Как редактировать файл robots txt. Рекомендации по настройке файла robots txt
В сем нужны инструкции для работы, поисковые системы не исключения из правил, поэтому и придумали специальный файл под названием robots.txt . Этот файл должен лежать в корневой папке вашего сайта, или он может быть виртуальным, но обязательно открываться по запросу: www.вашсайт.ru/robots.txt
Поисковые системы уже давно научились отличать нужные файлы html, от внутренних наборов скриптов вашей CMS системы, точнее они научились распознавать ссылки на контентные статьи и всяких хлам. Поэтому многие вебмастера уже забывают делать роботс для своих сайтов и думают, что все и так хорошо будет. Да они правы на 99%, ведь если у вашего сайта нет этого файла, то поисковые системы безграничны в своих поисках контента, но случаются нюансы, над ошибками которых, можно позаботиться заранее.
Если у вас возникли проблемы с этим файлом на сайте, пишите комментарии к этой статье и я быстро помогу вам в этом, абсолютно бесплатно. Очень часто вебмастера делают мелкие ошибки в нем, что приносит сайту плохую индексацию, или вообще исключение из индекса.
Д ля чего нужен robots.txt
Файл robots.txt создается для настройки правильной индексации сайта поисковым системам. То есть в нем содержатся правила разрешений и запретов на определенные пути вашего сайта или тип контента. Но это не панацея. Все правила в файле robots не являются указаниями точно им следовать, а просто рекомендация для поисковых систем. Google например пишет:
Нельзя использовать файл robots.txt, чтобы скрыть страницу из результатов Google Поиска. На нее могут ссылаться другие страницы, и она все равно будет проиндексирована.
Поисковые роботы сами решают что индексировать, а что нет, и как себя вести на сайте. У каждого поисковика свои задачи и свои функции. Как бы мы не хотели, этим способ их не укротить.
Но есть один трюк, который не касается напрямую тематики этой статьи. Чтобы полностью запретить роботам индексировать и показывать страницу в поисковой выдаче, нужно написать:
Вернемся к robots. Правилами в этой файле можно закрыть или разрешить доступ к следующим типам файлов:
- Неграфические файлы . В основном это html файлы, на которых содержится какая-либо информация. Вы можете закрыть дубликаты страниц, или страницы, которые не несут никакой полезной информации (страницы пагинации, страницы календаря, страницы с архивами, страницы с профилями и т.д.).
- Графические файлы . Если вы хотите, чтобы картинки сайта не отображались в поиске, вы можете это прописать в файле robots.
- Файлы ресурсов . Также с помощью robots вы можете заблокировать индексацию различных скриптов, файлы стилей CSS и другие маловажные ресурсы. Но не стоит блокировать ресурсы, которые отвечают за визуальную часть сайта для посетителей (например, если вы закроете css и js сайта, которые выводят красивые блоки или таблицы, этого не увидит поисковой робот, и будет ругаться на это).
Чтобы наглядно показать, как работает robots, посмотрите на картинку ниже:
Поисковой робот, следуя на сайт, смотрит на правила индексации, затем начинает индексацию по рекомендациям файла.  В зависимости от настроек правил, поисковик знает, что можно индексировать, а что нет.
В зависимости от настроек правил, поисковик знает, что можно индексировать, а что нет.
С интаксис файла robots.txt
Для написания правил поисковым системам в файле роботса используются директивы с различными параметрами, с помощью которых следуют роботы. Начнем с самой первой и наверное самой главной директивы:
Д иректива User-agent
User-agent — Этой директивой вы задает название роботу, которому следует использовать рекомендации в файле. Этих роботов официально в мире интернета — 302 штуки . Вы конечно можете прописать правила для всех по отдельности, но если у вас нет времени на это, просто пропишите:
User-agent: *
*-в данном примере означает «Все». Т.е. ваш файл robots.txt, должен начинаться с того, «для кого именно» предназначен файл. Чтобы не заморачиваться над всеми названиями роботов, просто пропишите «звездочку» в директиве user-agent.
Приведу вам подробные списки роботов популярных поисковых систем:
Google — Googlebot — основной робот
Остальные роботы GoogleGooglebot-News
— робот поиска новостей
Googlebot-Image
— робот картинок
Googlebot-Video
— робот видео
Googlebot-Mobile
— робот мобильной версии
AdsBot-Google
— робот проверки качества целевой страницы
Mediapartners-Google
— робот сервиса AdSense
Яндекс — YandexBot - основной индексирующий робот;
Остальные роботы ЯндексаД ирективы Disallow и Allow
Disallow — самое основное правило в robots, именно с помощью этой директивы вы запрещаете индексировать определенные места вашего сайта. Пишется директива так:
Disallow:
Очень часто можно наблюдать директиву Disallow: пустую, т.е. якобы говоря роботу, что ничего не запрещено на сайте, индексируй что хочешь. Будьте внимательны! Если вы поставите / в disallow, то вы полностью закроете сайт для индексации.
Поэтому самый стандартный вариант robots.txt, который «разрешает индексацию всего сайта для всех поисковых систем» выглядит так:
User-Agent: * Disallow:
Если вы не знаете что писать в robots.txt, но где-то слышали о нем, просто скопируйте код выше, сохраните в файл под названием robots.txt и загрузите его в корень вашего сайта. Или ничего не создавайте, так как и без него роботы будут индексировать все на вашем сайте. Или прочитайте статью до конца, и вы поймете, что закрывать на сайте, а что нет.
По правилам robots, директива disallow должна быть обязательна.
Этой директивой можно запретить как папку, так и отдельный файл.
Если вы хотите запретить папку вам следует написать:
Disallow: /papka/
Если вы хотите запретить определенный файл :
Disallow: /images/img.jpg
Если вы хотите запретить определенные типы файлов :
Disallow: /*.png$
Регулярные выражения не поддерживаются многими поисковыми системами. Google поддерживает.
Allow — разрешающая директива в Robots.txt. Она разрешает роботу индексировать определенный путь или файл в запрещающей директории. До недавнего времени использовалась только Яндексом. Google догнал это, и тоже начал ее использовать. Например:
Allow: /content Disallow: /
эти директивы запрещают индексировать весь контент сайта, кроме папки content. Или вот еще популярные директивы в последнее время:
Allow: /themplate/*.js Allow: /themplate/*.css Disallow: /themplate
эти значения разрешают индексировать все файлы CSS и JS на сайте , но запрещают индексировать все в папке с вашим шаблоном. За последний год Google очень много отправил писем вебмастерам такого содержания:
Googlebot не может получить доступ к файлам CSS и JS на сайте
И соответствующий комментарий: Мы обнаружили на Вашем сайте проблему, которая может помешать его сканированию. Робот Googlebot не может обработать код JavaScript и/или файлы CSS из-за ограничений в файле robots.txt. Эти данные нужны, чтобы оценить работу сайта. Поэтому если доступ к ресурсам будет заблокирован, то это может ухудшить позиции Вашего сайта в Поиске .
Если вы добавите две директивы allow, которые написаны в последнем коде в ваш Robots.txt, то вы не увидите подобных сообщений от Google.
И спользование спецсимволов в robots.txt
Теперь про знаки в директивах. Основные знаки (спецсимволы) в запрещающих или разрешающих это /,*,$
Про слеши (forward slash) «/»
Слеш очень обманчив в robots.txt. Я несколько десятков раз наблюдал интересную ситуацию, когда по незнанию в robots.txt добавляли:
User-Agent: * Disallow: /
Потому, что они где-то прочитали о структуре сайта и скопировали ее себе на сайте. Но, в данном случае вы запрещаете индексацию всего сайта. Чтобы запрещать индексацию именно каталога, со всеми внутренностями вам обязательно нужно ставить / в конце. Если вы например пропишите Disallow: /seo, то абсолютно все ссылки на вашем сайте, в котором есть слово seo — не будут индексироваться. Хоть это будет папка /seo/, хоть это будет категория /seo-tool/, хоть это будет статья /seo-best-of-the-best-soft.html, все это не будет индексироваться.
Внимательно смотрите на все / в вашем robots.txt
Всегда в конце директорий ставьте /. Если вы поставите / в Disallow, вы запретите индексацию всего сайта, но если вы не поставите / в Allow, вы также запретите индексацию всего сайта. / — в некотором понимании означает «Все что следует после директивы /».
Про звездочки * в robots.txt
Спецсимвол * означает любую (в том числе пустую) последовательность символов. Вы можете ее использовать в любом месте robots по примеру:
User-agent: * Disallow: /papka/*.aspx Disallow: /*old
Запрещает все файлы с расширением aspx в директории papka, также запрещает не только папку /old, но и директиву /papka/old. Замудрено? Вот и я вам не рекомендую баловаться символом * в вашем robots.
По умолчанию в файле правил индексации и запрета robots.txt стоит * на всех директивах!
Про спецсимвол $
Спецсимвол $ в robots заканчивает действие спецсимвола *. Например:
Disallow: /menu$
Это правило запрещает ‘/menu’, но не запрещает ‘/menu.html’, т.е. файл запрещает поисковым системам только директиву /menu, и не может запретить все файлы со словом menu в URL`е.
Д иректива host
Правило host работает только в Яндекс, поэтому является не обязательным , оно определяет основной домен из ваших зеркал сайта, если таковы есть. Например у вас есть домен dom.com, но и так же прикуплены и настроены следующие домены: dom2.com, dom3,com, dom4.com и с них идет редирект на основной домен dom.com
Чтобы Яндексу быстрее определить, где из них главных сайт (хост), пропишите директорию host в ваш robots.txt:
Host: сайт
Если у вашего сайта нет зеркал, то можете не прописывать это правило. Но сначала проверьте ваш сайт по IP адрессу, возможно и по нему открывается ваша главная страница, и вам следует прописать главное зеркало. Или возможно кто-то скопировал всю информацию с вашего сайта и сделал точную копию, запись в robots.txt, если она также была украдена, поможет вам в этом.
Запись host должны быть одна, и если нужно, с прописанным портом. (Host: сайт:8080)
Д иректива Crawl-delay
Эта директива была создана для того, чтобы убрать возможность нагрузки на ваш сервер. Поисковые роботы могут одновременно делать сотни запросов на ваш сайт и если ваш сервер слабый, это может вызвать незначительные сбои. Чтобы такого не произошло, придумали правило для роботов Crawl-delay — это минимальный период между загрузками страницы вашего сайта. Стандартное значение для этой директивы рекомендуют ставить 2 секунды. В Robots это выглядит так:
Crawl-delay: 2
Эта директива работает для Яндекса. В Google вы можете выставить частоту сканирования в панеле вебмастера, в разделе Настройки сайта, в правом верхнем углу с «шестеренкой».
Д иректива Clean-param
Этот параметр тоже только для Яндекса. Если адреса страниц сайта содержат динамические параметры, которые не влияют на их содержимое (например: идентификаторы сессий, пользователей, рефереров и т. п.), вы можете описать их с помощью директивы Clean-param.
Робот Яндекса, используя эту информацию, не будет многократно перезагружать дублирующуюся информацию. Таким образом, увеличится эффективность обхода вашего сайта, снизится нагрузка на сервер.
Например, на сайте есть страницы:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос и не меняет содержимое, по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом:
User-agent: Yandex Disallow: Clean-param: ref /some_dir/get_book.pl
робот Яндекса сведет все адреса страницы к одному:
www.site.com/some_dir/get_book.pl?ref=site_1&book_id=123,
Если на сайте доступна страница без параметров:
www.site.com/some_dir/get_book.pl?book_id=123
то все сведется именно к ней, когда она будет проиндексирована роботом. Другие страницы вашего сайта будут обходиться чаще, так как нет необходимости обновлять страницы:
www.site.com/some_dir/get_book.pl?ref=site_2&book_id=123
www.site.com/some_dir/get_book.pl?ref=site_3&book_id=123
#для адресов вида: www.site1.com/forum/showthread.php?s=681498b9648949605&t=8243 www.site1.com/forum/showthread.php?s=1e71c4427317a117a&t=8243 #robots.txt будет содержать: User-agent: Yandex Disallow: Clean-param: s /forum/showthread.php
Д иректива Sitemap
Этой директивой вы просто указываете месторасположение вашего sitemap.xml. Робот запоминает это, «говорит вам спасибо», и постоянно анализирует его по заданному пути. Выглядит это так:
Sitemap: http://сайт/sitemap.xml
А сейчас давайте рассмотрим общие вопросы, которые возникают при составлении роботса. В интернете много таких тем, поэтому разберем самые актуальные и самые частые.
П равильный robots.txt
Очень много но в этом слове «правильный», ведь для одного сайта на одной CMS он будет правильный, а на другой CMS — будет выдавать ошибки. «Правильно настроенный» для каждого сайта индивидуальный. В Robots.txt нужно закрывать от индексации те разделы и те файлы, которые не нужны пользователям и не несут никакой ценности для поисковиков. Самый простой и самый правильный вариант robots.txt
User-Agent: * Disallow: Sitemap: http://сайт/sitemap.xml User-agent: Yandex Disallow: Host: site.com
