Creating rib in 1s 8.3 retail. Instructions for setting up a Distributed Information Base (DIB) via FTP resource. Setting up an FTP resource
The technology of distributed information bases (RIB) allows you to create a geographically distributed system based on 1C Enterprise configurations. This allows you to have a common information space even with those departments that do not have a reliable communication channel, combining high autonomy of nodes with the ability to quickly exchange information. In our articles we will look at the features and practical implementation of this mechanism on the 8.2 platform
First of all, let’s ask ourselves: why autoexchange? Modern technologies, combined with inexpensive and fast Internet, make it possible to organize remote work without any difficulties. The choice of methods is as wide as ever: RDP, thin and web clients, connecting networks using VPN - there is a lot to think about. However, all these methods have one significant drawback - a strong dependence on the quality of the communication channel.
Even with ideal operation of the local provider, it is impossible to guarantee 100% availability of the communication channel. Problems with the backbone provider, lack of power supply, physical damage to the communication line and many other factors make this task insurmountable. At the same time, the inaccessibility of the information base at a remote warehouse or retail store leads to quite significant losses. And finally, let’s not forget that there are places (for example, industrial zones on the outskirts of cities) where providing a high-quality communication channel is expensive and/or problematic.
The RIB mechanism allows you to get rid of these shortcomings; each department has its own copy of the information base with which you can work autonomously even in the complete absence of communication with the outside world. And the small amount of transmitted information allows you to use any communication channel, including the mobile Internet, for exchange.
RIB on platform 8.2 is not something fundamentally new, representing a further development of RIB platform 7.7, only now this technology has become more accessible and simpler. Unlike the RIB component, which had to be purchased separately, the RIB is an integral part of many standard configurations and works entirely in user mode, allowing you to do without the Configurator even at the setup stage.
At this point it would be time to move on to the practical part, but we will have to make one more digression. The fact is that the transition to the 8.2 platform, which seems to have already happened, in fact led to the emergence of two types of configurations: based on a managed application, “native” for the 8.2 platform, and adapted from 8.1, continuing to use outdated technologies and mechanisms. Since a significant part of the configurations (Enterprise Accounting, Payroll and HR Management) are adapted or transitional, they cannot be discounted, so the first part of our article will be devoted to these configurations (essentially the 8.1 platform), while in the second we will examine setting up auto-exchange for configurations based on a managed application (platform 8.2).
Let's consider a practical task: setting up automatic exchange via FTP for the Enterprise Accounting 2.0 configuration. Despite the fact that RIB allows you to exchange using email or file shares, we recommend using FTP as the simplest and most reliable method of communication. You can read how to set up your own FTP server, or you can use the FTP service of any hosting provider.
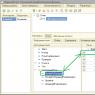
First of all, we need to configure exchange nodes. To do this, launch the configuration with administrator rights and select Transactions - Exchange Plans.
In the list that appears, select Full plan or By organization, if records are kept for several companies in one database and the exchange needs to be made only for one of them. In the window that opens, there is already one node - the central one, we need to edit it by indicating the code and name.
Then we will create another node for the branch, filling it in the same way (to add, click the green circle with a plus). The next step is to create an initial image for this node, which is a ready-made information base in file mode. To do this, right-click on the desired node and select from the drop-down list Create a starting image.
Now let's move on Service - Distributed Information Base (DIB) - Configure RIB nodes.
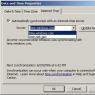
In the window that opens, click the button Add and configure a new exchange by specifying the remote host, exchange type (via FTP) and server connection parameters.
Bookmark Automatic exchange allows you to set up an exchange schedule, exchange by events (start and end of work, etc.), these settings are made for the user on whose behalf the exchange will be performed, so make sure he has rights to exchange data.
Don't forget to specify the node prefix for document numbering (otherwise you will receive different documents with the same numbers) in Tools - Program Settings; here you can also configure some other exchange parameters. On the same tab, you should select a user to perform exchange tasks; if you do not do this, the schedule will not work. Remember that the exchange will only be made if the user is logged into the program.
This completes the configuration of the central node; now you need to make similar settings for the peripheral node, connecting the initial image as an existing information security system. After which you can start exchanging data. To control you should use Communication monitor, it allows you not only to monitor the success of the upload/download, but also shows any collisions that have arisen or delayed movements (if the user who made the exchange does not have enough rights to perform any actions in the database). The presence of this tool allows you to quickly and effectively solve various types of problems that arise during autoexchange.
At this point, the exchange setup can be considered complete and you can begin working in distributed mode. It is worthwhile to dwell specifically on updating or making changes to the configuration. These actions are only available on the central node; all changes made will be automatically propagated to the peripheral nodes during the next exchange. To make changes automatically, the peripheral database must be in exclusive mode, otherwise you will need to run Configurator and execute Updating the Database Configuration manually.
Creating and configuring a distributed database (RDB) in 1C 8.3 Accounting (and other configurations) is necessary in cases where it is not possible for several users to work while simultaneously connecting to one database. Nowadays this is quite a rare occurrence, since the standard remote desktop works fine and there are other programs that provide a remote connection to the central computer where the database is located.
But nevertheless, there are situations when there is simply no Internet. And the data should ultimately end up in one information base. This is why a distributed database is created.
Usually the main base is called central, and the rest are called peripheral. The bottom line is that either manually or automatically (depending on the settings) the databases are combined into one. To ensure that numbers of newly entered documents and directory codes are not duplicated, a prefix is assigned to each database.
In this instruction, we will use an example to create a central and peripheral database and check the exchange between them. This manual is suitable for both 1C 8.3 Accounting and 1C Trade Management (UT) and other configurations.
Setting up the main (central) distributed RIB database
Let’s go to the 1C “Administration” menu, then click on the “Data synchronization settings” link. In the window that opens, you need to check the “Data synchronization” checkbox. The “Data Synchronization” link will become active. Right here we will set a prefix for the main information base - for example, “CB”:
Click on the “Data synchronization” link and a window with a “Set up data synchronization” button will open. When you click on this button, a drop-down list will open where you need to select the “Full” mode. If synchronization is required for only one organization, you need to select “By organization...”.
In the next window, the program will prompt us to make a backup copy. I strongly recommend doing this, as the following setup steps may be irreversible.
After creating a backup, click the “Next” button. At the next step, we need to decide how synchronization will occur:
- through a local directory or a directory on the local network;
- over the Internet via FTP.
For simplicity and clarity of the example, we will select a local directory. I specified the following path: “D:\1C Databases\Synchronization”. It would be a good idea to check entries in this directory; there is a special button for this:
Get 267 video lessons on 1C for free:

We skip the next steps with setting up synchronization via FTP and email. Let's look at the settings for the names of the main and peripheral databases. Here we will set the prefix for the peripheral database:

Don't forget that the prefixes for each database must be unique. Otherwise, you will receive the error “The prefix value of the first infobase is not unique.”
Click “Next”, check the entered information and click “Next” again, then “Finish”. In the “Full name of the file base” field, indicate the file 1Cv8.1CD in the directory that was created for synchronization. We create the initial image of the distributed 1C database:

After creating the initial image of the RIB in 1C, you can set a synchronization schedule or synchronize manually:

After synchronization, you can connect to the new database and make sure that information from the central database has been uploaded there:

Just immediately create at least one user with Administrator rights in the new peripheral database.
Setting up synchronization in the peripheral database
In the 1C peripheral database, configuration is much simpler. Just check the “Data synchronization” checkbox and follow the link of the same name. And we almost immediately find ourselves in a window with the “Synchronize” button. Let's try to create a test item in the peripheral database and upload it to the main one using RIB:
October 25th, 2016
There is no big difference between setting up and supporting RIB for 2 nodes and for 10, but when the number of remote points exceeds a hundred, completely different issues have to be solved
Initial data:
Configuration: Retail 2.2
Platform 1C: 8.3.7.1970
Project duration: one year.
Architecture:
First, we decided on the RIB scheme. It was decided to focus on the “star” scheme for as long as possible; when technological limitations are reached - a snowflake.
Limitations:
- 2 GB RAM
- 1 physical processor
Of all the above, the main annoying thing is the limitation on the maximum database size.
But this just means that you need to carefully organize a procedure for cleaning it from outdated data on site.
A separate physical server is allocated for the 1C and MS SQL server. It will bear the main burden of exchanges and long-term operations.
The end client computers are not replaced, because they will work with the thin client and the load on them will be minimal.
.
basic settings
Since the time of UT 10.3, during which I had my first project of implementing RIB for 60 knots, of course, “a lot of water has passed under the bridge.”
1C did not stand still. Retail 2.2 now takes into account the need for selective data upload.
Only information that is relevant to it will be uploaded to the store database:
- All reference books (except specialized ones)
- Documents for this store
Another question is that one way or another, adding a node to the database means adding another entry to the registration table for each common element when it is written.
1) It is necessary to divide into separate synchronization scenarios for uploading and downloading
The point is that unloading takes a long time and involves blocking, while loading is quite hassle-free. At the same time, it often happens that we need to quickly receive data from retail outlets, while giving it away only a few times a day.
2) Identify problem stores and remove them from the general synchronization scenario. There may be large unloadings on them - this will slow down the entire exchange, including other nodes. Once the problems are resolved they are added back.
3) Create several scripts for sending and receiving data. But the main thing here is to catch the right balance of their quantity.
(since version 8.1).
Consequently, parallelism in unloading RIB is limited. In practice, it turns out to run 2-3 scripts in parallel.
What had to be improved
The most important problem in the standard logic of 1C RIB is updates
Another problem of exchange is information registers. Uploading each record of the information register into XML creates a separate XML node with service elements, etc. In addition, the “SelectChanges()” function for an information register in which there are 100 records will receive a resulting table of 100 rows, at the same time, if this A directory with 100 rows will have only one entry selected in its tabular section. And this is the time of exclusive blocking. So if there are a lot of records in the PC that are regularly registered for exchange to other stores, then it is of course more correct to present this in the form of a directory with a tabular part, which, in extreme cases, when recording, can form rows of the same register. Anyway, .
