Кейс: учим поисковый движок распознавать грамматические ошибки. Ещё один велосипед, или пишем свой поисковый движок
- Индексы можно создавать только на полях MyISAM-таблиц.
- Размер индекса - примерно половина от размера данных. Правда, нужно иметь ввиду, что отключить сохранение самих текстов вы не можете, поэтому к этим 50 % нужно добавить ещё 100 % - данные-то хранятся.
- Скорость индексации - в чистом виде приличная, примерно 1.5 МБ/с. Понятно, что ещё нужно прогонять через стеммер. Если наполнять индекс, на ходу вытаскивая данные из той же базы, и прогоняя через Perl-порт русского Snowball-стеммера - получается 314 КБ/с. На самом деле в MySQL есть архитектура для подключения стеммеров плагинами («fulltext parser plugins»), вот только самих плагинов как-то нет… :)
- Встроенного стеммера нет, стоп-слова вшиты английские, свои добавить нельзя. По умолчанию булев поиск идёт по «ИЛИ», поэтому для поиска по «И» нужно каждое слово превращать в «+слово».
- Есть два режима - булев и обычный («natural language») поиск. Булев поиск просто проверяет, есть ли слова в документе и поддерживает логические операции, фразы и префиксный поиск, но не возвращает оценку релевантности (только 0 или 1). Обычный поиск умеет релевантность, но не умеет операторы. Поэтому, чтобы поддерживать и то, и другое - нужно дёргать один и тот же запрос в двух режимах.
- Префиксный поиск в MySQL феерически медленный. На нескольких словах, развёрнутых в префиксы, легко может получиться и 15, и 40 секунд. Так что его не нужно использовать вообще.
- По нескольким полям одновременно искать не умеет - то есть, синтаксис-то такой MATCH() позволяет, но никакой оптимизации поиска при этом не происходит, а происходит фулскан. Поэтому лучше писать (select id where match(field1) ...) UNION (select id where match(field2) ...) .
- Скорость поиска, по запросам, взятым из заголовков случайных багов, с лимитом количества найденного 1000:
- В 5 потоков на 3 словах - в среднем 175 мс, максимум 3.46 сек.
- В 5 потоков на 3 словах, первые 10 результатов - так же.
- В 5 потоков на 2 словах - в среднем 210 мс, максимум 3.1 сек.
- В 1 поток на 3 словах - в среднем 63 мс, максимум 764 мс.
- Зависит в основном от количества найденного.
- Основное достоинство - наличие поиска «искаропки».
Sphinx (2.0.1-beta)
- Отдельный поисковый сервер. Интерфейсные библиотеки к нему есть для кучи разных языков. Очень прикольно, что в 0.9.9, кроме «родного» интерфейса, появился SphinxQL - SQL-интерфейс к Sphinx’у по протоколу MySQL, то есть, с использованием обычных MySQL-клиентов.
- Изначально обновляемых (realtime) индексов в сфинксе не было, единственное, что он умел - это построить индекс целиком и потом по нему искать.
- Не умеет нормально обновлять/удалять документы в индексе до сих пор, нормально только добавляет. Удаление производится установкой флажка «старая запись», и последующим её удалением из всех результатов поиска каждый раз.
- Realtime индексы поддерживают не всё - например, не поддерживают префиксы/инфиксы и MVA.
- Немножко бардак с интерфейсами и фичами: обновление реалтайм индекса только через SphinxQL; синтаксис поиска во всех трёх интерфейсах разный (обычный, SphinxQL, SphinxSE); штук 5 режимов поиска, из которых 4 obsolete; indexer не может перестраивать реалтайм индексы; TRUNCATE индекса через SphinxQL сделать нельзя, посмотреть, сколько в индексе записей, тоже нельзя…
- На этом недостатки заканчиваются - есть сервер поиска, с которым можно общаться по собственному протоколу или протоколу MySQL, куча разных возможностей, индексирует и ищет очень быстро, размер индекса - примерно 1/3 данных. Может увеличиться раза в 2, если включить индексацию точных словоформ.
- Встроены русский, английский и чешский стеммеры и препроцессоры Soundex и Metaphone (для сравнения английских слов по звучанию). Стеммеры для других языков можно тоже подключить, только нужно собирать с ключиком --with-libstemmer . Поддержка стоп-слов, разумеется, есть. Синонимы тоже, причём есть обычные, а есть «tokenizing exceptions», которые могут включать в себя спецсимволы. Также есть «blend_chars » - символы, которые одновременно считаются и разделителями, и входящими в слова - например, чтобы «AT&T» превратилось в слова «AT», «T» и «AT&T».
- Из прикольных необычных фич - умеет инфиксный поиск (для тех, кто хотел быстро искать по подстроке!), многозначные поля (MVA), умеет индексировать по абзацам и предложениям и даже по содержимому заранее заданных HTML-тегов. Также может подсвечивать искомые слова в цитатах и многое другое. Правда, MVA и инфиксы не поддерживаются (пока что?) в обновляемых индексах.
- Индексация очень быстрая - чистая скорость с реалтайм индексом 6.7 МБ/с (загрузка SQL-дампа), с обычным индексом - вообще 12 МБ/с (загрузка xmlpipe2 -дампа). «Нечистая» скорость (из Perl’а, с вычиткой данных на лету из MySQL) - 4.5 МБ/с. С инфиксами всё, естественно, сильно замедляется - 440 КБ/с, куча ввода-вывода - 10.5 ГБ, и индекс получается 3 ГБ размером на 330 МБ данных.
- Поиск вообще реактивный:
- В 5 потоков на 3 словах - в среднем 7 мс, максимум 75 мс.
- В 5 потоков на 2 словах - в среднем 7 мс, максимум 81 мс.
- В 5 потоков на 3 словах, первые 10 результатов - в среднем 5 мс, максимум 57 мс.
- В 1 поток на 3 словах - в среднем 2 мс, максимум 35 мс.
Xapian (1.2.6)
- Библиотека, готового сервера поиска нет. C++ API довольно вменяемое. Конкурентную работу вроде поддерживает (много читателей, один писатель).
- Куча доступных биндингов под разные языки: C++, Java, Perl, Python, PHP, Tcl, C#, Ruby, Lua.
- Индекс - инвертированный на основе B-дерева.
- Круто то, что Xapian не обязательно использовать именно как полнотекстовый индекс - по сути, это просто реализация инвертированного индекса, которую можно использовать как в голову взбредёт, потому что ограничений на «слова», содержащиеся в документе, нет, кроме ограничения длины 245 байтами. По идее, можно его использовать в качестве БД.
- Откровенно хреновая документация. Какое-то сборище кусочков информации, в котором ещё и не всё есть. Чтобы понять какие-то моменты, приходится тупо лазать в код. Я обнаглел и поставил баг даже на эту тему - баг 564 . Ну а что, правда - движок-то вроде неплохой, но мало кто о нём знает.
- Забавно, что начав его тестировать, нашёл странный баг - сегфолт в libuuid , не позволяющий создать базу, если параллельно загружен Image::Magick . Оказалось, что это даже не баг ImageMagick’а, а ещё серьёзнее - это баг libc6 ! В 2.12 и 2.13 поломана инициализация Thread-Local Storage при динамической загрузке библиотек, о как. В 2.14 пофикшено, но в дебиане-то пока 2.13. Поставил в дебиан баг 637239 (там же есть ссылки на баги в gentoo и самой libc).
- Perl-биндинги требуют допиливания для возможности выбора бэкенда, а по умолчанию не новейший Brass, а стабильный Chert. Допиливание лёгкое. На эту тему я тоже поставил им баг - баг 565 .
