Tóm tắt thống kê hồi quy. Hồi quy trong Excel: phương trình, ví dụ. Hồi quy tuyến tính
Cho thấy ảnh hưởng của một số giá trị (độc lập, độc lập) đến biến phụ thuộc. Ví dụ, số lượng dân số hoạt động kinh tế phụ thuộc như thế nào vào số lượng doanh nghiệp, tiền lương và các thông số khác. Hoặc: đầu tư nước ngoài, giá năng lượng, v.v. ảnh hưởng như thế nào đến mức GDP.
Kết quả phân tích cho phép bạn làm nổi bật các ưu tiên. Và dựa trên các yếu tố chính để dự đoán, lập kế hoạch phát triển các lĩnh vực ưu tiên và đưa ra các quyết định quản lý.
Hồi quy xảy ra:
tuyến tính (y = a + bx);
· parabol (y = a + bx + cx 2);
· hàm mũ (y = a * exp(bx));
· công suất (y = a*x^b);
· hyperbol (y = b/x + a);
logarit (y = b * 1n(x) + a);
· hàm mũ (y = a * b^x).
Hãy xem một ví dụ về xây dựng mô hình hồi quy trong Excel và diễn giải kết quả. Hãy lấy kiểu hồi quy tuyến tính.
Nhiệm vụ. Tại 6 doanh nghiệp, mức lương bình quân tháng và số lao động nghỉ việc được phân tích. Cần xác định sự phụ thuộc của số lượng nhân viên nghỉ việc vào mức lương bình quân.
Mô hình hồi quy tuyến tính trông như thế này:
Y = a 0 + a 1 x 1 +…+a k x k.
Trong đó a là hệ số hồi quy, x là các biến ảnh hưởng, k là số lượng nhân tố.
Trong ví dụ của chúng tôi, Y là chỉ báo về việc nhân viên nghỉ việc. Yếu tố ảnh hưởng là tiền lương (x).
Excel có sẵn các hàm có thể giúp bạn tính toán các tham số của mô hình hồi quy tuyến tính. Nhưng tiện ích bổ sung “Gói phân tích” sẽ thực hiện việc này nhanh hơn.
Chúng tôi kích hoạt một công cụ phân tích mạnh mẽ:
1. Nhấp vào nút “Office” và chuyển đến tab “Tùy chọn Excel”. "Tiện ích bổ sung".

2. Ở dưới cùng, trong danh sách thả xuống, trong trường “Quản lý” sẽ có dòng chữ “Phần bổ trợ Excel” (nếu không có ở đó, hãy nhấp vào hộp kiểm bên phải và chọn). Và nút “Đi”. Nhấp chuột.
3. Danh sách các tiện ích bổ sung có sẵn sẽ mở ra. Chọn “Gói phân tích” và nhấp vào OK.

Sau khi được kích hoạt, tiện ích bổ sung sẽ có sẵn trong tab Dữ liệu.

Bây giờ chúng ta hãy tự phân tích hồi quy.
1. Mở menu của công cụ “Phân tích dữ liệu”. Chọn "Hồi quy".

2. Một menu sẽ mở ra để chọn các giá trị đầu vào và tùy chọn đầu ra (nơi hiển thị kết quả). Trong các trường dành cho dữ liệu ban đầu, chúng tôi chỉ ra phạm vi của tham số được mô tả (Y) và yếu tố ảnh hưởng đến nó (X). Phần còn lại không cần phải điền.

3. Sau khi nhấn OK, chương trình sẽ hiển thị các phép tính trên một trang tính mới (bạn có thể chọn khoảng thời gian hiển thị trên trang tính hiện tại hoặc gán đầu ra cho một sổ làm việc mới).

Trước hết, chúng ta chú ý đến R bình phương và các hệ số.
R bình phương là hệ số xác định. Trong ví dụ của chúng tôi – 0,755, hoặc 75,5%. Điều này có nghĩa là các tham số tính toán của mô hình giải thích được 75,5% mối liên hệ giữa các tham số nghiên cứu. Hệ số xác định càng cao thì mô hình càng tốt. Tốt - trên 0,8. Xấu – dưới 0,5 (phân tích như vậy khó có thể được coi là hợp lý). Trong ví dụ của chúng tôi – “không tệ”.
Hệ số 64,1428 cho thấy Y sẽ bằng bao nhiêu nếu tất cả các biến trong mô hình đang xem xét đều bằng 0. Nghĩa là giá trị của tham số phân tích cũng bị ảnh hưởng bởi các yếu tố khác không được mô tả trong mô hình.
Hệ số -0,16285 thể hiện trọng số của biến X trên Y. Nghĩa là, mức lương trung bình hàng tháng trong mô hình này ảnh hưởng đến số người bỏ việc có trọng số -0,16285 (đây là mức độ ảnh hưởng nhỏ). Dấu “-” biểu thị tác động tiêu cực: lương càng cao thì càng ít người bỏ việc. Điều đó là công bằng.
Phương pháp hồi quy tuyến tính cho phép chúng ta mô tả một đường thẳng phù hợp nhất với một chuỗi các cặp có thứ tự (x, y). Phương trình của một đường thẳng, được gọi là phương trình tuyến tính, được đưa ra dưới đây:
ŷ là giá trị kỳ vọng của y đối với giá trị x cho trước,
x là một biến độc lập,
a là đoạn thẳng trên trục y của một đường thẳng,
b là độ dốc của đường thẳng
Hình dưới đây minh họa khái niệm này bằng đồ họa:
Hình trên thể hiện đường thẳng được mô tả bởi phương trình ŷ =2+0,5x. Giao điểm y là điểm tại đó đường thẳng cắt trục y; trong trường hợp của chúng ta, a = 2. Độ dốc của đường b, tỷ lệ giữa độ cao của đường thẳng và chiều dài của đường thẳng, có giá trị là 0,5. Độ dốc dương có nghĩa là đường tăng dần từ trái sang phải. Nếu b = 0 thì đường nằm ngang, nghĩa là không có mối quan hệ giữa biến phụ thuộc và biến độc lập. Nói cách khác, việc thay đổi giá trị của x không ảnh hưởng đến giá trị của y.
ŷ và y thường bị nhầm lẫn. Đồ thị thể hiện 6 cặp điểm và một đường thẳng có thứ tự theo phương trình đã cho
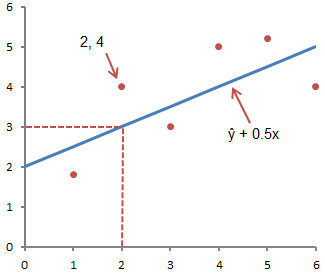
Hình này thể hiện điểm tương ứng với cặp thứ tự x = 2 và y = 4. Lưu ý rằng giá trị kỳ vọng của y theo đường thẳng tại X= 2 là ŷ. Chúng ta có thể xác nhận điều này bằng phương trình sau:
ŷ = 2 + 0,5х =2 +0,5(2) =3.
Giá trị y biểu thị điểm thực tế và giá trị ŷ là giá trị mong đợi của y bằng cách sử dụng phương trình tuyến tính cho giá trị x cho trước.
Bước tiếp theo là xác định phương trình tuyến tính phù hợp nhất với tập hợp các cặp có thứ tự, chúng ta đã nói về vấn đề này trong bài viết trước, trong đó chúng ta đã xác định loại phương trình bằng .
Sử dụng Excel để xác định hồi quy tuyến tính
Để sử dụng được công cụ phân tích hồi quy tích hợp trong Excel, bạn phải kích hoạt add-in Gói phân tích. Bạn có thể tìm thấy nó bằng cách nhấp vào tab Tệp -> Tùy chọn(2007+), trong hộp thoại xuất hiện Tùy chọnExcelđi tới tab Tiện ích bổ sung. Trong lĩnh vực Điều khiển chọn Tiện ích bổ sungExcel và nhấp vào Đi. Trong cửa sổ xuất hiện, đánh dấu vào ô bên cạnh Gói phân tích, nhấp chuột ĐƯỢC RỒI.

Trong tab Dữ liệu trong nhóm Phân tích một nút mới sẽ xuất hiện Phân tích dữ liệu.

Để chứng minh hoạt động của tiện ích bổ sung, chúng tôi sẽ sử dụng dữ liệu trong đó một chàng trai và một cô gái ngồi chung bàn trong phòng tắm. Nhập dữ liệu từ ví dụ về bồn tắm của chúng tôi vào Cột A và B của trang trống.
Chuyển đến tab Dữ liệu, trong nhóm Phân tích nhấp chuột Phân tích dữ liệu. Trong cửa sổ hiện ra Phân tích dữ liệu lựa chọn hồi quy như trong hình và nhấn OK.

