Кэш страницы в google. Что такое кэш страницы и для чего он нужен? Как найти в кэше Гугла и Яндекса определенную страницу
Категория ~ Браузер – Игорь (Администратор)Google достаточно часто обновляет свой браузер Chrome. Но, на момент написания этого совета, в нем до сих пор нет настройки для задания ограничения размера кэша. А ведь кэш может очень сильно разрастись, если его периодически не чистить. Вы можете сильно удивиться, узнав сколько места занимает кэш. Например, на текущий момент времени кэш моего браузера занимает 423 Мб. Согласитесь, что это не совсем уж маленькая цифра. По умолчанию весь кэш находится в папке "C:\Users\{Пользователь}\AppData\Local\Google\Chrome\User Data\Default", где "{Пользователь}" - это ваш пользователь. Просто посмотрите на размер этой папки.
Конечно, ограничить размер можно при помощи специальных параметров, которые необходимо прописать в ярлык для запуска, но это не совсем то, что хотелось бы. Если вам интересно, то сделать это можно при помощи следующих параметров: –disk-cache-dir=”c:\cache” –disk-cache-size=102345678. Где параметр "–disk-cache-dir" - задает место хранения кэша. А параметр "–disk-cache-size" - максимальный размер в байтах.
Примечание: кэш так же стоит чистить в случаях, если у вас возникают проблемы с отображением ваших любимых сайтов. Если не вдаваться в технические подробности, то основная проблема в том, что часть элементов сайта обновилась, но при этом браузер при загрузке сайта по прежнему загружает элементы из кэша.
Просмотр кэша при помощи "about:cache"
Есть несколько различных способов для просмотр кэша. Сам браузер имеет специальную команду для просмотра кэша. Введите в адресной строке "about:cache" (без кавычек и без пробелов, но с двоеточием). Содержимое кэша отобразиться в окне браузера. Если у вас достаточно большой кэш, то эта операция может занять некоторое время. Конечно, это не самый удобный способ просмотра, и он больше подойдет технически подкованным пользователям. Но, тем не менее, это все же способ.
Очистка кэша из браузера
Вы можете очистить кэш за определенный период времени из панели инструментов Chrome.
![]()
- Откройте выпадающее меню. Значок из трех полосок
- Наведите мышку на "Инструменты"
- Выберите пункт "Удаление данных о просмотренных страницах..."
- В появившемся меню выберите период, за который необходимо очистить данные
- Выберите необходимые данные для очистки. Для тех данных, которые вы хотите сохранить, снимите галочки
- Нажмите кнопку "Очистить историю"
Просмотр кэша с помощью программы ChromeCacheView от NirSoft
ChromeCacheView это небольшая бесплатная утилита, которая позволяет просматривать и выборочно копировать записи кэша браузера Chrome. Она так же позволяет посмотреть информацию о каждом файле кэша. Скачать эту утилиту вы можете по этой ссылке . Программа не требует установки и прекрасно работает в Windows XP, Vista и 7.
На главной странице архива, есть блок «Wayback Machine» . Здесь вам нужно ввести адрес удаленной страницы, и нажать Enter .

Обратите внимание на интерфейс. В верхней части экрана есть календарь. На нем отображены имеющиеся копии страницы. Если их несколько, вы сможете просмотреть каждую из них. Давайте попробуем отдалиться на 2012 года, и посмотреть, что было на моей странице в то время. На календаре выбираем нужную дату, и получаем вот такой результат.

Если удаленной страницы нет в архиве, вы получите вот такое сообщение.

Просмотр копии профиля в поисковиках
Яндекс и гугл добавляют в свою базу информацию обо всех найденных страницах в сети. Это касается также и аккаунтов в ВК. Версия копии изменяется с каждым обновлением базы (разумеется, при наличии изменений). Этот процесс занимает несколько дней.
Если пользователь совсем недавно, есть шанс, что в поисковых системах еще есть ее сохраненная копия. И мы можем просмотреть ее.
Давайте посмотрим, как это выглядит в яндексе.
Чтобы принцип работы стал более понятен, рассмотрим копию, которая гарантирована существует.
Заходим в яндекс, и набираем в поиске адрес своего аккаунта.

