Scopul limbajului SQL. Operatori de manipulare a datelor. Structura comenzilor SQL
SQL este un limbaj de interogare structurat. SQL nu există fără baze de date – nu poți scrie programe în el, iar în acest sens nu este un limbaj de programare precum PHP, dar atunci când ai de-a face cu un anumit SGBD, nu te mai poți descurca fără cunoștințe de SQL. Puteți scrie interogări simple pe el sau puteți efectua tranzacții mari constând din mai multe interogări complexe. O interogare SQL este un fel de comandă către o bază de date. O astfel de comandă poate solicita returnarea informațiilor care îndeplinesc anumite criterii sau poate oferi instrucțiuni de ștergere a oricăror înregistrări etc. O comandă SQL este un șir simplu, de exemplu:
SELECTAȚI * DIN departamentul Staff WHERE
Interogările SQL sunt de obicei aproape de o expresie simplă în limba engleză. Comanda de mai sus poate fi tradusă în rusă după cum urmează
SELECTAȚI TOTUL DIN Staff WHERE clwjiertme"
Este o comandă complet de înțeles, este doar păcat că este scrisă exclusiv în engleză. Ca rezultat al executării unei astfel de interogări, DBMS va returna toate înregistrările din tabelul Staff în care câmpul depart* Mit_id este egal cu trei. În exemplul nostru, această interogare selectează de fapt numai programatori din întreaga bază de angajați.
Dacă nu ați mai lucrat cu un SGBD, atunci este posibil să aveți o întrebare rezonabilă: unde și cum puteți executa această interogare? Există trei moduri de a executa interogări SQL.
1. Mediu interactiv pentru interacțiunea cu SGBD. Pentru majoritatea serverelor DBMS, există programe client (încorporate sau furnizate de terți), în mediul de lucru al cărora puteți scrie interogări SQL, le puteți executa și obține rezultatul. De obicei, astfel de instrumente sunt folosite de administratorii bazelor de date și nu au legătură directă cu programarea PHP. Un exemplu de program client pentru lucrul cu MySQL este programul MySQL Administrator (http: /www.mysgl.coin/product-s/administratoT/) sau foarte popularul sistem PHP phpMyAdmin (http: / /www. phpmyadi'ln. r»et /itummjiage/index.php). Pentru a începe, va fi suficient un kit de distribuție deja instalat, care are o interfață de consolă. Pe Linux, trebuie să tastați comanda mysql din linia de comandă pentru a deschide o fereastră care vă solicită să introduceți interogări SQL, iar pe Windows, pentru a lansa aceeași interfață, trebuie să rulați fișierul mysql. exe din directorul bin.
2. Interogări SQL statice. De obicei, astfel de interogări sunt scrise în cadrul procedurilor stocate în bazele de date în sine sau codificate în aplicațiile în sine. O interogare SQL statică este predefinită și se modifică numai dacă programul sau codul procedurii stocate este rescris manual. Din PHP, o astfel de interogare SQL este executată folosind funcții speciale, despre care vor fi discutate mai târziu.
3. Interogări SQL dinamice. Acest tip include interogări care nu pot fi complet definite la scrierea unei aplicații. i" exemplu, atunci când scrie un program pentru a obține o listă de angajați" mt diferite divizii ale întreprinderii, programatorul nu știe, ci "> despre diviziile din companie și care angajați vor fi incluși în ele i„. Desigur , aceste date pot fi scrise strict în program, dar atunci când Prima modificare a structurii companiei, programul poate fi aruncat sau va trebui rescris. Interogările dinamice vă permit să creați programe de program care sunt flexibile la schimbările în date.În PHP, astfel de interogări sunt efectuate cu aproape aceleași funcții ca și cele statice, doar că în ele există mai mult '^v'> Nu este posibil să treci unii parametri.
Ca un rezumat al celor trei puncte descrise mai sus, putem spune că interogările SQL sunt executate din programe administrative speciale sau în diverse moduri din scripturi PHP.
Deoarece un SGBD rezolvă multe probleme, SQL este, de asemenea, forțat să fie un limbaj multifuncțional. Există mai multe tipuri de operații care pot fi< \ ществлять с помощью SQL.
1. Definirea structurii bazei de date. Acest tip include interogări care creează și modifică tabele și indecși. Acestea sunt de obicei comenzi CRE; „E TA’ LE, ALI’R TA’ LE, ‘ ” ’.TE INDEX Etc.
2. Manipularea datelor. Acest tip include interogări de inserare (mutare), ștergere sau modificare a datelor din tabele. Acestea sunt cele trei comenzi principale: INSERT. ȘTERGEȚI ȘI ACTUALIZAȚI.
3. Selectarea datelor Aceasta include o singură comandă SELECT. Nu aduce modificări datelor în sine, dar vă permite să le preluați din baza de date. Chiar dacă o singură comandă este folosită pentru a prelua date, este foarte puternică și este folosită foarte des în aplicații.
4. Managementul serverului DBMS. Acest tip include în principal interogări pentru a gestiona utilizatorii și drepturile lor de acces (de exemplu, comanda GRANT).
Cunoașterea bună a SQL facilitează foarte mult munca unui programator atunci când lucrează cu o bază de date. Aplicațiile pot fi mici, dar au funcționalități grozave doar datorită faptului că SQL preia multe sarcini.
Ca în orice altă zonă a IT, există standarde în SQL - acestea sunt ANSI SQL. Abrevierea ANSI înseamnă Institutul Național de Standarde din America. Cu toate acestea, nu în ultimul rând din cauza diferențelor de funcționalitate ale SGBD-urilor SQL în sine pentru diferite
SGBD-urile sunt încă diferite unele de altele. În prezent, aproape fiecare DBMS are propriul său dialect, care de obicei nu diferă mult de standardul general, dar are propriile sale caracteristici. De exemplu, limbajul PL/SQL este compatibil cu Oracle și PostgreSQL, iar T-SQL este folosit pentru a lucra cu MS SQL Server.
Pentru munca ulterioară cu bazele de date, vă recomandăm să studiați imediat standardul cu care intenționați să lucrați în viitor. Pentru majoritatea dezvoltatorilor Web în acest moment, funcționalitatea SGBD-ului MySQL este suficientă (și poate fi folosită gratuit), așa că în această carte toate exemplele cu MySQL vor fi date, în consecință, în dialectul acestui SGBD. Documentația despre limbajul de interogare pentru MySQL poate fi găsită la www.mysql.com.
PHP și baze de date
Capacitatea de a stoca și de a prelua eficient cantități mari de informații a adus o contribuție uriașă la dezvoltarea cu succes a Internetului. De obicei, bazele de date sunt folosite pentru a stoca informații. Funcționarea site-urilor cunoscute precum Yahoo, Amazon și Ebay depinde în mare măsură de fiabilitatea bazelor de date care stochează cantități enorme de informații. Desigur, suportul pentru baze de date nu este doar în beneficiul corporațiilor gigantice – programatorii web au la dispoziție câteva implementări puternice de baze de date, distribuite la un cost relativ scăzut (sau chiar gratuit).
Organizarea corectă a bazei de date oferă capabilități de recuperare a datelor mai rapide și mai flexibile. Simplifică foarte mult implementarea instrumentelor de căutare și sortare, iar problemele privind drepturile de acces la informații sunt rezolvate folosind controalele de privilegii găsite în multe sisteme de gestionare a bazelor de date (DBMS). În plus, procesele de replicare și arhivare a datelor sunt simplificate.
Capitolul începe cu o descriere detaliată a recuperării și actualizării datelor în MySQL, probabil cel mai popular DBMS folosit în PHP (http://www.mysql.com). Folosind MySQL ca exemplu, vom arăta cum datele din baza de date sunt încărcate și actualizate în PHP; Vom analiza instrumentele de bază de căutare și sortare utilizate în multe aplicații web. Vom trece apoi la suportul PHP pentru ODBC (Open Data Base Connectivity), o interfață generică care poate fi folosită pentru a se conecta la diferite SGBD-uri în același timp. Suportul ODBC în PHP va fi demonstrat prin conectarea și preluarea datelor dintr-o bază de date Microsoft Access. Capitolul se încheie cu un proiect care folosește PHP și MySQL pentru a crea un director ierarhic care conține informații despre site-urile preferate. Când site-uri noi sunt incluse în catalog, utilizatorul le atribuie uneia dintre categoriile standard definite de administratorul site-ului.
Înainte de a discuta despre MySQL, vreau să spun câteva cuvinte despre SQL, cel mai comun limbaj pentru lucrul cu baze de date. Limbajul SQL este baza aproape a tuturor SGBD-urilor existente. Pentru a continua să priviți exemple de lucru cu baze de date, trebuie să aveți cel puțin o înțelegere generală a modului în care funcționează SQL.
SQL este în general descris ca limbajul standard folosit pentru a interacționa cu bazele de date relaționale (vezi mai jos). Cu toate acestea, SQL nu este un limbaj de programare precum C, C++ sau PHP. Mai degrabă, este un instrument de interfață pentru efectuarea diferitelor operațiuni de bază de date, oferind utilizatorului un set standard de comenzi. Capacitățile SQL nu se limitează la preluarea datelor dintr-o bază de date. SQL acceptă o varietate de opțiuni pentru interacțiunea cu o bază de date, inclusiv:
- definirea structurii datelor-- definirea structurilor utilizate la stocarea datelor;
- eșantionarea datelor-- încărcarea datelor din baza de date și prezentarea acestora într-un format convenabil pentru ieșire;
- procesarea datelor-- inserarea, actualizarea și ștergerea informațiilor;
- controlul accesului-- capacitatea de a permite/interzice eșantionarea, inserarea, actualizarea și ștergerea datelor la nivelul utilizatorilor individuali;
- controlul integrității datelor-- Păstrarea structurii datelor în cazul unor probleme precum actualizări paralele sau defecțiuni ale sistemului.
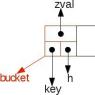
Vă rugăm să rețineți că definiția SQL a declarat că acest limbaj este destinat să funcționeze relaționale baze de date. În SGBD-urile relaționale, datele sunt organizate ca un set de tabele interconectate. Relațiile dintre tabele sunt implementate sub formă de legături către date din alte tabele. Masa poate fi gândit ca o matrice bidimensională în care locația fiecărui element este caracterizată de valori specifice de rând și coloană. Un exemplu de bază de date relațională este prezentat în Fig. 11.1.
Orez. 11.1.Exemplu de bază de date relațională
După cum se poate observa din fig. 11.1, fiecare tabel este format din rânduri (înregistrări) și coloane (câmpuri). Fiecărui câmp i se atribuie un nume unic (în cadrul tabelului). Observați relația dintre tabelele client și comenzi, indicată de o săgeată. Un scurt identificator de client este inclus în informațiile despre comandă, ceea ce evită stocarea redundantă a numelui clientului și a altor detalii. Mai există o relație în baza de date prezentată - între tabelele comenzi și produse. Această conexiune se stabilește folosind câmpul prod_id, care stochează identificatorul produsului comandat de acest client (definit de câmpul custjd). Având aceste conexiuni, este ușor să faceți referire la date complete despre clienți și produse folosind identificatori simpli. O bază de date bine organizată devine un instrument puternic pentru organizarea și stocarea eficientă a datelor cu redundanță minimă. Amintiți-vă această bază de date, mă voi referi la ea des în exemple suplimentare.