В этом файле стоят такие правила: настройки правил запрета для всех поисковых систем (User-Agent: *), полностью разрешена индексация всего сайта («Disallow:» или можете указать «Allow: /»), указан хост основного зеркала для Яндекса (Host: site.ncom) и месторасположение вашего Sitemap.xml (Sitemap: .
R obots.txt для WordPress
Опять же много вопросов, один сайт может быть интернет-магазинов, другой блог, третий — лендинг, четвертый — сайт-визитка фирмы, и это все может быть на CMS WordPress и правила для роботов будут совершенно разные. Вот мой robots.txt для этого блога:
User-Agent: * Allow: /wp-content/uploads/ Allow: /wp-content/*.js$ Allow: /wp-content/*.css$ Allow: /wp-includes/*.js$ Allow: /wp-includes/*.css$ Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content Disallow: /category Disallow: /archive Disallow: */trackback/ Disallow: */feed/ Disallow: /?feed= Disallow: /job Disallow: /?.net/sitemap.xml
Тут очень много настроек, давайте их разберем вместе.
Allow в WordPress . Первые разрешающие правила для контента, который нужен пользователям (это картинки в папке uploads), и роботам (это CSS и JS для отображения страниц). Именно по css и js часто ругается Google, поэтому мы оставили их открытыми. Можно было использовать метод всех файлов просто вставив «/*.css$», но запрещающая строка именно этих папок, где лежат файлы — не разрешала использовать их для индексации, поэтому пришлось прописать путь к запрещающей папке полностью.
Allow всегда указывает на путь запрещенного в Disallow контента. Если у вас что-то не запрещено, не стоит ему прописывать allow, якобы думая, что вы даете толчок поисковикам, типа «Ну на же, вот тебе URL, индексируй быстрее». Так не получится.
Disallow в WordPress . Запрещать в CMS WP нужно очень многое. Множество различных плагинов, множество различных настроек и тем, куча скриптов и различных страниц, которые не несут в себе никакой полезной информации. Но я пошел дальше и совсем запретил индексировать все на своем блоге, кроме самих статей (записи) и страниц (об Авторе, Услуги). Я закрыл даже категории в блоге, открою, когда они будут оптимизированы под запросы и когда там появится текстовое описание для каждой из них, но сейчас это просто дубли превьюшек записей, которые не нужны поисковикам.
Ну Host и Sitemap стандартные директивы. Только нужно было вынести host отдельно для Яндекса, но я не стал заморачиваться по этому поводу. Вот пожалуй и закончим с Robots.txt для WP.
К ак создать robots.txt
Это не так сложно как кажется на первый взгляд. Вам достаточно взять обычный блокнот (Notepad) и скопировать туда данные для вашего сайта по настройкам из этой статьи. Но если и это для вас сложно, в интернете есть ресурсы, которые позволяют генерировать роботс для ваших сайтов:
Никто не расскажет больше про ваш Robots.txt, как эти товарищи. Ведь именно для них вы и создаете свой «запретный файлик».
Теперь поговорим о некоторых мелких ошибках, которые могут быть в robots.
- «Пустая строка » — недопустимо делать пустую строку в директиве user-agent.
- При конфликте между двумя директивами с префиксами одинаковой длины приоритет отдается директиве Allow .
- Для каждого файла robots.txt обрабатывается только одна директива Host . Если в файле указано несколько директив, робот использует первую.
- Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла robots.txt . В случае, если директив указано несколько, все они будут учтены роботом.
- Шесть роботов Яндекса не следуют правилам Robots.txt (YaDirectFetcher, YandexCalendar, YandexDirect, YandexDirectDyn, YandexMobileBot, YandexAccessibilityBot). Чтобы запретить им индексацию на сайте, следует сделать отдельные параметры user-agent для каждого из них.
- Директива User-agent , всегда должна писаться выше запрещающей директивы.
- Одна строка, для одной директории. Нельзя писать множество директорий на одной строке.
- Имя файл должно быть только таким: robots.txt . Никаких Robots.txt, ROBOTS.txt, и так далее. Только маленькие буквы в названии.
- В директиве host следует писать путь к домену без http и без слешей. Неправильно: Host: http://www.site.ru/, Правильно: Host: www.site.ru
- При использовании сайтом защищенного протокола https в директиве host (для робота Яндекса) нужно обязательно указывать именно с протоколом, так Host: https://www.site.ru
Эта статья будет обновляться по мере поступления интересных вопросов и нюансов.
С вами был, ленивый Staurus.
- это появление в поиске страниц, которые не несут никакой полезной информации для пользователя, и скорее всего пользователь на них все равно не зайдет, а если зайдет, то ненадолго.
- это появление в поиске копий одной и той же страницы с разными адресами. (Дублирование контента)
- это тратится драгоценное время на индексацию ненужных страниц поисковыми роботами. Поисковый робот вместо того чтобы заниматься нужным и полезным контентом будет тратить время на бесполезное блуждание по сайту. А так как роботы не индексируют весь сайт целиком и сразу (сайтов много и всем нужно уделить внимание), то важные страницы, которые Вы хотите увидеть в поиске, вы можете увидеть очень не скоро.
Было решено закрыть доступ для поисковых роботов к некоторым страницам сайта. В этом нам поможет файл robots.txt.
Зачем нужен robots.txt.
robots.txt – это обычный текстовый файл, в котором прописаны инструкции для поисковых роботов. Первое что делает поисковый робот при попадании на сайт, это ищет файл robots.txt. Если файл robots.txt не найден или он пустой, то поисковый робот будет бродить по всем доступным страницам и каталогам сайта (включая системные каталоги), в попытке проиндексировать содержимое. И не факт, что он проиндексирует нужную Вам страницу, если вообще доберется до нее.
С помощью robots.txt мы можем указать поисковым роботам, на какие страницы можно заходить и как часто, а куда ходить не стоит. Инструкции могут быть указаны, как для всех роботов, так и для каждого робота в отдельности. Страницы, которые закрыты от поисковых роботов, не будут появляться в поисковиках. Если этого файла нет, то его обязательно необходимо создать.
Файл robots.txt должен находиться на сервере, в корне вашего сайта. Файл robots.txt можно посмотреть на любом сайте в Интернет, для этого достаточно после адреса сайта добавить /robots.txt . Для сайта адрес, по которому можно посмотреть robots..txt.
Файл robots.txt , обычно у каждого сайта имеет свои особенности и бездумное копирование чужого файла, может создать проблемы с индексированием вашего сайта поисковыми роботами. Поэтому нужно четко понимать назначение файла robots.txt и назначение инструкций (директив), которые мы будем использовать, при его создании.
Директивы файла robots.txt.