Тот же принцип и в гугл.

Теперь давайте попробуем просмотреть сохраненную копию. Для этого разверните дополнительное меню (кнопка в виде треугольника, расположена рядом с адресом). Здесь нажмите «Сохраненная копия» .


Теперь попробуйте проделать те же действия, для удаленной страницы, которую вы хотите увидеть.
Просмотр кэша браузера
Каждый раз, когда вы открываете страницу сайта, ваш браузер сохраняет ее копию к себе в историю. Это делается для того, чтобы при повторном открытии, не загружать ее заново через интернет, а моментально предоставить вам готовую копию. Это существенно увеличивает скорость работы.
В том случае, если вы совсем недавно заходили к пользователю на страницу, есть вероятность того, что она есть в кэше браузера, и вы можете просмотреть ее.
Давайте сделаем это на примере Mozilla Firefox.
Включите автономный режим. Для этого откройте меню, затем пункт «Разработка» , и далее поставьте галочку «Работать автономно» .

Теперь в адресной строке браузера, вам нужно указать урл нужной страницы, и нажать «Enter» . Если ее копия существует — она будет загружена. Если нет, вы увидите сообщение об ошибке.

Я сделал обзор всех трех способов в видеоформате.
Заключение
Есть вероятность того, что не один из описанных методов, не даст результата, и вам не удастся увидеть информацию с удаленной страницы. В таком случае останется только надеяться на то, что пользователь решит восстановить свой профиль.
Решение рассматривается (пока) только для одного сайта - того, на котором мы находимся. Идея появилась в результате того, что один пользователь сделал юзерскрипт, который переадресует страницу на кеш Гугла, если вместо статьи видим «Доступ к публикации закрыт». Понятно, что это решение будет работать лишь частично, но полного решения пока не существует. Можно повысить вероятность нахождения копии выбором результата из нескольких сервисов. Этим стал заниматься скрипт HabrAjax (наряду с 3 десятками других функций). Теперь (с версии 0.859), если пользователь увидел полупустую страницу, с которой можно перейти лишь на главную, в личную страницу автора (если повезёт) и назад, юзерскрипт предоставляет несколько альтернативных ссылок, в которых можно попытаться найти потерю. И тут начинается самое интересное, потому что ни один сервис не заточен на качественное архивирование одного сайта.
Кстати, статья и исследования порождены интересным опросом А вас раздражает постоянное «Доступ к публикации закрыт»? и скриптом пользователя dotneter - комментарий habrahabr.ru/post/146070/#comment_4914947 .
Требуется, конечно, более качественный сервис, поэтому, кроме описания нынешней скромной функциональности (вероятность найти в Гугл-кеше и на нескольких сайтах-копировщиках), поднимем в статье краудсорсинговые вопросы - чтобы «всем миром» задачу порешать и прийти к качественному решению, тем более, что решение видится близким для тех, кто имеет сервис копирования контента. Но давайте обо всём по порядку, рассмотрим все предложенные на данный момент решения.
Кеш Гугла
В отличие от кеша Яндекса, к нему имеется прямой доступ по ссылке, не надо просить пользователя «затем нажать кнопку „копия“». Однако, все кеширователи, как и известный archive.org, имеют ряд ненужных особенностей.1) они просто не успевают мгновенно и многократно копировать появившиеся ссылки. Хотя надо отдать должное, что к популярным сайтам обращение у них частое, и за 2 и более часов они кешируют новые страницы. Каждый в своё время.
3) поэтому результат кеширования - как повезёт. Можно обойти все такие кеширующие ссылки, если очень надо, но и оттуда информацию стоит скопировать себе, потому что вскоре может пропасть или замениться «более актуальной» бессмысленной копией пустой страницы.
