Tạo mạng lưới thần kinh trong python. Học mạng lưới thần kinh theo bốn bước
James Loy, Georgia Tech. Hướng dẫn dành cho người mới bắt đầu tạo mạng lưới thần kinh của riêng bạn bằng Python.
Động lực: tập trung vào kinh nghiệm cá nhân trong học tập học kĩ càng, Tôi quyết định tạo một mạng lưới thần kinh từ đầu mà không phức tạp thư viện giáo dục, chẳng hạn như, ví dụ, . Tôi tin rằng đối với một Nhà khoa học dữ liệu mới bắt đầu, điều quan trọng là phải hiểu cấu trúc bên trong.
Bài viết này chứa đựng những gì tôi đã học được và hy vọng nó cũng sẽ hữu ích cho bạn! Các bài viết hữu ích khác về chủ đề này:
Mạng lưới thần kinh là gì?
Hầu hết các bài viết về mạng lưới thần kinh đều có sự tương đồng với bộ não khi mô tả chúng. Tôi dễ dàng hơn khi mô tả mạng lưới thần kinh như hàm toán học, ánh xạ đầu vào nhất định tới đầu ra mong muốn mà không đi sâu vào chi tiết.
Mạng lưới thần kinh bao gồm các thành phần sau:
- lớp đầu vào, x
- số lượng tùy ý lớp ẩn
- lớp đầu ra, ŷ
- bộ dụng cụ quy mô Và chuyển vị giữa mỗi lớp W Và b
- lựa chọn cho từng lớp ẩn σ ; trong công việc này chúng tôi sẽ sử dụng hàm kích hoạt Sigmoid
Sơ đồ bên dưới thể hiện kiến trúc của mạng nơ-ron hai lớp (lưu ý rằng lớp đầu vào thường bị loại trừ khi đếm số lớp trong mạng nơ-ron).
Tạo một lớp Mạng thần kinh trong Python rất đơn giản:
Đào tạo mạng lưới thần kinh
Lối ra ŷ Mạng nơ-ron hai lớp đơn giản:
Trong phương trình trên, trọng số W và độ lệch b là các biến duy nhất ảnh hưởng đến đầu ra ŷ.
Đương nhiên, các giá trị chính xác cho trọng số và độ lệch sẽ xác định độ chính xác của dự đoán. Quá trình tinh chỉnh trọng số và độ lệch từ dữ liệu đầu vào được gọi là .
Mỗi lần lặp lại của quá trình học tập bao gồm các bước sau
- tính toán đầu ra dự đoán ŷ, được gọi là lan truyền thuận
- cập nhật trọng số và độ lệch, được gọi là
Biểu đồ tuần tự dưới đây minh họa quá trình:
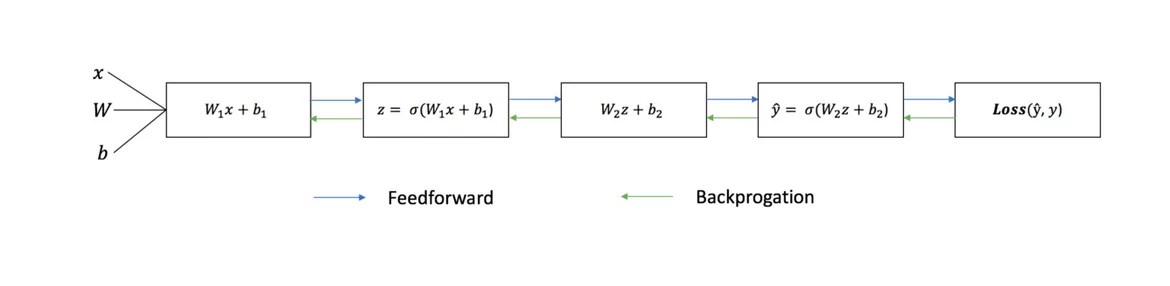
Phân phối trực tiếp
Như chúng ta đã thấy trong biểu đồ trên, việc lan truyền tiến chỉ là một phép tính đơn giản và đối với mạng nơ-ron 2 lớp cơ bản, đầu ra của mạng nơ-ron được cho bởi:
Hãy thêm hàm lan truyền thuận vào mã Python của chúng ta để thực hiện việc này. Lưu ý rằng để đơn giản, chúng tôi giả định độ lệch là 0.
Tuy nhiên, chúng tôi cần một cách để đánh giá mức độ “tốt” của các dự báo của mình, tức là dự báo của chúng tôi sai đến mức nào). Mất chức năng chỉ cho phép chúng tôi làm điều này.
Mất chức năng
Có nhiều chức năng có sẵn tổn thất và bản chất của vấn đề sẽ quyết định sự lựa chọn của chúng ta về hàm tổn thất. Trong công việc này chúng tôi sẽ sử dụng tổng các sai số bình phương như một hàm mất mát.

Tổng sai số bình phương là giá trị trung bình của chênh lệch giữa mỗi giá trị dự đoán và giá trị thực tế.
Mục tiêu của việc học là tìm ra một tập hợp các trọng số và độ lệch làm giảm thiểu hàm mất mát.
Lan truyền ngược
Bây giờ chúng ta đã đo được sai số trong dự báo (mất mát), chúng ta cần tìm cách truyền lại lỗi và cập nhật trọng số và thành kiến của chúng tôi.
Để biết mức độ thích hợp để điều chỉnh trọng số và độ lệch, chúng ta cần biết đạo hàm của hàm mất mát đối với trọng số và độ lệch.
Chúng ta hãy nhớ lại từ phân tích rằng Đạo hàm của hàm số là độ dốc của hàm số.

Nếu chúng ta có đạo hàm thì chúng ta có thể chỉ cần cập nhật trọng số và độ lệch bằng cách tăng/giảm chúng (xem sơ đồ ở trên). Nó được gọi là .
Tuy nhiên, chúng ta không thể tính trực tiếp đạo hàm của hàm mất mát theo trọng số và độ lệch vì phương trình hàm mất mát không chứa trọng số và độ lệch. Vì vậy, chúng ta cần một quy tắc dây chuyền để hỗ trợ tính toán.
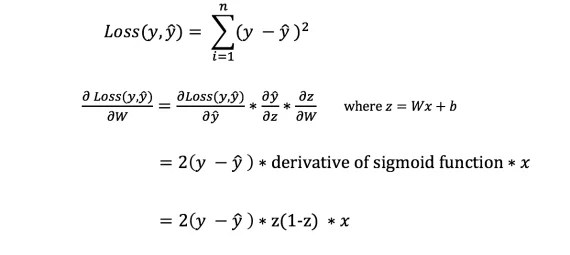
Phù! Điều này thật rắc rối, nhưng nó cho phép chúng tôi có được những gì chúng tôi cần — đạo hàm (độ dốc) của hàm mất đối với các trọng số. Bây giờ chúng ta có thể điều chỉnh trọng số cho phù hợp.
Hãy thêm hàm lan truyền ngược vào mã Python của chúng ta:
Kiểm tra hoạt động của mạng nơ-ron
Bây giờ chúng tôi có mã đầy đủ trong Python để thực hiện lan truyền tiến và lùi, hãy xem mạng nơ-ron của chúng ta làm ví dụ và xem nó hoạt động như thế nào.
 Bộ cân lý tưởng
Bộ cân lý tưởng Mạng lưới thần kinh của chúng ta phải học tập trọng số lý tưởng để biểu diễn hàm này.
Hãy huấn luyện mạng lưới thần kinh trong 1500 lần lặp và xem điều gì sẽ xảy ra. Nhìn vào biểu đồ tổn thất lặp lại bên dưới, chúng ta có thể thấy rõ rằng tổn thất giảm dần đến mức tối thiểu. Điều này phù hợp với thuật toán giảm độ dốc mà chúng ta đã thảo luận trước đó.

Hãy xem dự đoán cuối cùng (đầu ra) từ mạng lưới thần kinh sau 1500 lần lặp.

