Зона особого внимания – Опция Maximum Degree of Parallelism. О интересных вещах из мира IT, инструкции и рецензии Sql максимальная степень параллелизма
Оптимизация работы 1С. Настройка сервера MS SQL
Включите возможность мгновенной инициализации файлов (Database instant file initialization)
- Создание базы данных
- Добавление файлов, журналов или данных в существующую базу данных
- Увеличение размера существующего файла (включая операции автоувеличения)
- Восстановление базы данных или файловой группы
Для включения настройки:
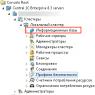
- На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.msc).
- Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей.
- На правой панели дважды кликните Выполнение задач по обслуживанию томов.
- Нажмите кнопку «Добавить» пользователя или группу и добавьте сюда пользователя, под которым запущен сервер MS SQL Server.
- Нажмите кнопку Применить.
Включите параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Для включения настройки:
- В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc.
- В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows.
- Разверните узлы Настройки безопасности и Локальные политики.
- Выберите папку Назначение прав пользователя.
- Политики будут показаны на панели подробностей.
- На этой панели дважды кликните параметр Блокировка страниц в памяти.
- В диалоговом окне Параметр локальной безопасности - блокировка страниц в памяти выберите «Добавить» пользователя или группу.
- В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server.
- Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server.
Отключите механизм DFSS для дисков.
Механизм Dynamic Fair Share Scheduling отвечает за балансировку и распределение аппаратных ресурсов между пользователями. Иногда его работа может негативно сказываться на производительности 1С. Чтобы отключить его только для дисков, нужно:
- Найти в реестре ветку HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\TSFairShare\Disk
- Установить значение параметра EnableFairShare в 0
Отключите сжатие данных для каталогов, в которых лежат файлы базы.
При включенном сжатии ОС будет пытаться дополнительно обрабатывать файлы при модификации, что замедлит сам процесс записи, но сэкономит место.
Чтобы отключить сжатие файлов в каталоге, необходимо:
- Открыть свойства каталога
- На закладке Общие нажать кнопку Другие
- Снять флаг «Сжимать» содержимое для экономии места на диске.
Установите параметр «Максимальная степень параллелизма» (Max degree of parallelism) в значение 1.
Данный параметр определяет, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов.
Для настройки параметра необходимо:
- Открыть свойства сервера и выбрать закладку Дополнительно
- Установить значение параметра равное единице.
Ограничьте максимальный объем памяти сервера MS SQL Server.
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства сервера и выбрать закладку Память
- Указать значение параметра Максимальный размер памяти сервера.
Включите флаг «Поддерживать» приоритет SQL Server (Boost SQL Server priority).
Данный флаг позволяет повысить приоритет процесса MS SQL Server над другими процессами.
Имеет смысл включать флаг только в том случае, если на компьютере с сервером СУБД не установлен сервер 1С.
Для установки флага необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства сервера и выбрать закладку Процессоры
- Включить флаг «Поддерживать приоритет SQL Server (Boost SQL Server priority)» и нажать Ок.
Установите размер авто увеличения файлов базы данных.
Автоувеличение позволяет указать величину, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуется установить значение от 512 МБ до 5 ГБ.
- Запустить Management Studio и подключиться к нужному серверу
- Напротив каждого файла в колонке Автоувеличение поставить необходимое значение
Данная настройка будет действовать только для выбранной базы. Если вы хотите, чтобы такая настройка действовала для всех баз, нужно выполнить эти же действия для служебной базы model. После этого все вновь созданные базы будет иметь те же настройки, что и база model.
Разнесите файлы данных mdf и файлы логов ldf на разные физические диски.
В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
- Запустить Management Studio и подключиться к нужному серверу
- Открыть свойства нужной базы и выбрать закладку Файлы
- Запомнить имена и расположение файлов
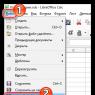
- Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
- Поставить флаг Удалить соединения и нажать Ок
- Открыть Проводник и переместить файл данных и файл журнала на нужные носители
- В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
- Нажать кнопку Добавить и указать файл mdf с нового диска
- В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок.
