Phân tích txt của robot quản trị trang web Yandex. Làm cách nào để biết liệu rô-bốt có thu thập dữ liệu một URL cụ thể hay không
Robot.txt được soạn đúng cách sẽ giúp lập chỉ mục trang web một cách chính xác và loại bỏ nội dung trùng lặp có trong bất kỳ CMS nào. Tôi biết rằng nhiều tác giả chỉ đơn giản là sợ hãi khi phải vào thư mục gốc của blog và thay đổi nội dung nào đó trong tệp “dịch vụ”. Nhưng nỗi sợ hãi sai lầm này phải được vượt qua. Hãy tin tôi: blog của bạn sẽ không “sụp đổ” ngay cả khi bạn đưa chân dung của chính mình vào robots.txt (tức là làm hỏng nó!). Nhưng bất kỳ thay đổi có lợi nào cũng sẽ nâng cao vị thế của nó trong mắt các công cụ tìm kiếm.
Tệp robots.txt là gì?
Tôi sẽ không giả vờ là một chuyên gia bằng cách tra tấn bạn bằng các điều khoản. Tôi sẽ chỉ chia sẻ cách hiểu khá đơn giản của mình về các chức năng của tệp này:
robot.txt– đây là hướng dẫn, lộ trình cho robot công cụ tìm kiếm truy cập blog của chúng tôi để kiểm tra. Chúng tôi chỉ cần cho họ biết nội dung nào, có thể nói, là nội dung phục vụ và nội dung nào có giá trị nhất mà độc giả phấn đấu (hoặc nên phấn đấu) vì chúng tôi. Và chính phần nội dung này cần được lập chỉ mục và xuất hiện trong kết quả tìm kiếm!
Điều gì sẽ xảy ra nếu chúng ta không quan tâm đến những hướng dẫn như vậy? – Mọi thứ đều được lập chỉ mục. Và vì đường dẫn của các thuật toán của công cụ tìm kiếm thực tế không thể hiểu được, nên một thông báo bài viết mở ra tại địa chỉ lưu trữ có vẻ phù hợp hơn với Yandex hoặc Google so với toàn bộ nội dung của bài viết nằm ở một địa chỉ khác. Và một người truy cập vào blog sẽ thấy một điều gì đó hoàn toàn khác với những gì bạn muốn và những gì bạn muốn: không bài đăng và danh sách tất cả các bài báo trong tháng... Kết quả rất rõ ràng - rất có thể anh ấy sẽ rời đi.
Mặc dù có những ví dụ về các trang web hoàn toàn không có robot nhưng chúng chiếm vị trí khá cao trong kết quả tìm kiếm, nhưng tất nhiên đây là ngoại lệ, không phải quy luật.
Tệp robots.txt bao gồm những gì?
Và ở đây tôi không muốn viết lại. Có những lời giải thích trực tiếp khá rõ ràng - ví dụ: trong phần trợ giúp của Yandex. Tôi thực sự khuyên bạn nên đọc chúng nhiều lần. Nhưng tôi sẽ cố gắng giúp bạn vượt qua sự nhầm lẫn ban đầu về quá nhiều thuật ngữ bằng cách mô tả cấu trúc chung của tệp robots.txt.
Ở trên cùng, ở phần đầu của robots.txt, chúng tôi khai báo chúng tôi đang viết hướng dẫn cho ai:
Tác nhân người dùng: Yandex
Tất nhiên, mọi công cụ tìm kiếm tự trọng đều có nhiều robot - có tên và không tên. Cho đến khi bạn hoàn thiện quy trình robots.txt của mình, tốt nhất bạn nên tập trung vào sự đơn giản và những khái quát hóa có thể có. Vì vậy, tôi đề xuất trao quyền cho Yandex và đoàn kết mọi người khác bằng cách viết ra một quy tắc chung:
Tác nhân người dùng: * - đây là tất cả, bất kỳ, robot nào
Chúng tôi cũng chỉ ra bản sao chính của trang web - địa chỉ sẽ tham gia tìm kiếm. Điều này đặc biệt đúng nếu bạn có nhiều gương. Bạn cũng có thể chỉ định một số tham số khác. Nhưng xét cho cùng, điều quan trọng nhất đối với chúng tôi là khả năng chặn lập chỉ mục các phần dịch vụ của blog.
Dưới đây là ví dụ về việc cấm lập chỉ mục:
Không cho phép: /cgi-bin* - tập tin script;
Không cho phép: /wp-admin* - bảng điều khiển quản trị;
Không cho phép: /wp-includes* - thư mục dịch vụ;
Không cho phép: /wp-content/plugins* - thư mục dịch vụ;
Không cho phép: /wp-content/cache* - thư mục dịch vụ;
Không cho phép: /wp-content/themes* - thư mục dịch vụ;
Không cho phép: */nguồn cấp dữ liệu
Không cho phép: /bình luận* - bình luận;
Không cho phép: */bình luận
Không cho phép: /*/?replytocom=* - trả lời nhận xét
Không cho phép: /tag/* - thẻ
Không cho phép: /archive/* - archive
Không cho phép: /category/* - danh mục
Cách tạo tệp robots.txt của riêng bạn
Cách dễ nhất và rõ ràng nhất là tìm một ví dụ về tệp robots.txt làm sẵn trên một blog nào đó và nghiêm túc viết lại nó cho chính bạn. Thật tốt nếu các tác giả đừng quên thay thế địa chỉ blog mẫu bằng địa chỉ đứa con tinh thần của mình.
Robot của bất kỳ trang web nào đều có sẵn tại:
https://site/robots.txt
Tôi cũng làm như vậy và tôi không cảm thấy mình có quyền can ngăn bạn. Điều duy nhất tôi thực sự hỏi là: hãy tìm hiểu những gì được viết trong tệp robots.txt được sao chép! Sử dụng sự trợ giúp của Yandex, bất kỳ nguồn thông tin nào khác - giải mã tất cả các dòng. Khi đó, chắc chắn bạn sẽ thấy rằng một số quy tắc không phù hợp với blog của bạn và ngược lại, một số quy tắc là không đủ.
Bây giờ hãy xem cách kiểm tra tính chính xác và hiệu quả của tệp robots.txt của chúng tôi.
Vì mọi thứ liên quan đến tệp robots.txt lúc đầu có vẻ quá khó hiểu và thậm chí nguy hiểm nên tôi muốn chỉ cho bạn một công cụ đơn giản và rõ ràng để kiểm tra nó. Đây là một đường dẫn rõ ràng sẽ giúp bạn không chỉ kiểm tra mà còn xác minh robots.txt của mình, bổ sung tất cả các hướng dẫn cần thiết và đảm bảo rằng robot của công cụ tìm kiếm hiểu những gì bạn muốn từ chúng.
Kiểm tra tệp robots.txt trong Yandex
Quản trị trang web Yandex cho phép chúng tôi tìm hiểu thái độ của robot tìm kiếm của hệ thống này đối với sự sáng tạo của chúng tôi. Để làm điều này, rõ ràng, bạn cần mở thông tin liên quan đến blog và:
- đi tới tab Công cụ-> phân tích Robots.txt
- hãy nhấp vào nút “tải lên” và hy vọng rằng bạn đã đặt tệp robots.txt ở nơi bạn cần và robot sẽ tìm thấy nó :) (nếu không tìm thấy, hãy kiểm tra xem tệp của bạn nằm ở đâu: nó phải ở thư mục gốc của blog, trong đó các thư mục wp là -admin, wp-includes, v.v. và bên dưới là các tệp riêng biệt - robots.txt nên nằm trong số đó)
- bấm vào “kiểm tra”.
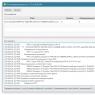
Nhưng thông tin quan trọng nhất nằm trong tab tiếp theo - “Các phần đang được sử dụng”! Trên thực tế, điều quan trọng đối với chúng ta là robot hiểu phần chính của thông tin - và để nó bỏ qua mọi thứ khác:
Sử dụng ví dụ này, chúng ta thấy rằng Yandex hiểu mọi thứ liên quan đến robot của mình (dòng 1 đến 15 và 32) - thật tuyệt vời!
Kiểm tra tệp robots.txt trong Google
Google cũng có một công cụ xác minh sẽ cho chúng ta thấy cách công cụ tìm kiếm này nhìn thấy (hoặc không nhìn thấy) robots.txt của chúng ta:
- Các công cụ quản trị trang web của Google (nơi blog của bạn cũng phải được đăng ký) có dịch vụ riêng để kiểm tra tệp robots.txt. Nó nằm trong tab Quét
- Sau khi tìm thấy tệp, hệ thống sẽ phân tích tệp và cung cấp thông tin về lỗi. Nó đơn giản.
Những điều bạn nên chú ý khi phân tích tệp robots.txt
Không phải vô cớ mà chúng tôi đã xem xét các công cụ phân tích từ hai công cụ tìm kiếm quan trọng nhất - Yandex và Google. Sau cùng, chúng tôi cần đảm bảo rằng mỗi người trong số họ đều đọc các đề xuất mà chúng tôi đưa ra trong robots.txt.
Trong các ví dụ được đưa ra ở đây, bạn có thể thấy Yandex hiểu các hướng dẫn mà chúng tôi để lại cho robot của nó và bỏ qua tất cả những hướng dẫn khác (mặc dù điều tương tự được viết ở mọi nơi, chỉ có lệnh User-agent: - là khác :)))
Điều quan trọng là phải hiểu rằng mọi thay đổi đối với robots.txt phải được thực hiện trực tiếp đối với tệp nằm trong thư mục gốc blog của bạn. Nghĩa là, bạn cần mở nó trong bất kỳ sổ ghi chú nào để viết lại, xóa hoặc thêm bất kỳ dòng nào. Sau đó, bạn cần lưu nó trở lại thư mục gốc của trang web và kiểm tra lại phản hồi với những thay đổi của công cụ tìm kiếm.
Không khó để hiểu những gì được viết trong đó và những gì cần thêm vào. Và việc quảng cáo blog mà không thiết lập tệp robots.txt đúng cách (theo cách bạn cần!) đang làm phức tạp thêm nhiệm vụ của bạn.
Xin chào các độc giả thân mến! Tôi xin dành bài viết hôm nay của mình cho một tập tin quan trọng và cực kỳ cần thiết robot.txt.
Tôi sẽ cố gắng giải thích càng chi tiết càng tốt và quan trọng nhất là rõ ràng, tệp này có chức năng gì và cách soạn nó một cách chính xác cho blog Wordpress.
Thực tế là mọi blogger mới làm quen đều mắc phải một sai lầm giống nhau; anh ta không coi trọng tập tin này, cả vì mù chữ và thiếu hiểu biết về vai trò mà nó được tạo ra.
Hôm nay chúng ta sẽ xem xét các câu hỏi sau:
- Tại sao bạn cần tệp robot trên trang web?
- Cách tạo robots.txt;
- Ví dụ về một tập tin chính xác;
- Robot kiểm tra trong Yandex Webmaster.
Tệp robots.txt dùng để làm gì?
Tôi quyết định sử dụng công cụ WordPress để tạo blog của mình vì nó rất tiện lợi, đơn giản và đa chức năng.
Tuy nhiên, không có một điều gì là lý tưởng. Thực tế là cms này được thiết kế để khi viết một bài viết, nó sẽ tự động được sao chép trong kho lưu trữ, danh mục, kết quả tìm kiếm trang web, .
Hóa ra một bài viết của bạn sẽ có nhiều bản sao chính xác trên trang web nhưng có các URL khác nhau.
 Kết quả là, bạn vô tình lấp đầy dự án với nội dung không độc đáo và các công cụ tìm kiếm sẽ không quan tâm đến tài liệu trùng lặp đó và sẽ sớm đưa nó vào các bộ lọc: từ Yandex hoặc Google.
Kết quả là, bạn vô tình lấp đầy dự án với nội dung không độc đáo và các công cụ tìm kiếm sẽ không quan tâm đến tài liệu trùng lặp đó và sẽ sớm đưa nó vào các bộ lọc: từ Yandex hoặc Google.
Cá nhân tôi đã bị thuyết phục về điều này bằng ví dụ của chính mình.
Khi tôi mới bắt đầu viết blog này, tất nhiên, tôi không hề biết rằng có một loại tệp robot nào đó, càng không biết nó nên là gì và nên viết gì vào đó.
Điều quan trọng nhất đối với tôi là viết nhiều bài hơn để sau này có thể bán liên kết từ họ trên sàn giao dịch. Tôi muốn kiếm tiền nhanh chóng, nhưng đó không phải là trường hợp...
Tôi đã viết khoảng 70 bài báo, nhưng bảng điều khiển Yandex Webmaster cho thấy robot tìm kiếm đã lập chỉ mục 275.
Tất nhiên, tôi nghi ngờ rằng mọi thứ không thể tốt như vậy, nhưng tôi không thực hiện bất kỳ hành động nào, hơn nữa tôi còn thêm blog vào trao đổi liên kết. sape.ru và bắt đầu nhận được 5 rúp. mỗi ngày.
Và một tháng sau, dự án của tôi bị áp đặt, tất cả các trang đều không còn được liệt kê, và do đó cửa hàng sinh lời của tôi bị đóng cửa.
Do đó, bạn cần nói cho robot công cụ tìm kiếm biết những trang, tệp, thư mục, v.v. cần được lập chỉ mục và những trang nào cần tránh.
Robots.txt- một tệp cung cấp lệnh cho các công cụ tìm kiếm những gì có thể được lập chỉ mục trên blog và những gì không thể.
Tệp này được tạo trong trình soạn thảo văn bản thông thường (notepad) với phần mở rộng txt và nằm ở thư mục gốc của tài nguyên.