- Поддержки разных полей в индексе как бы нет, но она делается добавлением в начало каждого слова префиксов: http://xapian.org/docs/omega/termprefixes.html
- Это «официальный подход», Xapian его умеет сам, только префиксы укажи.
- Такой подход имеет как минимум один небольшой недостаток - по умолчанию запрос не ищет по всем полям, а чтобы искал по всем, нужно руками вставлять в запрос OR.
- Да, документация опять неполная и не там, где надо - должна быть в мануале Xapian’а, а она - в мануале Omega, которая являет собой готовый простенький CGI-поисковичок.
- Неприятный момент - быстренько нашёл баг в парсере запросов - он неправильно генерирует термины для поиска основ слов в полях (которые с префиксами). Индексатор ко всем основам в начале приписывает префикс «Z», то есть основа для слова «идея» в заголовке (скажем, префикс T) проиндексируется как «ZTиде». А парсер запросов пытается искать по «Tиде» и, естественно, ничего не находит. Поставил им на эту тему баг 562 . Фиксится, на самом деле, одной строчкой.
- Стеммеры есть встроенные для 15 языков, как обычно, сгенерённые из Snowball "а. Есть поддержка стоп-слов (разумеется) и синонимов. Ещё интереснее - оно может исправлять опечатки без использования словарей, а лишь на основе индексированных данных (должно включаться настройкой). То есть, например, для «Xapain» оно честно подскажет «Xapian». Ещё есть поддержка поиска по «недовведённому запросу», то есть, для подсказок при вводе запроса побуквенно. По сути, это просто добавление * к последнему слову в поиске, но с учтёнными нюансами синтаксиса запросов.
- Ещё есть «Faceted Search» - подсчёт агрегатных значений по всем или почти всем найденным документам (скажем, с лимитом в 10000). То есть, эти 10000 документов вам возвращены не будут, но будут проверены и по ним будет подсчитано какое-то агрегатное значение. Например, таким образом можно выдать 10 результатов (страницу) и одновременно ответить на вопрос «из каких категорий найдены документы».
- Паршиво, что если при индексации раз в 256 багов делать flush() (commit), то скорость с ~1.5 МБ/с снижается до 412 КБ/с, причём, сильно возрастает количество операций ввода- вывода - раз в 10-20. В принципе, это заявлено и логично для любого инвертированного индекса - гораздо оптимальнее накапливать изменения, чем пытаться обновлять по одному, ибо количество обновляемых лексем возрастает.
- Размер индекса - пишут, что примерно равен размеру данных, это не так, реально больше раза в 2. Пишут, если не хранить позиции слов в документах, станет в 2 раза меньше. Но извините, Sphinx тоже хранит позиции, а индекс у него в 2 раза меньше данных. Если прогнать xapian-compact (дефрагментация БД) - индекс таки да, уменьшается, но всё равно остаётся где-то в 1.7 раза больше данных.
- Ага, причина найдена - Xapian всегда индексирует и основы, и точные формы слов. Отключить индексацию точных форм нельзя, обидно, поставил на эту тему им баг 563 .
- Ищет быстро. Тестировал так: искал по нескольким соседним словам длиной не меньше 2 символов, в режиме STEM_ALL, взятым из заголовков багов (искал не по «ИЛИ», а «И»), причём каждое слово заменял на (слово OR title:слово OR private:слово) , то есть на поиск по трём полям вместо одного, ограничивал количество результатов 1000.
- В 5 потоков на 3 словах - в среднем 14 мс, максимум 135 мс.
- В 5 потоков на 2 словах - в среднем 29 мс, максимум 137 мс.
- В 5 потоков на 3 словах, первые 10 результатов - в среднем 2 мс, максимум 26 мс.
- В 1 поток на 3 словах - в среднем 7 мс, максимум 51 мс.
- Скорость поиска зависит в основном от количества найденных результатов, чем больше - тем дольше ищет.
Xapian имеет 3 backend’а (реализации самого индекса) - в порядке новизны Flint, Chert и Brass. Это как в Debian’е oldstable, stable и testing:) в 1.2.x бэкенд по умолчанию - Chert. До Flint’а ещё был Quartz.
PostgreSQL Textsearch (9.1)
- Индекс - инвертированный на основе GIN (обобщённый инвертированный индекс - Generalized Inverted iNdex). Раньше назывался Tsearch2 , создан Олегом Бартуновым и Фёдором Сигаевым.
- Есть встроенные стеммеры, поддержка стоп-слов, синонимов, тезауруса (что-то типа словаря понятий, заменяет слова на другие «предпочитаемые»), словарей ISpell (хотя они, говорят, жутко тормозят при инициализации).
- Есть возможность при индексации прицепить к каждой лексеме «вес», который на самом деле не «вес», а аналог Xapian-префикса, то есть, название поля, из которого лексема пришла. Таких «весов» может быть всего 4 - A, B, C, D, и в дальнейшем их можно использовать при поиске. Пример построения tsvector "а из двух полей с «весами»: setweight(to_tsvector(coalesce(title,"")), "A") || setweight(to_tsvector(coalesce(keyword,"")), "B") .
- Есть отдельные функции для ранжирования результатов и подсветки искомых слов в цитатах. Ранжировать можно, присваивая численные веса «весам» ABCD, указанным выше (которые «поля»). Причём по умолчанию веса равны {0.1, 0.2, 0.4, 1.0}.
- Индексируемый тип данных называется tsvector (text search vector). PostgreSQL позволяет создавать функциональные индексы, и в мануале по умолчанию предлагают создавать именно их - CREATE INDEX i ON t USING gin(to_tsvector(<поле>)) . Так вот: не надо так делать!
А то очень неприятно удивитесь скорости запросов. Обязательно создавайте отдельную колонку типа tsvector , складывайте в неё свои tsvector "ы, и создавайте индекс на ней.
- Объясняю, почему: функция ранжирования результатов отдельная, и тоже работает с tsvector "ом. Если он не хранится, то должен вычисляться на лету при каждом запросе для каждого документа, а это очень хреново влияет на производительность, особенно, когда запрос находит много документов. То есть, если в запрос тупо включить сортировку по релевантности - ORDER BY ts_rank(to_tsvector(field),
) DESC - будет гораздо медленнее MySQL’я:). - Заодно, в качестве оптимизации дискового пространства, можно не хранить полный текст документов в индексе.
- Объясняю, почему: функция ранжирования результатов отдельная, и тоже работает с tsvector "ом. Если он не хранится, то должен вычисляться на лету при каждом запросе для каждого документа, а это очень хреново влияет на производительность, особенно, когда запрос находит много документов. То есть, если в запрос тупо включить сортировку по релевантности - ORDER BY ts_rank(to_tsvector(field),
- Из операторов поиска - AND, OR и NOT и префиксный поиск. Поиска близлежащих слов, точных форм, фраз нет.
- Размер индекса - где-то 150 % от размера данных, если сами тексты не хранить, а хранить только tsvector "ы.
- Скорость индексации - пока данных мало, 1.5 МБ/с, с ростом индекса потихоньку падает, но если сами тексты не хранить, то, вроде, устаканивается. На всё тех же данных багзиллы получилось в среднем 522 КБ/с, хотя к концу индексации было меньше, чем в начале.
- Скорость поиска:
- В 5 потоков на 3 словах - в среднем 28 мс, максимум 2.1 сек.
- В 5 потоков на 2 словах - в среднем 54 мс, максимум 2.3 сек.
- В 5 потоков на 3 словах, первые 10 результатов - в среднем 26 мс, максимум 611 мс.
- В 1 поток на 3 словах - в среднем 10 мс, максимум 213 мс.
Lucene , Solr (3.3)
- Lucene - это Java-библиотека поиска (не сервер), заобзорить и протестировать её полностью очень сложно - движок самый мощный (но и самый монструозный) из всех рассмотренных.