Đặt các tham số hồi quy cần thiết trong cửa sổ hồi quy, như thể hiện trên hình ảnh:

Nhấp chuột ĐƯỢC RỒI. Hình dưới đây thể hiện kết quả thu được:

Những kết quả này phù hợp với những kết quả chúng tôi thu được bằng cách thực hiện các phép tính của riêng mình trong .
Theo tôi, khi còn là sinh viên, kinh tế lượng là một trong những ngành khoa học ứng dụng nhất mà tôi có thể làm quen trong khuôn viên trường đại học của mình. Với sự trợ giúp của nó, thực sự có thể giải quyết các vấn đề ứng dụng ở quy mô doanh nghiệp. Câu hỏi thứ ba là những quyết định này sẽ có hiệu quả như thế nào. Điểm mấu chốt là hầu hết kiến thức sẽ vẫn là lý thuyết, nhưng kinh tế lượng và phân tích hồi quy vẫn đáng được quan tâm đặc biệt nghiên cứu.
Hồi quy giải thích điều gì?
Trước khi chúng ta bắt đầu xem xét các chức năng của MS Excel cho phép chúng ta giải quyết những vấn đề này, tôi muốn giải thích chi tiết cho bạn về bản chất, phân tích hồi quy bao gồm những gì. Điều này sẽ giúp bạn vượt qua kỳ thi dễ dàng hơn và quan trọng nhất là việc học môn này sẽ thú vị hơn.
Hy vọng rằng bạn đã quen với khái niệm hàm số trong toán học. Hàm là mối quan hệ giữa hai biến. Khi một biến thay đổi, điều gì đó sẽ xảy ra với biến khác. Chúng ta thay đổi X và Y thay đổi tương ứng. Chức năng mô tả các luật khác nhau. Biết hàm này, chúng ta có thể thay thế các giá trị tùy ý của X và xem Y thay đổi như thế nào.
Điều này rất quan trọng vì hồi quy là một nỗ lực nhằm giải thích, thoạt nhìn, các quá trình hỗn loạn và không có hệ thống bằng cách sử dụng một chức năng nhất định. Ví dụ, có thể xác định mối quan hệ giữa tỷ giá hối đoái của đồng đô la và tỷ lệ thất nghiệp ở Nga.
Nếu mô hình này có thể được phát hiện, thì bằng cách sử dụng hàm chúng tôi thu được trong quá trình tính toán, chúng tôi sẽ có thể đưa ra dự báo về tỷ lệ thất nghiệp sẽ là bao nhiêu theo tỷ giá hối đoái của đô la thứ N so với đồng rúp.
Mối quan hệ này sẽ được gọi là tương quan. Phân tích hồi quy bao gồm việc tính toán hệ số tương quan sẽ giải thích mối quan hệ chặt chẽ giữa các biến số mà chúng ta đang xem xét (tỷ giá hối đoái đồng đô la và số lượng việc làm).
Hệ số này có thể dương hoặc âm. Giá trị của nó nằm trong khoảng từ -1 đến 1. Theo đó, chúng ta có thể quan sát thấy mối tương quan âm hoặc dương cao. Nếu nó là tích cực, thì sự gia tăng tỷ giá hối đoái của đồng đô la sẽ kéo theo việc tạo ra việc làm mới. Nếu nó âm, điều đó có nghĩa là tỷ giá hối đoái tăng sẽ kéo theo việc giảm việc làm.
Có một số loại hồi quy. Nó có thể là tuyến tính, parabol, lũy thừa, hàm mũ, v.v. Chúng tôi chọn một mô hình tùy thuộc vào hồi quy nào sẽ tương ứng cụ thể với trường hợp của chúng tôi, mô hình nào sẽ càng gần với mối tương quan của chúng tôi càng tốt. Hãy xem xét vấn đề này bằng cách sử dụng một vấn đề mẫu và giải nó trong MS Excel.
Hồi quy tuyến tính trong MS Excel
Để giải quyết các vấn đề hồi quy tuyến tính, bạn sẽ cần chức năng Phân tích dữ liệu. Nó có thể không được kích hoạt cho bạn, vì vậy bạn cần kích hoạt nó.
- Nhấp vào nút “Tệp”;
- Chọn mục “Tùy chọn”;
- Nhấp vào tab áp chót “Tiện ích bổ sung” ở phía bên trái;
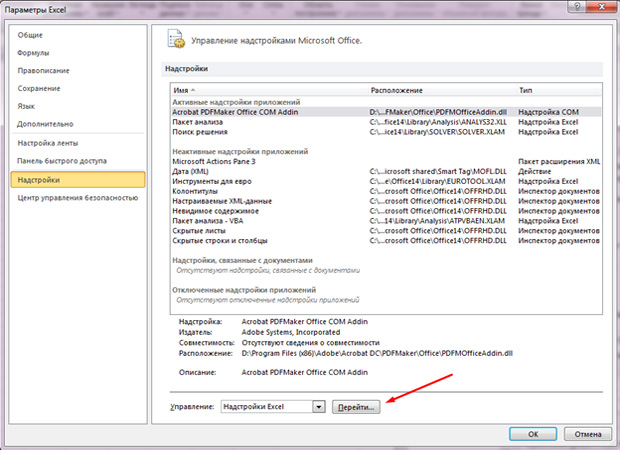
- Bên dưới chúng ta sẽ thấy dòng chữ “Quản lý” và nút “Đi”. Nhấn vào nó;
- Đánh dấu vào ô “Gói phân tích”;
- Nhấp vào “được”.

Nhiệm vụ mẫu
Chức năng phân tích hàng loạt được kích hoạt. Hãy giải quyết vấn đề sau. Chúng tôi có một mẫu dữ liệu trong vài năm về số lượng tình huống khẩn cấp trên lãnh thổ của doanh nghiệp và số lượng công nhân được tuyển dụng. Chúng ta cần xác định mối quan hệ giữa hai biến này. Có một biến giải thích X – đây là số lượng công nhân và một biến giải thích – Y – đây là số sự cố khẩn cấp. Hãy phân phối dữ liệu nguồn thành hai cột.

Hãy chuyển đến tab “dữ liệu” và chọn “Phân tích dữ liệu”
Trong danh sách xuất hiện, chọn “Hồi quy”. Chúng tôi chọn các giá trị phù hợp trong các khoảng đầu vào Y và X.

Nhấp vào “Được”. Quá trình phân tích hoàn tất và chúng ta sẽ thấy kết quả trong một trang tính mới.
Các giá trị quan trọng nhất đối với chúng tôi được đánh dấu trong hình bên dưới.

Nhiều R là hệ số xác định. Nó có một công thức tính toán phức tạp và cho thấy bạn có thể tin tưởng hệ số tương quan của chúng tôi đến mức nào. Theo đó, giá trị này càng cao thì càng có nhiều sự tin cậy, mô hình của chúng tôi nói chung càng thành công.
Y-Intercept và X1-Intercept là các hệ số hồi quy của chúng tôi. Như đã đề cập, hồi quy là một hàm và nó có các hệ số nhất định. Do đó, hàm của chúng ta sẽ có dạng: Y = 0,64*X-2,84.
Điều này mang lại cho chúng ta điều gì? Điều này cho chúng ta cơ hội để đưa ra dự báo. Giả sử chúng ta muốn thuê 25 công nhân cho một doanh nghiệp và chúng ta cần hình dung đại khái số lượng sự cố khẩn cấp sẽ là bao nhiêu. Chúng ta thay giá trị này vào hàm của mình và nhận được kết quả Y = 0,64 * 25 – 2,84. Chúng ta sẽ có khoảng 13 trường hợp khẩn cấp.
Hãy xem nó hoạt động như thế nào. Hãy xem hình dưới đây. Hàm chúng tôi thu được chứa các giá trị thực tế của các nhân viên có liên quan. Xem mức độ gần gũi của các giá trị với người chơi thực sự.

Bạn cũng có thể xây dựng trường tương quan bằng cách chọn vùng của Y và X, nhấp vào tab "chèn" và chọn biểu đồ phân tán.

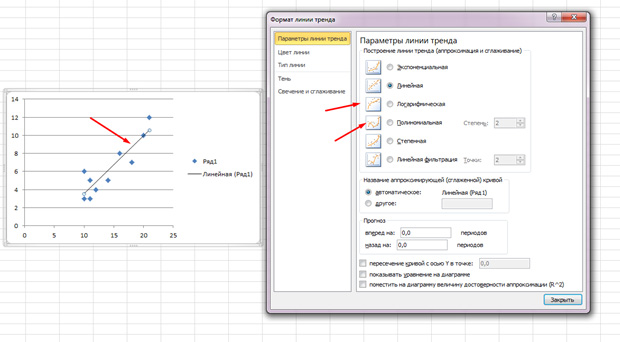
Các chấm nằm rải rác nhưng nhìn chung di chuyển lên trên, như thể có một đường thẳng ở giữa. Và bạn cũng có thể thêm dòng này bằng cách vào tab “Bố cục” trong MS Excel và chọn “Đường xu hướng”
Nhấp đúp vào dòng xuất hiện và bạn sẽ thấy những gì đã được đề cập trước đó. Bạn có thể thay đổi loại hồi quy tùy thuộc vào trường tương quan của bạn trông như thế nào.
Bạn có thể cảm thấy rằng các điểm vẽ một hình parabol chứ không phải một đường thẳng và sẽ tốt hơn nếu bạn chọn một kiểu hồi quy khác.
Phần kết luận
Hy vọng bài viết này đã giúp bạn hiểu rõ hơn về phân tích hồi quy là gì và tại sao nó lại cần thiết. Tất cả điều này có tầm quan trọng thực tế lớn.
Nó được biết đến là hữu ích trong nhiều lĩnh vực hoạt động khác nhau, bao gồm cả lĩnh vực như kinh tế lượng, nơi tiện ích phần mềm này được sử dụng trong công việc. Về cơ bản, tất cả các hành động của lớp thực hành và phòng thí nghiệm đều được thực hiện trong Excel, điều này hỗ trợ rất nhiều cho công việc bằng cách cung cấp giải thích chi tiết về một số hành động nhất định. Do đó, một trong những công cụ phân tích “Hồi quy” được sử dụng để chọn biểu đồ cho một tập hợp các quan sát bằng phương pháp bình phương tối thiểu. Hãy cùng xem công cụ chương trình này là gì và nó mang lại lợi ích gì cho người dùng. Dưới đây bạn cũng sẽ tìm thấy những hướng dẫn ngắn gọn nhưng rõ ràng để xây dựng mô hình hồi quy.
Nhiệm vụ chính và các loại hồi quy
Hồi quy thể hiện mối quan hệ giữa các biến nhất định, từ đó giúp dự đoán hành vi trong tương lai của các biến này. Biến số là những hiện tượng có tính chu kỳ khác nhau, bao gồm cả hành vi của con người. Kiểu phân tích Excel này được sử dụng để phân tích tác động lên một biến phụ thuộc cụ thể của các giá trị của một hoặc một số biến. Ví dụ: doanh số bán hàng tại một cửa hàng bị ảnh hưởng bởi một số yếu tố, bao gồm chủng loại, giá cả và vị trí của cửa hàng. Nhờ hồi quy trong Excel, bạn có thể xác định mức độ ảnh hưởng của từng yếu tố này dựa trên kết quả bán hàng hiện tại, sau đó áp dụng dữ liệu thu được để dự báo doanh số bán hàng trong một tháng khác hoặc cho một cửa hàng khác nằm gần đó.
Thông thường, hồi quy được trình bày dưới dạng một phương trình đơn giản cho thấy mối quan hệ và điểm mạnh của mối quan hệ giữa hai nhóm biến, trong đó một nhóm phụ thuộc hoặc nội sinh và nhóm kia độc lập hoặc ngoại sinh. Nếu có một nhóm các chỉ tiêu có liên quan với nhau thì biến phụ thuộc Y được xác định dựa trên logic suy luận, còn lại đóng vai trò là các biến X độc lập.
Nhiệm vụ chính của việc xây dựng mô hình hồi quy như sau:
- Lựa chọn các biến độc lập có ý nghĩa (X1, X2,..., Xk).
- Lựa chọn loại chức năng.
- Xây dựng ước lượng cho các hệ số.
- Xây dựng khoảng tin cậy và hàm hồi quy.
- Kiểm tra tầm quan trọng của các ước tính được tính toán và phương trình hồi quy được xây dựng.
Có một số loại phân tích hồi quy:
- ghép đôi (1 biến phụ thuộc và 1 biến độc lập);
- nhiều (một số biến độc lập).
Có hai loại phương trình hồi quy:
- Tuyến tính, minh họa mối quan hệ tuyến tính chặt chẽ giữa các biến.
- Phi tuyến tính - Các phương trình có thể bao gồm lũy thừa, phân số và hàm lượng giác.
Hướng dẫn xây dựng mô hình
Để thực hiện một công trình nhất định trong Excel, bạn phải làm theo hướng dẫn:

Để tính toán thêm, hãy sử dụng hàm “Tuyến tính()”, chỉ định Giá trị Y, Giá trị X, Const và Thống kê. Sau đó, xác định tập hợp các điểm trên đường hồi quy bằng hàm "Xu hướng" - Giá trị Y, Giá trị X, Giá trị mới, Const. Sử dụng các tham số đã cho, tính giá trị chưa biết của các hệ số, dựa trên điều kiện đã cho của bài toán.
Phân tích hồi quy trong Microsoft Excel - hướng dẫn toàn diện nhất về cách sử dụng MS Excel để giải quyết các vấn đề về phân tích hồi quy trong lĩnh vực phân tích kinh doanh. Konrad Carlberg giải thích rõ ràng các vấn đề lý thuyết, kiến thức về lý thuyết này sẽ giúp bạn tránh được nhiều sai lầm khi tự mình tiến hành phân tích hồi quy và khi đánh giá kết quả phân tích do người khác thực hiện. Tất cả tài liệu, từ các mối tương quan đơn giản và thử nghiệm t đến phân tích hiệp phương sai, đều dựa trên các ví dụ thực tế và đi kèm với các quy trình chi tiết từng bước.
Cuốn sách thảo luận về những điểm bất thường và tranh cãi về các hàm hồi quy của Excel, xem xét ý nghĩa của từng lựa chọn và lập luận, đồng thời giải thích cách áp dụng các phương pháp hồi quy một cách đáng tin cậy trong các lĩnh vực từ nghiên cứu y học đến phân tích tài chính.
Konrad Carlberg. Phân tích hồi quy trong Microsoft Excel. – M.: Phép biện chứng, 2017. – 400 tr.
Tải xuống ghi chú ở định dạng hoặc, ví dụ ở định dạng
Chương 1: Đánh giá sự biến đổi của dữ liệu
Các nhà thống kê có nhiều thước đo về sự biến thiên theo ý của họ. Một trong số đó là tổng độ lệch bình phương của các giá trị riêng lẻ so với mức trung bình. Trong Excel, hàm SQUARE() được sử dụng cho việc này. Nhưng phương sai được sử dụng thường xuyên hơn. Độ phân tán là giá trị trung bình của độ lệch bình phương. Phương sai không nhạy cảm với số lượng giá trị trong tập dữ liệu đang nghiên cứu (trong khi tổng độ lệch bình phương tăng theo số lần đo).
Excel cung cấp hai hàm trả về phương sai: DISP.G() và DISP.V():
- Sử dụng hàm DISP.G() nếu các giá trị được xử lý tạo thành một tập hợp. Nghĩa là, các giá trị có trong phạm vi là những giá trị duy nhất mà bạn quan tâm.
- Sử dụng hàm DISP.B() nếu các giá trị cần xử lý tạo thành một mẫu từ tổng thể lớn hơn. Giả định rằng có những giá trị bổ sung mà bạn cũng có thể ước tính phương sai của chúng.
Nếu một đại lượng như giá trị trung bình hoặc hệ số tương quan được tính từ tổng thể thì nó được gọi là tham số. Một đại lượng tương tự được tính toán trên cơ sở mẫu được gọi là số liệu thống kê. Đếm độ lệch từ mức trung bình trong một tập hợp nhất định, bạn sẽ nhận được tổng bình phương độ lệch có độ lớn nhỏ hơn so với khi bạn đếm chúng từ bất kỳ giá trị nào khác. Một tuyên bố tương tự là đúng cho phương sai.
Cỡ mẫu càng lớn thì giá trị thống kê tính toán càng chính xác. Nhưng không có cỡ mẫu nào nhỏ hơn cỡ tổng thể mà bạn có thể tin tưởng rằng giá trị thống kê khớp với giá trị tham số.
Giả sử bạn có một tập hợp gồm 100 độ cao có giá trị trung bình khác với giá trị trung bình của tổng thể, cho dù sự khác biệt có nhỏ đến đâu. Bằng cách tính phương sai cho một mẫu, bạn sẽ nhận được một giá trị, giả sử là 4. Giá trị này nhỏ hơn bất kỳ giá trị nào khác có thể thu được bằng cách tính độ lệch của từng giá trị trong số 100 giá trị chiều cao so với bất kỳ giá trị nào khác ngoài giá trị trung bình của mẫu , bao gồm cả tương đối với mức trung bình thực sự của dân số nói chung. Do đó, phương sai được tính toán sẽ khác và nhỏ hơn so với phương sai mà bạn sẽ nhận được nếu bằng cách nào đó bạn tìm ra và sử dụng tham số tổng thể thay vì giá trị trung bình mẫu.
Tổng bình phương trung bình được xác định cho mẫu cung cấp ước tính thấp hơn về phương sai tổng thể. Phương sai được tính theo cách này được gọi là di dờiđánh giá. Hóa ra là để loại bỏ độ lệch và có được ước tính không thiên vị, việc chia tổng bình phương độ lệch không cho N, Ở đâu N- cỡ mẫu, và n – 1.
Kích cỡ n – 1được gọi là số (số) bậc tự do. Có nhiều cách khác nhau để tính toán đại lượng này, mặc dù tất cả đều liên quan đến việc trừ một số số khỏi cỡ mẫu hoặc đếm số loại mà các quan sát rơi vào.
Bản chất của sự khác biệt giữa hàm DISP.G() và DISP.V() như sau:
- Trong hàm VAR.G(), tổng bình phương được chia cho số lượng quan sát và do đó thể hiện ước tính sai lệch của phương sai, giá trị trung bình thực.
- Trong hàm DISP.B(), tổng bình phương được chia cho số lượng quan sát trừ đi 1, tức là. bằng số bậc tự do, điều này đưa ra ước tính chính xác hơn, không thiên vị hơn về phương sai của tổng thể mà mẫu được rút ra.
Độ lệch chuẩn độ lệch chuẩn, SD) – là căn bậc hai của phương sai:
Bình phương các độ lệch sẽ biến thang đo thành một số liệu khác, là bình phương của thước đo ban đầu: mét - thành mét vuông, đô la - thành đô la vuông, v.v. Độ lệch chuẩn là căn bậc hai của phương sai và do đó đưa chúng ta trở về đơn vị đo ban đầu. Cái nào thuận tiện hơn.
Thông thường cần phải tính độ lệch chuẩn sau khi dữ liệu đã bị xử lý. Và mặc dù trong những trường hợp này, kết quả chắc chắn là độ lệch chuẩn nhưng chúng thường được gọi là lỗi chuẩn. Có một số loại sai số chuẩn, bao gồm sai số chuẩn của phép đo, sai số chuẩn của tỷ lệ và sai số chuẩn của giá trị trung bình.
Giả sử bạn đã thu thập dữ liệu chiều cao của 25 người đàn ông trưởng thành được chọn ngẫu nhiên ở mỗi bang trong số 50 tiểu bang. Tiếp theo, bạn tính chiều cao trung bình của nam giới trưởng thành ở mỗi tiểu bang. Lần lượt, 50 giá trị trung bình thu được có thể được coi là quan sát. Từ đó, bạn có thể tính được độ lệch chuẩn của chúng, đó là sai số chuẩn của giá trị trung bình. Cơm. 1. so sánh sự phân bố của 1.250 giá trị cá nhân thô (dữ liệu chiều cao của 25 nam giới ở mỗi trong số 50 tiểu bang) với sự phân bổ của mức trung bình của 50 tiểu bang. Công thức ước tính sai số chuẩn của giá trị trung bình (nghĩa là độ lệch chuẩn của giá trị trung bình, không phải các quan sát riêng lẻ):
![]()
sai số chuẩn của giá trị trung bình ở đâu; S- độ lệch chuẩn của các quan trắc ban đầu; N– số lượng quan sát trong mẫu.

