Перенаправление потоков ввода вывода c. Программные каналы и потоки, перенаправление
1403
Потоки вывода
Сообщения скриптов выводятся во вполне определенные потоки - потоки вывода. Таким образом то, что мы выводим через
echo "Hello, world!"
Не просто выводится на экран, а, с точки зрения системы, а конкретно - командных интерпретаторов sh и bash - выводится через определенный поток вывода. В случае echo - поток под номером 1 (stdout), с которым ассоциирован экран.
Некоторые программы и скрипты так-же используют другой поток вывода - под номером 2 (stderr). В него они выводят сообщения об ошибках. Благодаря этому можно раздельно выхватывать из потоков обычные информационные сообщения и сообщения об ошибках и направлять и обрабатывать их раздельно.
Например, Вы можете заблокировать вывод информационных сообщения, оставив только сообщения об ошибках. Или направить вывод сообщений об ошибках в отдельный файл для логирования.
Что такое ">somefile"
Такой записью в Unix (в интерпретаторах bash и sh) указывается перенаправление потоков вывода.
В следующем примере мы перенаправим все информационные (обычные) сообщения команды ls в файл myfile.txt, получив таким образом в этом файле просто список ls:
$ ls > myfile.txt
При этом после нажатия на Enter Вы не увидите ничего на экране, зато в файле myfile.txt будет находится все то, что должно было отобразиться на экране.
Однако давайте сделаем заведомо ошибочную операцию:
$ ls /masdfasdf > myfile.txt
И что случится? Т.к. директории masdfasdf в корне файловой системы не существует (я так предполагаю - вдруг у Вас есть?), то команда ls сгенерирует ошибку. Однако вывалит эту ошибку она уже не через обычный поток stdout (1), а через поток ошибок stderr (2). А перенаправление задано лишь для stdout ("> myfile.txt").
Т.к. поток stderr (2) мы никуда не перенаправили - сообщение об ошибке появится на экране и НЕ появится в файле myfile.txt
А теперь давайте выполним команду ls так, чтобы информационные данные записались в файл myfile.txt, а сообщения об ошибках - в файл myfile.err, при этом на экране во время выполнения не появится ничего:
$ ls >myfile.txt 2>myfile.err
Здесь нам встречается впервые указание номера потока в качестве перенаправления. Запись "2>myfile.err" указывает, что поток с номером 2 (stderr) нужно перенаправить в файл myfile.err.
Конечно, мы можем оба потока направить в один файл или в одно и то же устройство.
2>&1
Нередко в скриптах можно встретить такую запись. Она означает: "Поток с номером 2 перенаправить в поток с номером 1", или "Поток stderr - направить через поток stdout". Т.е. все сообщения об ошибках мы направляем через поток, через который обычно печатаются обычные, не ошибочные сообщения.
$ ls /asfasdf 2>&1
А вот еще пример, в котором все сообщения перенаправляются в файл myfile.txt:
$ ls /asfasdf >myfile.txt 2>&1
При этом все сообщения, как об ошибках, так и обычные, будут записаны в myfile.txt, т.к. поток stdout мы сначала перенаправлили в файл, а потом указали, что ошибки нужно вываливать в stdout - соответственно, в файл myfile.txt
/dev/null
Однако иногда нам нужно просто скрыть все сообщения - не сохраняя их. Т.е. просто блокировать вывод. Для этого служит виртуальное устройство /dev/null. В следующем примере весь вывод обычных сообщений команды ls мы направим в /dev/null:
$ ls > /dev/null
На экране не будет отображено ничего, кроме сообщений об ошибках. А в следующем примере - и сообщения об ошибках будут блокированы:
$ ls > /dev/null 2>&1
Причем эта запись эквивалентна записи вида:
$ ls >/dev/null 2>/dev/null
А в следующем примере мы заблокируем только сообщения об ошибках:
$ ls 2>/dev/null
Заметьте, что здесь уже нельзя указывать "2>&1", т.к. поток (1) не перенаправлен никуда и в таком случае сообщения об ошибках будут банально вывалены на экран.
Что первее - яйцо или курица?
Я приведу Вам здесь 2 примера.
Пример 1)
$ ls >/dev/null 2>&1
Пример 2)
$ ls 2>&1 >/dev/null
С виду - от перестановки мест слогаемых сумма не меняется. Но порядок указателей перенаправления играет роль!
Дело в том, что интерпретаторы читают и применяют перенаправления слева направо. И сейчас мы разберем оба примера.
Пример 1
1) ">/dev/null" - мы направляем поток 1 (stdout) в /dev/null. Все сообщения, попадающие в поток (1) - будут направлены в /dev/null.
2) "2>&1" - мы перенаправляем поток 2 (stderr) в поток 1 (stdout). Но, т.к. поток 1 уже ассоциирован с /dev/null - все сообщения все-равно попадут в /dev/null.
Результат: на экране - пусто.
Пример 2
1) "2>&1" - мы перенаправляем поток ошибок stderr (2) в поток stdout (1). При этом, т.к. поток 1 по-умолчанию ассоциирован с терминалом - сообщения об ошибках мы успешно увидим на экране.
2) ">/dev/null" - а уже здесь мы перенаправляем поток 1 в /dev/null. И обычные сообщения мы не увидим.
Результат: мы будем видеть сообщения об ошибках на экране, но не будет видеть обычные сообщения.
Вывод: сначала перенаправьте поток, а потом на него ссылайтесь.
В системе по-умолчанию всегда открыты три "файла" — (клавиатура), (экран) и (вывод сообщений об ошибках на экран). Эти, и любые другие открытые файлы, могут быть перенапрвлены. В данном случае, термин "перенаправление" означает получить вывод из файла, команды, программы, сценария или даже отдельного блока в сценарии (см. Пример 3-1 и Пример 3-2) и передать его на вход в другой файл, команду, программу или сценарий.
С каждым открытым файлом связан дескриптор файла. Дескрипторы файлов, и — 0, 1 и 2, соответственно. При открытии дополнительных файлов, дескрипторы с 3 по 9 остаются незанятыми. Иногда дополнительные дескрипторы могут сослужить неплохую службу, временно сохраняя в себе ссылку на, или. Это упрощает возврат дескрипторов в нормальное состояние после сложных манипуляций с перенаправлением и перестановками (см. Пример 16-1).
COMMAND_OUTPUT > # Перенаправление stdout (вывода) в файл. # Если файл отсутствовал, то он создется, иначе — перезаписывается. ls -lR > dir-tree.list # Создает файл, содержащий список дерева каталогов. : > filename # Операция > усекает файл "filename" до нулевой длины. # Если до выполнения операции файла не существовало, # то создается новый файл с нулевой длиной (тот же эффект дает команда "touch"). # Символ: выступает здесь в роли местозаполнителя, не выводя ничего. > filename # Операция > усекает файл "filename" до нулевой длины. # Если до выполнения операции файла не существовало, # то создается новый файл с нулевой длиной (тот же эффект дает команда "touch"). # (тот же результат, что и выше — ": >", но этот вариант неработоспособен # в некоторых командных оболочках.) COMMAND_OUTPUT >> # Перенаправление stdout (вывода) в файл. # Создает новый файл, если он отсутствовал, иначе — дописывает в конец файла. # Однострочные команды перенаправления # (затрагивают только ту строку, в которой они встречаются): # ——————————————————————— 1>filename # Перенаправление вывода (stdout) в файл "filename". 1>>filename # Перенаправление вывода (stdout) в файл "filename", файл открывается в режиме добавления. 2>filename # Перенаправление stderr в файл "filename". 2>>filename # Перенаправление stderr в файл "filename", файл открывается в режиме добавления. &>filename # Перенаправление stdout и stderr в файл "filename". #============================================================================== # Перенаправление stdout, только для одной строки. LOGFILE=script.log echo "Эта строка будет записана в файл \"$LOGFILE\"." 1>$LOGFILE echo "Эта строка будет добавлена в конец файла \"$LOGFILE\"." 1>>$LOGFILE echo "Эта строка тоже будет добавлена в конец файла \"$LOGFILE\"." 1>>$LOGFILE echo "Эта строка будет выведена на экран и не попадет в файл \"$LOGFILE\"." # После каждой строки, сделанное перенаправление автоматически "сбрасывается". # Перенаправление stderr, только для одной строки. ERRORFILE=script.errors bad_command1 2>$ERRORFILE # Сообщение об ошибке запишется в $ERRORFILE. bad_command2 2>>$ERRORFILE # Сообщение об ошибке добавится в конец $ERRORFILE. bad_command3 # Сообщение об ошибке будет выведено на stderr, #+ и не попадет в $ERRORFILE. # После каждой строки, сделанное перенаправление также автоматически "сбрасывается". #============================================================================== 2>&1 # Перенаправляется stderr на stdout. # Сообщения об ошибках передаются туда же, куда и стандартный вывод. i> i
в j
. # Вывод в файл с дескриптором i
передается в файл с дескриптором j
. >&j # Перенаправляется файл с дескриптором 1
(stdout) в файл с дескриптором j
. # Вывод на stdout передается в файл с дескриптором j
. 0< FILENAME < FILENAME # Ввод из файла. # Парная команде ">", часто встречается в комбинации с ней. # # grep search-word
Операции перенаправления и/или конвейеры могут комбинироваться в одной командной строке.