Разберем основные инструкции (директивы), которые мы будем использовать при создании файла robots.txt.
User-agent: — указываем имя робота, для которого будут работать все нижеприведенные инструкции. Если инструкции нужно использовать для всех роботов, то в качестве имени используем * (звездочку)
Например:
User-agent:*
#инструкции действуют на всех поисковых роботов
User-agent: Yandex
#инструкции действуют только на поискового робота Яндекс
Имена самых популярных поисковиков Рунета это Googlebot (для Google) и Yandex (для Яндекса). Имена остальных поисковиков, если интересно, можно найти на просторах Интернет, но создавать для них отдельные правила, мне кажется, нет необходимости.
Disallow – запрещает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Disallow /wp-includes/
#запрещает роботам доступ в wp-includes
Disallow /
# запрещает роботам доступ ко всему сайту.
Allow – разрешает для поисковых роботов доступ к некоторым частям сайта или сайту целиком.
Например:
Allow /wp-content/
#разрешает роботам доступ в wp-content
Allow /
#разрешает роботам доступ ко всему сайту.
Sitemap: — можно использовать для указания пути к файлу с описанием структуры вашего сайта (карты сайта). Она нужна для ускорения и улучшения индексации сайта поисковыми роботами.
Например:
.xml
Host: — Если у вашего сайта есть зеркала (копии сайта на другом домене)..сайт. С помощью файла Host можно указать главное зеркало сайта. В поиске будет участвовать только главное зеркало.
Например:
Host: сайт
Также можно использовать спецсимволы. * # и $
*(звездочка) – обозначает любую последовательность символов.
Например:
Disallow /wp-content*
#запрещает роботам доступ в /wp-content/plugins, /wp-content/themes и.т.д.
$(знак доллара) – По умолчанию в конце каждого правила предполагается наличие *(звездочка) чтобы отменить симовол *(звездочка) можно использовать символ $(знак доллара).
Например:
Disallow /example$
#запрещает роботам доступ в /example но не запрещает в /example.html
#(знак решетки) – можно использовать для комментариев в файле robots.txt
Подробнее с этими директивами, а также несколькими дополнительными, можно ознакомиться на сайте Яндекса.
Как написать robots.txt для WordPress.
Теперь приступим к созданию файла robots.txt. Так как наш блог работает на WordPress, то разберем процесс создания robots.txt для WordPress более подробно.
Вначале нужно определиться, что мы хотим разрешить поисковым роботам, а что запретить. Я для себя решил оставить только самое необходимое, это записи, страницы и разделы. Все остальное будем закрывать.
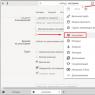
Какие папки есть в WordPress и что необходимо закрыть мы можем увидеть, если посмотрим в директорию нашего сайта. Я сделал это через панель управления хостингом на сайте , и увидел следующую картину.
 Разберемся с назначением каталогов и решим, что можно закрыть.
Разберемся с назначением каталогов и решим, что можно закрыть.
/cgi-bin (каталог скриптов на сервере – в поиске он нам не нужен.)
/files (каталог с файлами для загрузки. Здесь, например, лежит архивный файл с таблицей Excel для подсчета прибыли, о которой я писал в статье « «. В поиске этот каталог нам не нужен.)
/playlist(этот каталог я сделал для себя, для плейлистов на IPTV – в поиске не нужен.)
/test (этот каталог я создал для экспериментов, в поиске этот каталог не нужен)
/wp-admin/ (админка WordPress, в поиске она нам не нужна)
/wp-includes/ (системная папка от WordPress, в поиске она нам не нужна)
/wp-content/ (из этого каталога нам нужен только /wp-content/uploads/ в этом каталоге находятся картинки с сайта, поэтому каталог /wp-content/ мы запретим, а каталог с картинками разрешим отдельной инструкцией.)
Также нам не нужны в поиске следующие адреса:
Архивы – адреса вида //сайт/2013/ и похожие.
Метки — в адресе меток содержится /tag/
RSS фиды — в адресе всех фидов есть /feed
На всякий случай закрою адреса с PHP на конце так, как многие страницы доступны, как с PHP на конце, так и без. Это, как мне кажется, позволит избежать дублирования страниц в поиске.
Также закрою адреса с /GOTO/ я их использую для перехода по внешним ссылкам, в поиске им точно делать нечего.
И напоследок, уберем из поиска короткие адреса, вида //сайт/?p=209 и поиск по сайту //сайт/?s=, а также комментарии (адреса в которых содержится /?replytocom=)
А вот что у нас должно остаться:
/images (в этот каталог я закидываю некоторые картинки, пускай этот каталог роботы посещают)
/wp-content/uploads/ — содержит картинки от сайта.
А теперь придумаем инструкции для robots.txt. Вот, что у меня получилось:
#Указываем, что эти инструкции будут выполнять все роботы
User-agent: *
#Разрешаем роботам бродить по каталогу uploads.
Allow: /wp-content/uploads/
#Запрещаем папку со скриптами
Disallow: /cgi-bin/
#Запрещаем папку files
Disallow: /files/
#Запрещаем папку playlist
Disallow: /playlist/
#Запрещаем папку test
Disallow: /test/
#Запрещаем все, что начинается с /wp- , это позволит закрыть сразу несколько папок, имена которых начинаются с /wp- , эта команда вполне может помешать индексации страниц или записей которые начинаются с /wp-, но давать таких имен я не планирую.
Disallow: /wp-*
#Запрещаем адреса, в которых содержится /?p= и /?s=. Это короткие ссылки и поиск.
Disallow: /?p=
Disallow: /?s=
#Запрещаем все архивы до 2099 года.
Disallow: /20
#Запрещаем адреса с расширением PHP на конце.
Disallow: /*.php
#Запрещаем адреса, которые содержат /goto/. Можно было не прописывать, но на всякий случай вставлю.
Disallow: /goto/
#Запрещаем адреса меток
Disallow: /tag/
#Запрещаем все фиды.
Disallow: */feed
#Запрещаем индексацию комментариев.
Disallow: /?replytocom=
#Ну и напоследок прописываем путь к нашей карте сайта.
.xml
Написать файл robots.txt для WordPress можно с помощью обычного блокнота. Создадим файл и запишем в него следующие строки.
User-agent: *
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
.xml
Вначале я планировал сделать один общий блок правил для всех роботов, но Яндекс работать с общим блоком отказался. Пришлось сделать для Яндекса отдельный блок правил. Для этого просто скопировал общие правила, изменил имя робота и указал роботу главное зеркало сайта, с помощью директивы Host.
User-agent: Yandex
Allow: /wp-content/uploads/
Disallow: /cgi-bin/
Disallow: /files/
Disallow: /playlist/
Disallow: /test/
Disallow: /wp-*
Disallow: /?p=
Disallow: /?s=
Disallow: /20
Disallow: /*.php
Disallow: /goto/
Disallow: /tag/
Disallow: /author/
Disallow: */feed
Disallow: /?replytocom=
.xml
Host: сайт
Указать главное зеркало сайта можно также через , в разделе «Главное зеркало»

