Яндекс вебмастер анализ robots txt. Как узнать, обойдет ли робот определенный URL
Правильно составленный robots.txt помогает правильно индексировать сайт и избавляет от дублей контента, которые есть в любой CMS. Я знаю, что многих авторов просто пугает необходимость лезть куда-то в корневые папки блога и что-то менять в «служебных» файлах. Но этот ложный страх нужно перебороть. Поверьте: ваш блог не «рухнет», даже если вы поместите в robots.txt собственный портрет (т.е. испортите его!). Зато, любые благотворные изменения повысят его статус в глазах поисковых систем.
Что такое файл robots.txt
Я не буду изображать эксперта, мучая вас терминами. Просто поделюсь своим, довольно простым, пониманием функций этого файла:
robots.txt – это инструкция, дорожная карта для роботов поисковых систем, посещающих наш блог с инспекцией. Нам только нужно указать им, какой контент является, так сказать, служебным, а какой – то самое ценное содержание, ради которого к нам стремятся (или должны стремиться) читатели. И именно эта часть контента должна индексироваться и попадать в поисковую выдачу!
А что случается, если мы не заботимся о подобных инструкциях? – Индексируется все подряд. И поскольку пути алгоритмов поисковых систем, практически, неисповедимы, то анонс статьи, открывающийся по адресу архива, может показаться Яндексу или Гуглу более релевантным, чем полный текст статьи, находящийся по другому адресу. И посетитель, заглянув на блог, увидит совсем не то, чего хотел и чего хотели бы вы: не пост, а списки всех статей месяца… Итог ясен – скорее всего, он уйдет.
Хотя есть примеры сайтов, у которых робоста нет вообще, но они занимают приличные позиции в поисковой выдаче, но это конечно исключение, а не правило.
Из чего состоит файл robots.txt
И здесь мне не хочется заниматься рерайтом. Существуют довольно понятные объяснения из первых уст – например, в разделе помощи Яндекса . Очень советую прочитать их и не один раз. Но я попытаюсь помочь вам преодолеть первую оторопь перед обилием терминов, описав общую структуру файла robots.txt.
В самом верху, в начале robots.txt, мы объявляем, для кого пишем инструкцию:
User-agent: Yandex
Конечно, у каждого уважающего себя поисковика есть множество роботов – поименованных и безымянных. Пока вы не отточили свое мастерство создания robots.txt, лучше придерживаться простоты и возможных обобщений. Поэтому предлагаю отдать должное Яндексу, а всех остальных объединить, прописав общее правило:
User-Agent: * - это все, любые, роботы
Также, мы указываем главное зеркало сайта – тот адрес, который будет участвовать в поиске. Это особенно актуально, если у вас несколько зеркал. Еще можно указать и некоторые другие параметры. Но самым важным для нас, все-таки, является возможность закрыть от индексации служебные части блога.
Вот примеры запрещения индексировать:
Disallow: /cgi-bin* - файлы скриптов;
Disallow: /wp-admin* - административную консоль;
Disallow: /wp-includes* - служебные папки;
Disallow: /wp-content/plugins* - служебные папки;
Disallow: /wp-content/cache* - служебные папки;
Disallow: /wp-content/themes* - служебные папки;
Disallow: */feed
Disallow: /comments* - комментарии;
Disallow: */comments
Disallow: /*/?replytocom=* - ответы на комментарии
Disallow: /tag/* - метки
Disallow: /archive/* - архивы
Disallow: /category/* - рубрики
Как создать собственный файл robots.txt
Самый легкий и очевидный путь – найти пример готового файла robots.txt на каком-нибудь блоге и торжественно переписать его себе. Хорошо, если при этом авторы не забывают заменить адрес блога-примера на адрес своего детища.
Роботс любого сайта доступен по адресу:
https://сайт/robots.txt
Я тоже поступал подобным образом и не чувствую себя в праве отговаривать вас. Единственное, о чем очень прошу: разберитесь, что написано в копируемом файле robots.txt! Используйте помощь Яндекса, любые другие источники информации – расшифруйте все строки. Тогда, наверняка, вы увидите, что некоторые правила не подходят для вашего блога, а каких-то правил, наоборот, не хватает.
Теперь посмотрим, как проверить корректность и эффективность нашего файла robots.txt.
Поскольку все, что связано с файлом robots.txt, может поначалу казаться слишком непонятным и даже опасным - я хочу показать вам простой и понятный инструмент его проверки. Это очевидный путь, который поможет вам не просто проверить, но и выверить ваш robots.txt, дополнив его всеми необходимыми инструкциями и убедившись, что роботы поисковых систем понимают, чего вы от них хотите.
Проверка файла robots.txt в Яндексе
Яндекс-вебмастер позволяет нам узнать отношение поискового робота этой системы к нашему творению. Для этого, очевидно, нужно открыть сведения, относящиеся к блогу и:
- перейти по вкладке Инструменты-> Анализ robots.txt
