Un exemplu de rețea neuronală în codul Python. Python și rețele neuronale
- Traducere
Despre ce este articolul?
Personal, învăț cel mai bine cu un cod de lucru mic cu care mă pot juca. În acest tutorial, vom învăța algoritmul de backpropagation folosind o rețea neuronală mică implementată în Python ca exemplu.Dă-mi codul!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random ((4,1)) - 1 pentru j în xrange(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) l2 = 1/(1+np. exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1) )) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Prea comprimat? Să-l împărțim în părți mai simple.
Partea 1: Mică rețea neuronală de jucărie
O rețea neuronală antrenată prin retropropagare încearcă să folosească datele de intrare pentru a prezice datele de ieșire.Să presupunem că trebuie să prezicem cum va arăta coloana de ieșire pe baza datelor de intrare. Această problemă ar putea fi rezolvată prin calcularea corespondenței statistice dintre ele. Și am vedea că coloana din stânga este 100% corelată cu rezultatul.
Propagarea inversă, de fapt, caz simplu, calculează statistici similare pentru a crea modelul. Sa incercam.
Rețea neuronală în două straturi
import numpy as np # Sigmoid def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x) )) # set de date de intrare X = np.array([ , , , ]) # date de ieșire y = np.array([]).T # do numere aleatorii mai specific np.random.seed(1) # inițializați greutăți aleatoriu cu medie 0 syn0 = 2*np.random.random((3,1)) - 1 pentru iter în xrange(10000): # propagare înainte l0 = X l1 = nonlin(np.dot(l0,syn0)) # cât de greșit am greșit? l1_error = y - l1 # înmulțiți acest lucru cu panta sigmoidului # pe baza valorilor din l1 l1_delta = l1_error * nonlin(l1,True) # !!! # actualizați ponderile syn0 += np.dot(l0.T,l1_delta) # !!! print "Ieșire după antrenament:" print l1Ieșire după antrenament: [[ 0,00966449] [ 0,00786506] [ 0,99358898] [ 0,99211957]]
Variabilele și descrierile lor.
"*" - înmulțire în funcție de elemente - doi vectori de aceeași dimensiune înmulțesc valorile corespunzătoare, iar rezultatul este un vector de aceeași dimensiune
„-” – scăderea vectorilor în funcție de elemente
x.dot(y) – dacă x și y sunt vectori, atunci rezultatul va fi un produs scalar. Dacă acestea sunt matrici, atunci rezultatul este înmulțirea matricei. Dacă matricea este doar una dintre ele, este înmulțirea unui vector și a unei matrice.
- comparați l1 după prima iterație și după ultima
- uită-te la funcția nonlin.
- uite cum se schimba l1_error
- analiza linia 36 - principalele ingrediente secrete sunt colectate aici (marcate!!!)
- parse line 39 - întreaga rețea se pregătește tocmai pentru această operațiune (marcată!!!)
Să defalcăm codul linie cu linie
import numpy ca npImportă numpy, o bibliotecă de algebră liniară. Singura noastră dependență.
Def nonlin(x,deriv=False):
Neliniaritatea noastră. Această funcție specifică creează un „sigmoid”. Se potrivește oricărui număr cu o valoare de la 0 la 1 și convertește numerele în probabilități și, de asemenea, are câteva alte proprietăți utile pentru antrenarea rețelelor neuronale.
Dacă(deriv==Adevărat):
Această funcție poate produce și derivata sigmoidului (deriv=True). Acesta este unul de-al ei proprietăți utile. Dacă ieșirea funcției este o variabilă out, atunci derivata va fi out * (1-out). Efectiv.
X = np.array([ , …
Inițializarea matricei de date de intrare ca o matrice numpy. Fiecare linie este un exemplu de antrenament. Coloanele sunt noduri de intrare. Ajungem cu 3 noduri de intrare în rețea și 4 exemple de antrenament.
Y = np.array([]).T
Inițializează datele de ieșire. „.T” – funcție de transfer. După translație, matricea y are 4 rânduri cu o coloană. Ca și în cazul datelor de intrare, fiecare rând este un exemplu de antrenament, iar fiecare coloană (una în cazul nostru) este un nod de ieșire. Se pare că rețeaua are 3 intrări și 1 ieșire.
Np.semințe.aleatoare.(1)
Datorită acestui fapt, distribuția aleatoare va fi aceeași de fiecare dată. Acest lucru ne va permite să monitorizăm mai ușor rețeaua după ce facem modificări la cod.
Syn0 = 2*np.random.random((3,1)) – 1
Matricea greutății rețelei. syn0 înseamnă „synapse zero”. Deoarece avem doar două straturi, intrare și ieșire, avem nevoie de o matrice de greutate care le va conecta. Dimensiunea sa este (3, 1), deoarece avem 3 intrări și 1 ieșire. Cu alte cuvinte, l0 are dimensiunea 3 și l1 are dimensiunea 1. Deoarece conectăm toate nodurile din l0 la toate nodurile din l1, avem nevoie de o matrice de dimensiune (3, 1).
Rețineți că este inițializat aleatoriu și media este zero. În spatele acestui lucru se află o teorie destul de complexă. Deocamdată vom lua asta doar ca pe o recomandare. De asemenea, rețineți că rețeaua noastră neuronală este chiar această matrice. Avem „straturi” l0 și l1, dar acestea sunt valori temporare bazate pe setul de date. Nu le depozităm. Toate antrenamentele sunt stocate în syn0.
