Paired linear regression: Statistical analysis of the model. Methods of mathematical statistics. Regression analysis
In his works dating back to 1908. He described it using the example of the work of an agent selling real estate. In his records, the house sales specialist kept track of a wide range of input data for each specific building. Based on the results of the auction, it was determined which factor had the greatest influence on the transaction price.
Analysis of a large number of transactions yielded interesting results. The final price was influenced by many factors, sometimes leading to paradoxical conclusions and even obvious “outliers” when a house with high initial potential was sold at a reduced price.
The second example of the application of such an analysis is the work of which was entrusted with determining employee remuneration. The complexity of the task lay in the fact that it required not the distribution of a fixed amount to everyone, but its strict correspondence to the specific work performed. The emergence of many problems with practically similar solutions required a more detailed study of them at the mathematical level.
A significant place was allocated to the section “regression analysis”, which combined practical methods used to study dependencies that fall under the concept of regression. These relationships are observed between data obtained from statistical studies.
Among the many tasks to be solved, the main goals are three: determination of a general regression equation; constructing estimates of parameters that are unknowns that are part of the regression equation; testing of statistical regression hypotheses. In the course of studying the relationship that arises between a pair of quantities obtained as a result of experimental observations and constituting a series (set) of the type (x1, y1), ..., (xn, yn), they rely on the provisions of regression theory and assume that for one quantity Y there is a certain probability distribution, while the other X remains fixed.
The result Y depends on the value of the variable X; this dependence can be determined by various patterns, while the accuracy of the results obtained is influenced by the nature of the observations and the purpose of the analysis. The experimental model is based on certain assumptions that are simplified but plausible. The main condition is that the parameter X is a controlled quantity. Its values are set before the start of the experiment.
If a pair of uncontrolled variables XY is used during an experiment, then regression analysis is carried out in the same way, but methods are used to interpret the results, during which the relationship of the random variables under study is studied. Methods of mathematical statistics are not an abstract topic. They find application in life in various spheres of human activity.
In the scientific literature, the term linear regression analysis is widely used to define the above method. For variable X, the term regressor or predictor is used, and dependent Y variables are also called criterion variables. This terminology reflects only the mathematical dependence of the variables, but not the cause-and-effect relationship.
Regression analysis is the most common method used in processing the results of a wide variety of observations. Physical and biological dependencies are studied using this method; it is implemented both in economics and in technology. A lot of other fields use regression analysis models. Analysis of variance and multivariate statistical analysis work closely with this method of study.
CONCLUSION OF RESULTS
| Regression statistics | |
| Plural R | 0,998364 |
| R-square | 0,99673 |
| Normalized R-squared | 0,996321 |
| Standard error | 0,42405 |
| Observations | 10 |
First, let's look at the top part of the calculations, presented in table 8.3a - regression statistics.
The value R-square, also called a measure of certainty, characterizes the quality of the resulting regression line. This quality is expressed by the degree of correspondence between the source data and the regression model (calculated data). The measure of certainty is always within the interval.
In most cases, the R-squared value falls between these values, called extreme values, i.e. between zero and one.
If the R-squared value is close to one, this means that the constructed model explains almost all the variability in the relevant variables. Conversely, an R-squared value close to zero means the quality of the constructed model is poor.
In our example, the measure of certainty is 0.99673, which indicates a very good fit of the regression line to the original data.
Plural R- multiple correlation coefficient R - expresses the degree of dependence of the independent variables (X) and the dependent variable (Y).
Multiple R is equal to the square root of the coefficient of determination; this quantity takes values in the range from zero to one.
In simple linear regression analysis, multiple R is equal to the Pearson correlation coefficient. Indeed, the multiple R in our case is equal to the Pearson correlation coefficient from the previous example (0.998364).
| Odds | Standard error | t-statistic | |
| Y-intersection | 2,694545455 | 0,33176878 | 8,121757129 |
| Variable X 1 | 2,305454545 | 0,04668634 | 49,38177965 |
| * A truncated version of the calculations is provided | |||
Now consider the middle part of the calculations, presented in table 8.3b. Here the regression coefficient b (2.305454545) and the displacement along the ordinate axis are given, i.e. constant a (2.694545455).
Based on the calculations, we can write the regression equation as follows:
Y= x*2.305454545+2.694545455
The direction of the relationship between variables is determined based on the signs (negative or positive) regression coefficients(coefficient b).
If the sign at regression coefficient- positive, the relationship between the dependent variable and the independent variable will be positive. In our case, the sign of the regression coefficient is positive, therefore, the relationship is also positive.
If the sign at regression coefficient- negative, the relationship between the dependent variable and the independent variable is negative (inverse).
