Sơ đồ trang web xml nơi nó nằm. Hướng dẫn chi tiết về tệp Sơ đồ trang web. Chi tiết kỹ thuật của sơ đồ trang web
Thông thường, để tạo sitemap.xml, hãy sử dụng một trong các tùy chọn sau: dịch vụ trực tuyến S, Mô-đun CMS, chương trình chuyên ngành hoặc bằng tay. Dưới đây chúng ta sẽ xem xét chi tiết từng công cụ.
Cách tạo sơ đồ trang web trực tuyến
Có rất nhiều dịch vụ trên Internet cho phép bạn tạo sơ đồ trang web cho robot tìm kiếm. Dưới đây là những cái phổ biến nhất:
Các dịch vụ này hoạt động tốt và thực hiện các chức năng của chúng. Tuy nhiên, theo quy định, họ có giới hạn về số lượng trang được tính đến (thường là 500 trang). Ngoài ra, nếu trang web có điều hướng kém và một số tài liệu khá khó tiếp cận với bưu kiện thì rất có thể những trang này sẽ không được đưa vào sitemap.xml.
Cách tạo sitemap.xml bằng tiện ích bổ sung CMS
Hầu hết hệ thống phổ biến quản trị có các tiện ích bổ sung cho phép họ tạo sơ đồ trang web một cách tự động hoặc chế độ thủ công. Đây là nhiều nhất Một cách thuận tiện làm việc với sơ đồ trang web để có được nguồn tài nguyên lớn, với các tài liệu mới được xuất bản liên tục. Như thực tế cho thấy, bạn có thể tìm thấy một số tiện ích bổ sung phù hợp, bạn chỉ cần chọn một tiện ích bổ sung phù hợp nhất với mục tiêu của mình.
Ví dụ: đối với WordPress, plugin như vậy là Google Sơ đồ trang web XML và cho Joomla - thành phần Xmap. Ngoài ra, trên nhiều công cụ, khả năng tạo tệp sơ đồ trang web có trong cấu hình ban đầu (ví dụ: 1c-Bitrix hoặc DataLife Engine).
Cách tạo sơ đồ trang web bằng Xenu
Xenu là một trong những phổ biến nhất sản phẩm phần mềmđược tạo cho các chuyên gia SEO. Chương trình này không chỉ có thể tạo sơ đồ trang web cho một trang web mà nó còn có rất nhiều chức năng hữu ích– kiểm tra các liên kết bị hỏng, xác định các chuyển hướng và hơn thế nữa.
Cần lưu ý rằng Xenu không phải là chương trình duy nhất cho phép bạn tạo sơ đồ trang web.
Cách tạo sơ đồ trang web cho một trang web theo cách thủ công
Việc sử dụng nhiều lao động nhất, nhưng đồng thời đúng cách– bằng tay. Nó được sử dụng khi các tùy chọn khác không phù hợp. Điều này có thể xảy ra, ví dụ, nếu có quá nhiều số lượng lớn những trang không cần thiết vào sơ đồ trang web hoặc trang web có điều hướng kém không sử dụng CMS.

Sau khi bạn tạo sitemap.xml, hãy nhớ kiểm tra tệp kết quả. Điều này có thể được thực hiện bằng cách sử dụng dịch vụ trong bảng quản trị trang web Yandex, được đặt tại
Các tệp robots.txt và sitemap.xml giúp tổ chức lập chỉ mục trang web. Hai tệp này bổ sung tốt cho nhau, mặc dù chúng đồng thời giải quyết các vấn đề trái ngược nhau. Nếu robots.txt dùng để cấm lập chỉ mục toàn bộ các phần hoặc các trang riêng lẻ, thì ngược lại, sitemap.xml sẽ cho robot tìm kiếm biết URL nào cần được lập chỉ mục. Hãy phân tích từng tệp riêng biệt.
Tệp robot.txt
robots.txt là một tệp trong đó các quy tắc được viết nhằm hạn chế quyền truy cập của rô-bốt tìm kiếm vào các thư mục và tệp trang web nhằm tránh nội dung của chúng bị đưa vào chỉ mục của công cụ tìm kiếm. Tệp phải nằm trong thư mục gốc của trang web và có sẵn tại: site.ru/robots.txt.