Кеш archive.org
Он работает на весь интернет с мощностями, меньшими, чем у поисковиков, поэтому обходит страницы какого-то далёкого русскоязычного сайта редко. Частоту можно увидеть здесь: wayback.archive.org/web/20120801000000*/http://habrahabr.ruДа и цель сайта - запечатлеть фрагменты истории веба, а не все события на каждом сайте. Поэтому мы редко будем попадать на полезную информацию.
Кеш Яндекса
Нет прямой ссылки, поэтому нужно просить (самое простое) пользователя нажать на ссылку «копия» на странице поиска, на которой будет одна эта статья (если её Яндекс вообще успел увидеть).Как показывает опыт, статья, повисевшая пару часов и закрытая автором, довольно успешно сохраняется в кешах поисковиков. Впоследствии, скорее всего, довольно быстро заменится на пустую. Всё это, конечно, не устроит пользователей веба, который по определению должен хранить попавшую в него информацию.
Из живых я нашёл пока что 4, некоторые давно существовавшие (itgator) на данный момент не работали. В общем, пока что они почти бесполезны, потому что заставляют искать статью по названию или ключевым словам, а не по адресу, по которому пользователь пришёл на закрытую страницу (а по словам отлично ищет Яндекс и не только по одному их сайту). Приведены в скрипте для какой-нибудь полезной информации.
Задача
Перед сообществом стоит задача, не утруждая организаторов сайта, довести продукт до качественного, не теряющего информацию ресурса. Для этого, как правильно заметили в комментариях к опросу, нужен архиватор актуальных полноценных статей (и комментариев к ним заодно).В настоящее время неполное решение её, как описано выше, выглядит так:
Если искать в Яндексе, то подобранный адрес выведет единственную ссылку (или ничего):
Нажав ссылку «копия», увидим (если повезёт) сохранённую копию (страница выбрана исключительно для актуального на данный момент примера):
В Гугле несколько проще - сразу попадаем на копию, если тоже повезёт, и Гугл успел сохранить именно то, что нам надо, а не дубль отсутствующей страницы.
Забавно, что скрипт теперь предлагает «выбор альтернативных сервисов» и в этом случае («профилактические работы»):
Жду предложений по добавлению сервисов и копировщиков (или хотя бы проектов) (для неавторизованных - на почту spmbt0 на известном гуглоресурсе, далее выберем удобный формат).
UPD
23:00: опытным путём для mail.ru
было выяснено строение прямой ссылки на кеш:
"http://hl.mailru.su/gcached?q=cache:"+ window.location
Знатоки или инсайдеры, расскажите, что это за ссылка, насколько она стабильна (не изменится ли, например, домен 3-го уровня), что значит приставка «g»-cached? Значит ли это кеш Гугла или это кеш движка Gogo?
Сервисы и трюки, с которыми найдётся ВСЁ.
Зачем это нужно: с утра мельком прочитали статью, решили вечером ознакомиться внимательнее, а ее на сайте нет? Несколько лет назад ходили на полезный сайт, сегодня вспомнили, а на этом же домене ничего не осталось? Это бывало с каждым из нас. Но есть выход.
Всё, что попадает в интернет, сохраняется там навсегда. Если какая-то информация размещена в интернете хотя бы пару дней, велика вероятность, что она перешла в собственность коллективного разума. И вы сможете до неё достучаться.
Поговорим о простых и общедоступных способах найти сайты и страницы, которые по каким-то причинам были удалены.
1. Кэш Google, который всё помнит
Google специально сохраняет тексты всех веб-страниц, чтобы люди могли их просмотреть в случае недоступности сайта. Для просмотра версии страницы из кэша Google надо в адресной строке набрать:
http://webcache.googleusercontent.com/search?q=cache:http://www.сайт/
Где http://www.сайт/ надо заменить на адрес искомого сайта.
2. Web-archive, в котором вся история интернета

