FAQ on practical implementation of RAID. What is a raid array - types and settings
(+) : Has high reliability - it works as long as at least one disk in the array is functioning. The probability of failure of two disks at once is equal to the product of the probabilities of failure of each disk. In practice, if one of the disks fails, immediate action must be taken to restore redundancy. To do this, it is recommended to use hot spare disks with any RAID level (except zero). The advantage of this approach is maintaining constant availability.
(-) : The disadvantage is that you have to pay the cost of two hard drives, getting the usable capacity of only one hard drive.
RAID 1+0 and RAID 0+1
Mirror on many disks - RAID 1+0 or RAID 0+1. RAID 10 (RAID 1+0) refers to the option when two or more RAID 1 are combined into RAID 0. RAID 0+1 can mean two options:
RAID 2
Arrays of this type are based on the use of Hamming code. Disks are divided into two groups: for data and for error correction codes, and if data is stored on disks, then disks are needed to store correction codes. Data is distributed across disks intended for storing information, the same as in RAID 0, i.e. they are divided into small blocks according to the number of disks. The remaining disks store error correction codes, which can be used to restore information if any hard disk fails. The Hamming method has long been used in ECC memory and allows on-the-fly correction of single errors and detection of double errors.
Dignity RAID 2 is an improvement in the speed of disk operations compared to the performance of a single disk.
Disadvantage RAID 2 array is that the minimum number of disks at which it makes sense to use it is 7. In this case, a structure of almost double the number of disks is needed (for n=3 the data will be stored on 4 disks), so this type of array is not widespread . If there are about 30-60 disks, then the overrun is 11-19%.
RAID 3
In a RAID 3 array of disks, data is split into smaller-than-sector-sized chunks (broken into bytes) or blocks and distributed across the disks. Another disk is used to store parity blocks. RAID 2 used a disk for this purpose, but most of the information on the control disks was used for on-the-fly error correction, while most users are satisfied with simply restoring information in the event of a disk failure, which is enough information to fit on one dedicated hard drive.
Differences between RAID 3 and RAID 2: the inability to correct errors on the fly and less redundancy.
Advantages:
- high speed reading and writing data;
- The minimum number of disks to create an array is three.
Flaws:
- an array of this type is only good for single-task work with large files, since the access time to an individual sector, divided across disks, is equal to the maximum of the access intervals to the sectors of each disk. For small blocks, the access time is much longer than the read time.
- there is a large load on the control disk, and, as a result, its reliability drops significantly compared to disks storing data.
RAID 4
RAID 4 is similar to RAID 3, but differs in that the data is divided into blocks rather than bytes. Thus, it was possible to partially overcome the problem of low data transfer speed of small volumes. Writing is slow due to the fact that parity for the block is generated during recording and written to a single disk. Among the widely used storage systems, RAID-4 is used on NetApp storage devices (NetApp FAS), where its shortcomings are successfully eliminated due to the operation of disks in a special group recording mode, determined by the internal WAFL file system used on the devices.
RAID 5
The main disadvantage of RAID levels 2 to 4 is the inability to perform parallel write operations, since a separate control disk is used to store parity information. RAID 5 does not have this disadvantage. Data blocks and checksums are cyclically written to all disks of the array; there is no asymmetry in the disk configuration. Checksums mean the result of an XOR (exclusive or) operation. Xor has a feature that is used in RAID 5, which makes it possible to replace any operand with the result, and, using the algorithm xor, get the missing operand as a result. For example: a xor b = c(Where a, b, c- three disks of the raid array), in case a refuses, we can get him by putting him in his place c and after spending xor between c And b: c xor b = a. This applies regardless of the number of operands: a xor b xor c xor d = e. If it refuses c Then e takes his place and holding xor as a result we get c: a xor b xor e xor d = c. This method essentially provides version 5 fault tolerance. To store the result of xor, only 1 disk is required, the size of which is equal to the size of any other disk in the raid.
(+) : RAID5 has become widespread, primarily due to its cost-effectiveness. The capacity of a RAID5 disk array is calculated using the formula (n-1)*hddsize, where n is the number of disks in the array, and hddsize is the size of the smallest disk. For example, for an array of 4 disks of 80 gigabytes, the total volume will be (4 - 1) * 80 = 240 gigabytes. Writing information to a RAID 5 volume requires additional resources and performance decreases, since additional calculations and write operations are required, but when reading (compared to a separate hard drive), there is a gain because data streams from several disks in the array can be processed in parallel.
(-) : The performance of RAID 5 is noticeably lower, especially on operations such as Random Write, in which performance drops by 10-25% of the performance of RAID 0 (or RAID 10), since it requires more disk operations (each The server write operation is replaced on the RAID controller by three - one read operation and two write operations). The disadvantages of RAID 5 appear when one of the disks fails - the entire volume goes into critical mode (degrade), all write and read operations are accompanied by additional manipulations, and performance drops sharply. In this case, the reliability level is reduced to the reliability of RAID-0 with the corresponding number of disks (that is, n times lower than the reliability of a single disk). If, before the array is completely restored, a failure occurs, or an unrecoverable read error occurs on at least one more disk, then the array is destroyed and the data on it cannot be restored using conventional methods. It should also be taken into account that the process of RAID Reconstruction (recovery of RAID data through redundancy) after a disk failure causes an intensive read load from the disks for many hours continuously, which can cause the failure of any of the remaining disks in the least protected period of RAID operation, as well as identify previously undetected read failures in cold data arrays (data that is not accessed during normal operation of the array, archived and inactive data), which increases the risk of failure during data recovery. The minimum number of disks used is three.
RAID 5EE
Note: Not supported on all controllers RAID level-5EE is similar to RAID-5E, but with more efficient use of the spare disk and shorter recovery time. Similar to RAID level-5E, this RAID array level creates rows of data and checksums across all drives in the array. RAID-5EE provides improved security and performance. When using RAID level-5E, the capacity of a logical volume is limited by the capacity of two physical hard drives of the array (one for control, one backup). The spare disk is part of a RAID level-5EE array. However, unlike RAID level-5E, which uses unpartitioned free space for reserve, RAID level-5EE inserts checksum blocks into the spare disk, as shown in the following example. This allows you to rebuild data faster if a physical disk fails. With this configuration, you will not be able to use it with other arrays. If you need a spare drive for another array, you should have another spare hard drive. RAID level-5E requires a minimum of four drives and, depending on the firmware level and their capacity, supports from 8 to 16 drives. RAID level-5E has specific firmware. Note: For RAID level-5EE, you can only use one logical volume in the array.
Advantages:
- 100% data protection
- Large physical disk capacity compared to RAID-1 or RAID -1E
- Greater performance compared to RAID-5
- Faster RAID recovery compared to RAID-5E
Flaws:
- Lower performance than RAID-1 or RAID-1E
- Supports only one logical volume per array
- Inability to share a spare drive with other arrays
- Not all controllers supported
RAID 6
RAID 6 is similar to RAID 5, but has a higher degree of reliability - the capacity of 2 disks is allocated for checksums, 2 amounts are calculated using different algorithms. Requires a more powerful RAID controller. Ensures operation after the simultaneous failure of two disks - protection against multiple failures. To organize an array, a minimum of 4 disks is required. Typically, using RAID-6 causes approximately a 10-15% drop in disk group performance compared to similar RAID-5 performance, which is caused by the large amount of processing for the controller (the need to calculate a second checksum, as well as read and rewrite more disk blocks when writing each block).
RAID 7
RAID 7 is a registered trademark of Storage Computer Corporation and is not a separate RAID level. The structure of the array is as follows: data is stored on disks, one disk is used to store parity blocks. Writing to disks is cached using RAM; the array itself requires a mandatory UPS; In case of power failure, data corruption occurs.
RAID 10

