Trường hợp: dạy công cụ tìm kiếm nhận biết lỗi ngữ pháp. Thêm một chiếc xe đạp nữa, nếu không chúng ta sẽ tạo ra công cụ tìm kiếm của riêng mình
- Chỉ mục chỉ có thể được tạo trên các trường của bảng MyISAM.
- Kích thước chỉ mục xấp xỉ một nửa kích thước của dữ liệu. Tuy nhiên, bạn cần lưu ý rằng bạn không thể vô hiệu hóa tính năng lưu văn bản, vì vậy, với 50% này, bạn cần thêm 100% khác - dữ liệu đã được lưu trữ.
- Tốc độ lập chỉ mục khá tốt ở dạng thuần túy, khoảng 1,5 MB/s. Rõ ràng là bạn vẫn cần phải chạy nó qua trình khởi chạy. Nếu bạn điền vào chỉ mục bằng cách lấy dữ liệu từ cùng một cơ sở dữ liệu một cách nhanh chóng và chạy nó qua cổng Perl của trình tạo gốc Snowball của Nga, bạn sẽ nhận được 314 KB/s. Trên thực tế, MySQL có kiến trúc để kết nối các trình khởi tạo gốc với các plugin (“plugin trình phân tích cú pháp toàn văn bản”), nhưng bằng cách nào đó, bản thân nó lại không có plugin nào... :)
- Không có trình bắt đầu tích hợp sẵn, các từ dừng tiếng Anh được nhúng, bạn không thể thêm từ của riêng mình. Theo mặc định, tìm kiếm Boolean là “OR”, vì vậy để tìm kiếm bằng “AND” bạn cần biến mỗi từ thành “+word”.
- Có hai chế độ - tìm kiếm Boolean và bình thường (“ngôn ngữ tự nhiên”). Tìm kiếm Boolean chỉ kiểm tra xem các từ có trong tài liệu hay không và hỗ trợ các phép toán Boolean, cụm từ và tìm kiếm tiền tố nhưng không trả về điểm liên quan (chỉ 0 hoặc 1). Tìm kiếm thông thường có thể có liên quan, nhưng không phải toán tử. Do đó, để hỗ trợ cả hai, bạn cần chạy cùng một yêu cầu ở hai chế độ.
- Tìm kiếm tiền tố trong MySQL mê hoặc chậm. Với một vài từ, được mở rộng thành tiền tố, có thể dễ dàng mất 15 hoặc 40 giây. Vì vậy, nó không cần phải được sử dụng chút nào.
- Nó không thể tìm kiếm trong một số trường cùng một lúc - nghĩa là cú pháp của MATCH() cho phép nó, nhưng không xảy ra tối ưu hóa tìm kiếm mà chỉ xảy ra quá trình quét toàn bộ. Vì vậy, tốt hơn là viết (select idwhere match(field1) ...) UNION (select idwhere match(field2) ...) .
- Tốc độ tìm kiếm cho các truy vấn lấy từ tiêu đề lỗi ngẫu nhiên, với giới hạn 1000 được tìm thấy:
- Trong 5 luồng trên 3 từ - trung bình là 175 ms, tối đa là 3,46 giây.
- Trong 5 thread 3 chữ thì 10 kết quả đầu đều giống nhau.
- Trong 5 chủ đề trên 2 từ - trung bình 210 mili giây, tối đa 3,1 giây.
- Trong 1 luồng trên 3 từ - trung bình là 63 ms, tối đa là 764 ms.
- Phụ thuộc chủ yếu vào số lượng tìm thấy.
- Ưu điểm chính là sự hiện diện của tìm kiếm "tia lửa".
Nhân sư (2.0.1-beta)
- Chia máy chủ tìm kiếm. Có các thư viện giao diện cho nó cho nhiều ngôn ngữ khác nhau. Thật thú vị khi trong phiên bản 0.9.9, ngoài giao diện “gốc”, SphinxQL đã xuất hiện - một giao diện SQL cho Sphinx sử dụng giao thức MySQL, tức là sử dụng các máy khách MySQL thông thường.
- Ban đầu, không có chỉ mục nào được cập nhật (thời gian thực) trong Sphinx; điều duy nhất nó có thể làm là xây dựng toàn bộ chỉ mục và sau đó tìm kiếm nó.
- Nó vẫn chưa biết cách cập nhật/xóa tài liệu trong chỉ mục một cách chính xác mà chỉ thêm bình thường. Việc loại bỏ được thực hiện bằng cách kiểm tra “ bài cũ”, rồi xóa nó khỏi tất cả kết quả tìm kiếm mọi lúc.
- Các chỉ mục thời gian thực không hỗ trợ mọi thứ - ví dụ: chúng không hỗ trợ tiền tố/trung tố và MVA.
- Hơi lộn xộn về giao diện và tính năng: chỉ cập nhật chỉ mục thời gian thực thông qua SphinxQL; cú pháp tìm kiếm khác nhau ở cả ba giao diện (thông thường, SphinxQL, SphinxSE); 5 chế độ tìm kiếm, trong đó 4 chế độ đã lỗi thời; người lập chỉ mục không thể xây dựng lại các chỉ mục thời gian thực; Không thể TRUNCATE một chỉ mục bằng SphinxQL và bạn không thể xem có bao nhiêu bản ghi trong chỉ mục...
- Đây là lúc những nhược điểm kết thúc - có một máy chủ tìm kiếm mà bạn có thể giao tiếp bằng giao thức của riêng mình hoặc giao thức MySQL, một loạt các khả năng, chỉ mục và tìm kiếm khác nhau rất nhanh chóng, kích thước chỉ mục xấp xỉ 1/3 dữ liệu. Nó có thể tăng gấp 2 lần nếu bạn kích hoạt lập chỉ mục các dạng từ chính xác.
- Tích hợp sẵn bộ phát âm tiếng Nga, tiếng Anh và tiếng Séc cũng như bộ tiền xử lý Soundex và Metaphone (để so sánh các từ tiếng Anh bằng âm thanh). Stemmers cho các ngôn ngữ khác cũng có thể được kết nối, bạn chỉ cần xây dựng chúng bằng key --with-libstemmer. Tất nhiên, có hỗ trợ cho các từ dừng. Các từ đồng nghĩa cũng vậy, có những từ thông thường và có những “ngoại lệ mã hóa”, có thể bao gồm các ký tự đặc biệt. Ngoài ra còn có "blend_chars" - các ký tự vừa được coi là dấu phân cách vừa là một phần của từ - ví dụ: để "AT&T" trở thành các từ "AT", "T" và "AT&T".
- Trong số các tính năng thú vị khác thường - nó có thể thực hiện tìm kiếm infix (dành cho những người muốn tìm kiếm nhanh theo chuỗi con!), trường đa giá trị (MVA), có thể lập chỉ mục theo đoạn văn và câu và thậm chí theo nội dung của các thẻ HTML được xác định trước. Nó cũng có thể đánh dấu các từ được tìm kiếm trong dấu ngoặc kép và hơn thế nữa. Tuy nhiên, MVA và các bản sửa lỗi chưa được hỗ trợ (chưa?) trong các chỉ mục được cập nhật.
- Lập chỉ mục rất nhanh - tốc độ mạng với chỉ mục thời gian thực là 6,7 MB/s (tải xuống kết xuất SQL), với chỉ mục thông thường - thường là 12 MB/s (tải xuống kết xuất xmlpipe2). Tốc độ “không sạch” (từ Perl, với việc đọc dữ liệu nhanh chóng từ MySQL) - 4,5 MB/s. Với các bản sửa lỗi, mọi thứ tự nhiên chậm lại rất nhiều - 440 KB / s, vùng I/O là 10,5 GB và chỉ mục có kích thước 3 GB cho 330 MB dữ liệu.
- Tìm kiếm nói chung là phản ứng:
- Trong 5 chủ đề trên 3 từ - trung bình 7 mili giây, tối đa 75 mili giây.
- Trong 5 chủ đề trên 2 từ - trung bình 7 mili giây, tối đa 81 mili giây.
- Trong 5 luồng trên 3 từ, 10 kết quả đầu tiên trung bình 5 ms, tối đa 57 ms.
- Trong 1 luồng trên 3 từ - trung bình 2 mili giây, tối đa 35 mili giây.
Xapian (1.2.6)
- Thư viện, không có máy chủ tìm kiếm làm sẵn. API C++ khá lành mạnh. Nó dường như hỗ trợ công việc cạnh tranh (nhiều độc giả, một nhà văn).
- Rất nhiều ràng buộc có sẵn cho ngôn ngữ khác nhau: C++, Java, Perl, Python, PHP, Tcl, C#, Ruby, Lua.
- Chỉ mục này là chỉ mục dựa trên cây B đảo ngược.
- Điều thú vị là Xapian không nhất thiết phải được sử dụng cụ thể như một chỉ mục toàn văn bản - trên thực tế, nó chỉ là việc triển khai một chỉ mục đảo ngược mà bạn có thể sử dụng theo ý muốn, vì không có hạn chế nào đối với “từ” có trong tài liệu, ngoại trừ giới hạn độ dài là 245 byte. Về lý thuyết, bạn có thể sử dụng nó làm cơ sở dữ liệu.
- Thành thật mà nói tài liệu tệ hại. Một số loại tập hợp thông tin chưa chứa đựng tất cả mọi thứ. Để hiểu một số điểm, bạn phải ngu ngốc trèo vào mã. Tôi đã trở nên xấc xược và đã phạm lỗi ngay cả trong chủ đề này - lỗi 564. Chà, đúng là vậy - động cơ có vẻ khá tốt nhưng ít người biết về nó.
- Thật buồn cười là khi tôi bắt đầu thử nghiệm nó, tôi đã phát hiện ra một lỗi lạ - một lỗi phân tách trong libuuid, lỗi này không cho phép tạo cơ sở dữ liệu nếu Image::Magick được tải song song. Hóa ra đây thậm chí không phải là lỗi ImageMagick mà thậm chí còn nghiêm trọng hơn - đó là lỗi libc6! Trong 2.12 và 2.13, quá trình khởi tạo Bộ nhớ cục bộ theo luồng bị hỏng khi tải động thư viện, ồ thế nào. Nó đã được sửa ở phiên bản 2.14, nhưng Debian vẫn là 2.13. Tôi đã thêm lỗi 637239 vào Debian (cũng có liên kết đến các lỗi trong gentoo và libc).
- Các ràng buộc Perl yêu cầu hoàn thiện để có thể chọn phần phụ trợ và theo mặc định, đó không phải là Brass mới nhất mà là Chert ổn định. Việc hoàn thiện thật dễ dàng. Tôi cũng đã cung cấp cho họ một lỗi về chủ đề này - lỗi 565.
- Dường như không có hỗ trợ cho các trường khác nhau trong chỉ mục, nhưng nó được thực hiện bằng cách thêm tiền tố vào đầu mỗi từ: http://xapian.org/docs/omega/termprefixes.html
- Đây là “cách tiếp cận chính thức”, Xapian có thể tự thực hiện, chỉ cần chỉ định các tiền tố.