Trong robots.txt, bạn cần chặn lập chỉ mục tất cả các trang trùng lặp và trang dịch vụ của trang web. CMS công cộng thường tạo ra các bản sao, chẳng hạn như các bài viết có thể được truy cập bằng nhiều URL cùng một lúc; trong danh mục site.ru/category/post-1/, gắn thẻ site.ru/tag/post-1/ và lưu trữ site.ru/arhive/post-1/. Để tránh trùng lặp, cần cấm lập chỉ mục các thẻ và kho lưu trữ; chỉ các danh mục mới được giữ lại trong chỉ mục. Theo các trang dịch vụ, ý tôi là các trang thuộc phần quản trị của trang web và các trang được tạo tự động, ví dụ: kết quả khi tìm kiếm trên trang web.
Điều đơn giản là cần thiết để loại bỏ các bản sao vì chúng làm mất đi tính độc đáo của các trang của trang web. Xét cho cùng, nếu chỉ mục chứa một số trang có cùng nội dung nhưng có thể truy cập được ở các URL khác nhau thì nội dung của không trang nào trong số đó sẽ được coi là duy nhất. Kết quả là các công cụ tìm kiếm sẽ hạ thấp vị trí của những trang đó trong kết quả tìm kiếm một cách mạnh mẽ.
Chỉ thị Robots.txt
Chỉ thị là quy tắc hoặc bạn cũng có thể nói lệnh cho robot tìm kiếm. Điều quan trọng nhất là Tác nhân người dùng, với sự trợ giúp của nó, bạn có thể đặt quy tắc cho tất cả rô-bốt hoặc cho một bot cụ thể. Chỉ thị này được viết đầu tiên và sau đó tất cả các quy tắc khác được chỉ định.
# Dành cho tất cả robot Tác nhân người dùng: * # Dành cho robot Yandex Tác nhân người dùng: Yandex
Một lệnh bắt buộc khác là Disallow, với các phần trợ giúp và các trang của trang web bị đóng và ngược lại là lệnh Allow, ngược lại, lệnh này buộc phải cho phép lập chỉ mục các phần và trang được chỉ định của trang web.
# Cấm lập chỉ mục phần Không cho phép: /folder/ # Cho phép lập chỉ mục phần phụ có hình ảnh Cho phép: /folder/images/
Để chỉ ra bản sao chính của trang web, ví dụ: có hoặc không có www, chỉ thị Máy chủ được sử dụng. Điều đáng chú ý là máy nhân bản chính được đăng ký mà không chỉ định giao thức http://, nhưng phải chỉ định giao thức https://. Máy chủ chỉ được hiểu bởi các bot Yandex và Mail.ru và bạn chỉ cần nhập lệnh một lần.
# Nếu gương chính hoạt động giao thức http không có www Máy chủ: site.ru # Nếu gương chính hoạt động theo giao thức https từ www Máy chủ: https://www.site.ru
Sơ đồ trang web là một lệnh chỉ đường dẫn đến tệp sitemap.xml, đường dẫn phải được chỉ định đầy đủ với giao thức, lệnh này có thể được viết ở bất kỳ đâu trong tệp.
# Chỉ định đường dẫn đầy đủ đến tệp sitemap.xml Sơ đồ trang web: http://site.ru/sitemap.xml
Để đơn giản hóa các quy tắc viết, có các toán tử ký hiệu đặc biệt:
- * - biểu thị bất kỳ số lượng ký tự nào cũng như sự vắng mặt của chúng;
- $ - có nghĩa là ký hiệu trước ký hiệu đô la là ký hiệu cuối cùng;
- # - biểu thị một nhận xét, mọi thứ ở dòng sau của nhà điều hành này sẽ bị robot tìm kiếm bỏ qua.
Sau khi làm quen với các chỉ dẫn cơ bản và toán tử đặc biệt Bạn đã có thể phác thảo nội dung của một tệp robots.txt đơn giản.