RAID 10 architecture diagram
RAID 10 is a mirrored array in which data is written sequentially to several disks, as in RAID 0. This architecture is a RAID 0 array, the segments of which are RAID 1 arrays instead of individual disks. Accordingly, an array of this level must contain at least 4 disks. RAID 10 combines high fault tolerance and performance.
Current controllers use this mode by default for RAID 1+0. That is, one disk is the main one, the second is a mirror, data is read from them one by one. Now we can assume that RAID 10 and RAID 1+0 are just different names for the same disk mirroring method. The statement that RAID 10 is the most reliable option for data storage is erroneous, because, despite the fact that for this RAID level it is possible to maintain data integrity if half of the disks fail, irreversible destruction of the array occurs if already two fail disks if they are in the same mirror pair.
Combined levels
In addition to the basic RAID 0 - RAID 5 levels described in the standard, there are combined RAID 1+0, RAID 3+0, RAID 5+0, RAID 1+5 levels, which are interpreted differently by different manufacturers.
- RAID 1+0 is a combination mirroring And alternation(see above).
- RAID 5+0 is alternation volumes of the 5th level.
- RAID 1+5 - RAID 5 of mirrored steam.
Combined levels inherit both the advantages and disadvantages of their “parents”: the appearance alternation at RAID level 5+0 does not add any reliability to it, but it has a positive effect on performance. RAID level 1+5 is probably very reliable, but not the fastest and, moreover, extremely uneconomical: the useful capacity of the volume is less than half the total capacity of the disks...
It is worth noting that the number of hard drives in combined arrays will also change. For example, for RAID 5+0, 6 or 8 hard drives are used, for RAID 1+0 - 4, 6 or 8.
Comparison of standard levels
| Level | Number of disks | Effective capacity* | fault tolerance | Advantages | Flaws |
|---|---|---|---|---|---|
| 0 | from 2 | S*N | No | highest performance | very low reliability |
| 1 | 2 | S | 1 disk | reliability | |
| 1E | from 3 | S*N/2 | 1 disc** | high data security and good performance | double cost of disk space |
| 10 or 01 | from 4, even | S*N/2 | 1 disc*** | highest performance and highest reliability | double cost of disk space |
| 5 | from 3 to 16 | S*(N - 1) | 1 disk | economical, high reliability, good performance | performance below RAID 0 |
| 50 | from 6, even | S*(N - 2) | 2 disks** | high reliability and performance | high cost and difficulty of maintenance |
| 5E | from 4 | S*(N - 2) | 1 disk | cost-effective, high reliability, speed higher than RAID 5 | |
| 5EE | from 4 | S*(N - 2) | 1 disk | fast data reconstruction after a failure, cost-effective, high reliability, speed higher than RAID 5 | performance is lower than RAID 0 and 1, the backup drive is idling and not checked |
| 6 | from 4 | S*(N - 2) | 2 disks | economical, highest reliability | performance below RAID 5 |
| 60 | from 8, even | S*(N - 2) | 2 disks | high reliability, large amount of data | |
| 61 | from 8, even | S * (N - 2) / 2 | 2 disks** | very high reliability | high cost and complexity of organization |
* N is the number of disks in the array, S is the volume of the smallest disk. ** Information will not be lost if all disks within one mirror fail. *** Information will not be lost if two disks within different mirrors fail.
Matrix RAID
Matrix RAID is a technology implemented by Intel in its chipsets starting with ICH6R. Strictly speaking, this technology is not a new RAID level (its analogue exists in high-level hardware RAID controllers), it allows, using a small number of disks, to simultaneously organize one or more arrays of the RAID 1, RAID 0 and RAID 5 levels. This allows for a relatively little money can provide increased reliability for some data, and high speed of access and production for others.
Additional features of RAID controllers
Many RAID controllers are equipped with a set of additional functions:
- "Hot Swap"
- "Hot Spare"
- Stability check.
Software (English) software) RAID
To implement RAID, you can use not only hardware, but also entirely software components (drivers). For example, in systems based on the Linux kernel, there are special kernel modules, and you can manage RAID devices using the mdadm utility. Software RAID has its advantages and disadvantages. On the one hand, it costs nothing (unlike hardware RAID controllers, which start at $250). On the other hand, software RAID uses CPU resources, and at times of peak load on the disk system, the processor can spend a significant portion of its power on servicing RAID devices.
Linux kernel 2.6.28 (the last one released in 2008) supports software RAID of the following levels: 0, 1, 4, 5, 6, 10. The implementation allows you to create RAID on separate disk partitions, which is similar to the Matrix RAID described above. Booting from RAID is supported.
Further development of the RAID idea
The idea of RAID arrays is to combine disks, each of which is treated as a set of sectors, and as a result, the file system driver “sees” as if a single disk and works with it, without paying attention to its internal structure. However, you can achieve a significant increase in the performance and reliability of a disk system if the file system driver “knows” that it is working not with one disk, but with a set of disks.
Moreover, if any of the disks in RAID-0 are destroyed, all information in the array will be lost. But if the file system driver places each file on one disk, and the directory structure is correctly organized, then if any of the disks is destroyed, only the files located on that disk will be lost; and the files located entirely on the preserved disks will remain accessible.
An employee of Y-E Data Corporation, which is the world's largest manufacturer of USB floppy drives, Daniel Olson, as an experiment, created a RAID array of four
RAID array. What is this? For what? And how to create?
Over the long decades of development of the computer industry, information storage means for computers have gone through a serious evolutionary path of development. Punched tapes and punched cards, magnetic tapes and drums, magnetic, optical and magneto-optical disks, semiconductor drives - this is just a short list of already tested technologies. Currently, laboratories around the world are attempting to create holographic and quantum storage devices that will greatly increase the recording density and reliability of its storage.
In the meantime, hard drives have remained the most common means of storing information on a personal computer for a long time. Otherwise, they can be called HDDs (hard magnetic disk drives), hard drives, hard disks, but the essence does not change from changing the name - these are drives with a package of magnetic disks in a single housing.
The first hard drive, called the IBM 350, was assembled on January 10, 1955 in the laboratory of the American company IBM. With the size of a good cabinet and a weight of a ton, this hard drive could hold five megabytes of information. From a modern point of view, such a volume cannot even be called funny, but during the mass use of punched cards and magnetic tapes with serial access, this was a colossal technological breakthrough.