Pentru iter în xrange(10000):
Aici începe codul de antrenament al rețelei principale. Bucla de cod se repetă de mai multe ori și optimizează rețeaua pentru setul de date.
Primul strat, l0, este doar date. X conține 4 exemple de antrenament. Le vom procesa pe toate deodată - aceasta se numește antrenament de grup. În total, avem 4 linii l0 diferite, dar ele pot fi considerate ca un exemplu de antrenament - în această etapă nu contează (puteți încărca 1000 sau 10000 dintre ele fără nicio modificare a codului).
L1 = nonlin(np.dot(l0,syn0))
Acesta este pasul de predicție. Lăsăm rețeaua să încerce să prezică rezultatul pe baza intrării. Apoi vom vedea cum o face, astfel încât să o putem modifica pentru îmbunătățire.
Există doi pași pe linie. Primul face înmulțirea matriceală a lui l0 și syn0. Al doilea trece ieșirea prin sigmoid. Dimensiunile lor sunt următoarele:
(4 x 3) punct (3 x 1) = (4 x 1)
Înmulțirile matricelor necesită ca dimensiunile să fie aceleași în mijlocul ecuației. Matricea finală are același număr de rânduri ca prima și același număr de coloane ca a doua.
Am încărcat 4 exemple de antrenament și am obținut 4 presupuneri (matrice 4x1). Fiecare ieșire corespunde ipotezei rețelei pentru o anumită intrare.
L1_error = y - l1
Deoarece l1 conține presupuneri, putem compara diferența lor cu realitatea scăzând l1 din răspunsul corect y. l1_error – vector de pozitiv și numere negative, care caracterizează „ratul” rețelei.
Și aici este ingredientul secret. Această linie trebuie analizată bucată cu bucată.
Prima parte: derivat
Nonlin(l1, True)
L1 reprezintă aceste trei puncte, iar codul produce panta dreptelor prezentate mai jos. Rețineți că atunci când valori mari precum x=2.0 (punct verde) și cele foarte mici precum x=-1.0 (violet) liniile au o pantă ușoară. Cel mai mare unghi în punctul x=0 (albastru). Are mare importanță. De asemenea, rețineți că toate derivatele variază de la 0 la 1.

Expresie completă: derivată ponderată în funcție de eroare
L1_delta = l1_error * nonlin(l1,True)
Matematic sunt mai multe moduri exacte, dar în cazul nostru este potrivit și acesta. l1_error este o matrice (4,1). nonlin(l1,True) returnează matricea (4,1). Aici le înmulțim element cu element, iar la ieșire obținem și matricea (4,1), l1_delta.
Înmulțind derivatele cu erori, reducem erorile predicțiilor făcute cu mare încredere. Dacă panta liniei era mică, atunci rețeaua conținea fie o valoare foarte mare, fie foarte mică. Dacă estimarea rețelei este aproape de zero (x=0, y=0,5), atunci nu este deosebit de sigură. Actualizăm aceste predicții incerte și lăsăm predicțiile cu încredere ridicată în pace, înmulțindu-le cu valori apropiate de zero.
Syn0 += np.dot(l0.T,l1_delta)
Suntem gata să actualizăm rețeaua. Să ne uităm la un exemplu de antrenament. În el vom actualiza greutățile. Actualizați greutatea cea mai din stânga (9,5)

Weight_update = input_value * l1_delta
Pentru greutatea cea mai din stânga ar fi 1,0 * l1_delta. Probabil că acest lucru va crește doar ușor 9,5. De ce? Pentru că predicția era deja destul de încrezătoare, iar previziunile erau practic corecte. O mică eroare și o pantă ușoară a liniei înseamnă o actualizare foarte mică.

Dar, deoarece facem antrenament de grup, repetăm pasul de mai sus pentru toate cele patru exemple de antrenament. Deci arată foarte asemănător cu imaginea de mai sus. Deci, ce face linia noastră? Numărează actualizările de greutate pentru fiecare greutate, pentru fiecare exemplu de antrenament, le însumează și actualizează toate greutățile - toate într-o singură linie.
După ce observăm actualizarea rețelei, să revenim la datele noastre de antrenament. Când atât intrarea cât și ieșirea sunt 1, creștem greutatea dintre ele. Când intrarea este 1 și ieșirea este 0, reducem greutatea.
Intrare Ieșire 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
Deci, în cele patru exemple de antrenament de mai jos, greutatea primei intrări în raport cu rezultatul fie va crește, fie va rămâne constantă, iar celelalte două greutăți vor crește și vor scădea în funcție de exemple. Acest efect contribuie la învățarea în rețea bazată pe corelațiile datelor de intrare și de ieșire.
Partea 2: o sarcină mai dificilă
Intrare Ieșire 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 1 0Să încercăm să prezicem datele de ieșire bazat pe trei coloane de date de intrare. Niciuna dintre coloanele de intrare nu este 100% corelată cu rezultatul. A treia coloană nu este deloc conectată la nimic, deoarece le conține pe tot parcursul. Cu toate acestea, aici puteți vedea modelul - dacă una dintre primele două coloane (dar nu ambele simultan) conține 1, atunci rezultatul va fi, de asemenea, egal cu 1.