Tác nhân người dùng: * Không cho phép: /admin/ Không cho phép: /arhive/ Không cho phép: /tag/ Không cho phép: /modules/ Không cho phép: /search/ Không cho phép: *?s= Không cho phép: /login.php Tác nhân người dùng: Yandex Không cho phép: / quản trị viên/ Không cho phép: /arhive/ Không cho phép: /tag/ Không cho phép: /modules/ Không cho phép: /search/ Không cho phép: *?s= Không cho phép: /login.php # Cho phép robot Yandex lập chỉ mục hình ảnh trong phần mô-đun Cho phép: /mô-đun /*. png Cho phép: /modules/*.jpg Máy chủ: site.ru Sơ đồ trang web: http://site.ru/sitemap.xml
Quen với việc miêu tả cụ thể Tất cả các chỉ thị kèm theo ví dụ về việc sử dụng chúng có thể được tìm thấy trong ấn phẩm trên trang web Yandex trong phần trợ giúp.
Tệp sơ đồ trang web.xml
sitemap.xml được gọi là bản đồ trang web cho các công cụ tìm kiếm. Tệp sitemap.xml chứa thông tin cho robot tìm kiếm về các trang trên trang web cần được lập chỉ mục. Nội dung của tệp phải chứa địa chỉ URL của các trang, nhưng không cần thiết phải chỉ ra mức độ ưu tiên của các trang, tần suất thu thập lại trang, ngày giờ thay đổi cuối cùng trang.
Cần lưu ý rằng sitemap.xml là không bắt buộc và các công cụ tìm kiếm có thể không tính đến nó, nhưng đồng thời, tất cả các công cụ tìm kiếm đều nói rằng việc có tệp này là điều mong muốn và giúp lập chỉ mục trang web một cách chính xác, đặc biệt nếu các trang được tạo động hoặc trang web có cấu trúc lồng ghép phức tạp.
Chỉ có một kết luận duy nhất: các tệp robots.txt và sitemap.xml là cần thiết. Cài đặt đúng lập chỉ mục là một trong những yếu tố giúp đặt các trang của trang web ở những vị trí cao hơn trong kết quả tìm kiếm và đây là mục tiêu của bất kỳ trang web nào ít nhiều nghiêm túc.
Xin chào các độc giả thân mến của trang blog. Tôi quyết định tóm tắt trong một bài viết mọi thứ tôi đã viết về sơ đồ trang web ( Sơ đồ trang web xml), điều này chủ yếu cần thiết để chỉ ra cho các công cụ tìm kiếm những trang mà chúng nên lập chỉ mục trước tiên. Nó rất quan trọng và thực sự thuộc tính bắt buộc bất kỳ dự án web nào, nhưng nhiều người không biết điều này hoặc không coi trọng Sơ đồ trang web.
Hãy chấm tất cả chữ i ngay lập tức và cố gắng tách biệt hai khái niệm - sơ đồ trang web trong định dạng xml và ở định dạng Html (cũng có cách giải thích địa lý của từ này mà tôi đã viết trong bài “”). Tùy chọn thứ hai là danh sách thường xuyên tất cả các vật liệu tài nguyên web, sẽ có sẵn cho bất kỳ ai bằng cách nhấp vào mục menu tương ứng. Tùy chọn này cũng hữu ích và giúp tăng tốc cũng như cải thiện việc lập chỉ mục tài nguyên của bạn bằng các công cụ tìm kiếm.
Sơ đồ trang web Sơ đồ trang web ở định dạng xml - nhưng tôi cần nó
Nhưng công cụ chính được thiết kế cho hướng dẫn trực tiếpđối với các công cụ tìm kiếm của những trang tài nguyên cần được lập chỉ mục, có một tệp có tên là Sitemap.xml (đây là tên phổ biến nhất của nó, nhưng trên lý thuyết nó có thể được gọi là bất cứ thứ gì, không thành vấn đề), sẽ không hiển thị cho khách truy cập vào dự án web của bạn.
Nó được biên soạn có tính đến một cú pháp đặc biệt dễ hiểu công cụ tìm kiếm, nơi tất cả các trang được lập chỉ mục sẽ được liệt kê, cho biết mức độ quan trọng, ngày tháng của chúng cập nhật mới nhất và tần suất cập nhật gần đúng.
Có hai tệp chính mà bất kỳ dự án web nào cũng nên có - robots.txt và sitemap.xml. Nếu dự án của bạn không có chúng hoặc chúng không được điền chính xác, thì khả năng cao là bạn đang làm tổn hại nghiêm trọng đến tài nguyên của mình và không cho phép nó bộc lộ hết tiềm năng của mình.