Trong tệp robots.txt, bạn có thể chỉ định:
- Những trang, tập tin hoặc thư mục nào cần được loại trừ khỏi việc lập chỉ mục;
- Những công cụ tìm kiếm nào bị cấm hoàn toàn lập chỉ mục dự án;
- Chỉ định đường dẫn đến tệp sitemap.xml (sơ đồ trang web);
- Xác định bản sao chính và bản sao bổ sung của trang web (có www hoặc không có www);
Những gì có trong robots.txt - danh sách các lệnh
Vì vậy, bây giờ chúng ta đang chuyển sang thời điểm khó khăn và quan trọng nhất, chúng ta sẽ phân tích các lệnh và lệnh chính có thể được ghi trong tệp nền tảng robot WordPress.
1) Đại lý người dùng
Trong chỉ thị này, bạn chỉ ra công cụ tìm kiếm nào sẽ được xử lý các quy tắc (lệnh) sau đây.
Ví dụ: nếu bạn muốn tất cả các quy tắc được xử lý cụ thể cho dịch vụ Yandex thì nó sẽ nêu rõ:
Tác nhân người dùng: Yandex
Nếu bạn cần hỏi hoàn toàn tất cả các công cụ tìm kiếm thì hãy nhập dấu hoa thị “*” và kết quả sẽ như sau:
Đại lý người dùng: *
2) Không cho phép và cho phép
Không cho phép - cấm lập chỉ mục các phần, thư mục hoặc trang blog được chỉ định;
Cho phép - theo đó cho phép lập chỉ mục các phần này;
Trước tiên, bạn cần chỉ định lệnh Cho phép và chỉ sau đó là lệnh Disallow. Ngoài ra, hãy nhớ rằng không được có dòng trống giữa các lệnh này, cũng như sau lệnh User-agent. Nếu không, robot tìm kiếm sẽ cho rằng hướng dẫn đã kết thúc.
Ví dụ bạn muốn mở hoàn toàn việc lập chỉ mục của trang web thì chúng ta viết như sau:
Cho phép: /
Không cho phép:
Nếu chúng tôi muốn cấm Yandex lập chỉ mục một trang web, thì chúng tôi viết như sau:
Tác nhân người dùng: Yandex
Không cho phép: /
Bây giờ hãy ngăn việc lập chỉ mục tệp rss.html, nằm ở thư mục gốc của trang web của tôi.
Không cho phép: /rss.html
Và đây là lệnh cấm đối với một tập tin nằm trong một thư mục "tư thế".
Không cho phép: /posumer/rss.html
Bây giờ hãy cấm các thư mục chứa các trang trùng lặp và rác không cần thiết. Điều này có nghĩa là tất cả các tệp nằm trong các thư mục này sẽ không thể truy cập được bởi robot công cụ tìm kiếm.
Không cho phép: /cgi-bin/
Không cho phép: /wp-admin/
Không cho phép: /wp-includes/
Vì vậy, bạn cần cấm rô-bốt truy cập tất cả các trang, thư mục và tệp có thể ảnh hưởng tiêu cực đến sự phát triển của trang web trong tương lai.
3) Máy chủ
Lệnh này cho phép robot của công cụ tìm kiếm xác định trang web nhân bản nào sẽ được coi là trang web chính (có www hoặc không có www). Điều này sẽ bảo vệ dự án khỏi sự trùng lặp hoàn toàn và do đó, sẽ giúp bạn không phải áp dụng bộ lọc.
Bạn chỉ cần đăng ký lệnh này cho công cụ tìm kiếm Yandex, sau Disallow và Allow.
Máy chủ: trang web
4) Sơ đồ trang web
Với lệnh này, bạn chỉ ra vị trí của sơ đồ trang web của mình ở định dạng XML. Nếu ai đó chưa tạo sơ đồ trang web XML cho dự án của họ, tôi khuyên bạn nên sử dụng bài viết “”, trong đó mọi thứ được mô tả chi tiết.
Ở đây chúng ta cần chỉ định địa chỉ đầy đủ cho sơ đồ trang web ở định dạng xml.
Sơ đồ trang web: https://site/sitemap.xml
Xem đoạn video ngắn sẽ giải thích rất rõ ràng cách hoạt động của tệp robots.txt.
Ví dụ về một tập tin hợp lệ
Bạn không cần phải biết tất cả những điều phức tạp khi thiết lập tệp robot mà chỉ cần xem cách các quản trị viên web khác soạn nó và lặp lại tất cả các bước sau họ.
Trang blog của tôi được các công cụ tìm kiếm lập chỉ mục hoàn hảo và không có bản sao hoặc tài liệu rác nào khác trong chỉ mục.
Đây là tập tin được sử dụng trong dự án này:
| Tác nhân người dùng: * Không cho phép: / wp- Host: seoslim. ru Sơ đồ trang web: https: //site/sitemap.xml Tác nhân người dùng: Googlebot- Image Allow: / wp- content/ uploads/ Người dùng- tác nhân: YandexImages Cho phép: / wp- content/ uploads/ |
Tác nhân người dùng: * Không cho phép: /wp- Máy chủ: site.xml Tác nhân người dùng: Googlebot-Image Cho phép: /wp-content/uploads/ Tác nhân người dùng: YandexImages Cho phép: /wp-content/uploads/
Nếu muốn, bạn có thể lấy ví dụ này làm ví dụ, chỉ cần nhớ đổi tên trang web của tôi thành tên trang web của bạn.
Bây giờ hãy để tôi giải thích chính xác những gì một robot như vậy sẽ mang lại cho chúng ta. Thực tế là nếu bạn cấm một số trang trong tệp này bằng cách sử dụng các chỉ thị được mô tả ở trên, thì robot của công cụ tìm kiếm vẫn sẽ đưa chúng vào chỉ mục, điều này chủ yếu liên quan đến Google.
Nếu PS bắt đầu cấm một cái gì đó, thì ngược lại, nó chắc chắn sẽ lập chỉ mục cho nó, đề phòng. Do đó, ngược lại, chúng tôi phải cho phép các công cụ tìm kiếm lập chỉ mục tất cả các trang và tệp của trang web, đồng thời cấm các trang mà chúng tôi không cần (phân trang, bản sao trùng lặp và rác khác) bằng các lệnh sau bằng thẻ meta:
| < meta name= "robots" content= "noindex,follow" /> |
Trước hết, thêm các dòng sau vào tệp .htaccess:
| RewriteRule (.+ ) / Feed / $1 [ R= 301 , L] RewriteRule (.+ ) / comment- page / $1 [ R= 301 , L] RewriteRule (.+ ) / trackback / $1 [ R= 301 , L] RewriteRule (.+ ) / comments / $1 [ R= 301 , L] RewriteRule (.+ ) / attachment / $1 [ R= 301 , L] RewriteCond % ( QUERY_STRING) ^attachment_id= [ NC] RewriteRule (.* ) $1 ? [R= 301, L] |
RewriteRule (.+)/feed /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/trackback /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/attachment /$1 RewriteCond %( QUERY_STRING) ^attachment_id= Quy tắc viết lại (.*) $1?
Do đó, chúng tôi thiết lập chuyển hướng từ các trang trùng lặp (nguồn cấp dữ liệu, trang bình luận, trackback, bình luận, tệp đính kèm) đến các bài viết gốc.
Tệp này nằm ở thư mục gốc của trang web của bạn và sẽ trông giống như thế này:
| #BẮT ĐẦU WordPress< IfModule mod_rewrite. c>RewriteEngine Trên RewriteBase / RewriteCond % ( QUERY_STRING) ^replytocom= [ NC] RewriteRule (.* ) $1 ? [ R= 301 , L] RewriteRule (.+ ) / Feed / $1 [ R= 301 , L] RewriteRule (.+ ) / comment- page / $1 [ R= 301 , L] RewriteRule (.+ ) / trackback / $1 [ R= 301 , L] RewriteRule (.+ ) / comments / $1 [ R= 301 , L] RewriteRule (.+ ) / attachment / $1 [ R= 301 , L] RewriteCond % ( QUERY_STRING) ^attachment_id= [ NC] Quy tắc viết lại (.* ) $1 ? [ R= 301 , L] RewriteRule ^index\. php$ - [ L] RewriteCond % ( REQUEST_FILENAME) !- f RewriteCond % ( REQUEST_FILENAME) !- d RewriteRule . /mục lục. php[L]#ENDWordPress |
#BẮT ĐẦU WordPress
| /*** Chúng tôi đóng các trang phân trang khỏi việc lập chỉ mục bằng cách sử dụng noindex, nofollow ***/ hàm my_meta_noindex () ( if ( is_paged() // Trỏ tới tất cả các trang phân trang) ( tiếng vang "" . "" . "\N"; ) ) add_action("wp_head" , "my_meta_noindex" , 3 ) ; // thêm lệnh noindex,nofollow vào đầu template |
/*** Chúng tôi đóng các trang phân trang khỏi việc lập chỉ mục bằng cách sử dụng noindex, nofollow ***/ function my_meta_noindex () ( if (is_paged() // Trỏ tới tất cả các trang phân trang) (echo ""." "."\n";) ) add_action("wp_head", "my_meta_noindex", 3); // thêm lệnh noindex,nofollow vào đầu mẫu
Để đóng các danh mục, kho lưu trữ, thẻ, hãy đi tới cài đặt của plugin All in One Seo Pack và đánh dấu mọi thứ như trong ảnh chụp màn hình:

Tất cả cài đặt đã được thực hiện, bây giờ hãy đợi cho đến khi trang web của bạn được lập chỉ mục lại để các bản sao trùng lặp sẽ thoát khỏi kết quả tìm kiếm và lưu lượng truy cập sẽ lên hàng đầu.
Để xóa kết quả của snot, chúng tôi phải cho phép tệp robot lập chỉ mục các trang rác, nhưng khi robot PS truy cập chúng, chúng sẽ thấy thẻ meta noindex và sẽ không đưa chúng vào chỉ mục của chúng.
Kiểm tra robot trong Yandex Webmaster
Sau khi biên soạn chính xác tệp robots.txt và tải tệp đó lên thư mục gốc của trang web, bạn có thể thực hiện kiểm tra đơn giản về chức năng của tệp trong bảng Quản trị trang web.
Để thực hiện việc này, hãy truy cập bảng điều khiển Yandex Webmaster bằng cách sử dụng liên kết Ở cuối bài viết, tôi muốn nói rằng nếu bạn thực hiện bất kỳ thay đổi nào đối với tệp robots.txt, chúng sẽ chỉ có hiệu lực sau một vài tháng. Để các thuật toán của công cụ tìm kiếm quyết định loại trừ một trang, chúng cần có một quyết định có chủ ý - nó không chỉ chấp nhận chúng ở đó. Tôi muốn bạn xem xét việc tạo tệp này một cách nghiêm túc, vì số phận tương lai của trang web sẽ phụ thuộc vào nó. Nếu có thắc mắc gì hãy cùng nhau giải quyết nhé. Để lại một bình luận và nó sẽ không bao giờ không được trả lời. Hẹn sớm gặp lại!Phần kết luận
Sơ đồ trang web giúp đơn giản hóa rất nhiều việc lập chỉ mục blog của bạn. Mỗi trang web và blog đều phải có sơ đồ trang web. Nhưng mỗi trang web và blog cũng nên có một tập tin robot.txt. Tệp robots.txt chứa một bộ hướng dẫn dành cho robot tìm kiếm. Bạn có thể nói đây là những quy tắc ứng xử của robot tìm kiếm trên blog của bạn. Tệp này cũng chứa đường dẫn đến sơ đồ trang web của blog của bạn. Và trên thực tế, với tệp robots.txt được soạn chính xác, rô-bốt tìm kiếm không lãng phí thời gian quý báu để tìm kiếm sơ đồ trang web và lập chỉ mục các tệp không cần thiết.
Tệp robots.txt là gì?
robot.txt– đây là một tệp văn bản có thể được tạo trong một “notepad” thông thường, nằm ở thư mục gốc blog của bạn, chứa các hướng dẫn dành cho robot tìm kiếm.
Các hướng dẫn này ngăn robot tìm kiếm lập chỉ mục ngẫu nhiên tất cả các tệp thần thánh của bạn và tập trung vào việc lập chỉ mục chính xác những trang cần được đưa vào kết quả tìm kiếm.
Sử dụng tệp này, bạn có thể ngăn việc lập chỉ mục các tệp công cụ WordPress. Hoặc giả sử, phần bí mật trên blog của bạn. Bạn có thể chỉ định đường dẫn tới bản đồ blog và bản sao chính của blog. Ở đây ý tôi là tên miền của bạn có www và không có www.
Lập chỉ mục trang web có và không có robots.txt
Ảnh chụp màn hình này cho thấy rõ cách tệp robots.txt cấm lập chỉ mục các thư mục nhất định trên trang web. Nếu không có tệp, mọi thứ trên trang web của bạn đều có sẵn cho robot.
Các lệnh cơ bản của tệp robots.txt
Để hiểu được các hướng dẫn có trong tệp robots.txt, bạn cần hiểu các lệnh (chỉ thị) cơ bản.
Đại lý người dùng– lệnh này cho biết robot truy cập vào trang web của bạn. Sử dụng lệnh này, bạn có thể tạo hướng dẫn riêng cho từng robot.
Tác nhân người dùng: Yandex – quy tắc cho robot Yandex
Tác nhân người dùng: * - quy tắc cho tất cả robot
Không cho phép và cho phép– chỉ thị cấm và cho phép. Sử dụng lệnh Disallow, việc lập chỉ mục bị cấm, trong khi Allow cho phép điều đó.
Ví dụ về lệnh cấm:
Đại lý người dùng: *
Disallow: / - cấm toàn bộ trang web.
Tác nhân người dùng: Yandex
Disallow: /admin – cấm robot Yandex truy cập các trang nằm trong thư mục quản trị.
Ví dụ về độ phân giải:
Đại lý người dùng: *
Cho phép: /ảnh
Disallow: / - cấm toàn bộ trang web, ngoại trừ các trang nằm trong thư mục ảnh.
Ghi chú! lệnh Disallow: không có tham số sẽ cho phép mọi thứ và lệnh Allow: không có tham số sẽ cấm mọi thứ. Và không nên có lệnh Allow mà không có Disallow.
Sơ đồ trang web– chỉ định đường dẫn đến sơ đồ trang web ở định dạng xml.
Sơ đồ trang web: https://site/sitemap.xml.gz
Sơ đồ trang web: https://site/sitemap.xml
Chủ nhà– lệnh này xác định bản sao chính của blog của bạn. Người ta tin rằng lệnh này chỉ được quy định cho robot Yandex. Lệnh này phải được chỉ định ở cuối tệp robots.txt.
Tác nhân người dùng: Yandex
Không cho phép: /wp-includes
Máy chủ: trang web
Ghi chú! Địa chỉ máy nhân bản chính được chỉ định mà không chỉ định giao thức truyền siêu văn bản (http://).
Cách tạo robots.txt
Bây giờ chúng ta đã quen với các lệnh cơ bản của tệp robots.txt, chúng ta có thể bắt đầu tạo tệp của mình. Để tạo tệp robots.txt của riêng bạn với các cài đặt riêng, bạn cần biết cấu trúc blog của mình.
Chúng ta sẽ xem xét việc tạo tệp robots.txt tiêu chuẩn (phổ quát) cho blog WordPress. Bạn luôn có thể thêm cài đặt của riêng bạn vào nó.
Vậy hãy bắt đầu. Chúng ta sẽ cần một “notepad” thông thường, có trong mọi hệ điều hành Windows. Hoặc TextEdit trên MacOS.
Mở một tài liệu mới và dán các lệnh này vào đó:
Tác nhân người dùng: * Không cho phép: Sơ đồ trang web: https://site/sitemap.xml.gz Sơ đồ trang web: https://site/sitemap.xml Tác nhân người dùng: Yandex Không cho phép: /wp-login.php Không cho phép: /wp-register .php Không cho phép: /cgi-bin Không cho phép: /wp-admin Không cho phép: /wp-includes Không cho phép: /xmlrpc.php Không cho phép: /wp-content/plugins Không cho phép: /wp-content/cache Không cho phép: /wp-content/themes Không cho phép: /wp-content/ngôn ngữ Không cho phép: /category/*/* Không cho phép: /trackback Không cho phép: */trackback Không cho phép: */*/trackback Không cho phép: /tag/ Không cho phép: /feed/ Không cho phép: */*/ Feed/ */ Không cho phép: */feed Không cho phép: */*/feed Không cho phép: /?feed= Không cho phép: /*?* Không cho phép: /?s= Máy chủ: trang web
Đừng quên thay thế các tham số của chỉ thị Sơ đồ trang web và Máy chủ lưu trữ bằng thông số của riêng bạn.
Quan trọng! Khi viết lệnh, chỉ được phép có một khoảng trắng. Giữa chỉ thị và tham số. Trong mọi trường hợp, bạn không nên đặt dấu cách sau một tham số hoặc bất kỳ vị trí nào.
Ví dụ:
Không cho phép:<пробел>/cho ăn/
Tệp robots.txt mẫu này rất phổ biến và phù hợp với bất kỳ blog WordPress nào có URL CNC. Tìm hiểu về CNC là gì. Nếu bạn chưa định cấu hình CNC, tôi khuyên bạn nên xóa Disallow: /*?* Disallow: /?s= khỏi tệp được đề xuất

