Crearea unei rețele neuronale în python. Învățarea rețelelor neuronale în patru pași
James Loy, Georgia Tech. Un ghid pentru începători pentru crearea propriei rețele neuronale în Python.
Motivație: concentrându-se pe experienta personalaîn studiu invatare profunda, am decis să creez o rețea neuronală de la zero, fără complicații bibliotecă educațională, cum ar fi, de exemplu, . Cred că pentru un Data Scientist începător este important să înțeleagă structura internă.
Acest articol conține ceea ce am învățat și sper să vă fie de folos și vouă! Alte articole utile pe această temă:
Ce este o rețea neuronală?
Cele mai multe articole despre rețelele neuronale fac paralele cu creierul atunci când le descriu. Îmi este mai ușor să descriu rețelele neuronale ca functie matematica, care mapează o intrare dată la o ieșire dorită fără a intra în detalii.
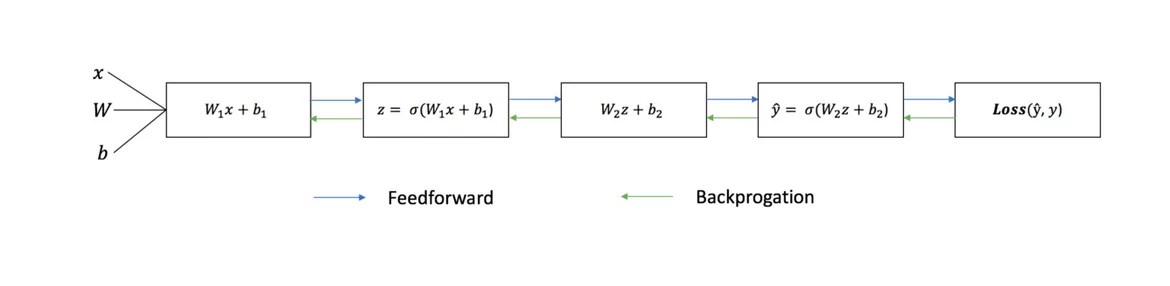
Rețelele neuronale constau din următoarele componente:
- strat de intrare, x
- cantitate arbitrară straturi ascunse
- strat de ieșire, ŷ
- trusa cântareȘi deplasariîntre fiecare strat W Și b
- selecție pentru fiecare strat ascuns σ ; in aceasta lucrare vom folosi functia de activare sigmoid
Diagrama de mai jos arată arhitectura unei rețele neuronale cu două straturi (rețineți că stratul de intrare este de obicei exclus atunci când se numără numărul de straturi dintr-o rețea neuronală).
Crearea unei clase de rețea neuronală în Python este simplă:
Antrenamentul rețelei neuronale
Ieșire ŷ rețea neuronală simplă cu două straturi:
În ecuația de mai sus, ponderile W și părtinirea b sunt singurele variabile care afectează ieșirea ŷ.
Desigur, valorile corecte pentru ponderi și părtiniri determină acuratețea predicțiilor. Proces reglaj fin ponderile și părtinirile din datele de intrare sunt cunoscute ca .
Fiecare iterație a procesului de învățare constă din următorii pași
- calculând ieșirea prezisă ŷ, numită propagare directă
- actualizare ponderi și părtiniri, numit
Graficul secvenţial de mai jos ilustrează procesul:
Distributie directa
După cum am văzut în graficul de mai sus, propagarea directă este doar un calcul simplu, iar pentru o rețea neuronală de bază cu 2 straturi, rezultatul rețelei neuronale este dată de:
Să adăugăm o funcție de propagare înainte la codul nostru Python pentru a face acest lucru. Rețineți că, pentru simplitate, am presupus că decalajele sunt 0.
Cu toate acestea, avem nevoie de o modalitate de a evalua „bonitatea” prognozelor noastre, adică cât de departe sunt previziunile noastre). Funcția de pierdere doar ne permite să facem asta.
Funcția de pierdere
Există multe funcții disponibile pierderile, iar natura problemei noastre ar trebui să ne dicteze alegerea funcției de pierdere. În această lucrare vom folosi suma erorilor pătrate ca functie de pierdere.

Suma erorilor pătrate este media diferenței dintre fiecare valoare prezisă și cea reală.
Scopul învățării este de a găsi un set de ponderi și părtiniri care să minimizeze funcția de pierdere.
Propagarea inversă
Acum că am măsurat eroarea în prognoza noastră (pierderea), trebuie să găsim o cale propagarea erorii înapoiși actualizați ponderile și părtinirile noastre.
Pentru a cunoaște cantitatea adecvată pentru a ajusta ponderile și prejudecățile, trebuie să cunoaștem derivata funcției de pierdere în raport cu ponderile și părtinirile.
Să reamintim din analiză că Derivata unei functii este panta functiei.

Dacă avem o derivată, atunci putem pur și simplu să actualizăm ponderile și părtinirile prin creșterea/scăderea lor (vezi diagrama de mai sus). Se numeste .
Cu toate acestea, nu putem calcula direct derivata funcției de pierdere în raport cu ponderi și părtiniri, deoarece ecuația funcției de pierdere nu conține ponderi și părtiniri. Deci avem nevoie de o regulă de lanț care să ne ajute la calcul.
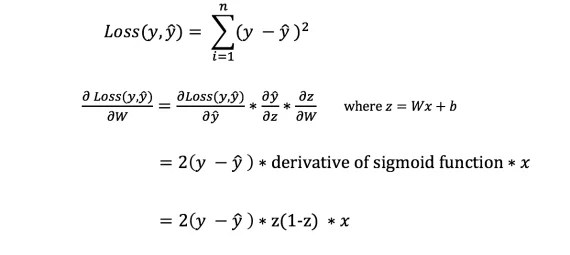
Pf! Acest lucru a fost greoi, dar ne-a permis să obținem ceea ce aveam nevoie — derivata (panta) a funcției de pierdere în raport cu ponderile. Acum putem ajusta greutățile în consecință.
Să adăugăm funcția de backpropagation la codul nostru Python:
Verificarea funcționării rețelei neuronale
Acum că avem noastre cod completîn Python pentru a efectua propagarea înainte și înapoi, să ne uităm la rețeaua neuronală ca exemplu și să vedem cum funcționează.
 Setul ideal de cântare
Setul ideal de cântare Rețeaua noastră neuronală trebuie să învețe setul ideal de greutăți pentru a reprezenta această funcție.
Să antrenăm rețeaua neuronală pentru 1500 de iterații și să vedem ce se întâmplă. Privind graficul pierderilor de iterație de mai jos, putem vedea clar că pierderea scade în mod monoton la minim. Acest lucru este în concordanță cu algoritmul de coborâre a gradientului despre care am discutat mai devreme.

Să ne uităm la predicția finală (ieșirea) din rețeaua neuronală după 1500 de iterații.

