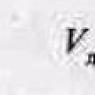Кодировка из международного стандарта юникод. Юникод в вебе: введение для начинающих
Уникод или Юникод (от англ. слова Unicode ) является стандартом кодирования знаков-символов. Он даёт возможность быть представленными в кодировке почти всем письменным языкам.
В конце 1980-х роль стандарта закрепилась за 8-битными символами. 8-битные кодировки были представлены разными модификациями, число которых постоянно росло. Главным образом, это было результатом активного расширения спектра используемых языков. Имело место и стремление разработчиков придумать кодировку, претендующую хотя бы на частичную универсальность.
В итоге возникла необходимость заниматься решением нескольких проблем:
- проблемы индикации документов в некорректной кодировке. Решить её было можно, либо последовательно внедряя методы указания применяемой кодировки, либо вводя единую кодировку для всех;
- проблемы ограниченности пакета символов, решаемую либо путём переключения шрифтов в документе, либо внедряя расширенную кодировку;
- проблемы трансформирования кодировки из одной в другую, которую представлялось возможным решить либо используя промежуточное преобразование (третья кодировка), включающую символы разных кодировок, либо составляя таблицы перекодировки для каждых двух кодировок;
- проблемы дублирования отдельных шрифтов. Традиционно каждая кодировка предполагала наличие своего шрифта, даже когда кодировки полностью или частично совпадали в наборе символов. В какой-то мере проблема решалась с помощью «больших» шрифтов, из которых затем выбирались символы, нужные для конкретной кодировки. Но для того, чтобы определить степень соответствия, требовалось создать единый реестр символов.
Таким образом, на повестке дня встал вопрос о необходимости создания «широкой» единой кодировки. Используемые в Юго-восточной Азии кодировки с меняющейся длиной символа выглядели чересчур сложными в применении. Поэтому упор был сделан на использование символа, имеющего фиксированную ширину. 32-битные символы казались слишком громоздкими и победу в итоге одержали 16-битные.
Стандарт в 1991 году предложила интернет-сообществу некоммерческая организация «Консорциум Юникода» . Его использование даёт возможность закодировать большое количество символов разных видов письменности. В Unicode-документах не тесно в плотном соседстве ни китайским иероглифам, ни математическим символам, ни кириллице, ни латинице. При этом кодовые страницы в процессе работы не требуют никаких переключений.
Состоит стандарт из двух главных разделов: универсального набора символов (англ. UCS) и семейства кодировок (в английской интерпретации - UTF). Универсальным набором символов задаётся однозначная пропорциональность кодам символов. Коды в этом случае представляют собой элементы кодовой сферы, являющиеся неотрицательными целыми числами. Функция семейства кодировок - определение машинного представления последовательности UCS-кодов.
В Юникод-стандарте коды градированы по нескольким областям. Ареал с кодами, начиная с U+0000 и заканчивая U+007F, - включает символы комплекта ASCII с необходимыми кодами. Дальше находятся области символов разных письменностей, символов технических, знаков пунктуации. Отдельную партию кодов хранят в резерве для будущего применения. Под кириллицу определены следующие области символов с кодами: U+0400 - U+052F, U+2DE0 - U+2DFF, U+A640 - U+A69F.
Значение данной кодировки в веб-пространстве неумолимо растёт. Доля сайтов, применяющих Юникод, составляла в начале 2010 года почти 50 процентов.
Сегодня мы поговорим с вами про то, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная от базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8. Оглавление:
- Расширенные версии Аски - кодировки CP866 и KOI8-R
- Windows 1251 - вариация ASCII и почему вылезают кракозябры
ASCII - базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки не благозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами. Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями - латинские буквы, арабские цифры и знаки препинания. Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы навроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их: Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII
, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
Именно эти 128 символов из первоначального вариант ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке.
Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII
, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Тут, наверное, стоит еще немного сказать про системы счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет из себя двойку в степени, начиная с нулевой, и до двойки в седьмой:
 Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное
прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички.
В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получает 233 в десятичной системе счисления. Как видите, все очень просто.
Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать).
Ну так вот, для перевода двоичного числа в шестнадцатеричное
прибегают к следующему простому и наглядному способу. Каждый байт информации разбивают на две части по четыре бита, как показано на приведенном выше скриншоте. Т.о. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом.
Причем, в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате, путем нехитрых вычислений, мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Расширенные версии Аски - кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8). Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка. Тут нужно будет еще раз отвлечься, чтобы пояснить - зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей - наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место. Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста. Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально. Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), должно быть выполнено два условия - векторная форма этого знака должна быть в используемом шрифте и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски. Например, изначально появилась CP866 , в которой была возможность использовать символы русского алфавита и она являлась расширенной версией ASCII. Т.е. ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866
? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R
:
Видите, в правом столбце цифры начинаются с 8, т.к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Т.о. русская буква «М» в CP866 будет иметь код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте.