Не секрет, что обдумывая проблемы конфигурирования SQL сервера, связанные с увеличением производительности, IT-специалисты в своем большинстве, делают выбор в пользу увеличения аппаратных средств. Но всегда ли это оправдано? Все ли методы настройки сервера при этом уже использованы? Известно, что работа с параметрами конфигурации и изменение их значений по умолчанию, способна улучшить производительность и другие характеристики данной системы. Среди этих опций конфигурации SQL есть одна опция, с которой связано много вопросов, это опция - Max degree of parallelism (DOP) - вот о ней и поговорим.
Опция Maximum Degree of Parallelism (DOP) определяет число потоков, на которые SQL Server может распараллелить запрос и означает число используемых процессоров сервера. Параметр этот умолчанию имеет значение 0 – максимальную степень параллелизма. Например, если вы имеете 24 ядра – тогда значение ‘max degree of parallelism’ будет равно 24 и оптимизатор, если он посчитает нужным, может задействовать все процессоры на выполнение одной инструкции, то есть запрос будет распараллелен на 24 потока. Для большинства случаев это хорошо, но не для всех. Также, далеко не всегда хорошо, использование значение этого параметра по умолчанию. Конфигурирование этого параметра может быть нужно, например, в следующей ситуации: допустим, у нас есть приложение, в которое все сотрудники вносят информацию о ежедневных операциях, и, в определенный промежуток времени каждый из пользователей выполняет запрос, который строит отчет обо всех операциях пользователя за некий промежуток времени. Естественно, что если промежуток времени большой, этот запрос будет выполняться долго и, при установке DOP по умолчанию, займет все доступные процессоры, что, естественно, скажется на работе остальных пользователей. Следовательно, изменяя значение DOP, мы можем без изменения самого запроса повысить время отклика SQL сервера у других пользователей.
MS рекомендует устанавливать значение следующим образом:
Установка параметра на TSQL целиком для сервера:
EXEC sp_configure "max degree of parallelism", 4; reconfigure
Так же вы можете установить это значение для конкретного TSQL запроса:
USE AdventureWorks2008R2 ; GO SELECT ProductID, OrderQty, SUM(LineTotal) AS TotalFROM Sales.SalesOrderDetail WHERE UnitPrice < $5.00 GROUP BY ProductID, OrderQty ORDER BY ProductID, OrderQty OPTION (MAXDOP 2); GO
В этом примере «хинт» maxdop меняет значение по умолчанию параметра max degree of parallelism на 2. Посмотреть текущую настройку можно так:
EXEC sp_configure "Show Advanced",1; RECONFIGURE; EXEC sp_configure "max degree of parallelism"
Теперь давай те посмотрим как влияет это значение на скорость выполнения запроса. Для того что бы тестовый запрос, написанный выше, выполнялся более продолжительное время, добавим в него ещё один select. Запрос приобретет следующий вид:
< $5.00) dt2 WHERE dt.UnitPrice < $5.00 GROUP BY dt.ProductID, dt.OrderQty ORDER BY dt.ProductID, dt.OrderQty
На моей тестовой машине значение ‘max degree of parallelism’ выставлено в 0. MSSQL запущен на машине с 4-х ядерным процессором. Я провел серию экспериментов с разными значениями MAXDOP: равным 1 – без распараллеливания запроса; равным 2 - с использованием только 2 ядер; равным 4 – с использованием всех и без хинта для определения варианта, который использует сиквел по умолчанию. Для того, чтобы получить статистику выполнения, в запрос нужно включить опцию SET STATISTICS TIME ON, а также включить кнопку отображения плана запроса в Management studio. Для усреднения полученных результатов я выполнял каждый запрос в цикле 3 раза. Результаты можно видеть ниже:
SELECT dt.ProductID, dt.OrderQty, SUM(dt.LineTotal) AS Total FROM Sales.SalesOrderDetail dt, (SELECT * FROM Sales.SalesOrderDetail WHERE UnitPrice < $5.00) dt2 WHERE dt.UnitPrice < $5.00 GROUP BY dt.ProductID, dt.OrderQty ORDER BY dt.ProductID, dt.OrderQty OPTION (MAXDOP 1); SQL Server Execution Times: CPU time = 45942 ms, elapsed time = 46118 ms. SQL Server Execution Times: CPU time = 45926 ms, elapsed time = 46006 ms. SQL Server Execution Times: CPU time = 45506 ms, elapsed time = 45653 ms.
