"Mapping" - новый инструмент LPgenerator! Подготовка правил трансформации. Продажи – основная деятельность
В предыдущей части были рассмотрены виды связей (один-к-одному, один-ко-многим, многие-ко-многим), а также один класс Book и его маппинг-класс BookMap. Во второй части обновим класс Book, создадим остальные классы и связи между ними, как это было изображено в предыдущей главе в Диаграмме баз данных, расположившейся над подзаголовком 1.3.1 Связи.
Код классов и маппингов (С комментариями)
Класс Книга
Public class Book {
//Уникальный идентификатор
public virtual int Id { get; set; }
//Название
public virtual string Name { get; set; }
//Описание
public virtual string Description { get; set; }
//Оценка Мира фантастики
public virtual int MfRaiting { get; set; }
//Номера страниц
public virtual int PageNumber { get; set; }
//Ссылка на картинку
public virtual string Image { get; set; }
//Дата поступления книги (фильтр по новинкам!)
public virtual DateTime IncomeDate { get; set; }
//Жанр (Многие-ко-Многим)
//Почему ISet а не IList? Только одна коллекция (IList) может выбираться с помощью JOIN выборки, если нужно более одной коллекции для выборки JOIN, то лучше их преобразовать в коллекцию ISet
public virtual ISet
Public class Author {
public virtual int Id { get; set; }
//Имя-Фамилия
public virtual string Name { get; set; }
//Биография
public virtual string Biography { get; set; }
//Книжки
public virtual ISet
Класс Жанр
Public class Genre {
public virtual int Id { get; set; }
//Название жанра
public virtual string Name { get; set; }
//Английское название жанра
public virtual string EngName { get; set; }
//Книжки
public virtual ISet
Класс Мнение:
Public class Mind {
public virtual int Id { get; set; }
//Мое мнение
public virtual string MyMind { get; set; }
//Мнение фантлаба
public virtual string MindFantLab { get; set; }
//Книга
public virtual Book Book { get; set; }
}
//Маппинг Мind
public class MindMap:ClassMap
Класс Цикл(Серия):
Public class Series {
public virtual int Id { get; set; }
public virtual string Name { get; set; } //Я создал IList, а не ISet, потому что кроме Book, Series больше ни с чем не связана, хотя можно сделать и ISet
public virtual IList
Небольшое объяснение
public virtual ISet
public virtual ISet
Почему ISet
Cannot simultaneously fetch multiple bags.
В таких случаях используем ISet, тем более множества для этого и предназначены (игнорируют дублирующие записи).
Отношение многие-ко-многим.
В NHibernate есть понятие, «главной» таблицы. Хотя отношения «многие-ко-многим» между таблицами “Book” и “Автор” равнозначны (У автора может быть много книг, у книги может быть множество авторов), Nhibernate требует, чтобы программист указывал таблицу, которая сохраняется второй (имеет метод.inverse()), то есть вначале будет создана/обновлена/удалена запись в таблице Book, а только потом в таблице Author.
Cascade.All означает выполнение каскадных операций при save-update и delete. То есть когда объект сохраняется, обновляется или удаляется, проверяются и создаются/обновляются/добавляются все зависимые объекты (Ps. Можно прописать вместо Cascade.All -> .Cascade.SaveUpdate().Cascade.Delete())
Метод.Table(«Book_Author»); создает «промежуточную» таблицу “Book_Author” в БД.
Отношение многие-к-одному, один-ко-многим.
Метод.Constrained() говорит NHibernate, что для записи из таблицы Book должна соответствовать запись из таблицы Mind (id таблицы Mind должен быть равен id таблицы Book)
Если сейчас запустить проект и посмотреть БД Bibilioteca, то появятся новые таблицы с уже сформированными связями.