Am reusit! Algoritmul nostru de propagare înainte și înapoi a arătat că rețeaua neuronală funcționează cu succes, iar predicțiile converg către valorile adevărate.
Rețineți că există o mică diferență între predicții și valorile reale. Acest lucru este de dorit deoarece previne supraadaptarea și permite rețelei neuronale să generalizeze mai bine la datele nevăzute.
Gânduri finale
Am învățat multe în procesul de scriere a propriei mele rețele neuronale de la zero. Deşi bibliotecile invatare profunda, precum TensorFlow și Keras, permit crearea rețele profunde fără înțelegere deplină munca internă rețeaua neuronală, consider că este util pentru aspiranții cercetători ai datelor să obțină o înțelegere mai profundă a acestora.
Am investit mult din timpul meu personal în acest lucruși sper să vă fie de folos!
Rețelele neuronale sunt create și antrenate în principal pe Limbajul Python. Prin urmare, este foarte important să aveți o înțelegere de bază despre cum să scrieți programe în el. În acest articol voi vorbi pe scurt și clar despre conceptele de bază ale acestui limbaj: variabile, funcții, clase și module.
Materialul este destinat persoanelor care nu sunt familiarizate cu limbajele de programare.
Mai întâi trebuie să instalați Python. Apoi, trebuie să instalați un mediu convenabil pentru scrierea programelor în Python. Portalul este dedicat acestor doi pași.
Dacă totul este instalat și configurat, puteți începe.
Variabile
Variabil- un concept cheie în orice limbaj de programare (și nu numai în ele). Cel mai simplu mod de a te gândi la o variabilă este ca o cutie cu o etichetă. Această cutie conține ceva (un număr, o matrice, un obiect, ...) care este valoros pentru noi.
De exemplu, dorim să creăm o variabilă x care să stocheze valoarea 10. În Cod Python crearea acestei variabile va arăta astfel:

În stânga noi anuntam noi o variabilă numită x. Acest lucru este echivalent cu a pune o etichetă de nume pe cutie. Urmează semnul egal și numărul 10. Semnul egal joacă un rol neobișnuit aici. Nu înseamnă că „x este egal cu 10”. Egalitatea în în acest caz, pune numărul 10 în casetă. Pentru a spune mai corect, noi atribui variabila x este numărul 10.
Acum, în codul de mai jos putem accesa această variabilă și, de asemenea, putem efectua diverse acțiuni cu ea.
Puteți afișa pur și simplu valoarea acestei variabile pe ecran:
X=10 print(x)
print(x) reprezintă un apel de funcție. Le vom lua în considerare în continuare. Important este acum că această funcție imprimă pe consolă ceea ce este situat între paranteze. Între paranteze avem x. Anterior, am atribuit lui x valoarea 10. Acesta este ceea ce 10 este tipărit în consolă dacă rulați programul de mai sus.
Se pot efectua diverse operații simple cu variabile care stochează numere: adunare, scădere, înmulțire, împărțire și exponențiere.
X = 2 y = 3 # Adunarea z = x + y print(z) # 5 # Diferența z = x - y print(z) # -1 # Produs z = x * y print(z) # 6 # Diviziunea z = x / y print(z) # 0,66666... # Exponentiation z = x ** y print(z) # 8
În codul de mai sus, creăm mai întâi două variabile care conțin 2 și 3. Apoi creăm o variabilă z care stochează rezultatul operației pe x și y și tipărește rezultatele pe consolă. Acest exemplu arată clar că o variabilă își poate schimba valoarea în timpul execuției programului. Deci, variabila noastră z își schimbă valoarea de până la 5 ori.
Funcții
Uneori devine necesar să efectuați aceleași acțiuni din nou și din nou. De exemplu, în proiectul nostru avem deseori nevoie să afișăm 5 rânduri de text.
„Acesta este un text foarte important!”
„Acest text nu poate fi citit”
„Greșeala din linia de sus a fost făcută intenționat”
"Bună și la revedere"
"Sfârşit"
Codul nostru va arăta astfel:
X = 10 y = x + 8 - 2 print("Acesta este un text foarte important!") print("Acest text nu poate fi citit") print("Eroarea din linia de sus a fost făcută intenționat") print(" Bună și pa") print ("The End") z = x + y print(„Acesta este un text foarte important!") print(„Acest text nu poate fi citit") print(„Greșeala din linia de sus a fost făcută intenționat”) print(„Bună ziua și pa”) print („Sfârșitul”) test = z print(„Acesta este un text foarte important!”) print(„Acest text nu poate fi citit”) print(„Greșeala în linia de sus a fost făcută intenționat") print("Salut și pa") print("Sfârșit")
Totul pare foarte redundant și incomod. În plus, a existat o eroare în a doua linie. Poate fi reparat, dar va trebui să fie fixat în trei locuri deodată. Ce se întâmplă dacă aceste cinci linii sunt apelate de 1000 de ori în proiectul nostru? Și totul este în locuri diferite si fisiere?
Mai ales pentru cazurile în care trebuie să executați frecvent aceleași comenzi, puteți crea funcții în limbaje de programare.
Funcţie- un bloc separat de cod care poate fi numit după nume.
O funcție este definită folosind cuvântul cheie def. Acesta este urmat de numele funcției, apoi de paranteze și două puncte. În continuare, trebuie să enumerați, indentat, acțiunile care vor fi efectuate la apelarea funcției.
Def print_5_lines(): print("Acesta este un text foarte important!") print("Acest text nu poate fi citit") print("Eroarea din linia de sus a fost făcută intenționat") print("Salut și pa") print(„Sfârșitul”)
Acum am definit funcția print_5_lines(). Acum, dacă în proiectul nostru trebuie din nou să inserăm cinci linii, atunci pur și simplu numim funcția noastră. Acesta va efectua automat toate acțiunile.
# Definiți funcția def print_5_lines(): print("Acesta este un text foarte important!") print("Acest text nu poate fi citit") print("Eroarea din linia de sus a fost intenționată") print("Salut și pa ") print(" End") # Codul proiectului nostru x = 10 y = x + 8 - 2 print_5_lines() z = x + y print_5_lines() test = z print_5_lines()
Convenabil, nu-i așa? Am îmbunătățit serios lizibilitatea codului. În plus, funcțiile sunt de asemenea bune, deoarece dacă doriți să schimbați unele dintre acțiuni, atunci trebuie doar să corectați funcția în sine. Această modificare va funcționa în toate locurile în care este apelată funcția dvs. Adică, putem corecta eroarea din a doua linie a textului de ieșire („nu” > „nu”) din corpul funcției. Opțiune corectă va fi apelat automat în toate locurile din proiectul nostru.

