Определение ключевых полей.
Таблица
Это термин, который очень часто употребляется в FoxPro и также часто он употребляется совсем не в том смысле, как его понимают новички. Можно сказать, что у этого термина есть два определения (как и у термина "база данных")
Таблица - это файл с расширением DBF и связанные с ним файлы с тем же именем, но с расширением FPT (файл для хранения полей типа Memo и General ) и с расширением CDX (структурный индексный файл)
Формально, это абсолютно правильное определение. Проблема только в том, что в подавляющем большинстве случаев, когда в FoxPro употребляют термин "таблица" , то под этим подразумевают вовсе не это. Точнее, не совсем это .
Таблица - это некий образ файла с расширением DBF открытый в указанной сессии данных и в указанной рабочей области .
Со стремлением американцев все сокращать они не потрудились придумать соответствующий термин. Поэтому постоянно возникает путаница. Уместнее было бы использовать вместо термина "таблица" термины "курсор" или "алиас" , поскольку они более точно отображают суть. И действительно, в некоторых случаях эти термины именно в таком смысле и употребляются, чем только окончательно все запутывают, поскольку они используются также и в других смыслах.
Алиас (alias ) - это "псевдоним" файла DBF открытого в какой-либо рабочей области. Как правило, алиас совпадает с именем файла DBF. Однако это не всегда так. Дело в том, что в одном сеансе данных не может быть двух одинаковых алиасов. Поэтому, если алиас таблицы не указан явно при ее открытии (опция ALIAS в команде USE, или каким-либо другим способом), то FoxPro самостоятельно назначит уникальный алиас для таблицы, начав разумееется с алиаса совпадающего с именем файла DBF если это возможно.
Имейте в виду, что в абсолютном большинстве случаев под термином "таблица" подразумевается именно "образ файла" , т.е. файл уже открытый через команду USE (или каким-либо еще способом) в среде FoxPro. Если же подразумевается именно файл DBF, то как правило это оговаривается особо.
В версиях FoxPro 2.x в том смысле, в котором используется термин "таблица" использовался термин "база данных" (видимо отсюда пошло расширение - первые буквы английской фразы DataBase File ), поскольку в тех версиях еще не существовало файла DBC. Соответственно, когда программисты переходят на версию Visual FoxPro, то их бывает достаточно трудно понять из-за этой путаницы с терминами.
Следует всегда помнить, что таблицы открываются в так называемых "рабочих областях" . Что это такое нигде внятно не объясняется (дескать, и так понятно). Попробую определить это так
Рабочая область (Work area ) - это некий числовой идентификатор, который может быть присвоен таблице. Если у Вас был опыт программирования в других языках, то можно сказать, что рабочая область - это "хэндл " или "дескриптор " таблицы внутри среды FoxPro
Одновременно одной рабочей области может соответствовать только одна таблица, в то время как одной таблице может соответствовать несколько рабочих областей. Другими словами, одну и ту же таблицу можно одновременно открыть в нескольких рабочих областях , но в одной конкретной рабочей области может быть открыта только одна таблица.
До тех пор, пока таблица не будет открыта в какой-либо рабочей области она для FoxPro как бы не существует. Точнее с ней нельзя производить никакие операции по чтению/модификации данных используя штатные команды и функции.
Кроме понятия "рабочая область" в FoxPro введено понятие "сеанс данных" (DataSession )
Сеанс данных (DataSession) - это некоторая динамическая копия среды FoxPro. Открывая среду FoxPro Вы автоматически открываете сеанс данных, который автоматически же и завершается при выходе из FoxPro. Но внутри собственно FoxPro Вы имеете возможность сделать как бы копию среды FoxPro используя так называемые "частные сеансы данных" (Private DataSession)
Что собственно дает эти "частные сеансы данных" ? А дает это возможность симулировать внутри одного приложения FoxPro работу нескольких, независимых друг от друга пользователей.
В результате таблицы открытые в одном сеансе данных "не видны" в другом сеансе данных. И соответственно манипуляции (не все) производимые с таблицами в одном сеансе данных не влияют на другие сеансы данных.
Самый распростарненный случай применения Private DataSession - это одновременное открытие нескольких форм, рассматривающих один и тот же документ с разных сторон. Как правило, для этой цели между таблицами устанавливается связь по SET RELATION . Если открыть подобные формы в одном сеансе данных, то зачастую это становится большой проблемой, поскольку в одной форме требуется наложить на таблицы одни индексы и связи, а в другой - другие. И переключение из одной формы в другую приводит к непредсказуемым изменениям содержимого.
Название таблицы
Файл таблицы, как и любой другой файл в системе Windows может содержать до 128 символов, содержать пробелы, русские символы, цифры и некоторые спец.символы. Однако для упрощения работы в FoxPro я бы порекомендовал следующие ограничения в наименовании файла таблицы
Расположение таблицы
Причины этой рекомендации подробно изложены в разделе Где расположить файлы проекта . Вкратце, суть сводится к тому, что в противном случае возрастает риск непреднамеренной порчи файлов данных и соответственно потере данных. А также облегчается поиск нужных файлов и создание резервной копии.
По большому счету, конечно можно держать файл базы данных в одной директории, а включенные в него файлы DBF в другой. Но это усложняет сам процесс разработки проекта. Например, создание резервной копии в простейшем случе заключается в простом копировании директории с рабочими файлами в другое место. Если же рабочие файлы отделены от файла базы данных, то потребуется уже копирование 2-х директорий. Соответственно усложнится код.
Кроме того, в этом случае несколько увеличится размер файла базы данных (точнее файла DCT - мемо-файла), поскольку непосредственно в нем хранится относительный путь к включенным в него таблицам. Если таблицы расположены в той же директории, что и сам файл базы данных, то этого относительного пути просто нет. Справедливости ради, следует заметить, что относительный путь к базе данных хранится и в заголовках таблиц, которые в эту базу данных включены. Но на размер таблиц это не влияет, поскольку под этот относительный путь всегда выделяется фиксированное место вне зависимости от факта его наличия.
Собственно работа с таблицами
Как уже было замечено выше, таблицы всегда открываются в конкретной рабочей области и для перехода в нужную рабочую область есть 2 способа адресации: либо по номеру этой рабочей области, либо по имени алиаса (alias) таблицы открытой в этой рабочей области.
Причина этой рекомендации в том, что конкретной рабочей области абсолютно все-равно, какая именно таблица в ней открыта. А при определенных условиях таблица может быть переоткрыта, но уже в другой рабочей области. Соответственно, адресуясь к рабочей области по ее номеру невозможно быть до конца уверенным, что в ней открыта именно нужная таблица. Да и вообще, что в ней открыта хоть какая-нибудь таблица. С другой стороны, обращение по алиасу с большей вероятностью укажет на нужную таблицу (тут тоже могут быть варианты, но это уже более экзотические случаи)
Рабочая область с номером 0
Отдельного упоминания заслуживает нулевая рабочая область. Ссылка на нулевую рабочую область означает ссылку на первую свободную рабочую область. Т.е. рабочую область, которая в настоящий момент не связана ни с какой таблицей
Такая адресация позволяет делать несколько вещей
Во-первых, это позволяет открывать новые таблицы не заботясь о том,
не занята ли текущая рабочая область другой таблицей. Т.е. дается команда
вида
| USE MyTable IN 0 |
Указание нулевой рабочей области необходимо потому, что в противном случае таблица будет открыта в текущей рабочей области одновременно закрыв таблицу, которая могла бы быть в ней открыта. А в таком синтаксисе открытие новой таблицы никак не повлияет на ранее открытые таблицы
Другое применение нулевой рабочей области - это настройки по умолчанию.
