How to disable full-text search control 1s 8.3. Tip3: Disable object versioning
Implemented in version 8.3.5.1068.
We have redesigned the search mechanism in lists, making it more convenient and understandable.
The first external difference is that now there are two new elements in the form’s command panel: search line And search management:

As before, to find something, you just need to start typing the words you are looking for on the keyboard. The cursor will automatically move to the search bar and the characters you type will be displayed in it.
For example, if you want to find what “Shlyuzovaya LLC” bought in bulk from an average warehouse, then to do this, simply type on the keyboard: “gateway wholesale medium”:
Video loading...
In this case, the platform will search in all columns of the list simultaneously using several values (string fragments). When typing from the keyboard, you separated these fragments from each other by spaces. To make it easier to navigate search results, the platform highlights found string fragments.
A very convenient new search option is to search by number without taking into account leading zeros. That is, if you want to find an invoice with the number 000000011, to do this, just type “11” on the keyboard (or directly in the search bar):

Search by current value
We have returned the search command for the current value to the platform. It was possible to search by the current value before. To do this, you had to call up the search dialog and press Enter. But without a special separate command, many users did not understand this.
Now you can easily find all the table rows that contain the same value as the selected cell. The easiest way to do this is to use the command that is in the context menu of the table:
Video loading...
Please note that the values by which the table rows were found are now displayed above the table. This is convenient for two reasons. Firstly, it is now clearly visible that the table does not show all the data, but only some part. Secondly, you can now easily delete or change the searched values to other values:
Video loading...
Another convenient point is that the platform remembers the current values by which the search was performed. They are saved in the search history, which is accessible through the search control button. Therefore, at any time you can return back to the search values that you used before:
Video loading...
Advanced Search
The search mechanism that existed in the platform before remains, and is now called Advanced Search. We slightly changed the appearance of its dialog and added the ability to search by the beginning of a line.
We have created a separate command to call the advanced search, in case you want to use it specifically. And besides this, the platform uses it when you change values that have already been searched:
Video loading...
Select period
We have significantly redesigned the period selection dialog. This dialog is used in reports to specify the period for which data should be shown. The same dialog is used in document lists to search for documents relating to a specific period.
Selecting a list of documents by period can be considered one of the ways to search for them - search by date. Therefore, we placed the period setting command in the search control.
When first opened, the dialog prompts you to select one or more months of the current, previous or subsequent year. According to our estimates, this is the most common search scenario:
Video loading...
You can easily choose a period of several months. To do this, you just need to select the required months with the mouse:
Video loading...
If necessary, you can immediately set an arbitrary period by specifying the start date and end date. Or you can go to another dialogue page and select one of the standard periods available in the platform. To make it easier for you to navigate a large number of standard periods, we have grouped them by intervals: day, week, decade, etc.:
Video loading...
What does the new search look like in the configurator?
To work with the new search mechanism, we have added a new element to the form. It is called Adding a Form Element. Previously, the form had 5 elements: Field, Table, Button, Group And Decoration. Now there are six such elements.
For dynamic list tables, the platform automatically creates three such elements: Search line, View State And Search management. The appearance of these elements in the form is controlled by three new table properties: Search Line Position, ViewStatePosition And Search Control Position.
If desired, the developer may not use standard elements ( Adding a Form Element), and create your own. To do this, just add to the form Adding a Form Element and ask him the source. Depending on the specific source, this element will take on one or another appearance. At the moment, only the dynamic list table has sources (three sources), but in the future we may expand this mechanic:
Video loading...
Tip1: Disable full text search*
Most accountants do not know about the existence of this function and never use it (Service - Data Search)
The full-text search mechanism in 1C allows you to find information in 1C using keywords (similar to searching on the Internet, when you enter a word and you are given query results). In this case, the search time significantly depends on the volume of the database and can take several hours. Disabling the full-text search mechanism does not affect other functions and stability of work in 1C.
The full-text search mechanism in 1C is enabled by default. To disable full text search, you need to go to Operations - Full text search management-Setting and removing the sign " Allow full text search»
Disabling the full-text search mechanism is carried out in exclusive mode (no one should work in the program except you)**
Disabling the full-text search engine increases performance by up to 10%.
Tip2: Recalculation of results*
Most accountants do not know about the existence of this operation, and it must be performed every month.
Results are 1C mechanisms for quick access to data when generating reports and performing various computational operations.
In order to recalculate the totals, you need to go to Operations - Totals Management, set the date by which to calculate the totals (the beginning of the current month) in the “All registers” section and click the “Run” button
Recalculation of results is carried out in exclusive mode (no one should work in the program except you)**
Recalculation of the results gives an increase in productivity of up to 10%.
Tip3: Disable object versioning***
Most accountants do not know about the existence of this function and do not use it.
Unlike a standard log, versioning objects will allow you to store information not only about which user worked with the document, but also what exactly he changed (Service - History of object changes). This mode can be useful, but it is recommended to enable it only for a specific list of documents, because it leads to a decrease in 1C performance and an increase in the information base
Versioning is configured through Operations - Program Settings - Versioning. If the setting is not required, then you need to remove the “Use object versioning” checkbox.
If the setting is needed for a specific list of documents, then go to “Object versioning settings” and right-click to set the “Version” setting for the required objects**
Disabling versioning gives a performance increase of up to 5%.
_________________________________________________________________
*For configurations based on “1C: Industrial Enterprise Management”, “1C: Integrated Automation”, “1C: Enterprise Accounting 2.0”, “1C: Trade Management 10.3”
**Before performing routine operations with the database, it is necessary to create a copy of the database.
***For configurations based on “1C: Manufacturing Enterprise Management”, “1C: Integrated Automation”.
Good afternoon, colleagues, today I will describe the search in 1C 8.3 lists, the algorithms used, the main problems, errors and rational use of resources when searching in lists.
Brief Description of Search Elements