Tải tệp robots.txt lên máy chủ
Cách tốt nhất cho kiểu thao tác này là kết nối FTP. Đọc về cách thiết lập kết nối FTP cho TotolCommander. Hoặc bạn có thể sử dụng trình quản lý tệp trên máy chủ của mình.
Tôi sẽ sử dụng kết nối FTP trên TotolCommander.
Mạng > Kết nối với máy chủ FTP.

Chọn kết nối mong muốn và nhấp vào nút “Kết nối”.

Mở thư mục gốc của blog và sao chép tệp robots.txt của chúng tôi bằng cách nhấn phím F5.

Sao chép robots.txt vào máy chủ
Bây giờ tệp robots.txt của bạn sẽ thực hiện các chức năng thích hợp. Nhưng tôi vẫn khuyên bạn nên phân tích robots.txt để đảm bảo không có lỗi.
Để thực hiện việc này, bạn cần đăng nhập vào tài khoản quản trị trang web Yandex hoặc Google của mình. Hãy xem ví dụ về Yandex. Tại đây bạn có thể tiến hành phân tích ngay cả khi không xác nhận quyền của mình đối với trang web. Tất cả những gì bạn cần là một hộp thư Yandex.
Mở tài khoản Yandex.webmaster.

Trên trang chính tài khoản của quản trị viên web, mở liên kết "Kiểm trarobot.txt".

Để phân tích, bạn sẽ cần nhập địa chỉ URL của blog của mình và nhấp vào “ Tải xuống robot.txt từ trang web" Ngay sau khi tập tin được tải xuống, hãy nhấp vào nút "Kiểm tra".

Việc không có mục cảnh báo cho thấy tệp robots.txt đã được tạo chính xác.

Kết quả sẽ được trình bày dưới đây. Nơi rõ ràng và dễ hiểu những tài liệu nào được phép hiển thị cho robot tìm kiếm và tài liệu nào bị cấm.