Откуда взялось такое количество псевдографики в CP866
? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда не было такого распространения графических операционных систем как сейчас. А в Досе, и подобных ей текстовых операционках, псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски.
CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R
:
 Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 - каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 - каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье.
Среди особенностей кодировки KOI8-R можно отметить то, что русские буквы в ее таблице идут не в алфавитном порядке, как это, например, сделали в CP866.
Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
Windows 1251 - современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики. Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251 . Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.): Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры
, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры
, когда происходила путаница с используемой в тексте версией.
Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально.
Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
 Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом.
В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы, наконец, на корню проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Юникод (Unicode) - универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode - Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста. Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32 . Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF. В результате чего, один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов , которые покроют любое реально необходимое значение с колоссальным запасом). Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить. В результате развития Юникода появилась UTF-16 , которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит. В операционной системе Windows вы можете пройти по пути «Пуск» - «Программы» - «Стандартные» - «Служебные» - «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, то сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16 , состоящий из четырех шестнадцатеричных цифр: Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку
переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские - в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему - теперь у нас в шрифтах существует единое кодовое пространство
. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста.
Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них, после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку
переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт.
На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII.
Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. Т.е. базовая часть Аски просто перешла в это детище консорциума Unicode.
Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские - в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему - теперь у нас в шрифтах существует единое кодовое пространство
. И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста.
В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
Кракозябры вместо русских букв - как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов. Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++ . Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке. В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию: В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM
. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM
(Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров
.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же - читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема - вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows
для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows - какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
Чтобы избежать кракозябров
, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<
?
xml version=
"1.0"
encoding=
"windows-1251"
?
>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta
, который прописывается между открывающим и закрывающим тегом Head:
<
head>
.
.
.
<
meta charset=
"utf-8"
>
.
.
.
<
/
head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа
, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Ссылка на перво
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM
. А что такое приставка BOM?
Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM
(Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов.
В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код. Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров
.
Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же - читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема - вылезут кракозябры.
Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows
для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств.
В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация?
Она прописана в реестре вашей операционной системы Windows - какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка.
После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название:
Чтобы избежать кракозябров
, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы.
Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
<
?
xml version=
"1.0"
encoding=
"windows-1251"
?
>
Прежде, чем начать разбирать код, браузер узнает, какая версия используется и как именно нужно интерпретировать коды символов этого языка. Но что примечательно, в случае, если вы сохраняете документ в принятом по умолчанию юникоде, то это объявление xml можно будет опустить (кодировка будет считаться UTF-8, если нет BOM или ЮТФ-16, если BOM есть).
В случае же документа языка Html для указания кодировки используется элемент Meta
, который прописывается между открывающим и закрывающим тегом Head:
<
head>
.
.
.
<
meta charset=
"utf-8"
>
.
.
.
<
/
head>
Эта запись довольно сильно отличается от принятой в стандарте в Html 4.01, но полностью соответствует новому внедряемому потихоньку стандарту Html 5, и она будет стопроцентно правильно понята любыми используемыми на текущий момент браузерами.
По идее, элемент Meta с указание кодировки Html документа лучше будет ставить как можно выше в шапке документа
, чтобы на момент встречи в тексте первого знака не из базовой ANSI (которые правильно прочитаются всегда и в любой вариации) браузер уже должен иметь информацию о том, как интерпретировать коды этих символов.
Ссылка на перво
Юникод - это очень большой и сложный мир, ведь стандарт позволяет ни много ни мало представлять и работать в компьютере со всеми основными письменностями мира. Некоторые системы письма существуют уже более тысячи лет, причём многие из них развивались почти независимо друг от друга в разных уголках мира. Люди так много всего придумали и оно зачастую настолько непохоже друг на друга, что объединить всё это в единый стандарт было крайне непростой и амбициозной задачей.
Чтобы по-настоящему разобраться с Юникодом нужно хотя бы поверхностно представлять себе особенности всех письменностей, с которыми позволяет работать стандарт. Но так ли это нужно каждому разработчику? Мы скажем, что нет. Для использования Юникода в большинстве повседневных задач, достаточно владеть разумным минимумом сведений, а дальше углубляться в стандарт по мере необходимости.
В статье мы расскажем об основных принципах Юникода и осветим те важные практические вопросы, с которыми разработчики непременно столкнутся в своей повседневной работе.
Зачем понадобился Юникод?
До появления Юникода, почти повсеместно использовались однобайтные кодировки, в которых граница между самими символами, их представлением в памяти компьютера и отображением на экране была довольно условной. Если вы работали с тем или иным национальным языком, то в вашей системе были установлены соответствующие шрифты-кодировки, которые позволяли отрисовывать байты с диска на экране таким образом, чтобы они представляли смысл для пользователя.