Cơm. 1. Sự khác biệt về giá trị trung bình giữa các tiểu bang nhỏ hơn đáng kể so với sự khác biệt trong các quan sát riêng lẻ.
Trong thống kê, có một quy ước liên quan đến việc sử dụng các chữ cái Hy Lạp và Latinh để biểu thị số lượng thống kê. Thông thường, người ta thường biểu thị các tham số của tổng thể bằng các chữ cái Hy Lạp và số liệu thống kê mẫu bằng các chữ cái Latinh. Vì vậy, khi nói về độ lệch chuẩn của dân số, chúng ta viết là σ; nếu xem xét độ lệch chuẩn của mẫu thì chúng ta sử dụng ký hiệu s. Đối với các ký hiệu để chỉ mức trung bình, chúng không ăn khớp với nhau lắm. Giá trị trung bình của dân số được ký hiệu bằng chữ cái Hy Lạp μ. Tuy nhiên, ký hiệu X̅ thường được sử dụng để biểu thị giá trị trung bình mẫu.
điểm z biểu thị vị trí của một quan sát trong phân bố theo đơn vị độ lệch chuẩn. Ví dụ: z = 1,5 có nghĩa là quan sát cách giá trị trung bình 1,5 độ lệch chuẩn. Thuật ngữ điểm zđược sử dụng để đánh giá cá nhân, tức là cho các kích thước được gán cho các phần tử mẫu riêng lẻ. Thuật ngữ dùng để chỉ số liệu thống kê đó (chẳng hạn như mức trung bình của tiểu bang) điểm z:

trong đó X̅ là giá trị trung bình mẫu, μ là giá trị trung bình tổng thể, là sai số chuẩn của giá trị trung bình của một tập hợp mẫu:
![]()
trong đó σ là sai số chuẩn của tổng thể (các phép đo riêng lẻ), N- cỡ mẫu.
Giả sử bạn làm việc với tư cách là người hướng dẫn tại một câu lạc bộ chơi gôn. Bạn đã có thể đo khoảng cách các cú đánh của mình trong một khoảng thời gian dài và biết rằng trung bình là 205 thước Anh và độ lệch chuẩn là 36 thước Anh. Bạn được cung cấp một cây gậy mới, tuyên bố rằng nó sẽ tăng khoảng cách đánh của bạn thêm 10 thước. Bạn yêu cầu mỗi người trong số 81 khách hàng tiếp theo của câu lạc bộ đánh thử một cây gậy mới và ghi lại khoảng cách vung gậy của họ. Hóa ra khoảng cách trung bình với câu lạc bộ mới là 215 thước Anh. Xác suất để sự khác biệt 10 yard (215 – 205) chỉ do lỗi lấy mẫu là bao nhiêu? Hay nói cách khác: Khả năng là, trong thử nghiệm rộng rãi hơn, gậy mới sẽ không cho thấy sự gia tăng khoảng cách đánh so với mức trung bình dài hạn hiện tại là 205 yard là bao nhiêu?
Chúng ta có thể kiểm tra điều này bằng cách tạo ra điểm z. Sai số chuẩn của giá trị trung bình:
![]()
Sau đó, điểm z:

Chúng ta cần tìm xác suất để trung bình mẫu cách trung bình tổng thể 2,5σ. Nếu xác suất nhỏ thì sự khác biệt không phải do ngẫu nhiên mà do chất lượng của câu lạc bộ mới. Excel không có chức năng làm sẵn để xác định xác suất điểm z. Tuy nhiên, bạn có thể sử dụng công thức =1-NORM.ST.DIST(z-score,TRUE), trong đó hàm NORM.ST.DIST() trả về diện tích dưới đường cong pháp tuyến ở bên trái của điểm z (Hình 2).

Cơm. 2. Hàm NORM.ST.DIST() trả về diện tích dưới đường cong bên trái của giá trị z; Để phóng to hình ảnh, nhấp chuột phải vào hình ảnh và chọn Mở hình ảnh trong trang mới
Đối số thứ hai của hàm NORM.ST.DIST() có thể nhận hai giá trị: TRUE – hàm trả về diện tích của vùng dưới đường cong bên trái điểm được chỉ định bởi đối số thứ nhất; FALSE – hàm trả về chiều cao của đường cong tại điểm được chỉ định bởi đối số đầu tiên.
Nếu không biết trung bình tổng thể (μ) và độ lệch chuẩn (σ), thì giá trị t sẽ được sử dụng (xem chi tiết). Cấu trúc điểm z và điểm t khác nhau ở chỗ độ lệch chuẩn s thu được từ kết quả mẫu được sử dụng để tìm điểm t thay vì giá trị đã biết của tham số tổng thể σ. Đường cong chuẩn có một hình dạng duy nhất và hình dạng của phân bố giá trị t thay đổi tùy thuộc vào số bậc tự do df. bậc tự do) của mẫu mà nó đại diện. Số bậc tự do của mẫu bằng n – 1, Ở đâu N- cỡ mẫu (Hình 3).

Cơm. 3. Hình dạng của phân phối t phát sinh trong trường hợp tham số σ chưa biết khác với hình dạng của phân phối chuẩn
Excel có hai hàm phân phối t, còn được gọi là phân phối Sinh viên: STUDENT.DIST() trả về diện tích dưới đường cong bên trái của một giá trị t nhất định và STUDENT.DIST.PH() trả về diện tích cho Phải.
Chương 2. Mối tương quan
Tương quan là thước đo sự phụ thuộc giữa các phần tử của một tập hợp các cặp có thứ tự. Sự tương quan được đặc trưng Hệ số tương quan Pearson–r. Hệ số có thể lấy các giá trị trong khoảng từ –1.0 đến +1.0.

Ở đâu Sx Và S y– độ lệch chuẩn của các biến X Và Y, S xy– hiệp phương sai:

Trong công thức này, hiệp phương sai được chia cho độ lệch chuẩn của các biến X Và Y, do đó loại bỏ các hiệu ứng chia tỷ lệ liên quan đến đơn vị khỏi hiệp phương sai. Excel sử dụng hàm CORREL(). Tên của hàm này không chứa các phần tử đủ điều kiện Г và В, được sử dụng trong tên của các hàm như STANDARDEV(), VARIANCE() hoặc COVARIANCE(). Mặc dù hệ số tương quan mẫu cung cấp ước tính sai lệch, lý do dẫn đến sai lệch là khác so với trường hợp phương sai hoặc độ lệch chuẩn.
Tùy thuộc vào độ lớn của hệ số tương quan tổng quát (thường được ký hiệu bằng chữ Hy Lạp ρ ), Hệ số tương quan r tạo ra ước tính sai lệch, với hiệu ứng sai lệch tăng lên khi cỡ mẫu giảm. Tuy nhiên, chúng tôi không cố gắng điều chỉnh độ lệch này theo cách tương tự như cách chúng tôi đã làm khi tính độ lệch chuẩn, khi chúng tôi thay thế không phải số lượng quan sát mà thay vào đó là số bậc tự do vào công thức tương ứng. Trong thực tế, số lượng quan sát được sử dụng để tính hiệp phương sai không ảnh hưởng đến độ lớn.
Hệ số tương quan tiêu chuẩn được thiết kế để sử dụng với các biến có liên quan với nhau bằng mối quan hệ tuyến tính. Sự hiện diện của tính phi tuyến và/hoặc sai sót trong dữ liệu (các giá trị ngoại lệ) dẫn đến tính toán sai hệ số tương quan. Để chẩn đoán các vấn đề về dữ liệu, nên tạo các biểu đồ phân tán. Đây là loại biểu đồ duy nhất trong Excel coi cả trục ngang và trục dọc là trục giá trị. Biểu đồ đường xác định một trong các cột là trục danh mục, điều này làm biến dạng hình ảnh dữ liệu (Hình 4).

Cơm. 4. Các đường hồi quy tưởng chừng giống nhau nhưng so sánh phương trình của chúng với nhau
Các quan sát dùng để xây dựng biểu đồ đường được sắp xếp cách đều nhau dọc theo trục hoành. Các nhãn phân chia dọc theo trục này chỉ là nhãn chứ không phải giá trị số.
Mặc dù mối tương quan thường có nghĩa là có mối quan hệ nhân quả nhưng nó không thể được sử dụng để chứng minh trường hợp này. Thống kê không được sử dụng để chứng minh liệu một lý thuyết là đúng hay sai. Để loại trừ những lời giải thích cạnh tranh cho các kết quả quan sát, hãy đặt thí nghiệm theo kế hoạch. Thống kê được sử dụng để tóm tắt thông tin được thu thập trong các thí nghiệm như vậy và để định lượng khả năng quyết định được đưa ra có thể không chính xác dựa trên cơ sở bằng chứng sẵn có.
Chương 3: Hồi quy đơn giản
Nếu hai biến có liên quan với nhau, do đó giá trị của hệ số tương quan vượt quá 0,5, thì trong trường hợp này có thể dự đoán (với độ chính xác nhất định) giá trị chưa biết của một biến từ giá trị đã biết của biến kia . Để có được giá trị dự báo dựa trên dữ liệu được hiển thị trong Hình. 5, bạn có thể sử dụng bất kỳ phương pháp nào trong số các phương pháp có thể, nhưng bạn gần như chắc chắn sẽ không sử dụng phương pháp được hiển thị trong Hình. 5. Tuy nhiên, bạn nên làm quen với nó, vì không có phương pháp nào khác cho phép bạn chứng minh mối liên hệ giữa mối tương quan và dự đoán rõ ràng như phương pháp này. Trong bộ lễ phục. 5 trong phạm vi B2:C12 hiển thị mẫu ngẫu nhiên gồm mười ngôi nhà và cung cấp dữ liệu về diện tích của mỗi ngôi nhà (tính bằng feet vuông) và giá bán của nó.

