Ví dụ về hệ thống Dlp Hệ thống DLP phức tạp. Cách hệ thống DLP ngăn chặn rò rỉ thông tin
Giới thiệu
Bài đánh giá này dành cho tất cả những ai quan tâm đến thị trường giải pháp DLP và trước hết là dành cho những ai muốn chọn giải pháp DLP phù hợp cho công ty của mình. Đánh giá này xem xét thị trường cho các hệ thống DLP theo nghĩa rộng của thuật ngữ, cung cấp mô tả ngắn gọn về thị trường toàn cầu và mô tả chi tiết hơn về phân khúc Nga.
Các hệ thống bảo vệ dữ liệu có giá trị đã tồn tại kể từ khi thành lập. Qua nhiều thế kỷ, những hệ thống này đã phát triển và tiến hóa cùng với nhân loại. Với sự khởi đầu của kỷ nguyên máy tính và sự chuyển đổi của nền văn minh sang thời kỳ hậu công nghiệp, thông tin dần trở thành giá trị chính của các quốc gia, tổ chức và thậm chí cả cá nhân. Và hệ thống máy tính đã trở thành công cụ chính để lưu trữ và xử lý nó.
Các quốc gia luôn bảo vệ bí mật của mình, nhưng các quốc gia có phương tiện và phương pháp riêng, theo quy luật, không ảnh hưởng đến sự hình thành thị trường. Trong thời kỳ hậu công nghiệp, các ngân hàng và các tổ chức tài chính khác thường xuyên trở thành nạn nhân của việc máy tính rò rỉ thông tin có giá trị. Hệ thống ngân hàng toàn cầu là hệ thống đầu tiên cần được pháp luật bảo vệ thông tin của mình. Nhu cầu bảo vệ quyền riêng tư cũng đã được thừa nhận trong y học. Ví dụ, kết quả là Đạo luật về trách nhiệm giải trình và cung cấp thông tin bảo hiểm y tế (HIPAA), Đạo luật Sarbanes–Oxley (SOX) đã được thông qua ở Hoa Kỳ và Ủy ban Basel về giám sát ngân hàng đã ban hành một loạt khuyến nghị có tên là “Hiệp định Basel”. Những bước đi như vậy đã tạo động lực mạnh mẽ cho sự phát triển của thị trường hệ thống bảo vệ thông tin máy tính. Theo nhu cầu ngày càng tăng, các công ty bắt đầu xuất hiện cung cấp hệ thống DLP đầu tiên.
Hệ thống DLP là gì?
Có một số định nghĩa được chấp nhận rộng rãi về thuật ngữ DLP: Ngăn ngừa mất dữ liệu, Ngăn chặn rò rỉ dữ liệu hoặc Bảo vệ rò rỉ dữ liệu, có thể dịch sang tiếng Nga là “ngăn chặn mất dữ liệu”, “ngăn chặn rò rỉ dữ liệu”, “bảo vệ rò rỉ dữ liệu”. Thuật ngữ này trở nên phổ biến và có mặt trên thị trường vào khoảng năm 2006. Và các hệ thống DLP đầu tiên xuất hiện sớm hơn một chút chính xác như một phương tiện ngăn chặn sự rò rỉ thông tin có giá trị. Chúng được thiết kế để phát hiện và chặn việc truyền tải thông tin qua mạng được xác định bằng từ khóa hoặc biểu thức và bằng “dấu vân tay” kỹ thuật số được tạo trước của các tài liệu bí mật.
Một mặt, sự phát triển hơn nữa của hệ thống DLP được xác định bởi các sự cố và mặt khác là các hành vi lập pháp của các quốc gia. Dần dần, nhu cầu bảo vệ chống lại các loại mối đe dọa khác nhau đã khiến các công ty cần phải tạo ra các hệ thống bảo vệ toàn diện. Hiện tại, các sản phẩm DLP đã phát triển, ngoài khả năng bảo vệ trực tiếp chống rò rỉ dữ liệu, còn cung cấp khả năng bảo vệ chống lại các mối đe dọa bên trong và thậm chí bên ngoài, theo dõi giờ làm việc của nhân viên và giám sát mọi hành động của họ tại máy trạm, bao gồm cả làm việc từ xa.
Đồng thời, việc chặn truyền dữ liệu bí mật, một chức năng tiêu chuẩn của hệ thống DLP, đã không còn tồn tại trong một số giải pháp hiện đại được các nhà phát triển quy cho thị trường này. Các giải pháp như vậy chỉ phù hợp để giám sát môi trường thông tin doanh nghiệp, nhưng do thao túng thuật ngữ, chúng bắt đầu được gọi là DLP và đề cập đến thị trường này theo nghĩa rộng.
Hiện tại, mối quan tâm chính của các nhà phát triển hệ thống DLP đã chuyển sang phạm vi bao phủ các kênh rò rỉ thông tin tiềm năng và phát triển các công cụ phân tích để điều tra và phân tích sự cố. Các sản phẩm DLP mới nhất chặn việc xem tài liệu, in và sao chép chúng sang phương tiện bên ngoài, khởi chạy ứng dụng trên máy trạm và kết nối các thiết bị bên ngoài với chúng, đồng thời phân tích hiện đại về lưu lượng mạng bị chặn cho phép bạn phát hiện rò rỉ ngay cả thông qua một số giao thức đường hầm và mã hóa.
Ngoài việc phát triển chức năng của riêng mình, các hệ thống DLP hiện đại còn mang đến nhiều cơ hội tích hợp với nhiều sản phẩm liên quan và thậm chí là cạnh tranh. Các ví dụ bao gồm hỗ trợ rộng rãi cho giao thức ICAP do máy chủ proxy cung cấp và tích hợp mô-đun DeviceSniffer, một phần của Mạch bảo mật thông tin SearchInform, với Kiểm soát thiết bị Lumension. Sự phát triển hơn nữa của hệ thống DLP dẫn đến sự tích hợp của chúng với các sản phẩm IDS/IPS, giải pháp SIEM, hệ thống quản lý tài liệu và bảo vệ máy trạm.
Hệ thống DLP được phân biệt bằng phương pháp phát hiện rò rỉ dữ liệu:
- khi được sử dụng (Dữ liệu đang sử dụng) - tại nơi làm việc của người dùng;
- trong quá trình truyền (Data-in‑Motion) - trong mạng công ty;
- trong quá trình lưu trữ (Data-at‑Rest) - trên máy chủ và máy trạm của công ty.
Hệ thống DLP có thể nhận dạng các tài liệu quan trọng:
- theo tiêu chí hình thức thì đáng tin cậy nhưng yêu cầu phải đăng ký sơ bộ tài liệu vào hệ thống;
- bằng phân tích nội dung - điều này có thể đưa ra kết quả dương tính giả nhưng cho phép bạn phát hiện thông tin quan trọng trong bất kỳ tài liệu nào.
Theo thời gian, cả bản chất của các mối đe dọa cũng như thành phần khách hàng và người mua hệ thống DLP đều đã thay đổi. Thị trường hiện đại đặt ra các yêu cầu sau cho các hệ thống này:
- hỗ trợ một số phương pháp phát hiện rò rỉ dữ liệu (Dữ liệu đang sử dụng, Dữ liệu đang chuyển động, Dữ liệu ở trạng thái nghỉ);
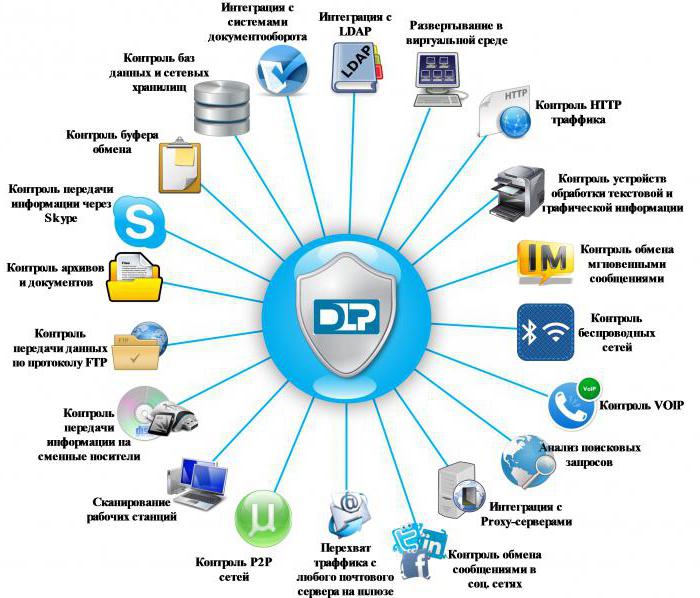
- hỗ trợ tất cả các giao thức truyền dữ liệu mạng phổ biến: HTTP, SMTP, FTP, OSCAR, XMPP, MMP, MSN, YMSG, Skype, các giao thức P2P khác nhau;
- sự hiện diện của một thư mục tích hợp của các trang web và xử lý chính xác lưu lượng truy cập được truyền đến chúng (thư web, mạng xã hội, diễn đàn, blog, trang tìm kiếm việc làm, v.v.);
- Hỗ trợ các giao thức đường hầm là mong muốn: Vlan, MPLS, PPPoE và các giao thức tương tự;
- kiểm soát minh bạch các giao thức SSL/TLS an toàn: HTTPS, FTPS, SMTPS và các giao thức khác;
- hỗ trợ các giao thức điện thoại VoIP: SIP, SDP, H.323, T.38, MGCP, SKINNY và các giao thức khác;
- sự hiện diện của phân tích kết hợp - hỗ trợ một số phương pháp nhận biết thông tin có giá trị: theo đặc điểm hình thức, theo từ khóa, bằng cách kết hợp nội dung với biểu thức chính quy, dựa trên phân tích hình thái;
- khả năng chặn có chọn lọc việc truyền thông tin quan trọng qua bất kỳ kênh được kiểm soát nào trong thời gian thực là mong muốn; chặn có chọn lọc (đối với người dùng, nhóm hoặc thiết bị cá nhân);
- Điều mong muốn là có thể kiểm soát hành động của người dùng đối với các tài liệu quan trọng: xem, in, sao chép sang phương tiện bên ngoài;
- Khả năng kiểm soát các giao thức mạng để làm việc với máy chủ thư Microsoft Exchange (MAPI), IBM Lotus Notes, Kerio, Microsoft Lync, v.v. để phân tích và chặn tin nhắn trong thời gian thực bằng các giao thức: (MAPI, S/MIME, NNTP, SIP, v.v.);
- mong muốn chặn, ghi âm và nhận dạng lưu lượng thoại: Skype, điện thoại IP, Microsoft Lync;
- Có sẵn mô-đun nhận dạng đồ họa (OCR) và phân tích nội dung;
- hỗ trợ phân tích tài liệu bằng nhiều ngôn ngữ;
- duy trì các tài liệu lưu trữ và nhật ký chi tiết để dễ dàng điều tra sự cố;
- Điều mong muốn là đã phát triển các công cụ để phân tích các sự kiện và mối liên hệ của chúng;
- khả năng tạo các báo cáo khác nhau, bao gồm cả báo cáo đồ họa.
Nhờ các xu hướng mới trong sự phát triển của công nghệ thông tin, các chức năng mới của sản phẩm DLP đang ngày càng có nhu cầu. Với việc sử dụng rộng rãi ảo hóa trong các hệ thống thông tin doanh nghiệp, cần có sự hỗ trợ của nó trong các giải pháp DLP. Việc sử dụng rộng rãi các thiết bị di động như một công cụ kinh doanh đã kích thích sự xuất hiện của DLP di động. Việc tạo ra các “đám mây” công cộng và doanh nghiệp đều yêu cầu sự bảo vệ của chúng, bao gồm cả các hệ thống DLP. Và, như một sự tiếp nối hợp lý, nó đã dẫn đến sự xuất hiện của các dịch vụ bảo mật thông tin “đám mây” (bảo mật như một dịch vụ - SECaaS).