Например, Вы вероятно уже знаете, что любое
View
по-умолчанию открывается в режиме оптимистической буферизации
строк (3)
, но если Вам необходимо использовать его в режиме
оптимистической буферизации таблиц (5)
, то необходимо после его открытия
сделать это переключение используя функцию CursorSetProp()
примерно
так
Правда использовать такие глобальные настройки надо с осторожностью, поскольку это именно глобальная, т.е. действующая на все рабочие области без исключения.
Замечу еще, что глобальная настрока нулевой рабочей области никак не затронет рабочие области, в которых уже есть открытые таблицы. Она влияет только на пока не используемые рабочие области.
Большая таблица
Очень часто в конференциях проскакивает словосочетание "большая таблица" .
Я бы сказал, что понятие "большая таблица" весьма субъективно. По моим наблюдениям, в большинстве случаев, под "большой" понимают такую таблицу, выполнение операций чтения/записи с которой занимает ощутимо заметное время. Заметное для пользователя.
Одним из важнейших критериев, влияющих на время выполнения любой операции с таблицей является количество записей в этой таблице. Но тогда встает вопрос: большая таблица - это сколько записей ?
Предельно допустимое количество записей, которое может содержаться в одной таблице - это 1 миллиард записей (1 billion) . Т.е. единица и девять нулей. Так вот, "большой" можно считать таблицу содержащую не менее нескольких миллионов записей .
Но опять-таки термин "большая" всплывает не тогда, когда оценивают просто количество записей, а когда оцениваю время выполнения некоторых операций с такими таблицами. Но ведь есть множество причин влияющих на время чтения/записи. Соответственно, та таблица, которая считается "большой" в одном случае в другом уже не такая "большая".
В очередной раз вспоминается лень американцев и их стремление все сокращать (впрочем русские здесь ушли еще дальше - могут сказать почти все используя только несколько специфических слов). Термин "курсор" употребляется сразу в нескольких смыслах в зависимости от контекста.
Курсор - это образ файла DBF открытого в одной из рабочих областей
Курсор - это временная таблица являющаяся результатом выполнения команды Select-SQL
Курсор - это указатель положения индикатора ввода текста с клавиатуры
Ну, последнее определение не очень-то интересно. В том смысле, что здесь все ясно, кроме того, почему этот термин был использован еще и для временных таблиц, ведь слово "cursor" собственно и переводится как "указатель" .
Курсор как образ файл DBF
Опять же такое краткое определение не совсем точно, поскольку в этом смысле используется некий специфический объект. Введение этого объекта объясняется необходимостью визуализации таблицы при проектировании форм и отчетов.
Замечу еще, что курсор, как объект, используется не только как образ файлов DBF, но и как образ View . А View и таблица - это не одно и то же .
Курсор как временная таблица
Вот это наиболее употребительное использование данного термина. Собственно есть 2 способа создания таких курсоров
Первый способ - это использование команды CREATE CURSOR . Созданный таким способом курсор будет редактируемым. И это будет именно временная таблица, т.е. она будет автоматически уничтожена в момент закрытия. Ну про этот способ сказать особо нечего. Здесь нет каких-то проблем и особенностей
Второй
способ
- это использование опции CURSOR
в команде SELECT-SQL
.
Примерно в следующем синтаксисе
| SELECT * FROM MyTable INTO CURSOR TmpTable |
Вот этот-то TmpTable и есть курсор
В зависимости от различных условий этот курсор может иметь разное физическое "воплощение" и разные свойства
Если SQL-запрос
полностью оптимизируем, то вместо создания нового файла будет просто открыта та
же самая таблица с наложенным на нее фильтром. Зачастую это очень неприятная
неожиданность. Проверить, чем же физически является сформированный курсор, можно
используя функцию DBF()
| SELECT * FROM MyTable INTO CURSOR TmpTable ?DBF ("TmpTable") |
Если будет возвращено имя файла с расширением DBF, то данный курсор является той же самой исходной таблицей с наложенным на нее фильтром.
Если Вы хотите при любых запросах быть
уверенными, что курсор - это именно временная таблица, а не исходная таблица с
наложенным фильтром, то Вам следует добавить опцию NOFILTER
| SELECT * FROM MyTable INTO CURSOR TmpTable NOFILTER |
Эта опция появилась только в 5 версии Visual FoxPro, хотя там она еще не была документирована. В более ранних версиях необходимо добавлять фиктивные условия или признаки группировки, чтобы исключить возможность оптимизации.
Однако если курсор - это временная таблица , то это еще не значит, что эта временная таблица будет непременно физически расположена на диске. Вполне возможно, что вся временная таблица целиком поместится в оперативную память. Т.е. функция DBF("TmpTable") будет исправно показывать некий временный файл, но попытка найти его физически на диске окончится неудачей и функция FILE(DBF("TmpTable")) вернет .F.
Правда расположение временной таблицы целиком в памяти ни в коем случае не помешает работе с этой временной таблицей. Собственно, в подавляющем большинстве случаев Вас и не должно заботить где физически расположена та или иная таблица.
Еще один немаловажный вопрос связан с
тем, что полученные таким образом курсоры нельзя редактировать. Они доступны
только на чтение
. Начиная с 7 версии Visual FoxPro для решения этой проблемы
появилась специальная опция ReadWrite
| SELECT * FROM MyTable INTO CURSOR TmpTable NOFILTER READWRITE |
Использование этой опции позволяет
создавать курсор, который можно редактировать
. Для более младших версий
FoxPro для того, чтобы курсор можно было редактировать его следует
переоткрыть
| SELECT * FROM MyTable INTO CURSOR TmpReadTable NOFILTER USE (DBF ("TmpReadTable")) IN 0 AGAIN ALIAS TmpWriteTable USE IN TmpReadTable |
Переоткрытый таким образом курсор TmpWriteTable уже можно будет редактировать
Курсоры можно индексировать также как и обычные таблицы. Правда если курсор открыт в режиме только для чтения, то Вы сможете создать для него только один индексный тэг.
Все созданные таким образом курсоры автоматически удаляются с диска (если временный файл физически был создан на диске) в момент их закрытия. Если Вы создали для такого курсора структурный индексный файл, то этот файл также будет автоматически удален в момент закрытия курсора.
Формирование имени курсора в команде Select-SQL
Это не такой простой вопрос, как может показаться. Проблема здесь в том, что имя курсора - это фактически алиас (alias) временной таблицы. Но в FoxPro в одном сеансе данных не может быть открыто 2 таблиц с одинаковыми алиасам.
Курсор всегда создается на машине клиента, поэтому конфликтов с другими пользователями можно не опасаться. Более того, даже если запущен дважды один и тот же проект на одной машине все-равно не будет конфликат связанного с одинаковыми именами курсоров, поскольку они открыты в разных сеансах данных. Конфликт возможен если Вы создаете несколько курсоров с одним и тем же именем в одном сеансе данных
Ну например, Вы открыли 2 формы использующих Default DataSession и в обоих создали курсор с одинаковым именем. В этом случае, курсор созданный позднее затрет курсор созданный ранее. При этом настройка SET SAFETY не играет никакой роли. Курсор будет пересоздан молча. Без каких-либо дополнительных запросов.