In table 8.3c. The results of the derivation of residuals are presented. In order for these results to appear in the report, you must activate the “Residuals” checkbox when running the “Regression” tool.
WITHDRAWAL OF THE REST
| Observation | Predicted Y | Leftovers | Standard balances |
|---|---|---|---|
| 1 | 9,610909091 | -0,610909091 | -1,528044662 |
| 2 | 7,305454545 | -0,305454545 | -0,764022331 |
| 3 | 11,91636364 | 0,083636364 | 0,209196591 |
| 4 | 14,22181818 | 0,778181818 | 1,946437843 |
| 5 | 16,52727273 | 0,472727273 | 1,182415512 |
| 6 | 18,83272727 | 0,167272727 | 0,418393181 |
| 7 | 21,13818182 | -0,138181818 | -0,34562915 |
| 8 | 23,44363636 | -0,043636364 | -0,109146047 |
| 9 | 25,74909091 | -0,149090909 | -0,372915662 |
| 10 | 28,05454545 | -0,254545455 | -0,636685276 |
Using this part of the report, we can see the deviations of each point from the constructed regression line. Largest absolute value
y=f(x), when each value of the independent variable x corresponds to one specific value of quantity y, with regression connection to the same value x may correspond depending on the case to different values of the quantity y. If for each value there is n i (\displaystyle n_(i)) values y i 1 …y in 1 magnitude y, then the dependence of the arithmetic averages y ¯ i = (y i 1 + . . . + y i n 1) / n i (\displaystyle (\bar (y))_(i)=(y_(i1)+...+y_(in_(1))) /n_(i)) from x = x i (\displaystyle x=x_(i)) and is a regression in the statistical sense of the term.Encyclopedic YouTube
-
1 / 5
This term in statistics was first used by Francis Galton (1886) in connection with the study of the inheritance of human physical characteristics. Human height was taken as one of the characteristics; it was found that, in general, the sons of tall fathers, not surprisingly, turned out to be taller than the sons of short fathers. What was more interesting was that the variation in the heights of sons was smaller than the variation in the heights of fathers. This is how the tendency of sons’ heights to return to average was manifested ( regression to mediocrity), that is, “regression”. This fact was demonstrated by calculating the average height of the sons of fathers whose height is 56 inches, by calculating the average height of the sons of fathers who are 58 inches tall, etc. The results were then plotted on a plane, along the ordinate axis of which the average height of the sons was plotted. , and on the x-axis - the values of the average height of fathers. The points (approximately) lie on a straight line with a positive angle of inclination less than 45°; it is important that the regression was linear.
Description
Suppose we have a sample from a bivariate distribution of a pair of random variables ( X, Y). Straight line in plane ( x, y) was a selective analogue of the function
g (x) = E (Y ∣ X = x) . (\displaystyle g(x)=E(Y\mid X=x).) E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) , (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac ( \sigma _(2))(\sigma _(1)))(x-\mu _(1)),) v a r (Y ∣ X = x) = σ 2 2 (1 − ϱ 2) . (\displaystyle \mathrm (var) (Y\mid X=x)=\sigma _(2)^(2)(1-\varrho ^(2)).)In this example, regression Y on X is a linear function. If regression Y on X is different from linear, then the given equations are a linear approximation of the true regression equation.
In general, a regression of one random variable on another is not necessarily linear. It is also not necessary to limit yourself to a couple of random variables. Statistical regression problems involve determining the general form of the regression equation, constructing estimates of the unknown parameters included in the regression equation, and testing statistical hypotheses about the regression. These problems are addressed within the framework of regression analysis.
A simple example of regression Y By X is the relationship between Y And X, which is expressed by the relation: Y=u(X)+ε, where u(x)=E(Y | X=x), and random variables X and ε are independent. This representation is useful when designing an experiment to study functional connectivity y=u(x) between non-random quantities y And x. In practice, usually the regression coefficients in Eq. y=u(x) are unknown and are estimated from experimental data.
Linear regression
Let's imagine the dependence y from x in the form of a first order linear model:
y = β 0 + β 1 x + ε . (\displaystyle y=\beta _(0)+\beta _(1)x+\varepsilon .)We will assume that the values x are determined without error, β 0 and β 1 are the model parameters, and ε is the error, the distribution of which obeys the normal law with zero mean value and constant deviation σ 2. The values of the parameters β are not known in advance and must be determined from a set of experimental values ( x i, y i), i=1, …, n. Thus we can write:
y i ^ = b 0 + b 1 x i , i = 1 , … , n (\displaystyle (\widehat (y_(i)))=b_(0)+b_(1)x_(i),i=1,\ dots,n)where means the value predicted by the model y given x, b 0 and b 1 - sample estimates of model parameters. Let us also define e i = y i − y i ^ (\displaystyle e_(i)=y_(i)-(\widehat (y_(i))))- approximation error value for i (\displaystyle i) th observation.