Deci, cum sunt efectuate operațiunile de baze de date relaționale? Pentru a face acest lucru, SQL are un set special de comenzi generale - cum ar fi SELECT, INSERT, UPDATE și DELETE. De exemplu, dacă trebuie să obțineți adresa de e-mail a unui client cu ID 2001cu (vezi Figura 11.1), trebuie doar să rulați următoarea comandă SQL:
SELECTAȚI cust_email FROM clienții WHERE custjd = "2001cu"
Totul este destul de logic, nu-i așa? În rezumat, comanda arată astfel:
SELECTAȚI nume_câmp FROM nume_tabel [condiția WHERE]
Parantezele pătrate indică faptul că partea finală a comenzii este opțională. De exemplu, pentru a obține adresele de e-mail ale tuturor clienților din tabelul clienți, trebuie doar să rulați următoarea interogare:
SELECTează cust_email FROM clienți
Să presupunem că doriți să adăugați o nouă intrare la tabelul cu produse. Cea mai simplă comandă de inserare arată astfel:
INSERT în produse VALORI ("1009pr", "Roșii roșii", "1.43");
Dacă mai târziu trebuie să ștergeți aceste date, utilizați următoarea comandă:
DELETE FROM produsele WHERE prod_id = 1009r";
Există multe tipuri de comenzi SQL și o descriere completă a acestora depășește scopul acestei cărți. O carte separată ar putea fi scrisă cu ușurință pe această temă! Am încercat să păstrez comenzile SQL folosite în exemple relativ simple, dar suficient de realiste. Există o mulțime de informații și resurse de instruire SQL pe Web. Unele link-uri sunt furnizate la sfârșitul acestei secțiuni.
Nu este necesar să scrieți comenzile SQL cu caractere mari. Cu toate acestea, prefer această notație deoarece ajută la distingerea componentelor cererii.
Din moment ce citiți această carte, probabil vă întrebați cum să lucrați cu baze de date pe Web? De regulă, mai întâi, folosind unele
sau un limbaj de interfață (PHP, Java sau Perl), se creează o conexiune la baza de date, după care programul accesează baza de date cu interogări folosind un set standard de instrumente. Un limbaj de interfață poate fi gândit ca un fel de „clei” care leagă baza de date de Web. Mă îndrept către limbajul meu favorit pentru front-end - PHP.
Leran2002 9 aprilie 2015 la 12:31
Un manual despre limbajul SQL (DDL, DML) folosind dialectul MS SQL Server ca exemplu. Prima parte
- Microsoft SQL Server,
- SQL
- Tutorial
Despre ce este acest tutorial?
Acest tutorial este ceva ca o „ștampilă a memoriei mele” în limbajul SQL (DDL, DML), adică. Acestea sunt informații care s-au acumulat pe parcursul activităților mele profesionale și sunt stocate constant în capul meu. Acesta este un minim suficient pentru mine, care este folosit cel mai des atunci când lucrez cu baze de date. Dacă este nevoie să utilizez constructe SQL mai complete, de obicei apelez la biblioteca MSDN aflată pe Internet pentru ajutor. După părerea mea, este foarte greu să ții totul în cap și nu este nevoie în mod special de acest lucru. Dar cunoașterea structurilor de bază este foarte utilă, pentru că... sunt aplicabile aproape în aceeași formă în multe baze de date relaționale, cum ar fi Oracle, MySQL, Firebird. Diferențele sunt în principal în tipurile de date, care pot diferi în detaliu. Nu există multe construcții SQL de bază și, cu o practică constantă, acestea sunt memorate rapid. De exemplu, pentru a crea obiecte (tabele, constrângeri, indexuri etc.), este suficient să aveți la îndemână un mediu de editor de text (IDE) pentru a lucra cu baza de date și nu este nevoie să studiați instrumente vizuale adaptate pentru lucrul cu un anumit tip de bază de date (MS SQL, Oracle, MySQL, Firebird, ...). Acest lucru este, de asemenea, convenabil, deoarece tot textul este în fața ochilor și nu trebuie să parcurgeți numeroase file pentru a crea, de exemplu, un index sau o constrângere. Când lucrați în mod constant cu o bază de date, crearea, modificarea și mai ales re-crearea unui obiect folosind scripturi este de multe ori mai rapidă decât dacă o faceți în modul vizual. Tot în modul script (și, în consecință, cu atenția cuvenită), este mai ușor să stabiliți și să controlați regulile de denumire a obiectelor (parerea mea subiectivă). În plus, scripturile sunt convenabile de utilizat atunci când modificările făcute într-o bază de date (de exemplu, test) trebuie transferate în aceeași formă într-o altă bază de date (productivă).Limbajul SQL este împărțit în mai multe părți, aici mă voi uita la cele mai importante 2 părți:
- DML – Limbajul de manipulare a datelor, care conține următoarele constructe:
- SELECT – selectarea datelor
- INSERT – introducerea de date noi
- UPDATE – actualizare de date
- DELETE – ștergerea datelor
- MERGE – fuziunea datelor
Acest manual a fost creat conform principiului Step by Step, adică. trebuie să-l citiți secvențial și, de preferință, să urmați imediat exemplele. Dar dacă pe parcurs trebuie să aflați mai detaliat despre o anumită comandă, atunci utilizați o căutare specifică pe Internet, de exemplu, în biblioteca MSDN.
Când am scris acest tutorial, am folosit baza de date MS SQL Server versiunea 2014 și am folosit MS SQL Server Management Studio (SSMS) pentru a executa scripturile.
Pe scurt despre MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) este un utilitar pentru Microsoft SQL Server pentru configurarea, gestionarea și administrarea componentelor bazei de date. Acest utilitar conține un editor de scripturi (pe care îl vom folosi în principal) și un program grafic care funcționează cu obiectele și setările serverului. Instrumentul principal al SQL Server Management Studio este Object Explorer, care permite utilizatorului să vizualizeze, să preia și să gestioneze obiectele serverului. Acest text este împrumutat parțial de la Wikipedia.
Pentru a crea un nou editor de scripturi, utilizați butonul „Interogare nouă”:
Pentru a schimba baza de date curentă, puteți utiliza lista derulantă:

Pentru a executa o anumită comandă (sau un grup de comenzi), selectați-o și apăsați butonul „Execute” sau tasta „F5”. Dacă în editor există o singură comandă în prezent sau trebuie să executați toate comenzile, atunci nu trebuie să selectați nimic.

După rularea scripturilor, în special a celor care creează obiecte (tabele, coloane, indexuri), pentru a vedea modificările, utilizați reîmprospătarea din meniul contextual prin evidențierea grupului corespunzător (de exemplu, Tabele), tabelul în sine sau grupul Coloane din acesta.

De fapt, asta este tot ce trebuie să știm pentru a completa exemplele date aici. Restul utilitarului SSMS este ușor de învățat pe cont propriu.
Puțină teorie
O bază de date relațională (RDB, sau în continuare în context pur și simplu DB) este o colecție de tabele interconectate. În linii mari, o bază de date este un fișier în care datele sunt stocate într-o formă structurată.DBMS – Sistem de management al bazelor de date, de ex. acesta este un set de instrumente pentru lucrul cu un anumit tip de bază de date (MS SQL, Oracle, MySQL, Firebird, ...).
Notă
Deoarece în viață, în vorbirea colocvială, spunem mai ales: „Oracle DB”, sau chiar doar „Oracle”, adică de fapt „Oracle DBMS”, apoi în contextul acestui manual se va folosi uneori termenul DB. Din context, cred că va fi clar despre ce vorbim exact.
Un tabel este o colecție de coloane. Coloanele pot fi numite și câmpuri sau coloane; toate aceste cuvinte vor fi folosite ca sinonime care exprimă același lucru.
Tabelul este obiectul principal al RDB; toate datele RDB sunt stocate rând cu rând în coloanele tabelului. Liniile și înregistrările sunt, de asemenea, sinonime.
Pentru fiecare tabel, precum și coloanele sale, sunt specificate nume prin care acestea sunt accesate ulterior.
Numele obiectului (numele tabelului, numele coloanei, numele indexului etc.) în MS SQL poate avea o lungime maximă de 128 de caractere.
Pentru trimitere– în baza de date ORACLE, numele obiectelor pot avea o lungime maximă de 30 de caractere. Prin urmare, pentru o anumită bază de date, trebuie să vă dezvoltați propriile reguli de denumire a obiectelor pentru a îndeplini limita numărului de caractere.
SQL este un limbaj care vă permite să interogați o bază de date folosind un SGBD. Într-un anumit SGBD, limbajul SQL poate avea o implementare specifică (propul său dialect).
DDL și DML sunt un subset al limbajului SQL:
- Limbajul DDL este folosit pentru a crea și modifica structura bazei de date, de ex. pentru a crea/modifica/sterge tabele si relatii.
- Limbajul DML vă permite să manipulați datele din tabel, de ex. cu replicile ei. Vă permite să selectați date din tabele, să adăugați date noi în tabele, precum și să actualizați și să ștergeți datele existente.
În SQL, puteți utiliza 2 tipuri de comentarii (pe o singură linie și pe mai multe rânduri):
Comentariu pe un rând
Și
/* comentariu pe mai multe linii */
De fapt, asta va fi suficient pentru teorie.
DDL – Limbajul de definire a datelor
De exemplu, luați în considerare un tabel cu date despre angajați, într-o formă familiară unei persoane care nu este programator:În acest caz, coloanele din tabel au următoarele nume: Număr de personal, Nume complet, Data nașterii, E-mail, Funcție, Departament.
