Prognoza intervalului în Excel pentru analiza regresiei. Ne bucurăm că am putut să vă ajutăm să rezolvați problema. Activați pachetul de analiză
Arată influența unor valori (independente, independente) asupra variabilei dependente. De exemplu, cum depinde numărul populației active din punct de vedere economic de numărul de întreprinderi, salarii și alți parametri. Sau: cum afectează investițiile străine, prețurile la energie etc. nivelul PIB-ului.
Rezultatul analizei vă permite să evidențiați prioritățile. Și pe baza factorilor principali, preziceți și planificați dezvoltarea domenii prioritare, luați decizii de management.
Are loc regresia:
liniară (y = a + bx);
· parabolic (y = a + bx + cx 2);
· exponenţial (y = a * exp(bx));
· putere (y = a*x^b);
· hiperbolic (y = b/x + a);
logaritmică (y = b * 1n(x) + a);
· exponențial (y = a * b^x).
Să ne uităm la construcție ca exemplu model de regresieîn Excel și interpretarea rezultatelor. Hai sa luam tip liniar regresie.
Sarcină. La 6 întreprinderi au fost analizate salariul mediu lunar și numărul de angajați care au demisionat. Este necesar să se determine dependența numărului de angajați care au demisionat salariu mediu.
Model regresie liniara Are următoarea vedere:
Y = a 0 + a 1 x 1 +…+a k x k.
Unde a sunt coeficienți de regresie, x sunt variabile de influență, k este numărul de factori.
În exemplul nostru, Y este indicatorul renunțării angajaților. Factorul de influență este salariul (x).
Excel are funcții încorporate care vă pot ajuta să calculați parametrii unui model de regresie liniară. Dar suplimentul „Pachet de analiză” va face acest lucru mai repede.
Activăm un instrument analitic puternic:
1. Faceți clic pe butonul „Office” și accesați fila „”. Opțiuni Excel" „Suplimente”.

2. În partea de jos, sub lista derulantă, în câmpul „Management” va apărea inscripția „ Suplimente Excel» (dacă nu este acolo, faceți clic pe caseta de selectare din dreapta și selectați). Și butonul „Du-te”. Clic.
3. Se deschide o listă de suplimente disponibile. Selectați „Pachet de analiză” și faceți clic pe OK.

Odată activat, suplimentul va fi disponibil în fila Date.

Acum să facem însăși analiza de regresie.
1. Deschideți meniul instrumentului „Analiza datelor”. Selectați „Regresie”.

2. Se va deschide un meniu pentru a selecta valorile de intrare și opțiunile de ieșire (unde se afișează rezultatul). În câmpurile pentru datele inițiale, indicăm intervalul parametrului descris (Y) și factorul care îl influențează (X). Restul nu trebuie completat.

3. După ce faceți clic pe OK, programul va afișa calculele pe o foaie nouă (puteți selecta un interval de afișat pe foaia curentă sau puteți atribui rezultatul unui nou registru de lucru).