The least squares method gives the following formulas for calculating the parameters of a given model and their deviations:
b 1 = ∑ i = 1 n (x i − x ¯) (y i − y ¯) ∑ i = 1 n (x i − x ¯) 2 = c o v (x , y) σ x 2 ; (\displaystyle b_(1)=(\frac (\sum _(i=1)^(n)(x_(i)-(\bar (x)))(y_(i)-(\bar (y) )))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))=(\frac (\mathrm (cov) (x,y ))(\sigma _(x)^(2)));) b 0 = y ¯ − b 1 x ¯ ; (\displaystyle b_(0)=(\bar (y))-b_(1)(\bar (x));) s e 2 = ∑ i = 1 n (y i − y ^) 2 n − 2 ; (\displaystyle s_(e)^(2)=(\frac (\sum _(i=1)^(n)(y_(i)-(\widehat (y)))^(2))(n- 2));) s b 0 = s e 1 n + x ¯ 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(b_(0))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((\bar (x))^(2))(\sum _ (i=1)^(n)(x_(i)-(\bar (x)))^(2)))));) s b 1 = s e 1 ∑ i = 1 n (x i − x ¯) 2 , (\displaystyle s_(b_(1))=s_(e)(\sqrt (\frac (1)(\sum _(i=1 )^(n)(x_(i)-(\bar (x)))^(2)))),)here the average values are determined as usual: x ¯ = ∑ i = 1 n x i n (\displaystyle (\bar (x))=(\frac (\sum _(i=1)^(n)x_(i))(n))), y ¯ = ∑ i = 1 n y i n (\displaystyle (\bar (y))=(\frac (\sum _(i=1)^(n)y_(i))(n))) And s e 2 denotes the regression residual, which is an estimate of the variance σ 2 if the model is correct.
Standard errors of regression coefficients are used similarly to the standard error of the mean - to find confidence intervals and test hypotheses. We use, for example, the Student’s test to test the hypothesis that the regression coefficient is equal to zero, that is, that it is insignificant for the model. Student statistics: t = b / s b (\displaystyle t=b/s_(b)). If the probability for the obtained value and n−2 degrees of freedom is quite small, for example,<0,05 - гипотеза отвергается. Напротив, если нет оснований отвергнуть гипотезу о равенстве нулю, скажем, b 1 (\displaystyle b_(1))- there is reason to think about the existence of the desired regression, at least in this form, or about collecting additional observations. If the free term is equal to zero b 0 (\displaystyle b_(0)), then the straight line passes through the origin and the estimate of the slope is equal to
b = ∑ i = 1 n x i y i ∑ i = 1 n x i 2 (\displaystyle b=(\frac (\sum _(i=1)^(n)x_(i)y_(i))(\sum _(i= 1)^(n)x_(i)^(2)))),and its standard error
s b = s e 1 ∑ i = 1 n x i 2 . (\displaystyle s_(b)=s_(e)(\sqrt (\frac (1)(\sum _(i=1)^(n)x_(i)^(2)))).)Usually the true values of the regression coefficients β 0 and β 1 are not known. Only their estimates are known b 0 and b 1 . In other words, the true regression line may work differently than the one built from sample data. You can calculate the confidence region for the regression line. For any value x corresponding values y normally distributed. The average is the value of the regression equation y ^ (\displaystyle (\widehat (y))). The uncertainty of its estimate is characterized by the standard regression error:
s y ^ = s e 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(\widehat (y))=s_(e)(\sqrt ((\frac (1)(n))+(\frac ((x-(\bar (x)))^(2) )(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))));)Now you can calculate the -percentage confidence interval for the value of the regression equation at point x:
y ^ − t (1 − α / 2 , n − 2) s y ^< y < y ^ + t (1 − α / 2 , n − 2) s y ^ {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{\widehat {y}}Where t(1−α/2, n−2) - t-value of the Student distribution. The figure shows a regression line constructed using 10 points (solid dots), as well as the 95% confidence region of the regression line, which is limited by dotted lines. With 95% probability we can say that the true line is located somewhere inside this area. Or otherwise, if we collect similar data sets (indicated by circles) and build regression lines on them (indicated in blue), then in 95 cases out of 100 these straight lines will not leave the confidence region. (Click on the image to visualize) Please note that some points were outside the confidence region. This is completely natural, since we are talking about the confidence region of the regression line, and not the values themselves. The spread of values consists of the spread of values around the regression line and the uncertainty of the position of this line itself, namely:
s Y = s e 1 m + 1 n + (x − x ¯) 2 ∑ i = 1 n (x i − x ¯) 2 ; (\displaystyle s_(Y)=s_(e)(\sqrt ((\frac (1)(m))+(\frac (1)(n))+(\frac ((x-(\bar (x )))^(2))(\sum _(i=1)^(n)(x_(i)-(\bar (x)))^(2)))));)Here m- frequency of measurement y given x. AND 100 ⋅ (1 − α 2) (\displaystyle 100\cdot \left(1-(\frac (\alpha )(2))\right))-percentage confidence interval (forecast interval) for the average of m values y will:
y ^ − t (1 − α / 2 , n − 2) s Y< y < y ^ + t (1 − α / 2 , n − 2) s Y {\displaystyle {\widehat {y}}-t_{(1-\alpha /2,n-2)}s_{Y}In the figure, this 95% confidence region at m=1 is limited by solid lines. 95% of all possible values of the quantity fall into this area y in the studied range of values x.