На плане запроса видно что при установке хинта (MAXDOP 1) запрос выполнялся без распараллеливания. Среднее время выполнения запроса 45925.66 ms
SELECT dt.ProductID, dt.OrderQty, SUM(dt.LineTotal) AS Total FROM Sales.SalesOrderDetail dt, (SELECT * FROM Sales.SalesOrderDetail WHERE UnitPrice < $5.00) dt2 WHERE dt.UnitPrice < $5.00 GROUP BY dt.ProductID, dt.OrderQty ORDER BY dt.ProductID, dt.OrderQty OPTION (MAXDOP 2); SQL Server Execution Times: CPU time = 51684 ms, elapsed time = 28983 ms. SQL Server Execution Times: CPU time = 51060 ms, elapsed time = 26165 ms. SQL Server Execution Times: CPU time = 50903 ms, elapsed time = 26015 ms.

При установке хинта (MAXDOP 2) запрос выполнялся параллельно на 2 cpu, это можно увидеть на Number of Execution в плане выполнения запроса. Среднее время выполнения запроса 27054.33 ms
SELECT dt.ProductID, dt.OrderQty, SUM(dt.LineTotal) AS Total FROM Sales.SalesOrderDetail dt, (SELECT * FROM Sales.SalesOrderDetail WHERE UnitPrice < $5.00) dt2 WHERE dt.UnitPrice < $5.00 GROUP BY dt.ProductID, dt.OrderQty ORDER BY dt.ProductID, dt.OrderQty OPTION (MAXDOP 4); SQL Server Execution Times: CPU time = 82275 ms, elapsed time = 23133 ms. SQL Server Execution Times: CPU time = 83788 ms, elapsed time = 23846 ms. SQL Server Execution Times: CPU time = 53571 ms, elapsed time = 27227 ms.

При установке хинта (MAXDOP 4) запрос выполнялся параллельно на 4 cpu. Среднее время выполнения запроса 24735.33 ms
SELECT dt.ProductID, dt.OrderQty, SUM(dt.LineTotal) AS Total FROM Sales.SalesOrderDetail dt, (SELECT * FROM Sales.SalesOrderDetail WHERE UnitPrice < $5.00) dt2 WHERE dt.UnitPrice < $5.00 GROUP BY dt.ProductID, dt.OrderQty ORDER BY dt.ProductID, dt.OrderQty SQL Server Execution Times: CPU time = 85816 ms, elapsed time = 23190 ms. SQL Server Execution Times: CPU time = 85800 ms, elapsed time = 23307 ms. SQL Server Execution Times: CPU time = 58515 ms, elapsed time = 26575 ms.

запрос выполнялся параллельно, так же 4 cpu. Среднее время выполнения запроса 24357.33ms
links: http://support.microsoft.com/kb/2023536
В этой небольшой заметке я бы хотел немного рассказать о тонкостях в настройках параллелизма в Microsoft SQL Server. Очень многим из вас давно известна опция Max Degree od Parallelism, которая присутствует в SQL Server уже очень давно. По умолчанию она выставлена в 0, что значит, что SQL Server будет сам выбирать оптимальную степень параллелизма, то есть количество процессоров\потоков, задействованных для выполнения одной инструкции. Я сейчас не буду останавливаться и рассуждать, в какое же именно значении лучше выставлять эту опцию – это тема для отдельное заметки. Я лишь рассмотрю, как значение этой опции влияет на выполнение запросов. Например, ниже на рисунке, эта опция выставлена в 1, что означет, что параллельные планы для всех запросов по умолчанию отключены.
