Codurile de litere Ascii. Codificarea informațiilor text
Un computer înțelege procesul de conversie a acestuia într-o formă care permite transmiterea, stocarea sau procesarea automată mai convenabilă a acestor date. În acest scop sunt folosite diverse tabele. ASCII a fost primul sistem dezvoltat în Statele Unite pentru a lucra cu text în limba engleză, care a devenit ulterior răspândit în întreaga lume. Articolul de mai jos este dedicat descrierii, caracteristicilor, proprietăților și utilizării ulterioare.
Afișarea și stocarea informațiilor într-un computer
Simbolurile pe un monitor de computer sau pe unul sau altul gadget digital mobil sunt formate pe baza unor seturi de forme vectoriale de diferite caractere și a unui cod care vă permite să găsiți printre ele simbolul care trebuie introdus la locul potrivit. Reprezintă o secvență de biți. Astfel, fiecare caracter trebuie să corespundă în mod unic unui set de zerouri și unu, care apar într-o anumită ordine unică.
Cum a început totul
Din punct de vedere istoric, primele computere erau de limba engleză. Pentru a codifica informațiile simbolice în ele, a fost suficient să folosiți doar 7 biți de memorie, în timp ce 1 octet format din 8 biți a fost alocat în acest scop. Numărul de caractere înțeles de computer în acest caz a fost de 128. Aceste caractere includ alfabetul englez cu semnele de punctuație, numerele și unele caractere speciale. Codificarea de șapte biți în limba engleză cu tabelul corespunzătoare (pagina de cod), dezvoltată în 1963, a fost numită Codul standard american pentru schimbul de informații. De obicei, abrevierea „codificare ASCII” a fost și este încă folosită pentru a o desemna.
Trecerea la multilingvism
De-a lungul timpului, computerele au devenit utilizate pe scară largă în țările care nu vorbesc engleza. În acest sens, a fost nevoie de codificări care să permită utilizarea limbilor naționale. S-a decis să nu se reinventeze roata și să se ia ca bază ASCII. Tabelul de codificare din noua ediție s-a extins semnificativ. Utilizarea celui de-al 8-lea bit a făcut posibilă traducerea a 256 de caractere într-un limbaj de calculator.

Descriere
Codificarea ASCII are un tabel care este împărțit în 2 părți. Doar prima jumătate a acestuia este considerată a fi un standard internațional general acceptat. Include:
- Caractere cu numere de serie de la 0 la 31, codificate în secvențe de la 00000000 la 00011111. Sunt rezervate caracterelor de control care controlează procesul de afișare a textului pe ecran sau imprimantă, emiterea unui semnal sonor etc.
- Caracterele cu NN în tabel de la 32 la 127, codificate prin secvențe de la 00100000 la 01111111 formează partea standard a tabelului. Acestea includ un spațiu (N 32), litere ale alfabetului latin (minuscule și majuscule), numere din zece cifre de la 0 la 9, semne de punctuație, paranteze de diferite stiluri și alte simboluri.
- Caractere cu numere de serie de la 128 la 255, codificate prin secvențe de la 10000000 la 11111111. Acestea includ litere ale alfabetului național, altele decât cele latine. Această parte alternativă a tabelului ASCII este folosită pentru a converti caracterele rusești în formă de computer.

Unele proprietăți
Caracteristicile codificării ASCII includ diferența dintre literele „A” - „Z” ale literelor mici și mari de doar un bit. Această circumstanță simplifică foarte mult conversia registrului, precum și verificarea dacă aceasta aparține unui anumit interval de valori. În plus, toate literele din sistemul de codificare ASCII sunt reprezentate de propriile numere de succesiune în alfabet, care sunt scrise cu 5 cifre în sistemul de numere binar, precedate de 011 2 pentru literele mici și 010 2 pentru literele mari.
Printre caracteristicile codificării ASCII se numără reprezentarea a 10 cifre - „0” - „9”. În al doilea sistem numeric ele încep cu 00112 și se termină cu 2 valori numerice. Astfel, 0101 2 este echivalent cu numărul zecimal cinci, astfel încât caracterul „5” este scris ca 0011 01012. Pe baza celor de mai sus, puteți converti cu ușurință numerele BCD într-un șir ASCII adăugând secvența de biți 00112 la fiecare ciugulit de pe stânga.

„Unicode”
După cum știți, sunt necesare mii de caractere pentru a afișa texte în limbile grupului din Asia de Sud-Est. Un astfel de număr dintre ele nu poate fi descris în niciun fel într-un octet de informații, astfel încât nici măcar versiunile extinse de ASCII nu ar mai putea satisface nevoile crescute ale utilizatorilor din diferite țări.
Astfel, a apărut necesitatea creării unei codări universale a textului, a cărei dezvoltare, în colaborare cu mulți lideri ai industriei IT globale, a fost întreprinsă de consorțiul Unicode. Specialiștii săi au creat sistemul UTF 32 în acesta, 32 de biți au fost alocați pentru a codifica 1 caracter, constituind 4 octeți de informații. Principalul dezavantaj a fost o creștere bruscă a cantității de memorie necesară de până la 4 ori, ceea ce a implicat multe probleme.
În același timp, pentru majoritatea țărilor cu limbi oficiale aparținând grupului indo-european, numărul de caractere egal cu 232 este mai mult decât excesiv.
Ca urmare a lucrărilor ulterioare ale specialiștilor din consorțiul Unicode, a apărut codificarea UTF-16. A devenit opțiunea de conversie a informațiilor simbolice care se potrivea tuturor atât în ceea ce privește cantitatea de memorie necesară, cât și numărul de caractere codificate. De aceea, UTF-16 a fost adoptat implicit și necesită rezervarea a 2 octeți pentru un caracter.
Chiar și această versiune de Unicode destul de avansată și de succes a avut unele dezavantaje, iar după trecerea de la versiunea extinsă a ASCII la UTF-16, greutatea documentului s-a dublat.
În acest sens, s-a decis să se utilizeze codificarea cu lungime variabilă UTF-8. În acest caz, fiecare caracter al textului sursă este codificat ca o secvență de lungime de la 1 la 6 octeți.

Contactați codul standard american pentru schimbul de informații
Toate caracterele latine cu lungime variabilă UTF-8 sunt codificate în 1 octet, ca în sistemul de codificare ASCII.
O caracteristică specială a YTF-8 este că, în cazul textului în latină fără a utiliza alte caractere, chiar și programele care nu înțeleg Unicode vor putea să-l citească. Cu alte cuvinte, codarea de bază a textului ASCII devine pur și simplu parte a noului UTF cu lungime variabilă. Caracterele chirilice din YTF-8 ocupă 2 octeți și, de exemplu, caracterele georgiane - 3 octeți. Prin crearea UTF-16 și 8, principala problemă a creării unui singur spațiu de cod în fonturi a fost rezolvată. De atunci, producătorii de fonturi pot completa tabelul doar cu forme vectoriale de caractere text în funcție de nevoile lor.
Sistemele de operare diferite preferă codificări diferite. Pentru a putea citi și edita textele tastate într-o altă codificare, se folosesc programe de conversie a textului rusesc. Unele editoare de text conțin transcoduri încorporate și vă permit să citiți text indiferent de codificare.

Acum știți câte caractere sunt în codificarea ASCII și cum și de ce a fost dezvoltată. Desigur, astăzi standardul Unicode este cel mai răspândit în lume. Totuși, nu trebuie să uităm că se bazează pe ASCII, așa că trebuie apreciată contribuția dezvoltatorilor săi în domeniul IT.
După cum știți, un computer stochează informații în formă binară, reprezentând-o ca o secvență de unu și zero. Pentru a traduce informațiile într-o formă convenabilă pentru percepția umană, fiecare secvență unică de numere este înlocuită cu simbolul său corespunzător atunci când este afișată.
Unul dintre sistemele de corelare a codurilor binare cu caracterele tipărite și de control este
La nivelul actual de dezvoltare a tehnologiei informatice, utilizatorului nu i se cere să cunoască codul fiecărui caracter specific. Cu toate acestea, o înțelegere generală a modului în care se realizează codarea este extrem de utilă, iar pentru unele categorii de specialiști, chiar necesară.
Crearea ASCII
Codificarea a fost dezvoltată inițial în 1963 și apoi actualizată de două ori pe parcursul a 25 de ani.
În versiunea originală, tabelul de caractere ASCII includea 128 de caractere mai târziu a apărut o versiune extinsă, în care au fost salvate primele 128 de caractere, iar caracterele lipsă anterior au fost atribuite codurilor cu al optulea bit implicat.