Some more statistics
It can be strictly proven that if the conditional expectation E (Y ∣ X = x) (\displaystyle E(Y\mid X=x)) some two-dimensional random variable ( X, Y) is a linear function of x (\displaystyle x), then this conditional expectation is necessarily representable in the form E (Y ∣ X = x) = μ 2 + ϱ σ 2 σ 1 (x − μ 1) (\displaystyle E(Y\mid X=x)=\mu _(2)+\varrho (\frac (\ sigma _(2))(\sigma _(1)))(x-\mu _(1))), Where E(X)=μ 1 , E(Y)=μ 2 , var( X)=σ 1 2 , var( Y)=σ 2 2 , cor( X, Y)=ρ.
Moreover, for the previously mentioned linear model Y = β 0 + β 1 X + ε (\displaystyle Y=\beta _(0)+\beta _(1)X+\varepsilon ), Where X (\displaystyle X) and are independent random variables, and ε (\displaystyle \varepsilon) has zero expectation (and arbitrary distribution), it can be proven that E (Y ∣ X = x) = β 0 + β 1 x (\displaystyle E(Y\mid X=x)=\beta _(0)+\beta _(1)x). Then, using the previously stated equality, we can obtain formulas for and: β 1 = ϱ σ 2 σ 1 (\displaystyle \beta _(1)=\varrho (\frac (\sigma _(2))(\sigma _(1)))),
β 0 = μ 2 − β 1 μ 1 (\displaystyle \beta _(0)=\mu _(2)-\beta _(1)\mu _(1))
If from somewhere it is known a priori that a set of random points on the plane is generated by a linear model, but with unknown coefficients β 0 (\displaystyle \beta _(0)) And β 1 (\displaystyle \beta _(1)), you can obtain point estimates of these coefficients using the specified formulas. To do this, instead of mathematical expectations, variances and correlations of random variables, these formulas X And Y we need to substitute their unbiased estimates. The resulting estimation formulas will exactly coincide with the formulas derived based on the least squares method.
In statistical modeling, regression analysis is a study used to evaluate the relationship between variables. This mathematical method includes many other methods for modeling and analyzing multiple variables where the focus is on the relationship between a dependent variable and one or more independent ones. More specifically, regression analysis helps us understand how the typical value of a dependent variable changes if one of the independent variables changes while the other independent variables remain fixed.
In all cases, the target estimate is a function of the independent variables and is called a regression function. In regression analysis, it is also of interest to characterize the change in the dependent variable as a function of regression, which can be described using a probability distribution.
Regression Analysis Problems
This statistical research method is widely used for forecasting, where its use has significant advantage, but sometimes it can lead to illusion or false relationships, so it is recommended to use it carefully in the said matter, since, for example, correlation does not mean causation.
A large number of methods have been developed for regression analysis, such as linear and ordinary least squares regression, which are parametric. Their essence is that the regression function is defined in terms of a finite number of unknown parameters that are estimated from the data. Nonparametric regression allows its function to lie within a specific set of functions, which can be infinite-dimensional.
As a statistical research method, regression analysis in practice depends on the form of the data generation process and how it relates to the regression approach. Since the true form of the data process generating is usually an unknown number, regression analysis of the data often depends to some extent on assumptions about the process. These assumptions are sometimes testable if there is enough data available. Regression models are often useful even when the assumptions are moderately violated, although they may not perform at peak efficiency.