Далее заполним созданные таблицы данными…
Для этого создадим тестовое приложение, которое будет сохранять данные в БД, обновлять и удалять их, изменив HomeController следующим образом (Ненужные участки кода комментируем):
public ActionResult Index()
{
using (ISession session = NHibernateHelper.OpenSession()) {
using (ITransaction transaction = session.BeginTransaction()) {
//Создать, добавить
var createBook = new Book();
createBook.Name = "Metro2033";
createBook.Description = "Постапокалипсическая мистика";
createBook.Authors.Add(new Author { Name = "Глуховский" });
createBook.Genres.Add(new Genre { Name = "Постапокалипсическая мистика" });
createBook.Series = new Series { Name = "Метро" };
createBook.Mind = new Mind { MyMind = "Постапокалипсическая мистика" };
session.SaveOrUpdate(createBook);
//Обновить (По идентификатору)
//var series = session.Get
Небольшое объяснение
- var books = session.QueryOver
() Select * From Book ; - .JoinAlias(p => p.Genres, () => genreAl, JoinType.LeftOuterJoin)
- подобно выполнению скрипта SQL:
SELECT *FROM Book
inner JOIN Book_Genre ON book.id = Book_Genre.Book_id
LEFT JOIN Genre ON Book_Genre.Genre_id = Genre.id - .TransformUsing(Transformers.DistinctRootEntity) - Подобно выполнению скрипта SQL: SELECT distinct Book.Id... , (убирает дублирующие записи с одинаковыми id)
Виды объединений
.JoinAlias(p => p.Genres, () => genreAl, JoinType.LeftOuterJoin)
- LeftOuterJoin - выбирает все записи из левой таблицы (Book ), а затем присоединяет к ним записи правой таблицы (Genre ). Если не найдена соответствующая запись в правой таблицы, отображает её как Null
- RightOuterJoin действует в противоположность LEFT JOIN - выбирает все записи из правой таблицы (Genre ), а затем присоединяет к ним записи левой таблицы (Book )
- InnerJoin - выбирает только те записи из левой таблиц (Book ) у которой есть соответствующая запись из правой таблицы (Genre ), а затем присоединяет к ним записи из правой таблицы
Изменим представление следующим образом:
Представление index
@model IEnumerable @Html.ActionLink("Create New", "Create")
@foreach (var item in Model) {
@Html.DisplayNameFor(model => model.Name)
@Html.DisplayNameFor(model => model.Mind)
@Html.DisplayNameFor(model => model.Series)
@Html.DisplayNameFor(model => model.Authors)
@Html.DisplayNameFor(model => model.Genres)
Операции
}
@Html.DisplayFor(modelItem => item.Name)
@Html.DisplayFor(modelItem => item.Mind.MyMind)
@{string strSeries = item.Series != null ? item.Series.Name: null;}
@Html.DisplayFor(modelItem => strSeries)
@foreach (var author in item.Authors) {
string strAuthor = author != null ? author.Name: null;
@Html.DisplayFor(modelItem => strAuthor)
}
@foreach (var genre in item.Genres) {
string strGenre = genre!= null ? genre.Name: null;
@Html.DisplayFor(modelItem => strGenre)
}
@Html.ActionLink("Edit", "Edit", new { id = item.Id }) |
@Html.ActionLink("Details", "Details", new { id = item.Id }) |
@Html.ActionLink("Delete", "Delete", new { id = item.Id })
Проверив поочередно все операции, мы заметим, что:
- При операциях Create и Update обновляются все данные, связанные с таблицей Book (уберите Cascade=«save-update» или cascade=«all» и связанные данные не будут сохранены)
- При удалении удаляются данные из таблиц Book, Mind, Book_Author, а остальные данные не удаляются, потому что у них Cascade=«save-update»
Маппинг для классов, у которых есть наследование.
А как маппить классы у которых есть наследование? Допустим, имеем такой пример:
//Класс Двумерных фигур
public class TwoDShape {
//Ширина
public virtual int Width { get; set; }
//Высота
public virtual int Height { get; set; }
}
//Класс треугольник
public class Triangle: TwoDShape {
//Идентификационный номер
public virtual int Id { get; set; }
//Вид треугольника
public virtual string Style { get; set; }
}
В принципе, ничего сложного в этом маппинге нет, мы просто создадим один маппинг для производного класса, то есть таблицы Triangle.