- То, что это библиотека, написанная на Java, является её главным недостатком - обращаться к Java из других языков сложно, поэтому и у Lucene с интерфейсами проблемы:(. Производительность от Java, возможно, тоже несколько страдает, но скорее всего очень некритично.
- Из биндингов к языкам есть только вполне живой PyLucene - в Python-процесс подсаживается JVM с Lucene на борту, а некий JCC обеспечивает взаимодействие. Но я бы сильно подумал, нужно ли использовать такую комбинацию…
- Для поправки ситуации есть Solr - уже всё-таки поисковый сервер, реализованный в виде веб-сервиса с XML/JSON/CSV-интерфейсами. Для запуска требует servlet-контейнер - Tomcat , или чтобы попроще - Jetty . Вот с ним уже можно работать из многих языков.
- Заявлено, что скорость индексации Lucene «типа, очень большая», больше 20 МБ/с, памяти при этом, типа, требуется очень мало (от 1 МБ), а инкрементальная индексация (по одному документу) такая же быстрая, как и индексация множества документов разом. Размер индекса заявлен 20-30 % от размера данных.
- Lucene очень расширяемая, поэтому есть куча различных фич и приблуд, особенно в сочетании Solr’а с другими библиотеками:
- 31 встроенный стеммер , куча анализаторов - обрабатывающих звучание (Soundex, Metaphone и вариации), аббревиатуры, стоп-слова, синонимы, «protect-слова» (обратное стоп-словам), словосочетания, шинглы, разделение слов (Wi-Fi, WiFi -> Wi Fi), URL’ы, и так далее, множество различных вариантов генерации запросов (например, FuzzyLikeThisQuery - поиск по «запросу, похожему на заданный»).
- Репликация индексов, автоматическая кластеризация (группировка) результатов поиска (Carrot2), поисковый робот (Nutch), поддержка разбора бинарных документов (Word, PDF и т.п) с помощью Tika .
- Есть даже приблуда для «поднятия» заданных результатов по заданным запросам независимо от нормального ранжирования (здравствуй, SEO).
- И даже это ещё не всё.
- Размер индекса совершенно Lucene’ский - 20 % от данных. Скорость индексации Solr’ом по 256 документов за запрос, без промежуточных коммитов, у меня получилась 2.75 МБ/с, а с коммитами раз в 1024 документа - 2.3 МБ/с. Если не коммитить, то памяти кушает больше - у меня в районе 110 МБ resident, если коммитить - 55 МБ.
- Скорость поиска Solr:
- В 5 потоков на 3 словах - в среднем 25 мс, максимум 212 мс.
- В 5 потоков на 2 словах - в среднем 35 мс, максимум 227 мс.
- В 5 потоков на 3 словах, первые 10 результатов - в среднем 15 мс, максимум 190 мс.
- В 1 поток на 3 словах - в среднем 11 мс, максимум 79 мс.
2.3.3.4, Lucene++ 3.0.3.4
- Lucene написана на Java, и поэтому есть некоторое количество портов её на разные языки, наиболее живые из которых - это C++ и C# порты - , Lucene++ и Lucene.NET . Есть и другие порты, но они (полу)заброшенные и/или нестабильные.
- С CLucene тоже не всё идеально:
- Развивается медленнее Lucene - в то время, как Lucene уже 3.3, CLucene стабильный (0.9.2.1) всё ещё соответствует Lucene 1.9, и в нём даже нет стеммеров, а CLucene «тестируемый» - Lucene 2.3.
- Биндингов к языкам мало / устаревшие, например Perl-биндинги поддерживают только 0.9.2.1. Называется «Write Your Own». Потратив пару часов, я их запатчил (поставив баг авторам) и даже добавил поддержку стеммеров, которые в 2.3, к счастью, всё-таки есть. Вообще сыроваты эти биндинги, я вот уже ещё один сегфолт выловил и запатчил.
- По-видимому, есть баги, документация в интернете устаревшая (но можно сгенерировать doxygen’ом из исходников нормальную), хостится на SourceForge, на котором всё медленно и грустно, а багтрекер время от времени сам закрывает баги (если на них никто не реагирует O_O).
- По фичам - большая часть фич Lucene в портах есть. Фич всяких Solr’ов, естественно, нет.
- Скорость индексации CLucene - у меня получилась 3.8 МБ/с. Не 20+ заявленных Lucene, но это же со стеммером и через Perl-интерфейс, так что весьма неплохо.
- Размер индекса, как и у Lucene/Solr, получился примерно 20 % от размера данных - это и рекорд среди всех движков, и соответствует заявленным 20-30 %!
- Lucene++ отличается от CLucene следующим:
- Реализация полнее и новее (3.0.3.4), например, есть анализаторы под разные языки со вшитыми стоп-словами.
- Lucene++ везде использует shared_ptr (автоматический подсчёт ссылок на объекты с помощью C++-шаблонов). Причём это очень конкретно заметно даже при компиляции, очень уж она долго происходит по сравнению с CLucene.
- С биндингами ещё хуже, чем в CLucene - есть только полудохлые под питон , сгенерённые SWIG "ом - то есть, наверняка текут как сволочи и вообще неизвестно, работают ли. Хотя мне, честно говоря, сходу даже не очень понятно, как нормально сделать Perl-биндинги к этим shared_ptr’ам.
- Lucene++, по-видимому, используют совсем мало, судя по тому, что в баг-трекере всего 9 багов.
- Скорость поиска - замеры аналогично замерам Xapian, только с использованием MultiFieldQueryParser вместо замены слов на дизъюнкции:
- В 5 потоков на 3 словах получается в среднем 10 мс, максимум 212 мс.
- В 5 потоков на 2 словах - в среднем 19 мс, максимум 201 мс.
- В 5 потоков на 3 словах, первые 10 результатов - в среднем 3 мс, максимум 26 мс.
- В 1 поток на 3 словах - в среднем 4 мс, максимум 39 мс.
- Зависит опять-таки в основном от количества найденного, что соответствует заметке о сложности поиска .
Для тех, кто в танке
- Инвертированный индекс - сопоставляет каждому слову набор документов, в которых оно встречается, в отличие от прямого индекса, который документу сопоставляет набор слов. Практически все движки полнотекстового поиска используют именно инвертированные индексы, ибо искать по ним быстро, хотя обновлять тяжелее, чем прямые.
- Стеммер - от английского слова «stem» - основа слова. Откусывает от слов окончания, делая из них основы. Предназначен для того, чтобы по слову «кошка» нашлись и «кошки», и «кошку», и так далее. Snowball - DSL для написания стеммеров.
- Стоп-слова - список очень часто употребляемых слов (предлогов-союзов и т. п.), индексировать которые нет смысла, потому что значения они содержат мало и встречаются почти везде.
- Позиционная информация - позиции слов в документах, сохраняемые в индексе, для дальнейшего поиска фраз или просто слов, расположенных друг от друга не дальше, чем на …
- Префиксный поиск (слов*) - поиск слов, начинающихся на заданное (например, кошк*). Иногда называется Wildcard-поиском, но строго говоря, Wildcard-поиск - это поиск слов, начинающихся на заданный префикс и оканчивающихся на заданный суффикс (например, ко*а - найдёт и слово «кошка», и «коала»).
- Багзилла - open-source баг-трекер, используемый у нас в компании, на содержимом которого тестировался поиск.