Timp de mulți ani, această codificare a fost cea mai populară din lume. În 2006, Latin 1252 a ocupat poziția de lider, iar de la sfârșitul lui 2007 până în prezent, Unicode a deținut ferm poziția de lider.
Reprezentarea computerizată a ASCII
Fiecare caracter ASCII are propriul cod, format din 8 caractere reprezentând un zero sau unul. Numărul minim din această reprezentare este zero (opt zerouri în sistemul binar), care este codul primului element din tabel.
Două coduri din tabel au fost rezervate pentru comutarea între standardul US-ASCII și varianta sa națională.

După ce ASCII a început să includă nu 128, ci 256 de caractere, s-a răspândit o variantă de codificare, în care versiunea originală a tabelului a fost stocată în primele 128 de coduri cu al 8-lea bit zero. Caracterele scrise naționale au fost stocate în jumătatea superioară a tabelului (pozițiile 128-255).
Utilizatorul nu trebuie să cunoască direct codurile de caractere ASCII. De obicei, un dezvoltator de software trebuie să cunoască numărul elementului din tabel pentru a-și calcula codul folosind sistemul binar, dacă este necesar.
Limba rusă
După dezvoltarea codificărilor pentru limbile scandinave, chineză, coreeană, greacă etc. la începutul anilor '70, Uniunea Sovietică a început să creeze propria versiune. Curând, a fost dezvoltată o versiune a codificării pe 8 biți numită KOI8, păstrând primele 128 de coduri de caractere ASCII și alocând același număr de poziții pentru literele alfabetului național și caractere suplimentare.
Înainte de introducerea Unicode, KOI8 domina segmentul rus al internetului. Au existat opțiuni de codare atât pentru alfabetul rus, cât și pentru cel ucrainean.
Probleme ASCII
Deoarece numărul de elemente chiar și în tabelul extins nu a depășit 256, nu a existat nicio posibilitate de a găzdui mai multe scripturi diferite într-o singură codificare. În anii 90, problema „crocozyabr” a apărut pe Runet, când textele tastate cu caractere ASCII rusești erau afișate incorect.
Problema a fost că diferitele coduri ASCII nu se potriveau între ele. Să ne amintim că diferite caractere ar putea fi localizate în pozițiile 128-255, iar la schimbarea unei codări chirilice cu alta, toate literele textului au fost înlocuite cu altele având un număr identic într-o versiune diferită a codificării.
Starea curenta
Odată cu apariția Unicode, popularitatea ASCII a început să scadă brusc.
Motivul pentru aceasta constă în faptul că noua codificare a făcut posibilă găzduirea caracterelor din aproape toate limbile scrise. În acest caz, primele 128 de caractere ASCII corespund acelorași caractere în Unicode.

În 2000, ASCII era cea mai populară codare de pe Internet și era folosită pe 60% din paginile web indexate de Google. Până în 2012, ponderea acestor pagini a scăzut la 17%, iar Unicode (UTF-8) a luat locul celei mai populare codări.
Astfel, ASCII este o parte importantă a istoriei tehnologiei informației, dar utilizarea sa în viitor pare nepromițătoare.
Suprapunere de caractere
Caracterul BS (backspace) permite imprimantei să imprime un caracter peste altul. ASCII prevedea adăugarea de semne diacritice la litere în acest fel, de exemplu:
- a BS "→ á
- a BS ` → à
- a BS ^ → â
- o BS / → ø
- c BS , → ç
- n BS ~ → с
Notă: în fonturi vechi, apostroful „ a fost desenat înclinat spre stânga, iar tildele ~ a fost deplasată în sus, astfel încât să se potrivească doar cu rolul unui acut și a unei tilde deasupra.
Dacă același caracter este suprapus unui caracter, rezultatul este un efect de font aldine, iar dacă o subliniere este suprapusă unui caracter, rezultatul este text subliniat.
- a BS a → A
- aBS_→ A
Notă: Acesta este folosit, de exemplu, în sistemul de ajutor pentru om.
Variante naționale ASCII
Standardul ISO 646 (ECMA-6) prevede posibilitatea de a plasa simboluri naționale @ [ \ ] ^ ` { | } ~ . Pe lângă asta, la fața locului # poate fi postat £ , și pe loc $ - ¤ . Acest sistem este potrivit pentru limbile europene unde sunt necesare doar câteva caractere suplimentare. Versiunea de ASCII fără caractere naționale se numește US-ASCII sau „International Reference Version”.
Ulterior, s-a dovedit a fi mai convenabil să folosești codificări pe 8 biți (pagini de cod), în care jumătatea inferioară a tabelului de coduri (0-127) este ocupată de caractere US-ASCII, iar jumătatea superioară (128-255) prin caractere suplimentare, inclusiv un set de caractere naționale. Astfel, jumătatea superioară a tabelului ASCII, înainte de adoptarea pe scară largă a Unicode, a fost folosită în mod activ pentru a reprezenta caractere localizate, litere ale limbii locale. Lipsa unui standard unificat pentru plasarea caracterelor chirilice în tabelul ASCII a cauzat multe probleme cu codificările (KOI-8, Windows-1251 și altele). Alte limbi cu scripturi non-latine au suferit, de asemenea, de a avea mai multe codificări diferite.
| .0 | .1 | .2 | .3 | .4 | .5 | .6 | .7 | .8 | .9 | .A | .B | .C | .D | .E | .F | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0. | NUL | SOM | EOA | EOM | EQT | W.R.U. | RU | CLOPOT | BKSP | HT | LF | VT | FF | CR | ASA DE | SI. |
| 1. | DC 0 | DC 1 | DC 2 | DC 3 | DC 4 | ERR | SINCRONIZARE | L.E.M. | S 0 | S 1 | S 2 | S 3 | S 4 | S 5 | S 6 | S 7 |
| 2. | ||||||||||||||||
| 3. | ||||||||||||||||
| 4. | GOL | ! | " | # | $ | % | & | " | ( | ) | * | + | , | - | . | / |
| 5. | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; | < | = | > | ? |
| 6. | ||||||||||||||||
| 7. | ||||||||||||||||
| 8. | ||||||||||||||||
| 9. | ||||||||||||||||
| A. | @ | A | B | C | D | E | F | G | H | eu | J | K | L | M | N | O |
| B. | P | Q | R | S | T | U | V | W | X | Y | Z | [ | \ | ] | ← | |
| C. | ||||||||||||||||
| D. | ||||||||||||||||
| E. | A | b | c | d | e | f | g | h | i | j | k | l | m | n | o | |
| F. | p | q | r | s | t | u | v | w | X | y | z | ESC | DEL |
Pe acele computere în care unitatea minimă de memorie adresabilă a fost un cuvânt de 36 de biți, au fost utilizate inițial caractere de 6 biți (1 cuvânt = 6 caractere). După trecerea la ASCII, astfel de computere au început să conțină fie 5 caractere de șapte biți (1 bit a rămas în plus), fie 4 caractere de nouă biți într-un cuvânt.
Codurile ASCII sunt, de asemenea, folosite pentru a determina ce tastă este apăsată în timpul programării. Pentru o tastatură QWERTY standard, tabelul de coduri arată astfel:
|
Să ne amintim câteva fapte pe care le știm: Setul de simboluri cu care este scris textul se numește alfabet. Numărul de caractere dintr-un alfabet este cardinalitatea acestuia. Formula pentru determinarea cantității de informații: N = 2 b, unde N este puterea alfabetului (numărul de caractere), b - numărul de biți (greutatea informației simbolului). Alfabetul cu o capacitate de 256 de caractere poate găzdui aproape toate caracterele necesare. Un astfel de alfabet se numește suficient. Deoarece 256 = 2 8 , atunci greutatea unui caracter este de 8 biți. Unitatea de măsură 8 biți a primit numele 1 octet: 1 octet = 8 biți. Codul binar al fiecărui caracter din textul computerului ocupă 1 octet de memorie. Cum sunt reprezentate informațiile text în memoria computerului?
Comoditatea codificării caracterelor octet cu octet este evidentă deoarece un octet este cea mai mică parte adresabilă a memoriei și, prin urmare, procesorul poate accesa fiecare caracter separat atunci când procesează text. Pe de altă parte, 256 de caractere reprezintă un număr destul de suficient pentru a reprezenta o mare varietate de informații simbolice. Acum se pune întrebarea, ce cod binar de opt biți să aloce fiecărui caracter. Este clar că aceasta este o chestiune condiționată; puteți veni cu multe metode de codare. Tabelul ASCII a devenit standardul internațional pentru computere (citiți aski) (Codul standard american pentru schimbul de informații). Doar prima jumătate a tabelului este standardul internațional, adică. caractere cu numere de la 0 (00000000), la 127 (01111111).