Chúng ta làm được rồi! Thuật toán lan truyền tiến và lùi của chúng tôi đã chỉ ra rằng mạng thần kinh hoạt động thành công và các dự đoán hội tụ về giá trị thực.
Lưu ý rằng có một chút khác biệt giữa dự đoán và giá trị thực tế. Điều này là mong muốn vì nó ngăn chặn việc trang bị quá mức và cho phép mạng lưới thần kinh khái quát hóa tốt hơn các dữ liệu không nhìn thấy được.
suy nghĩ cuối cùng
Tôi đã học được rất nhiều điều trong quá trình viết mạng lưới thần kinh của riêng mình từ đầu. Mặc dù các thư viện học kĩ càng, chẳng hạn như TensorFlow và Keras, cho phép tạo mạng lưới sâu không có sự hiểu biết đầy đủ công việc nội bộ mạng lưới thần kinh, tôi thấy nó hữu ích cho những Nhà khoa học dữ liệu đầy tham vọng hiểu sâu hơn về chúng.
Tôi đã đầu tư rất nhiều thời gian cá nhân của mình vào công việc này, và tôi hy vọng bạn thấy nó hữu ích!
Mạng lưới thần kinh được tạo ra và huấn luyện chủ yếu trên Ngôn ngữ Python. Vì vậy, điều rất quan trọng là phải có hiểu biết cơ bản về cách viết chương trình trong đó. Trong bài viết này tôi sẽ nói ngắn gọn và rõ ràng về các khái niệm cơ bản của ngôn ngữ này: biến, hàm, lớp và mô-đun.
Tài liệu này dành cho những người không quen với ngôn ngữ lập trình.
Đầu tiên bạn cần cài đặt Python. Sau đó, bạn cần cài đặt một môi trường thuận tiện để viết chương trình bằng Python. Cổng thông tin được dành riêng cho hai bước này.
Nếu mọi thứ đã được cài đặt và cấu hình, bạn có thể bắt đầu.
Biến
Biến đổi- một khái niệm quan trọng trong bất kỳ ngôn ngữ lập trình nào (và không chỉ trong chúng). Cách dễ nhất để nghĩ về một biến là một hộp có nhãn. Hộp này chứa thứ gì đó (một số, một ma trận, một đồ vật, ...) có giá trị đối với chúng ta.
Ví dụ: chúng tôi muốn tạo một biến x sẽ lưu giá trị 10. Trong Mã Python việc tạo biến này sẽ trông như thế này:

Ở bên trái chúng tôi chúng tôi công bố một biến có tên x. Điều này tương đương với việc dán thẻ tên lên hộp. Tiếp theo là dấu bằng và số 10. Ở đây dấu bằng đóng một vai trò đặc biệt. Nó không có nghĩa là "x bằng 10". Bình đẳng trong trong trường hợp này bỏ số 10 vào ô Nói một cách chính xác hơn, chúng ta giao phó biến x là số 10.
Bây giờ, trong đoạn mã bên dưới, chúng ta có thể truy cập biến này và cũng có thể thực hiện nhiều hành động khác nhau với nó.
Bạn chỉ có thể hiển thị giá trị của biến này trên màn hình:
X=10 in(x)
print(x) đại diện cho một lệnh gọi hàm. Chúng tôi sẽ xem xét chúng hơn nữa. Điều quan trọng bây giờ là hàm này sẽ in ra bảng điều khiển những gì nằm giữa các dấu ngoặc. Giữa các dấu ngoặc chúng ta có x. Trước đây, chúng ta đã gán x giá trị 10. Đây là giá trị 10 được in trong bảng điều khiển nếu bạn chạy chương trình trên.
Có thể thực hiện nhiều phép toán đơn giản khác nhau với các biến lưu trữ số: cộng, trừ, nhân, chia và lũy thừa.
X = 2 y = 3 # Phép cộng z = x + y print(z) # 5 # Hiệu z = x - y print(z) # -1 # Sản phẩm z = x * y print(z) # 6 # Phép chia z = x / y print(z) # 0.66666... # Lũy thừa z = x ** y print(z) # 8
Trong đoạn mã trên, trước tiên chúng ta tạo hai biến chứa 2 và 3. Sau đó, chúng ta tạo một biến z lưu trữ kết quả của phép toán trên x và y và in kết quả ra bàn điều khiển. Ví dụ này cho thấy rõ ràng rằng một biến có thể thay đổi giá trị của nó trong quá trình thực hiện chương trình. Vì vậy, biến z của chúng tôi thay đổi giá trị của nó tới 5 lần.
Chức năng
Đôi khi việc thực hiện đi thực hiện lại các hành động tương tự là điều cần thiết. Ví dụ, trong dự án của chúng tôi, chúng tôi thường cần hiển thị 5 dòng văn bản.
“Đây là một văn bản rất quan trọng!”
“Văn bản này không thể đọc được”
“Sai lầm ở dòng trên là cố ý”
"Xin chào và tạm biệt"
"Kết thúc"
Mã của chúng tôi sẽ trông như thế này:
X = 10 y = x + 8 - 2 print("Đây là một văn bản rất quan trọng!") print("Văn bản này không thể đọc được") print("Lỗi ở dòng trên cùng là cố ý") print(" Xin chào và tạm biệt") print (“The End”) z = x + y print(“Đây là một văn bản rất quan trọng!”) print(“Không thể đọc được văn bản này”) print(“Đã xảy ra lỗi ở dòng trên cùng có mục đích”) print(“Xin chào và tạm biệt”) print (“Kết thúc”) test = z print("Đây là một văn bản rất quan trọng!") print("Văn bản này không thể đọc được") print("Lỗi trong dòng trên cùng được viết có chủ đích") print("Xin chào và tạm biệt") print(" End")
Tất cả trông rất dư thừa và bất tiện. Ngoài ra, còn có lỗi ở dòng thứ hai. Nó có thể được sửa, nhưng nó sẽ phải được sửa ở ba nơi cùng một lúc. Điều gì sẽ xảy ra nếu năm dòng này được gọi 1000 lần trong dự án của chúng ta? Và mọi thứ đều ở trong Những nơi khác nhau và tập tin?
Đặc biệt đối với trường hợp bạn cần thường xuyên thực hiện cùng một lệnh, bạn có thể tạo hàm bằng ngôn ngữ lập trình.
Chức năng- một khối mã riêng biệt có thể được gọi bằng tên.
Một hàm được xác định bằng từ khóa def. Tiếp theo là tên hàm, sau đó là dấu ngoặc đơn và dấu hai chấm. Tiếp theo, bạn cần liệt kê, thụt lề các hành động sẽ được thực hiện khi gọi hàm.
Def print_5_lines(): print("Đây là một văn bản rất quan trọng!") print("Không thể đọc được văn bản này") print("Lỗi ở dòng trên cùng là cố ý") print("Xin chào và tạm biệt") print("Kết thúc")
Bây giờ chúng ta đã định nghĩa hàm print_5_lines(). Bây giờ, nếu trong dự án của mình, một lần nữa chúng ta cần chèn năm dòng, thì chúng ta chỉ cần gọi hàm của mình. Nó sẽ tự động thực hiện tất cả các hành động.
# Xác định hàm def print_5_lines(): print("Đây là một văn bản rất quan trọng!") print("Văn bản này không thể đọc được") print("Lỗi ở dòng trên cùng là cố ý") print("Xin chào và tạm biệt ") print(" End") # Mã dự án của chúng tôi x = 10 y = x + 8 - 2 print_5_lines() z = x + y print_5_lines() test = z print_5_lines()
Thật tiện lợi phải không? Chúng tôi đã cải thiện nghiêm túc khả năng đọc mã. Ngoài ra, các chức năng cũng tốt vì nếu muốn thay đổi một số thao tác thì bạn chỉ cần sửa chính chức năng đó là được. Thay đổi này sẽ hoạt động ở tất cả những nơi mà hàm của bạn được gọi. Nghĩa là, chúng ta có thể sửa lỗi ở dòng thứ hai của văn bản đầu ra (“không” > “không”) trong nội dung hàm. Tùy chọn đúng sẽ được gọi tự động ở tất cả các nơi trong dự án của chúng tôi.