Теперь, когда файл robots.txt для WordPress
создан, нам его необходимо загрузить на сервер, в корневой каталог нашего сайта. Это можно сделать любым удобным для Вас способом.
Также для создания и редактирования robots.txt можно воспользоваться плагином WordPress SEO. Подробнее об этом полезном плагине я напишу позже. В этом случае файл robots.txt на рабочем столе можно не создавать, а просто вставить код файла robots.txt в соответствующий раздел плагина.

Как проверить robots.txt
Теперь, когда мы создали файл robots.txt, его нужно проверить. Для этого заходим в панель управления Яндекс.Вебмастер. Далее заходим в раздел “Настройка индексирования”, а далее “анализ robots.txt” . Здесь нажимаем кнопку «Загрузить robots.txt с сайта», после этого в соответствующем окне должно появиться содержимое вашего robots.txt.

Затем нажимаем «добавить» и в появившемся окне вводим различные url с вашего сайта, которые вы хотите проверить. Я ввел несколько адресов, которые должны быть запрещены и несколько адресов, которые должны быть разрешены.

Нажимаем кнопку «Проверить», после этого Яндекс выдаст нам результаты проверки файла robots.txt. Как видим, наш файл проверку удачно прошел. То, что должно быть запрещено для поисковых роботов, у нас запрещено. То, что должно быть разрешено, у нас разрешено.