Сравнительная таблица
| MySQL | PostgreSQL | Xapian | Sphinx | Solr | CLucene | |
|---|---|---|---|---|---|---|
| Скорость индексации | 314 КБ/с | 522 КБ/с | 1.36 МБ/с | 4.5 МБ/с | 2.75 МБ/с | 3.8 МБ/с |
| Скорость поиска | 175 мс / 3.46 сек | 28 мс / 2.1 сек | 14 мс / 135 мс | 7 мс / 75 мс | 25 мс / 212 мс | 10 мс / 212 мс |
| Размер индекса | 150 % | 150 % | 200 % | 30 % | 20 % | 20 % |
| Реализация | СУБД | СУБД | Библиотека | Сервер | Сервер | Библиотека |
| Интерфейс | SQL | SQL | API | API, SQL | Веб-сервис | API |
| Биндинги | ∀ | ∀ | 9 | 6 + ∀ | 8 | 3.5 |
| Операторы поиска | &*" | &* | &*"N-~ | &*"N-| &*"N-~
| &*"N-~
|
|
| Стеммеры | Нет | 15 | 15 | 15 | 31 | 15 + CJK |
| Стоп-слова, синонимы | Нет | Да | Да | Да | Да | Да |
| Soundex | Нет | Нет | Нет | Да | Да | Нет |
| Подсветка | Нет | Да | Нет | Да | Да | Да |
Ранжирование результатов и сортировка по разным полям есть везде.
Дополнительно:
Заключение
Самый простой и самый быстрый движок - Sphinx. Минус в том, что обновляемые индексы там пока не очень юзабельны - их можно использовать, только если никогда ничего не удалять из индекса. Если это пофиксят, проблема выбора отпадёт совсем, Sphinx всех сделает.
Тоже быстрый, очень фичастый, эффективный и расширяемый, но не самый простой в использовании движок - Lucene. Главная проблема с интерфейсами - либо Java, либо C++ порты и проблемы с биндингами. То есть, если вы пишете не под Java, C++, Python или Perl, надо использовать Solr. Solr памяти уже немножко кушает, индексирует и ищет чуть помедленнее, может быть неудобен как отдельный Java-сервер в сервлет-контейнере, но зато имеет огромную кучу разных возможностей.
Xapian… Ищет шустро, индексирует не очень, и сам индекс получается великоват. Его плюс - куча интерфейсов под разные языки (C++, Java, Perl, Python, PHP, Tcl, C#, Ruby, Lua). Если появится режим для отключения индексации точных форм - размер индекса раза в 2 сразу уменьшится.
Если вы уже используете PostgreSQL и готовы мириться с не очень высокой скоростью индексации и полным отсутствием хитрых операторов поиска, то вполне можно использовать Textsearch, потому что ищет он быстрее MySQL и вполне сравнимо с остальными. Но нужно помнить о том, что индекс обязательно создавать на реальной колонке типа tsvector , а не на выражении to_tsvector() .
MySQL FULLTEXT тоже можно использовать в простых случаях, когда база небольшая. Но ни в коем случае не делать MATCH(несколько полей) и ни в коем случае не использовать префиксный поиск.
Любые правки этой статьи будут перезаписаны при следующем сеансе репликации. Если у вас есть серьезное замечание по тексту статьи, запишите его в раздел «discussion» .
Иван Максимов
Возможности поискового движка DataparkSearch
Как организовать поиск информации на файловом сервере не только по названию и типу документа, но и по его контенту? Возможно ли создать подходящий инструмент, доступный и прозрачный для пользователей?
В настоящее время вопрос поиска информации становится все более и более актуален. В сети Интернет давно идет конкурентная борьба между поисковыми системами, постоянно предлагающими новые сервисы, возможности и совершенные механизмы поиска. Но нужные данные сложно найти не только в Интернете. На домашних компьютерах пользователей также накапливается огромное количество и разобраться в этом многообразии иногда очень не просто. В организациях чаще всего информацию централизуют и сортируют на файловых серверах, но со временем поиск нужных документов затрудняется. Производители программного обеспечения отреагировали на данную потребность. На сегодня существуют десятки поисковых машин, работающих локально на PC, также появились серверные поисковые машины.
Локальные поисковые машины в большинстве своем распространяются бесплатно, тогда как корпоративные версии, позволяющие пользователям производить поиск информации на сервере, стоят достаточно дорого. Несомненно, покупая коммерческий продукт, мы получаем грамотную техническую поддержку и другие преимущества, но небольшие организации или владельцы частных сетей не всегда в состоянии заплатить тысячи долларов за подобные продукты. К счастью, в мире Open Source существуют свободные проекты, не уступающие по функциональности своим коммерческим конкурентам, с качественной поддержкой и обновлениями.
Сейчас мы рассмотрим один из вариантов по организации поиска документов на файловом сервере, который был реализован на конкретной задаче.
Начальные условия
Имеется файловый сервер под управлением ОС Linux. Для совместного использования файлов установлены популярные пакеты samba и pro-ftp. На диске используется файловая система reiserfs, как наиболее производительная для работы с большим количеством маленьких файлов (документы, около 3 тысяч, различных форматов: txt, html, doc, xls, rtf). Данные отсортированы, но их объем растет с каждым днем, удаление устаревшей информации не решает проблему. Как организовать поиск по именам и типам документов, а также по контенту? Как сделать его доступным для пользователей в локальной сети?
Для решения этих вопросов нам понадобится поисковый движок, сервер баз данных (MySQL, firebirg, ...), веб-сервер Apache и около гигабайта дискового пространства для работы комплекса.
Какой из поисковых движков выбрать?
Существуют локальные поисковые машины, такие как Google Desktop Search или Ask Jeeves Desktop Search . Возможно, для организации поиска в маленькой компании или на рабочей станции пользователя, под управлением ОС Windows, эти движки могут быть полезны, но не в данном случае. Поисковые «монстры» вроде Яндекса очень дороги, но если требуется качественная помощь разработчиков, то крупным компаниям, возможно, следует подумать об его аренде. Для *nix-семейства существует несколько проектов. Это движки:
- DataparkSearch
- Wordindex
- ASPseek
- Beagle
- MnogoSearch
Перечисленные движки позиционируются как свободно распространяемые поисковые машины для работы в локальной и/или глобальной сетях. Хочу заметить, что многие проекты не мультиплатформенные и не работают под операционными системами компании Microsoft. Для Windows-систем существуют серверные решения, такие как: MnogoSearch и «Ищейка» .
Итак, коротко рассмотрим поисковые машины под *nix-платформу:
Beagle – преемник в SUSE Linux движка Htdig . Последний дистрибутив SUSE, в который вошел движок Htdig, был за номером 9, в последующих версиях компания Novell заменила его на beagle. Htdig закончил свое развитие в 2004 году, последняя доступная версия – 3.2.0b6 от 31 мая 2004 года. Новый движок в SUSE позиционируется как локальный поисковик, но возможно использовать его и в корпоративной среде.
MnogoSearch (бывший UdmSearch) – известный многим и достаточно распространенный движок. Существуют версии как под Windows (30-дневная бесплатна версия), так и под *nix-платформы (лицензия GNU). Возможна работа практически со всеми распространенными версиями СУБД SQL под обе платформы. К сожалению, на данный движок достаточно много нареканий, поэтому я не остановил свой выбор на нём.
Wordindex – движок, находящийся в стадии разработки (на момент написания статьи последняя доступная версия 0.5 от 31 августа 2000 года). Работает в связке СУБД MySQL и веб-сервера Apache. Работоспособный проект представлен только на сайте разработчиков.
ASPseek – поисковая машина, получившая в прошлом достаточно большое распространение, но в 2002 году этот движок прекратил свое развитие (последняя доступная версия данной поисковой системы 1.2.10 от 22 июля 2002 года).