Acesta este un design neliniar deoarece nu există o corespondență directă unu-la-unu între coloane. Potrivirea se bazează pe o combinație de intrări, coloanele 1 și 2.
Interesant, recunoașterea modelelor este o sarcină foarte similară. Daca ai 100 de poze aceeași mărime, care înfățișează biciclete și pipe care fumează, prezența anumitor pixeli în anumite locuri de pe ele nu se corelează direct cu prezența unei biciclete sau a unei țevi în imagine. Statistic, culoarea lor poate apărea aleatorie. Dar unele combinații de pixeli nu sunt aleatorii - cele care formează o imagine a unei biciclete (sau tub).


Strategie
Pentru a combina pixelii în ceva care poate avea o corespondență unu-la-unu cu rezultatul, trebuie să adăugați un alt strat. Primul strat combină intrarea, al doilea atribuie o potrivire la ieșire folosind ieșirea primului strat ca intrare. Atenție la masă.Intrare (l0) Greutăți ascunse (l1) Ieșire (l2) 0 0 1 0,1 0,2 0,5 0,2 0 0 1 1 0,2 0,6 0,7 0,1 1 1 0 1 0,3 0,2 0,3 0,9 1 1 1 0,2 0,9
La întâmplare Prin atribuirea de greutăți, vom obține valori ascunse pentru stratul nr. 1. Este interesant că a doua coloană greutăți ascunse există deja o ușoară corelație cu producția. Nu ideal, dar acolo. Și asta este, de asemenea parte importantă procesul de formare în rețea. Antrenamentul nu va face decât să întărească această corelație. Acesta va actualiza syn1 pentru a-și atribui maparea datelor de ieșire și syn0 pentru a obține mai bine datele de intrare.
Rețea neuronală în trei straturi
import numpy ca np def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) X = np.array([, , , ]) y = np.array([, , , ]) np.random.seed(1) # inițializați aleatoriu ponderile, în medie - 0 syn0 = 2*np.random. aleatoriu ((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 pentru j în xrange(60000): # mergi înainte prin straturile 0, 1 și 2 l0 = X l1 = nonlin(np.dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # cât de mult am greșit cu privire la valoarea cerută? l2_error = y - l2 if (j% 10000) == 0: tipăriți „Eroare:” + str(np.mean(np.abs(l2_error))) # în ce direcție ar trebui să vă mutați? # dacă eram încrezători în predicție, atunci nu trebuie să o schimbăm mult l2_delta = l2_error*nonlin(l2,deriv=True) # cât de mult afectează valorile lui l1 erorile din l2? l1_error = l2_delta.dot(syn1.T) # în ce direcție ar trebui să ne deplasăm pentru a ajunge la l1? # dacă am fost încrezători în predicție, atunci nu trebuie să o schimbăm mult l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot (l1_delta)Eroare: 0,496410031903 Eroare: 0,00858452565325 Eroare: 0,00578945986251 Eroare: 0,00462917677677 Eroare: 0,00395876528027 Eroare: 0,002356701
Variabilele și descrierile lor
X este matricea setului de date de intrare; coarde - exemple de antrenamenty – matricea setului de date de ieșire; coarde - exemple de antrenament
l0 – primul strat de rețea definit de datele de intrare
l1 – al doilea strat al rețelei, sau strat ascuns
l2 este stratul final, aceasta este ipoteza noastră. Pe măsură ce exersați, ar trebui să vă apropiați de răspunsul corect.
syn0 – primul strat de greutăți, Synapse 0, combină l0 cu l1.
syn1 – Al doilea strat de greutăți, Synapse 1, combină l1 cu l2.
l2_error – eroare de rețea în termeni cantitativi
l2_delta – eroare de rețea, în funcție de încrederea predicției. Aproape identică cu eroarea, cu excepția predicțiilor sigure
l1_error – cântărind l2_delta cu greutăți din syn1, calculăm eroarea în stratul mijlociu/ascuns
l1_delta – erori de rețea de la l1, scalate de încrederea predicțiilor. Aproape identic cu l1_error, cu excepția predicțiilor sigure
Codul ar trebui să fie destul de clar - este doar implementarea anterioară a rețelei, stivuită în două straturi, unul peste altul. Ieșirea primului strat l1 este intrarea celui de-al doilea strat. Există ceva nou doar în linia următoare.
L1_error = l2_delta.dot(syn1.T)
Utilizează erori ponderate cu încrederea predicțiilor de la l2 pentru a calcula eroarea pentru l1. Obținem, s-ar putea spune, o eroare ponderată cu contribuții - calculăm cât de mult contribuie valorile la nodurile l1 la erorile din l2. Acest pas se numește backpropagation. Apoi actualizăm syn0 folosind același algoritm ca și rețeaua neuronală cu două straturi.
Această parte conține link-uri către articole din RuNet despre ce sunt rețelele neuronale. Multe dintre articole sunt scrise într-un limbaj original, plin de viață și sunt foarte inteligibile. Cu toate acestea, aici, în cea mai mare parte, sunt luate în considerare doar elementele de bază, cele mai simple modele. Aici puteți găsi, de asemenea, link-uri către literatura despre rețelele neuronale. Manualele și cărțile, așa cum ar trebui să fie, sunt scrise într-un limbaj academic sau similar și conțin exemple obscure, abstracte de construire a rețelelor neuronale, pregătirea lor etc. Trebuie avut în vedere că terminologia din diferite articole „plutește”, așa cum poate se vede din comentariile la articole. Din această cauză, la început poate exista o „mizerie în cap”.