Vă rugăm să rețineți că în tabelul de codificare, literele (majuscule și mici) sunt aranjate în ordine alfabetică, iar numerele sunt ordonate crescător. Această respectare a ordinii lexicografice în aranjarea caracterelor se numește principiul codificării secvențiale a alfabetului.
Cea mai comună codificare utilizată în prezent este Microsoft Windows, prescurtat CP1251. De la sfârșitul anilor 90, problema standardizării codificării caracterelor a fost rezolvată prin introducerea unui nou standard internațional numit Unicode. . Aceasta este o codificare pe 16 biți, adică alocă 2 octeți de memorie pentru fiecare caracter. Desigur, acest lucru crește de 2 ori cantitatea de memorie ocupată. Dar un astfel de tabel de coduri permite includerea a până la 65536 de caractere. Specificația completă a standardului Unicode include toate alfabetele existente, dispărute și create artificial din lume, precum și multe simboluri matematice, muzicale, chimice și alte simboluri. Să încercăm să folosim un tabel ASCII pentru a ne imagina cum vor arăta cuvintele în memoria computerului.
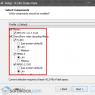
La introducerea informațiilor text într-un computer, caracterele (litere, cifre, semne) sunt codificate folosind diferite sisteme de codare, care constau dintr-un set de tabele de coduri situate pe paginile corespunzătoare ale standardelor pentru codificarea informațiilor text. În astfel de tabele, fiecărui caracter i se atribuie un cod numeric specific într-un sistem numeric hexazecimal sau zecimal, adică tabelele de coduri reflectă corespondența dintre imaginile simbol și codurile numerice și sunt destinate codificării și decodării informațiilor de text. Când introduceți informații de text folosind tastatura de computer, fiecare caracter introdus este codificat, adică convertit într-un cod numeric, atunci când informațiile text sunt transmise unui dispozitiv de ieșire a computerului (afișaj, imprimantă sau plotter), imaginea acestuia este construită folosind codul numeric; caracterul. Atribuirea unui anumit cod numeric unui simbol este rezultatul unui acord între organizațiile relevante din diferite țări. În prezent, nu există un singur tabel universal de coduri care să se potrivească cu literele alfabetelor naționale ale diferitelor țări. Tabelele moderne de coduri includ părți internaționale și naționale, adică conțin litere ale alfabetului latin și național, numere, operații aritmetice și semne de punctuație, simboluri matematice și de control și simboluri pseudografice. Parte internațională a tabelului de coduri bazată pe standard ASCII (Codul standard american pentru schimbul de informații), codifică prima jumătate a caracterelor din tabelul de coduri cu coduri numerice de la 0 la 7 F 16, sau în sistemul numeric zecimal de la 0 la 127. În acest caz, codurile de la 0 la 20 16 (0 ? 32 10) sunt alocate tastelor funcționale (F1, F2, F3 etc.) ale tastaturii computerului personal. În fig. 3.1 prezintă partea internațională a tabelelor de coduri bazate pe standard ASCII. Celulele de tabel sunt numerotate în sisteme de numere zecimale și, respectiv, hexazecimale.
Figura 3.1. Partea internațională a tabelului de coduri (standard ASCII) cu numere de celule prezentate în sisteme numerice zecimal (a) și hexazecimal (b). Partea națională a tabelelor de coduri conține coduri ale alfabetelor naționale, care se mai numește și un tabel de seturi de caractere (set de caractere). În prezent, pentru a sprijini literele alfabetului rus (chirilic), există mai multe tabele de coduri (codificări) care sunt utilizate de diferite sisteme de operare, ceea ce reprezintă un dezavantaj semnificativ și, în unele cazuri, duce la probleme asociate cu operațiunile de decodare a valorilor de caractere numerice. În tabel 3.1 arată numele paginilor de coduri (standarde) pe care se află tabelele de coduri chirilice (codificări). Tabelul 3.1
Unul dintre primele standarde pentru codificarea alfabetului chirilic pe computere a fost standardul KOI8-R. Partea națională a tabelului de coduri al acestui standard este prezentată în Fig. 3.2.
Orez. 3.2. Partea națională a tabelului de coduri al standardului KOI8-R În prezent, se utilizează și tabelul de coduri situat la pagina CP866 a standardului de codificare a informațiilor text, care este utilizat în sistemul de operare. MS DOS sau sesiune MS DOS pentru codificarea alfabetului chirilic (Fig. 3.3, A).
Orez. 3.3. Partea națională a tabelului de coduri, situată la pagina CP866 (a) și la pagina CP1251 (b) a standardului de codificare a informațiilor text În prezent, cel mai utilizat tabel de coduri pentru codificarea alfabetului chirilic se află pe pagina CP1251 a standardului corespunzător, care este utilizat în sistemele de operare ale familiei Windows companiilor Microsoft(Fig. 3.2, b).În toate tabelele de coduri prezentate, cu excepția tabelului standard Unicode Pentru a codifica un caracter, sunt alocate 8 cifre binare (8 biți). La sfârșitul secolului trecut, a apărut un nou standard internațional Unicodeîn care un caracter este reprezentat ca un cod binar de doi octeți. Aplicarea acestui standard este o continuare a dezvoltării unui standard internațional universal pentru a rezolva problema compatibilității codificărilor naționale de caractere. Folosind acest standard, pot fi codificate 2 16 = 65536 de caractere diferite. În fig. 3.4 arată tabelul de coduri 0400 (alfabet rus) al standardului Unicode.  Orez. 3.4. Tabelul de coduri Unicode 0400 Să explicăm ce s-a spus cu privire la codificarea informațiilor text folosind un exemplu. Exemplul 3.1Codați cuvântul „Computer” ca o secvență de numere zecimale și hexazecimale utilizând codificarea CP1251. Ce caractere vor fi afișate în tabelele de coduri CP866 și KOI8-R când se utilizează codul primit. Secvențe de cod hexazecimal și binar ale cuvântului „Computer” bazate pe tabelul de codificare CP1251 (vezi Fig. 3.3, b) va arata asa: Această secvență de cod în codificări SR866 și KOI8-R va avea ca rezultat afișarea următoarelor caractere: Pentru a converti documentele text în limba rusă dintr-un standard de codificare a informațiilor text în altul, se folosesc programe speciale - convertoare. Convertoarele sunt de obicei încorporate în alte programe. Un exemplu ar fi un program de browser - Internet Explorer (IE), care are un convertor încorporat. Un program de browser este un program special pentru vizualizarea conținutului. pagini web pe rețeaua globală de calculatoare Internet. Să folosim acest program pentru a confirma rezultatul mapării simbolurilor obținut în exemplul 3.1. Pentru a face acest lucru, vom efectua următorii pași. 1. Lansați programul Notepad (NotePad). Programul Notepad în sistemul de operare Windows XP lansat folosind comanda: [Button start– Programe – Standard – Notepad]. În fereastra programului Notepad care se deschide, tastați cuvântul „Computer” folosind sintaxa limbajului de marcare a documentului hipertext - HTML (Hyper Text Markup Language). Acest limbaj este folosit pentru a crea documente pe Internet. Textul ar trebui să arate astfel: Apa de calculator, UndeȘitag-uri (constructe speciale) ale limbajului HTML pentru marcarea antetului. În fig. Figura 3.5 prezintă rezultatul acestor acțiuni. Orez. 3.5. Afișarea textului în fereastra Notepad Să salvăm acest text executând comanda: [Fișier - Salvare ca...] în folderul corespunzător de pe computer la salvarea textului, vom da fișierului un nume - Notă, cu extensia de fișier; html. 2. Să lansăm programul Internet Explorer, prin executarea comenzii: [Buton start- Programe - Internet Explorer]. Când porniți programul, fereastra prezentată în Fig. 3.6  Orez. 3.6. Fereastra de acces offline Selectați și activați butonul DeconectatÎn acest caz, computerul nu se va conecta la internetul global. Va apărea fereastra principală a programului Microsoft Internet Explorer, prezentată în fig. 3.7.