Fiecare dintre aceste coloane poate fi caracterizată prin tipul de date pe care le conține:
- Număr de personal – număr întreg
- Nume complet – șir
- Data nașterii - data
- E-mail – șir
- Poziție - șir
- Departament - linie
Pentru început, va fi suficient să ne amintim doar următoarele tipuri de date de bază utilizate în MS SQL:
| Sens | Notare în MS SQL | Descriere |
|---|---|---|
| Șir de lungime variabilă | varchar(N) Și nvarchar(N) |
Folosind numărul N, putem specifica lungimea maximă posibilă a șirului pentru coloana corespunzătoare. De exemplu, dacă vrem să spunem că valoarea coloanei „Nume” poate conține maximum 30 de caractere, atunci trebuie să setăm tipul acesteia la nvarchar(30). Diferența dintre varchar și nvarchar este că varchar vă permite să stocați șiruri în format ASCII, unde un caracter ocupă 1 octet, iar nvarchar stochează șiruri în format Unicode, unde fiecare caracter ocupă 2 octeți. Tipul varchar ar trebui folosit numai dacă sunteți 100% sigur că acest câmp nu va trebui să stocheze caractere Unicode. De exemplu, varchar poate fi folosit pentru a stoca adrese de e-mail deoarece... de obicei conțin doar caractere ASCII. |
| Snur de lungime fixă | char(N) Și nchar(N) |
Acest tip diferă de un șir de lungime variabilă prin faptul că, dacă lungimea șirului este mai mică de N caractere, atunci este întotdeauna completat în dreapta la o lungime de N cu spații și stocat în baza de date sub această formă, adică. în baza de date ocupă exact N caractere (unde un caracter ocupă 1 octet pentru char și 2 octeți pentru nchar). În practica mea, acest tip este foarte rar folosit, iar dacă este folosit, este folosit în principal în formatul char(1), adică. când un câmp este definit de un singur caracter. |
| Întreg | int | Acest tip ne permite să folosim numai numere întregi în coloană, atât pozitive, cât și negative. Pentru referință (acum acest lucru nu este atât de relevant pentru noi), intervalul de numere pe care le permite tipul int este de la -2.147.483.648 la 2.147.483.647. De obicei, acesta este tipul principal care este utilizat pentru a specifica identificatorii. |
| Număr real sau real | pluti | În termeni simpli, acestea sunt numere care pot conține un punct zecimal (virgulă). |
| Data | Data | Dacă coloana trebuie să stocheze doar Data, care constă din trei componente: Ziua, Luna și Anul. De exemplu, 15.02.2014 (15.02.2014). Acest tip poate fi folosit pentru coloana „Data admiterii”, „Data nașterii”, etc., adică în cazurile în care este important pentru noi să înregistrăm doar data, sau când componenta de timp nu este importantă pentru noi și poate fi aruncată sau dacă nu este cunoscută. |
| Timp | timp | Acest tip poate fi utilizat dacă coloana trebuie să stocheze numai date de timp, de exemplu. Ore, minute, secunde și milisecunde. De exemplu, 17:38:31.3231603 De exemplu, zilnic „Ora de plecare a zborului”. |
| data si ora | datetime | Acest tip vă permite să salvați simultan atât data, cât și ora. De exemplu, 15/02/2014 17:38:31.323 De exemplu, aceasta ar putea fi data și ora unui eveniment. |
| Steag | pic | Acest tip este convenabil de utilizat pentru a stoca valori de forma „Da”/„Nu”, unde „Da” va fi stocat ca 1, iar „Nu” va fi stocat ca 0. |
De asemenea, valoarea câmpului, dacă nu este interzisă, poate să nu fie specificată; în acest scop este folosit cuvântul cheie NULL.
Pentru a rula exemplele, să creăm o bază de date de testare numită Test.
O bază de date simplă (fără a specifica parametri suplimentari) poate fi creată prin rularea următoarei comenzi:
Test CREATE DATABASE
Puteți șterge baza de date cu comanda (ar trebui să fiți foarte atenți cu această comandă):
Testul DROP DATABASE
Pentru a trece la baza noastră de date, puteți rula comanda:
Test de utilizare
Alternativ, selectați baza de date Test din lista derulantă din zona de meniu SSMS. Când lucrez, folosesc adesea această metodă de comutare între baze de date.
Acum în baza noastră de date putem crea un tabel folosind descrierile așa cum sunt, folosind spații și caractere chirilice:
CREATE TABLE [Angajați]([Număr de personal] int, [Nume] nvarchar(30), [Data nașterii] data, nvarchar(30), [Posiție] nvarchar(30), [Departament] nvarchar(30))
În acest caz, va trebui să introducem numele între paranteze drepte […].
Dar în baza de date, pentru o mai mare comoditate, este mai bine să specificați toate numele obiectelor în latină și să nu folosiți spații în nume. În MS SQL, de obicei, în acest caz, fiecare cuvânt începe cu o literă majusculă, de exemplu, pentru câmpul „Personnel Number”, am putea seta numele PersonnelNumber. De asemenea, puteți utiliza numere în nume, de exemplu, PhoneNumber1.
Pe o notă
În unele SGBD, următorul format de denumire „PHONE_NUMBER” poate fi mai preferabil; de exemplu, acest format este adesea folosit în baza de date ORACLE. Desigur, atunci când se specifică un nume de câmp, este de dorit ca acesta să nu coincidă cu cuvintele cheie utilizate în SGBD.
Din acest motiv, puteți uita de sintaxa parantezelor drepte și puteți șterge tabelul [Angajați]:
DROP TABLE [Angajați]
De exemplu, un tabel cu angajați poate fi numit „Angajați”, iar câmpurile sale pot primi următoarele nume:
- ID – Număr de personal (ID de angajat)
- Nume - nume complet
- Ziua de naștere – Data nașterii
- E-mail – E-mail
- Poziție - Poziție
- Departament - Departament
Acum să creăm tabelul nostru:
CREATE TABLE Angajații (ID int, Nume nvarchar(30), Data nașterii, Email nvarchar(30), Poziția nvarchar(30), Departament nvarchar(30))
Pentru a specifica coloanele necesare, puteți utiliza opțiunea NOT NULL.
Pentru un tabel existent, câmpurile pot fi redefinite folosind următoarele comenzi:
Actualizați câmpul ID ALTER TABLE Angajații ALTER COLUMN ID int NOT NULL -- update Nume câmp ALTER TABLE Angajații ALTER COLUMN Nume nvarchar(30) NOT NULL
Pe o notă
Conceptul general al limbajului SQL rămâne același pentru majoritatea SGBD-urilor (cel puțin, asta este ceea ce pot judeca din SGBD-urile cu care am lucrat). Diferențele dintre DDL în diferite SGBD-uri constă în principal în tipurile de date (nu numai numele lor pot diferi aici, ci și detaliile implementării lor), iar specificul implementării limbajului SQL poate diferi, de asemenea, ușor (adică, esența comenzilor este aceeași, dar pot exista mici diferențe în dialect, din păcate, dar nu există un singur standard). După ce stăpânești elementele de bază ale SQL, poți trece cu ușurință de la un SGBD la altul, deoarece... În acest caz, va trebui doar să înțelegeți detaliile implementării comenzilor în noul SGBD, de exemplu. în cele mai multe cazuri, este suficient să desenezi o analogie.Crearea unui tabel CREATE TABLE Angajații (ID int, -- în ORACLE tipul int este echivalentul (învelișului) pentru numărul (38) Nume nvarchar2(30), -- nvarchar2 în ORACLE este echivalent cu nvarchar în MS SQL Data nașterii, e-mail nvarchar2(30) , Poziția nvarchar2(30), Departamentul nvarchar2(30)); -- actualizarea câmpurilor ID și Nume (aici se folosește MODIFY(...) în loc de ALTER COLUMN) ALTER TABLE Angajații MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- adăugarea PK (în acest caz construcția arată la fel ca în MS SQL, va fi afișată mai jos) ALTER TABLE Angajații ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
Pentru ORACLE există diferențe în ceea ce privește implementarea tipului varchar2; codificarea acestuia depinde de setările bazei de date și textul poate fi salvat, de exemplu, în codificare UTF-8. În plus, lungimea câmpului în ORACLE poate fi specificată atât în octeți, cât și în caractere; pentru aceasta se folosesc opțiuni suplimentare BYTE și CHAR, care sunt specificate după lungimea câmpului, de exemplu:NAME varchar2(30 BYTE) -- capacitatea câmpului va fi de 30 de octeți NAME varchar2(30 CHAR) -- capacitatea câmpului va fi de 30 de caractere
Ce opțiune va fi folosită implicit BYTE sau CHAR, în cazul pur și simplu specificării tipului varchar2(30) în ORACLE, depinde de setările bazei de date, iar uneori poate fi setată în setările IDE. În general, uneori te poți încurca cu ușurință, așa că în cazul ORACLE, dacă se folosește tipul varchar2 (și uneori acest lucru este justificat aici, de exemplu, când folosești codificarea UTF-8), prefer să scriu în mod explicit CHAR (deoarece de obicei este mai convenabil să se calculeze lungimea șirului în caractere).
Dar în acest caz, dacă există deja unele date în tabel, atunci pentru executarea cu succes a comenzilor este necesar ca câmpurile ID și Nume să fie completate în toate rândurile tabelului. Să demonstrăm acest lucru cu un exemplu: inserați date în tabel în câmpurile ID, Poziție și Departament; acest lucru se poate face cu următorul script:
INSERT Angajații (ID, Poziție, Departament) VALORI (1000,N"Director",N"Administrație"), (1001,N"Programator",N"IT"), (1002,N"Contabil", N"Contabilitate" ), (1003,N"Programator senior",N"IT")
În acest caz, comanda INSERT va genera și o eroare, deoarece La inserare, nu am specificat valoarea câmpului obligatoriu Nume.
Dacă aveam deja aceste date în tabelul original, atunci comanda „ALTER TABLE Employees ALTER COLUMN ID int NOT NULL” ar fi executată cu succes, iar comanda „ALTER TABLE Employees ALTER COLUMN Name int NOT NULL” ar produce un mesaj de eroare, că câmpul Nume conține valori NULL (nespecificate).
Să adăugăm valori pentru câmpul Nume și să completăm din nou datele:
Opțiunea NOT NULL poate fi folosită și direct atunci când se creează un tabel nou, de exemplu. în contextul comenzii CREATE TABLE.
Mai întâi, ștergeți tabelul folosind comanda:
DROP TABLE Angajații
Acum să creăm un tabel cu coloanele necesare ID și Nume:
CREATE TABLE Angajații (ID int NU NULL, Nume nvarchar(30) NU NULL, Data nașterii, E-mail nvarchar(30), Poziția nvarchar(30), Departament nvarchar(30))
De asemenea, puteți scrie NULL după numele coloanei, ceea ce va însemna că valorile NULL (nespecificate) vor fi permise în ea, dar acest lucru nu este necesar, deoarece această caracteristică este implicită implicită.
Dacă, dimpotrivă, doriți să faceți opțională o coloană existentă, atunci utilizați următoarea sintaxă a comenzii:
ALTER TABLE Angajații ALTER COLUMN Nume nvarchar(30) NULL
Sau pur și simplu:
ALTER TABLE Angajații ALTER COLUMN Nume nvarchar(30)
Cu această comandă putem, de asemenea, să schimbăm tipul câmpului cu un alt tip compatibil, sau să modificăm lungimea acestuia. De exemplu, să extindem câmpul Nume la 50 de caractere:
ALTER TABLE Angajații ALTER COLUMN Nume nvarchar(50)
Cheia principala
La crearea unui tabel, este de dorit ca acesta să aibă o coloană unică sau un set de coloane unic pentru fiecare dintre rândurile sale - o înregistrare poate fi identificată în mod unic prin această valoare unică. Această valoare se numește cheia primară a tabelului. Pentru tabelul nostru de angajați, o astfel de valoare unică ar putea fi coloana ID (care conține „Numărul de personal al angajatului” - chiar dacă în cazul nostru această valoare este unică pentru fiecare angajat și nu poate fi repetată).Puteți crea o cheie primară pentru un tabel existent utilizând comanda:
ALTER TABLE Angajații ADD CONSTRAINT PK_Angajații CHEIE PRIMĂRĂ(ID)
Unde „PK_Angajați” este numele constrângerii responsabile pentru cheia primară. De obicei, cheia primară este numită folosind prefixul „PK_” urmat de numele tabelului.
Dacă cheia primară constă din mai multe câmpuri, atunci aceste câmpuri trebuie listate între paranteze, separate prin virgulă:
ALTER TABLE nume_tabel ADD CONSTRAINT nume_constrângere PRIMARY KEY(câmp1, câmp2,...)
Este de remarcat faptul că în MS SQL, toate câmpurile care sunt incluse în cheia primară trebuie să aibă caracteristica NOT NULL.