Cơm. 5. Dự báo giá trị giá bán tạo thành một đường thẳng
Tìm giá trị trung bình, độ lệch chuẩn và hệ số tương quan (phạm vi A14:C18). Tính điểm z diện tích (E2:E12). Ví dụ: ô E3 chứa công thức: =(B3-$B$14)/$B$15. Tính điểm z của giá dự báo (F2:F12). Ví dụ: ô F3 chứa công thức: =ЕЗ*$В$18. Chuyển đổi điểm z thành giá đô la (H2:H12). Trong ô NZ, công thức là: =F3*$C$15+$C$14.
Lưu ý rằng giá trị dự đoán luôn có xu hướng dịch chuyển về phía giá trị trung bình bằng 0. Hệ số tương quan càng gần 0 thì điểm z dự đoán càng gần 0. Trong ví dụ của chúng tôi, hệ số tương quan giữa diện tích và giá bán là 0,67 và giá dự báo là 1,0 * 0,67, tức là. 0,67. Điều này tương ứng với việc vượt quá một giá trị trên giá trị trung bình bằng hai phần ba độ lệch chuẩn. Nếu hệ số tương quan bằng 0,5 thì giá dự báo sẽ là 1,0 * 0,5, tức là. 0,5. Điều này tương ứng với sự vượt quá một giá trị trên giá trị trung bình chỉ bằng một nửa độ lệch chuẩn. Bất cứ khi nào giá trị của hệ số tương quan khác với giá trị lý tưởng, tức là. lớn hơn -1,0 và nhỏ hơn 1,0, điểm của biến dự đoán phải gần với giá trị trung bình của nó hơn điểm của biến dự đoán (độc lập) với chính nó. Hiện tượng này được gọi là hồi quy về giá trị trung bình, hay đơn giản là hồi quy.
Excel có một số hàm để xác định các hệ số của phương trình đường hồi quy (được gọi là đường xu hướng trong Excel) y =kx + b. Để xác định k phục vụ chức năng
=SLOPE(giá trị_y_đã biết, giá trị_x_đã biết)
Đây Tại là biến dự đoán và X- biến độc lập. Bạn phải tuân thủ nghiêm ngặt thứ tự biến đổi này. Độ dốc của đường hồi quy, hệ số tương quan, độ lệch chuẩn của các biến và hiệp phương sai có liên quan chặt chẽ với nhau (Hình 6). Hàm INTERMEPT() trả về giá trị bị chặn bởi đường hồi quy trên trục tung:
=LIMIT(giá_trị_y_đã_biết, giá trị_x_đã_biết)

Cơm. 6. Mối quan hệ giữa độ lệch chuẩn chuyển đổi hiệp phương sai thành hệ số tương quan và độ dốc của đường hồi quy
Lưu ý rằng số lượng giá trị x và y được cung cấp làm đối số cho hàm SLOPE() và INTERCEPT() phải giống nhau.
Trong phân tích hồi quy, một chỉ báo quan trọng khác được sử dụng - R 2 (R-square) hoặc hệ số xác định. Nó xác định sự đóng góp nào vào sự biến thiên tổng thể của dữ liệu được tạo ra bởi mối quan hệ giữa X Và Tại. Trong Excel, có một hàm gọi là CVPIERSON(), hàm này nhận các đối số chính xác giống như hàm CORREL().
Hai biến có hệ số tương quan khác 0 giữa chúng được cho là phương sai giải thích hoặc có phương sai giải thích. Phương sai được giải thích thông thường được biểu thị bằng phần trăm. Vì thế R 2 = 0,81 có nghĩa là 81% phương sai (tán xạ) của hai biến được giải thích. 19% còn lại là do biến động ngẫu nhiên.
Excel có hàm TREND giúp việc tính toán trở nên dễ dàng hơn. Hàm TREND():
- chấp nhận các giá trị đã biết mà bạn cung cấp X và các giá trị đã biết Tại;
- tính toán độ dốc của đường hồi quy và hằng số (chặn);
- trả về giá trị dự đoán Tại, được xác định bằng cách áp dụng phương trình hồi quy cho các giá trị đã biết X(Hình 7).
Hàm TREND() là một hàm mảng (tôi khuyên bạn nên sử dụng nếu bạn chưa từng gặp những hàm như vậy trước đây).

Cơm. 7. Sử dụng hàm TREND() cho phép bạn tăng tốc và đơn giản hóa các phép tính so với việc sử dụng cặp hàm SLOPE() và INTERCEPT()
Để nhập hàm TREND() dưới dạng công thức mảng trong các ô G3:G12, hãy chọn phạm vi G3:G12, nhập công thức TREND (NW:S12;V3:B12), nhấn và giữ các phím
Hàm TREND() có thêm hai đối số: giá trị mới_x Và hằng số. Giá trị đầu tiên cho phép bạn đưa ra dự báo cho tương lai và giá trị thứ hai có thể buộc đường hồi quy đi qua gốc tọa độ (giá trị TRUE yêu cầu Excel sử dụng hằng số được tính toán, giá trị FALSE yêu cầu Excel sử dụng hằng số = 0 ). Excel cho phép bạn vẽ đường hồi quy trên biểu đồ để nó đi qua gốc tọa độ. Bắt đầu bằng cách vẽ biểu đồ phân tán, sau đó nhấp chuột phải vào một trong các điểm đánh dấu chuỗi dữ liệu. Chọn mục trong menu ngữ cảnh mở ra Thêm đường xu hướng; chọn một tùy chọn tuyến tính; nếu cần, hãy cuộn xuống bảng, chọn hộp Thiết lập giao lộ; Đảm bảo hộp văn bản liên quan của nó được đặt thành 0,0.
Nếu bạn có ba biến và bạn muốn xác định mối tương quan giữa hai trong số chúng đồng thời loại bỏ ảnh hưởng của biến thứ ba, bạn có thể sử dụng tương quan một phần. Giả sử bạn quan tâm đến mối quan hệ giữa tỷ lệ phần trăm cư dân thành phố đã hoàn thành đại học và số lượng sách trong thư viện của thành phố. Bạn đã thu thập dữ liệu của 50 thành phố, nhưng... Vấn đề là cả hai thông số này có thể phụ thuộc vào mức độ hạnh phúc của cư dân của một thành phố cụ thể. Tất nhiên, rất khó để tìm thấy 50 thành phố khác có đặc điểm giống hệt nhau về mức độ hạnh phúc của người dân.
Bằng cách sử dụng các phương pháp thống kê để kiểm soát ảnh hưởng của của cải đối với cả hỗ trợ tài chính của thư viện và khả năng chi trả của trường đại học, bạn có thể định lượng chính xác hơn về độ mạnh của mối quan hệ giữa các biến số quan tâm, cụ thể là số lượng sách và số lượng sinh viên tốt nghiệp. Mối tương quan có điều kiện như vậy giữa hai biến, khi giá trị của các biến khác cố định, được gọi là tương quan từng phần. Một cách để tính toán nó là sử dụng phương trình:

Ở đâu rC.B. . W- hệ số tương quan giữa biến Đại học và Sách với ảnh hưởng (giá trị cố định) của biến Tài sản bị loại trừ; rC.B.- hệ số tương quan giữa biến College và Books; rCW- hệ số tương quan giữa biến Cao đẳng và Phúc lợi; rB.W.- hệ số tương quan giữa biến Sách vở và biến Phúc lợi.
Mặt khác, mối tương quan một phần có thể được tính toán dựa trên phân tích phần dư, tức là sự khác biệt giữa các giá trị dự đoán và kết quả liên quan của các quan sát thực tế (cả hai phương pháp được trình bày trong Hình 8).

Cơm. 8. Tương quan từng phần là tương quan của phần dư
Để đơn giản hóa việc tính toán ma trận hệ số tương quan (B16:E19), hãy sử dụng gói phân tích Excel (menu Dữ liệu –> Phân tích –> Phân tích dữ liệu). Theo mặc định, gói này không hoạt động trong Excel. Để cài đặt nó, hãy đi qua menu Tài liệu –> Tùy chọn –> Tiện ích bổ sung. Ở dưới cùng của cửa sổ đang mở Tùy chọnExcel tìm trường Điều khiển, lựa chọn Tiện ích bổ sungExcel, nhấp chuột Đi. Chọn hộp bên cạnh bổ trợ Gói phân tích. Bấm vào A phân tích dữ liệu, chọn tùy chọn Tương quan. Chỉ định $B$2:$D$13 làm khoảng thời gian đầu vào, chọn hộp Nhãn ở dòng đầu tiên, chỉ định $B$16:$E$19 làm khoảng thời gian đầu ra.
Một khả năng khác là xác định mối tương quan bán phần. Ví dụ: bạn đang nghiên cứu ảnh hưởng của chiều cao và tuổi tác đến cân nặng. Do đó, bạn có hai biến dự đoán - chiều cao và tuổi và một biến dự đoán - cân nặng. Bạn muốn loại trừ ảnh hưởng của một biến dự đoán đến một biến dự đoán khác, nhưng không loại trừ ảnh hưởng của biến dự đoán:
![]()
trong đó H – Chiều cao, W – Cân nặng, A – Tuổi; Chỉ số hệ số tương quan bán phần sử dụng dấu ngoặc đơn để cho biết biến nào đang bị loại bỏ và biến nào đang bị loại bỏ. Trong trường hợp này, ký hiệu W(H.A) chỉ ra rằng ảnh hưởng của biến Tuổi bị loại bỏ khỏi biến Chiều cao, nhưng không loại bỏ khỏi biến Cân nặng.
Có vẻ như vấn đề đang được thảo luận không có tầm quan trọng đáng kể. Rốt cuộc, điều quan trọng nhất là phương trình hồi quy tổng thể hoạt động chính xác đến mức nào, trong khi vấn đề về sự đóng góp tương đối của các biến riêng lẻ vào tổng phương sai được giải thích dường như chỉ có tầm quan trọng thứ yếu. Tuy nhiên, đây không phải là trường hợp. Khi bạn bắt đầu tự hỏi liệu một biến có đáng sử dụng trong phương trình hồi quy bội hay không thì vấn đề sẽ trở nên quan trọng. Nó có thể ảnh hưởng đến việc đánh giá tính đúng đắn của việc lựa chọn mô hình để phân tích.
Chương 4. Hàm LINEST()
Hàm LINEST() trả về 10 thống kê hồi quy. Hàm LINEST() là hàm mảng. Để nhập nó, hãy chọn một phạm vi chứa năm hàng và hai cột, nhập công thức và nhấp vào
LINEST(B2:B21,A2:A21,TRUE,TRUE)