Nguyên lý hoạt động của hệ thống DLP
Theo quy luật, hệ thống bảo vệ rò rỉ thông tin hiện đại là một tổ hợp phần mềm và phần cứng phân tán bao gồm một số lượng lớn các mô-đun cho các mục đích khác nhau. Một số mô-đun hoạt động trên các máy chủ chuyên dụng, một số trên máy trạm của nhân viên công ty và một số trên máy trạm của nhân viên an ninh.
Máy chủ chuyên dụng có thể được yêu cầu cho các mô-đun như cơ sở dữ liệu và đôi khi cho các mô-đun phân tích thông tin. Trên thực tế, các mô-đun này là cốt lõi và không một hệ thống DLP nào có thể hoạt động nếu không có chúng.
Cần có cơ sở dữ liệu để lưu trữ thông tin, từ các quy tắc kiểm soát và thông tin chi tiết về sự cố đến tất cả các tài liệu được hệ thống xem trong một khoảng thời gian nhất định. Trong một số trường hợp, hệ thống thậm chí có thể lưu trữ bản sao của tất cả lưu lượng truy cập mạng của công ty bị chặn trong một khoảng thời gian nhất định.
Các mô-đun phân tích thông tin có nhiệm vụ phân tích các văn bản được trích xuất bởi các mô-đun khác từ nhiều nguồn khác nhau: lưu lượng mạng, tài liệu trên bất kỳ thiết bị lưu trữ thông tin nào trong công ty. Một số hệ thống có khả năng trích xuất văn bản từ hình ảnh và nhận dạng tin nhắn thoại bị chặn. Tất cả các văn bản được phân tích đều được so sánh với các quy tắc được xác định trước và được đánh dấu tương ứng khi tìm thấy kết quả phù hợp.
Để giám sát hành động của nhân viên, các đặc vụ có thể được cài đặt trên máy trạm của họ. Một đại lý như vậy phải được bảo vệ khỏi sự can thiệp của người dùng vào công việc của mình (trong thực tế, điều này không phải lúc nào cũng như vậy) và có thể tiến hành giám sát thụ động các hành động của mình và chủ động can thiệp vào những hành động bị cấm đối với người dùng theo chính sách bảo mật của công ty. Danh sách các hành động được kiểm soát có thể bị giới hạn ở việc người dùng đăng nhập/đăng xuất và kết nối các thiết bị USB, đồng thời có thể bao gồm việc chặn và chặn các giao thức mạng, sao chép ẩn tài liệu sang bất kỳ phương tiện bên ngoài nào, in tài liệu sang máy in cục bộ và mạng, truyền thông tin qua Wi- Fi và Bluetooth Và nhiều hơn nữa. Một số hệ thống DLP có khả năng ghi lại tất cả các lần gõ phím (ghi nhật ký phím) và lưu ảnh chụp màn hình (ảnh chụp màn hình), nhưng điều này nằm ngoài phạm vi các thông lệ được chấp nhận chung.
Thông thường, hệ thống DLP bao gồm một mô-đun điều khiển được thiết kế để giám sát hoạt động của hệ thống và quản lý nó. Mô-đun này cho phép bạn giám sát hiệu suất của tất cả các mô-đun hệ thống khác và định cấu hình chúng.
Để giúp công việc của nhà phân tích bảo mật thuận tiện hơn, hệ thống DLP có thể có một mô-đun riêng cho phép bạn định cấu hình chính sách bảo mật của công ty, giám sát các vi phạm của công ty, tiến hành điều tra chi tiết về chúng và tạo báo cáo cần thiết. Thật kỳ lạ, tất cả những thứ khác đều như nhau, khả năng phân tích sự cố, tiến hành điều tra và báo cáo chính thức lại trở nên quan trọng hàng đầu trong hệ thống DLP hiện đại.
Thị trường DLP toàn cầu
Thị trường hệ thống DLP đã bắt đầu hình thành trong thế kỷ này. Như đã đề cập ở đầu bài viết, khái niệm “DLP” đã lan rộng vào khoảng năm 2006. Số lượng lớn nhất các công ty tạo ra hệ thống DLP phát sinh ở Hoa Kỳ. Nhu cầu lớn nhất về những giải pháp này và môi trường thuận lợi để thành lập và phát triển một doanh nghiệp như vậy.
Hầu hết tất cả các công ty bắt đầu tạo ra hệ thống DLP và đạt được thành công đáng kể trong lĩnh vực này đều được mua hoặc mua lại, đồng thời các sản phẩm và công nghệ của họ đều được tích hợp vào các hệ thống thông tin lớn hơn. Ví dụ: Symantec mua lại Vontu (2007), Websense mua lại PortAuthority Technologies Inc. (2007), Tập đoàn EMC. mua lại RSA Security (2006) và McAfee mua lại một số công ty: Onigma (2006), SafeBoot Holding B.V. (2007), Reconnex (2008), TrustDigital (2010), tenCube (2010).
Hiện nay, các nhà sản xuất hệ thống DLP hàng đầu thế giới là: Symantec Corp., RSA (một bộ phận của EMC Corp.), Verdasys Inc., Websense Inc. (được công ty tư nhân Vista Equity Partners mua lại vào năm 2013), McAfee (được Intel mua lại vào năm 2011). Giải pháp an ninh mạng Fidelis (được General Dynamics mua lại vào năm 2012), CA Technologies và GTB Technologies đóng một vai trò quan trọng trên thị trường. Một minh họa rõ ràng về vị trí của họ trên thị trường, trong một trong các phần, có thể là góc phần tư kỳ diệu của công ty phân tích Gartner vào cuối năm 2013 (Hình 1).
Hình 1. Phân phốichức vụDLP-Hệ thống trên thị trường thế giớiQuaGartner
Thị trường DLP Nga
Ở Nga, thị trường hệ thống DLP bắt đầu hình thành gần như đồng thời với thị trường thế giới, nhưng có những đặc điểm riêng. Điều này xảy ra dần dần khi các sự cố nảy sinh và người ta đã cố gắng giải quyết chúng. Jet Infosystems là công ty đầu tiên ở Nga bắt đầu phát triển giải pháp DLP vào năm 2000 (ban đầu nó là một kho lưu trữ thư). Một thời gian sau, vào năm 2003, InfoWatch được thành lập với tư cách là công ty con của Kaspersky Lab. Chính quyết định của hai công ty này đã đặt ra những nguyên tắc cho những người chơi khác. Sau đó một thời gian ngắn, chúng bao gồm các công ty Perimetrix, SearchInform, DeviceLock, SecureIT (được đổi tên thành Zecurion vào năm 2011). Khi nhà nước ban hành các đạo luật liên quan đến bảo vệ thông tin (Bộ luật Dân sự Liên bang Nga, Điều 857 “Bí mật ngân hàng”, 395-1-FZ “Về ngân hàng và hoạt động ngân hàng”, 98-FZ “Về bí mật thương mại”, 143 -FZ “Về đạo luật hộ tịch” ", 152-FZ "Về dữ liệu cá nhân" và các đạo luật khác, tổng cộng khoảng 50 loại bí mật), nhu cầu về các công cụ bảo vệ tăng lên và nhu cầu về hệ thống DLP cũng tăng lên. Và vài năm sau, “làn sóng thứ hai” các nhà phát triển tràn vào thị trường: Falcongaze, MFI Soft, Trafica. Điều đáng chú ý là tất cả các công ty này đều có sự phát triển trong lĩnh vực DLP sớm hơn nhiều, nhưng các sản phẩm thay thế bắt đầu xuất hiện trên thị trường tương đối gần đây. Ví dụ: công ty MFI Soft đã bắt đầu phát triển giải pháp DLP của mình vào năm 2005 và chỉ công bố trên thị trường vào năm 2011.
Thậm chí sau này, thị trường Nga còn trở nên hấp dẫn đối với các công ty nước ngoài. Trong năm 2007-2008, chúng tôi đã có sẵn các sản phẩm Symantec, Websense và McAfee. Gần đây hơn, vào năm 2012, GTB Technologies đã giới thiệu các giải pháp của mình tới thị trường của chúng tôi. Các nhà lãnh đạo thị trường thế giới khác cũng không từ bỏ nỗ lực thâm nhập thị trường Nga nhưng cho đến nay vẫn chưa có kết quả đáng chú ý. Trong những năm gần đây, thị trường DLP của Nga đã chứng tỏ mức tăng trưởng ổn định (trên 40% hàng năm) trong nhiều năm, điều này đang thu hút các nhà đầu tư và nhà phát triển mới. Ví dụ: chúng ta có thể đặt tên công ty là Iteranet, từ năm 2008 đã phát triển các phần tử của hệ thống DLP cho mục đích nội bộ, sau đó là cho khách hàng doanh nghiệp. Công ty hiện đang cung cấp giải pháp Business Guardian cho người mua ở Nga và nước ngoài.
Công ty tách khỏi Kaspersky Lab vào năm 2003. Vào cuối năm 2012, InfoWatch chiếm hơn 1/3 thị trường DLP của Nga. InfoWatch cung cấp đầy đủ các giải pháp DLP cho khách hàng, từ các doanh nghiệp cỡ trung bình đến các tập đoàn lớn và cơ quan chính phủ. Giải pháp phổ biến nhất trên thị trường là InfoWatch Traffic Monitor. Ưu điểm chính của các giải pháp của họ: chức năng nâng cao, công nghệ phân tích lưu lượng truy cập được cấp bằng sáng chế độc đáo, phân tích kết hợp, hỗ trợ nhiều ngôn ngữ, thư mục tài nguyên web tích hợp, khả năng mở rộng, một số lượng lớn cấu hình và chính sách đặt trước cho các ngành khác nhau. Các tính năng đặc biệt của giải pháp InfoWatch là một bảng điều khiển quản lý duy nhất, giám sát hành động của nhân viên bị nghi ngờ, giao diện trực quan, tạo chính sách bảo mật mà không sử dụng đại số Boolean, tạo vai trò người dùng (nhân viên bảo mật, giám đốc công ty, giám đốc nhân sự, v.v.). Nhược điểm: thiếu khả năng kiểm soát hành động của người dùng trên máy trạm, InfoWatch Traffic Monitor nặng đối với các doanh nghiệp có quy mô vừa, chi phí cao.

Công ty được thành lập vào năm 1991 và ngày nay là một trong những trụ cột của thị trường DLP của Nga. Ban đầu, công ty phát triển các hệ thống để bảo vệ các tổ chức khỏi các mối đe dọa từ bên ngoài và việc tham gia vào thị trường DLP là một bước đi hợp lý. Công ty Jet Infosystems là một công ty quan trọng trong thị trường bảo mật thông tin của Nga, cung cấp các dịch vụ tích hợp hệ thống và phát triển phần mềm của riêng mình. Đặc biệt là giải pháp DLP của riêng Dozor-Jet. Ưu điểm chính của nó: khả năng mở rộng, hiệu suất cao, khả năng làm việc với Dữ liệu lớn, bộ chặn lớn, thư mục tài nguyên web tích hợp, phân tích kết hợp, hệ thống lưu trữ được tối ưu hóa, giám sát tích cực, hoạt động “trong khoảng trống”, các công cụ để tìm kiếm và phân tích nhanh chóng các sự cố, hỗ trợ kỹ thuật được phát triển, kể cả trong khu vực. Tổ hợp này còn có khả năng tích hợp với các hệ thống thuộc các lớp SIEM, BI, MDM, Security Intelligence, System và Network Management. Bí quyết riêng của chúng tôi là mô-đun “Hồ sơ”, được thiết kế để điều tra các sự cố. Nhược điểm: chức năng của các tác nhân cho máy trạm không đủ, khả năng kiểm soát hành động của người dùng kém phát triển, giải pháp chỉ tập trung vào các công ty lớn, chi phí cao.
