Yandex webmaster robots txt analysis. How to tell if a robot will crawl a specific URL
Properly composed robots.txt helps to correctly index the site and eliminates duplicate content that is found in any CMS. I know that many authors are simply scared by the need to go into the root folders of the blog and change something in the “service” files. But this false fear must be overcome. Believe me: your blog will not “collapse” even if you put your own portrait in robots.txt (i.e. ruin it!). But any beneficial changes will increase its status in the eyes of search engines.
What is a robots.txt file?
I won't pretend to be an expert by tormenting you with terms. I’ll just share my rather simple understanding of the functions of this file:
robots.txt– this is an instruction, a road map for search engine robots visiting our blog for inspection. We just need to indicate to them which content is, so to speak, service content, and which is the most valuable content for which readers strive (or should strive) for us. And it is this part of the content that should be indexed and appear in search results!
What happens if we don't care about such instructions? – Everything is indexed. And since the paths of search engine algorithms are practically inscrutable, an article announcement that opens at the archive address may seem more relevant to Yandex or Google than the full text of the article located at a different address. And a visitor, looking at the blog, will see something completely different from what you wanted and what you would like: not post, and lists of all the articles of the month... The result is clear - most likely he will leave.
Although there are examples of sites that have no robotics at all, they occupy decent positions in search results, but this is of course the exception, not the rule.
What does the robots.txt file consist of?
And here I don’t want to rewrite. There are fairly clear first-hand explanations - for example, in the Yandex help section. I highly recommend reading them more than once. But I will try to help you overcome the initial confusion of the abundance of terms by describing the general structure of the robots.txt file.
At the very top, at the beginning of robots.txt, we declare for whom we are writing instructions:
User-agent: Yandex
Of course, every self-respecting search engine has many robots - named and unnamed. Until you've perfected your robots.txt craft, it's best to stick to simplicity and possible generalizations. Therefore, I propose to give Yandex its due, and unite everyone else by writing a general rule:
User-Agent: * - these are all, any, robots
We also indicate the main mirror of the site - the address that will participate in the search. This is especially true if you have multiple mirrors. You can also specify some other parameters. But the most important thing for us, after all, is the ability to block the service parts of the blog from indexing.
Here are examples of prohibiting indexing:
Disallow: /cgi-bin* - script files;
Disallow: /wp-admin* - administrative console;
Disallow: /wp-includes* - service folders;
Disallow: /wp-content/plugins* - service folders;
Disallow: /wp-content/cache* - service folders;
Disallow: /wp-content/themes* - service folders;
Disallow: */feed
Disallow: /comments* - comments;
Disallow: */comments
Disallow: /*/?replytocom=* - replies to comments
Disallow: /tag/* - tags
Disallow: /archive/* - archives
Disallow: /category/* - categories
How to create your own robots.txt file
The easiest and most obvious way is to find an example of a ready-made robots.txt file on some blog and solemnly rewrite it for yourself. It’s good if the authors do not forget to replace the address of the example blog with the address of their brainchild.
Robots of any site are available at:
https://site/robots.txt
I also did the same and I don’t feel I have the right to dissuade you. The only thing I really ask is: figure out what is written in the copied robots.txt file! Use the help of Yandex, any other sources of information - decipher all the lines. Then, for sure, you will see that some rules are not suitable for your blog, and some rules, on the contrary, are not enough.
Now let's see how to check the correctness and effectiveness of our robots.txt file.
Since everything related to the robots.txt file may seem too confusing and even dangerous at first, I want to show you a simple and clear tool for checking it. This is an obvious path that will help you not only check, but also verify your robots.txt, supplementing it with all the necessary instructions and making sure that search engine robots understand what you want from them.
Checking the robots.txt file in Yandex
Yandex webmaster allows us to find out the attitude of the search robot of this system to our creation. To do this, obviously, you need to open the information related to the blog and:
- go to the Tools tab-> Robots.txt analysis