Hàm có tham số
Chắc chắn là thuận tiện khi chỉ cần lặp lại một số hành động. Nhưng đó không phải là tất cả. Đôi khi chúng ta muốn truyền một số biến vào hàm của mình. Bằng cách này, hàm có thể chấp nhận dữ liệu và sử dụng nó trong khi thực hiện lệnh.
Các biến chúng ta truyền vào hàm được gọi là tranh luận.
Cùng viết nào chức năng đơn giản, cộng hai số đã cho và trả về kết quả.
Def sum(a, b): result = a + b trả về kết quả
Dòng đầu tiên trông gần giống như các hàm thông thường. Nhưng giữa các dấu ngoặc bây giờ có hai biến. Cái này tùy chọn chức năng. Hàm của chúng ta có hai tham số (nghĩa là nó có hai biến).
Các tham số có thể được sử dụng bên trong một hàm giống như các biến thông thường. Ở dòng thứ hai, chúng ta tạo một kết quả thay đổi, bằng tổng của tham số a và b. Ở dòng thứ ba, chúng ta trả về giá trị của biến kết quả.
Bây giờ, trong mã tiếp theo, chúng ta có thể viết một cái gì đó như:
Mới = tổng(2, 3) in(mới)
Chúng ta gọi hàm tổng và lần lượt truyền cho nó hai đối số: 2 và 3. 2 trở thành giá trị của biến a và 3 trở thành giá trị của biến b. Hàm của chúng ta trả về một giá trị (tổng của 2 và 3) và chúng ta sử dụng nó để tạo một biến mới, new .
Nhớ. Trong đoạn mã trên, số 2 và 3 là đối số của hàm tính tổng. Và trong chính hàm tổng, các biến a và b là các tham số. Nói cách khác, các biến mà chúng ta truyền vào hàm khi nó được gọi được gọi là đối số. Nhưng bên trong hàm, những biến được truyền này được gọi là tham số. Trên thực tế, đây là hai tên cho cùng một thứ, nhưng không nên nhầm lẫn chúng.
Hãy xem một ví dụ khác. Hãy tạo một hàm Square(a) nhận vào một số và bình phương nó:
Bình phương Def(a): trả về a * a
Chức năng của chúng tôi chỉ bao gồm một dòng. Nó ngay lập tức trả về kết quả nhân tham số a với a .
Tôi nghĩ bạn đã đoán được rằng chúng tôi cũng xuất dữ liệu ra bảng điều khiển bằng một hàm. Hàm này được gọi là print() và nó in đối số được truyền vào bảng điều khiển: một số, một chuỗi, một biến.
Mảng
Nếu một biến có thể được coi là một chiếc hộp lưu trữ thứ gì đó (không nhất thiết phải là số), thì mảng có thể được coi là giá sách. Chúng chứa một số biến cùng một lúc. Đây là một ví dụ về một mảng gồm ba số và một chuỗi:
Mảng =
Đây là một ví dụ khi một biến không chứa số mà chứa một số đối tượng khác. Trong trường hợp này, biến của chúng tôi chứa một mảng. Mỗi phần tử mảng được đánh số. Hãy thử hiển thị một số phần tử của mảng:
Mảng = in(mảng)
Trong bảng điều khiển, bạn sẽ thấy số 89. Nhưng tại sao lại là 89 mà không phải 1? Vấn đề là trong Python, cũng như trong nhiều ngôn ngữ lập trình khác, việc đánh số mảng bắt đầu từ 0. Do đó, mảng cung cấp cho chúng ta thứ hai phần tử của mảng chứ không phải phần tử đầu tiên. Để gọi cái đầu tiên, bạn phải viết array .
Kích thước mảng
Đôi khi việc lấy số phần tử trong một mảng rất hữu ích. Bạn có thể sử dụng hàm len() cho việc này. Nó sẽ đếm số phần tử và trả về số của chúng.
Mảng = in(len(mảng))
Bảng điều khiển sẽ hiển thị số 4.
Điều kiện và chu kỳ
Theo mặc định, bất kỳ chương trình nào cũng chỉ thực hiện tất cả các lệnh liên tiếp từ trên xuống dưới. Nhưng có những tình huống chúng ta cần kiểm tra một điều kiện nào đó, và tùy theo điều đó có đúng hay không mà thực hiện các hành động khác nhau.
Ngoài ra, thường có nhu cầu lặp lại gần như cùng một chuỗi lệnh nhiều lần.
Trong tình huống đầu tiên, các điều kiện sẽ giúp ích và trong tình huống thứ hai, các chu kỳ sẽ giúp ích.
Điều kiện
Cần có các điều kiện để thực hiện hai nhóm hành động khác nhau tùy thuộc vào câu lệnh đang được kiểm tra là đúng hay sai.

Trong Python, các điều kiện có thể được viết bằng cấu trúc if: ... else: .... Chúng ta hãy có một số biến x = 10. Nếu x nhỏ hơn 10 thì chúng ta muốn chia x cho 2. Nếu x lớn hơn hoặc bằng 10 thì chúng ta muốn tạo một biến mới khác bằng tổng của x và số 100. Đây là mã sẽ trông như thế nào:
X = 10 nếu(x< 10): x = x / 2 print(x) else: new = x + 100 print(new)
Sau khi tạo biến x, chúng ta bắt đầu viết điều kiện.
Tất cả đều bắt đầu bằng từ khóa if (dịch từ tiếng Anh là “if”). Trong ngoặc đơn, chúng tôi chỉ ra biểu thức cần kiểm tra. Trong trường hợp này, chúng tôi kiểm tra xem biến x của chúng tôi có thực sự nhỏ hơn 10 hay không. Nếu nó thực sự nhỏ hơn 10 thì chúng tôi chia nó cho 2 và in kết quả ra bảng điều khiển.
Rồi đến từ khóa else , sau đó bắt đầu một khối hành động sẽ được thực thi nếu biểu thức trong ngoặc đơn sau if là sai.
Nếu nó lớn hơn hoặc bằng 10 thì chúng ta tạo một biến mới new, bằng x + 100 và cũng xuất nó ra bàn điều khiển.
Chu kỳ
Cần có vòng lặp để lặp lại hành động nhiều lần. Giả sử chúng ta muốn hiển thị một bảng gồm các ô vuông của 10 ô vuông đầu tiên số tự nhiên. Nó có thể được thực hiện như thế này.
Print("Hình vuông 1 là " + str(1**2)) print("Hình vuông 2 là " + str(2**2)) print("Hình vuông 3 là " + str(3**2)) print( "Hình vuông 4 là " + str(4**2)) print("Hình vuông 5 là " + str(5**2)) print("Hình vuông 6 là " + str(6**2)) print("Hình vuông 7 là " + str(7**2)) print("Bình phương của 8 là " + str(8**2)) print("Bình phương của 9 là " + str(9**2)) print("Square của 10 là " + str(10**2))
Đừng ngạc nhiên khi chúng tôi thêm dòng. "đầu dòng" + "cuối" trong Python chỉ đơn giản có nghĩa là nối các chuỗi: "bắt đầu cuối dòng". Tương tự như trên, chúng ta thêm chuỗi “Bình phương của x bằng ” và kết quả của việc nâng số lên lũy thừa 2, được chuyển đổi bằng hàm str(x**2).
Đoạn mã trên trông rất dư thừa. Nếu chúng ta cần in bình phương của 100 số đầu tiên thì sao? Chúng tôi đau khổ phải rút lui...
Chính trong những trường hợp như vậy mà chu kỳ mới tồn tại. Có 2 loại vòng lặp trong Python: while và for. Hãy giải quyết chúng từng cái một.
Vòng lặp while lặp lại các lệnh cần thiết miễn là điều kiện vẫn đúng.
X = 1 trong khi x<= 100: print("Квадрат числа " + str(x) + " равен " + str(x**2)) x = x + 1
Đầu tiên chúng ta tạo một biến và gán số 1 cho nó. Sau đó, chúng ta tạo một vòng lặp while và kiểm tra xem x của chúng ta có nhỏ hơn (hoặc bằng) 100 hay không. Nếu nhỏ hơn (hoặc bằng) thì chúng ta thực hiện hai thao tác:
- Xuất ra hình vuông x
- Tăng x lên 1
Sau lệnh thứ hai, chương trình trở về điều kiện. Nếu điều kiện vẫn đúng thì chúng ta thực hiện lại hai hành động này. Và cứ như vậy cho đến khi x bằng 101. Khi đó điều kiện sẽ trả về sai và vòng lặp sẽ không được thực thi nữa.
Vòng lặp for được thiết kế để lặp qua các mảng. Hãy viết ví dụ tương tự với bình phương của một trăm số tự nhiên đầu tiên nhưng thông qua vòng lặp for.
Đối với x trong phạm vi (1,101): print("Bình phương của số " + str(x) + " là " + str(x**2))
Chúng ta hãy nhìn vào dòng đầu tiên. Chúng tôi sử dụng từ khóa for để tạo một vòng lặp. Tiếp theo, chúng ta chỉ định rằng chúng ta muốn lặp lại một số hành động nhất định cho tất cả x trong phạm vi từ 1 đến 100. Hàm range(1.101) tạo một mảng gồm 100 số, bắt đầu bằng 1 và kết thúc bằng 100.
Đây là một ví dụ khác về việc lặp qua một mảng bằng vòng lặp for:
Đối với i in : print(i * 2)
Đoạn mã trên xuất ra 4 số: 2, 20, 200 và 2000. Ở đây bạn có thể thấy rõ cách nó lấy từng phần tử của mảng và thực hiện một tập hợp hành động. Sau đó, nó lấy phần tử tiếp theo và lặp lại cùng một tập hợp hành động. Và cứ như vậy cho đến khi hết phần tử trong mảng.
Lớp và đối tượng
Trong cuộc sống thực, chúng ta không hoạt động với các biến hoặc hàm mà với các đối tượng. Bút, ô tô, người, mèo, chó, máy bay - đồ vật. Bây giờ chúng ta hãy bắt đầu xem xét con mèo một cách chi tiết.
Nó có một số thông số. Chúng bao gồm màu lông, màu mắt và biệt danh của cô ấy. Nhưng đó không phải là tất cả. Ngoài các thông số, mèo có thể thực hiện nhiều hành động khác nhau: kêu gừ gừ, rít và cào.
Chúng tôi vừa mô tả sơ đồ tất cả các con mèo nói chung. Tương tự mô tả thuộc tính và hành động một số đối tượng (ví dụ: một con mèo) trong Python được gọi là một lớp. Một lớp chỉ đơn giản là một tập hợp các biến và hàm mô tả một đối tượng.
Điều quan trọng là phải hiểu sự khác biệt giữa một lớp và một đối tượng. Lớp học - cơ chế, mô tả đối tượng. Đối tượng là cô ấy hiện thân vật chất. Lớp mèo là sự mô tả các thuộc tính và hành động của nó. Đối tượng con mèo chính là con mèo thật. Có thể có nhiều con mèo thật khác nhau - nhiều đồ vật về mèo. Nhưng chỉ có một loại mèo. Một minh chứng tốt là hình ảnh dưới đây:

Các lớp học
Để tạo một lớp (lược đồ của con mèo của chúng ta), bạn cần viết từ khóa class và sau đó chỉ định tên của lớp này:
Lớp mèo:
Tiếp theo chúng ta cần liệt kê các hành động của lớp này (hành động của mèo). Các hành động, như bạn có thể đoán, là các hàm được định nghĩa trong một lớp. Các hàm như vậy trong một lớp thường được gọi là các phương thức.
Phương pháp- một hàm được định nghĩa bên trong một lớp.
Chúng tôi đã mô tả các phương pháp của mèo bằng lời ở trên: kêu gừ gừ, rít lên, gãi. Bây giờ hãy làm điều đó bằng Python.
# Lớp mèo lớp Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Shhh!") # Scratch def scrabble(self): print("Scratch-scratch !")
Nó đơn giản mà! Chúng ta đã lấy và định nghĩa ba hàm thông thường, nhưng chỉ bên trong lớp.
Để giải quyết tham số self khó hiểu, hãy thêm một phương thức nữa cho con mèo của chúng ta. Phương thức này sẽ gọi cả ba phương thức đã được tạo cùng một lúc.
# Lớp mèo lớp Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Shhh!") # Scratch def scrabble(self): print("Scratch-scratch !") # Tất cả cùng nhau def all_in_one(self): self.purr() self.hiss() self.scrabble()
Như bạn có thể thấy, tham số self, được yêu cầu cho bất kỳ phương thức nào, cho phép chúng ta truy cập các phương thức và biến của chính lớp đó! Nếu không có lập luận này, chúng ta sẽ không thể thực hiện những hành động như vậy.
Bây giờ chúng ta hãy thiết lập các thuộc tính cho con mèo của chúng ta (màu lông, màu mắt, biệt hiệu). Làm thế nào để làm nó? Trong bất kỳ lớp nào bạn cũng có thể định nghĩa hàm __init__(). Hàm này luôn được gọi khi chúng ta tạo một đối tượng thực sự của lớp.
Trong phương thức __init__() được đánh dấu ở trên, chúng ta đặt các biến cho con mèo của mình. Chung ta se lam như thê nao? Đầu tiên, chúng ta chuyển 3 đối số cho phương thức này, chúng chịu trách nhiệm về màu lông, màu mắt và biệt danh. Sau đó, chúng ta sử dụng tham số self để đặt ngay con mèo của mình thành 3 thuộc tính được mô tả ở trên khi tạo một đối tượng.
Dòng này có nghĩa là gì?
Self.wool_color = wool_color
Ở phía bên trái, chúng ta tạo một thuộc tính cho con mèo của mình có tên là wool_color, sau đó chúng ta gán cho thuộc tính này giá trị có trong tham số wool_color mà chúng ta đã truyền cho hàm __init__(). Như bạn có thể thấy, dòng trên không khác gì việc tạo biến thông thường. Chỉ có tiền tố self chỉ ra rằng biến này thuộc về lớp Cat.
Thuộc tính- một biến thuộc về một lớp.
Vì vậy, chúng tôi đã tạo ra một lớp mèo làm sẵn. Đây là mã của anh ấy:
# Lớp mèo lớp Cat: # Các hành động cần thực hiện khi tạo đối tượng "Cat" def __init__(self, wool_color, Eyes_color, name): self.wool_color = wool_color self.eyes_color = Eyes_color self.name = name # Purr def purr( self): print("Purrr!") # Hiss def hiss(self): print("Suỵt!") # Scratch def scrabble(self): print("Scratch-scratch!") # Tất cả cùng nhau def all_in_one(self) : self.purr() self.hiss() self.scrabble()
Các đối tượng
Chúng tôi đã tạo ra một sơ đồ con mèo. Bây giờ hãy tạo một đối tượng mèo thực sự bằng cách sử dụng sơ đồ này:
My_cat = Cat("đen", "xanh", "Zosya")
Trong dòng trên, chúng ta tạo một biến my_cat và sau đó gán cho nó một đối tượng của lớp Cat. Tất cả điều này trông giống như một cuộc gọi đến một số chức năng Cat(...) . Trên thực tế, điều này là đúng. Với mục này, chúng ta gọi phương thức __init__() của lớp Cat. Hàm __init__() trong lớp của chúng ta có 4 đối số: chính đối tượng lớp tự, không cần phải chỉ định, cũng như 3 đối số khác nhau, sau đó trở thành thuộc tính của con mèo của chúng ta.
Vì vậy, bằng cách sử dụng dòng trên, chúng ta đã tạo ra một đối tượng mèo thực sự. Con mèo của chúng tôi có các đặc điểm sau: lông đen, mắt xanh và biệt danh Zosya. Hãy in các thuộc tính này ra bàn điều khiển:
In(my_cat.wool_color) in(my_cat.eyes_color) in(my_cat.name)
Tức là chúng ta có thể truy cập các thuộc tính của một đối tượng bằng cách viết tên đối tượng đó, đặt dấu chấm và chỉ ra tên của thuộc tính mong muốn.
Thuộc tính của con mèo có thể được thay đổi. Ví dụ: hãy thay đổi tên con mèo của chúng ta:
My_cat.name = "Nyusha"
Bây giờ, nếu bạn hiển thị lại tên của con mèo trong bảng điều khiển, bạn sẽ thấy Nyusha thay vì Zosia.
Hãy để tôi nhắc bạn rằng lớp học của con mèo của chúng tôi cho phép cô ấy thực hiện một số hành động nhất định. Nếu chúng ta vuốt ve Zosya/Nyusha của mình, cô ấy sẽ bắt đầu kêu gừ gừ:
My_cat.purr()
Thực hiện lệnh này sẽ in dòng chữ “Purrr!” ra bàn điều khiển. Như bạn có thể thấy, việc truy cập các phương thức của đối tượng cũng dễ dàng như truy cập các thuộc tính của nó.
Mô-đun
Bất kỳ tệp nào có phần mở rộng .py đều là một mô-đun. Ngay cả cái mà bạn đang làm việc trong bài viết này. Họ cần chúng để làm gì? Để thoải mái. Rất nhiều người tạo các tệp có chức năng và lớp hữu ích. Các lập trình viên khác kết nối các mô-đun của bên thứ ba này và có thể sử dụng tất cả các chức năng và lớp được xác định trong chúng, từ đó đơn giản hóa công việc của họ.
Ví dụ: bạn không cần lãng phí thời gian viết các hàm của riêng mình để làm việc với ma trận. Chỉ cần kết nối mô-đun gọn gàng và sử dụng các chức năng và lớp của nó là đủ.
TRÊN khoảnh khắc này các lập trình viên Python khác đã viết hơn 110.000 mô-đun khác nhau. Mô-đun numpy được đề cập ở trên cho phép bạn làm việc nhanh chóng và thuận tiện với ma trận và mảng đa chiều. Mô-đun toán học cung cấp nhiều phương pháp làm việc với các số: sin, cosin, đổi độ sang radian, v.v., v.v....
Cài đặt mô-đun
Python được cài đặt cùng với một bộ mô-đun tiêu chuẩn. Bộ này bao gồm một số lượng rất lớn các mô-đun cho phép bạn làm việc với toán học, yêu cầu web, đọc và ghi tệp cũng như thực hiện các hành động cần thiết khác.
Nếu bạn muốn sử dụng một mô-đun không có trong bộ tiêu chuẩn, bạn sẽ cần phải cài đặt nó. Để cài đặt mô-đun, hãy mở dòng lệnh (Win + R, sau đó nhập “cmd” vào trường xuất hiện) và nhập lệnh vào đó:
Cài đặt Pip [module_name]
Quá trình cài đặt mô-đun sẽ bắt đầu. Khi quá trình hoàn tất, bạn có thể sử dụng mô-đun đã cài đặt trong chương trình của mình một cách an toàn.
Kết nối và sử dụng module
Mô-đun của bên thứ ba rất dễ kết nối. Bạn chỉ cần viết một dòng mã ngắn:
Nhập [tên_mô-đun]
Ví dụ: để nhập một mô-đun cho phép bạn làm việc với các hàm toán học, bạn cần viết như sau:
Nhập toán
Làm thế nào để truy cập một chức năng mô-đun? Bạn cần ghi tên module, sau đó chấm và ghi tên hàm/class. Ví dụ: giai thừa 10 được tìm thấy như thế này:
Toán. giai thừa(10)
Nghĩa là, chúng ta đã chuyển sang hàm giai thừa (a), được xác định bên trong mô-đun toán học. Điều này rất tiện lợi vì chúng ta không cần lãng phí thời gian và tự tạo một hàm tính giai thừa của một số. Bạn có thể kết nối mô-đun và thực hiện ngay hành động cần thiết.
Lần này tôi quyết định nghiên cứu mạng lưới thần kinh. Tôi đã có thể có được những kỹ năng cơ bản về vấn đề này trong mùa hè và mùa thu năm 2015. Theo các kỹ năng cơ bản, ý tôi là tôi có thể tự tạo một mạng lưới thần kinh đơn giản ngay từ đầu. Bạn có thể tìm thấy các ví dụ trong kho GitHub của tôi. Trong bài viết này, tôi sẽ đưa ra một số giải thích và chia sẻ các tài nguyên mà bạn có thể thấy hữu ích trong quá trình học tập của mình.
Bước 1. Neuron và phương pháp tiếp liệu
Vậy “mạng lưới thần kinh” là gì? Hãy chờ đợi điều này và xử lý một nơ-ron trước.
Một nơ-ron giống như một hàm: nó lấy một số giá trị làm đầu vào và trả về một giá trị.
Vòng tròn bên dưới tượng trưng cho một nơ-ron nhân tạo. Nó nhận 5 và trả về 1. Đầu vào là tổng của ba khớp thần kinh được kết nối với nơ-ron (ba mũi tên ở bên trái).
Ở phía bên trái của hình ảnh, chúng ta thấy 2 giá trị đầu vào (màu xanh lá cây) và giá trị offset (màu nâu).
Dữ liệu đầu vào có thể là biểu diễn số của hai thuộc tính khác nhau. Ví dụ: khi tạo bộ lọc thư rác, chúng có thể có nghĩa là sự hiện diện của nhiều từ được viết bằng CHỮ HOA và sự hiện diện của từ "Viagra".
Các giá trị đầu vào được nhân với cái gọi là "trọng số" của chúng, 7 và 3 (được đánh dấu màu xanh lam).
Bây giờ chúng ta cộng các giá trị kết quả với phần bù và nhận được một số, trong trường hợp của chúng ta là 5 (được đánh dấu màu đỏ). Đây là đầu vào của nơ-ron nhân tạo của chúng tôi.