//Маппинг треугольника
public class TriangleMap: ClassMap
После запуска приложения, в БД Biblioteca появится следующая (пустая) таблица
Теги:
- asp.net mvc 4
- nhibernate
- sql server
Port mapping - это переадресация принимаемых данных таким образом, чтобы данные, принимаемые на какой-то порт одного компьютера автоматически переадресовывались на какой-то другой порт другого компьютера.
На самом деле это гораздо легче технически реализовать, чем объяснить сам принцип. Это можно сравнить с солнечным зайчиком: если Вы направляете луч света в зеркало, он "автоматически" отражается и освещает какой-либо предмет. При этом если вы осветили какого-либо человека и этот человек не знает, что луч отразился от зеркала, он будет думать, что свет исходит от того места, где находится зеркало. Так же и здесь: все передаваемые Вами данные безо всяких искажений передаются на другой компьютер, который может быть расположен где угодно.
Эта технология в чем-то аналогична прокси серверу, однако она гораздо проще и гораздо менее гибкая.
Схема примерно такая же, как и при использовании прокси (можно сказать, что port mapping похож на proxy - но это будет то же. что сказать "дедушка похож на внука" - вообще-то это как раз proxy похож на port mapping):
Ваш компьютер >>> компьютер с port mapping >>> удаленный сервер.
Для чего нужен port mapping?
- Если в организации используется корпоративный прокси, то настроив на нем port mapping на внешний почтовый сервер (mail.ru), Вы сможете использовать любую почтовую программу изнутри корпоративной сети - и Вам не потребуется устанавливать/настраивать никаких дополнительных программ!
- Точно таким же образом как почтовую программу, Вы можете настроить практически любую другую программу! Лишь бы она поддерживала TCP/IP.
Разумеется это только основные способы применения port mapping. Существует еще масса видов деятельности, где он также будет весьма и весьма полезен.
Преимущества port mapping
- Эта система очень проста и в интернет имеется множество программ, позволяющих реализовать эту функцию;
- Поскольку данные передаются 100% безо всяких искажений, Вам обеспечена 100% анонимность;
- Если Вы используете эту систему, Вам не нужны никакие "соксификаторы" - поскольку не требуется никаких дополнительных инициализаций соединения, соединение с port mapper-ом эквивалентно соединению с удаленным компьютером.
Недостатки port mapping
- Эта система не отличается гибкостью. В отличие от прокси, у которого через один прокси можно подключиться на множество сайтов, через один port mapping можно подключиться только к одному серверу.
- Для каждого нового port mapping нужно изменять настройки на сервере, где реализована эта функция - с клиентского компьютера это недоступно.
- В интернете нет бесплатных port mapper-ов (ввиду их крайней ограниченности - один port mapping дает доступ только на один сервер), поэтому если Вы хотите быть действительно анонимным на своем компьютере, Вам нужно где-то иметь сервер, на котором будет установлена программа для маппинга портов - и вот уже адрес этого сервера и будет "светиться" в логах веб-сайтов.
Как работать с port mapping
Учтите, схема работы с port mapping примерно та же, что и при работе с proxy, только еще проще. Port mapping - это алиас (дополнительное имя) для компьютера, на который он настроен.
Предположим, что сделан port mapping:
192.168.1.255:1234 => www.mail.ru:80 (80-й порт - это порт web серверов)
Тогда для того, чтобы открыть сайт mail.ru, Вы можете использовать 2 способа - откройте в окошке браузера сайт:
- http://www.mail.ru
- http://192.168.1.255:1234/
(в данном случае обязательно пишите http:// )
Хотелось бы заметить: если Вам нужно использовать port mapping, то Вы должны пользоваться только вторым адресом . То есть если Вы не можете подключиться к mail.ru, то Вы должны использовать только внутренний адрес (http://192.168.1.255:1234/).
Port mapping на локальном компьютере
В случае, когда у Вас делается port mapping на Вашем же компьютере, то обычно указывают:
- local port - локальный порт на Вашем компьютере, к которому Вы должны будете подключаться для использования port mapping. Это число может быть любым (от 1 до 65535), желательно больше 1000;
- remote host - тот компьютер (хост), на который указывает port mapping. Например, это может быть почтовый сервер pop.mail.ru ;
- remote port - порт компьютера, к которому будет происходить подключение через port mapping. Для получения почты (POP3) это обычно порт 110 , для отправки почты (SMTP) - порт 25, для web серверов (www...) - это обычно порт 80.