- click the “upload” button and let’s hope that you have placed the robots.txt file where you need it and the robot will find it :) (if it doesn’t find it, check where your file is located: it should be in the root of the blog, where the wp folders are -admin, wp-includes, etc., and below are separate files - robots.txt should be among them)
- click on “check”.
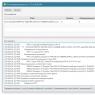
But the most important information is in the next tab - “Sections in Use”! After all, in fact, it is important for us that the robot understands the main part of the information - and let it skip everything else:
Using the example, we see that Yandex understands everything that concerns its robot (lines 1 to 15 and 32) - that’s great!
Checking the robots.txt file in Google
Google, too, has a verification tool that will show us how this search engine sees (or does not see) our robots.txt:
- Google's webmaster tools (where your blog must also be registered) have their own service for checking the robots.txt file. It is located in the Scanning tab
- Having found the file, the system analyzes it and provides information about errors. It's simple.
What you should pay attention to when analyzing the robots.txt file
It is not without reason that we reviewed the analysis tools from the two most important search engines - Yandex and Google. After all, we need to make sure that each of them reads the recommendations we give in robots.txt.
In the examples given here, you can see that Yandex understands the instructions that we left for its robot and ignores all the others (although the same thing is written everywhere, only the User-agent directive: - is different :)))
It is important to understand that any changes to robots.txt must be made directly to the file that is located in your blog root folder. That is, you need to open it in any notepad to rewrite, delete, or add any lines. Then you need to save it back to the root of the site and re-check the response to changes in search engines.
It is not difficult to understand what is written in it and what should be added. And promoting a blog without setting up the robots.txt file properly (the way you need it!) is complicating your task.
Hello dear readers! I would like to dedicate my article today to an important and extremely necessary file robots.txt.
I will try to explain in as much detail as possible, and most importantly, clearly, what function this file has and how to correctly compose it for Wordpress blogs.
The fact is that every second novice blogger makes the same mistake; he does not attach much importance to this file, both because of his illiteracy and lack of understanding of the role for which it is created.
Today we will look at the following questions:
- Why do you need a robots file on the website?
- How to create robots.txt;
- Example of a correct file;
- Robots check in Yandex Webmaster.
What is the robots.txt file used for?
I decided to use the WordPress engine to create my blog, as it is very convenient, simple and multifunctional.
However, there is no one thing that is ideal. The fact is that this cms is designed in such a way that when writing an article, it is automatically duplicated in archives, categories, site search results, .
It turns out that your one article will have several exact copies on the site, but with different URLs.
 As a result, you, unwittingly, fill the project with non-unique content, and search engines will not pat you on the head for such duplicated material and will soon put it under filters: from Yandex or Google.
As a result, you, unwittingly, fill the project with non-unique content, and search engines will not pat you on the head for such duplicated material and will soon put it under filters: from Yandex or Google.
Personally, I was convinced of this by my own example.
When I first started writing this blog, naturally, I had no idea that there was some kind of robots file, much less any idea what it should be and what should be written into it.
The most important thing for me was to write more articles so that in the future I could sell links from them on the exchange. I wanted quick money, but that was not the case...
I wrote about 70 articles, but the Yandex Webmaster panel showed that search robots had indexed 275.
Of course, I suspected that everything could not be so good, but I did not take any action, plus I added the blog to the link exchange sape.ru and began to receive 5 rubles. per day.
And a month later, my project was imposed, all the pages fell out of the index, and thus my profitable shop was closed.
Therefore, you need to tell search engine robots which pages, files, folders, etc. need to be indexed and which ones to avoid.
Robots.txt- a file that gives commands to search engines what can be indexed on a blog and what cannot.
This file is created in a regular text editor (notepad) with the extension txt and is located at the root of the resource.