Избежать подобных конфликтов можно несколькими способами
Последний вариант кажется наиболее предпочтительным. Однако тут следует быть осторожным. Дело в том, что в описании к FoxPro для генерации уникальных имен файлов предлагается использовать следующую функцию
| lcCursorName=SubStr (SYS (2015),3,10) |
Проблема в том, что функция
SYS(2015)
может содержать в возвращаемом значении как буквы, так и цифры.
Это значит, что при использовании выделения строки по SubStr() Вы вполне можете
получить первым символом цифру. А использование в качестве имени переменной
цифры в синтаксисе FoxPro недопустимо и Вы неожиданно получите сообщение о
синтаксической ошибке. Чтобы этого избежать следует либо принудительно подмешать
букву
Соответсвенно выполнение запроса
станет выглядеть так:
| LOCAL lcCursorName lcCursorName=SYS (2015) SELECT * FROM MyTable INTO CURSOR &lcCursorName NOFILTER |
Такой способ создания уникальных имен курсоров действительно обеспечит уникальность, но это очень неудобный способ из-за необходимости при обращении к такому курсору постоянного использовать макроподстановки. Поэтому по возможности желательно его избегать.
Поля таблицы
Поле таблицы - это столбец который Вы видите каждый раз открывая таблицу на просмотр.
Название полей таблицы
Поле таблицы, включенной в {базу данных} может содержать до 128 символов, содержать русские символы, цифры и некоторые спец.символы. Однако для упрощения работы в FoxPro я бы порекомендовал следующие ограничения в наименовании файла таблицы
Ну, например, если в таблице необходимо указать сумму платежа и сумму налога, то Вы конечно можете создать 2 поля Platezh1 и Platezh2 . Но в этом случае, вам каждый раз придется вспоминать, что собственно обозначает цифра 1, а что цифра 2. Если Вы работаете постоянно только с одним проектом, то это не страшно, как-нибудь да запомните. Но если Вы отложили этот проект и вернулсь к нему через несколько месяцев, то напряженные размышления на тему - а что это собственно такое? - Вам обеспечены. Гораздо разумнее дать значимые имена: Platezh и Nalog
Если воображение Вам напрочь отказывает и Вы не знаете как по другому назвать поле кроме как например "Order" или "Group" , то добавьте в качестве первого символа букву, обозначающую тип данных, используемых в данном поле. Например, "nOrder" или "cGroup"
Собственно работа с полями таблицы
Дело в том, что если алиас не указан, то FoxPro предполагает, что речь идет о поле таблицы, расположенной в текущей рабочей области. А если у таблицы в текущей рабочей области нет такого поля, то о переменной памяти с тем же именем. Но при написании относительно сложной программы далеко не всегда можно с уверенностью сказать, что мы находимся в нужной рабочей области. Явное указание алиаса таблицы снимает эту проблему.
Ключевое поле
Это одно из важнейших понятий, используемое при работе с таблицами и базами данных
Ключевое поле - это такое поле (или набор полей) по содержимому которого можно однозначно идентифицировать запись таблицы. Т.е. по значению ключевого поля всегда однозначно можно сказать о какой записи идет речь и не может существовать 2 записей с одинаковыми значениями ключевого поля.
Внешний ключ - это поле таблицы, содержащее в себе значение ключевого поля другой таблицы. Т.е. просто ссылка на запись другой таблицы.
Начну сразу с вывода:
Для большинства задач в FoxPro
удобно использовать в качестве ключевого поля суррогатный ключ типа Integer.
Ключевое поле желательно вводить для всех без исключения таблиц базы
данных
Ну а теперь рассмотрим как же я дошел до выводов таких
Естесственные или Суррогатные ключи
До сих пор не утихают споры о том, что лучше использовать: суррогатные или естесственные ключи.
Естесственный ключ - это поле или набор полей, которые имеют некий физический смысл. Ну например, табельный номер, номер паспорта, и т.п.
Суррогатный ключ - это поле которое не имеет никакого физического смысла и введено исключительно с целью однозначной идентификации записи. Информация, которая в нем содержится никак логически не связана с информацией из прочих полей той же таблицы.
Рассмотрим какие преимущества и недостатки имеют естесственные и суррогатные ключи
Фактически самый главный и определяющий критерий по которому можно судить о том, пригодно ли данное поле для использования его в качестве ключевого или нет - это однозначность идентификации записи. Здесь имеется в виду, действительно ли значение выбранного поля для каждой записи уникально?
Ну с суррогатным ключем все понятно - мы сами формируем его значение без участия со стороны пользователя, поэтому можем проследить за уникальностью, а вот как тут у естесственного ключа?
На первый взгляд кажется, что тоже все в порядке. Разве может номер паспорта быть не уникальным? Или табельный номер? Оказывается еще как может!
Во-первых, любая информация вводимая пользователем заведомо может содержать ошибки. Ну не могут люди не ошибаться. Кто-то ошибается чаще, кто-то реже, но ошибаются все. Часть ошибок безусловно можно отловить программно, но далеко не все.
Например, если речь идет о некотором цифро-буквенном номере (номер паспорта) и пользователь ввел "123 АБВ", а надо было "423 АБВ", то синтаксически это правильно, но по содержанию - это ошибка. Если впоследствии окажется что теперь надо ввести новый номер паспорта, но уже "123 АБВ", то программа откажется это сделать, поскольку такой номер уже есть. А на что его исправить неизвестно, поскольку документов, с которых он был введен уже нет.
Во-вторых (и это пожалуй более существенно), информация имеет тенденцию меняться. Например, не так давно был произведена замена паспортов в Российской Федерации и если бы программа опиралась в качестве идентификатора на его номер, то теперь все пришло в большой беспорядок в связи с этой заменой
Опять же, не так давно в Российской Федерации были введены так называемые "Идентификационные Номера Налогоплательщика". Так называемые "ИНН". Ну казалось бы, ну вот он уникальный идентификатор контрагента. Но наша родная бюрократия и здесь сумела все испортить. Оказалось, что ИНН нарушает все критерии уникальности, в связи с некоторыми особенностями его формирования
В одной из конференций, один
из посетителей выразился по этому поводу достаточно эмоционально
Я отдаю предпочтение СК просто потому, что СК предоставляет возможность пользователю решать, Иванов И.И. и Петров И.И. - один и тот же человек или разные. Может быть, он сменил фамилию, может быть даже пол, может быть он сменил и тип паспорта, и его номер. Может быть, он сменил гражданство, вернулся с войны без рук, ног и головы, наплодил детей, сделал пластическую операцию по изменению веса... Но от этого он не перестал быть самим собой.
Таким образом, в общем случае, естесственный ключ не
обеспечивает главного - однозначности идентификации записи по значению ключевого
поля. А если все-таки обеспечивает, то он перестает быть естесственным в
первоначальном смысле этого слова, поскольку вынуждает пользователя
приспосабливаться и изворачиваться.
Так почему же, несмотря на столь явные
аргументы против, все равно есть достаточно большое количество приверженцев
использования естесственного ключа?