Orez. 3.7. Fereastra principală Microsoft Internet Explorer Să executăm următoarea comandă: [Fișier – Deschidere], va apărea o fereastră (Fig. 3.8), în care trebuie să specificați numele fișierului și să faceți clic pe butonul Bine sau apăsați butonul Revizuire…și găsiți fișierul Prim.html.  Orez. 3.8. Deschide fereastra Fereastra principală a programului Internet Explorer va lua forma prezentată în Fig. 3.9. Cuvântul „Computer” va apărea în fereastră. Apoi, folosind meniul de sus al programului Internet Explorer, rulați următoarea comandă: [Vizualizare – Codificare – Chirilic (DOS)]. După executarea acestei comenzi în fereastra programului Internet Explorer Vor fi afișate simbolurile prezentate în fig. 3.10. La executarea comenzii: [Vizualizare – Codificare – Chirilic (KOI8-R)]în fereastra programului Internet Explorer Vor fi afișate simbolurile prezentate în fig. 3.11.
Orez. 3.9. Caractere afișate cu codificare CP1251
Orez. 3.10. Caractere afișate atunci când codarea CP866 este activată pentru o secvență de cod reprezentată în codificarea CP1251
Orez. 3.11. Caractere afișate atunci când codarea KOI8-R este activată pentru o secvență de cod reprezentată în codificarea CP1251 Astfel, obținut folosind programul Internet Explorer secvențele de caractere coincid cu secvențele de caractere obținute folosind tabelele de coduri CP866 și KOI8-R din exemplul 3.1. 3.2. Codificarea informațiilor graficeInformațiile grafice prezentate sub formă de imagini, fotografii, diapozitive, imagini în mișcare (animație, video), diagrame, desene pot fi create și editate folosind un computer și sunt codificate corespunzător. În prezent, există un număr destul de mare de programe de aplicație pentru procesarea informațiilor grafice, dar toate implementează trei tipuri de grafică pe computer: raster, vectorială și fractală. Dacă aruncați o privire mai atentă la imaginea grafică de pe ecranul monitorului computerului, puteți vedea un număr mare de puncte multicolore (pixeli - din engleză. pixel educat din element de imagine - element al imaginii), care, atunci când sunt colectate, formează o anumită imagine grafică. Din aceasta putem concluziona: o imagine grafică pe un computer este codificată într-un anumit mod și trebuie prezentată sub forma unui fișier grafic. Un fișier este unitatea structurală de bază de organizare și stocare a datelor pe un computer și, în acest caz, trebuie să conțină informații despre cum să prezinte acest set de puncte pe ecranul monitorului. Fișierele create pe baza graficelor vectoriale conțin informații sub formă de relații matematice (funcții matematice care descriu relații liniare) și date corespunzătoare despre cum se construiește o imagine a unui obiect folosind segmente de linie (vectori) atunci când sunt afișate pe un monitor de computer. Fișierele create pe baza graficelor raster necesită stocarea datelor despre fiecare punct individual din imagine. Pentru a afișa grafice raster, nu sunt necesare calcule matematice complexe, este suficient să obțineți pur și simplu date despre fiecare punct al imaginii (coordonatele și culoarea acestuia) și să le afișați pe ecranul monitorului computerului. În timpul procesului de codificare a unei imagini, aceasta este discretizată spațial, adică imaginea este împărțită în puncte individuale și fiecărui punct i se atribuie un cod de culoare (galben, roșu, albastru etc.). Pentru a codifica fiecare punct al unei imagini grafice color, se folosește principiul descompunerii unei culori arbitrare în componentele sale principale, pentru care se folosesc trei culori primare: roșu (cuvânt englezesc). Roșu, notat printr-o literă LA), verde (Verde, notat printr-o literă G), albastru (Albastru, notat cu fag ÎN). Orice culoare a unui punct percepută de ochiul uman poate fi obținută prin adăugarea (amestecarea) aditivă (proporțională) a trei culori primare - roșu, verde și albastru. Acest sistem de codare se numește sistem de culoare RGB. Fișiere grafice care utilizează un sistem de culoare RGB reprezintă fiecare punct al imaginii ca un triplet de culoare - trei valori numerice R, GȘi ÎN, intensitățile corespunzătoare ale culorilor roșu, verde și albastru. Procesul de codificare a unei imagini grafice se realizează folosind diverse mijloace tehnice (scanner, cameră digitală, cameră video digitală etc.); rezultatul este o imagine raster. La reproducerea imaginilor grafice color pe un monitor color de computer, culoarea fiecărui punct (pixel) al unei astfel de imagini este obținută prin amestecarea a trei culori primare R,GȘi B. Calitatea unei imagini raster este determinată de doi parametri principali - rezoluția (numărul de pixeli pe orizontală și pe verticală) și paleta de culori utilizată (numărul de culori specificate pentru fiecare pixel din imagine). Rezoluția este specificată indicând numărul de pixeli pe orizontală și pe verticală, de exemplu 800 pe 600 pixeli. Există o relație între numărul de culori atribuite unui punct dintr-o imagine raster și cantitatea de informații care trebuie alocată pentru a stoca culoarea punctului, determinată de relație (formula lui R. Hartley): Unde eu– cantitatea de informații; N – numărul de culori atribuite punctului. Cantitatea de informații necesare pentru a stoca culoarea unui punct se mai numește și adâncimea culorii sau calitatea redării culorii. Deci, dacă numărul de culori specificat pentru un punct de imagine este N= 256, atunci cantitatea de informații necesară pentru stocarea acesteia (adâncimea culorii) în conformitate cu formula (3.1) va fi egală cu eu= 8 biți. Calculatoarele folosesc diferite moduri grafice ale monitorului pentru a afișa informații grafice. Trebuie remarcat aici că, pe lângă modul grafic al monitorului, există și un mod text, în care ecranul monitorului este împărțit în mod convențional în 25 de linii a câte 80 de caractere pe linie. Aceste moduri grafice sunt caracterizate de rezoluția ecranului monitorului și de calitatea culorii (adâncimea culorii). Pentru a seta modul grafic al ecranului monitorului în sistemul de operare MS Windows XP trebuie să executați comanda: [Button start– Setări – Panou de control – Ecran]. În caseta de dialog „Properties: Screen” care apare (Fig. 3.12), trebuie să selectați fila „Parameters” și să utilizați glisorul „Screen Resolution” pentru a selecta rezoluția corespunzătoare a ecranului (800 x 600 pixeli, 1024 x 768 pixeli, etc.). Folosind lista derulantă „Calitatea culorii”, puteți selecta adâncimea culorii - „Cea mai mare (32 biți)”, „Mediu (16 biți)”, etc., iar numărul de culori atribuit fiecărui punct din imagine va să fie egal egal cu 2 32 (4294967296), 2 16 (65536), etc.  Orez. 3.12. Caseta de dialog Display Properties Pentru a implementa fiecare dintre modurile grafice ale ecranului monitorului, este necesară o anumită cantitate de memorie video de computer. Volumul de informații necesar al memoriei video (V) este determinată din relație Unde LA - numărul de puncte de imagine de pe ecranul monitorului (K = A · B); A - numărul de puncte orizontale de pe ecranul monitorului; IN - numărul de puncte verticale de pe ecranul monitorului; eu– cantitatea de informații (profunzimea culorii). Deci, dacă ecranul monitorului are o rezoluție de 1024 pe 768 pixeli și o paletă constând din 65.536 de culori, atunci adâncimea culorii conform formulei (3.1) va fi I = log 2 65.538 = 16 biți, numărul de pixeli ai imaginii va fi fi egal cu: K = 1024 x 768 = 786432, iar volumul de informații necesar al memoriei video în conformitate cu (3.2) va fi egal cu V= 786432 · 16 biți = 12582912 biți = 1572864 octeți = 1536 KB = 1,5 MB. În concluzie, trebuie menționat că, pe lângă caracteristicile enumerate, cele mai importante caracteristici ale unui monitor sunt dimensiunile geometrice ale ecranului și punctele de imagine. Dimensiunile geometrice ale ecranului sunt determinate de dimensiunea diagonală a monitorului. Dimensiunea diagonală a monitoarelor este specificată în inci (1 inch = 1" = 25,4 mm) și poate lua valori egale cu: 14", 15", 17", 21", etc. Tehnologiile moderne de producție a monitoarelor pot oferi o imagine dimensiunea punctului egală cu 0,22 mm. Astfel, pentru fiecare monitor există o rezoluție maximă fizică posibilă a ecranului, determinată de dimensiunea diagonalei sale și de dimensiunea punctului imaginii. Exerciții de făcut pe cont propriu1. Utilizarea programului MS Excel convertiți tabelele de coduri ASCII, SR866, SR1251, KOI8-R în tabele de forma: în celulele primei coloane a tabelelor scrieți în ordine alfabetică literele mari și apoi mici ale alfabetului latin și chirilic, în celulele a doua coloană - codurile corespunzătoare literelor din sistemul numeric zecimal, în celulele a treia coloană - codurile corespunzătoare literelor din sistemul numeric hexazecimal. Valorile codului trebuie selectate din tabelele de coduri corespunzătoare. 