In the robots.txt file you can specify:
- Which pages, files or folders need to be excluded from indexing;
- Which search engines are completely prohibited from indexing the project;
- Specify the path to the sitemap.xml file (site map);
- Determine the main and additional mirror of the site (with www or without www);
What is contained in robots.txt - a list of commands
So, now we are moving on to the most difficult and important moment, we will analyze the main commands and directives that can be written in the file of WordPress robots platforms.
1) User-agent
In this directive, you indicate which search engine the following rules (commands) will be addressed to.
For example, if you want all the rules to be addressed specifically to the Yandex service, then it states:
User-agent: Yandex
If you need to ask absolutely all search engines, then enter the asterisk “*” and the result will be as follows:
User-agent: *
2) Disallow and Allow
Disallow - prohibits indexing of specified sections, folders or blog pages;
Allow - accordingly allows indexing of these sections;
First you need to specify the Allow directive, and only then Disallow. Also remember that there should be no empty lines between these directives, as well as after the User-agent directive. Otherwise, the search robot will think that the instructions are over.
For example, you want to completely open the site’s indexing, then we write like this:
Allow: /
Disallow:
If we want to ban Yandex from indexing a site, then we write the following:
User-agent: Yandex
Disallow: /
Now let's prevent the file from being indexed rss.html, which is at the root of my site.
Disallow: /rss.html
And this is what this ban on a file located in a folder will look like "posumer".
Disallow: /posumer/rss.html
Now let's ban directories that contain duplicate pages and unnecessary garbage. This means that all files located in these folders will not be accessible to search engine robots.
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Thus, you need to prohibit robots from visiting all pages, folders and files that could negatively affect the development of the site in the future.
3) Host
This directive allows search engine robots to determine which site mirror should be considered the main one (with www or without www). Which in turn will protect the project from complete duplication and, as a result, will save you from applying a filter.
You need to register this directive only for the Yandex search engine, after Disallow and Allow.
Host: website
4) Sitemap
With this command you indicate where your sitemap is located in XML format. If someone has not yet created an XML sitemap for their project, I recommend using my article “”, where everything is described in detail.
Here we need to specify the full address to sitemaps in xml format.
Sitemap: https://site/sitemap.xml
Watch a short video that will very clearly explain how the robots.txt file works.
Example of a valid file
You don’t have to know all the intricacies of setting up the robots file, but just watch how other webmasters compose it and repeat all the steps after them.
My blog site is perfectly indexed by search engines and there are no duplicates or other garbage material in the index.
Here is the file used in this project:
| User-agent: * Disallow: / wp- Host: seoslim. ru Sitemap: https: //site/sitemap.xml User-agent: Googlebot- Image Allow: / wp- content/ uploads/ User- agent: YandexImages Allow: / wp- content/ uploads/ |
User-agent: * Disallow: /wp- Host: site.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
If you want, you can use this as an example, just remember to change the name of my site to yours.
Now let me explain what exactly such a robot will give us. The fact is that if you prohibit some pages in this file using the above-described directives, then search engine robots will still take them into the index, this mainly concerns Google.
If the PS starts to prohibit something, then on the contrary it will definitely index it, just in case. Therefore, we must, on the contrary, allow search engines to index all pages and files of the site, and already prohibit pages that we do not need (pagination, duplicate copies and other garbage) with the following commands using meta tags:
| < meta name= "robots" content= "noindex,follow" /> |
First of all, add the following lines to the .htaccess file:
| RewriteRule (.+ ) / feed / $1 [ R= 301 , L] RewriteRule (.+ ) / comment- page / $1 [ R= 301 , L] RewriteRule (.+ ) / trackback / $1 [ R= 301 , L] RewriteRule (.+ ) / comments / $1 [ R= 301 , L] RewriteRule (.+ ) / attachment / $1 [ R= 301 , L] RewriteCond % ( QUERY_STRING) ^attachment_id= [ NC] RewriteRule (.* ) $1 ? [R= 301, L] |
RewriteRule (.+)/feed /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/trackback /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/attachment /$1 RewriteCond %( QUERY_STRING) ^attachment_id= RewriteRule (.*) $1?
Thus, we set up a redirect from duplicate pages (feed, comment-page, trackback, comments, attachment) to original articles.
This file is located at the root of your site and should look something like this:
| # BEGIN WordPress< IfModule mod_rewrite. c>RewriteEngine On RewriteBase / RewriteCond % ( QUERY_STRING) ^replytocom= [ NC] RewriteRule (.* ) $1 ? [ R= 301 , L] RewriteRule (.+ ) / feed / $1 [ R= 301 , L] RewriteRule (.+ ) / comment- page / $1 [ R= 301 , L] RewriteRule (.+ ) / trackback / $1 [ R= 301 , L] RewriteRule (.+ ) / comments / $1 [ R= 301 , L] RewriteRule (.+ ) / attachment / $1 [ R= 301 , L] RewriteCond % ( QUERY_STRING) ^attachment_id= [ NC] RewriteRule (.* ) $1 ? [ R= 301 , L] RewriteRule ^index\. php$ - [ L] RewriteCond % ( REQUEST_FILENAME) !- f RewriteCond % ( REQUEST_FILENAME) !- d RewriteRule . /index. php[L]#ENDWordPress |
# BEGIN WordPress
| /*** We close pagination pages from indexing using noindex, nofollow ***/ function my_meta_noindex () ( if ( is_paged() // Point to all pagination pages) ( echo "" . "" . "\n"; ) ) add_action("wp_head" , "my_meta_noindex" , 3 ) ; // add the command noindex,nofollow to the head of the template |
/*** We close pagination pages from indexing using noindex, nofollow ***/ function my_meta_noindex () ( if (is_paged() // Point to all pagination pages) (echo ""." "."\n";) ) add_action("wp_head", "my_meta_noindex", 3); // add the noindex,nofollow command to the head of the template
In order to close categories, archives, tags, go to the settings of the All in One Seo Pack plugin and mark everything as in the screenshot:

All settings have been made, now wait until your site is re-indexed so that duplicates fall out of the search results and traffic goes to the top.
In order to clear the results of snot, we had to allow the robots file to index garbage pages, but when the PS robots get to them, they will see noindex meta tags and will not take them into their index.
Checking robots in Yandex Webmaster
After you have correctly compiled the robots.txt file and uploaded it to the root of the site, you can perform a simple check of its functionality in the Webmaster panel.
To do this, go to the Yandex Webmaster panel using this link At the end of the post, I want to say that if you make any changes to the robots.txt file, they will take effect only in a few months. In order for search engine algorithms to decide to exclude a page, they need a deliberate decision - it doesn’t just accept them there. I want you to take the creation of this file seriously, since the future fate of the site will depend on it. If there are any questions, let's solve them together. Leave a comment and it will never go unanswered. See you soon!Conclusion
A site map greatly simplifies the indexing of your blog. Every website and blog must have a site map. But also every website and blog should have a file robots.txt. The robots.txt file contains a set of instructions for search robots. You could say these are the rules of behavior for search robots on your blog. This file also contains the path to the sitemap of your blog. And, in fact, with a correctly composed robots.txt file, the search robot does not waste precious time searching for a sitemap and indexing unnecessary files.
What is the robots.txt file?
robots.txt– this is a text file that can be created in a regular “notepad”, located in the root of your blog, containing instructions for search robots.
These instructions prevent search robots from randomly indexing all your god's files, and focus on indexing exactly those pages that should be included in search results.
Using this file, you can prevent indexing of WordPress engine files. Or, say, the secret section of your blog. You can specify the path to your blog map and the main mirror of your blog. Here I mean your domain name with www and without www.
Site indexing with and without robots.txt
This screenshot clearly shows how the robots.txt file prohibits the indexing of certain folders on the site. Without a file, everything on your site is available to the robot.
Basic directives of the robots.txt file
In order to understand the instructions that the robots.txt file contains, you need to understand the basic commands (directives).
User-agent– this command means robots have access to your site. Using this directive, you can create instructions individually for each robot.
User-agent: Yandex – rules for the Yandex robot
User-agent: * - rules for all robots
Disallow and Allow– prohibition and permission directives. Using the Disallow directive, indexing is prohibited, while Allow allows it.
Example of a ban:
User-agent: *
Disallow: / - ban on the entire site.
User-agent: Yandex
Disallow: /admin – prohibits the Yandex robot from accessing pages located in the admin folder.
Resolution example:
User-agent: *
Allow: /photo
Disallow: / - ban on the entire site, except for pages located in the photo folder.
Note! the Disallow directive: without a parameter allows everything, and the Allow directive: without a parameter prohibits everything. And there should not be an Allow directive without Disallow.
Sitemap– specifies the path to the site map in xml format.
Sitemap: https://site/sitemap.xml.gz
Sitemap: https://site/sitemap.xml
Host– the directive defines the main mirror of your blog. It is believed that this directive is prescribed only for Yandex robots. This directive should be specified at the very end of the robots.txt file.
User-agent: Yandex
Disallow: /wp-includes
Host: website
Note! The main mirror address is specified without specifying the hypertext transfer protocol (http://).
How to create robots.txt
Now that we are familiar with the basic commands of the robots.txt file, we can begin creating our file. In order to create your own robots.txt file with your individual settings, you need to know the structure of your blog.
We will look at creating a standard (universal) robots.txt file for a WordPress blog. You can always add your own settings to it.
So let's get started. We will need a regular “notepad”, which is found in every Windows operating system. Or TextEdit on MacOS.
Open a new document and paste these commands into it:
User-agent: * Disallow: Sitemap: https://site/sitemap.xml.gz Sitemap: https://site/sitemap.xml User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register .php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /xmlrpc.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-content/languages Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: /tag/ Disallow: /feed/ Disallow: */*/feed/ */ Disallow: */feed Disallow: */*/feed Disallow: /?feed= Disallow: /*?* Disallow: /?s= Host: site
Don't forget to replace the parameters of the Sitemap and Host directives with your own.
Important! When writing commands, only one space is allowed. Between directive and parameter. Under no circumstances should you put spaces after a parameter or just anywhere.
Example:
Disallow:<пробел>/feed/
This example robots.txt file is universal and fits any WordPress blog with CNC URLs. Read about what CNC is. If you have not configured the CNC, I recommend removing Disallow: /*?* Disallow: /?s= from the proposed file