6. Archive.is, для собственного кэша

Если вам нужно сохранить какую-то веб-страницу, то это можно сделать на archive.is без регистрации и смс. Еще там есть глобальный поиск по всем версиям страниц, когда-либо сохраненных пользователями сервиса..
7. Кэши других поисковиков, мало ли
Если Google, Baidu и Yandeх не успели сохранить ничего толкового, но копия страницы очень нужна, то идем на seacrhenginelist.com , перебираем поисковики и надеемся на лучшее (чтобы какой-нибудь бот посетил сайт в нужное время).
8. Кэш браузера, когда ничего не помогает
Страницу целиком таким образом не посмотришь, но картинки и скрипты с некоторых сайтов определенное время хранятся на вашем компьютере. Их можно использовать для поиска информации. К примеру, по картинке из инструкции можно найти аналогичную на другом сайте. Кратко о подходе к просмотру файлов кэша в разных браузерах:
Safari
Ищем файлы в папке ~/Library/Caches/Safari .
Google Chrome
В адресной строке набираем chrome://cache
Opera
В адресной строке набираем opera://cache
Mozilla Firefox
Набираем в адресной строке about:cache и находим на ней путь к каталогу с файлами кеша.
9. Пробуем скачать файл страницы напрямую с сервера
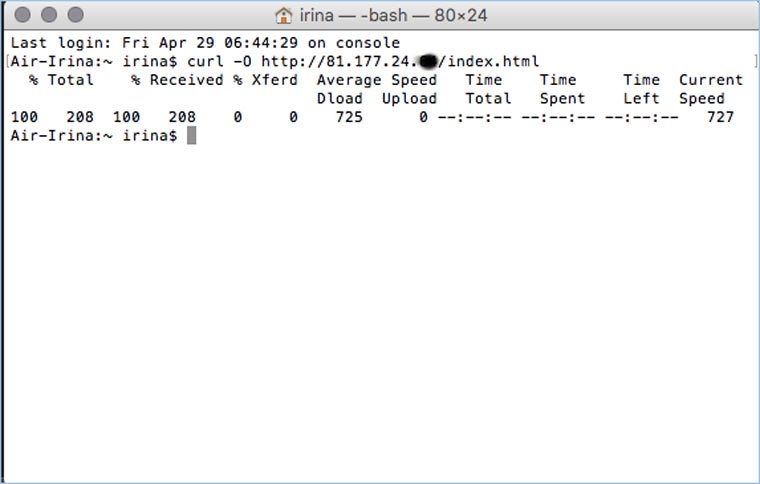
Идем на whoishostingthis.com и узнаем адрес сервера, на котором располагается или располагался сайт:

После этого открываем терминал и с помощью команды curl пытаемся скачать нужную страницу:
Что делать, если вообще ничего не помогло
Если ни один из способов не дал результатов, а найти удаленную страницу вам позарез как надо, то остается только выйти на владельца сайта и вытрясти из него заветную инфу. Для начала можно пробить контакты, связанные с сайтом на emailhunter.com :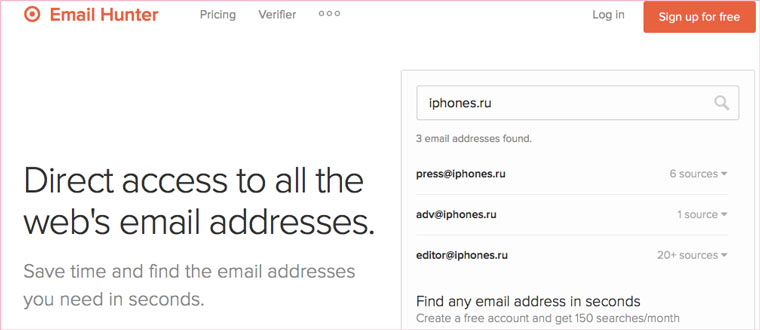
А о сборе информации про людей читайте в статьях и .