Funcții cu parametri
Este cu siguranță convenabil să repeți pur și simplu mai multe acțiuni. Dar asta nu este tot. Uneori vrem să transmitem o variabilă funcției noastre. În acest fel, funcția poate accepta date și le poate folosi în timpul executării comenzilor.
Variabilele pe care le transmitem funcției sunt numite argumente.
Hai să scriem funcție simplă, care adaugă două numere date și returnează rezultatul.
Def sum(a, b): rezultat = a + b returnează rezultat
Prima linie arată aproape la fel ca funcțiile obișnuite. Dar între paranteze există acum două variabile. Acest Opțiuni funcții. Funcția noastră are doi parametri (adică necesită două variabile).
Parametrii pot fi utilizați în interiorul unei funcții la fel ca variabilele obișnuite. Pe a doua linie creăm un rezultat variabil, care este egal cu suma parametrilor a și b. Pe a treia linie returnăm valoarea variabilei rezultat.
Acum, în cod suplimentar, putem scrie ceva de genul:
Nou = suma(2, 3) print(nou)
Numim funcția sum și îi transmitem pe rând două argumente: 2 și 3. 2 devine valoarea variabilei a, iar 3 devine valoarea variabilei b. Funcția noastră returnează o valoare (suma 2 și 3) și o folosim pentru a crea o nouă variabilă, new .
Tine minte. În codul de mai sus, numerele 2 și 3 sunt argumentele funcției de sumă. Și în funcția de sumă în sine, variabilele a și b sunt parametri. Cu alte cuvinte, variabilele pe care le transmitem unei funcții atunci când este apelată se numesc argumente. Dar în interiorul funcției, aceste variabile transmise sunt numite parametri. De fapt, acestea sunt două nume pentru același lucru, dar nu trebuie confundate.
Să ne uităm la un alt exemplu. Să creăm o funcție pătrat(a) care ia un număr și îl pătratează:
Def pătrat(a): returnează a * a
Funcția noastră constă dintr-o singură linie. Returnează imediat rezultatul înmulțirii parametrului a cu a .
Cred că ați ghicit deja că trimitem și date către consolă folosind o funcție. Această funcție se numește print() și afișează argumentul transmis în consolă: un număr, un șir, o variabilă.
Matrice
Dacă o variabilă poate fi gândită ca o cutie care stochează ceva (nu neapărat un număr), atunci matricele pot fi gândite ca rafturi de cărți. Acestea conțin mai multe variabile simultan. Iată un exemplu de matrice de trei numere și un șir:
Matrice =
Iată un exemplu când o variabilă nu conține un număr, ci un alt obiect. În acest caz, variabila noastră conține o matrice. Fiecare element de matrice este numerotat. Să încercăm să afișăm un element al matricei:
Array = print(matrice)
În consolă vei vedea numărul 89. Dar de ce 89 și nu 1? Chestia este că în Python, ca și în multe alte limbaje de programare, numerotarea matricelor începe de la 0. Prin urmare, array ne oferă al doilea element al matricei, nu primul. Pentru a apela primul, a trebuit să scrieți array .
Dimensiunea matricei
Uneori este foarte util să obțineți numărul de elemente dintr-o matrice. Puteți utiliza funcția len() pentru aceasta. Acesta va număra numărul de elemente și va returna numărul acestora.
Matrice = print(len(matrice))
Consola va afișa numărul 4.
Condiții și cicluri
În mod implicit, orice program pur și simplu execută toate comenzile într-un rând de sus în jos. Dar există situații în care trebuie să verificăm o anumită condiție și, în funcție de faptul că este adevărată sau nu, să realizăm diferite acțiuni.
În plus, este adesea nevoie să repeți aproape aceeași secvență de comenzi de multe ori.
În prima situație, condițiile ajută, iar în a doua, ciclurile ajută.
Condiții
Sunt necesare condiții pentru a efectua două seturi diferite de acțiuni, în funcție de dacă afirmația testată este adevărată sau falsă.

În Python, condițiile pot fi scrise folosind constructul if: ... else: .... Să avem o variabilă x = 10. Dacă x este mai mic de 10, atunci vrem să împărțim x la 2. Dacă x este mai mare sau egal cu 10, atunci vrem să creăm o altă variabilă nouă, care este egală cu suma lui x și numărul 100. Aceasta este cum va arata codul:
X = 10 dacă (x< 10): x = x / 2 print(x) else: new = x + 100 print(new)
După crearea variabilei x, începem să ne scriem condiția.
Totul începe cu cuvântul cheie dacă (tradus din engleză ca „dacă”). În paranteză indicăm expresia care trebuie verificată. În acest caz, verificăm dacă variabila noastră x este într-adevăr mai mică de 10. Dacă este într-adevăr mai mică de 10, atunci o împărțim la 2 și imprimăm rezultatul pe consolă.
Apoi vine cuvânt cheie else , după care începe un bloc de acțiuni care vor fi executate dacă expresia dintre paranteze după if este falsă.
Dacă este mai mare sau egală cu 10, atunci creăm o nouă variabilă, care este egală cu x + 100 și, de asemenea, o scoatem în consolă.
Cicluri
Buclele sunt necesare pentru a repeta acțiunile de mai multe ori. Să presupunem că vrem să afișăm un tabel cu pătratele primelor 10 numere naturale. Se poate face așa.
Print("Patratul 1 este " + str(1**2)) print("Patratul 2 este " + str(2**2)) print("Patratul 3 este " + str(3**2)) print( "Pătratul 4 este " + str(4**2)) print("Pătratul 5 este " + str(5**2)) print("Pătratul 6 este " + str(6**2)) print("Pătrat 7 este " + str(7**2)) print("Patratul lui 8 este " + str(8**2)) print("Patratul lui 9 este " + str(9**2)) print("Patrat din 10 este " + str(10**2))
Nu fi surprins de faptul că adăugăm linii. „începutul liniei” + „sfârșitul” în Python înseamnă pur și simplu concatenarea șirurilor: „începutul sfârșitului liniei”. În același mod mai sus, adăugăm șirul „Pătratul lui x este egal cu ” și rezultatul ridicării numărului la puterea a 2-a, convertit folosind funcția str(x**2).
Codul de mai sus pare foarte redundant. Ce se întâmplă dacă trebuie să tipărim pătratele primelor 100 de numere? Suntem chinuiti sa ne retragem...
Pentru astfel de cazuri există cicluri. Există 2 tipuri de bucle în Python: while și for. Să ne ocupăm de ele unul câte unul.
Bucla while repetă comenzile necesare atâta timp cât condiția rămâne adevărată.
X = 1 în timp ce x<= 100: print("Квадрат числа " + str(x) + " равен " + str(x**2)) x = x + 1
Mai întâi creăm o variabilă și îi atribuim numărul 1. Apoi creăm o buclă while și verificăm dacă x-ul nostru este mai mic decât (sau egal cu) 100. Dacă este mai mică (sau egală), atunci efectuăm două acțiuni:
- Ieșiți pătratul x
- Măriți x cu 1
După a doua comandă, programul revine la starea. Dacă condiția este din nou adevărată, atunci executăm din nou aceste două acțiuni. Și așa mai departe până când x devine egal cu 101. Atunci condiția va reveni fals și bucla nu va mai fi executată.
Bucla for este concepută pentru a repeta peste matrice. Să scriem același exemplu cu pătratele primei sute de numere naturale, dar printr-o buclă for.
Pentru x în interval (1.101): print("Pătratul numărului " + str(x) + " este " + str(x**2))
Să ne uităm la prima linie. Folosim cuvântul cheie for pentru a crea o buclă. În continuare, specificăm că vrem să repetăm anumite acțiuni pentru toți x din intervalul de la 1 la 100. Funcția range(1,101) creează o matrice de 100 de numere, începând de la 1 și terminând cu 100.
Iată un alt exemplu de iterare printr-o matrice folosind o buclă for:
Pentru i în: print(i * 2)
Codul de mai sus scoate 4 numere: 2, 20, 200 și 2000. Aici puteți vedea clar cum ia fiecare element al matricei și efectuează un set de acțiuni. Apoi ia următorul element și repetă același set de acțiuni. Și așa mai departe până când elementele din matrice se epuizează.
Clase și obiecte
În viața reală, nu operăm cu variabile sau funcții, ci cu obiecte. Pix, mașină, persoană, pisică, câine, avion - obiecte. Acum să începem să privim pisica în detaliu.
Are niște parametri. Acestea includ culoarea hainei, culoarea ochilor și porecla ei. Dar asta nu este tot. Pe lângă parametri, pisica poate efectua diverse acțiuni: toarcă, șuiera și zgârie.
Tocmai am descris schematic toate pisicile în general. Similar descrierea proprietăților și acțiunilor un obiect (de exemplu, o pisică) în Python se numește clasă. O clasă este pur și simplu un set de variabile și funcții care descriu un obiect.
Este important să înțelegeți diferența dintre o clasă și un obiect. Clasa - sistem, care descrie obiectul. Obiectul este ea realizare materială. Clasa unei pisici este o descriere a proprietăților și acțiunilor sale. Obiectul pisicii este pisica reală în sine. Pot exista multe pisici reale diferite - multe obiecte pentru pisici. Dar există o singură clasă de pisici. O bună demonstrație este imaginea de mai jos:

Clase
Pentru a crea o clasă (schema pisicii noastre), trebuie să scrieți clasa de cuvinte cheie și apoi să specificați numele acestei clase:
Clasa pisica:
În continuare trebuie să enumerăm acțiunile acestei clase (acțiuni pisici). Acțiunile, după cum probabil ați ghicit, sunt funcții definite în cadrul unei clase. Astfel de funcții din cadrul unei clase sunt de obicei numite metode.
Metodă- o funcție definită în interiorul unei clase.
Am descris deja verbal metodele pisicii mai sus: toarcet, șuierat, zgâriat. Acum să o facem în Python.
# Clasa clasa pisicii Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Shhh!") # Scratch def scrabble(self): print("Scratch-scratch !")
Este atat de simplu! Am luat și definit trei funcții obișnuite, dar numai în interiorul clasei.
Pentru a face față parametrului de sine de neînțeles, să mai adăugăm o metodă pisicii noastre. Această metodă va apela simultan toate cele trei metode deja create.
# Clasa clasa pisicii Cat: # Purr def purr(self): print("Purrr!") # Hiss def hiss(self): print("Shhh!") # Scratch def scrabble(self): print("Scratch-scratch !") # Toate împreună def all_in_one(self): self.purr() self.hiss() self.scrabble()
După cum puteți vedea, parametrul self, necesar oricărei metode, ne permite să accesăm metode și variabile ale clasei în sine! Fără acest argument, nu am putea efectua astfel de acțiuni.
Să setăm acum proprietățile pisicii noastre (culoarea blanii, culoarea ochilor, porecla). Cum să o facă? În absolut orice clasă puteți defini funcția __init__(). Această funcție este întotdeauna apelată atunci când creăm un obiect real al clasei noastre.
În metoda __init__() evidențiată mai sus, setăm variabilele pisicii noastre. Cum facem asta? În primul rând, trecem 3 argumente acestei metode, care sunt responsabile pentru culoarea hainei, culoarea ochilor și porecla. Apoi, folosim parametrul self pentru a seta imediat pisica noastră la cele 3 atribute descrise mai sus atunci când creăm un obiect.
Ce înseamnă această linie?
Self.wool_culo = culoare_lană
În partea stângă, creăm un atribut pentru pisica noastră numit wool_color, iar apoi atribuim acestui atribut valoarea conținută în parametrul wool_color pe care l-am transmis funcției __init__(). După cum puteți vedea, linia de mai sus nu este diferită de crearea variabilă normală. Doar prefixul self indică faptul că această variabilă aparține clasei Cat.
Atribut- o variabilă care aparține unei clase.
Deci, am creat o clasă de pisici gata făcută. Iată codul lui:
# Cat class class Cat: # Acțiuni care trebuie efectuate la crearea unui obiect „Cat” def __init__(self, wool_culo, eyes_culo, name): self.wool_color = wool_color self.eyes_color = eyes_color self.name = name # Purr def purr( self): print("Purrr!") # Hiss def hiss(self): print("Shhh!") # Scratch def scrabble(self): print("Scratch-scratch!") # Toate împreună def all_in_one(self) : self.purr() self.hiss() self.scrabble()
Obiecte
Am creat o diagramă a pisicii. Acum să creăm un obiect de pisică reală folosind această schemă:
Pisica_mea = Pisica ("negru", "verde", "Zosya")
În rândul de mai sus, creăm o variabilă my_cat și apoi îi atribuim un obiect din clasa Cat. Toate acestea arată ca un apel la o funcție Cat(...) . De fapt, acest lucru este adevărat. Cu această intrare numim metoda __init__() a clasei Cat. Funcția __init__() din clasa noastră ia 4 argumente: obiectul self class, care nu trebuie specificat, precum și încă 3 argumente diferite, care devin apoi atribute ale pisicii noastre.
Deci, folosind linia de mai sus, am creat un obiect de pisică reală. Pisica noastră are următoarele atribute: blană neagră, ochi verzi și porecla Zosya. Să imprimăm aceste atribute pe consolă:
Imprimare (culoarea_pisica_mea.lână) imprimare (culoarea_pisica_mea.ochii) imprimare (numele_pisica_mea)
Adică putem accesa atributele unui obiect scriind numele obiectului, punând un punct și indicând numele atributului dorit.
Atributele pisicii pot fi modificate. De exemplu, să schimbăm numele pisicii noastre:
My_cat.name = „Nyusha”
Acum, dacă afișați din nou numele pisicii în consolă, veți vedea Nyusha în loc de Zosia.
Permiteți-mi să vă reamintesc că clasa pisicii noastre îi permite să efectueze anumite acțiuni. Dacă ne mângâim pe Zosya/Nyusha, ea va începe să toarcă:
My_cat.purr()
Executarea acestei comenzi va imprima textul „Purrr!” pe consolă. După cum puteți vedea, accesarea metodelor unui obiect este la fel de ușor ca accesarea atributelor acestuia.
Module
Orice fișier cu extensia .py este un modul. Chiar și cel în care lucrezi la acest articol. Pentru ce sunt necesare? Pentru confort. Mulți oameni creează fișiere cu funcții și clase utile. Alți programatori conectează aceste module terțe și pot folosi toate funcțiile și clasele definite în ele, simplificându-le astfel munca.
De exemplu, nu trebuie să pierdeți timpul scriind propriile funcții pentru a lucra cu matrice. Este suficient să conectați modulul numpy și să utilizați funcțiile și clasele acestuia.
Pe acest moment alți programatori Python au scris deja peste 110.000 de module diferite. Modulul numpy menționat mai sus vă permite să lucrați rapid și convenabil cu matrici și matrice multidimensionale. Modulul de matematică oferă multe metode de lucru cu numere: sinusuri, cosinus, conversia grade în radiani etc., etc....
Instalarea modulului
Python este instalat împreună cu un set standard de module. Acest set include un număr foarte mare de module care vă permit să lucrați cu matematică, solicitări web, să citiți și să scrieți fișiere și să efectuați alte acțiuni necesare.
Dacă doriți să utilizați un modul care nu este inclus în setul standard, va trebui să îl instalați. Pentru a instala modulul, deschideți linia de comandă (Win + R, apoi introduceți „cmd” în câmpul care apare) și introduceți comanda în ea:
Pip install [nume_modul]
Procesul de instalare a modulului va începe. Când se finalizează, puteți utiliza în siguranță modulul instalat în programul dvs.
Conectarea și utilizarea modulului
Modulul terță parte este foarte ușor de conectat. Trebuie doar să scrieți o linie scurtă de cod:
Importă [nume_modul]
De exemplu, pentru a importa un modul care vă permite să lucrați cu funcții matematice, trebuie să scrieți următoarele:
Importă matematică
Cum se accesează o funcție de modul? Trebuie să scrieți numele modulului, apoi să puneți un punct și să scrieți numele funcției/clasei. De exemplu, factorialul 10 se găsește astfel:
Math.factorial(10)
Adică, am apelat la funcția factorial(a), care este definită în interiorul modulului de matematică. Acest lucru este convenabil, deoarece nu trebuie să pierdem timpul și să creăm manual o funcție care calculează factorialul unui număr. Puteți conecta modulul și puteți efectua imediat acțiunea necesară.
De data aceasta am decis să studiez rețelele neuronale. Am reușit să dobândesc abilități de bază în această chestiune în vara și toamna lui 2015. Prin abilități de bază, vreau să spun că pot crea o rețea neuronală simplă de la zero. Puteți găsi exemple în depozitele mele GitHub. În acest articol, voi oferi câteva explicații și voi împărtăși resurse pe care le puteți găsi utile în studiul dumneavoastră.
Pasul 1. Neuroni și metoda feedforward
Deci, ce este o „rețea neuronală”? Să așteptăm cu asta și să ne ocupăm mai întâi de un neuron.
Un neuron este ca o funcție: ia mai multe valori ca intrare și returnează una.
Cercul de mai jos reprezintă un neuron artificial. Primește 5 și returnează 1. Intrarea este suma celor trei sinapse conectate la neuron (trei săgeți în stânga).
În partea stângă a imaginii vedem 2 valori de intrare (în verde) și un offset (în maro).
Datele de intrare pot fi reprezentări numerice a două proprietăți diferite. De exemplu, la crearea unui filtru de spam, acestea ar putea însemna prezența a mai mult de un cuvânt scris cu MAJUSCULE și prezența cuvântului „Viagra”.
Valorile de intrare sunt înmulțite cu așa-numitele „greutăți”, 7 și 3 (evidențiate cu albastru).
Acum adăugăm valorile rezultate cu offset și obținem un număr, în cazul nostru 5 (evidențiat cu roșu). Aceasta este intrarea neuronului nostru artificial.