Если вы распечатывали на принтере текстовый файл и на бумажной странице видели набор непонятных кракозябр, это означало, что в печатающее устройство не загружены соответствующие шрифты и оно интерпретирует байты не так, как вам бы этого хотелось.
У такого подхода в целом и однобайтовых кодировок в частности был ряд существенных недостатков:
- Можно было одновременно работать лишь с 256 символами, причём первые 128 были зарезервированы под латинские и управляющие символы, а во второй половине кроме символов национального алфавита нужно было найти место для символов псевдографики (╔ ╗).
- Шрифты были привязаны к конкретной кодировке.
- Каждая кодировка представляла свой набор символов и конвертация из одной в другую была возможна только с частичными потерями, когда отсутствующие символы заменялись на графически похожие.
- Перенос файлов между устройствами под управлением разных операционных систем был затруднителен. Нужно было либо иметь программу-конвертер, либо таскать вместе с файлом дополнительные шрифты. Существование Интернета каким мы его знаем было невозможным.
- В мире существуют неалфавитные системы письма (иероглифическая письменность), которые в однобайтной кодировке непредставимы в принципе.
Основные принципы Юникода
Все мы прекрасно понимаем, что компьютер ни о каких идеальных сущностях знать не знает, а оперирует битами и байтами. Но компьютерные системы пока создают люди, а не машины, и для нас с вами иногда бывает удобнее оперировать умозрительными концепциями, а затем уже переходить от абстрактного к конкретному.
Важно! Одном из центральных принципов в философии Юникода является чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
Вводится понятие абстрактного юникод-символа, существующего исключительно в виде умозрительной концепции и договорённости между людьми, закреплённой стандартом. Каждому юникод-символу поставлено в соответствие неотрицательное целое число, именуемое его кодовой позицией (code point).
Так, например, юникод-символ U+041F - это заглавная кириллическая буква П. Существует несколько возможностей представления данного символа в памяти компьютера, ровно как и несколько тысяч способов отображения его на экране монитора. Но при этом П, оно и в Африке будет П или U+041F.
Это хорошо нам знакомая инкапсуляция или отделение интерфейса от реализации - концепция, отлично зарекомендовавшая себя в программировании.
Получается, что руководствуясь стандартом, любой текст можно закодировать в виде последовательности юникод-символов
Привет U+041F U+0440 U+0438 U+0432 U+0435 U+0442
записать на листочке, упаковать в конверт и переслать в любой конец Земли. Если там знают о существовании Юникода, то текст будет воспринят ими ровно так же, как и нами с вами. У них не будет ни малейших сомнений, что предпоследний символ - это именно кириллическая строчная е (U+0435), а не скажем латинская маленькая e (U+0065). Обратите внимание, что мы ни слова не сказали о байтовом представлении.
Кодовое пространство Юникода
Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF. Из них к девятой версии стандарта значения присвоены лишь 128 237. Часть пространства зарезервирована для частного использования и консорциум Юникода обещает никогда не присваивать значения позициям из этих специальный областей.
Ради удобства всё пространство поделено на 17 плоскостей (сейчас задействовано шесть их них). До недавнего времени было принято говорить, что скорее всего вам придётся столкнуться только с базовой многоязыковой плоскостью (Basic Multilingual Plane, BMP), включающей в себя юникод-символы от U+0000 до U+FFFF. (Забегая немного вперёд: символы из BMP представляются в UTF-16 двумя байтами, а не четырьмя). В 2016 году этот тезис уже вызывает сомнения. Так, например, популярные символы Эмодзи вполне могут встретиться в пользовательском сообщении и нужно уметь их корректно обрабатывать.
Кодировки
Если мы хотим переслать текст через Интернет, то нам потребуется закодировать последовательность юникод-символов в виде последовательности байтов.
Стандарт Юникода включает в себя описание ряда юникод-кодировок, например UTF-8 и UTF-16BE/UTF-16LE, которые позволяют кодировать всё пространство кодовых позиций. Конвертация между этими кодировками может свободно осуществляться без потерь информации.
Также никто не отменял однобайтные кодировки, но они позволяют закодировать свой индивидуальный и очень узкий кусочек юникод-спектра - 256 или менее кодовых позиций. Для таких кодировок существуют и доступны всем желающим таблицы, где каждому значению единственного байта сопоставлен юникод-символ (см. например CP1251.TXT). Несмотря на ограничения, однобайтные кодировки оказываются весьма практичными, если речь идёт о работе с большим массивом моноязыковой текстовой информации.
