ansi là gì Các lớp áp suất ANSI. Sơ lược về lịch sử mã hóa
Đôi khi, ngay cả một chuyên gia khá có kinh nghiệm cũng sẽ không cho bạn biết ngay giá trị áp suất hoặc độ dài cụ thể trong một hệ thống này tương ứng với các giá trị trong hệ đại lượng khác.
ĐẾN xoa dịu nhiệm vụ này dành cho bạn, chúng tôi đưa ra các bảng về mối quan hệ giữa giá trị áp suất và chiều dài trong hệ thống Châu Âu và Châu Mỹ với các giá trị nhỏ lời giải thích. Nhưng trước tiên, hãy nói một vài lời về các tiêu chuẩn.
DIN- đây là tiêu chuẩn của Đức (viết tắt của từ Viện Deutsches für Normung, tức là do Viện Tiêu chuẩn hóa Đức phát triển), được phát triển nghiêm ngặt trong khuôn khổ các quy định của Tổ chức Tiêu chuẩn hóa Quốc tế - ISO (Tổ chức Tiêu chuẩn hóa Quốc tế).
ANSI- tiêu chuẩn được thông qua tại Hoa Kỳ. Viết tắt của Viện Tiêu chuẩn Quốc gia Hoa Kỳ, tức là tiêu chuẩn của Viện Tiêu chuẩn Quốc gia Hoa Kỳ.
Theo đó, các tiêu chuẩn ANSI được xác định bởi viện này và cho đến nay không phải lúc nào cũng vậy giữa các tiêu chuẩn DIN Và ANSI bạn có thể theo dõi chính xác Tuân thủ trong các lĩnh vực khác nhau.
Chuyển đổi đơn vị áp suất từ ANSI sang DIN
Mọi thứ đều đơn giản ở đây: nếu theo tiêu chuẩn ANSIđối diện với áp suất là số 150 - điều này có nghĩa là áp suất danh nghĩa (được thiết kế cho các phụ kiện) là 20 bar, 300 - 50 bar, v.v. Giá trị tối đa cho Lớp ANSI– 2500 sẽ bằng 420 bar theo tiêu chuẩn Châu Âu DIN.
Sử dụng bảng này, không khó chuyển đổi giá trị áp suất và ngược lại: từ DIN V. ANSI, mặc dù các kỹ sư của chúng tôi phải mất nhiều thời gian hơn để thực hiện bản dịch như vậy ít hơn thường lệ.
Chuyển đổi đơn vị độ dài từ hệ thống của Mỹ sang hệ thống châu Âu (Nga)
Như đã biết, người Mỹ mọi thứ đều được đo bằng inch và feet, và chúng tôi người châu Âu- milimet, centimet và mét, nghĩa là giống như đại đa số các quốc gia trên thế giới chúng ta đang sống Hệ mét hệ thống đơn vị.
Làm thế nào để chuyển đổi inch sang milimét? Trên thực tế, điều này cũng không có gì phức tạp cả, chỉ cần nhớ rằng 1 inch bằng 25,4 mm. Tuy nhiên, thường thì số sau dấu thập phân bị bỏ rơi và để có biện pháp tốt, họ chỉ ra rằng 1 inch = 25 mm.
Do đó, ví dụ, nếu mặt cắt ngang của lỗ đầu vào bằng 2 inch theo hệ thống đo lường của Mỹ, thì bằng cách sử dụng quy tắc trên, chuyển giá trị này sang hệ thống đo lường của chúng tôi, chúng ta thu được 50 mm hoặc, chính xác hơn là 51 mm (làm tròn 50,8 theo quy định).
Vẫn còn phải nói thêm rằng đường kính là kỹ thuậtđặc điểm được đánh dấu bằng chữ cái Latinh DN và thường được chỉ định chính xác trong inch, và áp suất được biểu thị bằng các chữ cái PN và thường được chỉ định trong thanh- trong mọi trường hợp, chúng tôi sử dụng chính xác dấu hiệu này nhất thoải mái.
Và bàn tiếp theo sẽ giúp bạn cần phải tính toán không chỉ chính xác số milimét trong một inch (chính xác đến một phần nghìn milimét), nhưng cũng sẽ giúp bạn biết có bao nhiêu milimét được chứa, chẳng hạn như trong 2,5 inch.
Để làm điều này, chúng tôi tìm cột 2"" (2 inch) và ở bên trái, chúng tôi tìm giá trị 1/2. Tổng 2,5 inch = 63,501 mm, có thể làm tròn lên 64 mm và, ví dụ: 6,25 inch (nghĩa là 6 và 1/4) = 158,753 mm hoặc 159 mm.
|
| Inch "" tính bằng milimét |
|||||||
|
| ||||||||
|
| ||||||||
Thông thường, khi lập trình web và bố cục các trang html, bạn phải nghĩ đến việc mã hóa tệp đang được chỉnh sửa - xét cho cùng, nếu chọn mã hóa không chính xác thì có khả năng trình duyệt sẽ không thể tự động phát hiện nó và vì kết quả là người dùng sẽ thấy cái gọi là. "krakozyabry"
Có lẽ chính bạn đã từng nhìn thấy những biểu tượng và dấu hỏi lạ trên một số trang web thay vì văn bản thông thường. Tất cả điều này xảy ra khi mã hóa của trang html và mã hóa tệp của chính trang này không khớp.
Ở tất cả, mã hóa văn bản là gì? Nó chỉ là một bộ ký tự bằng tiếng Anh "bộ ký tự" (bộ ký tự). Nó cần thiết để chuyển đổi thông tin văn bản thành các bit dữ liệu và truyền tải, chẳng hạn như qua Internet.
Trên thực tế, các tham số chính để phân biệt mã hóa là số byte và tập hợp các ký tự đặc biệt mà mỗi ký tự của văn bản nguồn được chuyển đổi thành.
Tóm tắt lịch sử của mã hóa:
Một trong những thiết bị đầu tiên truyền tải thông tin kỹ thuật số là sự xuất hiện của bảng mã ASCII - Mã tiêu chuẩn Mỹ để trao đổi thông tin - Bảng mã hóa tiêu chuẩn Mỹ,được Viện Tiêu chuẩn Quốc gia Hoa Kỳ thông qua - Viện Tiêu chuẩn Quốc gia Hoa Kỳ (ANSI).
Bạn có thể bị nhầm lẫn trong các chữ viết tắt này. Để thực hành, điều quan trọng là phải hiểu rằng mã hóa nguồn của tệp văn bản được tạo có thể không hỗ trợ tất cả các ký tự của một số bảng chữ cái (ví dụ: chữ tượng hình), do đó có xu hướng chuyển sang cái gọi là. tiêu chuẩn bảng mã Unicode, hỗ trợ mã hóa phổ quát - Utf-8, Utf-16, Utf-32 và vân vân.
Mã hóa Unicode phổ biến nhất là Utf-8. Thông thường, các trang web hiện được trình bày trong đó và nhiều tập lệnh khác nhau được viết. Nó cho phép bạn dễ dàng hiển thị nhiều chữ tượng hình, chữ cái Hy Lạp và các ký hiệu có thể tưởng tượng và không thể tưởng tượng khác (kích thước ký tự lên tới 4 byte). Đặc biệt, tất cả các tệp WordPress và Joomla đều được viết bằng mã hóa này. Và một số công nghệ web (đặc biệt là AJAX) chỉ có thể xử lý các ký tự utf-8 một cách bình thường.
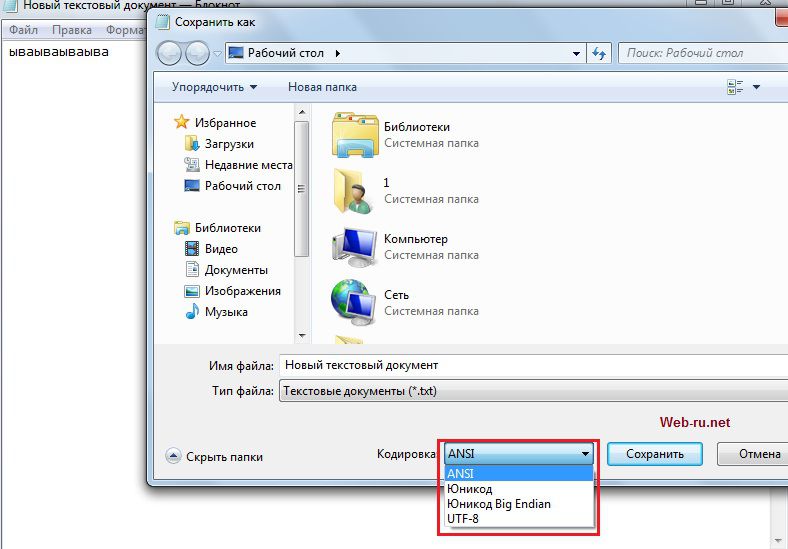
Đặt mã hóa tệp văn bản khi tạo tệp bằng notepad thông thường. Có thể nhấp
Trên RuNet, bạn vẫn có thể tìm thấy các trang web được viết bằng mã hóa. Windows-1251 (hoặc cp-1251).Đây là một bảng mã đặc biệt được thiết kế dành riêng cho bảng chữ cái Cyrillic.
Điều đáng chú ý là tất cả các ký hiệu cấp áp suất ANSI đều mang một ý nghĩa nhất định, cụ thể là giá trị áp suất, nhưng chỉ ở các đơn vị khác với đơn vị chúng ta quen thuộc. Tất cả các số sau ANSI biểu thị giá trị của Áp suất có điều kiện (danh nghĩa): ANSI 150, ANSI 300, ANSI 600, ANSI 900, ANSI 1500, ANSI 2500 và ANSI 4500. Ví dụ: ANSI 150 có nghĩa là áp suất danh nghĩa là 150 pound mỗi lần. inch vuông. Trong tiếng Anh, nó được viết là Pound-force per Square Inch hoặc viết tắt là PSI.
Theo đó, bằng cách này, bạn có thể tự thực hiện chuyển đổi từ psi sang bar (100 kPa) hoặc MPa. Để tính toán chính xác một cách độc lập, bạn cần biết rằng 1 PSI = 6894,76 Pa. Tất cả các phép tính áp suất Pascal và thanh ANSI có thể được thực hiện khi có thời gian và cần dữ liệu chính xác, trong khi hầu hết các loại áp suất ANSI tiêu chuẩn đều đã có giá trị thanh và MPa tiêu chuẩn. Để dễ dàng hơn, chúng tôi đã biên soạn một bảng ngắn để bạn sử dụng:
Bảng các cấp áp suất ANSI có chuyển đổi sang Bar và MPa
|
Lớp áp suất ANSI |
||
ANSI là tổ chức tiêu chuẩn hóa các phương pháp và công nghệ công nghiệp. Nó là thành viên của Tổ chức Tiêu chuẩn Quốc tế (ISO). Ở Đức có tổ chức tương tự như vậy - Viện Tiêu chuẩn hóa Đức (DIN), ở Áo - Viện Tiêu chuẩn Áo (ASI), ở Thụy Sĩ - Hiệp hội Tiêu chuẩn Thụy Sĩ (SNV).
Mặc dù các tiêu chuẩn ANSI phổ biến trong nhiều lĩnh vực công nghiệp, một chữ viết tắt riêng "ANSI" trong công nghệ máy tính đề cập đến một nhóm ký tự cụ thể dựa trên ASCII. Không có tiêu chuẩn ANSI thực sự, tuy nhiên, các dự án ANSI đã áp dụng tiêu chuẩn ISO 8859 một cách liền mạch.
nhiệm vụ ANSI
Nhiệm vụ chính của Viện Tiêu chuẩn Quốc gia Hoa Kỳ (ANSI) là phổ biến và áp dụng các tiêu chuẩn quốc gia Hoa Kỳ trên toàn thế giới, tại các doanh nghiệp của tất cả các quốc gia.
Ngoài ra, công việc của viện này còn giải quyết các vấn đề trên quy mô toàn cầu:
- bảo vệ môi trường,
- an toàn công nghiệp,
- an toàn hộ gia đình.
Được biết, ở Mỹ cũng như ở Nga, các tiêu chuẩn chủ yếu do nhà nước quy định (mặc dù ANSI tự nhận mình là một tổ chức phi lợi nhuận, phi chính phủ) nên mong muốn lấp đầy khoảng trống này và đưa mọi tiêu chuẩn đến với người Mỹ. mẫu số là một ý tưởng hoàn toàn hợp lý và nhất quán. Rốt cuộc, thông qua các tiêu chuẩn, có thể phổ biến không chỉ những cải tiến kỹ thuật thuần túy mà còn theo đuổi chính sách đối ngoại của nhà nước về toàn cầu hóa và hội nhập thế giới.
Nhà nước dành một khoản ngân sách đáng kể để hỗ trợ chương trình ANSI, chủ yếu dành cho việc tối ưu hóa, cập nhật và tổ chức lại phương thức sản xuất. Trong ngành thép, các tiêu chuẩn ANSI từ lâu đã được chứng minh là một trong những tiêu chuẩn tốt nhất trên thế giới.
Công ty chúng tôi cũng sẵn sàng hợp tác sản xuất các sản phẩm có mặt bích, được bán với số lượng lớn cho các doanh nghiệp công nghiệp ở Nga và các nước CIS.
Reg.ru: tên miền và lưu trữ
Nhà đăng ký và cung cấp dịch vụ lưu trữ lớn nhất ở Nga.
Hơn 2 triệu tên miền đang được sử dụng.
Khuyến mãi, mail tên miền, giải pháp kinh doanh.
Hơn 700 nghìn khách hàng trên khắp thế giới đã đưa ra lựa chọn của mình.
* Di chuột qua để tạm dừng cuộn.
Quay lại phía trước
Mã hóa: thông tin hữu ích và hồi tưởng ngắn gọn
Tôi quyết định viết bài này như một bài đánh giá ngắn về vấn đề mã hóa.
Chúng ta sẽ tìm hiểu mã hóa nói chung là gì và đề cập một chút về lịch sử về cách chúng xuất hiện về nguyên tắc.
Chúng ta sẽ nói về một số tính năng của chúng và cũng xem xét các điểm cho phép chúng ta làm việc với mã hóa một cách có ý thức hơn và tránh xuất hiện cái gọi là krakozyabrov, I E. ký tự không thể đọc được.
Vì vậy, chúng ta hãy đi...
Mã hóa là gì?
Nói một cách đơn giản, mã hóa- đây là bảng ánh xạ các ký tự mà chúng ta có thể nhìn thấy trên màn hình với các mã số nhất định.
Những thứ kia. Mỗi ký tự mà chúng ta nhập từ bàn phím hoặc nhìn thấy trên màn hình điều khiển đều được mã hóa bằng một chuỗi bit nhất định (số 0 và số 1). 8 bit, như bạn có thể biết, tương đương với 1 byte thông tin, nhưng sau này sẽ nói nhiều hơn về điều đó.
Bản thân sự xuất hiện của các ký tự được xác định bởi các tập tin phông chữđược cài đặt trên máy tính của bạn. Do đó, quá trình hiển thị văn bản trên màn hình có thể được mô tả như một sự so sánh liên tục giữa các chuỗi số 0 và số 1 với một số ký tự cụ thể là một phần của phông chữ.
Tổ tiên của tất cả các bảng mã hiện đại có thể được coi là ASCII.
Chữ viết tắt này là viết tắt của Mã tiêu chuẩn Mỹ về trao đổi thông tin(Bộ ký tự tiêu chuẩn của Mỹ dành cho các ký tự in được và một số mã đặc biệt).
Cái này mã hóa một byte, ban đầu chỉ chứa 128 ký tự: các chữ cái trong bảng chữ cái Latinh, chữ số Ả Rập, v.v.

Sau đó, nó được mở rộng (ban đầu nó không sử dụng tất cả 8 bit), vì vậy nó có thể sử dụng không phải 128 mà là 256 (2 đến lũy thừa thứ 8) các ký tự khác nhau có thể được mã hóa thành một byte thông tin.
Cải tiến này giúp có thể thêm vào ASCII biểu tượng của ngôn ngữ quốc gia, ngoài bảng chữ cái Latinh hiện có.
Có nhiều lựa chọn để mã hóa ASCII mở rộng do trên thế giới cũng có nhiều ngôn ngữ. Tôi nghĩ rằng nhiều bạn đã nghe nói về mã hóa như KOI8-R cũng là mã hóa ASCII mở rộng, được thiết kế để hoạt động với các ký tự tiếng Nga.
Bước tiếp theo trong quá trình phát triển mã hóa có thể được coi là sự xuất hiện của cái gọi là Mã hóa ANSI.
Về cơ bản chúng giống nhau phiên bản mở rộng của ASCII tuy nhiên, nhiều yếu tố đồ họa giả khác nhau đã bị xóa khỏi chúng và các ký hiệu typographic đã được thêm vào mà trước đây không có đủ "khoảng trống".
Một ví dụ về mã hóa ANSI như vậy là mã hóa nổi tiếng Windows-1251. Ngoài các ký hiệu typographic, mã hóa này còn bao gồm các chữ cái trong bảng chữ cái của các ngôn ngữ gần với tiếng Nga (tiếng Ukraina, tiếng Belarus, tiếng Serbia, tiếng Macedonia và tiếng Bungari).

Mã hóa ANSI là tên gọi chung. Trên thực tế, mã hóa thực tế khi sử dụng ANSI sẽ được xác định bởi những gì được chỉ định trong sổ đăng ký hệ điều hành Windows của bạn. Trong trường hợp tiếng Nga, đây sẽ là Windows-1251, tuy nhiên, đối với các ngôn ngữ khác, nó sẽ là một phiên bản khác của ANSI.
Như bạn hiểu, việc viết mã nhiều và thiếu một tiêu chuẩn thống nhất sẽ không dẫn đến bất kỳ điều tốt đẹp nào, đó là lý do khiến các cuộc họp thường xuyên với cái gọi là ngựa vằn- một bộ ký tự vô nghĩa, không thể đọc được.
Lý do cho sự xuất hiện của họ rất đơn giản - đó là cố gắng hiển thị các ký tự được mã hóa bằng một bộ ký tự bằng cách sử dụng bộ ký tự khác.
Trong bối cảnh phát triển web, chúng ta có thể gặp phải lỗi khi, chẳng hạn như: Văn bản tiếng Nga bị lưu nhầm ở một mã hóa khác với mã hóa được sử dụng trên máy chủ.
Tất nhiên, đây không phải là trường hợp duy nhất khi chúng ta có thể nhận được văn bản không thể đọc được - có rất nhiều tùy chọn ở đây, đặc biệt nếu chúng ta xem xét rằng cũng có một cơ sở dữ liệu trong đó thông tin cũng được lưu trữ trong một mã hóa nhất định, có ánh xạ kết nối vào cơ sở dữ liệu, v.v.
Sự xuất hiện của tất cả những vấn đề này đóng vai trò là động lực để tạo ra một cái gì đó mới. Nó phải là một bảng mã có thể mã hóa bất kỳ ngôn ngữ nào trên thế giới (xét cho cùng, với sự trợ giúp của mã hóa từng byte, cho dù bạn có cố gắng thế nào đi chăng nữa, bạn cũng không thể mô tả tất cả các ký tự của tiếng Trung Quốc, chẳng hạn như ở đâu). rõ ràng là nhiều hơn 256), bất kỳ ký tự đặc biệt và kiểu chữ bổ sung nào.
Nói tóm lại, cần phải tạo ra một mã hóa phổ quát có thể giải quyết vấn đề bẻ khóa một lần và mãi mãi.
Unicode - Mã hóa văn bản phổ quát (UTF-32, UTF-16 và UTF-8)
Bản thân tiêu chuẩn này đã được đề xuất vào năm 1991 bởi tổ chức phi lợi nhuận "Tập đoàn Unicode"(Unicode Consortium, Unicode Inc.), và kết quả đầu tiên trong công việc của ông là tạo ra bộ mã hóa UTF-32.
Nhân tiện, chính chữ viết tắt UTF là viết tắt của Định dạng chuyển đổi Unicode(Định dạng chuyển đổi Unicode).
Trong cách mã hóa này, để mã hóa một ký tự người ta phải sử dụng nhiều nhất 32 bit, I E. 4 byte thông tin. Nếu chúng ta so sánh con số này với mã hóa một byte, chúng ta sẽ đi đến một kết luận đơn giản: để mã hóa 1 ký tự trong mã hóa phổ quát này, bạn cần gấp 4 lần số bit, làm cho tập tin nặng hơn gấp 4 lần.
Rõ ràng là số lượng ký tự có thể được mô tả bằng cách sử dụng mã hóa này vượt quá mọi giới hạn hợp lý và bị giới hạn về mặt kỹ thuật ở mức 2 mũ 32. Rõ ràng là điều này rõ ràng là quá mức cần thiết và lãng phí về mặt trọng lượng của tệp, vì vậy mã hóa này không được phổ biến rộng rãi.
Nó đã được thay thế bằng một sự phát triển mới - UTF-16.
Như rõ ràng từ tên, trong mã hóa này, một ký tự được mã hóa không còn 32 bit nữa mà chỉ còn 16(tức là 2 byte). Rõ ràng, điều này làm cho bất kỳ ký tự nào cũng "nhẹ" gấp đôi so với UTF-32, nhưng cũng "nặng" gấp đôi so với bất kỳ ký tự nào được mã hóa bằng mã hóa một byte.
Số lượng ký tự có sẵn để mã hóa trong UTF-16 ít nhất là từ 2 mũ 16, tức là. 65536 ký tự. Mọi thứ có vẻ ổn và bên cạnh đó, không gian mã cuối cùng trong UTF-16 đã được mở rộng lên hơn 1 triệu ký tự.
Tuy nhiên, mã hóa này chưa đáp ứng đầy đủ nhu cầu của các nhà phát triển. Ví dụ: nếu bạn viết chỉ sử dụng các ký tự Latinh thì sau khi chuyển từ phiên bản mở rộng của mã hóa ASCII sang UTF-16, trọng lượng của mỗi tệp sẽ tăng gấp đôi.
Kết quả là, một nỗ lực khác đã được thực hiện để tạo ra một cái gì đó phổ quát, và thứ này đã trở thành mã hóa UTF-8 nổi tiếng.
UTF-8- Cái này mã hóa có độ dài thay đổi nhiều byte. Nhìn vào tên, bạn có thể nghĩ, tương tự như UTF-32 và UTF-16, 8 bit được sử dụng ở đây để mã hóa một ký tự, nhưng thực tế không phải vậy. Chính xác hơn thì không hoàn toàn như vậy.
Thực tế là UTF-8 cung cấp khả năng tương thích tốt nhất với các hệ thống cũ sử dụng ký tự 8 bit. Để mã hóa một ký tự trong UTF-8 thực sự được sử dụng từ 1 đến 4 byte(theo giả thuyết, có thể lên tới 6 byte).
Trong UTF-8, tất cả các ký tự Latinh được mã hóa thành 8 bit, giống như trong ASCII.. Nói cách khác, phần cơ bản của mã hóa ASCII (128 ký tự) đã chuyển sang UTF-8, cho phép bạn chỉ dành 1 byte cho cách biểu diễn của chúng, trong khi vẫn duy trì tính phổ biến của mã hóa, vì lợi ích của mọi thứ. đa băt đâu.
Vì vậy, nếu 128 ký tự đầu tiên được mã hóa bằng 1 byte thì tất cả các ký tự khác được mã hóa bằng 2 byte trở lên. Đặc biệt, mỗi ký tự Cyrillic được mã hóa chính xác bằng 2 byte.
Do đó, chúng tôi đã có được một mã hóa phổ quát cho phép chúng tôi bao gồm tất cả các ký tự có thể cần được hiển thị mà không làm cho tệp nặng hơn một cách không cần thiết.
Có BOM hay không có BOM?
Nếu bạn đã làm việc với các trình soạn thảo văn bản (trình soạn thảo mã), ví dụ: Sổ tay++, phpDesigner, PHP nhanh v.v., thì bạn có thể nhận thấy rằng khi chỉ định mã hóa mà trang sẽ được tạo, bạn thường có thể chọn 3 tùy chọn:
ANSI
- UTF-8
- UTF-8 không có BOM

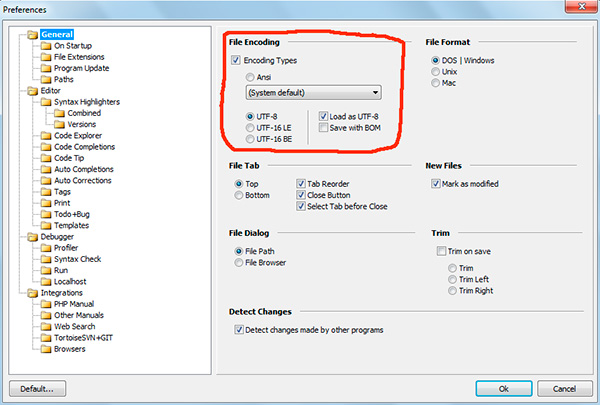

Tôi sẽ nói ngay rằng bạn nên luôn chọn tùy chọn cuối cùng - UTF-8 không có BOM.
Vậy BOM là gì và tại sao chúng ta không cần đến nó?
BOM là viết tắt của Dấu thứ tự byte. Đây là ký tự Unicode đặc biệt được sử dụng để biểu thị thứ tự byte của tệp văn bản. Theo đặc điểm kỹ thuật, việc sử dụng nó là không bắt buộc, nhưng nếu BOMđược sử dụng thì nó phải được đặt ở đầu tệp văn bản.
Chúng tôi sẽ không đi vào chi tiết công việc BOM. Đối với chúng tôi, kết luận chính là như sau: sử dụng ký tự dịch vụ này cùng với UTF-8 sẽ ngăn các chương trình đọc mã hóa bình thường, dẫn đến lỗi trong tập lệnh.