- Cách tiếp cận này có ít nhất một nhược điểm nhỏ - theo mặc định, truy vấn không tìm kiếm trong tất cả các trường và để tìm kiếm trong tất cả, bạn cần chèn OR vào truy vấn theo cách thủ công.
- Đúng, tài liệu lại không đầy đủ và không ở đúng vị trí - lẽ ra nó phải có trong sách hướng dẫn của Xapian, nhưng nó lại nằm trong sách hướng dẫn của Omega, một công cụ tìm kiếm CGI đơn giản được tạo sẵn.
- Khoảnh khắc khó chịu - nhanh chóng được tìm thấy sâu bọ trong trình phân tích cú pháp truy vấn - nó tạo ra các thuật ngữ tìm kiếm gốc từ trong các trường không chính xác (có tiền tố). Người lập chỉ mục gán tiền tố “Z” cho tất cả các gốc ở đầu, nghĩa là gốc của từ “ý tưởng” trong tiêu đề (giả sử tiền tố T) được lập chỉ mục là “ZTide”. Và trình phân tích cú pháp truy vấn cố gắng tìm kiếm theo “Tida” và tất nhiên là không tìm thấy gì. Tôi đã đưa cho họ lỗi 562 về chủ đề này. Trên thực tế, đã sửa bằng một dòng.
- Stemmers được tích hợp sẵn cho 15 ngôn ngữ, như thường lệ, được tạo từ Snowball "a. Có hỗ trợ cho các từ dừng (tất nhiên) và từ đồng nghĩa. Thú vị hơn nữa - nó có thể sửa lỗi chính tả mà không cần sử dụng từ điển mà chỉ dựa trên dữ liệu được lập chỉ mục ( phải được bật bằng cài đặt). Ví dụ: đối với “Xapain”, nó sẽ gợi ý một cách trung thực “Xapian”. Ngoài ra còn có hỗ trợ tìm kiếm “truy vấn chưa hoàn thành”, tức là các gợi ý khi nhập từng chữ cái truy vấn. Thực ra đây chỉ là thêm * vào. tư cuôi cung trong tìm kiếm nhưng có tính đến các sắc thái của cú pháp truy vấn.
- Ngoài ra còn có “Tìm kiếm theo khía cạnh” - tính toán giá trị tổng hợp cho tất cả hoặc hầu hết mọi người tài liệu được tìm thấy (giả sử với giới hạn 10.000). Nghĩa là, 10.000 tài liệu này sẽ không được trả lại cho bạn nhưng chúng sẽ được kiểm tra và một số giá trị tổng hợp sẽ được tính toán từ chúng. Ví dụ: bằng cách này, bạn có thể trả về 10 kết quả (trang) và đồng thời trả lời câu hỏi "tài liệu được tìm thấy từ danh mục nào?"
- Thật tệ khi nếu bạn thực hiện tuôn ra () (cam kết) khi lập chỉ mục cứ sau 256 lỗi một lần, thì tốc độ từ ~ 1,5 MB/s giảm xuống còn 412 KB/s và số lượng thao tác tăng lên rất nhiều Vào/ra- 10-20 lần một lần. Về nguyên tắc, điều này được nêu rõ và hợp lý đối với bất kỳ chỉ mục đảo ngược nào - việc tích lũy các thay đổi sẽ tối ưu hơn nhiều so với việc cố gắng cập nhật từng thay đổi một, vì số lượng mã thông báo được cập nhật tăng lên.
- Kích thước của chỉ mục - họ viết rằng nó xấp xỉ bằng kích thước của dữ liệu, điều này không phải vậy, thực tế nó lớn hơn gấp 2 lần. Họ viết rằng nếu bạn không lưu trữ vị trí của các từ trong tài liệu thì nó sẽ xảy ra. trở nên nhỏ hơn 2 lần. Nhưng xin lỗi, Sphinx cũng lưu trữ các vị trí và chỉ mục của nó ít dữ liệu hơn 2 lần. Nếu bạn chạy xapian-compact (chống phân mảnh cơ sở dữ liệu) - vâng, chỉ số sẽ giảm, nhưng vẫn còn lại khoảng 1,7 lần dữ liệu.
- Đúng, lý do đã được tìm ra - Xapian luôn lập chỉ mục cả những điều cơ bản và dạng chính xác của từ. Không thể vô hiệu hóa việc lập chỉ mục các biểu mẫu chính xác, thật đáng tiếc, tôi đã đưa ra cho họ lỗi 563 về chủ đề này.
- Tìm kiếm nhanh chóng. Tôi đã thử nghiệm theo cách này: Tôi tìm kiếm một số từ liền kề có độ dài ít nhất 2 ký tự, ở chế độ STEM_ALL, lấy từ tiêu đề lỗi (tôi không tìm kiếm bằng “OR” mà bằng “AND”) và thay thế từng từ với (từ HOẶC tiêu đề: từ HOẶC riêng tư: từ), nghĩa là tìm kiếm trong ba trường thay vì một, giới hạn số lượng kết quả ở mức 1000.
- Trong 5 luồng trên 3 từ - trung bình là 14 ms, tối đa là 135 ms.
- Trong 5 luồng trên 2 từ - trung bình là 29 ms, tối đa là 137 ms.
- Trong 5 luồng trên 3 từ, 10 kết quả đầu tiên trung bình 2 ms, tối đa 26 ms.
- Trong 1 luồng trên 3 từ - trung bình 7 mili giây, tối đa 51 mili giây.
- Tốc độ tìm kiếm chủ yếu phụ thuộc vào số lượng kết quả tìm được; càng nhiều thì thời gian tìm kiếm càng lâu.
Xapian có 3 phần phụ trợ (triển khai chỉ mục) - theo thứ tự mới Flint, Chert và Brass. Nó giống như trong Debian oldstable, ổn định và đang thử nghiệm :) trong 1.2.x, phần phụ trợ mặc định là Chert. Trước Flint đã có Quartz.
Tìm kiếm văn bản PostgreSQL (9.1)
- Chỉ mục được đảo ngược dựa trên GIN (iNdex đảo ngược tổng quát). Trước đây được gọi là Tsearch2, được tạo bởi Oleg Bartunov và Fedor Sigaev.
- Có các công cụ bắt nguồn tích hợp sẵn, hỗ trợ các từ dừng, từ đồng nghĩa, từ điển đồng nghĩa (thứ gì đó giống như từ điển các khái niệm, thay thế các từ bằng các “từ ưa thích” khác), từ điển ISpel (mặc dù chúng được cho là rất chậm trong quá trình khởi tạo).
- Khi lập chỉ mục, có thể gắn một “trọng số” cho mỗi từ vị, đây thực ra không phải là “trọng số”, mà là một dạng tương tự của tiền tố Xapian, tức là tên của trường mà từ đó xuất hiện. Chỉ có thể có 4 “trọng số” như vậy - A, B, C, D và trong tương lai chúng có thể được sử dụng khi tìm kiếm. Một ví dụ về xây dựng tsvector "a từ hai trường có “trọng số”: setweight(to_tsvector(coalesce(title,""), "A") || setweight(to_tsvector(coalesce(keyword,"")), "B") .
- Ăn chia chức năng xếp hạng kết quả và đánh dấu các từ được tìm kiếm trong trích dẫn. Việc xếp hạng có thể được thực hiện bằng cách gán các trọng số bằng số cho các “trọng số” ABCD ở trên (là các “trường”). Hơn nữa, theo mặc định, các trọng số bằng (0,1, 0,2, 0,4, 1,0).
- Kiểu dữ liệu được lập chỉ mục được gọi là tsvector (vectơ tìm kiếm văn bản). PostgreSQL cho phép bạn tạo các chỉ mục chức năng và hướng dẫn mặc định đề xuất chỉ tạo những chỉ mục này - CREATE INDEX i ON t USING gin(to_tsvector(<поле>)). Vì vậy, đây là: đừng làm thế! Nếu không, bạn sẽ rất ngạc nhiên về tốc độ của các yêu cầu. Đảm bảo tạo một cột riêng thuộc loại tsvector , thêm tsvector "s của bạn vào đó và tạo chỉ mục trên đó.
- Tôi sẽ giải thích lý do: chức năng xếp hạng kết quả là riêng biệt và cũng hoạt động với tsvector ". Nếu nó không được lưu trữ, nó phải được tính toán nhanh chóng với mỗi yêu cầu cho mỗi tài liệu và điều này ảnh hưởng rất xấu đến hiệu suất , đặc biệt là khi truy vấn tìm thấy nhiều tài liệu. Nghĩa là, nếu bạn ngu ngốc đưa việc sắp xếp theo mức độ liên quan vào truy vấn của mình - ORDER BY ts_rank(to_tsvector(field),
) DESC - sẽ chậm hơn nhiều so với MySQL :). - Đồng thời, để tối ưu hóa dung lượng ổ đĩa, bạn không cần phải lưu trữ toàn văn các tài liệu trong chỉ mục.
- Tôi sẽ giải thích lý do: chức năng xếp hạng kết quả là riêng biệt và cũng hoạt động với tsvector ". Nếu nó không được lưu trữ, nó phải được tính toán nhanh chóng với mỗi yêu cầu cho mỗi tài liệu và điều này ảnh hưởng rất xấu đến hiệu suất , đặc biệt là khi truy vấn tìm thấy nhiều tài liệu. Nghĩa là, nếu bạn ngu ngốc đưa việc sắp xếp theo mức độ liên quan vào truy vấn của mình - ORDER BY ts_rank(to_tsvector(field),
- Toán tử tìm kiếm bao gồm AND, OR và NOT và tìm kiếm tiền tố. Không có tìm kiếm các từ gần đó, các hình thức hoặc cụm từ chính xác.
- Kích thước chỉ mục nằm ở khoảng 150% kích thước dữ liệu, nếu bản thân văn bản không được lưu trữ mà chỉ lưu trữ tsvector ".
- Tốc độ lập chỉ mục - mặc dù có ít dữ liệu, 1,5 MB/s, nó giảm dần khi chỉ mục tăng lên, nhưng nếu bản thân văn bản không được lưu trữ thì nó có vẻ ổn định lại. Đối với tất cả dữ liệu bugzilla giống nhau, kết quả là trung bình 522 KB/s, mặc dù khi kết thúc lập chỉ mục, tốc độ này thấp hơn lúc đầu.
- Tốc độ tìm kiếm:
- Trong 5 luồng trên 3 từ - trung bình là 28 mili giây, tối đa là 2,1 giây.
- Trong 5 luồng trên 2 từ - trung bình là 54 ms, tối đa là 2,3 giây.
- Trong 5 luồng trên 3 từ, 10 kết quả đầu tiên trung bình 26 ms, tối đa 611 ms.
- Trong 1 luồng trên 3 từ - trung bình 10 mili giây, tối đa 213 mili giây.