Также данная опция доступна для просмотра с помощью следующей команды T-SQL:

И действительно, любой план запроса по умолчанию будет последовательным. Например:

Однако, у разработчика и любого пользователя по-прежнему остается возможность повлиять на это путем использования подсказок (hints). Для этого всего лишь нужно указать нужную степень параллелизма, и генерируется нужный план запроса, например:

И если мы понаблюдаем на этот запрос через представление sys.dm_exec_query_profiles, то увидим, что он действительно выполняется в 10 потоков.

Таким образом, в системе остается потайной лаз, который могут использовать разработчики и пользователи, чтобы «ускорить» (тут я специально поставил в кавычки, т.к. не всегда большая степень параллелизма ведет к уменьшению времени выполнения запроса) свои запросы путем увеличения степени параллелизма. Но, таким образом, они могут просто «убить» сервер, запуская множество неконтролируемых параллельных запросов одновременно. Что же мы можем с этим сделать? Вот тут нам на помощь приходит Resource Governor, очень мощная и совершенно недооцененная система, которая позволяет очень гибко распределить ресурсы между разными группами пользователей. Опять же, я сейчас не буду останавливаться на том, как он устроен, и какими возможностями обладает. Я лишь остановлюсь подробно, как влияют его настройки ограничения параллелизма. Давайте для начала взглянем в настройки по умолчанию:

Опять мы видим, что по умолчанию опция выставлена в 0 и решение о выборе максимальной степени отдано на откуп SQL Server. Теперь посмотрим, что будет, если я поменяю это значение в 5. Внимание, ни в коем случае не делайте такие настройки на реальной системе, т.к. я даже не определил функцию классификации для Resource Governor и меняю default группу. Но для теста и понимания, как все работает конкретно сейчас на моем примере, этого хватит. Таким образом, я ограничиваю для всех максимальную степень параллелизма 5 потоками. Напомню, что опция Max Degree of Parallelism , которую мы рассматривали ранее выставлена по-прежнему в значение 1. Если мы теперь посмотрим на план выполнения нашего изначального запроса, то по умолчанию он будет последовательный, а с опцией maxdop 10 – параллельный. Но, если мы запустим параллельный план, то увидим кое-что интересное.

Теперь наш запрос выполняется только в 5 потоков, несмотря на то, что опция maxdop для него имеет значение 10. И, если вы укажете для запроса опцию maxdop 4, он будет выполняться в 4 потока (опция в Resource Governor установлена в 5). В этом случае подсказка maxdop меньше настройки Resource Governor, поэтому дополнительного ограничения не накладывается. Пример этого я уже не привожу.
Таким образом, Resource Governor является более мощным средством, который уже реально ограничивает максимальную степень параллелизма для запросов, и эту степень можно задать разную для разных групп пользователей. При этом опция Max Degree of Parallelism по-прежнему продолжает работать и вносит свою лепту (или слегка запутывает администраторов, разработчиков и пользователей, когда работает в купе с Resource Governor). Далее, лишь только вашей фантазией ограничены варианты выставления значений этих 2х параметров, но важно помнить лишь две вещи: Max Degree of Parallelism и подсказка (hint) maxdop для запроса влияет на то, какой план будет сгенерирован, сколько максимальное количество потоков будет возможно для этого запроса, а Resource Governor еще дополнительно сверху ограничивает запрос уже во время выполнения.
Max degree of parallelism (DOP) - дополнительна опция конфигурации SQL Server, с
которой связано много вопросов и которой посвящено множество публикаций. В этой
статье своего блога, автор надеется внести немного ясности в то, что эта опция
делает и как её нужно использовать.
Во-первых, автор хотел бы рассеять любые сомнения по поводу того, что указанная
опция устанавливает, сколько процессоров может использовать SQL Server при
обслуживании нескольких подключений (или пользователей) - это не так! Если SQL
Server имеет доступ к четырем неактивным процессорам, и он настроен на использование
всех четырёх процессоров, он будет использовать все четыре процессора, независимо
от максимальной степени параллелизма.
Так, что же эта опция даёт? Эта опция устанавливает максимальное число процессоров,
которые SQL Server может использовать для одного запроса. Если запрос к SQL Server
должен вернуть большой объём данных (много записей), его иногда имеет смысл
распараллелить, разбив на несколько маленьких запросов, каждый из которых будет
возвращать своё подмножество строк. Таким образом, SQL Server может использовать
несколько процессоров, и, следовательно, на многопроцессорных системах большое
количество записей всего запроса потенциально может быть возвращено быстрее, чем
на однопроцессорной системе.