In front of you is a familiar window. In it we see a search line, a search control button, and the actual tabular part in which we will search.
We receive the table in this form from the 1c server. Moreover, 1C server stores this table in its RAM and not in the database, for faster user access to it. for example, the memory request speed is 32 GB/s, and the disk request is at a maximum of 6 GB/s, that is minimum 5 times slower. This is called caching - storing part of the data that is requested most often. In this particular example, the data is sorted by number, so this cache is quite static, that is, it changes extremely rarely and is requested extremely often. If the table were sorted by date in descending order, then each new document would be added to the beginning of the list, thereby changing the data in the cache.
Nobody forbids caching absolutely everything, but firstly, server memory is limited, and secondly, the cache may become outdated in relation to real data and thirdly, it may simply no longer be needed. To solve these problems, various caching algorithms have been developed; more information about them and the cache can be found at the link.
Search using the search bar
Let's go back to 1c and try to find something:

As you can see, the search works using the like method, that is, it selects the specified template from the list, the time for entering, by the way, is also limited, that is, if you press 1, wait a second and then press 1 again, the search will actually be carried out twice. In this case, the platform will search in all columns of the list simultaneously using several values (string fragments). To make it easier to navigate search results, the platform highlights found string fragments. Results may also be cached, depending on demand.
Here we found one result, but if we used real databases, then for this request the search would return 0000111 and 0144100111 and buyer No. 11 and warehouse No. 11, and comments containing the number 11, in some situations related to setting up the 1c configuration and dates from 2011 of the year. This significantly increases the output data and slows down the response, besides taking up memory on the 1c server. Imagine that the list contains millions of lines, that you work on this server together with other employees, and the server uses several databases. To avoid these problems, guided search is used.
Guided Search

There are three main criteria used here
Where to look– table column selection
What to look for– search purpose
How to search– which search template to use
I think the first two points are clear, despite the fact that they are built as a context menu for columns and a context menu with a search by values with transition to the result parameters.
The third parameter looks like this:
At the beginning of the line:
Search string: “1 sk”
Results: 1 warehouse, 1 SK, 1 Skolkovo.....
Part of the line:
Search string: “skl”
Results: 1 warehouse hell, warehouse hell room No. 1, folding bed, …..
By exact coincidence:
The result will match the search string.
Naturally, if you select a column with homogeneous values, then you can use any search template, but if you select a column with heterogeneous values, for example, a comment or supplier, then the search results for the first two templates may be more than what the user needs, which is not rational.
Indexes in 1s
To speed up searches in the 1C database, indexes are used. A little theory is needed here.
The easiest analogy to understand is a dictionary, where the table of contents and pagination are the index table, and the words are the columns of the table. Searching by table of contents, you understand, is faster than flipping through the entire dictionary. The index of ordered values is called cluster, for simplicity we will analyze only it
This index is static, but let's say we added a new word to the dictionary, or two or a hundred. Numbering static index tables is not appropriate here. There are two possible solutions: the first is a complete rebuild of the index, that is, reading the entire dictionary and compiling a new table of contents, or complicating the index architecture. The main implementation of the index architecture is a B-tree, logically it looks like this.