Apoi neuronul efectuează un calcul și produce o valoare de ieșire. Avem 1 pentru că valoarea rotunjită a sigmoidului la punctul 5 este 1 (vom vorbi mai detaliat despre această funcție mai târziu).
Dacă acesta ar fi un filtru de spam, faptul că ieșirea 1 ar însemna că textul a fost marcat ca spam de către neuron.

Ilustrație a unei rețele neuronale de pe Wikipedia.
Dacă combinați acești neuroni, obțineți o rețea neuronală care se propagă direct - procesul merge de la intrare la ieșire, prin neuroni conectați prin sinapse, ca în imaginea din stânga.
Pasul 2. Sigmoid
După ce ați urmărit lecțiile Welch Labs, este o idee bună să consultați Săptămâna 4 din cursul de învățare automată al Coursera despre rețelele neuronale, pentru a vă ajuta să înțelegeți cum funcționează acestea. Cursul intră foarte adânc în matematică și se bazează pe Octave, în timp ce eu prefer Python. Din acest motiv, am sărit peste exerciții și am obținut toate cunoștințele necesare din videoclipuri.

Un sigmoid mapează pur și simplu valoarea ta (pe axa orizontală) într-un interval de la 0 la 1.
Prima mea prioritate a fost să studiez sigmoidul, așa cum a figurat în multe aspecte ale rețelelor neuronale. Știam deja ceva despre asta din a treia săptămână a cursului mai sus menționat, așa că am urmărit videoclipul de acolo.
Dar nu vei ajunge departe doar cu videoclipurile. Pentru o înțelegere completă, am decis să-l codez eu. Așa că am început să scriu o implementare a unui algoritm de regresie logistică (care folosește un sigmoid).
A durat o zi întreagă, iar rezultatul a fost cu greu satisfăcător. Dar nu contează, pentru că mi-am dat seama cum funcționează totul. Codul poate fi văzut.
Nu trebuie să faceți acest lucru singur, deoarece necesită cunoștințe speciale - principalul lucru este că înțelegeți cum funcționează sigmoidul.
Pasul 3. Metoda de backpropagation
Înțelegerea modului în care funcționează o rețea neuronală de la intrare la ieșire nu este atât de dificilă. Este mult mai dificil de înțeles cum o rețea neuronală învață din seturile de date. Principiul pe care l-am folosit se numește
- Traducere
Despre ce este articolul?
Personal, învăț cel mai bine cu un cod de lucru mic cu care mă pot juca. În acest tutorial, vom învăța algoritmul de backpropagation folosind o rețea neuronală mică implementată în Python ca exemplu.Dă-mi codul!
X = np.array([ ,,, ]) y = np.array([]).T syn0 = 2*np.random.random((3,4)) - 1 syn1 = 2*np.random.random ((4,1)) - 1 pentru j în xrange(60000): l1 = 1/(1+np.exp(-(np.dot(X,syn0)))) l2 = 1/(1+np. exp(-(np.dot(l1,syn1)))) l2_delta = (y - l2)*(l2*(1-l2)) l1_delta = l2_delta.dot(syn1.T) * (l1 * (1-l1) )) syn1 += l1.T.dot(l2_delta) syn0 += X.T.dot(l1_delta)Prea comprimat? Să-l împărțim în părți mai simple.
Partea 1: Mică rețea neuronală de jucărie
O rețea neuronală antrenată prin retropropagare încearcă să folosească datele de intrare pentru a prezice datele de ieșire.Să presupunem că trebuie să prezicem cum va arăta coloana de ieșire pe baza datelor de intrare. Această problemă ar putea fi rezolvată prin calcularea corespondenței statistice dintre ele. Și am vedea că coloana din stânga este 100% corelată cu rezultatul.
Backpropagation, în cel mai simplu caz, calculează statistici similare pentru a crea un model. Sa incercam.
Rețea neuronală în două straturi
import numpy as np # Sigmoid def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x) )) # set de date de intrare X = np.array([ , , , ]) # date de ieșire y = np.array([]).T # face numerele aleatoare mai specifice np.random.seed(1) # inițializează ponderi în mod aleatoriu cu medie 0 syn0 = 2*np.random.random((3,1)) - 1 pentru iter în xrange(10000): # propagare înainte l0 = X l1 = nonlin(np.dot(l0,syn0) )) # Cât de greșit am greșit? l1_error = y - l1 # înmulțiți acest lucru cu panta sigmoidului # pe baza valorilor din l1 l1_delta = l1_error * nonlin(l1,True) # !!! # actualizați ponderile syn0 += np.dot(l0.T,l1_delta) # !!! print "Ieșire după antrenament:" print l1Ieșire după antrenament: [[ 0,00966449] [ 0,00786506] [ 0,99358898] [ 0,99211957]]
Variabilele și descrierile lor.
"*" - înmulțire în funcție de elemente - doi vectori de aceeași dimensiune înmulțesc valorile corespunzătoare, iar rezultatul este un vector de aceeași dimensiune
„-” – scăderea vectorilor în funcție de elemente
x.dot(y) – dacă x și y sunt vectori, atunci rezultatul va fi un produs scalar. Dacă acestea sunt matrici, atunci rezultatul este înmulțirea matricei. Dacă matricea este doar una dintre ele, este înmulțirea unui vector și a unei matrice.
- comparați l1 după prima iterație și după ultima
- uită-te la funcția nonlin.
- uite cum se schimba l1_error
- analiza linia 36 - principalele ingrediente secrete sunt colectate aici (marcate!!!)
- parse line 39 - întreaga rețea se pregătește tocmai pentru această operațiune (marcată!!!)
Să defalcăm codul linie cu linie
import numpy ca npImportă numpy, o bibliotecă de algebră liniară. Singura noastră dependență.
Def nonlin(x,deriv=False):
Neliniaritatea noastră. Această funcție specifică creează un „sigmoid”. Se potrivește oricărui număr cu o valoare de la 0 la 1 și convertește numerele în probabilități și, de asemenea, are câteva alte proprietăți utile pentru antrenarea rețelelor neuronale.