Cơm. 9. Hàm LINEST(): a) chọn phạm vi D2:E6, b) nhập công thức như hiển thị trên thanh công thức, c) nhấp vào
Hàm LINEST() trả về:
- hệ số hồi quy (hoặc độ dốc, ô D2);
- đoạn (hoặc hằng số, ô E3);
- sai số chuẩn của hệ số hồi quy và hằng số (phạm vi D3:E3);
- hệ số xác định R 2 cho hồi quy (ô D4);
- sai số chuẩn của ước tính (ô E4);
- Kiểm tra F cho hồi quy đầy đủ (ô D5);
- số bậc tự do của tổng bình phương còn lại (ô E5);
- hồi quy tổng bình phương (ô D6);
- tổng bình phương còn lại (ô E6).
Chúng ta hãy xem từng số liệu thống kê này và cách chúng tương tác.
Lỗi tiêu chuẩn trong trường hợp của chúng tôi, đó là độ lệch chuẩn được tính cho các lỗi lấy mẫu. Nghĩa là, đây là tình huống trong đó dân số nói chung có một số liệu thống kê và mẫu có một số liệu thống kê khác. Chia hệ số hồi quy cho sai số chuẩn sẽ cho bạn giá trị 2,092/0,818 = 2,559. Nói cách khác, hệ số hồi quy 2,092 là hai sai số chuẩn rưỡi so với 0.
Nếu hệ số hồi quy bằng 0 thì ước tính tốt nhất của biến dự đoán là giá trị trung bình của nó. Sai số chuẩn hai rưỡi là khá lớn và bạn có thể giả định một cách an toàn rằng hệ số hồi quy của tổng thể là khác không.
Bạn có thể xác định xác suất đạt được hệ số hồi quy mẫu là 2,092 nếu giá trị thực của nó trong dân số là 0,0 bằng cách sử dụng hàm
STUDENT.DIST.PH (t-tiêu chí = 2,559; số bậc tự do = 18)
Nói chung, số bậc tự do = n – k – 1, trong đó n là số lượng quan sát và k là số biến dự đoán.
Công thức này trả về 0,00987 hoặc được làm tròn thành 1%. Nó cho chúng ta biết rằng nếu hệ số hồi quy cho tổng thể là 0% thì xác suất lấy được mẫu gồm 20 người có hệ số hồi quy ước tính là 2,092 là khiêm tốn 1%.
Kiểm tra F (ô D5 trong Hình 9) thực hiện các chức năng tương tự liên quan đến hồi quy hoàn toàn như kiểm tra t liên quan đến hệ số hồi quy theo cặp đơn giản. Kiểm định F được sử dụng để kiểm tra xem hệ số xác định R 2 cho một hồi quy có đủ lớn để bác bỏ giả thuyết rằng trong quần thể nó có giá trị 0,0, điều này cho thấy rằng không có phương sai được giải thích bởi biến dự đoán và biến dự đoán. Khi chỉ có một biến dự đoán, phép thử F chính xác bằng bình phương của phép thử t.
Cho đến nay chúng ta đã xem xét các biến khoảng. Nếu bạn có các biến có thể nhận nhiều giá trị, đại diện cho các tên đơn giản, ví dụ: Đàn ông và Phụ nữ hoặc Bò sát, Lưỡng cư và Cá, hãy biểu thị chúng dưới dạng mã số. Các biến như vậy được gọi là danh nghĩa.
Thống kê R2định lượng tỷ lệ phương sai được giải thích.
Sai số chuẩn của ước tính. Trong bộ lễ phục. Hình 4.9 trình bày các giá trị dự đoán của biến Weight, thu được trên cơ sở mối quan hệ của nó với biến Height. Phạm vi E2:E21 chứa các giá trị dư cho biến Weight. Chính xác hơn, những phần dư này được gọi là sai số - do đó có thuật ngữ sai số chuẩn của ước lượng.

Cơm. 10. Cả R 2 và sai số chuẩn của ước tính đều thể hiện độ chính xác của dự báo thu được bằng phương pháp hồi quy
Sai số chuẩn của ước tính càng nhỏ thì phương trình hồi quy càng chính xác và bạn càng mong đợi bất kỳ dự đoán nào do phương trình tạo ra phù hợp với quan sát thực tế càng gần hơn. Sai số chuẩn của ước tính cung cấp một cách để định lượng những kỳ vọng này. Cân nặng của 95% người có chiều cao nhất định sẽ nằm trong khoảng:
(chiều cao * 2,092 – 3,591) ± 2,092 * 21,118
Thống kê F là tỷ lệ giữa phương sai giữa các nhóm với phương sai trong nhóm. Tên này được giới thiệu bởi nhà thống kê George Snedesign để vinh danh Ngài, người đã phát triển phân tích phương sai (ANOVA, Phân tích phương sai) vào đầu thế kỷ 20.
Hệ số xác định R 2 biểu thị tỷ lệ của tổng bình phương liên quan đến hồi quy. Giá trị (1 – R 2) biểu thị tỷ lệ của tổng bình phương liên quan đến phần dư - sai số dự báo. Có thể thu được phép thử F bằng cách sử dụng hàm LINEST (ô F5 trong Hình 11), sử dụng tổng bình phương (phạm vi G10:J11), sử dụng tỷ lệ phương sai (phạm vi G14:J15). Các công thức có thể được nghiên cứu trong tệp Excel đính kèm.

Cơm. 11. Tính chỉ tiêu F
Khi sử dụng các biến danh nghĩa, mã hóa giả được sử dụng (Hình 12). Để mã hóa các giá trị, thuận tiện nhất là sử dụng giá trị 0 và 1. Xác suất F được tính bằng hàm:
F.DIST.PH(K2;I2;I3)
Ở đây, hàm F.DIST.PH() trả về xác suất đạt được tiêu chí F tuân theo phân phối F trung tâm (Hình 13) cho hai bộ dữ liệu với số bậc tự do được cho trong các ô I2 và I3, giá trị trùng với giá trị được cho trong ô K2.

Cơm. 12. Phân tích hồi quy sử dụng biến giả

Cơm. 13. Phân bố F trung tâm tại λ = 0
Chương 5. Hồi quy bội
Khi bạn chuyển từ hồi quy cặp đơn giản với một biến dự đoán sang hồi quy bội, bạn thêm một hoặc nhiều biến dự đoán. Lưu trữ giá trị của các biến dự đoán trong các cột liền kề, chẳng hạn như cột A và B trong trường hợp có hai yếu tố dự đoán hoặc A, B và C trong trường hợp có ba yếu tố dự đoán. Trước khi nhập công thức bao gồm hàm LINEST(), hãy chọn năm hàng và số cột tùy theo số biến dự đoán, cộng thêm một cột nữa cho hằng số. Trong trường hợp hồi quy với hai biến dự đoán, có thể sử dụng cấu trúc sau:
DÒNG(A2: A41; B2: C41;;TRUE)
Tương tự trong trường hợp ba biến:
LINEST(A2:A61,B2:D61,;TRUE)
Giả sử bạn muốn nghiên cứu những tác động có thể có của tuổi tác và chế độ ăn uống đối với mức LDL - lipoprotein mật độ thấp, được cho là nguyên nhân hình thành các mảng xơ vữa động mạch, gây ra chứng huyết khối động mạch (Hình 14).

Cơm. 14. Hồi quy bội
R 2 của hồi quy bội (được phản ánh trong ô F13) lớn hơn R 2 của bất kỳ hồi quy đơn giản nào (E4, H4). Hồi quy bội sử dụng nhiều biến dự đoán cùng một lúc. Trong trường hợp này, R2 hầu như luôn tăng.
Đối với bất kỳ phương trình hồi quy tuyến tính đơn giản nào có một biến dự đoán, sẽ luôn có mối tương quan hoàn hảo giữa giá trị dự đoán và giá trị của biến dự đoán vì phương trình nhân các giá trị dự đoán với một hằng số và thêm một hằng số khác vào mỗi sản phẩm. Hiệu ứng này không tồn tại trong hồi quy bội.
Hiển thị kết quả được hàm LINEST() trả về cho hồi quy bội (Hình 15). Các hệ số hồi quy được đưa ra như một phần của kết quả được trả về bởi hàm LINEST() theo thứ tự ngược lại của các biến(G–H–I tương ứng với C–B–A).

Cơm. 15. Các hệ số và sai số chuẩn của chúng được hiển thị theo thứ tự ngược trên bảng tính.
Các nguyên tắc và quy trình được sử dụng trong phân tích hồi quy biến dự đoán đơn có thể dễ dàng được điều chỉnh để tính đến nhiều biến dự đoán. Hóa ra phần lớn sự thích ứng này phụ thuộc vào việc loại bỏ ảnh hưởng của các biến dự đoán lẫn nhau. Cái sau được liên kết với các mối tương quan một phần và bán một phần (Hình 16).

Cơm. 16. Hồi quy bội có thể được biểu thị thông qua hồi quy cặp phần dư (xem công thức trong tệp Excel)
Trong Excel, có các hàm cung cấp thông tin về phân phối t và F. Các hàm có tên bao gồm phần DIST, chẳng hạn như STUDENT.DIST() và F.DIST(), lấy t-test hoặc F-test làm đối số và trả về xác suất quan sát được một giá trị được chỉ định. Các hàm có tên bao gồm phần OBR, chẳng hạn như STUDENT.INV() và F.INR(), lấy giá trị xác suất làm đối số và trả về giá trị tiêu chí tương ứng với xác suất đã chỉ định.
Vì chúng tôi đang tìm kiếm các giá trị tới hạn của phân phối t cắt các cạnh của vùng đuôi của nó, nên chúng tôi chuyển 5% làm đối số cho một trong các hàm STUDENT.INV(), hàm này trả về giá trị tương ứng với xác suất này (Hình 17, 18).