Sau đó, nơ-ron thực hiện một số phép tính và tạo ra giá trị đầu ra. Chúng tôi có 1 vì giá trị làm tròn của sigmoid tại điểm 5 là 1 (chúng ta sẽ nói về hàm này chi tiết hơn sau).
Nếu đây là một bộ lọc thư rác thì thực tế là đầu ra 1 có nghĩa là văn bản đã bị nơ-ron đánh dấu là thư rác.

Minh họa mạng lưới thần kinh từ Wikipedia.
Nếu bạn kết hợp các nơ-ron này, bạn sẽ có được một mạng lưới thần kinh lan truyền trực tiếp - quá trình đi từ đầu vào đến đầu ra, thông qua các nơ-ron được kết nối bằng các khớp thần kinh, như trong hình bên trái.
Bước 2. Sigmoid
Sau khi xem các bài học của Welch Labs, bạn nên xem lại Tuần 4 của khóa học máy học trên mạng thần kinh của Coursera để giúp bạn hiểu cách chúng hoạt động. Khóa học đi sâu vào toán học và dựa trên Octave, trong khi tôi thích Python hơn. Vì vậy, tôi đã bỏ qua các bài tập và tiếp thu tất cả kiến thức cần thiết từ các video.

Sigmoid chỉ ánh xạ giá trị của bạn (trên trục hoành) vào phạm vi từ 0 đến 1.
Ưu tiên hàng đầu của tôi là nghiên cứu sigmoid, vì nó đã xuất hiện trong nhiều khía cạnh của mạng lưới thần kinh. Tôi đã biết đôi điều về nó từ tuần thứ ba của khóa học nói trên nên tôi đã xem video từ đó.
Nhưng bạn sẽ không thể tiến xa chỉ với video. Để hiểu đầy đủ, tôi quyết định tự mình viết mã. Vì vậy, tôi bắt đầu viết phần triển khai thuật toán hồi quy logistic (sử dụng sigmoid).
Phải mất cả ngày và kết quả khó có thể như ý. Nhưng điều đó không thành vấn đề, vì tôi đã hiểu mọi thứ diễn ra như thế nào. Mã có thể được nhìn thấy.
Bạn không cần phải tự mình làm việc này vì nó đòi hỏi kiến thức đặc biệt - điều chính là bạn hiểu cách hoạt động của sigmoid.
Bước 3. Phương pháp lan truyền ngược
Hiểu cách mạng nơ-ron hoạt động từ đầu vào đến đầu ra không phải là điều khó khăn. Việc hiểu cách mạng lưới thần kinh học từ các tập dữ liệu khó hơn nhiều. Nguyên tắc tôi đã sử dụng được gọi là
- Dịch
Bài viết nói về cái gì?
Cá nhân tôi học tốt nhất với mã làm việc nhỏ mà tôi có thể sử dụng. Trong hướng dẫn này, chúng ta sẽ tìm hiểu thuật toán lan truyền ngược bằng cách sử dụng mạng thần kinh nhỏ được triển khai bằng Python làm ví dụ.Đưa tôi mã số!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random ((4,1)) - 1 cho j trong xrange(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) l2 = 1/(1+np. exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1 )) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Quá nén? Hãy chia nó thành những phần đơn giản hơn.
Phần 1: Mạng nơ-ron đồ chơi nhỏ
Mạng nơron được đào tạo thông qua lan truyền ngược nhằm sử dụng dữ liệu đầu vào để dự đoán dữ liệu đầu ra.Giả sử chúng ta cần dự đoán cột đầu ra sẽ trông như thế nào dựa trên dữ liệu đầu vào. Vấn đề này có thể được giải quyết bằng cách tính toán sự tương ứng thống kê giữa chúng. Và chúng ta sẽ thấy rằng cột bên trái tương quan 100% với đầu ra.
Lan truyền ngược, trong trường hợp đơn giản nhất, tính toán các số liệu thống kê như thế này để tạo ra một mô hình. Hãy thử.
Mạng nơ-ron hai lớp
import numpy as np # Sigmoid def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x )) # tập dữ liệu đầu vào X = np.array([ , , , ]) # dữ liệu đầu ra y = np.array([]).T # làm cho các số ngẫu nhiên trở nên cụ thể hơn np.random.seed(1) # khởi tạo trọng số theo cách ngẫu nhiên với giá trị trung bình 0 syn0 = 2*np.random.random((3,1)) - 1 for iter in xrange(10000): # lan truyền thuận l0 = X l1 = nonlin(np.dot(l0,syn0 )) # Chúng ta đã sai như thế nào? l1_error = y - l1 # nhân số này với độ dốc của sigmoid # dựa trên các giá trị trong l1 l1_delta = l1_error * nonlin(l1,True) # !!! # cập nhật trọng số syn0 += np.dot(l0.T,l1_delta) # !!! print "Kết quả sau khi huấn luyện:" print l1Đầu ra sau khi đào tạo: [[ 0,00966449] [ 0,00786506] [ 0,99358898] [ 0,99211957]]
Các biến và mô tả của chúng.
"*" - phép nhân theo phần tử - hai vectơ có cùng kích thước nhân các giá trị tương ứng và đầu ra là một vectơ có cùng kích thước
"-" – phép trừ vectơ theo phần tử
x.dot(y) – nếu x và y là vectơ thì đầu ra sẽ là tích vô hướng. Nếu đây là ma trận thì kết quả là phép nhân ma trận. Nếu ma trận chỉ là một trong số đó thì đó là phép nhân của một vectơ và một ma trận.
- so sánh l1 sau lần lặp đầu tiên và sau lần lặp cuối cùng
- nhìn vào hàm nonlin.