Dacă(deriv==Adevărat):
Această funcție poate produce și derivata sigmoidului (deriv=True). Aceasta este una dintre proprietățile sale benefice. Dacă ieșirea funcției este o variabilă out, atunci derivata va fi out * (1-out). Efectiv.
X = np.array([ , …
Inițializarea matricei de date de intrare ca o matrice numpy. Fiecare linie este un exemplu de antrenament. Coloanele sunt noduri de intrare. Ajungem cu 3 noduri de intrare în rețea și 4 exemple de antrenament.
Y = np.array([]).T
Inițializează datele de ieșire. „.T” – funcție de transfer. După translație, matricea y are 4 rânduri cu o coloană. Ca și în cazul datelor de intrare, fiecare rând este un exemplu de antrenament, iar fiecare coloană (una în cazul nostru) este un nod de ieșire. Se pare că rețeaua are 3 intrări și 1 ieșire.
Np.semințe.aleatoare.(1)
Datorită acestui fapt, distribuția aleatoare va fi aceeași de fiecare dată. Acest lucru ne va permite să monitorizăm mai ușor rețeaua după ce facem modificări la cod.
Syn0 = 2*np.random.random((3,1)) – 1
Matricea greutății rețelei. syn0 înseamnă „synapse zero”. Deoarece avem doar două straturi, intrare și ieșire, avem nevoie de o matrice de greutate care le va conecta. Dimensiunea sa este (3, 1), deoarece avem 3 intrări și 1 ieșire. Cu alte cuvinte, l0 are dimensiunea 3 și l1 are dimensiunea 1. Deoarece conectăm toate nodurile din l0 la toate nodurile din l1, avem nevoie de o matrice de dimensiune (3, 1).
Rețineți că este inițializat aleatoriu și media este zero. În spatele acestui lucru se află o teorie destul de complexă. Deocamdată vom lua asta doar ca pe o recomandare. De asemenea, rețineți că rețeaua noastră neuronală este chiar această matrice. Avem „straturi” l0 și l1, dar acestea sunt valori temporare bazate pe setul de date. Nu le depozităm. Toate antrenamentele sunt stocate în syn0.
Pentru iter în xrange(10000):
Aici începe codul de antrenament al rețelei principale. Bucla de cod se repetă de mai multe ori și optimizează rețeaua pentru setul de date.
Primul strat, l0, este doar date. X conține 4 exemple de antrenament. Le vom procesa pe toate deodată - aceasta se numește antrenament de grup. În total, avem 4 linii l0 diferite, dar ele pot fi considerate ca un exemplu de antrenament - în această etapă nu contează (puteți încărca 1000 sau 10000 dintre ele fără nicio modificare a codului).
L1 = nonlin(np.dot(l0,syn0))
Acesta este pasul de predicție. Lăsăm rețeaua să încerce să prezică rezultatul pe baza intrării. Apoi vom vedea cum o face, astfel încât să o putem modifica pentru îmbunătățire.
Există doi pași pe linie. Primul face înmulțirea matriceală a lui l0 și syn0. Al doilea trece ieșirea prin sigmoid. Dimensiunile lor sunt următoarele:
(4 x 3) punct (3 x 1) = (4 x 1)
Înmulțirile matricelor necesită ca dimensiunile să fie aceleași în mijlocul ecuației. Matricea finală are același număr de rânduri ca prima și același număr de coloane ca a doua.
Am încărcat 4 exemple de antrenament și am obținut 4 presupuneri (matrice 4x1). Fiecare ieșire corespunde ipotezei rețelei pentru o anumită intrare.
L1_error = y - l1
Deoarece l1 conține presupuneri, putem compara diferența lor cu realitatea scăzând l1 din răspunsul corect y. l1_error este un vector de numere pozitive și negative care caracterizează o rețea „miss”.
Și aici este ingredientul secret. Această linie trebuie analizată bucată cu bucată.
Prima parte: derivat
Nonlin(l1, True)
L1 reprezintă aceste trei puncte, iar codul produce panta dreptelor prezentate mai jos. Rețineți că pentru valori mari precum x=2,0 (punct verde) și valori foarte mici precum x=-1,0 (violet) liniile au o pantă ușoară. Cel mai mare unghi în punctul x=0 (albastru). Acest lucru face o mare diferență. De asemenea, rețineți că toate derivatele variază de la 0 la 1.

Expresie completă: derivată ponderată în funcție de eroare
L1_delta = l1_error * nonlin(l1,True)
Din punct de vedere matematic, există metode mai precise, dar în cazul nostru este potrivită și aceasta. l1_error este o matrice (4,1). nonlin(l1,True) returnează matricea (4,1). Aici le înmulțim element cu element, iar la ieșire obținem și matricea (4,1), l1_delta.
Înmulțind derivatele cu erori, reducem erorile predicțiilor făcute cu mare încredere. Dacă panta liniei era mică, atunci rețeaua conținea fie o valoare foarte mare, fie foarte mică. Dacă estimarea rețelei este aproape de zero (x=0, y=0,5), atunci nu este deosebit de sigură. Actualizăm aceste predicții incerte și lăsăm predicțiile cu încredere ridicată în pace, înmulțindu-le cu valori apropiate de zero.
Syn0 += np.dot(l0.T,l1_delta)
Suntem gata să actualizăm rețeaua. Să ne uităm la un exemplu de antrenament. În el vom actualiza greutățile. Actualizați greutatea cea mai din stânga (9,5)

Weight_update = input_value * l1_delta
Pentru greutatea cea mai din stânga ar fi 1,0 * l1_delta. Probabil că acest lucru va crește doar ușor 9,5. De ce? Pentru că predicția era deja destul de încrezătoare, iar previziunile erau practic corecte. O mică eroare și o pantă ușoară a liniei înseamnă o actualizare foarte mică.

Dar, deoarece facem antrenament de grup, repetăm pasul de mai sus pentru toate cele patru exemple de antrenament. Deci arată foarte asemănător cu imaginea de mai sus. Deci, ce face linia noastră? Numărează actualizările de greutate pentru fiecare greutate, pentru fiecare exemplu de antrenament, le însumează și actualizează toate greutățile - toate într-o singură linie.
După ce observăm actualizarea rețelei, să revenim la datele noastre de antrenament. Când atât intrarea cât și ieșirea sunt 1, creștem greutatea dintre ele. Când intrarea este 1 și ieșirea este 0, reducem greutatea.
Intrare Ieșire 0 0 1 0 1 1 1 1 1 0 1 1 0 1 1 0
Deci, în cele patru exemple de antrenament de mai jos, greutatea primei intrări în raport cu rezultatul fie va crește, fie va rămâne constantă, iar celelalte două greutăți vor crește și vor scădea în funcție de exemple. Acest efect contribuie la învățarea în rețea bazată pe corelațiile datelor de intrare și de ieșire.
Partea 2: o sarcină mai dificilă
Intrare Ieșire 0 0 1 0 0 1 1 1 1 0 1 1 1 1 1 1 0Să încercăm să anticipăm datele de ieșire pe baza a trei coloane de date de intrare. Niciuna dintre coloanele de intrare nu este 100% corelată cu rezultatul. A treia coloană nu este deloc conectată la nimic, deoarece le conține pe tot parcursul. Cu toate acestea, aici puteți vedea modelul - dacă una dintre primele două coloane (dar nu ambele simultan) conține 1, atunci rezultatul va fi, de asemenea, egal cu 1.
Acesta este un design neliniar deoarece nu există o corespondență directă unu-la-unu între coloane. Potrivirea se bazează pe o combinație de intrări, coloanele 1 și 2.
Interesant, recunoașterea modelelor este o sarcină foarte similară. Dacă aveți 100 de poze cu biciclete și țevi de aceeași dimensiune, prezența anumitor pixeli în anumite locuri nu se corelează direct cu prezența unei biciclete sau a unei țevi în imagine. Statistic, culoarea lor poate apărea aleatorie. Dar unele combinații de pixeli nu sunt întâmplătoare - cele care formează o imagine a unei biciclete (sau tub).


Strategie
Pentru a combina pixelii în ceva care poate avea o corespondență unu-la-unu cu rezultatul, trebuie să adăugați un alt strat. Primul strat combină intrarea, al doilea atribuie o potrivire la ieșire folosind ieșirea primului strat ca intrare. Atenție la masă.Intrare (l0) Greutăți ascunse (l1) Ieșire (l2) 0 0 1 0,1 0,2 0,5 0,2 0 0 1 1 0,2 0,6 0,7 0,1 1 1 0 1 0,3 0,2 0,3 0,9 1 1 1 0,2 0,9
Prin atribuirea aleatorie a greutăților, obținem valori ascunse pentru stratul nr. 1. Interesant este că a doua coloană de ponderi ascunse are deja o mică corelație cu rezultatul. Nu ideal, dar acolo. Și aceasta este, de asemenea, o parte importantă a procesului de formare în rețea. Antrenamentul nu va face decât să întărească această corelație. Acesta va actualiza syn1 pentru a-și atribui maparea datelor de ieșire și syn0 pentru a obține mai bine datele de intrare.
Rețea neuronală în trei straturi
import numpy ca np def nonlin(x,deriv=False): if(deriv==True): return f(x)*(1-f(x)) return 1/(1+np.exp(-x)) X = np.array([, , , ]) y = np.array([, , , ]) np.random.seed(1) # inițializați aleatoriu ponderile, în medie - 0 syn0 = 2*np.random. aleatoriu ((3,4)) - 1 syn1 = 2*np.random.random((4,1)) - 1 pentru j în xrange(60000): # mergi înainte prin straturile 0, 1 și 2 l0 = X l1 = nonlin(np.dot(l0,syn0)) l2 = nonlin(np.dot(l1,syn1)) # cât de mult am greșit cu privire la valoarea cerută? l2_error = y - l2 if (j% 10000) == 0: tipăriți „Eroare:” + str(np.mean(np.abs(l2_error))) # în ce direcție ar trebui să vă mutați? # dacă eram încrezători în predicție, atunci nu trebuie să o schimbăm mult l2_delta = l2_error*nonlin(l2,deriv=True) # cât de mult afectează valorile lui l1 erorile din l2? l1_error = l2_delta.dot(syn1.T) # în ce direcție ar trebui să ne deplasăm pentru a ajunge la l1? # dacă am fost încrezători în predicție, atunci nu trebuie să o schimbăm mult l1_delta = l1_error * nonlin(l1,deriv=True) syn1 += l1.T.dot(l2_delta) syn0 += l0.T.dot (l1_delta)Eroare: 0,496410031903 Eroare: 0,00858452565325 Eroare: 0,00578945986251 Eroare: 0,00462917677677 Eroare: 0,00395876528027 Eroare: 0,002356701
Variabilele și descrierile lor
X este matricea setului de date de intrare; coarde - exemple de antrenamenty – matricea setului de date de ieșire; coarde - exemple de antrenament
l0 – primul strat de rețea definit de datele de intrare
l1 – al doilea strat al rețelei, sau strat ascuns
l2 este stratul final, aceasta este ipoteza noastră. Pe măsură ce exersați, ar trebui să vă apropiați de răspunsul corect.
syn0 – primul strat de greutăți, Synapse 0, combină l0 cu l1.
syn1 – Al doilea strat de greutăți, Synapse 1, combină l1 cu l2.
l2_error – eroare de rețea în termeni cantitativi
l2_delta – eroare de rețea, în funcție de încrederea predicției. Aproape identică cu eroarea, cu excepția predicțiilor sigure
l1_error – cântărind l2_delta cu greutăți din syn1, calculăm eroarea în stratul mijlociu/ascuns
l1_delta – erori de rețea de la l1, scalate de încrederea predicțiilor. Aproape identic cu l1_error, cu excepția predicțiilor sigure
Codul ar trebui să fie destul de clar - este doar implementarea anterioară a rețelei, stivuită în două straturi, unul peste altul. Ieșirea primului strat l1 este intrarea celui de-al doilea strat. Există ceva nou doar în linia următoare.
L1_error = l2_delta.dot(syn1.T)
Utilizează erori ponderate cu încrederea predicțiilor de la l2 pentru a calcula eroarea pentru l1. Obținem, s-ar putea spune, o eroare ponderată cu contribuții - calculăm cât de mult contribuie valorile la nodurile l1 la erorile din l2. Acest pas se numește backpropagation. Apoi actualizăm syn0 folosind același algoritm ca și rețeaua neuronală cu două straturi.
Original: Crearea unei rețele neuronale în Python
Autor: John Serrano
Data publicării: 26 mai 2016
Traducere: A. Panin
Data traducerii: 6 decembrie 2016
Rețelele neuronale sunt programe extrem de complexe, de înțeles doar academicienilor și geniilor, cu care prin definiție nu pot fi lucrate de către dezvoltatorii obișnuiți, ca să nu mai vorbim de mine. Asta crezi, nu?
Ei bine, de fapt nu este deloc așa. După o discuție excelentă susținută de Louis Monier și Greg Renard la Holberton College, mi-am dat seama că rețelele neuronale sunt suficient de simple pentru ca orice dezvoltator de programe să le înțeleagă și să le implementeze. Desigur, cele mai complexe rețele sunt proiecte de anvergură, cu arhitectură elegantă și complicată, dar și conceptele care stau la baza sunt mai mult sau mai puțin evidente. Dezvoltarea oricărei rețele neuronale de la zero poate fi o provocare, dar, din fericire, există mai multe biblioteci grozave care pot face toată munca de nivel scăzut pentru tine.
În acest context, un neuron este o entitate destul de simplă. Acceptă mai multe valori de intrare și dacă suma acestor valori depășește o limită specificată, se activează. În acest caz, fiecare valoare de intrare este înmulțită cu greutatea sa. Procesul de învățare este în esență procesul de stabilire a ponderilor valorilor pentru a genera valorile de ieșire necesare. Rețelele despre care vor fi discutate în acest articol se numesc rețele „feedforward”, ceea ce înseamnă că neuronii din ele sunt aranjați în straturi, datele lor de intrare provenind de la nivelul anterior și datele de ieșire fiind trimise la nivelul următor.

Există și alte tipuri de rețele neuronale, cum ar fi rețelele neuronale recurente, care sunt organizate într-un mod diferit, dar acesta este un subiect pentru un alt articol.
Un neuron care funcționează conform principiului descris mai sus se numește perceptron și se bazează pe un model original de neuroni artificiali, care este folosit extrem de rar astăzi. Problema cu perceptronii este că o mică modificare a valorilor de intrare poate duce la o schimbare mare a valorii de ieșire din cauza funcției de activare în trepte. În acest caz, o scădere ușoară a valorii de intrare poate duce la faptul că valoarea internă nu va depăși limita setată și neuronul nu va fi activat, ceea ce va duce la modificări și mai semnificative în starea neuronilor care îl urmăresc. . Din fericire, această problemă se rezolvă cu ușurință cu funcția de activare mai fluidă găsită pe majoritatea rețelelor moderne.


Cu toate acestea, rețeaua noastră neuronală va fi atât de simplă încât perceptronii sunt destul de potriviti pentru crearea ei. Vom crea o rețea care efectuează o operație logică și. Aceasta înseamnă că vom avea nevoie de doi neuroni de intrare și un neuron de ieșire, precum și de mai mulți neuroni în stratul intermediar „ascuns”. Ilustrația de mai jos arată arhitectura acestei rețele, care ar trebui să fie destul de evidentă.

Monier și Renard au folosit scriptul convnet.js pentru a crea rețele demo pentru discuțiile lor. Convnet.js poate fi folosit pentru a crea rețele neuronale direct în browserul dvs. web, permițându-vă să le explorați și să le modificați pe aproape orice platformă. Desigur, această implementare în JavaScript are și dezavantaje semnificative, dintre care unul este viteza redusă. Ei bine, în scopul acestui articol vom folosi biblioteca FANN (Fast Artificial Neural Networks). În acest caz, la nivelul limbajului de programare Python se va folosi modulul pyfann, care conține legături pentru biblioteca FANN. Ar trebui să instalați pachetul software cu acest modul chiar acum.
Importarea unui modul pentru lucrul cu biblioteca FANN se realizează după cum urmează:
>>> de la pyfann import libfann
Acum putem începe! Prima operație pe care va trebui să o facem este crearea unei rețele neuronale goale.
>>> neuronal_net = libfann.neural_network()
Obiectul neural_net creat nu conține în prezent neuroni, așa că să încercăm să creăm unii. În acest scop vom folosi funcția libfann.create_standard_array(). Funcția create_standard_array() creează o rețea neuronală în care toți neuronii sunt conectați la neuronii din straturile învecinate, deci poate fi numită o rețea „complet conectată”. Funcția create_standard_array() preia o matrice cu valori numerice, corespunzător numărului de neuroni de la fiecare nivel. În cazul nostru, aceasta este o matrice.
>>> neural_net.create_standard((2, 4, 1))
După aceasta va trebui să setăm valoarea ratei de învățare. Această valoare corespunde numărului de modificări de greutate într-o iterație. Vom instala suficient de mare viteză antrenament egal cu 0,7, deoarece vom rezolva o problemă destul de simplă folosind rețeaua noastră.
>>> neural_net.set_learning_rate(0,7)
Acum este timpul să instalați funcția de activare, al cărei scop a fost discutat mai sus. Vom folosi modul de activare SIGMOID_SYMMETRIC_STEPWISE, care corespunde funcției de pas tangente hiperbolice. Este mai puțin precisă și mai rapidă decât funcția tangentă hiperbolică obișnuită și este perfectă pentru sarcina noastră.
>>> neural_net.set_activation_function_output(libfann.SIGMOID_SYMMETRIC_STEPWISE)
În cele din urmă, trebuie să rulăm algoritmul de antrenament al rețelei și să salvăm datele rețelei într-un fișier. Funcția de antrenament în rețea are patru argumente: numele fișierului cu datele pe care se va efectua antrenamentul, suma maximaîncearcă să ruleze algoritmul de învățare, numărul de operațiuni de învățare înainte de a scoate date despre starea rețelei și rata de eroare.
>>> neuronal_network.train_on_file(„and.data”, 10000, 1000, .00001) >>> neuronal_network.save(„and.net”)
Fișierul „and.data” ar trebui să conțină următoarele date:
4 2 1 -1 -1 -1 -1 1 -1 1 -1 -1 1 1 1
Prima linie conține trei valori: numărul de exemple din fișier, numărul de valori de intrare și numărul de valori de ieșire. Mai jos sunt exemple de linii, în care liniile cu două valori conțin valori de intrare, iar liniile cu o singură valoare arată valorile de ieșire.
Ați finalizat cu succes instruirea în rețea și acum doriți să-l încercați, nu? Dar mai întâi va trebui să încărcăm datele de rețea din fișierul în care au fost salvate mai devreme.
>>> neural_net = libfann.neural_net() >>> neural_net.create_from_file("and.net")
După aceea, îl putem activa pur și simplu într-un mod similar:
>>> print neural_net.run()
Rezultatul ar trebui să fie [-1.0] sau o valoare similară, în funcție de datele de rețea generate în timpul procesului de antrenament.
Felicitări! Tocmai ți-ai învățat computerul cum să efectueze operațiuni logice de bază!