Một công ty của Mỹ bắt đầu hoạt động kinh doanh vào năm 1994 với tư cách là nhà sản xuất phần mềm bảo mật thông tin. Năm 1996, nó giới thiệu phát triển độc quyền đầu tiên của mình, Hệ thống sàng lọc Internet, để giám sát hành động của nhân viên trên Internet. Sau đó, công ty tiếp tục hoạt động trong lĩnh vực bảo mật thông tin, phát triển các phân khúc mới và mở rộng phạm vi sản phẩm, dịch vụ. Năm 2007, công ty củng cố vị thế của mình trên thị trường DLP bằng cách mua lại PortAuthority. Năm 2008, Websense gia nhập thị trường Nga. Công ty hiện cung cấp một sản phẩm toàn diện, Websense Triton, để bảo vệ khỏi rò rỉ dữ liệu bí mật cũng như các mối đe dọa từ bên ngoài. Ưu điểm chính: kiến trúc thống nhất, hiệu suất, khả năng mở rộng, nhiều tùy chọn phân phối, chính sách được xác định trước, công cụ phân tích sự kiện và báo cáo nâng cao. Nhược điểm: không hỗ trợ một số giao thức IM, không hỗ trợ hình thái của tiếng Nga.
Symantec Corporation là công ty hàng đầu thế giới được công nhận trong thị trường giải pháp DLP. Điều này xảy ra sau khi mua Vontu, một nhà sản xuất hệ thống DLP lớn vào năm 2007. Từ năm 2008, Symantec DLP đã chính thức có mặt tại thị trường Nga. Vào cuối năm 2010, Symantec là công ty nước ngoài đầu tiên nội địa hóa sản phẩm DLP cho thị trường nước ta. Ưu điểm chính của giải pháp này là: chức năng mạnh mẽ, số lượng lớn các phương pháp phân tích, khả năng chặn rò rỉ qua bất kỳ kênh được kiểm soát nào, thư mục trang web tích hợp, khả năng mở rộng quy mô, tác nhân được phát triển để phân tích các sự kiện ở cấp độ máy trạm , kinh nghiệm triển khai quốc tế phong phú và tích hợp với các sản phẩm khác của Symantec. Nhược điểm của hệ thống bao gồm chi phí cao và thiếu khả năng kiểm soát đối với một số giao thức IM phổ biến.
Công ty Nga này được thành lập năm 2007 với tư cách là nhà phát triển các công cụ bảo mật thông tin. Ưu điểm chính của giải pháp Falcongaze SecureTower: dễ cài đặt và cấu hình, giao diện thân thiện với người dùng, kiểm soát số lượng kênh truyền dữ liệu lớn hơn, công cụ phân tích thông tin nâng cao, khả năng giám sát hành động của nhân viên trên máy trạm (bao gồm xem ảnh chụp màn hình máy tính để bàn), phân tích biểu đồ các mối quan hệ nhân sự, khả năng mở rộng, tìm kiếm nhanh thông qua dữ liệu bị chặn, hệ thống báo cáo trực quan dựa trên các tiêu chí khác nhau.
Nhược điểm: không có điều khoản để làm việc trong khoảng trống ở cấp cổng, khả năng chặn truyền dữ liệu bí mật (chỉ SMTP, HTTP và HTTPS) bị hạn chế, thiếu mô-đun để tìm kiếm dữ liệu bí mật trong mạng doanh nghiệp.

Công ty Mỹ thành lập năm 2005. Nhờ có sự phát triển riêng trong lĩnh vực bảo mật thông tin nên nó có tiềm năng phát triển rất lớn. Cô gia nhập thị trường Nga vào năm 2012 và thực hiện thành công một số dự án của công ty. Ưu điểm của các giải pháp của nó: chức năng cao, kiểm soát nhiều giao thức và kênh có khả năng rò rỉ dữ liệu, công nghệ được cấp bằng sáng chế ban đầu, tính mô đun, tích hợp với IRM. Nhược điểm: bản địa hóa một phần bằng tiếng Nga, không có tài liệu tiếng Nga, thiếu phân tích hình thái.
Công ty Nga thành lập năm 1999 với tư cách là nhà tích hợp hệ thống. Vào năm 2013, nó đã được tổ chức lại thành một tổ chức. Một trong những lĩnh vực hoạt động là cung cấp nhiều loại dịch vụ và sản phẩm để bảo mật thông tin. Một trong những sản phẩm của công ty là hệ thống DLP của Business Guardian do chính họ thiết kế.
Ưu điểm: tốc độ xử lý thông tin cao, tính mô đun, khả năng mở rộng lãnh thổ, phân tích hình thái bằng 9 ngôn ngữ, hỗ trợ nhiều giao thức đường hầm.
Nhược điểm: khả năng chặn truyền thông tin hạn chế (chỉ được hỗ trợ bởi các plugin cho MS Exchange, MS ISA/TMG và Squid), hỗ trợ hạn chế cho các giao thức mạng được mã hóa.

MFI Soft là công ty Nga phát triển hệ thống bảo mật thông tin. Trước đây, công ty chuyên về các giải pháp phức tạp cho các nhà khai thác viễn thông nên rất chú trọng đến tốc độ xử lý dữ liệu, khả năng chịu lỗi và lưu trữ hiệu quả. MFI Soft phát triển trong lĩnh vực bảo mật thông tin từ năm 2005. Công ty cung cấp trên thị trường hệ thống DLP của tổ hợp nông-công nghiệp Garda Enterprise, hướng tới các doanh nghiệp vừa và lớn. Ưu điểm của hệ thống: dễ triển khai và cấu hình, hiệu suất cao, cài đặt linh hoạt cho các quy tắc phát hiện (bao gồm khả năng ghi lại tất cả lưu lượng truy cập), khả năng giám sát các kênh liên lạc mở rộng (ngoài bộ tiêu chuẩn, bao gồm điện thoại VoIP, P2P và đường hầm giao thức). Nhược điểm: thiếu một số loại báo cáo nhất định, thiếu khả năng chặn truyền thông tin và tìm kiếm nơi lưu trữ thông tin bí mật trên mạng doanh nghiệp.
Một công ty của Nga được thành lập vào năm 1995, ban đầu chuyên phát triển công nghệ lưu trữ và truy xuất thông tin. Sau đó, công ty đã áp dụng kinh nghiệm và sự phát triển của mình trong lĩnh vực bảo mật thông tin và tạo ra giải pháp DLP mang tên “Mạch bảo mật thông tin”. Ưu điểm của giải pháp này: khả năng mở rộng để chặn lưu lượng truy cập và phân tích các sự kiện trên máy trạm, theo dõi thời gian làm việc của nhân viên, tính mô-đun, khả năng mở rộng, công cụ tìm kiếm nâng cao, tốc độ xử lý truy vấn tìm kiếm, kết nối biểu đồ của nhân viên, thuật toán tìm kiếm được cấp bằng sáng chế của chúng tôi “Tìm kiếm Tương tự”, trung tâm đào tạo riêng của chúng tôi dành cho các nhà phân tích đào tạo và chuyên gia kỹ thuật của khách hàng. Nhược điểm: khả năng chặn truyền thông tin hạn chế, thiếu bảng điều khiển quản lý duy nhất.
Một công ty của Nga được thành lập vào năm 1996 và chuyên phát triển các giải pháp DLP và EDPC. Công ty đã chuyển sang danh mục nhà sản xuất DLP vào năm 2011, bổ sung thêm giải pháp DeviceLock nổi tiếng thế giới trong danh mục EDPC (điều khiển thiết bị và cổng trên máy trạm Windows) cung cấp khả năng kiểm soát các kênh mạng cũng như công nghệ lọc và phân tích nội dung. Ngày nay DeviceLock DLP triển khai tất cả các phương pháp phát hiện rò rỉ dữ liệu (DiM, DiU, DaR). Ưu điểm: kiến trúc linh hoạt và cấp phép mô-đun, dễ cài đặt và quản lý các chính sách DLP, bao gồm. thông qua các chính sách của nhóm AD, các công nghệ ban đầu được cấp bằng sáng chế để giám sát thiết bị di động, hỗ trợ môi trường ảo hóa, sự hiện diện của các đại lý cho Windows và Mac OS, toàn quyền kiểm soát nhân viên di động bên ngoài mạng công ty, mô-đun OCR thường trú (được sử dụng, cùng với những thứ khác, khi quét các vị trí lưu trữ dữ liệu). Nhược điểm: thiếu tác nhân DLP cho Linux; phiên bản tác nhân dành cho máy tính Mac chỉ thực hiện các phương pháp điều khiển theo ngữ cảnh.
Một công ty trẻ của Nga chuyên về các công nghệ phân tích sâu lưu lượng mạng (Deep Packet Inspection -DPI). Dựa trên những công nghệ này, công ty đang phát triển hệ thống DLP của riêng mình có tên Monitorium. Ưu điểm của hệ thống: dễ cài đặt và cấu hình, giao diện người dùng thuận tiện, cơ chế tạo chính sách linh hoạt và trực quan, phù hợp ngay cả với các công ty nhỏ. Nhược điểm: khả năng phân tích hạn chế (không có phân tích kết hợp), khả năng kiểm soát hạn chế ở cấp độ máy trạm, thiếu khả năng tìm kiếm những nơi lưu trữ các bản sao thông tin bí mật trái phép trên mạng công ty.
kết luận
Việc phát triển hơn nữa các sản phẩm DLP theo hướng hợp nhất và tích hợp với các sản phẩm trong các lĩnh vực liên quan: kiểm soát nhân sự, bảo vệ trước các mối đe dọa từ bên ngoài và các phân khúc khác về bảo mật thông tin. Đồng thời, hầu hết tất cả các công ty đang nỗ lực tạo ra các phiên bản nhẹ của sản phẩm cho các doanh nghiệp vừa và nhỏ, trong đó việc dễ dàng triển khai hệ thống DLP và dễ sử dụng quan trọng hơn chức năng phức tạp và mạnh mẽ. Ngoài ra, sự phát triển DLP cho thiết bị di động, hỗ trợ công nghệ ảo hóa và SECaaS trên đám mây vẫn tiếp tục.
Xem xét tất cả những gì đã nói, chúng ta có thể giả định rằng sự phát triển nhanh chóng của thị trường DLP toàn cầu và đặc biệt là Nga sẽ thu hút các khoản đầu tư mới và các công ty mới. Và điều này sẽ dẫn đến sự gia tăng hơn nữa về số lượng và chất lượng của các sản phẩm và dịch vụ DLP được cung cấp.
Ngày nay bạn có thể thường xuyên nghe nói về công nghệ như hệ thống DLP. Nó là gì và nó được sử dụng ở đâu? Đây là phần mềm được thiết kế để ngăn ngừa mất dữ liệu bằng cách phát hiện những bất thường có thể xảy ra trong quá trình truyền và lọc dữ liệu. Ngoài ra, các dịch vụ như vậy còn giám sát, phát hiện và chặn việc sử dụng, di chuyển (lưu lượng mạng) và lưu trữ của nó.
Theo quy định, việc rò rỉ dữ liệu bí mật xảy ra do người dùng thiếu kinh nghiệm vận hành thiết bị hoặc là kết quả của các hành động độc hại. Những thông tin đó dưới dạng thông tin cá nhân hoặc doanh nghiệp, sở hữu trí tuệ (IP), thông tin tài chính hoặc y tế, thông tin thẻ tín dụng và những thông tin tương tự đòi hỏi các biện pháp bảo vệ nâng cao mà công nghệ thông tin hiện đại có thể cung cấp.
Các thuật ngữ “mất dữ liệu” và “rò rỉ dữ liệu” có liên quan với nhau và thường được sử dụng thay thế cho nhau, mặc dù chúng hơi khác nhau. Các trường hợp mất thông tin sẽ chuyển thành rò rỉ thông tin khi nguồn chứa thông tin bí mật biến mất và sau đó rơi vào tay một bên trái phép. Tuy nhiên, có thể rò rỉ dữ liệu mà không mất dữ liệu.
Danh mục DLP
Các công cụ công nghệ được sử dụng để chống rò rỉ dữ liệu có thể được chia thành các loại sau: các biện pháp bảo mật tiêu chuẩn, các biện pháp thông minh (nâng cao), kiểm soát truy cập và mã hóa, cũng như các hệ thống DLP chuyên dụng (những gì được mô tả chi tiết bên dưới).