- hãy xem l1_error thay đổi như thế nào
- dòng phân tích 36 - các thành phần bí mật chính được thu thập ở đây (được đánh dấu!!!)
- dòng phân tích 39 - toàn bộ mạng đang chuẩn bị chính xác cho thao tác này (được đánh dấu!!!)
Hãy chia nhỏ từng dòng mã
nhập numpy dưới dạng npNhập numpy, một thư viện đại số tuyến tính. Chứng nghiện duy nhất của chúng tôi.
Def nonlin(x,deriv=False):
Tính phi tuyến của chúng tôi. Hàm đặc biệt này tạo ra một “sigmoid”. Nó khớp với bất kỳ số nào có giá trị từ 0 đến 1 và chuyển đổi số thành xác suất, đồng thời có một số thuộc tính khác hữu ích cho việc đào tạo mạng lưới thần kinh.
Nếu(đạo hàm==Đúng):
Hàm này cũng có thể tạo ra đạo hàm của sigmoid (deriv=True). Đây là một trong những đặc tính có lợi của nó. Nếu đầu ra của hàm là biến out thì đạo hàm sẽ là out * (1-out). Hiệu quả.
X = np.array([ , …
Đang khởi tạo mảng dữ liệu đầu vào dưới dạng ma trận gọn gàng. Mỗi dòng là một ví dụ đào tạo. Cột là các nút đầu vào. Chúng tôi kết thúc với 3 nút đầu vào trong mạng và 4 ví dụ đào tạo.
Y = np.array([]).T
Khởi tạo dữ liệu đầu ra. ".T" – hàm truyền. Sau khi dịch, ma trận y có 4 hàng một cột. Giống như dữ liệu đầu vào, mỗi hàng là một ví dụ huấn luyện và mỗi cột (trong trường hợp của chúng tôi là một cột) là một nút đầu ra. Hóa ra mạng có 3 đầu vào và 1 đầu ra.
Np.random.seed(1)
Nhờ đó, việc phân phối ngẫu nhiên sẽ giống nhau ở mọi thời điểm. Điều này sẽ cho phép chúng tôi giám sát mạng dễ dàng hơn sau khi thực hiện các thay đổi đối với mã.
Syn0 = 2*np.random.random((3,1)) – 1
Ma trận trọng số mạng. syn0 có nghĩa là "khớp thần kinh số 0". Vì chúng ta chỉ có hai lớp, đầu vào và đầu ra, nên chúng ta cần một ma trận trọng số để kết nối chúng. Kích thước của nó là (3, 1), vì chúng ta có 3 đầu vào và 1 đầu ra. Nói cách khác, l0 có kích thước 3 và l1 có kích thước 1. Vì chúng ta đang kết nối tất cả các nút trong l0 với tất cả các nút trong l1, nên chúng ta cần một ma trận có chiều (3, 1).
Lưu ý rằng nó được khởi tạo ngẫu nhiên và giá trị trung bình bằng 0. Có một lý thuyết khá phức tạp đằng sau điều này. Hiện tại chúng tôi sẽ chỉ coi đây là một đề xuất. Cũng lưu ý rằng mạng lưới thần kinh của chúng ta chính là ma trận này. Chúng tôi có "lớp" l0 và l1, nhưng đây là các giá trị tạm thời dựa trên tập dữ liệu. Chúng tôi không lưu trữ chúng. Tất cả đào tạo được lưu trữ trong syn0.
Đối với lần lặp trong xrange (10000):
Đây là nơi mã đào tạo mạng chính bắt đầu. Vòng mã được lặp lại nhiều lần và tối ưu hóa mạng cho tập dữ liệu.
Lớp đầu tiên, l0, chỉ là dữ liệu. X chứa 4 mẫu huấn luyện. Chúng tôi sẽ xử lý tất cả chúng cùng một lúc - đây được gọi là đào tạo nhóm. Tổng cộng chúng ta có 4 dòng l0 khác nhau, nhưng chúng có thể được coi là một ví dụ đào tạo - ở giai đoạn này điều đó không thành vấn đề (bạn có thể tải 1000 hoặc 10000 dòng trong số đó mà không có bất kỳ thay đổi nào trong mã).
L1 = nonlin(np.dot(l0,syn0))
Đây là bước dự đoán. Chúng tôi để mạng cố gắng dự đoán đầu ra dựa trên đầu vào. Sau đó, chúng ta sẽ xem cô ấy làm như thế nào để có thể điều chỉnh để cải thiện.
Có hai bước trên mỗi dòng. Cái đầu tiên thực hiện phép nhân ma trận của l0 và syn0. Cái thứ hai chuyển đầu ra qua sigmoid. Kích thước của chúng như sau:
(4 x 3) chấm (3 x 1) = (4 x 1)
Phép nhân ma trận yêu cầu các kích thước ở giữa phương trình phải giống nhau. Ma trận cuối cùng có cùng số hàng với ma trận đầu tiên và cùng số cột với ma trận thứ hai.
Chúng tôi đã tải 4 ví dụ đào tạo và nhận được 4 lần đoán (ma trận 4x1). Mỗi đầu ra tương ứng với dự đoán của mạng đối với một đầu vào nhất định.
L1_error = y - l1
Vì l1 chứa các dự đoán nên chúng ta có thể so sánh sự khác biệt của chúng với thực tế bằng cách trừ l1 khỏi câu trả lời đúng y. l1_error là một vectơ gồm các số dương và số âm đặc trưng cho mạng “miss”.
Và đây là thành phần bí mật. Dòng này cần được phân tích từng phần một.
Phần thứ nhất: phái sinh
Nonlin(l1,True)
L1 đại diện cho ba điểm này và mã tạo ra độ dốc của các đường hiển thị bên dưới. Lưu ý rằng đối với các giá trị lớn như x=2.0 (chấm xanh) và các giá trị rất nhỏ như x=-1.0 (màu tím), các đường có độ dốc nhẹ. Góc lớn nhất tại điểm x=0 (màu xanh). Đây là một sự khác biệt lớn. Cũng lưu ý rằng tất cả các dẫn xuất nằm trong khoảng từ 0 đến 1.