În primul rând, acordăm atenție R-pătratului și coeficienților.
R-pătrat este coeficientul de determinare. În exemplul nostru – 0,755 sau 75,5%. Aceasta înseamnă că parametrii calculați ai modelului explică 75,5% din relația dintre parametrii studiați. Cu cât coeficientul de determinare este mai mare, cu atât model de calitate mai buna. Bun - peste 0,8. Rău – mai puțin de 0,5 (o astfel de analiză poate fi considerată cu greu rezonabilă). În exemplul nostru – „nu e rău”.
Coeficientul 64,1428 arată ce va fi Y dacă toate variabilele din modelul luat în considerare sunt egale cu 0. Adică valoarea parametrului analizat este influențată și de alți factori nedescriși în model.
Coeficientul -0,16285 arată ponderea variabilei X pe Y. Adică salariul mediu lunar în cadrul acestui model afectează numărul de renunțați cu o pondere de -0,16285 (acesta este un grad mic de influență). Semnul „-” indică influenta negativa: cu cât salariul este mai mare, cu atât mai puțini oameni renunță. Ceea ce este corect.
Analiza regresiei- Acest metoda statistica cercetare care vă permite să arătați dependența unui anumit parametru de una sau mai multe variabile independente. În era pre-computer, utilizarea sa era destul de dificilă, mai ales când era vorba de volume mari de date. Astăzi, după ce ați învățat cum să construiți regresia în Excel, puteți rezolva probleme statistice complexe în doar câteva minute. Mai jos sunt exemple concrete din domeniul economiei.
Tipuri de regresie
Acest concept în sine a fost introdus în matematică în 1886. Are loc regresia:
- liniar;
- parabolic;
- potolit;
- exponențial;
- hiperbolic;
- demonstrativ;
- logaritmică.
Exemplul 1
Să luăm în considerare problema determinării dependenței numărului de membri ai echipei care renunță la salariul mediu la 6 întreprinderi industriale.
Sarcină. La șase întreprinderi, salariul mediu lunar și numărul de angajați care au demisionat din cauza după plac. ÎN formă tabelară avem:
Numărul de persoane care au renunțat | Salariu |
||
30.000 de ruble |
|||
35.000 de ruble |
|||
40.000 de ruble |
|||
45.000 de ruble |
|||
50.000 de ruble |
|||
55.000 de ruble |
|||
60.000 de ruble |
Pentru sarcina de a determina dependența numărului de lucrători care renunță la salariul mediu la 6 întreprinderi, modelul de regresie are forma ecuației Y = a 0 + a 1 x 1 +...+a k x k, unde x i sunt variabilele de influență, a i sunt coeficienții de regresie și k este numărul de factori.
Pentru această problemă, Y este indicatorul renunțării angajaților, iar factorul de influență este salariul, pe care îl notăm cu X.
Folosind capacitățile procesorului de foi de calcul Excel
Analiza de regresie în Excel trebuie să fie precedată de aplicarea funcțiilor încorporate la datele tabelare existente. Cu toate acestea, în aceste scopuri este mai bine să utilizați extensia foarte utilă „Analysis Pack”. Pentru a-l activa aveți nevoie de:
- din fila „Fișier” accesați secțiunea „Opțiuni”;
- în fereastra care se deschide, selectați linia „Suplimente”;
- faceți clic pe butonul „Go” situat mai jos, în dreapta liniei „Management”;
- bifați caseta de lângă numele „Pachet de analiză” și confirmați acțiunile făcând clic pe „Ok”.
Dacă totul este făcut corect, în partea dreaptă a filei „Date”, situată deasupra foii de lucru „Excel”, veți vedea butonul dorit.
în Excel
Acum că ai tot ce ai nevoie la îndemână instrumente virtuale pentru a efectua calcule econometrice, putem începe să ne rezolvăm problema. Pentru aceasta:
- Faceți clic pe butonul „Analiza datelor”;
- în fereastra care se deschide, faceți clic pe butonul „Regresie”;
- în fila care apare, introduceți intervalul de valori pentru Y (numărul de angajați care demisionează) și pentru X (salariile acestora);
- Confirmăm acțiunile noastre apăsând butonul „Ok”.
Ca rezultat, programul se va completa automat frunză nouă procesor de masă datele analizei de regresie. Notă! Excel vă permite să setați manual locația pe care o preferați în acest scop. De exemplu, ar putea fi aceeași foaie în care sunt situate valorile Y și X, sau chiar O carte noua, special conceput pentru stocarea unor astfel de date.
Analiza rezultatelor regresiei pentru R-pătrat
ÎN date Excel obţinute în timpul prelucrării, datele exemplului luat în considerare au forma:
În primul rând, ar trebui să acordați atenție valorii R pătrat. Reprezintă coeficientul de determinare. ÎN în acest exemplu R-pătrat = 0,755 (75,5%), adică parametrii calculați ai modelului explică dependența dintre parametrii considerați cu 75,5%. Cu cât valoarea coeficientului de determinare este mai mare, cu atât modelul selectat este considerat mai aplicabil pentru sarcina specifica. Se consideră că se descrie corect situația reală când valoarea R-pătratului este peste 0,8. Dacă R-pătrat<0,5, то такой анализа регрессии в Excel нельзя считать резонным.
Analiza cotelor
Numărul 64,1428 arată care va fi valoarea lui Y dacă toate variabilele xi din modelul pe care îl luăm în considerare sunt resetate la zero. Cu alte cuvinte, se poate susține că valoarea parametrului analizat este influențată și de alți factori care nu sunt descriși într-un anumit model.
Următorul coeficient -0,16285, situat în celula B18, arată ponderea influenței variabilei X asupra Y. Aceasta înseamnă că salariul mediu lunar al angajaților din cadrul modelului luat în considerare afectează numărul de renunțați cu o pondere de -0,16285, adică. gradul de influență este complet mic. Semnul „-” indică faptul că coeficientul este negativ. Acest lucru este evident, deoarece toată lumea știe că, cu cât salariul la întreprindere este mai mare, cu atât mai puține persoane își exprimă dorința de a rezilia contractul de muncă sau de a renunța.
Regresie multiplă
Acest termen se referă la o ecuație de relație cu mai multe variabile independente de forma:
y=f(x 1 +x 2 +…x m) + ε, unde y este caracteristica rezultantă (variabilă dependentă), iar x 1, x 2,…x m sunt caracteristici factoriale (variabile independente).
Estimarea parametrilor
Pentru regresia multiplă (MR), se efectuează folosind metoda celor mai mici pătrate (OLS). Pentru ecuații liniare de forma Y = a + b 1 x 1 +…+b m x m + ε construim un sistem de ecuații normale (vezi mai jos)

Pentru a înțelege principiul metodei, luați în considerare un caz cu doi factori. Atunci avem o situație descrisă de formula

De aici obținem:

unde σ este varianța caracteristicii corespunzătoare reflectate în indice.
OLS este aplicabilă ecuației MR pe o scară standardizată. În acest caz obținem ecuația:

în care t y, t x 1, … t xm sunt variabile standardizate, pentru care valorile medii sunt egale cu 0; β i sunt coeficienții de regresie standardizați, iar abaterea standard este 1.
Vă rugăm să rețineți că toate β i în în acest caz, sunt specificate ca standardizate și centralizate, prin urmare compararea lor între ele este considerată corectă și acceptabilă. În plus, se obișnuiește să se elimine factorii prin eliminarea celor cu cele mai mici valori βi.
Problemă folosind ecuația de regresie liniară
Să presupunem că avem un tabel cu dinamica prețurilor pentru un anumit produs N în ultimele 8 luni. Este necesar să luați o decizie cu privire la oportunitatea achiziționării unui lot la un preț de 1850 de ruble/t.
numărul lunii | numele lunii | pretul produsului N |
|
1750 de ruble pe tonă |
|||
1755 de ruble pe tonă |
|||
1767 de ruble pe tonă |
|||
1760 de ruble pe tonă |
|||
1770 de ruble pe tonă |
|||
1790 de ruble pe tonă |
|||
1810 ruble pe tonă |
|||
1840 de ruble pe tonă |
|||
Pentru a rezolva această problemă în procesorul de foi de calcul Excel, trebuie să utilizați instrumentul „Analiza datelor”, deja cunoscut din exemplul prezentat mai sus. Apoi, selectați secțiunea „Regresie” și setați parametrii. Trebuie reținut că în câmpul „Interval de intrare Y” trebuie introdus un interval de valori pentru variabila dependentă (în acest caz, prețurile pentru mărfuri în anumite luni ale anului), iar în „Intervalul de intrare X” - pentru variabila independentă (numărul lunii). Confirmați acțiunea făcând clic pe „Ok”. Pe o foaie nouă (dacă este indicat) obținem date pentru regresie.
Construim conform lor ecuație liniară de forma y=ax+b, unde parametrii a și b sunt coeficienții dreptei cu denumirea numărului lunii și coeficienții și liniile „Y-intersection” din foaia cu rezultatele analizei de regresie. Astfel, ecuația de regresie liniară (LR) pentru sarcina 3 este scrisă ca:
Prețul produsului N = 11,714* număr lunar + 1727,54.
sau în notaţie algebrică
y = 11,714 x + 1727,54
Analiza rezultatelor
Pentru a decide dacă ecuația de regresie liniară rezultată este adecvată, se folosesc coeficienții de corelație multiplă (MCC) și de determinare, precum și testul Fisher și testul t Student. În foaia de calcul Excel cu rezultate de regresie, acestea sunt numite multiple R, R-pătrat, F-statistic și, respectiv, t-statistic.
KMC R face posibilă evaluarea gradului de apropiere a relației probabilistice dintre variabilele independente și dependente. Valoarea sa ridicată indică o legătură destul de puternică între variabilele „Numărul lunii” și „Prețul produsului N în ruble pe 1 tonă”. Cu toate acestea, natura acestei relații rămâne necunoscută.
Pătratul coeficientului de determinare R2 (RI) este o caracteristică numerică a proporției împrăștierii totale și arată a cărei împrăștiere este parte din datele experimentale, i.e. valorile variabilei dependente corespund ecuației de regresie liniară. În problema luată în considerare, această valoare este egală cu 84,8%, adică datele statistice sunt descrise cu un grad ridicat de acuratețe de către SD-ul rezultat.
F-statisticile, numite și testul lui Fisher, sunt folosite pentru a evalua semnificația unei relații liniare, infirmând sau confirmând ipoteza existenței acesteia.
(Testul Studentului) ajută la evaluarea semnificației coeficientului cu un termen necunoscut sau liber al relației liniare. Dacă valoarea testului t > tcr, atunci ipoteza despre nesemnificația termenului liber al ecuației liniare este respinsă.
În problema luată în considerare pentru termenul liber, folosind instrumentele Excel, s-a obținut că t = 169,20903 și p = 2,89E-12, adică avem probabilitate zero ca ipoteza corectă despre nesemnificația termenului liber să fie respinsă. . Pentru coeficientul necunoscutului t=5,79405 și p=0,001158. Cu alte cuvinte, probabilitatea ca ipoteza corectă despre nesemnificația coeficientului pentru o necunoscută să fie respinsă este de 0,12%.
Astfel, se poate susține că ecuația de regresie liniară rezultată este adecvată.
Problema fezabilității achiziționării unui bloc de acțiuni
Regresia multiplă în Excel este efectuată folosind același instrument de analiză a datelor. Să luăm în considerare o problemă specifică de aplicare.
Conducerea companiei NNN trebuie să decidă oportunitatea achiziționării unui pachet de 20% din MMM JSC. Costul pachetului (SP) este de 70 de milioane de dolari SUA. Specialiștii NNN au colectat date despre tranzacții similare. S-a decis evaluarea valorii blocului de acțiuni în funcție de astfel de parametri, exprimați în milioane de dolari SUA, astfel:
- conturi de plătit (VK);
- volumul anual al cifrei de afaceri (VO);
- conturi de încasat (VD);
- costul mijloacelor fixe (COF).
În plus, se utilizează parametrul restanțelor salariale ale întreprinderii (V3 P) în mii de dolari SUA.
Soluție folosind procesorul de foi de calcul Excel
În primul rând, trebuie să creați un tabel de date sursă. Arata cam asa:

- apelați fereastra „Analiza datelor”;
- selectați secțiunea „Regresie”;
- În caseta „Interval de intrare Y”, introduceți intervalul de valori ale variabilelor dependente din coloana G;
- faceți clic pe pictograma săgeată roșie din dreapta ferestrei „Input Range X” și evidențiați pe foaie intervalul tuturor valorilor de la coloanele B,C,D,F.
Marcați elementul „Foaie de lucru nouă” și faceți clic pe „Ok”.
Obțineți o analiză de regresie pentru o anumită problemă.

