Ứng dụng logic mờ. Logic mờ: Giải pháp logic mờ rõ ràng
Lập luận mờ– logic dựa trên lý thuyết tập mờ. Chủ đề của nó là xây dựng các mô hình suy luận gần đúng của con người và cách sử dụng chúng trong các hệ thống máy tính. Trong logic mờ, ranh giới đánh giá đã được mở rộng từ đánh giá hai giá trị (0 hoặc 1) sang đánh giá đa giá trị không giới hạn (Trên khoảng).
Tập mờ A trong không gian X đầy đủ được xác định thông qua hàm thành viên m A(x):

Logic xác định khái niệm tập mờ không có bất kỳ sự mơ hồ nào. Thay vì chỉ định một giá trị cụ thể (Ví dụ: 0,8), người ta thường sử dụng giá trị dưới và trên để đặt giới hạn đánh giá có thể chấp nhận được (Ví dụ).
Với logic mờ, bạn có thể tạo số lượng thao tác không giới hạn nên không sử dụng các thao tác cơ bản để viết phần còn lại. Việc mở rộng NOT, AND, OR cho các phép toán mờ là đặc biệt quan trọng. Chúng được gọi tương ứng – phủ định mờ, t-norm và s-norm. Vì số lượng trạng thái là không giới hạn nên không thể mô tả các hoạt động này bằng bảng chân lý. Các phép toán được giải thích bằng các hàm và tiên đề và được biểu diễn bằng đồ thị.
Biểu diễn tiên đề của các phép toán mờ:
Từ chối mờ

Tiên đề N1 bảo toàn tính chất của NOT có giá trị kép và N2 bảo toàn quy tắc phủ định kép. N3 – quan trọng nhất: phủ định mờ đảo ngược trình tự đánh giá.

Một phép toán phủ định mờ điển hình là phép trừ từ 1.
Khi bị phủ định, giá trị 0,5 là giá trị trung tâm và thường x và xθ lấy các giá trị đối xứng so với 0,5.
T-chuẩn mực.

Tiên đề T1 đúng, vì rõ ràng I. T2 và T3 là luật giao và hội. Tiên đề T4 là yêu cầu về tính ngăn nắp.
Một t-norm điển hình là phép toán tối thiểu hoặc tích logic:

Với tích logic, đồ thị được dựng đối xứng với mặt phẳng tạo thành bởi các góc nghiêng x1 và x2.
S-chuẩn mực.

Một s-norm điển hình là một tổng logic, được xác định bởi phép toán max.
![]()
Ngoài ra, còn có tổng đại số, tổng biên và tổng quyết liệt:


Như có thể thấy từ các hình vẽ, thứ tự ngược lại so với trường hợp t-chuẩn.
Ví dụ về định nghĩa mờ bao gồm nhiệt độ và hoạt động của van:

Điểm tương đồng
Logic mờ là sự khái quát hóa của logic rõ ràng cổ điển. Cả logic rõ ràng và logic mờ đều dựa trên các tập hợp và các phép toán quan hệ. Các phép toán mờ là sự mở rộng của các phép toán logic chính xác.
Sự khác biệt
Trong logic rõ ràng, các biến là thành viên đầy đủ của tập hợp và trong logic mờ chúng chỉ là thành viên một phần của tập hợp.
Theo logic rõ ràng, một tuyên bố là đúng hoặc sai và quy luật loại bỏ phần giữa hoạt động trong đó. Trong logic mờ, sự thật hay giả không còn tuyệt đối và các phát biểu có thể đúng một phần và sai một phần. Trong logic rõ ràng, số lượng hoạt động có thể là hữu hạn và phụ thuộc vào số lượng đầu vào, trong khi ở logic mờ, số lượng hoạt động có thể là vô hạn.
3. Ví dụ
Đầu tiên chúng ta sẽ xem xét tập X gồm tất cả các số thực từ 0 đến 10, mà chúng ta sẽ gọi là vùng nghiên cứu. Bây giờ, hãy xác định một tập con X gồm tất cả các số thực nằm trong khoảng từ 5 đến 8.
A=
Bây giờ hãy tưởng tượng bộ MỘT sử dụng một chức năng tượng trưng, tức là hàm này gán số 1 hoặc 0 cho mỗi phần tử trong X, tùy thuộc vào việc phần tử có nằm trong tập hợp con hay không MỘT hay không. Điều này dẫn đến sơ đồ sau:

Chúng ta có thể hiểu các phần tử được gán số 1 là là các phần tử thuộc tập hợp A, và các phần tử được gán số 0, là các phần tử không thuộc tập A.
Khái niệm này là đủ cho nhiều lĩnh vực ứng dụng. Nhưng chúng ta có thể dễ dàng nhận thấy những tình huống mất đi tính linh hoạt. Để chỉ ra điều này, hãy xem xét ví dụ sau cho thấy sự khác biệt giữa tập mờ và tập rõ:
Trong ví dụ này, chúng tôi muốn mô tả một nhóm người trẻ tuổi. Chính thức hơn chúng ta có thể biểu thị
B = (nhóm người trẻ)
Vì nói chung, tuổi bắt đầu từ 0 nên giới hạn dưới của tập hợp này phải bằng 0. Mặt khác, giới hạn trên phải được xác định. Lần đầu tiên, hãy xác định giới hạn trên của tập hợp, chẳng hạn là 20 năm. Vì vậy chúng tôi nhận được B như một khoảng rõ ràng, cụ thể là:
B=
Bây giờ câu hỏi được đặt ra: tại sao một người vẫn trẻ vào ngày sinh nhật thứ 20 của mình nhưng lại không trẻ vào ngày hôm sau? Rõ ràng đây là một vấn đề về cấu trúc, bởi vì nếu chúng ta di chuyển giới hạn trên từ 20 đến một điểm tùy ý, chúng ta có thể đặt ra câu hỏi tương tự.
Một cách tự nhiên hơn để mô tả một tập hợp B là nới lỏng sự phân chia chặt chẽ giữa người trẻ và người không trẻ. Chúng tôi sẽ thực hiện điều này bằng cách không chỉ cho phép một giải pháp (rõ ràng) CÓ: anh ấy/cô ấy còn trẻ, hoặc KHÔNG: anh ấy/cô ấy không nằm trong số những người trẻ tuổi, nhưng các cụm từ linh hoạt hơn như: Được rồi, anh ấy/cô ấy thuộc về giới trẻ nhiều hơn một chút hoặc KHÔNG, anh ấy/cô ấy hầu như không thuộc về đám đông người trẻ.
Trong ví dụ đầu tiên, chúng tôi đã mã hóa tất cả các phần tử của Khu vực nghiên cứu là 0 hoặc 1. Một cách đơn giản để khái quát khái niệm này thành tập mờ là xác định nhiều giá trị hơn từ 0 đến 1. Trên thực tế, chúng tôi xác định vô số tùy chọn từ 0 đến 1. 1, tức là khoảng đơn vị tôi =.
Việc giải thích các con số trong tập mờ được gán cho tất cả các phần tử của Khu vực Nghiên cứu khó khăn hơn. Tất nhiên, một lần nữa số 1 được gán cho phần tử như một cách để xác định phần tử có trong tập hợp B và 0 - cách phần tử không được xác định trong tập hợp B. Tất cả các giá trị khác có nghĩa là dần dần thuộc vềđến vô số B.
Để rõ ràng hơn, bây giờ chúng tôi hiển thị tập hợp các phần tử trẻ, giống như ví dụ đầu tiên của chúng tôi, bằng cách sử dụng một hàm biểu tượng bằng đồ họa.