command < input-file > output-file command1 | command2 | command3 > output-file См. Пример 12-23 и Пример A-17.
Допускается перенаправление нескольких потоков в один файл.
ls -yz >> command.log 2>&1 # Сообщение о неверной опции "yz" в команде "ls" будет записано в файл "command.log". # Поскольку stderr перенаправлен в файл.
Закрытие дескрипторов файлов
Закрыть дескриптор входного файла.
0<&-, <&-
Закрыть дескриптор выходного файла.
1>&-, >&-
Дочерние процессы наследуют дескрипторы открытых файлов. По этой причине и работают конвейеры. Чтобы предотвратить наследование дескрипторов — закройте их перед запуском дочернего процесса.
# В конвейер передается только stderr. exec 3>&1 # Сохранить текущее "состояние" stdout. ls -l 2>&1 >&3 3>&- | grep bad 3>&- # Закрыть дескр. 3 для "grep" (но не для "ls"). # ^^^^ ^^^^ exec 3>&- # Теперь закрыть его для оставшейся части сценария. # Спасибо S.C.
Дополнительные сведения о перенаправлении ввода/вывода вы найдете в Приложение D.
16.1. С помощью команды exec
Команда exec
Пример 16-1. Перенаправление с помощью exec
#!/bin/bash # Перенаправление stdin с помощью "exec". exec 6<&0 # Связать дескр. #6 со стандартным вводом (stdin). # Сохраняя stdin. exec < data-file # stdin заменяется файлом "data-file" read a1 # Читается первая строка из "data-file". read a2 # Читается вторая строка из "data-file." echo echo "Следующие строки были прочитаны из файла." echo "——————————————" echo $a1 echo $a2 echo; echo; echo exec 0<&6 6<&- # Восстанавливается stdin из дескр. #6, где он был предварительно сохранен, #+ и дескр. #6 закрывается (6<&-) освобождая его для других процессов. # # <&6 6<&- дает тот же результат. echo -n "Введите строку " read b1 # Теперь функция "read", как и следовало ожидать, принимает данные с обычного stdin. echo "Строка, принятая со stdin." echo "—————————" echo "b1 = $b1" echo exit 0
Аналогично, конструкция exec >filename перенаправляет вывод на в заданный файл. После этого, весь вывод от команд, который обычно направляется на, теперь выводится в этот файл.
Пример 16-2. Перенаправление с помощью exec
#!/bin/bash # reassign-stdout.sh LOGFILE=logfile.txt exec 6>&1 # Связать дескр. #6 со stdout. # Сохраняя stdout. exec > $LOGFILE # stdout замещается файлом "logfile.txt". # ———————————————————— # # Весь вывод от команд, в данном блоке, записывается в файл $LOGFILE. echo -n "Logfile: " date echo "————————————-" echo echo "Вывод команды \"ls -al\"" echo ls -al echo; echo echo "Вывод команды \"df\"" echo df # ———————————————————— # exec 1>&6 6>&- # Восстановить stdout и закрыть дескр. #6. echo echo "== stdout восстановлено в значение по-умолчанию == " echo ls -al echo exit 0
Пример 16-3. Одновременное перенаправление устройств, и, с помощью команды exec
#!/bin/bash # upperconv.sh # Преобразование символов во входном файле в верхний регистр. E_FILE_ACCESS=70 E_WRONG_ARGS=71 if [ ! -r "$1" ] # Файл доступен для чтения? then echo "Невозможно прочитать из заданного файла!" echo "Порядок использования: $0 input-file output-file" exit $E_FILE_ACCESS fi # В случае, если входной файл ($1) не задан #+ код завершения будет этим же. if [ -z "$2" ] then echo "Необходимо задать выходной файл." echo "Порядок использования: $0 input-file output-file" exit $E_WRONG_ARGS fi exec 4<&0 exec < $1 # Назначить ввод из входного файла. exec 7>&1 exec > $2 # Назначить вывод в выходной файл. # Предполагается, что выходной файл доступен для записи # (добавить проверку?). # ———————————————— cat — | tr a-z A-Z # Перевод в верхний регистр # ^^^^^ # Чтение со stdin. # ^^^^^^^^^^ # Запись в stdout. # Однако, и stdin и stdout были перенаправлены. # ———————————————— exec 1>&7 7>&- # Восстановить stdout. exec 0<&4 4<&- # Восстановить stdin. # После восстановления, следующая строка выводится на stdout, чего и следовало ожидать. echo "Символы из \"$1\" преобразованы в верхний регистр, результат записан в \"$2\"." exit 0
Next: Перенаправление ошибок в файл Up: Перенаправление ввода-вывода Previous: Перенаправление ввода из файла Contents Index
Перенаправление вывода в файл
Для перенаправления стандартного вывода в файл используйте оператор `>’.
Перенаправление ввода/вывода в Linux
Укажите после имени команды оператор >, а затем имя файла, который будет служить приемником вывода. Например, чтобы записать вывод результатов работы программы в файл, введите:
Если Вы перенаправите стандартный вывод в уже существующий файл, он будет перезаписан с начала. Чтобы добавить стандартный вывод к содержимому существующего файла, необходимо использовать оператор `»’. Например, для добавления результатов работы при повторном запуске программы в файл, введите:
Alex Otwagin 2002-12-16
Программа обычно ценна тем, что может обрабатывать данные: принимать одно, на выходе выдавать другое, причём в качестве данных может выступать практически что угодно: текст, числа, звук, видео… Потоки входных и выходных данных для команды называются ввод и вывод . Потоков ввода и вывода у каждой программы может быть и по несколько. В каждый процесс, при создании в обязательном порядке получает так называемые стандартный ввод (standard input, stdin) и стандартный вывод (standard output, stdout) и стандартный вывод ошибок (standard error, stderr).
Стандартные потоки ввода/вывода предназначены в первую очередь для обмена текстовой информацией. Тут даже не важно, кто общается с помощью текстов: человек с программой или программы междй собой - главное, чтобы у них был канал передачи данных и чтобы они говорили «на одном языке».
Текстовый принцип работы с машиной позволяет отвлечься от конкретных частей компьютера, вроде системной клавиатуры и видеокарты с монитором, рассматривая единое оконечное устройство , посредством которого пользователь вводит текст (команды) и передаёт его системе, а система выводит необходимые пользователю данные и сообщения (диагностику и ошибки). Такое устройство называется терминалом . В общем случае терминал - это точка входа пользователя в систему, обладающая способностью передавать текстовую информацию. Терминалом может быть отдельное внешнее устройство, подключаемое к компьютеру через порт последовательной передачи данных (в персональном компьютере он называется «COM port»). В роли терминала может работать (с некоторой поддержкой со стороны системы) и программа (например, xterm или ssh). Наконец, виртуальные консоли - тоже терминалы, только организованные программно с помощью подходящих устройств современного компьютера.