2. Codați și scrieți următoarele cuvinte ca o secvență de numere în sistemele numerice zecimal și hexazecimal: A) Internet Explorer, b) Microsoft Office; V) Corel Draw. Codificarea se realizează folosind tabelul de codificare ASCII modernizat obținut în exercițiul anterior. 3. Folosind tabelul de codificare KOI8-R modernizat, decodați secvențe de numere scrise în sistemul numeric hexazecimal: a) FC CB DA C9 D3 D4 C5 CE C3 C9 D1; b) EB CF CE C6 CF D2 CD C9 DA CD; c) FC CB D3 D0 D2 C5 D3 C9 CF CE C9 DA CD. 4. Cum va arăta cuvântul „Cibernetică” scris în codificarea SR1251 când se utilizează codificări SR866 și KOI8-R? Verificați rezultatele utilizând programul Internet Explorer. 5. Folosind tabelul de coduri prezentat în Fig. 3.1 A, decodificați următoarele secvențe de cod scrise în sistem de numere binar: a) 01010111 01101111 01110010 01100100; b) 01000101 01111000 01100011 01100101 01101100; c) 01000001 01100011 01100011 01100101 01110011 01110011. 6. Determinați volumul de informații al cuvântului „Economie”, codificat folosind tabelele de coduri SR866, SR1251, Unicode și KOI8-R. 7. Determinați volumul de informații al fișierului obținut în urma scanării unei imagini color de 12x12 cm. Rezoluția scanerului utilizat pentru scanarea acestei imagini este de 600 dpi. Scanerul setează adâncimea de culoare a punctului de imagine la 16 biți. Rezoluția scanerului 600 dpi (dotper inch - puncte pe inch) determină capacitatea unui scaner cu această rezoluție de a distinge 600 de puncte pe un segment de 1 inch. 8. Determinați volumul de informații al fișierului obținut în urma scanării unei imagini color de dimensiune A4. Rezoluția scanerului utilizat pentru scanarea acestei imagini este de 1200 dpi. Scanerul setează adâncimea de culoare a punctului de imagine la 24 de biți. 9. Determinați numărul de culori din paletă la adâncimi de culoare de 8, 16, 24 și 32 de biți. 10. Determinați cantitatea necesară de memorie video pentru modurile grafice ale ecranului monitorului 640 x 480, 800 x 600, 1024 x 768 și 1280 x 1024 pixeli cu o adâncime de culoare de 8, 16, 24 și 32 de biți. Rezumați rezultatele într-un tabel. Dezvoltați în MS Excel program de automatizare a calculelor. 11. Determinați numărul maxim de culori care pot fi folosite pentru a stoca o imagine de 32 pe 32 de pixeli, dacă computerul are 2 KB de memorie alocată pentru imagine. 12. Determinați rezoluția maximă posibilă a unui ecran de monitor cu o lungime a diagonalei de 15" și o dimensiune a punctului imaginii de 0,28 mm. 13. Ce moduri grafice ale monitorului pot fi furnizate de 64 MB de memorie video? Cuprins I. Istoricul codificării informațiilor………………………………………..3 II. Codificarea informațiilor……………………………………………………4 III. Codificarea informațiilor de tip text………………………….4 IV. Tipuri de tabele de codificare………………………………………………………….6 V. Calculul cantității de informații text………………………14 Lista referințelor………………………………………..16 eu . Istoricul codificării informațiilor Omenirea folosește criptarea textului (codificarea) chiar din momentul în care au apărut primele informații secrete. Iată câteva tehnici de codificare a textului care au fost inventate în diferite etape ale dezvoltării gândirii umane: Criptografia este scriere secretă, un sistem de schimbare a scrisului pentru a face textul de neînțeles pentru cei neinițiați; Cod Morse sau cod telegrafic neuniform, în care fiecare literă sau semn este reprezentat de propria sa combinație de rafale elementare scurte de curent electric (puncte) și rafale elementare de durată triplă (liniuță);
Una dintre cele mai vechi metode de criptare cunoscute este numită după împăratul roman Iulius Cezar (secolul I î.Hr.). Această metodă se bazează pe înlocuirea fiecărei litere a textului criptat cu alta, prin deplasarea alfabetului de la litera originală cu un număr fix de caractere, iar alfabetul se citește în cerc, adică după litera i se consideră a . Deci, cuvântul „octet”, atunci când este deplasat cu două caractere la dreapta, este codificat ca cuvântul „gwlf”. Procesul invers de descifrare a unui anumit cuvânt este necesar pentru a înlocui fiecare literă criptată cu a doua din stânga acesteia. II. Codificarea informațiilor Un cod este un set de convenții (sau semnale) pentru înregistrarea (sau comunicarea) unor concepte predefinite. Codarea informațiilor este procesul de formare a unei reprezentări specifice a informațiilor. Într-un sens mai restrâns, termenul „codificare” este adesea înțeles ca o tranziție de la o formă de reprezentare a informațiilor la alta, mai convenabilă pentru stocare, transmitere sau procesare. De obicei, la codificare (uneori se spune criptare), fiecare imagine este reprezentată printr-un semn separat. Un semn este un element dintr-un set finit de elemente distincte unele de altele. Într-un sens mai restrâns, termenul „codificare” se referă adesea la trecerea de la o formă de reprezentare a informației la alta, mai convenabilă pentru stocare, transmitere sau procesare. Puteți procesa informații text pe un computer. Când este introdusă într-un computer, fiecare literă este codificată cu un anumit număr, iar atunci când este transmisă către dispozitive externe (ecran sau imprimare), imaginile literelor sunt construite din aceste numere pentru percepția umană. Corespondența dintre un set de litere și numere se numește codificare de caractere. De regulă, toate numerele dintr-un computer sunt reprezentate folosind zerouri și unu (nu zece cifre, așa cum este de obicei pentru oameni). Cu alte cuvinte, computerele funcționează de obicei în sistemul de numere binar, deoarece acest lucru face ca dispozitivele pentru procesarea lor să fie mult mai simple. Introducerea numerelor într-un computer și scoaterea lor pentru citire umană se poate face în forma zecimală obișnuită, iar toate conversiile necesare sunt efectuate de programe care rulează pe computer. III. Codificarea informațiilor text Aceeași informații pot fi prezentate (codificate) sub mai multe forme. Odată cu apariția computerelor, a apărut nevoia de a codifica toate tipurile de informații cu care se confruntă atât un individ, cât și umanitatea în ansamblu. Dar omenirea a început să rezolve problema codificării informațiilor cu mult înainte de apariția computerelor. Realizările grandioase ale omenirii - scrisul și aritmetica - nu sunt altceva decât un sistem de codificare a vorbirii și a informațiilor numerice. Informația nu apare niciodată în forma ei pură, este întotdeauna prezentată cumva, codificată cumva. Codarea binară este una dintre modalitățile comune de reprezentare a informațiilor. În calculatoare, roboți și mașini controlate numeric, de regulă, toate informațiile cu care se ocupă dispozitivul sunt codificate sub formă de cuvinte din alfabetul binar. De la sfârșitul anilor 60, computerele au fost din ce în ce mai folosite pentru a procesa informații text, iar în prezent majoritatea computerelor personale din lume (și de cele mai multe ori) sunt ocupate cu procesarea informațiilor text. Toate aceste tipuri de informații dintr-un computer sunt prezentate în cod binar, adică se folosește un alfabet cu puterea doi (doar două caractere 0 și 1). Acest lucru se datorează faptului că este convenabil să se reprezinte informația sub forma unei secvențe de impulsuri electrice: nu există impuls (0), există un impuls (1). O astfel de codificare este de obicei numită binară, iar secvențele logice de zerouri și unități în sine sunt numite limbaj mașină. Din punct de vedere informatic, textul este format din caractere individuale. Simbolurile includ nu numai litere (majuscule sau mici, latină sau rusă), ci și numere, semne de punctuație, caractere speciale precum „=", „(”, „&”, etc., și chiar (acordați o atenție deosebită!) spații dintre cuvinte. Textele sunt introduse în memoria computerului folosind tastatura. Literele, cifrele, semnele de punctuație și alte simboluri cu care suntem familiarizați sunt scrise pe taste. Ei introduc RAM în cod binar. Aceasta înseamnă că fiecare caracter este reprezentat ca un cod binar de 8 biți.  