Tất nhiên, bạn có thể không nghe tôi (vì tôi không phải là người có thẩm quyền, do tài liệu thực tế tích lũy được tương đối ít), nhưng tôi nghĩ rằng bạn sẽ không tranh cãi bừa bãi với các chuyên gia có số liệu thống kê từ hàng chục nghìn dự án trong tay. .
Nhân dịp này, tôi đã có sẵn một “cây đàn piano lớn trong bụi rậm”. Ngay trước khi viết bài này, tôi đã xem qua một ấn phẩm của các chuyên gia từ khắp nơi trên thế giới. hệ thống đã biết khuyến mãi tự động dưới tên khác thường“Bàn tay” (đây là một dạng tương tự của MegaIndex mà tôi đã viết).
Rõ ràng là bất kỳ hệ thống nào tương tự như họ đều quan tâm đến việc đảm bảo rằng các dự án của khách hàng của họ tiến triển thành công, nhưng họ chỉ có thể bơm tài nguyên của khách hàng bằng khối lượng liên kết, đồng thời ảnh hưởng đến nội dung và sửa lỗi. thiết lập kỹ thuật Thật không may, các trang web không thể.
Do đó, một nghiên cứu rất thú vị và tiết lộ đã được thực hiện, được thiết kế để xác định 10 lý do phổ biến nhất gây khó khăn cho việc quảng bá dự án và đưa những dữ liệu này trực tiếp đến khách hàng...
Tất nhiên, ở vị trí đầu tiên là “không Nội dung độc đáo"(bạn đã sao chép hoặc bạn có nó, điều này không làm thay đổi bản chất). Nhưng ở vị trí thứ hai chính xác là sơ đồ trang web ở định dạng xml, hay nói đúng hơn là nó không có hoặc không nhất quán với định dạng tạo được công nhận. Chà, ở vị trí thứ ba là tệp robots.txt được đề cập trước đó (không có hoặc tạo không chính xác):

Khi bạn khẳng định một cách vô căn cứ rằng dự án của bạn phải có bản đồ (nếu không thì thật lãng phí), nghe có vẻ không thuyết phục như thể tuyên bố này được hỗ trợ bởi dữ kiện thực tế từ một nghiên cứu khá mang tính đại diện.
Được rồi, giả sử rằng tôi đã thuyết phục bạn và hãy xem cách bạn có thể tự tạo sơ đồ trang web (cú pháp định dạng), cách tạo sơ đồ trang web cho Joomla và WordPress, đồng thời xem cách bạn có thể tạo sơ đồ trang web bằng cách sử dụng các trình tạo trực tuyến đặc biệt.
Nhưng chỉ tạo sơ đồ trang web là không đủ để đảm bảo rằng dự án của bạn sẽ được các công cụ tìm kiếm lập chỉ mục chính xác. Cũng cần phải đảm bảo rằng các công cụ tìm kiếm (trong trường hợp của chúng tôi là Google và Yandex) tìm hiểu về chính sơ đồ trang web này. Điều này có thể được thực hiện theo hai cách, nhưng chúng ta sẽ nói về điều này sau (ít nhất phải có một âm mưu nào đó thu hút sự chú ý của độc giả).
Tại sao bạn cần trang web bản đồ và tệp robots.txt?
Trước tiên, hãy cố gắng chứng minh sự cần thiết hợp lý của việc sử dụng cả tệp robots.txt cấm lập chỉ mục một số yếu tố nhất định dự án web của bạn và tệp sơ đồ trang web quy định việc lập chỉ mục một số trang nhất định. Để làm điều này, chúng ta hãy quay trở lại năm hoặc mười năm trước, khi hầu hết các tài nguyên trên Internet chỉ là một tập hợp các tệp Html chứa văn bản của tất cả các bài báo.
Robot tìm kiếm của Google hoặc Yandex chỉ cần truy cập vào một dự án Html như vậy và bắt đầu lập chỉ mục mọi thứ mà nó có thể có được, vì hầu hết mọi thứ đều chứa nội dung của dự án. Và những gì đang xảy ra hiện nay, trong điều kiện chung sử dụng CMS(Hệ thống quản lý nội dung)? Trên thực tế, ngay cả sau khi cài đặt công cụ, robot tìm kiếm sẽ tìm thấy hàng nghìn tệp về bạn và điều này mặc dù thực tế là bạn có thể chưa có bất kỳ nội dung nào (à, bạn vẫn chưa viết một bài báo nào).