На мой взгляд, здесь существует явное непонимаение того, что суррогатный ключ - это информация, которая нигде, никоим образом не предоставляется пользователю. Суррогатный ключ - это некоторая скрытая, невидимая пользователем "внутренняя" механика.
Дело в том, что главным аргументом приверженцев естесственного ключа является его "понятность" пользователю. Т.е. предполагается, что пользователь что-то ищет опираясь на значение ключевого поля. Иными словами, пользователь сам вводит, исправляет и просматирвает значение ключевого поля.
Но в отношении суррогатного ключа
- такое его использование просто недопустимо! Ну не должен пользователь знать
как там внутри программы все "тикает". Пользователю интересно показание часов, а
не вские там "шестеренки". Если Вы хотите предоставить пользователю некую
аббревиатуру (краткое название, "ник"), то это ни в коем случае не должен быть
суррогатный ключ. Введите для этой цели еще одно дополнительное поле.
Есть и
еще один, более хитрый аргумент, в пользу хотя бы частичного использования
естесственных ключей. Дело в том, что очень часто возникает необходимость в
некоторой внутренней классификации. Ну например, если речь идет о документах, то
они могут находится в некоторых взаимоисключающих сотояниях:
Есть очень большое искушение не делать дополнительную таблицу с этими 3 записями, а просто использовать коды 1,2,3 Ну действительно, ну не может же пользователь изменить количество и название состояний. Вот тут приверженцы естесственного ключа и поднимают голос - дескать, что говорят программисту какие-то цифирки, пускай уж сразу слова пишет
В
данном случае лично я рекомендовал бы не поддаваться искушению "упростить" базу
данных и ввести-таки дополнительную служебную табличку с 3 записями состояния.
Пусть даже пользователь и не имеет возможность ее редактировать. Вы сами
убедитесь, насколько она окажется уместна, а в некоторых случаях просто
незаменима при написании Вами программы.
Вывод однозначен - суррогатные ключи
предпочтительнее по всем критериям перед естесственными ключами
Какой тип данных использовать: Character или Integer
Раньше, когда для хранения числовых данных в FoxPro существовали только поля типа Numeric перевес в аргументации склонялся в пользу использования полей типа Character , но с появлением полей типа Integer все стало не так однозначно
При сравнении способа хранения ключевого поля в символьном или числовом формате выдвигаются 3 аргумента
Числовые поля легче формировать
Тут числовые поля вне конкуренции, поскольку стандартным способом формирования числовых ключевых полей является "максимальное значение плюс один". В случае же символьных полей, как правило используется некий генератор псевдо-случайных чисел. Здесь не место, для обсуждения способа генерации символьных ключей, но используемые процедуры обычно достаточно сложны из-за сложности обеспечения действительно уникального значения.
Замечу еще, что не стоит для генерации нового значения ключа использовать именно определение максимального значения в текущей таблице. Это хорошо в однопользовательском режиме, но в многопользовательском Вы рискуете получить 2 одинаковых значения ключа при одновременном добавлении новой записи двумя пользователями одновременно. Обычно используют специальную служебную таблицу, хранящуюю значение последнего использованного (или первого не использованного) значения ключа. Примеры использования такой таблицы приведены в стандартных проектах примеров FoxPro: Solution.pjx (форма NewID.scx ) и TasTrade.pjx . А в 8 версии FoxPro появились автоинкрементные поля , которые совсем упростили данную задачу.
Символьные поля "экономичнее", т.е. можно уместить больше значений в том же размере
Начнем с вопроса, а сколько вообще необходимо значений для идентификации вообщех всех записей таблицы?
Из системных ограничений известно, что предельно допустимое количество записей в DBF-таблице - это 1 миллиард записей (1 billion) . Т.е. это единица и девять нулей
Поле типа Integer может принимать знаячение в диапазоне от -2,147,483,647 до 2,147,483,647. Ну, отрицательные значения как правило не используются, но и положительные значения в 2 раза больше, чем максимально возможное количество записей. С учетом возможного удаления записей - в самый раз.
Поскольку поле типа Integer физически занимает 4 байта (4 символа), то посмотрим, сколько же значений может быть присвоено при таком же размере для символьного поля
В одном байте может быть записано 256 значений, т.е. это составит 256**4=4,294,967,296. Но поскольку некоторые значения нельзя использовать по ряду соображений (например, символ перевода строки, Esc и т.п.), то получается, что в смысле количества значений поля типа Integer ничуть не уступает полю типа Caracter(4) , даже пожалуй несколько превосходит
Замечание
Следует заметить, что в FoxPro поля типа Numeric храняться как символьные поля, т.е. для хранения каждой цифры нужен один байт. Это значит, что если предполагаемое количество значений в данной таблице не превышает тысячи (меньше 4 символов), то возникает искушение "сэкономить" и вместо типа Integer ввести скажем поле типа N(2)
Так вот, я бы не советовал этого делать по следующим соображениям:
Символьные поля "универсальнее" при так назваемых задачах репликации
Репликация - это объединение информации из двух не связанных между собой баз данных, например, из двух филиалов одной организации территориально удаленных друг от друга
Да, действительно, в подобных задачах удобнее пользоваться символьными полями, хотя даже в такой, казалось бы заведомо проигрышной ситуации числовым полям есть что "возразить"
Здесь
не место для обсуждения данной проблемы в связи с ее обширностью, поэтому замечу
только, что для очень большого круга задач сама задача репликации не актуальна.
Либо используется файл-серверная технология, либо объединение необходимо только
в одну сторону для получения справок и отчетов
Вывод не столь категоричен,
как в случае с суррогатными ключами:
Но поскольку большинству программистов не придется сталкиваться с задачами репликации, то можно смело использовать для ключевых полей тип Integer .
Надо ли использовать ключевое поле во всех без исключения таблицах
На первый взгляд, вопрос может показаться странным. Разве можно без ключевого поля? Оказывается, в некоторых случаях можно.
Например, для организации связи много-ко-многим стандартным способом является создание таблицы-посредника. Что имеется в виду?
Допустим, у Вас есть список контрагентов и список банков. Разумеется, один и тот же контрагент может иметь счет в нескольких банках. Но верно и обратное - один банк работает с несколькими контрагентами. В этом случае Вы не можете сделать внешний ключ банка в таблице контрагента или внешний ключ контрагента в таблице банков. Вам необходимо ввести таблицу-посредник, которая будет хранить в себе внешний ключ банка и внешний ключ контрагента.
При такой организации, каждая запись в этой таблице посреднике однозначно идентифицирется парой значений: код контрагента-код банка. Поэтому возникает искушение не вводить еще одно поле для суррогатного ключа этой таблицы-посредника.
Если вернуться к примеру с контрагентами и банками, то легко заметить, что я обошел вниманием тот момент, что один контрагент может иметь несколько счетов в одном и том же банке. Этот самый реквизит (счет контрагента в банке) невозможно прицепить ни к банку, ни к контрагенту. Но он очень удачно подходит к этой таблице-посреднику. Если бы для идентификации записи в этой таблице Вы опирались бы на пару: код банка - код контрагента, то Вам пришлось бы серьезно переделывать значительную часть программы. А в случае существования собственного кода записи никаких проблем. Ну добавили еще одно поле, ну и что?