- нажмите кнопку «загрузить» и будем надеяться, что разместили файл robots.txt там, где нужно и робот его найдет:) (если не найдет - проверьте, где находится ваш файл: он должен быть в корне блога, там, где лежат папки wp-admin, wp-includes и т.д., а ниже отдельные файлы - среди них должен быть robots.txt)
- кликаем на «проверить».
Но самая важная информация находится в соседней вкладке - «Используемые секции»! Ведь, собственно, нам важно, чтобы робот понимал основную часть информации - а все остальное пусть пропускает:
На примере мы видим, что Яндекс понимает все, что касается его робота (строки с 1 по 15 и 32) - вот и прекрасно!
Проверка файла robots.txt в Гугле
У Гугл, тоже, есть инструмент проверки, который покажет нам, как эта поисковая система видит (или не видит) наш robots.txt:
- В инструментах для вебмастеров от Гугл (где ваш блог тоже обязательно должен быть зарегистрирован) есть свой сервис для проверки файла robots.txt. Он находится во вкладке Сканирование
- Найдя файл, система показывает анализирует его и выдает информацию об ошибках. Все просто.
На что стоит обратить внимание, анализируя файл robots.txt
Мы недаром рассмотрели инструменты анализа от двух, наиболее важных поисковых систем - Яндекс и Гугл. Ведь нам нужно убедиться, что каждая из них прочитает рекомендации, данные нами в robots.txt.
В примерах, приведенных здесь, можно увидеть, что Яндекс понимает инструкции, которые мы оставили для его робота и игнорирует все остальные (хотя везде написано одно и то же, только директива User-agent: - различная:)))
Важно понимать, что любые изменения в robots.txt нужно производить непосредственно с тем файлом, который находится у вас в корневой папке блога. То есть, вам нужно открыть его в любом блокноте, чтобы переписать, удалить, добавить какие-либо строки. Потом его нужно сохранить обратно в корень сайта и заново проверить реакцию на изменения поисковых систем.
Понять, что в нем написано, что следует добавить - нетрудно. А заниматься продвижением блога, не настроив файл robots.txt как следует (так, как нужно именно вам!) - усложнять себе задачу.
Привет уважаемые читатели! Свою сегодняшнюю статью мне бы хотелось посвятить важному и крайне необходимому файлу robots.txt .
Я постараюсь максимально подробно, а главное понятно рассказать, какую в себе функцию несет это файл и как его правильно составить для wordpress блогов.
Дело в том, что каждый второй начинающий блоггер совершает одну и ту же ошибку, он не придает особого значения этому файлу, как из-за своей неграмотности, так и непонимания той роли, ради которой он создается.
Разберем сегодня следующие вопросы:
- Зачем нужен файл роботс на сайте;
- Как создать robots.txt;
- Пример правильного файла;
- Проверка robots в Яндекс Вебмастер.
Для чего служит файл robots.txt
Я для создания своего блога решил использовать движок WordPress, так как он очень удобный, простой и многофункциональный.
Однако не бывает чего-то одного идеального. Дело в том, что эта cms устроена таким образом, что при написании статьи происходит ее автоматическое дублирование в архивах, рубриках, результатах поиска по сайту, .
Получается, что ваша одна статья будет иметь несколько точных копий на сайте, но с различными url-адресами.
 В итоге вы сами того не желая, заполняете проект не уникальным контентом, а за такой дублированный материал поисковые системы по головке не погладят и в скором времени загонят его под фильтры: от Яндекс или от Google.
В итоге вы сами того не желая, заполняете проект не уникальным контентом, а за такой дублированный материал поисковые системы по головке не погладят и в скором времени загонят его под фильтры: от Яндекс или от Google.
Лично я в этом убедился на своем собственном примере.
Когда я только начинал вести этот блог естественно я не имел никакого понятия о том, что есть какой-то там файл роботс, а тем более понятия каким он должен быть и что в него надо записывать.
Для меня было самым главным это побольше написать статей, чтобы в будущем с них продать ссылки в бирже . Хотелось быстрых денег, но не тут-то было...
Мной было написано около 70 статей, однако в панели Яндекс Вебмастер показывалось, что роботы поиска проиндексировали 275.
Конечно, я подозревал, что не может быть так все хорошо, однако никаких действий не предпринял, плюс добавил блог в биржу ссылок sape.ru и стал получать 5 р . в сутки.
А уже через месяц на мой проект был наложен , из индекса выпали все страницы и тем самым прикрылась моя доходная лавочка.
Поэтому вам нужно указать роботам поисковых систем, какие страницы, файлы, папки и др. необходимо индексировать, а какие обходить стороной.
Robots.txt — файл, который дает команду поисковым машинам, что на блоге можно индексировать, а что нет.
Этот файл создается в обычном текстовом редакторе (блокноте) с расширением txt и располагается в корне ресурса.