При работе с командной строкой, стандартный ввод командной оболочки связан с клавиатурой, а стандартный вывод и вывод ошибок - с экраном монитора (или окном эмулятора терминала). Покажем на примере простейшей команды - cat. Обычно команда cat читает данные из всех файлов, которые указаны в качестве её параметров, и посылает считанное непосредственно в стандартный вывод (stdout). Следовательно, команда
/home/larry/papers# cat history-final masters-thesis
выведет на экран сначала содержимое файла, а затем - файла.
Однако если имя файла не указано, программа cat читает входные данные из stdin и немедленно возвращает их в stdout (никак не изменяя). Данные проходят через cat , как через трубу. Приведём пример:
/home/larry/papers# cat Hello there. Hello there. Bye. Bye. Ctrl —D /home/larry/papers#
Каждую строчку, вводимую с клавиатуры, программа cat немедленно возвращает на экран. При вводе информации со стандартного ввода конец текста сигнализируется вводом специальной комбинации клавиш, как правило Ctrl —D .
Приведём другой пример. Команда sort читает строки вводимого текста (также из stdin, если не указано ни одного имени файла) и выдаёт набор этих строк в упорядоченном виде на stdout. Проверим её действие.
/home/larry/papers# sort bananas carrots apples Ctrl+D apples bananas carrots /home/larry/papers#
Как видно, после нажатия Ctrl —D , sort вывела строки упорядоченными в алфавитном порядке.
Стандартный ввод и стандартный вывод
Допустим, вы хотите направить вывод команды sort в некоторый файл, чтобы сохранить упорядоченный по алфавиту список на диске. Командная оболочка позволяет перенаправить стандартный вывод команды в файл, используя символ. Приведём пример:
/home/larry/papers# sort > shopping-list bananas carrots apples Ctrl —D /home/larry/papers#
Можно увидеть, что результат работы команды sort не выводится на экран, однако он сохраняется в файле с именем. Выведем на экран содержимое этого файла:
/home/larry/papers# cat shopping-list apples bananas carrots /home/larry/papers#
Пусть теперь исходный неупорядоченный список находится в файле. Этот список можно упорядочить с помощью команды sort , если указать ей, что она должна читать из данного файла, а не из своего стандартного ввода, и кроме того, перенаправить стандартный вывод в файл, как это делалось выше. Пример:
/home/larry/papers# sort items shopping-list /home/larry/papers# cat shopping-list apples bananas carrots /home/larry/papers#
Однако можно поступить иначе, перенаправив не только стандартный вывод, но и стандартный ввод утилиты из файла, используя для этого символ:
/home/larry/papers# sort < items apples bananas carrots /home/larry/papers#
Результат команды sort < items эквивалентен команде sort items , однако первая из них демонстрирует следующее: при выдаче команды sort < items система ведёт себя так, как если бы данные, которые содержатся в файле, были введены со стандартного ввода. Перенаправление осуществляется командной оболочкой. Команде sort не сообщалось имя файла: эта команда читала данные из своего стандартного ввода, как если бы мы вводили их с клавиатуры.
Введём понятие фильтра . Фильтром является программа, которая читает данные из стандартного ввода, некоторым образом их обрабатывает и результат направляет на стандартный вывод. Когда применяется перенаправление, в качестве стандартного ввода и вывода могут выступать файлы. Как указывалось выше, по умолчанию, stdin и stdout относятся к клавиатуре и к экрану соответственно. Программа sort является простым фильтром - она сортирует входные данные и посылает результат на стандартный вывод. Совсем простым фильтром является программа cat - она ничего не делает с входными данными, а просто пересылает их на выход.
Выше уже демонстрировалось, как использовать программу sort в качестве фильтра. В этих примерах предполагалось, что исходные данные находятся в некотором файле или что эти исходные данные будут введены с клавиатуры (стандартного ввода). Однако как поступить, если вы хотите отсортировать данные, которые являются результатом работы какой-либо другой команды, например, ls ?
Будем сортировать данные в обратном алфавитном порядке; это делается опцией команды sort . Если вы хотите перечислить файлы в текущем каталоге в обратном алфавитном порядке, один из способов сделать это будет таким.
Перенаправление ввода-вывода
Применим сначала команду ls :
/home/larry/papers# ls english-list history-final masters-thesis notes /home/larry/papers#
Теперь перенаправляем выход команды ls в файл с именем file-list
/home/larry/papers# ls > file-list /home/larry/papers# sort -r file-list notes masters-thesis history-final english-list /home/larry/papers#
Здесь выход команды ls сохранен в файле, а после этого этот файл был обработан командой sort . Однако этот путь является неизящным и требует использования временного файла для хранения выходных данных программы ls .
Решением в данной ситуации может служить создание состыкованных команд (pipelines). Стыковку осуществляет командная оболочка, которая stdout первой команды направляет на stdin второй команды. В данном случае мы хотим направить stdout команды ls на stdin команды sort . Для стыковки используется символ, как это показано в следующем примере:
/home/larry/papers# ls | sort -r notes masters-thesis history-final english-list /home/larry/papers#
Эта команда короче, чем совокупность команд, и её проще набирать.
Рассмотрим другой полезный пример. Команда
/home/larry/papers# ls /usr/bin
выдаёт длинный список файлов. Большая часть этого списка пролетает по экрану слишком быстро, чтобы содержимое этого списка можно было прочитать. Попробуем использовать команду more для того, чтобы выводить этот список частями:
/home/larry/papers# ls /usr/bin | more
Теперь можно этот список «перелистывать».
Можно пойти дальше и состыковать более двух команд. Рассмотрим команду head , которая является фильтром следующего свойства: она выводит первые строки из входного потока (в нашем случае на вход будет подан выход от нескольких состыкованных команд). Если мы хотим вывести на экран последнее по алфавиту имя файла в текущем каталоге, можно использовать следующую длинную команду:
/home/larry/papers# ls | sort -r | head -1 notes /home/larry/papers\#
где команда head выводит на экран первую строку получаемого ей входного потока строк (в нашем случае поток состоит из данных от команды ls ), отсортированных в обратном алфавитном порядке.
Использование состыкованных команд (конвейер)
Эффект от использования символа для перенаправления вывода файла является деструктивным; иными словами, команда
/home/larry/papers# ls > file-list
уничтожит содержимое файла, если этот файл ранее существовал, и создаст на его месте новый файл.
Если вместо этого перенаправление будет сделано с помощью символов, то вывод будет приписан в конец указанного файла, при этом исходное содержимое файла не будет уничтожено. Например, команда
/home/larry/papers# ls >> file-list
приписывает вывод команды ls в конец файла.
Следует иметь в виду, что перенаправление ввода и вывода и стыкование команд осуществляется командными оболочками, которые поддерживают использование символов, и. Сами команды не способны воспринимать и интерпретировать эти символы.
Недеструктивное перенаправление вывода
Что-то вроде этого должно делать то, что вам нужно?
Проверьте это: wintee
Нет необходимости в cygwin.
Однако я столкнулся и сообщил о некоторых проблемах.
Также вы можете проверить http://unxutils.sourceforge.net/ потому что он содержит tee (и не нужен cygwin), но будьте осторожны, что выходные EOL являются UNIX-подобными.
И последнее, но не менее важно, если у вас есть PowerShell, вы можете попробовать Tee-Object. Введите в консоли PowerShell для получения дополнительной информации.
Это работает, хотя это немного уродливо:
Это немного более гибко, чем некоторые другие решения, поскольку он работает по-своему, поэтому вы можете использовать его для добавления.
Я использую это довольно много в пакетных файлах для регистрации и отображения сообщений:
Да, вы могли бы просто повторить инструкцию ECHO (один раз для экрана и второй раз перенаправляясь на файл журнала), но это выглядит так же плохо, и это проблема обслуживания.
Перенаправление ввода и вывода
По крайней мере, таким образом вам не нужно вносить изменения в сообщения в двух местах.