In a narrower sense, regression may refer specifically to the estimation of continuous response variables, as opposed to the discrete response variables used in classification. The continuous output variable case is also called metric regression to distinguish it from related problems.
Story
The earliest form of regression is the well-known least squares method. It was published by Legendre in 1805 and Gauss in 1809. Legendre and Gauss applied the method to the problem of determining from astronomical observations the orbits of bodies around the Sun (mainly comets, but later also newly discovered minor planets). Gauss published a further development of least squares theory in 1821, including a version of the Gauss–Markov theorem.

The term "regression" was coined by Francis Galton in the 19th century to describe a biological phenomenon. The idea was that the height of descendants from that of their ancestors tends to regress downwards towards the normal mean. For Galton, regression had only this biological meaning, but later his work was continued by Udney Yoley and Karl Pearson and brought into a more general statistical context. In the work of Yule and Pearson, the joint distribution of response and explanatory variables is assumed to be Gaussian. This assumption was rejected by Fischer in papers of 1922 and 1925. Fisher suggested that the conditional distribution of the response variable is Gaussian, but the joint distribution need not be. In this regard, Fischer's proposal is closer to Gauss's formulation of 1821. Before 1970, it sometimes took up to 24 hours to get the result of a regression analysis.

Regression analysis methods continue to be an area of active research. In recent decades, new methods have been developed for robust regression; regressions involving correlated responses; regression methods that accommodate different types of missing data; nonparametric regression; Bayesian regression methods; regressions in which predictor variables are measured with error; regression with more predictors than observations, and cause-and-effect inference with regression.
Regression models
Regression analysis models include the following variables:
- Unknown parameters, designated beta, which can be a scalar or a vector.
- Independent Variables, X.
- Dependent Variables, Y.
Different fields of science where regression analysis is used use different terms in place of dependent and independent variables, but in all cases the regression model relates Y to a function of X and β.
The approximation is usually written as E(Y | X) = F(X, β). To carry out regression analysis, the type of function f must be determined. Less commonly, it is based on knowledge about the relationship between Y and X, which does not rely on data. If such knowledge is not available, then the flexible or convenient form F is chosen.
Dependent variable Y
Let us now assume that the vector of unknown parameters β has length k. To perform regression analysis, the user must provide information about the dependent variable Y:
- If N data points of the form (Y, X) are observed, where N< k, большинство классических подходов к регрессионному анализу не могут быть выполнены, так как система уравнений, определяющих модель регрессии в качестве недоопределенной, не имеет достаточного количества данных, чтобы восстановить β.
- If exactly N = K are observed and the function F is linear, then the equation Y = F(X, β) can be solved exactly rather than approximately. This amounts to solving a set of N-equations with N-unknowns (elements β) that has a unique solution as long as X is linearly independent. If F is nonlinear, there may be no solution, or many solutions may exist.
- The most common situation is where N > data points are observed. In this case, there is enough information in the data to estimate a unique value for β that best fits the data, and a regression model where the application to the data can be viewed as an overdetermined system in β.
In the latter case, regression analysis provides tools for:
- Finding a solution for the unknown parameters β, which will, for example, minimize the distance between the measured and predicted value of Y.
- Under certain statistical assumptions, regression analysis uses excess information to provide statistical information about the unknown parameters β and the predicted values of the dependent variable Y.
Required number of independent measurements
Consider a regression model that has three unknown parameters: β 0 , β 1 and β 2 . Suppose the experimenter makes 10 measurements on the same value of the independent variable vector X. In this case, regression analysis does not produce a unique set of values. The best you can do is estimate the mean and standard deviation of the dependent variable Y. Similarly, by measuring two different values of X, you can obtain enough data for regression with two unknowns, but not with three or more unknowns.

If the experimenter's measurements were made at three different values of the independent variable vector X, then the regression analysis will provide a unique set of estimates for the three unknown parameters in β.
In the case of general linear regression, the above statement is equivalent to the requirement that the matrix X T X is invertible.
Statistical Assumptions
When the number of measurements N is greater than the number of unknown parameters k and the measurement errors ε i , then, as a rule, the excess information contained in the measurements is then disseminated and used for statistical predictions regarding the unknown parameters. This excess information is called the regression degree of freedom.
Fundamental Assumptions
Classic assumptions for regression analysis include:
- Sampling is representative of inference prediction.
- The error term is a random variable with a mean of zero, which is conditional on the explanatory variables.
- Independent variables are measured without errors.
- As independent variables (predictors), they are linearly independent, that is, it is not possible to express any predictor as a linear combination of the others.
- The errors are uncorrelated, that is, the error covariance matrix of the diagonals and each non-zero element is the error variance.