Và nói chung, nội dung trong các CMS hiện đại, theo quy định, được lưu trữ không phải trong tệp mà trong cơ sở dữ liệu, điều mà robot tìm kiếm đương nhiên không thể lập chỉ mục trực tiếp (để làm việc với cơ sở dữ liệu, tôi khuyên dùng nó miễn phí).
Rõ ràng là sau khi tìm kiếm khắp nơi, các robot tìm kiếm của Yandex và Google vẫn sẽ tìm thấy nội dung của bạn và lập chỉ mục nội dung đó, nhưng điều này sẽ diễn ra nhanh như thế nào và Việc lập chỉ mục sẽ hoàn chỉnh đến mức nào? dự án của bạn là một câu hỏi rất lớn.
Chính xác là việc đơn giản hóa và tăng tốc độ lập chỉ mục các dự án của các công cụ tìm kiếm trong bối cảnh CMS được sử dụng rộng rãi là điều mà người ta nên làm bắt buộc tạo robots.txt và sitemap.xml. Bằng cách sử dụng tệp đầu tiên, bạn cho rô-bốt công cụ tìm kiếm biết tệp nào không nên lãng phí thời gian lập chỉ mục (ví dụ: đối tượng công cụ) và bạn cũng có thể sử dụng tệp này để chặn lập chỉ mục một số trang nhằm loại bỏ ảnh hưởng của việc sao chép nội dung vốn có trong nhiều trang. CMS (đọc thêm chi tiết về điều này trong bài viết về).
Và với sự trợ giúp của tệp sơ đồ trang web, bạn nói rõ ràng và rõ ràng cho các robot Yandex và Google biết chính xác dự án của bạn chứa nội dung gì, để chúng không lục lọi một cách vô ích trong các góc quản lý tệp của công cụ được sử dụng. Đừng quên rằng bot có những giới hạn nhất định về thời gian và số lượng tài liệu được xem. Nó sẽ đi lang thang qua các tập tin công cụ của bạn và rời đi, nhưng nội dung sẽ vẫn không được lập chỉ mục trong một khoảng thời gian dài. Ôi thế nào.
Hãy nhớ rằng trong một bộ phim hài nổi tiếng, một nhân vật đầy màu sắc đã nói: “Đừng đến đó, bạn hãy đến đây, nếu không thì…”. Chính chức năng của ký tự này được thực hiện bởi robots.txt và trang bản đồ với phần mở rộng xmlđể điều chỉnh chuyển động của các bot tìm kiếm thông qua các ngóc ngách trong dự án web của bạn. Rõ ràng là các bot có thể hoạt động, nhưng rất có thể chúng sẽ ngoan ngoãn thực hiện các hướng dẫn cấm và quy định (trong bản đồ trang web) được viết rất hay của bạn.
Rõ ràng? Sau đó, hãy trực tiếp tiến hành giải quyết câu hỏi về cách tạo sơ đồ trang web.xml theo nhiều cách khác nhau và cách thông báo về sự tồn tại của nó cho hai trụ cột tìm kiếm trong RuNet - Google và Yandex, để chúng không dò dẫm xung quanh dự án của bạn một cách vô ích, đồng thời tạo thêm tải cho máy chủ lưu trữ của bạn, tuy nhiên, điều này rất Điều thứ yếu, điều chính là đây là lập chỉ mục chính xác (nhanh và toàn diện).
Không giống như robots.txt, mà rất có thể bạn sẽ phải tự viết, một tệp sơ đồ trang web ở định dạng xml, theo quy định, chúng sẽ cố gắng tạo theo một cách nào đó một cách tự động. Điều này cũng dễ hiểu vì khi số lượng lớn các trang trong một dự án được cập nhật thường xuyên, việc tạo nó theo cách thủ công có thể làm tổn hại đến tâm trí của quản trị viên web.
Vâng, điều này không cần thiết chút nào, bởi vì... Đối với hầu hết mọi CMS đều có một tiện ích mở rộng cho phép bạn tạo và khi tài liệu mới xuất hiện, hãy tạo lại tệp sơ đồ trang web. Chà, hoặc bạn luôn có thể sử dụng một số trình tạo sơ đồ trang web trực tuyến như một giải pháp làm sẵn.