Обратите внимание, что _ — это просто короткое имя файла, поэтому вам нужно будет удалить его в конце вашего пакетного файла (если вы используете пакетный файл).
Это создаст файл журнала с текущим временем и временем, и вы можете использовать линии консоли во время процесса
Если у вас есть cygwin в вашем пути к среде Windows, вы можете использовать:
Простое консольное приложение C # сделало бы трюк:
Чтобы использовать это, вы просто передаете исходную команду в программу и указываете путь к любым файлам, для которых вы хотите дублировать вывод. Например:
Будет отображать результаты поиска, а также сохранять результаты в файлах files1.txt и files2.txt.
Обратите внимание, что на пути обработки ошибок не так много (ничего!), И поддержка нескольких файлов может не потребоваться.
Я также искал одно и то же решение, после небольшой попытки, я смог успешно выполнить это в командной строке. Вот мое решение:
Он даже захватывает любую команду PAUSE.
Альтернативой является tee stdout для stderr в вашей программе:
Затем в вашем dos batchfile:
Stdout перейдет в файл журнала, и stderr (те же данные) отобразятся на консоли.
Как отобразить и перенаправить вывод в файл. Предположим, что если я использую команду dos, dir> test.txt, эта команда перенаправляет вывод в файл test.txt без отображения результатов. как написать команду для вывода вывода и перенаправления вывода в файл с помощью DOS, т. е. командной строки Windows, а не в UNIX / LINUX.
Вы можете найти эти команды в biterscripting (http://www.biterscripting.com) полезными.
Это вариант предыдущего answer MTS, однако он добавляет некоторые функции, которые могут быть полезны другим. Вот метод, который я использовал:
- Команда задается как переменная, которая может использоваться позже в коде, для вывода в командное окно и добавления в файл журнала с использованием
- команда избегает redirection с использованием символа моркови, чтобы команды не оценивались первоначально
- Временной файл создается с именем файла, аналогичным пакетному файлу с именем который использует синтаксис расширения параметра командной строки чтобы получить имя командного файла.
- Результат добавляется в отдельный файл журнала
Вот последовательность команд:
- Сообщения вывода и ошибки отправляются во временный файл
- Содержимое временного файла тогда равно:
- добавлен в файл журнала
- вывод в командное окно
- Временный файл с сообщением удаляется
Вот пример:
Таким образом, команда может быть просто добавлена после более поздних команд в пакетном файле, который выглядит намного чище:
Это может быть добавлено и в конце других команд. Насколько я могу судить, это будет работать, когда сообщения имеют несколько строк. Например, следующая команда выводит две строки, если есть сообщение об ошибке:
Я согласен с Брайаном Расмуссеном, порт unxutils — самый простой способ сделать это. В разделе « Пакетные файлы » его страниц Scripting Rob van der Woude предоставляет массу информации об использовании команд MS-DOS и CMD. Я подумал, что у него может быть собственное решение вашей проблемы, и после того, как я TEE.BAT там копаться, я нашел TEE.BAT , который, кажется, именно так, представляет собой пакетный языковой пакет MS-DOS. Это довольно сложный пакетный файл, и я бы склонен использовать порт unxutils.
Я устанавливаю perl на большинстве своих машин, поэтому ответ с помощью perl: tee.pl
dir | perl tee.pl или каталог | perl tee.pl dir.bat
сырой и непроверенный.
Одна из самых интересных и полезных тем для системных администраторов и новых пользователей, которые только начинают разбираться в работе с терминалом - это перенаправление потоков ввода вывода Linux. Эта особенность терминала позволяет перенаправлять вывод команд в файл, или содержимое файла на ввод команды, объединять команды вместе, и образовать конвейеры команд.
В этой статье мы рассмотрим как выполняется перенаправление потоков ввода вывода в Linux, какие операторы для этого используются, а также где все это можно применять.
Все команды, которые мы выполняем, возвращают нам три вида данных:
- Результат выполнения команды, обычно текстовые данные, которые запросил пользователь;
- Сообщения об ошибках - информируют о процессе выполнения команды и возникших непредвиденных обстоятельствах;
- Код возврата - число, которое позволяет оценить правильно ли отработала программа.
В Linux все субстанции считаются файлами, в том числе и потоки ввода вывода linux - файлы. В каждом дистрибутиве есть три основных файла потоков, которые могут использовать программы, они определяются оболочкой и идентифицируются по номеру дескриптора файла:
- STDIN или 0 - этот файл связан с клавиатурой и большинство команд получают данные для работы отсюда;
- STDOUT или 1 - это стандартный вывод, сюда программа отправляет все результаты своей работы. Он связан с экраном, или если быть точным, то с терминалом, в котором выполняется программа;
- STDERR или 2 - все сообщения об ошибках выводятся в этот файл.
Перенаправление ввода / вывода позволяет заменить один из этих файлов на свой. Например, вы можете заставить программу читать данные из файла в файловой системе, а не клавиатуры, также можете выводить ошибки в файл, а не на экран и т д. Все это делается с помощью символов "<" и ">" .
Перенаправить вывод в файл
Все очень просто. Вы можете перенаправить вывод в файл с помощью символа >. Например, сохраним вывод команды top:
top -bn 5 > top.log
Опция -b заставляет программу работать в не интерактивном пакетном режиме, а n - повторяет операцию пять раз, чтобы получить информацию обо всех процессах. Теперь смотрим что получилось с помощью cat:

Символ ">" перезаписывает информацию из файла, если там уже что-то есть. Для добавления данных в конец используйте ">>" . Например, перенаправить вывод в файл linux еще для top:
top -bn 5 >> top.log
По умолчанию для перенаправления используется дескриптор файла стандартного вывода. Но вы можете указать это явно. Эта команда даст тот же результат:
top -bn 5 1>top.log
Перенаправить ошибки в файл
Чтобы перенаправить вывод ошибок в файл вам нужно явно указать дескриптор файла, который собираетесь перенаправлять. Для ошибок - это номер 2. Например, при попытке получения доступа к каталогу суперпользователя ls выдаст ошибку:

Вы можете перенаправить стандартный поток ошибок в файл так:
ls -l /root/ 2> ls-error.log
$ cat ls-error.log

Чтобы добавить данные в конец файла используйте тот же символ:
ls -l /root/ 2>>ls-error.log

Перенаправить стандартный вывод и ошибки в файл
Вы также можете перенаправить весь вывод, ошибки и стандартный поток вывода в один файл. Для этого есть два способа. Первый из них, более старый, состоит в том, чтобы передать оба дескриптора:
ls -l /root/ >ls-error.log 2>&1

Сначала будет отправлен вывод команды ls в файл ls-error.log c помощью первого символа перенаправления. Дальше в тот же самый файл будут направлены все ошибки. Второй метод проще:
ls -l /root/ &> ls-error.log
Также можно использовать добавление вместо перезаписи:
ls -l /root/ &>> ls-error.log
Стандартный ввод из файла
Большинство программ, кроме сервисов, получают данные для своей работы через стандартный ввод. По умолчанию стандартный ввод ожидает данных от клавиатуры. Но вы можете заставить программу читать данные из файла с помощью оператора "<" :
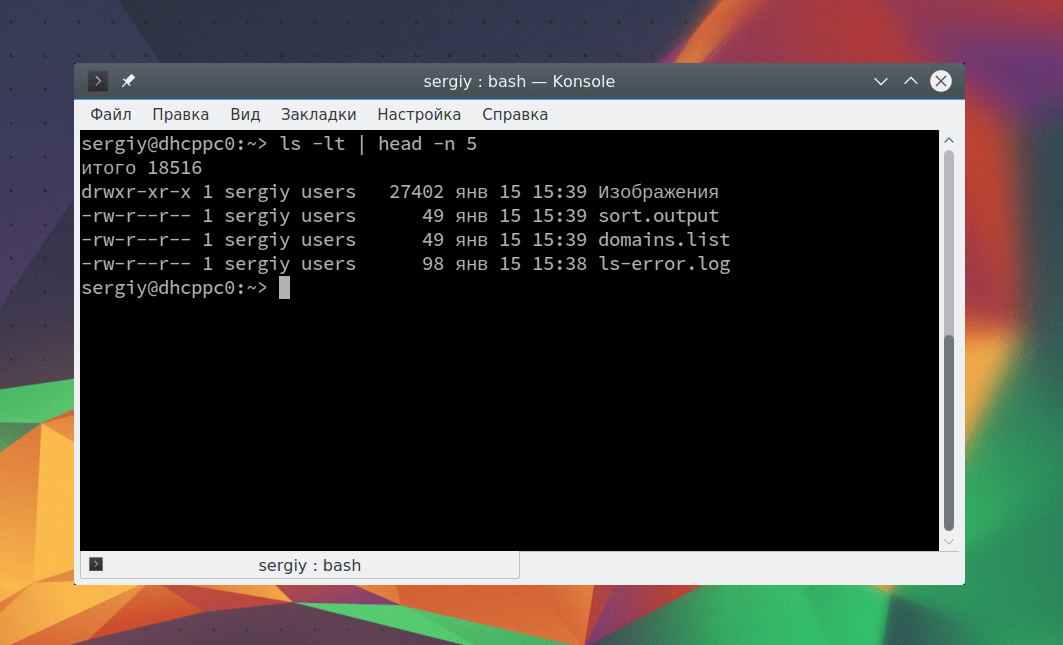