DataparkSearch – клон поискового движка MnogoSearch. Позволяет производить поиск как по именам файлов, так и по их контенту. Обработка txt-файлов, HTML-документов и тэгов mp3 встроена, для обработки содержимого документов иного типа необходимы дополнительные модули. Возможен поиск информации, как на локальном жестком диске, так и в локальной/глобальной сети (http, https, ftp, nntp и news).
Поисковая машина функционирует с самыми распространенными СУБД SQL, такими как MySQL , firebird , PostgreSQL и другими. По заявлению разработчиков, DataparkSearch стабильно работает на различных *nix-операционных системах: FreeBSD, Solaris, Red Hat, SUSE Linux и других. По сравнению с MnogoSearch в движке были исправлены некоторые ошибки, изменены в лучшую сторону некоторые функции. На сайте разработчиков приведены ссылки на рабочие версии движка в сети Интернет. Большой плюс – качественная документация на русском языке.
Итак, сравнив все «за» и «против», для реализации поиска на файловом сервере был выбран движок поисковой машины DataparkSearch.
Установка
Для работы нам понадобятся: веб-сервер Apache, сервер базы данных MySQL и исходные коды DataparkSearch. Устанавливаем сервер Apache и БД MySQL (со всеми необходимыми библиотеками). Если на вашем сервере установлена иная СУБД, то можно использовать и ее (см. документацию по движку). Далее распакуем архивы DataparkSearch и приступим к сборке нашего комплекса.
Запустим скрипт install.pl и ответим на необходимые вопросы: выбор папки установки движка, базы данных и другие относящиеся к параметрам работы движка. Рекомендуется оставит настройки по умолчанию. Опытные пользователи, прочитав документацию, расположенную в папке doc, могут вручную сконфигурировать движок (команда configure). Если при инсталляции скрипт не может найти mysql, возможно не установлены библиотеки для разработчиков (libmysql14 devil). Теперь скомпилируем и установим DataparkSearch командами make и make install.
Минимальное конфигурирование
Создадим базу данных:
sh$ mysqladmin create search
Командой mysqlshow просмотрим все таблицы в БД. Сразу хочу отметить, что удобнее работать с MySQL с помощью веб-консоли phpmyadmin, но можно обойтись и стандартным набором утилит. Необходимо создать нового пользователя в MySQL:
sh#mysql --user=root mysql
mysql> GRANT ALL PRIVILEGES ON *.* TO пользователь@localhost
IDENTIFIED BY "пароль" WITH GRANT OPTION;
exit
Перезагрузим MySQL.
Допустим, имя пользователя – searcher, пароль – qwerty.
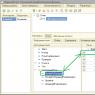
Теперь создаём файл indexer.conf в папке /etc/ движка, примеры данного файла (для некоторых задач) можно найти в папке /doc/samples исходников DataparkSearch. Пример с минимальными настройками приведен на рис. 1.
Рассмотрим файл подробнее. Как упомянуто в комментарии, команда DBAddr указывает путь к SQL-серверу (в нашем случае это MySQL), способ хранения данных и другие параметры (если необходимо). Существуют несколько режимов хранения: если не указывать dpmode, то по умолчанию будет значение single – самый медленный. Рекомендуется использовать режим cache, но если с ним возникли проблемы, можно использовать менее эффективный, но более простой в конфигурировании режим multi. Подробное описание всех параметров dbmode находится в документации.
DoStore хранит сжатые копии проиндексированных документов. Sections – модуль, предоставляющий гибкие возможности индексирования. Допустим, можно создать ограничение по тэгу или настроить индексацию не только содержимого файлов, но и URL (хост, путь, имя). Langmap – специальные языковые карты для распознавания кодировок и языков, эффективны, если документы размером более 500 байт.
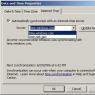
Второй необходимый конфигурационный файл – файл результатов поиска search.conf. Рекомендуется взять готовый шаблон (файл /etc/search.htm-dist) и отредактировать его под свои запросы. Нужно заметить, что основные параметры, указанные в файле indexer.conf, должны совпадать с параметрами в search.htm, иначе будут ошибки при работе движка. Search.htm состоит из нескольких блоков: первый – variables – содержит данные для работы движка (скрипт search.cgi), а все остальные блоки необходимы для формирования html-страницы результатов поиска. Пример блока variables в search.conf приведен на рис. 2.
Рассмотрим search.htm подробнее. Как видно, параметры DBAddr и LocalCharset совпадают с идентичными параметрами в indexer.conf. Если ваш веб-клиент поддерживает формат xml, то можно установить параметр ResultContentType text/xml. Ниже идут HTML-блоки, необходимые для дизайна страницы результатов, они здесь не представлены из-за большого объема. Рекомендуется пользоваться готовым шаблоном, расположенным в файле /etc/search.htm-dist. В сопроводительной документации полностью описан формат HTML-блоков (дизайна), желающие могут настроить его по своему вкусу.
Теперь можно запускать файл indexer из папки sbin движка DataparkSearch с параметром -Ecreate. Если все было сделано правильно, то будут созданы необходимы sql-таблицы в БД. Если появились ошибки, следует проверить имя пользователя mysql и пароль в файле indexer.conf, это наиболее распространенная ошибка.
Для тестирования рекомендуется проиндексировать небольшой участок ресурса, чтобы если возникнут ошибки, новая переиндексация не заняла много времени. Индексирование выполняется командой indexer без параметров, в итоге нам выведут результаты: затраченное время, количество документов и скорость работы.
Скопируем файл bin/search.cgi из директории DataparkSearch в папку cgi-bin нашего веб-сервера и отредактируем файл index.shtml нашего веб-сервера Apache (расположенный в папке html), добавив в него код формы поиска:
Теперь можно зайти на ресурс localhost, используя любой доступный браузер. В появившейся форме ввести искомое слово, допустим «процессор» (см. рис. 3). В итоге мы должны получить страницу с результатами поиска, если, конечно, такие документы существуют (см. рис. 4). Если вместо страницы с результатами поиска появится документ с ошибками, то следует проверить работу скрипта. Зайдя в директорию cgi-bin веб-сервера, выполним скрипт «seach.cgi test >> test.htm». Если страница результатов сформирована правильно, следует проверить конфигурацию сервера Apache: правильно ли указан путь до cgi-скрипта, выполняется ли тестовый скрипт test.cgi в директории веб-сервера.
Если test.htm пуст или также содержит ошибки, рекомендуется проверить, существуют ли данные в базе, делается это командой «indexer -S». Возможно, следует переиндексировать сервер командой «indexer – v 5» – максимальный уровень выдачи отладочной информации. Выставив в файле search.htm команду LogLevel 5 и внимательно просмотрев логи веб-сервера, можно выяснить, как выполняется обработка данных в SQL-сервере.
Добавление дополнительных модулей (парсетов)
По умолчанию движок работает только с файлами html и txt, но возможно установить дополнительные модули (парсеты), которые преобразуют иные типы документов в html или txt (plain text). Возможна работа с xls (Excel), doc (Word), rtf (Word), ppt (Power Point), pdf (Acrobat Reader) и даже rpm (RedHar Package Manager)-файлами, в последнем будут отображаться только метаданные. В нашем случае понадобится обработка офисных форматов. Для xls и doc существует несколько парсетов: catdoc преобразует документы в txt-формат, XLHTML и vwHtml конвертируют файлы в HTML-формат.
Я рекомендую использовать пакет catdoc, так как скорость преобразования в txt-формат намного выше преобразования в HTML-формат, к тому же программа XLHTML иногда «подвисала» при конвертировании документов. Хотя разработчики предвидели данную проблему и рекомендуют во избежание «зависания» парсета установить в indexer.conf параметр ParserTimeOut 300 (число указывается в секундах), но время индексирования тогда еще более возрастет.