Unloading the first IBM 350 hard drive from an airplane
Less than six decades have passed since that day, but now you won’t surprise anyone with a hard drive weighing less than two hundred grams, ten centimeters long and a volume of information of a couple of terabytes. At the same time, the technology for recording, storing and reading data is no different from that used in the IBM 350 - the same magnetic plates and read/write heads sliding above them.

The evolution of hard drives against the background of an inch ruler (photo from " Wikipedia " )
Unfortunately, it is precisely the features of this technology that cause two main problems associated with the use of hard drives. The first of them is the too low speed of writing, reading and transferring information from the disk to the processor. In a modern computer, it is the hard drive that is the slowest device, which often determines the performance of the entire system as a whole.
The second problem is the insufficient security of information stored on the hard drive. If your hard drive breaks, you can irretrievably lose all the data stored on it. And it’s good if the losses are limited to the loss of a family photo album (although there is actually little good in this). The destruction of important financial and marketing information can cause the collapse of a business.
Partially helping to protect stored information is regular backup of all or only important data on the hard drive. But even in this case, if it breaks down, that part of the data that has been updated since the last backup will be lost.
Fortunately, there are methods that can help overcome the above disadvantages of traditional hard drives. One such method is to create RAID arrays of several hard drives.
What is RAID
On the Internet and even modern computer literature, you can often come across the term “RAID array,” which is actually a tautology, since the abbreviation RAID (redundant array of independent disks) already stands for “redundant array of independent disks.”
The name fully reveals the physical meaning of such arrays - this is a set of two or more hard drives. The joint operation of these disks is controlled by a special controller. As a result of the controller’s operation, such arrays are perceived by the operating system as one hard drive and the user may not think about the nuances of managing the operation of each hard drive separately.
There are several main types of RAID, each of which has a different impact on the overall reliability and speed of the array compared to single disks. They are designated by a conventional number from 0 to 6. A similar designation with a detailed description of the architecture and operating principle of the arrays was proposed by specialists from the University of California at Berkeley. In addition to the main seven types of RAID, various combinations of them are also possible. Let's consider them further.
This is the simplest type of hard drive array, the main purpose of which is to increase the performance of the computer's disk subsystem. This is achieved by dividing the streams of written (read) information into several substreams, which are simultaneously written (read) to several hard drives. As a result, the total speed of information exchange, for example, for two-disk arrays increases by 30-50% compared to one hard drive of the same type.