Kết quả phân tích file robots.txt
Tại đây, bạn có thể thực hiện các thay đổi đối với robots.txt và thử nghiệm cho đến khi nhận được kết quả mong muốn. Nhưng hãy nhớ rằng tập tin nằm trên blog của bạn không thay đổi. Để thực hiện việc này, bạn sẽ cần sao chép kết quả thu được ở đây vào sổ ghi chú, lưu dưới dạng robots.txt và sao chép blog cho bạn.
Nhân tiện, nếu bạn đang thắc mắc tệp robots.txt trông như thế nào trên blog của ai đó, bạn có thể dễ dàng xem qua nó. Để thực hiện việc này, bạn chỉ cần thêm /robots.txt vào địa chỉ trang web
https://site/robots.txt
Bây giờ robots.txt của bạn đã sẵn sàng. Và hãy nhớ, đừng trì hoãn việc tạo tệp robots.txt, việc lập chỉ mục blog của bạn sẽ phụ thuộc vào nó.
Nếu bạn muốn tạo đúng tệp robots.txt, đồng thời đảm bảo rằng chỉ những trang cần thiết mới được đưa vào chỉ mục của công cụ tìm kiếm thì việc này có thể được thực hiện tự động bằng cách sử dụng plugin.
Đó là tất cả những gì tôi có. Tôi chúc các bạn thành công. Nếu bạn có bất kỳ câu hỏi hoặc bổ sung, hãy viết trong phần bình luận.
Hẹn sớm gặp lại.
Trân trọng, Maxim Zaitsev.
Theo dõi các bài viết mới!
- Đây là sự xuất hiện khi tìm kiếm các trang không mang bất kỳ thông tin hữu ích nào cho người dùng và rất có thể người dùng sẽ không truy cập chúng và nếu có thì sẽ không lâu nữa.
- Đây là sự xuất hiện khi tìm kiếm các bản sao của cùng một trang với các địa chỉ khác nhau. (Nội dung trùng lặp)
- Điều này lãng phí thời gian quý báu vào việc lập chỉ mục các trang không cần thiết bằng robot tìm kiếm. Robot tìm kiếm thay vì tham gia vào các nội dung cần thiết và hữu ích sẽ lãng phí thời gian lang thang khắp trang web một cách vô ích. Và vì robot không lập chỉ mục toàn bộ trang web cùng một lúc (có nhiều trang web và mọi người đều cần chú ý), nên bạn có thể không sớm thấy các trang quan trọng mà bạn muốn xem trong tìm kiếm.
Người ta đã quyết định chặn quyền truy cập của robot tìm kiếm vào một số trang của trang web. Tệp robots.txt sẽ giúp chúng ta việc này.
Tại sao bạn cần robots.txt?
robots.txt là một tệp văn bản thông thường chứa hướng dẫn dành cho robot tìm kiếm. Điều đầu tiên robot tìm kiếm thực hiện khi truy cập một trang web là tìm tệp robots.txt. Nếu không tìm thấy hoặc tệp robots.txt trống, trình thu thập thông tin sẽ đi qua tất cả các trang và thư mục có sẵn trên trang web (bao gồm cả thư mục hệ thống) nhằm cố gắng lập chỉ mục nội dung. Và thực tế không phải là nó sẽ lập chỉ mục trang bạn cần, nếu nó truy cập được.
Bằng cách sử dụng robots.txt, chúng tôi có thể cho robot tìm kiếm biết chúng có thể truy cập những trang nào, tần suất truy cập cũng như nơi chúng không nên truy cập. Hướng dẫn có thể được chỉ định cho tất cả các robot hoặc cho từng robot riêng lẻ. Các trang bị đóng khỏi rô-bốt tìm kiếm sẽ không xuất hiện trong công cụ tìm kiếm. Nếu tập tin này không tồn tại thì nó phải được tạo.
Tệp robots.txt phải được đặt trên máy chủ, ở thư mục gốc của trang web của bạn. Bạn có thể xem tệp robots.txt trên bất kỳ trang web nào trên Internet; để thực hiện việc này, chỉ cần thêm /robots.txt sau địa chỉ trang web. Đối với trang web, địa chỉ nơi bạn có thể xem robots..txt.
Tệp robots.txt, thông thường mỗi trang web đều có những đặc điểm riêng và việc sao chép thiếu suy nghĩ tệp của người khác có thể gây ra vấn đề khi robot tìm kiếm lập chỉ mục trang web của bạn. Vì vậy, chúng ta cần hiểu rõ mục đích của file robots.txt và mục đích của những hướng dẫn (chỉ thị) mà chúng ta sẽ sử dụng khi tạo ra nó.
Chỉ thị tệp Robots.txt.
Hãy xem các hướng dẫn (chỉ thị) cơ bản mà chúng ta sẽ sử dụng khi tạo tệp robots.txt.
Tác nhân người dùng: — chỉ định tên của robot mà tất cả các hướng dẫn bên dưới sẽ hoạt động. Nếu cần sử dụng hướng dẫn cho tất cả robot thì hãy sử dụng * (dấu hoa thị) làm tên.
Ví dụ:
Đại lý người dùng:*
#inguides áp dụng cho tất cả robot tìm kiếm
Tác nhân người dùng: Yandex
#instructions chỉ áp dụng cho robot tìm kiếm Yandex
Tên của các công cụ tìm kiếm Runet phổ biến nhất là Googlebot (cho Google) và Yandex (cho Yandex). Tên của các công cụ tìm kiếm khác, nếu quan tâm, có thể tìm thấy trên Internet, nhưng đối với tôi, có vẻ như không cần thiết phải tạo ra các quy tắc riêng cho chúng.
Disallow – cấm robot tìm kiếm truy cập vào một số phần của trang web hoặc toàn bộ trang web.
Ví dụ:
Không cho phép /wp-includes/
#denies quyền truy cập của robot vào wp-includes
Không cho phép /
# ngăn robot truy cập vào toàn bộ trang web.
Allow – cho phép robot tìm kiếm truy cập vào một số phần của trang web hoặc toàn bộ trang web.
Ví dụ:
Cho phép /wp-content/
#cho phép robot truy cập vào nội dung wp
Cho phép /
#Cho phép robot truy cập vào toàn bộ trang web.
Sơ đồ trang web: - có thể được sử dụng để chỉ định đường dẫn đến tệp mô tả cấu trúc trang web của bạn (sơ đồ trang web). Cần tăng tốc và cải thiện việc lập chỉ mục trang web bằng robot tìm kiếm.
Ví dụ:
.xml
Máy chủ: - Nếu trang web của bạn có bản sao (bản sao của trang web trên tên miền khác)..site. Sử dụng tệp Máy chủ, bạn có thể chỉ định bản sao chính của trang web. Chỉ có gương chính mới tham gia tìm kiếm.
Ví dụ:
Máy chủ: trang web
Bạn cũng có thể sử dụng các ký tự đặc biệt. *# và $
*(dấu hoa thị) – biểu thị bất kỳ chuỗi ký tự nào.
Ví dụ:
Không cho phép /wp-content*
#denies quyền truy cập của robot vào /wp-content/plugins, /wp-content/themes, v.v.
$(dấu đô la) – Theo mặc định, phần cuối của mỗi quy tắc được giả sử có một *(dấu hoa thị) để ghi đè ký tự *(dấu hoa thị), bạn có thể sử dụng ký tự $(ký hiệu đô la).
Ví dụ:
Không cho phép /example$
#denies quyền truy cập của robot vào /example nhưng không từ chối quyền truy cập vào /example.html