- Cum un fermier japonez a sortat castraveții folosind deep learning și TensorFlow
- Rețele neuronale în imagini: de la un singur neuron la arhitecturi profunde
- Un exemplu de program de rețea neuronală cu cod sursă în C++.
- Implementarea unei rețele neuronale cu un singur strat - perceptron pentru problema clasificării vehiculelor
- Descărcați cărți despre rețelele neuronale. Sănătos!
- Tehnologii bursiere: 10 concepții greșite despre rețelele neuronale
- Algoritm pentru antrenarea unei rețele neuronale multistrat folosind metoda backpropagation
Rețele neuronale în Python
Puteți citi pe scurt despre ce biblioteci există pentru Python. De aici voi lua exemple de testare pentru a mă asigura că pachetul necesar este instalat corect.
tensorflow
Obiectul central al TensorFlow este graficul fluxului de date care reprezintă calculul. Vârfurile graficului reprezintă operații, iar muchiile reprezintă tensori (tensor) ( tablouri multidimensionale, care stau la baza TensorFlow). Graficul fluxului de date în ansamblu este descriere completa calcule care sunt implementate în cadrul unei sesiuni și efectuate pe dispozitive (CPU sau GPU). Ca mulți alții sisteme moderne pentru calcularea științifică și învățarea automată, TensorFlow are un API bine documentat pentru Python, unde tensorii sunt reprezentați ca șirurile familiare NumPy ndarray. TensorFlow efectuează calcule folosind C++ foarte optimizat și, de asemenea, acceptă API-uri native pentru C și C++.
- Introducere în învățarea automată cu tensorflow. Până acum, a fost publicat doar primul articol din patru anunțat.
- TensorFlow este dezamăgitor. Învățarea profundă a Google nu are „profunzime”
- Învățarea automată dintr-o privire: Clasificarea textului cu rețele neuronale și TensorFlow
- Biblioteca de învățare automată Google TensorFlow – primele impresii și comparație cu propria noastră implementare
Instalarea tensorflow este bine descrisă în articolul de pe primul link. Cu toate acestea, Python 3.6.1 a fost lansat acum. Nu se va putea folosi. Cel puțin sulf pe acest moment(06.03.2017). Necesită versiunea 3.5.3, care poate fi descărcată. Mai jos voi da secvența care a funcționat pentru mine (puțin diferită de articolul din Habr). Nu este clar de ce, dar Python pe 64 de biți este făcut pentru procesor AMDîn consecință, orice altceva trece sub ea. După instalarea Phyton, nu uitați să setați accesul complet pentru utilizatori dacă Python a fost instalat pentru toată lumea.
pip install --upgrade pip
pip install -U pip setuptools
pip3 install --upgrade tensorflow
pip3 install --upgrade tensorflow-gpu
pip install matplotlib /*Descărcă 8,9 MB și încă câteva fișiere mici */
pip install jupyter
„Naked Python” poate părea neinteresant. Prin urmare, mai jos sunt instrucțiuni de instalare în mediul Anaconda. Aceasta este o construcție alternativă. Python este deja integrat în el.
Site-ul prezintă din nou o nouă versiune pentru Python 3.6, pe care noul produs Google nu o acceptă încă. Prin urmare, am luat imediat o versiune anterioară din arhivă, și anume Anaconda3-4.2.0 - este potrivită. Nu uitați să bifați caseta de înregistrare Python 3.5. Mai exact, înainte de a instala Anaconda, este mai bine să închideți terminalul, altfel acesta va continua să funcționeze cu un PATH învechit. De asemenea, nu uitați să schimbați drepturile de acces ale utilizatorilor, altfel nimic nu va funcționa.
conda create -n tensorflow
activa fluxul tensor
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/cpu/tensorflow-1.1.0-cp35-cp35m-win_amd64.whl /*Descărcat de pe Internet 19,4 MB, apoi 7 , 7 MB și încă 0,317 MB*/
pip install --ignore-installed --upgrade https://storage.googleapis.com/tensorflow/windows/gpu/tensorflow_gpu-1.1.0-cp35-cp35m-win_amd64.whl /*Descărcați 48,6 MB */
Captură de ecran a ecranului de instalare: totul merge bine în Anaconda.
La fel și pentru al doilea dosar.
Ei bine, în concluzie: pentru ca toate acestea să funcționeze, trebuie să instalați pachetul CUDA Toolkits de la NVIDEA (în cazul utilizării unui GPU). Versiunea actuală acceptată este 8.0. De asemenea, va trebui să descărcați și să despachetați biblioteca cuDNN v5.1 în folderul CUDA, dar nu mai mult versiune noua! După toate aceste manipulări, TensorFlow va funcționa.

