Construirea unui clasificator de învățare automată folosind Scikit-learn în Python. Ghidul autostopul pentru învățarea automată în Python
Învățarea automată este în creștere, iar termenul se strecoară încet în așa-numitul teritoriu al cuvintelor la modă. Aceasta este în într-o mare măsură din cauza faptului că mulți nu înțeleg pe deplin ce înseamnă de fapt acest termen. Mulțumită Analiza Google Tendințe (statistici privind interogări de căutare), putem studia graficul și putem înțelege cum a crescut interesul pentru termenul „învățare automată” în ultimii 5 ani:
Ţintă
Dar acest articol nu este despre popularitate.învățare automată. Opt algoritmi majori de învățare automată și utilizările lor practice sunt descrise pe scurt aici. Vă rugăm să rețineți că toate modelele sunt implementate în Python și trebuie să aveți cel puțin cunoștințe minime despre acest limbaj de programare. O explicație detaliată a fiecărei secțiuni este conținută în videoclipurile în limba engleză atașate. Să facem imediat o rezervă că începătorii completi vor găsi acest text dificil pentru dezvoltatorii continuați și avansați, dar capitolele din material pot fi folosite ca un plan pentru formarea de construcție: ce merită să știi, ce merită înțeles; primul.
Clasificare
Simțiți-vă liber să omiteți algoritmul dacă nu înțelegeți ceva. Utilizați acest ghid cum doriți. Iată lista:
- Regresie liniara.
- Regresie logistică.
- Arbori de decizie.
- Suport mașină vectorială.
- Metoda k-cei mai apropiati vecini.
- Algoritm forestier aleatoriu.
- Metoda K-means.
- Metoda componentelor principale.
Punând lucrurile în ordine
În mod evident, vei fi supărat dacă, când încerci să rulezi codul altcuiva, se dovedește brusc că nu ai trei pachetele necesare, iar codul a fost lansat și în versiune veche limba. Deci, pentru a vă economisi timp prețios, mergeți direct la Python 3.6.2 și importați bibliotecile necesare din pasta de cod de mai jos. Datele au fost preluate din seturi de date Diabet și iris de la Depozitul UCI Machine Learning . În cele din urmă, dacă doriți să săriți peste toate acestea și să priviți codul, iată un link către Depozitul GitHub.
Import panda ca pd import matplotlib.pyplot ca plt import numpy ca np import seaborn ca sns %matplotlib inline
Regresie liniara
Este probabil cel mai popular algoritm de învățare automată din lume. acest momentși în același timp cel mai subestimat. Mulți cercetători uită că între doi algoritmi cu aceeași performanță, este mai bine să-l alegeți pe cel mai simplu.Regresie liniara este un algoritm de învățare automată supravegheat care prezice un rezultat bazat pe caracteristici continue. Regresia liniară este versatilă în sensul că are capacitatea de a rula pe o singură variabilă de intrare (regresie liniară simplă) sau pe mai multe variabile ( regresie multiplă). Esența acestui algoritmeste de a atribui ponderi optime variabilelor pentru a crea o linie (ax + b) care va fi folosită pentru a prezice rezultatul. Urmărește videoclipul pentru o explicație mai clară.
Acum că înțelegeți esența regresiei liniare, să mergem mai departe și să o implementăm în Python.
Începutul lucrării
din sklearn import linear_model df = pd.read_csv("linear_regression_df.csv") df.columns = ["X", "Y"] df.head()Vizualizarea
sns.set_context("notebook", font_scale=1.1) sns.set_style("ticks") sns.lmplot("X","Y", data=df) plt.ylabel("Respons") plt.xlabel("Explicative ")Implementarea
linear = linear_model.LinearRegression() trainX = np.asarray(df.X).reshape(-1, 1) trainY = np.asarray(df.Y).reshape(-1, 1) testX = np.asarray(df .X[:20]).reshape(-1, 1) testY = np.asarray(df.Y[:20]).reshape(-1, 1) linear.fit(trainX, trainY) linear.score(trainX , trainY) print("Coeficient: \n", linear.coef_) print("Intercept: \n", linear.intercept_) print("Valoare R²: \n", linear.score(trainX, trainY)) prezis = linear.predict(testX)Cheat sheets îți vor elibera mintea pentru sarcini mai importante. Am adunat 27 dintre cele mai bune foi de cheat pe care le poți și ar trebui să le folosești.
Da, învățarea automată se dezvoltă treptat și cred că colecția mea va deveni depășită, dar pentru iunie 2017 este mai mult decât relevantă.
Dacă nu doriți să descărcați toate foile de cheat separat, descărcați arhiva zip gata făcută.
Învățare automată
Există destul de multe diagrame și tabele utile care acoperă învățarea automată. Mai jos sunt cele mai complete și necesare.
Arhitecturi de rețele neuronale
Odată cu apariția noilor arhitecturi de rețele neuronale, acestea au devenit dificil de urmărit. Numărul mare de acronime (BiLSTM, DCGAN, DCIGN, le știe cineva pe toate?) poate fi descurajantă.
Așa că am decis să alcătuiesc o foaie de cheat care să conțină multe dintre aceste arhitecturi. Cele mai multe dintre ele se referă la rețelele neuronale. Există o singură problemă cu această vizualizare: principiul de utilizare nu este afișat. De exemplu, autoencoderele variaționale (VAE) pot arăta ca autoencodere (AE), dar procesul de învățare este diferit.
Diagramă de flux al algoritmului Microsoft Azure
Fișe de înșelăciune Microsoft Azure pentru a vă ajuta să alegeți algoritm corect pentru un model de analiză predictivă. Studio de mașini Instruire Microsoft Azure include o bibliotecă mare de algoritmi de regresie, clasificare, grupare și detecție a anomaliilor.