#(dấu thăng) – có thể được sử dụng để nhận xét trong tệp robots.txt
Bạn có thể tìm thêm thông tin chi tiết về các chỉ thị này cũng như một số chỉ thị bổ sung trên trang web Yandex.
Cách viết robots.txt cho WordPress.
Bây giờ hãy bắt đầu tạo tệp robots.txt. Vì blog của chúng tôi chạy trên WordPress nên hãy xem quá trình tạo robots.txt cho WordPress một cách chi tiết.
Đầu tiên, chúng ta cần quyết định những gì chúng ta muốn cho phép robot tìm kiếm và những gì cần cấm. Tôi quyết định chỉ để lại những thứ cần thiết cho mình, đó là các bài đăng, trang và phần. Chúng tôi sẽ đóng mọi thứ khác.
Chúng ta có thể biết những thư mục nào trong WordPress và những thư mục nào cần phải đóng nếu chúng ta xem thư mục trên trang web của mình. Tôi đã làm điều này thông qua bảng điều khiển lưu trữ trên trang web reg.ru, và nhìn thấy hình ảnh sau đây.
 Hãy xem mục đích của các thư mục và quyết định những gì có thể được đóng lại.
Hãy xem mục đích của các thư mục và quyết định những gì có thể được đóng lại.
/cgi-bin (thư mục tập lệnh trên máy chủ - chúng tôi không cần nó khi tìm kiếm.)
/files (thư mục chứa các tệp để tải xuống. Ví dụ: đây là một tệp lưu trữ có bảng Excel để tính toán lợi nhuận, mà tôi đã viết trong bài viết ““. Chúng tôi không cần thư mục này trong tìm kiếm.)
/playlist (Tôi đã tạo thư mục này cho chính mình, dành cho danh sách phát trên IPTV - nó không cần thiết khi tìm kiếm.)
/test (Tôi đã tạo thư mục này để thử nghiệm; thư mục này không cần thiết khi tìm kiếm)
/wp-admin/ (Quản trị viên WordPress, chúng tôi không cần nó trong tìm kiếm)
/wp-includes/ (thư mục hệ thống từ WordPress, chúng tôi không cần nó khi tìm kiếm)
/wp-content/ (trong thư mục này chúng ta chỉ cần /wp-content/uploads/; thư mục này chứa ảnh từ trang web nên chúng tôi sẽ cấm thư mục /wp-content/, và cho phép thư mục có ảnh có hướng dẫn riêng .)
Chúng tôi cũng không cần các địa chỉ sau trong tìm kiếm:
Lưu trữ – địa chỉ như //site/2013/ và tương tự.
Thẻ - địa chỉ thẻ chứa /tag/
Nguồn cấp dữ liệu RSS - tất cả các nguồn cấp dữ liệu đều có /feed trong địa chỉ của chúng
Để đề phòng, tôi sẽ đóng các địa chỉ có PHP ở cuối, vì có nhiều trang có sẵn, cả có PHP ở cuối và không có. Đối với tôi, điều này có vẻ sẽ tránh được sự trùng lặp của các trang khi tìm kiếm.
Tôi cũng sẽ đóng các địa chỉ bằng /GOTO/; tôi sử dụng chúng để theo các liên kết bên ngoài; chúng chắc chắn không liên quan gì đến việc tìm kiếm.
P=209 và tìm kiếm trang web //site/?s=, cũng như các nhận xét (địa chỉ chứa /?replytocom=)
Đây là những gì chúng ta nên để lại:
/images (mình đặt một số hình ảnh vào thư mục này, cho robot vào thư mục này)
/wp-content/uploads/ - chứa hình ảnh từ trang web.
Các bài viết, trang và phần có địa chỉ rõ ràng, dễ đọc.
Ví dụ: hoặc
Bây giờ hãy cùng đưa ra hướng dẫn cho robots.txt. Đây là những gì tôi có:
#Chúng tôi chỉ ra rằng tất cả các robot sẽ thực hiện các hướng dẫn này
Đại lý người dùng: *
#Chúng tôi cho phép robot đi lang thang trong thư mục tải lên.
Cho phép: /wp-content/uploads/
#Cấm thư mục có tập lệnh
Không cho phép: /cgi-bin/
#Cấm thư mục tập tin
Không cho phép: /files/
#Cấm thư mục danh sách phát
Không cho phép: /danh sách phát/
#Cấm thư mục kiểm tra
Không cho phép: /test/
#Chúng tôi cấm mọi thứ bắt đầu bằng /wp- , điều này sẽ cho phép bạn đóng một số thư mục có tên bắt đầu bằng /wp- , lệnh này có thể ngăn chặn việc lập chỉ mục các trang hoặc bài đăng bắt đầu bằng /wp-, nhưng tôi thì có không có ý định đặt những cái tên như vậy.
Không cho phép: /wp-*
#Chúng tôi cấm các địa chỉ chứa /?p= và /?s=. Đây là những liên kết ngắn và tìm kiếm.
Không cho phép: /?p=
Không cho phép: /?s=
#Chúng tôi cấm tất cả các tài liệu lưu trữ trước năm 2099.
Không cho phép: /20
#Chúng tôi cấm các địa chỉ có phần mở rộng PHP ở cuối.
Không cho phép: /*.php
#Chúng tôi cấm các địa chỉ chứa /goto/. Tôi không cần phải viết nó ra nhưng tôi sẽ ghi nó vào để đề phòng.
Không cho phép: /goto/
#Chúng tôi cấm địa chỉ thẻ
Không cho phép: /tag/
#Chúng tôi cấm tất cả các nguồn cấp dữ liệu.
Không cho phép: */nguồn cấp dữ liệu
#Chúng tôi cấm lập chỉ mục các bình luận.
Không cho phép: /?replytocom=
#Và cuối cùng, chúng tôi viết đường dẫn đến sơ đồ trang web của mình.
.xml
Viết tập tin robots.txt cho WordPress Bạn có thể sử dụng notepad thông thường. Hãy tạo một tập tin và viết những dòng sau vào đó.
Đại lý người dùng: *
Cho phép: /wp-content/uploads/
Không cho phép: /cgi-bin/
Không cho phép: /files/
Không cho phép: /danh sách phát/
Không cho phép: /test/
Không cho phép: /wp-*
Không cho phép: /?p=
Không cho phép: /?s=
Không cho phép: /20
Không cho phép: /*.php
Không cho phép: /goto/
Không cho phép: /tag/
Không cho phép: /tác giả/
Không cho phép: */nguồn cấp dữ liệu
Không cho phép: /?replytocom=
.xml
Lúc đầu, tôi dự định tạo một khối quy tắc chung cho tất cả robot, nhưng Yandex từ chối làm việc với khối quy tắc chung. Tôi đã phải tạo một khối quy tắc riêng cho Yandex. Để làm điều này, tôi chỉ cần sao chép các quy tắc chung, thay đổi tên của robot và trỏ robot vào bản sao chính của trang web bằng chỉ thị Máy chủ.
Tác nhân người dùng: Yandex
Cho phép: /wp-content/uploads/
Không cho phép: /cgi-bin/
Không cho phép: /files/
Không cho phép: /danh sách phát/
Không cho phép: /test/
Không cho phép: /wp-*
Không cho phép: /?p=
Không cho phép: /?s=
Không cho phép: /20
Không cho phép: /*.php
Không cho phép: /goto/
Không cho phép: /tag/
Không cho phép: /tác giả/
Không cho phép: */nguồn cấp dữ liệu
Không cho phép: /?replytocom=
.xml
Máy chủ: trang web
Bạn cũng có thể chỉ định bản sao chính của trang web thông qua phần “Gương chính”