Các biện pháp tiêu chuẩn
Các biện pháp bảo mật tiêu chuẩn như hệ thống phát hiện xâm nhập (IDS) và phần mềm chống vi-rút là những cơ chế phổ biến có sẵn để bảo vệ máy tính khỏi các cuộc tấn công từ bên ngoài cũng như bên trong. Ví dụ, việc kết nối tường lửa sẽ ngăn chặn những người không được phép truy cập vào mạng nội bộ và hệ thống phát hiện xâm nhập sẽ phát hiện các nỗ lực xâm nhập. Có thể ngăn chặn các cuộc tấn công nội bộ bằng cách kiểm tra bằng phần mềm chống vi-rút phát hiện những phần mềm được cài đặt trên PC gửi thông tin bí mật cũng như bằng cách sử dụng các dịch vụ hoạt động theo kiến trúc máy khách-máy chủ mà không có bất kỳ dữ liệu cá nhân hoặc bí mật nào được lưu trữ trên máy tính.
Các biện pháp an ninh bổ sung
Các biện pháp bảo mật bổ sung sử dụng các dịch vụ chuyên môn cao và thuật toán định thời gian để phát hiện hoạt động truy cập dữ liệu bất thường (tức là cơ sở dữ liệu hoặc hệ thống truy xuất thông tin) hoặc trao đổi email bất thường. Ngoài ra, các công nghệ thông tin hiện đại như vậy xác định các chương trình và yêu cầu có mục đích xấu và thực hiện quét sâu hệ thống máy tính (ví dụ: nhận dạng tổ hợp phím hoặc âm thanh của loa). Một số dịch vụ như vậy thậm chí có thể giám sát hoạt động của người dùng để phát hiện hoạt động truy cập dữ liệu bất thường.

Hệ thống DLP được thiết kế tùy chỉnh - nó là gì?
Được thiết kế để bảo mật thông tin, các giải pháp DLP được thiết kế để phát hiện và ngăn chặn các nỗ lực trái phép nhằm sao chép hoặc truyền dữ liệu nhạy cảm (cố ý hoặc vô ý) mà không được phép hoặc truy cập, thường là bởi những người dùng có quyền truy cập vào dữ liệu nhạy cảm.
Để phân loại thông tin nhất định và điều chỉnh quyền truy cập vào thông tin đó, các hệ thống này sử dụng các cơ chế như khớp chính xác dữ liệu, lấy dấu vân tay có cấu trúc, chấp nhận quy tắc và biểu thức chính quy, xuất bản cụm từ mã, định nghĩa khái niệm và từ khóa. Các loại và so sánh các hệ thống DLP có thể được trình bày như sau.
Mạng DLP (còn được gọi là dữ liệu chuyển động hoặc DiM)
Theo quy định, đó là một giải pháp phần cứng hoặc phần mềm được cài đặt tại các điểm mạng có nguồn gốc gần vành đai. Nó phân tích lưu lượng mạng để phát hiện dữ liệu nhạy cảm được gửi vi phạm
Endpoint DLP (dữ liệu khi sử dụng )
Các hệ thống như vậy hoạt động trên máy trạm hoặc máy chủ của người dùng cuối ở nhiều tổ chức khác nhau.
Giống như các hệ thống mạng khác, điểm cuối có thể đối mặt với cả giao tiếp bên trong và bên ngoài và do đó có thể được sử dụng để kiểm soát luồng thông tin giữa các loại hoặc nhóm người dùng (ví dụ: tường lửa). Họ cũng có khả năng giám sát email và tin nhắn tức thời. Điều này xảy ra như sau - trước khi tin nhắn được tải xuống thiết bị, chúng sẽ được dịch vụ kiểm tra và nếu chúng chứa yêu cầu không thuận lợi, chúng sẽ bị chặn. Kết quả là chúng không được sửa chữa và không tuân theo các quy tắc lưu trữ dữ liệu trên thiết bị.
Hệ thống (công nghệ) DLP có ưu điểm là có thể kiểm soát và quản lý quyền truy cập vào các thiết bị vật lý (ví dụ: thiết bị di động có khả năng lưu trữ) và đôi khi truy cập thông tin trước khi được mã hóa.

Một số hệ thống dựa trên điểm cuối cũng có thể cung cấp khả năng kiểm soát ứng dụng để chặn các nỗ lực truyền thông tin nhạy cảm cũng như cung cấp phản hồi ngay lập tức cho người dùng. Tuy nhiên, chúng có nhược điểm là phải được cài đặt trên mọi máy trạm trên mạng và không thể sử dụng trên các thiết bị di động (ví dụ: điện thoại di động và PDA) hoặc ở những nơi không thể cài đặt trên thực tế (ví dụ: tại máy trạm ở một quán cà phê Internet). Trường hợp này phải được tính đến khi chọn hệ thống DLP cho bất kỳ mục đích nào.
Nhận dạng dữ liệu
Hệ thống DLP bao gồm một số phương pháp nhằm xác định thông tin bí mật hoặc bí mật. Quá trình này đôi khi bị nhầm lẫn với việc giải mã. Tuy nhiên, nhận dạng dữ liệu là quá trình các tổ chức sử dụng công nghệ DLP để xác định những gì cần tìm kiếm (đang chuyển động, ở trạng thái nghỉ hoặc đang sử dụng).
Dữ liệu được phân loại là có cấu trúc hoặc không có cấu trúc. Loại đầu tiên được lưu trữ trong các trường cố định trong một tệp (chẳng hạn như bảng tính), trong khi loại không có cấu trúc đề cập đến văn bản dạng tự do (ở dạng tài liệu văn bản hoặc tệp PDF).
Theo các chuyên gia, 80% dữ liệu là không có cấu trúc. Theo đó, 20% được cơ cấu. dựa trên phân tích nội dung tập trung vào thông tin có cấu trúc và phân tích theo ngữ cảnh. Nó được thực hiện tại nơi tạo ra ứng dụng hoặc hệ thống chứa dữ liệu. Vì vậy, câu trả lời cho câu hỏi “Hệ thống DLP - nó là gì?” sẽ dùng để xác định thuật toán phân tích thông tin.
Phương pháp được sử dụng
Ngày nay có rất nhiều phương pháp mô tả nội dung nhạy cảm. Chúng có thể được chia thành hai loại: chính xác và không chính xác.
Các phương pháp chính xác là những phương pháp liên quan đến phân tích nội dung và giảm các phản hồi dương tính giả đối với các truy vấn xuống gần như bằng không.
Tất cả những thứ khác đều không chính xác và có thể bao gồm: từ điển, từ khóa, biểu thức chính quy, biểu thức chính quy mở rộng, thẻ meta dữ liệu, phân tích Bayesian, phân tích thống kê, v.v.

Hiệu quả của việc phân tích trực tiếp phụ thuộc vào độ chính xác của nó. Hệ thống DLP được xếp hạng cao sẽ có hiệu suất cao ở thông số này. Độ chính xác của việc nhận dạng DLP là điều cần thiết để tránh các kết quả dương tính giả và hậu quả tiêu cực. Độ chính xác có thể phụ thuộc vào nhiều yếu tố, một số yếu tố có thể là tình huống hoặc công nghệ. Kiểm tra độ chính xác có thể đảm bảo độ tin cậy của hệ thống DLP - gần như không có kết quả dương tính giả.
Phát hiện và ngăn chặn rò rỉ thông tin
Đôi khi nguồn phân phối dữ liệu cung cấp thông tin nhạy cảm cho bên thứ ba. Sau một thời gian, một số trong số đó rất có thể sẽ được tìm thấy ở một vị trí trái phép (ví dụ: trên Internet hoặc trên máy tính xách tay của người dùng khác). Các hệ thống DLP, giá của nó được các nhà phát triển cung cấp theo yêu cầu và có thể dao động từ vài chục đến vài nghìn rúp, sau đó phải điều tra xem dữ liệu bị rò rỉ như thế nào - từ một hoặc nhiều bên thứ ba, liệu nó có được thực hiện độc lập với nhau hay không. sự rò rỉ đã được cung cấp bởi bất kỳ phương tiện nào khác, v.v.
Dữ liệu ở trạng thái nghỉ
“Dữ liệu ở trạng thái lưu trữ” đề cập đến thông tin lưu trữ cũ được lưu trữ trên bất kỳ ổ cứng nào của PC khách, trên máy chủ tệp từ xa, trên đĩa. Định nghĩa này cũng áp dụng cho dữ liệu được lưu trữ trong hệ thống sao lưu (trên ổ đĩa flash hoặc CD). Thông tin này rất được các doanh nghiệp và cơ quan chính phủ quan tâm vì một lượng lớn dữ liệu không được sử dụng trong các thiết bị lưu trữ và có nhiều khả năng bị truy cập trái phép bởi những người bên ngoài mạng.
Nếu chúng tôi khá nhất quán trong các định nghĩa của mình, chúng tôi có thể nói rằng bảo mật thông tin bắt đầu chính xác từ sự ra đời của hệ thống DLP. Trước đó, tất cả các sản phẩm liên quan đến “bảo mật thông tin” thực sự không được bảo vệ thông tin mà là cơ sở hạ tầng - nơi lưu trữ, truyền tải và xử lý dữ liệu. Máy tính, ứng dụng hoặc kênh lưu trữ, xử lý hoặc truyền thông tin nhạy cảm được các sản phẩm này bảo vệ giống như cơ sở hạ tầng xử lý thông tin vô hại. Nghĩa là, với sự ra đời của các sản phẩm DLP, các hệ thống thông tin cuối cùng đã học được cách phân biệt thông tin bí mật với thông tin không bí mật. Có lẽ, với việc tích hợp công nghệ DLP vào cơ sở hạ tầng thông tin, các công ty sẽ có thể tiết kiệm rất nhiều cho việc bảo vệ thông tin - ví dụ: chỉ sử dụng mã hóa trong trường hợp thông tin bí mật được lưu trữ hoặc truyền đi và không mã hóa thông tin trong các trường hợp khác.
Tuy nhiên, đây là vấn đề của tương lai và hiện tại, những công nghệ này được sử dụng chủ yếu để bảo vệ thông tin khỏi bị rò rỉ. Công nghệ phân loại thông tin là cốt lõi của hệ thống DLP. Mỗi nhà sản xuất coi các phương pháp phát hiện thông tin bí mật của mình là duy nhất, bảo vệ chúng bằng các bằng sáng chế và đưa ra các nhãn hiệu đặc biệt cho chúng. Xét cho cùng, các thành phần còn lại của kiến trúc khác với các công nghệ này (bộ chặn giao thức, bộ phân tích định dạng, quản lý sự cố và lưu trữ dữ liệu) đều giống hệt nhau đối với hầu hết các nhà sản xuất và đối với các công ty lớn, chúng thậm chí còn được tích hợp với các sản phẩm bảo mật cơ sở hạ tầng thông tin khác. Về cơ bản, để phân loại dữ liệu trong các sản phẩm bảo vệ thông tin doanh nghiệp khỏi bị rò rỉ, hai nhóm công nghệ chính được sử dụng - phương pháp phân tích và thống kê ngôn ngữ (hình thái, ngữ nghĩa) (Dấu vân tay kỹ thuật số, DNA tài liệu, chống đạo văn). Mỗi công nghệ đều có điểm mạnh và điểm yếu riêng, quyết định phạm vi ứng dụng của nó.
Phân tích ngôn ngữ
Việc sử dụng các từ dừng ("bí mật", "bí mật" và những thứ tương tự) để chặn các email gửi đi trong máy chủ thư có thể được coi là tiền thân của các hệ thống DLP hiện đại. Tất nhiên, điều này không bảo vệ khỏi những kẻ tấn công - việc loại bỏ từ dừng, thường được đặt trong một phần riêng biệt của tài liệu, không khó và ý nghĩa của văn bản sẽ không thay đổi chút nào.