Với phương pháp này, người 25 tuổi vẫn sẽ trẻ bằng 50 phần trăm (0,5). Bây giờ bạn đã biết tập mờ là gì.
Epimenides of Knossos đến từ đảo Crete là một nhà thơ và triết gia bán thần thoại sống ở thế kỷ thứ 6. BC, từng tuyên bố: “Tất cả người Crete đều là kẻ nói dối!” Vì bản thân ông là người Crete nên ông được nhớ đến như người phát minh ra cái gọi là nghịch lý Cretan.
Theo logic của Aristoteles, trong đó một tuyên bố không thể vừa đúng vừa sai, và những sự tự phủ định như vậy chẳng có ý nghĩa gì. Nếu chúng đúng thì chúng sai, nhưng nếu chúng sai thì chúng đúng.
Và ở đây logic mờ phát huy tác dụng, trong đó các biến có thể là thành viên một phần của tập hợp. Sự thật hay giả không còn tuyệt đối nữa - những phát biểu có thể một phần đúng và một phần sai. Sử dụng phương pháp này cho phép chúng ta chứng minh một cách chặt chẽ về mặt toán học rằng nghịch lý Epimenides chính xác là 50% đúng và 50% sai.
Như vậy, logic mờ về cơ bản là không tương thích với logic Aristoteles, đặc biệt là đối với định luật Tertium non datur (“Không có thứ ba” - tiếng Latin), còn được gọi là luật loại trừ số trung bình1. Nói một cách ngắn gọn thì nó như thế này: nếu một tuyên bố không đúng thì nó là sai. Những định đề này cơ bản đến mức chúng thường được coi là đương nhiên.
Một ví dụ tầm thường hơn về tính hữu ích của logic mờ có thể được đưa ra trong bối cảnh khái niệm lạnh. Hầu hết mọi người đều có thể trả lời câu hỏi: "Bây giờ bạn có lạnh không?" Trong hầu hết các trường hợp (trừ khi bạn đang nói chuyện với một sinh viên tốt nghiệp ngành vật lý), mọi người hiểu rằng chúng ta không nói về nhiệt độ tuyệt đối trên thang Kelvin. Mặc dù nhiệt độ 0 K chắc chắn có thể được gọi là lạnh, nhưng nhiều người sẽ không coi nhiệt độ +15 C là lạnh.
Nhưng máy móc không có khả năng tạo ra sự chuyển màu tốt như vậy. Nếu định nghĩa tiêu chuẩn về lạnh là “nhiệt độ dưới +15 C” thì +14,99 C sẽ được coi là lạnh, nhưng +15 C thì không.
Lý thuyết tập mờ
Chúng ta hãy nhìn vào hình. 1. Nó hiển thị biểu đồ giúp bạn hiểu cách một người cảm nhận về nhiệt độ. Một người cảm nhận nhiệt độ +60 F (+12 C) là lạnh và nhiệt độ +80 F (+27 C) là nóng. Nhiệt độ +65 F (+15 C) có vẻ lạnh đối với một số người nhưng lại khá thoải mái với những người khác. Chúng tôi gọi nhóm định nghĩa này là chức năng của các thành viên trong các tập hợp mô tả nhận thức chủ quan của một người về nhiệt độ.
Thật dễ dàng để tạo ra các bộ bổ sung mô tả nhận thức của con người về nhiệt độ. Ví dụ: bạn có thể thêm các nhóm như “rất lạnh” và “rất nóng”. Có thể mô tả các chức năng tương tự cho các khái niệm khác, chẳng hạn như trạng thái mở và đóng, nhiệt độ máy làm lạnh hoặc nhiệt độ tháp làm lạnh.
Nghĩa là, hệ thống mờ có thể được sử dụng như một công cụ xấp xỉ phổ quát (trung bình) cho một lớp rất rộng các hệ thống tuyến tính và phi tuyến. Điều này không chỉ làm cho các chiến lược điều khiển trở nên đáng tin cậy hơn trong các trường hợp phi tuyến mà còn cho phép sử dụng các đánh giá của chuyên gia để xây dựng các mạch logic máy tính.
Toán tử mờ
Để áp dụng đại số cho các giá trị mờ, bạn cần xác định các toán tử sẽ sử dụng. Thông thường, logic Boolean chỉ sử dụng một tập hợp giới hạn các toán tử, với sự trợ giúp của các phép toán khác được thực hiện: NOT (toán tử NOT), AND (toán tử AND) và OR (toán tử OR).
Có thể đưa ra nhiều định nghĩa cho ba toán tử cơ bản này, ba trong số đó được đưa ra trong bảng. Nhân tiện, tất cả các định nghĩa đều có giá trị như nhau đối với logic Boolean (để kiểm tra, chỉ cần thay 0 và 1 vào chúng). Trong logic Boolean, FALSE tương đương với 0 và TRUE tương đương với 1. Tương tự, trong logic mờ, mức độ đúng có thể nằm trong khoảng từ 0 đến 1, do đó giá trị "Cold" đúng với lũy thừa 0,1 và phép toán NOT("Cold") sẽ cho giá trị 0,9.
Bạn có thể quay lại nghịch lý Epimenides và thử giải nó (về mặt toán học, nó được biểu thị bằng A = NOT(A), trong đó A là mức độ đúng của phát biểu tương ứng). Nếu bạn muốn một bài toán khó hơn, hãy thử giải bài toán về âm thanh của tiếng vỗ tay do một tay tạo ra...
Giải bài toán bằng phương pháp logic mờ
Chỉ có một số van có khả năng mở “chỉ một chút”. Khi vận hành thiết bị, các giá trị rõ ràng thường được sử dụng (ví dụ: trong trường hợp tín hiệu lưỡng kim 0-10 V), có thể thu được bằng cách sử dụng cái gọi là "giải quyết vấn đề logic mờ". Cách tiếp cận này giúp chuyển đổi kiến thức ngữ nghĩa có trong hệ mờ thành một chiến lược điều khiển có thể thực hiện được2.
Điều này có thể được thực hiện bằng nhiều kỹ thuật khác nhau, nhưng để minh họa toàn bộ quá trình, chúng ta hãy chỉ xem một ví dụ.
Trong phương pháp giải mờ độ cao, kết quả là tổng của các đỉnh tập mờ, được tính bằng các trọng số. Phương pháp này có một số nhược điểm, bao gồm việc xử lý kém các hàm thành viên của tập hợp không đối xứng, nhưng nó có ưu điểm là là phương pháp dễ hiểu nhất.
Giả sử rằng tập hợp các quy tắc chi phối việc mở van cho chúng ta kết quả sau:
"Van đóng một phần": 0,2
"Van mở một phần": 0,7
"Van mở": 0,3
Nếu sử dụng phương pháp giải mờ độ cao để xác định độ mở của van thì ta sẽ thu được kết quả:
"Van đóng": 0,1
(0,1*0% + 0,2*25% + 0,7*75% + 0,3*100%)/ /(0,1 + 0,2 + 0,7 + 0,3) =
= (0% + 5% + 52,5% + 30%)/(1,3) = = 87,5/1,3 = = 67,3%,
những thứ kia. van phải mở đến 67,3%.
Ứng dụng thực tế của logic mờ
Khi lý thuyết logic mờ lần đầu tiên xuất hiện, các bài viết về các lĩnh vực ứng dụng có thể có của nó có thể được tìm thấy trên các tạp chí khoa học. Khi sự phát triển trong lĩnh vực này tiến triển, số lượng ứng dụng thực tế của logic mờ bắt đầu tăng lên nhanh chóng. Danh sách này có thể còn quá dài vào thời điểm này, nhưng đây là một vài ví dụ giúp bạn hiểu logic mờ được sử dụng rộng rãi như thế nào trong các hệ thống điều khiển và hệ thống chuyên gia3.