Tuy nhiên, đối với tôi, có vẻ như sẽ rất hữu ích nếu bạn làm quen với cú pháp đơn giản (tôi có thể nói gì - đơn giản nhất) để tạo sơ đồ trang web. Ngoài ra, trên các dự án nhỏ và hiếm khi được cập nhật, bạn có thể phác thảo thủ công.
Cách tự tạo Sitemap.xml trong Joomla và WordPress
Thông thường, chỉ thị “Sơ đồ trang web” được viết ở cuối. Lần tới khi robot tìm kiếm truy cập vào dự án web của bạn, chúng chắc chắn sẽ xem nội dung của robots.txt và tải bản đồ của bạn xuống để nghiên cứu. Tuy nhiên, bằng cách này, tất cả các loại củ cải đều có thể phát hiện ra sự tồn tại của nó, trang web bản đồ sẽ giúp đánh cắp nội dung của bạn.
Nhưng có một cách khác để truyền trực tiếp thông tin về vị trí của bản đồ trang web đến các công cụ tìm kiếm mà không cần qua trung gian robots.txt. Việc này được thực hiện thông qua giao diện và bảng điều khiển Yandex Webmaster công cụ của Google, mặc dù nó có thể được sử dụng. Bạn đã quen thuộc với các công cụ tìm kiếm này chưa?
Nếu không, hãy nhớ thêm dự án của bạn vào cả , và vào , sau đó chỉ ra đường dẫn đến sơ đồ trang web của bạn ở định dạng Xml trong các tab thích hợp.
Đây là biểu mẫu để thêm sơ đồ trang web cho Yandex Webmaster trông như thế nào:
Và đây là biểu mẫu tương tự để nhập đường dẫn trên thanh công cụ của Google:
Trình tạo trực tuyến Trình tạo sơ đồ trang web và Sơ đồ trang web XML
Nếu bạn không muốn tìm kiếm tiện ích mở rộng cho CMS cho phép bạn tự động tạo trang web bản đồ thì bạn có thể sử dụng máy phát điện trực tuyến tôi. Tuy nhiên, ở đây có một nhược điểm so với việc tự động tạo bản đồ trong chính CMS - sau khi thêm tài liệu mới, bạn sẽ phải truy cập lại dịch vụ trực tuyến và tạo lại tệp này, sau đó tải nó lên máy chủ của mình.
Có lẽ một trong những trình tạo sơ đồ trang web trực tuyến nổi tiếng nhất là Trình tạo sơ đồ trang web. Nó có khá nhiều chức năng và sẽ cho phép bạn tạo sơ đồ trang web cho 1500 trang miễn phí, khá nhiều.
Trình tạo Sơ đồ trang web sẽ tính đến nội dung của tệp robots.txt của bạn để các trang bị cấm lập chỉ mục sẽ không được đưa vào bản đồ. Bản thân điều này không đáng sợ, vì lệnh cấm robot trong mọi trường hợp sẽ có mức độ ưu tiên cao hơn, nhưng nó sẽ cứu bạn khỏi thông tin không cần thiết V. tập tin đã tạo Sơ đồ trang web. Để tạo bản đồ, bạn chỉ cần chỉ định URL trang chủ và cung cấp email của bạn, sau đó bạn sẽ được đưa vào hàng đợi để tạo:

Khi đến lượt bạn, bạn sẽ được thông báo về điều đó. thông báo qua bưu điện và bằng cách nhấp vào liên kết trong thư, bạn có thể tải xuống tệp mà Trình tạo Sơ đồ trang web đã tạo cho bạn. Tất cả những gì bạn phải làm là tải nó lên đúng nơi trên máy chủ của bạn. Chà, thỉnh thoảng bạn sẽ phải lặp lại quy trình này để cập nhật sơ đồ trang web của mình.
Có một dịch vụ tạo trực tuyến bằng tiếng Anh tương tự mà bạn có thể tìm thấy tại liên kết này - Sơ đồ trang web XML. Nó có giới hạn 500 trang, nhưng nếu không thì mọi thứ gần như giống như mô tả ở trên.