cat Вы также можете сразу же перенаправить вывод тоже в файл. Например, пересортируем список: sort Таким образом, мы в одной команде перенаправляем ввод вывод linux. Можно работать не только с файлами, но и перенаправлять вывод одной команды в качестве ввода другой. Это очень полезно для выполнения сложных операций. Например, выведем пять недавно измененных файлов: ls -lt | head -n 5 С помощью утилиты xargs вы можете комбинировать команды таким образом, чтобы стандартный ввод передавался в параметры. Например, скопируем один файл в несколько папок: echo test/ tmp/ | xargs -n 1 cp -v testfile.sh Здесь параметр -n 1 задает, что для одной команды нужно подставлять только один параметр, а опция -v в cp позволяет выводить подробную информацию о перемещениях. Еще одна, полезная в таких случаях команда - это tee. Она читает данные из стандартного ввода и записывает в стандартный вывод или файлы. Например: echo "Тест работы tee" | tee file1 В сочетании с другими командами все это может использоваться для создания сложных инструкций из нескольких команд. В этой статье мы рассмотрели основы перенаправления потоков ввода вывода Linux. Теперь вы знаете как перенаправить вывод в файл linux или вывод из файла. Это очень просто и удобно. Если у вас остались вопросы, спрашивайте в комментариях! Встроенные возможности перенаправления в Linux предоставляют вам широкий набор инструментов, используемых упрощения для всех видов задач. Умение управлять различными потоками ввода-вывода в значительно увеличит производительность, как при разработке сложного программного обеспечения, так и при управлении файлами с помощью командной строки. Ввод и вывод в окружении Linux распределяется между тремя потоками: При взаимодействии пользователя с терминалом стандартный ввод передается через клавиатуру пользователя. Стандартный вывод и стандартная ошибка отображаются на терминале пользователя в виде текста. Все эти три потока называются стандартными потоками. Стандартный входной поток обычно передаёт данные от пользователя к программе. Программы, которые предполагают стандартный ввод, обычно получают входные данные от устройства (например, клавиатуры). Стандартный ввод прекращается по достижении EOF (end-of-file, конец файла). EOF указывает на то, что больше данных для чтения нет. Чтобы увидеть, как работает стандартный ввод, запустите программу cat. Название этого инструмента означает «concatenate» (связать или объединить что-либо). Обычно этот инструмент используется для объединения содержимого двух файлов. При запуске без аргументов cat открывает командную строку и принимает содержание стандартного ввода. Теперь введите несколько цифр: 1 Вводя цифру и нажимая enter, вы отправляете стандартный ввод запущенной программе cat, которая принимает эти данные. В свою очередь, программа cat отображает полученный ввод в стандартном выводе. Пользователь может задать EOF, нажав ctrl-d, после чего программа cat остановится. Стандартный вывод записывает данные, сгенерированные программой. Если стандартный выходной поток не был перенаправлен, он выведет текст в терминал. Попробуйте запустить следующую команду для примера: echo Sent to the terminal through standard output Команда echo без дополнительных опций отображает на экране все аргументы, переданные ей в командной строке. Теперь запустите echo без аргументов: Команда вернёт пустую строку. Этот стандартный поток записывает ошибки, создаваемые программой, которая вышла из строя. Как и стандартный вывод, этот поток отправляет данные в терминал. Рассмотрим пример потока ошибок команды ls. Команда ls отображает содержимое каталогов. Без аргументов эта команда возвращает содержимое текущего каталога. Если указать в качестве аргумента ls имя каталога, команда вернёт его содержимое. Поскольку каталога % не существует, команда вернёт стандартную ошибку: ls: cannot access %: No such file or directory Linux предоставляет специальные команды для перенаправления каждого потока. Эти команды записывают стандартный вывод в файл. Если вывод перенаправлен в несуществующий файл, команда создаст новый файл с таким именем и сохранит в него перенаправленный вывод. Команды с одной угловой скобкой переписывают существующий контент целевого файла: Команды с двойными угловыми скобками не переписывают содержимое целевого файла: Рассмотрим следующий пример: cat > write_to_me.txt В данном примере команда cat используется для записи выходных данных в файл. Просмотрите содержимое write_to_me.txt: cat write_to_me.txt Команда должна вернуть: Снова перенаправьте cat в файл write_to_me.txt и введите три цифры. cat > write_to_me.txt Теперь проверьте содержимое файла. cat write_to_me.txt Команда должна вернуть: Как видите, файл содержит только последние выходные данные, поскольку в команде, перенаправляющей выход, использовалась одна угловая скобка. Теперь попробуйте запустить ту же команду с двумя угловыми скобками: cat >> write_to_me.txt Откройте write_to_me.txt: 1 Команды с двойными угловыми скобками не перезаписывают существующий контент, а дополняют его. Конвейеры (pipes) перенаправляют потоки вывода одной команды на вход другой. При этом данные, передаваемые второй программе, не отображаются в терминале. На экране данные появятся только после обработки второй программой. Конвейеры в Linux представлены вертикальной чертой. Например: Такая команда передаст вывод ls (содержимое текущего каталога) программе less, которая отображает передаваемые ей данные построчно. Как правило, ls выводит содержимое каталогов подряд, не разбивая на строки. Если перенаправить вывод ls в less, то последняя команда разделит вывод на строки. Как видите, конвейер может перенаправить вывод одной команды на вход другой, в отличие от > и >>, которые перенаправляют данные только в файлы. Фильтры – это команды, которые могут изменить перенаправление и вывод конвейера. Примечание
: Фильтры также являются стандартными командами Linux, которые можно использовать и без конвейера. Теперь, когда вы ознакомились с основными понятиями и механизмами перенаправления, рассмотрим несколько базовых примеров их использования. Такой шаблон перенаправляет стандартный вывод команды в файл. ls ~ > root_dir_contents.txt Эта команда передает содержимое root каталога системы в качестве стандартного вывода и записывает вывод в файл root_dir_contents. Это удалит все предыдущее содержимое в файле, так как в команде использована одна угловая скобка. /dev/null – это специальный файл (так называемое «пустое устройство»), который используется для подавления стандартного потока вывода или диагностики, чтобы избежать нежелательного вывода в консоль. Все данные, попадающие в /dev/null, сбрасываются. Перенаправление в /dev/null обычно используется в сценариях оболочки. ls > /dev/null Такая команда сбрасывает стандартный выходной поток, возвращаемый командой ls, передав его в /dev/null. Этот шаблон перенаправляет стандартный поток ошибок команды в файл, перезаписывая его текущее содержимое. mkdir "" 2> mkdir_log.txt Эта команда перенаправит ошибку, вызванную неверным именем каталога, и запишет её в log.txt. Обратите внимание: ошибка по-прежнему отображается в терминале. Этот шаблон перенаправляет стандартный выход команды в файл, не переписывая текущего содержимого файла. echo Written to a new file > data.txt Эта пара команд сначала перенаправляет вводимый пользователем текст в новый файл, а затем вставляет его в существующий файл, не переписывая его содержимого. Этот шаблон перенаправляет стандартный поток ошибок команды в файл, не перезаписывая существующего содержимого файла. Он подходит для создания логов ошибок программы или сервиса, поскольку содержимое лога не будет постоянно обновляться. find "" 2> stderr_log.txt Приведенная выше команда перенаправляет сообщение об ошибке, вызванное неверным аргументом find, в файл stderr_log.txt, а затем добавляет в него сообщение об ошибке, вызванной недействительным аргументом wc. Этот шаблон перенаправляет стандартный выход первой команды на стандартный вход второй команды. find /var lib | grep deb Эта команда ищет в каталоге /var и его подкаталогах имена файлов и расширения deb и возвращает пути к файлам, выделяя шаблон поиска красным цветом. Такой шаблон перенаправляет стандартный вывод команды в файл и переписывает его содержимое, а затем отображает перенаправленный выход в терминале. Если указанного файла не существует, он создает новый файл. В данном шаблоне команда tee, как правило, используется для просмотра вывода программы и одновременного сохранения его в файл. wc /etc/magic | tee magic_count.txt Такая команда передаёт количество символов, строк и слов в файле magic (Linux использует его для определения типов файлов) команде tee, которая отправляет эти данные в терминал и в файл magic_count.txt. Этот шаблон перенаправляет стандартный вывод первой команды и фильтрует ее через следующие две команды, а затем добавляет окончательный результат в файл. ls ~ | grep *tar | tr e E >> ls_log.txt Такая команда отправляет вывод ls для каталога root команде grep. В свою очередь, grep ищет в полученных данных файлы tar. После этого результат grep передаётся команде tr, которая заменит все символы е символом Е. Полученный результат будет добавлен в файл ls_log.txt (если такого