Another important detail - For what? There are already close to 3 million discount cards. An external online system is used to work with them. If you continue to transfer discount cards to all stores, this will increase exchanges significantly, and may also lead to the base exceeding the volume of 10 GB.
Some of the mechanisms are implemented by online access to the central database: balances in other stores, return by receipt from another store, checking the validity of a gift certificate.
Replication
Creating an initial RIB node in a regular manner would make replication impossible in principle.
Therefore, a new node is created as follows:
2) This database exchanges all general data in the RIB but does not receive specialized (documents)
5) The base for the store is ready.
A ready-made software package is deployed onto the server, so it does not take much time. Then the newly created database is uploaded to the server and it is ready to be sent to the store.
Benefits of a thin client
Two significant advantages of Retail 2.2 (Thin Client) that “warmed the soul”:
Support and updates
1) Update manually from stores (not very correct, changes may not be received, there will be calls and problems) - this was the case before
3) Write a *.cmd or 1C script for updating or take a ready-made one. As practice shows, such a solution is always half-hearted (unstable), and it will be possible to build little functionality into it.
What were our tasks:
2) When updating, interactive interaction with the user is possible (messages, confirmation, progress bar).
Main functions:
4) Checking the status of agents
5) Update reports
6) backup
For example, this is what the error message looks like after an update:
Thus, the project had a good chance of being completed successfully. At least halfway through the flight the flight is normal.
If we come to any other solutions that may seem interesting, I will write separately
P.S. and most importantly: Proper planning of further support is one of the key factors for the further success of such projects. :)
October 25th, 2016
There is no big difference between setting up and supporting RIB for 2 nodes and for 10, but when the number of remote points exceeds a hundred, completely different issues have to be solved.
So, the initial data:
Configuration: Retail 2.2
Platform 1C: 8.3.7.1970
Estimated number of nodes at the end of the project: 200
Equipment resources in the center: without significant restrictions
Equipment at the point: a discussed issue.
Project duration: one year.
Architecture:
First, we decided on the RIB scheme. It was decided to focus on the “star” scheme, before
At retail outlets, a client-server version of work is used, with a dedicated server running Windows OS.
Server 1C will be used in the version "Server 1C MINI" https://1c.ru/news/info.jsp?id=17577
DBMS server - MS SQL Express 2008 R2.
SQL Express 2008 R2 is the current latest version of this SQL Server line.
Limitations:
2 GB RAM
- 1 physical processor
- 10 GB maximum database size
Of all the above, the most annoying thing, of course, is the limitation on the maximum database size. But in fact, this just means that it will be necessary to carefully organize the procedure for cleaning it from outdated data on site.
A separate server is allocated for 1C and MS SQL server. It will bear the main burden of exchanges and transactions.
The end client computers are not replaced, because they will work with a thin client and the load on the bottom will be minimal.
The server in the store is simply a powerful PC. But a prerequisite is the presence of an SSD disk - on which the MS SQL databases are located.
The server will also provide the ability to carry out routine operations at night and access to the store’s database without interruption from work.
basic settings
Since the time of UT 10.3, during which I had my first project of implementing RIB for 60 knots, of course, “a lot of water has flown under the bridge.” 1C did not stand still. Retail 2.2 now takes into account the need for selective data upload.
Only information that is relevant to the store will be uploaded to the store database:
- All directories (except some)
- Documents for this store
Data registration occurs according to registration rules, everything that can be cached. There are no significant slowdowns during registration.
Another question is that one way or another, adding a node to the database means adding another record for each common element for all databases.
There is nothing specific in setting up the upload itself. There are some nuances when setting up synchronization scenarios:

1) It is necessary to separate uploading and loading into separate synchronization scenarios
The point is that unloading takes a long time and involves blocking, while loading is quite trouble-free. At the same time, it often happens that we need to quickly receive data from retail outlets, while giving it away only a few times a day.
2) Identify problematic stores and remove them from the general synchronization scenario. There may be large unloads on them - this will slow down the entire exchange, including other nodes
3) Create some send and receive scripts to send and receive data. But the main thing here is balance.
Some things in 1C do not change. The same "SelectChanges" method can only be executed sequentially(since version 8.1).
Consequently, parallelism in unloading RIB is limited. In practice, you end up uploading 2-3 scripts at a time.
As for the receiving scenario, much greater parallelism is possible here, if necessary, of course.
What had to be improved
Of course it’s sad and sad, but I had to thoroughly interfere with the BSP. The most important problem in the standard 1C logic is updates. After the update, a window similar to this appears:
This all happens in monopoly mode. Among other things, the system will still try to make an exchange after updating in exclusive mode. It’s not hard to guess where this all leads.
During this entire period of time, the store cannot operate, there are customers at the checkout, and the company is losing money.
Another problem of exchange is information registers. Uploading each information register entry into XML creates a separate XML node with service elements and everything that follows. In addition, the “select changes” function for an information register in which there are 100 records, the resulting table will contain 100 rows, at the same time, if this is a directory with 100 rows, only one record will be selected in the table section. So if there are a lot of records in the PC that are regularly registered for exchange to other stores, then it is of course more correct to present this in the form of a directory with a tabular part, which, in extreme cases, when recording, can generate records of the same register. Anyway, information registers in exchanges are evil.
Another important detail - Discount cards are completely excluded from the exchange, and only employees of a specific store are excluded from the exchange. For what? There are already close to 3 million discount cards. An external online system is used to work with them. If you continue to transfer discount cards to all stores, this will increase exchanges significantly, and in addition, it may lead to the base exceeding the volume of 3GB.
Some of the mechanisms are implemented online by contacting the central database: balances in other stores, returning a receipt from another store, checking the validity of a gift certificate.
Replication
Of course, replication is being carried out at an accelerated pace.
Creating the initial RIB node in a standard way would, of course, make replication impossible.
Therefore, a new node is created as follows:
1) There is a separate database with a fake store
2) This database exchanges all general data in the RIB but does not receive specialized
3) When we want to create a new database, we simply copy this one
4) Then we set the settings - store, prefix, etc.
5) The base for the store is ready.
A ready-made software package is deployed onto the server, so it does not take much time. Then the newly created database of stores is uploaded to the server and it is ready to be sent to the store.
Benefits of a thin client
two significant advantages that “warmed the soul.”
1) There is no need to change the entire computer park at retail outlets. 90% of operations are performed on the server, and the server is brought there with a “relatively powerful computer”
2) Equipment has the ability to refuse to work, this especially often happens with newly installed or already worn-out equipment.
In this case, the actions are now extremely simple - the store switches to working in the central database.
This process takes no more than 5-10 minutes, so trading is not interrupted even if there are significant problems with the equipment.
Support and updates
Finally we reached the most interesting point - how to maintain and update all this?
For us, updates have also been a dilemma for a long time:
1) Update manually from stores (not very correct, changes may not be received, there will be calls and problems)
2) Update using technical support (there are not so many resources)
3) Write *.cmd for updating or take a ready-made one. As practice shows, such a solution is always half-hearted (unstable), and there is little functionality in it.
What were our tasks:
1) The update must take place in several modes and be managed centrally
2) When updating, interactive interaction with the user is possible.
3) Reports on update status and errors must be received
4) There must be a backup
5) The update system should be able to update itself without problems.
6) The system should be expandable without any problems.
Of course, the problems went far beyond the list of those solvable by simple methods. Because we can’t do without automation with so many endpoints, and we haven’t found anything more or less ready-made with similar functionality
I had to start developing software, which eventually acquired the name MU (MagicUpdater).
Main functions:
1) Dynamic database update (command or scheduled)
2) Static database update (command or scheduled)
3) automatic agents on end computers when they are modified
4) Checking the status of agents
5) Update reports
6) backup
7) Administrative actions with 1C server and MS SQL
8) Closing all 1C client applications on network computers
9) Static update with acceptance at the main checkout
10) Displaying descriptions of modifications after updating
11) Setting up the order of actions
12) Perform all these actions on a schedule
Approximate interaction schemes:

Where MU Agent is a service that is installed and configured in the store. Actually, she receives a command from the center to carry out certain tasks.
MU Server - The server that accepts all requests to the system.
MU monitor - what ordinary technical support employees see - is used to view logs and set tasks for updating, or others.
It turned out quite well, in my opinion. Now updates take place almost automatically.
This is, for example, what the error message looks like after the update; everything is still waiting in the center.

This is how we send commands to client computers

The applications are certainly not 1C, but with a fairly decent set of interface capabilities. For example, this is what selection by date looks like:

Now they are ready for further replication. Proper planning of further support is one of the key factors for the further success of such projects.
This material contains detailed instructions for setting up the RIB exchange for 1C:Enterprise 8 and the problems that the author encountered.
1. Creating nodes
We create new nodes (master and slave): in the user mode "Operations / Exchange Plans / Full"
Let's choose the exchange plan "Full"
We create two records:
- let’s call the first record “CB” (main node), indicate the code “CB”,
- let’s call the second entry “Subordinate node”, indicate the code “PU”.
Icon with a green circle - "CB" (main node)
For the slave node, click on the “Create initial image” icon. (Requires exclusive access)
Create a starting image
Next, in the window that opens, fill in the parameters of the new database. When finished, click the “Finish” button.
Creating an initial information security image
The creation of the initial image of the slave node of the distributed infobase will begin, and upon completion the message “Creation of the initial image has been successfully completed” will appear. Click the "OK" button.
We add the base of the slave node to the list of bases and launch it.
In this subordinate database we open the full exchange plan - the “CB” icon is red, this means that this node is the main node for the information base in which we are located.
2. Setting up prefixes
For each database, in the accounting parameters settings (in the UPP "Service / Accounting Parameters") on the "Data Exchange" tab, we set prefixes. This is done so that there are no conflicts in the numbers and codes of documents and directories created in two databases.
For automatic exchange, check the box "Use automatic exchange mechanism..."
Tab "Data exchange"
3. Add a setting for data exchange between nodes
Open: "Service\Distributed Information Base (RIB)\Configure RIB nodes"
Click "Add" and the "Data exchange settings" window will open.
Setting up data exchange
Click on the "Exchange according to current settings" icon
Execute the exchange according to the current setting
Now about the pitfalls
1. Data exchange can be carried out automatically and can be initiated in the following cases:
* When starting the program. The exchange will be performed when the program starts,
* When you finish working with the program. The exchange will be performed before the user finishes working with the program,
* When the catalog appears. The exchange will be performed only if the directory specified by the user was invisible, but has now become visible. The setting can be used to perform automatic exchange when connected to a local network or flash card. The program will periodically check the visibility of the directory specified in the settings and note its current state,
* When the file appears. It is recommended to use data mode when you need to exchange if an incoming data exchange file appears. In this case, it is enough to specify the full path to the incoming data exchange file. The program periodically analyzes the presence of the file, and as soon as it appears, the exchange will be performed, and after the exchange, this file will be forcibly DELETED (this is done so that the exchange procedure is not carried out constantly),
* Periodic data exchange. The exchange will be carried out according to the settings for periodic data exchange. If the infobase operates in file server mode, then periodic exchange is performed only for the user who is specified in the accounting policy settings as “User for routine tasks in file mode.” In the Client-server version, the exchange is performed on the 1C:Enterprise server.
I have a Client-Server option - for routine auto-exchange to work, I had to overload the server
2. Windows encoding.
The exchange was interrupted by an error because the file was not compressed. This is due to a Cyrillic error in the command line during compression.