Так вот, в этом случае Вам нужно (настроив port mapping) подключаться не к mail.ru (и им подобным), а указать в качестве сервера Ваш же компьютер:
127.0.0.1:localport
где localport - это номер порта, заданный при настройке port mapping. Например это может быть порт 1234.
То есть если Вы сделали port mapping на web сайт, то Вам нужно писать: http://127.0.0.1:1234/
Если же Вы настраиваете почту - то в качестве почтового сервера укажите 127.0.0.1 - как для получения, так и для отправки почты. И не забудьте найти настройки номеров портов (POP3 и SMTP) в Вашем почтовом клиенте и изменить их в соответствии с Вашими же настройками в port mapping!
Проблема
Вы выгрузили бухгалтерский отчет о затратах и хотите продемонстрировать его руководству. Для этого вам необходимо скомпоновать данные статей бухгалтерского учета - по статьям управленечского учета. Вы знаете, как соотносятся между собой статьи БУ и УУ, но каждый раз подготовка такого отчета вручную у вас занимает слишком много времени.
Решение
Будем рассматривать данный кейс как продолжение предыдущего. Представим себе, что вы создали в Excel такой справочник:
Рис.2.1. Справочник: мэппинг статей БУ и УУ
Слева - статья затрат (БУ), справа статья управленческого учета (УУ). Важно при этом, чтобы в первом колонке статья затрат встречалась только один раз, иначе механизм мэппинга будет работать не корректно.
(Кстати, английское слово mapping переводится как отображение или соответствие, поэтому справочник в данном случае - это некое общее правило того, как статьи БУ находят свое отображение в статья УУ).
Рис.2.2. Плоская таблица: отчет о затратах (из "Оборотов счета 20")

Обратим внимание, что в 7-м столбце появилась графа "Статья УУ". Напротив каждой статьи затрат мы проставили статью управленческого учета. Это можно сделать вручную, но гораздо удобнее воспользоваться таким инструментом:
Рис.2.3. Плоская таблица: отчет о затратах (из "Оборотов счета 20")

В нижней части формы указаны наименования страниц: "Главная" - это плоская таблица, в которой содержатся данные о затратах (рис.2.2), "спр" - это справочник (рис.2.1).
В верхней части формы указаны номер столбцов. Так, в данном случае, если данные в столбцах 1 справочника и 3 главной страницы совпадают, то данные из 2-го столбца справочника копируются в 7-й столбец главной страницы.
В этой форме также мнржество дополнительных опций. Например, можно включить галочки "Признак #2" и "Признак #3", и тогда перенесение данных из столбца 2 справочника в столбец 7 главной страницы будет возможно, если справочник и главная страница будуь совпадать сразу по двум или даже трем реквизитам.
В результате такой несложной операции с помощью сводной таблицы можно построить целый ряд различных аналитических отчетов, в которых одним из разрезов будет фигурироватл аналитика "Стаьья УУ". Например, такой:
Рис.2.4. Отчет по затратам арматурного цеха

Сравнение мэппинга с ВПР()
Многие пользователи хорошо знакомы и пользуются функцией ВПР() в такого рода ситуациях. Однако функция ВПР() хорошо работает только на небольших объемах данны, в то время как данная форма отлично справляется с обработкой таблтц Excel, даже если у вас в справочнике, скажем, 5000 строк, а на гоавной странице - 300 000 строк. Попробуйте проверить, и вы убедитесь, что на таких объемах ВПР() дает сбои. Кроме того, функция ВПР() создает значительную нагрузку на Excel, вынуждая его проводить большие объесы калькуляций. Форма мэппинга позволяет избежать этого недостатка: она запускается один раз, действует несколько секунд (при больших объемах минут) и после этого никаких дополнительных нагрузок на файл Excel уже не создается.