В файле robots.txt можно указать:
- Какие страницы, файлы или папки необходимо исключить из индексации;
- Каким поисковым машинам полностью запретить индексировать проект;
- Указать путь к файлу sitemap.xml (карте сайта);
- Определить основное и дополнительное зеркало сайта (с www или без www);
Что содержится в robots.txt — список команд
Итак, сейчас мы приступаем к самому сложному и важному моменту, будем разбирать основные команды и директивы, которые можно прописывать в фале роботс wordpress площадок.
1) User-agent
В этой директиве вы указываете, какому именно поисковику будут адресованы нижеприведенные правила (команды).
Например, если вы хотите, чтобы все правила были адресованы конкретно сервису Яндекс, тогда прописывает:
User-agent: Yandex
Если необходимо задать обращение абсолютно всем поисковым системам, тогда прописываем звездочку «*» результат получится следующий:
User-agent: *
2) Disallow и Allow
Disallow — запрещает индексацию указанных разделов, папок или страниц блога;
Allow — соответственно разрешает индексацию данных разделов;
Сначала вам необходимо указывать директиву Allow, а только затем Disallow. Также запомните, что не должно быть пустых строк между этими директивами, как и после директивы User-agent. Иначе поисковый робот подумает, что указания на этом закончились.
Например, вы хотите полностью открыть индексацию сайта, тогда пишем так:
Allow: /
Disallow:
Если хотим наложить запрет на индексацию сайта Яндексу, тогда пишем следующее:
User-agent: Yandex
Disallow: /
Теперь давайте запретим индексировать файл rss.html , который находится в корне моего сайта.
Disallow: /rss.html
А вот как будет выглядеть этот запрет на файл, расположенный в папке «posumer» .
Disallow: /posumer/rss.html
Теперь давайте запретим директории, которые содержат дубли страниц и ненужный мусор. Это значит, что все файлы, находящиеся в этих папках не будут доступны роботам поисковиков.
Disallow: /cgi-bin/
Disallow: /wp-admin/
Disallow: /wp-includes/
Таким образом, вам нужно запретить роботам ходить по всем страницам, папкам и файлам, которые могут негативно повлиять на развитие сайта в будущем.
3) Host
Данная директива позволяет определить роботам поисковиков, какое зеркало сайта необходимо считать главным (с www или без www). Что в свою очередь убережет проект от полного дублирования и как результат спасет от наложения фильтра.
Вам необходимо прописать эту директиву, только для поисковой системы Яндекс, после Disallow и Allow.
Host: сайт
4) Sitemap
Этой командой вы указывает, где у вас расположена карта сайта в формате XML. Если кто-то еще не создал у себя на проекте XML карту сайта, я рекомендую воспользоваться моей статьей « », где все подробно расписано.
Здесь нам необходимо указать полный адреса до карт сайта в формате xml.
Sitemap: https://сайт/sitemap.xml
Посмотрите коротенькое видео, которое очень доходчиво объяснит принцип работы файла robots.txt.
Пример правильного файла
Вам необязательно знать все тонкости настройки файла robots, а достаточно посмотреть, как его составляют другие вебмастера и повторить все действия за ними.
Мой блог сайт отлично индексируется поисковиками и в индексе нет никаких дублей и прочего мусорного материала.
Вот какой файл использован на этом проекте:
| User- agent: * Disallow: / wp- Host: seoslim. ru Sitemap: https: //сайт/sitemap.xml User- agent: Googlebot- Image Allow: / wp- content/ uploads/ User- agent: YandexImages Allow: / wp- content/ uploads/ |
User-agent: * Disallow: /wp- Host: сайт.xml User-agent: Googlebot-Image Allow: /wp-content/uploads/ User-agent: YandexImages Allow: /wp-content/uploads/
Если хотите, можете использовать в качестве примера именно его, только не забудьте изменить имя моего сайта на свой.
Теперь давайте поясню, что нам даст именно такой роботс. Дело в том, что если вы будите запрещать в этом файле какие-то страницы с помощью вышеописанных директив, то роботы поисковиков все равно из заберут в индекс, в основном это касается Google.
Если ПС начать запрещать что-то, то он наоборот это обязательно проиндексирует, так на всякий случай. Поэтому мы должны поисковикам наоборот разрешить индексацию всех страниц и файлов площадки, а уже запрещать ненужные нам страницы (пагинацию, дубли реплитоком и прочий мусор) вот такими командами метатегами:
| < meta name= "robots" content= "noindex,follow" /> |
Первым делом к файлу.htaccess добавляем следующие строки:
| RewriteRule (.+ ) / feed / $1 [ R= 301 , L] RewriteRule (.+ ) / comment- page / $1 [ R= 301 , L] RewriteRule (.+ ) / trackback / $1 [ R= 301 , L] RewriteRule (.+ ) / comments / $1 [ R= 301 , L] RewriteRule (.+ ) / attachment / $1 [ R= 301 , L] RewriteCond % { QUERY_STRING} ^attachment_id= [ NC] RewriteRule (.* ) $1 ? [ R= 301 , L] |
RewriteRule (.+)/feed /$1 RewriteRule (.+)/comment-page /$1 RewriteRule (.+)/trackback /$1 RewriteRule (.+)/comments /$1 RewriteRule (.+)/attachment /$1 RewriteCond %{QUERY_STRING} ^attachment_id= RewriteRule (.*) $1?
Тем самым мы настроили редирект с дублей страниц (feed, comment-page, trackback, comments, attachment) на оригинальные статьи.
Этот файл расположен в корне вашего сайте и должен выглядеть примерно таким образом:
| # BEGIN WordPress < IfModule mod_rewrite. c> RewriteEngine On RewriteBase / RewriteCond % { QUERY_STRING} ^replytocom= [ NC] RewriteRule (.* ) $1 ? [ R= 301 , L] RewriteRule (.+ ) / feed / $1 [ R= 301 , L] RewriteRule (.+ ) / comment- page / $1 [ R= 301 , L] RewriteRule (.+ ) / trackback / $1 [ R= 301 , L] RewriteRule (.+ ) / comments / $1 [ R= 301 , L] RewriteRule (.+ ) / attachment / $1 [ R= 301 , L] RewriteCond % { QUERY_STRING} ^attachment_id= [ NC] RewriteRule (.* ) $1 ? [ R= 301 , L] RewriteRule ^index\. php$ - [ L] RewriteCond % { REQUEST_FILENAME} !- f RewriteCond % { REQUEST_FILENAME} !- d RewriteRule . / index. php [ L] # END WordPress |
# BEGIN WordPress
| /*** Закрываем от индексации с помощью noindex, nofollow страницы пагинации ***/ function my_meta_noindex () { if ( is_paged() // Указывать на все страницы пагинации ) { echo "" . "" . "\n " ; } } add_action("wp_head" , "my_meta_noindex" , 3 ) ; // добавляем команду noindex,nofollow в head шаблона |
/*** Закрываем от индексации с помощью noindex, nofollow страницы пагинации ***/ function my_meta_noindex () { if (is_paged() // Указывать на все страницы пагинации) {echo "".""."\n";} } add_action("wp_head", "my_meta_noindex", 3); // добавляем команду noindex,nofollow в head шаблона
Для того чтобы закрыть категории, архивы, метки переходим в настройки плагина All in One Seo Pack и отмечаем все как на скриншоте:

Все настройки сделаны, теперь ждите пока ваш сайт переиндексируется, чтобы дубли выпали из выдачи, а трафик пошел в верх.
Для того чтобы очистить выдачу от соплей, нам пришлось разрешить файлом robots индексировать мусорные страницы, но когда роботы ПС будут на них попадать, то там они увидят метатеги noindex и не заберут их к себе в индекс.
Проверка роботс в Яндекс Вебмастер
После того, как вы правильно составили файл robots.txt и закинули его в корень сайта, можно выполнить простую проверку его работоспособности в панели Вебмастер.
Для этого переходим в панель Яндекс Вебмастер по этой ссылке
В завершении поста хочу сказать, что если вы сделаете какие-либо изменения в фале robots.txt, то они вступят в силу только через несколько месяцев. Для того чтобы алгоритмы поисковиков приняли решение об исключении какой-то страницы им нужно обдуманное решение — не принимает же он их туда просто так. Хочу, чтобы вы отнеслись серьезно к созданию данного файла, так как от него будет зависеть дальнейшая судьба площадки. Если есть какие-либо вопросы давайте их вместе решать. Оставьте комментарий и он никогда не останется без ответа. До скорой встречи!Заключение
Карта сайта, значительно упрощает индексацию вашего блога. Карта сайта должна быть в обязательном порядке у каждого сайта и блога. Но также на каждом сайте и блоге должен быть файл robots. txt . Файл robots.txt содержит свод инструкций для поисковых роботов. Можно сказать, — правила поведения поисковых роботов на вашем блоге. А также в данном файле содержится путь к карте сайта вашего блога. И, по сути, при правильно составленном файле robots.txt поисковый робот не тратит драгоценное время на поиск карты сайта и индексацию не нужных файлов.
Что же из себя представляет файл robots.txt?
robots.txt – это текстовый файл, может быть создан в обычном «блокноте», расположенный в корне вашего блога, содержащий инструкции для поисковых роботов.
Эти инструкции ограничивают поисковых роботов от беспорядочной индексации всех файлов вашего бога, и нацеливают на индексацию именно тех страниц, которым следует попасть в поисковую выдачу.
С помощью данного файла, вы можете запретить индексацию файлов движка WordPress. Или, скажем, секретного раздела вашего блога. Вы можете указать путь к карте Вашего блога и главное зеркало вашего блога. Здесь я имею ввиду, ваше доменное имя с www и без www.
Индексация сайта с robots.txt и без
Данный скриншот, наглядно показывает, как файл robots.txt запрещает индексацию определённых папок на сайте. Без файла, роботу доступно всё на вашем сайте.
Основные директивы файла robots.txt
Для того чтобы разобраться с инструкциями, которые содержит файл robots.txt нужно разобраться с основными командами (директивы).
User-agent – данная команда обозначает доступ роботам к вашему сайту. Используя эту директиву можно создать инструкции индивидуально под каждого робота.
User-agent: Yandex – правила для робота Яндекс
User-agent: * — правила для всех роботов
Disallow и Allow – директивы запрета и разрешения. С помощью директивы Disallow запрещается индексация а с помощью Allow разрешается.
Пример запрета:
User-agent: *
Disallow: / — запрет ко всему сайта.
User-agent: Yandex
Disallow: /admin – запрет роботу Яндекса к страницам лежащим в папке admin.
Пример разрешения:
User-agent: *
Allow: /photo
Disallow: / — запрет ко всему сайту, кроме страниц находящихся в папке photo.
Примечание! директива Disallow: без параметра разрешает всё, а директива Allow: без параметра запрещает всё. И директивы Allow без Disallow не должно быть.
Sitemap – указывает путь к карте сайта в формате xml.
Sitemap: https://сайт/sitemap.xml.gz
Sitemap: https://сайт/sitemap.xml
Host – директива определяет главное зеркало Вашего блога. Считается, что данная директива прописывается только для роботов Яндекса. Данную директиву следует указывать в самом конце файла robots.txt.
User-agent: Yandex
Disallow: /wp-includes
Host: сайт
Примечание! адрес главного зеркала указывается без указания протокола передачи гипертекста (http://).
Как создать robots.txt
Теперь, когда мы познакомились с основными командами файла robots.txt можно приступать к созданию нашего файла. Для того чтобы создать свой файл robots.txt с вашими индивидуальными настройками, вам необходимо знать структуру вашего блога.
Мы рассмотрим создание стандартного (универсального) файла robots.txt для блога на WordPress. Вы всегда сможете дополнить его своими настройками.
Итак, приступаем. Нам понадобится обычный «блокнот», который есть в каждой операционной системе Windows. Или TextEdit в MacOS.
Открываем новый документ и вставляем в него вот эти команды:
User-agent: * Disallow: Sitemap: https://сайт/sitemap.xml.gz Sitemap: https://сайт/sitemap.xml User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /xmlrpc.php Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-content/languages Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: /tag/ Disallow: /feed/ Disallow: */*/feed/*/ Disallow: */feed Disallow: */*/feed Disallow: /?feed= Disallow: /*?* Disallow: /?s= Host: сайт
Не забудьте заменить параметры директив Sitemap и Host на свои.
Важно! при написании команд, допускается лишь один пробел. Между директивой и параметром. Ни в коем случае не делайте пробелов после параметра или просто где попало.
Пример
:
Disallow:<пробел>/feed/
Данный пример файла robots.txt универсален и подходит под любой блог на WordPress с ЧПУ адресами url. О том что такое ЧПУ читайте . Если же Вы не настраивали ЧПУ, рекомендую из предложенного файла удалить Disallow: /*?* Disallow: /?s=