Есть множество критериев, которые должны быть учтены до того, как SQL Server вызовет
"Intra Query Parallelism" (разбивку запроса на несколько потоков), и
нет смысла их здесь детализировать. Вы можете найти их в BOL, поискав фразу
"Degree of parallelism". Там написано, что решение о распараллеливании основано
на доступности памяти процессору и, особенно, на доступности самих процессоров.
Итак, почему мы должны продумать использование этой опции - потому что, оставляя
её в значении по умолчанию (SQL Server сам принимает решение о распараллеливании),
иногда можно получить нежелательные эффекты. Эти эффекты выглядят примерно так:
Распараллеленные запросы выполняются медленнее.
Время исполнения запросов может стать недетерминированным, и это может раздражить пользователей. Время исполнения может измениться потому что:
Запрос может иногда распараллеливаться, а иногда нет.
Запрос может блокироваться параллельным запросом, если перед этим процессоры были перегружены работой.
Прежде, чем мы продолжим, автор хотел бы заметить, что нет особой необходимости погружаться во внутреннюю организацию параллелизма. Если же Вы этим интересуетесь, Вы можете почитать статью "Parallel Query Processing" в Books on Line, в которой эта информация изложена более детально. Автор считает, что есть только две важные вещи, которые стоит знать о внутренней организации параллелизма:
Параллельные запросы могут породить больше потоков, чем указано в опции "Max degree of parallelism". DOP 4 может породить более двенадцати потоков, четыре для запроса и дополнительные потоки, используемые для сортировок, потоков, агрегатов и сборок и т.д.
Распараллеливание запросов может провоцировать разные SPID ожидать с типом ожидания CXPACKET или 0X0200. Этим можно воспользоваться для того, что бы найти те SPID, которые находятся в состоянии ожидания при параллельных операциях, и имеют в sysprocesses waittype: CXPACKET. Для облегчения этой задачи, автор предлагает воспользоваться имеющейся в его блоге хранимой процедурой: track_waitstats.
И так "Запрос может выполняться медленнее при распараллеливании" почему?
Если у системы очень слабая пропускная способность дисковых подсистем, тогда при анализе запроса, его декомпозиция может выполняться дольше, чем без параллелизма.
Возможен перекос данных или блокировки диапазонов данных для процессора, порождённые другим, используемым параллельно и запущенным позже процессом, и т.д.
Если отсутствует индекс для предиката, что приводит к сканированию таблицы. Параллельная операция в рамках запроса может скрыть тот факт, что запрос выполнился бы намного быстрее с последовательным планом исполнения и с правильным индексом.
Из всего этого следует рекомендация проверять исполнение запроса без параллелизма
(DOP=1), это поможет идентифицировать возможные проблемы.
Упомянутые выше эффекты параллелизма, сами собой должны навести Вас на мысль о
том, что внутренняя механика распараллеливания запросов не подходит для применения
в OLTP - приложениях. Это такие приложения, для которых изменение времени исполнения
запроса может раздражать пользователей и для которых сервер, одновременно обслуживающий
множество пользователей, вряд ли выберет параллельный план исполнения из-за присущих
этим приложениям особенностей профиля рабочей нагрузки процессора.
Поэтому, если Вы собираетесь использовать параллелизм, то, скорее всего это
понадобится, для задач извлечения данных (data warehouse), поддержки принятия
решений или отчётных систем, где не много запросов, но они являются достаточно
тяжёлыми и исполняются на мощном сервере с большим объёмом оперативной памяти.
Если Вы решили использовать параллелизм, какое же значение нужно установить для DOP?.