В данном случае я
рассмотрел достаточно очевидный случай, но зачастую кажется, что по другому быть
не может и уж вот здесь-то собственный идентификатор записи не нужен. Не
обольщайтесь. Если Вам кажется, что чего-то не может быть - это всего-лишь
значит, что Вы чего-то не знаете.
Вывод - используйте собственное ключевое
поле во всех без исключения таблицах. Даже если Вам кажется, что без него можно
обойтись.
Название ключевого поля
Поскольку ключевое поле - это обычное поле таблицы , то на него распространяются все рекомендации приведенные в разделе "Поля таблицы" . Однако поскольку это все-таки очень специфическое поле, то для него я бы добавил следующие рекомендации
Собственно работа с ключевыми полями
таблицы
Такая стратегия сильно облегчает отлов ошибок пользователей, поскольку в большинстве случаев, если пользователь делает ошибку в документе, то он не исправляет ошибочный документ, а удаляет его и создает заново! Вот и докажи потом, что это не программа плохая!
Кроме того, такая стратегия позволяет с меньшими проблемами интегрировать несколько баз данных в один комплекс если в этом возникает необходимость.
Дело в том, что любая информация, которую вводит пользователь по определению является не надежной и как бы Вы ни защищали информацию, пользователь найдет как ее обойти или просто заставит Вас это сделать! А то, о чем он не подозревает и испортить не может.
Например, в некоторых случаях возникает соблазн использовать ключевые поля еще и как порядковый номер элемента в списке. Так вот, не надо этого делать. Введите для реализации этой функциональности дополнительное поле. Также не следует использовать ключевое поле, как краткое название элемента
Если Вы навесите на ключевое поле еще какую-либо функциональность, кроме однозначной идентификации записей, то просто создадите себе массу проблем (сильно усложнится программный код). А в качестве преимуществ только некоторая экономия дискового пространства. Думаю, оно того не стоит.
Опубликовал: Владимир Максимов
A primary key is a field or set of fields with values that are unique throughout a table. Values of the key can be used to refer to entire records, because each record has a different value for the key. Each table can only have one primary key. Access can automatically create a primary key field for you when you create a table, or you can specify the fields that you want to use as the primary key. This article explains how and why to use primary keys.
To set a table’s primary key, open the table in Design view. Select the field (or fields) that you want to use, and then on the ribbon, click Primary Key .
Note: This article is intended for use only with Access desktop databases. Access automatically manages primary keys for new tables in Access web apps and web databases. Although it is possible to override these automated primary keys, we don’t recommend that you do.
In this article
Overview of primary keys in Access
Access uses primary key fields to quickly associate data from multiple tables and combine that data in a meaningful way. You can include the primary key fields in other tables to refer back to the table that is the source of the primary key. In those other tables, the fields are called foreign keys. For example, a Customer ID field in the Customers table might also appear in the Orders table. In the Customers table, it is the primary key. In the Orders table it is called a foreign key. A foreign key, simply stated, is another table"s primary key. For more information, see Database design basics .
If you are moving existing data into a database, you may already have a field that you can use as the primary key. Often, a unique identification number, such as an ID number or a serial number or code, serves as a primary key in a table. For example, you might have a Customers table where each customer has a unique customer ID number. The customer ID field is the primary key.
Access automatically creates an index for the primary key, which helps speed up queries and other operations. Access also ensures that every record has a value in the primary key field, and that it is always unique.
When you create a new table in Datasheet view, Access automatically creates a primary key for you and assigns it a field name of "ID" and the AutoNumber data type.
What makes a good primary key?
A good candidate for a primary key has several characteristics:
It uniquely identifies each row
It is never empty or null - it always contains a value
The values it contains rarely (ideally, never) change
If you can’t identify a good key, create an AutoNumber field to use as the key. An AutoNumber field automatically generates a value for itself when each record is first saved. Therefore, an AutoNumber field meets all three characteristics of a good primary key. For more information on adding an AutoNumber field, see the article Add an AutoNumber field as a primary key .
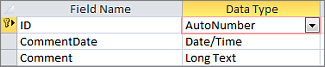
An AutoNumber field makes a good primary key.
Examples of poor primary keys
Any field that is missing one or more of the characteristics of a good candidate key is a poor choice for a primary key. Here are a few examples of fields that would make poor primary keys for a Contacts table, along with reasons why they would be poor choices.
|
Poor primary key |
|
|
Might not be reliably unique, and may change |
|
|
Likely to change. |
|
|
Likely to change. |
|
|
More than one person may share a ZIP code |
|
|
Combinations of facts and numbers |
The fact portion might change, creating a maintenance burden. Could lead to confusion if the fact portion is repeated as a separate field. For example, combining the city and an incremented number (e.g., NEWYORK0579) would be a poor choice if the city is also stored as a field. |
|
Social Security Numbers |
Private information and not allowed in government departments and some organizations. Some people don’t have a SSN An individual may have more than one in a lifetime |
Composite keys: using multiple fields in combination as a primary key
In some cases, you want to use two or more fields in a table as the primary key. For example, an Order Details table that stores line items for orders might use two fields in its primary key: Order ID and Product ID. A key that has more than one field is called a composite key.
Set the primary key using fields you already have in Access
For a primary key to work well, the field must uniquely identify each row, never contain an empty or null value, and rarely (ideally, never) change. To set the primary key:

База данных – это организационная структура, предназначенная для хранения информации.
Система управления базой данных это комплекс программных средств, который предназначен для создания структуры новой базы, редактирования содержимого и визуализации информации, т.е. отбор отображаемых данных в соответствии с заданным критерием, их упорядочение, оформление и последующая выдача на устройство вывода или передача по каналам связи.
Access – это реляционная система управления базами данных (СУБД), входящая в пакет MS Office.
Все составляющие базы данных, такие, как таблицы, отчеты, запросы, формы и объекты, в Access хранятся в едином дисковом файле, который имеет расширение.mdb.
Основным структурным компонентом базы данных является таблица. В таблицах хранятся вводимые данные. Каждая таблица состоит из столбцов, называемых полями, и строк, называемых записями. Каждая запись таблицы содержит всю необходимую информацию об отдельном элементе базы данных.
При разработке структуры таблицы, прежде всего, необходимо задать поля, определив их свойства.
Свойства полей базы данных Access
Свойство |
Его назначение |
|
Определяет, как следует обращаться к данным этого поля. Должно быть уникальным, желательно таким, чтобы функция поля узнавалась по его имени. |
|
|
Определяет тип данных, которые содержаться в данном поле. |
|
|
Размер поля |
Определяет предельную длину (в символах) данных, которые могут размещаться в данном поле. |
|
Формат поля |
Определяет способ форматирования данных в ячейках, принадлежащих полю. |
|
Маска ввода |
Определяет форму, в которой вводятся данные в поле. |
|
Определяет заголовок столбца таблицы для данного поля. Если не указана, то в качестве заголовка используется имя поля. |
|
|
Значение по умолчанию |
Значение, которое вводится в ячейки поля автоматически. |
|
Условие на значение |
Ограничение, используемое для проверки правильности ввода данных |
|
Сообщение об ошибке |
Текстовое сообщение, которое выдается автоматически при попытке ввода в поле ошибочных данных. |
|
Обязательное поле |
Определяет обязательность заполнения поля данными. |
|
Разрешает ввод пустых строковых данных |
|
|
Индексированное поле |
Позволяет ускорять все операции, связанные с поиском или сортировкой данных этого поля. Можно также задать проверку на наличие повторов для этого поля, чтобы исключить дублирование данных. |
Необходимо отметить, что свойства полей существенно зависят от типа данных, содержащихся в поле.
