How to find out the indexing date of a page. The modtime parameter in Yandex.Xml. Does Yandex really mark the age of a page out of concern for SEOs? Checking the number of pages in the Yandex index using operators
For a number of SEO analytics tasks, it is necessary to determine how long the search engine “knows” about the existence of a specific page on the site. One of the common ways to find out the age of a document in Yandex is to search for the url using Yandex.Xml to obtain the modtime parameter. Due to the breakdown of the “&how=tm” parameter, the method gained even more popularity.
It turns out convenient and fast, fortunately there is a visual interface at https://xml.yandex.ru/test/. But I with great doubt I relate to this method.
What's wrong with modtime?
Firstly, the service documentation only states this:
Thus, the idea that the tag displays the date of first indexing belongs entirely to SEO people.
Secondly, Yandex.Xml users are, to put it mildly, not the most important clients for the search engine. Access is given free of charge, there are no advertisements there. Why would Yandex LLC be especially concerned about the accuracy, relevance and reliability of xml parameters? Although you can still believe this - well, good programmers do everything well. But why provide undocumented capabilities is completely unclear.
However, all this is lyrics and my speculation. Let's get down to the facts.
What is “document age from the point of view of Yandex”?
As logic and Google tell me, this is the time that has passed since the first indexing. Most often, we are interested in exactly this - from what date the page began to attract traffic, accumulate age, and so on.
In reality it varies. You don't have to look far for an example.
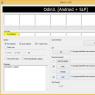
Let's check modtime for several pages of my old hobby project smmup.ru.
| Address | Date from modtime | |
|---|---|---|
| / | 20140916T170528 | 2014-09-16 |
| /activity.php | 20150422T103533 | 2015-04-22 |
| /target.php | 20150208T173922 | 2015-02-08 |
| /kogda.php | 20141112T210047 | 2014-11-12 |
I already wrote about the history of the resource in the article For a long time it was not properly indexed by Yandex. I have preserved correspondence with Plato, dated April 20, 2015. At this moment, there was only one page in the search - the main page.
That is, modtime for at least two urls turned out to be not the date of appearance in the index at all. For /kogda.php, the difference between the value from this parameter and the final indexing time is almost six months! The document is not in the index - but modtime is already with experience (the soldier is sleeping - the service is in progress).
What does this mean? To exaggerate a little: we analyzed competitors for the request, saw a bunch of old pages there, got scared and did not move forward on it. And half of the competitors have actually been under strict filters for a long time and it is not so difficult to overcome them.
The situation is theoretical, I described it simply as a clear example of why you need to rely on modtime with great caution.
But these are still flowers.
Modtime may contain a date LATER than the actual indexing
In the case of smmup.ru, we can at least interpret modtime as the time of the robot's first visit. The dates correlate well with the actual appearance of pages on the site.
Here's another example. Here I simply do not dare to put forward a hypothesis about where everything comes from.

- My blog has no problems with indexing (especially since that article was reposted in several popular groups).
- There were no redirects, changes of addresses, or the like.
To dispel any last doubts:

That is: modtime significantly underestimated the age of the page.
This example was found in exactly 2 minutes (I just looked at the parameter for blog pages, without additional tricks), which indicates the high prevalence of such results. In addition, I saw many similar cases on sites that I audited (I don’t show them for obvious reasons), sometimes the error was years.
Results
- Modtime does not always display the correct indexation date (in fact, no one from Yandex promised this).
- Rely only on this parameter in determining the age of pages it is forbidden. The results are unreliable.
- Therefore, its use for analyzing competitors’ websites is a big question. You can use it when working with your own projects - thanks to the availability of other data for control. However, the range of problems that can be solved in this way is quite narrow.
I will be glad to receive additional interpretations and interesting examples!
p.s. There was a long and not particularly productive discussion on this topic on FB. Perhaps I was not able to formulate the message of the article well enough. The point is not that there are some glitches with modtime. It is clear that Yandex can, for one reason or another, reset the “age” of a page. The main thing is that these examples illustrate: a) you cannot rely on modtime as the date of first indexing b) there is no certainty that an age “reset” according to modtime means a complete clearing of the page from accumulated factors that are directly or indirectly related to age .
Two methods for obtaining the date a page was first indexed stopped working:
- the date operator does not work correctly;
- adding the &how=tm parameter to the query string no longer displays indexing dates.
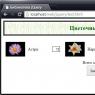
But this information can still be obtained via Yandex XML. To do this, you need to follow the link https://xml.yandex.ru/test/ and in the “&query” field enter a query like url:%page%, where %page% is the page address. Next, click on “Find” and in the resulting result we look for a tag that will indicate the date the page was first indexed.

Date of crawl by search robot and status in the search database
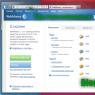
To find out the date of the last crawl of the page and information about which version is located when building search results, you need to select “Check URL status” in the Yandex.Webmaster service in the “Indexing” section. Next, indicate the required address and receive the data. This method only works for a verified site.

Date of creation of the saved copy
To find out the date of creation of the saved copy, you need to click on the drop-down menu in the search results (next to the name of the page address).





Viewing saved copies in the Bing and Mail search engines will show older versions of pages, since they re-index them more slowly than Yandex and Google search robots.
Conclusion
- As shown in the example above, the saved copy of the page is not always used to build the index base. But, often, this is true.
- In addition, if you have made any changes to the page and are waiting for these changes to be re-indexed, then you should not conclude that the changes have been taken into account based on the date of the last crawl by the search robot.
Website indexing in search engines is important for every webmaster. After all, for high-quality promotion of a project, you should monitor its indexing. I will describe the process of checking indexing in Yandex.
Indexing in Yandex
The Yandex robot scans sites day after day in search of something “tasty.” Collects in the top results those sites and pages that, in his opinion, most deserve it. Well, or Yandex just wanted it that way, who knows :)
We, as real webmasters, will adhere to the theory that the better the site is made, the higher its position and the more traffic.
There are several ways to check site indexing in Yandex:
- using Yandex Webmaster;
- using search engine operators;
- using extensions and plugins;
- using online services.
Indexing website pages in Yandex Webmaster
To understand what the search engine dug up on our site, you need to go to our beloved Yandex Webmaster in the “Indexing” section.
Bypass statistics in Yandex Webmaster
First, let’s go to the “Bypass Statistics” item. This section allows you to find out which pages of your site the robot crawls. You can identify addresses that the robot was unable to load due to the unavailability of the server on which the site is located, or due to errors in the content of the pages themselves.
The section contains information about the pages:
- new - pages that recently appeared on the site or the robot has just crawled them;
- changed - pages that the Yandex search engine previously saw, but they have changed;
- crawl history - the number of pages that Yandex crawled, taking into account the server response code (200, 301, 404 and others).
The graph shows new (green) and changed (blue) pages.
And this is a graph of the crawl history.

This item displays the pages that Yandex found.
N/a — URL is not known to the robot, i.e. the robot had never met her before.
What conclusions can be drawn from the screenshot:
- Yandex did not find the address /xenforo/xenforostyles/, which, in fact, is logical, because this page no longer exists.
- Yandex found the address /bystrye-ssylki-v-yandex-webmaster/, which is also quite logical, because new page.
So, in my case, Yandex Webmaster reflects what I expected to see: what is not needed, Yandex has removed, and what is needed, Yandex has added. This means that everything is fine with the bypass, there are no blockages.
Pages in search
Search results are constantly changing - new sites are added, old ones are deleted, positions in search results are adjusted, and so on.
You can use the information in the “Pages in Search” section:
- to track changes in the number of pages in Yandex;
- to track added and excluded pages;
- to find out the reasons for excluding a site from search results;
- to obtain information about the date the search engine visited the site;
- to receive information about changes in search results.
This section is needed to check the indexing of pages. Here Yandex Webmaster shows pages added to search results. If all your pages are added to the section (a new one will be added within a week), then everything is in order with the pages.

Checking the number of pages in the Yandex index using operators
In addition to Yandex Webmaster, you can check the indexing of a page using operators directly in the search itself.
We will use two operators:
- “site” - search across all subdomains and pages of the specified site;
- “host” - search for pages hosted on a given host.
Let's use the "site" operator. Note that there is no space between the operator and the site. 18 pages are in Yandex search.

Let's use the "host" operator. 19 pages indexed by Yandex.

Checking indexing using plugins and extensions

Check site indexing using services
There are a lot of such services. I'll show you two.
Serphunt
Serphunt is an online service for website analysis. They have a useful tool for checking page indexing.
You can simultaneously check up to 100 website pages using two search engines - Yandex and Google.
To check the indexing of a page, add it to the list:

Click “Start scanning” and after a few seconds we get the result:

Two methods for obtaining the date a page was first indexed stopped working:
- the date operator does not work correctly;
- adding the &how=tm parameter to the query string no longer displays indexing dates.
But this information can still be obtained via Yandex XML. To do this, you need to follow the link https://xml.yandex.ru/test/ and in the “&query” field enter a query like url:%page%, where %page% is the page address. Next, click on “Find” and in the resulting result we look for a tag that will indicate the date the page was first indexed.
Date of crawl by search robot and status in the search database
To find out the date of the last crawl of the page and information about which version is located when building search results, you need to select “Check URL status” in the Yandex.Webmaster service in the “Indexing” section. Next, indicate the required address and receive the data. This method only works for a verified site.
Date of creation of the saved copy
To find out the date of creation of the saved copy, you need to click on the drop-down menu in the search results (next to the name of the page address).
Viewing saved copies in the Bing and Mail search engines will show older versions of pages, since they re-index them more slowly than Yandex and Google search robots.
Conclusion
- As shown in the example above, the saved copy of the page is not always used to build the index base. But, often, this is true.
- In addition, if you have made any changes to the page and are waiting for these changes to be re-indexed, then you should not conclude that the changes have been taken into account based on the date of the last crawl by the search robot.