Studiul rezultatelor și concluziilor
„Colectăm” ecuația de regresie din datele rotunjite prezentate mai sus pe foaia de calcul Excel:
SP = 0,103*SOF + 0,541*VO - 0,031*VK +0,405*VD +0,691*VZP - 265,844.
Într-o formă matematică mai familiară, poate fi scrisă astfel:
y = 0,103*x1 + 0,541*x2 - 0,031*x3 +0,405*x4 +0,691*x5 - 265,844
Datele pentru MMM JSC sunt prezentate în tabel:
Înlocuindu-le în ecuația de regresie, obținem o cifră de 64,72 milioane de dolari SUA. Aceasta înseamnă că acțiunile MMM JSC nu merită cumpărate, deoarece valoarea lor de 70 de milioane de dolari SUA este destul de umflată.
După cum puteți vedea, utilizarea foii de calcul Excel și a ecuației de regresie au făcut posibilă luarea unei decizii informate cu privire la fezabilitatea unei tranzacții foarte specifice.
Acum știi ce este regresia. Exemplele Excel discutate mai sus vă vor ajuta să decideți probleme practice din domeniul econometriei.
În opinia mea, ca student, econometria este una dintre cele mai aplicate științe cu care am putut să mă familiarizez între zidurile universității mele. Cu ajutorul acestuia, este într-adevăr posibil să se rezolve probleme aplicate la scară de întreprinderi. Cât de eficiente vor fi aceste decizii este a treia întrebare. Concluzia este că majoritatea cunoștințelor vor rămâne teorie, dar econometria și analiza de regresie merită totuși studiate cu o atenție specială.
Ce explică regresia?
Înainte de a începe să luăm în considerare funcțiile MS Excel care ne permit să rezolvăm aceste probleme, aș dori să vă explic în detaliu ce presupune, în esență, analiza regresiei. Acest lucru vă va face mai ușor să promovați examenul și, cel mai important, va fi mai interesant să studiați materia.
Sper că sunteți familiarizat cu conceptul de funcție din matematică. O funcție este relația dintre două variabile. Când o variabilă se schimbă, ceva i se întâmplă alteia. Schimbăm X și Y se schimbă în consecință. Funcțiile descriu diverse legi. Cunoscând funcția, putem înlocui valorile arbitrare ale lui X și vedem cum se modifică Y.
Are mare importanță, deoarece regresia este o încercare de a explica, la prima vedere, procesele nesistematice și haotice folosind o anumită funcție. De exemplu, este posibil să se identifice relația dintre cursul de schimb al dolarului și șomaj în Rusia.
Dacă acest model poate fi descoperit, atunci folosind funcția pe care am obținut-o în timpul calculelor, vom putea face o prognoză a ratei șomajului la cursul de schimb al al-lea dolar față de rublă.
Această relație se va numi corelație. Analiza de regresie presupune calcularea unui coeficient de corelație care să explice relația strânsă dintre variabilele pe care le luăm în considerare (cursul de schimb al dolarului și numărul de locuri de muncă).
Acest coeficient poate fi pozitiv sau negativ. Valorile sale variază de la -1 la 1. În consecință, putem observa o corelație negativă sau pozitivă ridicată. Dacă este pozitivă, atunci creșterea cursului dolarului va fi urmată de crearea de noi locuri de muncă. Dacă este negativă, înseamnă că o creștere a cursului de schimb va fi urmată de o scădere a locurilor de muncă.
Există mai multe tipuri de regresie. Poate fi liniar, parabolic, de putere, exponențial etc. Alegem un model în funcție de care regresie va corespunde în mod specific cazului nostru, care model va fi cât mai aproape de corelația noastră. Să ne uităm la asta folosind un exemplu de problemă și să o rezolvăm în MS Excel.
Regresia liniară în MS Excel
Pentru a rezolva probleme de regresie liniară, veți avea nevoie de funcționalitatea de analiză a datelor. Este posibil să nu fie activat pentru dvs., așa că trebuie să îl activați.
- Faceți clic pe butonul „Fișier”;
- Selectați elementul „Opțiuni”;
- Faceți clic pe penultima filă „Suplimente” din partea stângă;

- Mai jos vom vedea inscripția „Management” și butonul „Go”. Apasa pe el;
- Bifați caseta pentru „Pachet de analiză”;
- Faceți clic pe „ok”.

Exemplu de sarcină
Funcția de analiză a lotului este activată. Să rezolvăm următoarea problemă. Avem un eșantion de date de câțiva ani privind numărul de situații de urgență pe teritoriul întreprinderii și numărul de lucrători angajați. Trebuie să identificăm relația dintre aceste două variabile. Există o variabilă explicativă X - acesta este numărul de lucrători și o variabilă explicativă - Y - acesta este numărul de incidente de urgență. Să distribuim datele sursă în două coloane.
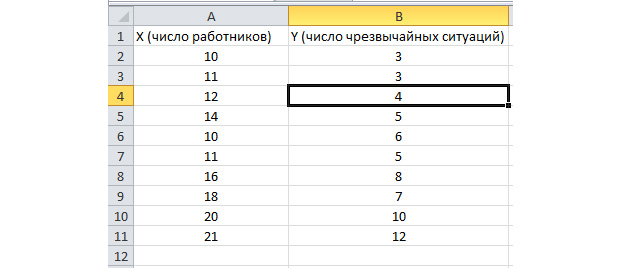
Să mergem la fila „date” și să selectăm „Analiza datelor”
În lista care apare, selectați „Regresie”. În intervalele de intrare Y și X selectăm valorile corespunzătoare.

Faceți clic pe „Ok”. Analiza este finalizată, iar rezultatele vom vedea într-o nouă fișă.
Cele mai semnificative valori pentru noi sunt marcate în figura de mai jos.
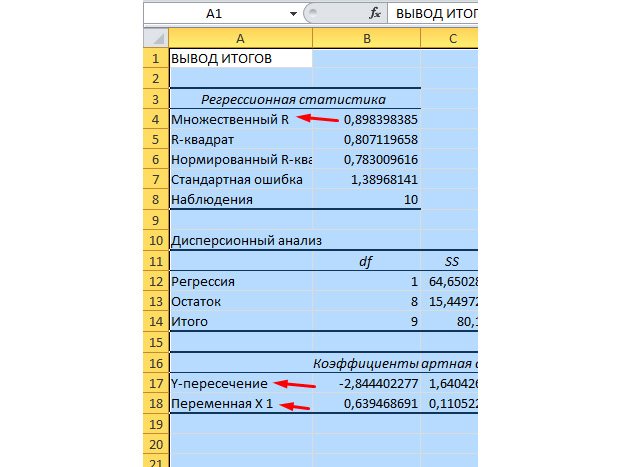
Multiplu R este coeficientul de determinare. Are o formulă de calcul complexă și arată cât de mult poți avea încredere în coeficientul nostru de corelație. În consecință, cu cât această valoare este mai mare, cu atât mai multă încredere, cu atât modelul nostru în ansamblu este mai de succes.
Y-Intercept și X1-Intercept sunt coeficienții noștri de regresie. După cum am menționat deja, regresia este o funcție și are anumiți coeficienți. Astfel, funcția noastră va arăta astfel: Y = 0,64*X-2,84.
Ce ne oferă asta? Acest lucru ne oferă posibilitatea de a face o prognoză. Să presupunem că vrem să angajăm 25 de lucrători pentru o întreprindere și trebuie să ne imaginăm aproximativ care va fi numărul de incidente de urgență. Îl înlocuim în funcția noastră valoare datăși obținem rezultatul Y = 0,64 * 25 – 2,84. Vom avea aproximativ 13 urgențe.
Să vedem cum funcționează. Aruncă o privire la poza de mai jos. Valorile reale pentru angajații implicați sunt înlocuite în funcția pe care am primit-o. Vedeți cât de aproape sunt valorile de jucătorii adevărați.