Также нам понадобится еще один парсет – unrtf – для работы с rtf-файлами, он конвертирует документы в html-код или text/plain-формат на выбор пользователя.
Скачаем и установим нужные пакеты, для подключения парсета нужно добавить строки в indexer.conf:
Для формата xls (программа xls2csv входит в пакет catdoc):
Mime application/vnd.ms-excel text/plain "xls2csv $1"
AddType application/vnd.ms-excel *.xls *.XLS
для документов doc параметры выглядят так:
Mime application/msword text/plain "catdoc $1"
AddType application/vnd.ms-excel *.doc *.DOC
обработка RTF-документов:
AddType text/rtf* *.rtf *.RTF
AddType application/rtf *.rtf *.RTF
Mime text/rtf* text/html "/usr/local/bin/unrtf --text $1"
Mime application/rtf text/html "/usr/local/bin/unrtf --text $1"
Cтоит напомнить, что некоторые Windows-приложения иногда создают файлы с тем же расширением в верхнем регистре, поэтому добавим в список AddType те же расширения, но с иными названиями.
Для индексации можно добавлять любые типы документов, но движок будет показывать только ссылки на имена файлов.
Допустим, если необходимо проиндексировать rpm или iso-файлы и получить из них метаданные, вам понадобится сначала найти соответствующую программу (парсет) и добавить нужные параметры в index.conf. Список поддерживаемых типов документов можно посмотреть, например, в файле mime.types сервера Apache. Готовые решения для конвертации файлов или получения из них метаданных можно найти среди настроек пакета Midnight Commander, в файле mc.ext.
Режим хранения cache
Существует несколько способов ускорить работу движка, один из них – использовать метод хранения данных cache. Для работы в этом режиме нам потребуются утилиты cached и run-splitter, находящиеся в директории sbin относительно движка. Если у вас уже создана SQL-база данных в другом режиме (dpmode), не забудьте сначала ее удалить и только потом изменить режим хранения. Очистим базу данных командами: «indexer -С» (очистка SQL-таблиц) и «indexer Edrop» (удаление таблиц). Далее создайте из файла шаблона cached.conf-dist, расположенного в папке etc нашего движка, файл cached.conf. Не забудем изменить в нем параметры доступа к SQL БД:
Теперь можно отредактировать файлы index.conf и search.conf, изменив в них параметры:
indexer.conf
DBAddr mysql://searcher:qwerty@localhost/search/?dbmode=cache&cached=localhost:7000
search.htm
DBAddr mysql://searcher:qwerty/search/?dbmode=cache
Этого изменения в целом достаточно, но если вы желаете достичь еще большей гибкости движка, то рекомендуется ознакомиться с дополнительными параметрами режима cache и внести необходимые изменения в конфигурационные файлы.
cached & 2> cached.out
Демон запустится и будет записывать отладочную информацию в файл cached.out. Порт работы cached по умолчанию – 7000, но если необходимо, его можно изменить (в cached.conf).
Заново создадим SQL-таблицы для нового режима хранения данных командой «indexer -Ecreate» и проиндексируем сервер – indexer. После завершения выполним команду:
run-splitter -k
Должен сказать, что данный метод ускоряет не только скорость поиска по базе, а также скорость индексирования. Теперь можно попробовать произвести поиск по БД, если все было сделано правильно, то мы получим результаты поиска.
Дополнительные функции
В приведенной конфигурации использовались минимальные параметры настройки, с помощью дополнительных можно добиться большей функциональности и гибкости движка, все зависит от поставленных задач. Для повышения скорости работы поиска движка можно использовать модуль mod_dpsearch для сервера Apache. Потребность в данном модуле возникает, если индексируются сотни тысяч документов и необходимо повысить скорость работы движка до максимума. Также в документации можно найти и другие методы ускорения работы движка, например: оптимизация SQL БД или использование виртуальной памяти в качестве кэша.
Достаточно часто возникает необходимость в поиске грамматических форм слов. Допустим, нам нужны все формы слова «процессор» (процессоры, процессоров, ...), для этого можно настроить модули ispell или aspell. Более подробно о них написано в документации.
В DataparkSearch имеется возможность индексировать сегменты сетей, за это отвечает параметр: subnet 192.168.0.0/24 в indexer.conf.
Также возможно запрещать индексировать определенные типы файлов или конкретные папки на серверах: Disallow *.avi или Disallow */cgi-bin/*.
В шаблонах конфигурационных файлов можно найти описания (с примерами) других полезных параметров, которые могут понадобиться для реализации определенной задачи.
Выводы
Поисковый движок DataparkSearch – мощное средство для работы c веб-ресурсами, расположенными как в локальной сети, так и в глобальной. Проект постоянно развивается и дорабатывается, на момент написания статьи последняя стабильная версия движка 4.38 (от 13.03.2006) и снапшота 4.39 (от 19.04.2006). Должен заметить, что обновления последней версии происходят почти через день.
Мы не рассматривали вопрос о создании публичного поискового сервиса в Интернете, если же вам это требуется, ознакомтесь с соответствующей документацией по СУБД, веб-серверу и другим моментам, касающимся защиты информации от несанкционированного доступа.
Приложение
Работа
Сервер был установлен на машине: AMD Athlon 2500 Barton, 512 Мб DDR 3200 (Dual), HDD WD 200 Гб SATA (8 Мб кэш, 7200 оборотов). Конфигурация движка: движок DataparkSearch (v4.38), СУБД MySQL (v4.1.11), веб-сервер Apache (v1.3.33), производится индексация doc, xls, rtf (конвертация в text/plain), html, txt-файлов. Используется режим хранения данных multi. Обработка примерно 2 тыс. файлов, расположенных на данной машине (размер на диске ~1 Гб), и индексация их контента требует 40 мин, размер БД после работы примерно равен 1 Гб. Должен заметить, что скорость работы движка с нелокальными ресурсами будет зависеть от скорости канала. Также скорость индексирования зависит от используемых парсетов. Использование режима хранения cache улучшает скорость работы примерно на 15-20%. В качестве клиентского ПО используются веб-браузеры, проверялась работа на: Firefox, Opera, Konqueror, Microsoft Internet Explorer и даже Lynx – проблем не возникло. Всю работу серверной части движка можно автоматизировать с помощью всем известного демона cron, поместив в него нужные параметры для индексации данных.
Вконтакте
На тысячах анонимных FTP-сайтов. В этом многообразии пользователям было достаточно сложно обнаружить программу, подходящую для решения их задачи.
Более того, они заранее не знали, существует ли искомый инструмент. Поэтому приходилось вручную просматривать FTP-хранилища, структура которых значительно отличалась. Именно эта проблема и привела к появлению одного из ключевых аспектов современного мира - интернет-поиска.
История создания
Считается, что создателем первого поискового движка выступил Алан Эмтейдж (Alan Emtage). В 1989 году он работал в университете Макгилла в Монреале, куда переехал из родного Барбадоса. Одной из его задач как администратора университетского факультета информационных технологий было нахождение программ для студентов и преподавателей. Чтобы облегчить себе работу и сэкономить время, Алан написал код, который выполнял поиск за него.«Вместо того чтобы тратить свое время на брожение по FTP-сайтам и пытаться понять, что на них есть, я написал скрипты, которые делали это за меня, - рассказывает Алан, - и делали быстро».
<поле>:<необязательный пробел><значение><необязательный пробел>
Запись <поле> могла принимать два значения: User-agent или Disallow. User-agent конкретизировала имя робота, для которого описывалась политика, а Disallow определял разделы, к которым закрывался доступ.