Diagrama de flux al algoritmului SAS
Cheat sheets cu algoritmi SAS vă vor permite să găsiți rapid un algoritm potrivit pentru rezolvarea unei anumite probleme. Algoritmii prezentați aici sunt rezultatul unei compilații de feedback și sfaturi de la mai mulți oameni de știință ai datelor, dezvoltatori și experți în învățarea automată.

Culegere de algoritmi
Regresia, regularizarea, gruparea, arborele de decizie, bayesian și alți algoritmi sunt prezentați aici. Toate sunt grupate după principii de funcționare.

De asemenea, lista în format infografic:

Algoritm de prognoză: „pentru/împotrivă”
Aceste cheat sheets au colectat cei mai buni algoritmi care sunt utilizați în analiza predictivă. Prognoza este un proces în care valoarea unei variabile de ieșire este determinată dintr-un set de variabile de intrare.

Piton
Nu este surprinzător că limbajul Python a adunat o comunitate mare și multe resurse online. Pentru aceasta sectiune am selectat cele mai bune foi de trucuri cu care am lucrat.
Aceasta este o colecție a celor mai folosiți 10 algoritmi de învățare automată cu coduri în Python și R. Foaia de cheat este potrivită ca referință pentru a vă ajuta să utilizați algoritmi utili de învățare automată.

Nu se poate nega că Python este în creștere astăzi. Cheat sheets include tot ce aveți nevoie, inclusiv funcții și definiția programării orientate pe obiecte folosind limbajul Python ca exemplu.

Și această foaie de cheat va fi o completare excelentă la partea introductivă a oricărui tutorial Python:

NumPy
NumPy este o bibliotecă care îi permite lui Python să proceseze datele rapid. Când studiați pentru prima dată, este posibil să aveți probleme în reamintirea tuturor funcțiilor și metodelor, așa că aici am adunat cele mai utile cheat sheets care pot facilita foarte mult studiul bibliotecii. Sunt acoperite importul/exportul, crearea de matrice, copierea, sortarea, mutarea elementelor și multe altele.

Și aici este prezentată în plus partea teoretică:

O reprezentare schematică a unora dintre date poate fi găsită în această foaie de cheat:

Toate informatie necesara cu diagrame:

Pandas este o bibliotecă de nivel înalt concepută pentru analiza datelor. Rame, panouri, obiecte, funcționalitate pachet și altele corespunzătoare informatie necesara colectate într-o foaie de cheat organizată convenabil:

O reprezentare schematică a informațiilor despre biblioteca Pandas:

Și această foaie de cheat include o prezentare detaliată cu exemple și tabele:

Dacă completați biblioteca anterioară Pandas cu pachetul matplotlib, veți putea desena grafice pentru datele primite. Matplotlib este responsabil pentru trasarea graficelor în Python. Acesta este adesea primul pachet legat de vizualizare pe care îl folosesc programatorii Python începători, iar fișele de cheat prezentate vă vor ajuta să navigați rapid prin funcționalitatea acestei biblioteci.

În a doua foaie de cheat veți găsi mai multe exemple reprezentare vizuala grafice:

Biblioteca Scikit-Learn Python cu algoritmi de învățare automată nu este cel mai ușor de învățat, dar cu cheat sheets principiul funcționării sale devine cât se poate de clar.

Reprezentare schematică:

Cu teorie, exemple și materiale suplimentare:

TensorFlow
O altă bibliotecă pentru învățarea automată, dar cu propriile sale funcționalități și dificultăți în înțelegerea acesteia. Mai jos este o foaie de cheat utilă pentru a învăța TensorFlow.
Fiecare expert în analiza datelor se întreabă ce limbaj de programare să aleagă. — R sau Python, ei scriu? Pentru a găsi cel mai bun răspuns la această întrebare, în cele mai multe cazuri cel mai mult popular motor de căutare Google. Fără răspunsurile potrivite, potențialii candidați nu devin niciodată experți în învățarea automată sau în analiza datelor. Acest articol încearcă să explice specificul limbajelor R și Python pentru utilizarea lor în dezvoltarea tehnologiilor de învățare automată.
Învățarea automată și știința datelor sunt segmente înfloritoare și în continuă creștere ale tehnologiilor avansate de astăzi care ajută la rezolvarea diferitelor probleme și provocări complexe în dezvoltarea de soluții și aplicații. În acest sens, la scară globală, analiștii și experții în analiza datelor se confruntă cu cel mai mult oportunități ample aplicarea punctelor forte și abilităților lor în tehnologii precum inteligenţă artificială, IoT și big data. Pentru a rezolva noi sarcini complexe experții și specialiștii solicită Unealtă puternică procesarea unei cantități uriașe de date și pentru automatizarea sarcinilor de analiză, recunoaștere și agregare a datelor au fost dezvoltate diverse instrumenteși biblioteci de învățare automată.
În dezvoltarea bibliotecilor de învățare automată, limbaje de programare precum R și Python ocupă poziții de frunte. Mulți experți și analiști își petrec timpul alegând limba necesară. Ce limbaj de programare este mai preferabil în scopuri de învățare automată?
Care sunt asemănările dintre R și Python
- Ambele limbi — R și Python — sunt limbaje de programare open source cod sursa. Un număr mare de membri ai comunității de programare au contribuit la dezvoltarea documentației și dezvoltarea acestor limbaje.
- Limbile pot fi folosite pentru analiza datelor, analiză și proiecte de învățare automată.
- Ambele au instrumente avansate pentru finalizarea proiectelor de știință a datelor.
- Experții în analiza datelor care preferă să lucreze în R și Python sunt plătiți aproape la fel.
- Versiunile actuale de Python și R — x.x
R și Python – competiție între concurenți
Excursie istorica:
- În 1991, Guido Van Rossum, inspirat de dezvoltarea limbajelor C, Modula-3 și ABC, a propus Limba noua; limbaj nou programare - Python.
- În 1995, Ross Ihaka și Robert Gentleman au creat limbajul R, care a fost dezvoltat prin analogie cu limbajul de programare S.
Obiective:
- Scopul dezvoltării Python este de a crea produse software, simplificând procesul de dezvoltare și asigurând lizibilitatea codului.
- În timp ce limbajul R a fost dezvoltat în primul rând pentru analiza de date ușor de utilizat și pentru rezolvarea problemelor statistice complexe. Este un limbaj orientat în primul rând statistic.
Ușurință de învățare:
- Datorită lizibilității codului, Python este ușor de învățat. Este un limbaj prietenos pentru începători, care poate fi învățat fără nicio experiență anterioară de programare.
- Limbajul R este dificil, dar cu cât folosești mai mult acest limbaj în programare, cu atât este mai ușor de învățat și cu atât eficiența ta în rezolvarea formulelor statistice complexe este mai mare. Pentru programatorii experimentați, R este o opțiune mergi la.
Comunitățile:
- Python are sprijinul diferitelor comunități ai căror membri sunt dedicați dezvoltării limbajului pentru aplicații promițătoare. Programatorii și dezvoltatorii sunt, ca și membrii StackOverflow, participanți activi Comunitatea Python.
- Limbajul R este susținut și de membrii unei comunități diverse prin liste de corespondență, documentare a contribuțiilor utilizatorilor și altele. Majoritatea statisticienilor, cercetătorilor și experților în analiza datelor sunt implicați activ în dezvoltarea limbajului.
Flexibilitate:
- Python este un limbaj care pune accent pe productivitate, deci este destul de flexibil în dezvoltare. aplicatii diverse. Pentru a dezvolta aplicații la scară largă, Python conține diverse module și biblioteci.
- Limbajul R este, de asemenea, flexibil în dezvoltarea de formule complexe, efectuarea de teste statistice, vizualizarea datelor și multe altele. Include o varietate de pachete gata de utilizare.
Aplicație:
- Python este lider în dezvoltarea de aplicații. Este folosit pentru a sprijini dezvoltarea site-urilor web, dezvoltarea jocurilor și știința datelor.
- Limbajul R este folosit în principal pentru a dezvolta proiecte de analiză a datelor care se concentrează pe statistici și vizualizare.
Atât limbajele R, cât și Python au avantaje și dezavantaje. În cele mai multe cazuri, acestea sunt limbaje centrate pe specific, deoarece R este axat pe statistici și vizualizare, iar Python este pe simplitate în dezvoltarea oricărei aplicații.
Pe baza acestui fapt, R poate fi folosit în principal pentru cercetare în institute științifice, atunci când se desfășoară analize statisticeși vizualizarea datelor. Pe de altă parte, Python este folosit pentru a simplifica procesul de îmbunătățire a programelor, procesare a datelor etc. Limbajul R poate fi foarte productiv pentru statisticienii care lucrează în domeniul analizei datelor și Python este mai bun Potrivit pentru programatori și dezvoltatori care creează produse pentru experții în știința datelor.
Bună, habr!
Import numpy ca np import urllib # url with dataset url = "http://archive.ics.uci.edu/ml/machine-learning-databases/pima-indians-diabetes/pima-indians-diabetes.data" # descărcați fișier raw_data = urllib.urlopen(url) # încărcați fișierul CSV ca un set de date matrice numpy = np.loadtxt(raw_data, delimiter=",") # separați datele de atributele țintă X = set de date[:,0:7] y = set de date[:,8]
Mai departe, în toate exemplele vom lucra cu acest set de date, și anume cu matricea obiect-atribut Xși valorile variabilei țintă y.
Normalizarea datelor
Toată lumea știe că majoritatea metodelor de gradient (pe care se bazează în esență aproape toți algoritmii de învățare automată) sunt foarte sensibile la scalarea datelor. Prin urmare, înainte de a rula algoritmi, cel mai adesea se face fie normalizare, sau așa-numitul standardizare. Normalizarea implică înlocuirea caracteristicilor nominale, astfel încât fiecare dintre ele să se afle în intervalul de la 0 la 1. Standardizarea implică o astfel de preprocesare a datelor, după care fiecare caracteristică are o medie de 0 și o varianță de 1. Scikit-Learn are deja funcții pregătite pentru aceasta:Din sklearn import preprocessing # normalize the data attributes normalized_X = preprocessing.normalize(X) # standardize the data attributes standardized_X = preprocessing.scale(X)
Selectarea caracteristicilor