файла не существует, команда создаст его автоматически). Функции перенаправления ввода-вывода в Linux сначала кажутся слишком сложными. Однако работа с перенаправлением – один из важнейших навыков системного администратора. Чтобы узнать больше о какой-либо команде, используйте: man command | less Например: Такая команда вернёт полный список команд для tee. Изучаем Linux, 101 Изучение основ работы с конвейерами Linux Из этой статьи вы узнаете об основных приемах перенаправления стандартных потоков ввода/вывода в Linux. Вы научитесь: Эта статья поможет вам подготовиться к сдаче экзамена LPI 101 на администратора начального уровня (LPIC-1) и содержит материалы цели 103.4 темы 103. Цель имеет вес 4. Эта серия статей поможет вам освоить задачи администрирования операционной системы Linux. Вы также можете использовать материал этих статей для подготовки к . Чтобы посмотреть описания статей этой серии и получить ссылки на них, обратитесь к нашему . Этот перечень постоянно дополняется новыми статьями по мере их готовности и содержит самые последние (по состоянию на апрель 2009 года) цели экзаменов сертификации LPIC-1. Если какая-либо статья отсутствует в перечне, можно найти ее более раннюю версию, соответствующую предыдущим целям LPIC-1 (до апреля 2009 года), обратившись к нашим . Чтобы извлечь наибольшую пользу из наших статей, необходимо обладать базовыми знаниями о Linux и иметь работоспособный компьютер с Linux, на котором можно будет выполнять все встречающиеся команды. Иногда различные версии программ выводят результаты по-разному, поэтому содержимое листингов и рисунков может отличаться от того, что вы увидите на вашем компьютере. Ян – один из наших наиболее популярных и плодовитых авторов. Ознакомьтесь со (EN), опубликованными на сайте developerWorks. Вы можете найти контактные данные в и связаться с ним, а также с другими авторами и участниками ресурса My developerWorks. Для выполнения примеров в этой статье мы будем использовать некоторые файлы, созданные ранее в статье " ". Если вы не читали эту статью или не сохранили эти файлы, не расстраивайтесь! Давайте начнем с создания новой директории lpi103-4 и всех необходимых файлов. Для этого откройте текстовое окно и перейдите в вашу домашнюю директорию. Скопируйте содержимое листинга 1 в текстовое окно; в результате выполнения команд в вашей домашней директории будет создана поддиректория lpi103-4 и все необходимые файлы в ней, которые мы и будем использовать в наших примерах. Ваше окно должно выглядеть так, как показано в листинге 2, а вашей текущей рабочей директорией должна стать вновь созданная директория lpi103-4. Командный интерпретатор Linux, такой как Bash, получает входные данные и направляет выходные данные в виде последовательностей или потоков
символов. Любой символ не зависит ни от предыдущих, ни от последующих символов. Символы не упорядочены в виде структурированных записей или блоков с фиксированным размером. Доступ к потокам осуществляется с помощью механизмов ввода/вывода независимо от того, откуда поступают и куда передаются потоки символов (файл, клавиатура, окно, экран или другое устройство ввода/вывода). Командные интерпретаторы Linux используют три стандартных потока ввода/вывода, каждому из которых назначен определенный файловый дескриптор. Потоки ввода обеспечивают передачу входных данных (обычно поступающих с клавиатуры) командам. Потоки вывода обеспечивают печать текстовых символов, как правило, на терминал. Изначально терминал представлял собой ASCII печатающее устройство или дисплейный терминал, но сейчас, как правило, это просто окно на рабочем столе компьютера. Если вы уже прочитали руководство " ", то часть материала из этой статьи окажется вам знакомой. Существует два способа перенаправления вывода в файл: Символ n
в операторах n> или n>> является файловым дескриптором
. Если он не указан, то предполагается, что используется стандартное устройство вывода. В листинге 3 продемонстрирована операция перенаправления для разделения стандартного потока вывода и стандартного потока ошибок команды ls с использованием файлов, которые были созданы ранее в директории lpi103-4. Также продемонстрировано добавление вывода команды в существующие файлы. Мы уже говорили, что перенаправление вывода с помощью оператора n> обычно приводит к перезаписи существующих файлов. Вы можете управлять этим свойством при помощи опции noclobber встроенной команды set . Если эта опция определена, то вы можете переопределить ее с помощью оператора n>|, как показано в листинге 4. Иногда может потребоваться перенаправить в файл как стандартный вывод, так и стандартный поток ошибок. Часто это используется в автоматизированных процессах или фоновых заданиях для того, чтобы впоследствии можно было просмотреть результаты работы. Чтобы перенаправить стандартный вывод и стандартный поток ошибок в одно и то же место, используйте оператор &> или
&>>. Альтернативный вариант – перенаправить файловый дескриптор n
и затем файловый дескриптор m
в одно и то же место с помощью конструкции m>&n или
m>>&n. В этом случае важен порядок перенаправления потоков. Например, команда В других ситуациях вам может потребоваться полностью проигнорировать стандартный вывод или стандартный поток ошибок. Для этого следует перенаправить соответствующий поток в пустой файл /dev/null. В листинге 6 показано, как проигнорировать поток ошибок команды ls и как с помощью команды cat убедиться в том, что файл /dev/null на самом деле пуст. Так же, как мы можем перенаправить потоки stdout и stderr, мы можем перенаправить поток stdin из файла с помощью оператора <. Если вы прочли руководство " ", то должны помнить, что в разделе была использована команда tr для замены пробелов в файле text1 на символы табуляции. В том примере мы использовали вывод команды cat чтобы создать стандартный поток ввода для команды tr . Теперь для преобразования пробелов в символы табуляции вместо бесполезного вызова команды cat мы можем использовать перенаправление ввода, как показано в листинге 7. В командных интерпретаторах, в том числе и в bash, реализована концепция here-document
, которая является одним из способов перенаправления ввода. В ней используется конструкция << и какое-либо слово, например END, являющееся маркером, или сигнальной меткой, означающей конец ввода. Эта концепция продемонстрирована в листинге 8. Но почему нельзя просто набрать команду sort -k2 , ввести данные и нажать комбинацию Ctrl-d
, означающую конец ввода? Разумеется, вы могли бы выполнить эту команду, но тогда вы не узнали бы о концепции here-document, которая очень часто используется в сценариях командной оболочки (в которых не существует другой возможности указать, какие именно строки должны восприниматься в качестве ввода). Поскольку для выравнивания текста и обеспечения удобства чтения в сценариях широко используются символы табуляции, существует другой прием использования концепции here-document. При использовании оператора <<- вместо оператора
<< начальные символы табуляции удаляются. В листинге 9 мы использовали подстановку команд для создания символа табуляции, а затем создали небольшой сценарий командной оболочки, содержащий две команды cat , каждая из которых считывает данные из блока here-document. Заметьте, что мы использовали слово END в качестве сигнальной метки блока here-document, который мы считываем с терминала. Если бы мы использовали это же слово в нашем сценарии, то наш ввод закончился бы преждевременно. Поэтому вместо слова END мы используем в сценарии слово EOF. После того, как наш сценарий создан, мы используем команду. (точка) чтобы запустить его в контексте текущего командного интерпретатора. В следующих статях этой серии вы узнаете больше о подстановке команд и сценариях. Ссылки на все статьи этой серии вы можете найти в . Команда xargs считывает данные со стандартного устройства ввода, а затем строит и выполняет команды, параметрами которых являются полученные входные данные. Если не указана никакая команда, то используется команда echo . В листинге 12 приведен простой пример использования нашего файла text1, содержащего три строки по два слова в каждой. Почему же тогда вывод xargs содержит только одну строку? По умолчанию xargs разбивает входные данные, если встречает символы-разделители, и