Theano
- O rețea neuronală recurentă în 10 rânduri de cod a evaluat feedback-ul telespectatorilor la noul episod din „Războiul Stelelor”
Pachetul Theano este inclus în propriul PyPI al lui Python. În sine, este mic - 3,1 MB, dar trage încă 15 MB de dependențe - scipy. Pentru a-l instala pe acesta din urmă, aveți nevoie și de modulul lapack... În general, instalarea pachetului theano sub Windows va însemna „dans cu tamburină”. Mai jos voi încerca să arăt secvența de acțiuni pentru a face pachetul să funcționeze.
Când utilizați Anaconda, „dansul cu o tamburină” în timpul instalării nu este relevant. Comanda este suficientă:
conda install theano
iar procesul are loc automat. Apropo, sunt încărcate și pachetele GCC.

Scikit-Learn
Sub Python 3.5.3, doar mai mult de versiunea timpurie 0.17.1 pe care îl puteți lua. Există un instalator normal. Cu toate acestea, nu va funcționa direct sub Windows - aveți nevoie de biblioteca scipy.
Instalarea pachetelor de ajutor
Pentru ca cele două pachete de mai sus să funcționeze (vorbim despre Phyton „god”), trebuie să faceți câțiva pași preliminari.
SciPy
Pentru a lansa Scikit-Learn și Theano, așa cum a devenit deja clar din cele de mai sus, va trebui să „dansezi cu o tamburină”. Primul lucru pe care ni-l oferă Yandex este un depozit de înțelepciune, deși în engleză, resursa stackoverflow.com, unde găsim un link către o arhivă excelentă a aproape toate pachetele Python existente compilate pentru Windows - lfd.uci.edu
Aici există ansambluri gata de instalat de pachete care vă interesează în prezent, compilate pentru versiuni diferite Piton. În cazul nostru, sunt necesare versiuni de fișiere, care conțin linia „-cp35-win_amd64” în numele său, deoarece exact asta este Pachetul Python a fost folosit pentru instalare. Pe stakowerflow, dacă căutați, puteți găsi și „instrucțiuni” pentru instalarea pachetelor noastre specifice.
pip install --upgrade --ignore-installed http://www.lfd.uci.edu/~gohlke/pythonlibs/vu0h7y4r/numpy-1.12.1+mkl-cp35-cp35m-win_amd64.whl
pip install --upgrade --ignore-insalled http://www.lfd.uci.edu/~gohlke/pythonlibs/vu0h7y4r/scipy-0.19.0-cp35-cp35m-win_amd64.whl
pip --upgrade --ignore-instalați panda
pip install --upgrade --ignore-installed matplotlib
Două ultimul pachet a apărut în lanțul meu din cauza „dansului cu tamburin” al altor oameni. Nu le-am observat în dependențele pachetelor instalate, dar se pare că unele dintre componentele lor sunt necesare pentru procesul normal de instalare.
Lapack/Blas
Aceste două biblioteci de nivel scăzut asociate, scrise în Fortran, sunt necesare pentru a instala pachetul Theano. Scikit-Learn poate funcționa și pe cele care sunt deja instalate „ascuns” în alte pachete (vezi mai sus). De fapt, dacă versiunea Theano 0.17 este instalată din fișierul exe, va funcționa și. Cel puțin în Anaconda. Cu toate acestea, aceste biblioteci pot fi găsite și pe Internet. De exemplu . Construcții mai recente. Pentru ca pachetul finit să funcționeze versiunea anterioara Este potrivit. Construirea unui pachet nou va necesita versiuni noi.
De asemenea, trebuie remarcat faptul că într-o versiune complet proaspătă a lui Anaconda, pachetul Theano este instalat mult mai ușor - cu o singură comandă, dar sincer să fiu, nu-mi pasă în această etapă(zero) stăpânind rețelele neuronale, mi-a plăcut mai mult TensorFlow, dar încă nu este prietenos cu noile versiuni de Python.
Unii dintre voi probabil că ați urmat recent cursuri la Stanford, în special ai-class și ml-class. Cu toate acestea, una este să vizionați mai multe prelegeri video, să răspundeți la întrebări de tip test și să scrieți o duzină de programe în Matlab / Octave și un alt lucru este să începeți folosind cunoștințele acumulate în practică. Pentru ca cunoștințele primite de la Andrew Ng să nu ajungă în același colț întunecat al creierului meu în care s-au pierdut dft, Teoria Relativității Speciale și Ecuația Lagrange a lui Euler, am decis să nu repet greșelile institutului și, în timp ce cunoștințele sunt încă proaspete. în memoria mea, exersează cât mai mult posibil.Și chiar atunci a sosit DDoS pe site-ul nostru. A fost posibil să lupți cu ajutorul metodelor de administrare/programare (grep/awk/etc) sau să recurgi la utilizarea tehnologiilor de învățare automată.
