Cum să recunoașteți textul utilizând ABBYY FineReader: instrucțiuni pas cu pas. Corectarea erorilor de scanare în ABBYY Finereader Abbyy finereader cum se utilizează programul
Deci, avem FineReader instalat pe computerul nostru. Pornim scanerul și digitalizăm un document cu mai multe pagini. Să-i spunem, condiționat, „Acord”.
Așezați prima pagină a documentului pe geamul scanerului și închideți capacul. Lansați programul FineReader. Faceți clic pe butonul „Scanare” sau apăsați combinația „Ctrl+K”. Se deschide fereastra „Scanare ABBYY FineReader”. Când digitizați o pagină de text obișnuită, introdusă cu font de 11-12 puncte, lăsați setările implicite în fereastră și faceți clic pe butonul „Vizualizare”.
Scanerul funcționează și după câteva secunde ne vedem pagina în fereastra de vizualizare. Aici putem schimba dimensiunea scanării dacă este necesar. Apoi faceți clic pe butonul „Scanați”.
FineReader începe procesul de recunoaștere a textului și într-un minut imaginea paginii se deschide în fereastra programului. Partea dreaptă a ferestrei este acum împărțită în trei secțiuni. În secțiunea din stânga „Imagine” putem edita imaginea. Puteți citi mai multe despre editarea imaginilor în lecția: Scanarea unei cărți. În secțiunea din dreapta „Text” puteți face imediat modificări textului - editați conținutul paginii chiar înainte de a o salva. Acest lucru este foarte convenabil atunci când trebuie, de exemplu, să schimbați rapid datele, detaliile și numele de familie într-un document.
O pictogramă a paginii recunoscute apare în partea stângă a ferestrei „Pagini”:
Dacă nu trebuie să editați nimic, înlocuiți prima pagină de pe sticla scanerului cu a doua pagină și repetați tehnologia. După ce am ajustat o dată dimensiunile de scanare în fereastra „ABBYY FineReader Scanning” în modul „Previzualizare” pentru prima pagină, faceți imediat clic pe butonul „Scanare”. Setările pentru prima pagină sunt salvate, iar paginile ulterioare sunt scanate fără previzualizare. Așa că scanăm toate paginile documentului nostru.
Am terminat, iar acum, făcând clic pe pictograme una câte una, deschidem paginile, verificând succesiunea lor corectă.
După aceea, în partea stângă a ferestrei „Pagini”, selectați toate pictogramele cu butonul: „Editare – Selectați tot” sau cu comanda rapidă de la tastatură: „Ctrl + A”. Apoi, în lista derulantă de lângă butonul „Salvare”, selectați comanda: „Salvare ca document PDF”:

Acum faceți clic pe butonul în sine și salvați documentul cu numele „Agreement.pdf” în folderul „Agreement”:

Drept urmare, obținem un document text cu mai multe pagini în format pdf - o versiune electronică a documentului nostru cu numele de cod „Acord”.
Deci, digitizăm documente text folosind FineReader.
Schimbând modul de scanare la „color” în fereastra „ABBYY FineReader Scanning”, putem digitiza cu ușurință imaginile și fotografiile color.
Și setând în meniul contextual, de exemplu, comanda: „Salvați ca document Microsoft Word 2007”, ne vom transforma proiectul într-un singur document Word editabil cu mai multe pagini.
În general, programul este ușor de înțeles, intuitiv și are sfaturi pop-up peste tot.
Conversația va fi despre programul ABBYY FineReader 12, adică despre ultima sa versiune. Fără să ne uităm prea departe, am ales cel mai faimos produs de la ABBYY, care, după meritul său, este perfect rusificat. Deja la prima vedere, Fine Reader (FR) dă impresia unui program cu suport bun pentru limba rusă: în acest sens, într-adevăr, totul se face la un nivel foarte decent, inclusiv informațiile de bază.
În primul rând - retragere. Întrebarea cum să convertiți întreaga arhivă sau o parte a unei arhive în format digital este întotdeauna relevantă (și ce se înțelege, de fapt, prin cuvântul „digital”). Cumpărarea unui scaner este puțin probabil să rezolve toate problemele. Desigur, de foarte multe ori documentația pentru scaner vine cu un disc sau mai multe cu software proprietar. Cu toate acestea, deja în etapa de igienizare se dovedește că calitatea programului de scanare lasă de dorit sau formatul în care are loc salvarea nu este, din păcate, potrivit pentru stocare. De ce? Majoritatea formatelor grafice nu separă textul de spațiul non-text al documentului și, prin urmare, nu este posibil să copiați niciun pasaj dintr-un astfel de fișier.
În astfel de cazuri vin în ajutor programele funcționale de recunoaștere a textului, ale căror capacități includ, în special, extragerea textului dintr-o imagine.
Cunoașterea ABBYY FineReader
Punga de plastic ABBYY Finereader 12- Sistem de recunoaștere optică a caracterelor (OCR). Proiectat atât pentru introducerea automată a documentelor tipărite într-un computer, cât și pentru conversia documentelor PDF și a fotografiilor în formate editabile (din manualul programului)
Acronimul „OCR” este aplicabil tuturor aplicațiilor de recunoaștere a datelor (nu doar text). Sursa pentru extragerea datelor poate fi un document tipărit sau electronic. Pe vremuri, nu cu mult timp în urmă, puțini oameni știau despre OCR, într-o formă sau alta, iar procesul de conversie a textului în formă electronică s-a transformat într-o simplă rutină, până la retipărirea manuală a textului original. Astăzi, având un scaner plat (doar câțiva folosesc un scaner manual acasă) și cititor fin 12- fiți siguri că nu vor fi dificultăți în scanare și recunoaștere.
Începând cu a șasea versiune, FineReader acceptă importul și exportul în format PDF, patentat de Adobe. Mulți cititori au întâmpinat probabil dificultăți în a traduce din acest format în oricare altul (doc, etc.), deoarece nu există atât de multe programe cu adevărat utile în acest domeniu (singurul demn de atenție este produsul subsidiar al ABBYY, PDF Transformer). Cert este că astfel de programe efectuează recunoașterea textului o singură dată, drept urmare „identitatea” rezultatului nu este deloc semnificativă (în funcție de complexitatea documentului), plus formatarea documentului este aproape pierdută.
În cazul FineReader, totul este diferit. A noua versiune a programului introduce o tehnologie numită Document OCR. Se bazează pe principiul recunoașterii integrale a documentelor: este analizat și recunoscut ca un întreg, și nu pagină cu pagină. În același timp, tot felul de coloane, anteturi, fonturi, stiluri, note de subsol și imagini rămân neatinse sau sunt înlocuite cu cele apropiate de original.
Instalarea pachetului
Versiunea demo a Finereader 12 poate fi descărcată de pe site-ul Abbyy.ru, în secțiunea Descărcare, versiunea completă cu licență este distribuită pe un CD. Puteți afla despre metodele de cumpărare pe același site în secțiunea „Cumpărați”.
Pe site-ul web pentru dezvoltatori ABBYY puteți descărca o versiune demonstrativă a pachetului ABBYY FineReader versiunea 12 (sau alta actuală în prezent)
ABBYY FineReader este distribuit în mai multe versiuni: Professional Edition, Corporate Edition, Site License Edition etc. Diferența dintre versiunea Professional și celelalte este că este conceput pentru a funcționa într-o rețea corporativă cu posibilitatea de a colabora la recunoașterea documentelor. În caz contrar, diferența este nesemnificativă și depinde de alegerea termenilor din acordul de licență.
Este greu de imaginat că acum 12 ani exista FineReader 2.0, care ocupa aproximativ 10 MB de spațiu pe disc. De-a lungul timpului, pachetul a crescut de zece ori și acum, când este instalat, durează până la 300 MB. Este mult sau puțin - judecă singur. Noul FR acceptă 179 de limbi de recunoaștere, inclusiv limbaje artificiale puțin cunoscute (Ido, Interlingua, Occidental și Esperanto), limbaje de programare, formule etc. Să nu uităm de suportul pentru diverse formate și scripturi. Deci, dacă dintr-un motiv oarecare doriți să limitați spațiul pe care îl ocupă un pachet, în timpul instalării, selectați doar acele componente care vor fi necesare în timpul funcționării.
Alegerea componentelor afectează durata instalării, care, totuși, nu ar trebui să dureze mult. În timpul procesului de instalare, veți fi prezentate principalele caracteristici ale FR. După activare (prin Internet, prin e-mail, folosind codul primit etc.), programul este pregătit pentru funcționalitate completă. În modul demo, cu siguranță veți întâlni diverse restricții care, din păcate, nu vă permit să utilizați pe deplin pachetul.
Interfață FineReader. Funcționalitate
Accesul la capacitățile programului este disponibil atât prin intermediul scripturilor care vor apărea în meniul principal imediat după procesul de instalare, cât și, de fapt, prin interfața principală.
 Screensaver la pornirea FineReader
Screensaver la pornirea FineReader Aspectul programului nu suferă modificări semnificative de la o versiune la alta: dezvoltatorii nu văd rostul să-l schimbe radical. O atenție considerabilă este acordată ergonomiei, care este vizibilă în toate produsele ABBYY (Lingvo, PDF Transformer, FlexiCapture...). Cu alte cuvinte, interfața Fine Reader 12 este bine gândită și potrivită pentru toți utilizatorii, inclusiv pentru începători. Principiul „Obține rezultate cu un singur clic” va atrage cei care nu sunt obișnuiți să configureze și să schimbe ceva. Pe de altă parte, utilizatorii mai experimentați pot configura cu atenție FineReader prin dialogul de setări (Instrumente -> Opțiuni...). Singura avertizare: pentru lucrul confortabil în aplicație, este recomandabil să setați rezoluția ecranului la 1280×800, astfel încât toate instrumentele să fie întotdeauna, după cum se spune, la îndemână.
După lansarea programului Fine Reader, va apărea o fereastră cu butoane pentru acces rapid la funcțiile programului. Acest meniu este disponibil și prin meniul Tools -> ABBYY FineReader, butonul „Main Scripts” din colțul din dreapta al programului sau prin combinația de taste Ctrl+N (similar cu Word, unde această combinație deschide un nou document) .
Scanați către Microsoft Word:în cea de-a noua versiune de FineReader, a apărut suport pentru Microsoft Word 2007, care încă nu a devenit popular, la rândul său, pe bara de instrumente din aplicațiile Microsoft Office, în secțiunea de suplimente, după instalarea FR, apare o pictogramă roșie „de marcă”.
 Meniu pentru exportul unui document FineReader recunoscut
Meniu pentru exportul unui document FineReader recunoscut  Selectarea limbilor pentru scanare și recunoaștere a documentelor
Selectarea limbilor pentru scanare și recunoaștere a documentelor Pe lângă Microsoft Office, FR acceptă integrarea cu Microsoft Outlook și exportă rezultatele recunoașterii în Microsoft Word, Excel, Lotus Word Pro, Corel WordPerect și Adobe Acrobat. Aceste caracteristici fac lucrul cu programul oarecum mai ușor și mai rapid, mai ales dacă trebuie să lucrați cu el în mod regulat.
PDF sau imagini în Microsoft Word: recunoașteți datele dintr-un PDF sau alt tip de fișier grafic acceptat de Finereader versiunea 12. Trebuie remarcat faptul că tehnologia de extragere a textului dintr-un fișier PDF în FR nu este doar „desprinderea” conținutului textului (stratul de text în PDF poate fi absent) din cel grafic. De fapt, tehnologia de recunoaștere este destul de complicată: după analizarea conținutului documentului, programul decide ce și cum să facă cu textul: pur și simplu extrage sau recunoaște și așa mai departe pentru fiecare fragment de text.
Scanați în Microsoft Excel: Scanarea în XLS (format Microsoft Excel) poate fi justificată dacă imaginea scanată conține tabele.
Scanare în PDF: Există multe motive pentru a scana în PDF. Una dintre ele este securitatea: acesta este singurul format familiar FR în setările căruia puteți seta o blocare cu parolă. Parola este setată nu numai pentru deschiderea unui document, ci și pentru imprimarea acestuia și alte operațiuni. Este posibil să alegeți unul dintre cele trei niveluri de criptare: 40 de biți, 128 de biți pe baza standardului RC4, nivelul de 128 de biți pe baza standardului AES (Advanced Encryption Standard).
Convertiți fotografia în Microsoft Word: conversia unui fișier dintr-un format grafic (și poate fi PDF sau o imagine cu mai multe pagini) în DOC / DOCX.
Deschideți în Fine Reader: deschideți un fișier grafic (PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG) pentru recunoașterea FineReader.
Lucrează în FineReader
Acum - pe scurt despre caracteristicile programului. Întregul proces este împărțit în scanare, recunoaștere și salvare a rezultatelor. După ce ați ales tipul de acțiune a programului, ați specificat fișierul sau dispozitivul de scanat, FineReader își îndeplinește sarcina pas cu pas, ceea ce, apropo, necesită destul de mult resurse pentru procesorul central.
Dacă sunteți norocosul proprietar al unui procesor dual-core, atunci lucrând în pachetul Fine Reader 12 puteți aprecia puterea performanței computerului dvs. Cert este că FR, după ce a detectat un procesor dual-core, recunoaște nu una, ci două pagini ale unui document în paralel. E un lucru mic, dar e frumos.
Mai întâi vine scanarea, apoi recunoașterea și exportul unui document temporar în formatul selectat.
 Procesul de recunoaștere a documentelor PDF
Procesul de recunoaștere a documentelor PDF Scanare. Nu este nevoie să faceți setări preliminare în aplicația FineReader (cu excepția selectării unui dispozitiv de citire) înainte de scanare. De aceea au fost inventate scripturile: sunt concepute pentru a simplifica execuția unor acțiuni similare.
Recunoaştere. Simplificarea a afectat și alte lucruri mărunte. Deci, dacă ne amintim versiunile anterioare ale programului, înainte trebuia să schimbăm manual limba (limbi, dacă erau mai multe) documentului. Acum acest lucru se întâmplă automat, deși nu întotdeauna. În acest din urmă caz, FR sugerează în mod discret verificarea limbii documentului.
Revenind la tehnologia de recunoaștere FR: de ce programul scanează mai întâi întregul document ca întreg, și nu pagină cu pagină? După cum sa menționat deja, textul este recunoscut pe baza întregului conținut: sunt selectate fonturi de dimensiune/tip de caractere similare, tabele și chenare, indentări etc.
Nu fi surprins dacă FineReader 12 afișează un mesaj care spune că pagina nu poate fi recunoscută deoarece nu au fost găsite zone de text. De dragul experimentului, am fotografiat o zonă a unui document text folosind un telefon mobil de pe ecranul LCD (cu toate acestea, știam deja rezultatul în avans). Fine Reader 12 nu a recunoscut textul imaginii, deoarece era în mod clar de o calitate care în mod clar nu era suficientă pentru aceasta. La a doua vizită, am făcut o fotografie a unei pagini cu text în iluminare normală cu o cameră digitală.
FineReader a recunoscut pasajul fără probleme, păstrând formatarea și evidențiind cu markere unele momente îndoielnice sau caractere care pot avea ortografie variabilă.
După cum puteți vedea în imagine, acestea sunt în principal puncte, cratime, virgule - în general, caractere mici. În plus, este clar că programul a ținut cont de neuniformitatea și curbura paginii fotografiate și a aliniat liniile de text. Concluzie - FR a făcut o treabă excelentă cu sarcina sa, deși nu foarte dificilă.
Ocazional, unele probleme minore pot trece neobservate de programul Fine Reader, dar pot fi corectate cu ușurință manual. Din fericire, pachetul are propriul editor WYSIWYG, ale cărui capabilități sunt destul de suficiente pentru a face editarea finală a documentului. Verificarea ortografică este, de asemenea, disponibilă.
Cum putem îmbunătăți acuratețea recunoașterii, astfel încât să putem petrece mai puțin timp editand text? În primul rând, puteți conecta un dicționar Microsoft Word personalizat. Adevărat, este dificil să judeci creșterea preciziei, cu excepția, poate, a creșterii vocabularului corectorului ortografic (un modul care verifică ortografia și gramatica). Printre altele, pentru a îmbunătăți recunoașterea, este logic să vă familiarizați cu setările programului (Instrumente -> Opțiuni) și să selectați unul dintre cele două moduri:
recunoaștere atentă- poate fi selectat atunci când recunoașteți documente de orice „complexitate”: cu tabele fără linii de grilă, text, grafice, tabele pe un fundal colorat etc. Poate ajuta și cu sursa de recunoaștere de calitate scăzută
recunoaștere rapidă- acest mod este recomandat pentru prelucrarea unor volume mari de documente cu design simplu sau in cazurile in care timpul nu permite recunoasterea aprofundata. În cele mai multe cazuri, când aveți text tipărit în negru pe un fundal alb, vă puteți mulțumi cu recunoașterea rapidă.
În general, îmbunătățirea calității muncii FineReader este un subiect separat de conversație, ale cărui detalii le puteți afla din ajutorul oficial, și anume în secțiunea „Cum să îmbunătățiți rezultatele obținute”.
Salvarea documentului. Ultima etapă de lucru în programul Fine Reader 12 este salvarea rezultatului final într-un anumit format grafic/text. Setările de pre-salvare pot fi specificate în opțiunile FR: Instrumente -> Opțiuni, fila „Salvare”. Fiecare format are propriile setări. Când salvați în format DOCX, ar trebui să fiți atenți la compatibilitatea formatelor (fișierele DOCX nu sunt recunoscute în Word 2003<). В txt-файлах не забудьте проверить правильность кодировки (особенно в случае с текстом в кириллице).
Cititor de capturi de ecran ABBYY
În multe pachete mari, dezvoltatorilor le place adesea să adauge mici utilități de servicii. Să presupunem că binecunoscuta aplicație de inscripționare a discurilor Nero include un set de 3 - 5 utilitare care vă permit să faceți ceva ce chiar și Nero însuși nu poate face. Recenzie (o puteți descărca și aici ca parte a Fine Reader 12).
În ceea ce privește FineReader, acesta conține o aplicație mică, Screenshot Reader. Cu acesta, puteți face o captură de ecran și o puteți converti rapid în formatul dorit folosind FR. Programul este disponibil prin meniul Start (Start -> Toate programele -> ABBYY FineReader 12.0 -> ABBYY Screenshot Reader.).
Capacitățile Screenshot Reader sunt oarecum mai largi decât ar părea la prima vedere. (în caz contrar, ați putea face acest lucru apăsând pur și simplu tasta „PrintScreen” de pe tastatură). Pe lângă realizarea unei capturi de ecran a ecranului (sau mai precis, a unei zone selectate a ecranului), Screenshot Reader este strâns integrat cu FR.
Când faceți clic pe butonul „Instantaneu” din panoul Cititor de capturi de ecran, cursorul își schimbă forma și instrumentul de selectare a zonei ecranului este activat. Zona selectată a imaginii este încadrată pentru recunoașterea ulterioară a textului (se rulează automat).
În lista derulantă, puteți selecta acțiunea dorită: de fapt, Screenshot Reader duplică scripturile FR rapide cu diferența că în loc de o captură de ecran de la scaner, se primește o captură de ecran ca intrare.
Trebuie remarcat faptul că programul, împreună cu întregul pachet, necesită activare. La înregistrarea produsului, ABBYY FineReader 12 Professional Edition Screenshot Reader este oferit gratuit ca „bonus”.
Concluzie
FineReader este un program indispensabil pentru scanarea și recunoașterea datelor grafice. Interfața în limba rusă și accesibilitatea setărilor nu vor speria un utilizator neexperimentat. Suportul pentru cele mai recente formate, tehnologii inovatoare și, ca urmare, recunoașterea de înaltă calitate fac din program alegerea optimă, mai ales că ABBYY FineReader încă nu are concurenți în acest domeniu.
FineReader 12 taste rapide
- Creați un nou document ABBYY FineReader- CTRL +N
- Deschideți documentul ABBYY FineReader 12 - CTRL +SHIFT+N
- Salvați pagini- CTRL + S
- Salvați imaginea în fișier- CTRL + ALT + S
- Recunoașteți toate paginile unui document- CTRL + SHIFT + R
- Închideți pagina curentă- CTRL + F4
- Recunoașteți paginile selectate ale unui document ABBYY FineReader- CTRL + R
- Deschideți Managerul de scenarii- CTRL +T
- Deschideți caseta de dialog Fine Reader Options- CTRL + SHIFT + O
- Deschide ajutor- F1
- Accesați fereastra Documentului-ALT +1
- Accesați fereastra Imagine- ALT +2
- Accesați fereastra Text- ALT +3
- Accesați fereastra Prim-plan- ALT +4
Lucrarea de recunoaștere a imaginilor constă în următoarele etape:
- Primiți imagini scanate (scanări).
- Deschideți-le într-un program OCR (FineReader).
- Aranjați paginile în blocuri. Adică, împărțiți pagina în zone, fiecare dintre acestea va conține fie text, fie imagini, fie tabele, fie alt conținut omogen.
- De fapt, recunoaștere.
- Corectarea textului recunoscut, verificarea textului primit și a scanărilor originale.
- Salvarea rezultatelor obținute într-unul dintre formatele de document (DOC, RTF, PDF, HTML etc.).
La recunoașterea textelor, există două opțiuni: fie scanați singur materialul, fie lucrați cu textul deja scanat.
În primul caz, etapele „Obține imagini” și „Deschide imagini” sunt combinate într-una singură - FineReader deschide imediat scanările primite în pachetul său. În al doilea caz, etapa „Obțineți imagini” a fost deja finalizată; trebuie doar să le deschideți în program.
Să luăm în considerare ambele opțiuni pe rând.
Scanați text în FineReader
Scanarea este lansată prin „Fișier → Scanare pagini” sau butonul de meniu „Scanare” sau Ctrl-K.
Orez. 1 Interfață de scanare
Cu toate acestea, înainte de a începe scanarea, ar fi bine să vă dați seama cum să obțineți scanări care sunt cele mai optime pentru recunoaștere. Și pentru a face acest lucru, înțelegeți cum o scanare „bună” (din punctul de vedere al FineReader) diferă de una „nu foarte bună”.
Pentru o recunoaștere de înaltă calitate, programul necesită trei lucruri. În primul rând, capacitatea de a distinge în mod fiabil textul și ilustrațiile de fundalul paginii. În al doilea rând, literele, cifrele și alt conținut ar trebui să fie clare și lizibile, astfel încât să nu apară situații în care „ochiul uman nu va înțelege întotdeauna ce este tipărit exact”. În al treilea rând, liniile de text de pe scanare ar trebui să se desfășoare la fel de ușor precum sunt tipărite pe pagina cărții, fără distorsiuni sau distorsiuni. Există și alte cerințe pentru o scanare de înaltă calitate, dar acestea pot fi considerate cheie.
1. Pentru a face diferența între „textul aici și fundalul paginii aici”, tranziția dintre unul și celălalt trebuie să fie clară și să nu fie neclară. Iată exemple de pagini cu claritate slabă și bună. În primul caz, în mod natural va fi recunoscut mai rău, cu mai multe erori.

Orez. 2. Chenarele neclare ale literelor

Orez. 3. Limitele clare ale literelor
O cauză obișnuită a limitelor încețoșate ale textului și fundalului este scanarea nefocalizată, ceea ce se numește în mod obișnuit „nefocalizat”. Prin urmare, înainte de a începe lucrul, este recomandabil să vă verificați scanerul în acest moment.
Un alt motiv care poate interfera cu distincția dintre text și fundal este că fundalul paginii este prea „dens”. În mod normal, ar trebui să fie alb pur sau alb, cu un mic amestec de culoare. Dacă sunt scanate cărți din ediții vechi, unde hârtia este adesea îngălbenită, atunci fundalul poate fi și gălbui (dar moderat).
Dacă fundalul pare vizibil întunecat, atunci astfel de pagini vor fi din nou mai puțin recunoscute.
Aspectul fundalului depinde de setarea luminozității scanării. Poate fi ajustat prin glisorul „Luminozitate”. Pentru început, este logic să îl setați la 50%, să verificați ce se întâmplă și să îl corectați dacă este necesar.
2. Lizibilitatea caracterelor textului depinde în principal de luminozitate și rezoluție de scanare.
Dacă luminozitatea este prea mare, liniile literelor vor fi rupte, vor părea să se prăbușească în bucăți separate. Dacă luminozitatea este scăzută, atunci detaliile literelor încep să se îmbine unele cu altele, apar pete fără formă. Ambele nu sunt „hrană” foarte comestibilă pentru programele de recunoaștere.
Luminozitatea aici este reglată în același mod ca în cazul precedent - mai întâi o setăm la 50% în interfața de scanare și apoi în funcție de situație.

Orez. 4. Pagina cu prea multă luminozitate

Orez. 5. Pagina cu prea puțină luminozitate (fondul paginii este întunecat)

Orez. 6. Și aici este aceeași pagină, dar în formă normală
Rezoluția de scanare determină câți pixeli vor fi în scanare pentru fiecare literă. Dacă acești pixeli sunt suficienți pentru a desena conturul literei, atunci nu vor fi probleme de recunoaștere. Dacă nu este suficient, atunci literele pot deveni greu de distins chiar și pentru ochiul uman, ca să nu mai vorbim de programele de recunoaștere.

Orez. 8. Același lucru, dar pentru 200 de puncte

Orez. 9. Același lucru, dar pentru 400 de puncte
Atunci când alegeți o rezoluție, de obicei sunt respectate următoarele reguli:
- 300 de puncte sunt selectate pentru cărțile de ediții în masă (pagini pline cu text de dimensiune normală, aproape fără desene);
- Se selectează 400 de puncte pentru cărți și reviste cu o cantitate notabilă de text în dimensiuni mici (note, legende sub figuri, tabele, casete de text mici);
- Se selectează 600 de puncte pentru cărțile tipărite la dimensiuni foarte mici (multe cărți de referință și enciclopedii, cărți în miniatură). Sau cu desene fin detaliate, de exemplu, gravuri. Acestea includ și multe cărți publicate în anii 1990 - apoi edituri salvate pe hârtie și adesea tipărite cu litere foarte mici.
Interfața de scanare din FineReader vă permite să selectați doar 300 de puncte sau 600 (linia „Rezoluție”). Prin urmare, dacă aveți o mulțime de materiale pe care este de dorit să le faceți la 400 de puncte, atunci este mai bine să scanați nu din FineReader, ci din programul care vine cu scanerul.
Sau, în setările FineReader, comutați de la interfața proprie a programului la interfața TWAIN a scanerului dvs. („Instrumente → Setări → fila „Scanare/Deschidere” → faceți clic pe „Utilizați interfața scanerului” în partea de jos). Apoi veți putea scana din FineReader, dar veți lucra în interfața scanerului (de obicei există un volum mai mare de setări și funcții).
3. Liniile de text netede, cu aspect îngrijit sunt obținute în principal prin preprocesarea imaginii („pre-” în acest caz înseamnă „terminat după scanare, dar înainte de recunoaștere”). După preprocesarea corectă, conținutul paginii va fi recunoscut cu o calitate mai bună.
FineReader are un set destul de bogat de funcții pentru aceasta, care pot fi văzute în setările programului, în fila „Scanare/Deschidere”. Această fereastră poate fi accesată și prin butonul „Setări” din fereastra interfeței de scanare.

Orez. 10. Setări de preprocesare
„Împărțire carte” ar trebui să fie selectată atunci când cartea a fost scanată nu pagină cu pagină, ci pe pagini. Apoi, pentru recunoaștere, acestea vor fi tăiate pagină cu pagină.
„Detectează orientarea paginii” este utilizat dacă cartea a fost scanată întoarsă pe o parte. Apoi va fi rotit în poziția sa normală. Dar dacă cartea conține pagini care sunt tipărite rotite cu 90 de grade față de corpul principal, atunci este mai bine să debifați această casetă. În caz contrar, atunci când scoateți documentul recunoscut în PDF, este posibil să ajungeți cu unele pagini în orientare „portret”, iar altele în orientare „peisaj”. În acest caz, este mai bine să rotiți paginile necesare manual, în editorul de imagini încorporat
Corect Skew remediază paginile deformate. Setarea este cu siguranță necesară, dar trebuie să rețineți că PDF-ul „Text sub imaginea paginii” obținut din astfel de scanări nu va avea un aspect foarte îngrijit - pene cenușie de-a lungul marginilor paginii (unde s-a făcut întoarcerea).
„Correct Line Distorsions” îndreptează îndoirile liniei care se formează adesea în apropierea legăturii în timpul scanării (numite și „muștați”).

Orez. 11. Exemplu de pagină cu linii curbe
„Remove Keystone Distortion” corectează distorsiunile paginii care apar dacă cartea nu este apăsată foarte strâns pe geamul scanerului.
„Inversați imagini” este necesar dacă materialul pe care îl scanați conține o mulțime de text „litere deschise pe fundal întunecat” și doriți să îl convertiți în textul obișnuit „litere întunecate pe fundal deschis”.
„Eliminați elementele colorate” este utilă dacă pe o pagină care arată ca „litere negre pe fundal alb” trebuie să eliminați diverse lucruri inutile, cum ar fi urme de pix în margini, semnături și sigilii (documentație de birou) sau chiar doar pete. . Dar dacă pe aceeași pagină există unele „nevoi” făcute color - grafice, diagrame sau fotografii, atunci nu puteți bifa caseta. În caz contrar, vor fi și ele șterse.
„Rezoluția corectă a imaginii” este un element care necesită o explicație mai detaliată decât cele anterioare. Faptul este că procesul de recunoaștere în FineReader este foarte sensibil la rezoluția setată în proprietățile unei imagini date. Acest lucru determină în mod semnificativ cât de exact se va determina dimensiunea literelor de text, spația dintre litere și linii și așa mai departe. Prin urmare, o bifă este necesară aici. În plus, nu fi surprins dacă în timpul procesului de recunoaștere primești în mod constant mesaje FineReader „pe o pagină așa și așa rezoluția este setată incorect și ar fi bine să o corectezi.”
Pe lângă setările de preprocesare, pe fila „Scanare/Deschidere” există un bloc de setări „General”. Aici setați un set de acțiuni de bază care vor fi efectuate pe paginile deschise. Opțiunile pentru astfel de acțiuni pot fi următoarele:
- pur și simplu deschideți imaginile scanate fără a face nimic cu ele. Pentru a face acest lucru, debifați caseta de selectare „Procesează automat paginile adăugate”.
Acest lucru are sens doar dacă scanările dvs. sunt de o calitate atât de înaltă încât nu se poate face nimic pentru a le îmbunătăți. Îl puteți trimite imediat pentru recunoaștere. Desigur, acest lucru se întâmplă, dar mult mai rar decât ne-am dori :-), așa că este mai bine să lăsați caseta de selectare. - deschideți imaginile, efectuați preprocesarea, dar nu faceți nimic altceva până la comanda dvs. Pentru a face acest lucru, selectați elementul „Preprocesare imagine”.
Acest lucru se face de obicei dacă nu trebuie să începeți recunoașterea imediat, dar mai întâi vedeți ce s-a întâmplat ca urmare a preprocesării, cât de bine a funcționat pentru un anumit set de imagini. - deschideți imagini, efectuați preprocesare, marcați-le în blocuri, nu începeți încă recunoașterea. Pentru a face acest lucru, selectați elementul „Analiză imagini (inclusiv preprocesare)”.
Opțiunea cel mai frecvent selectată. Scanările dvs. sunt de o calitate destul de decentă, aveți o idee bună despre ce le va face preprocesarea, nu este nevoie să verificați după aceasta. Aceasta înseamnă că combinăm cele trei etape de lucru cu imaginile descrise mai sus într-una singură și începem să vedem cât de bine este făcută marcarea. - Toate etapele de recunoaștere au loc automat, fără niciun control intermediar. Obțineți imediat rezultatul final și începeți să-l corectați. Pentru a face acest lucru, selectați elementul „Recunoaștere imagini (inclusiv preprocesare)”. Este logic să faceți acest lucru numai dacă aveți scanări de bună calitate și cu un aspect foarte simplu - de exemplu, text solid într-o singură limbă și nimic mai mult. În toate celelalte cazuri, este mai bine să alegeți opțiunea 2 sau 3. Mai ales dacă aveți pagini cu formatare complexă, tabele, diagrame, imagini etc.

Orez. 12. Exemplu de pagină cu aspect complex

Orez. 13. Exemplu de pagină cu aspect complex
Deschideți imagini în FineReader
Aceasta este a doua opțiune de lucru cu imagini: nu le scanați singur, ci primiți-le într-o formă gata făcută și deschideți-le în FineReader. Acest lucru se face prin butonul „Deschide” din meniul ferestrei principale sau prin „Fișier → Deschide PDF sau imagine”, sau prin Ctrl-O.

Orez. 14. Fereastra „Deschide imaginea”.
În fereastra Explorer care se deschide, selectați imagini, setați setările necesare (butonul „Setări”) și faceți clic pe „Deschidere”. Setările folosite aici sunt aceleași cu cele descrise pentru scanare, trebuie să lucrați cu ele în același mod.
Când paginile sunt deschise în FineReader, pachetul implicit este creat fără nume („Document fără titlu”) și stocat în folderul TMP, numai în cadrul sesiunii curente. Pentru a nu pierde accidental rezultatele muncii dvs., este recomandat să salvați pachetul imediat după creare sub un nume permanent („Fișier → Salvare document FineReader”).
Aspectul paginilor în blocuri
După ce ați deschis scanările, trebuie să marcați paginile în blocuri. Acest lucru se face prin „Document → Analiza documentului” sau prin Ctrl-Shift-E.
Marcarea are două scopuri principale de lucru.
Mai întâi, separați ceea ce este text pe pagină de ceea ce nu este text. „Text” în acest caz este tot ceea ce FineReader este capabil să recunoască. În consecință, tot ceea ce nu este capabil să recunoască este considerat „non-text”. Aceasta este în principal partea ilustrativă a paginii - desene, desene, grafice, diagrame și altele asemenea. Formulele, notele scrise de mână și notele din acest punct de vedere sunt, de asemenea, considerate non-text - FineReader nu este încă capabil să le recunoască. Aceasta înseamnă că atunci când marcați, acestea trebuie marcate ca „imagine”.
În al doilea rând, ceea ce este text trebuie încă clasificat - doar text, tabele, note (note de subsol), anteturi și subsoluri, cuprins și altele asemenea. Pentru ca mai târziu, când veți citi ceea ce a fost recunoscut într-un editor de text, toate aceste elemente să arate exact așa cum sunteți obișnuit (ar fi formatate în consecință).
Pagina marcată ar putea arăta cam așa:

Orez. 15. Fereastra imagine cu aspectul paginii
Acum trebuie să vă uitați la marcajul făcut de program pe fiecare dintre pagini și, dacă este necesar, să îl corectați.
Erorile de marcare sunt de obicei de următoarele tipuri.
1. O parte din conținutul paginii (text, desen etc.) este selectată corect în ceea ce privește limitele zonei, dar i se atribuie conținut greșit. De exemplu, o bucată de text este marcată ca o imagine sau invers.
În acest caz, trebuie să faceți clic pe o astfel de zonă, să deschideți meniul contextual, să selectați „Schimbați tipul zonei” în el, să selectați tipul dorit în submeniul care se deschide („Text”, „Tabel”, „Imagine”, „ Imagine de fundal”, cod „Stroke””).

Orez. 16. Meniul contextual „Schimbați tipul zonei”
Puteți vedea rapid unde se află fiecare zonă după culoarea cadrelor. „Text” este evidențiat cu rame verde închis, „Tabel” – albastru, „Imagine” – roșu deschis, „Imagine de fundal” – roșu închis, „Cod de bare” – verde deschis.
2. Din punct de vedere al conținutului, zona este evidențiată corect, dar din punct de vedere al dimensiunilor (limitelor), nu este evidențiat tot ceea ce s-a cerut în acest caz. Sau invers - o piesă a venit dintr-o zonă învecinată cu conținut diferit.

Orez. 17. O pagină cu marcare incorectă
Legendele din jurul acestuia sunt atașate zonei de sus „imagine” (trebuie marcate ca „text”).
În timpul marcajului, o parte a imaginii nu a fost inclusă în zona inferioară „imagine”.
Pentru a remedia acest lucru, trebuie mai întâi să faceți clic pe butonul „Săgeată” din fereastra „Imagine”.
Apoi faceți clic pe fiecare zonă marcată incorect și mutați-i marginile. Aproximativ în același mod în care mutați de obicei marginile ferestrelor deschise ale programului.
3. O parte din conținutul paginii a fost omisă complet de markup și nu a intrat în niciuna dintre zonele create.

Orez. 18. Formula a căzut din marcaj (nu a căzut în niciunul dintre blocuri)
Aici va trebui să creați o zonă nouă pe pagină (evidențiați partea lipsă a paginii cu un cadru), apoi să atribuiți tipul dorit zonei create.
Pentru a face acest lucru, trebuie mai întâi să faceți clic pe pictograma „Selectați zona de recunoaștere” din fereastra „Imagine”.
După aceasta, trageți un cadru în jurul zonei dorite (ca de obicei într-un editor grafic, selectați o parte a imaginii) și, în final, setați tipul zonei. Ultima operațiune este deja descrisă în paragraful 1.
Dacă aveți nevoie doar de partea de text a paginii ca text solid (ceea ce este cel mai adesea cazul), atunci acest lucru este suficient. Dacă doriți ca diferitele elemente de design ale paginilor recunoscute (note, anteturi și subsoluri) să arate exact ca notele și anteturile din Word, atunci trebuie să verificați și acest punct.
Este reglat prin meniul contextual. Faceți clic pe zona „Text” dorită de pe pagina pe care o verificați, selectați elementul „Atribuire text” din meniul contextual și, în submeniul acestuia, uitați-vă la ce element este bifat (de obicei „Detecție automată”). Dacă nu este în locul potrivit, treceți la elementul dorit.

Orez. 19. Meniul contextual „Atribuire text”
Recunoaştere
După ce erorile de marcare sunt corectate, recunoașterea poate fi începută. Acest lucru se face prin „Document → Recunoaștere document” sau prin Ctrl-Shift-R. Înainte de a face acest lucru, nu uitați să setați limba de recunoaștere și să setați setările necesare.
Limba este setată prin fereastra „Limba documentului” din bara de butoane din fereastra principală a programului.

Orez. 20. Selectarea unei limbi prin meniul principal
Sau în setări („Instrumente → Setări → fila „Document”).

Orez. 21. Selectarea unei limbi prin setările FineReader
Dacă lista care se deschide nu conține limba de care aveți nevoie, atunci faceți clic pe „Selectare limbi” în partea de jos a listei și în fereastra care se deschide, bifați caseta de lângă limba (setul de limbi) de care aveți nevoie. După aceea, va fi adăugat în listă.
În setările de recunoaștere („Instrumente → Setări → fila „Recunoaștere””), este mai bine să lăsați modul de recunoaștere la valoarea sa implicită („Recunoaștere atentă”). „Recunoașterea rapidă” are sens numai dacă aveți ceva simplu ca aspect și cu o calitate foarte bună de scanare. De exemplu, o imprimare alb-negru scanată a unui document text fără ilustrații.

Orez. 22. Setări, fila „Recunoaștere”.
Dintre celelalte setări, grupul „Definiția elementelor structurale” este de importanță primordială. Iată detaliile designului paginii: note de subsol (note), anteturi, liste, cuprins. Când un element este bifat, acesta va fi recunoscut și salvat în DOC/RTF/DOCX nu doar ca parte a textului de pe pagină, ci ca notă de subsol, subsol, listă sau cuprins.
Doar nu uitați un punct important. Dacă trebuie să recunoașteți zone cu conținut similar, atunci o bifă în setările filei „Recunoaștere” poate să nu fie suficientă. În plus, în etapa de marcare este, de asemenea, necesar să marcați corect aceste zone cu marcatorul „Atribuire text” din meniul contextual.
Corectare
Corectarea textului recunoscut în FineReader se poate face în două moduri. Fie folosind funcția „Verificare”, fie în mod obișnuit, vizualizarea paginilor în editorul FineReader încorporat. Prin fereastra „Prim-plan” o verificăm cu scanarea acolo unde există erori, o corectăm.
Funcția „Verificare” este lansată de butonul din colțul din dreapta sus al meniului sau prin Ctrl-F7. Activitatea sa se bazează pe faptul că în timpul recunoașterii, FineReader marchează caracterele și cuvintele care au fost recunoscute cu un nivel de încredere insuficient. Adică, programul are unele îndoieli cu privire la ele: „poate că acesta este într-adevăr simbolul care ți-a fost prezentat, dar ar putea fi și altceva.” În timpul scanării, astfel de locuri dubioase sunt afișate utilizatorului unul câte unul pentru ca acesta să le poată corecta dacă este necesar.
Fereastra de verificare este destul de simplă. În partea de sus, este afișat un fragment al paginii care conține simbolul care se verifică. În partea de jos, este afișată o linie de text recunoscut cu acest simbol și există și câteva butoane pentru editare simplă.

Orez. 23. Fereastra „Verificare”.
Dacă totul este în ordine, simbolul este definit corect, apoi faceți clic pe „Skip”. Dacă este definit incorect, atunci introduceți valoarea corectă fie folosind tastatura, fie dacă aceasta nu este pe tastatură, apoi folosind butonul „Inserați simbol” (litera greacă „omega”). Apoi faceți clic pe „Confirmare”.
Acționăm în mod similar dacă un caracter este recunoscut corect, dar formatarea lui este incorectă. De exemplu, în textul unei cărți există italice pe alocuri, dar a fost recunoscut ca un font obișnuit. Pentru a reformata, utilizați butoanele din partea de jos a ferestrei.
Dar capacitățile ferestrei de verificare sunt încă destul de limitate. Atât prin dimensiunea unei părți a paginii care poate fi afișată în partea de sus a ferestrei, cât și prin capacitățile de editare disponibile aici. Prin urmare, toate mișcările prin text, de la un punct de verificare la altul, sunt urmărite și în ferestrele „Text” și „Prim plan”. Tot timpul, în timp ce lucrul este în desfășurare, cursoarele din „Text” și „Prim-plan” se deplasează sincron cu poziția lor în „Verificare”.
Dacă în fragmentul paginii pe care îl verificați (în scanarea acesteia) trebuie brusc să vedeți mai mult de câteva cuvinte afișate în „Verificare”, atunci puteți face acest lucru în „Prim-plan”. Dacă editarea erorii curente necesită capabilitățile editorului din „Text”, atunci puteți trece temporar la ea (pur și simplu făcând clic pe fereastra acesteia), faceți lucrările necesare și reveniți la „Verificare” (făcând clic pe fereastra sa) . După revenirea la „Verificare”, toate modificările pe care le-ați făcut în „Text” vor fi afișate acolo.

Orez. 24. Un exemplu de lucru în ferestrele deschise simultan „Verificare”, „Text” și „Primar”
Dacă fereastra „Verifică” cu capabilitățile sale limitate nu este foarte convenabilă pentru tine (ești obișnuit să lucrezi cu toate facilitățile editorilor de text și nu îți vei schimba obiceiurile), atunci poți face această lucrare în „Text” fereastra de la bun început.
Locurile care necesită verificare sunt afișate acolo în întregime - acestea sunt simboluri și cuvinte evidențiate cu albastru deschis. Posibilitatea de a trece de la o eroare la alta fără a vizualiza întreaga pagină este, de asemenea, disponibilă - butoanele „Eroare următoare” și „Eroare anterioară” din bara de butoane din partea stângă a ferestrei.
Teoretic, conform creatorilor FineReader, fereastra „Verificare” ar trebui să fie suficientă pentru corectarea completă a textului recunoscut. Toate locurile dubioase sunt marcate, ne deplasăm de-a lungul lor, corectăm erorile, iar la final obținem un text complet curățat.
Dar, așa cum se întâmplă adesea, teoria de aici se abate de la practica de zi cu zi. În textele recunoscute, există locuri sistematic eronate care nu sunt marcate ca erori. Adică, FineReader recunoaște incorect un simbol/cuvânt, dar în același timp cu deplină încredere că l-a recunoscut corect.
Prin urmare, pentru o corectare completă, fereastra „Verificare” nu este de obicei suficientă - mai ales dacă textul conține o mulțime de termeni științifici sau tehnici, jargon profesional și alte „non-vocabulare” similare. Încă trebuie să parcurgeți ceea ce a fost recunoscut manual - priviți-l cu atenție în fereastra „Text” și verificați toate locurile mai mult sau mai puțin dubioase.
Textul de corectare din fereastra „Text” nu este mult diferit de munca obișnuită de corectare. Configurați ferestrele „Text” și „Primar” astfel încât să ocupe cea mai mare parte a ferestrei de lucru a programului, mergeți la următoarea pagină pe care o verificați și vizualizați textul acestuia. Dacă găsiți un loc dubios sau clar eronat, faceți clic pe el - în acest caz, cursorul din „Prim plan” este plasat exact în același loc în original (scanare). Comparați originalul și cel recunoscut, editați dacă este necesar și continuați.

Orez. 25. Corectarea utilizând ferestrele „Text” și „Prim-plan”.
Funcționalitatea editorului de ferestre de text nu este diferită de funcționalitatea oricărui editor de text moderat complex. Aspectul butoanelor din meniu este destul de standard, nu ar trebui să existe probleme atunci când lucrați cu ele. Dacă trebuie să corectați un caracter care lipsește de pe tastatură, atunci, ca în fereastra „Verificare”, trebuie să faceți clic pe butonul cu „omega” grecesc și să selectați pe cel necesar din tabelul care se deschide.
Salvarea rezultatelor
Când materialul scanat este recunoscut și corectat, acesta trebuie salvat într-unul dintre formatele de document - DOC, DOCX, RTF, PDF, HTML etc. Acest lucru se face prin „Fișier → Salvare document ca → selectați formatul dorit” sau prin butonul „Salvare” din meniul principal FineReader.
În fereastra Explorer care se deschide, selectați formatul, utilizați butonul „Setări” pentru a seta parametrii de salvare și faceți clic pe „OK”. Dacă doriți să vedeți imediat dacă există erori vizibile în aspectul textului salvat, atunci, în plus, bifați caseta de selectare „Deschidere document după salvare”. Apoi va fi deschis imediat în editor (browser, vizualizator).

Orez. 26. Fereastra pentru salvarea textului recunoscut
Practica obișnuită de recunoaștere este aceea că textul scanat al unei cărți sau reviste este primit ca intrare, iar la ieșire toate paginile sale sunt salvate într-un fișier cu numele acestei cărți. Aceasta este setarea implicită „Creați un fișier pentru toate paginile” în linia „Opțiuni fișiere”. Dacă nu recunoașteți niciun text solid, ci doar o împrăștiere de pagini (de exemplu, documentația de birou), atunci aici va trebui să setați „Salvați un fișier separat pentru fiecare pagină”.
Setări pentru salvarea în formate DOC, DOCX, RTF

Orez. 27. Setări pentru salvare în DOC/DOCX/RTF
Cheia și principalul lucru de ales aici este gradul de acuratețe cu care va fi afișat aspectul originalului în documentul salvat (unul dintre modurile de salvare din fereastra „Proiectare document”). Toate celelalte setări nu sunt altceva decât clarificări și detalii ale acestui articol.
Există patru opțiuni din care puteți alege: Copiere pe hârtie, Copie editabilă, Text îmbogățit și Text simplu.
1. „Copie exactă”.
Potrivit dezvoltatorilor, ar fi trebuit să existe o imagine aproape în oglindă a paginii recunoscute. De aceea se numește așa. Cu reproducerea exactă a fonturilor, dimensiunilor literelor (puncte), distanțelor dintre litere în cuvinte, distanțelor dintre cuvinte, linii și paragrafe și alte detalii de aspect. Ideea, în general, nu este rea, dar FineReader nu are de obicei capacitatea de a o implementa în măsura dorită.
Fonturile și stilurile lor (Normal, Italic, Bold) sunt adesea reproduse conform principiului „cum iese, așa merge”. Poate fi transmis cu precizie. Se poate întâmpla ca fontul folosit pe pagina recunoscută să fie înlocuit cu un alt font (similar ca aspect, dar diferit). Se poate întâmpla ca stilul Normal să fie recunoscut ca Bold sau invers. Și așa mai departe și așa mai departe.
Când vine vorba de reproducerea dimensiunilor punctelor, spațierea și alte formatări, situația nu este cu mult mai bună - de obicei este posibil să reproduci mai mult sau mai puțin corect aspectul (aspectul) unei pagini recunoscute doar în cazurile de ceva nu foarte complex.
Rezultatul este ceva care nu este foarte clar - un document Word care poate fi doar citit (și copia text de acolo). Editarea acestuia dincolo de „eliminați câteva litere, introduceți câteva litere” este nerealistă. Dar editarea este încă necesară - la urma urmei, va continua cu un fel de lucru, ceea ce înseamnă că va fi necesar să refaceți formatarea pentru a se potrivi nevoilor utilizării viitoare.
Pe de o parte, tot textul de aici este împrăștiat în numeroase cadre, ceea ce face lucrul cu acesta destul de dificil. Pe de altă parte, în timpul recunoașterii, programul generează o grămadă de stiluri Word - toată formatarea textului se face exclusiv prin stiluri. Este destul de comun ca textul unei cărți de dimensiuni medii (300-400 de pagini) să genereze câteva sute de stiluri diferite. Ceea ce face editarea și mai dificilă.
Rezumat - alegerea acestui mod de salvare nu are prea mult sens lucrul cu textul salvat aici este destul de incomod.
Dacă aveți nevoie de o reproducere completă a aspectului originalului, atunci este mai ușor și mai practic să faceți acest lucru sub formă de PDF „Text sub imaginea paginii” sau PDF „Numai text și imagini” (mai multe despre aceste metode de ieșire). de mai jos).
2. „Copie editabilă”.
În esență, aceasta este o versiune mai ușoară a „Copie exactă”. Aspectul originalului nu este reprodus cu același grad de meticulozitate ca în cazul precedent sunt vizibil mai puține cadre cu text (deși sunt ocazionale); Cu toate acestea, chiar dacă această opțiune este numită „editabilă”, lucrul cu ea nu este, de asemenea, foarte convenabil.
Dacă aveți nevoie de un document Word așa cum este, doar pentru a-i vedea conținutul și a copia fragmentul de text dorit, atunci puteți utiliza această opțiune. Dacă trebuie să refaceți multe, să reformați și așa mai departe, atunci este mai bine să alegeți altceva.
Motivul este același - există prea multă agitație pentru a converti textul din forma pe care o va produce „Copie editată” în forma de care ați putea avea nevoie. Mai există ceva text în cadre și există încă tendința în formatare de a reproduce cu acuratețe aspectul (aspectul) originalului. Și obiceiul de a genera o grămadă de stiluri nu a dispărut.
Rezumat - lucrul cu textul de aici nu este la fel de supărător ca în „Copie exactă”, dar încă lasă mult de dorit.
3. „Text bogat”.
Gradul de corespondență cu originalul este minimizat aici - reproducerea fonturilor și a dimensiunilor, locația aproximativă a materialului pe paginile originale, aspectul general al textului și al tabelelor.
Lucrul cu această opțiune este vizibil mai ușor decât cu cele anterioare, dar este încă dificil din cauza numărului mare de stiluri. Cu toate acestea, acest lucru poate fi tratat destul de simplu - puteți parcurge rapid textul și îi puteți aplica propriul set de stiluri.
4. „Text simplu”.
Deși se numește „Text simplu”, aici puteți salva atât textul în sine, cât și textul cu imagini. Formatarea în această versiune este redusă la minimum - paragrafe Word obișnuite de la o margine la alta a paginii, plus imagini introduse între ele. Nu este generată nici o grămadă obișnuită de stiluri din opțiunile anterioare.
Dar dacă doriți, chiar și aici puteți lăsa defalcarea originală în rânduri și pagini. În plus, salvați stilurile de font - obișnuit, cursiv, aldine.
De obicei, fie „Text îmbogățit”, fie „Text simplu” este selectat pentru salvare, în funcție de ceea ce veți face în continuare și de cum să utilizați ceea ce este recunoscut.
Acum despre setările rămase ale acestei ferestre.
- „Dimensiunea implicită a hârtiei”.
Aici setați setarea „Opțiuni pagină → Dimensiune hârtie” din Word, adică dimensiunea hârtiei pe care veți imprima. Setat de obicei la A4. Dar trebuie să ținem cont de faptul că în modurile „Copie exactă” și „Copie editabilă”, nu numai conținutul paginii recunoscute este salvat unul la unul, ci și dimensiunea sa originală. Ca rezultat, dacă puneți aici o dimensiune de hârtie mai mare decât dimensiunea paginii, atunci când imprimați vor exista margini goale în jurul textului. Dacă utilizați un format mai mic, atunci o parte din materialul paginii se poate pierde (va ajunge în afara limitelor foii de hârtie). - „Păstrează întreruperile și diviziunile.”
Dacă caseta de selectare este bifată, defalcarea liniei care este în original va fi salvată. Întreruperile de linie în acest caz sunt făcute moi. Dacă nu bifați casetele, atunci textul va merge în paragrafe obișnuite de Word, cu linii de la o margine la cealaltă a paginii. - „Păstrează paginarea”.
Dacă caseta de selectare este bifată, paginarea care este în original va fi salvată. Dacă nu bifați casetele, Word însuși va împărți textul în pagini. - „Păstrează anteturile și subsolurile și numerele paginilor.”
Dacă caseta de selectare este bifată, atunci textul, marcat și recunoscut ca antete și numere de pagină, va fi salvat și plasat în câmpurile Word corespunzătoare. Dacă nu bifați caseta, atunci această parte a textului nu este afișată deloc. - „Păstrează numerele de rând”.
Dacă caseta de selectare este bifată, atunci în listele cu linii numerotate se va păstra numerotarea acestor linii. - „Păstrează culoarea fundalului și a literelor.”
Dacă caseta de selectare este bifată, atunci textul imprimat color (sau pe un fundal color) va fi afișat ca în original. Dacă nu bifați caseta, atunci tot textul va fi afișat în mod obișnuit - negru pe fundal alb (sau alb pe fundal negru). - „Păstrați caracterele aldine, cursive și subliniat în text simplu.”
Ieșirea în „Text simplu” poate fi realizată conform principiului „toate cu același stil, Normal”, sau poate fi realizată păstrând stilul care a fost în original. Aici este reglementat acest moment. - „Evidențiați personaje recunoscute nesigur.”
Această casetă de selectare ar trebui să fie bifată dacă preferați să corectați textul recunoscut nu în FineReader, ci într-un editor de text. Apoi toate marcajele caracterelor și cuvintelor pe care le aveați în fereastra „Text” vor fi reproduse în documentul salvat. - „Salvați imaginile”.
Se stabilește dacă, pe lângă text, vor fi salvate și imagini. - "Calitatea imaginii."
Aici se determină gradul de compresie al imaginilor din original. Poate fi reglat în trei direcții - prin diverși algoritmi de compresie, prin rezoluția imaginii salvate și prin adâncimea culorii din aceasta. Detaliile pot fi vizualizate dacă selectați opțiunea „Personalizat” în linia „Calitate imagine”. Este cel mai practic să îl utilizați, și nu presetările „Dimensiune mică (150 dpi)” și „Calitate înaltă (rezoluție imagine sursă)”.
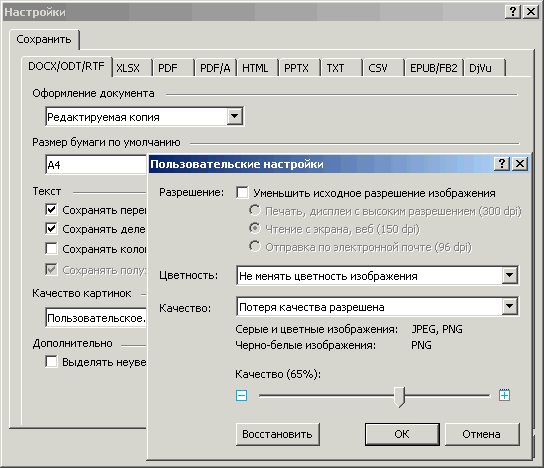
Orez. 28. Fereastra de setări pentru calitatea imaginii
Deoarece atunci când reduceți rezoluția originală și compresia ulterioară, sunt posibile distorsiuni slab previzibile, este mai bine să debifați caseta de selectare „Reducere rezoluția imaginii originale”.
Setați adâncimea culorii în funcție de situație. Dacă aveți nevoie de imagini așa cum sunt, selectați „Nu schimbați culoarea imaginii”. Dacă doar o vizualizare generală este suficientă, reproducerea corectă a culorilor nu este necesară, apoi selectați „Convertiți imaginile color în gri”. Este mai bine să nu alegeți să convertiți imaginile color și gri în alb-negru, deoarece binarizarea poate produce o mulțime de distorsiuni (și puțin previzibile). De asemenea, este mai bine să nu selectați opțiunea „Automat” - nu este foarte clar ce logică există și ce veți obține ca rezultat.
Setări pentru salvarea în formatele PDF și PDF/A

Orez. 29. Setări de salvare PDF
Există, de asemenea, patru moduri de salvare: „Numai text și imagini”, „Text peste imaginea paginii”, „Text sub imaginea paginii”, „Numai imagine”.
- „Numai text și imagini.”
Aici veți primi de fapt o versiune PDF a ceea ce este produs în „Copie exactă” - text recunoscut și ilustrații din fereastra „Text” într-o formă cât mai apropiată de original. Calitatea reproducerii originale aici este mai mare decât în DOC/DOCX/RTF, deoarece formatul PDF are mult mai multe posibilități pentru aceasta. - „Text peste imaginea paginii”.
Acesta este un PDF format din două straturi - imaginea originală (stratul de jos), pe care este suprapus textul recunoscut (stratul superior). Această opțiune este destul de convenabilă dacă PDF-ul va fi editat ulterior - „Text sub imaginea paginii.”
Acesta este un PDF format din aceleași două straturi - imaginea originală și textul recunoscut. Doar ele merg în ordine inversă - imaginea este stratul superior, textul este stratul inferior (invizibil). Această metodă de ieșire este numită și „PDF cu suport de text” și este utilizată atunci când trebuie să obțineți, pe de o parte, o copie exactă a aspectului originalului și, pe de altă parte, posibilitatea de a copia textul acestuia. original. - „Numai imagine”.
Acesta este un PDF compilat din imaginile originale. Nu există nimic altceva acolo decât imaginile în sine.
Acum despre setările rămase ale acestei ferestre.
1. „Dimensiunea implicită a hârtiei”.
În ieșirea PDF, semnificația acestei setări este aceeași ca în cazul precedent - formatul foii pe care va fi tipărită pagina.
În cazul precedent, am vorbit despre regula „dacă pagina este mai mică decât formatul specificat, atunci vor exista câmpuri goale în jurul textului, dacă este mai mare, o parte din text va fi tăiată”. În PDF se respectă și mai strict, deoarece aici pagina sursă în orice versiune este reprodusă una la una. Prin urmare, este cel mai logic să setați „Utilizați dimensiunea originală” aici.
2. „Păstrează fundalul și culorile literelor.”
3. „Salvați anteturile și subsolurile.”
Semnificația acestor două setări este aceeași ca în cazul precedent.
4. „Creați un cuprins.”
Dacă caseta de selectare „Detecția elementelor structurale → Cuprins” a fost bifată în setările de recunoaștere, atunci cuprinsul cărții recunoscut în acest mod poate fi folosit pentru a crea automat un cuprins într-un fișier PDF.
5. „Permite etichete PDF”.
În PDF, etichetele sunt un analog funcțional al stilurilor Word, o modalitate de a marca structural conținutul unui fișier PDF. Cu ajutorul lor, sunt salvate informații despre împărțirea textului în capitole, titluri, cuprins, ilustrații, tabele, note, hyperlinkuri, formule matematice și altele asemenea.
Dacă deseori trebuie să copiați fragmente de text din PDF, atunci ar trebui să bifați această casetă. Textul copiat va fi apoi mult mai consistent cu modul în care apare pe pagina PDF.
Etichetele sunt utile și dacă PDF-ul trebuie vizualizat pe ecrane de diferite dimensiuni - de la desktopuri la smartphone-uri. În astfel de cazuri, cititorii PDF trebuie să reformateze conținutul paginilor pentru a se potrivi cu dimensiunea actuală a ecranului, iar cu marcajul etichetat acest lucru se întâmplă mult mai precis, fără distorsiuni vizibile ale aspectului original.
6. „Utilizați conținut raster mixt (MRC).”
MRC (Mixed Raster Content) este numele unei tehnologii de compresie capabilă să producă rapoarte de compresie vizibil mai mari decât binecunoscutele JPEG și JPEG 2000. Mulți sunt familiarizați cu acesta din formatul DjVu - este construit special pe baza MRC. Alegerea „ar trebui să bifez această casetă sau nu” este ambiguă aici și este determinată în funcție de situația dvs.
Principalul avantaj este dimensiunea PDF-ului rezultat. Poate fi de câteva ori mai mic decât un PDF obținut cu aceleași setări de compresie, dar fără MRC.
Care ar putea fi dezavantajele:
Compresia MRC este proiectată în așa fel încât în timpul funcționării să producă întotdeauna o cantitate slab previzibilă de distorsiune. Datorită faptului că distorsiunea aici depinde doar parțial de setările de compresie și, în mare măsură, de conținutul paginii. Text, desene, grafice, fotografii - cu compresia MRC, toate se comportă semnificativ diferit și produc cantități diferite de distorsiune.
Există un consum de resurse considerabil mai mare la comprimarea și vizualizarea unor astfel de PDF-uri. Chiar și pe computerele de astăzi, MRC-PDF poate fi deschis și derulat nu în maniera obișnuită, ci în salturi, atunci când pagina următoare este afișată pe ecran nu în totalitate odată, ci în părți.
7. „Salvați imaginile”.
8. „Calitatea imaginii”.
Semnificația acestor setări este aceeași ca în cazul precedent - dacă este sau nu necesară salvarea imaginilor la crearea unui PDF și la ce nivel de compresie să le salvezi. Recomandările sunt, de asemenea, similare - debifați „Reduceți rezoluția originală”, este mai bine să nu schimbați culoarea, setați motorul „Calitate” în același mod ca și compresia în JPEG 2000.
9. „Fonturi”.
Dacă selectați „Utilizați fonturi Windows”, atunci pentru recunoaștere și ieșire ulterioară va fi folosit setul de fonturi care este instalat pe computer. Dacă selectați „Utilizați fonturi predefinite”, atunci numai setul de fonturi care este instalat la instalarea FineReader.
Este de preferat să selectați prima opțiune, deoarece aceasta va folosi o varietate mult mai mare de fonturi și va fi mai ușor pentru program să se potrivească cu fonturile cărților recunoscute.
10. „Încorporați fonturi”.
Dacă doriți ca atunci când vizualizați un fișier PDF pe alt computer, acesta va fi vizibil exact așa cum l-ați primit (în aceste fonturi), atunci trebuie să bifați această casetă.
11. „Opțiuni de securitate PDF”.
Aici puteți seta protecția cu parolă pentru vizualizarea PDF, imprimarea, copierea textului și a imaginilor din acesta și editare.
Dacă aveți întrebări despre funcționarea FineReader la care nu ați găsit răspunsuri în textul articolului, le puteți adresa dezvoltatorilor programului.
De data aceasta, vă voi spune cum să transformați documentele de hârtie în format PDF electronic, precum și cum să transferați un document pe hârtie pe un computer pentru a modifica textul. Deci, să începem.
Am un document pe hârtie în mâini.
SCANĂ în PDF
Sarcină: transferați acest document pe computer (traduceți în formă electronică). Mai mult, trebuie făcută exact în această formă, astfel încât să nu poată fi schimbată în viitor (în linii mari, trebuie să faceți o fotografie a documentului). Apoi, acest document electronic trebuie trimis prin poștă la o adresă de e-mail. Mai mult, clientul o solicita in format pdf.
Pe etape:
1) Trec documentul prin scanner
2) Salvez imprimarea rezultată în format pdf pe computer
3) Trimit fisierul primit prin posta
În munca mea, folosesc 2 programe pentru a rezolva această problemă:
Foxit Phantom sau ABBYY FineReader. Pentru claritate, atașez capturi de ecran:
În Foxit Phantom, când scanerul este pornit, trebuie să selectați FILE-CREATE PDF FROM SCANNER în meniul principal...
Scanarea va avea loc și vi se va solicita să salvați fișierul. Selectați o locație, scrieți numele fișierului și salvați.

ABBYY FineReader are butoane uriașe în bara de instrumente. Una dintre ele se numește SCAN to PDF. Îl folosim.

Dacă trebuie să scanați un document cu mai multe pagini, atunci, în etape:
1) Apăsați butonul numărul 1 SCANARE

Primim un document scanat

Scanăm și o altă pagină (apăsăm din nou butonul numărul 1 SCANARE).
2) Salvați ca PDF


Ca rezultat, obținem un document finit cu mai multe pagini sub forma unui fișier PDF.

Acum acest fișier poate fi trimis prin e-mail.
RECUNOAȘTEREA TEXTULUI
Sarcină: convertiți un document de hârtie în formă electronică (în computer)
Pe etape:
1) Scanare (butonul 1 SCANARE)

2) Recunoaștere (butonul 2 RECOGNIZE ALL)

Recunoașterea ar trebui înțeleasă ca procesul de traducere a unei fotografii (imagine) în text (litere, cifre, semne). Dacă ați fotografiat o pagină de text, atunci după ce recunoașteți 99% din text de pe hârtie, acesta se va transforma în text electronic. Textul electronic poate fi deja modificat (editat) pe un computer așa cum doriți.
3) Salvare într-un editor de text (butonul 4 Salvare)
Vă sfătuiesc să selectați TRANSFER TOATE PAGINILE ÎN MICROSOFT WORD

Primim

Aș dori să subliniez puncte importante în timpul procedurii de RECUNOAȘTERE. Există nuanțe atunci când lucrezi.
Imediat după recunoaștere, vă sfătuiesc să vă uitați la rezultat. Mai ales pe blocurile pe care le creează programul FineReader.

Acestea sunt zone evidențiate în cadre dreptunghiulare. Aceste rame sunt de diferite culori. Dacă este roșu, atunci acest bloc este recunoscut ca IMAGINE. Dacă este negru, atunci TEXT. Blocurile vin în diferite tipuri. Tipul de bloc poate fi găsit făcând clic pe bloc cu butonul DREAPTA al mouse-ului și selectând MODIFICARE TIP BLOC.

Un mic truc: puteți selecta o zonă arbitrară și o etichetați cu orice tip de bloc. De exemplu, să selectăm acea parte a textului care este prost recunoscută folosind butonul stâng al mouse-ului (clic, țineți apăsat și trageți, cadrul își schimbă dimensiunea).



Drept urmare, documentul din Word va avea un bloc de text și un bloc de imagini. Imaginea blocului va avea un aspect absolut neschimbat. Folosesc această metodă când salvez timbre, fonturi non-standard, imagini și fotografii.
PS: Cunoștințele și capacitatea de a lucra cu PDF, de a scana și de a recunoaște documente ajută foarte des în munca de birou. Cunoașterea vă economisește timp!
Una dintre cele mai populare funcționalități pentru lucrul cu scanarea și procesarea fișierelor de diferite tipuri este Fine Reader. Funcționalitatea produsului software a fost dezvoltată de compania rusă ABBYY, care permite nu numai recunoașterea, ci și procesarea documentelor (traducerea, modificarea formatelor etc.); Mulți utilizatori îl pot instala doar, dar nu își pot da seama imediat cum să folosească ABBYY FineReader. Puteți găsi răspunsuri la multe întrebări în acest articol.
Programul vă permite să scanați și să recunoașteți text - și multe altele
Pentru a înțelege în detaliu ce fel de program este ABBYY FineReader 12, trebuie să luați în considerare în detaliu toate capacitățile sale. Prima și cea mai simplă funcție este scanarea unui document. Există două opțiuni de scanare: cu și fără recunoaștere. În cazul unei scanări regulate a unei foi tipărite, veți primi imaginea pe care ați scanat-o în folderul specificat de pe dispozitivul dvs. de calcul.
ATENŢIE. Foaia trebuie plasată uniform pe partea de scanare a imprimantei, de-a lungul contururilor indicate pe imprimantă. Nu permiteți fișierului sursă să devină strâmb, deoarece acest lucru poate duce la o calitate slabă a scanării finale.

Trebuie să decideți singur de ce aveți nevoie de FineReader, deoarece utilitarul are o funcționalitate semnificativă, de exemplu, puteți alege independent în ce culoare doriți să primiți imaginea, este posibil să convertiți toate fotografiile în alb-negru. În alb-negru, recunoașterea este mai rapidă și calitatea procesării crește.
Dacă sunteți interesat de funcția de recunoaștere a textului ABBYY FineReader, trebuie să apăsați un buton special înainte de a scana. În acest caz, există mai multe opțiuni pentru obținerea de informații. În mod standard, pe ecran va fi afișată o foaie recunoscută, pe care o puteți copia sau edita manual.
Dacă selectați alte funcții, puteți primi imediat fișierul ca document Word sau tabel Excel. Selectarea functiilor este foarte simpla, meniul este intuitiv si usor de personalizat datorita faptului ca toate butoanele de care ai nevoie sunt in fata ochilor tai.
IMPORTANT. Înainte ca ABBYY FineReader să poată recunoaște textul, trebuie să selectați cu precizie limba de procesare. În ciuda faptului că utilitatea funcționează complet automat, se întâmplă ca calitatea scăzută a sursei să nu ne permită să înțelegem ce fel de limbă a fost în sursă. Acest lucru reduce foarte mult calitatea rezultatelor finale ale aplicației.
Mai multe moduri de operare
Pentru a înțelege pe deplin cum să utilizați ABBYY FineReader 12, trebuie să încercați două moduri de operare: „Atenție” și „Recunoaștere rapidă”. Al doilea mod este potrivit pentru imagini de înaltă calitate, iar primul pentru fișiere de calitate scăzută. Procesul fișierelor în modul Aprofundat durează de 3-5 ori mai mult.

Ilustrația arată rezultatul programului - recunoașterea textului dintr-o imagine
Ce alte funcții există?
Recunoașterea textului în ABBYY FineReader nu este singura caracteristică utilă. Pentru o mai mare comoditate pentru utilizator, este posibilă traducerea documentului în formatele cerute de utilizator (pdf, doc, xls etc.).
Schimbarea textului
Pentru a înțelege cum să schimbați textul în Fine Reader, utilizatorul trebuie să deschidă fila „Instrumente” - „Verificare”. După aceasta, se va deschide o fereastră care vă va permite să editați fontul, să schimbați simboluri, culori etc. Dacă editați o imagine, atunci ar trebui să deschideți „Editor de imagini”, acesta corespunde aproape complet programului simplu Paint, dar vă va permite să faceți modificări minime.
ATENŢIE. Dacă încă nu ați reușit să vă dați seama cum să utilizați ABBYY FineReader în mod productiv, puteți citi secțiunea „Ajutor”, care poate fi găsită în fereastra aplicației, în fila „Despre”.
Acum știi la ce servește programul FineReader și îl poți folosi corect acasă sau la birou. Functionalitatea aplicatiei este enorma, foloseste-o si te vei convinge de indispensabilitatea acestui produs software atunci cand procesezi documente si fisiere in timpul muncii de birou.