But in fact, this is a separate table or several tables that divide the index into parts. A close analogy would be the ability to add new pages to the table of contents of a dictionary, with subsequent table of contents values shifted by the number of added elements.
As you can see, the figure shows a three-level b-tree, but there can be 10, 20, 30 levels...
There are many index types and index implementations. You can read more at the link.
1C server works with sql servers and all work with storing, changing and indexing data lies on the sql server, in most cases sql indexing is used in search, in some it is not. This mainly depends on the complexity of the query and how fragmented the index is.
conclusions
Technologies have developed enough and use a large number of algorithms for the fastest access to data. But the user also needs to understand the logic and rationality of his search queries; the more accurate the user’s query is, the fewer resources will be spent, and the faster the computer will produce the result. Pressing one button will not always work faster than pressing five. Moreover, the keyboards are standard and the buttons do not change their position on it over time.
In the latest editions of the configuration based on 1C 8.3, an excellent opportunity has appeared to automate the search and replacement of duplicate directories. This is done using special processing 1C - Search and replacement of duplicates. It is built into such application solutions on managed forms as: , .
Let's look at a short instruction: how to find processing in the interface, how to use it to collapse duplicate items of items, contractors and other directories.
Attention! Before working with processing, be sure to make a backup copy of the database.
Processing to find duplicates
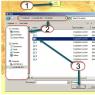
Processing Search and removal of duplicates is located on the “Administration” tab, in the “Support and Maintenance” section:
At the bottom:
Get 267 video lessons on 1C for free:
During processing, it is necessary to indicate which directory we want to “scan” (in our case, nomenclature), according to which selection (those not marked for deletion) and what will be a fact of a duplicate for us (let’s take a name match for similar words). After setting, click “Find duplicates”.
1C will offer options for duplicates:

Using the example of the STINOL refrigerator: the system marked the element with the ending “101” as the original, and the element “103” as a duplicate. In the window on the right we see in which documents this item is involved.
You can repurpose the "original" using the "Mark as original" button based on your beliefs. I recommend choosing as a standard the object that has more “use points” in order to speed up the process of gluing takes:
The new search functionality is based on two mechanisms:
- full-text search (works very quickly and requires minimal computing resources);
- search using DBMS (in general, the duration of the search and the cost of computing resources are proportional to the amount of information in the table).
In the current implementation, the list will be searched without use full-text search in the following cases ():
- full-text index is disabled at the infobase level;
- the main table object is not indexed by a full-text index;
- as a result of searching using full-text search, an error was received.
If full-text search is enabled in the information base, and the index is not updated completely or partially (from my experience, 95% of Customer information databases), then the user will receive either an unreliable or empty search result when searching.
We ask 1C Company - what to do? How to guarantee the reliability of search results always?
We get the answer: Yes, in order for search results to be up-to-date when full-text search is enabled, you need to ensure that the full-text search index is up-to-date. There are no other options for effective and up-to-date search yet
().
Does an “up-to-date full-text index” even exist? Depends on the number of users, the intensity of changes in information in the database and the frequency of index updates. Typically, index updates are run every 60 seconds. It’s good if not many objects were changed, and the procedure managed to process all the changes in these 60 seconds. What if you did a re-posting of a group of documents, or a massive rewrite of the directory? In this case, no one can guarantee the time after which the index search will again provide reliable data.
In principle, this is not particularly critical, except in a few situations. A common option for users is to set a selection in the list by some value, for example, “Account”, enter a new one or copy an existing document and write it down. With the old search, the new document was instantly visible in the list. Now the user will see it only after N seconds in the best case, where N is closer to 50-60 seconds rather than 2-3.
If you do not notice that there is no new document and provide information to someone based on the selected results, then it will be deliberately unreliable.
This was the case when working normally with the infobase. What will happen in specific situations? Let me give you a couple of examples.
1) In the working database, the full-text index is enabled and updated frequently. The user asks to deploy a copy of the working database so that he can analyze the data.
We restore the backup and give access. But full-text search will not work, because... the index is stored not in the DBMS, but in separate files (both in file and client-server versions). There is no index in the dt file.
those. In order for the user to be able to use list search, the full-text index in this database must be disabled. True, the user will be slightly surprised that the search will take much longer. Or rebuild the index across the entire database.
2) (Relevant for more or less large databases). The production database has a full-text index enabled and is updated frequently. The end of the month comes and the closing of the period begins. We are starting to load and forward documents en masse. To reduce the load on the system, we block the execution of routine tasks, and accordingly, the index update stops. Users will be, to put it mildly, perplexed as to why there are no new or changed documents in the lists. The only way out is to disable full-text search for the information base, and, accordingly, put an even greater load on the equipment due to a heavy search for all details.
Thus, it seems to me that the operation of updating the index will become another headache for information base administrators.
The system, which previously guaranteed 100% reliability and relevance of information at any time, is now turning into more of a reference system in which one cannot be completely sure.
And users get another reason to reproach IT people - “your system is not working correctly.”