Загрузка файла robots.txt на сервер
Лучшим способом для такого рода манипуляций является FTP соединение. О том как настроить FTP соединение для TotolCommander читайте . Или же Вы можете использовать файловый менеджер на Вашем хостинге.
Я воспользуюсь FTP соединением на TotolCommander.
Сеть > Соединится с FTP сервером.

Выбрать нужное соединение и нажимаем кнопку «Соединиться».

Открываем корень блога и копируем наш файл robots.txt, нажав клавишу F5.

Копирование robots.txt на сервер
Вот теперь Ваш файл robots.txt будет исполнять надлежащие ему функции. Но я всё же рекомендую провести анализ robots.txt, чтобы удостоверится в отсутствии ошибок.
Для этого Вам потребуется войти в кабинет вебмастера Яндекс или Google. Рассмотрим примере Яндекс. Здесь можно провести анализ даже не подтверждая прав на сайт. Вам достаточно иметь почтовый ящик на Яндекс.
Открываем кабинет Яндекс.вебмастер.

На главной странице кабинета вебмастер, открываем ссылку «Проверить robots. txt» .

Для анализа потребуется ввести url адрес вашего блога и нажать кнопку «Загрузить robots. txt с сайта ». Как только файл будет загружен нажимаем кнопку «Проверить».

Отсутствие предупреждающих записей, свидетельствует о правильности создания файла robots.txt.

Ниже будет представлен результат. Где ясно и понятно какие материалы разрешены для показа поисковым роботам, а какие запрещены.