Такую же проверку можно провести для робота Google, через GoogleWebmaster, но она не сильно отличается от проверки через Яндекс, поэтому я ее описывать не буду.
Вот и все. Мы создали robots.txt для WordPress и он отлично работает. Остается только иногда поглядывать за поведением поисковых роботов на нашем сайте. Чтобы вовремя заметить ошибку и в случае необходимости внести изменения в файл robots.txt. Страницы которые были исключены из индекса и причину исключения можно посмотреть в соответствующем разделе Яндекс.ВебМастер (или GoogleWebmaster).
Удачных Инвестиций и успехов во всех ваших делах.
Каждый блог дает свой ответ на этот счет. Поэтому новички в поисковом продвижении часто путаются, вот так:
Что за роботс ти экс ти?
Файл robots.txt или индексный файл — обычный текстовый документ в кодировке UTF-8, действует для протоколов http, https, а также FTP. Файл дает поисковым роботам рекомендации: какие страницы/файлы стоит сканировать. Если файл будет содержать символы не в UTF-8, а в другой кодировке, поисковые роботы могут неправильно их обработать. Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, протокола и номера порта, где размещен файл.
Файл должен располагаться в корневом каталоге в виде обычного текстового документа и быть доступен по адресу: https://site.com.ua/robots.txt .
В других файлах принято ставить отметку ВОМ (Byte Order Mark). Это Юникод-символ, который используется для определения последовательности в байтах при считывании информации. Его кодовый символ — U+FEFF. В начале файла robots.txt отметка последовательности байтов игнорируется.
Google установил ограничение по размеру файла robots.txt — он не должен весить больше 500 Кб.
Ладно, если вам интересны сугубо технические подробности, файл robots.txt представляет собой описание в форме Бэкуса-Наура (BNF). При этом используются правила RFC 822 .
При обработке правил в файле robots.txt поисковые роботы получают одну из трех инструкций:
- частичный доступ: доступно сканирование отдельных элементов сайта;
- полный доступ: сканировать можно все;
- полный запрет: робот ничего не может сканировать.
При сканировании файла robots.txt роботы получают такие ответы:
- 2xx — сканирование прошло удачно;
- 3xx — поисковый робот следует по переадресации до тех пор, пока не получит другой ответ. Чаще всего есть пять попыток, чтобы робот получил ответ, отличный от ответа 3xx, затем регистрируется ошибка 404;
- 4xx — поисковый робот считает, что можно сканировать все содержимое сайта;
- 5xx — оцениваются как временные ошибки сервера, сканирование полностью запрещается. Робот будет обращаться к файлу до тех пор, пока не получит другой ответ.Поисковый робот Google может определить, корректно или некорректно настроена отдача ответов отсутствующих страниц сайта, то есть, если вместо 404 ошибки страница отдает ответ 5xx, в этом случае страница будет обрабатываться с кодом ответа 404.
Пока что неизвестно, как обрабатывается файл robots.txt, который недоступен из-за проблем сервера с выходом в интернет.
Зачем нужен файл robots.txt
Например, иногда роботам не стоит посещать:
- страницы с личной информацией пользователей на сайте;
- страницы с разнообразными формами отправки информации;
- сайты-зеркала;
- страницы с результатами поиска.
Важно: даже если страница находится в файле robots.txt, существует вероятность, что она появится в выдаче, если на неё была найдена ссылка внутри сайта или где-то на внешнем ресурсе.
Так роботы поисковых систем видят сайт с файлом robots.txt и без него:

Без robots.txt та информация, которая должна быть скрыта от посторонних глаз, может попасть в выдачу, а из-за этого пострадаете и вы, и сайт.
Так робот поисковых систем видит файл robots.txt:

Google обнаружил файл robots.txt на сайте и нашел правила, по которым следует сканировать страницы сайта
Как создать файл robots.txt
С помощью блокнота, Notepad, Sublime, либо любого другого текстового редактора.
User-agent — визитка для роботов
User-agent— правило о том, каким роботам необходимо просмотреть инструкции, описанные в файле robots.txt. На данный момент известно 302 поисковых робота
Она говорит о том, что мы указываем правила в robots.txt для всех поисковых роботов.
Для Google главным роботом является Googlebot. Если мы хотим учесть только его, запись в файле будет такой:
В этом случае все остальные роботы будут сканировать контент на основании своих директив по обработке пустого файла robots.txt.
Для Yandex главным роботом является... Yandex:
Другие специальные роботы:
- Googlebot-News — для поиска новостей;
- Mediapartners-Google — для сервиса AdSense;
- AdsBot-Google — для проверки качества целевой страницы;
- YandexImages — индексатор Яндекс.Картинок;
- Googlebot-Image — для картинок;
- YandexMetrika — робот Яндекс.Метрики;
- YandexMedia — робот, индексирующий мультимедийные данные;
- YaDirectFetcher — робот Яндекс.Директа;
- Googlebot-Video — для видео;
- Googlebot-Mobile — для мобильной версии;
- YandexDirectDyn — робот генерации динамических баннеров;
- YandexBlogs — робот поиск по блогам, индексирующий посты и комментарии;
- YandexMarket — робот Яндекс.Маркета;
- YandexNews — робот Яндекс.Новостей;
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы;
- YandexPagechecker — валидатор микроразметки;
- YandexCalendar — робот Яндекс.Календаря.
Disallow — расставляем «кирпичи»
Ее стоит использовать, если сайт находится в процессе доработок, и вы не хотите, чтобы он в нынешнем состоянии засветился в выдаче.
Важно снять это правило, как только сайт будет готов к тому, чтобы его увидели пользователи. К сожалению, об этом забывают многие вебмастера.
Пример. Как прописать правило Disallow, чтобы дать рекомендации роботам не просматривать содержимое папки /papka/ :


Данная строка запрещает индексировать все файлы с расширением.gif
Allow — направляем роботов
Allow разрешает сканировать какой-либо файл/директиву/страницу. Допустим, необходимо, чтобы роботы могли посмотреть только страницы, которые начинались бы с /catalog, а весь остальной контент закрыть. В этом случае прописывается следующая комбинация:

Правила Allow и Disallow сортируются по длине префикса URL (от меньшего к большему) и применяются последовательно. Если для страницы подходит несколько правил, робот выбирает последнее правило в отсортированном списке.
Host — выбираем зеркало сайта
Host — одно из обязательных для robots.txt правил, оно сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
Зеркало сайта — точная или почти точная копия сайта, доступная по разным адресам.
Робот не будет путаться при нахождении зеркал сайта и поймет, что главное зеркало указано в файле robots.txt. Адрес сайта указывается без приставки «http://», но если сайт работает на HTTPS, приставку «https://» указать нужно.
Как необходимо прописать это правило:

Пример файла robots.txt, если сайт работает на протоколе HTTPS:

Sitemap — медицинская карта сайта
Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу http://site.ua/sitemap.xml . При каждом обходе робот будет смотреть, какие изменения вносились в этот файл, и быстро освежать информацию о сайте в базах данных поисковой системы.

Crawl-delay — секундомер для слабых серверов
Crawl-delay — параметр, с помощью которого можно задать период, через который будут загружаться страницы сайта. Данное правило актуально, если у вас слабый сервер. В таком случае возможны большие задержки при обращении поисковых роботов к страницам сайта. Этот параметр измеряется в секундах.

Clean-param — охотник за дублирующимся контентом
Clean-param помогает бороться с get-параметрами для избежания дублирования контента, который может быть доступен по разным динамическим адресам (со знаками вопроса). Такие адреса появляются, если на сайте есть различные сортировки, id сессии и так далее.
Допустим, страница доступна по адресам:
www.site.com/catalog/get_phone.ua?ref=page_1&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_2&phone_id=1
www.site.com/catalog/get_phone.ua?ref=page_3&phone_id=1
В таком случае файл robots.txt будет выглядеть так:

Здесь ref указывает, откуда идет ссылка, поэтому она записывается в самом начале, а уже потом указывается остальная часть адреса.
Но прежде чем перейти к эталонному файлу, необходимо еще узнать о некоторых знаках, которые применяются при написании файла robots.txt.
Символы в robots.txt
Основные символы файла — «/, *, $, #».
С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами. Например, если стоит один слеш в правиле Disallow, мы запрещаем сканировать весь сайт. С помощью двух знаков слэш можно запретить сканирование какой-либо отдельной директории, например: /catalog/.
Такая запись говорит, что мы запрещаем сканировать все содержимое папки catalog, но если мы напишем /catalog, запретим все ссылки на сайте, которые будут начинаться на /catalog.
Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
Эта запись говорит, что все роботы не должны индексировать любые файлы с расширением.gif в папке /catalog/
Знак доллара «$» ограничивает действия знака звездочки. Если необходимо запретить все содержимое папки catalog, но при этом нельзя запретить урлы, которые содержат /catalog, запись в индексном файле будет такой:
Решетка «#» используется для комментариев, которые вебмастер оставляет для себя или других вебмастеров. Робот не будет их учитывать при сканировании сайта.
Например:
Как выглядит идеальный robots.txt

Файл открывает содержимое сайта для индексирования, прописан хост и указана карта сайта, которая позволит поисковым системам всегда видеть адреса, которые должны быть проиндексированы. Отдельно прописаны правила для Яндекса, так как не все роботы понимают инструкцию Host.
Но не спешите копировать содержимое файл к себе — для каждого сайта должны быть прописаны уникальные правила, которые зависит от типа сайта и CMS. поэтому тут стоит вспомнить все правила при заполнении файла robots.txt.
Как проверить файл robots.txt
Если хотите узнать, правильно ли заполнили файл robots.txt, проверьте его в инструментах вебмастеров Google и Яндекс . Просто введите исходный код файла robots.txt в форму по ссылке и укажите проверяемый сайт.
Как не нужно заполнять файл robots.txt
Часто при заполнении индексного файла допускаются досадные ошибки, причем они связаны с обычной невнимательностью или спешкой. Чуть ниже — чарт ошибок, которые я встречала на практике.


