệu thì không bắt buộc. Xem tài liệu MySQL để biết chi tiết.