Часть 3. Отображение данных из таблицы (Операция LIST)
В предыдущей части были рассмотрены виды связей (один-к-одному, один-ко-многим, многие-ко-многим), а также один класс Book и его маппинг-класс BookMap. Во второй части обновим класс Book, создадим остальные классы и связи между ними, как это было изображено в предыдущей главе в Диаграмме баз данных, расположившейся над подзаголовком 1.3.1 Связи.
Код классов и маппингов (С комментариями)
Класс Книга
Public class Book {
//Уникальный идентификатор
public virtual int Id { get; set; }
//Название
public virtual string Name { get; set; }
//Описание
public virtual string Description { get; set; }
//Оценка Мира фантастики
public virtual int MfRaiting { get; set; }
//Номера страниц
public virtual int PageNumber { get; set; }
//Ссылка на картинку
public virtual string Image { get; set; }
//Дата поступления книги (фильтр по новинкам!)
public virtual DateTime IncomeDate { get; set; }
//Жанр (Многие-ко-Многим)
//Почему ISet а не IList? Только одна коллекция (IList) может выбираться с помощью JOIN выборки, если нужно более одной коллекции для выборки JOIN, то лучше их преобразовать в коллекцию ISet
public virtual ISet
Public class Author {
public virtual int Id { get; set; }
//Имя-Фамилия
public virtual string Name { get; set; }
//Биография
public virtual string Biography { get; set; }
//Книжки
public virtual ISet
Класс Жанр
Public class Genre {
public virtual int Id { get; set; }
//Название жанра
public virtual string Name { get; set; }
//Английское название жанра
public virtual string EngName { get; set; }
//Книжки
public virtual ISet
Класс Мнение:
Public class Mind {
public virtual int Id { get; set; }
//Мое мнение
public virtual string MyMind { get; set; }
//Мнение фантлаба
public virtual string MindFantLab { get; set; }
//Книга
public virtual Book Book { get; set; }
}
//Маппинг Мind
public class MindMap:ClassMap
Класс Цикл(Серия):
Public class Series {
public virtual int Id { get; set; }
public virtual string Name { get; set; } //Я создал IList, а не ISet, потому что кроме Book, Series больше ни с чем не связана, хотя можно сделать и ISet
public virtual IList
Небольшое объяснение
public virtual ISet
public virtual ISet
Почему ISet
Cannot simultaneously fetch multiple bags.
В таких случаях используем ISet, тем более множества для этого и предназначены (игнорируют дублирующие записи).
Отношение многие-ко-многим.
В NHibernate есть понятие, «главной» таблицы. Хотя отношения «многие-ко-многим» между таблицами “Book” и “Автор” равнозначны (У автора может быть много книг, у книги может быть множество авторов), Nhibernate требует, чтобы программист указывал таблицу, которая сохраняется второй (имеет метод.inverse()), то есть вначале будет создана/обновлена/удалена запись в таблице Book, а только потом в таблице Author.
Cascade.All означает выполнение каскадных операций при save-update и delete. То есть когда объект сохраняется, обновляется или удаляется, проверяются и создаются/обновляются/добавляются все зависимые объекты (Ps. Можно прописать вместо Cascade.All -> .Cascade.SaveUpdate().Cascade.Delete())
Метод.Table(«Book_Author»); создает «промежуточную» таблицу “Book_Author” в БД.
Отношение многие-к-одному, один-ко-многим.
Метод.Constrained() говорит NHibernate, что для записи из таблицы Book должна соответствовать запись из таблицы Mind (id таблицы Mind должен быть равен id таблицы Book)
Если сейчас запустить проект и посмотреть БД Bibilioteca, то появятся новые таблицы с уже сформированными связями.
