Removing pages from the search engine index. What bonuses does a non-existent page in Odnoklassniki give?
— The storage period for the uploaded file to the file hosting service has expired
— Changing the structure of the blog/site
— Changing page addresses on the site or implementing CNC
— The addresses of the pages of the sites you link to have changed
In the process of such changes, dozens of non-existent pages may appear that your resource will link to.
It’s easy to find such non-existent pages. It is enough to know several services and be able to use them.
We will look at the 4 main methods of checking a site for broken links, and you will decide which one to use for yourself.
On-line services for checking broken links:
I found many different services on the Internet, but I can only recommend 2 that really accurately identify problematic links:
— creatingonline.com
— anybrowser.com
I won’t describe the principle of their operation, everything is very simple. Enter the URL you are interested in into the verification form and press the verification button. After a certain period of time has elapsed, a page with the results of the scan will appear.
Using Yandex
IN webmaster panels We follow the path – – Excluded pages and follow the link HTTP status: Resource not found (404). The screenshot shows the path.

After you click on the link, a window will open, at the bottom of which there will be a list of links to non-existent pages from your site. In the same window there will be information about the robot’s last visit to the page and links to problematic pages indicated by a small square with a down arrow. Now you need to follow these links and correct the situation.

Via Google
In the same way we go through authorization in webmaster panels and follow the path – Scanning – Scanning errors. In the lower half of the page we see a list of links to non-existent pages. There is one wonderful option in the Google Webmaster Panel that allows you to mark links to non-existent pages that you have previously corrected. I showed her.

Xenu Link Sleuth program
Follow the link and download program. Then we install it. Once the installation is complete, launch the program and enter the address of the resource being checked. Click the OK button, and the program begins collecting information.

Busy – queued for review.

After finishing collecting information, the program will sound a sound signal indicating the completion of the work, and you can view a report on the work performed. A very good program, I use it all the time.
And the last method we will look at is checking the site for broken links using the Broken Link Checker plugin.
For this download the plugin, activate it and go to the address – Options – Check links and go to the Advanced tab in which we click Recheck all pages.
If you have a large website with a large number of pages, then search promotion of such a project often comes down to identifying and eliminating many technical problems.
One of the common errors is the presence of broken links to pages with a “404 not found” response code. Moreover, pages with 404 errors may be linked to from other sites, and their weight will be lost. In this article, you will learn how to regain lost external link weight.
“I can tell you for sure that on a more or less large website something breaks all the time”
— Mikhail Slivinsky (Wikimart.ru), SEO Conference 2014.
The essence of the method
Links from other sites don't carry weight if they point to broken pages on your site. The task is to set up a redirect (301 redirect) from non-existent pages that have incoming links to other relevant pages on the site. This way, the weight of incoming external links will begin to be transferred to the site.
This method is more suitable for older projects with a large number of pages. The operating algorithm is as follows:
1. Search and compile a list of pages with 404 errors.
2. Checking the received URLs for the presence of incoming external links.
3. Installing 301 redirects from broken pages to suitable working pages.
How to Find 404 Error Pages and Other Broken Pages
At this stage, you need to identify non-existent pages on the site, pages with errors and compile as detailed a list of URLs as possible. There are several tools for this, which will be discussed in detail below.
Yandex.Webmaster and Google Webmaster Tools panels
If your site has not yet been added to the Yandex and Google webmaster panels, be sure to add it now. This way you can promptly identify broken links and other indexing errors.
To get a list of pages with 404 errors in the Yandex.Webmaster panel, go to http://webmaster.yandex.ru/sites/ in the “Site Indexing” → “Excluded Pages” section.
(click on image to enlarge) 
To get a list of non-existent pages from the Google Webmaster Tools panel ( https://www.google.com/webmasters/tools/) follow the link “Scanning errors”.
(click on image to enlarge) 
The page will contain a list of URLs with errors. You can export the list by clicking the “Download” button and selecting a convenient upload format.
(click on image to enlarge) 
Crawlers programs
Here you can highlight well-known programs for searching for broken links and duplicates:
All of them allow you to find on the site and download a list of pages with 404 errors. For these purposes, I use Screaming Frog Seo Spider, since it has a version for Mac, unlike the others. Using Screaming Frog as an example, the list of 404 pages is unloaded like this:
(click on image to enlarge) 
Server error log
If possible, it is worth looking at the server error log. This is usually the "error_log" file. Depending on the software used on the server, the error log may differ. But the essence is still the same - look at the server error log and download from it a list of URLs with 404 errors.
The resulting lists of links must be combined into one list and duplicates removed. There are many ways to do this, but I use the text editor Sublime Text 2 (on Windows I recommend Notepad++ with the TextFX plugin).
(click on image to enlarge) 
Checking the list of broken pages for incoming links
To check the final list of URLs for the presence of incoming links from other sites, use the Ahrefs.com service, namely the “Batch Analysis” section - https://ahrefs.com/labs/batch-analysis/.
(click on image to enlarge) 
Unfortunately, this function has a limit of 200 urls per 1 request on paid plans and 2 urls per 1 request on free plans. Therefore, you need to enter your list into several portions of 200 addresses. After each check, you need to export to a file.
(click on image to enlarge) 
The resulting downloads of 200 URLs need to be combined into 1 table. To do this, you need to open 1 file and copy the contents of other files to the end. Extra columns can be removed. We are only interested in the “Total” column; it means the total number of external links to the page.
(click on image to enlarge) 
The resulting list needs to be sorted and the rows in which “Total” is equal to zero removed. As a result, you will end up with a list of broken pages that have incoming links from other sites.
Selection of pages for redirect
The resulting list needs to be uploaded again to Batch Analysis on Ahrefs so that you can see from which sites and with which anchors there are links to each page of our list. To do this, use the icon next to the url address.
(click on image to enlarge) 
Next, you need to look at which pages and with which anchors external sites linked. For convenience, create a table with two columns, which will contain a list of broken addresses and a list of “live” addresses to which the redirect will go. If the url of a page on your site has simply changed, then enter the new page url. In other cases, select the most relevant page in your opinion, based on the text of the donor page and anchor.
(click on image to enlarge) 
Setting up 301 redirects to new pages
At the end, all that remains is to add the necessary commands for the .htaccess file. To redirect from one page to another, use the following command:
For each address of the final table, you need to write the following command and add it to the “.htaccess” file. At this stage, I recommend using the services of a programmer to ensure everything works correctly.
As a result, we will receive link juice for free, simply by not losing it.
Hello, friends! In today's article we will talk to you about achievements: what they are, what rewards you can get and what you need to do for this, and how to spend the accumulated points.
The developers of the social network Odnoklassniki decided that if a user is active on the site, then he needs to be encouraged in some way for this. That is why Odnoklassniki has a whole “Achievements” section, where you can see your awards and the number of points accumulated for them. But let's talk about everything in order.
Achievements are a special section on the Odnoklassniki website, where the user can view all the awards received, which are given for active use of the site and fulfillment of certain conditions.
How to view achievements
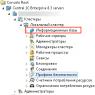
If you are wondering where this list is located, then on your page, click on the “More” menu item. Then select the appropriate item from the drop-down list.
The required page will open. On the “My Achievements” tab, icons will be shown - these are, in a way, rewards. If the icon is gray, it means you have not yet met the conditions to receive it; if the icon looks like a color image, then the reward is yours.

How to get achievements
To do this, you need to complete a task that corresponds to it. To view the task, hover your mouse over the desired italic icon. A pop-up window will appear describing what needs to be done to receive the selected reward.
They are divided into groups: Missions, Photos, Videos, Groups, Music and Games. The tasks are very varied: use Odnoklassniki from your phone, upload a certain number of photos to the site, participate in discussions and photo competitions, create your own group, etc. The most incomprehensible task, in my opinion, is this. By following the link, you can read a detailed article about this.
For each reward received, a certain number of points are awarded, exactly how many are shown at the bottom of the pop-up window in the “Bonus” field.

How to spend achievement points
Now let's talk about why accumulated points are needed. You can see how many points you have on the page in the upper right corner in the “Accumulated Points” field.

How to view achievements in the Odnoklassniki mobile app from your phone
If you use the Odnoklassniki mobile application, you can view them as follows. Open the side menu and click on your profile name.

There are menu items under the avatar; click on the arrow to open the entire list, and select “Achievements” from it.

There are two tabs at the top of the page. The My tab shows all the icons. If the icon is gray, it means you have not yet fulfilled the condition; if it is colored, it means that you are awarded points for this achievement. To see what needs to be done, click on the icon.

After you click on the icon, a small window will appear containing a description. There you can see how many points will be awarded for fulfilling the condition.

I think you understand what Achievements in Odnoklassniki mean, where they are located, and how to see the condition that must be met to receive a reward.
Recently someone asked me about a feature of Google. We were talking about site indexing. Google has added non-existent pages with bizarre URLs to its index. Moreover, many of them were closed in robots.txt. Answering the question, in order to help the reader of my site, I did not notice how I wrote a short article.
The question turned out to be very familiar to me. A couple of years ago, I myself was looking harder for the answer to this question, when I had the task of aligning the ratio of indexed pages for several sites in the search engine index before monetizing them. Whatever I did, physically removed it from the index, closed it in robots.txt, edited site templates and engine source files. Absolutely nothing helped, and my more experienced colleagues did not help me at the time.
This problem has turned out to be everywhere, but not many people pay attention to it. Google does not make saved copies of pages closed in robots.txt, but adds all found URLs to its database. If you search among all the pages on the site, Google will return a bunch of non-existent pages. Code 404 and closing in robots.txt do not help. That’s why, if you crawl a dozen different sites, the number of pages indexed in Google will be greater, sometimes by a couple of pages, and for large sites the difference can reach several hundred pages.
Google adds absolutely all URLs to which it finds links to its index. In most cases, these are internal links (due to CMS deployment errors on the server, there may be broken links in the code, this very often happens when the CNC is configured incorrectly), they can also be external links (someone wrote a link to your site on some some forum and made a mistake in spelling).
In addition, some pages are very often deleted on sites - the URL has been changed or the material has been physically removed; the page will still remain in the index, only saved as an empty link.
In any case, these “dummy pages” will not appear in the results for any queries, unless we look at the total number of indexed pages. The difference between the actual number of pages on the site and the indexed one plays a role only when monetizing the site. If there is a large gap, space for selling links will sell out less quickly.
Methods of control and prevention
There are ways to avoid such situations, let’s consider solutions:
- In the panel Google Webmasters It is possible to physically remove unwanted pages from the index. If a page is closed in robots.txt or displays a 404 error code, upon receiving a request for deletion, the page leaves the index within a couple of days. If there are a lot of “dummy pages”, this method is not suitable, because for each page you need to submit a separate application, which in total will take a lot of time.
- The second method is more complicated, but it will permanently rid the site of the described problem. You need to hide the page from indexing using the robots construct, which is written in the head section directly on the page. Here's what it looks like:
You need to configure the site engine in such a way that when a 404 error occurs, a stub is loaded - its own error page (this can be configured with literally one line in .htaccess on Unix hosting). In the head section of this stub page we write the above code. Now, when Google detects broken links, it will not add them to the index.
Google developers explain this original approach to indexing by the fact that often pages that produce a 404 error code are not accessible only for a short time due to incorrect server settings or some kind of database failure. At the same time, very often such pages contain useful content. Google adds such pages to the index in the hope that they will eventually work. But this is why Google ignores robots.txt instructions - there are no objective explanations for this, but in practice, this is often what happens.