Tehnici de lucru cu planuri de execuție a interogărilor în Oracle. Înțelegerea rezultatelor Execute Explain Plan în Oracle SQL Developer
5 răspunsuri
Ieșirea EXPLAIN PLAN este ieșirea de depanare a optimizatorului Interogări Oracle. COST este rezultatul final optimizator de cost (CBO), al cărui scop este să selecteze care dintre o varietate de planuri posibile ar trebui să fie utilizat pentru a rula o interogare. CBO calculează costul relativ pentru fiecare plan, apoi selectează planul cu cel mai mic cost.
(Notă: În unele cazuri, CBO nu are suficient timp pentru a evalua toate planurile posibile, în aceste cazuri selectează pur și simplu planul cu cel mai mic cost găsit până acum)
În general, una dintre cele mai mari contribuții la o interogare lentă este numărul de rânduri citite pentru a servi interogarea (mai precis, blocuri), astfel încât costul se va baza parțial pe numărul de rânduri pe care va trebui să le citească estimările optimizatorului. .
De exemplu, să presupunem că aveți următoarea interogare:
SELECT emp_id FROM angajații WHERE luni_de_serviciu = 6;
(Coloana months_of_service are o constrângere NOT NULL și un index obișnuit pe ea.)
Există două planuri principale pe care optimizatorul le poate alege de aici:
- Planul 1: Citiți toate rândurile din tabelul „angajați”, pentru fiecare verificare dacă predicatul este adevărat (months_of_service=6).
- Planul 2: Citiți indexul unde months_of_service=6 (aceasta rezultă într-un set de ROWID-uri), apoi accesați tabelul pe baza ROWID-urilor returnate.
Să presupunem că tabelul „angajați” conține 1.000.000 (1 milion) de rânduri. Să ne imaginăm în continuare că valorile pentru months_of_service variază de la 1 la 12 și, din anumite motive, sunt distribuite destul de uniform.
Preţ Planul 1, care include SCANARE COMPLETĂ, va costa citirea tuturor rândurilor din tabelul de angajați, care este de aproximativ 1.000.000; dar, deoarece Oracle poate citi adesea blocuri folosind citiri cu mai multe blocuri, costul real va fi mai mic (în funcție de modul în care este configurată baza de date) - de exemplu, să presupunem că numărul de mostre cu mai multe blocuri este de 10 - costul estimat al unui întreg scanarea ar fi 1.000.000/10; Cost total = 100.000.
Preţ Planul 2, care include un INDEX RANGE SCAN și o căutare în tabel după ROWID, va costa scanarea indexului, precum și costul accesării tabelului folosind ROWID. Nu voi discuta cum ar costa o scanare a indexului intervalului, dar să ne imaginăm că costul unei scanări a indicelui intervalului este de 1 pe rând; ne așteptăm să găsim o potrivire de 1 din 12 ori, deci costul scanării indexului este 1.000.000/12 = 83.333; plus costul accesului la tabel (presupunem 1 bloc citit per acces, nu putem folosi citiri cu mai multe blocuri aici) = 83,333; Cost total = 166.666.
După cum puteți vedea, costul planului este de 1 ( scanare completă) este mai mic decât costul planului 2 (verificare index + acces rowid) - aceasta înseamnă că CBO va selecta scanare COMPLETĂ.
Dacă ipotezele făcute aici de optimizator sunt corecte, atunci de fapt Planul 1 va fi de preferat și mult mai eficient decât Planul 2 - care respinge mitul că scanările FULL sunt „întotdeauna proaste”.
Rezultatele ar fi destul de diferite dacă ținta optimizatorului ar fi FIRST_ROWS(n) în loc de ALL_ROWS - caz în care optimizatorul ar prefera planul 2, deoarece deseori ar returna primele câteva rânduri mai repede, cu prețul de a fi mai puțin eficient pentru întreaga interogare. .
CBO construiește un arbore de decizie, estimând costurile fiecăruia cale posibilă execuție, disponibilă pentru fiecare cerere. Costurile sunt stabilite de parametrul CPU_cost sau I/O_cost setat pe instanță. Și CBO estimează costul cât de bine poate cu statisticile existente ale tabelelor și indicilor care vor fi utilizați în interogare. Nu ar trebui să vă personalizați cererea doar pe baza costurilor. Costul vă permite să înțelegeți DE CE optimizatorul face ceea ce face. Fără costuri, ați putea înțelege de ce optimizatorul a ales planul pe care l-a făcut. Costul mai mic nu înseamnă mai mult cerere rapidă. Sunt momente când acest lucru este adevărat și vor fi momente când este greșit. Costul se bazează pe tabelul cu statistici și dacă sunt greșite, costul va fi incorect.
Când configurați o interogare, ar trebui să vă uitați la cardinalitatea și numărul de rânduri ale fiecărui pas. Au sens? Optimizatorul este considerat corect? Sunt șirurile returnate corect? Dacă informațiile nu sunt prezente corect, atunci cel mai probabil optimizatorul nu are informațiile adecvate necesare pentru a lua decizia. decizia corectă. Acest lucru se poate datora statisticilor învechite sau lipsă din tabel și index, precum și statistici CPU. Cel mai bine este să actualizați statisticile atunci când vă configurați interogarea pentru a profita la maximum de optimizator. Cunoașterea circuitului dvs. ajută foarte mult la configurare. Știind când optimizatorul a ales cu adevărat decizie proasta iar îndreptarea lui în direcția corectă cu un mic indiciu poate economisi timp.
Mențiunea dvs. de „FULL” îmi indică faptul că interogarea efectuează o scanare pe ecran complet pentru a vă găsi datele. În unele cazuri, acest lucru este în regulă, altfel este un indicator al unei intrări de indexare/interogare proaste.
Ca regulă generală, doriți ca interogarea dvs. să folosească chei, astfel încât Oracle să poată găsi datele de care aveți nevoie, accesând cel mai mic număr de rânduri. În cele din urmă, într-o zi vei putea accesa arhitectura meselor tale. Dacă costurile rămân prea mari, poate fi necesar să vă gândiți cum să vă reglați designul circuitului pentru o performanță mai bună.
În versiunile recente ale Oracle, COST este timpul în care optimizatorul așteaptă o interogare, exprimat în unități de timp necesar pentru a citi un bloc.