каждый полученный фрагмент становится отдельным параметром. Однако когда xargs строит команду, ей за один раз передается максимально возможное количество параметров. Это поведение можно изменить с помощью параметра –n или --max-args . В листинге 13 приведен пример использования обоих вариантов; также был выполнен явный вызов команды echo для использования с xargs . Если входные данные содержат пробелы, но при этом они заключены в одиночные или двойные кавычки (либо пробелы представлены в виде escape-последовательностей с использованием обратной косой черты), то xargs не будет разбивать их на отдельные части. Это показано в листинге 14. До сих пор все аргументы добавлялись в конец команды. Если вам необходимо, чтобы после них были добавлены другие дополнительные аргументы, то воспользуйтесь опцией -I для указания строки замещения. В том месте вызываемой через xargs команды, в котором используется строка замещения, вместо нее будет подставлен аргумент. При использовании такого подхода каждой команде передается только один аргумент. Однако аргумент будет создан из целой входной строки, а не из отдельного ее фрагмента. Также вы можете использовать опцию -L команды xargs , в результате чего в качестве аргумента будет использоваться вся строка целиком, а не отдельные ее фрагменты, разделенные пробелами. Использование опции -I неявно вызывает использование опции -L 1 . В листинге 15 приведены примеры использования опций -I и –L . Хотя в наших примерах используются простые текстовые файлы, вы не будете часто использовать команду xargs для таких случаев. Как правило, вы будете иметь дело с большим списком файлов, полученных в результате выполнения таких команд, как ls , find или grep . В листинге 16 показан один из способов передачи через xargs списка содержимого директории такой команде, как, например, grep . Что произойдет в последнем примере, если одно или несколько имен файлов будут содержать пробелы? Если вы попытаетесь использовать команду так, как это было сделано в листинге 16, то вы получите ошибку. В реальной ситуации список файлов может быть получен не от команды ls , а, например, в результате выполнения пользовательского сценария или команды; а может быть, вы захотите обработать его на других этапах конвейера с целью дополнительной фильтрации. Поэтому мы не берем во внимание тот факт, что вы могли бы просто использовать команду grep "1" * вместо существующей логической структуры. В случае с командой ls вы могли бы использовать опцию --quoting-style для того, чтобы имена файлов, содержащие пробелы, были заключены в скобки (или представлены в виде escape-последовательностей). Лучшим решением (когда это возможно) является использование опции -0 команды xargs , в результате чего для разделения входных аргументов используются пустые символы (\0). Хотя команда ls не имеет опции, позволяющей использовать в качестве вывода имена файлов с завершающим нулем, многие команды умеют делать это. В листинге 17 мы сначала скопируем файл text1 в "text 1", а затем приведем несколько примеров использования списка имен файлов, содержащих пробелы, с командой xargs . Эти примеры позволяют понять саму идею, поскольку полностью освоить работу с xargs может оказаться не так просто. В частности, последний пример преобразования символов новой строки в пустые символы не сработал бы в том случае, если некоторые имена файлов уже содержали бы символы новой строки. В следующем разделе этой статьи мы рассмотрим более надежное решение с применением команды find для генерации подходящего вывода, в котором в качестве разделителей используются пустые символы. Команда xargs не может строить сколь угодно длинные команды. Так, в Linux до версии ядра 2.26.3 максимальная длина команды была ограничена. Если вы попытаетесь выполнить такую команду, как, например, rm somepath/* , а директория содержит множество файлов с длинными именами, то выполнение может завершиться ошибкой, сообщающей, что список аргументов слишком длинный. Если вы работаете с более старыми версиями Linux или UNIX, в которых могут присутствовать такие ограничения, то будет полезно узнать, как можно использовать xargs таким образом, чтобы обойти их. Вы можете использовать опцию --show-limits для просмотра ограничений, установленных по умолчанию для команды xargs , и опцию -s – для задания максимальной длины выводимых команд. Об остальных опциях вы можете узнать из man-страниц. Из руководства " " вы узнали о том, как использовать команду find для поиска файлов на основе их имен, времени модификации, размера и прочих характеристик. Обычно над найденными файлами необходимо выполнять определенные действия – удалять, копировать, переименовывать их и так далее. Сейчас мы рассмотрим опцию -exec команды find , работа которой похожа на работу команды find с последующей передачей вывода команде xargs . Сопоставив результаты листинга 18 с тем, что вам уже известно о xargs , можно обнаружить несколько различий. Попробуйте самостоятельно выполнить команду find text |xargs cat text3 , чтобы увидеть различия. Теперь давайте вернемся к случаю, когда имя файла содержит пробелы. В листинге 19 мы попытались использовать команду find с опцией -exec вместо команд ls и xargs . Пока все хорошо. Однако не кажется ли вам, что чего-то здесь не хватает? В каких файлах присутствовали строки, найденные при помощи grep ? Здесь не хватает имен файлов, поскольку find вызывает grep один раз для каждого файла, а grep , будучи умной командой, знает о том, что если ей было передано имя лишь одного файла, то нет необходимости сообщать вам о том, что это был за файл. В этой ситуации мы могли бы воспользоваться командой xargs , однако мы уже знаем о проблеме с файлами, имена которых содержат пробелы. Также мы упоминали тот факт, что команда find может генерировать список имен с пустыми разделителями, благодаря опции -print0 . Современные версии команды find могут разделяться не точкой с запятой, а знаком +, благодаря чему, за один вызов команды find можно передать максимально возможное число имен, так же, как и в случае использования xargs . Излишне говорить о том, что в этом случае вы можете использовать конструкцию {} только один раз, и что она должна являться последним параметром команды. В листинге 20 продемонстрированы оба этих метода. Оба этих метода являются рабочими и выбор какого-то одного из них часто обусловлен лишь личными предпочтениями пользователя. Помните о том, что передавая по конвейеру объекты с необработанными символами-разделителями и пробелами, вы можете столкнуться с проблемами; поэтому если вы передаете вывод команде xargs , то используйте опцию -print0 команды find , а также опцию -0 команды xargs , которая сообщает, что во входных данных используются пустые разделители. Другие команды, включая tar , также поддерживают опцию -0 и работу с входными данными, содержащими пустые разделители, поэтому всегда следует использовать эту опцию для тех команд, которые ее поддерживают, если только вы уверены на все 100%, что входной список не создаст вам проблем. Наш последний комментарий затрагивает работу со списком файлов. Хорошей идеей будет всегда тщательно проверять ваш список и команды, прежде чем выполнять пакетные операции (например, удаление или переименование множества файлов). Наличие актуальной резервной копии в нужный момент также может оказаться неоценимым. В завершение этой статьи мы кратко рассмотрим еще одну команду. Иногда может возникнуть необходимость просматривать вывод на экране и одновременно сохранять его в файл. Для этого вы могли бы
перенаправить вывод команды в файл в одном окне, а затем с помощью tail -fn1 отслеживать вывод в другом окне, однако проще всего использовать команду tee . Команда tee используется в конвейере, а ее аргументом является имя файла (или имена нескольких файлов), в который будет передаваться стандартный вывод. Опция -a позволяет не замещать старое содержимое файла новым содержимым, а добавлять данные в конец файла. Как уже говорилось при рассмотрении конвейеризации, если вы хотите сохранить как стандартный вывод, так и поток ошибок, то необходимо перенаправлять поток stderr в поток stdout прежде, чем передавать данные на вход команде tee . В листинге 21 приведен пример использования команды tee для сохранения вывода в два файла, f1 и f2.

Использование тоннелей


Выводы
Потоки ввода-вывода
Стандартный ввод
2
3
ctrl-dСтандартный вывод
Стандартная ошибка
Перенаправление потоков
a
b
c
ctrl-d
1
2
3
ctrl-d
a
b
c
ctrl-d
2
3
a
b
cКонвейеры
Фильтры
Примеры перенаправления ввода-вывода
команда > файл
команда > /dev/null
команда 2 > файл
команда >> файл
echo Appended to an existing file"s contents >> data.txtкоманда 2>>файл
wc "" 2>> stderr_log.txtкоманда | команда
команда | tee файл
команда | команда | команда >> файл
Заключение
Потоки, программные каналы и перенаправления
Серия контента:
Краткий обзор
Об этой серии
Необходимые условия
Подготовка к выполнению примеров
Как связаться с Яном
Листинг 1. Создание файлов, необходимых для примеров этой статьи
mkdir -p lpi103-4 && cd lpi103-4 && {
echo -e "1 apple\n2 pear\n3 banana" > text1
echo -e "9\tplum\n3\tbanana\n10\tapple" > text2
echo "This is a sentence. " !#:* !#:1->text3
split -l 2 text1
split -b 17 text2 y; }
Листинг 2. Результаты создания необходимых файлов
$ mkdir -p lpi103-4 && cd lpi103-4 && {
> echo -e "1 apple\n2 pear\n3 banana" > text1
> echo -e "9\tplum\n3\tbanana\n10\tapple" > text2
> echo "This is a sentence. " !#:* !#:1->text3echo "This is a sentence. " "This is a sentence. " "This is a sentence.">text3
> split -l 2 text1
> split -b 17 text2 y; }
$
Перенаправление стандартного ввода/вывода
Перенаправление вывода
Листинг 3. Перенаправление вывода
$ ls x* z*
ls: cannot access z*: No such file or directory
xaa xab
$ ls x* z* >stdout.txt 2>stderr.txt
$ ls w* y*
ls: cannot access w*: No such file or directory
yaa yab
$ ls w* y* >>stdout.txt 2>>stderr.txt
$ cat stdout.txt
xaa
xab
yaa
yab
$ cat stderr.txt
ls: cannot access z*: No such file or directory
ls: cannot access w*: No such file or directory
Листинг 4. Перенаправление вывода с помощью опции noclobber
$ set -o noclobber
$ ls x* z* >stdout.txt 2>stderr.txt
-bash: stdout.txt: cannot overwrite existing file
$ ls x* z* >|stdout.txt 2>|stderr.txt
$ cat stdout.txt
xaa
xab
$ cat stderr.txt
ls: cannot access z*: No such file or directory
$ set +o noclobber #restore original noclobber setting
command 2>&1 >output.txt
это не то же самое, что команда
command >output.txt 2>&1
В первом случае поток ошибок stderr перенаправляется в текущее месторасположение потока stdout, а затем поток stdout перенаправляется в файл output.txt; однако второе перенаправление затрагивает только stdout, но не stderr. Во втором случае поток stderr перенаправляется в текущее месторасположение потока stdout, то есть, в файл output.txt. Эти перенаправления проиллюстрированы в листинге 5. Обратите внимание на последнюю команду, в которой стандартный вывод был перенаправлен после стандартного потока ошибок, и, как следствие, поток ошибок продолжает выводиться в окно терминала.Листинг 5. Перенаправление двух потоков в один файл
$ ls x* z* &>output.txt
$ cat output.txt
ls: cannot access z*: No such file or directory
xaa
xab
$ ls x* z* >output.txt 2>&1
$ cat output.txt
ls: cannot access z*: No such file or directory
xaa
xab
$ ls x* z* 2>&1 >output.txt # stderr does not go to output.txt
ls: cannot access z*: No such file or directory
$ cat output.txt
xaa
xab
Листинг 6. Игнорирование стандартного потока ошибок посредством использования /dev/null
$ ls x* z* 2>/dev/null
xaa xab
$ cat /dev/null
Перенаправление ввода
Листинг 7. Перенаправление ввода
$ tr " " "\t"Листинг 8. Перенаправление ввода с использованием концепции here-document
$ sort -k2 <Листинг 9. Перенаправление ввода с использованием концепции here-document
$ ht=$(echo -en "\t")
$ cat<Создание конвейеров
Использование команды xargs
Листинг 12. Использование команды xargs
$ cat text1
1 apple
2 pear
3 banana
$ xargsЛистинг 13. Использование команд xargs и echo
$ xargsЛистинг 14. Использование команды xargs и кавычек
$ echo ""4 plum"" | cat text1 -
1 apple
2 pear
3 banana
"4 plum"
$ echo ""4 plum"" | cat text1 - | xargs -n 1
1
apple
2
pear
3
banana
4 plum
Листинг 15. Использование команды xargs и строк ввода
$ xargs -I XYZ echo "START XYZ REPEAT XYZ END" Листинг 16. Использование команды xargs и списка файлов
$ ls |xargs grep "1"
text1:1 apple
text2:10 apple
xaa:1 apple
yaa:1
Листинг 17. Использование команды xargs и файлов, содержащих пробелы в именах
$ cp text1 "text 1"
$ ls *1 |xargs grep "1" # error
text1:1 apple
grep: text: No such file or directory
grep: 1: No such file or directory
$ ls --quoting-style escape *1
text1 text\ 1
$ ls --quoting-style shell *1
text1 "text 1"
$ ls --quoting-style shell *1 |xargs grep "1"
text1:1 apple
text 1:1 apple
$ # Illustrate -0 option of xargs
$ ls *1 | tr "\n" "\0" |xargs -0 grep "1"
text1:1 apple
text 1:1 apple
Использование команды find
с опцией -exec или совместно с командой xargs
Листинг 18. Использование команды find с опцией -exec
$ find text -exec cat text3 {} \;
This is a sentence. This is a sentence. This is a sentence.
1 apple
2 pear
3 banana
This is a sentence. This is a sentence. This is a sentence.
9 plum
3 banana
10 apple
Листинг 19. Использование команды find с опцией -exec и файлов, содержащих пробелы в именах
$ find . -name "*1" -exec grep "1" {} \;
1 apple
1 apple
Листинг 20. Использование команд find , xargs и файлов, содержащих пробелы в именах
$ find . -name "*1" -print0 |xargs -0 grep "1"
./text 1:1 apple
./text1:1 apple
$ find . -name "*1" -exec grep "1" {} +
./text 1:1 apple
./text1:1 apple
Разделение вывода
Листинг 21. Разделение потока stdout с помощью команды tee
$ ls text|tee f1 f2
text1
text2
text3
$ cat f1
text1
text2
text3
$ cat f2
text1
text2
text3