Nu este un secret pentru nimeni că, adesea, cel mai important lucru atunci când rezolvați o problemă este capacitatea de a selecta corect și chiar de a crea funcții. În literatura engleză acest lucru se numește Selectarea caracteristicilorȘi Inginerie caracteristică. În timp ce Future Engineering este destul de proces creativși se bazează mai mult pe intuiție și cunoștințe de specialitate, Feature Selection are deja un numar mare de algoritmi gata realizati. Algoritmii „Arbore” permit calcularea conținutului de informații al caracteristicilor:Din sklearn import metrics from sklearn.ensemble import ExtraTreesClassifier model = ExtraTreesClassifier() model.fit(X, y) # afișați importanța relativă a fiecărui atribut print(model.feature_importances_)
Toate celelalte metode se bazează într-un fel sau altul pe enumerarea eficientă a submulților de caracteristici pentru a găsi cel mai bun subset pe care modelul construit oferă cea mai bună calitate. Un astfel de algoritm de forță brută este algoritmul de eliminare a caracteristicilor recursive, care este disponibil și în biblioteca Scikit-Learn:
Din sklearn.feature_selection import RFE din sklearn.linear_model import LogisticRegression model = LogisticRegression() # creați modelul RFE și selectați 3 atribute rfe = RFE(model, 3) rfe = rfe.fit(X, y) # rezumați selecția atribute print(rfe.support_) print(rfe.ranking_)
Construcția algoritmului
După cum sa menționat deja, Scikit-Learn implementează toți algoritmii principali de învățare automată. Să ne uităm la unele dintre ele.Regresie logistică
Este folosit cel mai adesea pentru rezolvarea problemelor de clasificare (binară), dar este permisă și clasificarea cu mai multe clase (așa-numita metodă one-vs-all). Avantajul acestui algoritm este că la ieșire pentru fiecare obiect avem probabilitatea de a aparține claseiDin sklearn import metrics from sklearn.linear_model import LogisticRegression model = LogisticRegression() model.fit(X, y) print(model) # face predictions expected = y predicted = model.predict(X) # rezuma potrivirea modelului print( metrics.classification_report(așteptat, prezis)) print(metrics.confusion_matrix(așteptat, prezis))
Bayes naiv
Este, de asemenea, unul dintre cei mai faimoși algoritmi de învățare automată, a cărui sarcină principală este de a restabili densitățile de distribuție a datelor eșantionului de antrenament. Adesea, această metodă oferă o calitate bună în problemele de clasificare cu mai multe clase.Din sklearn import metrics from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X, y) print(model) # face predictions expected = y predicted = model.predict(X) # rezuma potrivirea modelului print( metrics.classification_report(așteptat, prezis)) print(metrics.confusion_matrix(așteptat, prezis))
K-cei mai apropiați vecini
Metodă kNN (k-Cei mai apropiați vecini) adesea folosit ca parte a unui algoritm de clasificare mai complex. De exemplu, evaluarea sa poate fi folosită ca semn pentru un obiect. Și uneori, un simplu kNN pe caracteristici bine alese oferă calitate excelenta. Cu setări adecvate ale parametrilor (în principal metrici), algoritmul oferă adesea o calitate bună în problemele de regresieDin sklearn import metrics from sklearn.neighbors import KNeighborsClassifier # potriviți un model de vecin cel mai apropiat k la modelul de date = KNeighborsClassifier() model.fit(X, y) print(model) # faceți predicții așteptate = y predicted = model.predict( X) # rezumați potrivirea modelului print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Arbori de decizie
Arbori de clasificare și regresie (CART) folosit adesea în probleme în care obiectele au caracteristici categoriale și este folosit pentru probleme de regresie și clasificare. Copacii sunt foarte potriviți pentru clasificarea în mai multe claseDin sklearn import metrics from sklearn.tree import DecisionTreeClassifier # potriviți un model CART la modelul de date = DecisionTreeClassifier() model.fit(X, y) print(model) # face predictions wait = y predicted = model.predict(X) # rezumați potrivirea modelului print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Suport Vector Machine
SVM (Suport Vector Machines) este unul dintre cei mai faimoși algoritmi de învățare automată, utilizat în principal pentru sarcini de clasificare. La fel ca regresia logistică, SVM permite clasificarea multiclasă folosind metoda one-vs-all.Din valorile de import sklearn din sklearn.svm import SVC # potriviți un model SVM la modelul de date = SVC() model.fit(X, y) print(model) # faceți predicții așteptate = y prezis = model.predict(X) # rezumați potrivirea modelului print(metrics.classification_report(expected, predicted)) print(metrics.confusion_matrix(expected, predicted))
Pe lângă algoritmii de clasificare și regresie, Scikit-Learn are o cantitate mare algoritmi mai complecși, inclusiv gruparea, precum și tehnici implementate pentru construirea de compoziții de algoritmi, inclusiv BagareȘi Amplificare.
Optimizarea parametrilor algoritmului
Una dintre cele mai dificile etape în construirea unui adevărat algoritmi eficienti este o alegere parametrii corecti. De obicei, acest lucru devine mai ușor cu experiența, dar într-un fel sau altul trebuie să treci peste bord. Din fericire, Scikit-Learn are deja destul de multe funcții implementate în acest scop.De exemplu, să ne uităm la selectarea unui parametru de regularizare, în care încercăm pe rând mai multe valori:
Import numpy ca np din sklearn.linear_model import Ridge din sklearn.grid_search import GridSearchCV # pregătiți o gamă de valori alfa pentru a testa alfa = np.array() # creați și potriviți un model de regresie de creastă, testând fiecare model alfa = Ridge( ) grid = GridSearchCV(estimator=model, param_grid=dict(alpha=alphas)) grid.fit(X, y) print(grid) # rezuma rezultatele căutării în grilă print(grid.best_score_) print(grid.best_estimator_. alfa)
Uneori se dovedește a fi mai eficient să selectezi aleatoriu un parametru dintr-un anumit segment de mai multe ori și să măsori calitatea algoritmului la acest parametruși astfel alege-l pe cel mai bun:
Import numpy ca np din scipy.stats import uniform ca sp_rand din sklearn.linear_model import Ridge din sklearn.grid_search import RandomizedSearchCV # pregătiți o distribuție uniformă pentru eșantionare pentru parametrul alfa param_grid = ("alpha": sp_rand()) # create and fit un model de regresie de creasta, testarea valorilor alfa aleatoare model = Ridge() rsearch = RandomizedSearchCV(estimator=model, param_distributions=param_grid, n_iter=100) rsearch.fit(X, y) print(rsearch) # rezuma rezultatele căutare parametri aleatoriu print(rsearch.best_score_) print(rsearch.best_estimator_.alpha)
Am analizat întregul proces de lucru cu biblioteca Scikit-Learn, cu excepția redării rezultatelor într-un fișier, care este oferit cititorului ca exercițiu, deoarece unul dintre avantajele Python (și Scikit- Învățați biblioteca în sine) în comparație cu R este documentația sa excelentă. În următoarele părți vom analiza în detaliu fiecare dintre secțiuni, în special, vom atinge un lucru atât de important precum Ingineria frumuseții.