Chúc bạn may mắn! Trước hẹn sớm gặp lại trên các trang của trang blog
Bạn có thể xem thêm video bằng cách vào");">

Bạn có thể quan tâm
 Chuyện gì đã xảy ra vậy địa chỉ URL, sự khác biệt giữa tuyệt đối và liên kết tương đối cho trang web
Chuyện gì đã xảy ra vậy địa chỉ URL, sự khác biệt giữa tuyệt đối và liên kết tương đối cho trang web  Chmod là gì, quyền nào được gán cho tệp và thư mục (777, 755, 666) và cách thực hiện thông qua PHP
Chmod là gì, quyền nào được gán cho tệp và thư mục (777, 755, 666) và cách thực hiện thông qua PHP  Tìm kiếm Yandex theo trang web và cửa hàng trực tuyến
Tìm kiếm Yandex theo trang web và cửa hàng trực tuyến  OpenServer - hiện đại Máy chủ cục bộ và một ví dụ về việc sử dụng nó cho Cài đặt WordPress trên may tinh
OpenServer - hiện đại Máy chủ cục bộ và một ví dụ về việc sử dụng nó cho Cài đặt WordPress trên may tinh  Quản trị trang web và RuNet - họ là ai và là ai, cũng như những người có thể sống tốt trên Internet tiếng Nga
Quản trị trang web và RuNet - họ là ai và là ai, cũng như những người có thể sống tốt trên Internet tiếng Nga
Chọn một trang web từ danh sách.
Trong trường này, hãy nhập URL nơi có tệp. Ví dụ, https://example.com/sitemap.xml.
Nhấp vào nút Thêm.
Sau khi thêm tệp, nó sẽ được xếp hàng để xử lý. Robot sẽ tải nó xuống trong vòng hai tuần. Mỗi tệp được thêm vào, bao gồm cả những tệp được đính kèm với tệp chỉ mục Sơ đồ trang web, đều được robot xử lý riêng biệt.
Sau khi tải xuống, bên cạnh mỗi tệp bạn sẽ thấy một trong các trạng thái:
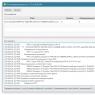
| Trạng thái | Sự miêu tả | Ghi chú |
|---|---|---|
| "ĐƯỢC RỒI" | ||
| "Chuyển hướng" | Xóa chuyển hướng và thông báo cho robot về bản cập nhật | |
| "Lỗi" | Tệp không được định dạng chính xác | thông báo cho robot về bản cập nhật |
| "Không được lập chỉ mục" | Kiểm tra phản hồi của máy chủ |
|
| Không cho phép | thông báo cho robot về bản cập nhật |
| Trạng thái | Sự miêu tả | Ghi chú |
|---|---|---|
| "ĐƯỢC RỒI" | Tệp được định dạng chính xác và được tải vào cơ sở dữ liệu robot | Ngày tải xuống cuối cùng sẽ được hiển thị bên cạnh tệp. Các trang được lập chỉ mục sẽ xuất hiện trong kết quả tìm kiếm trong vòng hai tuần |
| "Chuyển hướng" | URL được chỉ định chuyển hướng đến một địa chỉ khác | Xóa chuyển hướng và thông báo cho robot về bản cập nhật |
| "Lỗi" | Tệp không được định dạng chính xác | Nhấp vào liên kết Lỗi để biết chi tiết. Sau khi thực hiện thay đổi đối với tệp, hãy thông báo cho robot về bản cập nhật |
| "Không được lập chỉ mục" | Khi truy cập Sơ đồ trang web, máy chủ trả về mã HTTP khác 200 | Kiểm tra xem robot có thể truy cập được tệp hay không bằng cách sử dụng công cụ Kiểm tra phản hồi của máy chủ bằng cách chỉ định đường dẫn đầy đủ đến tệp. Nếu tệp không có sẵn, hãy liên hệ với quản trị viên của trang web hoặc máy chủ chứa tệp đó. |
| Quyền truy cập vào tệp bị từ chối trong robots.txt bằng lệnh Disallow | Cho phép truy cập vào Sơ đồ trang web và thông báo cho robot về bản cập nhật |
Cập nhật sơ đồ trang web
Nếu bạn đã thay đổi tệp Sơ đồ trang web được thêm vào Yandex.Webmaster, bạn không cần phải xóa tệp đó và tải lại - robot thường xuyên kiểm tra tệp để tìm các bản cập nhật và lỗi.