The total volume of RAID 0 is equal to the sum of the volumes of the hard drives included in it. Information is divided into data blocks of a fixed length, regardless of the length of the recorded files.
The main advantage of RAID 0 is a significant increase in the speed of information exchange between the disk system without losing the useful capacity of hard drives. The disadvantage is a decrease in the overall reliability of the storage system. If any of the RAID 0 disks fail, all information recorded in the array is lost forever.
Similar to the one discussed above, this type of array is also the simplest to organize. It is built on the basis of two hard drives, each of which is an exact (mirror) reflection of the other. Information is written in parallel to both disks in the array. Data is read simultaneously from both disks in sequential blocks (parallelization of requests), due to which a slight increase in reading speed is achieved compared to a single hard drive.
The total capacity of RAID 1 is equal to the capacity of the smaller hard drive in the array.
Advantages of RAID 1: high reliability of information storage (data is unharmed as long as at least one of the disks included in the array is intact) and some increase in read speed. The disadvantage is that when you buy two hard drives, you only get the usable capacity of one. Despite the loss of half the useful volume, "mirror" arrays are quite popular due to their high reliability and relatively low cost - a pair of disks is still cheaper than four or eight.
When constructing these arrays, an information recovery algorithm is used using Hamming codes (an American engineer who developed this algorithm in 1950 to correct errors in the operation of electromechanical computers). To ensure the operation of this RAID controller, two groups of disks are created - one for storing data, the second group for storing error correction codes.
This type of RAID has become less widespread in home systems due to the excessive redundancy of the number of hard drives - for example, in an array of seven hard drives, only four will be allocated for data. As the number of disks increases, redundancy decreases, which is reflected in the table below.
The main advantage of RAID 2 is the ability to correct errors on the fly without reducing the speed of data exchange between the disk array and the central processor.
RAID 3 and RAID 4
These two types of disk arrays are very similar in design. Both use multiple hard drives to store information, one of which is used exclusively for storing checksums. Three hard drives are enough to create RAID 3 and RAID 4. Unlike RAID 2, data recovery on the fly is not possible - information is restored after replacing a failed hard drive over a period of time.
The difference between RAID 3 and RAID 4 is the level of data partitioning. In RAID 3, information is broken down into individual bytes, which leads to serious slowdown when writing/reading a large number of small files. RAID 4 splits data into separate blocks, the size of which does not exceed the size of one sector on the disk. As a result, the processing speed of small files increases, which is critical for personal computers. For this reason, RAID 4 has become more widespread.
A significant disadvantage of the arrays under consideration is the increased load on the hard drive intended for storing checksums, which significantly reduces its resource.
Disk arrays of this type are actually a development of the RAID 3/RAID 4 scheme. A distinctive feature is that a separate disk is not used to store checksums - they are evenly distributed across all hard drives of the array. The result of the distribution is the possibility of parallel recording on several disks at once, which slightly increases the speed of data exchange compared to RAID 3 or RAID 4. However, this increase is not so significant, since additional system resources are spent on calculating checksums using the “exclusive or” operation. At the same time, the reading speed increases significantly, since simple parallelization of the process is possible.
The minimum number of hard drives to build RAID 5 is three.
Arrays built using the RAID 5 scheme have a very significant drawback. If any disk fails after replacing it, it takes several hours to completely restore the information. At this time, the intact hard drives of the array operate in super-intensive mode, which significantly increases the likelihood of failure of the second drive and complete loss of information. Although rare, this does happen. In addition, during RAID 5 restoration, the array is almost completely occupied by this process and ongoing write/read operations are performed with large delays. While this is not critical for most ordinary users, in the corporate sector such delays can lead to certain financial losses.
To a large extent, the above problem is solved by constructing arrays using the RAID 6 scheme. In these structures, a memory volume equal to the volume of two hard drives is allocated for storing checksums, which are also cyclically and evenly distributed to different disks. Instead of one, two checksums are calculated, which guarantees data integrity in the event of simultaneous failure of two hard drives in the array.
The advantages of RAID 6 are a high degree of information security and less performance loss than in RAID 5 during data recovery when replacing a damaged disk.
The disadvantage of RAID 6 is that the overall data exchange speed is reduced by approximately 10% due to an increase in the volume of necessary checksum calculations, as well as due to an increase in the amount of information written/read.
Combined RAID types
In addition to the main types discussed above, various combinations of them are widely used, which compensate for certain disadvantages of simple RAID. In particular, the use of RAID 10 and RAID 0+1 schemes is widespread. In the first case, a pair of mirrored arrays are combined into RAID 0, in the second, on the contrary, two RAID 0 are combined into a mirror. In both cases, the increased performance of RAID 0 is added to the information security of RAID 1.
Often, in order to increase the level of protection of important information, RAID 51 or RAID 61 construction schemes are used - mirroring of already highly protected arrays ensures exceptional data safety in the event of any failures. However, it is impractical to implement such arrays at home due to excessive redundancy.
Building a disk array - from theory to practice
A specialized RAID controller is responsible for building and managing the operation of any RAID. To the great relief of the average personal computer user, in most modern motherboards these controllers are already implemented at the chipset southbridge level. So, to build an array of hard drives, all you have to do is purchase the required number of them and determine the desired RAID type in the appropriate section of the BIOS settings. After this, instead of several hard drives in the system, you will see only one, which can be divided into partitions and logical drives if desired. Please note that those who are still using Windows XP will need to install an additional driver.
External RAID controller with four SATA ports
Note that integrated controllers, as a rule, are capable of creating RAID 0, RAID 1, and combinations thereof. To create more complex arrays, you will still need to purchase a separate controller.
And finally, one more piece of advice - to create a RAID, purchase hard drives of the same capacity, the same manufacturer, the same model, and preferably from the same batch. Then they will be equipped with the same logic sets and the operation of the array of these hard drives will be the most stable.
Making a request
Description of RAID arrays ( , )
Description of RAID 0
High-performance disk array without fault tolerance
Striped Disk Array without Fault Tolerance
RAID 0 is the most powerful and least secure of all RAIDs. Data is split into blocks proportional to the number of disks, resulting in higher throughput. The high performance of this structure is ensured by parallel recording and the absence of redundant copying. The failure of any drive in the array results in the loss of all data. This level is called striping.
Advantages:
- · highest performance for applications requiring intensive processing of I/O requests and large data volumes;
- · ease of implementation;
- · low cost per unit volume.
Flaws:
- · not a fault-tolerant solution;
- · failure of one disk entails the loss of all data in the array.
Description of RAID 1

Redundant or mirrored disk array
Duplexing & Mirroring
RAID 1 - mirroring - mirroring of two disks. The redundancy of the structure of this array ensures its high fault tolerance. The array is characterized by high cost and low productivity.
Advantages:
- · ease of implementation;
- · ease of array recovery in case of failure (copying);
- · sufficiently high performance for applications with high request intensity.
Flaws:
- · high cost per unit volume - 100% redundancy;
- · low data transfer speed.
Description of RAID 2