Результат анализа файла robots.txt
Здесь же вы можете вносить изменения в robots.txt и экспериментировать до получения нужного вам результата. Но помните, файл расположенный на вашем блоге при этом не меняется. Для этого вам потребуется полученный здесь результат скопировать в блокнот, сохранить как robots.txt и скопировать на Вас блог.
Кстати, если вам интересно как выглядит файл robots.txt на чьём-то блоге, вы может с лёгкостью его посмотреть. Для этого к адресу сайта нужно просто добавить /robots.txt
https://сайт/robots.txt
Вот теперь ваш robots.txt готов. И помните не откладывайте в долгий ящик создание файла robots.txt, от этого будет зависеть индексация вашего блога.
Если же вы хотите создать правильный robots.txt и при этом быть уверенным, что в индекс поисковых систем попадут только нужные страницы, то это можно сделать и автоматически с помощью плагина .
На этом у меня всё. Всем желаю успехов. Если будут вопросы или дополнения пишите в комментариях.
До скорой встречи.
С уважением, Максим Зайцев.
Подписывайтесь на новые статьи!
- это появление в поиске страниц, которые не несут никакой полезной информации для пользователя, и скорее всего пользователь на них все равно не зайдет, а если зайдет, то ненадолго.
- это появление в поиске копий одной и той же страницы с разными адресами. (Дублирование контента)
- это тратится драгоценное время на индексацию ненужных страниц поисковыми роботами. Поисковый робот вместо того чтобы заниматься нужным и полезным контентом будет тратить время на бесполезное блуждание по сайту. А так как роботы не индексируют весь сайт целиком и сразу (сайтов много и всем нужно уделить внимание), то важные страницы, которые Вы хотите увидеть в поиске, вы можете увидеть очень не скоро.
Было решено закрыть доступ для поисковых роботов к некоторым страницам сайта. В этом нам поможет файл robots.txt.
Зачем нужен robots.txt.
robots.txt – это обычный текстовый файл, в котором прописаны инструкции для поисковых роботов. Первое что делает поисковый робот при попадании на сайт, это ищет файл robots.txt. Если файл robots.txt не найден или он пустой, то поисковый робот будет бродить по всем доступным страницам и каталогам сайта (включая системные каталоги), в попытке проиндексировать содержимое. И не факт, что он проиндексирует нужную Вам страницу, если вообще доберется до нее.
С помощью robots.txt мы можем указать поисковым роботам, на какие страницы можно заходить и как часто, а куда ходить не стоит. Инструкции могут быть указаны, как для всех роботов, так и для каждого робота в отдельности. Страницы, которые закрыты от поисковых роботов, не будут появляться в поисковиках. Если этого файла нет, то его обязательно необходимо создать.
Файл robots.txt должен находиться на сервере, в корне вашего сайта. Файл robots.txt можно посмотреть на любом сайте в Интернет, для этого достаточно после адреса сайта добавить /robots.txt . Для сайта адрес, по которому можно посмотреть robots..txt.
Файл robots.txt , обычно у каждого сайта имеет свои особенности и бездумное копирование чужого файла, может создать проблемы с индексированием вашего сайта поисковыми роботами. Поэтому нужно четко понимать назначение файла robots.txt и назначение инструкций (директив), которые мы будем использовать, при его создании.
Директивы файла robots.txt.
Разберем основные инструкции (директивы), которые мы будем использовать при создании файла robots.txt.
User-agent: — указываем имя робота, для которого будут работать все нижеприведенные инструкции. Если инструкции нужно использовать для всех роботов, то в качестве имени используем * (звездочку)
Например:
User-agent:*
#инструкции действуют на всех поисковых роботов
User-agent: Yandex
#инструкции действуют только на поискового робота Яндекс
Имена самых популярных поисковиков Рунета это Googlebot (для Google) и Yandex (для Яндекса). Имена остальных поисковиков, если интересно, можно найти на просторах Интернет, но создавать для них отдельные правила, мне кажется, нет необходимости.
Disallow – запрещает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Disallow /wp-includes/
#запрещает роботам доступ в wp-includes
Disallow /
# запрещает роботам доступ ко всему сайту.
Allow – разрешает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Allow /wp-content/
#разрешает роботам доступ в wp-content
Allow /
#разрешает роботам доступ ко всему сайту.
Sitemap: — можно использовать для указания пути к файлу с описанием структуры вашего сайта (карты сайта). Она нужна для ускорения и улучшения индексации сайта поисковыми роботами.
Например:
.xml
Host: — Если у вашего сайта есть зеркала (копии сайта на другом домене)..сайт. С помощью файла Host можно указать главное зеркало сайта. В поиске будет участвовать только главное зеркало.
Например:
Host: сайт
Также можно использовать спецсимволы. * # и $