Из юникод-кодировок самой распространённой в Интернете является UTF-8 (она завоевала пальму первенства в 2008 году), главным образом благодаря её экономичности и прозрачной совместимости с семибитной ASCII. Латинские и служебные символы, основные знаки препинания и цифры - т.е. все символы семибитной ASCII - кодируются в UTF-8 одним байтом, тем же, что и в ASCII. Символы многих основных письменностей, не считая некоторых более редких иероглифических знаков, представлены в ней двумя или тремя байтами. Самая большая из определённых стандартом кодовых позиций - 10FFFF - кодируется четырьмя байтами.
Обратите внимание, что UTF-8 - это кодировка с переменной длиной кода. Каждый юникод-символ в ней представляется последовательностью кодовых квантов с минимальной длиной в один квант. Число 8 означает битовую длину кодового кванта (code unit) - 8 бит. Для семейства кодировок UTF-16 размер кодового кванта составляет, соответственно, 16 бит. Для UTF-32 - 32 бита.
Если вы пересылаете по сети HTML-страницу с кириллическим текстом, то UTF-8 может дать весьма ощутимый выигрыш, т.к. вся разметка, а также JavaScript и CSS блоки будут эффективно кодироваться одним байтом. К примеру главная страница Хабра в UTF-8 занимает 139Кб, а в UTF-16 уже 256Кб. Для сравнения, если использовать win-1251 с потерей возможности сохранять некоторые символы, то размер сократится всего на 11Кб.
Для хранения строковой информации в приложениях часто используются 16-битные юникод-кодировки в силу их простоты, а так же того факта, что символы основных мировых систем письма кодируются одним шестнадцатибитовым квантом. Так, например, Java для внутреннего представления строк успешно применяет UTF-16. Операционная система Windows внутри себя также использует UTF-16.
В любом случае, пока мы остаёмся в пространстве Юникода, не так уж и важно, как хранится строковая информация в рамках отдельного приложения. Если внутренний формат хранения позволяет корректно кодировать все миллион с лишним кодовых позиций и на границе приложения, например при чтении из файла или копировании в буфер обмена, не происходит потерь информации, то всё хорошо.
Для корректной интерпретации текста, прочитанного с диска или из сетевого сокета, необходимо сначала определить его кодировку. Это делается либо с использованием метаинформации, предоставленной пользователем, записанной в тексте или рядом с ним, либо определяется эвристически.
В сухом остатке
Информации много и имеет смысл привести краткую выжимку всего, что было написано выше:
- Юникод постулирует чёткое разграничение между символами, их представлением в компьютере и их отображением на устройстве вывода.
- Кодовое пространство Юникода состоит из 1 114 112 кодовых позиций в диапазоне от 0 до 10FFFF.
- Базовая многоязыковая плоскость включает в себя юникод-символы от U+0000 до U+FFFF, которые кодируются в UTF-16 двумя байтами.
- Любая юникод-кодировка позволяет закодировать всё пространство кодовых позиций Юникода и конвертация между различными такими кодировками осуществляется без потерь информации.
- Однобайтные кодировки позволяют закодировать лишь небольшую часть юникод-спектра, но могут оказаться полезными при работе с большим объёмом моноязыковой информации.
- Кодировки UTF-8 и UTF-16 обладают переменной длиной кода. В UTF-8 каждый юникод-символ может быть закодирован одним, двумя, тремя или четырьмя байтами. В UTF-16 - двумя или четырьмя байтами.
- Внутренний формат хранения текстовой информации в рамках отдельного приложения может быть произвольным при условии корректной работы со всем пространством кодовых позиций Юникода и отсутствии потерь при трансграничной передаче данных.
Краткое замечание про кодирование
С термином кодирование может произойти некоторая путаница. В рамках Юникода кодирование происходит дважды. Первый раз кодируется набор символов Юникода (character set), в том смысле, что каждому юникод-символу ставится с соответствие кодовая позиция. В рамках этого процесса набор символов Юникода превращается в кодированный набор символов (coded character set). Второй раз последовательность юникод-символов преобразуется в строку байтов и этот процесс также называется кодирование.
В англоязычной терминологии существуют два разных глагола to code и to encode, но даже носители языка зачастую в них путаются. К тому же термин набор символов (character set или charset) используется в качестве синонима к термину кодированный набор символов (coded character set).
Всё это мы говорим к тому, что имеет смысл обращать внимание на контекст и различать ситуации, когда речь идёт о кодовой позиции абстрактного юникод-символа и когда речь идёт о его байтовом представлении.
В заключение
В Юникоде так много различных аспектов, что осветить всё в рамках одной статьи невозможно. Да и ненужно. Приведённой выше информации вполне достаточно, чтобы не путаться в основных принципах и работать с текстом в большинстве повседневных задач (читай: не выходя за рамки BMP). В следующих статьях мы расскажем о нормализации, дадим более полный исторический обзор развития кодировок, побеседуем о проблемах русскоязычной юникод-терминологии, а также сделаем материал о практических аспектах использования UTF-8 и UTF-16.