It can be treated by correcting the encodings in the registry.
For example, for Windows Server 2008 -
Code
REGEDIT4
"1250"="c_1251.nls"
"1251"="c_1251.nls"
"1252"="c_1251.nls"
"1253"="c_1251.nls"
"1254"="c_1251.nls"
"1255"="c_1251.nls"
3. When creating a copy of the database (for example, for modification) in the client-server version, it is NECESSARY that the ROUTINE TASKS OF THE COPY OF THE DATABASE be OFF. Blocking routine tasks for copy ON
If they are not blocked, then the copy will make exchanges on the same schedule as the main database. This means that some messages to remote nodes will be generated from the working database, and some from a copy, which will lead to desynchronization of configurations.
OLEG FILIPOV, ANT-Inform, Deputy Head of Development Department, [email protected]
RIB in 1C. Limits of Possibilities
The technology of distributed information bases (RIB) in the 1C:Enterprise platform causes a lot of controversy. We will try to figure out when it is advisable to use it, and when it is better to prefer alternative solutions
Often, when reading forums or articles by online authors regarding RIB in 1C, you can come across conflicting opinions from “this is the best and only thing that can be used” to “it is hopelessly outdated.” Let's try to figure out how things really are.
In the November 2016 issue, I already wrote about some of the features of RIB in relation to a specific practical task, so just a few words about the basics, and let’s go a little deeper into the technological details.
RIB is a technology of distributed information bases 1C:Enterprise - not to be confused with universal exchange, with a similar technology, but fundamentally different support for centralized updating of information base configurations. It consists of the following functional parts (which can also be used separately):
- Change Registration Service– when enabled, it begins to automatically register changes to objects or records for exchange (or other purposes). In RIB mode it is also used to register changes to the infobase configuration.
- Serialization of objects/records in XML. Almost any 1C:Enterprise object is routinely serialized in XML.
- A mechanism for maintaining the same configuration of all nodes of a distributed information base. In RIB mode, data exchange between different nodes is possible only if they have the same configuration. It is transferred automatically during the exchange. The final node only needs to accept the changes.
- The infrastructure of messages exchanged in a distributed information system is guaranteed delivery. Registered changes are packaged into messages and sent to the end node in batches. Registrations are deleted only after confirmation of package delivery.
- Application level infrastructure. Of course, all of the above will not work without developed mechanisms at the level of application solutions, some of which are already included in the BSP. The solutions provide the ability to upload data according to certain rules, change the principles of their registration, and determine the method of package delivery.
As you can see, RIB in 1C can do quite a lot. In most cases, this functionality is more than enough. For example, in Fig. Figure 1 shows the form of the information base node in 1C, where you can see the ability to download registration rules, specify connection parameters, and view the list of objects registered for exchange.

From the description above we can conclude about the capabilities of RIB 1C as a distributed system:
- Support for a unified information base configuration (semi-automated).
- Change tracking support.
- Guaranteed delivery.
- Possibility of master-master circuit.
- Possibility of a star circuit.
- Possibility of selective filtering of changes.
Quite good - it will completely satisfy the needs of a small network. But RIB has certain limitations, largely related to the architectural features of the 1C platform, which impose certain restrictions on the use of this technology:
- The need to update the infobase configuration manually and shut down users. Stopping exchanges until the configuration is updated.
- Message infrastructure transactional limit on data retrieval. When selecting changes for uploading, the database table is blocked to record new changes; with large volumes of uploading, this can take a long time, stopping the work.
- Overhead for maintaining a large number of synchronization nodes (the number of service records is equal to the number of nodes).
- Problems loading large amounts of data.
Let us now try to compare this with some “advanced” system that has a replication mechanism.