Cheia primară poate fi, de asemenea, determinată direct la crearea unui tabel, de ex. în contextul comenzii CREATE TABLE. Să ștergem tabelul:
DROP TABLE Angajații
Și apoi îl vom crea folosind următoarea sintaxă:
CREATE TABLE Angajații(ID int NU NUL, Nume nvarchar(30) NU NULL, data nașterii, e-mail nvarchar(30), Poziția nvarchar(30), Departament nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) -- descrieți PK după toate câmpurile ca o limitare)
După creare, completați tabelul cu date:
INSERT Angajații (ID, Poziție, Departament, Nume) VALORI (1000,N"Director",N"Administrație",N"Ivanov I.I.", (1001,N"Programator",N"IT",N" Petrov P.P." ), (1002,N"Contabil",N"Contabilitate",N"Sidorov S.S.", (1003,N"Programator senior",N"IT",N"Andreev A. A.")
Dacă cheia primară dintr-un tabel constă numai din valorile unei coloane, atunci puteți utiliza următoarea sintaxă:
CREATE TABLE Employees(ID int NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, -- specificați ca caracteristică a câmpului Nume nvarchar(30) NOT NULL, Data nașterii, Email nvarchar(30), Poziția nvarchar(30), Departament nvarchar(30) )
De fapt, nu trebuie să specificați numele constrângerii, caz în care i se va atribui un nume de sistem (cum ar fi „PK__Employee__3214EC278DA42077”):
CREATE TABLE Angajații(ID int NU NULL, Nume nvarchar(30) NU NULL, Data nașterii, E-mail nvarchar(30), Poziția nvarchar(30), Departament nvarchar(30), CHEIE PRIMARIA (ID))
Sau:
CREATE TABLE Angajații (ID int NOT NULL CHEIE PRIMARĂ, Nume nvarchar(30) NU NULL, Data nașterii, E-mail nvarchar(30), Poziția nvarchar(30), Departament nvarchar(30))
Dar aș recomanda ca pentru tabelele permanente să setați întotdeauna în mod explicit numele constrângerii, deoarece Cu un nume specificat în mod explicit și ușor de înțeles, va fi mai ușor să îl manipulați mai târziu; de exemplu, îl puteți șterge:
ALTER TABLE Angajații DROP CONSTRAINT PK_Angajați
Dar o astfel de sintaxă scurtă, fără a specifica numele restricțiilor, este convenabilă de utilizat la crearea tabelelor de baze de date temporare (numele tabelului temporar începe cu # sau ##), care vor fi șterse după utilizare.
Să rezumam
Până acum ne-am uitat la următoarele comenzi:- CREAȚI TABEL table_name (lista de câmpuri și tipurile acestora, restricții) – folosit pentru a crea un nou tabel în baza de date curentă;
- DROP TABLE table_name – folosit pentru a șterge un tabel din baza de date curentă;
- ALTER TABLE nume_tabel ALTER COLONA nume_coloană... – folosit pentru a actualiza tipul coloanei sau pentru a modifica setările acesteia (de exemplu, pentru a seta caracteristica NULL sau NOT NULL);
- ALTER TABLE nume_tabel ADĂUGAȚI CONSTRINGERE nume_constrângere CHEIA PRINCIPALA(câmp1, câmp2,...) – adăugarea unei chei primare la un tabel existent;
- ALTER TABLE nume_tabel CONSTRINGERE DE CĂDERARE constraint_name – elimină o constrângere din tabel.
Câteva despre mesele temporare
Extras din MSDN. Există două tipuri de tabele temporare în MS SQL Server: locale (#) și globale (##). Tabelele temporare locale sunt vizibile numai pentru creatorii lor până când sesiunea de conectare la instanța SQL Server se termină când sunt create pentru prima dată. Tabelele temporare locale sunt șterse automat după ce un utilizator se deconectează de la instanța SQL Server. Tabelele temporare globale sunt vizibile pentru toți utilizatorii în timpul oricărei sesiuni de conexiune după crearea acestor tabele și sunt șterse atunci când toți utilizatorii care fac referire la aceste tabele se deconectează de la instanța SQL Server.
Tabelele temporare sunt create în baza de date a sistemului tempdb, de exemplu. Prin crearea acestora nu înfundam baza de date principală; în caz contrar, tabelele temporare sunt complet identice cu cele obișnuite; ele pot fi șterse și folosind comanda DROP TABLE. Tabelele temporare locale (#) sunt mai frecvent utilizate.
Pentru a crea un tabel temporar, puteți folosi comanda CREATE TABLE:
CREATE TABLE #Temp(ID int, Nume nvarchar(30))
Deoarece un tabel temporar în MS SQL este similar cu un tabel obișnuit, poate fi șters și folosind comanda DROP TABLE:
DROP TABLE #Temp
De asemenea, puteți crea un tabel temporar (cum ar fi un tabel obișnuit) și îl puteți completa imediat cu datele returnate de interogare folosind sintaxa SELECT ... INTO:
SELECT ID, Nume INTO #Temp FROM Angajati
Pe o notă
Implementarea tabelelor temporare poate diferi în diferite SGBD. De exemplu, în DBMS-ul ORACLE și Firebird, structura tabelelor temporare trebuie determinată în prealabil de comanda CREATE GLOBAL TEMPORARY TABLE, indicând specificul stocării datelor în acesta, apoi utilizatorul îl vede printre tabelele principale și lucrează cu el. ca la o masă obișnuită.
Normalizarea bazei de date – împărțirea în subtabele (directoare) și identificarea conexiunilor
Tabelul nostru actual de angajați are dezavantajul că în câmpurile Poziție și Departament utilizatorul poate introduce orice text, care este în primul rând plin de erori, deoarece pentru un angajat poate indica pur și simplu „IT” ca departament, iar pentru un al doilea angajat, pentru de exemplu, introduceți „departamentul IT”, al treilea are „IT”. Ca urmare, nu va fi clar ce a vrut să spună utilizatorul, adică. Acești angajați sunt angajați ai aceluiași departament sau s-a descris utilizatorul și acestea sunt 3 departamente diferite? Mai mult, în acest caz, nu vom putea grupa corect datele pentru un raport, unde poate fi necesar să arătăm numărul de angajați pe fiecare departament.Al doilea dezavantaj este volumul de stocare a acestor informații și duplicarea acesteia, adică. Pentru fiecare angajat este indicat numele complet al departamentului, care necesită spațiu în baza de date pentru a stoca fiecare caracter din numele departamentului.
Al treilea dezavantaj este dificultatea actualizării acestor câmpuri dacă numele unei poziții se schimbă, de exemplu, dacă trebuie să redenumiți poziția „Programator” în „Programator junior”. În acest caz, va trebui să facem modificări fiecărui rând al tabelului a cărui Poziție este egală cu „Programator”.
Pentru a evita aceste neajunsuri, se folosește așa-numita normalizare a bazei de date - împărțirea acesteia în subtabele și tabele de referință. Nu este necesar să intri în jungla teoriei și să studiezi ce sunt formele normale; este suficient să înțelegem esența normalizării.
Să creăm 2 tabele de director „Poziții” și „Departamente”, să le numim pe primele poziții, respectiv pe al doilea, Departamente:
CREATE TABLE Poziții(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions CHEIE PRIMARĂ, Nume nvarchar(30) NOT NULL) CREATE TABLE Departamente(ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments CHEIE PRIMARĂ, Nume nvarchar(30) ) NU NUL)
Rețineți că aici am folosit noua opțiune IDENTITATE, care spune că datele din coloana ID vor fi numerotate automat, începând de la 1, în trepte de 1, adică. La adăugarea de noi înregistrări, li se vor atribui succesiv valorile 1, 2, 3 etc. Astfel de câmpuri sunt de obicei numite auto-incrementare. Un tabel poate avea un singur câmp definit cu proprietatea IDENTITY și, de obicei, dar nu neapărat, acel câmp este cheia primară pentru acel tabel.
Pe o notă
În diferite SGBD, implementarea câmpurilor cu contor se poate face diferit. În MySQL, de exemplu, un astfel de câmp este definit folosind opțiunea AUTO_INCREMENT. În ORACLE și Firebird, această funcționalitate ar putea fi emulată anterior folosind SEQUENCE. Dar din câte știu, ORACLE a adăugat acum opțiunea GENERATE CA IDENTITATE.
Să completăm automat aceste tabele, pe baza datelor curente înregistrate în câmpurile Poziție și Departament din tabelul Angajați:
Completam câmpul Nume din tabelul de poziții cu valori unice din câmpul Poziție din tabelul Angajați INSERT Posiții (Nume) SELECTARE DISTINCT Poziția FROM Angajații WHERE Poziția NU ESTE NULL -- eliminați înregistrările pentru care nu este specificată postul
Să facem același lucru pentru tabelul Departamente:
INSERT Departments(Nume) SELECT DISTINCT Department FROM Angajații WHERE Departamentul NU ESTE NUL
Dacă deschidem acum tabelele Poziții și Departamente, vom vedea un set numerotat de valori pentru câmpul ID:
SELECTAȚI * FROM Poziții
SELECT * FROM Departamente
Aceste tabele vor juca acum rolul de cărți de referință pentru specificarea posturilor și departamentelor. Ne vom referi acum la ID-urile postului și departamentului. Mai întâi de toate, să creăm noi câmpuri în tabelul Angajați pentru a stoca datele de identificare:
Adăugați un câmp pentru ID-ul poziției ALTER TABLE Angajații ADD PositionID int -- adăugați un câmp pentru ID-ul departamentului ALTER TABLE Angajații ADD DepartmentID int
Tipul câmpurilor de referință trebuie să fie același ca în directoare, în acest caz este int.
De asemenea, puteți adăuga mai multe câmpuri la tabel simultan cu o singură comandă, listând câmpurile separate prin virgule:
ALTER TABLE Angajații ADD PositionID int, DepartmentID int
Acum să scriem linkuri (restricțiuni de referință - CHEIE STRĂINĂ) pentru aceste câmpuri, astfel încât utilizatorul să nu aibă posibilitatea de a scrie în aceste câmpuri valori care nu se află printre valorile ID găsite în directoare.
ALTER TABLE Angajații ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERINȚE Poziții(ID)
Și vom face același lucru pentru al doilea câmp:
ALTER TABLE Angajații ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERINȚE Departamente(ID)
Acum, utilizatorul va putea introduce în aceste câmpuri numai valori de ID din directorul corespunzător. În consecință, pentru a utiliza un nou departament sau poziție, va trebui mai întâi să adauge o nouă intrare în directorul corespunzător. Deoarece Pozițiile și departamentele sunt acum stocate în directoare într-o singură copie, așa că pentru a schimba numele, este suficient să îl schimbați doar în director.
Numele unei constrângeri de referință este de obicei un nume compus, constând din prefixul „FK_”, urmat de numele tabelului și urmat de un caracter de subliniere, urmat de numele câmpului care se referă la identificatorul tabelului de referință.
Un identificator (ID) este de obicei o valoare internă care este folosită numai pentru relații și ce valoare este stocată acolo este complet indiferentă în majoritatea cazurilor, așa că nu este nevoie să încerci să scapi de găurile din succesiunea de numere care apar în timpul lucrului. cu tabelul, de exemplu, după ștergerea înregistrărilor din director.