Поскольку в ряде компьютерных систем (например, Windows NT ) фиксированные 16-битные символы уже использовались в качестве кодировки по умолчанию, было решено все наиболее важные знаки кодировать только в пределах первых 65 536 позиций (так называемая англ. basic multilingual plane, BMP ). Остальное пространство используется для «дополнительных символов» (англ. supplementary characters ): систем письма вымерших языков или очень редко используемых китайских иероглифов, математических и музыкальных символов.
Для совместимости со старыми 16-битными системами была изобретена система UTF-16 , где первые 65 536 позиций, за исключением позиций из интервала U+D800…U+DFFF, отображаются непосредственно как 16-битные числа, а остальные представляются в виде «суррогатных пар» (первый элемент пары из области U+D800…U+DBFF, второй элемент пары из области U+DC00…U+DFFF). Для суррогатных пар была использована часть кодового пространства (2048 позиций), ранее отведённого для «символов для частного использования».
Поскольку в UTF-16 можно отобразить только 2 20 +2 16 −2048 (1 112 064) символов, то это число и было выбрано в качестве окончательной величины кодового пространства Юникода.
Хотя кодовая область Юникода была расширена за пределы 2 16 уже в версии 2.0, первые символы в «верхней» области были размещены только в версии 3.1.
Роль этой кодировки в веб-секторе постоянно растёт, на начало 2010 доля веб-сайтов, использующих Юникод, составила около 50 %.
Версии Юникода
По мере изменения и пополнения таблицы символов системы Юникода и выхода новых версий этой системы, - а эта работа ведётся постоянно, поскольку изначально система Юникод включала только Plane 0 - двухбайтные коды, - выходят и новые документы ISO . Система Юникод существует в общей сложности в следующих версиях:
- 1.1 (соответствует стандарту ISO/IEC 10646-1:), стандарт 1991-1995 годов.
- 2.0, 2.1 (тот же стандарт ISO/IEC 10646-1:1993 плюс дополнения: «Amendments» с 1-го по 7-е и «Technical Corrigenda» 1 и 2), стандарт 1996 года.
- 3.0 (стандарт ISO/IEC 10646-1:2000), стандарт 2000 года.
- 3.1 (стандарты ISO/IEC 10646-1:2000 и ISO/IEC 10646-2:2001), стандарт 2001 года.
- 3.2, стандарт 2002 года .
- 4.0, стандарт .
- 4.01, стандарт .
- 4.1, стандарт .
- 5.0, стандарт .
- 5.1, стандарт .
- 5.2, стандарт .
- 6.0, стандарт .
- 6.1, стандарт .
- 6.2, стандарт .
Кодовое пространство
Хотя формы записи UTF-8 и UTF-32 позволяют кодировать до 2 31 (2 147 483 648) кодовых позиций, было принято решение использовать лишь 1 112 064 для совместимости с UTF-16. Впрочем, даже и этого более чем достаточно - сегодня (в версии 6.0) используется чуть менее 110 000 кодовых позиций (109 242 графических и 273 прочих символов).
Кодовое пространство разбито на 17 плоскостей по 2 16 (65536) символов. Нулевая плоскость называется базовой , в ней расположены символы наиболее употребительных письменностей. Первая плоскость используется, в основном, для исторических письменностей, вторая - для редко используемых иероглифов ККЯ , третья зарезервирована для архаичных китайских иероглифов . Плоскости 15 и 16 выделены для частного употребления.
Для обозначения символов Unicode используется запись вида «U+xxxx » (для кодов 0…FFFF), или «U+xxxxx » (для кодов 10000…FFFFF), или «U+xxxxxx » (для кодов 100000…10FFFF), где xxx - шестнадцатеричные цифры. Например, символ «я» (U+044F) имеет код 044F = 1103 .
Система кодирования
Универсальная система кодирования (Юникод) представляет собой набор графических символов и способ их кодирования для компьютерной обработки текстовых данных.
Графические символы - это символы, имеющие видимое изображение. Графическим символам противопоставляются управляющие символы и символы форматирования.
Графические символы включают в себя следующие группы:
- буквы, содержащиеся хотя бы в одном из обслуживаемых алфавитов ;
- цифры;
- знаки пунктуации;
- специальные знаки (математические , технические, идеограммы и пр.);
- разделители.
Юникод - это система для линейного представления текста. Символы, имеющие дополнительные над- или подстрочные элементы, могут быть представлены в виде построенной по определённым правилам последовательности кодов (составной вариант, composite character) или в виде единого символа (монолитный вариант, precomposed character).