Để tăng tốc độ thu thập thông tin tệp, hãy nhấp vào biểu tượng. Nếu bạn đang sử dụng tệp chỉ mục Sơ đồ trang web, bạn có thể bắt đầu xử lý từng tệp được liệt kê trong đó. Robot sẽ tải dữ liệu xuống trong vòng ba ngày. Bạn có thể sử dụng chức năng này tối đa 10 lần cho một máy chủ.
Khi bạn đã sử dụng hết tất cả các lần thử, lần tiếp theo sẽ có sau lần thử đầu tiên 30 ngày. Ngày chính xác hiển thị trong giao diện Webmaster.
Xóa sơ đồ trang web
Trong giao diện Yandex.Webmaster, bạn có thể xóa những tệp đã được thêm trên trang Tệp Sơ đồ trang web: Nếu một lệnh đã được thêm cho Sơ đồ trang web trong tệp robots.txt, hãy xóa nó. Sau khi thực hiện thay đổi, thông tin về Sơ đồ trang web sẽ biến mất khỏi robot và cơ sở dữ liệu Yandex.Webmaster trong vòng vài tuần.
Sơ đồ trang web hoặc sơ đồ trang web là tập tin đặc biệt(thường có phần mở rộng xml), chứa thông tin về tất cả các trang hiện có trên trang web. Với sự trợ giúp của tập tin này, bạn có thể làm rõ máy tìm kiếm, trang nào của trang web nên được lập chỉ mục trước, tần suất cập nhật dữ liệu trên các trang và tầm quan trọng của việc lập chỉ mục các trang riêng lẻ của trang web. Điều này giúp đơn giản hóa đáng kể việc lập chỉ mục cho robot tìm kiếm. Tệp Sơ đồ trang web phải có trên tất cả các trang web bao gồm năm mươi trang trở lên.
Cách tạo tệp SiteMap trực tuyến và thêm nó vào trang web của bạn
Vì sơ đồ trang web là một tệp xml nên bạn có thể tạo nó trong định dạng văn bản, sử dụng bất kỳ trình chỉnh sửa nào và lưu với phần mở rộng xml. Tuy nhiên nỗ lực độc lập hoàn toàn không cần thiết, chúng tồn tại trên Internet những dịch vụ đặc biệt, với sự trợ giúp mà bạn có thể tạo miễn phí - tự động tạo tệp sitemap.xml trực tuyến và thêm nó vào bất kỳ trang web nào. Bạn có thể xem video chi tiết hơn về quá trình tạo tệp sitemap.xml:
[yt=QT21XhPmSSQ]
Vì tạo tự động sơ đồ trang web, bạn cần nhập địa chỉ của trang mong muốn vào trường thích hợp, chọn định dạng tệp thích hợp, xác định trình tự lập chỉ mục các trang trên trang web, cho biết tần suất cập nhật trang và đặt các tham số khác mà bạn quan tâm. Sau tất cả các thao tác này, bạn cần nhấp vào nút “thực thi” và sau một thời gian ngắn, mã cho sơ đồ trang web đã tạo sẽ xuất hiện trong cửa sổ bên dưới. Bạn chỉ cần sao chép và dán mã này vào tệp bạn đã tạo trong trình chỉnh sửa sơ đồ trang web.xml, lưu nó và tải nó lên thư mục gốc của trang web của bạn.
Nhưng để tệp này có được hiệu quả như mong đợi, việc chỉ tạo và thêm Sơ đồ trang web vào trang web của bạn là chưa đủ mà bạn còn cần phải truyền tải nó tới robot tìm kiếm thông tin về tính sẵn có của nó. Để thực hiện việc này, bạn cần ghi đường dẫn đến nó vào tệp, thêm dòng vào đó:
Sơ đồ trang web: http://YASH_SITE.ru/sitemap.xml
Sau đó, mọi thao tác đã hoàn tất, sơ đồ trang web của bạn đã sẵn sàng thực hiện các chức năng của nó. Bạn chỉ cần nhớ rằng trong một lần tạo tập tin xml không được quá 50.000 trang và dung lượng của nó không được quá 10 megabyte. Nếu không, bạn sẽ cần tạo một tệp khác như vậy.