Uploading the robots.txt file to the server
The best way for this kind of manipulation is an FTP connection. Read about how to set up an FTP connection for TotolCommander. Or you can use a file manager on your hosting.
I will use an FTP connection on TotolCommander.
Network > Connect to FTP server.

Select the desired connection and click the “Connect” button.

Open the root of the blog and copy our robots.txt file by pressing the F5 key.

Copying robots.txt to the server
Now your robots.txt file will perform its proper functions. But I still recommend analyzing robots.txt to make sure there are no errors.
To do this, you will need to log into your Yandex or Google webmaster account. Let's look at the example of Yandex. Here you can conduct an analysis even without confirming your rights to the site. All you need is a Yandex mailbox.
Open the Yandex.webmaster account.

On the main page of the webmaster's account, open the link "Checkrobots.txt".

To analyze, you will need to enter the URL address of your blog and click the “ Download robots.txt from the site" As soon as the file is downloaded, click the button "Check".

The absence of warning entries indicates that the robots.txt file was created correctly.

The result will be presented below. Where it is clear and understandable which materials are allowed to be shown to search robots and which are prohibited.

The result of analyzing the robots.txt file
Here you can make changes to robots.txt and experiment until you get the result you want. But remember, the file located on your blog does not change. To do this, you will need to copy the result obtained here into a notepad, save it as robots.txt and copy the blog to you.
By the way, if you are wondering what the robots.txt file looks like on someone's blog, you can easily look at it. To do this, you just need to add /robots.txt to the site address
https://site/robots.txt
Now your robots.txt is ready. And remember, don’t put off creating the robots.txt file, the indexing of your blog will depend on it.
If you want to create the correct robots.txt and at the same time be sure that only the necessary pages will be included in the search engine index, then this can be done automatically using the plugin.
That's all I have. I wish you all success. If you have any questions or additions, write in the comments.
See you soon.
Best regards, Maxim Zaitsev.
Subscribe to new articles!
- This is the appearance in the search of pages that do not carry any useful information for the user, and most likely the user will not visit them anyway, and if he does, it will not be for long.
- This is the appearance in searches of copies of the same page with different addresses. (Duplicate content)
- This wastes precious time on indexing unnecessary pages by search robots. The search robot, instead of engaging in necessary and useful content, will waste time uselessly wandering around the site. And since robots do not index the entire site at once (there are many sites and everyone needs attention), you may not see the important pages that you want to see in the search very soon.
It was decided to block access for search robots to some pages of the site. The robots.txt file will help us with this.
Why do you need robots.txt?
robots.txt is a regular text file that contains instructions for search robots. The first thing a search robot does when it hits a site is look for the robots.txt file. If the robots.txt file is not found or is empty, the crawler will wander through all available pages and directories on the site (including system directories) in an attempt to index the content. And it’s not a fact that it will index the page you need, if it gets to it at all.
Using robots.txt, we can tell search robots which pages they can visit and how often, and where they should not go. Instructions can be specified for all robots, or for each robot individually. Pages that are closed from search robots will not appear in search engines. If this file does not exist, then it must be created.
The robots.txt file should be located on the server, at the root of your site. The robots.txt file can be viewed on any website on the Internet; to do this, just add /robots.txt after the website address. For the site, the address where you can view robots..txt.
The robots.txt file, usually each site has its own characteristics, and thoughtlessly copying someone else’s file can create problems with indexing your site by search robots. Therefore, we need to clearly understand the purpose of the robots.txt file and the purpose of the instructions (directives) that we will use when creating it.
Robots.txt file directives.
Let's look at the basic instructions (directives) that we will use when creating the robots.txt file.
User-agent: — specify the name of the robot for which all the instructions below will work. If instructions need to be used for all robots, then use * (asterisk) as the name.
For example:
User-agent:*
#instructions apply to all search robots
User-agent: Yandex
#instructions apply only to the Yandex search robot
The names of the most popular Runet search engines are Googlebot (for Google) and Yandex (for Yandex). The names of other search engines, if interested, can be found on the Internet, but it seems to me that there is no need to create separate rules for them.
Disallow – prohibits search robots from accessing some parts of the site or the entire site.
For example:
Disallow /wp-includes/
#denies robots access to wp-includes
Disallow /
# prevents robots from accessing the entire site.
Allow – allows search robots access to some parts of the site or the entire site.
For example:
Allow /wp-content/
#allows robots access to wp-content
Allow /
#Allows robots access to the entire site.
Sitemap: - can be used to specify the path to a file describing the structure of your site (site map). It is needed to speed up and improve site indexing by search robots.
For example:
.xml
Host: - If your site has mirrors (copies of the site on another domain)..site. Using the Host file, you can specify the main mirror of the site. Only the main mirror will participate in the search.
For example:
Host: website
You can also use special characters. *# and $
*(asterisk) – denotes any sequence of characters.
For example:
Disallow /wp-content*
#denies robots access to /wp-content/plugins, /wp-content/themes, etc.
$(dollar sign) – By default, each rule is expected to have an *(asterisk) at the end of the rule; to override the *(asterisk) character, you can use the $(dollar sign) character.
For example:
Disallow /example$
#denies robots access to /example but does not deny access to /example.html
#(pound sign) – can be used for comments in the robots.txt file
More details about these directives, as well as several additional ones, can be found on the Yandex website.
How to write robots.txt for WordPress.
Now let's start creating the robots.txt file. Since our blog runs on WordPress, let’s look at the creation process robots.txt for WordPress in details.
First, we need to decide what we want to allow search robots and what to prohibit. I decided to leave only the essentials for myself, these are posts, pages and sections. We will close everything else.
We can see what folders are in WordPress and what needs to be closed if we look at the directory of our site. I did this through the hosting control panel on the site reg.ru, and saw the following picture.
 Let's look at the purpose of the directories and decide what can be closed.
Let's look at the purpose of the directories and decide what can be closed.
/cgi-bin (directory of scripts on the server - we don’t need it in the search.)
/files (directory with files for downloading. Here, for example, is an archive file with an Excel table for calculating profits, which I wrote about in the article ““. We do not need this directory in the search.)
/playlist (I made this directory for myself, for playlists on IPTV - it’s not needed in the search.)
/test (I created this directory for experiments; this directory is not needed in the search)
/wp-admin/ (WordPress admin, we don’t need it in search)
/wp-includes/ (system folder from WordPress, we don’t need it in the search)
/wp-content/ (from this directory we only need /wp-content/uploads/; this directory contains pictures from the site, so we will prohibit the /wp-content/ directory, and allow the directory with pictures with a separate instruction.)
We also do not need the following addresses in the search:
Archives – addresses like //site/2013/ and similar.
Tags - the tag address contains /tag/
RSS feeds - all feeds have /feed in their address
Just in case, I will close the addresses with PHP at the end, since many pages are available, both with PHP at the end and without. This, it seems to me, will avoid duplication of pages in the search.
I will also close addresses with /GOTO/; I use them to follow external links; they definitely have nothing to do in searches.
P=209 and site search //site/?s=, as well as comments (addresses containing /?replytocom=)
Here's what we should be left with:
/images (I put some pictures in this directory, let robots visit this directory)
/wp-content/uploads/ - contains images from the site.
Articles, pages and sections that contain clear, readable addresses.
For example: or
Now let’s come up with instructions for robots.txt. Here's what I got:
#We indicate that these instructions will be executed by all robots
User-agent: *
#We allow robots to roam the uploads directory.
Allow: /wp-content/uploads/
#Forbid the folder with scripts
Disallow: /cgi-bin/
#Forbid the files folder
Disallow: /files/
#Forbid the playlist folder
Disallow: /playlist/
#Forbid the test folder
Disallow: /test/
#We prohibit everything that begins with /wp- , this will allow you to close several folders at once whose names begin with /wp- , this command may well prevent the indexing of pages or posts that begin with /wp-, but I do not plan to give such names.
Disallow: /wp-*
#We prohibit addresses containing /?p= and /?s=. These are short links and search.
Disallow: /?p=
Disallow: /?s=
#We ban all archives before 2099.
Disallow: /20
#We prohibit addresses with a PHP extension at the end.
Disallow: /*.php
#We prohibit addresses that contain /goto/. I didn’t have to write it down, but I’ll put it in just in case.
Disallow: /goto/
#We prohibit tag addresses
Disallow: /tag/
#We ban all feeds.
Disallow: */feed
#We prohibit indexing of comments.
Disallow: /?replytocom=
#And finally, we write the path to our site map.
.xml
Write file robots.txt for WordPress You can use a regular notepad. Let's create a file and write the following lines into it.
User-agent: *
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
.xml
At first, I planned to make one common block of rules for all robots, but Yandex refused to work with the common block. I had to make a separate block of rules for Yandex. To do this, I simply copied the general rules, changed the name of the robot and pointed the robot to the main mirror of the site using the Host directive.
User-agent: Yandex
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
.xml
Host: website
You can also specify the main mirror of the site through, in the “Main Mirror” section

Now that the file robots.txt for WordPress created, we need to upload it to the server, to the root directory of our site. This can be done in any way convenient for you.
You can also use the WordPress SEO plugin to create and edit robots.txt. I will write more about this useful plugin later. In this case, you don’t have to create a robots.txt file on the desktop, but simply paste the code of the robots.txt file into the appropriate section of the plugin.

How to check robots.txt
Now that we have created the robots.txt file, we need to check it. To do this, go to the Yandex.Webmaster control panel. Next, go to the “Indexing setup” section, and then “robots.txt analysis”. Here we click the “Load robots.txt from the site” button, after which the contents of your robots.txt should appear in the corresponding window.

Then click “add” and in the window that appears, enter various urls from your site that you want to check. I entered several addresses that should be denied and several addresses that should be allowed.

Click the “Check” button, after which Yandex will give us the results of checking the robots.txt file. As you can see, our file passed the test successfully. What should be prohibited for search robots is prohibited here. What should be allowed is allowed here.

The same check can be carried out for the Google robot, through GoogleWebmaster, but it is not much different from checking through Yandex, so I will not describe it.
That's all. We created robots.txt for WordPress and it works great. All that remains is to occasionally look at the behavior of search robots on our site. To notice an error in time and, if necessary, make changes to the robots.txt file. The pages that were excluded from the index and the reason for the exclusion can be viewed in the corresponding section of Yandex.WebMaster (or GoogleWebmaster).
Good Investments and success in all your endeavors.