În mod tradițional, pentru a codifica un caracter, se utilizează o cantitate de informații egală cu 1 octet, adică I = 1 octet = 8 biți. Folosind o formulă care conectează numărul de evenimente posibile K și cantitatea de informații I, puteți calcula câte simboluri diferite pot fi codificate (presupunând că simbolurile sunt evenimente posibile): K = 2 I = 2 8 = 256, adică pentru To reprezintă informații text, puteți utiliza un alfabet cu o capacitate de 256 de caractere. În mod tradițional, pentru a codifica un caracter, se utilizează o cantitate de informații egală cu 1 octet, adică I = 1 octet = 8 biți. Folosind o formulă care conectează numărul de evenimente posibile K și cantitatea de informații I, puteți calcula câte simboluri diferite pot fi codificate (presupunând că simbolurile sunt evenimente posibile): K = 2 I = 2 8 = 256, adică pentru To reprezintă informații text, puteți utiliza un alfabet cu o capacitate de 256 de caractere. Acest număr de caractere este suficient pentru a reprezenta informații text, inclusiv litere mari și mici ale alfabetului rus și latin, numere, semne, simboluri grafice etc. Codarea constă în atribuirea fiecărui caracter un cod zecimal unic de la 0 la 255 sau un cod binar corespunzător de la 00000000 la 11111111. Astfel, o persoană distinge caracterele după conturul lor, iar un computer după codul lor. Comoditatea codificării caracterelor octet cu octet este evidentă deoarece un octet este cea mai mică parte adresabilă a memoriei și, prin urmare, procesorul poate accesa fiecare caracter separat atunci când procesează text. Pe de altă parte, 256 de caractere reprezintă un număr destul de suficient pentru a reprezenta o mare varietate de informații simbolice. În procesul de afișare a unui simbol pe ecranul unui computer, se efectuează procesul invers - decodificare, adică conversia codului simbolului în imaginea sa. Este important ca atribuirea unui anumit cod unui simbol să fie o chestiune de acord, care este înregistrată în tabelul de coduri. Acum se pune întrebarea, ce cod binar de opt biți să aloce fiecărui caracter. Este clar că aceasta este o chestiune condiționată; puteți veni cu multe metode de codare. Toate caracterele alfabetului computerului sunt numerotate de la 0 la 255. Fiecare număr corespunde unui cod binar de opt biți de la 00000000 la 11111111. Acest cod este pur și simplu numărul de serie al caracterului din sistemul de numere binar. IV . Tipuri de tabele de codificare Un tabel în care tuturor caracterelor alfabetului computerului li se atribuie numere de serie se numește tabel de codificare. Diferite tipuri de computere folosesc tabele de codificare diferite. Tabelul de coduri ASCII (American Standard Code for Information Interchange) a fost adoptat ca standard internațional, codând prima jumătate a caracterelor cu coduri numerice de la 0 la 127 (codurile de la 0 la 32 sunt atribuite nu caracterelor, ci tastelor funcționale) . Tabelul de coduri ASCII este împărțit în două părți. Doar prima jumătate a tabelului este standardul internațional, adică. caractere cu numere de la 0 (00000000), la 127 (01111111). Structura tabelului de codificare ASCII
Prima jumătate a tabelului de coduri ASCII Vă rugăm să rețineți că în tabelul de codificare, literele (majuscule și mici) sunt aranjate în ordine alfabetică, iar numerele sunt ordonate crescător. Această respectare a ordinii lexicografice în aranjarea caracterelor se numește principiul codificării secvențiale a alfabetului. Pentru literele alfabetului rus, se respectă și principiul codificării secvențiale. A doua jumătate a tabelului de coduri ASCII
Din păcate, în prezent există cinci codificări chirilice diferite (KOI8-R, Windows. MS-DOS, Macintosh și ISO). Din această cauză, apar adesea probleme cu transferul textului rusesc de la un computer la altul, de la un sistem software la altul. Din punct de vedere cronologic, unul dintre primele standarde pentru codificarea literelor rusești pe computere a fost KOI8 („Cod de schimb de informații, 8 biți”). Această codificare a fost folosită încă din anii 70 pe computerele din seria de calculatoare ES, iar de la mijlocul anilor 80 a început să fie folosită în primele versiuni rusificate ale sistemului de operare UNIX.
De la începutul anilor 90, vremea dominației sistemului de operare MS DOS, codificarea CP866 rămâne („CP” înseamnă „Pagină de coduri”, „pagină de coduri”).
Computerele Apple care rulează sistemul de operare Mac OS folosesc propria lor codificare Mac.
În plus, Organizația Internațională de Standardizare (ISO) a aprobat o altă codificare numită ISO 8859-5 ca standard pentru limba rusă.
Cea mai comună codificare utilizată în prezent este Microsoft Windows, prescurtat CP1251. Introdus de Microsoft; Luând în considerare distribuția pe scară largă a sistemelor de operare (OS) și a altor produse software ale acestei companii în Federația Rusă, a găsit o distribuție largă.
De la sfârșitul anilor 90, problema standardizării codificării caracterelor a fost rezolvată prin introducerea unui nou standard internațional numit Unicode.
Aceasta este o codificare pe 16 biți, adică alocă 2 octeți de memorie pentru fiecare caracter. Desigur, acest lucru crește de 2 ori cantitatea de memorie ocupată. Dar un astfel de tabel de coduri permite includerea a până la 65536 de caractere. Specificația completă a standardului Unicode include toate alfabetele existente, dispărute și create artificial din lume, precum și multe simboluri matematice, muzicale, chimice și alte simboluri. Reprezentarea internă a cuvintelor în memoria computerului folosind un tabel ASCII Uneori se întâmplă ca un text format din litere ale alfabetului rus primit de la un alt computer să nu poată fi citit - un fel de „abracadabra” este vizibil pe ecranul monitorului. Acest lucru se întâmplă deoarece computerele folosesc diferite codificări de caractere pentru limba rusă.
Astfel, fiecare codificare este specificată de propria sa tabelă de coduri. După cum se poate vedea din tabel, caractere diferite sunt atribuite aceluiași cod binar în codificări diferite.
Din fericire, în cele mai multe cazuri, utilizatorul nu trebuie să-și facă griji cu privire la transcodarea documentelor text, deoarece aceasta se face prin programe speciale de conversie încorporate în aplicații. V . Calculul cantității de informații text Sarcina 1: Codificați cuvântul „Roma” folosind tabelele de codificare KOI8-R și CP1251. Soluţie:
Sarcina 2: Presupunând că fiecare caracter este codificat într-un octet, estimați volumul de informații al următoarei propoziții: „Unchiul meu are cele mai oneste reguli, Când m-am îmbolnăvit grav, S-a obligat să respecte Și nu m-am putut gândi la ceva mai bun.” Soluţie: Această expresie are 108 caractere, inclusiv semne de punctuație, ghilimele și spații. Înmulțim acest număr cu 8 biți. Obținem 108*8=864 biți. Sarcina 3: Cele două texte conțin același număr de caractere. Primul text este scris în rusă, iar al doilea în limba tribului Naguri, al cărui alfabet este format din 16 caractere. Al cui text conține mai multe informații? Soluţie: 1) I = K * a (volumul de informații al textului este egal cu produsul dintre numărul de caractere și greutatea informațională a unui caracter). 2) Pentru că Ambele texte au același număr de caractere (K), apoi diferența depinde de conținutul informațional al unui caracter al alfabetului (a). 3) 2 a1 = 32, i.e. a 1 = 5 biți, 2 a2 = 16, adică și 2 = 4 biți. 4) I 1 = K * 5 biți, I 2 = K * 4 biți. 5) Aceasta înseamnă că textul scris în limba rusă conține de 5/4 ori mai multe informații. Sarcina 4: Dimensiunea mesajului, care conține 2048 de caractere, a fost de 1/512 dintr-un MB. Determinați puterea alfabetului. Soluţie: 1) I = 1/512 * 1024 * 1024 * 8 = 16384 biți - a convertit volumul de informații al mesajului în biți. 2) a = I / K = 16384 /1024 = 16 biți - reprezintă un caracter al alfabetului. 3) 2*16*2048 = 65536 caractere – puterea alfabetului folosit. Sarcina 5: Imprimanta laser Canon LBP imprimă la o viteză medie de 6,3 Kbps. Cât timp va dura să tipăriți un document de 8 pagini, dacă știți că o pagină are în medie 45 de linii și 70 de caractere pe linie (1 caracter - 1 octet)? Soluţie: 1) Găsiți cantitatea de informații conținute pe 1 pagină: 45 * 70 * 8 biți = 25200 biți 2) Găsiți cantitatea de informații pe 8 pagini: 25200 * 8 = 201600 biți 3) Reducem la unități de măsură comune. Pentru a face acest lucru, convertim Mbiți în biți: 6,3*1024=6451,2 biți/sec. 4) Găsiți timpul de imprimare: 201600: 6451.2 =31 secunde. Bibliografie 1. Ageev V.M. Teoria informației și codării: eșantionarea și codificarea informațiilor de măsurare. - M.: MAI, 1977. 2. Kuzmin I.V., Kedrus V.A. Fundamentele teoriei și codificării informației. - Kiev, școala Vishcha, 1986. 3. Cele mai simple metode de criptare a textului / D.M. Zlatopolsky. – M.: Chistye Prudy, 2007 – 32 p. 4. Ugrinovich N.D. Informatica si tehnologia informatiei. Manual pentru clasele 10-11 / N.D. Ugrinovich. – M.: BINOM. Laboratorul de cunoștințe, 2003. – 512 p. 5. http://school497.spb.edu.ru/uchint002/les10/les.html#n Material pentru auto-studiu pe tema Lecției 2 Codificare ASCII Tabel de codificare ASCII (ASCII - American Standard Code for Information Interchange - American Standard Code for Information Interchange). În total, 256 de caractere diferite pot fi codificate folosind tabelul de codificare ASCII (Figura 1). Acest tabel este împărțit în două părți: cea principală (cu coduri de la OOh la 7Fh) și cea suplimentară (de la 80h la FFh, unde litera h indică faptul că codul aparține sistemului numeric hexazecimal). Poza 1 Pentru a codifica un caracter din tabel, sunt alocați 8 biți (1 octet). La procesarea informațiilor text, un octet poate conține codul unui anumit caracter - o literă, un număr, un semn de punctuație, un semn de acțiune etc. Fiecare caracter are propriul cod sub forma unui număr întreg. În acest caz, toate codurile sunt colectate în tabele speciale numite tabele de codificare. Cu ajutorul lor, codul simbol este convertit în reprezentarea sa vizibilă pe ecranul monitorului. Ca rezultat, orice text din memoria computerului este reprezentat ca o secvență de octeți cu coduri de caractere. De exemplu, cuvântul salut! vor fi codificate după cum urmează (Tabelul 1). tabelul 1
Figura 1 prezintă caracterele incluse în codarea ASCII standard (engleză) și extinsă (rusă). Prima jumătate a tabelului ASCII este standardizată. Conține coduri de control (de la 00h la 20h și 77h). Aceste coduri au fost eliminate din tabel deoarece nu se aplică elementelor de text. Aici sunt plasate și semnele de punctuație și simbolurile matematice: 2lh - !, 26h - &, 28h - (, 2Bh -+,..., litere mari și mici latine: 41h - A, 61h – a. A doua jumătate a tabelului conține fonturi naționale, simboluri pseudografice din care pot fi construite tabele și simboluri matematice speciale. Partea inferioară a tabelului de codificare poate fi înlocuită folosind drivere adecvate - programe auxiliare de control. Această tehnică vă permite să utilizați mai multe fonturi și fonturile lor. Afișajul pentru fiecare cod de simbol ar trebui să afișeze o imagine a simbolului - nu doar un cod digital, ci o imagine corespunzătoare, deoarece fiecare simbol are propria sa formă. O descriere a formei fiecărui caracter este stocată într-o memorie specială de afișare - un generator de caractere. Afișarea unui caracter pe ecranul unui afișaj IBM PC, de exemplu, se realizează folosind puncte care formează o matrice de caractere. Fiecare pixel dintr-o astfel de matrice este un element de imagine și poate fi luminos sau întunecat. Un punct întunecat este codificat ca 0, un punct deschis (luminos) ca 1. Dacă reprezentați pixeli întunecați în câmpul matricei al unui semn sub formă de punct și pixeli deschisi ca un asterisc, puteți reprezenta grafic forma simbolului. Oamenii din diferite țări folosesc simboluri pentru a scrie cuvinte în limba lor maternă. În zilele noastre, majoritatea aplicațiilor, inclusiv sistemele de e-mail și browserele web, sunt puri pe 8 biți, ceea ce înseamnă că pot afișa și accepta corect doar caractere de 8 biți, conform standardului ISO-8859-1. Există peste 256 de caractere în lume (dacă luați în considerare chirilica, arabă, chineză, japoneză, coreeană și thailandeză) și apar tot mai multe caractere noi. Și acest lucru creează următoarele lacune pentru mulți utilizatori: Nu este posibil să utilizați caractere din seturi de codare diferite în același document. Deoarece fiecare document text folosește propriul set de codificări, există mari dificultăți cu recunoașterea automată a textului. Apar simboluri noi (de exemplu: Euro), drept urmare ISO dezvoltă un nou standard, ISO-8859-15, care este foarte asemănător cu standardul ISO-8859-1. Diferența constă în faptul că vechiul tabel de codificare ISO-8859-1 a eliminat simbolurile pentru vechile monede care nu sunt utilizate în prezent pentru a face loc pentru simbolurile nou introduse (cum ar fi euro). Drept urmare, utilizatorii pot avea aceleași documente pe discuri, dar în codificări diferite. Soluția la aceste probleme este adoptarea unui singur set internațional de codificări numit Universal Coding sau Unicode. Codificare Unicode Standardul a fost propus în 1991 de către organizația non-profit Unicode Consortium (Unicode Inc.). Utilizarea acestui standard vă permite să codificați un număr foarte mare de caractere din diferite scripturi: documentele Unicode pot conține caractere chinezești, simboluri matematice, litere ale alfabetului grecesc, alfabet latin și chirilic, iar schimbarea paginilor de cod devine inutilă. Standardul constă din două secțiuni principale: setul de caractere universal (UCS) și familia de codare (UTF, format de transformare Unicode). Setul de caractere universal specifică o corespondență unu-la-unu între caractere și coduri - elemente ale spațiului de cod reprezentând numere întregi nenegative. O familie de codificare definește reprezentarea automată a unei secvențe de coduri UCS. Standardul Unicode a fost dezvoltat pentru a crea o singură codificare a caracterelor pentru toate limbile scrise moderne și pentru multe limbi antice. Fiecare caracter din acest standard este codificat cu 16 biți, ceea ce îi permite să acopere un număr incomparabil mai mare de caractere decât codificările de 8 biți acceptate anterior. O altă diferență importantă între Unicode și alte sisteme de codare este că nu numai că atribuie un cod unic fiecărui caracter, ci și definește diferite caracteristici ale caracterului respectiv, de exemplu: tipul de caractere (majuscule, minuscule, număr, semn de punctuație etc.); atributele caracterului (afișare de la stânga la dreapta sau de la dreapta la stânga, spațiu, întrerupere de linie etc.); litera majuscule sau minuscule corespunzătoare (pentru litere mici, respectiv majuscule); valoarea numerică corespunzătoare (pentru caractere numerice). Întreaga gamă de coduri de la 0 la FFFF este împărțită în mai multe subseturi standard, fiecare dintre ele corespunde fie alfabetului unei limbi, fie unui grup de caractere speciale care sunt similare în funcțiile lor. Diagrama de mai jos conține o listă generală de subseturi Unicode 3.0 (Figura 2).