Biểu thức đầy đủ: đạo hàm có trọng số lỗi
L1_delta = l1_error * nonlin(l1,True)
Về mặt toán học, có nhiều phương pháp chính xác hơn, nhưng trong trường hợp của chúng tôi, phương pháp này cũng phù hợp. l1_error là ma trận (4,1). nonlin(l1,True) trả về ma trận (4,1). Ở đây chúng ta nhân chúng với từng phần tử và ở đầu ra chúng ta cũng thu được ma trận (4.1), l1_delta.
Bằng cách nhân đạo hàm với sai số, chúng tôi giảm thiểu sai sót trong các dự đoán được đưa ra với độ tin cậy cao. Nếu độ dốc của đường nhỏ thì mạng chứa giá trị rất lớn hoặc rất nhỏ. Nếu dự đoán của mạng gần bằng 0 (x=0, y=0,5) thì mạng đó không có độ tin cậy đặc biệt. Chúng tôi cập nhật những dự đoán không chắc chắn này và chỉ để lại những dự đoán có độ tin cậy cao bằng cách nhân chúng với các giá trị gần bằng 0.
Syn0 += np.dot(l0.T,l1_delta)
Chúng tôi đã sẵn sàng cập nhật mạng. Hãy xem xét một ví dụ đào tạo. Trong đó chúng tôi sẽ cập nhật trọng số. Cập nhật trọng lượng ngoài cùng bên trái (9,5)

Trọng lượng_update = giá trị đầu vào * l1_delta
Đối với trọng lượng ngoài cùng bên trái, nó sẽ là 1,0 * l1_delta. Có lẽ điều này sẽ chỉ tăng 9,5 một chút. Tại sao? Bởi vì dự đoán đã khá tự tin và thực tế những dự đoán đó đã chính xác. Một lỗi nhỏ và độ dốc nhẹ của đường có nghĩa là một bản cập nhật rất nhỏ.

Nhưng vì chúng ta đang thực hiện huấn luyện nhóm nên chúng ta lặp lại bước trên cho cả bốn ví dụ huấn luyện. Vì vậy, nó trông rất giống với hình ảnh trên. Vậy đường dây của chúng tôi làm gì? Nó đếm số lần cập nhật trọng lượng cho từng mức tạ, cho từng ví dụ tập luyện, tổng hợp chúng và cập nhật tất cả trọng lượng - tất cả trên một dòng.
Sau khi quan sát cập nhật mạng, hãy quay lại dữ liệu đào tạo của chúng tôi. Khi cả đầu vào và đầu ra đều bằng 1, chúng ta tăng trọng số giữa chúng. Khi đầu vào là 1 và đầu ra là 0, chúng ta giảm trọng số.
Đầu vào Đầu ra 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
Vì vậy, trong bốn ví dụ huấn luyện dưới đây của chúng tôi, trọng số của đầu vào đầu tiên so với đầu ra sẽ tăng hoặc không đổi, còn hai trọng số còn lại sẽ tăng và giảm tùy thuộc vào ví dụ. Hiệu ứng này góp phần vào việc học mạng dựa trên mối tương quan giữa dữ liệu đầu vào và đầu ra.
Phần 2: một nhiệm vụ khó khăn hơn
Đầu vào Đầu ra 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 0Hãy thử dự đoán dữ liệu đầu ra dựa trên ba cột dữ liệu đầu vào. Không có cột đầu vào nào tương quan 100% với đầu ra. Cột thứ ba hoàn toàn không được kết nối với bất kỳ thứ gì vì nó chứa tất cả các cột. Tuy nhiên, ở đây bạn có thể thấy mẫu - nếu một trong hai cột đầu tiên (nhưng không phải cả hai cùng một lúc) chứa 1 thì kết quả cũng sẽ bằng 1.
Đây là thiết kế phi tuyến tính vì không có sự tương ứng trực tiếp một-một giữa các cột. Việc so khớp dựa trên sự kết hợp của các đầu vào, cột 1 và 2.
Điều thú vị là nhận dạng mẫu là một nhiệm vụ rất giống nhau. Nếu bạn có 100 bức ảnh về xe đạp và ống tẩu có cùng kích thước, sự hiện diện của một số pixel nhất định ở một số vị trí nhất định không tương quan trực tiếp với sự hiện diện của một chiếc xe đạp hoặc một chiếc ống trong ảnh. Theo thống kê, màu sắc của chúng có thể xuất hiện ngẫu nhiên. Nhưng một số kết hợp pixel không phải là ngẫu nhiên - những kết hợp tạo thành hình ảnh của một chiếc xe đạp (hoặc ống).


Chiến lược
Để kết hợp các pixel thành một thứ có thể tương ứng một-một với đầu ra, bạn cần thêm một lớp khác. Lớp đầu tiên kết hợp đầu vào, lớp thứ hai gán kết quả khớp với đầu ra bằng cách sử dụng đầu ra của lớp đầu tiên làm đầu vào. Hãy chú ý đến cái bàn.Đầu vào (l0) Trọng số ẩn (l1) Đầu ra (l2) 0 0 1 0,1 0,2 0,5 0,2 0 0 1 1 0,2 0,6 0,7 0,1 1 1 0 1 0,3 0,2 0,3 0,9 1 1 1 1 0,2 0,1 0,3 0,8 0
Bằng cách gán trọng số ngẫu nhiên, chúng ta nhận được các giá trị ẩn cho lớp số 1. Điều thú vị là cột trọng số ẩn thứ hai đã có mối tương quan nhỏ với kết quả đầu ra. Không lý tưởng, nhưng ở đó. Và đây cũng là một phần quan trọng của quá trình huấn luyện mạng. Đào tạo sẽ chỉ tăng cường mối tương quan này. Nó sẽ cập nhật syn1 để gán ánh xạ của nó cho dữ liệu đầu ra và syn0 để thu được dữ liệu đầu vào tốt hơn.
Mạng nơ-ron ba lớp
nhập numpy dưới dạng np def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) X = np.array([, , , ]) y = np.array([, , , ]) np.random.seed(1) # khởi tạo ngẫu nhiên các trọng số, trung bình - 0 syn0 = 2*np.random. ngẫu nhiên ((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 for j in xrange(60000): # đi tiếp qua các lớp 0, 1 và 2 l0 = X l1 = nonlin(np.dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # chúng ta đã sai bao nhiêu về giá trị bắt buộc? l2_error = y - l2 if (j% 10000) == 0: print "Error:" + str(np.mean(np.abs(l2_error))) # bạn nên di chuyển theo hướng nào? # nếu chúng ta tự tin vào dự đoán thì không cần thay đổi nhiều l2_delta = l2_error*nonlin(l2,deriv=True) # các giá trị của l1 ảnh hưởng đến các lỗi trong l2 đến mức nào? l1_error = l2_delta.dot(syn1.T) # chúng ta nên di chuyển theo hướng nào để đến l1? # nếu đã tự tin vào dự đoán thì không cần thay đổi nhiều l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot (l1_delta)Lỗi: 0,496410031903 Lỗi: 0,00858452565325 Lỗi: 0,00578945986251 Lỗi: 0,00462917677677 Lỗi: 0,00395876528027 Lỗi: 0,00351012256786
Các biến và mô tả của chúng
X là ma trận của tập dữ liệu đầu vào; chuỗi - ví dụ đào tạoy – ma trận của tập dữ liệu đầu ra; chuỗi - ví dụ đào tạo
l0 – lớp mạng đầu tiên được xác định bởi dữ liệu đầu vào
l1 – lớp thứ hai của mạng hoặc lớp ẩn
l2 là lớp cuối cùng, đây là giả thuyết của chúng tôi. Khi luyện tập, bạn sẽ tiến gần hơn đến câu trả lời đúng.
syn0 – lớp trọng số đầu tiên, Synapse 0, kết hợp l0 với l1.
syn1 – Lớp trọng số thứ hai, Synapse 1, kết hợp l1 với l2.
l2_error – lỗi mạng về mặt định lượng
l2_delta – lỗi mạng, tùy thuộc vào độ tin cậy của dự đoán. Hầu như giống hệt với lỗi, ngoại trừ những dự đoán tự tin
l1_error – bằng cách cân l2_delta với các trọng số từ syn1, chúng tôi tính toán lỗi ở lớp giữa/ẩn
l1_delta – lỗi mạng từ l1, được chia tỷ lệ theo độ tin cậy của dự đoán. Gần giống với l1_error, ngoại trừ những dự đoán chắc chắn
Mã phải khá rõ ràng - đó chỉ là quá trình triển khai mạng trước đó, được xếp thành hai lớp, lớp này chồng lên lớp kia. Đầu ra của lớp thứ nhất l1 là đầu vào của lớp thứ hai. Có một cái gì đó mới chỉ ở dòng tiếp theo.
L1_error = l2_delta.dot(syn1.T)
Sử dụng sai số được tính theo độ tin cậy của dự đoán từ l2 để tính sai số cho l1. Người ta có thể nói, chúng tôi nhận được một lỗi được tính theo mức độ đóng góp - chúng tôi tính toán xem các giá trị tại các nút l1 đóng góp bao nhiêu vào các lỗi trong l2. Bước này được gọi là lan truyền ngược. Sau đó, chúng tôi cập nhật syn0 bằng thuật toán tương tự như mạng nơ-ron hai lớp.
Bản gốc: Tạo mạng thần kinh bằng Python
Tác giả: John Serrano
Ngày xuất bản: 26 tháng 5 năm 2016
Bản dịch: A. Panin
Ngày dịch: 06/12/2016
Mạng lưới thần kinh là những chương trình cực kỳ phức tạp, chỉ có các học giả và thiên tài mới hiểu được, mà theo định nghĩa, các nhà phát triển bình thường không thể làm việc được, chưa kể đến tôi. Đó là những gì bạn nghĩ, phải không?
À, thực ra nó không hề như thế chút nào. Sau bài nói chuyện xuất sắc của Louis Monier và Greg Renard tại trường Cao đẳng Holberton, tôi nhận ra rằng mạng lưới thần kinh đủ đơn giản để bất kỳ nhà phát triển chương trình nào cũng có thể hiểu và thực hiện. Tất nhiên, các mạng phức tạp nhất là các dự án quy mô lớn với kiến trúc trang nhã và phức tạp, nhưng các khái niệm cơ bản cũng ít nhiều rõ ràng. Phát triển bất kỳ mạng lưới thần kinh nào từ đầu có thể là một thách thức khá lớn, nhưng may mắn thay, có một số thư viện tuyệt vời có thể thực hiện tất cả các công việc cấp thấp cho bạn.
Trong bối cảnh này, nơ-ron là một thực thể khá đơn giản. Nó chấp nhận một số giá trị đầu vào và nếu tổng các giá trị này vượt quá giới hạn đã chỉ định thì nó sẽ được kích hoạt. Trong trường hợp này, mỗi giá trị đầu vào được nhân với trọng số của nó. Quá trình học về cơ bản là quá trình thiết lập các trọng số giá trị để tạo ra các giá trị đầu ra được yêu cầu. Các mạng sẽ được thảo luận trong bài viết này được gọi là mạng “feedforward”, có nghĩa là các nơ-ron trong chúng được sắp xếp thành các lớp, với dữ liệu đầu vào đến từ cấp độ trước và dữ liệu đầu ra của chúng được gửi đến cấp độ tiếp theo.