Sper cu adevărat că acest material îi va ajuta pe oamenii de știință de date începători să înceapă să rezolve în practică problemele de învățare automată cât mai curând posibil. În concluzie, aș dori să urez succes și răbdare celor care abia încep să participe la competițiile de învățare automată!
Piton este un limbaj de programare excelent de implementat dintr-o varietate de motive. In primul rand, Piton are o sintaxă clară. În al doilea rând, în Piton Este foarte ușor să manipulezi textul. Piton Folosit de un număr mare de oameni și organizații din întreaga lume, este în evoluție și bine documentat. Limbajul este multiplatform și poate fi folosit complet gratuit.
Pseudocod executabil
Sintaxă intuitivă Piton adesea numit pseudo-cod executabil. Instalare Piton implicit include deja tipuri de date de nivel înalt, cum ar fi liste, tupluri, dicționare, seturi, secvențe și așa mai departe, pe care utilizatorul nu mai trebuie să le implementeze. Aceste tipuri de date de nivel înalt facilitează implementarea conceptelor abstracte. Piton vă permite să programați în orice stil care vă este familiar: orientat pe obiecte, procedural, funcțional și așa mai departe.
ÎN Piton Textul este ușor de procesat și manipulat, ceea ce îl face ideal pentru procesarea datelor nenumerice. Există o serie de biblioteci de utilizat Piton pentru a accesa paginile web, iar manipularea intuitivă a textului facilitează preluarea datelor din HTML-cod.
Piton popular
Limbaj de programare Piton populare și numeroasele exemple de cod disponibile fac învățarea ușoară și destul de rapidă. În al doilea rând, popularitatea înseamnă că există multe module disponibile pentru diferite aplicații.
Piton este un limbaj de programare popular în cercurile științifice și financiare. Un număr de biblioteci pentru calcul științific, cum ar fi SciPyȘi NumPy vă permit să efectuați operații pe vectori și matrice. De asemenea, face codul și mai ușor de citit și vă permite să scrieți cod care arată ca expresii de algebră liniară. In afara de asta, biblioteci științifice SciPyȘi NumPy compilate folosind limbaje nivel scăzut (CUȘi Fortran), ceea ce face calculele la utilizarea acestor instrumente mult mai rapide.
Instrumente științifice Piton funcționează grozav împreună cu instrument grafic intitulat Matplotlib. Matplotlib poate produce diagrame 2D și 3D și poate gestiona majoritatea tipurilor de diagrame utilizate în mod obișnuit în comunitatea științifică.
Piton De asemenea, are un shell interactiv care vă permite să vizualizați și să verificați elementele programului în curs de dezvoltare.
Modul nou Piton, sub nume Pylab, se străduiește să combine oportunitățile NumPy, SciPy, Și Matplotlibîntr-un singur mediu și instalație. Pachetul de azi Pylab Este încă în dezvoltare, dar are un viitor mare.
Avantaje și dezavantaje Piton
Oamenii folosesc diferite limbaje de programare. Dar pentru mulți, un limbaj de programare este pur și simplu un instrument pentru rezolvarea unei probleme. Piton este o limbă nivel superior, ceea ce vă permite să petreceți mai mult timp înțelegând datele și mai puțin timp gândindu-vă la modul în care ar trebui să fie prezentate computerului.
Singurul dezavantaj real Piton este că nu execută codul de program la fel de repede ca, de exemplu, Java sau C. Motivul pentru aceasta este că Piton- limbaj interpretat. Cu toate acestea, este posibil să apelați compilated C-programe de la Piton. Acest lucru vă permite să utilizați tot ce este mai bun limbi diferite programarea și dezvoltarea programului pas cu pas. Dacă ați experimentat cu o idee folosind Pitonși a decis că acesta este exact ceea ce doriți să fie implementat în sistemul finit, atunci această tranziție de la prototip la programul de lucru va fi ușor posibilă. Dacă programul este construit conform principiul modular, apoi vă puteți asigura mai întâi că ceea ce aveți nevoie funcționează în codul în care este scris Piton, iar apoi, pentru a îmbunătăți viteza de execuție a codului, rescrieți secțiunile critice în limbaj C. Bibliotecă C++ Boost face acest lucru ușor de făcut. Alte instrumente precum CythonȘi PyPy vă permit să creșteți performanța programului în comparație cu cea normală Piton.
Dacă ideea în sine implementată de program este „rea”, atunci este mai bine să înțelegeți acest lucru petrecând un minim de timp prețios scriind cod. Dacă ideea funcționează, atunci puteți îmbunătăți întotdeauna performanța prin rescrierea secțiunilor parțial critice ale codului programului.
ÎN anul trecut un număr mare de dezvoltatori, inclusiv cei cu diplome academice, au lucrat pentru a îmbunătăți performanța limbii și a pachetelor sale individuale. Prin urmare, nu este un fapt în care veți scrie cod C, care va funcționa mai rapid decât ceea ce este deja disponibil în Piton.
Ce versiune de Python ar trebui să folosesc?
În prezent, sunt utilizate pe scară largă versiuni diferite acesta și anume 2.x și 3.x. A treia versiune este încă în dezvoltare activă, majoritatea diferitelor biblioteci sunt garantate să funcționeze pe a doua versiune, așa că folosesc a doua versiune și anume 2.7.8, ceea ce vă sfătuiesc să faceți. Nu există modificări fundamentale în cea de-a treia versiune a acestui limbaj de programare, astfel încât codul dvs., cu modificări minime în viitor, dacă este necesar, poate fi transferat pentru a fi utilizat cu a treia versiune.
Pentru a instala, accesați site-ul oficial: www.python.org/downloads/
alege-l pe al tău sistem de operareși descărcați programul de instalare. Nu mă voi opri în detaliu asupra problemei instalării; motoarele de căutare vă vor ajuta cu ușurință în acest sens.
Sunt pe MacOs am instalat versiunea pentru mine Piton diferit de cel care a fost instalat pe sistem și pachete prin managerul de pachete Anaconda(apropo, există și opțiuni de instalare pentru WindowsȘi Linux).
Sub Windows, Ei spun, Piton se cântă cu o tamburină, dar nu am încercat eu însumi, nu voi minți.
NumPy
![]()
NumPy este pachetul principal pentru calculul științific în Piton. NumPy este o extensie a limbajului de programare Piton, care adaugă suport pentru matrice și matrice multidimensionale mari, împreună cu o bibliotecă mare de nivel înalt functii matematice pentru a lucra cu aceste matrice. Predecesor NumPy, punga de plastic Numeric, a fost creat inițial de Jim Haganin cu contribuții de la o serie de alți dezvoltatori. În 2005, Travis Oliphant a creat NumPy prin încorporarea caracteristicilor unui pachet concurent Numarray V Numeric, făcând modificări ample.
Pentru instalare în Terminal Linux do:
sudo apt-get update sudo apt-get install python-numpy
sudo apt - obțineți actualizare sudo apt - get install python - numpy |
Un cod simplu folosind NumPy care formează un vector unidimensional de 12 numere de la 1 la 12 și îl convertește într-o matrice tridimensională:
din numpy import * a = arange(12) a = a.reshape(3,2,2) print a
din importul numpy * a = interval (12) a = a. remodelare (3, 2, 2) imprima a |
Rezultatul pe computerul meu arată astfel:

În general, în Terminal codul este Piton Nu o fac foarte des, decât pentru a calcula ceva rapid, ca pe un calculator. Îmi place să lucrez în IDE PyCharm. Așa arată interfața sa când rulează codul de mai sus

SciPy
![]() SciPy este o bibliotecă open-source pentru calcul științific. Pentru munca SciPy necesită preinstalare NumPy, oferind tranzacții convenabile și rapide cu tablouri multidimensionale. Bibliotecă SciPy funcționează cu matrice NumPy, și oferă multe proceduri de calcul convenabile și eficiente, de exemplu, pentru integrarea și optimizarea numerică. NumPyȘi SciPy ușor de utilizat, dar suficient de puternic pentru a efectua o varietate de calcule științifice și tehnice.
SciPy este o bibliotecă open-source pentru calcul științific. Pentru munca SciPy necesită preinstalare NumPy, oferind tranzacții convenabile și rapide cu tablouri multidimensionale. Bibliotecă SciPy funcționează cu matrice NumPy, și oferă multe proceduri de calcul convenabile și eficiente, de exemplu, pentru integrarea și optimizarea numerică. NumPyȘi SciPy ușor de utilizat, dar suficient de puternic pentru a efectua o varietate de calcule științifice și tehnice.
Pentru a instala biblioteca SciPy V Linux, executați în terminal:
sudo apt-get update sudo apt-get install python-scipy
sudo apt - obțineți actualizare sudo apt - obțineți instalarea python - scipy |
Voi da un exemplu de cod pentru găsirea extremului unei funcții. Rezultatul este afișat deja folosind pachetul matplotlib, discutat mai jos.
import numpy ca np din scipy import special, optimiza import matplotlib.pyplot ca plt f = lambda x: -special.jv(3, x) sol = optimize.minimize(f, 1.0) x = np.linspace(0, 10, 5000) plt.plot(x, special.jv(3, x), "-", sol.x, -sol.fun, "o") plt.show()
import numpy ca np din scipy import special , optimize f = lambda x : - special . jv(3, x) sol = optimizare . minimiza (f, 1,0) x = np. linspace(0, 10, 5000) plt. complot (x , special . jv (3 , x ) , "-" , sol . x , - sol . fun , "o" ) plt. spectacol() |
Rezultatul este un grafic cu punctul extrem marcat:

Doar pentru distracție, încercați să implementați același lucru în limbă Cși comparați numărul de linii de cod necesare pentru a obține rezultatul. Câte linii ai primit? O sută? Cinci sute? Doua mii?
panda
![]() panda este un pachet Piton, conceput pentru a oferi structuri de date rapide, flexibile și expresive, care facilitează lucrul cu date „relative” sau „etichetate” într-un mod simplu și intuitiv. panda se străduiește să devină blocul principal de construcție la nivel înalt pentru conducere Piton analiza practică a datelor obţinute din lumea reala. În plus, acest pachet se pretinde a fi cel mai puternic și mai flexibil sursa deschisa un instrument de analiză/prelucrare a datelor, disponibil în orice limbaj de programare.
panda este un pachet Piton, conceput pentru a oferi structuri de date rapide, flexibile și expresive, care facilitează lucrul cu date „relative” sau „etichetate” într-un mod simplu și intuitiv. panda se străduiește să devină blocul principal de construcție la nivel înalt pentru conducere Piton analiza practică a datelor obţinute din lumea reala. În plus, acest pachet se pretinde a fi cel mai puternic și mai flexibil sursa deschisa un instrument de analiză/prelucrare a datelor, disponibil în orice limbaj de programare.
panda potrivit pentru lucrul cu diferite tipuri de date:
- Date tabelare cu coloane de diferite tipuri, ca în tabele SQL sau excela.
- Date de serie temporală ordonate și neordonate (nu neapărat cu frecvență constantă).
- Date matrice arbitrare (omogene sau eterogene) cu rânduri și coloane etichetate.
- Orice altă formă de seturi de date observaționale sau statistice. Datele nu necesită de fapt o etichetă pentru a fi plasate într-o structură de date panda.
Pentru a instala pachetul panda executați în Terminal Linux:
sudo apt-get update sudo apt-get install python-pandas
sudo apt - obțineți actualizare sudo apt - obțineți instalarea python - panda |
Un cod simplu care convertește matrice unidimensionalăîn structura datelor panda:
import panda ca pd import numpy ca np valori = np.array() ser = pd.Series(valori) print ser
import panda ca pd import numpy ca np valori = np. matrice ([ 2.0 , 1.0 , 5.0 , 0.97 , 3.0 , 10.0 , 0.0599 , 8.0 ] ) ser = pd . Seria (valori) print ser |
Rezultatul va fi:

matplotlib
![]()
matplotlib este o bibliotecă constructii grafice pentru limbajul de programare Pitonși extensiile sale la matematica computațională NumPy. Biblioteca oferă un API orientat pe obiecte pentru încorporarea graficelor în aplicații care utilizează instrumente GUI scop general, ca WxPython, Qt, sau GTK+. Există și o procedură pilab-interfață care amintește MATLAB. SciPy utilizări matplotlib.
Pentru a instala biblioteca matpoltlib V Linux rulați următoarele comenzi:
sudo apt-get update sudo apt-get install python-matplotlib
sudo apt - obțineți actualizare sudo apt - obțineți instalarea python - matplotlib |
Exemplu de cod folosind biblioteca matplotlib pentru a crea histograme:
import numpy ca np import matplotlib.mlab ca mlab import matplotlib.pyplot ca plt # exemplu de date mu = 100 # media distribuției sigma = 15 # abaterea standard a distribuției x = mu + sigma * np.random.randn(10000) num_bins = 50 # histograma datelor n, bins, patches = plt.hist(x, num_bins, normed=1, facecolor="green", alpha=0.5) # adăugați o linie „best fit” y = mlab.normpdf(bins , mu, sigma) plt.plot(bins, y, "r--") plt.xlabel("Smarts") plt.ylabel("Probability") plt.title(r"Histograma IQ: $\mu=100 $, $\sigma=15$") # Modificați spațierea pentru a preveni tăierea etichetei plt.subplots_adjust(left=0.15) plt.show()
import numpy ca np import matplotlib. mlab ca mlab import matplotlib. pyplot ca plt # exemple de date mu = 100 # medie de distribuție sigma = 15 # abaterea standard a distribuției x = mu + sigma * np . Aleatoriu. randn (10000) num_bins = 50 # histograma datelor n, bins, patchs = plt. hist(x, num_bins, normat = 1, facecolor = „verde”, alfa = 0,5) # adăugați o linie „cel mai potrivit”. y = mlab . normpdf (bins, mu, sigma) plt. plot(bins, y, "r--") plt. xlabel(„Inteligent”) plt. ylabel(„Probabilitate”) plt. titlu (r „Histograma IQ: $\mu=100$, $\sigma=15$”) # Modificați distanța pentru a preveni tăierea etichetei plt. subplots_adjust (stânga = 0,15) plt. spectacol() |
Rezultatul căruia este:
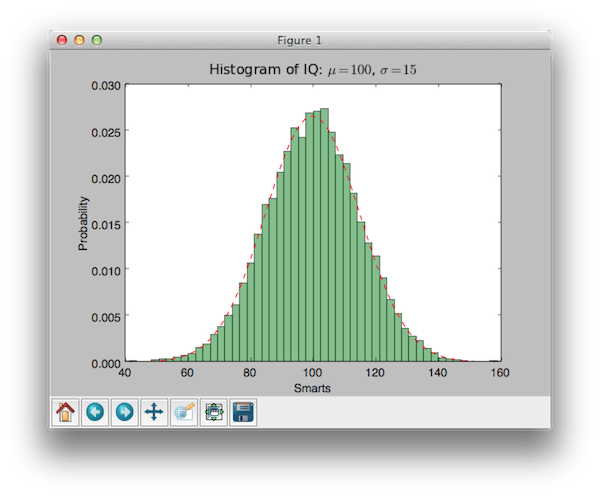
Cred că este foarte drăguț!
este un shell de comandă pentru calcul interactiv în mai multe limbaje de programare, dezvoltat inițial pentru limbajul de programare Piton. vă permite să extindeți capacitățile de prezentare, adaugă sintaxă shell, completare automată și un istoric extins de comenzi. oferă în prezent următoarele caracteristici:
- Shell-uri interactive puternice (tip terminal și bazat pe Qt).
- Editor bazat pe browser cu suport pentru cod, text, expresii matematice, grafice încorporate și alte capabilități de prezentare.
- Sprijină vizualizare interactivă date și utilizarea instrumentelor GUI.
- Interpreți flexibili, încorporați, pentru a lucra în propriile proiecte.
- Instrumente de calcul paralele de înaltă performanță, ușor de utilizat.
Site-ul IPython:
Pentru a instala IPython pe Linux, rulați următoarele comenzi în terminal:
sudo apt-get update sudo pip install ipython
Voi da un exemplu de cod care se construiește regresie liniara pentru un set de date disponibile în pachet scikit-learn:
import matplotlib.pyplot as plt import numpy as np din sklearn import datasets, linear_model # Încărcați setul de date diabet diabet = datasets.load_diabetes() # Folosiți o singură caracteristică diabet_X = diabet.data[:, np.newaxis] diabet_X_temp = diabet_X[: , :, 2] # Împărțiți datele în seturi de antrenament/testare diabet_X_train = diabet_X_temp[:-20] diabet_X_test = diabet_X_temp[-20:] # Împărțiți țintele în seturi de antrenament/testare diabet_y_train = diabet.target[:-20] diabet_y_test = diabet.target[-20:] # Creați obiect de regresie liniară regr = linear_model.LinearRegression() # Antrenați modelul folosind seturile de antrenament regr.fit(diabetes_X_train, diabet_y_train) # Coeficienții print("Coeficienți: \n", regr .coef_) # Tipărirea erorii pătrate medii ("Suma reziduală a pătratelor: %.2f" % np.mean((regr.predict(test_diabet_X) - testul_diabet_y) ** 2)) # Scorul de varianță explicat: 1 este imprimarea predicției perfecte ("Scor de variație: %.2f" % regr.score(diabetes_X_test, diabet_y_test)) # Plot outputs plt.scatter(diabetes_X_test, diabet_y_test, color="black") plt.plot(diabetes_X_test, regr.predict(diabetes_X_test), color ="blue", linewidth=3) plt.xticks()) plt.yticks()) plt.show()
import matplotlib. pyplot ca plt import numpy ca np din sklearn import datasets , linear_model # Încărcați setul de date despre diabet diabet=seturi de date. load_diabet() # Utilizați o singură caracteristică diabet_X = diabet . date [: , np . newaxis ] |