– Thiết bị tự động duy trì tốc độ xe và tăng hiệu suất/độ ổn định của động cơ ô tô (các hãng Nissan, Subaru).
cơ chế tư duy, nhận thấy rằng trên thực tế không chỉ có một logic (ví dụ: Boolean), mà có nhiều logic như chúng ta mong muốn, bởi vì mọi thứ đều được quyết định bởi việc lựa chọn hệ thống tiên đề thích hợp. Tất nhiên, một khi các tiên đề được chọn, mọi phát biểu được xây dựng trên cơ sở của chúng phải chặt chẽ, không mâu thuẫn, liên kết với nhau theo các quy tắc được thiết lập trong hệ thống tiên đề này.Tư duy của con người là sự kết hợp giữa trực giác và sự chặt chẽ, một mặt, nó nhìn thế giới như một tổng thể hoặc bằng cách loại suy, mặt khác, một cách logic và nhất quán và do đó, thể hiện một cơ chế mờ nhạt. Các quy luật tư duy mà chúng ta muốn đưa vào các chương trình máy tính nhất thiết phải có tính hình thức; các quy luật tư duy thể hiện trong đối thoại giữa con người với con người là không rõ ràng. Do đó chúng ta có thể nói rằng logic mờ có thể thích ứng tốt với cuộc đối thoại của con người không? Có - nếu phần mềm, được phát triển có tính đến logic mờ, sẽ đi vào hoạt động và có thể được triển khai về mặt kỹ thuật, khi đó giao tiếp giữa người và máy sẽ trở nên thuận tiện hơn, nhanh hơn và phù hợp hơn để giải quyết vấn đề.
Thuật ngữ " lập luận mờ" thường được sử dụng với hai nghĩa khác nhau. Theo nghĩa hẹp, logic mờ là phép tính logic, là sự mở rộng của logic nhiều giá trị. Theo nghĩa rộng, vốn được sử dụng phổ biến hiện nay, logic mờ tương đương với logic mờ lý thuyết tập hợp.Theo quan điểm này, logic mờ theo nghĩa hẹp là một nhánh của logic mờ theo nghĩa rộng.
Sự định nghĩa. Bất kì biến mờđặc trưng bởi ba
Tên của biến ở đâu, - bộ phổ quát, là tập con mờ của tập hợp, biểu thị ràng buộc mờ về giá trị của biến, được điều hòa bởi .
Sử dụng sự tương tự của một chiếc túi du lịch, biến mờ có thể được ví như một chiếc túi du lịch có nhãn có thành “mềm”. Sau đó - dòng chữ trên nhãn (tên của túi), - danh sách các vật phẩm mà về nguyên tắc có thể được đặt trong túi và - một phần của danh sách này, trong đó mỗi vật phẩm được chỉ định một số, đặc trưng cho mức độ dễ dàng để đồ vật đó vào trong túi.
Bây giờ chúng ta hãy xem xét các cách tiếp cận khác nhau để xác định các hoạt động cơ bản trên biến mờ, cụ thể là kết hợp, phân tách và phủ định. Những phép toán này là nền tảng của logic mờ theo nghĩa là tất cả các cấu trúc của nó đều dựa trên những phép toán này. Hiện nay trong logic mờ như hoạt động kết hợp và sự tách rời sử dụng rộng rãi -norms và -conorms, vốn đi đến logic mờ từ lý thuyết về không gian số liệu xác suất. Chúng được nghiên cứu khá kỹ lưỡng và tạo thành nền tảng cho nhiều cấu trúc hình thức của logic mờ. Đồng thời, việc mở rộng phạm vi ứng dụng của logic mờ và khả năng mô hình hóa mờ đòi hỏi phải khái quát hóa các hoạt động này. Một hướng liên quan đến việc làm suy yếu các tiên đề của chúng để mở rộng các công cụ mô hình hóa mờ. Một hướng khái quát hóa khác hoạt động kết hợp và sự tách biệt của logic mờ có liên quan đến việc thay thế tập hợp các giá trị thành viên bằng một tập hợp đánh giá độ tin cậy ngôn ngữ được sắp xếp tuyến tính hoặc một phần. Một mặt, sự khái quát hóa các hoạt động cơ bản của logic mờ này là do nhu cầu phát triển các hệ thống chuyên gia trong đó các giá trị chân lý của các sự kiện và quy tắc được mô tả trực tiếp bởi một chuyên gia hoặc người dùng trên thang đo ngôn ngữ và có tính chất có tính chất chất lượng. Mặt khác, những khái quát hóa như vậy là do sự chuyển dịch theo hướng phát triển tích cực của logic mờ từ mô hình hóa các quá trình định lượng có thể đo lường được sang mô hình hóa các quá trình tư duy của con người, trong đó nhận thức về thế giới và ra quyết định diễn ra trên cơ sở tổng hợp thông tin và tính toán bằng lời.
Sự khái quát hóa tự nhiên của các phép toán phủ định liên quan của logic mờ là các phủ định không liên quan. Chúng được quan tâm độc lập và được xem xét trong logic mờ và logic phi cổ điển khác. Nhu cầu nghiên cứu các hoạt động phủ định như vậy cũng xuất phát từ việc đưa vào xem xét các khái niệm tổng quát hoạt động kết hợp và sự phân tách được kết nối với nhau bằng cách sử dụng phép toán phủ định.
Giới thiệu về logic mờ
Logic mờ là một hệ thống điều khiển hoặc logic có giá trị n sử dụng mức độ trạng thái (“mức độ chân lý”) của đầu vào và tạo ra đầu ra phụ thuộc vào trạng thái của đầu vào và tốc độ thay đổi của các trạng thái đó. Đây không phải là logic "đúng hoặc sai" (1 hoặc 0), Boolean (nhị phân) thông thường mà các máy tính hiện đại dựa trên. Nó chủ yếu cung cấp cơ sở cho việc lập luận gần đúng bằng cách sử dụng các nghiệm không chính xác và cho phép sử dụng các biến ngôn ngữ.
Logic mờ được phát triển vào năm 1965 bởi Giáo sư Lotfi Zadeh tại Đại học California, Berkeley. Ứng dụng đầu tiên là thực hiện xử lý dữ liệu máy tính dựa trên các giá trị tự nhiên.
Nói một cách đơn giản, các trạng thái logic mờ không chỉ có thể là 1 hoặc 0 mà còn có các giá trị giữa chúng, tức là 0,15, 0,8, v.v. Ví dụ, trong logic nhị phân, chúng ta có thể nói rằng chúng ta có một cốc nước nóng (tức là 1 hoặc mức logic cao) hoặc một cốc nước lạnh tức là (0 hoặc mức logic thấp), nhưng trong logic mờ, chúng ta có thể nói rằng chúng ta có một cốc nước ấm (không nóng cũng không lạnh, nghĩa là ở đâu đó giữa hai trạng thái cực đoan này). Logic rõ ràng: có hoặc không (1, 0). Logic mờ: tất nhiên là có; có lẽ là không; Khó nói; có lẽ có, v.v.
Kiến trúc cơ bản của hệ logic mờ
Hệ thống logic mờ bao gồm các module sau:

Bộ làm mờ (hoặc toán tử làm mờ). Nó lấy các biến đo làm đầu vào và chuyển đổi các giá trị số thành các biến ngôn ngữ. Nó biến đổi các giá trị vật lý cũng như tín hiệu lỗi thành một tập con mờ được chuẩn hóa, bao gồm một khoảng cho một phạm vi các giá trị đầu vào và các hàm thành viên mô tả xác suất trạng thái của các biến đầu vào. Tín hiệu đầu vào chủ yếu được chia thành năm trạng thái, chẳng hạn như: dương lớn, dương trung bình, nhỏ, âm trung bình và âm lớn.
Người điều khiển. Nó bao gồm một cơ sở tri thức và một công cụ suy luận. Cơ sở tri thức lưu trữ các hàm thành viên và các luật mờ thu được khi biết hoạt động của hệ thống trong môi trường. Công cụ suy luận xử lý các hàm thành viên thu được và các luật mờ. Nói cách khác, công cụ suy luận tạo ra kết quả đầu ra dựa trên thông tin ngôn ngữ.
Toán tử giải mờ hoặc khôi phục độ rõ nét. Nó thực hiện quá trình ngược lại của Phasefire. Nói cách khác, nó chuyển đổi các giá trị mờ thành tín hiệu số hoặc vật lý thông thường và gửi chúng đến hệ thống vật lý để điều khiển hoạt động của hệ thống.
Nguyên lý hoạt động của hệ logic mờ
Phép toán mờ liên quan đến việc sử dụng các tập mờ và các hàm thành viên. Mỗi tập mờ là một biểu diễn của một biến ngôn ngữ xác định trạng thái đầu ra có thể có. Hàm thành viên là hàm của giá trị tổng quát trong tập mờ, sao cho cả giá trị tổng quát và tập mờ đều thuộc về tập phổ quát.
Mức độ thành viên của giá trị chung này trong tập mờ xác định đầu ra dựa trên nguyên tắc IF-THEN. Tư cách thành viên được chỉ định dựa trên giả định về đầu ra từ đầu vào và tốc độ thay đổi của đầu vào. Hàm thành viên về cơ bản là biểu diễn đồ họa của một tập mờ.
Xét một giá trị "x" sao cho x ∈ X cho toàn bộ khoảng và một tập mờ A, là tập con của X. Hàm thành viên của "x" trong tập con A được cho bởi: fA(x), Lưu ý rằng "x" biểu thị giá trị thành viên. Dưới đây là biểu diễn đồ họa của tập mờ.