Далее заполним созданные таблицы данными…
Для этого создадим тестовое приложение, которое будет сохранять данные в БД, обновлять и удалять их, изменив HomeController следующим образом (Ненужные участки кода комментируем):
public ActionResult Index()
{
using (ISession session = NHibernateHelper.OpenSession()) {
using (ITransaction transaction = session.BeginTransaction()) {
//Создать, добавить
var createBook = new Book();
createBook.Name = "Metro2033";
createBook.Description = "Постапокалипсическая мистика";
createBook.Authors.Add(new Author { Name = "Глуховский" });
createBook.Genres.Add(new Genre { Name = "Постапокалипсическая мистика" });
createBook.Series = new Series { Name = "Метро" };
createBook.Mind = new Mind { MyMind = "Постапокалипсическая мистика" };
session.SaveOrUpdate(createBook);
//Обновить (По идентификатору)
//var series = session.Get
Небольшое объяснение
- var books = session.QueryOver
() Select * From Book ; - .JoinAlias(p => p.Genres, () => genreAl, JoinType.LeftOuterJoin)
- подобно выполнению скрипта SQL:
SELECT *FROM Book
inner JOIN Book_Genre ON book.id = Book_Genre.Book_id
LEFT JOIN Genre ON Book_Genre.Genre_id = Genre.id - .TransformUsing(Transformers.DistinctRootEntity) - Подобно выполнению скрипта SQL: SELECT distinct Book.Id... , (убирает дублирующие записи с одинаковыми id)
Виды объединений
.JoinAlias(p => p.Genres, () => genreAl, JoinType.LeftOuterJoin)
- LeftOuterJoin - выбирает все записи из левой таблицы (Book ), а затем присоединяет к ним записи правой таблицы (Genre ). Если не найдена соответствующая запись в правой таблицы, отображает её как Null
- RightOuterJoin действует в противоположность LEFT JOIN - выбирает все записи из правой таблицы (Genre ), а затем присоединяет к ним записи левой таблицы (Book )
- InnerJoin - выбирает только те записи из левой таблиц (Book ) у которой есть соответствующая запись из правой таблицы (Genre ), а затем присоединяет к ним записи из правой таблицы
Изменим представление следующим образом:
Представление index
@model IEnumerable @Html.ActionLink("Create New", "Create")
@foreach (var item in Model) {
@Html.DisplayNameFor(model => model.Name)
@Html.DisplayNameFor(model => model.Mind)
@Html.DisplayNameFor(model => model.Series)
@Html.DisplayNameFor(model => model.Authors)
@Html.DisplayNameFor(model => model.Genres)
Операции
}
@Html.DisplayFor(modelItem => item.Name)
@Html.DisplayFor(modelItem => item.Mind.MyMind)
@{string strSeries = item.Series != null ? item.Series.Name: null;}
@Html.DisplayFor(modelItem => strSeries)
@foreach (var author in item.Authors) {
string strAuthor = author != null ? author.Name: null;
@Html.DisplayFor(modelItem => strAuthor)
}
@foreach (var genre in item.Genres) {
string strGenre = genre!= null ? genre.Name: null;
@Html.DisplayFor(modelItem => strGenre)
}
@Html.ActionLink("Edit", "Edit", new { id = item.Id }) |
@Html.ActionLink("Details", "Details", new { id = item.Id }) |
@Html.ActionLink("Delete", "Delete", new { id = item.Id })
Проверив поочередно все операции, мы заметим, что:
- При операциях Create и Update обновляются все данные, связанные с таблицей Book (уберите Cascade=«save-update» или cascade=«all» и связанные данные не будут сохранены)
- При удалении удаляются данные из таблиц Book, Mind, Book_Author, а остальные данные не удаляются, потому что у них Cascade=«save-update»
Маппинг для классов, у которых есть наследование.
А как маппить классы у которых есть наследование? Допустим, имеем такой пример:
//Класс Двумерных фигур
public class TwoDShape {
//Ширина
public virtual int Width { get; set; }
//Высота
public virtual int Height { get; set; }
}
//Класс треугольник
public class Triangle: TwoDShape {
//Идентификационный номер
public virtual int Id { get; set; }
//Вид треугольника
public virtual string Style { get; set; }
}
В принципе, ничего сложного в этом маппинге нет, мы просто создадим один маппинг для производного класса, то есть таблицы Triangle.
//Маппинг треугольника
public class TriangleMap: ClassMap
После запуска приложения, в БД Biblioteca появится следующая (пустая) таблица
Теги: Добавить метки
Дорогие друзья!