Động lực cho sự phát triển của công nghệ ngôn ngữ được tạo ra vào đầu thế kỷ này bởi những người tạo ra bộ lọc email. Trước hết, để bảo vệ email khỏi thư rác. Hiện nay, các phương pháp danh tiếng đang chiếm ưu thế trong các công nghệ chống thư rác, nhưng vào đầu thế kỷ này đã xảy ra một cuộc chiến ngôn ngữ thực sự giữa đạn và áo giáp - kẻ gửi thư rác và kẻ chống thư rác. Bạn có nhớ các phương pháp đơn giản nhất để đánh lừa các bộ lọc dựa trên các từ dừng không? Thay thế các chữ cái bằng các chữ cái tương tự từ bảng mã hoặc số khác, phiên âm, khoảng trắng ngẫu nhiên, gạch chân hoặc ngắt dòng trong văn bản. Những người chống gửi thư rác nhanh chóng học cách đối phó với những thủ thuật như vậy, nhưng sau đó, thư rác đồ họa và các loại thư từ không mong muốn xảo quyệt khác xuất hiện.
Tuy nhiên, không thể sử dụng công nghệ chống thư rác trong các sản phẩm DLP nếu không có sự sửa đổi nghiêm túc. Suy cho cùng, để chống thư rác, việc chia luồng thông tin thành hai loại: thư rác và không thư rác là đủ. Phương pháp Bayes, được sử dụng để phát hiện thư rác, chỉ đưa ra kết quả nhị phân: “có” hoặc “không”. Điều này là không đủ để bảo vệ dữ liệu của công ty khỏi bị rò rỉ - bạn không thể đơn giản chia thông tin thành bí mật và không bí mật. Bạn cần có khả năng phân loại thông tin theo liên kết chức năng (tài chính, sản xuất, công nghệ, thương mại, tiếp thị) và trong các lớp - phân loại thông tin theo mức độ truy cập (để phân phối miễn phí, để truy cập hạn chế, để sử dụng chính thức, bí mật, tuyệt mật , và như thế).
Hầu hết các hệ thống phân tích ngôn ngữ hiện đại không chỉ sử dụng phân tích ngữ cảnh (nghĩa là trong ngữ cảnh nào, kết hợp với những từ khác mà một thuật ngữ cụ thể được sử dụng) mà còn sử dụng phân tích ngữ nghĩa của văn bản. Những công nghệ này hoạt động hiệu quả hơn khi mảnh được phân tích càng lớn. Việc phân tích được thực hiện chính xác hơn trên một đoạn văn bản lớn, đồng thời có nhiều khả năng xác định được danh mục và loại tài liệu hơn. Khi phân tích các tin nhắn ngắn (SMS, Internet Messenger), không có gì tốt hơn các từ dừng vẫn chưa được phát minh. Tác giả đã phải đối mặt với một vấn đề như vậy vào mùa thu năm 2008, khi hàng nghìn tin nhắn như “chúng tôi đang bị sa thải”, “họ sẽ tước giấy phép của chúng tôi”, “dòng người gửi tiền chảy ra”, đã phải bị chặn ngay lập tức khỏi tài khoản của họ. khách hàng, được gửi tới Internet từ nơi làm việc của nhiều ngân hàng thông qua tin nhắn tức thời.
Ưu điểm của công nghệ
Ưu điểm của công nghệ ngôn ngữ là chúng làm việc trực tiếp với nội dung của tài liệu, nghĩa là đối với họ, tài liệu được tạo ra ở đâu và như thế nào, loại tem nào hoặc tệp được gọi là gì - tài liệu không quan trọng. được bảo vệ ngay lập tức. Điều này rất quan trọng, ví dụ như khi xử lý bản nháp của tài liệu bí mật hoặc để bảo vệ tài liệu đến. Nếu các tài liệu được tạo và sử dụng trong công ty bằng cách nào đó có thể được đặt tên, đóng dấu hoặc đánh dấu theo một cách cụ thể thì các tài liệu đến có thể có tem và nhãn không được tổ chức chấp nhận. Các bản nháp (tất nhiên trừ khi chúng được tạo trong hệ thống quản lý tài liệu an toàn) cũng có thể chứa thông tin bí mật, nhưng chưa có tem và nhãn cần thiết.
Một ưu điểm khác của công nghệ ngôn ngữ là khả năng học tập của chúng. Nếu bạn đã từng nhấn nút “Không phải thư rác” trong ứng dụng email của mình ít nhất một lần trong đời, thì bạn có thể hình dung ứng dụng khách là một phần của hệ thống đào tạo công cụ ngôn ngữ. Hãy để tôi lưu ý rằng bạn hoàn toàn không cần phải là một nhà ngôn ngữ học được chứng nhận và biết chính xác những gì sẽ thay đổi trong cơ sở dữ liệu danh mục - chỉ cần cho hệ thống biết kết quả dương tính giả và nó sẽ tự thực hiện phần còn lại.
Ưu điểm thứ ba của công nghệ ngôn ngữ là khả năng mở rộng của chúng. Tốc độ xử lý thông tin tỷ lệ thuận với số lượng của nó và hoàn toàn không phụ thuộc vào số lượng danh mục. Cho đến gần đây, việc xây dựng cơ sở dữ liệu phân cấp theo danh mục (trước đây gọi là BKF - cơ sở dữ liệu lọc nội dung, nhưng tên này không còn phản ánh ý nghĩa thực sự) trông giống như một kiểu pháp sư của các nhà ngôn ngữ học chuyên nghiệp, vì vậy việc thiết lập BKF có thể dễ dàng được coi là một thiếu sót. Nhưng với việc phát hành một số sản phẩm “tự động ngôn ngữ” vào năm 2010, việc xây dựng cơ sở dữ liệu chính về các danh mục trở nên cực kỳ đơn giản - hệ thống hiển thị những nơi lưu trữ tài liệu của một danh mục nhất định và chính nó xác định các đặc điểm ngôn ngữ của danh mục này và trong trường hợp dương tính giả, nó sẽ học độc lập. Vì vậy, giờ đây tính dễ thiết lập đã được thêm vào những lợi thế của công nghệ ngôn ngữ.
Và một ưu điểm nữa của công nghệ ngôn ngữ mà tôi muốn lưu ý trong bài viết đó là khả năng phát hiện các danh mục trong các luồng thông tin không liên quan đến tài liệu đặt trong công ty. Công cụ giám sát nội dung của luồng thông tin có thể xác định các danh mục như hoạt động bất hợp pháp (vi phạm bản quyền, phân phối hàng bị cấm), sử dụng cơ sở hạ tầng của công ty cho mục đích riêng, gây tổn hại đến hình ảnh của công ty (ví dụ: lan truyền tin đồn phỉ báng) và sớm.
Nhược điểm của công nghệ
Nhược điểm chính của công nghệ ngôn ngữ là sự phụ thuộc vào ngôn ngữ. Không thể sử dụng một công cụ ngôn ngữ được thiết kế cho một ngôn ngữ để phân tích ngôn ngữ khác. Điều này đặc biệt đáng chú ý khi các nhà sản xuất Mỹ thâm nhập thị trường Nga - họ chưa sẵn sàng đối mặt với sự hình thành từ tiếng Nga và sự hiện diện của sáu bảng mã. Việc dịch các danh mục và từ khóa sang tiếng Nga là chưa đủ - trong tiếng Anh, việc hình thành từ khá đơn giản và các trường hợp được đưa vào giới từ, nghĩa là khi trường hợp thay đổi, giới từ thay đổi chứ không phải chính từ đó. Hầu hết các danh từ trong tiếng Anh đều trở thành động từ mà không cần thay đổi từ. Và như thế. Trong tiếng Nga, mọi thứ không như vậy - một gốc có thể tạo ra hàng chục từ trong các phần khác nhau của lời nói.
Ở Đức, các nhà sản xuất công nghệ ngôn ngữ của Mỹ phải đối mặt với một vấn đề khác - cái gọi là “từ ghép”, từ ghép. Trong tiếng Đức, người ta thường gắn định nghĩa vào từ chính, dẫn đến những từ đôi khi bao gồm hàng chục gốc. Không có thứ như vậy trong tiếng Anh, trong đó một từ là một chuỗi các chữ cái nằm giữa hai dấu cách, vì vậy công cụ ngôn ngữ tiếng Anh hóa ra không thể xử lý các từ dài xa lạ.
Công bằng mà nói, cần phải nói rằng những vấn đề này hiện nay phần lớn đã được các nhà sản xuất Mỹ giải quyết. Công cụ ngôn ngữ đã phải được thiết kế lại (và đôi khi được viết lại) khá nhiều, nhưng các thị trường lớn như Nga và Đức chắc chắn xứng đáng với điều đó. Việc xử lý văn bản đa ngôn ngữ bằng công nghệ ngôn ngữ cũng gặp khó khăn. Tuy nhiên, hầu hết các công cụ vẫn xử lý được hai ngôn ngữ, thường là ngôn ngữ quốc gia + tiếng Anh - đối với hầu hết các công việc kinh doanh, điều này là khá đủ. Mặc dù tác giả đã gặp phải các văn bản mật có chứa, chẳng hạn như tiếng Kazakh, tiếng Nga và tiếng Anh cùng một lúc, nhưng đây là ngoại lệ chứ không phải là quy luật.
Một nhược điểm khác của công nghệ ngôn ngữ trong việc kiểm soát toàn bộ thông tin bí mật của công ty là không phải tất cả thông tin bí mật đều ở dạng văn bản mạch lạc. Mặc dù trong cơ sở dữ liệu thông tin được lưu trữ ở dạng văn bản và không có vấn đề gì khi trích xuất văn bản từ DBMS, thông tin nhận được thường chứa tên riêng - tên đầy đủ, địa chỉ, tên công ty, cũng như thông tin kỹ thuật số - số tài khoản, thẻ tín dụng, số dư của họ, v.v. Việc xử lý dữ liệu đó bằng ngôn ngữ học sẽ không mang lại nhiều lợi ích. Điều tương tự cũng có thể nói về các định dạng CAD/CAM, tức là các bản vẽ thường chứa tài sản trí tuệ, mã chương trình và định dạng phương tiện (video/âm thanh) - một số văn bản có thể được trích xuất từ chúng, nhưng quá trình xử lý chúng cũng không hiệu quả. Chỉ ba năm trước, điều này cũng được áp dụng cho các văn bản được quét, nhưng các nhà sản xuất hệ thống DLP hàng đầu đã nhanh chóng bổ sung tính năng nhận dạng quang học và giải quyết vấn đề này.
Nhưng thiếu sót lớn nhất và thường bị chỉ trích nhất của công nghệ ngôn ngữ vẫn là cách tiếp cận xác suất để phân loại. Nếu bạn đã từng đọc một email có danh mục "Có thể là SPAM", bạn sẽ hiểu ý tôi. Nếu điều này xảy ra với thư rác, nơi chỉ có hai danh mục (thư rác/không phải thư rác), bạn có thể tưởng tượng điều gì sẽ xảy ra khi hàng tá danh mục và lớp bảo mật được tải vào hệ thống. Mặc dù việc đào tạo hệ thống có thể đạt được độ chính xác 92-95%, nhưng đối với hầu hết người dùng, điều này có nghĩa là cứ mỗi một phần mười hoặc hai mươi chuyển động thông tin sẽ bị gán nhầm vào loại sai, với tất cả các hậu quả kinh doanh tiếp theo (rò rỉ hoặc gián đoạn một quy trình hợp pháp).