Cơm. 17. Kiểm định t hai đuôi

Cơm. 18. Kiểm tra t một đuôi
Bằng cách thiết lập quy tắc quyết định cho vùng alpha đuôi đơn, bạn sẽ tăng sức mạnh thống kê của thử nghiệm. Nếu bạn tham gia một thử nghiệm và tự tin rằng bạn có mọi lý do để mong đợi hệ số hồi quy dương (hoặc âm), thì bạn nên thực hiện thử nghiệm một đuôi. Trong trường hợp này, khả năng bạn đưa ra quyết định đúng đắn khi bác bỏ giả thuyết về hệ số hồi quy bằng 0 trong tổng thể sẽ cao hơn.
Các nhà thống kê thích sử dụng thuật ngữ này kiểm tra theo hướng dẫn thay vì thuật ngữ thử nghiệm đuôi đơn và thời hạn kiểm tra vô hướng thay vì thuật ngữ thử nghiệm hai đuôi. Các thuật ngữ có hướng và không có hướng được ưa chuộng hơn vì chúng nhấn mạnh đến loại giả thuyết hơn là bản chất của các đuôi của phân phối.
Một cách tiếp cận để đánh giá tác động của các yếu tố dự đoán dựa trên so sánh mô hình. Trong bộ lễ phục. Hình 19 trình bày kết quả phân tích hồi quy nhằm kiểm tra sự đóng góp của biến Diet vào phương trình hồi quy.

Cơm. 19. So sánh hai mô hình bằng cách kiểm tra sự khác biệt trong kết quả của chúng
Kết quả của hàm LINEST() (phạm vi H2:K6) có liên quan đến cái mà tôi gọi là mô hình đầy đủ, mô hình này hồi quy biến LDL trên các biến Chế độ ăn uống, Tuổi và HDL. Phạm vi H9:J13 trình bày các phép tính mà không tính đến biến dự đoán Diet. Tôi gọi đây là mô hình giới hạn. Trong mô hình đầy đủ, 49,2% phương sai của biến phụ thuộc LDL được giải thích bằng các biến dự đoán. Trong mô hình hạn chế, chỉ có 30,8% LDL được giải thích bằng các biến Tuổi và HDL. Tổn thất trong R 2 do loại biến Diet khỏi mô hình là 0,183. Trong phạm vi G15:L17, các phép tính được thực hiện cho thấy rằng chỉ có xác suất 0,0288 rằng tác động của biến Chế độ ăn kiêng là ngẫu nhiên. Trong 97,1% còn lại, Chế độ ăn có ảnh hưởng đến LDL.
Chương 6: Các giả định và lưu ý khi phân tích hồi quy
Thuật ngữ "giả định" không được định nghĩa đủ chặt chẽ và cách sử dụng nó cho thấy rằng nếu giả định không được đáp ứng thì ít nhất kết quả của toàn bộ phân tích cũng có vấn đề hoặc có thể không hợp lệ. Thực tế không phải vậy, mặc dù chắc chắn có những trường hợp vi phạm một giả định về cơ bản sẽ làm thay đổi bức tranh. Các giả định cơ bản: a) phần dư của biến Y được phân phối chuẩn tại bất kỳ điểm X nào dọc theo đường hồi quy; b) Giá trị Y phụ thuộc tuyến tính vào giá trị X; c) độ phân tán của phần dư gần như giống nhau tại mỗi điểm X; d) không có sự phụ thuộc giữa các dư lượng.
Nếu các giả định không đóng vai trò quan trọng thì các nhà thống kê cho rằng phân tích này có khả năng vi phạm giả định đó. Cụ thể, khi bạn sử dụng hồi quy để kiểm tra sự khác biệt giữa các giá trị trung bình của nhóm, giả định rằng các giá trị Y - và do đó phần dư - được phân phối bình thường không đóng một vai trò quan trọng: các thử nghiệm chắc chắn sẽ vi phạm giả định về tính quy tắc. Điều quan trọng là phân tích dữ liệu bằng biểu đồ. Ví dụ: được bao gồm trong tiện ích bổ sung Phân tích dữ liệu dụng cụ hồi quy.
Nếu dữ liệu không đáp ứng các giả định của hồi quy tuyến tính, bạn có thể sử dụng các cách tiếp cận khác ngoài hồi quy tuyến tính. Một trong số đó là hồi quy logistic (Hình 20). Gần giới hạn trên và giới hạn dưới của biến dự đoán, hồi quy tuyến tính tạo ra những dự đoán không thực tế.

Cơm. 20. Hồi quy logistic
Trong bộ lễ phục. Hình 6.8 hiển thị kết quả của hai phương pháp phân tích dữ liệu nhằm kiểm tra mối quan hệ giữa thu nhập hàng năm và khả năng mua nhà. Rõ ràng, khả năng mua hàng sẽ tăng lên khi thu nhập ngày càng tăng. Biểu đồ giúp bạn dễ dàng nhận ra sự khác biệt giữa kết quả mà hồi quy tuyến tính dự đoán khả năng mua nhà và kết quả bạn có thể nhận được khi sử dụng một cách tiếp cận khác.
Theo cách nói của các nhà thống kê, việc bác bỏ giả thuyết không trong khi thực tế nó đúng được gọi là lỗi Loại I.
Trong tiện ích bổ sung Phân tích dữ liệu cung cấp một công cụ thuận tiện để tạo số ngẫu nhiên, cho phép người dùng chỉ định hình dạng mong muốn của phân phối (ví dụ: Bình thường, Nhị thức hoặc Poisson), cũng như giá trị trung bình và độ lệch chuẩn.
Sự khác biệt giữa các hàm của họ STUDENT.DIST(). Bắt đầu với Excel 2010, có sẵn ba dạng hàm khác nhau trả về tỷ lệ phân bố ở bên trái và/hoặc bên phải của một giá trị kiểm tra t nhất định. Hàm STUDENT.DIST() trả về phần diện tích bên dưới đường cong phân phối ở bên trái giá trị t-test mà bạn chỉ định. Giả sử bạn có 36 quan sát, vậy số bậc tự do cho phân tích là 34 và giá trị t-test = 1,69. Trong trường hợp này công thức
SINH VIÊN.DIST(+1.69,34,TRUE)
trả về giá trị 0,05 hoặc 5% (Hình 21). Đối số thứ ba của hàm STUDENT.DIST() có thể là TRUE hoặc FALSE. Nếu được đặt thành TRUE, hàm sẽ trả về diện tích tích lũy dưới đường cong bên trái của phép thử t đã chỉ định, được biểu thị dưới dạng tỷ lệ. Nếu là FALSE, hàm trả về chiều cao tương đối của đường cong tại điểm tương ứng với phép thử t. Các phiên bản khác của hàm STUDENT.DIST() - STUDENT.DIST.PH() và STUDENT.DIST.2X() - chỉ lấy giá trị t-test và số bậc tự do làm đối số và không yêu cầu chỉ định giá trị thứ ba lý lẽ.

Cơm. 21. Vùng tô bóng đậm hơn ở phần đuôi bên trái của phân bố tương ứng với tỷ lệ diện tích dưới đường cong bên trái của giá trị t-test dương lớn
Để xác định diện tích bên phải của phép thử t, hãy sử dụng một trong các công thức:
1 — STIODENT.DIST (1, 69;34;TRUE)
SINH VIÊN.DIST.PH(1.69;34)
Toàn bộ diện tích bên dưới đường cong phải là 100%, do đó, trừ đi 1 phần diện tích bên trái của giá trị t-test mà hàm trả về sẽ là phần diện tích bên phải của giá trị t-test. Bạn có thể thấy tốt hơn là lấy trực tiếp phần diện tích mà bạn quan tâm bằng cách sử dụng hàm STUDENT.DIST.PH(), trong đó PH có nghĩa là phần đuôi bên phải của phân bố (Hình 22).

Cơm. 22. Vùng alpha 5% cho thử nghiệm định hướng
Việc sử dụng các hàm STUDENT.DIST() hoặc STUDENT.DIST.PH() ngụ ý rằng bạn đã chọn một giả thuyết làm việc có hướng. Giả thuyết làm việc định hướng kết hợp với việc đặt giá trị alpha thành 5% có nghĩa là bạn đặt tất cả 5% vào đuôi bên phải của phân bố. Bạn sẽ chỉ phải bác bỏ giả thuyết không nếu xác suất của giá trị kiểm định t mà bạn đạt được là 5% hoặc ít hơn. Các giả thuyết mang tính định hướng thường dẫn đến các kiểm định thống kê có độ nhạy cao hơn (độ nhạy cao hơn này còn được gọi là sức mạnh thống kê lớn hơn).
Trong thử nghiệm vô hướng, giá trị alpha vẫn ở mức 5% như cũ nhưng mức phân phối sẽ khác. Vì bạn phải cho phép xảy ra hai kết quả nên xác suất xảy ra kết quả dương tính giả phải được phân bổ giữa hai đầu của phân phối. Người ta thường chấp nhận phân phối xác suất này một cách đồng đều (Hình 23).

Sử dụng cùng giá trị t-test thu được và cùng số bậc tự do như trong ví dụ trước, hãy sử dụng công thức
SINH VIÊN.DIST.2Х(1.69;34)
Không vì lý do cụ thể nào, hàm STUDENT.DIST.2X() trả về mã lỗi #NUM! nếu nó được cung cấp một giá trị t-test âm làm đối số đầu tiên.
Nếu các mẫu chứa lượng dữ liệu khác nhau, hãy sử dụng phép thử t hai mẫu với các phương sai khác nhau có trong gói Phân tích dữ liệu.
Chương 7: Sử dụng hồi quy để kiểm tra sự khác biệt giữa các phương tiện nhóm
Các biến trước đây xuất hiện dưới tên biến dự đoán sẽ được gọi là biến kết quả trong chương này và thuật ngữ biến nhân tố sẽ được sử dụng thay cho thuật ngữ biến dự đoán.
Cách tiếp cận đơn giản nhất để mã hóa một biến danh nghĩa là mã hóa giả(Hình 24).