Хорошей практикой для этого механизма является то, что если Вы имеете 8 процессоров,
тогда устанавливайте DOP = 4, и это с большой степенью вероятности будет оптимальной
установкой. Однако, нет никаких гарантий, что так оно и будет работать. Единственный
способ убедиться в этом - протестировать разные значения для DOP. В дополнение к этому,
автор хотел предложить свой, основанный на эмпирических наблюдениях совет, никогда
не устанавливать это число больше, чем половине от числа процессоров, которые есть
в наличии. Если бы автор имел процессоров меньше шести, он установил бы DOP в 1,
что просто запрещает распараллеливание. Он мог бы сделать исключение, если бы имел
базу данных, которая поддерживает процесс только одного пользователя (некоторые
технологии извлечения данных или задачи отчётности), в этом случае, в порядке
исключения, можно будет установить DOP в 0 (значение по умолчанию), которое
позволяет SQL Server самому принимать решение о необходимости распараллеливания запроса.
Прежде, чем закончить статью, автор хотел предостеречь Вас по поводу того, что
параллельное создание индексов зависит от числа, которое Вы устанавливаете для DOP.
Это означает, что Вы можете захотеть изменять его на время создания или пересоздания
индексов, чтобы повысить производительность этой операции, и, конечно же, Вы можете
использовать в запросе хинт MAXDOP, который позволяет игнорировать установленное
в конфигурации значение и может быть использован в часы минимальной нагрузки.
Наконец, ваш запрос может замедляться при распараллеливании из-за ошибок, поэтому
убедитесь, что на вашем сервере установлен последний сервисный пакет (service pack).
| CREATE proc track_waitstats (@num_samples int =10 ,@delaynum int =1 ,@delaytype nvarchar (10 )="minutes" ) AS -- T. Davidson -- This stored procedure is provided =AS IS= with no warranties, -- and confers no rights. -- Use of included script samples are subject to the terms -- specified at http://www.microsoft.com/info/cpyright.htm -- @num_samples is the number of times to capture waitstats, -- default is 10 times. default delay interval is 1 minute -- delaynum is the delay interval. delaytype specifies whether -- the delay interval is minutes or seconds -- create waitstats table if it does not exist, otherwise truncate set nocount on if not exists (select 1 from sysobjects where name = "waitstats" ) create table waitstats ( varchar (80 ), requests numeric (20 ,1 ), numeric (20 ,1 ), numeric (20 ,1 ), now datetime default getdate ()) else truncate table waitstats dbcc sqlperf (waitstats,clear) -- clear out waitstats declare @i int ,@delay varchar (8 ) ,@dt varchar (3 ) ,@now datetime ,@totalwait numeric (20 ,1 ) ,@endtime datetime ,@begintime datetime ,@hr int ,@min int ,@sec int select @i = 1 select @dt = case lower (@delaytype) when "minutes" then "m" when "minute" then "m" when "min" then "m" when "mm" then "m" when "mi" then "m" when "m" then "m" when "seconds" then "s" when "second" then "s" when "sec" then "s" when "ss" then "s" when "s" then "s" else @delaytype end if @dt not in ("s" ,"m" ) begin print "please supply delay type e.g. seconds or minutes" return end if @dt = "s" begin select @sec = @delaynum % 60 select @min = cast ((@delaynum / 60 ) as int ) select @hr = cast ((@min / 60 ) as int ) select @min = @min % 60 end if @dt = "m" begin select @sec = 0 select @min = @delaynum % 60 select @hr = cast ((@delaynum / 60 ) as int ) end select @delay = right ("0" + convert (varchar (2 ),@hr),2 2 ),@min),2 ) + ":" + + right ("0" +convert (varchar (2 ),@sec),2 ) if @hr > 23 or @min > 59 or @sec > 59 begin select "hh:mm:ss delay time cannot > 23:59:59" select "delay interval and type: " + convert (varchar (10 ) ,@delaynum) + "," + @delaytype + " converts to " + @delay return end while (@i <= @num_samples) begin insert into waitstats (, requests, ,) exec ("dbcc sqlperf(waitstats)" ) select @i = @i + 1 waitfor delay @delay End --- create waitstats report execute get_waitstats --//--//--//--//--//--//--//--//--//-//--//--//--//--//--//--//--//--/ CREATE proc get_waitstats AS -- This stored procedure is provided =AS IS= with no warranties, and -- confers no rights. -- Use of included script samples are