*(звездочка) – обозначает любую последовательность символов.
Например:
Disallow /wp-content*
#запрещает роботам доступ в /wp-content/plugins, /wp-content/themes и.т.д.
$(знак доллара) – По умолчанию в конце каждого правила предполагается наличие *(звездочка) чтобы отменить симовол *(звездочка) можно использовать символ $(знак доллара).
Например:
Disallow /example$
#запрещает роботам доступ в /example но не запрещает в /example.html
#(знак решетки) – можно использовать для комментариев в файле robots.txt
Подробнее с этими директивами, а также несколькими дополнительными, можно ознакомиться на сайте Яндекса.
Как написать robots.txt для WordPress.
Теперь приступим к созданию файла robots.txt. Так как наш блог работает на WordPress, то разберем процесс создания robots.txt для WordPress более подробно.
Вначале нужно определиться, что мы хотим разрешить поисковым роботам, а что запретить. Я для себя решил оставить только самое необходимое, это записи, страницы и разделы. Все остальное будем закрывать.
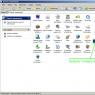
Какие папки есть в WordPress и что необходимо закрыть мы можем увидеть, если посмотрим в директорию нашего сайта. Я сделал это через панель управления хостингом на сайте reg.ru , и увидел следующую картину.
 Разберемся с назначением каталогов и решим, что можно закрыть.
Разберемся с назначением каталогов и решим, что можно закрыть.
/cgi-bin (каталог скриптов на сервере – в поиске он нам не нужен.)
/files (каталог с файлами для загрузки. Здесь, например, лежит архивный файл с таблицей Excel для подсчета прибыли, о которой я писал в статье « «. В поиске этот каталог нам не нужен.)
/playlist(этот каталог я сделал для себя, для плейлистов на IPTV – в поиске не нужен.)
/test (этот каталог я создал для экспериментов, в поиске этот каталог не нужен)
/wp-admin/ (админка WordPress, в поиске она нам не нужна)
/wp-includes/ (системная папка от WordPress, в поиске она нам не нужна)
/wp-content/ (из этого каталога нам нужен только /wp-content/uploads/ в этом каталоге находятся картинки с сайта, поэтому каталог /wp-content/ мы запретим, а каталог с картинками разрешим отдельной инструкцией.)
Также нам не нужны в поиске следующие адреса:
Архивы – адреса вида //сайт/2013/ и похожие.
Метки — в адресе меток содержится /tag/
RSS фиды — в адресе всех фидов есть /feed
На всякий случай закрою адреса с PHP на конце так, как многие страницы доступны, как с PHP на конце, так и без. Это, как мне кажется, позволит избежать дублирования страниц в поиске.
Также закрою адреса с /GOTO/ я их использую для перехода по внешним ссылкам, в поиске им точно делать нечего.
P=209 и поиск по сайту //сайт/?s=, а также комментарии (адреса в которых содержится /?replytocom=)
А вот что у нас должно остаться:
/images (в этот каталог я закидываю некоторые картинки, пускай этот каталог роботы посещают)
/wp-content/uploads/ — содержит картинки от сайта.
Статьи, страницы и разделы, которые содержат понятные, читаемые адреса.
Например: или
А теперь придумаем инструкции для robots.txt. Вот, что у меня получилось:
#Указываем, что эти инструкции будут выполнять все роботы
User-agent: *
#Разрешаем роботам бродить по каталогу uploads.
Allow: /wp-content/uploads/
#Запрещаем папку со скриптами
Disallow: /cgi-bin/
#Запрещаем папку files
Disallow: /files/
#Запрещаем папку playlist
Disallow: /playlist/
#Запрещаем папку test
Disallow: /test/
#Запрещаем все, что начинается с /wp- , это позволит закрыть сразу несколько папок, имена которых начинаются с /wp- , эта команда вполне может помешать индексации страниц или записей которые начинаются с /wp-, но давать таких имен я не планирую.
Disallow: /wp-*
#Запрещаем адреса, в которых содержится /?p= и /?s=. Это короткие ссылки и поиск.
Disallow: /?p=
Disallow: /?s=
#Запрещаем все архивы до 2099 года.
Disallow: /20
#Запрещаем адреса с расширением PHP на конце.
Disallow: /*.php
#Запрещаем адреса, которые содержат /goto/. Можно было не прописывать, но на всякий случай вставлю.
Disallow: /goto/
#Запрещаем адреса меток
Disallow: /tag/
#Запрещаем все фиды.
Disallow: */feed
#Запрещаем индексацию комментариев.
Disallow: /?replytocom=
#Ну и напоследок прописываем путь к нашей карте сайта.
.xml
Написать файл robots.txt для WordPress можно с помощью обычного блокнота. Создадим файл и запишем в него следующие строки.
User-agent: *
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
.xml
Вначале я планировал сделать один общий блок правил для всех роботов, но Яндекс работать с общим блоком отказался. Пришлось сделать для Яндекса отдельный блок правил. Для этого просто скопировал общие правила, изменил имя робота и указал роботу главное зеркало сайта, с помощью директивы Host.
User-agent: Yandex
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
.xml
Host: сайт
Указать главное зеркало сайта можно также через , в разделе «Главное зеркало»