Figura 2 Standardul Unicode este baza pentru stocarea textului în multe sisteme informatice moderne. Cu toate acestea, nu este compatibil cu majoritatea protocoalelor de Internet, deoarece codurile sale pot conține orice valoare de octet, iar protocoalele folosesc de obicei octeții 00 - 1F și FE - FF ca octeți de serviciu. Pentru a obține compatibilitatea, au fost dezvoltate mai multe formate de transformare Unicode (UTF, Unicode Transformation Formats), dintre care UTF-8 este cel mai comun astăzi. Acest format definește următoarele reguli pentru conversia fiecărui cod Unicode într-un set de octeți (unu până la trei) potriviti pentru transport prin protocoale Internet. Aici x,y,z indică biții codului sursă care ar trebui extrași, începând cu cel mai puțin semnificativ, și introduși în octeții de rezultat de la dreapta la stânga până când toate pozițiile specificate sunt umplute. Dezvoltarea ulterioară a standardului Unicode este asociată cu adăugarea de noi planuri de limbaj, de ex. caractere în intervalele 10000 - 1FFFF, 20000 - 2FFFF etc., unde ar trebui să includă codificarea pentru scripturi ale limbilor moarte care nu sunt incluse în tabelul de mai sus. Un nou format, UTF-16, a fost dezvoltat pentru a codifica aceste caractere suplimentare. Deci, există 4 moduri principale de a codifica octeții Unicode: UTF-8: 128 de caractere codificate într-un octet (format ASCII), 1920 de caractere codificate pe 2 octeți ((caractere romane, grecești, chirilice, copte, armene, ebraice, arabe), 63488 de caractere codificate în 3 octeți (chineză, japoneză etc. .) Cele 2.147.418.112 de caractere rămase (neutilizate încă) pot fi codificate cu 4, 5 sau 6 octeți. UCS-2: Fiecare caracter este reprezentat de 2 octeți. Această codificare include doar primele 65.535 de caractere din formatul Unicode. UTF-16: O extensie a UCS-2, conține 1.114.112 de caractere în format Unicode. Primele 65.535 de caractere sunt reprezentate de 2 octeți, restul de 4 octeți. USC-4: Fiecare caracter este codificat în 4 octeți. [Codări pe 8 biți: ASCII, KOI-8R și CP1251] Primele tabele de codificare create în Statele Unite nu au folosit al optulea bit dintr-un octet. Textul a fost reprezentat ca o secvență de octeți, dar al optulea bit nu a fost luat în considerare (a fost folosit în scopuri oficiale). Tabelul a devenit un standard general acceptat ASCII(Codul American Standard pentru Schimbul de Informații). Primele 32 de caractere ale tabelului ASCII (de la 00 la 1F) au fost folosite pentru caracterele care nu se imprimă. Au fost concepute pentru a controla un dispozitiv de imprimare etc. Restul - de la 20 la 7F - sunt caractere obișnuite (printabile). Tabelul 1 - Codificare ASCII
După cum puteți vedea cu ușurință, această codificare conține doar litere latine și cele care sunt folosite în limba engleză. Există, de asemenea, aritmetice și alte simboluri de serviciu. Dar nu există nici litere rusești, nici măcar latine speciale pentru germană sau franceză. Acest lucru este ușor de explicat - codificarea a fost dezvoltată special ca standard american. Pe măsură ce computerele au început să fie folosite în întreaga lume, alte caractere au trebuit să fie codificate. Pentru a face acest lucru, s-a decis să se folosească al optulea bit din fiecare octet. Acest lucru a făcut să fie disponibile încă 128 de valori (de la 80 la FF) care ar putea fi folosite pentru a codifica caractere. Primul dintre tabelele de opt biți este „ASCII extins” ( ASCII extins) - a inclus diverse variante de caractere latine utilizate în unele limbi ale Europei de Vest. Conținea și alte simboluri suplimentare, inclusiv pseudografice. Caracterele pseudografice vă permit să oferiți o imagine de grafică afișând doar caractere text pe ecran. De exemplu, programul de gestionare a fișierelor FAR Manager funcționează folosind pseudografice. Nu existau litere rusești în tabelul ASCII extins. Rusia (fosta URSS) și alte țări și-au creat propriile codificări care au făcut posibilă reprezentarea unor caractere „naționale” specifice în fișiere text pe 8 biți - litere latine ale limbilor poloneză și cehă, chirilice (inclusiv litere rusești) și alte alfabete. În toate codificările care au devenit răspândite, primele 127 de caractere (adică valoarea octetului cu al optulea bit egal cu 0) sunt aceleași cu ASCII. Deci, un fișier ASCII funcționează în oricare dintre aceste codificări; Literele limbii engleze sunt reprezentate în același mod. Organizare ISO(International Standardization Organization) a adoptat un grup de standarde ISO 8859. Acesta definește codificări pe 8 biți pentru diferite grupuri de limbi. Deci, ISO 8859-1 este un tabel ASCII extins pentru SUA și Europa de Vest. Și ISO 8859-5 este un tabel pentru alfabetul chirilic (inclusiv rus). Cu toate acestea, din motive istorice, codificarea ISO 8859-5 nu a prins rădăcini. În realitate, pentru limba rusă sunt folosite următoarele codificări: Pagina de cod 866 ( CP866), alias „DOS”, alias „codare GOST alternativă”. Folosit pe scară largă până la mijlocul anilor 90; folosit acum într-o măsură limitată. Practic nu este folosit pentru distribuirea de texte pe Internet. Principalul avantaj al CP866 a fost păstrarea caracterelor pseudo-grafice în aceleași locuri ca în ASCII extins; prin urmare, programele cu text străin, de exemplu, celebrul Norton Commander, ar putea funcționa fără modificări. CP866 este acum utilizat pentru programele Windows care rulează în ferestre text sau în modul text pe ecran complet, inclusiv FAR Manager. Textele din CP866 au fost destul de rare în ultimii ani (dar este folosit pentru a codifica numele fișierelor rusești în Windows). Prin urmare, ne vom opri mai detaliat asupra altor două codificări - KOI-8R și CP1251.
După cum puteți vedea, în tabelul de codificare CP1251, literele rusești sunt aranjate în ordine alfabetică (cu excepția, însă, a literei E). Acest aranjament facilitează sortarea alfabetică a programelor de calculator. Dar în KOI-8R ordinea literelor rusești pare aleatorie. Dar de fapt nu este. În multe programe mai vechi, al 8-lea bit a fost pierdut la procesarea sau transmiterea textului. (Acum, astfel de programe sunt practic „disparute”, dar la sfârșitul anilor 80 - începutul anilor 90 erau răspândite). Pentru a obține o valoare de 7 biți dintr-o valoare de 8 biți, doar scădeți 8 din cifra cea mai semnificativă; de exemplu, E1 devine 61. Acum comparați KOI-8R cu tabelul ASCII (Tabelul 1). Veți descoperi că literele rusești sunt plasate în corespondență clară cu cele latine. Dacă al optulea bit dispare, literele rusești mici se transformă în litere latine mari, iar literele rusești mari se transformă în litere latine. Deci, E1 în KOI-8 este „A” rusesc, în timp ce 61 în ASCII este „a” latin. Deci, KOI-8 vă permite să mențineți lizibilitatea textului rusesc atunci când al 8-lea bit este pierdut. „Salut tuturor” devine „pRIWET WSEM”. Recent, atât ordinea alfabetică a caracterelor din tabelul de codificare, cât și lizibilitatea cu pierderea celui de-al 8-lea bit și-au pierdut importanța decisivă. Al optulea bit în computerele moderne nu se pierde în timpul transmisiei sau procesării. Iar sortarea alfabetică se face ținând cont de codificare, și nu prin simpla comparare a codurilor. (Apropo, codurile CP1251 nu sunt complet aranjate alfabetic - litera E nu este la locul ei). Datorită faptului că există două codificări comune, atunci când lucrați cu Internetul (e-mail, navigarea pe site-uri web), uneori puteți vedea un set de litere fără sens în loc de text rusesc. De exemplu, „EU SUNT SBYUFEMHEL”. Acestea sunt doar cuvintele „cu respect”; dar au fost codificate în codificare CP1251, iar computerul a decodat textul folosind tabelul KOI-8. Dacă aceleași cuvinte, dimpotrivă, ar fi codificate în KOI-8, iar computerul ar decoda textul conform tabelului CP1251, rezultatul ar fi „U HCHBTSEOYEN”. Uneori se întâmplă ca un computer să descifreze literele în limba rusă folosind un tabel care nu este destinat limbii ruse. Apoi, în loc de litere rusești, apare un set de simboluri fără sens (de exemplu, litere latine ale limbilor est-europene); ele sunt adesea numite „crocozybras”. În cele mai multe cazuri, programele moderne se ocupă de determinarea în mod independent a codificărilor documentelor de pe Internet (e-mailuri și pagini web). Dar uneori „raușesc”, apoi puteți vedea secvențe ciudate de litere rusești sau „krokozyabry”. De regulă, într-o astfel de situație, pentru a afișa text real pe ecran, este suficient să selectați codarea manual în meniul programului. Pentru acest articol au fost folosite informații de pe pagina http://open-office.edusite.ru/TextProcessor/p5aa1.html. Material preluat de pe site: Ultimele note
| |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||











 limbajul semnelor este un limbaj semnelor folosit de persoanele cu deficiențe de auz.
limbajul semnelor este un limbaj semnelor folosit de persoanele cu deficiențe de auz.







 De exemplu, secvența codurilor numerice 221, 194, 204 din codificarea CP1251 formează cuvântul „calculator”, în timp ce în alte codificări va fi un set de caractere fără sens.
De exemplu, secvența codurilor numerice 221, 194, 204 din codificarea CP1251 formează cuvântul „calculator”, în timp ce în alte codificări va fi un set de caractere fără sens.