ALTER TABLE table ADD CONSTRAINT nume_constrângere FOREIGN KEY(câmp1, câmp2,…) REFERINȚE tabel_referință(câmp1, câmp2,…)
În acest caz, în tabelul „reference_table”, cheia primară este reprezentată de o combinație de mai multe câmpuri (câmp1, câmp2,...).
De fapt, acum să actualizăm câmpurile PositionID și DepartmentID cu valorile ID din directoare. Să folosim comanda DML UPDATE în acest scop:
UPDATE e SET PositionID=(SELECT ID FROM Poziții WHERE Nume=e.Posiție), DepartmentID=(SELECT ID FROM Departments WHERE Nume=e.Department) FROM Angajați e
Să vedem ce se întâmplă prin rularea cererii:
SELECTAȚI * FROM Angajați
Gata, câmpurile PositionID și DepartmentID sunt completate cu identificatorii corespunzătoare posturilor și departamentelor; câmpurile Poziție și Departament nu mai sunt necesare în tabelul Angajați, puteți șterge aceste câmpuri:
ALTER TABLE Angajații DROP COLUMN Poziția, Departamentul
Acum tabelul nostru arată astfel:
SELECTAȚI * FROM Angajați
| ID | Nume | Zi de nastere | ID poziție | ID departament | |
|---|---|---|---|---|---|
| 1000 | Ivanov I.I. | NUL | NUL | 2 | 1 |
| 1001 | Petrov P.P. | NUL | NUL | 3 | 3 |
| 1002 | Sidorov S.S. | NUL | NUL | 1 | 2 |
| 1003 | Andreev A.A. | NUL | NUL | 4 | 3 |
Acestea. În cele din urmă, am scăpat de stocarea informațiilor redundante. Acum, pe baza numerelor postului și departamentelor, putem determina fără ambiguitate numele acestora folosind valorile din tabelele de referință:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Angajați e LEFT JOIN Departamente d ON d.ID=e.DepartmentID LEFT JOIN Poziții p ON p.ID=e.PositionID
În inspectorul de obiecte putem vedea toate obiectele create pentru un tabel dat. De aici puteți efectua diverse manipulări cu aceste obiecte - de exemplu, redenumiți sau ștergeți obiecte.

De asemenea, este de remarcat faptul că tabelul se poate referi la el însuși, de ex. puteți crea un link recursiv. De exemplu, să adăugăm un alt câmp ManagerID la tabelul nostru cu angajați, care va indica angajatul căruia îi raportează acest angajat. Să creăm un câmp:
ALTER TABLE Angajații ADD ManagerID int
Acest câmp permite o valoare NULL; câmpul va fi gol dacă, de exemplu, nu există superiori peste angajat.
Acum să creăm o CHEIE STRĂINĂ pentru tabelul Angajați:
ALTER TABLE Angajații ADD CONSTRAINT FK_Employees_ManagerID CHEIE STRĂINĂ (ManagerID) REFERINȚE Angajații (ID)
Să creăm acum o diagramă și să vedem cum arată relațiile dintre tabelele noastre pe ea:


Ca rezultat, ar trebui să vedem următoarea imagine (tabelul Angajați este conectat la tabelele Poziții și Departamente și se referă și la sine):

În cele din urmă, merită spus că cheile de referință pot include opțiuni suplimentare ON DELETE CASCADE și ON UPDATE CASCADE, care indică cum să se comportă la ștergerea sau actualizarea unei înregistrări la care se face referință în tabelul de referință. Dacă aceste opțiuni nu sunt specificate, atunci nu putem schimba ID-ul din tabelul de director pentru o înregistrare care este referită dintr-un alt tabel și, de asemenea, nu vom putea șterge o astfel de înregistrare din director până când vom șterge toate rândurile care fac referire la această înregistrare. sau, Să actualizăm referințele din aceste rânduri la o valoare diferită.
De exemplu, să recreăm tabelul care specifică opțiunea ON DELETE CASCADE pentru FK_Employees_DepartmentID:
DROP TABLE Angajații CREATE TABLE Angajații(ID int NOT NULL, Nume nvarchar(30), data nașterii, e-mail nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY ) Referințe departamente (ID) pe delete cascade, constrângere fk_employees_posițiad cheie străină (pozițied) Referințe de referințe (ID), constrângere fk_employees_managerid Cheie străină (managerId) Referințe angajaților (ID)) Introduceți angajați (ID, nume, naștere, poziție, departamentd, manager, manager ID )VALORI (1000,N"Ivanov I.I.","19550219",2,1,NULL), (1001,N"Petrov P.P.","19831203",3,3,1003), (1002 ,N"Sidorov S.S. ","19760607",1,2,1000), (1003,N"Andreev A.A.","19820417",4,3,1000)
Să ștergem departamentul cu ID 3 din tabelul Departamente:
DELETE Departamentele WHERE ID=3
Să ne uităm la datele din tabelul Angajații:
SELECTAȚI * FROM Angajați
| ID | Nume | Zi de nastere | ID poziție | ID departament | ID manager | |
|---|---|---|---|---|---|---|
| 1000 | Ivanov I.I. | 1955-02-19 | NUL | 2 | 1 | NUL |
| 1002 | Sidorov S.S. | 1976-06-07 | NUL | 1 | 2 | 1000 |
După cum puteți vedea, datele pentru departamentul 3 din tabelul Angajați au fost și ele șterse.
Opțiunea ON UPDATE CASCADE se comportă în mod similar, dar este eficientă la actualizarea valorii ID din director. De exemplu, dacă schimbăm ID-ul unei poziții din directorul de poziții, atunci în acest caz DepartmentID din tabelul Angajați va fi actualizat la noua valoare ID pe care am setat-o în director. Dar în acest caz pur și simplu nu va fi posibil să se demonstreze acest lucru, deoarece coloana ID din tabelul Departamente are opțiunea IDENTITATE, care nu ne va permite să executăm următoarea interogare (modificați ID-ul departamentului de la 3 la 30):
UPDATE Departamente SET ID=30 WHERE ID=3
Principalul lucru este să înțelegeți esența acestor 2 opțiuni ON DELETE CASCADE și ON UPDATE CASCADE. Folosesc foarte rar aceste opțiuni și vă recomand să vă gândiți bine înainte de a le specifica într-o constrângere de referință, deoarece dacă ștergeți accidental o intrare dintr-un tabel de director, acest lucru poate duce la probleme mari și poate crea o reacție în lanț.
Să restabilim departamentul 3:
Oferim permisiunea de a adăuga/modifica valoarea IDENTITY SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N"IT") -- interzicem adăugarea/modificarea IDENTITY value SET IDENTITY_INSERT Departments OFF
Să ștergem complet tabelul de angajați folosind comanda TRUNCATE TABLE:
TRUNCATE TABLE Angajații
Și din nou vom reîncărca datele în ele folosind comanda anterioară INSERT:
INSERT Angajații (ID, Nume, Zi de naștere, ID Poziție, ID Departament, ID Manager) VALORI (1000,N"Ivanov I.I.","19550219",2,1,NULL), (1001,N"Petrov P.P." ,"19831203",3 ,3,1003), (1002,N"Sidorov S.S.","19760607",1,2,1000), (1003,N"Andreev A.A.","19820417" ,4,3,1000)
Să rezumam
În acest moment, mai multe comenzi DDL au fost adăugate la cunoștințele noastre:- Adăugarea proprietății IDENTITATE la un câmp – vă permite să faceți din acest câmp un câmp populat automat (câmp contor) pentru tabel;
- ALTER TABLE nume_tabel ADĂUGA list_of_fields_with_characteristics – vă permite să adăugați noi câmpuri la tabel;
- ALTER TABLE nume_tabel COLOCARE COLONA list_fields – vă permite să eliminați câmpuri din tabel;
- ALTER TABLE nume_tabel ADĂUGAȚI CONSTRINGERE nume_constrângere CHEIE EXTERNĂ(câmpuri) REFERINȚE table_reference (câmpuri) – vă permite să definiți relația dintre tabel și tabelul de referință.
Alte restricții – UNIC, DEFAULT, VERIFICARE
Folosind o constrângere UNIQUE, puteți spune că valoarea pentru fiecare rând dintr-un anumit câmp sau set de câmpuri trebuie să fie unică. În cazul tabelului Angajați, putem impune o astfel de constrângere câmpului Email. Doar precompletați e-mailul cu valori dacă acestea nu sunt deja definite:UPDATE Angajații SET Email=" [email protected]" WHERE ID=1000 UPDATE Angajații SET Email=" [email protected]" WHERE ID=1001 UPDATE Angajații SET Email=" [email protected]" WHERE ID=1002 UPDATE Angajații SET Email=" [email protected]„WHERE ID=1003
Acum puteți impune o constrângere de unicitate pe acest câmp:
ALTER TABLE Angajații ADD CONSTRAINT UQ_Employees_Email UNIQUE(E-mail)
Acum utilizatorul nu va putea introduce același e-mail pentru mai mulți angajați.
O constrângere unică este de obicei numită după cum urmează - mai întâi vine prefixul „UQ_”, apoi numele tabelului și după liniuță vine numele câmpului pe care se aplică această constrângere.
În consecință, dacă o combinație de câmpuri trebuie să fie unică în contextul rândurilor de tabel, atunci le enumerăm separate prin virgule:
ALTER TABLE nume_tabel ADD CONSTRAINT nume_constrângere UNIQUE(câmp1, câmp2,...)
Adăugând o constrângere DEFAULT unui câmp, putem specifica o valoare implicită care va fi înlocuită dacă, la inserarea unei noi înregistrări, acest câmp nu este listat în lista de câmpuri a comenzii INSERT. Această restricție poate fi setată direct la crearea tabelului.
Să adăugăm un nou câmp pentru Data angajării în tabelul Angajați și să îl numim HireDate și să spunem că valoarea implicită pentru acest câmp va fi data curentă:
ALTER TABLE Angajații ADD HireDate data NOT NULL DEFAULT SYSDATETIME()
Sau dacă coloana HireDate există deja, atunci se poate folosi următoarea sintaxă:
ALTER TABLE Angajații ADĂUGAȚI IMPLICIT SYSDATETIME() PENTRU HireDate
Aici nu am specificat numele constrângerii, pentru că... în cazul DEFAULT, am părerea că acest lucru nu este atât de critic. Dar dacă o faci într-un mod bun, atunci cred că nu trebuie să fii leneș și ar trebui să setezi un nume normal. Acest lucru se face după cum urmează:
ALTER TABLE Angajații ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
Deoarece această coloană nu exista înainte, atunci când este adăugată la fiecare înregistrare, valoarea datei curente va fi inserată în câmpul HireDate.