Например, файл с такой информацией запрещает всем роботам доступ к любым URL с /cyberworld/map/ или /tmp/, или /foo.html:
# robots.txt for http://www.example.com/
User-agent: *
Disallow: /cyberworld/map/ # This is an infinite virtual URL space
Disallow: /tmp/ # these will soon disappear
Disallow: /foo.html
В этом примере закрывается доступ к /cyberworld/map для всех роботов, кроме cybermapper:
# robots.txt for http://www.example.com/
User-agent: *
Disallow: /cyberworld/map/ # This is an infinite virtual URL space
# Cybermapper knows where to go.
User-agent: cybermapper
Disallow:
Этот файл «развернет» всех роботов, которые попробуют получить доступ к информации на сайте:
# go away User-agent: * Disallow: /
Бессмертный Archie
Созданный практически три десятилетия назад, Archie все это время не получал никаких обновлений. И он предлагал совершенно иной опыт общения с интернетом. Но даже сегодня с его помощью можно найти необходимую вам информацию. Одним из мест, которые до сих пор хостят поисковый движок Archie , является Варшавский университет. Правда большая часть находимых сервисом файлов датируются 2001 годом.
Несмотря на тот факт, что Archie - это поисковый движок, он все же предлагает несколько функций для настройки поиска. Помимо возможности указать базу данных (анонимные FTP или польский веб-индекс), система предлагает выбрать варианты трактовки введенной строки: как подстроку, как дословный поиск или регулярное выражение. Вам даже доступны функции по выбору регистра и три опции по изменению вариантов отображения результатов: ключевые слова, описание или ссылки.

Также имеются несколько опциональных параметров поиска, которые позволяют более точно определить необходимые файлы. Имеется возможность добавления служебных слов OR и AND, ограничение области поиска файлов определённым путем или доменом (.com, .edu, .org и др.), а также задание максимального числа выдаваемых результатов.
Хотя Archie очень старый поисковый движок, он все же предоставляет довольно мощную функциональность при поиске нужного файла. Однако по сравнению с современными поисковыми системами, он крайне примитивен. «Поисковики» ушли далеко вперед - достаточно лишь начать вводить желаемый запрос, как система уже предлагает варианты поиска. Не говоря уже об используемых алгоритмах машинного обучения.
Сегодня машинное обучение представляет собой одну из главных частей поисковых систем, таких как Google или «Яндекс». Примером использования этой технологии может быть ранжирование поиска: контекстуальное ранжирование, персонализированное ранжирование и др. При этом очень часто применяются системы Learning to Rank (LTR).
Машинное обучение также позволяет «понимать» запросы, вводимые пользователем. Сайт самостоятельно корректирует написание, обрабатывает синонимы, разрешает вопросы многозначности (что хотел найти пользователь, информацию о группе Eagles или же об орлах). Поисковые системы самостоятельно учатся классифицировать сайты по URL - блог, новостной ресурс, форум и т. д., а также самих пользователей для составления персонализированного поиска.
Прапрадедушка поисковых движков
Archie породил такие поисковые системы, как Google, потому в какой-то мере его можно считать прапрадедушкой поисковых движков. Это было почти тридцать лет назад. Сегодня индустрия поисковых систем зарабатывает порядка 780 миллиардов долларов ежегодно.Что касается Алана Эмтейджа, то когда его спрашивают об упущенной возможности разбогатеть, он отвечает с долей скромности. «Разумеется, я бы хотел разбогатеть, - говорит он. - Однако даже с оформленными патентами я мог бы и не стать миллиардером. Слишком легко допустить неточности в описании. Иногда выигрывает не тот, кто был первым, а тот, кто стал лучшим».
Google и другие компании не были первыми, но они превзошли своих конкурентов, что позволило основать многомиллиардную индустрию.
Когда нетпиковец сталкивается с задачей, требующей временных затрат (например, создать проект Звезды смерти или построить компактный аппарат холодного ядерного синтеза), он в первую очередь думает, как автоматизировать эту работу. Результаты таких размышлений мы собираем на cпециальной странице нашего сайта. Сегодня мы расскажем о том, как в недрах агентства Netpeak рождается новый полезный сервис.
Давным-давно, в далекой-далекой галактике мы решили изменить поисковый движок сайта клиента для повышения видимости страниц в обычном поиске.
Задача
Поисковый движок клиентского проекта, с которым нам пришлось работать, создавал отдельную страницу под каждый запрос. Так как запросы бывают с опечатками, то таких страниц накопилась целая гора — как правильных, так и с ошибками. В общем — более двух миллионов страниц: поровну для русского и английского языка. Страницы с ошибками индексировались и засоряли выдачу.
Нашей задачей было сделать так, чтобы все варианты запросов — как правильные, так и с ошибками — вели на одну страницу. Например, для каждого из запросов baseball, basaball, baaeball, baselball были свои страницы, а нужно было сделать так, чтобы все варианты сходились на одну страницу с правильным запросом — baseball. В таком случае страница будет соответствовать правильной форме запроса и мы сможем избавиться от мусора в выдаче.
Примеры групп:
Стоит отметить, что агентствам далеко не всегда доверяют внедрения изменений в движке сайта. Так что мы благодарны нашему клиенту за возможность реализации этого проекта.
Цель
Создать чёткий работающий механизм простановки редиректов со страниц для фраз с ошибками на страницу клиентского сайта с правильной фразой.
Это нужно как для улучшения сканирования и индексации целевых страниц поисковиком, так и для построения семантического ядра и использования его при разработке новой структуры сайта. Конечно, мы не знали общее количество языков, на которых вводились запросы, но основная масса фраз были на русском и английском, поэтому мы ориентировались на эти языки.
Как рождался новый метод
Самое простое решение, которое тут же приходит в голову — загнать запросы в Google, а он нам честно исправляет. Но организовать такую пробивку — довольно затратное мероприятие. Поэтому мы с товарищами пошли другим путем. Наш математик-аналитик решил использовать лингвистический подход (внезапно!) и построить языковую модель.
Что это значит? Мы определяем вероятность встретить слово в языке и для каждого слова находим вероятности допустить в нем разные ошибки. Все бы ничего, и теория тут красивая, но для сбора такой статистики нужно иметь огромный размеченный текстовый корпус для каждого языка (опять же, ближе всего к этому подошли поисковики). Естественно, возникли вопросы, как это делать и кто все это будет воплощать в код. До нас подобным делом никто не занимался (если знаете кейс — киньте ссылку в комментарии), поэтому методику разрабатывали с нуля. Было несколько идей и заранее не было очевидно, какая из них лучше. Поэтому мы ожидали, что разработка будет вестись циклически — подготовка идеи, реализация, тестирования, оценка качества, а затем решение — продолжать дорабатывать идею или нет.
Реализацию технологии можно условно разбить на три этапа. О каждом из них — подробнее.

Этап №1. Формирование проблемы. Первые грабли
Внимание! После этой строки будет много терминов, которые мы постарались объяснить максимально простым языком.
Так как дополнительная информация (словари, частоты, логи) недоступна, то были попытки решить задачу с теми ресурсами, которые у нас были. Мы испробовали разные методы кластеризации. Основная идея — в том, что слова из одной группы должны не слишком сильно различаться.
Кластеризация — процедура, выполняющая сбор данных, содержащих информацию о выборке объектов, и затем упорядочивающая объекты в сравнительно однородные группы.
Расстояние Левенштейна показывает, какое минимальное количество изменений (удаление, вставка и замена) в строке А надо сделать, чтобы получить строку В.
- Замена символа: sh[e]res — sh[i]res, sh[o]res;
- Вставка символа: sheres — s[p]heres;
- Удаление: gol[d][f] — golf, gold.
В каждом из примеров расстояние между словом с ошибкой и правильной формой — 1 исправление.