Un exemplu de construire a unui dicționar și a unui vector de caracteristici
Să presupunem că ne antrenăm rețeaua neuronală cu doar două exemple: unul bun și unul rău. Apoi vom încerca să-l activăm pe o înregistrare de test.Intrare din jurnalul „prost”:
0.0.0.0 - - "POST /forum/index.php HTTP/1.1" 503 107 "http://www.mozilla-europe.org/" "-"
Intrare din jurnalul „bun”:
0.0.0.0 - - "GET /forum/rss.php?topic=347425 HTTP/1.0" 200 1685 "-" "Mozilla/5.0 (Windows; U; Windows NT 5.1; pl; rv:1.9) Gecko/2008052906 Firefox/ 3.0"
Dicționarul rezultat:
["__UA___OS_U", "__UA_EMPTY", "__REQ___METHOD_POST", "__REQ___HTTP_VER_HTTP/1.0", "__REQ___URL___NETLOC_", "__REQ___URL___PATH_/forum/rss.php", "__REQ___URL___PATH_PATH_/forum", "Q_REQ_REQ_URL_/forum" _HTTP/ 1.1”, „__UA___VER_Firefox/3.0”, „__REFER___NETLOC_www.mozilla-europe.org”, „__UA___OS_Windows”, „__UA___BASE_Mozilla/5.0”, „__CODE_503”, „__UA___OS_pl”, „__REFER___PATH_/__, „______, „______, „_____ „__REQ___METHOD_GET”, „__UA___OS_Windows NT 5.1”, „__UA___OS_rv:1.9”, „__REQ___URL___QS_topic”, „__UA___VER_Gecko/2008052906”]
Înregistrare de testare:
0.0.0.0 - - "GET /forum/viewtopic.php?t=425550 HTTP/1.1" 502 107 "-" "BTWebClient/3000(25824)"
Vectorul său caracteristic:
Observați cât de „rarit” este vectorul de caracteristici - acest comportament va fi observat pentru toate interogările.
Diviziunea setului de date
O bună practică este împărțirea setului de date în mai multe părți. L-am împărțit în două părți într-un raport de 70/30:- Set de antrenament. Îl folosim pentru a ne antrena rețeaua neuronală.
- Set de testare. Îl folosim pentru a verifica cât de bine este antrenată rețeaua noastră neuronală.
În viitor, dacă va trebui să alegeți constantele optime, setul de date va trebui împărțit în 3 părți în raportul 60/20/20: Set de antrenament, Set de testare și Validare încrucișată. Acesta din urmă va servi tocmai pentru selecție parametrii optimi rețea neuronală (de exemplu decăderea greutății).
Rețeaua neuronală în special
Acum că nu mai avem jurnalele de text în mâinile noastre, ci doar matrice din vectori de caracteristici, putem începe să construim rețeaua neuronală în sine.Să începem cu alegerea unei structuri. Am ales o rețea cu un strat ascuns de dimensiunea de două ori a stratului de intrare. De ce? Este simplu: asta este ceea ce Andrew Ng a lăsat moștenire în cazul în care nu știi de unde să începi. Cred că te poți juca cu asta în viitor desenând grafice de antrenament.
Funcția de activare pentru stratul ascuns este sigmoidul îndelungat, iar pentru stratul de ieșire - Softmax. Ultima a fost aleasă în cazul în care trebuie făcută
clasificare multiclasă cu clase care se exclud reciproc. De exemplu, trimiteți cereri „bune” către backend, cele „rele” la o interdicție de firewall și solicitări „gri” pentru a rezolva un captcha.
Rețeaua neuronală tinde să meargă la un minim local, așa că în codul meu construiesc mai multe rețele și o aleg pe cea cu cea mai mică eroare de test (Notă, este eroarea de pe setul de testare, nu de setul de antrenament).
Disclaimer
Nu sunt un sudor adevărat. Știu doar despre Machine Learning ceea ce am învățat de la ml-class și ai-class. Am început să programez în Python relativ recent, iar codul de mai jos a fost scris în aproximativ 30 de minute (timpul, după cum ați înțeles, se scurgea) și apoi a fost doar ușor depus cu un fișier.De asemenea, acest cod nu este autonom. Mai are nevoie de un ham pentru scenarii. De exemplu, dacă un IP a făcut N cereri greșite în X minute, atunci interziceți-l pe firewall.
Performanţă
- lfu_cache. Portat din ActiveState pentru a accelera foarte mult procesarea cererilor de înaltă frecvență. Dezavantajul consum crescut memorie.
- PyBrain, desigur, este scris în python și, prin urmare, nu este foarte rapid, cu toate acestea, poate folosi modulul arac bazat pe ATLAS dacă specificați Fast=True la crearea rețelei. Puteți citi mai multe despre acest lucru în documentația PyBrain.
- Paralelizarea. Mi-am antrenat rețeaua neuronală pe un server destul de „gros” Nehalem, totuși, chiar și acolo s-au simțit dezavantajele antrenamentului cu un singur fir. Vă puteți gândi la subiectul paralelizării antrenamentului rețelelor neuronale. O soluție simplă este să antrenezi mai multe rețele neuronale în paralel și alegeți-l pe cel mai bun dintre ele, dar acest lucru va crea o încărcare suplimentară a memoriei, care nu este, de asemenea, foarte bună. solutie universala. Poate că are sens să rescrieți pur și simplu totul în C, deoarece întreaga bază teoretică din clasa ml a fost mestecată.
- Consumul de memorie și numărul de funcții. O bună optimizare a memoriei a fost trecerea de la matrice standard Python la matrice numpy.De asemenea, reducerea dimensiunii dicționarului și/sau utilizarea PCA poate ajuta foarte bine, mai multe despre asta mai jos.