Модифицирующие символы
Представление символа «Й» (U+0419) в виде базового символа «И» (U+0418) и модифицирующего символа « ̆» (U+0306)
Графические символы в Юникоде подразделяются на протяжённые и непротяжённые (бесширинные). Непротяжённые символы при отображении не занимают места в строке . К ним относятся, в частности, знаки ударения и прочие диакритические знаки . Как протяжённые, так и непротяжённые символы имеют собственные коды. Протяжённые символы иначе называются базовыми (англ. base characters ), а непротяжённые - модифицирующими (англ. combining characters ); причём последние не могут встречаться самостоятельно. Например, символ «á» может быть представлен как последовательность базового символа «a» (U+0061) и модифицирующего символа « ́» (U+0301) или как монолитный символ «á» (U+00C1).
Особый тип модифицирующих символов - селекторы варианта начертания (англ. variation selectors ). Они действуют только на те символы, для которых такие варианты определены. В версии 5.0 варианты начертания определены для ряда математических символов, для символов традиционного монгольского алфавита и для символов монгольского квадратного письма .
Формы нормализации
Поскольку одни и те же символы можно представить различными кодами, что иногда затрудняет обработку, существуют процессы нормализации, предназначенные для приведения текста к определённому стандартному виду.
В стандарте Юникода определены 4 формы нормализации текста:
- Форма нормализации D (NFD) - каноническая декомпозиция. В процессе приведения текста в эту форму все составные символы рекурсивно заменяются на несколько составных, в соответствии с таблицами декомпозиции.
- Форма нормализации C (NFC) - каноническая декомпозиция с последующей канонической композицией. Сначала текст приводится к форме D, после чего выполняется каноническая композиция - текст обрабатывается от начала к концу и выполняются следующие правила:
- Символ S является начальным , если он имеет нулевой класс модификации в базе символов Юникода.
- В любой последовательности символов, стартующей с начального символа S, символ C блокируется от S, если и только если между S и C есть какой-либо символ B, который или является начальным, или имеет одинаковый или больший класс модификации, чем C. Это правило распространяется только на строки, прошедшие каноническую декомпозицию.
- Первичным композитом считается символ, у которого есть каноническая декомпозиция в базе символов Юникода (или каноническая декомпозиция для хангыля и он не входит в список исключений).
- Символ X может быть первично совмещён с символом Y, если и только если существует первичный композит Z, канонически эквивалентный последовательности
- Если очередной символ C не блокируется последним встреченным начальным базовым символом L и он может быть успешно первично совмещён с ним, то L заменяется на композит L-C, а C удаляется.
- Форма нормализации KD (NFKD) - совместимая декомпозиция. При приведении в эту форму все составные символы заменяются, используя как канонические карты декомпозиции Юникода, так и совместимые карты декомпозиции, после чего результат ставится в каноническом порядке.
- Форма нормализации KC (NFKC) - совместимая декомпозиция с последующей канонической композицией.
Термины «композиция» и «декомпозиция» понимают под собой соответственно соединение или разложение символов на составные части.
Примеры
| Исходный текст | NFD | NFC | NFKD | NFKC |
|---|---|---|---|---|
| Français | Franc\u0327ais | Fran\xe7ais | Franc\u0327ais | Fran\xe7ais |
| А, Ё, Й | \u0410, \u0401, \u0419 | \u0410, \u0415\u0308, \u0418\u0306 | \u0410, \u0401, \u0419 | |
| が | \u304b\u3099 | \u304c | \u304b\u3099 | \u304c |
| Henry IV | Henry IV | Henry IV | Henry IV | Henry IV |
| Henry Ⅳ | Henry \u2163 | Henry \u2163 | Henry IV | Henry IV |
Двунаправленное письмо
Стандарт Юникод поддерживает письменности языков как с направлением написания слева направо (англ. left-to-right, LTR ), так и с написанием справа налево (англ. right-to-left, RTL ) - например, арабское и еврейское письмо. В обоих случаях символы хранятся в «естественном» порядке; их отображение с учётом нужного направления письма обеспечивается приложением.
Кроме того, Юникод поддерживает комбинированные тексты, сочетающие фрагменты с разным направлением письма. Данная возможность называется двунаправленность (англ. bidirectional text, BiDi ). Некоторые упрощённые обработчики текста (например, в сотовых телефонах) могут поддерживать Юникод, но не иметь поддержки двунаправленности. Все символы Юникода поделены на несколько категорий: пишущиеся слева направо, пишущиеся справа налево, и пишущиеся в любом направлении. Символы последней категории (в основном это знаки пунктуации) при отображении принимают направление окружающего их текста.
Представленные символы
Юникод включает практически все современные письменности , в том числе:
и другие.
С академическими целями добавлены многие исторические письменности, в том числе: руны , древнегреческая , египетские иероглифы , клинопись , письменность майя , этрусский алфавит .