Сегодня мы рады сообщить вам о том, что наши разработчики реализовали возможность транспортировки данных по URL (mapping, мэппинг) за “пределы” целевой страницы.
С помощью данной функции можно передать все данные с полей формы на страницу, на которую переходит пользователь, отправляя вам лид. Благодаря этому, лид попадает не только во , но также может попасть сразу и в вашу базу, если на странице редиректа его “встретит” соответствующий скрипт.
Теперь нет необходимости в экспорте данных из системы обработки лидов! Вы можете отправлять и обрабатывать их сразу в собственной базе!
Так же, благодаря данной функции, становится возможным поздравить или поблагодарить пользователя, предоставившего свои контактные данные лично.
Как работает мэппинг (mapping)?
Суть мэппинга в том, что при отправке данных с полей формы, в ссылку, по которой происходит переадресация, добавляются их содержимое. URL приобретает вид: //my_site.com/?name=ИМЯ&email=АДРЕС_ЭЛЕКТРОННОЙ _ПОЧТЫ&phone=НОМЕР_ТЕЛЕФОНА&lead_id=225298.
Важно! В дополнение ко всем данным полей, всегда передается ID лида в параметре lead_id.
На странице же, на которую осуществоляется переход, данную информацию “принимает” специальный скрипт, который, в свою очередь, распределяет данные по соответствующим “ячейкам”.
Обращаем ваше внимание! Мэппинг работает только в том случае, если “Результат формы” - “Переход по URL”!
Как настроить “транспортировку” лида по URL (mapping) на моей целевой странице?
1. Войдите в .
2. Выберите страницу с формой лида, с которой вы собираетесь “транслировать” данные.
3. В редакторе сделайте двойной щелчок по форме.

4. В появившемся окне заполните графу “Mapping” соответствующими названиями полей на английском языке. Например,name - имя, phone - телефон и т. п.

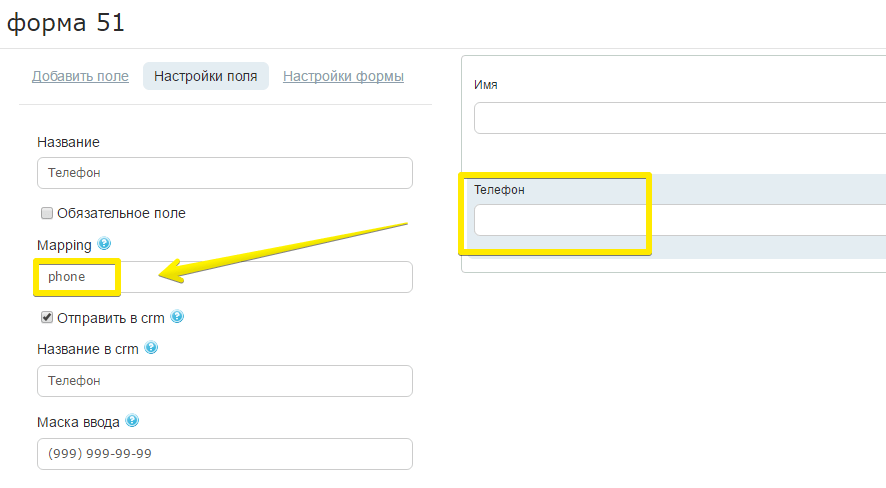
5. Сохраните изменения.
6. В свойствах формы настройте редирект на нужную страницу - это может быть или страница вашего сайта, в которую встроен JavaScript, который и будет обрабатывать данные с полей, поступившие с URL.
Установите флажок в чекбоксе “Передать поля формы”.

7. Сохраните изменения в основном меню редактора.

Вот и все! :-)
Теперь данные с полей вашей формы будут передаваться на страницу, на которую вы переадресовываете пользователя. Вам не придется экспортировать лиды из CRM LPgenerator - они могут “транспортироваться” в вашу CRM прямо по URL. Возможности мэппинга (mapping) по транспортировке данных воистину безграничны.