Fault-tolerant disk array using Hamming code
Hamming Code ECC
RAID 2 - uses Hamming Code ECC. The codes allow you to correct single faults and detect double faults.
Advantages:
- · fast error correction (“on the fly”);
- very high speed of large data transfer;
- · as the number of disks increases, overhead costs decrease;
- · quite simple implementation.
Flaws:
- · high cost with a small number of disks;
- · low speed of request processing (not suitable for transaction-oriented systems).
Description of RAID 3

Fault-tolerant array with parallel data transfer and parity
Parallel Transfer Disks with Parity
RAID 3 - data is stored using the striping principle at the byte level with a checksum (CS) on one of the disks. The array does not have the problem of some redundancy as in RAID level 2. Checksum drives used in RAID 2 are needed to detect erroneous charges. However, most modern controllers are able to determine when a disk has failed using special signals or additional encoding of information written to the disk and used to correct random failures.
Advantages:
- · very high data transfer speed;
- · disk failure has little effect on the speed of the array;
- · low overhead costs for implementing redundancy.
Flaws:
- · difficult implementation;
- · low performance with high intensity requests for small data.
The problem of increasing the reliability of information storage and simultaneously increasing the performance of a data storage system has been on the minds of computer peripheral developers for a long time. Regarding increasing the reliability of storage, everything is clear: information is a commodity, and often very valuable. To protect against data loss, many methods have been invented, the most famous and reliable of which is information backup.
The issue of increasing the performance of the disk subsystem is very complex. The growth in the computing power of modern processors has led to a clear imbalance between the capabilities of hard drives and the needs of processors. At the same time, neither expensive SCSI drives, nor even more so IDE drives, can save you. However, if the capabilities of one disk are not enough, then perhaps having several disks will partially solve this problem? Of course, the mere presence of two or more hard drives on a computer or server does not change the matter - you need to make these drives work together (in parallel) with each other so that this will improve the performance of the disk subsystem on write/read operations. In addition, is it possible, by using several hard drives, to improve not only performance, but also the reliability of data storage, so that the failure of one of the drives does not lead to loss of information? This is exactly the approach that was proposed back in 1987 by American researchers Patterson, Gibson and Katz from the University of California, Berkeley. In their paper, "A Case for Redundant Arrays of Inexpensive Discs, RAID," they described how multiple low-cost hard drives could be combined into a single logical device, resulting in increased system capacity and performance, and failure of individual disks did not lead to failure of the entire system.
15 years have passed since the article was published, but the technology of building RAID arrays has not lost its relevance today. The only thing that has changed since then is the decoding of the RAID acronym. The fact is that initially RAID arrays were not built on cheap disks at all, so the word Inexpensive (inexpensive) was changed to Independent (independent), which was more true.
Moreover, it is now that RAID technology has become widespread. So, if a few years ago RAID arrays were used in expensive enterprise-scale servers using SCSI disks, today they have become a kind of de facto standard even for entry-level servers. In addition, the market for IDE RAID controllers is gradually expanding, that is, the task of building RAID arrays on workstations using cheap IDE disks is becoming urgent. Thus, some motherboard manufacturers (Abit, Gigabyte) have already begun to integrate IDE RAID controllers onto the boards themselves.
So, RAID is a redundant array of independent disks (Redundant Arrays of Independent Discs), which is tasked with ensuring fault tolerance and increasing performance. Fault tolerance is achieved through redundancy. That is, part of the disk space capacity is allocated for official purposes, becoming inaccessible to the user.
Increased performance of the disk subsystem is ensured by the simultaneous operation of several disks, and in this sense, the more disks in the array (up to a certain limit), the better.
The joint operation of disks in an array can be organized using either parallel or independent access.
With parallel access, disk space is divided into blocks (strips) for recording data. Similarly, information to be written to disk is divided into the same blocks. When writing, individual blocks are written to different disks (Fig. 1), and several blocks are written to different disks simultaneously, which leads to increased performance in write operations. The necessary information is also read in separate blocks simultaneously from several disks (Fig. 2), which also increases performance in proportion to the number of disks in the array.
It should be noted that the parallel access model is implemented only if the size of the data write request is larger than the size of the block itself. Otherwise, it is simply impossible to implement parallel recording of several blocks. Let's imagine a situation where the size of an individual block is 8 KB, and the size of a request to write data is 64 KB. In this case, the source information is cut into eight blocks of 8 KB each. If you have a four-disk array, you can write four blocks, or 32 KB, at a time. Obviously, in the example considered, the write and read speeds will be four times higher than when using one disk. However, this situation is ideal, since the request size is not always a multiple of the block size and the number of disks in the array.
If the size of the recorded data is less than the block size, then a fundamentally different access model is implemented - independent access. Moreover, this model can also be implemented in the case when the size of the written data is larger than the size of one block. With independent access, all data from a single request is written to a separate disk, that is, the situation is identical to working with one disk. The advantage of the parallel access model is that if several write (read) requests arrive simultaneously, they will all be executed independently, on separate disks (Fig. 3). A similar situation is typical, for example, in servers.
In accordance with different types of access, there are different types of RAID arrays, which are usually characterized by RAID levels. In addition to the type of access, RAID levels differ in the way they allocate and generate redundant information. Redundant information can either be placed on a specially allocated disk, or shuffled between all disks. There are several more ways to generate this information. The simplest of them is complete duplication (100 percent redundancy), or mirroring. In addition, error correction codes are used, as well as parity calculations.
RAID levels
Currently, there are several standardized RAID levels: from RAID 0 to RAID 5. In addition, combinations of these levels are used, as well as proprietary levels (for example, RAID 6, RAID 7). The most common levels are 0, 1, 3 and 5.
RAID 0
RAID level 0, strictly speaking, is not a redundant array and, accordingly, does not provide reliable data storage. Nevertheless, this level is widely used in cases where it is necessary to ensure high performance of the disk subsystem. This level is especially popular in workstations. When creating a RAID level 0 array, information is divided into blocks, which are written to separate disks (Fig. 4), that is, a system with parallel access is created (if, of course, the block size allows this). By allowing simultaneous I/O from multiple disks, RAID 0 provides the fastest data transfer speeds and maximum disk space efficiency because no storage space is required for checksums. The implementation of this level is very simple. RAID 0 is mainly used in areas where fast transfer of large amounts of data is required.
RAID 1 (Mirrored disk)
RAID Level 1 is an array of disks with 100 percent redundancy. That is, the data is simply completely duplicated (mirrored), due to which a very high level of reliability (as well as cost) is achieved. Note that to implement level 1, it is not necessary to first partition the disks and data into blocks. In the simplest case, two disks contain the same information and are one logical disk (Fig. 5). If one disk fails, its functions are performed by another (which is absolutely transparent to the user). In addition, this level doubles the speed of reading information, since this operation can be performed simultaneously from two disks. This information storage scheme is used mainly in cases where the cost of data security is much higher than the cost of implementing a storage system.
RAID 2
RAID Level 2 is a data redundancy scheme that uses Hamming code (see below) for error correction. The written data is not formed on the basis of a block structure, as in RAID 0, but on the basis of words, and the word size is equal to the number of disks for recording data in the array. If, for example, the array has four disks for writing data, then the word size is equal to four disks. Each individual bit of a word is written to a separate disk in the array. For example, if an array has four disks for recording data, then a sequence of four bits, that is, a word, will be written to the disk array in such a way that the first bit will be on the first disk, the second bit on the second, etc.
In addition, an error correction code (ECC) is calculated for each word, which is written to dedicated disks for storing control information (Fig. 6). Their number is equal to the number of bits in the control word, and each bit of the control word is written to a separate disk. The number of bits in the control word and, accordingly, the required number of disks for storing control information is calculated based on the following formula: where K is the bit depth of the data word.
Naturally, when calculating using the specified formula, L is rounded up to the nearest integer. However, in order not to mess with formulas, you can use another mnemonic rule: the bit depth of the control word is determined by the number of bits required for the binary representation of the word size. If, for example, the word size is four (in binary notation 100), then to write this number in binary form, three digits are required, which means the control word size is three. Therefore, if there are four disks to store data, then three more disks will be required to store the control data. Similarly, if you have seven disks for data (in binary notation 111), you will need three disks to store control words. If eight disks are allocated for data (in binary notation 1000), then four disks are needed for control information.
The Hamming code that forms the control word is based on the use of the bitwise “exclusive OR” (XOR) operation (also called “dissimilarity”). Recall that the logical operation XOR gives one if the operands do not match (0 and 1) and zero if they match (0 and 0 or 1 and 1).
The control word itself, obtained using the Hamming algorithm, is the inversion of the result of the bitwise exclusive OR operation of the numbers of those information bits of the word whose values are equal to 1. For illustration, consider the original word 1101. In the first (001), third (011) and fourth (100) The digits of this word are worth one. Therefore, it is necessary to perform a bitwise exclusive OR operation for these bit numbers:
The control word itself (Hamming code) is obtained by bitwise inversion of the resulting result, that is, it is equal to 001.
When reading the data, the Hamming code is again calculated and compared with the source code. To compare two codes, a bitwise “exclusive OR” operation is used. If the comparison result in all bits is zero, then the reading is correct, otherwise its value is the number of the erroneously received bit of the main code. Let, for example, the source word be equal to 1100000. Since the ones are in the sixth (110) and seventh (111) positions, the control word is equal to:
If word 1100100 is recorded during reading, then the control word for it is equal to 101. Comparing the original control word with the received one (bitwise exclusive OR operation), we have:
that is, a reading error in the third position.
Accordingly, knowing exactly which bit is erroneous, it can be easily corrected on the fly.
RAID 2 is one of the few levels that allows you not only to correct single errors on the fly, but also to detect double ones. Moreover, it is the most redundant of all levels with correction codes. This data storage scheme is rarely used because it does not handle large numbers of requests well, is complex to organize, and has few advantages over RAID 3.
RAID 3
RAID Level 3 is a fault-tolerant array with parallel I/O and one additional disk on which control information is written (Figure 7). When recording, the data stream is divided into blocks at the byte level (although possibly at the bit level) and is written simultaneously to all disks of the array, except for the one allocated for storing control information. To calculate the control information (also called a checksum), an exclusive-or operation (XOR) is applied to the data blocks being written. If any disk fails, the data on it can be restored using control data and data remaining on healthy disks.
As an illustration, consider blocks of four bits. Let there be four disks for storing data and one disk for recording checksums. If there is a sequence of bits 1101 0011 1100 1011, divided into blocks of four bits, then to calculate the checksum it is necessary to perform the operation:
Thus, the checksum written to the fifth disk is 1001.
If one of the disks, for example the third, fails, then the block 1100 will be unavailable for reading. However, its value can be easily restored using the checksum and the values of the remaining blocks, using the same “exclusive OR” operation:
Block 3=Block 1Block 2Block 4
Check sum.
In our example we get:
Block 3=1101001110111001= 1100.
RAID Level 3 has much less redundancy than RAID 2. By dividing the data into blocks, RAID 3 has high performance. When reading information, the disk is not accessed with checksums (unless there is a failure), which happens every time a write operation occurs. Since each I/O operation accesses virtually all the disks in the array, processing multiple requests simultaneously is not possible. This level is suitable for applications with large files and low access frequency. In addition, the advantages of RAID 3 include a slight decrease in performance in the event of a failure and rapid recovery of information.
RAID 4
RAID Level 4 is a fault-tolerant array of independent disks with one drive for storing checksums (Figure 8). RAID 4 is in many ways similar to RAID 3, but differs from the latter primarily in the significantly larger block size of the data being written (larger than the size of the data being written). This is the main difference between RAID 3 and RAID 4. After writing a group of blocks, a checksum is calculated (in the same way as in the case of RAID 3), which is written to the disk allocated for this purpose. With a larger block size than RAID 3, multiple read operations can be performed simultaneously (independent access design).
RAID 4 improves the performance of small file transfers (by parallelizing the read operation). But since recording must calculate the checksum on the allocated disk, simultaneous operations are impossible here (there is an asymmetry of input and output operations). The level under consideration does not provide speed advantages when transmitting large amounts of data. This storage scheme was designed for applications in which data is initially split into small blocks, so there is no need to further split it. RAID 4 is a good solution for file servers where information is primarily read and rarely written. This data storage scheme has a low cost, but its implementation is quite complex, as is data recovery in case of failure.
RAID 5
RAID level 5 is a fault-tolerant array of independent disks with distributed storage of checksums (Fig. 9). Data blocks and checksums, which are calculated in the same way as in RAID 3, are written cyclically to all disks of the array, that is, there is no dedicated disk for storing checksum information.
In the case of RAID 5, all disks in the array are the same size, but the total capacity of the disk subsystem available for writing becomes exactly one disk smaller. For example, if five disks are 10 GB in size, then the actual size of the array is 40 GB because 10 GB is allocated for control information.
RAID 5, like RAID 4, has an independent access architecture, that is, unlike RAID 3, it provides a large size of logical blocks for storing information. Therefore, as in the case of RAID 4, such an array provides the main benefit when processing several requests simultaneously.
The main difference between RAID 5 and RAID 4 is the way the checksums are placed.
The presence of a separate (physical) disk storing information about checksums, here, as in the three previous levels, leads to the fact that read operations that do not require access to this disk are performed at high speed. However, each write operation changes the information on the control disk, so RAID 2, RAID 3, and RAID 4 do not allow parallel writes. RAID 5 does not have this disadvantage because checksums are written to all disks in the array, allowing multiple reads or writes to be performed simultaneously.
Practical implementation
For the practical implementation of RAID arrays, two components are required: the hard drive array itself and the RAID controller. The controller performs the functions of communicating with the server (workstation), generating redundant information when writing and checking when reading, distributing information across disks in accordance with the operating algorithm.
Structurally, controllers can be either external or internal. There are also RAID controllers integrated on the motherboard. In addition, controllers differ in the supported disk interface. Thus, SCSI RAID controllers are intended for use in servers, and IDE RAID controllers are suitable for both entry-level servers and workstations.
A distinctive characteristic of RAID controllers is the number of supported channels for connecting hard drives. Although multiple SCSI drives can be connected to one controller channel, the total throughput of the RAID array will be limited by the throughput of one channel, which corresponds to the throughput of the SCSI interface. Thus, the use of multiple channels can significantly improve the performance of the disk subsystem.
When using IDE RAID controllers, the multichannel problem becomes even more acute, since two hard drives connected to one channel (more drives are not supported by the interface itself) cannot provide parallel operation - the IDE interface allows you to access only one drive at a time . Therefore, IDE RAID controllers must be at least dual-channel. There are also four- and even eight-channel controllers.
Another difference between IDE RAID and SCSI RAID controllers is the number of levels they support. SCSI RAID controllers support all the main levels and, as a rule, several more combined and proprietary levels. The set of levels supported by IDE RAID controllers is much more modest. Usually these are zero and first levels. In addition, there are controllers that support the fifth level and a combination of the first and zero: 0+1. This approach is quite logical, since IDE RAID controllers are designed primarily for workstations, so the main emphasis is on increasing data integrity (level 1) or performance during parallel I/O (level 0). In this case, an independent disk scheme is not needed, since in workstations the flow of write/read requests is much lower than, say, in servers.
The main function of a RAID array is not to increase the capacity of the disk subsystem (as can be seen from its design, the same capacity can be obtained for less money), but to ensure reliable data storage and increase performance. For servers, in addition, there is a requirement for uninterrupted operation, even if one of the drives fails. Uninterrupted operation is ensured by hot swapping, that is, removing a faulty SCSI disk and installing a new one without turning off the power. Because the disk subsystem remains operational (except for level 0) when one drive fails, hot swapping provides recovery that is transparent to users. However, the transfer speed and access speed with one non-working disk are noticeably reduced due to the fact that the controller must recover data from redundant information. True, there is an exception to this rule - RAID systems of levels 2, 3, 4, when a drive with redundant information fails, they begin to work faster! This is natural, since in this case the level “on the fly” changes to zero, which has excellent speed characteristics.
So far, this article has been about hardware solutions. But there is also software offered, for example, by Microsoft for Windows 2000 Server. However, in this case, some initial savings are completely neutralized by the additional load on the central processor, which, in addition to its main work, is forced to distribute data across disks and calculate checksums. Such a solution can be considered acceptable only in the case of a significant excess of computing power and low server load.
Sergey Pakhomov
ComputerPress 3"2002Greetings to blog readers!
Today there will be another article on a computer topic, and it will be devoted to such a concept as Raid disk array— I’m sure this concept will mean absolutely nothing to many, and those who have already heard about it somewhere have no idea what it is. Let's figure it out together!
Without going into details of terminology, a Raid array is a kind of complex built from several hard drives, which allows you to more competently distribute functions between them. How do we usually place hard drives in a computer? We connect one hard drive to Sata, then another, then a third. And disks D, E, F and so on appear in our operating system. We can place some files on them or install Windows, but essentially these will be separate disks - if we take out one of them, we will not notice anything at all (if the OS was not installed on it) except that we will not have access to those recorded on them files. But there is another way - to combine these disks into a system, give them a certain algorithm for working together, as a result of which the reliability of information storage or the speed of their operation will significantly increase.
But before we can create this system, we need to know whether the motherboard supports Raid disk arrays. Many modern motherboards already have a built-in Raid controller, which allows you to combine hard drives. Supported array circuits are available in the descriptions for the motherboard. For example, let’s take the first ASRock P45R2000-WiFi board that caught my eye in Yandex Market.
Here, a description of the supported Raid arrays is displayed in the "Sata Disk Controllers" section.
In this example, we see that the Sata controller supports the creation of Raid arrays: 0, 1, 5, 10. What do these numbers mean? This is a designation for various types of arrays in which disks interact with each other according to different schemes, which are designed, as I already said, to either speed up their operation or increase reliability against data loss.
If the computer motherboard does not support Raid, then you can purchase a separate Raid controller in the form of a PCI card, which is inserted into the PCI slot on the motherboard and gives it the ability to create arrays of disks. For the controller to work after installing it, you will also need to install the raid driver, which either comes on the disk with this model, or can simply be downloaded from the Internet. It is best not to skimp on this device and buy from some well-known manufacturer, for example Asus, and with Intel chipsets.

I suspect that you still don’t have a good idea of what we’re talking about, so let’s take a closer look at each of the most popular types of Raid arrays to make everything clearer.
RAID 1 array
Raid 1 array is one of the most common and budget options that uses 2 hard drives. This array is designed to provide maximum protection for user data, because all files will be simultaneously copied to 2 hard drives. In order to create it, we take two hard drives of equal size, for example 500 GB each, and make the appropriate settings in the BIOS to create the array. After this, your system will see one hard drive measuring not 1 TB, but 500 GB, although physically two hard drives work - the calculation formula is given below. And all files will be simultaneously written to two disks, that is, the second will be a full backup copy of the first. As you understand, if one of the disks fails, you will not lose a single piece of your information, since you will have a second copy of this disk.

Also, the failure will not be noticed by the operating system, which will continue to work with the second disk - only a special program that monitors the functioning of the array will notify you of the problem. You just need to remove the faulty disk and connect the same one, only a working one - the system will automatically copy all the data from the remaining working disk to it and continue working.
The disk volume that the system will see is calculated here using the formula:
V = 1 x Vmin, where V is the total capacity and Vmin is the storage capacity of the smallest hard drive.
RAID 0 array
Another popular scheme, which is designed to increase not the reliability of storage, but, on the contrary, the speed of operation. It also consists of two HDDs, but in this case the OS already sees the full total volume of the two disks, i.e. if you combine 500 GB disks into Raid 0, the system will see one 1 TB disk. The speed of reading and writing increases due to the fact that blocks of files are written alternately to two disks - but at the same time, the fault tolerance of this system is minimal - if one of the disks fails, almost all files will be damaged and you will lose part of the data - the one that was written to broken disk. After this, you will have to restore the information at the service center.

The formula for calculating the total disk space visible to Windows is:
If, before reading this article, you weren’t really worried about the fault tolerance of your system, but would like to increase the speed of operation, then you can buy an additional hard drive and feel free to use this type. By and large, at home the vast majority of users do not store any super-important information, and some important files can be copied to a separate external hard drive.
Array Raid 10 (0+1)
As the name itself suggests, this type of array combines the properties of the previous two - it’s like two Raid 0 arrays combined into Raid 1. Four hard drives are used, information is written to two of them in blocks one by one, as was the case in Raid 0 , and for the other two, complete copies of the first two are created. The system is very reliable and at the same time quite fast, but very expensive to organize. To create, you need 4 HDDs, and the system will see the total volume using the formula:
That is, if we take 4 disks of 500 GB, then the system will see 1 disk of 1 TB in size.

This type, as well as the next one, is most often used in organizations, on server computers, where it is necessary to ensure both high speed of operation and maximum security against loss of information in case of unforeseen circumstances.
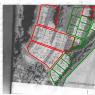
RAID 5 array
The Raid 5 array is the optimal combination of price, speed and reliability. In this array, a minimum of 3 HDDs can be used; the volume is calculated using a more complex formula:
V = N x Vmin – 1 x Vmin, where N is the number of hard drives.
So, let's say we have 3 disks of 500 GB each. The volume visible to the OS will be 1 TB.
The array's operation scheme is as follows: blocks of divided files are written to the first two disks (or three, depending on their number), and the checksum of the first two (or three) is written to the third (or fourth). Thus, if one of the disks fails, its contents can be easily restored using the checksum available on the last disk. The performance of such an array is lower than that of Raid 0, but is as reliable as Raid 1 or Raid 10 and at the same time cheaper than the latter, because You can save on the fourth hard drive.
The diagram below shows a Raid 5 layout of four HDDs.

There are also other modes - Raid 2,3, 4, 6, 30, etc., but they are largely derivative of those listed above.
How to install Raid disk array on Windows?
I hope you understand the theory. Now let's look at practice - inserting a PCI Raid controller into the PCI Raid slot and installing drivers, I think, will not be difficult for experienced PC users.
How can we now create an array of connected hard drives in the Windows Raid operating system?
It is best, of course, to do this when you have just purchased and connected clean hard drives without an installed OS. First, we restart the computer and go into the BIOS settings - here we need to find the SATA controllers to which our hard drives are connected and set them to RAID mode.

After that, save the settings and restart the PC. On a black screen, information will appear that you have Raid mode enabled and about the key with which you can access its settings. The example below asks you to press the "TAB" key.

Depending on the Raid controller model, it may be different. For example, "CNTRL+F"

We go to the configuration utility and click something like “Create array” or “Create Raid” in the menu - the labels may differ. Also, if the controller supports several Raid types, you will be asked to choose which one you want to create. In my example, only Raid 0 is available.

After this, we return back to the BIOS and in the boot order setting we see not several separate disks, but one in the form of an array.

That's all - RAID is configured and now the computer will treat your disks as one. This is how, for example, Raid will be visible when installing Windows.

I think you have already understood the benefits of using Raid. Finally, I will give a comparative table of measurements of disk writing and reading speeds separately or as part of Raid modes - the result, as they say, is obvious.