В Юникоде представлен широкий набор математических и музыкальных символов, а также пиктограмм .
Однако в Юникод принципиально не включаются логотипы компаний и продуктов, хотя они и встречаются в шрифтах (например, логотип Apple в кодировке MacRoman (0xF0) или логотип Windows в шрифте Wingdings (0xFF)). В юникодовских шрифтах логотипы должны размещаться только в области пользовательских символов.
ISO/IEC 10646
Консорциум Юникода работает в тесной связи с рабочей группой ISO/IEC/JTC1/SC2/WG2, которая занимается разработкой международного стандарта 10646 (ISO /IEC 10646). Между стандартом Юникода и ISO/IEC 10646 установлена синхронизация, хотя каждый стандарт использует свою терминологию и систему документации.
Сотрудничество Консорциума Юникода с Международной организацией по стандартизации (англ. International Organization for Standardization, ISO ) началось в 1991 году . В 1993 году ISO выпустила стандарт DIS 10646.1. Для синхронизации с ним Консорциум утвердил стандарт Юникода версии 1.1, в который были внесены дополнительные символы из DIS 10646.1. В результате значения закодированных символов в Unicode 1.1 и DIS 10646.1 полностью совпали.
В дальнейшем сотрудничество двух организаций продолжилось. В 2000 году стандарт Unicode 3.0 был синхронизирован с ISO/IEC 10646-1:2000. Предстоящая третья версия ISO/IEC 10646 будет синхронизирована с Unicode 4.0. Возможно, эти спецификации даже будут опубликованы как единый стандарт.
Аналогично форматам UTF-16 и UTF-32 в стандарте Юникода, стандарт ISO/IEC 10646 также имеет две основные формы кодирования символов: UCS-2 (2 байта на символ, аналогично UTF-16) и UCS-4 (4 байта на символ, аналогично UTF-32). UCS значит универсальный многооктетный (многобайтовый) кодированный набор символов (англ. universal multiple-octet coded character set ). UCS-2 можно считать подмножеством UTF-16 (UTF-16 без суррогатных пар), а UCS-4 является синонимом для UTF-32.
Способы представления
Юникод имеет несколько форм представления (англ. Unicode transformation format, UTF ): UTF-8 , UTF-16 (UTF-16BE, UTF-16LE) и UTF-32 (UTF-32BE, UTF-32LE). Была разработана также форма представления UTF-7 для передачи по семибитным каналам, но из-за несовместимости с ASCII она не получила распространения и не включена в стандарт. 1 апреля 2005 года были предложены две шуточные формы представления: UTF-9 и UTF-18 (RFC 4042).
Unicode UTF-8: 0x00000000 - 0x0000007F: 0xxxxxxx 0x00000080 - 0x000007FF: 110xxxxx 10xxxxxx 0x00000800 - 0x0000FFFF: 1110xxxx 10xxxxxx 10xxxxxx 0x00010000 - 0x001FFFFF: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Теоретически возможны, но не включены в стандарт также:
0x00200000 - 0x03FFFFFF: 111110xx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 0x04000000 - 0x7FFFFFFF: 1111110x 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx 10xxxxxx
Несмотря на то, что UTF-8 позволяет указать один и тот же символ несколькими способами, только наиболее короткий из них правильный. Остальные формы должны отвергаться по соображениям безопасности.
Порядок байтов
В потоке данных UTF-16 старший байт может записываться либо перед младшим (англ. UTF-16 big-endian ), либо после младшего (англ. UTF-16 little-endian ). Аналогично существует два варианта четырёхбайтной кодировки - UTF-32BE и UTF-32LE.
Для определения формата представления Юникода в начало текстового файла записывается сигнатура - символ U+FEFF (неразрывный пробел с нулевой шириной), также именуемый меткой порядка байтов (англ. byte order mark, BOM ). Это позволяет различать UTF-16LE и UTF-16BE, поскольку символа U+FFFE не существует. Также этот способ иногда применяется для обозначения формата UTF-8, хотя к этому формату и неприменимо понятие порядка байтов. Файлы, следующие этому соглашению, начинаются с таких последовательностей байтов:
UTF-8 EF BB BF UTF-16BE FE FF UTF-16LE FF FE UTF-32BE 00 00 FE FF UTF-32LE FF FE 00 00
К сожалению, этот способ не позволяет надёжно различать UTF-16LE и UTF-32LE, поскольку символ U+0000 допускается Юникодом (хотя реальные тексты редко начинаются с него).
Файлы в кодировках UTF-16 и UTF-32, не содержащие BOM, должны иметь порядок байтов big-endian (unicode.org).