subject to the terms specified -- at http://www.microsoft.com/info/cpyright.htm -- -- this proc will create waitstats report listing wait types by -- percentage -- can be run when track_waitstats is executing set nocount on declare @now datetime ,@totalwait numeric (20 ,1 ) ,@endtime datetime ,@begintime datetime ,@hr int ,@min int ,@sec int select @now=max (now),@begintime=min (now),@endtime=max (now) from waitstats where = "Total" --- subtract waitfor, sleep, and resource_queue from Total select @totalwait = sum () + 1 from waitstats where not in ("WAITFOR" ,"SLEEP" ,"RESOURCE_QUEUE" , "Total" , "***total***" ) and now = @now -- insert adjusted totals, rank by percentage descending delete waitstats where = "***total***" and now = @now insert into waitstats select "***total***" ,0 ,@totalwait ,@totalwait ,@now select , ,percentage = cast (100 */@totalwait as numeric (20 ,1 )) from waitstats where not in ("WAITFOR" ,"SLEEP" ,"RESOURCE_QUEUE" ,"Total" ) and now = @now order by percentage desc |
Параметр "max degree of parallelism" опеределяет максимальное количество потоков, на которые SQL Server может распараллелить запрос. По умолчанию этот параметр равен нулю, что означает использование числа процессоров сервера. Например, если у вас 24 ядра - фактическое значение "max degree of parallelism" будет равно 24 и оптимизатор, если он посчитает нужным, может распараллелить запрос на 24 потока. В общем случае это хорошо, но не всегда. Также, далеко не всегда хорошо использование значение этого параметра по умолчанию.
Теперь давайте разберём почему это не хорошо. Приведу один пример из своей практики. Есть запрос, который по идее должен использовать определённый индекс, и вначале так и происходит. Запускается запрос который выполняет поиск по индексу и возвращает необходимые данные. Всё отлично. Затем по мере роста базы данных в таблицу добавляются новые и новые записи и в определённый момент оптимизатор понимает, что есть возможность выполнить запрос быстрее: “Зачем мне выполнять поиск по индексу, если у меня есть 24 ядра? Значит я могу в 24 потока просканировать кластерный индекс и получить необходимые мне данные быстрее!”. Для этого конкретного запроса это хорошо - он выполняется быстрее. Но плохо всем остальным, т.к. они вынуждены ждать выделения им процессорных ресурсов. И в системах с большим количеством одновременно выполняющихся запросов такое распараллеливание скорее плохо, чем хорошо. И вместо повышения производительности она только ухудшается. До недавнего времени я решал эту проблему выставлением хинта MAXDOP в неугодных мне хранимках. Но сейчас нашёл конкретную рекомендацию Майкрософт и применил её на своих серверах. Рекомендации по выбору оптимального значения "max degree of parallelism" находятся здесь: Recommendations and Guidelines for "max degree of parallelism" configuration option . Цитирую данную рекомендацию:
For SQL Server 2008 R2, SQL Server 2008 and SQL Server 2005 servers, use the following guideline: a. For servers that have eight or less processors, use the following configuration where N equals the number of processors: max degree of parallelism = 0 to N. b. For servers that use more than eight processors, use the following configuration: max degree of parallelism = 8. c. For servers that have NUMA configured, max degree of parallelism should not exceed the number of CPUs that are assigned to each NUMA node with the max value capped to 8. This will increase the likelyhood of all parallel threads of a query to be located within a NUMA Node and avoid costly remote node data look ups. d. For servers that have hyper-threading enabled, the max degree of parallelism value should not exceed the number of physical processors.
Отсюда следует, что для систем, в которых больше 8-и процессоров рекомендуется ставить "max degree of parallelism" = 8. Далее следует ещё одно пояснение, в котором говорится, что 8 - общая рекомендация. И в системах, где число одновременно выполняющихся запросов невелико имеет смысл ставить большее значение, а в системах с большим количеством конкурентных запросов ноборот меньшее. И, выбирая конкретный параметр, необходимо смотреть на его влияние на систему и тестировать на конкретных запросах.