Trong khi trục x biểu thị tập phổ quát, trục y biểu thị mức độ thành viên. Các hàm thành viên này có thể có dạng hình tam giác, hình thang, điểm đơn hoặc dạng Gaussian.
Ví dụ thực tế về hệ logic mờ
Chúng ta hãy phát triển một hệ thống điều khiển mờ đơn giản để điều khiển hoạt động của máy giặt, sao cho hệ thống mờ điều khiển quá trình giặt, lượng nước nạp vào, thời gian giặt và tốc độ vắt. Các thông số đầu vào ở đây là khối lượng quần áo, mức độ bẩn và loại vết bẩn. Mặc dù khối lượng quần áo sẽ quyết định lượng nước nạp vào, nhưng mức độ ô nhiễm sẽ được xác định bởi độ trong của nước và loại chất bẩn sẽ được xác định theo thời gian màu của nước không đổi.
Bước đầu tiên là xác định các biến và thuật ngữ ngôn ngữ. Đối với dữ liệu đầu vào, các biến ngôn ngữ được đưa ra dưới đây:
- Loại bùn: (Nhờn, Trung bình, Không nhờn)
- Chất lượng bụi bẩn: (Lớn, Trung bình, Nhỏ)
Đối với đầu ra, các biến ngôn ngữ được đưa ra dưới đây:
- Thời gian giặt: (Ngắn, Rất ngắn, Dài, Trung bình, Rất dài) (ngắn, rất ngắn, dài, trung bình, rất dài).
Bước thứ hai liên quan đến việc xây dựng các hàm thành viên. Dưới đây là các sơ đồ xác định các hàm thành viên cho hai đầu vào. Chức năng phụ kiện cho chất lượng bùn:

Chức năng phụ kiện cho loại bùn:

Bước thứ ba liên quan đến việc phát triển một bộ quy tắc cho cơ sở tri thức. Dưới đây là một bộ quy tắc sử dụng logic IF-THEN:
NẾU chất lượng bụi bẩn nhỏ VÀ loại bụi bẩn nhờn thì thời gian giặt sẽ lâu.
NẾU chất lượng vết bẩn Trung bình VÀ Loại vết bẩn Dầu mỡ, THÌ Thời gian giặt lâu.
NẾU chất lượng vết bẩn Lớn và loại vết bẩn Nhờn, THÌ Thời gian giặt Rất lâu.
NẾU chất lượng vết bẩn Nhỏ VÀ Loại bụi bẩn Trung bình, THÌ Thời gian giặt Trung bình.
NẾU chất lượng bụi bẩn Trung bình VÀ Loại bụi bẩn Trung bình, THÌ Thời gian giặt Trung bình.
NẾU chất lượng vết bẩn Lớn và loại vết bẩn Trung bình, THÌ Thời gian giặt Trung bình.
NẾU chất lượng vết bẩn Nhỏ và loại vết bẩn Không nhờn, THÌ Thời gian giặt Rất ngắn.
NẾU chất lượng vết bẩn Trung bình VÀ Loại bụi bẩn Không nhờn, THÌ Thời gian giặt Trung bình.
NẾU chất lượng vết bẩn Lớn và loại vết bẩn Nhờn, THÌ Thời gian giặt Rất ngắn.
Fazifire, ban đầu chuyển đổi đầu vào cảm biến thành các biến ngôn ngữ này, giờ đây áp dụng các quy tắc trên để thực hiện các phép toán tập mờ (ví dụ: MIN và MAX) nhằm xác định các hàm mờ đầu ra. Hàm thành viên được phát triển dựa trên các tập mờ đầu ra. Bước cuối cùng là bước khử định dạng, trong đó bộ khử định dạng sử dụng các hàm thành viên đầu ra để xác định thời gian rửa.
Các lĩnh vực ứng dụng của logic mờ
Hệ thống logic mờ có thể được sử dụng trong các hệ thống ô tô như hộp số tự động. Các ứng dụng trong lĩnh vực thiết bị gia dụng bao gồm lò vi sóng, điều hòa, máy giặt, tivi, tủ lạnh, máy hút bụi, v.v.
Ưu điểm của logic mờ
- Hệ thống logic mờ rất linh hoạt và cho phép thay đổi các quy tắc.
- Những hệ thống như vậy cũng chấp nhận cả những thông tin không chính xác, bị bóp méo và sai sót.
- Hệ thống logic mờ có thể được thiết kế dễ dàng.
- Bởi vì các hệ thống này gắn liền với khả năng suy luận và ra quyết định của con người nên chúng rất hữu ích trong việc hình thành các quyết định trong các tình huống phức tạp trong nhiều loại ứng dụng khác nhau.
trang mạng
thẻ:
Cảm ơn bạn đã quan tâm đến dự án thông tin website.
Nếu bạn muốn các tài liệu thú vị và hữu ích được xuất bản thường xuyên hơn và ít quảng cáo hơn,
Bạn có thể hỗ trợ dự án của chúng tôi bằng cách quyên góp bất kỳ số tiền nào cho sự phát triển của nó.
Lý thuyết toán học về tập mờ và logic mờ là sự tổng quát hóa của lý thuyết tập hợp cổ điển và logic hình thức cổ điển. Những khái niệm này lần đầu tiên được đề xuất bởi nhà khoa học người Mỹ Lotfi Zadeh vào năm 1965. Lý do chính cho sự xuất hiện của lý thuyết mới là sự hiện diện của lý luận mờ và gần đúng khi con người mô tả các quá trình, hệ thống và đối tượng.
Trước khi cách tiếp cận mờ để mô hình hóa các hệ thống phức tạp được công nhận trên toàn thế giới, đã hơn một thập kỷ trôi qua kể từ khi lý thuyết về tập mờ ra đời. Và dọc theo con đường phát triển của hệ mờ, người ta thường phân biệt ba thời kỳ.
Thời kỳ đầu tiên (cuối thập niên 60 – đầu thập niên 70) được đặc trưng bởi sự phát triển của bộ máy lý thuyết về tập mờ (L. Zadeh, E. Mamdani, Bellman). Sang giai đoạn thứ hai (70–80), những kết quả thực tiễn đầu tiên xuất hiện trong lĩnh vực điều khiển mờ của các hệ thống kỹ thuật phức tạp (máy tạo hơi nước có điều khiển mờ). Đồng thời, người ta bắt đầu chú ý đến vấn đề xây dựng hệ chuyên gia dựa trên logic mờ và phát triển bộ điều khiển mờ. Hệ chuyên gia mờ để hỗ trợ quyết định được sử dụng rộng rãi trong y học và kinh tế. Cuối cùng, trong thời kỳ thứ ba, kéo dài từ cuối những năm 80 và tiếp tục cho đến ngày nay, các gói phần mềm xây dựng hệ chuyên gia mờ xuất hiện và các lĩnh vực ứng dụng logic mờ đang được mở rộng rõ rệt. Nó được sử dụng trong ngành công nghiệp ô tô, hàng không vũ trụ và vận tải, trong lĩnh vực thiết bị gia dụng, tài chính, phân tích và ra quyết định quản lý, v.v.
Cuộc diễu hành thắng lợi của logic mờ trên toàn thế giới bắt đầu sau khi Bartholomew Cosco chứng minh định lý FAT (Định lý xấp xỉ mờ) nổi tiếng vào cuối những năm 80. Trong kinh doanh và tài chính, logic mờ đã được công nhận sau năm 1988, một hệ thống chuyên gia dựa trên các quy tắc mờ để dự đoán các chỉ số tài chính là hệ thống duy nhất dự đoán sự sụp đổ của thị trường chứng khoán. Và số lượng các ứng dụng mờ thành công hiện nay đã lên tới hàng nghìn.
Bộ máy toán học
Một đặc điểm của tập mờ là hàm thành viên. Chúng ta hãy biểu thị bằng MF c(x) mức độ thành viên của tập mờ C, đây là sự khái quát hóa khái niệm hàm đặc trưng của một tập thông thường. Khi đó tập mờ C là tập các cặp có thứ tự có dạng C=(MF c (x)/x), MF c (x) . Giá trị MF c (x)=0 có nghĩa là không có thành viên nào trong tập hợp, 1 có nghĩa là thành viên hoàn toàn.
Hãy minh họa điều này bằng một ví dụ đơn giản. Hãy chính thức hóa định nghĩa không chính xác của "trà nóng". X (khu vực thảo luận) sẽ là thang đo nhiệt độ tính bằng độ C. Rõ ràng, nó sẽ thay đổi từ 0 đến 100 độ. Một tập hợp mờ cho khái niệm “trà nóng” có thể trông như thế này:
C=(0/0; 0/10; 0/20; 0,15/30; 0,30/40; 0,60/50; 0,80/60; 0,90/70; 1/80; 1/90; 1/100).
Như vậy, trà có nhiệt độ 60 C thuộc bộ “Nóng” với mức độ thành viên là 0,80. Đối với một người, trà ở nhiệt độ 60 C có thể nóng, đối với người khác thì có thể không quá nóng. Đây chính xác là nơi thể hiện sự mơ hồ trong việc chỉ định tập hợp tương ứng.
Đối với các tập mờ, cũng như đối với các tập thông thường, các phép toán logic cơ bản được xác định. Những cái cơ bản nhất cần thiết cho tính toán là giao và hợp.
Giao của hai tập mờ (Mờ “AND”): A B: MF AB (x)=min(MF A (x), MF B (x)).
Hợp hai tập mờ (mờ "OR"): A B: MF AB (x)=max(MF A (x), MF B (x)).
Trong lý thuyết về tập mờ, một cách tiếp cận chung để thực hiện các toán tử giao, hợp và bù đã được phát triển, triển khai trong cái gọi là chuẩn mực và đồng quy tam giác. Việc triển khai các phép toán giao và hợp ở trên là những trường hợp phổ biến nhất của t-norm và t-conorm.
Để mô tả các tập mờ, người ta đưa ra các khái niệm về biến mờ và biến ngôn ngữ.
Biến mờ được mô tả bằng một tập hợp (N,X,A), trong đó N là tên biến, X là tập phổ quát (miền suy luận), A là tập mờ trên X.
Các giá trị của biến ngôn ngữ có thể là biến mờ, tức là biến ngôn ngữ ở mức cao hơn biến mờ. Mỗi biến ngôn ngữ bao gồm:
- chức danh;
- tập các giá trị của nó, còn gọi là tập thuật ngữ cơ sở T. Các phần tử của tập thuật ngữ cơ sở là tên các biến mờ;
- bộ phổ quát X;
- quy tắc cú pháp G, theo đó các thuật ngữ mới được tạo ra bằng cách sử dụng các từ của ngôn ngữ tự nhiên hoặc ngôn ngữ hình thức;
- quy tắc ngữ nghĩa P, gán mỗi giá trị của một biến ngôn ngữ cho một tập con mờ của tập X.
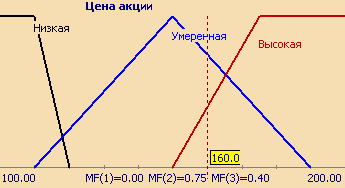
Hãy xem xét một khái niệm mơ hồ như “Giá cổ phiếu”. Đây là tên của biến ngôn ngữ. Hãy hình thành một tập hợp thuật ngữ cơ bản cho nó, bao gồm ba biến mờ: “Thấp”, “Trung bình”, “Cao” và đặt phạm vi suy luận ở dạng X= (đơn vị). Điều cuối cùng còn lại phải làm là xây dựng các hàm thành viên cho mỗi thuật ngữ ngôn ngữ từ tập thuật ngữ cơ sở T.
Có hơn chục hình dạng đường cong tiêu chuẩn để xác định các hàm thành viên. Được sử dụng rộng rãi nhất là: hàm thành viên tam giác, hình thang và Gaussian.
Hàm thành viên tam giác được xác định bởi bộ ba số (a,b,c) và giá trị của nó tại điểm x được tính theo biểu thức:
$$MF\,(x) = \,\begin(case) \;1\,-\,\frac(b\,-\,x)(b\,-\,a),\,a\leq \,x\leq \,b &\ \\ 1\,-\,\frac(x\,-\,b)(c\,-\,b),\,b\leq \,x\leq \ ,c &\ \\ 0, \;x\,\not \in\,(a;\,c)\ \end(case)$$
Khi (b-a)=(c-b) chúng ta có trường hợp hàm thành viên tam giác đối xứng, có thể được xác định duy nhất bởi hai tham số từ bộ ba (a,b,c).
Tương tự, để xác định hàm thành viên hình thang, bạn cần bốn số (a,b,c,d):
$$MF\,(x)\,=\, \begin(case) \;1\,-\,\frac(b\,-\,x)(b\,-\,a),\,a \leq \,x\leq \,b & \\ 1,\,b\leq \,x\leq \,c & \\ 1\,-\,\frac(x\,-\,c)(d \,-\,c),\,c\leq \,x\leq \,d &\\ 0, x\,\not \in\,(a;\,d) \ \end(case)$$
Khi (b-a)=(d-c) hàm thành viên hình thang có dạng đối xứng.
Hàm thành viên của kiểu Gaussian được mô tả bởi công thức
$$MF\,(x) = \exp\biggl[ -\,(\Bigl(\frac(x\,-\,c)(\sigma)\Bigr))^2\biggr]$$
và hoạt động với hai tham số. Tham số c biểu thị tâm của tập mờ và tham số chịu trách nhiệm về độ dốc của hàm.

Tập hợp các hàm thành viên cho mỗi số hạng trong tập hợp số hạng cơ bản T thường được vẽ cùng nhau trên một đồ thị. Hình 3 cho thấy một ví dụ về biến ngôn ngữ “Giá cổ phiếu” được mô tả ở trên; Hình 4 cho thấy sự chính thức hóa của khái niệm không chính xác “Tuổi của Người”. Như vậy, đối với một người 48 tuổi, mức độ thành viên trong nhóm “Trẻ” là 0, “Trung bình” – 0,47, “Trên trung bình” – 0,20.