Теперь, когда файл robots.txt для WordPress
создан, нам его необходимо загрузить на сервер, в корневой каталог нашего сайта. Это можно сделать любым удобным для Вас способом.
Также для создания и редактирования robots.txt можно воспользоваться плагином WordPress SEO. Подробнее об этом полезном плагине я напишу позже. В этом случае файл robots.txt на рабочем столе можно не создавать, а просто вставить код файла robots.txt в соответствующий раздел плагина.

Как проверить robots.txt
Теперь, когда мы создали файл robots.txt, его нужно проверить. Для этого заходим в панель управления Яндекс.Вебмастер. Далее заходим в раздел “Настройка индексирования”, а далее “анализ robots.txt” . Здесь нажимаем кнопку «Загрузить robots.txt с сайта», после этого в соответствующем окне должно появиться содержимое вашего robots.txt.

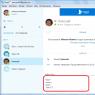
Затем нажимаем «добавить» и в появившемся окне вводим различные url с вашего сайта, которые вы хотите проверить. Я ввел несколько адресов, которые должны быть запрещены и несколько адресов, которые должны быть разрешены.

Нажимаем кнопку «Проверить», после этого Яндекс выдаст нам результаты проверки файла robots.txt. Как видим, наш файл проверку удачно прошел. То, что должно быть запрещено для поисковых роботов, у нас запрещено. То, что должно быть разрешено, у нас разрешено.

Такую же проверку можно провести для робота Google, через GoogleWebmaster, но она не сильно отличается от проверки через Яндекс, поэтому я ее описывать не буду.
Вот и все. Мы создали robots.txt для WordPress и он отлично работает. Остается только иногда поглядывать за поведением поисковых роботов на нашем сайте. Чтобы вовремя заметить ошибку и в случае необходимости внести изменения в файл robots.txt. Страницы которые были исключены из индекса и причину исключения можно посмотреть в соответствующем разделе Яндекс.ВебМастер (или GoogleWebmaster).
Удачных Инвестиций и успехов во всех ваших делах.