Deci, dacă citirea unui bloc durează 2 ms și costul este exprimat ca „250”, solicitarea poate dura 500 ms.
Optimizatorul calculează un cost pe baza numărului estimat de citiri cu un singur bloc și mai multe blocuri, precum și pe consumul CPU al planului. acesta din urmă poate fi foarte util pentru minimizarea costurilor prin efectuarea anumitor operațiuni înaintea altora pentru a încerca să evite costurile mari ale procesorului.
Acest lucru ridică întrebarea cum știe optimizatorul cât timp durează operațiunile pentru finalizare. ultimele versiuni Oracle vă permite să creați colecții de „statistici de sistem”, care cu siguranță nu trebuie confundate cu statisticile de tabel sau index. Statisticile sistemului sunt măsurători de performanță hardware, important în principal:
- Cât durează să citești un bloc.
- Cât durează lectura multitasking?
- Cât de mare este citirea multibloc (adesea diferită de cea maximă posibilă, deoarece dimensiunea tabelului este mai mică decât valoarea maximă și alte motive).
- Performanța procesorului
Aceste numere pot varia foarte mult în funcție de mediul de operare al sistemului și pot fi stocate diferite statistici pentru operațiunile „OLTP de zi” și operațiunile de „raportare periodică nocturnă” și pentru „raportarea de sfârșit de lună”, dacă doriți.
Având în vedere aceste seturi de statistici, un anumit plan de execuție a unei interogări poate fi estimat pentru costuri în diferite medii de operare, ceea ce poate încuraja utilizarea scanărilor de tabel complet în unele cazuri sau scanări de index în altele.
Costul nu este perfect, dar optimizatorul devine mai bun la auto-monitorizare cu fiecare lansare și poate răspunde la costul real față de costul estimat de acceptat cele mai bune solutiiîn viitor. de asemenea, face dificilă prognoza.
Vă rugăm să rețineți că costul nu este necesar timp de zid, deoarece operațiunile de interogare paralelă consumă o cantitate totală de timp pe mai multe fire.
În versiunile mai vechi de Oracle, costul operațiunilor CPU a fost ignorat, iar costul relativ al citirilor cu un singur și mai multe blocuri a fost corectat efectiv în funcție de parametrii inițiali.
De asemenea, puteți interoga v $sql și v $session pentru a obține statistici despre instrucțiunile SQL, iar aceasta va avea metrici detaliate pentru tot felul de resurse, timpi și execuții.
Este ca un cui în talpa pantofului tău preferat. Poți să mergi, dar tot mai des te surprinzi că dorești să rămâi pe loc sau să delezi sarcina altora. Neplăcerile minore nu numai că ne încetinesc munca, dar reduc și motivația, interferează cu procesul și reduc calitatea rezultatului. Și dacă ai găsit un prieten care te-a învățat să iei ciocan și ciocan în acel cui, nu numai că îi vei fi recunoscător pentru ajutorul lui, dar îi vei ajuta și tu pe ceilalți, salvându-i de un obstacol minor, dar foarte enervant. Acesta este motivul pentru care trebuie să comunicați, să împărtășiți nu numai cunoștințe profunde și intime în forumuri și site-uri precum Habr, ci și trucuri simple și „mici trucuri”
Ca orice text, interogările și programele din SQL pot fi create în orice editor de text. Dar dacă ești un profesionist, lucrezi mult și des cu SQL, atunci a avea evidențierea sintaxelor și reformatarea automată a codului nu va mai fi suficientă, mai ales dacă trebuie să comuți între versiuni diferite ale aceluiași SGBD sau platforme diferite SGBD.
Recent, mi s-a întâmplat să comunic cu unul dintre cei mai importanți profesioniști Oracle DBMS. A spus o mulțime de lucruri interesante despre lucrul cu planuri de execuție a interogărilor în versiuni diferite acest DBMS și nu a ezitat să spună tuturor despre instrumentele și tehnicile pe care le folosește și să ofere câteva sfaturi utile. Am tradus unul dintre articolele de pe blogul său și aș dori să-l aduc în atenția lui Khabravchan. În ciuda faptului că tehnica descrisă a fost folosită pentru a lucra cu Oracle, acum folosesc cu succes aceeași abordare pentru MS SQL și Sybase.
Rulați o interogare de execuție și va apărea fila Plan de interogare, completată cu planul de execuție. 
Plasați cursorul mouse-ului pe oricare dintre nodurile din diagramă și suplimentar informatii utile, legat de acest pas de execuție din planul de interogare!
În mod implicit, Rapid SQL arată planul de execuție în grafic. Am ieșit din vechea lume a optimizării... Prefer versiunea text, așa că dau clic dreapta în fereastra planului și selectez „Vizualizare ca text”.
Prefer să văd textul cererii și planul în același timp. 
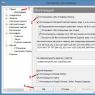
Este ușor de făcut. Vedeți filele ferestrei ISQL în partea de jos a ferestrei principale? Mai întâi, trebuie să configuram Rapid SQL astfel încât să afișeze planul într-o fereastră separată. 
Faceți clic pe butonul Opțiuni (cerc roșu din stânga) și apoi setați opțiunea „Ne atașat” pentru fereastra Rezultat. Acest lucru va crea două file separate în partea de jos a Rapid SQL odată ce interogarea este executată. Doar trageți puțin această fereastră de filă și va apărea un dreptunghi în care puteți muta această fereastră.
Sau puteți utiliza elementul Tile windows din meniul principal al programului
Și încă ceva: toate acestea funcționează și în DBArtisan - o soluție pentru administratorii de baze de date.
Reglarea performanței bazei de date Oracle 11g.
Cum să citiți planurile de interogare
Ce este un plan de execuție?
Planul de execuție este rezultatul optimizatorului interpretat în limba motorului de execuție. Instruiește motorul de execuție despre operațiunile care trebuie efectuate pentru a obține datele solicitate de expresie cât mai rapid și eficient.
Expresia EXPLAIN PLAN captează planul de execuție selectat de optimizator pentru executarea expresiilor precum SELECT, UPDATE, DELETE și INSERT. Etapele planului de execuție nu sunt executate în ordinea în care sunt specificate în plan. Există o relație părinte-copil între pași. arborele șirurilor sursă stă la baza planului de execuție. Acesta conține următoarele informații:
- Sortarea tabelelor la care face referire declarația
- Metoda de acces pentru fiecare tabel specificat în instrucțiune
- Metoda de îmbinare pentru tabele, utilizată de operatorii de îmbinare într-o expresie
- Operații de date, cum ar fi filtrarea, sortarea sau agregarea
- Date de optimizare, cum ar fi costul și cardinalitatea fiecărei operațiuni
- Datele partiției, cum ar fi setul de partiții accesate
- Date de concurență, cum ar fi metoda de distribuție a operațiunii de unire
Unde pot găsi planuri de execuție?
Există multe modalități de a obține planuri de execuție pentru expresii din baza de date, cele mai populare sunt enumerate mai jos:
- Comanda EXPLAIN PLAN vă permite să vizualizați planul de execuție pe care optimizatorul îl poate folosi pentru a executa o expresie. Această comandă este foarte utilă deoarece construiește un plan de execuție și îl scrie într-un tabel numit PLAN_TABLE fără a stoca instrucțiunea SQL.
- V$SQL_PLAN oferă posibilitatea de a vizualiza planurile de execuție pentru cursoarele care au fost executate recent. Informațiile stocate în V$SQL_LAN sunt foarte asemănătoare cu informațiile produse de comanda EXPLAIN PLAN. Cu toate acestea, Explain Plan arată un plan potențial de execuție, iar V$SQL_PLAN stochează planurile interogărilor deja executate.
- V$SQL_PLAN_MONITOR conține statistici de monitorizare la nivel de plan pentru fiecare instrucțiune SQL găsită în V$SQL_MONITOR. Fiecare linie conținută în V$SQL_PLAN_MONITOR corespunde unei operații specifice planului de execuție.
- Cadrul AWR și Statspack stochează planurile de execuție pentru cel mai frecvent numit SQL. Planurile sunt plasate în vizualizarea dBA_HIST_SQL_PLAN sau STATS$SQL_PLAN.
- Planurile de execuție și sursele de rând sunt, de asemenea, scrise în fișierele de urmărire generate de DBMS_MONITOR.
- Baza de management SQL face parte din dicționarul de date stocat în spațiul tabel SYSAUX. Informațiile din jurnal despre operațiuni, istoricul planurilor de execuție și liniile de referință sunt stocate aici, precum și profilurile pentru instrucțiunile SQL.
- Evenimentul de diagnosticare 10053, utilizat pentru a înregistra calculele de optimizare a costurilor, poate genera, de asemenea, planuri de execuție a interogărilor.
- Începând cu versiunea 10.2, atunci când descărcați o stare de proces, planul de execuție este de asemenea inclus în fișierul de urmărire generat.
Vizualizarea planurilor de execuție
Dacă executați comanda EXPLAIN PLAN în SQL*Plus, puteți selecta apoi date din tabelul PLAN_TABLE și puteți vizualiza planurile de execuție generate. Cele mai multe într-un mod simplu vizualizați planul de execuție este să utilizați pachetul DBMS_XPLAIN. Pachetul DBMS_XPLAIN conține cinci funcții disponibile:
- DISPLAY: Folosit pentru ieșirea formatată a planului de execuție.
- DISPLAY_AWR: utilizat pentru ieșirea planului formatat Execuția SQL expresii stocate în depozitul AWR.
- DISPLAY_CURSOR: Folosit pentru a formata ieșirea planului de execuție de la orice cursor încărcat
- DISPLAY_SQL_PLAN_BASELINE: Folosit pentru ieșirea formatată a unuia sau mai multor planuri de execuție pentru instrucțiunile SQL identificate prin anteturi.
- DISPLAY_SQLSET: Folosit pentru ieșirea formatată a planului de execuție stocat în setul de ajustare SQL.
Comanda EXPLAIN PLAN
- Comanda EXPLAIN PLAN este utilizată pentru a genera un plan de execuție a interogării.
- Odată ce planul a fost generat, acesta poate fi vizualizat interogând informațiile din tabelul PLAN_TABLE
PLAN TABLE este creat automat ca un tabel temporar global, care este ulterior folosit de toți utilizatorii pentru a stoca planurile de execuție. Vă puteți crea propriul PLAN TABLE folosind un script $ORACLE_HOME/rdbms/admin/utlxplan.sql dacă este necesară stocarea pe termen lung a planurilor de execuție.
EXPLICAȚI PLANUL Structura de comandă
Comanda EXPLAIN PLAN inserează un rând în PLAN TABLE pentru fiecare pas al planului de execuție.
Exemplu de comandă EXPLAIN PLAN
Această comandă inserează planul de execuție pentru expresie în PLAN TABLE și adaugă eticheta demo01 pentru referință ulterioară.
Există multe modalități de a obține un plan de execuție. Metoda de mai sus folosește comanda EXPLAIN PLAN. Această comandă generează un plan de execuție pentru o instrucțiune SQL fără a o executa și plasează rezultatul în PLAN TABLE. PLAN TABLE reprezintă o structură arborescentă cu care puteți returna planul de execuție pentru o expresie folosind coloanele ID și PARENT_ID și clauza CONNECT BY din SELECT expresia.
Ieșirea conținutului PLAN TABLE
Exemplul de mai sus folosește tasta ALL pentru funcția DBMS_XPLAIN.DISPLAY, care vă permite să vizualizați toate informatii disponibile despre planul de execuție, stocat în PLAN TABLE. Această concluzieîn afară de aceasta informații standard, conține Informații suplimentare precum PROIECTIE, ALIAS și informații SQL REMOTE dacă operația este distribuită.
Pentru a controla mai precis informațiile de ieșire, pot fi utilizați următorii parametri cheie. Fiecare cuvânt cheie adaugă un bloc separat la ieșirea informațiilor din PLAN TABLE. Cuvintele cheie trebuie separate prin virgulă sau spațiu:
- RÂNDURI, dacă este cazul, arată numărul de rânduri estimat a fi numărate de către optimizator.
- RÂNDURI, dacă este cazul, arată numărul de octeți estimați a fi numărați de către optimizator.
- COST dacă este cazul, arată costul,probabil calculat de către optimizator
- PARTIȚIE dacă este cazul, arată renunțarea patriciană de către optimizator
- PARALEL sau este potrivit, afișează informații PX (metodadistribuirea informațiilor și informații despre cozile de acces la tabel)
- PREDICATsau este potrivit, arată informații despre predicat
- PROIECTIE sau este cazul, arata sectiuneaproiecții
Utilizarea Explain Plan în SQL Developer
AUTOTRASE
Când expresiafuncţionare în SQL*Plus sau SQL Developer, puteți obține automat planul de execuție și statisticile de execuție ale unei expresii. Raportul este generat automat după efectuarea oricăror tipuri de operațiuni precum SELECTARE, INSERARE, UPDATE și ȘTERGERE. Aceste informații pot fi folosite pentru a diagnostica și regla performanța instrucțiunilor SQL.
Pentru a utiliza AUTOTRACE, trebuie creat un PLAN TABLE în baza de date și utilizatorului care efectuează AUTOTRACE trebuie să i se acorde rolul PLUSTRACE. RolPLUSTRACE este creat și eliberat rolului DBA folosind un script$ORACLE_HOME/sqlplus/admin/plusrce.sql
Sintaxă AUTOTRACE
Puteți efectua Autotrace folosind sintaxa prezentată în figura de mai sus. Următoarele opțiuni sunt, de asemenea, disponibile pentru utilizare:
- OFF Dezactivează utilizarea urmăririi
- ON Permite utilizarea rutare automată
- TRACE Activează urmărirea automată și suprimă ieșirea SQL
- EXPLAIN Afișează planul de execuție, dar nu arată statistici
- STATISTICI Afișează statistici fără plan de execuție
Exemple de utilizare a AUTOTRACE

AUTOTRASE: STATISTICA

Statisticile înregistrate de server la executarea expresiei reflectă volumul resursele sistemului, cheltuit pentru executarea expresiei și include următorii indicatori principali:
- apeluri recursive- numărul de apeluri recursive generate pe partea client și server Oracle Database menține tabelele utilizate pentru procesarea internă. Când Oracle Database trebuie să facă modificări la aceste tabele, generează o internă Declarație SQL, care la rândul său generează un apel recursiv.
- db block devine- de câte ori este solicitat blocul CURRENT
- consistenta devine- de câte ori se solicită operația de citire integrală a blocurilor de date.
- citirile fizice- numărul de blocuri de date citite de pe disc. Acest număr reprezintă suma valorilor citirile fizice directe și toate citirile din buffer cache.
- reface dimensiunea- numărul total de refacere generate în blocuri
- octeți trimiși prin SQL*Net către client- numărul total de octeți transferați către client din procesul de fundal.
- octeți primiți prin SQL*Net de la client- numărul total de octeți primiți de la clientul Oracle*Net
- Călătorii dus-întors SQL*Net către/de la client- Numărul total de mesaje Oracle NET trimise și primite de la client.
- sortare (memorie)- numărul de operațiuni de sortare care au fost finalizate cu succes în memorie și nu au necesitat scriere pe disc.
- sortare (disc)- numărul de operații de sortare care au necesitat cel puțin o operație pe disc.
- rând procesat- numarul de randuri prelucrate in timpul operatiei.
db_block_gets arată operațiunile de citire ale blocului curent din baza de date. consistenta devine- acestea sunt operații de citire a blocurilor care trebuie să satisfacă număr specific SCN. citirile fizice arată blocurile de citire de pe disc. db_block_getsŞi consistenta devine- indicatori statistici care sunt monitorizati constant. Acestea ar trebui să fie scăzute în comparație cu numărul de rânduri recuperate. Sortarea se face în memorie, nu pe disc.
AUTO TRACE folosind SQL*Developer
Vizualizați V$SQL_PLAN
Această vizualizare arată planuri de execuție pentru cursoarele care se află încă în memoria cache a bibliotecii. Informațiile stocate în această vizualizare sunt în multe privințe similare cu informațiile din PLAN TABLE. Cu toate acestea, V$SQL_PLAN conține planuri de execuție pentru expresiile care au fost deja executate. Planul de execuție produs de EXPLAIN PLAN poate diferi de planul de execuție real stocat în cursor. Acest lucru se întâmplă deoarece parametrii sesiunii și valorile variabilelor BIND pot diferi de cele actuale.
O altă vedere utilă: V$SQL_PLAN_STATISTICS care furnizează statistici de execuție pentru fiecare operație din planul de execuție al fiecărui cursor din cache. O altă idee utilă V$SQL_PLAN_STATISTIC_ALL combină informații de execuție din V$SQL_PLAN_STATISTICSŞi V$SQL_WORKAREA cu un plan de execuție stocat V$SQL_PLAN.

Descrierea coloanelor principale ale vizualizării V$SQL_PLAN
Vederea conține aceleași coloane ca PLAN TABLE și câteva coloane suplimentare. Coloane prezente în PLAN TABLE și având aceleași valori:
- ADRESA
- HASH_VALUE
PLAN_HASH_VALUE este o coloană care conține reprezentare numerică planificați expresia SQL pentru cursor. Comparând valorile coloanei PLAN_HASH_VALUE, puteți determina rapid dacă planul de execuție pentru aceeași expresie se modifică fără a le compara rând cu rând.
Vedeți V$SQL_PLAN_STATISTICS
Vizualizarea V$SQL_PLAN_STATISTICS oferă statistici de execuție actualizate pentru fiecare operație din planul de execuție, cum ar fi numărul de rânduri procesate sau timpul de execuție. Toate statisticile, cu excepția numărului de rânduri, sunt acumulate. De exemplu, statisticile privind îmbinările la tabel pot include 3 operațiuni de îmbinare la tabel. Statisticile stocate în V$SQL_PLAN_STATISTICS sunt disponibile pentru cursoarele care au fost compilate cu parametrul de inițializare STATISTICS_LEVEL = ALL sau folosind indicația de optimizare GATHER_PLAN_STATISTICS.
Vizualizarea V$SQL_STATISTICS_ALL conține statistici de utilizare a memoriei pentru toate rândurile sursă care au folosit memoria SQL (sortare sau unire HASH) Această vizualizare combină informațiile stocate în vizualizarea V$SQL_PLAN cu statisticile de execuție din vizualizările V$SQL_PLAN_STATISTICS și V$SQL_WORKAREA. .
Relații dintre vederile dinamice importante ale performanței

V$SQLAREA Afișează statistici pentru zonele SQL partajate și conține o linie pentru fiecare linie a expresiei SQL. Această vizualizare oferă statistici despre instrucțiunile SQL care sunt deja analizate, în memorie și gata pentru a fi executate:
- SQL_ID- Identificatorul SQL al cursorului părinte din memoria cache a bibliotecii
- VERSION_COUNT numărul de cursore copii care sunt prezente în memoria cache pentru un cursor părinte dat
V$SQL stochează statistici pe zonele SQL partajate și conține câte un rând pentru fiecare expresie SQL descendentă derivată din expresia SQL părinte:
- ADRESA reprezintă adresa antetului cursorului părinte pentru un cursor dat
- HASH_VALUE-valoarea expresiei părinte din memoria cache a bibliotecii
- SQL_ID- Identificatorul SQL al cursorului părinte din memoria cache a bibliotecii
- PLAN_HASH_VALUE- numerică Vedere SQL plan pentru acest cursor
- CHILD_NUMBER- numărul cursorului copil
Statisticile stocate în V$SQL sunt actualizate pe măsură ce instrucțiunile SQL sunt executate. Cu toate acestea, pentru expresiile de lungă durată, informațiile din vizualizare sunt actualizate la fiecare cinci secunde. Acest lucru face posibilă evaluarea impactului asupra performanței al interogărilor de lungă durată în timp ce acestea rulează.
V$SQL_PLAN conține informații despre planul de execuție pentru fiecare cursor copil încărcat în memoria cache a bibliotecii. Coloane ADRESA, HASH_VALUEŞi CHILD_NUMBER poate fi folosit pentru a conecta cu V$SQL pentru definirea ulterioară a cursorelor copil.
V$SQL_PLAN_STATISTICĂ furnizează statistici de execuție la nivel de rând sursă pentru fiecare cursor copil.Coloane ADRESA, HASH_VALUE poate fi folosit pentru a combina cu o vedere V$SQLAREA pentru a determina părintelecursor. Coloane ADRESA, HASH_VALUEŞi CHILD_NUMBERpoate fi folosit pentru a conecta cuV$SQLpentru a defini cursori copil.
V$SQL_PLAN_STATISTICS_ALL conține statistici de utilizare a memoriei pentru toate rândurile sursă care au folosit memoria SQL (sortare sau îmbinare HASH) Această vizualizare agregează informațiile stocate în vizualizare V$SQL_PLAN cu statistici de execuție din vizualizări V$SQL_PLAN_STATISTICSŞi V$SQL_WORKAREA.
V$SQL_WORKAREAoferă statistici despre spațiile de lucru implicate în procesul de operare a expresiei SQL. Fiecare instrucțiune SQL stocată într-un pool partajat are unul sau mai multe cursore copil, informații despre care sunt stocate V$SQL. V$SQL_WORKAREA conține informații despre toate spațiile de lucru necesare acestor cursore copil.
V$SQL_WORKAREAse poate conecta cu V$SQLAREA (ADDRESS, HASH_VALUE) si cu V$SQL ( ADDRESS, HASH_VALUE,CHILD_NUMBER).
Folosind această prezentare puteți obține răspunsuri la următoarele întrebări:
- Top 10 domenii de lucru care necesită cel mai multcantitatememorie pentru cache
- Pentru spațiile de lucru care rulează în modul AUTO, ce procent din spațiile de lucru sunt rulate folosind cantitate maxima memorie?
V$SQLSTATS afișează statistici de bază de performanță pentru cursoarele SQL, fiecare rând reprezentând date care combină textul expresiei SQL și planul de execuție SQL (combinație SQL_IDŞi PLAN_HASH_VALUE). Coloane în V$SQLSTATS identic, V$SQLŞi V$SQLAREA. Cu toate acestea, prezentarea V$SQLSTATS diferit de V$SQLŞi V$SQLAREA viteza de procesare, scalabilitate, perioadă lungă de stocare a datelor (datele statistice pot fi stocate în vizualizare, chiar și după ce cursorul a fost evacuat din pool-ul partajat).
Exemplu de interogare a datelor din vizualizarea V$SQL_PLAN

Puteți interoga datele dintr-o vizualizare V$SQL_PLAN folosind funcția DBMS_XPLAIN.DISPLAY_CURSOR() pentru a afișa expresia curentă sau ultima executată (după cum se arată în exemplu). Puteți trece valoarea SQL_ID ca parametru pentru a obține planul de execuție pentru o expresie dată. SQL_ID - SQL_ID expresii stocate în memoria cache a cursorului. Puteți obține valoarea corespunzătoare interogând informațiile coloanei SQL_ID V V$SQLŞi V$SQLAREA. Alternativ, puteți alege PREV_SQL_ID pentru o anumită sesiune de la V$SESIUNE. Implicit, această opțiune nu este specificată, caz în care este afișat planul stocat în ultimul cursor executat.
- IOSTATS: Presupunând că procesul de execuție SQL colectează statistici de bază pentru planurile de execuție, STATISTICS_LEVEL este setat la ALL sau este utilizat HINT GATHER_PLAN_STATISTICS), acest format afișează statistici I/O pentru toate, când se specifică ALL (sau numai ultima, când se specifică LAST) execuții ale cursorului.
- MEMSTATS: Presupunând folosit control automat PGA (parametrul pga_aggregate_target este setat la not valoare nulă) Acest format vă permite să afișați statistici de utilizare a memoriei. Acest tip de statistici este aplicabil numai operațiunilor care necesită multă memorie, cum ar fi HASH Join, sortarea sau unii dintre operatorii bitmap.
- ALLSTATS: Sinonim pentru „IOSTATS MEMSTATS”
- DURA: În mod implicit, statisticile planului de execuție sunt afișate pentru toate execuțiile cursorului. Folosind cuvântul cheie LAST, puteți vizualiza statisticile planului generate de ultima dată când a fost executat.
Vizualizări importante AWR
Puteți vizualiza datele AWR în Enterprise Manager sau generând un raport AWR și, în plus, puteți accesa următoarele vizualizări dinamice de performanță care stochează date AWR:
- V$ACTIVE_SESSION_HISTORY- această vizualizare arată informații despre cea mai recentă activitate de sesiune, actualizată în fiecare secundă.
- Vizualizările de valori V$ prezintă date de valori pentru a urmări performanța sistemului. Lista vizualizărilor de valori poate fi vizualizată accesând vizualizarea V$METRICGROUP.
- Vizualizările DBA_HIST conțin date istorice stocate în baza de date. Acest grup de vizualizări include:
- DBA_HIST_ACTIVE_SESS_HISTORY conţine conţinutul istoricului selectat din memorie sesiune activă de activitatea recentă a sistemului
- DBA_HIST_BASELINE conține informații despre liniile de referință stocate în baza de date.
- DBA_HIST_DATABASE_INSTANCE conține informații despre mediul bazei de date
- DBA_HIST_SNAPSHOT conține informații despre instantaneele stocate în sistem
- DBA_HIST_SQL_PLAN conţine informaţii despre planurile de execuţie
- DBA_HIST_WR_CONTROL conține informații despre setările AWR

Generarea de rapoarte pentru un anumeSQLdin depozitul AWR

Monitorizare SQL

Instrument Monitorizare SQL disponibil implicit atunci când opțiunea STATISTICS_LEVEL setat la valoare TIPIC sau TOATE. Pentru a folosi a acestui instrument trebuie să setați și valoarea parametrului CONTROL_MANAGEMENT_PACK_ACCESSîn sens DIAGNOSTIC+TUNING pentru a activa pachetul de diagnosticare și configurare.
În mod implicit, monitorizarea SQL este activată automat atunci când o instrucțiune SQL este executată în paralel sau când consumă mai mult de cinci secunde de timp CPU sau I/O în timpul unei singure execuții.
Există două sugestii de optimizare pentru a activa sau dezactiva în mod explicit monitorizarea SQL pentru o expresie - MONITORŞi NO_MONITOR.
Puteți urmări statisticile de execuție a instrucțiunilor SQL folosind vizualizări V$SQL_MONITORŞi V$SQL_PLAN_MONITOR.
După activarea SQL Statement Monitoring în Dynamic Performance View V$SQL_MONITOR Adaugă informațiile necesare pentru a urmări valorile cheie de performanță, cum ar fi timpul de execuție, timpul CPU, numărul de citiri și scrieri, latența I/O și alte valori de latență. Această statistică actualizat în timp real în timpul execuției SQL, implicit - la fiecare secundă. După finalizarea execuției, informațiile despre execuție sunt stocate în vizualizare V$SQL_MONITORîncă un minut, după care se scoate.
Exemplu de raport de monitorizare SQL

ÎN în acest exemplu Se presupune că selectați date din tabelul VÂNZĂRI și rulați Monitorizarea SQL într-o altă sesiune.
Funcția DBMS_SQLTUNE.REPORT_SQL_MONITOR poate accepta mai mulți parametri care limitează sau extind nivelul de detaliu al raportului, folosind parametri suplimentari se poate specifica și formatul de ieșire al raportului (TEXT, HTML sau XML), implicit raportul este generat în text format.
Pentru a identifica în mod unic două execuții ale aceleiași instrucțiuni SQL, este generată o cheie compusă numită cheie de execuție. Această cheie constă din trei atribute, fiecare dintre ele se referă la o coloană în V$SQL_MONITOR:
- SQL_ID
- Un identificator generat intern pentru a se asigura că o anumită cheie primară este de fapt unică (SQL_EXEC_ID)
- Timpul de începere a execuției expresiei (SQL_EXEC_START)
Interpretarea planului de execuție

Concluzie EXPLICAȚI PLANUL este prezentare tabelară structura arborescentă a planului de execuție. Fiecare pas (o linie dintr-un plan de execuție sau un nod dintr-un arbore) reprezintă o sursă de rând.
Ordinea nodurilor sub părinte arată ordinea de execuție a nodurilor la acel nivel. Dacă doi pași sunt la același nivel, primul în ordine va fi executat primul.
Într-un format arbore, frunzele din stânga la fiecare nivel al arborelui identifică punctul în care începe execuția.
Etapele planului de execuție nu sunt executate în ordinea în care sunt numerotate. Există o relație părinte-copil între pași.
În PLAN_TABLE și V$SQL_PLAN, coloanele ID, PARENT_ID și POSITION sunt elemente importante pentru obținerea unei structuri arborescente. În fișierul de urmărire, aceste coloane corespund câmpurilor id, pid și, respectiv, pos.
O modalitate de a citi un plan de execuție este de a-l converti într-un grafic care are o structură arborescentă. Puteți începe din partea de sus, intrarea cu ID=1 este punctul de sus al arborelui. Acest lucru este valabil pentru operațiunile care au o valoare parrent_id sau pid de 1.
Pentru a reprezenta planul ca arbore, procedați în felul următor:
- Luați actul de identitate cu cel mai mult valoare scăzutăși puneți-l în vârful copacului.
- Identificați rândurile care au PID (id-ul părinte) egal cu această valoare.
- Plasați-le în arborele de sub intrarea părinte în funcție de valorile lor POS, de la cel mai mic la cel mai mare de la stânga la dreapta.
- Odată ce toate ID-urile părintelui au fost găsite, treceți la un nivel în jos la următorul ID și repetați procesul, găsind noi rânduri cu același PID.
Metodă standard de interpretare a unui plan de execuție:
- Începeți de sus
- Deplasați operațiunile în jos până ajungeți la cea care produce date, dar nu consumă nimic. Acesta este începutul operațiunii.
- Uită-te la operațiile copilului pe care le are acest părinte. Operațiile copilului se vor efectua după cum urmează
- Deplasați-vă în arbore până când toate tranzacțiile au fost revizuite.
Metoda standard de interpretare a arborelui planului de execuție este:
- Începeți de sus
- Deplasați-vă în jos și la stânga de-a lungul copacului până ajungeți la nodul din stânga, acesta este executat mai întâi
- Uită-te la copiii acestui nod. aceşti copii vor fi executaţi în continuare.
- După ce copiii sunt executați, operația de părinte va continua să se execute.
- Acum, după ce această operațiune și toți descendenții ei sunt finalizate, deplasați-vă în arbore și priviți descendenții seriei originale de operațiuni și părinții săi. Se desfășoară după același principiu.
- Navigați în sus în arbore până când toate tranzacțiile au fost revizuite
Interpretarea planului de execuție: Exemplul 1

Figura de mai sus arată interpretarea planului de execuție pentru expresie. Interogarea prezentată în figură încearcă să găsească angajați ale căror salarii sunt diferite de grila de salarii. Interogarea selectează date din două tabele și include o subinterogare bazată pe o selecție dintr-un alt tabel pentru a verifica nivelurile salariale.
Să ne uităm la ordinea de executare a acestei cereri. Pe baza acestei cifre și a cifrei anterioare, ordinea de execuție va fi următoarea: 3-5-4-2-6-1:
- 3: execuția planului va începe cu o scanare completă a tabelului EMP (ID=3)
- 5: rândurile sunt trecute la pasul care controlează bucla imbricată (ID=2), care le folosește pentru a căuta rândurile în indexul PK_DEPT (ID=5)
- 4: ROWID-urile rândurilor obținute după scanarea PK_DEPT sunt folosite pentru a obține restul informațiilor din tabelul DEPT (ID=4)
- 2: ID=2, procesul de îmbinare a buclei imbricate va continua până când este finalizat
- 6: După ce ID=2 a procesat toate rândurile sursă pentru unire, va fi efectuată o scanare completă a tabelului SALGRADE (ID=6).
- 1: Datele primite după executarea ID=6 vor fi folosite pentru a filtra rândurile din ID=2 și ID=6
Interpretarea planului de execuție: Exemplul 2

Această interogare returnează numele, numele departamentelor și adresele angajaților ale căror departamente sunt situate în Seattle și care au un manager.
Pentru ușurința formatării, a fost adăugată o altă numerotare figurii. Coloana din stânga reprezintă ID-ul, iar coloana din dreapta reprezintă PID-ul. Planul de execuție a interogării arată două operațiuni NESTED LOOP JOIN. Interpretăm planul de execuție după metoda prezentată mai sus:
- Să începem de sus. ID=0
- Coboram operatiunile pana ajungem la cea care produce date dar nu consuma nimic. ÎN în acest caz,,ID 0,1,2 și 3 consumă date. ID=4 este prima operațiune de sus care nu consumă resurse, ci produce date. Aceasta este prima sursă de date. INDEX RANGE SCAN va returna ROWID-ul de rânduri care va fi folosit pentru a returna date din tabelul LOCATIONS (ID=3)
- Să ne uităm la frații acestei surse de rând care sunt la același nivel cu ea în arbore. Frații și surorile de la același nivel au ID=3 și ID=5. ID = 5 are un copil - ID = 6, care va fi executat înaintea acestuia. Aceasta este o operațiune INDEX RANGE SCAN pe alt index, returnând un ROWID care va fi folosit ulterior pentru a prelua date din tabelul DEPARTMENTS în timpul execuției ID=5.
- După ce se execută o operație copil, controlul este transferat strămoșului său. Următoarea operațiune va fi NESTED LOOPS cu ID=2 pentru a combina datele primite anterior.
- Acum că operațiunea părinte și toți descendenții ei au fost finalizate, urcăm în copac și vedem dacă operațiunea părinte are frați și surori care sunt la același nivel cu ea. ID=2 este la același nivel cu operația ID=7, care are un ID de copil=8. Acest copil va fi executat primul. Se va executa un INDEX UNIQUE SCAN pentru a obține ROWID-urile rândurilor, care vor fi apoi folosite pentru a prelua date din tabelul EMPLOYEES în operațiunea ID=7.
- trecem la un nivel superior după ce au fost procesate toate operațiunile de la nivelul actual și descendenții acestora. Ultima operațiune care va fi efectuată va fi îmbinarea NESTED LOOPS cu ID=1, după care rezultatul va fi transmis ID=0.
- Ordinea operației este următoarea: 4-3-6-5-2-8-7-1-0
Mai jos este descriere detaliată plan de executie:
Mai întâi, o buclă imbricată interioară este executată folosind LOCAȚII ca tabel principal, folosind accesul la index pe coloana CITY. Operațiunea funcționează pentru că căutați doar departamente în Seattle.
Rezultatul este alăturat tabelului DEPARTMENTS folosind indexul din coloana LOCATION_ID pentru unire. Rezultatul primei operații de îmbinare este sursa de date principală pentru a doua buclă imbricată.
A doua operație de îmbinare examinează indexul de pe coloana EMPLOYEE_ID a tabelului EMPLOYEES. Această operațiune poate fi efectuată deoarece sistemul cunoaște (de la prima operațiune de conectare) ID-urile tuturor managerilor de departament din Seattle. În acest caz, UNIQUE SCAN este efectuată deoarece scanarea este efectuată pe indexul cheii primare.
Ordinea de executare este următoarea: 3-5-6-4-2-1
Ordinea de îmbinare: T1-T2-T3
Citeşte mai mult planuri cuprinzătoare execuţie

Planul prezentat în figura din stânga este construit dintr-o interogare din dicționarul de date. Este foarte lung, deci este foarte dificil să aplici metodele anterioare de interpretare pentru a găsi prima operație.
Puteți scurta conturul pentru a-l face mai lizibil. Figura din dreapta arată același plan de execuție, doar scurtat. După cum se arată în figură, acest lucru este ușor de realizat Ajutor pentru întreprinderi manager sau SQL*Developer. După cum se poate observa în figură, planul include operațiunea de comasare a două ramuri. Cunoașterea dicționarului de date ne permite să înțelegem că cele două ramuri corespund tablespace-urilor gestionate de dicționar și administrate local. Cunoștințele despre baza de date vă permit să înțelegeți că baza de date nu are spații de tabel gestionate de dicționar. În acest fel, dacă există o problemă, este în a doua ramură. Pentru a vă confirma ipotezele, trebuie să vă uitați la informațiile planului și la statisticile de execuție ale fiecărei surse de rând pentru a determina partea din plan care consumă cele mai multe resurse. Apoi trebuie să extindeți ramura în care se găsesc probleme. Pentru a folosi această metodă trebuie să utilizați suplimentar statisticile de execuție, care pot fi găsite în vizualizarea V$SQL_PLAN_STATISTICS sau în raportul tkprof generat din fișierul de urmărire. De exemplu, tkprof însumează timpul necesar fiecărei operațiuni părinte pentru a se executa plus timpul de execuție al tuturor operațiunilor copil.
Prezentare generală a planului de execuție
Când configurați o expresie SQL într-un mediu OLTP, scopul este să începeți cu tabelul care are aplicat cel mai mare filtru de selectivitate. Aceasta înseamnă că mai puține rânduri vor fi transmise la următoarea operație. Dacă următorul pas este o îmbinare, înseamnă că vor fi unite mai puține rânduri. De asemenea, trebuie să vă asigurați că căile de acces la date sunt optime. Pe măsură ce examinați planul de execuție, rețineți următoarele:
- Planul este conceput în așa fel încât cel mai bun filtru aplicat la masa de conducere
- Ordinea de alăturare este concepută astfel încât cel mai mic număr de rânduri să fie trecut la pasul următor (adică, ordinea de alăturare ar trebui să meargă la cele mai bune filtre neutilizate încă)
- Metoda join se potrivește cu numărul de rânduri care îi sunt transmise pentru a se alătura. De exemplu, o îmbinare NESTED LOOP folosind un index poate să nu fie optimă atunci când sunt returnate multe rânduri.
- Vizualizările sunt folosite eficient. Uită-te la SELECTează lista pentru a determina unde trebuie accesată vizualizarea.
- Nu există operații cu produse carteziene ale tabelelor (chiar și cu mese mici).
- Fiecare tabel este citit eficient: luați în considerare predicatele expresiilor SQL în raport cu numărul de rânduri din tabel. Priviți operațiunile suspecte în detaliu, de exemplu scanarea completă a tabelelor pentru tabele cu un număr mareșiruri care sunt prezente în predicat.
Scanările de tabel complet pot fi utilizate eficient pentru mese mici sau pentru aplicații tip specificîmbinări (de ex. HASH JOIN) pentru rândurile returnate.
Dacă oricare dintre condițiile de mai sus nu este optimă, va trebui să rescrieți SQL-ul sau să revizuiți indecșii disponibili pe tabel.
Planul de execuție în sine nu poate oferi informații despre eficiența execuției interogărilor. De exemplu, rezultatul EXPLAIN PLAN poate arăta utilizarea indexului, dar aceasta nu înseamnă că expresia este eficientă. Uneori, folosirea unui index poate fi foarte ineficientă.
Pentru a determina planul optim de execuție, trebuie să obțineți un plan inițial, apoi să îl optimizați pentru o execuție mai optimă prin testare. În timp ce schimbați planul de execuție, trebuie să monitorizați consumul de resurse de sistem.
Permiteți-mi să clarific imediat că voi descrie folosind exemplul de utilizare a utilitarului gratuit OraDeveloper Studio. De ce? Pentru că nu a fost posibil să faceți acest lucru cu interogări obișnuite și nu a existat timp sau dorință de a-l afla, deoarece există o modalitate mai ușoară. 😉
Deci, pentru ce este asta? Îți voi descrie exemplu concret, din cauza căruia am fost nevoit să efectuez optimizarea.
Sarcina este de a încărca zeci de mii de rânduri de date în baza de date. Pentru fiecare rând, trebuie mai întâi să găsiți date suplimentare în baza de date cu o interogare destul de greoaie (4 tabele prin îmbinări).
Problema este că încărcarea a 15 mii de rânduri durează 8-9 ore. Deoarece, conform termenilor sarcinii, este necesar să o încărcăm des, și nu o dată la cinci ani... În general, trebuie să aducem timpul la un nivel acceptabil.
ce am facut?
1. Am aflat ca este selectul cel care incetineste (datele sunt inserate si actualizate in tabele unde sunt o gramada de randuri iar unele dintre tabele nu au nici indecsi, nici chei - de aici si indoielile legate de vina selectului) .
2. Verificarea prezenței indicilor pe câmpurile utilizate de cerere. Au adăugat cele lipsă.
3. A cerut ajutor celor care au știut. 🙂
Cei cunoscători ne-au sfătuit să analizăm planul de execuție a interogărilor și ne-au explicat cum să facem acest lucru în OraDev.
Creați o nouă fereastră de interogare (Ctrl+N). Copiem cererea noastră în ea. Apăsați Alt+G. Selectați unul existent sau creați un nou tabel de plan.
După execuție, va apărea arborele planului de execuție. Nu este atât de ușor să-ți dai seama singur și fără jumătate de litru. 😉
Ce ne interesează la acest copac? Suntem interesați de noduri (pași) pentru care este indicat un Cost mare al pasului. Puteți vedea prețul pasului în proprietățile pasului (am fereastra de proprietăți mereu deschisă și, prin urmare, trebuie doar să selectez pasul potrivit; poate fi necesar să selectați proprietăți făcând clic dreapta pe pas). Căutăm pasul lent (nu luăm în considerare nodul cel mai de sus, rădăcina arborelui plan - prețul total al cererii va fi indicat acolo și știm deja că problema este în această solicitare). L-ai găsit? Acum ne uităm la ce tabel, cu ce câmpuri și cu câte rânduri funcționează pasul - acesta este în proprietățile și numele pasului. Ne uităm și ne gândim, de ce este atât de lent aici?
De exemplu, unul dintre pași a funcționat cu 4000 de înregistrări în loc de una sau trei înregistrări (nu cu mii). Acest lucru nu ar fi trebuit să se întâmple în principiu - limitez eșantionul tocmai pentru a alege din intervalul necesar, și nu dintr-o grămadă de gunoi inutile. Privind cu atenție condiția de alăturare, am observat că ratasem unul dintre câmpuri. Am adăugat un câmp la cerere și totul a căzut la loc. Prețul solicitat (plin) a scăzut de la 531 la 6. :)
Mulțumesc camarazilor cuibăresc și detectează pentru ajutorul lor.
P.S. Ne pare rău că nu am inclus capturi de ecran. Cu ei ar fi mult mai clar, dar... Din cauza confidențialității unor informații, 80% ar trebui să fie trecute peste cap și apoi din nou ar fi neclar.
P.P.S. Timpul total de încărcare a fost redus semnificativ. A durat 12 minute pentru a încărca 17,5 mii de rânduri de date în baza de date. Față de 8-9 ore... Ei bine, deja ai înțeles totul singur. 😉