Pentru viitor
- Câmpuri suplimentare în jurnal. Puteți adăuga mult mai multe în jurnalul combinat; merită să vă gândiți la ce câmpuri vă vor ajuta la identificarea roboților. Ar putea avea sens să se țină cont de primul octet al adresei IP, deoarece într-un proiect web non-internațional, utilizatorii chinezi sunt cel mai probabil boți.
De data asta m-am hotarat sa studiez rețele neuronale. Am reușit să dobândesc abilități de bază în această chestiune în vara și toamna lui 2015. Prin abilități de bază, vreau să spun că pot crea o rețea neuronală simplă de la zero. Puteți găsi exemple în depozitele mele GitHub. În acest articol, voi oferi câteva explicații și voi împărtăși resurse pe care le puteți găsi utile în studiul dumneavoastră.
Pasul 1. Neuroni și metoda feedforward
Deci, ce este o „rețea neuronală”? Să așteptăm cu asta și să ne ocupăm mai întâi de un neuron.
Un neuron este ca o funcție: ia mai multe valori ca intrare și returnează una.
Cercul de mai jos reprezintă neuron artificial. Primește 5 și returnează 1. Intrarea este suma celor trei sinapse conectate la neuron (trei săgeți în stânga).
În partea stângă a imaginii vedem 2 valori de intrare ( Culoare verde) și offset (evidențiat cu maro).
Datele de intrare pot fi reprezentări numerice a două proprietăți diferite. De exemplu, la crearea unui filtru de spam, acestea ar putea însemna prezența a mai mult de un cuvânt scris cu MAJUSCULE și prezența cuvântului „Viagra”.
Valorile de intrare sunt înmulțite cu așa-numitele „greutăți”, 7 și 3 (evidențiate cu albastru).
Acum adăugăm valorile rezultate cu offset și obținem un număr, în cazul nostru 5 (evidențiat cu roșu). Aceasta este intrarea neuronului nostru artificial.

Apoi neuronul efectuează un calcul și produce o valoare de ieșire. Avem 1 pentru că valoarea rotunjită a sigmoidului la punctul 5 este 1 (vom vorbi mai detaliat despre această funcție mai târziu).
Dacă acesta ar fi un filtru de spam, faptul că ieșirea 1 ar însemna că textul a fost marcat ca spam de către neuron.

Ilustrație a unei rețele neuronale de pe Wikipedia.
Dacă combinați acești neuroni, obțineți o rețea neuronală care se propagă direct - procesul merge de la intrare la ieșire, prin neuroni conectați prin sinapse, ca în imaginea din stânga.
Pasul 2. Sigmoid
După ce ați urmărit lecțiile Welch Labs, este o idee bună să consultați Săptămâna 4 din cursul de învățare automată al Coursera despre rețelele neuronale, pentru a vă ajuta să înțelegeți cum funcționează acestea. Cursul intră foarte adânc în matematică și se bazează pe Octave, în timp ce eu prefer Python. Din această cauză am sărit peste exerciții și am învățat totul cunoștințe necesare din videoclip.

Un sigmoid mapează pur și simplu valoarea ta (pe axa orizontală) într-un interval de la 0 la 1.
Prima mea prioritate a fost să studiez sigmoidul, așa cum a figurat în multe aspecte ale rețelelor neuronale. Știam deja ceva despre asta din a treia săptămână a cursului mai sus menționat, așa că am urmărit videoclipul de acolo.
Dar nu vei ajunge departe doar cu videoclipurile. Pentru o înțelegere completă, am decis să-l codez eu. Așa că am început să scriu o implementare a unui algoritm de regresie logistică (care folosește un sigmoid).
A durat o zi întreagă, iar rezultatul a fost cu greu satisfăcător. Dar nu contează, pentru că mi-am dat seama cum funcționează totul. Codul poate fi văzut.
Nu trebuie să faceți acest lucru singur, deoarece necesită cunoștințe speciale - principalul lucru este că înțelegeți cum funcționează sigmoidul.
Pasul 3. Metoda de backpropagation
Înțelegerea modului în care funcționează o rețea neuronală de la intrare la ieșire nu este atât de dificilă. Este mult mai dificil de înțeles cum o rețea neuronală învață din seturile de date. Principiul pe care l-am folosit se numește
James Loy, Georgia Tech. Un ghid pentru începători pentru crearea propriei rețele neuronale în Python.
Motivație: concentrându-se pe experienta personalaîn studiu invatare profunda, am decis să creez o rețea neuronală de la zero, fără complicații bibliotecă educațională, cum ar fi, de exemplu, . Cred că pentru un Data Scientist începător este important să înțeleagă structura internă.
Acest articol conține ceea ce am învățat și sper să vă fie de folos și vouă! Alte articole utile pe această temă:
Ce este o rețea neuronală?
Cele mai multe articole despre rețelele neuronale fac paralele cu creierul atunci când le descriu. Îmi este mai ușor să descriu rețelele neuronale ca functie matematica, care mapează o intrare dată la o ieșire dorită fără a intra în detalii.
Rețelele neuronale constau din următoarele componente:
- strat de intrare, x
- cantitate arbitrară straturi ascunse
- strat de ieșire, ŷ
- trusa cântareȘi deplasariîntre fiecare strat W Și b
- selecție pentru fiecare strat ascuns σ ; in aceasta lucrare vom folosi functia de activare sigmoid
Diagrama de mai jos arată arhitectura unei rețele neuronale cu două straturi (rețineți că stratul de intrare este de obicei exclus atunci când se numără numărul de straturi dintr-o rețea neuronală).
Crearea unei clase de rețea neuronală în Python este simplă:
Antrenamentul rețelei neuronale
Ieșire ŷ rețea neuronală simplă cu două straturi:
În ecuația de mai sus, ponderile W și părtinirea b sunt singurele variabile care afectează ieșirea ŷ.
Desigur, valorile corecte pentru ponderi și părtiniri determină acuratețea predicțiilor. Proces reglaj fin ponderile și părtinirile din datele de intrare sunt cunoscute ca .
Fiecare iterație a procesului de învățare constă din următorii pași
- calculând ieșirea prezisă ŷ, numită propagare directă
- actualizare ponderi și părtiniri, numit
Graficul secvenţial de mai jos ilustrează procesul:

Distributie directa
După cum am văzut în graficul de mai sus, propagarea înainte este doar un calcul simplu, iar pentru o rețea neuronală de bază cu 2 straturi, rezultatul rețelei neuronale este dată de:
Să adăugăm o funcție de propagare înainte la codul nostru Python pentru a face acest lucru. Rețineți că, pentru simplitate, am presupus că decalajele sunt 0.
Cu toate acestea, avem nevoie de o modalitate de a evalua „bonitatea” prognozelor noastre, adică cât de departe sunt previziunile noastre). Funcția de pierdere doar ne permite să facem asta.
Funcția de pierdere
Există multe funcții disponibile pierderile, iar natura problemei noastre ar trebui să ne dicteze alegerea funcției de pierdere. În această lucrare vom folosi suma erorilor pătrate ca functie de pierdere.

Suma erorilor pătrate este media diferenței dintre fiecare valoare prezisă și cea reală.
Scopul învățării este de a găsi un set de ponderi și părtiniri care să minimizeze funcția de pierdere.
Propagarea inversă
Acum că am măsurat eroarea în prognoza noastră (pierderea), trebuie să găsim o cale propagarea erorii înapoiși actualizați ponderile și părtinirile noastre.
Pentru a cunoaște cantitatea adecvată de ajustare a ponderilor și a distorsiunilor, trebuie să cunoaștem derivata funcției de pierdere în raport cu ponderile și părtinirile.
Să reamintim din analiză că Derivata unei functii este panta functiei.

Dacă avem o derivată, atunci putem pur și simplu să actualizăm ponderile și părtinirile prin creșterea/scăderea lor (vezi diagrama de mai sus). Se numeste .
Cu toate acestea, nu putem calcula direct derivata funcției de pierdere în raport cu ponderi și părtiniri, deoarece ecuația funcției de pierdere nu conține ponderi și părtiniri. Deci avem nevoie de o regulă de lanț care să ne ajute la calcul.
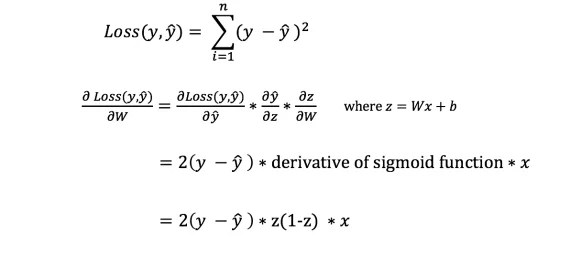
Pf! Acest lucru a fost greoi, dar ne-a permis să obținem ceea ce aveam nevoie — derivata (panta) a funcției de pierdere în raport cu ponderile. Acum putem ajusta greutățile în consecință.
Să adăugăm funcția de backpropagation la codul nostru Python:
Verificarea funcționării rețelei neuronale
Acum că avem noastre cod completîn Python pentru a efectua propagarea înainte și înapoi, să ne uităm la rețeaua neuronală ca exemplu și să vedem cum funcționează.
 Setul ideal de cântare
Setul ideal de cântare Rețeaua noastră neuronală trebuie să învețe setul ideal de greutăți pentru a reprezenta această funcție.
Să antrenăm rețeaua neuronală pentru 1500 de iterații și să vedem ce se întâmplă. Privind graficul pierderilor de iterație de mai jos, putem vedea clar că pierderea scade monoton la un minim. Acest lucru este în concordanță cu algoritmul de coborâre a gradientului despre care am discutat mai devreme.

Să ne uităm la predicția finală (ieșirea) din rețeaua neuronală după 1500 de iterații.

Am reusit! Algoritmul nostru de propagare înainte și înapoi a arătat că rețeaua neuronală funcționează cu succes, iar predicțiile converg către valorile adevărate.
Rețineți că există o mică diferență între predicții și valorile reale. Acest lucru este de dorit deoarece previne supraadaptarea și permite rețelei neuronale să generalizeze mai bine la datele nevăzute.
Gânduri finale
Am învățat multe în procesul de scriere a propriei mele rețele neuronale de la zero. Deşi bibliotecile invatare profunda, precum TensorFlow și Keras, permit crearea rețele profunde fără înțelegere deplină munca internă rețeaua neuronală, consider că este util pentru aspiranții cercetători ai datelor să obțină o înțelegere mai profundă a acestora.
Am investit mult din timpul meu personal în acest lucruși sper să vă fie de folos!