Când adăugați o nouă intrare, data curentă va fi de asemenea inserată automat, desigur, cu excepția cazului în care o setăm în mod explicit, de exemplu. Nu o vom indica în lista de coloane. Să arătăm acest lucru cu un exemplu fără a specifica câmpul HireDate din lista de valori adăugate:
INSERT Angajații(ID,Nume,E-mail)VALUES(1004,N"Sergeev S.S."," [email protected]")
Să vedem ce s-a întâmplat:
SELECTAȚI * FROM Angajați
| ID | Nume | Zi de nastere | ID poziție | ID departament | ID manager | Data angajării | |
|---|---|---|---|---|---|---|---|
| 1000 | Ivanov I.I. | 1955-02-19 | [email protected] | 2 | 1 | NUL | 2015-04-08 |
| 1001 | Petrov P.P. | 1983-12-03 | [email protected] | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Sidorov S.S. | 1976-06-07 | [email protected] | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Andreev A.A. | 1982-04-17 | [email protected] | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Sergheev S.S. | NUL | [email protected] | NUL | NUL | NUL | 2015-04-08 |
Constrângerea de verificare CHECK este utilizată atunci când este necesară verificarea valorilor introduse într-un câmp. De exemplu, să impunem această restricție în câmpul numărului de personal, care pentru noi este un identificator de angajat (ID). Folosind această constrângere, spunem că numerele de personal trebuie să aibă o valoare de la 1000 la 1999:
ALTER TABLE Angajații ADD CONSTRAINT CK_Employees_ID VERIFICARE (ID ÎNTRE 1000 ȘI 1999)
Constrângerea este de obicei denumită la fel, mai întâi cu prefixul „CK_”, apoi numele tabelului și numele câmpului asupra căruia se impune această constrângere.
Să încercăm să inserăm o înregistrare nevalidă pentru a verifica dacă constrângerea funcționează (ar trebui să obținem eroarea corespunzătoare):
INSERT Angajații(ID,E-mail) VALUES(2000," [email protected]")
Acum să schimbăm valoarea inserată la 1500 și să ne asigurăm că înregistrarea este inserată:
INSERT Angajații(ID,E-mail) VALUES(1500," [email protected]")
De asemenea, puteți crea constrângeri UNIQUE și CHECK fără a specifica un nume:
ALTER TABLE Angajații ADD UNIQUE(E-mail) ALTER TABLE Angajații ADD CHECK(ID ÎNTRE 1000 ȘI 1999)
Dar aceasta nu este o practică foarte bună și este mai bine să specificați în mod explicit numele constrângerii, deoarece Pentru a vă da seama mai târziu, ceea ce va fi mai dificil, va trebui să deschideți obiectul și să vă uitați la ce este responsabil.

Cu un nume bun, multe informații despre constrângere pot fi învățate direct din numele acesteia.
Și, în consecință, toate aceste restricții pot fi create imediat la crearea unui tabel, dacă acesta nu există încă. Să ștergem tabelul:
DROP TABLE Angajații
Și îl vom recrea cu toate restricțiile create cu o singură comandă CREATE TABLE:
CREATE TABLE Angajații(ID int NOT NULL, Nume nvarchar(30), Data nașterii, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- pentru DEFAULT voi face o excepție CONSTRAINT PK_Employees CHEIE PRIMARĂ (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERINȚE Departamente (ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERINȚE Poziții (ID), CONSTRAINT UQ_Employees_EmployeCKIDECKIDE-mail (Angajați_E-mail) WEEN 1000 ȘI 1999))
INSERT Angajații (ID, Nume, Zi de naștere, E-mail, ID Poziție, ID Departament) VALORI (1000,N"Ivanov I.I.","19550219"," [email protected]",2,1), (1001,N"Petrov P.P.","19831203"," [email protected]",3,3), (1002,N"Sidorov S.S.","19760607"," [email protected]",1,2), (1003,N"Andreev A.A.","19820417"," [email protected]",4,3)
Câteva despre indecșii creați la crearea constrângerilor PRIMARY KEY și UNIQUE
După cum puteți vedea în captura de ecran de mai sus, la crearea constrângerilor PRIMARY KEY și UNIQUE, au fost creați automat indici cu aceleași nume (PK_Employees și UQ_Employees_Email). În mod implicit, indexul pentru cheia primară este creat ca CLUSTERED, iar pentru toți ceilalți indecși ca NONCLUSTERED. Merită spus că conceptul de index de cluster nu este disponibil în toate SGBD-urile. Un tabel poate avea un singur index CLUSTERED. CLUSTERED – înseamnă că înregistrările din tabel vor fi sortate după acest index, mai putem spune că acest index are acces direct la toate datele din tabel. Acesta este indexul principal al tabelului, ca să spunem așa. Pentru a spune și mai aproximativ, acesta este un index atașat unui tabel. Un index grupat este un instrument foarte puternic care poate ajuta la optimizarea interogărilor, dar să ne amintim doar acest lucru pentru moment. Dacă vrem să spunem ca indexul grupat să fie folosit nu pe cheia primară, ci pe un alt index, atunci când creăm cheia primară trebuie să specificăm opțiunea NONCLUSTERED:ALTER TABLE nume_tabel ADD CONSTRAINT nume_constrângere PRIMARY KEY NONCLUSTERED(câmp1,câmp2,…)
De exemplu, să facem ca indicele de constrângere PK_Employees să nu fie în cluster, iar indicele de constrângere UQ_Employees_Email să fie grupat. În primul rând, să eliminăm aceste restricții:
ALTER TABLE Angajații DROP CONSTRAINT PK_Angajați ALTER TABLE Angajații DROP CONSTRAINT UQ_Employees_Email
Acum să le creăm cu opțiunile CLUSTERED și NONCLUSTERED:
ALTER TABLE Angajații ADD CONSTRAINT PK_Employees CHEIE PRIMARIA NONCLUSTERED (ID) ALTER TABLE Angajații ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (E-mail)
Acum, selectând din tabelul Angajați, vom vedea că înregistrările sunt sortate după indexul grupat UQ_Employees_Email:
SELECTAȚI * FROM Angajați
| ID | Nume | Zi de nastere | ID poziție | ID departament | Data angajării | |
|---|---|---|---|---|---|---|
| 1003 | Andreev A.A. | 1982-04-17 | [email protected] | 4 | 3 | 2015-04-08 |
| 1000 | Ivanov I.I. | 1955-02-19 | [email protected] | 2 | 1 | 2015-04-08 |
| 1001 | Petrov P.P. | 1983-12-03 | [email protected] | 3 | 3 | 2015-04-08 |
| 1002 | Sidorov S.S. | 1976-06-07 | [email protected] | 1 | 2 | 2015-04-08 |
Anterior, când indexul grupat era indexul PK_Employees, înregistrările erau sortate în mod implicit după câmpul ID.
Dar în acest caz, acesta este doar un exemplu care arată esența unui index cluster, deoarece Cel mai probabil, interogările vor fi făcute către tabelul Angajați folosind câmpul ID și, în unele cazuri, poate, acesta va acționa ca un director.
Pentru directoare, este de obicei recomandabil ca indexul clusterizat să fie construit pe cheia primară, deoarece în cereri ne referim adesea la identificatorul directorului pentru a obține, de exemplu, numele (Posiție, Departament). Să ne amintim aici ceea ce am scris mai sus, că un index grupat are acces direct la rândurile tabelului și rezultă că putem obține valoarea oricărei coloane fără suprasarcină suplimentară.
Este avantajos să aplicați un index de cluster câmpurilor care sunt eșantionate cel mai frecvent.
Uneori, tabelele sunt create cu o cheie bazată pe un câmp surogat; în acest caz, poate fi util să salvați opțiunea index CLUSTERED pentru un index mai potrivit și să specificați opțiunea NONCLUSTERED atunci când creați o cheie primară surogat.
Să rezumam
În această etapă, ne-am familiarizat cu toate tipurile de restricții, în forma lor cea mai simplă, care sunt create printr-o comandă precum „ALTER TABLE table_name ADD CONSTRAINT constraint_name...”:- CHEIA PRINCIPALA- cheia principala;
- CHEIE EXTERNĂ– stabilirea conexiunilor și monitorizarea integrității referențiale a datelor;
- UNIC– vă permite să creați unicitate;
- VERIFICA– vă permite să asigurați corectitudinea datelor introduse;
- MOD IMPLICIT– vă permite să setați o valoare implicită;
- De asemenea, merită remarcat faptul că toate restricțiile pot fi eliminate folosind comanda „ ALTER TABLE nume_tabel CONSTRINGERE DE CĂDERARE nume_constrângere”.
Crearea de indici autonomi
Prin independent ne referim aici la indecși care nu sunt creați sub constrângerea PRIMARY KEY sau UNIQUE.Indecșii unui câmp sau câmpuri pot fi creați cu următoarea comandă:
CREATE INDEX IDX_Employees_Name ON Angajati(Nume)
Tot aici puteți specifica opțiunile CLUSTERED, NONCLUSTERED, UNIQUE și, de asemenea, puteți specifica direcția de sortare a fiecărui câmp individual ASC (implicit) sau DESC:
CREAȚI INDEX UNIC NONCLUSTERED UQ_Employees_EmailDesc ON Angajații (E-mail DESC)
La crearea unui index non-clustered, opțiunea NONCLUSTERED poate fi omisă, deoarece este implicit implicit și este afișat aici pur și simplu pentru a indica poziția opțiunii CLUSTERED sau NONCLUSTERED în comandă.
Puteți șterge indexul cu următoarea comandă:
DROP INDEX IDX_Employees_Name ON Angajații
Indecșii simpli, precum și constrângerile, pot fi creați în contextul comenzii CREATE TABLE.
De exemplu, să ștergem din nou tabelul:
DROP TABLE Angajații
Și îl vom recrea cu toate restricțiile și indecșii creați cu o singură comandă CREATE TABLE:
CREATE TABLE Angajații(ID int NOT NULL, Nume nvarchar(30), Data zilei de naștere, Email nvarchar(30), PositionID int, DepartmentID int, HireDate data NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY (PRIMARY) ), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERINȚE Departamente(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERINȚE Poziții(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY(Employees_ManagerID) REFERINȚE CHEIE STRĂINĂ(Employees_Manager) REEMPLICAȚII es_Email UNIQUE(E-mail), CONSTRAINT CK_Employees_ID CHECK(ID ÎNTRE 1000 ȘI 1999), INDEX IDX_Employees_Name(Nume))
În cele din urmă, să introducem angajații noștri în tabel:
INSERT ANgajați (ID, Nume, Zi de naștere, E-mail, ID poziția, ID departament, ID manager) VALORI (1000,N"Ivanov I.I.","19550219"," [email protected]",2,1,NULL), (1001,N"Petrov P.P.","19831203"," [email protected]",3,3,1003), (1002,N"Sidorov S.S.","19760607"," [email protected]",1,2,1000), (1003,N"Andreev A.A.","19820417"," [email protected]",4,3,1000)
În plus, este de remarcat faptul că puteți include valori într-un index non-cluster, specificându-le în INCLUDE. Acestea. în acest caz, indicele INCLUDE va aminti oarecum de un index grupat, doar că acum indicele nu este atașat la tabel, dar valorile necesare sunt atașate la index. În consecință, astfel de indecși pot îmbunătăți considerabil performanța interogărilor de selecție (SELECT); dacă toate câmpurile listate sunt în index, atunci accesul la tabel poate să nu fie deloc necesar. Dar acest lucru crește în mod natural dimensiunea indicelui, deoarece valorile câmpurilor enumerate sunt duplicate în index.