Bây giờ tập tin đó robots.txt cho WordPressđược tạo, chúng ta cần tải nó lên máy chủ, vào thư mục gốc của trang web của chúng ta. Điều này có thể được thực hiện theo bất kỳ cách nào thuận tiện cho bạn.
Bạn cũng có thể sử dụng plugin WordPress SEO để tạo và chỉnh sửa robots.txt. Tôi sẽ viết thêm về plugin hữu ích này sau. Trong trường hợp này, bạn không cần phải tạo tệp robots.txt trên màn hình mà chỉ cần dán mã của tệp robots.txt vào phần thích hợp của plugin.

Cách kiểm tra robots.txt
Bây giờ chúng ta đã tạo xong tệp robots.txt, chúng ta cần kiểm tra nó. Để thực hiện việc này, hãy đi tới bảng điều khiển Yandex.Webmaster. Tiếp theo, đi đến phần “Thiết lập lập chỉ mục” rồi đến “phân tích robots.txt”. Ở đây, chúng tôi nhấp vào nút “Tải robots.txt từ trang web”, sau đó nội dung robots.txt của bạn sẽ xuất hiện trong cửa sổ tương ứng.

Sau đó nhấp vào “thêm” và trong cửa sổ xuất hiện, nhập các url khác nhau từ trang web của bạn mà bạn muốn kiểm tra. Tôi đã nhập một số địa chỉ nên bị từ chối và một số địa chỉ được cho phép.

Nhấp vào nút “Kiểm tra”, sau đó Yandex sẽ cung cấp cho chúng tôi kết quả kiểm tra tệp robots.txt. Như bạn có thể thấy, tệp của chúng tôi đã vượt qua bài kiểm tra thành công. Những gì nên bị cấm đối với robot tìm kiếm đều bị cấm ở đây. Những gì nên được cho phép được cho phép ở đây.

Việc kiểm tra tương tự có thể được thực hiện đối với robot Google, thông qua GoogleWebmaster, nhưng nó không khác nhiều so với việc kiểm tra qua Yandex, vì vậy tôi sẽ không mô tả nó.
Đó là tất cả. Chúng tôi đã tạo robots.txt cho WordPress và nó hoạt động rất tốt. Tất cả những gì còn lại là thỉnh thoảng xem xét hành vi của rô-bốt tìm kiếm trên trang web của chúng tôi. Để nhận thấy lỗi kịp thời và nếu cần, hãy thực hiện các thay đổi đối với tệp robots.txt. Bạn có thể xem các trang bị loại khỏi chỉ mục và lý do loại trừ trong phần tương ứng của Yandex.WebMaster (hoặc GoogleWebmaster).
Đầu tư tốt và thành công trong mọi nỗ lực của bạn.