- The error variance is constant across observations (homoscedasticity). If not, then weighted least squares or other methods can be used.
These sufficient conditions for least squares estimation have the required properties; in particular, these assumptions mean that parameter estimates will be objective, consistent, and efficient, especially when taken into account in the class of linear estimators. It is important to note that evidence rarely satisfies the conditions. That is, the method is used even if the assumptions are not correct. Variation from the assumptions can sometimes be used as a measure of how useful the model is. Many of these assumptions can be relaxed in more advanced methods. Statistical analysis reports typically include analysis of tests on sample data and methodology for the usefulness of the model.
Additionally, variables in some cases refer to values measured at point locations. There may be spatial trends and spatial autocorrelations in variables that violate statistical assumptions. Geographic weighted regression is the only method that deals with such data.
A feature of linear regression is that the dependent variable, which is Yi, is a linear combination of parameters. For example, simple linear regression uses one independent variable, x i , and two parameters, β 0 and β 1 , to model n-points.

In multiple linear regression, there are multiple independent variables or functions of them.
When a random sample is taken from a population, its parameters allow one to obtain a sample linear regression model.
In this aspect, the most popular is the least squares method. It is used to obtain parameter estimates that minimize the sum of squared residuals. This kind of minimization (which is typical of linear regression) of this function leads to a set of normal equations and a set of linear equations with parameters, which are solved to obtain parameter estimates.
Under the further assumption that population error is generally propagated, a researcher can use these standard error estimates to create confidence intervals and conduct hypothesis tests about its parameters.
Nonlinear regression analysis
An example where the function is not linear with respect to the parameters indicates that the sum of squares should be minimized using an iterative procedure. This introduces many complications that define the differences between linear and nonlinear least squares methods. Consequently, the results of regression analysis when using a nonlinear method are sometimes unpredictable.

Calculation of power and sample size
There are generally no consistent methods regarding the number of observations versus the number of independent variables in the model. The first rule was proposed by Dobra and Hardin and looks like N = t^n, where N is the sample size, n is the number of independent variables, and t is the number of observations needed to achieve the desired accuracy if the model had only one independent variable. For example, a researcher builds a linear regression model using a data set that contains 1000 patients (N). If the researcher decides that five observations are needed to accurately define the line (m), then the maximum number of independent variables that the model can support is 4.
Other methods
Although regression model parameters are typically estimated using the least squares method, there are other methods that are used much less frequently. For example, these are the following methods:
- Bayesian methods (for example, Bayesian linear regression).
- Percentage regression, used for situations where reducing percentage errors is considered more appropriate.
- Smallest absolute deviations, which is more robust in the presence of outliers leading to quantile regression.
- Nonparametric regression, which requires a large number of observations and calculations.
- A distance learning metric that is learned to find a meaningful distance metric in a given input space.

Software
All major statistical software packages perform least squares regression analysis. Simple linear regression and multiple regression analysis can be used in some spreadsheet applications as well as some calculators. Although many statistical software packages can perform various types of nonparametric and robust regression, these methods are less standardized; different software packages implement different methods. Specialized regression software has been developed for use in areas such as examination analysis and neuroimaging.
The main purpose of regression analysis consists in determining the analytical form of communication in which the change in the effective characteristic is due to the influence of one or more factor characteristics, and the set of all other factors that also influence the effective characteristic are taken as constant and average values.
Regression Analysis Problems:
a) Establishing the form of dependence. Regarding the nature and form of the relationship between phenomena, a distinction is made between positive linear and nonlinear and negative linear and nonlinear regression.
b) Determining the regression function in the form of a mathematical equation of one type or another and establishing the influence of explanatory variables on the dependent variable.
c) Estimation of unknown values of the dependent variable. Using the regression function, you can reproduce the values of the dependent variable within the interval of specified values of the explanatory variables (i.e., solve the interpolation problem) or evaluate the course of the process outside the specified interval (i.e., solve the extrapolation problem). The result is an estimate of the value of the dependent variable.Paired regression is an equation for the relationship between two variables y and x: , where y is the dependent variable (resultative attribute); x is an independent explanatory variable (feature-factor).
There are linear and nonlinear regressions.
Regressions that are nonlinear with respect to the estimated parameters: The construction of a regression equation comes down to estimating its parameters. To estimate the parameters of regressions linear in parameters, the least squares method (OLS) is used. The least squares method makes it possible to obtain such parameter estimates at which the sum of squared deviations of the actual values of the resultant characteristic y from the theoretical ones is minimal, i.e.