Số lượng thuật ngữ trong một biến ngôn ngữ hiếm khi vượt quá 7.
Suy luận mờ
Cơ sở để thực hiện thao tác suy luận logic mờ là cơ sở luật chứa các câu lệnh mờ dưới dạng “If-then” và các hàm thành viên cho các số hạng ngôn ngữ tương ứng. Trong trường hợp này, phải đáp ứng các điều kiện sau:
- Có ít nhất một quy tắc cho mỗi thuật ngữ ngôn ngữ của biến đầu ra.
- Đối với bất kỳ số hạng nào của biến đầu vào đều có ít nhất một quy tắc trong đó số hạng này được sử dụng làm điều kiện tiên quyết (phía bên trái của quy tắc).
Ngược lại, sẽ có một cơ sở không đầy đủ của các quy tắc mờ.
Giả sử cơ sở luật có m luật có dạng:
R 1: NẾU x 1 là A 11... VÀ... x n là A 1n, THÌ y là B 1
…
R i: IF x 1 là A i1 ... AND ... x n là A in , THÌ y là B i
…
R m: NẾU x 1 là A i1 ... VÀ ... x n là A mn, THÌ y là B m,
trong đó x k, k=1..n – biến đầu vào; y – biến đầu ra; Aik – tập mờ đã cho với các hàm thành viên.
Kết quả suy luận mờ là giá trị rõ ràng của biến y * dựa trên các giá trị rõ ràng x k , k=1..n.
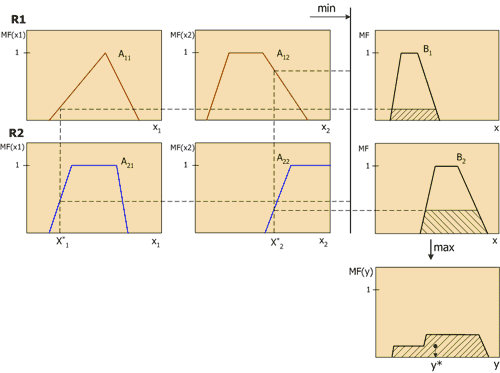
Nhìn chung, cơ chế suy luận bao gồm bốn giai đoạn: đưa vào tính mờ (phân pha), suy luận mờ, thành phần và giảm thiểu đến mức rõ ràng hoặc giải mờ (xem Hình 5).