De asemenea, puteți construi un câmp de corelare selectând zona Y și X, făcând clic pe fila „inserați” și selectând graficul de dispersie.

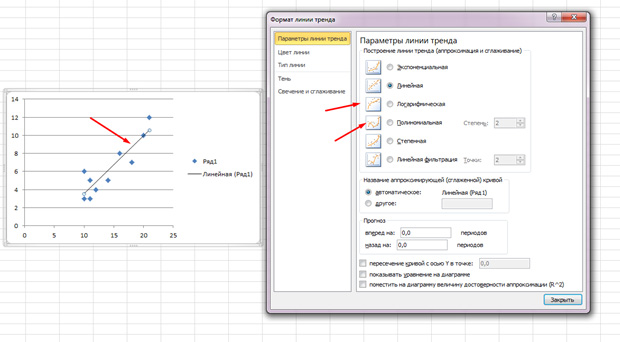
Punctele sunt împrăștiate, dar în general se deplasează în sus, ca și cum ar fi o linie dreaptă în mijloc. De asemenea, puteți adăuga această linie accesând fila „Layout” din MS Excel și selectând „Trend Line”
Faceți dublu clic pe linia care apare și veți vedea ce s-a menționat mai devreme. Puteți schimba tipul de regresie în funcție de cum arată câmpul de corelare.
S-ar putea să simți că punctele desenează mai degrabă o parabolă decât o linie dreaptă și că ar fi mai bine să alegi un alt tip de regresie.
Concluzie
Sperăm că acest articol v-a oferit o înțelegere mai bună a ce este analiza de regresie și de ce este necesară. Toate acestea au o mare importanță practică.
Metoda regresiei liniare ne permite să descriem o linie dreaptă care se potrivește cel mai bine unei serii de perechi ordonate (x, y). Ecuația pentru o linie dreaptă, cunoscută sub numele de ecuație liniară, este dată mai jos:
ŷ este valoarea așteptată a lui y at valoarea stabilită X,
x este o variabilă independentă,
a este un segment pe axa y pentru o linie dreaptă,
b este panta dreptei.
Figura de mai jos ilustrează acest concept grafic:
Figura de mai sus arată linia descrisă de ecuația ŷ =2+0,5x. Intersecția cu y este punctul în care linia intersectează axa y; în cazul nostru, a = 2. Panta dreptei, b, raportul dintre creșterea dreptei și lungimea dreptei, are o valoare de 0,5. O pantă pozitivă înseamnă că linia se ridică de la stânga la dreapta. Dacă b = 0, linia este orizontală, ceea ce înseamnă că nu există nicio relație între variabilele dependente și independente. Cu alte cuvinte, modificarea valorii lui x nu afectează valoarea lui y.
ŷ și y sunt adesea confundate. Graficul prezintă 6 perechi ordonate de puncte și o dreaptă, conform ecuației date
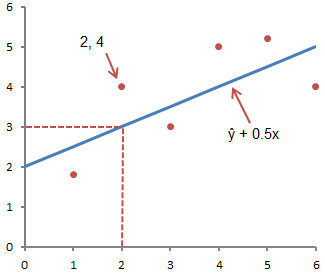
Această figură arată punctul corespunzător perechii ordonate x = 2 și y = 4. Rețineți că valoarea așteptată a lui y conform dreptei de la X= 2 este ŷ. Putem confirma acest lucru cu următoarea ecuație:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
Valoarea y reprezintă punctul real, iar valoarea ŷ este valoarea așteptată a lui y folosind o ecuație liniară pentru o valoare dată a lui x.
Următorul pas este determinarea ecuației liniare care se potrivește cel mai bine cu mulțimea de perechi ordonate, despre asta am vorbit în articolul anterior, unde am determinat tipul de ecuație prin .
Utilizarea Excel pentru a defini regresia liniară
Pentru a utiliza instrumentul de analiză de regresie încorporat în Excel, trebuie să activați programul de completare Pachet de analize. Îl puteți găsi făcând clic pe filă Fișier -> Opțiuni(2007+), în caseta de dialog care apare Opțiuniexcela accesați fila Suplimente.În câmp Control alege Suplimenteexcelași faceți clic Merge.În fereastra care apare, bifați caseta de lângă Pachet de analize, clic BINE.

În fila Date in grup Analiză va aparea buton nou Analiza datelor.

Pentru a demonstra funcționarea suplimentului, vom folosi date în care un tip și o fată împart o masă în baie. Introduceți datele din exemplul nostru de cadă în coloanele A și B ale foii goale.
Accesați fila Date, in grup Analiză clic Analiza datelor.În fereastra care apare Analiza datelor Selectați Regresia așa cum se arată în figură și faceți clic pe OK.

Setați parametrii necesari de regresie în fereastră Regresia, așa cum se arată în imagine:

Clic BINE.În figura de mai jos sunt prezentate rezultatele obținute:
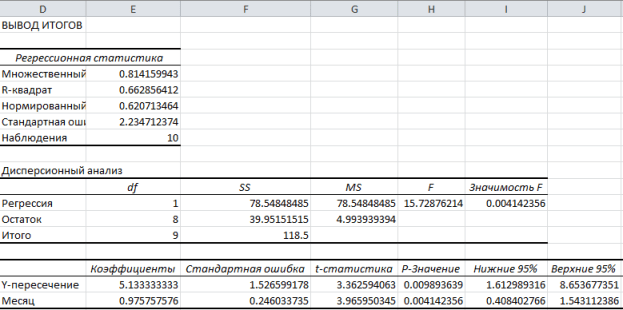
Aceste rezultate sunt în concordanță cu cele pe care le-am obținut făcând propriile calcule în .
Regresia în programul Excel
Prelucrarea datelor statistice poate fi efectuată și utilizând add-on-ul Pachet de analiză din sub-articolul din meniul „Serviciu”. În Excel 2003, dacă deschideți SERVICIU, nu putem găsi fila ANALIZA DATELOR, apoi faceți clic pe butonul stâng al mouse-ului pentru a deschide fila SUPERSTRUCTURILEși opus punctului PACHET DE ANALIZĂ Faceți clic pe butonul stâng al mouse-ului pentru a bifa (Fig. 17).
Orez. 17. Fereastra SUPERSTRUCTURILE
După aceea în meniu SERVICIU apare fila ANALIZA DATELOR.
În Excel 2007 pentru a instala PACHET DE ANALIZĂ trebuie să apăsați butonul OFFICE din stânga colțul de sus frunză (Fig. 18a). Apoi, faceți clic pe butonul SETĂRI EXCEL. În fereastra care apare SETĂRI EXCEL faceți clic stânga pe element SUPERSTRUCTURILE iar în partea dreaptă a listei derulante selectați articolul PACHET DE ANALIZĂ. Apoi faceți clic pe Bine.




Orez. 18. Instalare PACHET DE ANALIZĂîn Excel 2007
Pentru a instala pachetul de analiză, faceți clic pe butonul MERGE, situat în partea de jos a ferestrei deschise. Va apărea o fereastră așa cum se arată în Fig. 12. Pune o căpușă în față PACHET DE ANALIZĂ.În fila DATE va apărea un buton ANALIZA DATELOR(Fig. 19).

Din elementele sugerate, selectați elementul „ REGRESIE" și faceți clic pe el cu butonul stâng al mouse-ului. Apoi, faceți clic pe OK.

Va apărea o fereastră așa cum se arată în Fig. 21

Instrument de analiză " REGRESIE» este folosit pentru a potrivi un grafic la un set de observații folosind metoda celor mai mici pătrate. Regresia este utilizată pentru a analiza impactul asupra unui individ dependent variabilă de valoare una sau mai multe variabile independente. De exemplu, mai mulți factori influențează performanța atletică a unui atlet, inclusiv vârsta, înălțimea și greutatea. Este posibil să se calculeze gradul în care fiecare dintre acești trei factori influențează performanța unui atlet și apoi să se utilizeze acele date pentru a prezice performanța altui sportiv.
Instrumentul de regresie folosește funcția LINEST.
Caseta de dialog REGRESIUNE
Etichete Selectați caseta de validare dacă primul rând sau prima coloană a intervalului de intrare conține titluri. Debifați această casetă de validare dacă nu există antete. În acest caz, anteturile adecvate pentru datele din tabelul de ieșire vor fi create automat.
Nivel de fiabilitate Bifați caseta de validare pentru a include un nivel suplimentar în tabelul rezumat de ieșire. În câmpul corespunzător, introduceți nivelul de încredere pe care doriți să îl aplicați, în plus față de nivelul implicit de 95%.
Constant - zero Selectați caseta de selectare pentru a forța linia de regresie să treacă prin origine.
Interval de ieșire Introduceți o referință la celula din stânga sus a intervalului de ieșire. Furnizați cel puțin șapte coloane pentru tabelul rezumat de ieșire, care va include: rezultate ANOVA, coeficienți, eroarea standard a calculului Y, abaterile standard, numărul de observații, erori standard pentru coeficienți.
Foaie de lucru nouă Selectați această opțiune pentru a deschide o foaie de lucru nouă în registrul de lucru și a lipi rezultatele analizei, începând cu celula A1. Dacă este necesar, introduceți un nume pentru noua foaie în câmpul situat vizavi de butonul radio corespunzător.
Nou registrul de lucru Setați comutatorul în această poziție pentru a crea un nou registru de lucru în care rezultatele vor fi adăugate la o nouă foaie.
Reziduuri Selectați caseta de selectare pentru a include reziduurile în tabelul de ieșire.
Reziduuri standardizate Selectați caseta de validare pentru a include reziduurile standardizate în tabelul de ieșire.
Grafic rezidual Selectați caseta de validare pentru a reprezenta grafic reziduurile pentru fiecare variabilă independentă.
Fit Plot Selectați caseta de validare pentru a reprezenta graficul dintre valorile estimate și cele observate.
Graficul de probabilitate normală Bifați caseta de selectare pentru a reprezenta un grafic de probabilitate normală.
Funcţie LINEST
Pentru a efectua calcule, selectați cu cursorul celula în care dorim să afișăm valoarea medie și apăsați tasta = de pe tastatură. Apoi, în câmpul Nume, indicați funcția dorită, De exemplu IN MEDIE(Fig. 22).

Orez. 22 Găsirea funcțiilor în Excel 2003
Dacă în câmp NUME numele functiei nu apare, apoi click stanga pe triunghiul de langa camp, dupa care va aparea o fereastra cu o lista de functii. Dacă această funcție nu este în listă, faceți clic stânga pe elementul din listă ALTE FUNCȚII, va apărea o casetă de dialog MASTER FUNCȚIE, în care, folosind defilare verticală selectați funcția dorită, evidențiați-o cu cursorul și faceți clic pe Bine(Fig. 23).

Orez. 23. Asistent de funcții
Pentru a căuta o funcție în Excel 2007, se poate deschide orice filă în meniu apoi pentru a efectua calcule, selectați cu cursorul celula în care dorim să afișăm valoarea medie și apăsați tasta = de pe tastatură; Apoi, în câmpul Nume, specificați funcția IN MEDIE. Fereastra pentru calcularea funcției este similară cu cea afișată în Excel 2003.
De asemenea, puteți selecta fila Formule și faceți clic stânga pe butonul din „ FUNCȚIE DE INSERARE„(Fig. 24), va apărea o fereastră MASTER FUNCȚIE, al cărui aspect este similar cu Excel 2003. Tot în meniu puteți selecta imediat o categorie de funcții (folosite recent, financiare, logice, text, dată și oră, matematice, alte funcții) în care vom căuta funcțiile dorite. funcţie.




Orez. 24 Selectarea unei funcții în Excel 2007
Funcţie LINEST calculează statistici pentru o serie folosind cele mai mici pătrate pentru a calcula o linie dreaptă care cel mai bun mod aproximează datele disponibile și apoi returnează o matrice care descrie linia dreaptă rezultată. De asemenea, puteți combina funcția LINEST cu alte funcții pentru a calcula alte tipuri de modele care sunt liniare în parametri necunoscuți (ai căror parametri necunoscuți sunt liniari), inclusiv serii polinomiale, logaritmice, exponențiale și de putere. Deoarece este returnată o matrice de valori, funcția trebuie specificată ca formulă matrice.
Ecuația pentru o dreaptă este:
(în cazul mai multor intervale de valori x),
unde valoarea dependentă y este o funcție a valorii independente x, valorile m sunt coeficienții corespunzători fiecărei variabile independente x, iar b este o constantă. Rețineți că y, x și m pot fi vectori. Funcţie LINEST returnează o matrice ![]() . LINEST poate returna, de asemenea, suplimentar statistici de regresie.
. LINEST poate returna, de asemenea, suplimentar statistici de regresie.
LINEST(valori_cunoscute_y; valori_cunoscute_x; const; statistici)
Known_y_values - setul de valori y care sunt deja cunoscute pentru relație.
Dacă matricea known_y_values are o coloană, atunci fiecare coloană din matricea known_x_values este tratată ca o variabilă separată.
Dacă matricea known_y_values are un rând, atunci fiecare rând din matricea known_x_values este tratată ca o variabilă separată.
Valorile_x cunoscute sunt un set opțional de valori x care sunt deja cunoscute pentru relație.
Tabloul known_x_values poate conține unul sau mai multe seturi de variabile. Dacă este utilizată o singură variabilă, atunci tablourile cunoscute_y_values și cunoscute_x_values pot avea orice formă - atâta timp cât au aceeași dimensiune. Dacă se utilizează mai mult de o variabilă, atunci cunoscute_y_values trebuie să fie un vector (adică, un interval de un rând înălțime sau o coloană lată).
Dacă array_known_x_values este omisă, atunci matricea (1;2;3;...) se presupune că are aceeași dimensiune cu array_known_values_y.
Const este o valoare booleană care specifică dacă constanta b trebuie să fie egală cu 0.
Dacă argumentul „const” este TRUE sau omis, atunci constanta b este evaluată ca de obicei.
Dacă argumentul „const” este FALS, atunci valoarea lui b este setată la 0 și valorile lui m sunt selectate în așa fel încât relația să fie satisfăcută.
Statistici - O valoare booleană care indică dacă trebuie returnate statistici suplimentare de regresie.
Dacă statisticile este TRUE, LINEST returnează statistici de regresie suplimentare. Matricea returnată va arăta astfel: (mn;mn-1;...;m1;b:sen;sen-1;...;se1;seb:r2;sey:F;df:ssreg;ssresid).
Dacă statistica este FALSĂ sau omisă, LINEST returnează numai coeficienții m și constanta b.
Statistici suplimentare de regresie.
Figura de mai jos arată ordinea în care sunt returnate statisticile de regresie suplimentare.

Note:
Orice linie dreaptă poate fi descrisă prin panta și intersecția cu axa y:
Panta (m): Pentru a determina panta unei drepte, notată de obicei cu m, luați două puncte pe linie și ; panta va fi egală cu ![]() .
.
Intersecția cu Y (b): Intersecția cu y a unei linii, de obicei notat cu b, este valoarea y pentru punctul în care linia intersectează axa y.
Ecuația dreptei are forma . Dacă valorile lui m și b sunt cunoscute, atunci orice punct de pe linie poate fi calculat prin înlocuirea valorilor lui y sau x în ecuație. De asemenea, puteți utiliza funcția TREND.
Dacă există o singură variabilă independentă x, puteți obține direct panta și intersecția cu y folosind următoarele formule:
Pantă: INDEX(LINEST(valori_y_cunoscute; valori_x_cunoscute); 1)
Intersecție cu Y: INDEX(LINEST(valori_y_cunoscute; valori_x_cunoscute); 2)
Precizia aproximării folosind linia dreaptă calculată de funcția LINEST depinde de gradul de împrăștiere a datelor. Cu cât datele sunt mai aproape de o linie dreaptă, cu atât modelul utilizat de funcția LINEST este mai precis. Funcția LINEST folosește cele mai mici pătrate pentru a determina cea mai bună potrivire la date. Când există o singură variabilă independentă x, m și b sunt calculate folosind următoarele formule:

unde x și y sunt medii eșantion, de exemplu x = MEDIE(x_cunoscute) și y = MEDIE (y_cunoscute).
Funcțiile de potrivire LINEST și LGRFPRIBL pot calcula linia dreaptă sau curba exponențială care se potrivește cel mai bine datelor. Cu toate acestea, ele nu răspund la întrebarea care dintre cele două rezultate este mai potrivit pentru rezolvarea problemei. De asemenea, puteți evalua funcția TREND(cunoscute_y; cunoscute_x) pentru o linie dreaptă sau funcția GROW (cunoscute_y; cunoscute_x) pentru o curbă exponențială. Aceste funcții, cu excepția cazului în care sunt specificate valori noi_x, returnează o matrice de valori y calculate pentru valorile x reale de-a lungul unei linii sau curbe. Apoi puteți compara valorile calculate cu valorile reale. De asemenea, puteți crea diagrame pentru comparație vizuală.
Prin efectuarea analizei de regresie, Microsoft Excel calculează pentru fiecare punct pătratul diferenței dintre valoarea y prezisă și valoarea y reală. Suma acestor diferențe pătrate se numește suma reziduală a pătratelor (ssresid). Microsoft Excel calculează apoi suma totală de pătrate (sstotal). Dacă const = TRUE sau valoarea acestui argument nu este specificată, valoare totală pătratele vor fi egale cu suma pătratelor diferențelor dintre valorile reale ale lui y și valorile medii ale lui y. Când const = FALS, suma totală a pătratelor va fi egală cu suma pătratelor valorilor reale y (fără a scădea valoarea medie a y din valoarea parțială a y). Suma de regresie a pătratelor poate fi calculată după cum urmează: ssreg = sstotal - ssresid. Cu cât suma reziduală a pătratelor este mai mică, cu atât mai multă valoare coeficientul de determinare r2, care arată cât de bine explică ecuația obținută prin analiza de regresie relațiile dintre variabile. Coeficientul r2 este egal cu ssreg/sstotal.
În unele cazuri, una sau mai multe coloane X (să fie valorile Y și X în coloane) nu au o valoare predicativă suplimentară în alte coloane X. Cu alte cuvinte, eliminarea uneia sau mai multor coloane X poate avea ca rezultat calcularea valorilor Y cu aceeași precizie. În acest caz, coloanele X redundante vor fi excluse din modelul de regresie. Acest fenomen se numește „colinearitate” deoarece coloanele redundante ale lui X pot fi reprezentate ca suma mai multor coloane neredundante. Funcția LINEST verifică coliniaritatea și elimină orice coloane X redundante din modelul de regresie dacă le detectează. Coloanele X eliminate pot fi identificate în ieșirea LINEST printr-un factor de 0 și o valoare se de 0. Eliminarea uneia sau mai multor coloane ca redundante modifică valoarea df deoarece depinde de numărul de coloane X utilizate efectiv în scopuri predictive. Pentru mai multe informații despre calcularea df, consultați Exemplul 4 de mai jos. Când df se modifică din cauza eliminării coloanelor redundante, se modifică și valorile sey și F. Nu se recomandă utilizarea coliniarității des. Cu toate acestea, ar trebui utilizat dacă unele coloane X conțin 0 sau 1 ca indicator care indică dacă subiectul experimentului este inclus în grup separat. Dacă const = TRUE sau nu este specificată o valoare pentru acest argument, LINEST inserează o coloană X suplimentară pentru a modela punctul de intersecție. Dacă există o coloană cu valori de 1 pentru bărbați și 0 pentru femei și există o coloană cu valori de 1 pentru femei și 0 pentru bărbați, atunci ultima coloană este eliminată deoarece valorile sale pot fi obținute din coloana „indicator masculin”.
Calculul df pentru cazurile în care X coloane nu sunt eliminate din model din cauza coliniarității are loc după cum urmează: dacă există k cunoscute_x coloane și valoarea const = TRUE sau nu este specificată, atunci df = n – k – 1. Dacă const = FALS, atunci df = n - k. În ambele cazuri, eliminarea coloanelor X din cauza coliniarității crește valoarea df cu 1.
Formulele care returnează matrice trebuie introduse ca formule matrice.
Când introduceți o matrice de constante ca argument, de exemplu, cunoscute_x_values, ar trebui să utilizați un punct și virgulă pentru a separa valorile pe aceeași linie și două puncte pentru a separa liniile. Caracterele de separare pot varia în funcție de setările din fereastra Limbă și setări din Panoul de control.
Trebuie remarcat faptul că valorile y prezise de ecuația de regresie pot să nu fie corecte dacă nu se încadrează în intervalul valorilor y care au fost utilizate pentru a defini ecuația.
Algoritm de bază utilizat în funcție LINEST, diferă de algoritmul funcției principale ÎNCLINAŢIEȘi SEGMENT DE LINIE. Diferența dintre algoritmi poate duce la rezultate diferite cu date incerte și coliniare. De exemplu, dacă punctele de date argument cunoscute_y_values sunt 0 și punctele de date argument cunoscute_x_values sunt 1, atunci:
Funcţie LINEST returnează o valoare egală cu 0. Algoritmul funcției LINEST este folosit pentru a returna valori adecvate pentru datele coliniare, iar în acest caz poate fi găsit cel puțin un răspuns.
Funcțiile SLOPE și LINE returnează eroarea #DIV/0! Algoritmul funcțiilor SLOPE și INTERCEPT este folosit pentru a găsi un singur răspuns, dar în acest caz pot exista mai multe.
Pe lângă calcularea statisticilor pentru alte tipuri de regresie, LINEST poate fi utilizat pentru a calcula intervale pentru alte tipuri de regresie prin introducerea funcțiilor variabilelor x și y ca serii ale variabilelor x și y pentru LINEST. De exemplu, următoarea formulă:
LINIE(valori_y, valori_x^COLUMN($A:$C))
funcționează având o coloană de valori Y și o coloană de valori X pentru a calcula o aproximare a cubului (polinom de gradul 3) de următoarea formă:
Formula poate fi modificată pentru a calcula alte tipuri de regresie, dar în unele cazuri este posibil ca valorile de ieșire și alte statistici să fie nevoie să fie ajustate.