Типы данных Access
|
Тип данных |
Описание |
|
Текстовый (Значение по умолчанию) |
Текст или числа, не требующие проведения расчетов, например номера телефонов (до 255 знаков) |
|
Числовой |
Числовые данные различных форматов, используемые для проведения расчетов |
|
Дата/время |
Для хранения календарных дат и текущего времени |
|
Денежный |
Для хранения денежных сумм |
|
Для хранения больших объемов текста (до 65535 символов) |
|
|
Специальное числовое поле, в котором Access автоматически присваивает уникальный порядковый номер каждой записи. Значения полей типа счетчика обновлять нельзя |
|
|
Логический |
Может иметь только одно из двух возможных значений (True/False, Да/Нет) |
|
Поле объекта OLE |
Объект (например, электронная таблица Microsoft Excel, документMicrosoft Word, рисунок, звукозапись или другие данные в двоичном формате), связанный или внедренный в таблицу Access |
|
Для хранения адресов URL Web-объектов Интернета. |
|
|
Мастер подстановок |
Создает поле, в котором предлагается выбор значений из списка или из поля со списком, содержащего набор постоянных значений или значений из другой таблицы. Это в действительности не тип поля, а способ хранения поля |
Ключевое поле - это одно или несколько полей, комбинация значений которых однозначно определяет каждую запись в таблице. Если для таблицы определены ключевые поля, то Microsoft Access предотвращает дублирование или ввод пустых значений в ключевое поле. Ключевые поля используются для быстрого поиска и связи данных из разных таблиц при помощи запросов, форм и отчетов.
В Microsoft Access можно выделить три типа ключевых полей: счетчик, простой ключ и составной ключ. Рассмотрим каждый из этих типов.
Для создания ключевого поля типа Счетчик необходимо в режиме Конструктора таблиц:
- Включить в таблицу поле счетчика.
- Задать для него автоматическое увеличение на 1.
- Указать это поле в качестве ключевого путем нажатия на кнопку Ключевое поле Конструктор таблиц (Table Design).
Если до сохранения созданной таблицы ключевые поля не были определены, то при сохранении будет выдано сообщение о создании ключевого поля. При нажатии кнопки Да (Yes) будет создано ключевое поле счетчика с именем Код (ID) и типом данных Счетчик (AutoNumber).
Для создания простого ключа достаточно иметь поле, которое содержит уникальные значения (например, коды или номера). Если выбранное поле содержит повторяющиеся или пустые значения, его нельзя определить как ключевое. Для определения записей, содержащих повторяющиеся данные, можно выполнить запрос на поиск повторяющихся записей. Если устранить повторы путем изменения значений невозможно, следует либо добавить в таблицу поле счетчика и сделать его ключевым, либо определить составной ключ.
Составной ключ необходим в случае, если невозможно гарантировать уникальность записи с помощью одного поля. Он представляет собой комбинацию нескольких полей. Для определения составного ключа необходимо:
- Выделить поля, которые необходимо определить как ключевые.
- Нажать кнопку Ключевое поле (Primary Key) на панели инструментов Конструктор таблиц (Table Design).
Замечание
Для составного ключа существенным может оказаться порядок образующих ключ полей. Сортировка записей осуществляется в соответствии с порядком ключевых полей в окне Конструктора таблицы. Если необходимо указать другой порядок сортировки без изменения порядка ключевых полей, то сначала нужно определить ключ, а затем нажать кнопку Индексы (Indexes) на панели инструментов Конструктор таблиц (Table Design). Затем в появившемся окне Индексы (Indexes) нужно указать другой порядок полей для индекса с именем Ключевое поле (Primary Key).
Рассмотрим в качестве примера применения составного ключа таблицу "Заказано" (OrderDetails) базы данных (Northwind) (рис. 2.23).
В данном случае в качестве составного ключа используются поля "Код заказа" (OrderlD) и "КодТовара" (ProductID), т. к. ни одно из этих полей в отдельности не гарантирует уникальность записи. При этом в таблице выводится не код товара, а наименование товара, т. к. поле "КодТовара" (ProductID) данной таблицы содержит подстановку из таблицы "Товары" (Products), а значения полей "КодТовара" (ProductID) этих таблиц связаны отношением "один-ко-многим" (одной записи таблицы "Товары" (Products) может соответствовать несколько записей таблицы "Заказано" (OrderDetails)). Оба поля могут содержать повторяющиеся значения. Так, один заказ может включать в себя несколько товаров, а в разные заказы могут включаться одинаковые товары. В то же время сочетание полей "КодЗаказа" (OrderlD) и "КодТовара" (ProductID) однозначно определяет каждую запись таблицы "Заказы" (OrderDetails).
Чтобы изменить ключ, необходимо:
- Открыть таблицу в режиме Конструктора.
- Выбрать имеющиеся ключевые поля.
- Нажать на кнопку Ключевое поле Выкл., а из области выделения должны исчезнуть значки ключевого поля.
- Выбрать поле, которое необходимо сделать ключевым.
- Нажать на кнопку Ключевое поле (Primary Key). При этом в области выделения должен появиться значок ключевого поля.
Рис. 2.23. Пример таблицы с использованием составного ключа
Чтобы удалить ключ, необходимо:
- Открыть таблицу в режиме Конструктора.
- Выбрать имеющееся ключевое поле (ключевые поля).
- Нажать на кнопку Ключевое поле (Primary Key), при этом кнопка должна принять положение Выкл., а из области выделения должен исчезнуть значок (значки) ключевого поля.
Что такое связи между таблицами
В реляционной базе данных связи позволяют предотвратить появление избыточных данных. Например, при разработке базы данных, содержащей сведения о книгах, может иметь таблицу с именем Titles, хранится информация о каждой книге: книга? s название, дата публикации и издатель. Также указаны сведения, может потребоваться хранить об издательстве, например, телефонный номер издателя, адрес и почтовый индекс. Если сохранять эти данные в заголовки таблицы, издатель? s номер телефона будет дублироваться для каждой книги, им изданной.
Лучшим решением является хранение информации об издателе в отдельной таблице Publishers. Затем следует установить указатель в таблице Titles, на запись в таблице Publishers.
Чтобы убедиться в том, что ваши данные не синхронизированы, можно обеспечить целостность между таблицами Titles и Publishers. Условия целостности данных помогают убедиться, что данные в одной таблице соответствовали данным в другой. Например каждая книга из таблицы Titles должен быть связан с определенным издателем в таблице Publishers.Название невозможно добавить в базу данных издателя, который не существует в базе данных.
Типы связей между таблицами
Связь действует путем сопоставления данных в ключевых столбцах, обычно это столбцы с тем же именем в обеих таблицах.
Существует три типа связей между таблицами.
Отношения один ко многим
Отношение один ко многим является наиболее распространенным типом связи.
Отношение один ко многим создается, если только одного из связанных столбцов является первичным ключом или имеет ограничение уникальности.
В Microsoft Access сторона первичного ключа отношения «один ко многим» обозначается символом ключа.
Отношения многие ко многим
В отношение многие ко многим строке в таблице A может иметь несколько совпадающих строк таблицы Б и наоборот.
Отношения один к одному
Связи «один к одному» строке в таблице A может иметь не более одной соответствующей строки в таблице B и наоборот.
Этот тип связи не часто, поскольку большая часть сведений, связанных таким образом может быть помещена в одну таблицу.
- Разделение таблицы со многими столбцами.
- Изоляция части таблицы по соображениям безопасности.
- Хранить данные, которые можно легко удалить вместе со таблице кратковременных.
- Хранят сведения, применимые только к подмножеству основной таблицы.
В Microsoft Access сторона первичного ключа в связи «один к одному» обозначается символом ключа.
Создание связей между таблицами
При создании связи между таблицами связанные поля не требуется иметь те же имена. Однако связываемые поля должны иметь одинаковый тип, если поле первичного ключа не является полем счетчика данных. Можно сопоставить поля счетчика с числовым полем, если свойства FieldSize обоих полей совпадают. Например можно сопоставить поля счетчика с числовым полем, если свойство FieldSize обоих полей имеет значение длинное целое. Даже в том случае, когда связываются поля числовых полей, они должны же значение свойства FieldSize .
Определение отношения один ко многим "или" один к одному
Чтобы создать один ко многим или отношение, выполните следующие действия:
- Закройте все открытые таблицы. Нельзя создавать или изменять связи между открытыми таблицами.
- Нажмите клавишу F11, чтобы перейти в окно базы данных.
- В меню Сервис выберите пункт связи .
- Если в базе данных отсутствуют связи, автоматически отображается диалоговое окно Добавление таблицы . Если вы хотите добавить таблицы, которые необходимо связать, но не отображается в диалоговом окне Добавление таблицы , нажмите кнопку Отобразить таблицу меню связи .
- Дважды щелкните имена таблиц, которые требуется связать, а затем закройте диалоговое окно Добавление таблицы . Чтобы создать отношение между таблицей и сам, добавьте ее дважды.
- Перетащите поле, которое необходимо связать с одной таблицы на соответствующее поле в другой таблице.Чтобы перетащить несколько полей, удерживайте клавишу CTRL, выберите каждое поле и затем перетащите их.
В большинстве случаев перетащите поле первичного ключа (который отображается полужирным текстом) из одной таблицы на аналогичное поле (часто с тем же именем) называется внешнего ключа в другой таблице.
- Откроется диалоговое окно Изменение связей
. Проверьте правильность имен полей, присутствующих в двух столбцах. При необходимости их можно изменить.
При необходимости установите параметры связи. Для получения сведений о конкретном параметре в диалоговом окне « Изменение связей », нажмите кнопку с вопросительным знаком и щелкните элемент. Эти параметры будут описаны подробно далее в этой статье.
- Нажмите кнопку Создать , чтобы создать связь.
- Повторите шаги с 5 по 8 для каждой пары таблиц, которые необходимо связать.
При закрытии диалогового окна Изменение связей , Microsoft Access спросит, нужно ли сохранить макет. Ли или не сохранить макет, отношений, сохраняются в базе данных.
Примечание: В запросах, а также таблицы, можно создавать связи. Тем не менее ссылочная целостность не обеспечивается с запросами.
Как определить отношения многие ко многим
Чтобы создать отношение многие ко многим, выполните следующие действия.
- Создайте две таблицы, которые будут иметь отношение многие ко многим.
- Создание третьей таблицы, называемой связующей таблицей и затем добавить в поля с теми же определениями, как поля первичного ключа в каждой из двух связываемых таблиц. Поля первичных ключей в сводной таблице, служат внешними ключами. Так же, как и для любой другой таблицы, можно добавить другие поля в связующую таблицу.
- В сводной таблице задайте первичный ключ для включения поля первичных ключей из двух связываемых таблиц.Например в связующей таблице TitleAuthors первичный ключ может состоять из поля OrderID и ProductID.
Примечание : чтобы создать первичный ключ, выполните следующие действия:
- Откройте таблицу в режиме конструктора.
- Выберите поле или поля, которые необходимо определить как первичный ключ. Для выделения одного поля щелкните область выделения строки для нужного поля.
Чтобы выбрать несколько полей, удерживайте нажатой клавишу CTRL и щелкните область выделения строки для каждого поля.
- Нажмите кнопку Ключевое
поле на панели инструментов.
Примечание: Если порядок полей в нескольких полей первичного ключа должно отличаться от порядка полей в таблице, нажмите кнопку индексы на панели инструментов, чтобы открыть диалоговое окноиндексов , а затем порядок полей для индекса с именем PrimaryKey .
- Определите отношение "один ко многим" между каждой из двух главных таблиц и связующей таблицей.
Ссылочная целостность
Целостность данных означает систему правил, Microsoft Access использует для обеспечения связи между записями в связанных таблицах, а также случайного удаления или изменения связанных данных. Установить целостность данных можно при соблюдении всех следующих условий:
- Соответствующее поле из главной таблицы является первичным ключом или имеет уникальный индекс.
- Связанные поля имеют одинаковый тип данных. Существует два исключения. Поле счетчика может относиться к полю значение свойства FieldSize длинное целое число, а поле счетчика с параметрами свойства FieldSize код репликации могут быть связаны с числовым полем значение свойства FieldSize кода репликации.
- Обе таблицы принадлежат одной базе данных Microsoft Access. Если таблицы являются связанными, они должны быть в формате Microsoft Access и базы данных, в котором хранятся настройки целостности данных необходимо открыть. Целостность данных не может быть применена для связанных таблиц из баз данных в других форматах.
При использовании условия целостности данных действуют следующие правила:
- Нельзя ввести значение в поле внешнего ключа связанной таблицы не существует первичного ключа главной таблицы. Тем не менее можно ввести значение Null внешний ключ, указав, что записи не связаны. Например нельзя создать заказ, назначенный клиенту, не существует, но можно создать заказ, присвоенный никто, указав значение Null в поле «КодКлиента».
- Невозможно удалить запись из главной таблицы, если существуют совпадающие записи в связанной таблице.Например нельзя удалить запись сотрудника из таблицы «Сотрудники», если имеются заказы, относящиеся к сотрудника в таблице «Заказы».
- Нельзя изменить значение первичного ключа в главной таблице, если запись связанные записи. Например невозможно изменить код сотрудника в таблице «Сотрудники», если имеются заказы, относящиеся к этому сотруднику в таблице «Заказы».
Каскадное обновление и удаление
Для отношений, в которых применяется ссылочная целостность можно указать, требуется Microsoft Access автоматически каскадного обновления или . Если установить эти параметры операции удаления и обновления, будет запрещено правилами целостности данных. При удалении записей или изменении значений первичного ключа в главной таблице Microsoft Access вносит необходимые изменения в связанные таблицы для сохранения целостности данных.
Если щелкнуть флажок при определении связи, что при изменении первичного ключа записи в главной таблице Microsoft Access автоматически обновляет первичный ключ новое значение во всех связанных записях. Например при изменении кода клиента в таблице «Клиенты», поле «КодКлиента» в таблице «Заказы» автоматически обновляется для всех заказов этого клиента так, что связь не нарушена. Microsoft Access выполнит каскадное обновление без вывода дополнительных сообщений.