Коэффициент Жаккарда на би- и триграммах помогает выяснить, сколько общих комбинаций из двух- или трехсимвольных слогов есть у строк А и В.
Пример: пусть мы рассматриваем строки A = snowboard и B = border. Общая формула коэффициента для биграмм имеет вид:
J = (число одинаковых биграмм для А и В) / (общее число биграмм в А и В)
Разобьем строки на биграммы:
биграммы для A = { sn, no, ow, wb, bo+, oa, ar, rd+ } - 8 штук; биграммы для B = { bo+, or, rd+, de, er } - 5 штук; Плюсиками отмечены одинаковые биграммы их 2 штуки - bo и rd.
Для триграмм будет аналогично, только вместо двух букв будут использоваться три. Коэффициент Жаккарда для них будет такой:
Пример более похожих слов:
А = baseball и В = baaeball { ba+, as, se, eb+, ba+, al+, ll+ } { ba+, aa, ae, eb+, ba+, al+, ll+ } J = 5 / (7 + 7 - 5) = 0.56
Хотя коэффициент Жаккарда и работает быстрее, но не учитывает порядок слогов в слове. Поэтому использовался в основном для сравнения с расстоянием Левенштейна. Теоретически, тут все было просто. Методики кластеризации для малых данных решаются достаточно легко, но на практике оказалось, что для завершения разбивки нужны либо огромные вычислительные мощности, либо — годы времени (а в идеале — и то, и другое). За две недели работы был написан скрипт на Python. При запуске он читал фразы из файла и выдавал списки групп в другой файл. При этом, как и любая программа этот скрипт грузил процессор и использовал оперативную память.
Большинство испытанных методов требовали терабайтов памяти и недели процессорного времени. Мы же адаптировали методы так, чтобы программе хватало 2 гигабайта памяти и одного ядра. Впрочем, миллион запросов обрабатывался примерно 4-5 дней. Так что время выполнения задачи все равно оставляло желать лучшего. Результат работы алгоритма на небольшом примере можно представить в виде графика:

В применении к клиентскому проекту это означает, что страницы, соответствующие запросам в одном кластере, будут склеены друг с другом 301 редиректом . Напомним, что нашей целью было создать чёткий работающий механизм простановки редиректов со страниц для фраз с ошибками на страницу клиентского сайта с правильной фразой. Но даже на таком примере очевидны недочеты:
- Непонятно, как из групп находить правильные формы и есть ли они там вообще.
- Неизвестно, какие пороги для ошибок использовать. Если будет большой порог (больше 3-х ошибок), то группы будут очень большими и замусоренными, если слишком маленький — то каждое слово образует свою группу, что нас также не устраивало. Найти какое-то универсальное, приемлемое для всех групп значение — невозможно.
- Неясно, что делать со словами, которые могут быть отнесены одновременно к нескольким группам.
Этап №2. Упрощение. Новая надежда
Мы переделали алгоритм, приблизив его к традиционным механическим корректорам грамматики. Благо, таких достаточно. В качестве базы была выбрана библиотека для Python — Enchant. В этой библиотеке есть словари практически для любого языка мира, в использовании она довольно проста, и есть возможность получить подсказки — что на что нужно исправлять. В ходе предыдущего этапа мы многое узнали о видах запросов и о том, на каких языках могут быть эти запросы.
Из открытого доступа были собраны следующие словари:
- английский (Великобритания);
- английский (США);
- немецкий;
- французский;
- итальянский;
- испанский;
- русский;
- украинский.
- Если оно правильное (находится в одном из словарей) — оставляем его как есть;
- Если оно неправильное — получаем список подсказок и берем первую попавшуюся;
- Все слова вновь склеиваем в фразу. Если такой фразы мы раньше не встречали, то создаем для неё группу. Исправленная форма фразы становится её «центром». Если же встречали, то значит для этой фразы уже есть своя группа, и мы добавляем туда новую ошибочную форму.

В итоге мы получили центр группы и список слов из этой группы. Тут, конечно, все лучше, чем в первый раз, но появилась скрытая угроза. Из-за специфики проекта в запросах очень много имен собственных. Есть и имена-фамилии людей, и города, организации, и географические местности, и даже латинские названия динозавров. В дополнение ко всему, мы обнаружили слова с неправильной транслитерацией. Так что мы продолжили искать пути решения проблемы.
Этап №3. Дополнения и пробуждение Силы
Проблема транслитерации решилась довольно просто и традиционно. Во-первых, сделали словарик соответствия букв кириллицы и латиницы. 
В соответствии с ним преобразовали каждую букву в проверяемых словах и отметили, есть ли для полученного слова исправление по словарю. Если вариант с транслитерацией имел наименьшее количество ошибок, то мы выбирали его как правильный. А вот имена собственные — тот еще орешек. Самым простым вариантом пополнить словари оказался сбор слов из дампов Википедии. Однако и в Вики есть свои слабые места. Слов с ошибками там довольно много, а методика их фильтрации еще не идеальна. Мы собрали базу слов, которые начинались бы с большой буквы, и без знаков препинания перед ними. Эти слова и стали нашими кандидатами в имена собственные. Например, после обработки такого текста подчеркнутые слова добавлялись в словарь:

При внедрении алгоритма оказалось, что для поиска подсказок в дополненном словаре Enchant иногда требуется больше 3 секунд на слово. Чтоб ускорить этот процесс, была использована одна из реализаций автомата Левенштейна .
Если коротко, идея автомата состоит в том, что по имеющемуся словарю мы строим схему переходов. При этом нам заранее известно, сколько исправлений в словах будут для нас приемлемы. Каждый переход означает, что мы делаем какое-то преобразование над буквами в слове — оставляем букву или применяем один из видов исправления — удаление, замена или вставка. А каждая вершина — это один из вариантов изменения слова.
Теперь, допустим, у нас есть слово, которое мы хотим проверить. Если в нем есть ошибка, нам нужно найти все подходящие нам формы исправления. Последовательно мы начинаем двигаться по схеме, перебирая буквы проверяемого слова. Когда буквы закончатся, мы окажемся в одной или нескольких вершинах, они и укажут нам варианты правильных слов.

На изображении представлен автомат для слова food со всевозможными двумя ошибками. Стрелка вверх означает вставку символа в текущую позицию. Стрелка по диагонали со звездочкой — замена, с эпсилон — удаление, а по горизонтали — буква остается без изменений. Пусть у нас есть слово fxood. Ему будет соответствовать путь в автомате 00-10-11-21-31-41 — что равносильно вставке в слово food буквы x после f.
Кроме того, мы провели дополнительную работу по расширению собранных основных словарей, отсеиванию заранее не словарных фраз (названия моделей товаров и разные идентификаторы) в автоматическом режиме, внедрили транслитерацию и поиск по дополнительному словарю.
Что в итоге?
Мы еще работаем над модернизацией алгоритма, но уже на данном этапе разработки мы получили инструмент, которым можно чистить мусор, вроде облаков тегов, и склеивать 301 редиректами ненужные страницы. Такой инструмент будет особенно эффективен для небольшого количества слов с ошибками, но и на больших массивах показывает вполне удовлетворительные результаты. Промежуточный вариант скрипта отправлен клиенту для формирования блока перелинковки. По этому блоку можно будет собирать дополнительную информацию об исправлениях запросов. Полностью результаты работы скрипта на внедрение мы не отправляли, потому что все еще работаем над улучшением качества работы скрипта.

На создание кода и его испытания в общем ушло 40 часов работы математика-аналитика. Вывод: если вам однажды понадобится обработать около двух миллионов запросов — не отчаивайтесь. Такие задачи можно автоматизировать. Понятно, что добиться 100% точности будет очень сложно, но обработать корректно хотя бы 95% процентов информации — реально.