2. Запись нескольких папок/директорий в одной инструкции Disallow:

Такая запись может запутать поисковых роботов, они могут не понять, что именно им не следует индексировать: то ли первую папку, то ли последнюю, — поэтому нужно писать каждое правило отдельно.

3. Сам файл должен называться только robots.txt, а не Robots.txt, ROBOTS.TXT или как-то иначе.
4. Нельзя оставлять пустым правило User-agent — нужно сказать, какой робот должен учитывать прописанные в файле правила.
5. Лишние знаки в файле (слэши, звездочки).
6. Добавление в файл страниц, которых не должно быть в индексе.
Нестандартное применение robots.txt
Кроме прямых функций индексный файл может стать площадкой для творчества и способом найти новых сотрудников.
Вот сайт, в котором robots.txt сам является маленьким сайтом с рабочими элементами и даже рекламным блоком.




В качестве площадки для поиска специалистов файл используют в основном SEO-агентства. А кто же еще может узнать о его существовании? :)

А у Google есть специальный файл humans.txt , чтобы вы не допускали мысли о дискриминации специалистов из кожи и мяса.

Выводы
С помощью Robots.txt вы сможете задавать инструкции поисковым роботам, рекламировать себя, свой бренд, искать специалистов. Это большое поле для экспериментов. Главное, помните о грамотном заполнении файла и типичных ошибках.
Правила, они же директивы, они же инструкции файла robots.txt:
- User-agent — правило о том, каким роботам необходимо просмотреть инструкции, описанные в robots.txt.
- Disallow дает рекомендацию, какую именно информацию не стоит сканировать.
- Sitemap сообщает роботам, что все URL сайта, обязательные для индексации, находятся по адресу http://site.ua/sitemap.xml.
- Host сообщает роботу Яндекса, какое из зеркал сайта стоит учитывать для индексации.
- Allow разрешает сканировать какой-либо файл/директиву/страницу.
Знаки при составлении robots.txt:
- Знак доллара «$» ограничивает действия знака звездочки.
- С помощью слэша «/» мы показываем, что хотим закрыть от обнаружения роботами.
- Звездочка «*» означает любую последовательность символов в файле. Она ставится после каждого правила.
- Решетка «#» используется, чтобы обозначить комментарии, которые пишет вебмастер для себя или других вебмастеров.
Используйте индексный файл с умом — и сайт всегда будет в выдаче.
Файл robots.txt — это обыкновенный файл с расширением.txt, который можно создать с помощью обыкновенного блокнота Windows. Данный файл содержит инструкции по индексации для поисковых роботов. Размещают этот файл корневой директории на хостинге.
При заходе на сайт поисковый робот первым делом обращаются к файлу robots.txt для того, чтобы получить инструкции к дальнейшему действию и узнать, какие файлы и директории запрещены к индексированию. Файл robots.txt носит рекомендательный характер для поисковых систем. Нельзя стопроцентно сказать, что все файлы, на которые выставлен запрет к индексации, не будут в итоге индексироваться.
Рассмотрим простейший пример файла robots.txt. Данный файл содержит следующие строки:
User-agent: * Disallow: /wp-admin/ Disallow: /images/
Первая строка указывает для каких поисковых роботов действуют данные инструкции. В данном примере указана звездочка — это означает, что инструкции относятся ко всем поисковым роботам. В случае необходимости указания инструкции для конкретного поискового робота, необходимо прописать его имя. Вторая и третья строки запрещают индексацию директорий «wp-admin» и «images».
Для поискового робота Яндекса актуально также прописывать директорию Host для указания основного зеркала сайта:
User-agent: Yandex Disallow: /wp-admin/ Disallow: /images/ Host: yoursite.ru
Примеры написания файла robots.txt для конкретных задач
1. Не запрещать роботам любых поисковых систем индексировать сайт:
User-agent: googlebot Disallow: /
4. Не запрещать к индексации только одним роботом (например, googlebot) и запретить к индексации всем остальным поисковым роботам:
User-agent: googlebot Disallow:
User-agent: * Disallow: /admin/ Disallow: /wp-content/ Disallow: /images/
User-agent: * Disallow: /News/webnews.html Disallow: /content/page.php
User-agent: * Disallow: /page.php Disallow: /links.htm Disallow: /secret.html
Основные правила написания robots.txt
При написании файла robots.txt часто допускаются ошибки. Для того, чтобы их избежать, давайте рассмотрим основные правила:
1. Писать содержимое файла нужно только в прописными буквами.
2. В инструкции Disallow необходимо указывать только одну директорию или один файл.
3. Строка «User-agent» не должна быть пустой. Если инструкция относится ко всем поисковым роботам, то необходимо указывать звёздочку, а если к конкретному поисковому роботу, то указывать его название.
4. Менять местами инструкции Disallow и User-agent нельзя.
5. В директиве Host, которая используется для Яндекса, адрес нашего сайта необходимо указывать без протокола HTTP и без закрывающего слэша.
6. При запрещении к индексации директорий необходимо обязательно прописывать слэши.
7. Следует проверить файл robots.txt перед загрузкой его на сервер. Это позволит избежать в будущем возможных проблем с индексацией сайта.