Thông thường, người ta không coi sự phức tạp của việc phát triển công nghệ là một bất lợi, nhưng không thể bỏ qua. Việc phát triển một công cụ ngôn ngữ nghiêm túc với việc phân loại văn bản thành nhiều hơn hai loại là một quá trình đòi hỏi nhiều kiến thức và khá phức tạp về mặt công nghệ. Ngôn ngữ học ứng dụng là một ngành khoa học đang phát triển nhanh chóng, nhận được động lực phát triển mạnh mẽ nhờ sự phổ biến của tìm kiếm trên Internet, nhưng ngày nay trên thị trường chỉ có một số công cụ phân loại khả thi: đối với tiếng Nga chỉ có hai trong số đó, và đối với ngôn ngữ học ứng dụng. một số ngôn ngữ đơn giản là chúng chưa được phát triển. Do đó, chỉ có một số công ty trên thị trường DLP có thể phân loại đầy đủ thông tin một cách nhanh chóng. Có thể giả định rằng khi thị trường DLP phát triển lên quy mô hàng tỷ đô la, Google sẽ dễ dàng gia nhập. Với công cụ ngôn ngữ riêng, được thử nghiệm trên hàng nghìn tỷ truy vấn tìm kiếm trên hàng nghìn danh mục, sẽ không khó để anh ấy ngay lập tức giành được một phần quan trọng của thị trường này.
phương pháp thống kê
Nhiệm vụ tìm kiếm trên máy tính các trích dẫn quan trọng (tại sao chính xác là "có ý nghĩa" - muộn hơn một chút) đã khiến các nhà ngôn ngữ học quan tâm trở lại những năm 70 của thế kỷ trước, nếu không muốn nói là sớm hơn. Văn bản được chia thành nhiều phần có kích thước nhất định và một hàm băm được lấy từ mỗi phần đó. Nếu một chuỗi băm nhất định xảy ra trong hai văn bản cùng một lúc, thì khả năng cao là các văn bản trong các khu vực này trùng khớp với nhau.
Ví dụ, sản phẩm phụ của nghiên cứu trong lĩnh vực này là “niên đại thay thế” của Anatoly Fomenko, một học giả đáng kính, người đã nghiên cứu về “các mối tương quan văn bản” và từng so sánh biên niên sử Nga từ các giai đoạn lịch sử khác nhau. Ngạc nhiên vì biên niên sử của các thế kỷ khác nhau trùng khớp đến mức nào (hơn 60%), vào cuối những năm 70, ông đưa ra giả thuyết rằng niên đại của chúng ta ngắn hơn vài thế kỷ. Do đó, khi một số công ty DLP tham gia thị trường cung cấp “công nghệ mang tính cách mạng để tìm kiếm báo giá”, có thể nói rằng khả năng cao là công ty đó không tạo ra gì khác ngoài một thương hiệu mới.
Công nghệ thống kê xử lý văn bản không phải là một chuỗi từ mạch lạc mà là một chuỗi ký tự tùy ý, và do đó hoạt động tốt như nhau với văn bản ở bất kỳ ngôn ngữ nào. Vì bất kỳ đối tượng kỹ thuật số nào - có thể là hình ảnh hoặc chương trình - cũng là một chuỗi ký hiệu, nên các phương pháp tương tự có thể được sử dụng để phân tích không chỉ thông tin văn bản mà còn bất kỳ đối tượng kỹ thuật số nào. Và nếu giá trị băm trong hai tệp âm thanh khớp nhau thì một trong số chúng có thể chứa trích dẫn từ tệp kia, vì vậy, phương pháp thống kê là phương tiện hiệu quả để bảo vệ chống rò rỉ âm thanh và video, được sử dụng tích cực trong các studio âm nhạc và công ty điện ảnh.
Đã đến lúc quay lại khái niệm "một câu trích dẫn có ý nghĩa". Đặc điểm chính của hàm băm phức tạp được lấy từ một đối tượng được bảo vệ (trong các sản phẩm khác nhau được gọi là Dấu vân tay kỹ thuật số hoặc DNA tài liệu) là bước thực hiện hàm băm. Như có thể hiểu từ mô tả, “bản in” như vậy là một đặc điểm riêng của đối tượng, đồng thời có kích thước riêng. Điều này rất quan trọng vì nếu bạn in từ hàng triệu tài liệu (bằng dung lượng lưu trữ của một ngân hàng trung bình), bạn sẽ cần đủ dung lượng ổ đĩa để lưu trữ tất cả các bản in. Kích thước của dấu vân tay như vậy phụ thuộc vào bước băm - bước càng nhỏ thì dấu vân tay càng lớn. Nếu bạn lấy hàm băm theo gia số một ký tự, kích thước của dấu vân tay sẽ vượt quá kích thước của chính mẫu đó. Nếu bạn tăng kích thước bước (ví dụ: 10.000 ký tự) để giảm "trọng lượng" của dấu vân tay, thì đồng thời xác suất tăng lên là một tài liệu chứa trích dẫn từ một mẫu dài 9.900 ký tự sẽ được giữ bí mật, nhưng sẽ trượt qua mà không được chú ý.
Mặt khác, nếu bạn thực hiện một bước rất nhỏ, một vài ký hiệu, để tăng độ chính xác của việc phát hiện thì bạn có thể tăng số lượng kết quả dương tính giả lên giá trị không thể chấp nhận được. Về mặt văn bản, điều này có nghĩa là bạn không nên xóa hàm băm khỏi mỗi chữ cái - tất cả các từ đều bao gồm các chữ cái và hệ thống sẽ lấy sự hiện diện của các chữ cái trong văn bản làm nội dung trích dẫn từ văn bản mẫu. Thông thường, bản thân các nhà sản xuất đề xuất một số bước tối ưu để loại bỏ giá trị băm sao cho kích thước của báo giá vừa đủ, đồng thời trọng lượng của bản in nhỏ - từ 3% (văn bản) đến 15% (video nén). Ở một số sản phẩm, nhà sản xuất cho phép bạn thay đổi kích thước của ý nghĩa báo giá, tức là tăng hoặc giảm bước băm.
Ưu điểm của công nghệ
Như bạn có thể hiểu từ mô tả, để phát hiện một trích dẫn, bạn cần một đối tượng mẫu. Và các phương pháp thống kê có thể cho biết với độ chính xác cao (lên tới 100%) liệu tệp đang được kiểm tra có chứa trích dẫn quan trọng từ mẫu hay không. Tức là hệ thống không chịu trách nhiệm phân loại tài liệu - công việc đó hoàn toàn phụ thuộc vào lương tâm của người phân loại hồ sơ trước khi lấy dấu vân tay. Điều này hỗ trợ rất nhiều cho việc bảo vệ thông tin nếu doanh nghiệp lưu trữ các tệp đã được phân loại và thay đổi không thường xuyên ở một số nơi. Sau đó, chỉ cần lấy dấu vân tay từ mỗi tệp này là đủ và theo cài đặt, hệ thống sẽ chặn việc truyền hoặc sao chép các tệp có chứa các trích dẫn quan trọng từ các mẫu.
Tính độc lập của phương pháp thống kê với ngôn ngữ văn bản và thông tin phi văn bản cũng là một lợi thế không thể phủ nhận. Chúng rất giỏi trong việc bảo vệ các đối tượng kỹ thuật số tĩnh thuộc bất kỳ loại nào - hình ảnh, âm thanh/video, cơ sở dữ liệu. Tôi sẽ nói về việc bảo vệ các đối tượng động ở phần “nhược điểm”.
Nhược điểm của công nghệ
Giống như trường hợp của ngôn ngữ học, nhược điểm của công nghệ cũng chính là mặt trái của ưu điểm. Sự dễ dàng trong việc đào tạo hệ thống (chỉ ra tệp cho hệ thống và nó đã được bảo vệ) chuyển trách nhiệm đào tạo hệ thống sang người dùng. Nếu đột nhiên một tệp bí mật bị đặt sai vị trí hoặc không được lập chỉ mục do sơ suất hoặc mục đích xấu thì hệ thống sẽ không bảo vệ tệp đó. Theo đó, các công ty quan tâm đến việc bảo vệ thông tin bí mật khỏi bị rò rỉ phải cung cấp quy trình kiểm soát cách hệ thống DLP lập chỉ mục các tệp bí mật.
Một nhược điểm khác là kích thước vật lý của bản in. Tác giả đã nhiều lần chứng kiến các dự án thí điểm ấn tượng trên bản in khi hệ thống DLP với xác suất 100% chặn việc chuyển các tài liệu có chứa các trích dẫn quan trọng từ ba trăm tài liệu mẫu. Tuy nhiên, sau một năm vận hành hệ thống ở chế độ chiến đấu, dấu vân tay của mỗi lá thư gửi đi được so sánh không phải với ba trăm mà với hàng triệu dấu vân tay mẫu, điều này làm chậm đáng kể hoạt động của hệ thống thư, gây ra sự chậm trễ hàng chục phút. .
Như tôi đã hứa ở trên, tôi sẽ mô tả kinh nghiệm của mình trong việc bảo vệ các đối tượng động bằng phương pháp thống kê. Thời gian lấy dấu vân tay trực tiếp phụ thuộc vào kích thước và định dạng tệp. Đối với một tài liệu văn bản như bài viết này thì chỉ mất một phần nhỏ của một giây, đối với một bộ phim MP4 dài một tiếng rưỡi thì phải mất hàng chục giây. Đối với các tệp hiếm khi thay đổi, điều này không quan trọng, nhưng nếu một đối tượng thay đổi mỗi phút hoặc thậm chí một giây thì sẽ phát sinh một vấn đề: sau mỗi lần thay đổi đối tượng, một dấu vân tay mới cần được lấy từ nó... Mã đó lập trình viên đang làm việc không phải là vấn đề phức tạp nhất, nó còn tệ hơn nhiều với cơ sở dữ liệu được sử dụng trong thanh toán, ngân hàng lõi hoặc trung tâm cuộc gọi. Nếu thời gian lấy dấu vân tay lâu hơn thời gian đối tượng không thay đổi thì vấn đề không có lời giải. Đây không phải là một trường hợp kỳ lạ - ví dụ: dấu vân tay của cơ sở dữ liệu lưu trữ số điện thoại của khách hàng của một nhà khai thác di động liên bang phải mất vài ngày để lấy được nhưng thay đổi mỗi giây. Vì vậy, khi một nhà cung cấp DLP tuyên bố rằng sản phẩm của họ có thể bảo vệ cơ sở dữ liệu của bạn, hãy thêm từ “gần như tĩnh”.
Sự thống nhất và đấu tranh của các mặt đối lập
Như có thể thấy ở phần trước của bài viết, sức mạnh của công nghệ này thể hiện ở điểm yếu của công nghệ khác. Ngôn ngữ học không cần mẫu, nó phân loại dữ liệu một cách nhanh chóng và có thể bảo vệ thông tin chưa được lấy dấu vân tay, dù vô tình hay cố ý. Dấu vân tay cho độ chính xác tốt hơn và do đó thích hợp hơn để sử dụng ở chế độ tự động. Ngôn ngữ học hoạt động tốt với văn bản, dấu vân tay hoạt động tốt với các định dạng lưu trữ thông tin khác.
Do đó, hầu hết các công ty hàng đầu đều sử dụng cả hai công nghệ trong quá trình phát triển của mình, một trong số đó là công nghệ chính và công nghệ còn lại là bổ sung. Điều này là do ban đầu các sản phẩm của công ty chỉ sử dụng một công nghệ, sau đó công ty đã tiến bộ hơn nữa và sau đó, theo nhu cầu thị trường, công nghệ thứ hai đã được kết nối. Ví dụ: trước đây InfoWatch chỉ sử dụng công nghệ ngôn ngữ Morph-OLogic được cấp phép và Websense sử dụng công nghệ PrecisionID, thuộc danh mục Dấu vân tay kỹ thuật số, nhưng giờ đây các công ty sử dụng cả hai phương pháp. Lý tưởng nhất là hai công nghệ này không nên được sử dụng song song mà tuần tự. Ví dụ: dấu vân tay sẽ thực hiện công việc xác định loại tài liệu tốt hơn - ví dụ: đó là hợp đồng hay bảng cân đối kế toán. Sau đó, bạn có thể kết nối cơ sở dữ liệu ngôn ngữ được tạo riêng cho danh mục này. Điều này giúp tiết kiệm đáng kể tài nguyên máy tính.
Có một số loại công nghệ khác được sử dụng trong các sản phẩm DLP nằm ngoài phạm vi của bài viết này. Ví dụ, chúng bao gồm một bộ phân tích cấu trúc cho phép bạn tìm các cấu trúc chính thức trong các đối tượng (số thẻ tín dụng, hộ chiếu, mã số thuế, v.v.) mà không thể phát hiện được bằng ngôn ngữ học hoặc dấu vân tay. Ngoài ra, chủ đề về các loại nhãn khác nhau không được đề cập đến - từ các mục trong trường thuộc tính của tệp hoặc đơn giản là tên đặc biệt cho tệp cho đến các bộ chứa mật mã đặc biệt. Công nghệ thứ hai đang trở nên lỗi thời, vì hầu hết các nhà sản xuất không muốn tự mình phát minh lại bánh xe mà muốn tích hợp với các nhà sản xuất hệ thống DRM, chẳng hạn như Oracle IRM hoặc Microsoft RMS.
Các sản phẩm DLP là lĩnh vực bảo mật thông tin đang phát triển nhanh chóng; một số nhà sản xuất phát hành phiên bản mới rất thường xuyên, hơn một lần mỗi năm. Chúng tôi mong muốn sự xuất hiện của các công nghệ mới để phân tích lĩnh vực thông tin của doanh nghiệp nhằm tăng hiệu quả bảo vệ thông tin bí mật.
Công nghệ DLP
Xử lý ánh sáng kỹ thuật số (DLP) là một công nghệ tiên tiến được phát minh bởi Texas Instruments. Nhờ nó, người ta có thể tạo ra các máy chiếu đa phương tiện rất nhỏ, rất nhẹ (3 kg - đó có thực sự là trọng lượng không?) Và tuy nhiên, khá mạnh mẽ (hơn 1000 ANSI Lm).
Tóm tắt lịch sử hình thành
Cách đây rất lâu, ở một thiên hà xa xôi...
Năm 1987, TS. Larry J. Hornbeck đã phát minh ra thiết bị đa gương kỹ thuật số(Thiết bị vi gương kỹ thuật số hoặc DMD). Phát minh này đã kết thúc mười năm nghiên cứu của Texas Instruments về cơ khí vi mô thiết bị gương biến dạng(Thiết bị gương biến dạng hoặc DMD nữa). Bản chất của khám phá này là việc từ bỏ những tấm gương dẻo để thay thế bằng một ma trận gương cứng chỉ có hai vị trí ổn định.
Năm 1989, Texas Instruments trở thành một trong bốn công ty được chọn để triển khai phần “máy chiếu” trong chương trình của Hoa Kỳ. Màn hình độ nét cao, được tài trợ bởi Cơ quan quản lý dự án nghiên cứu nâng cao (ARPA).
Vào tháng 5 năm 1992, TI trình diễn hệ thống dựa trên DMD đầu tiên hỗ trợ tiêu chuẩn độ phân giải ARPA hiện đại.
Phiên bản DMD truyền hình độ nét cao (HDTV) dựa trên ba DMD độ nét cao đã được phát sóng vào tháng 2 năm 1994.
Việc bán hàng loạt chip DMD bắt đầu vào năm 1995.
Công nghệ DLP
Yếu tố chính của máy chiếu đa phương tiện được tạo ra bằng công nghệ DLP là ma trận gương siêu nhỏ (các phần tử DMD) được làm bằng hợp kim nhôm, có độ phản chiếu rất cao. Mỗi gương được gắn vào một đế cứng, được nối với đế ma trận thông qua các tấm di động. Các điện cực kết nối với các ô nhớ CMOS SRAM được đặt ở các góc đối diện của gương. Dưới tác dụng của điện trường, chất nền có gương chiếm một trong hai vị trí, lệch nhau chính xác 20° nhờ các bộ hạn chế nằm trên đế của ma trận.
Hai vị trí này tương ứng với sự phản xạ của luồng ánh sáng tới, tương ứng, vào thấu kính và bộ hấp thụ ánh sáng hiệu quả, mang lại khả năng loại bỏ nhiệt đáng tin cậy và phản xạ ánh sáng tối thiểu.
Bản thân bus dữ liệu và ma trận được thiết kế để cung cấp tới 60 khung hình ảnh trở lên mỗi giây với độ phân giải 16 triệu màu.
Ma trận gương cùng với CMOS SRAM tạo nên tinh thể DMD - nền tảng của công nghệ DLP.
Kích thước nhỏ của tinh thể rất ấn tượng. Diện tích của mỗi gương ma trận là 16 micron trở xuống và khoảng cách giữa các gương là khoảng 1 micron. Tinh thể, và nhiều hơn một tinh thể, dễ dàng nằm gọn trong lòng bàn tay của bạn.
Tổng cộng, nếu Texas Instruments không lừa dối chúng ta, ba loại tinh thể (hoặc chip) với độ phân giải khác nhau sẽ được sản xuất. Cái này:
- SVGA: 848x600; 508.800 gương
- XGA: 1024×768 với khẩu độ màu đen (không gian giữa các khe); 786.432 gương
- SXGA: 1280x1024; 1.310.720 gương
 |
 |
Vậy chúng ta có một ma trận, chúng ta có thể làm gì với nó? Tất nhiên, hãy chiếu sáng nó bằng quang thông mạnh hơn và đặt hệ thống quang học theo đường đi của một trong các hướng phản xạ của gương, tập trung hình ảnh lên màn hình. Ở lối đi của hướng khác, nên đặt vật hút sáng để ánh sáng không cần thiết không gây bất tiện. Bây giờ chúng ta có thể chiếu những bức ảnh đơn sắc. Nhưng màu sắc ở đâu? Độ sáng ở đâu?

Nhưng có vẻ như đây là phát minh của đồng chí Larry, điều này đã được thảo luận trong đoạn đầu tiên của phần về lịch sử hình thành DLP. Nếu bạn vẫn không hiểu chuyện gì đang xảy ra, hãy sẵn sàng, vì bây giờ một cú sốc có thể xảy ra với bạn :), bởi vì giải pháp tao nhã và khá rõ ràng này ngày nay là giải pháp tiên tiến và công nghệ tiên tiến nhất trong lĩnh vực chiếu hình ảnh.
Hãy nhớ thủ thuật của trẻ em với một chiếc đèn pin xoay, ánh sáng từ đó đến một lúc nào đó sẽ hợp nhất và biến thành một vòng tròn phát sáng. Trò đùa về tầm nhìn của chúng tôi cho phép chúng tôi cuối cùng từ bỏ các hệ thống hình ảnh tương tự để chuyển sang hệ thống hình ảnh kỹ thuật số hoàn toàn. Xét cho cùng, ngay cả màn hình kỹ thuật số ở giai đoạn cuối cũng có bản chất tương tự.
Nhưng điều gì sẽ xảy ra nếu chúng ta buộc gương chuyển từ vị trí này sang vị trí khác ở tần số cao? Nếu chúng ta bỏ qua thời gian chuyển đổi của gương (và do kích thước vi mô của nó, thời gian này có thể bị bỏ qua hoàn toàn), thì độ sáng nhìn thấy được sẽ giảm đi không dưới một nửa. Bằng cách thay đổi tỷ lệ thời gian mà gương ở vị trí này và vị trí khác, chúng ta có thể dễ dàng thay đổi độ sáng biểu kiến của ảnh. Và vì tần số chu kỳ rất rất cao nên sẽ không có dấu vết nhấp nháy nào có thể nhìn thấy được. Eureka. Dù không có gì đặc biệt nhưng điều này đã được biết đến từ lâu rồi :)
Vâng, bây giờ là lần chạm cuối cùng. Nếu tốc độ chuyển đổi đủ cao thì chúng ta có thể tuần tự đặt các bộ lọc ánh sáng dọc theo đường đi của luồng ánh sáng và từ đó tạo ra hình ảnh màu.
Trên thực tế, đó là toàn bộ công nghệ. Chúng ta sẽ theo dõi sự phát triển tiến hóa hơn nữa của nó bằng ví dụ về máy chiếu đa phương tiện.
Thiết kế máy chiếu DLP
Texas Instruments không sản xuất máy chiếu DLP, nhiều công ty khác sản xuất, chẳng hạn như 3M, ACER, PROXIMA, PLUS, ASK PROXIMA, OPTOMA CORP., DAVIS, LIESEGANG, INFOCUS, VIEWSONIC, SHARP, COMPAQ, NEC, KODAK, TOSHIBA , LIESEGANG, v.v... Hầu hết các máy chiếu được sản xuất đều là loại di động, nặng từ 1,3 đến 8 kg và có công suất lên tới 2000 ANSI lumen. Máy chiếu được chia thành ba loại.
Máy chiếu ma trận đơn
Loại đơn giản nhất mà chúng tôi đã mô tả là - máy chiếu ma trận đơn, trong đó một đĩa quay với các bộ lọc màu - xanh lam, xanh lục và đỏ - được đặt giữa nguồn sáng và ma trận. Tốc độ quay của đĩa quyết định tốc độ khung hình mà chúng ta quen dùng.

Hình ảnh được hình thành xen kẽ bởi từng màu cơ bản, tạo ra hình ảnh đầy đủ màu sắc thông thường.
Tất cả hoặc gần như tất cả các máy chiếu di động đều được chế tạo bằng loại ma trận đơn.
Một bước phát triển hơn nữa của loại máy chiếu này là sự ra đời của bộ lọc ánh sáng trong suốt thứ tư, giúp tăng đáng kể độ sáng của hình ảnh.
Máy chiếu ba ma trận
Loại máy chiếu phức tạp nhất là máy chiếu ba ma trận, trong đó ánh sáng được chia thành ba luồng màu và phản xạ từ ba ma trận cùng một lúc. Máy chiếu này có màu sắc và tốc độ khung hình thuần khiết nhất, không bị giới hạn bởi tốc độ quay đĩa như các máy chiếu ma trận đơn.

Sự kết hợp chính xác của thông lượng phản xạ từ mỗi ma trận (hội tụ) được đảm bảo bằng cách sử dụng lăng kính, như bạn có thể thấy trong hình.
Máy chiếu ma trận kép
Một loại máy chiếu trung gian là máy chiếu ma trận kép. Trong trường hợp này, ánh sáng được chia thành hai luồng: màu đỏ được phản xạ từ một ma trận DMD, còn màu xanh lam và xanh lục được phản xạ từ ma trận kia. Theo đó, bộ lọc ánh sáng sẽ lần lượt loại bỏ các thành phần màu xanh lam hoặc xanh lục khỏi quang phổ.

Máy chiếu ma trận kép cung cấp chất lượng hình ảnh ở mức trung bình so với loại máy chiếu ma trận đơn và máy chiếu ba ma trận.
So sánh máy chiếu LCD và DLP
So với máy chiếu LCD, máy chiếu DLP có một số ưu điểm quan trọng:

Công nghệ DLP có bất kỳ nhược điểm nào không?
Nhưng lý thuyết là lý thuyết, còn thực tế thì vẫn còn nhiều việc phải làm. Nhược điểm chính là sự không hoàn hảo của công nghệ và dẫn đến vấn đề dính gương.
Thực tế là với kích thước cực nhỏ như vậy, các bộ phận nhỏ có xu hướng “dính vào nhau” và một chiếc gương có đế cũng không ngoại lệ.
Bất chấp những nỗ lực của Texas Instruments nhằm phát minh ra vật liệu mới giúp giảm độ bám dính của gương vi mô, vấn đề như vậy vẫn tồn tại, như chúng ta đã thấy khi thử nghiệm máy chiếu đa phương tiện. Tập trung LP340. Nhưng tôi phải lưu ý rằng nó không thực sự can thiệp vào cuộc sống.
Một vấn đề khác không quá rõ ràng và nằm ở việc lựa chọn tối ưu các chế độ chuyển đổi gương. Mỗi công ty sản xuất máy chiếu DLP đều có quan điểm riêng về vấn đề này.
Vâng, một điều cuối cùng. Mặc dù có thời gian tối thiểu để chuyển gương từ vị trí này sang vị trí khác, quá trình này để lại một vệt hầu như không đáng chú ý trên màn hình. Một loại khử răng cưa miễn phí.
Sự phát triển công nghệ
- Ngoài việc giới thiệu bộ lọc ánh sáng trong suốt, công việc liên tục được tiến hành để giảm không gian giữa các gương và diện tích của cột gắn gương với đế (chấm đen ở giữa thành phần hình ảnh).
- Bằng cách chia ma trận thành các khối riêng biệt và mở rộng bus dữ liệu, tần số chuyển đổi nhân bản sẽ tăng lên.
- Công việc đang được tiến hành để tăng số lượng gương và giảm kích thước của ma trận.
- Công suất và độ tương phản của luồng ánh sáng không ngừng tăng lên. Hiện tại, đã có máy chiếu ba ma trận có công suất trên 10.000 ANSI Lm và tỷ lệ tương phản trên 1000:1, đã được ứng dụng trong các rạp chiếu phim cực kỳ hiện đại sử dụng phương tiện kỹ thuật số.
- Công nghệ DLP hoàn toàn sẵn sàng thay thế công nghệ CRT trong việc hiển thị hình ảnh tại rạp hát tại nhà.
Phần kết luận
Đây không phải là tất cả những gì có thể nói về công nghệ DLP, chẳng hạn như chúng tôi chưa đề cập đến chủ đề sử dụng ma trận DMD trong in ấn. Nhưng chúng tôi sẽ đợi cho đến khi Texas Instruments xác nhận thông tin có sẵn từ các nguồn khác để không lừa dối bạn. Tôi hy vọng câu chuyện ngắn này đủ để có được sự hiểu biết đầy đủ nhất nhưng đầy đủ nhất về công nghệ và không khiến người bán phải thắc mắc về ưu điểm của máy chiếu DLP so với những máy chiếu khác.
Cảm ơn Alexey Slepynin đã giúp đỡ chuẩn bị tài liệu
Ngày nay bạn có thể thường xuyên nghe nói về công nghệ như hệ thống DLP. Một hệ thống như vậy là gì? Làm thế nào có thể sử dụng nó? Hệ thống DLP nghĩa là phần mềm được thiết kế để ngăn ngừa mất dữ liệu bằng cách phát hiện các vi phạm có thể xảy ra trong quá trình lọc và gửi. Các dịch vụ này cũng giám sát, phát hiện và chặn thông tin bí mật trong quá trình sử dụng, di chuyển và lưu trữ. Theo quy luật, rò rỉ thông tin bí mật xảy ra do hoạt động của thiết bị bởi người dùng thiếu kinh nghiệm hoặc các hành động độc hại.
Những thông tin như vậy dưới dạng thông tin công ty hoặc cá nhân, sở hữu trí tuệ, thông tin y tế và tài chính, thông tin thẻ tín dụng cần có các biện pháp bảo vệ đặc biệt mà công nghệ thông tin hiện đại có thể cung cấp. Các trường hợp mất thông tin trở thành rò rỉ khi nguồn chứa thông tin bí mật biến mất và rơi vào tay một bên trái phép. Rò rỉ thông tin là có thể mà không mất mát.
Thông thường, các phương tiện công nghệ được sử dụng để chống rò rỉ thông tin có thể được chia thành các loại sau:
- các biện pháp an ninh tiêu chuẩn;
- các biện pháp trí tuệ (nâng cao);
- kiểm soát truy cập và mã hóa;
- hệ thống DLP chuyên dụng.
Các biện pháp tiêu chuẩn
Các biện pháp bảo mật tiêu chuẩn bao gồm tường lửa, hệ thống phát hiện xâm nhập (IDS) và phần mềm chống vi-rút. Họ bảo vệ máy tính khỏi các cuộc tấn công từ bên ngoài và bên trong. Vì thế. Ví dụ: việc kết nối tường lửa sẽ ngăn người ngoài truy cập vào mạng nội bộ. Một hệ thống phát hiện xâm nhập có thể phát hiện các nỗ lực xâm nhập. Để ngăn chặn các cuộc tấn công nội bộ, bạn có thể sử dụng các chương trình chống vi-rút phát hiện ngựa Trojan được cài đặt trên PC của bạn. Bạn cũng có thể sử dụng các dịch vụ chuyên dụng hoạt động theo kiến trúc máy khách-máy chủ mà không có bất kỳ thông tin bí mật hoặc thông tin cá nhân nào được lưu trữ trên máy tính.
Các biện pháp an ninh bổ sung
Các biện pháp bảo mật bổ sung sử dụng các dịch vụ chuyên môn cao và thuật toán định thời được thiết kế để phát hiện các truy cập bất thường vào dữ liệu, cụ thể hơn là vào cơ sở dữ liệu và hệ thống truy xuất thông tin. Những biện pháp bảo vệ như vậy cũng có thể phát hiện các trao đổi email bất thường. Các công nghệ thông tin hiện đại như vậy xác định các yêu cầu và chương trình có mục đích xấu và thực hiện kiểm tra sâu hệ thống máy tính, chẳng hạn như nhận dạng âm thanh của loa hoặc thao tác gõ phím. Một số dịch vụ loại này thậm chí còn có khả năng giám sát hoạt động của người dùng để phát hiện việc truy cập dữ liệu bất thường.
Hệ thống DLP được thiết kế tùy chỉnh là gì?
Các giải pháp DLP được thiết kế để bảo vệ thông tin nhằm phát hiện và ngăn chặn các nỗ lực trái phép nhằm sao chép và truyền thông tin nhạy cảm mà không được phép hoặc truy cập từ những người dùng được phép truy cập thông tin nhạy cảm. Để phân loại thông tin thuộc một loại nhất định và điều chỉnh quyền truy cập vào thông tin đó, các hệ thống này sử dụng các cơ chế như khớp dữ liệu chính xác, phương pháp thống kê, lấy dấu vân tay có cấu trúc, tiếp nhận các biểu thức và quy tắc thông thường, xuất bản các cụm từ mã, từ khóa và định nghĩa khái niệm. Hãy xem xét các loại và đặc điểm chính của hệ thống DLP.
Mạng DLP
Hệ thống này thường là một giải pháp phần cứng hoặc phần mềm được cài đặt tại các điểm mạng có nguồn gốc gần vành đai. Hệ thống như vậy phân tích lưu lượng mạng nhằm phát hiện thông tin bí mật được gửi vi phạm chính sách bảo mật thông tin.
DLP điểm cuối
Các hệ thống loại này hoạt động trên máy trạm hoặc máy chủ của người dùng cuối trong các tổ chức. Một điểm cuối, giống như trong các hệ thống mạng khác, có thể đối mặt với cả giao tiếp bên trong và bên ngoài và do đó có thể được sử dụng để kiểm soát luồng thông tin giữa các loại và nhóm người dùng. Họ cũng có khả năng giám sát tin nhắn tức thời và email. Điều này xảy ra như sau: trước khi dữ liệu tin nhắn được tải xuống thiết bị, nó sẽ được dịch vụ kiểm tra. Nếu có yêu cầu không thuận lợi, tin nhắn sẽ bị chặn. Do đó, chúng trở nên không được sửa chữa và không tuân theo các quy tắc lưu trữ thông tin trên thiết bị.
Ưu điểm của hệ thống DLP là nó có thể kiểm soát và quản lý quyền truy cập vào các thiết bị vật lý, cũng như truy cập thông tin trước khi được mã hóa. Một số hệ thống hoạt động dựa trên cơ sở rò rỉ cuối cũng có thể cung cấp khả năng kiểm soát ứng dụng để chặn các nỗ lực truyền tải thông tin nhạy cảm và cung cấp phản hồi ngay lập tức cho người dùng. Nhược điểm của các hệ thống như vậy là chúng phải được cài đặt trên mọi máy trạm trên mạng và không thể sử dụng trên các thiết bị di động như PDA hoặc điện thoại di động. Tình huống này phải được tính đến khi chọn hệ thống DLP để thực hiện một số nhiệm vụ nhất định.
Nhận dạng dữ liệu
Hệ thống DLP chứa một số phương pháp nhằm xác định thông tin bí mật và mật. Quá trình này thường bị nhầm lẫn với quá trình giải mã thông tin. Tuy nhiên, nhận dạng thông tin là quá trình các tổ chức sử dụng công nghệ DLP để xác định những gì cần tìm kiếm. Trong trường hợp này, dữ liệu được phân loại là có cấu trúc hoặc không có cấu trúc. Loại dữ liệu đầu tiên được lưu trữ trong các trường cố định trong một tệp, chẳng hạn như bảng tính. Dữ liệu phi cấu trúc đề cập đến văn bản dạng tự do. Theo ước tính của chuyên gia, 80% tất cả thông tin được xử lý có thể được phân loại là dữ liệu phi cấu trúc. Theo đó, chỉ có 20% tổng lượng thông tin được cấu trúc. Để phân loại thông tin, phân tích nội dung được sử dụng, tập trung vào thông tin có cấu trúc và phân tích theo ngữ cảnh. Nó được thực hiện tại nơi tạo ra ứng dụng hoặc hệ thống chứa thông tin. Do đó, câu trả lời cho câu hỏi “hệ thống DLP là gì” có thể là định nghĩa của thuật toán phân tích thông tin.
phương pháp
Các phương pháp mô tả nội dung nhạy cảm được sử dụng trong hệ thống DLP ngày nay rất nhiều. Thông thường, chúng có thể được chia thành hai loại: chính xác và không chính xác. Chính xác là các phương pháp liên quan đến phân tích nội dung và thực tế giảm tất cả các phản hồi dương tính giả đối với các truy vấn về 0. Các phương pháp khác là không chính xác. Chúng bao gồm phân tích thống kê, phân tích Bayes, thẻ meta, biểu thức chính quy nâng cao, từ khóa, từ điển, v.v. Hiệu quả của việc phân tích dữ liệu sẽ phụ thuộc trực tiếp vào độ chính xác của nó. Hệ thống DLP được xếp hạng cao sẽ có hiệu suất cao ở thông số này. Độ chính xác của nhận dạng DLP rất quan trọng để tránh kết quả dương tính giả và các hậu quả tiêu cực khác. Độ chính xác phụ thuộc vào nhiều yếu tố, có thể là công nghệ hoặc tình huống. Kiểm tra độ chính xác giúp đảm bảo độ tin cậy của hệ thống DLP.
Phát hiện và ngăn chặn rò rỉ thông tin
Trong một số trường hợp, nguồn phân phối dữ liệu cung cấp thông tin nhạy cảm cho bên thứ ba. Một số dữ liệu này rất có thể sẽ được tìm thấy ở một vị trí trái phép sau một thời gian, chẳng hạn như trên máy tính xách tay của người dùng khác hoặc trên Internet. Các hệ thống DLP, chi phí do các nhà phát triển cung cấp theo yêu cầu, có thể dao động từ vài chục đến vài nghìn rúp. Hệ thống DLP phải điều tra cách dữ liệu bị rò rỉ từ một hoặc nhiều bên thứ ba, liệu việc này được thực hiện độc lập hay liệu thông tin có bị rò rỉ bằng một số phương tiện khác hay không.
Dữ liệu ở trạng thái nghỉ
Mô tả “dữ liệu ở trạng thái nghỉ” đề cập đến thông tin lưu trữ cũ được lưu trữ trên bất kỳ ổ cứng nào của máy tính cá nhân khách hàng, trên máy chủ tệp từ xa hoặc trên ổ lưu trữ mạng. Định nghĩa này cũng áp dụng cho dữ liệu được lưu trữ trong hệ thống sao lưu trên đĩa CD hoặc ổ đĩa flash. Những thông tin như vậy rất được các cơ quan chính phủ hoặc doanh nghiệp quan tâm vì một lượng lớn dữ liệu được lưu trữ mà không được sử dụng trong các thiết bị bộ nhớ. Trong trường hợp này, có khả năng cao là những người không được ủy quyền bên ngoài mạng sẽ có được quyền truy cập vào thông tin.