Linear regression: y = a + bx + ε
Nonlinear regressions are divided into two classes: regressions that are nonlinear with respect to the explanatory variables included in the analysis, but linear with respect to the estimated parameters, and regressions that are nonlinear with respect to the estimated parameters.
Regressions that are nonlinear in explanatory variables: .
.
For linear and nonlinear equations reducible to linear ones, the following system is solved for a and b:
You can use ready-made formulas that follow from this system:
The closeness of the connection between the phenomena being studied is assessed by the linear coefficient of pair correlation for linear regression:
and correlation index - for nonlinear regression:
The quality of the constructed model will be assessed by the coefficient (index) of determination, as well as the average error of approximation.
Average approximation error - average deviation of calculated values from actual ones: .
.
The permissible limit of values is no more than 8-10%.
The average elasticity coefficient shows by what percentage on average the result y will change from its average value when the factor x changes by 1% from its average value:
.The purpose of analysis of variance is to analyze the variance of the dependent variable:
,
where is the total sum of squared deviations;
- the sum of squared deviations due to regression (“explained” or “factorial”);
- residual sum of squared deviations.
The share of variance explained by regression in the total variance of the resultant characteristic y is characterized by the coefficient (index) of determination R2:
The coefficient of determination is the square of the coefficient or correlation index.The F-test - assessing the quality of the regression equation - consists of testing the hypothesis No about the statistical insignificance of the regression equation and the indicator of the closeness of the relationship. To do this, a comparison is made between the actual F fact and the critical (tabular) F table values of the Fisher F-criterion. F fact is determined from the ratio of the values of factor and residual variances calculated per degree of freedom:
 ,
,
where n is the number of population units; m is the number of parameters for variables x.
F table is the maximum possible value of the criterion under the influence of random factors at given degrees of freedom and significance level a. The significance level a is the probability of rejecting the correct hypothesis, given that it is true. Usually a is taken equal to 0.05 or 0.01.
If F table< F факт, то Н о - гипотеза о случайной природе оцениваемых характеристик отклоняется и признается их статистическая значимость и надежность. Если F табл >F fact, then the hypothesis H o is not rejected and the statistical insignificance and unreliability of the regression equation is recognized.
To assess the statistical significance of regression and correlation coefficients, Student's t-test and confidence intervals for each indicator are calculated. A hypothesis is put forward about the random nature of the indicators, i.e. about their insignificant difference from zero. Assessing the significance of regression and correlation coefficients using Student's t-test is carried out by comparing their values with the magnitude of the random error:
; ; .
Random errors of the linear regression parameters and the correlation coefficient are determined by the formulas:
Comparing the actual and critical (tabular) values of t-statistics - t table and t fact - we accept or reject the hypothesis H o.
The relationship between the Fisher F-test and the Student t-statistic is expressed by the equality
If t table< t факт то H o отклоняется, т.е. a, b и не случайно отличаются от нуля и сформировались под влиянием систематически действующего фактора х. Если t табл >t is a fact that the hypothesis H o is not rejected and the random nature of the formation of a, b or is recognized.
To calculate the confidence interval, we determine the maximum error D for each indicator:
, .
The formulas for calculating confidence intervals are as follows:
; ;
; ;
If zero falls within the confidence interval, i.e. If the lower limit is negative and the upper limit is positive, then the estimated parameter is taken to be zero, since it cannot simultaneously take both positive and negative values.
The forecast value is determined by substituting the corresponding (forecast) value into the regression equation. The average standard error of the forecast is calculated: ,
,
Where
and a confidence interval for the forecast is constructed: ;
;  ;
; 
Where .
.Example solution
Task No. 1. For seven territories of the Ural region in 199X, the values of two characteristics are known.
Table 1.
Required: 1. To characterize the dependence of y on x, calculate the parameters of the following functions:
a) linear;
b) power (you must first perform the procedure of linearization of the variables by taking the logarithm of both parts);
c) demonstrative;
d) an equilateral hyperbola (you also need to figure out how to pre-linearize this model).
2. Evaluate each model using the average error of approximation and Fisher's F test.Solution (Option No. 1)
To calculate parameters a and b of linear regression (calculation can be done using a calculator).