Юникод и традиционные кодировки
Внедрение Юникода привело к изменению подхода к традиционным 8-битным кодировкам. Если раньше кодировка задавалась шрифтом, то теперь она задаётся таблицей соответствия между данной кодировкой и Юникодом. Фактически 8-битные кодировки превратились в форму представления некоторого подмножества Юникода. Это намного упростило создание программ, которые должны работать с множеством разных кодировок: теперь, чтобы добавить поддержку ещё одной кодировки, надо всего лишь добавить ещё одну таблицу перекодировки в Юникод.
Кроме того, многие форматы данных позволяют вставлять любые символы Юникода, даже если документ записан в старой 8-битной кодировке. Например, в HTML можно использовать коды с амперсандом .
Реализации
Большинство современных операционных систем в той или иной степени обеспечивают поддержку Юникода.
Одной из первых успешных коммерческих реализаций Юникода стала среда программирования Java . В ней принципиально отказались от 8-битного представления символов в пользу 16-битного. Сейчас большинство языков программирования поддерживают строки Юникода, хотя их представление может различаться в зависимости от реализации.
Методы ввода
Консоль GNU/Linux также допускает ввод символа Юникода по его коду - для этого десятичный код символа нужно ввести цифрами расширенного блока клавиатуры при зажатой клавише Alt. Можно вводить символы и по их шестнадцатеричному коду: для этого нужно зажать клавишу AltGr, и для ввода цифр A-F использовать клавиши расширенного блока клавиатуры от NumLock до Enter (по часовой стрелке). Поддерживается также и ввод в соответствии с ISO 14755. Для того чтобы перечисленные способы могли работать, нужно включить в консоли режим Юникода вызовом unicode_start (1) и выбрать подходящий шрифт вызовом setfont (8).
Написание «Юникод» уже твёрдо вошло в русскоязычные тексты. Согласно «Яндексу », частота использования этого слова примерно в 11 раз превышает «Уникод» . В Википедии используется более распространённый вариант.
На сайте Консорциума есть специальная страница, где рассматриваются проблемы передачи слова «Unicode» в различных языках и системах письма. Для русской кириллицы указан вариант «Юникод» .
Формы, принятые иностранными организациями для русской передачи слова «Unicode», являются рекомендательными.
См. также
- Проект:Внесение символов алфавитов народов России в Юникод
Примечания
- Unicode Transcriptions (англ.) . Архивировано из первоисточника 22 августа 2011. Проверено 10 мая 2010.
- Уникод в словаре Paratype
- The Unicode® Standard: A Technical Introduction . Архивировано
- History of Unicode Release and Publication Dates . Архивировано из первоисточника 22 августа 2011. Проверено 4 июля 2010.
- The Unicode Consortium . Архивировано из первоисточника 22 августа 2011. Проверено 4 июля 2010.
- Foreword . Архивировано из первоисточника 22 августа 2011. Проверено 4 июля 2010.
- General Structure . Архивировано из первоисточника 22 августа 2011. Проверено 5 июля 2010.
- European Alphabetic Scripts . Архивировано из первоисточника 22 августа 2011. Проверено 4 июля 2010.
- Unicode 88 . Архивировано из первоисточника 22 августа 2011. Проверено 8 июля 2010.
- Unicode and Microsoft Windows NT (англ.) . Microsoft Support . Архивировано
- Unicode используется почти на 50% веб-сайтов (рус.) . Архивировано из первоисточника 22 августа 2011.
- Roadmap to the TIP (Tertiary Ideographic Plane)
- http://www.cl.cam.ac.uk/~mgk25/ucs/utf-8-history.txt (англ.)
- Регистр в Unicode - это непросто
- В большинстве шрифтов для ПК реализованы «прописные» (маюскульные) моноширинные цифры.
- В некоторых случаях документ (не простой текст) в Юникоде может занимать существенно меньше места, чем документ в однобайтовой кодировке. Например, если некая веб-страница содержит примерно поровну русского и греческого текста, то в однобайтовой кодировке придётся либо русские, либо греческие буквы записывать, используя возможности формата документов, в виде кодов с амперсандом, которые занимают 6-7 байт на символ (при использовании десятичных кодов), т. е. в среднем на букву придётся 3,5-4 байта, в то время как UTF-8 занимает только 2 байта на греческую или русскую букву.
- Один из файлов шрифтов Arial Unicode имеет размер 24 мегабайта; существует Times New Roman размером 120 мегабайт, он содержит количество символов, близкое к 65536.
- Даже для самого современного и дорогого мобильного телефона затруднительно выделить 120 Мбайт памяти для полного Юникод-шрифта. На практике использование полных шрифтов требуется редко.
- 350 тыс. страниц «Юникод » против 31 тыс. страниц «Уникод ».
Ссылки
- Официальный сайт Консорциума Юникода (англ.)
- Unicode в каталоге ссылок Open Directory Project (dmoz). (англ.)
- Что такое Unicode? (рус.)
- Последняя версия