Примечание: Если поле счетчика первичного ключа в главной таблице, установив флажок Каскадное обновление связанных полей не повлияет, так как не может изменить значение в поле счетчика.
Если при определении отношения установить флажок Каскадное удаление связанных записей , при каждом удалении записи в главной таблице Microsoft Access автоматически удалит связанные записи в связанной таблице. Например при удалении записи клиента из таблицы «Клиенты» всех заказов этого клиента автоматически удаляются из таблицы Orders (включая записи в таблице Order Details, связанные с записями заказов). При удалении записей из формы или таблицы с установленным флажком Каскадное удаление связанных записей , Microsoft Access предупреждает, что связанные записи также будут удалены. Однако при удалении записей с помощью запроса на удаление Microsoft Access автоматически удалит записи из связанных таблиц без вывода предупреждения.
Типы соединения
Существует три типа соединения, как показано ниже:
Вариант 1 -внутреннее соединение. Внутреннее соединение является соединением, где записи из двух таблиц объединяются в результатах запроса только в том случае, если значения в связанных полях удовлетворяют заданному условию. В запросе по умолчанию соединение-это внутреннее соединение, которое выбирает записи только в том случае, если значения связанных полей совпадают.
Вариант 2 определяет левое внешнее объединение. Левое внешнее соединение является соединением, в котором все записи из левой стороне операции LEFT JOIN в запросе SQL инструкции добавляются результаты запроса, даже если отсутствуют соответствующие значения в связанном поле из таблицы на правой.
Вариант 3 определяет правое внешнее объединение. Правое внешнее соединение является соединением, в котором все записи из правой стороне операции RIGHT JOIN в запросе SQL инструкции добавляются результаты запроса, даже если в связанном поле из левой таблицы отсутствуют соответствующие значения.
Одно или несколько полей (столбцов), комбинация значений которых однозначно определяет каждую запись в таблице, называется первичным ключом. Ключевое поле позволяет избежать возникновения ошибок при вводе данных, так как они в этом поле не могут повторяться. В качестве ключевого поля можно использовать идентификационный номер, присваиваемый гражданам налоговой службой, серия и номер паспорта сотрудника. Ключевое поле может содержать число или последовательность символов, позволяющих идентифицировать каждую запись и избежать дублирования. Ключевое поле используется для быстрого поиска и связи данных из разных таблиц при помощи запросов, форм и отчетов. Первичный ключ не может содержать пустых значений (Null) и всегда должен иметь уникальный индекс. В любой таблице желательно иметь одно или несколько ключевых полей. Значение Null означает, что в поле нет никаких данных, например, потому, что они неизвестны. Значение Null нельзя приравнивать к строке, содержащей пробелы. В специальном поле Счетчик (AutoNumber) каждой записи присваивается уникальный для этого поля номер, который автоматически увеличивается с каждой новой записью. Его можно использовать для нумерации записей по порядку.
Составной ключ (composite primary key) представляет собой комбинацию из нескольких полей. Он используется в тех случаях, когда невозможно гарантировать уникальность записи с помощью одного поля. Чаще всего такая ситуация возникает для таблицы, используемой для связывания двух таблиц в отношении «многие ко многим».
Данные ключевого поля используются для индексирования таблицы, что ускоряет поиск и обработку информации. Если не задана сортировка таблицы, то записи располагаются по значению ключа. При включении новых записей или удалении старых записи таблицы не перемещаются, изменяется только местоположение каждого индекса. Первичный ключ используется для связывания одной таблицы с другой..
Для отображения на экране таблицы в окне базы данных выделите имя таблицы в списке и выберите команду Открыть в меню Файл или нажмите кнопку Открыть на панели инструментов. Щелкните ячейку, в которую необходимо ввести данные. Введите данные и нажмите клавиши Enter или Tab. Для перехода к пустой записи нажмите клавиши Ctrl + (символ «плюс») или нажмите кнопку перехода по записям Новая запись. Изменение значений полей, добавление или удаление данных и поиск данных выполняется в режиме таблицы. Ввод новых данных в выделенное поле автоматически заменяет старые. Количество вводимых символов зависит от размера поля, а не от ширины столбца. Текст не может быть разорван внутри ячейки. В одной ячейке нельзя отобразить несколько строк текста. Чтобы ввести одни и те же данные в несколько ячеек, выделите ячейки, наберите данные, а затем нажмите Ctrl+Enter. Для удаления данных в выделенном поле нажмите клавишу Delete .
Сегодня на занятии мы рассмотрим, что такое ключевое поле в таблице, узнаем виды ключевых полей и научимся определять ключевое поле в таблице Access на конкретном примере.
Основное свойство таблицы в реляционной БД состоит в том, что все записи должны быть уникальными, т.е. не должно быть в одной таблице двух абсолютно одинаковых записей:
- Иванов Иван Иванович
- Иванов Иван Иванович
Это не один человек записанный дважды в таблице, а два разных конкретных человека! Да, в таблице могут быть два совершенно разных человека с именами Иванов Иван Иванович. Как их различить? Это достигается с помощью ключевого поля.
Ключевое поле - это атрибут или группа атрибутов, которые обеспечивают уникальность каждой строки (записи).
Именно ключевое поле позволит каждую запись считать разной, в данном примере позволит различить двух Ивановых.
Ключевые поля бывают тех видов:
- счетчик;
- простой ключ;
- составной ключ.
В каждой таблице должно быть обязательно ключевое поле. Мы будем использовать ключевое поле типа счетчик. Для его создания достаточно выделить атрибут в контекстном меню ПКМ выбрать команду Ключевое поле. Если вы не определили атрибут, который будет ключевым, то при закрытии таблицы, Access обязательно предложит создать ключевое поле, выбрав ключ самостоятельно.
Обратите внимание, что ключевое поле очень важно при создании таблиц. Ключевое поле используется
- для связи таблиц между собой;
- для быстрого поиска информации в таблицах.
Давайте на примере конкретной таблицы попробуем определить ключевое поле . Пример подробно рассмотрен в видеоуроке :
Повторим:
- Если атрибут Фамилия сделать ключевым полем, то в таблице не должно быть двух одинаковых фамилия, что в реальной жизни невозможно, т.к. в классе, например, учатся брат и сестра с одинаковыми фамилиями.
- Если использовать в качестве первичного ключа (Фамилия, Домашний_Адрес), то не должно быть одинаковых адресов в записях таблицы, что так же невозможно, т.к. в одном классе могут учиться брат и сестра, проживающие по одному адресу.
- Перебрав все атрибуты на кандидаты в первичный ключ, приходим к выводу, что нужно ввести дополнительное поле, которое будем использовать в качестве ключа.
- Напомню, если название поля состоит из двух слов, то пробелы использовать не рекомендуется. Лучше в этом случае использовать нижнее подчеркивание для соединения слов.
P.S. Театр начинается с вешалки, а таблица с ключевого поля. Очень важно правильно научиться определять ключевое поле.
Напомню, что есть несколько способов создания БД, которые рассмотрены в уроке "Введение в Access" , есть также несколько способов создания таблиц. В уроке подробно рассмотрены первые два способа: с помощью мастера и ввода в таблицу.