solve a system of normal equations for A And b:
Based on the initial data, we calculate :
:
y x yx x 2 y 2 A i l 68,8 45,1 3102,88 2034,01 4733,44 61,3 7,5 10,9 2 61,2 59,0 3610,80 3481,00 3745,44 56,5 4,7 7,7 3 59,9 57,2 3426,28 3271,84 3588,01 57,1 2,8 4,7 4 56,7 61,8 3504,06 3819,24 3214,89 55,5 1,2 2,1 5 55,0 58,8 3234,00 3457,44 3025,00 56,5 -1,5 2,7 6 54,3 47,2 2562,96 2227,84 2948,49 60,5 -6,2 11,4 7 49,3 55,2 2721,36 3047,04 2430,49 57,8 -8,5 17,2 Total 405,2 384,3 22162,34 21338,41 23685,76 405,2 0,0 56,7 Wed. meaning (Total/n) 57,89 54,90 3166,05 3048,34 3383,68 X X 8,1 s 5,74 5,86 X X X X X X s 2 32,92 34,34 X X X X X X 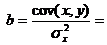

Regression equation: y = 76,88 - 0,35X. With an increase in the average daily wage by 1 rub. the share of expenses for the purchase of food products decreases by an average of 0.35 percentage points.
Let's calculate the linear pair correlation coefficient: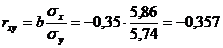
The connection is moderate, inverse.
Let's determine the coefficient of determination:
The 12.7% variation in the result is explained by the variation in the x factor. Substituting actual values into the regression equation X, let's determine the theoretical (calculated) values . Let's find the value of the average approximation error:
On average, calculated values deviate from actual ones by 8.1%.
Let's calculate the F-criterion:
since 1< F < ¥ , should be considered F -1 .
The resulting value indicates the need to accept the hypothesis But oh the random nature of the identified dependence and the statistical insignificance of the parameters of the equation and the indicator of the closeness of the connection.
1b. The construction of a power model is preceded by the procedure of linearization of variables. In the example, linearization is performed by taking logarithms of both sides of the equation:
WhereY=lg(y), X=lg(x), C=lg(a).For calculations we use the data in table. 1.3.
Table 1.3
Y X YX Y2 X 2 A i 1 1,8376 1,6542 3,0398 3,3768 2,7364 61,0 7,8 60,8 11,3 2 1,7868 1,7709 3,1642 3,1927 3,1361 56,3 4,9 24,0 8,0 3 1,7774 1,7574 3,1236 3,1592 3,0885 56,8 3,1 9,6 5,2 4 1,7536 1,7910 3,1407 3,0751 3,2077 55,5 1,2 1,4 2,1 5 1,7404 1,7694 3,0795 3,0290 3,1308 56,3 -1,3 1,7 2,4 6 1,7348 1,6739 2,9039 3,0095 2,8019 60,2 -5,9 34,8 10,9 7 1,6928 1,7419 2,9487 2,8656 3,0342 57,4 -8,1 65,6 16,4 Total 12,3234 12,1587 21,4003 21,7078 21,1355 403,5 1,7 197,9 56,3 Average value 1,7605 1,7370 3,0572 3,1011 3,0194 X X 28,27 8,0 σ 0,0425 0,0484 X X X X X X X σ 2 0,0018 0,0023 X X X X X X X Let's calculate C and b:
We get a linear equation: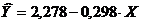 .
.
Having performed its potentiation, we get:
Substituting actual values into this equation X, we obtain theoretical values of the result. Using them, we will calculate the indicators: tightness of connection - correlation index and average approximation error
The characteristics of the power-law model indicate that it describes the relationship somewhat better than the linear function.1c. Constructing the equation of an exponential curve
preceded by a procedure for linearizing variables by taking logarithms of both sides of the equation:

For calculations we use the table data.Y x Yx Y2 x 2 A i 1 1,8376 45,1 82,8758 3,3768 2034,01 60,7 8,1 65,61 11,8 2 1,7868 59,0 105,4212 3,1927 3481,00 56,4 4,8 23,04 7,8 3 1,7774 57,2 101,6673 3,1592 3271,84 56,9 3,0 9,00 5,0 4 1,7536 61,8 108,3725 3,0751 3819,24 55,5 1,2 1,44 2,1 5 1,7404 58,8 102,3355 3,0290 3457,44 56,4 -1,4 1,96 2,5 6 1,7348 47,2 81,8826 3,0095 2227,84 60,0 -5,7 32,49 10,5 7 1,6928 55,2 93,4426 2,8656 3047,04 57,5 -8,2 67,24 16,6 Total 12,3234 384,3 675,9974 21,7078 21338,41 403,4 -1,8 200,78 56,3 Wed. zn. 1,7605 54,9 96,5711 3,1011 3048,34 X X 28,68 8,0 σ 0,0425 5,86 X X X X X X X σ 2 0,0018 34,339 X X X X X X X Values of regression parameters A and IN amounted to:
The resulting linear equation is: .
Let us potentiate the resulting equation and write it in the usual form:
.
Let us potentiate the resulting equation and write it in the usual form:
We will evaluate the closeness of the connection through the correlation index: