Cryptography. Ciphers, their types and properties. Traditional encryption methods
Sergey Panasenko,
Head of the software development department at Ankad,
[email protected]
Basic Concepts
The process of converting open data into encrypted data and vice versa is usually called encryption, and the two components of this process are called encryption and decryption, respectively. Mathematically, this transformation is represented by the following dependencies that describe actions with the original information:
C = Ek1(M)
M" = Dk2(C),
where M (message) is open information (in the literature on information security it is often called “source text”);
C (cipher text) - the ciphertext (or cryptogram) obtained as a result of encryption;
E (encryption) - an encryption function that performs cryptographic transformations on the source text;
k1 (key) - parameter of function E, called the encryption key;
M" - information obtained as a result of decryption;
D (decryption) - decryption function that performs inverse cryptographic transformations on the ciphertext;
k2 is the key used to decrypt information.
The concept of “key” in the GOST 28147-89 standard (symmetric encryption algorithm) is defined as follows: “a specific secret state of some parameters of a cryptographic transformation algorithm, ensuring the selection of one transformation from a set of possible transformations for a given algorithm.” In other words, the key is a unique element with which you can change the results of the encryption algorithm: the same source text will be encrypted differently when using different keys.
In order for the decryption result to match the original message (i.e., for M" = M), two conditions must be met simultaneously. First, the decryption function D must match the encryption function E. Second, the decryption key k2 must match encryption key k1.
If a cryptographically strong encryption algorithm was used for encryption, then in the absence of the correct key k2 it is impossible to obtain M" = M. Cryptographic strength is the main characteristic of encryption algorithms and primarily indicates the degree of complexity of obtaining the original text from an encrypted text without a key k2.
Encryption algorithms can be divided into two categories: symmetric and asymmetric encryption. For the former, the ratio of encryption and decryption keys is defined as k1 = k2 = k (i.e., functions E and D use the same encryption key). With asymmetric encryption, the encryption key k1 is calculated from the key k2 in such a way that the reverse transformation is impossible, for example, using the formula k1 = ak2 mod p (a and p are the parameters of the algorithm used).
Symmetric encryption
Symmetric encryption algorithms date back to ancient times: it was this method of hiding information that was used by the Roman emperor Gaius Julius Caesar in the 1st century BC. e., and the algorithm he invented is known as the “Caesar cryptosystem.”
Currently, the best known symmetric encryption algorithm is DES (Data Encryption Standard), developed in 1977. Until recently, it was the “US standard”, since the government of this country recommended its use for implementing various data encryption systems. Despite the fact that DES was originally planned to be used for no more than 10-15 years, attempts to replace it began only in 1997.
We will not consider DES in detail (almost all books on the list of additional materials have a detailed description of it), but will turn to more modern encryption algorithms. It is only worth noting that the main reason for changing the encryption standard is its relatively weak cryptographic strength, the reason for which is that the DES key length is only 56 significant bits. It is known that any strong encryption algorithm can be cracked by trying all possible encryption keys (the so-called brute force attack). It is easy to calculate that a cluster of 1 million processors, each of which calculates 1 million keys per second, will check 256 variants of DES keys in almost 20 hours. And since such computing power is quite realistic by today's standards, it is clear that a 56-bit key is too short and the DES algorithm needs to be replaced with a stronger one.
Today, two modern strong encryption algorithms are increasingly used: the domestic standard GOST 28147-89 and the new US crypto standard - AES (Advanced Encryption Standard).
Standard GOST 28147-89
The algorithm defined by GOST 28147-89 (Fig. 1) has an encryption key length of 256 bits. It encrypts information in blocks of 64 bits (such algorithms are called block algorithms), which are then divided into two subblocks of 32 bits (N1 and N2). Subblock N1 is processed in a certain way, after which its value is added with the value of subblock N2 (the addition is performed modulo 2, i.e. the logical XOR operation is applied - “exclusive or”), and then the subblocks are swapped. This transformation is performed a certain number of times (“rounds”): 16 or 32, depending on the operating mode of the algorithm. In each round, two operations are performed.
The first is keying. The contents of subblock N1 are added modulo 2 with the 32-bit part of the key Kx. The full encryption key is represented as a concatenation of 32-bit subkeys: K0, K1, K2, K3, K4, K5, K6, K7. During the encryption process, one of these subkeys is used, depending on the round number and the operating mode of the algorithm.
The second operation is table replacement. After keying, subblock N1 is divided into 8 parts of 4 bits, the value of each of which is replaced in accordance with the replacement table for this part of the subblock. The subblock is then bit-rotated to the left by 11 bits.
Table substitutions(Substitution box - S-box) are often used in modern encryption algorithms, so it is worth explaining how such an operation is organized. The output values of the blocks are recorded in the table. A data block of a certain dimension (in our case, 4-bit) has its own numerical representation, which determines the number of the output value. For example, if the S-box looks like 4, 11, 2, 14, 15, 0, 8, 13, 3, 12, 9, 7, 5, 10, 6, 1 and the 4-bit block “0100” came to the input (value 4), then, according to the table, the output value will be 15, i.e. “1111” (0 a 4, 1 a 11, 2 a 2 ...).
The algorithm, defined by GOST 28147-89, provides four modes of operation: simple replacement, gamma, gamma with feedback and generation of imitation attachments. They use the same encryption transformation described above, but since the purpose of the modes is different, this transformation is carried out differently in each of them.
In mode easy replacement To encrypt each 64-bit block of information, the 32 rounds described above are performed. In this case, 32-bit subkeys are used in the following sequence:
K0, K1, K2, K3, K4, K5, K6, K7, K0, K1, etc. - in rounds 1 to 24;
K7, K6, K5, K4, K3, K2, K1, K0 - in rounds 25 to 32.
Decryption in this mode is carried out in exactly the same way, but with a slightly different sequence of using subkeys:
K0, K1, K2, K3, K4, K5, K6, K7 - in rounds 1 to 8;
K7, K6, K5, K4, K3, K2, K1, K0, K7, K6, etc. - in rounds 9 to 32.
All blocks are encrypted independently of each other, i.e., the encryption result of each block depends only on its contents (the corresponding block of the original text). If there are several identical blocks of original (plain) text, the corresponding ciphertext blocks will also be identical, which provides additional useful information for a cryptanalyst trying to crack the cipher. Therefore, this mode is used mainly for encrypting the encryption keys themselves (multi-key schemes are very often implemented, in which, for a number of reasons, the keys are encrypted on each other). Two other operating modes are intended for encrypting the information itself - gamma and gamma with feedback.
IN gamma mode Each plaintext block is added bit by bit modulo 2 to a 64-bit cipher gamma block. The gamma cipher is a special sequence that is obtained as a result of certain operations with registers N1 and N2 (see Fig. 1).
1. Their initial filling is written to registers N1 and N2 - a 64-bit value called a synchronization message.
2. The contents of registers N1 and N2 (in this case, sync messages) are encrypted in simple replacement mode.
3. The contents of register N1 are added modulo (232 - 1) with the constant C1 = 224 + 216 + 28 + 24, and the result of the addition is written to register N1.
4. The contents of register N2 are added modulo 232 with the constant C2 = 224 + 216 + 28 + 1, and the result of the addition is written to register N2.
5. The contents of registers N1 and N2 are output as a 64-bit gamma block of the cipher (in this case, N1 and N2 form the first gamma block).
If the next gamma block is needed (i.e., encryption or decryption needs to continue), it returns to step 2.
For decryption, gamma is generated in a similar manner, and then the ciphertext and gamma bits are again XORed. Since this operation is reversible, in the case of a correctly developed scale, the original text (table) is obtained.
Encryption and decryption in gamma mode
To develop the cipher needed to decrypt the gamma, the user decrypting the cryptogram must have the same key and the same value of the synchronization message that were used when encrypting the information. Otherwise, it will not be possible to obtain the original text from the encrypted one.
In most implementations of the GOST 28147-89 algorithm, the synchronization message is not secret, however, there are systems where the synchronization message is the same secret element as the encryption key. For such systems, the effective key length of the algorithm (256 bits) is increased by another 64 bits of the secret synchronization message, which can also be considered as a key element.
In the feedback gamma mode, to fill the N1 and N2 registers, starting from the 2nd block, it is not the previous gamma block that is used, but the result of encrypting the previous plaintext block (Fig. 2). The first block in this mode is generated completely similarly to the previous one.
 |
Rice. 2. Development of a cipher gamma in the gamma mode with feedback. |
Considering the mode generation of imitation prefixes, the concept of the subject of generation should be defined. A prefix is a cryptographic checksum calculated using an encryption key and designed to verify the integrity of messages. When generating an imitation prefix, the following operations are performed: the first 64-bit block of the information array, for which the imitation prefix is calculated, is written to registers N1 and N2 and encrypted in the reduced simple replacement mode (the first 16 rounds out of 32 are performed). The resulting result is summed modulo 2 with the next block of information and the result is stored in N1 and N2.
The cycle repeats until the last block of information. The resulting 64-bit contents of the N1 and N2 registers or part of them as a result of these transformations is called the imitation prefix. The size of the imitation prefix is selected based on the required reliability of messages: with the length of the imitation prefix r bits, the probability that a change in the message will go unnoticed is equal to 2-r. Most often, a 32-bit imitation prefix is used, i.e., half the contents of the registers. This is enough, since, like any checksum, the imitation attachment is intended primarily to protect against accidental distortion of information. To protect against intentional modification of data, other cryptographic methods are used - primarily an electronic digital signature.
When exchanging information, the imitation prefix serves as a kind of additional means of control. It is calculated for the plaintext when any information is encrypted and is sent along with the ciphertext. After decryption, a new value of the imitation prefix is calculated and compared with the sent one. If the values do not match, it means that the ciphertext was corrupted during transmission or incorrect keys were used during decryption. The imitation prefix is especially useful for checking the correct decryption of key information when using multi-key schemes.
The GOST 28147-89 algorithm is considered a very strong algorithm - currently no more effective methods have been proposed for its disclosure than the “brute force” method mentioned above. Its high security is achieved primarily due to the large key length - 256 bits. When using a secret sync message, the effective key length increases to 320 bits, and encrypting the replacement table adds additional bits. In addition, cryptographic strength depends on the number of transformation rounds, which according to GOST 28147-89 should be 32 (the full effect of input data dispersion is achieved after 8 rounds).
AES standard
Unlike the GOST 28147-89 algorithm, which remained secret for a long time, the American AES encryption standard, designed to replace DES, was selected through an open competition, where all interested organizations and individuals could study and comment on the candidate algorithms.
A competition to replace DES was announced in 1997 by the US National Institute of Standards and Technology (NIST - National Institute of Standards and Technology). 15 candidate algorithms were submitted to the competition, developed by both well-known organizations in the field of cryptography (RSA Security, Counterpane, etc.) and individuals. The results of the competition were announced in October 2000: the winner was the Rijndael algorithm, developed by two cryptographers from Belgium, Vincent Rijmen and Joan Daemen.
The Rijndael algorithm is not similar to most known symmetric encryption algorithms, the structure of which is called the “Feistel network” and is similar to the Russian GOST 28147-89. The peculiarity of the Feistel network is that the input value is divided into two or more subblocks, part of which in each round is processed according to a certain law, after which it is superimposed on unprocessed subblocks (see Fig. 1).
Unlike the domestic encryption standard, the Rijndael algorithm represents a data block in the form of a two-dimensional byte array of size 4X4, 4X6 or 4X8 (the use of several fixed sizes of the encrypted block of information is allowed). All operations are performed on individual bytes of the array, as well as on independent columns and rows.
The Rijndael algorithm performs four transformations: BS (ByteSub) - table replacement of each byte of the array (Fig. 3); SR (ShiftRow) - shift of array rows (Fig. 4). With this operation, the first line remains unchanged, and the rest are cyclically shifted byte-by-byte to the left by a fixed number of bytes, depending on the size of the array. For example, for a 4X4 array, lines 2, 3 and 4 are shifted by 1, 2 and 3 bytes respectively. Next comes MC (MixColumn) - an operation on independent array columns (Fig. 5), when each column is multiplied by a fixed matrix c(x) according to a certain rule. And finally, AK (AddRoundKey) - adding a key. Each bit of the array is added modulo 2 with the corresponding bit of the round key, which, in turn, is calculated in a certain way from the encryption key (Fig. 6).
 |
| Rice. 3. Operation BS. |
 |
| Rice. 4. Operation SR. |
 |
| Rice. 5. Operation MC. |
The number of encryption rounds (R) in the Rijndael algorithm is variable (10, 12 or 14 rounds) and depends on the block size and the encryption key (there are also several fixed sizes for the key).
Decryption is performed using the following reverse operations. A table inversion and table replacement are performed on the inverse table (relative to the one used during encryption). The inverse operation to SR is to rotate rows to the right rather than to the left. The inverse operation for MC is multiplication using the same rules by another matrix d(x) satisfying the condition: c(x) * d(x) = 1. Adding the key AK is the inverse of itself, since it only uses the XOR operation. These reverse operations are applied during decryption in the reverse sequence to that used during encryption.
Rijndael has become the new standard for data encryption due to a number of advantages over other algorithms. First of all, it provides high encryption speed on all platforms: both software and hardware implementation. It is distinguished by incomparably better possibilities for parallelizing calculations compared to other algorithms submitted to the competition. In addition, the resource requirements for its operation are minimal, which is important when used in devices with limited computing capabilities.
The only disadvantage of the algorithm can be considered its inherent unconventional scheme. The fact is that the properties of algorithms based on the Feistel network have been well researched, and Rijndael, in contrast, may contain hidden vulnerabilities that can only be discovered after some time has passed since its widespread use began.
Asymmetric encryption
Asymmetric encryption algorithms, as already noted, use two keys: k1 - the encryption key, or public, and k2 - the decryption key, or secret. The public key is calculated from the secret: k1 = f(k2).
Asymmetric encryption algorithms are based on the use of one-way functions. By definition, a function y = f(x) is unidirectional if: it is easy to calculate for all possible values of x and for most possible values of y it is quite difficult to calculate a value of x such that y = f(x).
An example of a one-way function is the multiplication of two large numbers: N = P*Q. In itself, such multiplication is a simple operation. However, the inverse function (decomposition of N into two large factors), called factorization, according to modern time estimates, is a rather complex mathematical problem. For example, factorization N with a dimension of 664 bits at P ? Q will require approximately 1023 operations, and to inversely calculate x for the modular exponent y = ax mod p with known a, p and y (with the same dimensions of a and p) you need to perform approximately 1026 operations. The last example given is called the Discrete Logarithm Problem (DLP), and this kind of function is often used in asymmetric encryption algorithms, as well as in algorithms used to create an electronic digital signature.
Another important class of functions used in asymmetric encryption are one-way backdoor functions. Their definition states that a function is unidirectional with a backdoor if it is unidirectional and it is possible to efficiently calculate the inverse function x = f-1(y), i.e. if the "backdoor" (some secret number, applied to for asymmetric encryption algorithms - the value of the secret key).
One-way backdoor functions are used in the widely used asymmetric encryption algorithm RSA.
RSA algorithm
Developed in 1978 by three authors (Rivest, Shamir, Adleman), it got its name from the first letters of the developers' last names. The reliability of the algorithm is based on the difficulty of factoring large numbers and calculating discrete logarithms. The main parameter of the RSA algorithm is the system module N, which is used to carry out all calculations in the system, and N = P*Q (P and Q are secret random prime large numbers, usually of the same dimension).
The secret key k2 is chosen randomly and must meet the following conditions:
1 where GCD is the greatest common divisor, i.e. k1 must be coprime to the value of the Euler function F(N), the latter being equal to the number of positive integers in the range from 1 to N coprime to N, and is calculated as F(N) = (P - 1)*(Q - 1). The public key k1 is calculated from the relation (k2*k1) = 1 mod F(N), and for this purpose the generalized Euclidean algorithm (algorithm for calculating the greatest common divisor) is used. Encryption of data block M using the RSA algorithm is performed as follows: C=M [to the power k1] mod N. Note that since in a real cryptosystem using RSA the number k1 is very large (currently its dimension can reach up to 2048 bits), direct calculation of M [to the power k1] unreal. To obtain it, a combination of repeated squaring of M and multiplication of the results is used. Inversion of this function for large dimensions is not feasible; in other words, it is impossible to find M given the known C, N and k1. However, having a secret key k2, using simple transformations one can calculate M = Ck2 mod N. Obviously, in addition to the secret key itself, it is necessary to ensure the secrecy of the parameters P and Q. If an attacker obtains their values, he will be able to calculate the secret key k2. The main disadvantage of symmetric encryption is the need to transfer keys “from hand to hand”. This drawback is very serious, since it makes it impossible to use symmetric encryption in systems with an unlimited number of participants. However, otherwise, symmetric encryption has some advantages that are clearly visible against the background of the serious disadvantages of asymmetric encryption. The first of them is the low speed of encryption and decryption operations, due to the presence of resource-intensive operations. Another “theoretical” disadvantage is that the cryptographic strength of asymmetric encryption algorithms has not been mathematically proven. This is primarily due to the problem of the discrete logarithm - it has not yet been proven that its solution in an acceptable time is impossible. Unnecessary difficulties are also created by the need to protect public keys from substitution - by replacing the public key of a legal user, an attacker will be able to encrypt an important message with his public key and subsequently easily decrypt it with his private key. However, these shortcomings do not prevent the widespread use of asymmetric encryption algorithms. Today there are cryptosystems that support certification of public keys, as well as combining symmetric and asymmetric encryption algorithms. But this is a topic for a separate article. For those readers who are seriously interested in encryption, the author recommends broadening their horizons with the help of the following books. A complete description of encryption algorithms can be found in the following documents: In some sources, steganography, coding and compression of information are related to branches of knowledge adjacent to cryptography, but not included in it. Traditional (classical) encryption methods include permutation ciphers, simple and complex substitution ciphers, as well as some of their modifications and combinations. Combinations of permutation ciphers and substitution ciphers form the entire variety of symmetric ciphers used in practice. Permutation ciphers. In permutation encryption, the characters of the encrypted text are rearranged according to a certain rule within a block of this text. Permutation ciphers are the simplest and probably the oldest ciphers. Encryption tables. The following keys are used in encryption tables: the size of the table, a word or phrase that specifies the permutation, and features of the table structure. One of the most primitive table permutation ciphers is simple permutation, for which the key is the size of the table. Naturally, the sender and recipient of the message must agree in advance on a shared key in the form of a table size. It should be noted that combining ciphertext letters into 8-letter groups is not included in the cipher key and is carried out for the convenience of writing nonsense text. When decrypting, the steps are performed in reverse order. An encryption method called single key permutation is somewhat more resistant to disclosure. This method differs from the previous one in that the table columns are rearranged by a keyword, phrase, or set of numbers the length of a table row. To provide additional privacy, you can re-encrypt a message that has already been encrypted. This encryption method is called double permutation. In the case of double permutation of columns and rows, the permutations of the table are determined separately for columns and for rows. First, the text of the message is written into the table in columns, and then the columns are rearranged one by one, and then the rows. The number of double permutation options increases rapidly with increasing table size: for a 3x3 table - 36 options, for a 4x4 table - 576 options, for a 5x5 table - 14400 options. However, the double permutation is not highly secure and is relatively easy to “crack” for any size of the encryption table. Simple substitution ciphers. When encrypting by substitution (substitution), the characters of the encrypted text are replaced by characters of the same or another alphabet with a pre-established replacement rule. In a simple substitution cipher, each character of the original text is replaced by characters of the same alphabet using the same rule throughout the text. Simple substitution ciphers are often called monoalphabetic substitution ciphers. Caesar Cipher System .
The Caesar cipher is a special case of a simple substitution cipher (single-alphabetic substitution). This cipher got its name from the Roman emperor Gaius Julius Caesar, who used this cipher in correspondence. When encrypting the source text, each letter was replaced by another letter of the same alphabet according to the following rule. The replacement letter was determined by alphabetical displacement m from the original letter to k letters When the end of the alphabet was reached, a cyclic transition was performed to its beginning. Caesar used the Latin alphabet m= 26 and offset replacement cipher k= 3. Such a substitution cipher can be specified by a substitution table containing corresponding pairs of plaintext and ciphertext letters. The set of possible substitutions for k= 3 is shown in Table 6.1. Table 6.1 - Mono-alphabetic substitutions (k = 3, m = 26) The Caesar encryption system essentially forms a family of mono-alphabetic substitutions for selectable key values k, and 0 £ k < m. The advantage of the Caesar encryption system is the ease of encryption and decryption. The disadvantages of Caesar's system include the following: Substitutions performed according to the Caesar system do not mask the frequencies of occurrence of various letters in the original plaintext; The alphabetical order in the sequence of replacement letters is maintained; when the value of k changes, only the initial positions of such a sequence change; The number of possible keys k is small; The Caesar cipher can be easily broken by analyzing the frequency of occurrence of letters in the ciphertext. A cryptanalytic attack against a mono-alphabetic substitution system begins with counting the frequencies of symbols: the number of occurrences of each letter in the ciphertext is determined. The resulting frequency distribution of letters in the ciphertext is then compared with the frequency distribution of letters in the alphabet of the original messages. The letter with the highest frequency of occurrence in the ciphertext is replaced by the letter with the highest frequency of appearance in the alphabet, etc. The probability of successfully breaking the encryption system increases as the length of the ciphertext increases. At the same time, the ideas embedded in Caesar's encryption system turned out to be very fruitful, as evidenced by their numerous modifications. Caesar's affine substitution system. In this transformation, the letter corresponding to the number t, is replaced by the letter corresponding to the numeric value ( at + b) modulo m. Such a transformation is a one-to-one mapping on the alphabet if and only if GCD ( a, m) - the greatest common divisor of the numbers a and m is equal to one, i.e. if a and m are relatively prime numbers. The advantage of an affine system is convenient key management: encryption and decryption keys are represented in a compact form as a pair of numbers ( a, b). The disadvantages of the affine system are similar to those of the Caesar encryption system. In practice, the affine system was used several centuries ago. Complex substitution ciphers .
Complex substitution ciphers are called multi-alphabetic because a different simple substitution cipher is used to encrypt each character of the original message. Multi-alphabetic substitution sequentially and cyclically changes the alphabets used. At r-alphabetical substitution symbol x The 0 of the original message is replaced by the symbol y 0 from the alphabet B 0 , character x 1 - symbol y 1 from the alphabet B 1, etc.; symbol x r-1 is replaced by the symbol y r-1 from the alphabet B r-1 , character x r replaced by the symbol y r again from the alphabet B 0 , etc. The effect of using polyalphabetic substitution is that it provides masking of the natural statistics of the source language, since a particular character is from the source alphabet A can be converted to several different cipher alphabet characters Bj. The degree of protection provided is theoretically proportional to the length of the period r in the sequence of alphabets used Bj. System Viginaire encryption .
The Viginère system is similar to a Caesar encryption system in which the substitution key changes from letter to letter. This polyalphabetic substitution cipher can be described by an encryption table called a Viginère table (square). The Viginère table is used for both encryption and decryption. It has two inputs: The top line of underlined characters used to read the next letter of the original plaintext; The leftmost column of the key. The key sequence is usually derived from the numeric values of the letters of the keyword. When encrypting the original message, it is written out in a line, and a keyword (or phrase) is written under it. If the key is shorter than the message, it is repeated cyclically. During the encryption process, the next letter of the source text is found in the top row of the table and the next key value is found in the left column. The next ciphertext letter is located at the intersection of the column defined by the encrypted letter and the row defined by the numeric value of the key. One-time ciphers. Almost all ciphers used in practice are characterized as conditionally secure, since they can, in principle, be broken given unlimited computing power. Absolutely strong ciphers cannot be broken even with unlimited computing power. The only such cipher used in practice is the one-time encryption system. A characteristic feature of a one-time encryption system is the one-time use of the key sequence. This cipher is absolutely secure if the key set K i truly random and unpredictable. If a cryptanalyst tries to use all possible sets of keys for a given ciphertext and recover all possible versions of the original text, then they will all turn out to be equally probable. There is no way to select the original text that was actually sent. It has been theoretically proven that one-time systems are undecipherable systems because their ciphertext does not contain sufficient information to recover the plaintext. The possibilities of using a disposable system are limited by purely practical aspects. An essential point is the requirement for a one-time use of a random key sequence. A key sequence with a length no less than the length of the message must be transmitted to the message recipient in advance or separately through some secret channel. Such a requirement is practically difficult to implement for modern information processing systems, where it is necessary to encrypt many millions of characters, however, in justified cases, building systems with one-time ciphers is the most appropriate. Historically, encoders with external and internal scales have been distinguished. External gamma encryptors use a one-time random sequence as the key, the length of which is equal to the length of the encrypted message. In encryptors with an internal gamma, a reusable random sequence of length much smaller than the length of the encrypted text is used as a key, on the basis of which the gamma of the cipher is formed. Encryptors with an internal range, i.e., having the property of practical resistance, are currently predominant in the construction of encrypted communication systems. Their main advantage is the ease of key management, i.e. their preparation, distribution, delivery and destruction. This advantage makes it possible to create encrypted communication systems of almost any size based on encryptors with an internal range, without limiting their geography and the number of subscribers. Modern development of information technology makes it possible to concentrate a significant amount of information on small physical media, which also determines the practical applicability of this approach. The problem of building an encrypted communication system based on encryptors with an external gamma can have several approaches to its solution. For example, based on the established limit value of the volume of a key document, the optimal number of system subscribers and the permissible load are determined. On the other hand, it is possible, based on the required number of subscribers and the load on them, to calculate the required volume of the key document. Encryption method gamming .
Gamma is understood as the process of applying a cipher to open data according to a certain gamma law. A gamma cipher is a pseudo-random sequence generated according to a given algorithm to encrypt open data and decrypt received data. The encryption process consists of generating a cipher gamma and applying the resulting gamma to the original plaintext in a reversible manner, for example, using modulo-2 addition. Before encryption, the plaintext is divided into blocks of equal length, usually 64 bits. The cipher gamma is produced as a sequence of similar length. The decryption process comes down to re-generating the cipher gamma and applying this gamma to the received data. The ciphertext obtained by this method is quite difficult to crack, since the key is now variable. Essentially, the cipher gamma must change randomly for each encrypted block. If the gamma period exceeds the length of the entire encrypted text and the attacker does not know any part of the source text, then such a cipher can only be cracked by directly searching through all variants of the key. In this case, the cryptographic strength of the cipher is determined by the length of the key. Data encryption is extremely important to protect privacy. In this article, I will discuss the different types and methods of encryption that are used to protect data today. Did you know? As the capabilities of the Internet continue to grow, more and more of our businesses are being conducted online. Among these, the most important are Internet banking, online payment, emails, exchange of private and official messages, etc., which involve the exchange of confidential data and information. If this data falls into the wrong hands, it can harm not only the individual user, but also the entire online business system. To prevent this from happening, several network security measures have been taken to protect the transmission of personal data. Chief among these are the processes of encrypting and decrypting data, which is known as cryptography. There are three main encryption methods used in most systems today: hashing, symmetric and asymmetric encryption. In the following lines, I will talk about each of these encryption types in more detail. In symmetric encryption, normal readable data, known as plain text, is encrypted so that it becomes unreadable. This data scrambling is done using a key. Once the data is encrypted, it can be sent securely to the receiver. At the recipient, the encrypted data is decoded using the same key that was used for encoding. Thus, it is clear that the key is the most important part of symmetric encryption. It must be hidden from outsiders, since anyone who has access to it will be able to decrypt private data. This is why this type of encryption is also known as a "secret key". In modern systems, the key is usually a string of data that is derived from a strong password, or from a completely random source. It is fed into symmetric encryption software, which uses it to keep the input data secret. Data scrambling is achieved using a symmetric encryption algorithm, such as Data Encryption Standard (DES), Advanced Encryption Standard (AES), or International Data Encryption Algorithm (IDEA). Restrictions The weakest link in this type of encryption is the security of the key, both in terms of storage and transmission to the authenticated user. If a hacker is able to obtain this key, he can easily decrypt the encrypted data, defeating the entire purpose of encryption. Another disadvantage is that the software that processes the data cannot work with encrypted data. Therefore, to be able to use this software, the data must first be decoded. If the software itself is compromised, then an attacker can easily obtain the data. Asymmetric key encryption works similar to symmetric key in that it uses a key to encrypt the messages being transmitted. However, instead of using the same key, he uses a completely different one to decrypt this message. The key used for encoding is available to any and all network users. As such it is known as a "public" key. On the other hand, the key used for decryption is kept secret and is intended for private use by the user himself. Hence, it is known as the "private" key. Asymmetric encryption is also known as public key encryption. Since, with this method, the secret key needed to decrypt the message does not have to be transmitted every time, and it is usually known only to the user (receiver), the likelihood that a hacker will be able to decrypt the message is much lower. Diffie-Hellman and RSA are examples of algorithms that use public key encryption. Restrictions Many hackers use man-in-the-middle as a form of attack to bypass this type of encryption. In asymmetric encryption, you are given a public key that is used to securely exchange data with another person or service. However, hackers use network deception to trick you into communicating with them while you are led to believe that you are on a secure line. To better understand this type of hacking, consider two interacting parties, Sasha and Natasha, and a hacker, Sergei, with the intent to intercept their conversation. First, Sasha sends a message over the network intended for Natasha, asking for her public key. Sergei intercepts this message and obtains the public key associated with her and uses it to encrypt and send a false message to Natasha containing his public key instead of Sasha's. Natasha, thinking that this message came from Sasha, now encrypts it with Sergei's public key, and sends it back. This message was again intercepted by Sergei, decrypted, modified (if desired), encrypted again using the public key that Sasha originally sent, and sent back to Sasha. Thus, when Sasha receives this message, he has been led to believe that it came from Natasha and remains unaware of foul play. The hashing technique uses an algorithm known as a hash function to generate a special string from the given data, known as a hash. This hash has the following properties: Thus, the main difference between hashing and the other two forms of data encryption is that once the data is encrypted (hashed), it cannot be retrieved back in its original form (decrypted). This fact ensures that even if a hacker gets his hands on the hash, it will be of no use to him, since he will not be able to decrypt the contents of the message. Message Digest 5 (MD5) and Secure Hashing Algorithm (SHA) are two widely used hashing algorithms. Restrictions As mentioned earlier, it is almost impossible to decrypt data from a given hash. However, this is only true if strong hashing is implemented. In the case of a weak implementation of the hashing technique, using enough resources and brute force attacks, a persistent hacker can find data that matches the hash. As discussed above, each of these three encryption methods suffers from some disadvantages. However, when a combination of these methods is used, they form a secure and highly effective encryption system. Most often, private and public key techniques are combined and used together. The private key method allows for quick decryption, while the public key method offers a safer and more convenient way to transmit the secret key. This combination of methods is known as the "digital envelope". PGP email encryption software is based on the "digital envelope" technique. Hashing is used as a means of checking the strength of a password. If the system stores a hash of the password instead of the password itself, it will be more secure, since even if a hacker gets his hands on this hash, he will not be able to understand (read) it. During verification, the system will check the hash of the incoming password, and see if the result matches what is stored. This way, the actual password will only be visible during brief moments when it needs to be changed or verified, greatly reducing the likelihood of it falling into the wrong hands. Hashing is also used to authenticate data using a secret key. A hash is generated using the data and this key. Therefore, only the data and hash are visible, and the key itself is not transmitted. This way, if changes are made to either the data or the hash, they will be easily detected. In conclusion, these techniques can be used to efficiently encode data into an unreadable format that can ensure that it remains secure. Most modern systems typically use a combination of these encryption methods along with strong algorithm implementations to improve security. In addition to security, these systems also provide many additional benefits, such as verifying the user's identity and ensuring that the data received cannot be tampered with. On this day, the Russian Cryptographic Service celebrates its professional holiday. "Cryptography" from ancient Greek means "secret writing". A peculiar method of transmitting a secret letter existed during the reign of the dynasty of Egyptian pharaohs: they chose a slave. They shaved his head bald and painted the message on it with waterproof vegetable paint. When the hair grew back, it was sent to the recipient. Cipher- this is some kind of text conversion system with a secret (key) to ensure the secrecy of transmitted information. AiF.ru has made a selection of interesting facts from the history of encryption. 1. Acrostic- a meaningful text (word, phrase or sentence), made up of the initial letters of each line of the poem. Here, for example, is a riddle poem with the answer in the first letters: D I am known loosely by my name; 2. Litorrhea- a type of encrypted writing used in ancient Russian handwritten literature. It can be simple and wise. A simple one is called gibberish writing, it consists of the following: placing the consonant letters in two rows in the order: they use upper letters in writing instead of lower ones and vice versa, and the vowels remain unchanged; for example, tokepot = kitten and so on. Wise litorrhea involves more complex substitution rules. 3. "ROT1"- a code for kids? You may have used it as a child too. The key to the cipher is very simple: each letter of the alphabet is replaced by the next letter. A is replaced by B, B is replaced by C, and so on. "ROT1" literally means "rotate forward 1 letter in the alphabet." Phrase "I love borscht" will turn into a secret phrase “Ah myvmya”. This cipher is intended to be fun and easy to understand and decipher even if the key is used in reverse. 4. From rearranging terms...
During World War I, confidential messages were sent using so-called permutation fonts. In them, letters are rearranged using some given rules or keys. For example, words can be written backwards, so that the phrase “Mom washed the frame” turns into a phrase "amam alym umar". Another permutation key is to rearrange each pair of letters so that the previous message becomes “am am y al ar um”. It may seem that complex permutation rules can make these ciphers very difficult. However, many encrypted messages can be decrypted using anagrams or modern computer algorithms. 5. Caesar's sliding cipher
It consists of 33 different ciphers, one for each letter of the alphabet (the number of ciphers varies depending on the alphabet of the language used). The person had to know which Julius Caesar cipher to use in order to decipher the message. For example, if the cipher E is used, then A becomes E, B becomes F, C becomes Z, and so on alphabetically. If the Y cipher is used, then A becomes Y, B becomes Z, B becomes A, and so on. This algorithm is the basis for many more complex ciphers, but by itself does not provide reliable protection for the secrecy of messages, since checking 33 different cipher keys will take a relatively short time. Encrypted public messages tease us with their intrigue. Some of them still remain unsolved. Here they are: Kryptos. A sculpture created by artist Jim Sanborn that is located in front of the Central Intelligence Agency headquarters in Langley, Virginia. The sculpture contains four encryptions; the code of the fourth has not yet been cracked. In 2010, it was revealed that characters 64-69 NYPVTT in Part 4 meant the word BERLIN. Now that you have read the article, you will probably be able to solve three simple ciphers. Leave your options in the comments to this article. The answer will appear at 13:00 on May 13, 2014. Answer:
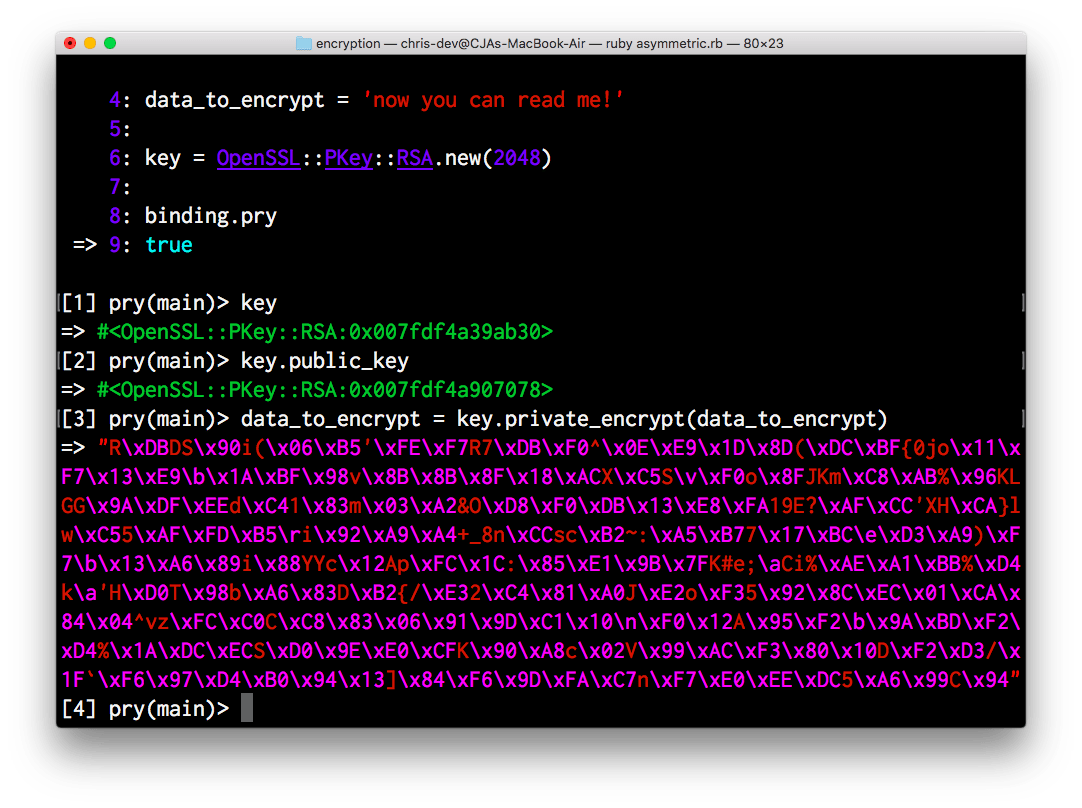
1) Saucer 2) The baby elephant is tired of everything 3) Good weather In the 21st century, cryptography plays a serious role in the digital lives of modern people. Let's briefly look at ways to encrypt information. Most likely, you have already encountered basic cryptography and perhaps know some encryption methods. For example, the Caesar Cipher is often used in educational children's games. ROT13 is another common type of message encryption. In it, each letter of the alphabet is shifted by 13 positions, as shown in the figure: As you can see, this cipher does not provide truly reliable information security: it is a simple and clear example of the whole idea of cryptography. Today we talk about cryptography most often in the context of some technology. How is personal and financial information transmitted securely when we make an online purchase or view bank accounts? How can you store data securely so that no one can just open up your computer, pull out the hard drive, and have full access to all the information on it? We will answer these and other questions in this article. In cybersecurity, there are a number of things that worry users when it comes to any data. These include confidentiality, integrity and availability of information. Confidentiality– data cannot be received or read by unauthorized users. Information integrity– confidence that the information will remain 100% intact and will not be changed by an attacker. Availability of information– gaining access to data when necessary. This article will also look at the different forms of digital cryptography and how they can help achieve the goals listed above. Before we dive into the topic, let's answer a simple question: what exactly is meant by “encryption”? Encryption is the transformation of information to hide it from unauthorized persons, while at the same time allowing authorized users access to it. To properly encrypt and decrypt data, you need two things: the data and the decryption key. When using symmetric encryption, the key for encrypting and decrypting data is the same. Let's take a string and encrypt it using Ruby and OpenSSL: Ruby require "openssl" require "pry" data_to_encrypt = "now you can read me!" cipher = OpenSSL::Cipher.new("aes256") cipher.encrypt key = cipher.random_key iv = cipher.random_iv data_to_encrypt = cipher.update(data_to_encrypt) + cipher.final binding.pry true require "openssl" require "pry" cipher = OpenSSL::Cipher. new("aes256") cipher encrypt key = cipher . random_key iv = cipher . random_iv data_to_encrypt = cipher . update(data_to_encrypt) + cipher. final binding. pry true This is what the program will output: Please note that the variable data_to_encrypt, which was originally the line “now you can read me!” is now a bunch of strange characters. Let's reverse the process using the key that was originally stored in a variable key. After using the same key that we set for encryption, we decrypt the message and get the original string. Let's look at other encryption methods. The problem with symmetric encryption is this: suppose you need to send some data over the Internet. If the same key is required to encrypt and decrypt data, then it turns out that the key must be sent first. This means that the key will need to be sent over an insecure connection. But this way the key can be intercepted and used by a third party. To avoid this outcome, asymmetric encryption was invented. To use asymmetric encryption, you need to generate two mathematically related keys. One is a private key that only you have access to. The second is open, which is publicly available. Let's look at an example of communication using asymmetric encryption. In it, the server and the user will send messages to each other. Each of them has two keys: private and public. It was said earlier that the keys are connected. Those. A message encrypted with a private key can only be decrypted using an adjacent public key. Therefore, to start communication, you need to exchange public keys. But how can you understand that the server’s public key belongs to this particular server? There are several ways to solve this problem. The most common method (and the one used on the Internet) is the use of a public key infrastructure (PKI). In the case of websites, there is a Certificate Authority, which has a directory of all the sites to which certificates and public keys have been issued. When you connect to a website, its public key is first verified by a certificate authority. Let's create a pair of public and private keys: Ruby require "openssl" require "pry" data_to_encrypt = "now you can read me!" key = OpenSSL::PKey::RSA.new(2048) binding.pry true require "openssl" require "pry" data_to_encrypt = "now you can read me!" key = OpenSSL::PKey::RSA. new (2048) binding. pry true It will turn out: Note that the private key and public key are separate entities with different identifiers. Using #private_encrypt, you can encrypt a string using a private key, and using #public_decrypt– decrypt the message: Hashing, unlike symmetric and asymmetric encryption, is a one-way function. It is possible to create a hash from some data, but there is no way to reverse the process. This makes hashing not a very convenient way to store data, but it is suitable for checking the integrity of some data. The function takes some information as input and outputs a seemingly random string that will always be the same length. An ideal hashing function produces unique values for different inputs. The same input will always produce the same hash. Therefore, hashing can be used to verify data integrity.Which encryption is better?
Additional sources of information
Back in Roman times, encryption was used by Julius Caesar to make letters and messages unreadable to the enemy. It played an important role as a military tactic, especially during wars.Encryption Types
Symmetric encryption
Asymmetric encryption
Hashing
Combination of encryption methods
How did you hide words before?
All secret writings have systems
R The rogue and the innocent swear by him,
U I am more than a technician in disasters,
AND Life is sweeter with me and in the best lot.
B I can serve the harmony of pure souls alone,
A between villains - I was not created.
Yuri Neledinsky-Meletsky
Sergei Yesenin, Anna Akhmatova, Valentin Zagoryansky often used acrostics.Nobody could. Try it

Cryptography is not just some computer thing
Cybersecurity Definitions and Quick Start Guide
Basic encryption methods:
Symmetric encryption


Asymmetric encryption

Hashing information