Cơm. 24. Phân tích hồi quy dựa trên mã hóa giả
Khi sử dụng bất kỳ loại mã hóa giả nào, cần tuân thủ các quy tắc sau:
- Số cột dành riêng cho dữ liệu mới phải bằng số cấp hệ số trừ đi
- Mỗi vectơ đại diện cho một cấp độ yếu tố.
- Các đối tượng ở một trong các cấp độ, thường là nhóm kiểm soát, được mã hóa 0 trong tất cả các vectơ.
Công thức trong các ô F2:H6 =LINEST(A2:A22,C2:D22,;TRUE) trả về số liệu thống kê hồi quy. Để so sánh, trong hình. Hình 24 cho thấy kết quả ANOVA truyền thống được công cụ trả về. ANOVA một chiều tiện ích bổ sung Phân tích dữ liệu.
Mã hóa hiệu ứng Trong một loại mã hóa khác được gọi là mã hóa hiệu ứng, Giá trị trung bình của mỗi nhóm được so sánh với giá trị trung bình của nhóm. Khía cạnh này của mã hóa hiệu ứng là do việc sử dụng -1 thay vì 0 làm mã cho nhóm, nhóm này nhận cùng một mã trong tất cả các vectơ mã (Hình 25).

Cơm. 25. Mã hóa hiệu ứng
Khi sử dụng mã hóa giả, giá trị không đổi được trả về bởi LINEST() là giá trị trung bình của nhóm được gán mã 0 trong tất cả các vectơ (thường là nhóm tham chiếu). Trong trường hợp mã hóa hiệu ứng, hằng số bằng giá trị trung bình tổng thể (ô J2).
Mô hình tuyến tính tổng quát là một cách hữu ích để khái niệm hóa các thành phần giá trị của biến kết quả:
Y ij = μ + α j + ε ij
Việc sử dụng các chữ cái Hy Lạp trong công thức này thay vì các chữ cái Latinh nhấn mạnh thực tế là nó đề cập đến tổng thể mà các mẫu được lấy ra, nhưng nó có thể được viết lại để chỉ ra rằng nó đề cập đến các mẫu được lấy từ một tổng thể nhất định:
Y ij = Y̅ + a j + e ij
Ý tưởng là mỗi quan sát Y ij có thể được xem là tổng của ba thành phần sau: trung bình tổng, μ; hiệu quả điều trị j, và j ; giá trị e ij, biểu thị độ lệch của chỉ báo định lượng riêng lẻ Y ij so với giá trị tổng hợp của mức trung bình chung và hiệu quả của biện pháp xử lý thứ j (Hình 26). Mục tiêu của phương trình hồi quy là cực tiểu hóa tổng bình phương của phần dư.

Cơm. 26. Các quan sát được phân tách thành các thành phần của mô hình tuyến tính tổng quát
Phân tích nhân tố. Nếu mối quan hệ giữa biến kết quả và hai hoặc nhiều yếu tố được nghiên cứu đồng thời thì trong trường hợp này chúng ta nói về việc sử dụng phân tích nhân tố. Việc thêm một hoặc nhiều yếu tố vào ANOVA một chiều có thể tăng sức mạnh thống kê. Trong phân tích phương sai một chiều, phương sai của biến kết quả không thể quy cho một yếu tố sẽ được đưa vào bình phương trung bình dư. Nhưng cũng có thể sự khác biệt này có liên quan đến một yếu tố khác. Sau đó, sự thay đổi này có thể được loại bỏ khỏi sai số bình phương trung bình, việc giảm sai số này dẫn đến tăng các giá trị kiểm tra F và do đó làm tăng khả năng thống kê của kiểm tra. Kiến trúc thượng tầng Phân tích dữ liệu bao gồm một công cụ xử lý đồng thời hai yếu tố (Hình 27).

Cơm. 27. Công cụ Phân tích phương sai hai chiều với sự lặp lại của Gói phân tích
Công cụ ANOVA được sử dụng trong hình này rất hữu ích vì nó trả về giá trị trung bình và phương sai của biến kết quả cũng như giá trị bộ đếm cho mỗi nhóm được đưa vào thiết kế. Trong bàn Phân tích phương sai hiển thị hai tham số không có trong đầu ra của phiên bản một yếu tố của công cụ ANOVA. Chú ý đến nguồn biến động Vật mẫu Và Cộtở dòng 27 và 28. Nguồn biến thể Cộtđề cập đến giới tính. Nguồn biến thiên Vật mẫuđề cập đến bất kỳ biến nào có giá trị chiếm các dòng khác nhau. Trong bộ lễ phục. 27 giá trị cho nhóm KursLech1 nằm ở dòng 2-6, nhóm KursLech2 nằm ở dòng 7-11 và nhóm KursLechZ nằm ở dòng 12-16.
Điểm chính là cả hai yếu tố, Giới tính (nhãn Cột trong ô E28) và Phương pháp xử lý (nhãn Mẫu trong ô E27), đều được đưa vào bảng ANOVA dưới dạng nguồn biến thể. Phương tiện dành cho nam giới khác với phương tiện dành cho phụ nữ và điều này tạo ra nguồn gốc của sự biến đổi. Phương tiện cho ba phương pháp điều trị cũng khác nhau, tạo ra một nguồn biến thể khác. Ngoài ra còn có nguồn thứ ba, Tương tác, đề cập đến tác động kết hợp của các biến Giới tính và Đối xử.
Chương 8. Phân tích hiệp phương sai
Phân tích hiệp phương sai, hay ANCOVA (Phân tích hiệp phương sai), làm giảm sai lệch và tăng sức mạnh thống kê. Hãy để tôi nhắc bạn rằng một trong những cách để đánh giá độ tin cậy của phương trình hồi quy là kiểm tra F:
F = Hồi quy MS/Dư lượng MS
trong đó MS (Bình phương trung bình) là bình phương trung bình và các chỉ số Hồi quy và Phần dư tương ứng biểu thị các thành phần hồi quy và phần dư. Phần dư MS được tính bằng công thức:
Số dư MS = Số dư SS / Số dư df
trong đó SS (Tổng bình phương) là tổng bình phương và df là số bậc tự do. Khi bạn thêm hiệp phương sai vào phương trình hồi quy, một phần của tổng bình phương không được bao gồm trong SS ResiduaI mà được bao gồm trong SS Regression. Điều này dẫn đến giảm SS Residua l và do đó giảm MS Residual. Phần dư MS càng nhỏ thì F-test càng lớn và bạn càng có nhiều khả năng bác bỏ giả thuyết không về việc không có sự khác biệt giữa các giá trị trung bình. Kết quả là bạn phân phối lại độ biến thiên của biến kết quả. Trong ANOVA, khi hiệp phương sai không được tính đến, độ biến thiên sẽ trở thành lỗi. Nhưng trong ANCOVA, một phần của sự thay đổi trước đây được quy cho thuật ngữ lỗi được gán cho hiệp phương sai và trở thành một phần của Hồi quy SS.
Hãy xem xét một ví dụ trong đó cùng một tập dữ liệu được phân tích trước tiên bằng ANOVA và sau đó bằng ANCOVA (Hình 28).

Cơm. 28. Phân tích ANOVA chỉ ra rằng kết quả thu được từ phương trình hồi quy là không đáng tin cậy
Nghiên cứu so sánh tác động tương đối của tập thể dục, giúp phát triển sức mạnh cơ bắp và tập thể dục nhận thức (làm trò chơi ô chữ), giúp kích thích hoạt động của não. Các đối tượng được phân ngẫu nhiên vào hai nhóm để cả hai nhóm đều được tiếp xúc với các điều kiện giống nhau khi bắt đầu thí nghiệm. Sau ba tháng, hiệu suất nhận thức của các đối tượng được đo lường. Kết quả của các phép đo này được thể hiện ở cột B.
Phạm vi A2:C21 chứa dữ liệu nguồn được chuyển đến hàm LINEST() để thực hiện phân tích bằng cách sử dụng mã hóa hiệu ứng. Kết quả của hàm LINEST() được đưa ra trong phạm vi E2:F6, trong đó ô E2 hiển thị hệ số hồi quy liên quan đến vectơ tác động. Ô E8 chứa t-test = 0,93 và ô E9 kiểm tra độ tin cậy của t-test này. Giá trị chứa trong ô E9 chỉ ra rằng xác suất gặp phải sự khác biệt giữa các giá trị trung bình của nhóm được quan sát trong thử nghiệm này là 36% nếu các giá trị trung bình của nhóm bằng nhau trong tổng thể. Rất ít người coi kết quả này là có ý nghĩa thống kê.
Trong bộ lễ phục. Hình 29 cho thấy điều gì sẽ xảy ra khi bạn thêm một hiệp phương sai vào phân tích. Trong trường hợp này, tôi đã thêm độ tuổi của từng đối tượng vào tập dữ liệu. Hệ số xác định R 2 cho phương trình hồi quy sử dụng hiệp phương sai là 0,80 (ô F4). Giá trị R 2 trong phạm vi F15:G19, trong đó tôi đã sao chép kết quả ANOVA thu được mà không có hiệp phương sai, chỉ là 0,05 (ô F17). Do đó, phương trình hồi quy bao gồm hiệp phương sai sẽ dự đoán các giá trị cho biến Điểm nhận thức chính xác hơn nhiều so với việc chỉ sử dụng vectơ Tác động. Đối với ANCOVA, xác suất nhận được giá trị kiểm tra F được hiển thị trong ô F5 một cách tình cờ là nhỏ hơn 0,01%.

Cơm. 29. ANCOVA mang lại một bức tranh hoàn toàn khác