Lucene, Solr (3.3)
- Lucene là một thư viện tìm kiếm Java (không phải máy chủ), rất khó để xem xét và kiểm tra nó một cách hoàn chỉnh - công cụ này mạnh nhất (nhưng cũng quái dị nhất) trong số những công cụ được đánh giá.
- Việc đây là thư viện được viết bằng Java là nhược điểm chính của nó - việc truy cập Java từ các ngôn ngữ khác rất khó, đó là lý do tại sao Lucene cũng gặp vấn đề với giao diện :(. Hiệu suất từ Java cũng có thể bị ảnh hưởng phần nào, nhưng rất có thể là như vậy rất thiếu phê bình.
- Trong số các ràng buộc với các ngôn ngữ, chỉ có một PyLucene hoàn toàn tồn tại - một JVM có Lucene tích hợp được thêm vào quy trình Python và một JCC nhất định đảm bảo sự tương tác. Nhưng tôi sẽ cân nhắc kỹ lưỡng xem có nên sử dụng sự kết hợp như vậy hay không...
- Để cải thiện tình hình, có Solr - xét cho cùng, một máy chủ tìm kiếm được triển khai dưới dạng dịch vụ web với giao diện XML/JSON/CSV. Để chạy nó cần một servlet container - Tomcat, hoặc đơn giản hơn - Jetty. Bây giờ bạn có thể làm việc với nó từ nhiều ngôn ngữ.
- Người ta nói rằng tốc độ lập chỉ mục của Lucene là "rất cao", hơn 20 MB/s, trong khi đó, cần rất ít bộ nhớ (từ 1 MB) và lập chỉ mục gia tăng (đối với một tài liệu) cũng nhanh như vậy như lập chỉ mục một tập hợp tài liệu cùng một lúc. Kích thước chỉ mục được nêu là 20-30% kích thước dữ liệu.
- Lucene có khả năng mở rộng rất cao nên có rất nhiều tính năng và tiện ích khác nhau, đặc biệt khi kết hợp với Solr và các thư viện khác:
- 31 bộ gốc tích hợp, một loạt bộ phân tích - xử lý âm thanh (Soundex, Metaphone và các biến thể), chữ viết tắt, từ dừng, từ đồng nghĩa, “bảo vệ từ” (ngược lại của từ dừng), cụm từ, bệnh zona, tách từ (Wi-Fi , WiFi -> Wi Fi), URL, v.v., nhiều Các tùy chọn khác nhau tạo truy vấn (ví dụ: FuzzyLikeThisQuery - tìm kiếm “truy vấn tương tự với truy vấn đã cho”).
- Sao chép chỉ mục, tự động phân cụm (nhóm) kết quả tìm kiếm (Carrot2), robot tìm kiếm(Nutch), hỗ trợ phân tích tài liệu nhị phân (Word, PDF, v.v.) bằng Tika.
- Thậm chí còn có một tiện ích để “nâng cao” các kết quả nhất định theo yêu cầu đưa ra bất kể xếp hạng bình thường (xin chào, SEO).
- Và thậm chí đó không phải là tất cả.
- Kích thước chỉ mục hoàn toàn giống Lucene - 20% dữ liệu. Tốc độ lập chỉ mục của Solr cho 256 tài liệu theo yêu cầu, không có cam kết trung gian, là 2,75 MB/s và với các cam kết cứ sau 1024 tài liệu - 2,3 MB/s. Nếu bạn không cam kết thì nó sẽ ngốn nhiều bộ nhớ hơn - Tôi có khoảng 110 MB, nếu bạn cam kết - 55 MB.
- Tốc độ tìm kiếm Solr:
- Trong 5 luồng trên 3 từ - trung bình là 25 mili giây, tối đa là 212 mili giây.
- Trong 5 luồng trên 2 từ - trung bình là 35 ms, tối đa là 227 ms.
- Trong 5 luồng trên 3 từ, 10 kết quả đầu tiên trung bình 15 ms, tối đa 190 ms.
- Trong 1 luồng trên 3 từ - trung bình 11 mili giây, tối đa 79 mili giây.
2.3.3.4, Lucene++ 3.0.3.4
- Lucene được viết bằng Java và do đó có một số cổng của nó sang các ngôn ngữ khác nhau, trong đó sôi động nhất là các cổng C++ và C# - , Lucene++ và Lucene.NET. Có những cổng khác, nhưng chúng (bán) bị bỏ hoang và/hoặc không ổn định.
- Không phải mọi thứ đều hoàn hảo với CLucene:
- Lucene đang phát triển chậm hơn - trong khi Lucene đã là 3.3, CLucene ổn định (0.9.2.1) vẫn tương ứng với Lucene 1.9, và nó thậm chí không có phần thân và “thử nghiệm” CLucene là Lucene 2.3.
- Có rất ít ràng buộc ngôn ngữ lỗi thời, ví dụ như ràng buộc Perl chỉ hỗ trợ 0.9.2.1. Nó được gọi là "Viết của riêng bạn". Sau khi dành vài giờ, tôi đã vá chúng (đưa ra lỗi cho tác giả) và thậm chí còn hỗ trợ thêm cho phần gốc, may mắn thay, vẫn tồn tại trong phiên bản 2.3. Nói chung, những ràng buộc này hơi ẩm, tôi đã phát hiện và vá một lỗi segfault khác.
- Rõ ràng là có lỗi, tài liệu trên Internet đã lỗi thời (nhưng bạn có thể tạo tài liệu thông thường bằng cách sử dụng doxygen từ nguồn), nó được lưu trữ trên SourceForge, nơi mọi thứ đều chậm và buồn, và trình theo dõi lỗi thỉnh thoảng sẽ đóng các lỗi chính nó (nếu không có ai phản hồi chúng O_O ).
- Về tính năng, hầu hết các tính năng của Lucene đều nằm ở các cổng. Đương nhiên, không có tính năng Solr.
- Tốc độ lập chỉ mục CLucene - Tôi nhận được 3,8 MB/s. Không phải là 20+ được Lucene khai báo, mà là với một trình phát gốc và thông qua giao diện Perl, vì vậy nó khá tốt.
- Kích thước chỉ mục, như Lucene/Solr, hóa ra xấp xỉ 20% kích thước dữ liệu - đây là một kỷ lục trong số tất cả các công cụ và tương ứng với mức 20-30% đã nêu!
- Lucene++ khác với CLucene ở những điểm sau:
- Việc triển khai hoàn thiện hơn và mới hơn (3.0.3.4), ví dụ: có các bộ phân tích cho các ngôn ngữ khác nhau được tích hợp sẵn các từ dừng.
- Lucene++ mọi nơi sử dụng Shared_ptr (tự động đếm các tham chiếu đến các đối tượng bằng mẫu C++). Hơn nữa, điều này rất đáng chú ý ngay cả trong quá trình biên dịch, nó mất rất nhiều thời gian so với CLucene.
- Các ràng buộc thậm chí còn tệ hơn trong CLucene - chỉ có những ràng buộc nửa vời dành cho Python, do SWIG tạo ra - nghĩa là, chúng có thể chảy như những kẻ khốn nạn và nói chung là không biết liệu chúng có hoạt động hay không. hiểu ngay cách làm cho Perl liên kết bình thường với các Shared_ptrs này.
- Lucene++ dường như được sử dụng rất ít, dựa trên thực tế là chỉ có 9 lỗi trong trình theo dõi lỗi.
- Tốc độ tìm kiếm - các phép đo tương tự như phép đo Xapian, chỉ sử dụng MultiFieldQueryParser thay vì thay thế các từ bằng các từ tách biệt:
- Trong 5 luồng trên 3 từ, thu được trung bình 10 ms, tối đa là 212 ms.
- Trong 5 luồng trên 2 từ - trung bình là 19 mili giây, tối đa là 201 mili giây.
- Trong 5 luồng trên 3 từ, 10 kết quả đầu tiên trung bình 3 ms, tối đa 26 ms.
- Trong 1 luồng trên 3 từ - trung bình 4 mili giây, tối đa 39 mili giây.
- Một lần nữa, nó phụ thuộc chủ yếu vào số lượng được tìm thấy, tương ứng với lưu ý về độ phức tạp của việc tìm kiếm.
Dành cho những người trong bể
- Chỉ mục đảo ngược khớp từng từ với tập hợp tài liệu mà nó xuất hiện, trái ngược với chỉ mục trực tiếp khớp một tài liệu với một tập hợp từ. Hầu như tất cả các động cơ tìm kiếm toàn văn Chúng sử dụng các chỉ mục đảo ngược vì chúng có thể tìm kiếm nhanh chóng, mặc dù chúng khó cập nhật hơn các chỉ mục trực tiếp.
- Stemmer - từ từ tiếng Anh “stem” - cơ sở của từ này. Anh ta cắn đứt phần cuối của từ, tạo cơ sở từ chúng. Được thiết kế sao cho từ “mèo” có thể được sử dụng để tìm cả “mèo” và “mèo”, v.v. Snowball - DSL để viết phần gốc.
- Từ dừng là danh sách các từ được sử dụng rất thường xuyên (giới từ, liên từ, v.v.), không có ích gì khi lập chỉ mục vì chúng chứa rất ít ý nghĩa và được tìm thấy ở hầu hết mọi nơi.
- Thông tin vị trí - vị trí của các từ trong tài liệu, được lưu trữ trong một chỉ mục, để tìm kiếm thêm các cụm từ hoặc chỉ các từ nằm không xa hơn ...
- Tìm kiếm tiền tố (từ*) - tìm kiếm các từ bắt đầu bằng một từ nhất định (ví dụ: mèo*). Đôi khi được gọi là tìm kiếm Ký tự đại diện, nhưng nói đúng ra, tìm kiếm Ký tự đại diện là tìm kiếm các từ bắt đầu bằng một tiền tố nhất định và kết thúc bằng một hậu tố nhất định (ví dụ: ko*a - sẽ tìm thấy cả từ “cat” và “koala”) .
- Bugzilla là một trình theo dõi lỗi nguồn mở được sử dụng trong công ty chúng tôi, nội dung mà tìm kiếm đã được thử nghiệm.
bảng so sánh
| MySQL | PostgreSQL | Xapian | Nhân sư | Solr | CLucene | |
|---|---|---|---|---|---|---|
| Tốc độ lập chỉ mục | 314 KB/giây | 522 KB/giây | 1,36 MB/giây | 4,5 MB/giây | 2,75 MB/giây | 3,8 MB/giây |
| Tốc độ tìm kiếm | 175 mili giây / 3,46 giây | 28 mili giây / 2,1 giây | 14 mili giây / 135 mili giây | 7 mili giây / 75 mili giây | 25 mili giây / 212 mili giây | 10 mili giây / 212 mili giây |
| Kích thước chỉ mục | 150 % | 150 % | 200 % | 30 % | 20 % | 20 % |
| Thực hiện | cơ sở dữ liệu | cơ sở dữ liệu | Thư viện | Máy chủ | Máy chủ | Thư viện |
| Giao diện | SQL | SQL | API | API, SQL | Dịch vụ web | API |
| Ràng buộc | ∀ | ∀ | 9 | 6 + ∀ | 8 | 3.5 |
| Toán tử tìm kiếm | &*" | &* | &*"K-~ | &*"N- | &*"K-~ | &*"K-~ |
|
| thân cây | KHÔNG | 15 | 15 | 15 | 31 | 15+CJK |
| Dừng từ, từ đồng nghĩa | KHÔNG | Đúng | Đúng | Đúng | Đúng | Đúng |
| Soundex | KHÔNG | KHÔNG | KHÔNG | Đúng | Đúng | KHÔNG |
| Đèn nền | KHÔNG | Đúng | KHÔNG | Đúng | Đúng | Đúng |
Xếp hạng kết quả và sắp xếp theo các lĩnh vực khác nhau có ở khắp mọi nơi.
Ngoài ra:
Phần kết luận
Động cơ đơn giản và nhanh nhất là Sphinx. Nhược điểm là các chỉ mục được cập nhật vẫn chưa hữu dụng lắm - chúng chỉ có thể được sử dụng nếu bạn không bao giờ xóa bất kỳ thứ gì khỏi chỉ mục. Nếu khắc phục được điều này thì vấn đề lựa chọn sẽ biến mất hoàn toàn, Sphinx sẽ làm tất cả.
Cũng nhanh, rất tính năng, hiệu quả và có thể mở rộng, nhưng không phải là công cụ dễ sử dụng nhất - Lucene. Vấn đề chính với các giao diện là các cổng Java hoặc C++ và các vấn đề với các ràng buộc. Nghĩa là, nếu bạn không viết bằng Java, C++, Python hoặc Perl, bạn cần sử dụng Solr. Solr đã ngốn một ít bộ nhớ, lập chỉ mục và tìm kiếm chậm hơn một chút, nó có thể bất tiện khi sử dụng một máy chủ Java riêng biệt trong một thùng chứa servlet, nhưng nó có rất nhiều khả năng khác nhau.
Xapian... Tìm kiếm nhanh, lập chỉ mục không tốt lắm và bản thân chỉ mục quá lớn. Điểm cộng của nó là một loạt giao diện cho các ngôn ngữ khác nhau (C++, Java, Perl, Python, PHP, Tcl, C#, Ruby, Lua). Nếu một chế độ xuất hiện để vô hiệu hóa việc lập chỉ mục các biểu mẫu chính xác, kích thước của chỉ mục sẽ ngay lập tức giảm theo hệ số 2.
Nếu bạn đang sử dụng PostgreSQL và sẵn sàng chấp nhận tốc độ lập chỉ mục không quá cao cũng như hoàn toàn không có các toán tử tìm kiếm phức tạp, thì bạn có thể sử dụng Textsearch, vì nó tìm kiếm nhanh hơn MySQL và khá tương đương với các phần mềm khác. Nhưng bạn cần nhớ rằng chỉ mục phải được tạo trên một cột thực thuộc loại tsvector chứ không phải trên biểu thức to_tsvector().
MySQL FULLTEXT cũng có thể được sử dụng trong những trường hợp đơn giản khi cơ sở dữ liệu nhỏ. Nhưng trong mọi trường hợp, bạn không nên thực hiện MATCH (một số trường) và trong mọi trường hợp không nên sử dụng tìm kiếm tiền tố.
Mọi chỉnh sửa đối với bài viết này sẽ bị ghi đè trong phiên sao chép tiếp theo. Nếu bạn có nhận xét nghiêm túc về nội dung bài viết, hãy viết nó vào phần “thảo luận”.
Ivan Maksimov
Khả năng của công cụ tìm kiếm DataparkSearch
Làm cách nào để tổ chức tìm kiếm thông tin trên máy chủ tệp không chỉ theo tên và loại tài liệu mà còn theo nội dung của nó? Có thể tạo ra một công cụ phù hợp mà người dùng có thể truy cập và minh bạch không?
Hiện nay, vấn đề tìm kiếm thông tin ngày càng trở nên cấp thiết. Trên Internet từ lâu đã có sự cạnh tranh giữa các công cụ tìm kiếm, liên tục đưa ra các dịch vụ, khả năng mới và cơ chế tìm kiếm nâng cao. Nhưng những dữ liệu cần thiết rất khó tìm thấy không chỉ trên Internet. Một lượng lớn cũng được tích lũy trên máy tính ở nhà của người dùng và việc hiểu được sự đa dạng này đôi khi rất khó khăn. Trong các tổ chức, thông tin thường được tập trung và sắp xếp trên các máy chủ tệp, nhưng theo thời gian, việc tìm kiếm các tài liệu cần thiết trở nên khó khăn. Các nhà sản xuất phần mềm đã đáp ứng nhu cầu này. Ngày nay có hàng tá công cụ tìm kiếm hoạt động cục bộ trên PC và các công cụ tìm kiếm dựa trên máy chủ cũng đã xuất hiện.
Các công cụ tìm kiếm cục bộ hầu hết được phân phối miễn phí, trong khi các phiên bản công ty cho phép người dùng tìm kiếm thông tin trên máy chủ thì khá đắt. Tất nhiên, bằng cách mua một sản phẩm thương mại, chúng tôi nhận được hỗ trợ kỹ thuật phù hợp và các lợi ích khác, nhưng các tổ chức nhỏ hoặc chủ sở hữu mạng riêng không phải lúc nào cũng có thể trả hàng nghìn đô la cho những sản phẩm đó. May mắn thay, trong thế giới Nguồn mở có những dự án miễn phí có chức năng tương tự như các đối thủ thương mại của chúng, với sự hỗ trợ và cập nhật chất lượng cao.
Bây giờ chúng ta sẽ xem xét một trong các tùy chọn để tổ chức tìm kiếm tài liệu trên máy chủ tệp, được triển khai cho một tác vụ cụ thể.
Điều kiện ban đầu
Có một máy chủ tập tin chạy hệ điều hành Linux. Các gói samba và pro-ftp phổ biến được cài đặt để chia sẻ tệp. Đĩa sử dụng hệ thống tệp reiserfs, vì nó hiệu quả nhất khi làm việc với một số lượng lớn tệp nhỏ (tài liệu, khoảng 3 nghìn, ở nhiều định dạng khác nhau: txt, html, doc, xls, rtf). Dữ liệu đã được sắp xếp nhưng khối lượng của nó ngày càng tăng; việc xóa thông tin lỗi thời không giải quyết được vấn đề. Làm cách nào để tổ chức tìm kiếm theo tên và loại tài liệu cũng như theo nội dung? Làm thế nào để cung cấp nó cho người dùng trong mạng nội bộ?
Để giải quyết những vấn đề này, chúng ta cần một công cụ tìm kiếm, một máy chủ cơ sở dữ liệu (MySQL, firebirg, ...), Máy chủ web Apache và khoảng một gigabyte dung lượng ổ đĩa để tổ hợp hoạt động.
Bạn nên chọn công cụ tìm kiếm nào?
Có các công cụ tìm kiếm cục bộ như Google Desktop Search hoặc Ask Jeeves Desktop Search. Có lẽ những công cụ này có thể hữu ích cho việc tổ chức tìm kiếm trong một công ty nhỏ hoặc trên máy trạm của người dùng chạy hệ điều hành Windows, nhưng không phải trong trường hợp này. Tìm kiếm “quái vật” như Yandex rất đắt tiền, nhưng nếu bạn cần sự trợ giúp của nhà phát triển chất lượng cao thì các công ty lớn có thể cần phải nghĩ đến việc thuê nó. Có một số dự án dành cho dòng *nix. Đây là những động cơ:
- DataparkTìm kiếm
- mục lục từ
- ASP tìm kiếm
- chó săn beagle
- MnogoTìm kiếm
Các công cụ được liệt kê được định vị là công cụ tìm kiếm được phân phối tự do để làm việc trên các mạng cục bộ và/hoặc toàn cầu. Tôi muốn lưu ý rằng nhiều dự án không đa nền tảng và không hoạt động trong hệ điều hành Microsoft. Đối với hệ thống Windows, có các giải pháp máy chủ, chẳng hạn như: MnogoSearch và “Snoop”.
Vì vậy, hãy xem xét ngắn gọn các công cụ tìm kiếm cho nền tảng *nix:
Beagle là sự kế thừa của công cụ SUSE Linux Htdig. Bản phân phối SUSE cuối cùng bao gồm công cụ Htdig là số 9; trong các phiên bản tiếp theo, Novell đã thay thế nó bằng beagle. Htdig kết thúc quá trình phát triển vào năm 2004, phiên bản mới nhất hiện có là 3.2.0b6 ngày 31 tháng 5 năm 2004. Công cụ mới trong SUSE được định vị là công cụ tìm kiếm cục bộ nhưng nó cũng có thể được sử dụng trong môi trường công ty.
MnogoSearch (trước đây là UdmSearch) là một công cụ nổi tiếng và khá phổ biến. Có phiên bản dành cho cả Windows (phiên bản miễn phí 30 ngày) và nền tảng *nix (giấy phép GNU). Có thể hoạt động với hầu hết các phiên bản SQL DBMS phổ biến cho cả hai nền tảng. Tiếc là có khá nhiều phàn nàn về động cơ này nên tôi không chọn.
Wordindex là một công cụ đang được phát triển (tại thời điểm viết bài, phiên bản mới nhất hiện có là 0,5 ngày 31 tháng 8 năm 2000). Hoạt động kết hợp với MySQL DBMS và web máy chủ Apache. Một dự án khả thi chỉ được trình bày trên trang web của nhà phát triển.
ASPseek là một công cụ tìm kiếm khá phổ biến trong quá khứ, nhưng vào năm 2002, công cụ này đã ngừng phát triển (phiên bản mới nhất hiện có của công cụ tìm kiếm này là 1.2.10 ngày 22 tháng 7 năm 2002).
DataparkSearch là bản sao của công cụ tìm kiếm MnogoSearch. Cho phép bạn tìm kiếm cả theo tên tệp và nội dung của chúng. Việc xử lý tệp txt, tài liệu HTML và thẻ mp3 được tích hợp sẵn; cần có các mô-đun bổ sung để xử lý nội dung của các loại tài liệu khác. Có thể tìm kiếm thông tin cả trên ổ cứng cục bộ và trên mạng cục bộ/toàn cầu (http, https, ftp, nntp và tin tức).
Công cụ tìm kiếm hoạt động với các DBMS SQL phổ biến nhất, chẳng hạn như MySQL, firebird, PostgreSQL và các công cụ khác. Theo các nhà phát triển, DataparkSearch hoạt động ổn định trên nhiều hệ điều hành *nix khác nhau: FreeBSD, Solaris, Red Hat, SUSE Linux và các hệ điều hành khác. So với MnogoSearch, một số lỗi đã được sửa trong công cụ và một số chức năng đã được thay đổi để tốt hơn. Trang web của nhà phát triển cung cấp liên kết đến các phiên bản hoạt động của công cụ trên Internet. Một điểm cộng lớn là tài liệu chất lượng cao bằng tiếng Nga.
Vì vậy, sau khi so sánh tất cả ưu và nhược điểm, công cụ tìm kiếm DataparkSearch đã được chọn để triển khai tìm kiếm trên máy chủ tệp.
Cài đặt
Để hoạt động, chúng ta sẽ cần: máy chủ web Apache, máy chủ cơ sở dữ liệu MySQL và mã nguồn DataparkSearch. Chúng tôi cài đặt máy chủ Apache và cơ sở dữ liệu MySQL (với tất cả các thư viện cần thiết). Nếu một DBMS khác được cài đặt trên máy chủ của bạn, bạn cũng có thể sử dụng DBMS đó (xem tài liệu về công cụ). Tiếp theo, hãy giải nén kho lưu trữ DataparkSearch và bắt đầu lắp ráp tổ hợp của chúng tôi.
Hãy chạy tập lệnh install.pl và trả lời các câu hỏi cần thiết: chọn thư mục cài đặt công cụ, cơ sở dữ liệu và những thứ khác liên quan đến thông số vận hành của công cụ. Nên để cài đặt mặc định. Người dùng có kinh nghiệm, sau khi đọc tài liệu có trong thư mục doc, có thể cấu hình công cụ theo cách thủ công (lệnh configure). Nếu tập lệnh không thể tìm thấy mysql trong khi cài đặt, thì thư viện dành cho nhà phát triển (libmysql14 Devil) có thể chưa được cài đặt. Bây giờ, hãy biên dịch và cài đặt DataparkSearch bằng cách sử dụng lệnh make và make install.
Cấu hình tối thiểu
Hãy tạo một cơ sở dữ liệu:
sh$ mysqladmin tạo tìm kiếm
Sử dụng lệnh mysqlshow, chúng ta sẽ xem tất cả các bảng trong cơ sở dữ liệu. Tôi muốn lưu ý ngay rằng sẽ thuận tiện hơn khi làm việc với MySQL bằng bảng điều khiển web phpmyadmin, nhưng bạn có thể thực hiện bằng một bộ tiện ích tiêu chuẩn. Bạn cần tạo một người dùng mới trong MySQL:
sh#mysql --user=root mysql
mysql> CẤP TẤT CẢ CÁC ĐẶC QUYỀN TRÊN *.* CHO user@localhost
ĐƯỢC XÁC ĐỊNH BẰNG "mật khẩu" VỚI TÙY CHỌN CẤP;
lối ra
Hãy khởi động lại MySQL.
Giả sử tên người dùng là người tìm kiếm và mật khẩu là qwerty.
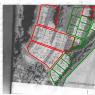
Bây giờ chúng ta tạo tệp indexer.conf trong thư mục /etc/ của công cụ; có thể tìm thấy các ví dụ về tệp này (đối với một số tác vụ) trong thư mục /doc/samples của mã nguồn DataparkSearch. Ví dụ với cài đặt tối thiểu thể hiện trong hình. 1.
Chúng ta hãy xem xét kỹ hơn về tập tin. Như đã đề cập trong nhận xét, lệnh DBAddr chỉ định đường dẫn đến máy chủ SQL (trong trường hợp của chúng tôi là MySQL), cách lưu trữ dữ liệu và các tham số khác (nếu cần). Có một số chế độ lưu trữ: nếu bạn không chỉ định dpmode, giá trị mặc định sẽ là đơn - chậm nhất. Bạn nên sử dụng chế độ bộ đệm, nhưng nếu gặp vấn đề với nó, bạn có thể sử dụng chế độ nhiều chế độ kém hiệu quả hơn nhưng dễ cấu hình hơn. Bạn có thể tìm thấy mô tả chi tiết về tất cả các tham số dbmode trong tài liệu.
DoStore lưu trữ bản sao nén của các tài liệu được lập chỉ mục. Phần là một mô-đun cung cấp các tùy chọn lập chỉ mục linh hoạt. Giả sử bạn có thể tạo hạn chế thẻ hoặc thiết lập lập chỉ mục không chỉ nội dung của tệp mà còn cả URL (máy chủ, đường dẫn, tên). Langmap - bản đồ ngôn ngữ đặc biệt để nhận dạng mã hóa và ngôn ngữ, có hiệu quả nếu tài liệu lớn hơn 500 byte.
Tệp cấu hình bắt buộc thứ hai là tệp kết quả tìm kiếm search.conf. Bạn nên lấy một mẫu có sẵn (tệp /etc/search.htm-dist) và chỉnh sửa nó cho phù hợp với nhu cầu của bạn. Cần lưu ý rằng các tham số chính được chỉ định trong file indexer.conf phải khớp với các tham số trong search.htm, nếu không sẽ xảy ra lỗi khi engine hoạt động. Search.htm bao gồm một số khối: khối đầu tiên - biến - chứa dữ liệu để công cụ hoạt động (tập lệnh search.cgi) và tất cả các khối khác đều cần thiết để tạo trang kết quả tìm kiếm html. Một ví dụ về khối biến trong search.conf được hiển thị trong Hình. 2.
Chúng ta hãy xem xét kỹ hơn về search.htm. Như bạn có thể thấy, các tham số DBAddr và LocalCharset giống với các tham số giống hệt nhau trong indexer.conf. Nếu ứng dụng khách web của bạn hỗ trợ định dạng xml thì bạn có thể đặt tham số văn bản/xml ResultContentType. Dưới đây là các khối HTML cần thiết để thiết kế trang kết quả; chúng không được trình bày ở đây do kích thước lớn. Bạn nên sử dụng mẫu tạo sẵn trong tệp /etc/search.htm-dist. Tài liệu đi kèm mô tả đầy đủ định dạng của các khối HTML (thiết kế); bất kỳ ai cũng có thể tùy chỉnh theo ý thích của mình.
Bây giờ bạn có thể chạy tệp chỉ mục từ thư mục sbin của công cụ DataparkSearch với tham số -Ecreate. Nếu mọi thứ được thực hiện chính xác, các bảng sql cần thiết sẽ được tạo trong cơ sở dữ liệu. Nếu xảy ra lỗi, bạn nên kiểm tra tên người dùng và mật khẩu mysql trong file indexer.conf, đây là lỗi thường gặp nhất.
Để thử nghiệm, nên lập chỉ mục một phần nhỏ của tài nguyên, để nếu xảy ra lỗi thì việc lập lại chỉ mục mới sẽ không mất nhiều thời gian. Việc lập chỉ mục được thực hiện bằng lệnh lập chỉ mục mà không có tham số, kết quả là chúng ta sẽ nhận được kết quả: thời gian sử dụng, số lượng tài liệu và tốc độ làm việc.
Hãy sao chép tệp bin/search.cgi từ thư mục DataparkSearch vào thư mục cgi-bin của máy chủ web của chúng tôi và chỉnh sửa tệp index.shtml của máy chủ web Apache của chúng tôi (nằm trong thư mục html), thêm mã biểu mẫu tìm kiếm vào đó :
Bây giờ bạn có thể truy cập tài nguyên localhost bằng bất kỳ trình duyệt có thể truy cập. Trong biểu mẫu xuất hiện, hãy nhập từ tìm kiếm, ví dụ: “bộ xử lý” (xem Hình 3). Kết quả là, chúng tôi sẽ nhận được một trang có kết quả tìm kiếm, tất nhiên, nếu những tài liệu đó tồn tại (xem Hình 4). Nếu một tài liệu có lỗi xuất hiện thay vì một trang có kết quả tìm kiếm, bạn nên kiểm tra hoạt động của tập lệnh. Vào thư mục cgi-bin của web server, thực thi đoạn script “seach.cgi test >> test.htm”. Nếu trang kết quả được định dạng chính xác, bạn nên kiểm tra cấu hình máy chủ Apache: đường dẫn đến tập lệnh cgi có được chỉ định chính xác không, nó có đang chạy không kịch bản thử nghiệm test.cgi trong thư mục máy chủ web.
Nếu test.htm trống hoặc cũng có lỗi, bạn nên kiểm tra xem dữ liệu có tồn tại trong cơ sở dữ liệu hay không, việc này được thực hiện bằng lệnh “indexer -S”. Có lẽ bạn nên lập chỉ mục lại máy chủ bằng lệnh “indexer – v 5” - mức tối đa để đưa ra thông tin gỡ lỗi. Bằng cách đặt lệnh LogLevel 5 trong tệp search.htm và xem cẩn thận nhật ký máy chủ web, bạn có thể tìm hiểu cách xử lý dữ liệu trong máy chủ SQL.
Thêm các mô-đun bổ sung (bộ phân tích cú pháp)
Theo mặc định, công cụ chỉ hoạt động với các tệp html và txt, nhưng có thể cài đặt thêm các mô-đun (phân tích cú pháp) để chuyển đổi các loại tài liệu khác thành html hoặc txt (văn bản thuần túy). Có thể làm việc với xls (Excel), doc (Word), rtf (Word), ppt (Power Point), pdf ( Trình đọc Acrobat) và thậm chí các tệp vòng/phút (Trình quản lý gói RedHar), tệp sau sẽ chỉ hiển thị siêu dữ liệu. Trong trường hợp của chúng tôi, chúng tôi sẽ cần xử lý định dạng văn phòng. Có một số bộ phân tích cú pháp cho xls và doc: catdoc chuyển đổi tài liệu sang định dạng txt, XLHTML và vwHtml chuyển đổi tệp sang định dạng HTML.
Tôi khuyên bạn nên sử dụng gói catdoc, vì tốc độ chuyển đổi sang định dạng txt nhanh hơn nhiều so với chuyển đổi sang định dạng HTML và chương trình XLHTML đôi khi bị treo khi chuyển đổi tài liệu. Mặc dù các nhà phát triển đã thấy trước vấn đề này và khuyên bạn nên đặt tham số ParserTimeOut 300 trong indexer.conf (con số được biểu thị bằng giây) để tránh tình trạng đóng băng phân tích cú pháp, thời gian lập chỉ mục khi đó sẽ còn tăng hơn nữa.
Chúng tôi cũng sẽ cần một bộ phân tích cú pháp khác - unrtf - để làm việc với các tệp rtf; nó chuyển đổi tài liệu thành mã html hoặc định dạng văn bản/thuần túy theo lựa chọn của người dùng.
Hãy tải xuống và cài đặt các gói cần thiết; để kết nối bộ phân tích cú pháp, bạn cần thêm các dòng sau vào indexer.conf:
Đối với định dạng xls (chương trình xls2csv được bao gồm trong gói catdoc):
Ứng dụng Mime/vnd.ms-excel text/plain "xls2csv $1"
Ứng dụng AddType/vnd.ms-excel *.xls *.XLS
đối với tài liệu doc, các tham số trông như thế này:
Ứng dụng Mime/văn bản msword/thuần túy "catdoc $1"
Ứng dụng AddType/vnd.ms-excel *.doc *.DOC
xử lý tài liệu RTF:
AddType văn bản/rtf* *.rtf *.RTF
Ứng dụng AddType/rtf *.rtf *.RTF
Văn bản Mime/rtf* văn bản/html "/usr/local/bin/unrtf --text $1"
Ứng dụng Mime/văn bản rtf/html "/usr/local/bin/unrtf --text $1"
Điều đáng ghi nhớ là một số ứng dụng Windows đôi khi tạo các tệp có cùng phần mở rộng bằng chữ hoa, vì vậy, hãy thêm cùng phần mở rộng nhưng có tên khác nhau vào danh sách AddType.
Bạn có thể thêm bất kỳ loại tài liệu nào để lập chỉ mục, nhưng công cụ sẽ chỉ hiển thị các liên kết đến tên tệp.
Giả sử, nếu bạn cần lập chỉ mục các tệp vòng/phút hoặc iso và lấy siêu dữ liệu từ chúng, trước tiên bạn cần tìm chương trình (bộ phân tích cú pháp) tương ứng và thêm thông số bắt buộc trong chỉ mục.conf. Ví dụ: có thể tìm thấy danh sách các loại tài liệu được hỗ trợ trong tệp mime.types của máy chủ Apache. Bạn có thể tìm thấy các giải pháp làm sẵn để chuyển đổi tệp hoặc lấy siêu dữ liệu từ chúng trong số cài đặt của gói Midnight Commander, trong tệp mc.ext.
chế độ lưu trữ bộ đệm
Có một số cách để tăng tốc động cơ, một trong số đó là sử dụng phương pháp lưu trữ dữ liệu bộ đệm. Để hoạt động ở chế độ này, chúng ta cần các tiện ích được lưu trong bộ nhớ đệm và bộ chia chạy, nằm trong thư mục sbin tương ứng với công cụ. Nếu bạn đã tạo cơ sở dữ liệu SQL ở chế độ khác (dpmode), đừng quên xóa nó trước và chỉ sau đó thay đổi chế độ lưu trữ. Hãy xóa cơ sở dữ liệu bằng các lệnh: “indexer -C” (dọn dẹp bảng SQL) và “indexer Edrop” (xóa bảng). Tiếp theo, tạo tệp cached.conf từ tệp mẫu cached.conf-dist nằm trong thư mục etc của công cụ của chúng tôi. Đừng quên thay đổi các tham số để truy cập cơ sở dữ liệu SQL:
Bây giờ bạn có thể chỉnh sửa các tệp index.conf và search.conf bằng cách thay đổi các tham số trong chúng:
người lập chỉ mục.conf
DBAddr mysql://searcher:qwerty@localhost/search/?dbmode=cache&cached=localhost:7000
tìm kiếm.htm
DBAddr mysql://searcher:qwerty/search/?dbmode=cache
Sự thay đổi này nói chung là đủ, nhưng nếu bạn muốn đạt được tính linh hoạt cao hơn nữa của động cơ, bạn nên tự làm quen với thông số bổ sung chế độ bộ đệm và thực hiện các thay đổi cần thiết đối với các tệp cấu hình.
được lưu trong bộ nhớ cache & 2> được lưu trong bộ nhớ cache.out
Trình nền sẽ khởi động và ghi thông tin gỡ lỗi vào tệp cached.out. Cổng được lưu trong bộ nhớ đệm mặc định là 7000, nhưng nó có thể được thay đổi nếu cần thiết (trong cached.conf).
Hãy tạo lại các bảng SQL cho chế độ lưu trữ dữ liệu mới bằng cách sử dụng lệnh “indexer -Ecreate” và lập chỉ mục cho máy chủ – bộ chỉ mục. Sau khi hoàn thành, chạy lệnh:
bộ chia chạy -k
Tôi phải nói chuyện đó phương pháp này tăng tốc không chỉ tốc độ tìm kiếm cơ sở dữ liệu mà còn tăng tốc độ lập chỉ mục. Bây giờ chúng ta có thể thử tìm kiếm cơ sở dữ liệu; nếu mọi thứ được thực hiện chính xác, chúng ta sẽ nhận được kết quả tìm kiếm.
Chức năng bổ sung
Trong cấu hình trên, các cài đặt tối thiểu đã được sử dụng; với sự trợ giúp của các cài đặt bổ sung, bạn có thể đạt được chức năng và tính linh hoạt cao hơn của động cơ, tất cả phụ thuộc vào nhiệm vụ. Để tăng tốc độ của công cụ tìm kiếm, bạn có thể sử dụng mô-đun mod_dpsearch cho máy chủ Apache. Sự cần thiết của mô-đun này sẽ phát sinh nếu hàng trăm nghìn tài liệu được lập chỉ mục và cần phải tăng tốc độ của động cơ lên mức tối đa. Ngoài ra, trong tài liệu, bạn có thể tìm thấy các phương pháp khác để tăng tốc động cơ, ví dụ: Tối ưu hóa SQL DB hoặc cách sử dụng bộ nhớ ảo như một bộ đệm.
Khá thường xuyên có nhu cầu tìm kiếm các dạng ngữ pháp của từ. Giả sử chúng ta cần tất cả các dạng của từ "bộ xử lý" (bộ xử lý, bộ xử lý, ...), để làm được điều này, chúng ta có thể định cấu hình mô-đun ispell hoặc aspell. Thông tin chi tiết về chúng được viết trong tài liệu.
DataparkSearch có khả năng lập chỉ mục các phân đoạn mạng; việc này được thực hiện bằng tham số: subnet 192.168.0.0/24 trong indexer.conf.
Cũng có thể ngăn chặn việc lập chỉ mục hoặc lập chỉ mục một số loại tệp nhất định. thư mục cụ thể trên máy chủ: Không cho phép *.avi hoặc Không cho phép */cgi-bin/*.
Trong các mẫu tập tin cấu hình Bạn có thể tìm thấy mô tả (kèm ví dụ) về các tham số hữu ích khác có thể cần thiết để triển khai một tác vụ cụ thể.
kết luận
Công cụ tìm kiếm DataparkSearch là một công cụ mạnh mẽ để làm việc với các tài nguyên web nằm trên cả mạng cục bộ và mạng toàn cầu. Dự án không ngừng phát triển và hoàn thiện, tính đến thời điểm viết bài mới nhất phiên bản ổn địnhđộng cơ 4.38 (ngày 13/03/2006) và ảnh chụp nhanh 4.39 (ngày 19/04/2006). Tôi nên lưu ý rằng các bản cập nhật lên phiên bản mới nhất hầu như diễn ra cách ngày.
Chúng tôi chưa xem xét vấn đề tạo ra một công chúng dịch vụ tìm kiếm trên Internet, nếu bạn cần, hãy đọc tài liệu liên quan về DBMS, máy chủ web và các vấn đề khác liên quan đến việc bảo vệ thông tin khỏi bị truy cập trái phép.
Ứng dụng
Công việc
Máy chủ đã được cài đặt trên máy: AMD Athlon 2500 Barton, 512 MB DDR 3200 (Dual), HDD WD 200 GB SATA (8 MB cache, 7200 vòng/phút). Cấu hình công cụ: Công cụ DataparkSearch (v4.38), MySQL DBMS (v4.1.11), máy chủ web Apache (v1.3.33), doc, xls, rtf (chuyển đổi sang văn bản/thuần túy), các tệp html, txt được lập chỉ mục. Chế độ lưu trữ đa dữ liệu được sử dụng. Việc xử lý khoảng 2 nghìn tệp nằm trên máy này (kích thước đĩa ~ 1 GB) và lập chỉ mục nội dung của chúng cần 40 phút, kích thước cơ sở dữ liệu sau khi làm việc là khoảng 1 GB. Tôi cần lưu ý rằng tốc độ của động cơ có tài nguyên không cục bộ sẽ phụ thuộc vào tốc độ của kênh. Ngoài ra, tốc độ lập chỉ mục phụ thuộc vào bộ phân tích cú pháp được sử dụng. Sử dụng chế độ lưu trữ bộ đệm cải thiện hiệu suất khoảng 15-20%. Các trình duyệt web được sử dụng làm phần mềm máy khách; đã được thử nghiệm trên: Firefox, Opera, Konqueror, Microsoft trình duyệt web IE và thậm chí cả Lynx - không vấn đề gì. Toàn bộ công việc của phần máy chủ của công cụ có thể được tự động hóa bằng cách sử dụng cron daemon nổi tiếng, đặt vào đó các tham số cần thiết để lập chỉ mục dữ liệu.
Liên hệ với
Trên hàng ngàn trang FTP ẩn danh. Trong loại này, người dùng khá khó khăn để tìm được một chương trình phù hợp để giải quyết vấn đề của mình.
Hơn nữa, họ không biết trước liệu công cụ họ đang tìm kiếm có tồn tại hay không. Do đó, chúng tôi phải xem thủ công các kho lưu trữ FTP, cấu trúc của chúng có sự khác biệt đáng kể. Chính vấn đề này đã dẫn đến sự xuất hiện của một trong những Những khía cạnh quan trọng thế giới hiện đại - Tìm kiếm trên Internet.
Lịch sử sáng tạo
Người ta tin rằng người tạo ra công cụ tìm kiếm đầu tiên là Alan Emtage. Năm 1989, ông làm việc tại Đại học McGill ở Montreal, nơi ông chuyển đến từ quê hương Barbados. Một trong những nhiệm vụ của ông với tư cách là người quản lý khoa công nghệ thông tin của trường đại học là tìm kiếm các chương trình dành cho sinh viên và giảng viên. Để làm cho công việc của mình dễ dàng hơn và tiết kiệm thời gian, Alan đã viết mã để tìm kiếm anh ấy.Alan nói: “Thay vì lãng phí thời gian lang thang quanh các trang FTP và cố gắng tìm hiểu xem có gì trên đó, tôi đã viết các tập lệnh giúp ích cho mình việc đó,” Alan nói, “và thực hiện nó một cách nhanh chóng”.
<поле>:<необязательный пробел><значение><необязательный пробел>
Ghi<поле>có thể nhận hai giá trị: Tác nhân người dùng hoặc Không cho phép. Tác nhân người dùng đã chỉ định tên của robot mà chính sách được mô tả và Disallow xác định các phần mà quyền truy cập bị từ chối.
Ví dụ: một tệp có thông tin như vậy sẽ từ chối tất cả quyền truy cập của rô-bốt vào bất kỳ URL nào có /cyberworld/map/ hoặc /tmp/ hoặc /foo.html:
# robots.txt cho http://www.example.com/ Tác nhân người dùng: * Không cho phép: /cyberworld/map/ # Đây là không gian URL ảo vô hạn Không cho phép: /tmp/ # những thứ này sẽ sớm biến mất Không cho phép: /foo. html
Ví dụ này chặn quyền truy cập vào /cyberworld/map đối với tất cả robot ngoại trừ cybermapper:
# robots.txt cho http://www.example.com/ Tác nhân người dùng: * Không cho phép: /cyberworld/map/ # Đây là không gian URL ảo vô hạn # Cybermapper biết phải đi đâu. Tác nhân người dùng: cybermapper Không cho phép:
Tệp này sẽ “triển khai” tất cả các robot cố gắng truy cập thông tin trên trang web:
# biến đi Tác nhân người dùng: * Không cho phép: /
Archie bất tử
Được tạo ra cách đây gần ba thập kỷ, Archie vẫn chưa nhận được bất kỳ bản cập nhật nào trong suốt thời gian qua. Và nó mang lại trải nghiệm Internet hoàn toàn khác. Nhưng ngay cả ngày nay, bạn vẫn có thể sử dụng nó để tìm thông tin bạn cần. Một trong những nơi vẫn còn lưu trữ công cụ tìm kiếm Archie là Đại học Warsaw. Đúng, hầu hết các tệp được dịch vụ tìm thấy đều có từ năm 2001.
Mặc dù Archie là một công cụ tìm kiếm nhưng nó vẫn cung cấp một số tính năng để tùy chỉnh tìm kiếm của bạn. Ngoài khả năng chỉ định cơ sở dữ liệu (FTP ẩn danh hoặc chỉ mục web tiếng Ba Lan), hệ thống còn cung cấp nhiều lựa chọn để diễn giải chuỗi đã nhập: dưới dạng chuỗi con, dưới dạng tìm kiếm nguyên văn hoặc biểu hiện thông thường. Bạn thậm chí còn có quyền truy cập vào các chức năng để chọn thanh ghi và ba tùy chọn để thay đổi tùy chọn hiển thị cho kết quả: từ khóa, mô tả hoặc liên kết.

Ngoài ra còn có một số tham số tìm kiếm tùy chọn cho phép bạn xác định chính xác hơn tập tin cần thiết. Có thể thêm các từ dịch vụ OR và AND, giới hạn khu vực tìm kiếm tệp theo một đường dẫn hoặc tên miền nhất định (.com, .edu, .org, v.v.), cũng như đặt số lượng kết quả trả về tối đa.
Mặc dù Archie là một công cụ tìm kiếm rất cũ nhưng nó vẫn cung cấp chức năng tìm kiếm khá mạnh mẽ tập tin mong muốn. Tuy nhiên, so với các công cụ tìm kiếm hiện đại, nó cực kỳ thô sơ. “Công cụ tìm kiếm” đã tiến xa - bạn chỉ cần bắt đầu nhập truy vấn mong muốn và hệ thống đã cung cấp các tùy chọn tìm kiếm. Chưa kể các thuật toán học máy được sử dụng.
Ngày nay, học máy là một trong những phần chính của các công cụ tìm kiếm như Google hay Yandex. Một ví dụ về việc sử dụng công nghệ này có thể là xếp hạng tìm kiếm: xếp hạng theo ngữ cảnh, xếp hạng được cá nhân hóa, v.v. Trong trường hợp này, hệ thống Học cách xếp hạng (LTR) rất thường được sử dụng.
Học máy cũng giúp có thể “hiểu” các truy vấn do người dùng nhập. Trang web sửa lỗi chính tả một cách độc lập, xử lý các từ đồng nghĩa, giải quyết các vấn đề mơ hồ (những gì người dùng muốn tìm, thông tin về nhóm Đại bàng hoặc về đại bàng). Các công cụ tìm kiếm học cách phân loại các trang web một cách độc lập theo URL - blog, nguồn tin tức, diễn đàn, v.v., cũng như chính người dùng để tạo tìm kiếm được cá nhân hóa.
Ông cố của công cụ tìm kiếm
Archie đã khai sinh ra công cụ tìm kiếm giống như Google nên ở một khía cạnh nào đó nó có thể được coi là ông cố của công cụ tìm kiếm. Chuyện này đã gần ba mươi năm trước. Ngày nay, ngành công cụ tìm kiếm kiếm được khoảng 780 tỷ USD mỗi năm.Về phần Alan Amtage, khi được hỏi về cơ hội làm giàu bị bỏ lỡ, ông trả lời với mức độ khiêm tốn. “Tất nhiên là tôi muốn trở nên giàu có,” anh nói. - Tuy nhiên, ngay cả khi được cấp bằng sáng chế, tôi cũng khó có thể trở thành tỷ phú. Rất dễ xảy ra sai sót trong mô tả. Đôi khi không phải người đầu tiên là người chiến thắng mà là người trở thành người giỏi nhất”.
Google và các công ty khác không phải là những công ty đầu tiên nhưng họ đã vượt trội so với các đối thủ cạnh tranh, tạo ra một ngành công nghiệp trị giá hàng tỷ đô la.
Khi một công nhân Netpikov phải đối mặt với một nhiệm vụ đòi hỏi thời gian (ví dụ: tạo dự án Death Star hoặc chế tạo một thiết bị nhiệt hạch lạnh nhỏ gọn), trước hết anh ta nghĩ đến cách tự động hóa công việc này. Chúng tôi thu thập kết quả của những phản ánh như vậy trên một trang đặc biệt trên trang web của chúng tôi. Hôm nay chúng ta sẽ nói về cách một dịch vụ hữu ích mới ra đời trong lòng cơ quan Netpeak.
Cách đây rất lâu, ở một thiên hà rất xa, chúng tôi đã quyết định thay đổi công cụ tìm kiếm trên trang web của khách hàng để tăng khả năng hiển thị của các trang trong tìm kiếm không phải trả tiền.
Nhiệm vụ
Công cụ tìm kiếm của dự án khách hàng mà chúng tôi phải làm việc đã tạo một trang riêng cho từng yêu cầu. Vì các truy vấn đôi khi có lỗi chính tả nên cả núi trang như vậy đã tích lũy lại—cả đúng lẫn có lỗi. Nói chung - hơn hai triệu trang: bằng nhau cho tiếng Nga và bằng tiếng Anh. Các trang có lỗi đã được lập chỉ mục và làm tắc nghẽn kết quả.
Nhiệm vụ của chúng tôi là đảm bảo rằng tất cả các tùy chọn truy vấn - cả chính xác và có lỗi - đều dẫn đến một trang. Ví dụ: mỗi truy vấn bóng chày, bóng chày, bóng chày, bóng chày đều có trang riêng, nhưng cần đảm bảo rằng tất cả các tùy chọn đều hội tụ trên một trang có truy vấn chính xác - bóng chày. Trong trường hợp này, trang sẽ tương ứng với đúng mẫu yêu cầu và chúng tôi sẽ có thể loại bỏ rác trong kết quả tìm kiếm.
Ví dụ về các nhóm:
Điều đáng chú ý là các đại lý không phải lúc nào cũng được tin cậy để thực hiện các thay đổi trong công cụ trang web. Vì vậy, chúng tôi rất biết ơn khách hàng đã cho chúng tôi cơ hội thực hiện dự án này.
Mục tiêu
Tạo cơ chế hoạt động rõ ràng để đặt chuyển hướng từ các trang có cụm từ có lỗi đến một trang trên trang khách hàng có cụm từ chính xác.
Điều này là cần thiết để cải thiện việc thu thập dữ liệu và lập chỉ mục trang đích công cụ tìm kiếm, xây dựng lõi ngữ nghĩa và sử dụng nó khi phát triển cấu trúc trang web mới. Tất nhiên, chúng tôi không biết tổng số ngôn ngữ mà truy vấn được nhập, nhưng phần lớn các cụm từ đều bằng tiếng Nga và tiếng Anh, vì vậy chúng tôi tập trung vào các ngôn ngữ này.
Một phương pháp mới ra đời như thế nào
Giải pháp đơn giản nhất mà bạn nghĩ ngay đến là đưa các truy vấn vào Google và nó sẽ sửa lỗi cho chúng tôi một cách trung thực. Nhưng tổ chức một cuộc thâm nhập như vậy là một công việc khá tốn kém. Vì vậy, tôi và các đồng chí đã đi một con đường khác. Nhà toán học phân tích của chúng tôi đã quyết định sử dụng phương pháp tiếp cận ngôn ngữ (bất ngờ!) Và xây dựng một mô hình ngôn ngữ.
Nó có nghĩa là gì? Chúng tôi xác định xác suất gặp một từ trong ngôn ngữ và với mỗi từ, chúng tôi tìm thấy xác suất cho phép nó chứa nhiều lỗi khác nhau. Mọi thứ sẽ ổn, và lý thuyết ở đây rất hay, nhưng để thu thập số liệu thống kê như vậy, bạn cần phải có một kho văn bản được đánh dấu khổng lồ cho mỗi ngôn ngữ (một lần nữa, các công cụ tìm kiếm lại gần nhất với điều này). Đương nhiên, các câu hỏi nảy sinh về cách thực hiện việc này và ai sẽ triển khai tất cả những điều này trong mã. Trước đây chưa có ai làm bất cứ điều gì như thế này (nếu bạn biết một trường hợp, hãy đăng liên kết trong phần bình luận), vì vậy phương pháp này đã được phát triển từ đầu. Có một số ý tưởng và không rõ trước ý tưởng nào tốt hơn. Do đó, chúng tôi kỳ vọng rằng quá trình phát triển sẽ được thực hiện theo chu kỳ - chuẩn bị ý tưởng, thực hiện, thử nghiệm, đánh giá chất lượng và sau đó quyết định xem có tiếp tục hoàn thiện ý tưởng đó hay không.
Việc thực hiện công nghệ có thể được chia thành ba giai đoạn. Đọc thêm về mỗi người trong số họ.

Giai đoạn số 1. Sự hình thành của vấn đề. Cào đầu tiên
Chú ý! Sau dòng này sẽ có nhiều thuật ngữ mà chúng tôi đã cố gắng giải thích bằng ngôn ngữ đơn giản nhất có thể.
Vì thông tin bổ sung (từ điển, tần số, nhật ký) không có sẵn nên chúng tôi đã nỗ lực giải quyết vấn đề bằng nguồn lực mà chúng tôi có. Chúng tôi đã thử các phương pháp phân cụm khác nhau. Ý tưởng chính là các từ trong cùng một nhóm không nên khác nhau quá nhiều.
Phân cụm- một quy trình thu thập dữ liệu chứa thông tin về một mẫu đối tượng và sau đó sắp xếp các đối tượng thành các nhóm tương đối đồng nhất.
Khoảng cách Levenshtein hiển thị số lượng thay đổi tối thiểu (xóa, thêm và thay thế) ở hàng A phải được thực hiện để có được hàng B.
- Thay thế ký hiệu: sh[e]res - sh[i]res, sh[o]res;
- Chèn ký hiệu: sheres - s[p]heres;
- Loại bỏ: gol[d][f] - golf, vàng.
Trong mỗi ví dụ, khoảng cách giữa từ sai chính tả và dạng đúng là 1 lần sửa.
Hệ số Jaccard trên bi và bát quái giúp tìm ra có bao nhiêu sự kết hợp phổ biến của âm tiết hai hoặc ba ký tự mà chuỗi A và B có.
Ví dụ: Hãy xem xét các đường A = ván trượt tuyết và B = đường viền. Công thức chung cho hệ số cho bigram là:
J = (số lượng bigram giống nhau của A và B) / ( Tổng số bigram trong A và B)
Hãy chia các dòng thành bigram:
bigram cho A = ( sn, no, ow, wb, bo+, oa, ar, rd+ ) - 8 miếng; bigram cho B = ( bo+, hoặc, rd+, de, er ) - 5 miếng; Có hai bigram giống hệt nhau được đánh dấu bằng dấu cộng - bo và rd.
Đối với bát quái, nó sẽ tương tự, chỉ thay vì hai chữ cái thì ba sẽ được sử dụng. Hệ số Jaccard cho chúng sẽ như sau:
Ví dụ về những từ tương tự hơn:
A = bóng chày và B = bóng chày ( ba+, as, se, eb+, ba+, al+, ll+ ) ( ba+, aa, ae, eb+, ba+, al+, ll+ ) J = 5 / (7 + 7 - 5) = 0,56
Mặc dù hệ số Jaccard hoạt động nhanh hơn nhưng nó không tính đến thứ tự các âm tiết trong một từ. Do đó, nó được sử dụng chủ yếu để so sánh với khoảng cách Levenshtein. Về lý thuyết, mọi thứ ở đây đều đơn giản. Các kỹ thuật phân cụm cho dữ liệu nhỏ khá dễ giải quyết, nhưng trên thực tế, để hoàn thành việc phân tích, người ta cần có sức mạnh tính toán khổng lồ hoặc nhiều năm thời gian (và lý tưởng nhất là cả hai). Trong hai tuần làm việc, một kịch bản đã được viết bằng Python. Khi khởi chạy, nó đọc các cụm từ từ một tệp và xuất danh sách nhóm sang tệp khác. Đồng thời, giống như bất kỳ chương trình nào, tập lệnh này tải bộ xử lý và sử dụng RAM.
Hầu hết các phương pháp được thử nghiệm đều yêu cầu hàng terabyte bộ nhớ và thời gian sử dụng CPU hàng tuần. Chúng tôi đã điều chỉnh các phương pháp để chương trình cần 2 gigabyte bộ nhớ và một lõi. Tuy nhiên, một triệu yêu cầu đã được xử lý trong khoảng 4-5 ngày. Vì vậy thời gian hoàn thành nhiệm vụ vẫn còn nhiều điều mong muốn. Kết quả của thuật toán trên một ví dụ nhỏ có thể được biểu diễn dưới dạng đồ thị:

Khi áp dụng cho dự án khách hàng, điều này có nghĩa là các trang phù hợp với yêu cầu trong cùng một cụm sẽ được dán lại với nhau bằng chuyển hướng 301. Chúng ta hãy nhớ rằng mục tiêu của chúng ta là tạo ra một cơ chế hoạt động rõ ràng để đặt chuyển hướng từ các trang có cụm từ có lỗi đến một trang của trang khách hàng có cụm từ chính xác. Nhưng ngay cả với ví dụ này, những thiếu sót vẫn rõ ràng:
- Không rõ làm thế nào để tìm thấy các biểu mẫu chính xác từ các nhóm và liệu chúng có ở đó hay không.
- Người ta không biết nên sử dụng ngưỡng lỗi nào. Nếu có ngưỡng lớn (hơn 3 lỗi) thì các nhóm sẽ rất lớn và rải rác; nếu quá nhỏ thì mỗi từ sẽ tạo thành một nhóm riêng, điều này cũng không phù hợp với chúng ta. Không thể tìm thấy một ý nghĩa phổ quát nào đó được tất cả các nhóm chấp nhận.
- Không rõ phải làm gì với những từ có thể được phân loại đồng thời thành nhiều nhóm.
Giai đoạn số 2. Đơn giản hóa. Hi vọng mới
Chúng tôi đã thiết kế lại thuật toán, đưa nó đến gần hơn với các trình sửa ngữ pháp cơ học truyền thống. May mắn thay, có đủ chúng. Thư viện Python Enchant được chọn làm cơ sở. Thư viện này có từ điển cho hầu hết mọi ngôn ngữ trên thế giới, sử dụng khá đơn giản và bạn có thể nhận được gợi ý về những gì cần sửa. Trong giai đoạn trước, chúng tôi đã tìm hiểu rất nhiều về các loại truy vấn và những ngôn ngữ mà các truy vấn này có thể sử dụng.
Từ truy cập mở Các từ điển sau đây đã được thu thập:
- Tiếng Anh UK);
- Tiếng Anh (Mỹ);
- Tiếng Đức;
- Người Pháp;
- Người Ý;
- Người Tây Ban Nha;
- Tiếng Nga;
- Tiếng Ukraina.
- Nếu nó đúng (nằm trong một trong các từ điển), chúng tôi để nguyên như vậy;
- Nếu sai, chúng tôi sẽ nhận được danh sách manh mối và chọn manh mối đầu tiên tìm thấy;
- Chúng tôi ghép tất cả các từ lại với nhau thành một cụm từ. Nếu trước đây chúng tôi chưa gặp một cụm từ như vậy thì chúng tôi sẽ tạo một nhóm cho cụm từ đó. Dạng sửa của cụm từ này sẽ trở thành “trung tâm” của nó. Nếu có, điều đó có nghĩa là cụm từ này đã có nhóm riêng và chúng tôi thêm một dạng sai mới vào đó.

Kết quả chúng ta đã nhận được tâm của nhóm và danh sách các từ của nhóm này. Tất nhiên ở đây mọi thứ tốt hơn lần đầu tiên, nhưng đã có mối đe dọa tiềm ẩn. Do đặc thù của dự án nên có rất nhiều tên riêng trong các truy vấn. Có họ và tên của người dân, thành phố, tổ chức, khu vực địa lý và thậm chí cả tên Latin của loài khủng long. Ngoài ra, chúng tôi còn tìm thấy những từ có phiên âm không chính xác. Vì vậy chúng tôi tiếp tục tìm cách giải quyết vấn đề.
Giai đoạn số 3. Thuốc bổ sung và Thần lực thức tỉnh
Vấn đề phiên âm được giải quyết khá đơn giản và truyền thống. Đầu tiên, chúng tôi tạo ra một từ điển tương ứng giữa các chữ cái Cyrillic và Latin. 
Theo đó, mỗi chữ cái trong các từ đang được kiểm tra đều được chuyển đổi và được ghi chú xem liệu có sửa từ điển cho từ kết quả hay không. Nếu tùy chọn chuyển ngữ có ít lỗi nhất thì chúng tôi đã chọn tùy chọn đó là chính xác. Nhưng tên riêng thì hơi rắc rối một chút. nhất tùy chọn đơn giản việc bổ sung từ điển hóa ra lại là một tập hợp các từ từ kho lưu trữ của Wikipedia. Tuy nhiên, Wiki cũng có những điểm yếu. Có khá nhiều từ sai chính tả và phương pháp lọc chúng vẫn chưa lý tưởng. Chúng tôi đã biên soạn một cơ sở dữ liệu các từ bắt đầu bằng chữ in hoa và không có dấu chấm câu ở phía trước chúng. Những từ này đã trở thành ứng cử viên cho tên riêng của chúng tôi. Ví dụ: sau khi xử lý văn bản như vậy, các từ được gạch chân sẽ được thêm vào từ điển:

Khi triển khai thuật toán, hóa ra việc tìm kiếm manh mối trong từ điển mở rộng của Enchant đôi khi cần tới hơn 3 giây cho mỗi từ. Để tăng tốc quá trình này, một trong những triển khai của máy tự động Levenshtein đã được sử dụng.
Tóm lại, ý tưởng của chiếc máy là chúng ta xây dựng sơ đồ chuyển tiếp bằng cách sử dụng từ điển hiện có. Đồng thời, chúng tôi biết trước có bao nhiêu sửa chữa trong từ ngữ sẽ được chúng tôi chấp nhận. Mỗi lần chuyển đổi có nghĩa là chúng tôi thực hiện một số loại chuyển đổi đối với các chữ cái trong từ - chúng tôi để lại chữ cái đó hoặc áp dụng một trong các kiểu chỉnh sửa - xóa, thay thế hoặc chèn. Và mỗi đỉnh là một trong những lựa chọn để thay đổi từ.
Bây giờ giả sử chúng ta có một từ mà chúng ta muốn kiểm tra. Nếu có lỗi trong đó, chúng ta cần tìm mọi hình thức sửa chữa phù hợp với mình. Một cách nhất quán, chúng tôi bắt đầu di chuyển theo sơ đồ, xem qua các chữ cái của từ đang được kiểm tra. Khi hết các chữ cái, chúng ta sẽ thấy mình ở một hoặc nhiều đỉnh và chúng sẽ hiển thị cho chúng ta các tùy chọn cho các từ chính xác.

Hình ảnh hiển thị một chiếc máy cho từ thực phẩm với tất cả hai lỗi có thể xảy ra. Mũi tên lên có nghĩa là chèn một ký tự vào vị trí hiện tại. Mũi tên chéo có dấu hoa thị có nghĩa là thay thế, mũi tên có epsilon có nghĩa là xóa và mũi tên ngang có nghĩa là chữ cái không thay đổi. Hãy để chúng tôi có từ fxood. Nó sẽ tương ứng với đường dẫn trong máy 00-10-11-21-31-41 – tương đương với việc chèn chữ x sau f vào chữ food.
Ngoài ra, chúng tôi đã thực hiện công việc bổ sung để mở rộng các từ điển chính được thu thập, lọc trước các cụm từ không phải từ điển (tên mẫu sản phẩm và các mã nhận dạng khác nhau) trong chế độ tự động, giới thiệu phiên âm và tìm kiếm trong từ điển bổ sung.
Kết quả là gì?
Chúng tôi vẫn đang nỗ lực nâng cấp thuật toán nhưng đã ở mức ở giai đoạn này phát triển, chúng tôi có một công cụ có thể dọn sạch rác, như đám mây thẻ và hợp nhất chuyển hướng 301 những trang không cần thiết. Công cụ này sẽ đặc biệt hiệu quả đối với số lượng nhỏ những từ viết sai chính tả nhưng cũng cho kết quả khá khả quan trên mảng lớn. Một phiên bản trung gian của tập lệnh đã được gửi tới máy khách để tạo thành khối liên kết. Khối này sẽ cho phép bạn thu thập thông tin bổ sung về việc sửa lỗi truy vấn. Chúng tôi chưa gửi kết quả đầy đủ của kịch bản để triển khai vì chúng tôi vẫn đang nỗ lực cải thiện chất lượng của kịch bản.

Việc tạo mã và kiểm tra phải mất tổng cộng 40 giờ làm việc của một nhà phân tích-toán học. Kết luận: nếu một ngày bạn cần xử lý khoảng hai triệu yêu cầu, đừng thất vọng. Những nhiệm vụ như vậy có thể được tự động hóa. Rõ ràng việc đạt được độ chính xác 100% sẽ rất khó nhưng có thể xử lý chính xác ít nhất 95% thông tin.