Các thuật toán suy luận mờ khác nhau chủ yếu ở loại quy tắc được sử dụng, các phép toán logic và loại phương pháp giải mờ. Các mô hình suy luận mờ Mamdani, Sugeno, Larsen, Tsukamoto đã được phát triển.
Chúng ta hãy xem xét kỹ hơn về suy luận mờ bằng cách sử dụng cơ chế Mamdani làm ví dụ. Đây là phương pháp suy luận phổ biến nhất trong các hệ thống mờ. Nó sử dụng thành phần minimax của các tập mờ. Cơ chế này bao gồm chuỗi hành động sau.
- Thủ tục phân giai đoạn: mức độ chân lý được xác định, tức là giá trị của hàm thành viên cho vế trái của mỗi quy tắc (điều kiện tiên quyết). Đối với cơ sở quy tắc có m quy tắc, chúng ta biểu thị mức độ đúng là A ik (x k), i=1..m, k=1..n.
Đầu ra mờ. Đầu tiên, mức giới hạn cho vế trái của mỗi quy tắc được xác định:
$$alfa_i\,=\,\min_i \,(A_(ik)\,(x_k))$$
$$B_i^*(y)= \min_i \,(alfa_i,\,B_i\,(y))$$
Thành phần hoặc sự kết hợp của các hàm rút gọn thu được, trong đó sử dụng thành phần tối đa của các tập mờ:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
trong đó MF(y) là hàm thành viên của tập mờ cuối cùng.
Khử pha, hoặc mang lại sự rõ ràng. Có một số phương pháp giải mờ. Ví dụ: phương pháp trung tâm trung bình hoặc phương pháp centroid:
$$MF\,(y)= \max_i \,(B_i^*\,(y))$$
Ý nghĩa hình học của giá trị này là trọng tâm của đường cong MF(y). Hình 6 thể hiện bằng đồ họa quá trình suy luận mờ Mamdani cho hai biến đầu vào và hai luật mờ R1 và R2.
Tích hợp với các mô hình thông minh
Sự kết hợp các phương pháp xử lý thông tin trí tuệ là phương châm được các nhà nghiên cứu phương Tây và Mỹ áp dụng trong thập niên 90. Là kết quả của sự kết hợp của một số công nghệ trí tuệ nhân tạo, một thuật ngữ đặc biệt đã xuất hiện - “điện toán mềm”, được L. Zadeh giới thiệu vào năm 1994. Hiện nay, điện toán mềm kết hợp các lĩnh vực như: logic mờ, mạng nơ-ron nhân tạo, lý luận xác suất và các thuật toán tiến hóa. Chúng bổ sung cho nhau và được sử dụng theo nhiều cách kết hợp khác nhau để tạo ra các hệ thống thông minh lai.
Ảnh hưởng của logic mờ có lẽ là rộng nhất. Giống như các tập mờ đã mở rộng phạm vi của lý thuyết tập hợp toán học cổ điển, logic mờ đã “xâm chiếm” hầu hết các phương pháp Khai thác dữ liệu, mang lại cho chúng những chức năng mới. Dưới đây là những ví dụ thú vị nhất về các hiệp hội như vậy.
Mạng lưới thần kinh mờ
Mạng nơ-ron mờ thực hiện các suy luận dựa trên logic mờ, nhưng các tham số của hàm thành viên được điều chỉnh bằng thuật toán học NN. Do đó, để chọn tham số của các mạng như vậy, chúng tôi áp dụng phương pháp lan truyền ngược lỗi, ban đầu được đề xuất để huấn luyện perceptron nhiều lớp. Với mục đích này, mô-đun điều khiển mờ được biểu diễn dưới dạng mạng nhiều lớp. Mạng nơron mờ thường bao gồm bốn lớp: một lớp phân pha các biến đầu vào, một lớp tổng hợp các giá trị kích hoạt điều kiện, một lớp tổng hợp các quy tắc mờ và một lớp đầu ra.
Kiến trúc mạng nơ-ron mờ được sử dụng rộng rãi nhất là ANFIS và TSK. Người ta đã chứng minh rằng các mạng như vậy là các mạng xấp xỉ phổ quát.
Các thuật toán học nhanh và khả năng diễn giải của kiến thức tích lũy - những yếu tố này đã khiến mạng nơ-ron mờ trở thành một trong những công cụ điện toán mềm hiệu quả và hứa hẹn nhất hiện nay.
Hệ thống mờ thích ứng
Các hệ thống mờ cổ điển có nhược điểm là để xây dựng các quy tắc và hàm thành viên cần có sự tham gia của các chuyên gia trong một lĩnh vực chủ đề cụ thể, điều này không phải lúc nào cũng có thể đảm bảo được. Hệ thống mờ thích ứng giải quyết được vấn đề này. Trong các hệ thống như vậy, việc lựa chọn tham số hệ thống mờ được thực hiện trong quá trình huấn luyện trên dữ liệu thực nghiệm. Các thuật toán để huấn luyện hệ mờ thích ứng tương đối tốn nhiều công sức và phức tạp so với các thuật toán huấn luyện mạng nơ-ron và theo quy luật, bao gồm hai giai đoạn: 1. Tạo ra các quy tắc ngôn ngữ; 2. Chỉnh sửa chức năng thành viên. Bài toán đầu tiên là bài toán loại tìm kiếm toàn diện, bài toán thứ hai là bài toán tối ưu hóa trong không gian liên tục. Trong trường hợp này, nảy sinh một mâu thuẫn nhất định: để tạo ra các luật mờ cần có các hàm thành viên và để thực hiện suy luận mờ cần có các luật. Ngoài ra, khi tự động tạo ra các luật mờ cần đảm bảo tính đầy đủ và nhất quán của chúng.
Một phần quan trọng của các phương pháp huấn luyện hệ mờ sử dụng thuật toán di truyền. Trong tài liệu tiếng Anh, điều này tương ứng với một thuật ngữ đặc biệt – Hệ thống mờ di truyền.
Một đóng góp đáng kể cho sự phát triển lý thuyết và thực tiễn của hệ thống mờ với khả năng thích ứng tiến hóa đã được thực hiện bởi một nhóm các nhà nghiên cứu Tây Ban Nha do F. Herrera đứng đầu.
Truy vấn mờ
Truy vấn mờ tới cơ sở dữ liệu là một hướng đầy hứa hẹn trong các hệ thống xử lý thông tin hiện đại. Công cụ này cho phép tạo các truy vấn bằng ngôn ngữ tự nhiên, ví dụ: “Nhận danh sách các ưu đãi nhà ở giá rẻ gần trung tâm thành phố”, điều này không thể thực hiện được khi sử dụng cơ chế truy vấn tiêu chuẩn. Với mục đích này, đại số quan hệ mờ và các phần mở rộng đặc biệt của ngôn ngữ SQL cho các truy vấn mờ đã được phát triển. Hầu hết các nghiên cứu trong lĩnh vực này thuộc về các nhà khoa học Tây Âu D. Dubois và G. Prade.
Luật kết hợp mờ
Các luật kết hợp mờ là một công cụ để trích xuất các mẫu từ cơ sở dữ liệu được xây dựng dưới dạng các câu lệnh ngôn ngữ. Ở đây, các khái niệm đặc biệt về giao dịch mờ, độ hỗ trợ và độ tin cậy của luật kết hợp mờ được giới thiệu.
Bản đồ nhận thức mờ
Bản đồ nhận thức mờ được B. Kosko đề xuất vào năm 1986 và được sử dụng để mô hình hóa các mối quan hệ nhân quả được xác định giữa các khái niệm của một lĩnh vực nhất định. Không giống như các bản đồ nhận thức đơn giản, bản đồ nhận thức mờ là một đồ thị có hướng mờ có các nút là các tập mờ. Các cạnh định hướng của đồ thị không chỉ phản ánh mối quan hệ nhân quả giữa các khái niệm mà còn xác định mức độ ảnh hưởng (trọng lượng) của các khái niệm được kết nối. Việc sử dụng tích cực các bản đồ nhận thức mờ như một phương tiện của các hệ thống mô hình hóa là do khả năng thể hiện trực quan của hệ thống được phân tích và sự dễ dàng diễn giải mối quan hệ nhân quả giữa các khái niệm. Các vấn đề chính liên quan đến quá trình xây dựng bản đồ nhận thức, không thể hình thức hóa được. Ngoài ra, cần chứng minh bản đồ nhận thức được xây dựng phù hợp với hệ thống thực tế đang được mô hình hóa. Để giải quyết những vấn đề này, các thuật toán tự động xây dựng bản đồ nhận thức dựa trên việc lấy mẫu dữ liệu đã được phát triển.
Phân cụm mờ
Các phương pháp phân cụm mờ, trái ngược với các phương pháp rõ ràng (ví dụ: mạng thần kinh Kohonen), cho phép cùng một đối tượng thuộc về một số cụm đồng thời, nhưng ở các mức độ khác nhau. Phân cụm mờ trong nhiều tình huống “tự nhiên” hơn so với phân cụm rõ ràng, ví dụ, đối với các đối tượng nằm ở rìa của cụm. Phổ biến nhất là thuật toán tự tổ chức mờ c-means và khái quát hóa nó dưới dạng thuật toán Gustafson-Kessel.
Văn học
- Zadeh L. Khái niệm về biến ngôn ngữ và ứng dụng của nó vào việc ra quyết định gần đúng. – M.: Mir, 1976.
- Kruglov V.V., Dli M.I. Hệ thống thông tin thông minh: máy tính hỗ trợ logic mờ và hệ thống suy luận mờ. – M.: Fizmatlit, 2002.
- Leolenkov A.V. Mô hình mờ trong MATLAB và FuzzyTECH. – St.Petersburg, 2003.
- Rutkowska D., Pilinski M., Rutkowski L. Mạng lưới thần kinh, thuật toán di truyền và hệ thống mờ. – M., 2004.
- Masalovich A. Logic mờ trong kinh doanh và tài chính. www.tora-centre.ru/library/fuzzy/fuzzy-.htm
- Kosko B. Hệ thống mờ như công cụ xấp xỉ phổ quát // Giao dịch IEEE trên máy tính, tập. 43, không. Ngày 11 tháng 11 năm 1994. – P. 1329-1333.
- Cordon O., Herrera F., Nghiên cứu tổng quát về hệ thống mờ di truyền // Thuật toán di truyền trong kỹ thuật và khoa học máy tính, 1995. – P. 33-57.