Extras din MSDN. Sintaxă generală de comandă pentru crearea indecșilorCREATE [UNIQUE] [CLUSTER | NONCLUSTERED ] INDEX nume_index ACTIVAT
Să rezumam
Indecșii pot crește viteza de regăsire a datelor (SELECT), dar indecșii reduc viteza de modificare a datelor din tabel, deoarece După fiecare modificare, sistemul va trebui să reconstruiască toți indecșii pentru un anumit tabel.În fiecare caz, este indicat să găsiți soluția optimă, media de aur, astfel încât atât performanța de eșantionare, cât și cea de modificare a datelor să fie la nivelul corespunzător. Strategia de creare a indicilor și numărul de indici pot depinde de mulți factori, cum ar fi cât de des se schimbă datele din tabel.
Concluzie despre DDL
După cum puteți vedea, DDL nu este atât de complicat pe cât ar părea la prima vedere. Aici am putut arăta aproape toate structurile sale principale folosind doar trei tabele.Principalul lucru este să înțelegeți esența, iar restul este o chestiune de practică.
Mult succes în stăpânirea acestui limbaj minunat numit SQL.
SQL yavl. instrument destinat pentru prelucrarea și citirea datelor conținute în calculator. DB. SQL este, în primul rând, logic informațional. limbaj, destinat pentru a descrie, modifica și prelua date stocate în baze de date relaționale. SQL este abrevierea pentru Limbajul de interogare structurat) . SQL este folosit pentru a organiza interacțiunea utilizatorului cu baza de date. De fapt, SQL funcționează doar cu baze de date relaționale tip . Se numește programul de calculator care gestionează baza de date Sistemul de gestionare a bazelor de date, sau SGBD . Dacă utilizatorul are nevoie citește datele din baza de date, le solicită din DBMS cu pom. SQL. SGBD procesează cererea, găsește datele necesare și le trimite utilizatorului. Procesul de solicitare a datelor și de obținere a unui rezultat este numit cerere la baza de date: de aici și numele - limbaj de interogare structurat. În ciuda faptului că citirea datelor este încă una dintre cele mai importante. important Funcții SQL, acum acest limbaj este folosit pentru a implementa toate funcţionalitate, pisică. SGBD-ul oferă utilizatorului, și anume:
Organizarea datelor. SQL oferă utilizatorului posibilitatea de a schimba structura prezentării datelor, precum și de a stabili relații între elementele bazei de date.
Citirea datelor. SQL oferă unui utilizator sau aplicație capacitatea de a citi și utiliza datele conținute într-o bază de date.
Procesarea datelor. SQL oferă utilizatorului sau aplicației capacitatea de a... schimba baza de date, de ex. adăugați-i date noi, precum și ștergeți sau actualizați datele existente.
Controlul accesului. Cu asistent SQL poate limita capacitatea utilizatorului de a citi și modifica datele și le poate proteja de accesul neautorizat.
Partajarea date. SQL coordonează partajarea datelor între utilizatori și lucrătorii concurenți, astfel încât aceștia să nu interfereze unul cu celălalt.
Integritatea datelor. SQL vă permite să asigurați integritatea bazelor de date, protejându-le împotriva distrugerii din cauza modificărilor inconsecvente sau a defecțiunii sistemului.
Astfel, SQL este un limbaj suficient de puternic pentru a interacționa cu SGBD.
Avantajele SQL.
SQL este un limbaj ușor de înțeles și, în același timp, un instrument software versatil de gestionare a datelor.
Următoarele caracteristici au adus succesul limbajului SQL:
Independență față de SGBD specific;
Portabilitatea de la un sistem de calcul la altul;
Disponibilitatea standardelor;
Cadrul relațional;
Structură de nivel înalt;
Abilitatea de a efectua interogări interactive speciale:
Furnizare de acces software la baze de date;
Posibilitatea de prezentare a datelor diferite;
Completitudine ca limbaj conceput pentru a lucra cu baze de date;
Posibilitatea determinării dinamice a datelor;
Suport arhitectură client/server.
Toți factorii de mai sus sunt motivul pentru care SQL a devenit instrumentul standard pentru gestionarea datelor pe computerele personale.
37 Structuri de bază ale propozițiilor limbajului în interogări
Fiecare instrucțiune SQL este cerere sau accesul la baza de date, ceea ce duce la o modificare a bazei de date. În funcție de modificările care apar în baza de date, se disting următoarele tipuri de interogări:
Solicitări de creare sau modificare a obiectelor noi sau existente în baza de date (în acest caz, cererea descrie tipul și structura obiectului creat sau modificat);
Cereri de date;
Solicitări de adăugare de date noi (înregistrări)
Solicitări de ștergere a datelor;
Apeluri către SGBD.
Orice cerere este un program scris în limbajul de interogare structurat SQL. De fapt, un program SQL este o expresie de interogare pentru un eșantion de date în limba engleză, scrisă într-o structură specifică, pe care SGBD-ul o convertește apoi în rezultatul necesar.
În majoritatea SGBD-urilor, propoziția se termină cu „;” iar SGBD nu procesează informații până când nu întâlnește „;”. Propozițiile sunt alcătuite din fraze și încep cu un cuvânt înregistrat. Fiecare frază are un nume.
Numirile unora operatori SQL de bază:
SELECTAȚI(selectați) – (selectați) datele din coloanele specificate și (dacă este necesar) efectuează transformarea acestora în conformitate cu expresiile și (sau) funcțiile specificate înainte de ieșire; DIN– indică tabelul din care au fost selectate câmpurile; UNDE– creează o condiție pentru selectarea datelor din înregistrări; COMANDA PENTRU– sortează înregistrările într-o ordine dată; A SE GRUPA CU– grupează înregistrările care se potrivesc la executarea interogărilor rezumative; DISTINCTROW– exclude înregistrările duplicate din setul de rezultate; TRANSFORMA– evaluează expresii în interogări încrucișate; PIVOT– Definește titlurile coloanelor din tabelul de interogări încrucișate.
Despre propunere SELECTAȚI. Toate solicitările pentru obținerea aproape orice cantitate de date de la unul sau mai multe. tabelele sunt realizate folosind o singură clauză SELECT. În general, rezultatul implementării unei clauze SELECT este un alt tabel. Operația SELECT poate fi aplicată din nou acestui nou tabel (de lucru), etc., de exemplu. astfel de operațiuni pot fi imbricate unele în altele. Este de interes istoric faptul că este posibilitatea de incl. o clauză SELECT în alta a fost motivația utilizării. adjectivul „structurat” în numele limbajului SQL. În desenele utilizate. simboluri: asterisc (*) pentru a indica „toate” – folosite. în sensul obișnuit pentru programare, adică „toate cazurile care îndeplinesc definiția”; (,) - Spaniolă pentru a separa elementele listei; () - înseamnă că construcțiile, concluzie. între paranteze, yavl. opțional ; linie dreaptă (|) – numerar. alegere dintre două sau mai multe posibilități etc.
36-37. Special - stilul limbajului SQL . Structuri de bază ale propozițiilor limbajului în interogări (a/c)
SQL - Limbajul de interogare structurat. Producția de informații - mai unificată. Acest lucru a condus la necesitatea creării unui limbaj standard care ar putea
SELECT în SQL (pentru un tabel): SELECTAȚI(selectați) câmpurile specificate
DIN(din) tabel specificat
UNDE(unde) o condiție specificată este adevărată
SELECTAȚI list_of_elements (câmpuri) pentru a fi selectat
FROM table_list (sau vizualizare)
]
Folosind calificativul AS
Acest calificator înlocuiește numele coloanei existente în tabelul rezultat cu cel specificat.
Funcții agregate
Funcțiile de agregare includ funcții pentru calcularea sumei (SUM), max (SUM) și min (MIN) a coloanelor de valori, medie aritmetică (AVG) și numărul de rânduri care îndeplinesc o anumită condiție (COUNT).
SELECT count(*), sumă (buget), avg (buget),
min (buget), max (buget)
WHERE head_dept = 100
calculați: numărul de departamente care sunt subdiviziuni ale departamentului 100 (Marketing și vânzări), bugetele lor totale, medii, minime și maxime COUNT SUM MEDIA MIN MAX
5 3800000.00 760000.00 500000.00 1500000.00
Clauza FROM a comenzii SELECT
Clauza FROM listează toate obiectele (unul sau mai multe) din care sunt preluate datele. Fiecare tabel sau vedere la care se face referire în interogare trebuie să fie listat în clauza FROM.
Tipuri de predicate utilizate în clauza WHERE :
comparaţie folosind operatori relaţionali
Egal<>nu este egal!= nu este egal > mai mare decât< меньше
>= mai mare sau egal cu<= меньше или равно
ÎNTRE ÎN LIKE CONTINING ESTE NUL
Operații de comparație Dacă domeniile sunt definite în baza de date, atunci articolele comparate trebuie să aparțină aceluiași domeniu.
SELECTează prenume, prenume, nr_departament,
UNDE job_tara<>"STATELE UNITE ALE AMERICII"
ÎNTRE
Predicatul BETWEEN specifică intervalul de valori pentru care expresia evaluează drept adevărat. De asemenea, este permisă utilizarea construcției NOT BETWEEN.
UNDE salariu INTRE 20000 SI 30000
obțineți o listă cu angajații al căror salariu anual este mai mare de 20.000 și mai mic de 30.000 FIRST_NAME LAST_NAME SALARY
Ann Bennet 22935.00
Kelly Brown 27000,00
Este posibil ca valorile care definesc intervalele inferioare și superioare să nu fie valorile reale din baza de date. Și acest lucru este foarte convenabil - pentru că nu putem indica întotdeauna valorile exacte ale intervalelor!
SELECTează prenume, prenume, salariu
UNDE prenume ÎNTRE „Nel” ȘI „Osb”
obțineți o listă cu angajații ale căror nume de familie sunt între „Nel” și „Osb” SALARIU FIRST_NAME LAST_NAME
Robert Nelson 105900.00
Carol Nordstrom 42742,50
Sue Anne O'Brien 31275.00
SELECTează prenume, prenume, data_închiriere
ÎN Predicatul IN verifică dacă valoarea specificată care precede cuvântul cheie „IN” (de exemplu, o valoare de coloană sau o funcție a unei coloane) este inclusă în lista specificată în paranteze. Dacă valoarea dată care este testată este egală cu orice element din listă, atunci predicatul se evaluează la adevărat. De asemenea, este permisă utilizarea construcției NOT IN.
SELECTează prenume, prenume, cod_post
WHERE job_code IN ("VP", "Admin", "Finan")
CA Predicatul LIKE este folosit numai cu date de caractere. Acesta verifică dacă valoarea caracterului dată se potrivește cu șirul cu masca specificată. Toate caracterele permise (inclusiv litere mari și mici), precum și caracterele speciale, sunt folosite ca mască:
% - înlocuiește orice număr de caractere (inclusiv 0),
Înlocuiește un singur caracter.
De asemenea, este permisă utilizarea constructului NOT LIKE.
SELECTează prenume, prenume
WHERE last_name LIKE „F%”
obțineți o listă cu angajații ale căror nume încep cu litera „F” FIRST_NAME LAST_NAME
Operatori logici Operatorii logici includ binecunoscuții operatori AND, OR, NOT, care vă permit să efectuați diverse operații logice: înmulțire logică (ȘI, „intersecția condițiilor”), adunare logică (OR, „uniunea condițiilor”), negație logică ( NU, „negarea condițiilor”). În exemplele noastre am folosit deja operatorul AND. Utilizarea acestor operatori vă permite să „personalizați” în mod flexibil condițiile de selectare a înregistrărilor.