Có các loại mạng thần kinh khác, chẳng hạn như mạng thần kinh tái phát, được tổ chức theo một cách khác, nhưng đó là chủ đề cho một bài viết khác.
Một nơ-ron hoạt động theo nguyên tắc mô tả ở trên được gọi là perceptron và dựa trên mô hình nơ-ron nhân tạo ban đầu, ngày nay cực kỳ hiếm được sử dụng. Vấn đề với perceptron là một thay đổi nhỏ trong giá trị đầu vào có thể dẫn đến thay đổi lớn về giá trị đầu ra do chức năng kích hoạt từng bước. Trong trường hợp này, giá trị đầu vào giảm nhẹ có thể dẫn đến giá trị bên trong sẽ không vượt quá giới hạn đã đặt và tế bào thần kinh sẽ không được kích hoạt, điều này sẽ dẫn đến những thay đổi đáng kể hơn nữa về trạng thái của các tế bào thần kinh theo sau nó. . May mắn thay, vấn đề này có thể được giải quyết dễ dàng nhờ tính năng kích hoạt mượt mà hơn trên hầu hết các mạng hiện đại.


Tuy nhiên, mạng lưới thần kinh của chúng ta sẽ đơn giản đến mức các perceptron khá phù hợp để tạo ra nó. Chúng tôi sẽ tạo một mạng thực hiện thao tác AND logic. Điều này có nghĩa là chúng ta sẽ cần hai nơ-ron đầu vào và một nơ-ron đầu ra, cũng như một số nơ-ron ở lớp "ẩn" trung gian. Hình minh họa dưới đây cho thấy kiến trúc của mạng này, khá rõ ràng.

Monier và Renard đã sử dụng tập lệnh convnet.js để tạo mạng demo cho buổi nói chuyện của họ. Convnet.js có thể được sử dụng để tạo mạng lưới thần kinh trực tiếp trong trình duyệt web của bạn, cho phép bạn khám phá và sửa đổi chúng trên hầu hết mọi nền tảng. Tất nhiên, việc triển khai bằng JavaScript này cũng có những nhược điểm đáng kể, một trong số đó là tốc độ thấp. Chà, với mục đích của bài viết này, chúng tôi sẽ sử dụng thư viện FANN (Mạng thần kinh nhân tạo nhanh). Trong trường hợp này, ở cấp độ ngôn ngữ lập trình Python, mô-đun pyfann sẽ được sử dụng, mô-đun này chứa các liên kết cho thư viện FANN. Bạn nên cài đặt gói phần mềm kèm theo mô-đun này ngay bây giờ.
Việc nhập mô-đun để làm việc với thư viện FANN được thực hiện như sau:
>>> từ pyfann nhập libfann
Bây giờ chúng ta có thể bắt đầu! Hoạt động đầu tiên chúng ta sẽ phải thực hiện là tạo một mạng lưới thần kinh trống.
>>> thần kinh_net = libfann.neural_network()
Đối tượng Neural_net được tạo hiện không chứa nơ-ron, vì vậy hãy thử tạo một số nơ-ron. Với mục đích này, chúng tôi sẽ sử dụng hàm libfann.create_standard_array(). Hàm create_standard_array() tạo ra một mạng lưới thần kinh trong đó tất cả các nơ-ron được kết nối với các nơ-ron từ các lớp lân cận, vì vậy nó có thể được gọi là mạng “được kết nối đầy đủ”. Hàm create_standard_array() lấy một mảng có Giá trị kiểu số, tương ứng với số lượng tế bào thần kinh ở mỗi cấp độ. Trong trường hợp của chúng tôi, đây là một mảng.
>>>neural_net.create_standard((2, 4, 1))
Sau này chúng ta sẽ phải thiết lập giá trị tốc độ học tập. Giá trị này tương ứng với số lần thay đổi trọng số trong một lần lặp. Chúng tôi sẽ cài đặt đủ tốc độ caođào tạo bằng 0,7, vì chúng tôi sẽ giải quyết một vấn đề khá đơn giản bằng cách sử dụng mạng của mình.
>>> Neural_net.set_learning_rate(0.7)
Bây giờ là lúc cài đặt chức năng kích hoạt, mục đích của nó đã được thảo luận ở trên. Chúng ta sẽ sử dụng chế độ kích hoạt SIGMOID_SYMMETRIC_STEPWISE, tương ứng với hàm bước tiếp tuyến hyperbol. Nó kém chính xác hơn và nhanh hơn hàm tang hyperbol thông thường và hoàn hảo cho nhiệm vụ của chúng ta.
>>> thần kinh_net.set_activation_function_output(libfann.SIGMOID_SYMMETRIC_STEPWISE)
Cuối cùng, chúng ta cần chạy thuật toán huấn luyện mạng và lưu dữ liệu mạng vào một tệp. Hàm huấn luyện mạng có bốn đối số: tên của tệp có dữ liệu sẽ được thực hiện huấn luyện, số tiền tối đa cố gắng chạy thuật toán học, số lượng hoạt động học trước khi xuất dữ liệu về trạng thái mạng và tỷ lệ lỗi.
>>>neural_network.train_on_file("and.data", 10000, 1000, .00001) >>>neural_network.save("and.net")
Tệp "and.data" phải chứa dữ liệu sau:
4 2 1 -1 -1 -1 -1 1 -1 1 -1 -1 1 1 1
Dòng đầu tiên chứa ba giá trị: số lượng ví dụ trong tệp, số lượng giá trị đầu vào và số lượng giá trị đầu ra. Dưới đây là các dòng ví dụ, trong đó các dòng có hai giá trị chứa các giá trị đầu vào và các dòng có một giá trị hiển thị các giá trị đầu ra.
Bạn đã hoàn thành khóa đào tạo mạng và bây giờ muốn dùng thử phải không? Nhưng trước tiên chúng ta sẽ phải tải dữ liệu mạng từ tệp đã lưu trước đó.
>>> nơ-ron_net = libfann.neural_net() >>> nơ-ron_net.create_from_file("and.net")
Sau đó, chúng ta có thể kích hoạt nó theo cách tương tự:
>>> in nơ-ron_net.run()
Kết quả phải là [-1.0] hoặc một giá trị tương tự, tùy thuộc vào dữ liệu mạng được tạo trong quá trình đào tạo.
Chúc mừng! Bạn vừa dạy máy tính của mình cách thực hiện các phép toán logic cơ bản!