Conexiune ( A TE ALATURA ) Operația de îmbinare este utilizată în SQL pentru a afișa informații asociate stocate în mai multe tabele într-o singură interogare. Legarea se face de obicei folosind cheia primară a unui tabel și cheia externă a altui tabel - pentru fiecare pereche de tabele. Este foarte important să țineți cont de toate câmpurile cheii externe, altfel rezultatul va fi distorsionat. Câmpurile care trebuie unite pot (dar nu sunt obligatorii!) să fie prezente în lista de elemente selectabile. Clauza WHERE poate conține mai multe condiții de îmbinare. Condiția de îmbinare poate fi combinată și cu alte predicate din clauza WHERE.
Funcționalitatea limbajului SQL
Funcționalitatea principală a limbajului SQL este prezentată mai jos.
Definiţia data. Această funcție SQL este o descriere a structurii datelor suportate și a organizării relațiilor relaționale (tabele). Operatorii pentru crearea unei baze de date, crearea tabelelor și accesarea datelor sunt destinate să o implementeze.
Crearea bazei de date. Pentru a crea o nouă bază de date, utilizați instrucțiunea CREATE DATABASE. Structura instrucțiunilor specifică numele bazei de date care urmează să fie creată.
Crearea de tabele. Tabelul de bază este creat folosind instrucțiunea CREATE TABLE. Această declarație specifică numele câmpurilor, tipurile de date pentru acestea și lungimea (pentru unele tipuri de date). SQL utilizează următoarele tipuri de date:
INTEGER – număr întreg;
CHAR – valoarea caracterului;
VARCHAR – valoarea caracterului, sunt stocate doar caracterele neblank;
DECIMAL – număr zecimal;
FLOAT – număr în virgulă mobilă;
DOUBLE PRECISION – virgulă flotantă de dublă precizie;
DATETIME – data și ora;
BOOL – valoare booleană.
Declarația de creare a tabelului specifică restricții asupra valorilor coloanei și asupra tabelului. Posibilele restricții sunt prezentate în tabel. 4.8
Tabelul 4.8 Limitări ale datelor definite
Pentru un model de date relaționale, specificarea unei chei străine (FOREIGNKEY) este esențială. Când declarați chei străine, trebuie să impuneți restricții corespunzătoare asupra coloanei, de exemplu, NOT NULL.
Într-o instrucțiune SQL, CHECK denotă constrângeri semantice care asigură integritatea datelor, cum ar fi limitarea setului de valori valide pentru o anumită coloană.
Nu puteți utiliza instrucțiunea create table de mai multe ori pe același tabel. Dacă, după crearea sa, se descoperă inexactități în definiția sa, atunci se pot face modificări folosind instrucțiunea ALTER TABLE. Această declarație este concepută pentru a schimba structura unui tabel existent: puteți elimina sau adăuga un câmp la un tabel existent.
Manipulare de date. SQL permite unui utilizator sau unui program de aplicație să modifice conținutul unei baze de date prin inserarea de date noi, ștergerea sau modificarea datelor existente.
Inserarea de date noi este o procedură pentru adăugarea de rânduri la o bază de date și se realizează folosind instrucțiunea INSERT.
Modificarea datelor implică modificări ale valorilor într-una sau mai multe coloane ale unui tabel și se efectuează folosind o instrucțiune UPDATE. Exemplu:
SET suma=suma+1000,00
UNDE suma>0
Eliminarea rândurilor dintr-un tabel folosind instrucțiunea DELETE. Sintaxa operatorului este:
DE LA masă
Clauza WHERE este opțională; totuși, dacă nu este inclusă, toate intrările din tabel vor fi șterse. Este util să folosiți instrucțiunea SELECT cu aceeași sintaxă ca și instrucțiunea DELETE pentru a verifica dinainte ce înregistrări vor fi șterse.
Asigurarea integritatii datelor. Limbajul SQL vă permite să definiți constrângeri de integritate destul de complexe, a căror satisfacție va fi verificată pentru toate modificările bazei de date. Monitorizarea rezultatelor tranzacțiilor, procesarea erorilor care apar și coordonarea lucrului paralel cu baza de date a mai multor aplicații sau utilizatori este asigurată de COMMIT (înregistrează finalizarea cu succes a tranzacției curente și începerea uneia noi) și ROLLBACK (necesitatea pentru un rollback - restaurarea automată a stării bazei de date la începutul tranzacției) operatori.
Eșantionarea datelor este una dintre cele mai importante funcții ale bazei de date care corespunde instrucțiunii SELECT. Un exemplu de utilizare a operatorului a fost discutat în secțiunea anterioară.
În SQL, puteți crea secvențe imbricate de interogări (subinterogări). Există anumite tipuri de interogări care sunt cel mai bine implementate folosind subinterogări. Aceste interogări includ așa-numitele verificări ale existenței. Să presupunem că doriți să obțineți date despre elevii care nu au o notă de șapte puncte. Dacă se returnează un set gol, atunci aceasta înseamnă un singur lucru - fiecare elev are cel puțin o astfel de notă.
Legătura de tabele. Instrucțiunile SQL vă permit să preluați date din mai mult de un tabel. O modalitate de a face acest lucru este să legați tabele folosind un câmp comun.
Instrucțiunea SELECT trebuie să conțină o constrângere privind potrivirea valorilor unei anumite coloane (câmp). Apoi numai acele rânduri în care se potrivesc valorile coloanei specificate vor fi preluate din tabelele aferente. Numele coloanei este indicat numai împreună cu numele tabelului; altfel afirmaţia va fi ambiguă.
Puteți utiliza și alte tipuri de legături de tabele: operatorul INTER JOIN (inner join) asigură că setul de înregistrări rezultat conține valori corespunzătoare în câmpurile aferente. Îmbinările externe (OUTER JOIN) vă permit să includeți în rezultatul interogării toate rândurile dintr-un tabel și rândurile corespunzătoare dintr-un altul
Controlul accesului. SQL asigură sincronizarea procesării bazei de date de către diverse programe de aplicație, protejând datele de accesul neautorizat.
Accesul la date într-un mediu multi-utilizator este controlat folosind instrucțiuni GRANT și REVOKE. În fiecare instrucțiune este necesar să se specifice utilizatorul, obiectul (tabelul, vizualizarea) în raport cu care sunt setate permisiunile și permisiunile în sine. De exemplu, instrucțiunea GRANT oferă utilizatorului X posibilitatea de a prelua date din tabelul PRODUCT:
Acordați SELECTAREA PE PRODUS LUI X
Declarația REVOKE revocă toate permisiunile acordate anterior.
Încorporarea SQL în programele de aplicație. Aplicațiile reale sunt de obicei scrise în alte limbi care generează cod SQL și îl transmit DBMS ca text ASCII.
Standardul IBM pentru produsele SQL reglementează utilizarea limbajului SQL încorporat. Când scrieți un program de aplicație, textul acestuia este un amestec de comenzi din limbajul principal de programare (de exemplu, C, Pascal, Cobol, Fortran, Assembler) și comenzi SQL cu un prefix special, de exemplu. ExecSQL. Structura instrucțiunilor SQL a fost extinsă pentru a se adapta variabilelor limbajului gazdă într-o construcție SQL.
Procesorul SQL modifică tipul de program în conformitate cu cerințele compilatorului limbajului principal de programare. Funcția compilatorului este de a traduce (traduce) un program din limbajul de programare sursă într-un limbaj apropiat de limbajul mașină. După compilare, programul de aplicație (aplicația) este un modul independent.
dialecte SQL
SGBD-urile relaționale moderne folosesc dialectele limbajului SQL pentru a descrie și a manipula datele. Un subset al limbajului SQL care vă permite să creați și să descrieți o bază de date se numește DDL (Data Definition Language).
Inițial, limbajul SQL a fost numit SEQUEL (Structured English Query Language), apoi SEQUEL/2 și apoi pur și simplu SQL. Astăzi, SQL este standardul de facto pentru SGBD-urile relaționale.
Primul standard de limbaj a apărut în 1989 - SQL-89 și a fost susținut de aproape toate SGBD-urile relaționale comerciale. Era de natură generală și supus unei interpretări ample. Avantajele SQL-89 pot fi considerate standardizarea sintaxei și semanticii operatorilor pentru eșantionare și manipulare a datelor, precum și fixarea mijloacelor pentru limitarea integrității bazei de date. Cu toate acestea, lipsea o secțiune atât de importantă precum manipularea schemei bazei de date. Incompletitudinea standardului SQL-89 a dus la apariția în 1992. următoarea versiune a limbajului SQL.
SQL2 (sau SQL-92) acoperă aproape toate problemele necesare: manipularea schemei bazei de date, gestionarea tranzacțiilor și a sesiunilor, suport pentru arhitecturi client-server sau instrumente de dezvoltare a aplicațiilor.
Următorul pas în dezvoltarea limbajului este versiunea SQL 3. Această versiune a limbajului este completată de un mecanism de declanșare, definirea unui tip de date arbitrar și o extensie de obiect.
În prezent există trei niveluri ale limbii: începător, intermediar și complet. Mulți producători de SGBD folosesc propriile lor implementări SQL, bazate cel puțin pe nivelul inițial al standardului ANSI corespunzător și care conțin unele extensii specifice unui anumit SGBD. În tabel 4.9 oferă exemple de dialecte SQL.
Tabelul 4.9 Dialecte SQL
| SGBD | Limbajul de interogare |
| SGBD System R | SQL |
| DB2 | SQL |
| Acces | SQL |
| SYBASE SQL oriunde | Watcom-SQL |
| SYBASE SQL Server | Transact_SQL |
| SQL-ul meu | SQL |
| Oracol | PL/SQL |
Bazele de date orientate pe obiecte folosesc limbajul de interogare obiect OQL (Object Query Language). Limbajul OQL s-a bazat pe comanda SELECT a limbajului SQL2 și a adăugat capacitatea de a direcționa o interogare către un obiect sau colecție de obiecte, precum și capacitatea de a apela metode într-o singură interogare.
Compatibilitatea multor dialecte SQL utilizate determină compatibilitatea DBMS. Astfel, SGBD-ul SYBASE SQL Anywhere este cât se poate de compatibil pentru un SGBD din această clasă cu SGBD-ul SYBASE SQL Server. Unul dintre aspectele acestei compatibilități este suportul în SYBASE SQL Anywhere a unui astfel de dialect al limbajului SQL precum Transact-SQL. Acest dialect este folosit în SYBASE SQL Server și poate fi folosit în SYBASE SQL Anywhere împreună cu dialectul nativ SQL - Watcom-SQL.
Întrebări de control
1. Cum poate fi clasificat un SGBD?
2. Ce modele de baze de date există?
3. Care sunt principalele elemente ale modelelor informaţionale?
4. Ce tipuri de relații există între entități?
5. Ce sunt diagramele ER și pentru ce sunt folosite?
6. Ce vă permite procedura de normalizare a tabelului?
7. Care sunt limbajul și instrumentele software ale SGBD?
8. Ce tip de MS Access DBMS este?
9. Care sunt principalele obiecte ale SGBD-ului MS Access?
10. Pentru ce se folosesc principalii operatori SQL?